

In diesem Artikel erfahren Sie:
- Was Datenvalidierung ist, wann sie verwendet wird, welche Überprüfungen sie umfasst und welche Bibliotheken Sie für ihre Implementierung verwenden sollten.
- Wie Sie die Datenvalidierung anhand eines realen Python-Beispiels durchführen.
- Was Datenverifizierung ist, wie sie funktioniert, Beispiele für Verifizierungsprüfungen und die besten Vorgehensweisen.
- Wie Sie die Datenüberprüfung mit einem speziellen KI-Agenten implementieren.
- Eine Übersichtstabelle, in der Datenvalidierung und Datenverifizierung verglichen werden.
Lassen Sie uns eintauchen!
Datenvalidierung: Alles, was Sie wissen müssen
Beginnen Sie diese Reise durch Datenvalidierung und Datenverifizierung mit dem ersten Ansatz: der Datenvalidierung.
Was ist Datenvalidierung und warum ist sie wichtig?
Datenvalidierung ist der Prozess der Überprüfung der Genauigkeit, Qualität und Integrität von Daten. Sie wird in der Regel vor der Speicherung, Verwendung oder Verarbeitung von Daten durchgeführt. Ihr oberstes Ziel ist es, ein einheitliches Qualitäts- und Vertrauensniveau zu gewährleisten.
Insbesondere überprüft diese Technik, ob die Daten definierten Regeln und Standards entsprechen. Sie verhindert, dass falsche oder unvollständige Informationen in ein System, eine Anwendung oder einen Workflow gelangen oder durch eine Datenpipeline weitergeleitet werden.
Die Datenvalidierung ist für die Aufrechterhaltung einer hohen Datenqualität von grundlegender Bedeutung. Die Validierung von Daten spielt auch eine wichtige Rolle bei der Erfüllung von Compliance-Anforderungen wie der DSGVO und dem CCPA sowie bei der Einhaltung von Best Practices im Bereich Sicherheit.
Durch die Anwendung der Datenvalidierung können Sie Fehler und Probleme in Ihren Daten frühzeitig erkennen. Dies hilft, Probleme im Datenlebenszyklus zu identifizieren, bevor sie eskalieren, und verhindert so kostspielige Fehler und schwerwiegende Komplikationen.
Beispiele für Datenvalidierungsprüfungen
Die Datenvalidierungsprüfungen, die Sie anwenden können, sind unzählig und hängen von Ihren spezifischen Anforderungen, der Art der Datenfelder und bestimmten Szenarien ab. Zu den wichtigsten Prüfungen gehören:
- Datentypprüfung: Bestätigt, dass die in ein Feld eingegebenen Daten vom richtigen Typ sind (z. B. sicherstellen, dass ein
Altersfeldnur Zahlen akzeptiert). - Formatprüfung: Überprüft, ob die Daten einem bestimmten Muster entsprechen, z. B. einem Telefonnummernformat wie
(XXX) XXX-XXXX, einem Datumsformat wieJJJJ-MM-TToder einem E-Mail-Format wie[email protected]. - Bereichsprüfung: Stellt sicher, dass ein numerischer Wert innerhalb eines vordefinierten Mindest- und Höchstbereichs liegt (z. B. muss ein
Punktfeldzwischen0und100liegen). - Präsenzprüfung: Stellt sicher, dass ein Pflichtfeld nicht leer oder null ist, damit keine wichtigen Informationen fehlen.
- Codeprüfung: Überprüft, ob eine Eingabe aus einer vordefinierten Liste zulässiger Werte ausgewählt wurde (z. B. ein Ländercode aus der ISO 3166-Liste).
- Konsistenzprüfung: Überprüft, ob die Daten in mehreren Feldern innerhalb desselben Eintrags oder in verschiedenen Einträgen logisch und konsistent sind (z. B. muss ein Bestelldatum vor dem Lieferdatum liegen).
- Eindeutigkeitsprüfung: Verhindert doppelte Einträge in Feldern, die eindeutige Werte erfordern, wie z. B. eine Mitarbeiter-ID oder eine E-Mail-Adresse.
Wann sollte sie durchgeführt werden?
Als Faustregel gilt, dass die Datenvalidierung kontinuierlich während des gesamten Datenlebenszyklus durchgeführt werden sollte. Je früher sie erfolgt, desto wirksamer verhindert sie die Ausbreitung von Fehlern. Dies wird als „Shift-Left“-Ansatz für die Datenqualität bezeichnet.
Der proaktivste und effizienteste Zeitpunkt für die Validierung von Daten ist also der Zeitpunkt der Eingabe. Durch das Erkennen von Fehlern an dieser Stelle wird sichergestellt, dass keine fehlerhaften Daten in Ihre Systeme gelangen, was Zeit und Ressourcen für die nachgelagerte Bereinigung spart. Dies gilt für Daten, die von Benutzern eingegeben werden (z. B. über Formulare oder Datei-Uploads), für Daten, die durch Web-Scraping abgerufen werden, oder für Daten aus öffentlichen oder offenen Repositorys, denen Sie nicht vollständig vertrauen.
Bei von Benutzern übermittelten Daten, z. B. über eine API in einem Backend-System, kann die Echtzeitvalidierung sofortiges Feedback liefern (z. B. durch Markieren einer falsch formatierten E-Mail-Adresse oder einer unvollständigen Telefonnummer direkt in der API-Antwort mit 400 Bad Request-Fehlern).
Es ist jedoch nicht immer möglich, Daten sofort zu validieren. In ETL- oder ELT-Pipelines wird die Validierung beispielsweise in der Regel in bestimmten Phasen durchgeführt:
- Nach der Extraktion: Um zu überprüfen, ob die aus einem Quellsystem abgerufenen Daten während der Übertragung nicht beschädigt wurden oder verloren gegangen sind.
- Nach der Transformation: Um zu überprüfen, ob die Ausgabe jedes Transformationsschritts (z. B. Aggregationen) den erwarteten Regeln und Standards entspricht.
Auch nach der Speicherung der Daten sollten Sie diese regelmäßig erneut überprüfen. Denn Daten sind nicht statisch, sondern können aktualisiert, angereichert oder für andere Zwecke verwendet werden. Daher ist eine kontinuierliche Validierung erforderlich.
So validieren Sie Daten
Der Prozess der Datenvalidierung umfasst die folgenden Schritte:
- Anforderungen definieren: Legen Sie klare Validierungsregeln fest, die auf den geschäftlichen Anforderungen, regulatorischen Standards und Erwartungen basieren (z. B. definieren Sie ein Schema mit Regeln für Ihre Daten).
- Daten sammeln: Sammeln Sie Daten aus verschiedenen Quellen, z. B. Web-Scraping, APIs oder Datenbanken.
- Validierung anwenden: Implementieren Sie die definierten Regeln, um die Daten auf Genauigkeit, Konsistenz und Vollständigkeit zu überprüfen.
- Fehler behandeln: Protokollieren, isolieren oder korrigieren Sie ungültige Datensätze gemäß den Richtlinien Ihres Unternehmens. Geben Sie Benutzern klares Feedback, wenn sie falsche Daten eingeben.
- Daten laden: Sobald die Daten validiert und bereinigt sind, laden Sie sie in das Zielsystem, z. B. ein Data Warehouse.
Hinweis: Im nächsten Kapitel erfahren Sie anhand eines geführten Python-Beispiels, wie Sie diese Schritte anwenden können.
Bibliotheken für die Datenvalidierung
Nachfolgend finden Sie eine Tabelle mit einigen der besten Open-Source-Bibliotheken für die Datenvalidierung:
| Bibliothek | Programmiersprache | GitHub-Sterne | Beschreibung |
|---|---|---|---|
| Pydantic | Python | 25,3k | Datenvalidierung mit Python-Typ-Hinweisen |
| Marshmallow | Python | 7,2k | Eine leichtgewichtige Bibliothek zum Konvertieren komplexer Objekte in einfache Python-Datentypen und umgekehrt. |
| Cerberus | Python | 3,2k | Leichte, erweiterbare Datenvalidierungsbibliothek für Python |
| jsonschema | Python | 4,8k | Eine Implementierung der JSON-Schema-Spezifikation für Python |
| Validator.js | JavaScript | 23,6k | Eine Bibliothek mit String-Validatoren und -Sanitizern. |
| Joi | JavaScript | 21,2k | Die leistungsstärkste Datenvalidierungsbibliothek für JS |
| Yup | JavaScript | 23,6k+ | Einfachste Objekt-Schema-Validierung |
| Ajv | JavaScript | 14,4k | Der schnellste JSON-Schema-Validator. Unterstützt JSON Schema draft-04/06/07/2019-09/2020-12 und JSON Type Definition (RFC8927) |
| FluentValidation | C# (.NET) | 9,5k | Eine beliebte .NET-Validierungsbibliothek zum Erstellen streng typisierter Validierungsregeln. |
| Validator | Go | 19,1k | Go Struktur- und Feldvalidierung, einschließlich Cross Field, Cross Struct, Map, Slice und Array Diving |
So wenden Sie die Datenvalidierung in Python an: Schritt-für-Schritt-Beispiel
In dieser Anleitung erfahren Sie, wie Sie mit Pydantic eine Datenvalidierung auf Eingabedaten in JSON anwenden. Dieses Tutorial behandelt die wichtigsten Aspekte der Erstellung eines Prozesses zur Datenvalidierung.
Szenariobeschreibung
Angenommen, Sie rufen Daten von einer E-Commerce-Website ab. Konzentrieren Sie sich insbesondere auf diese Produktwebseite:
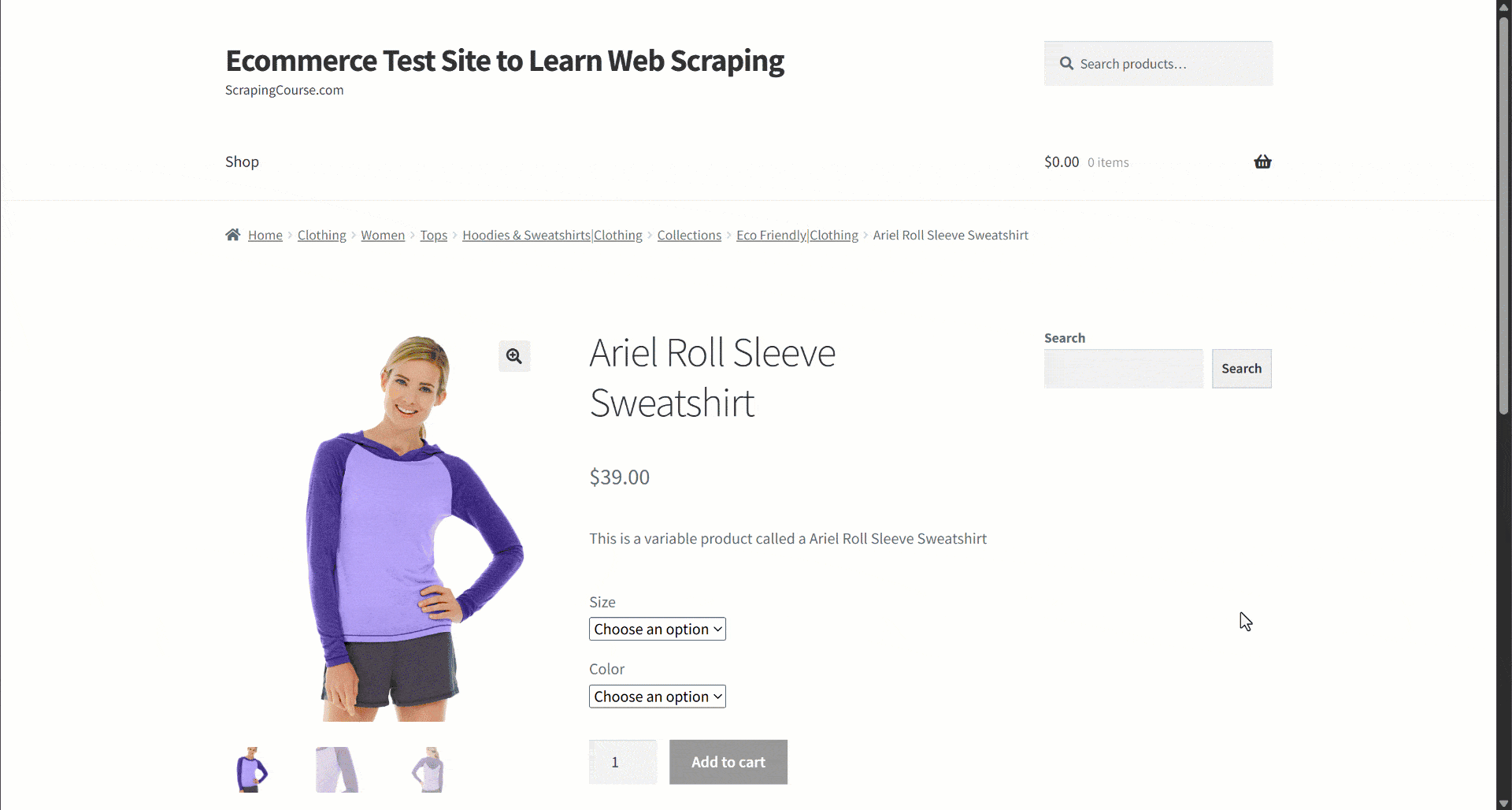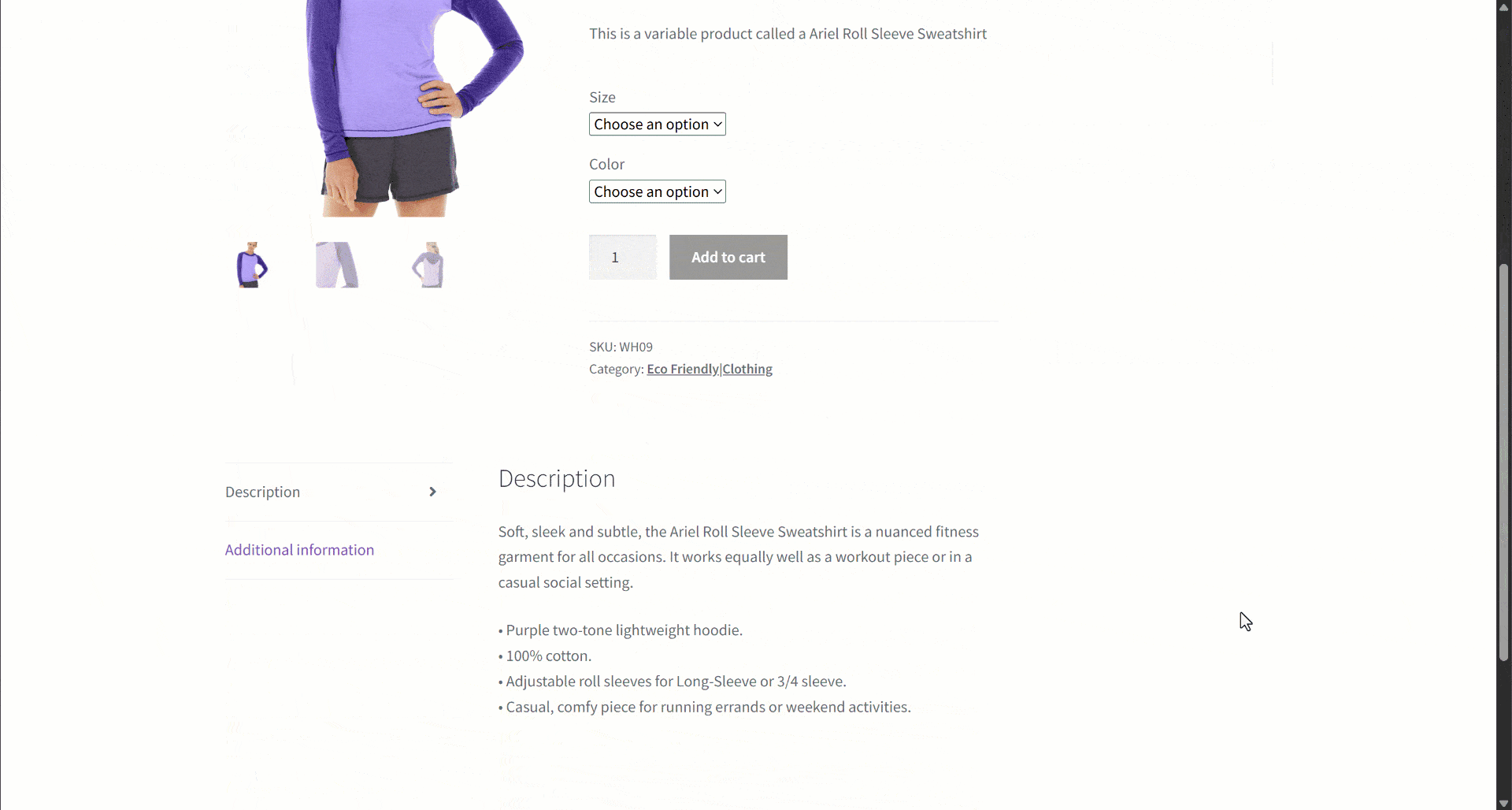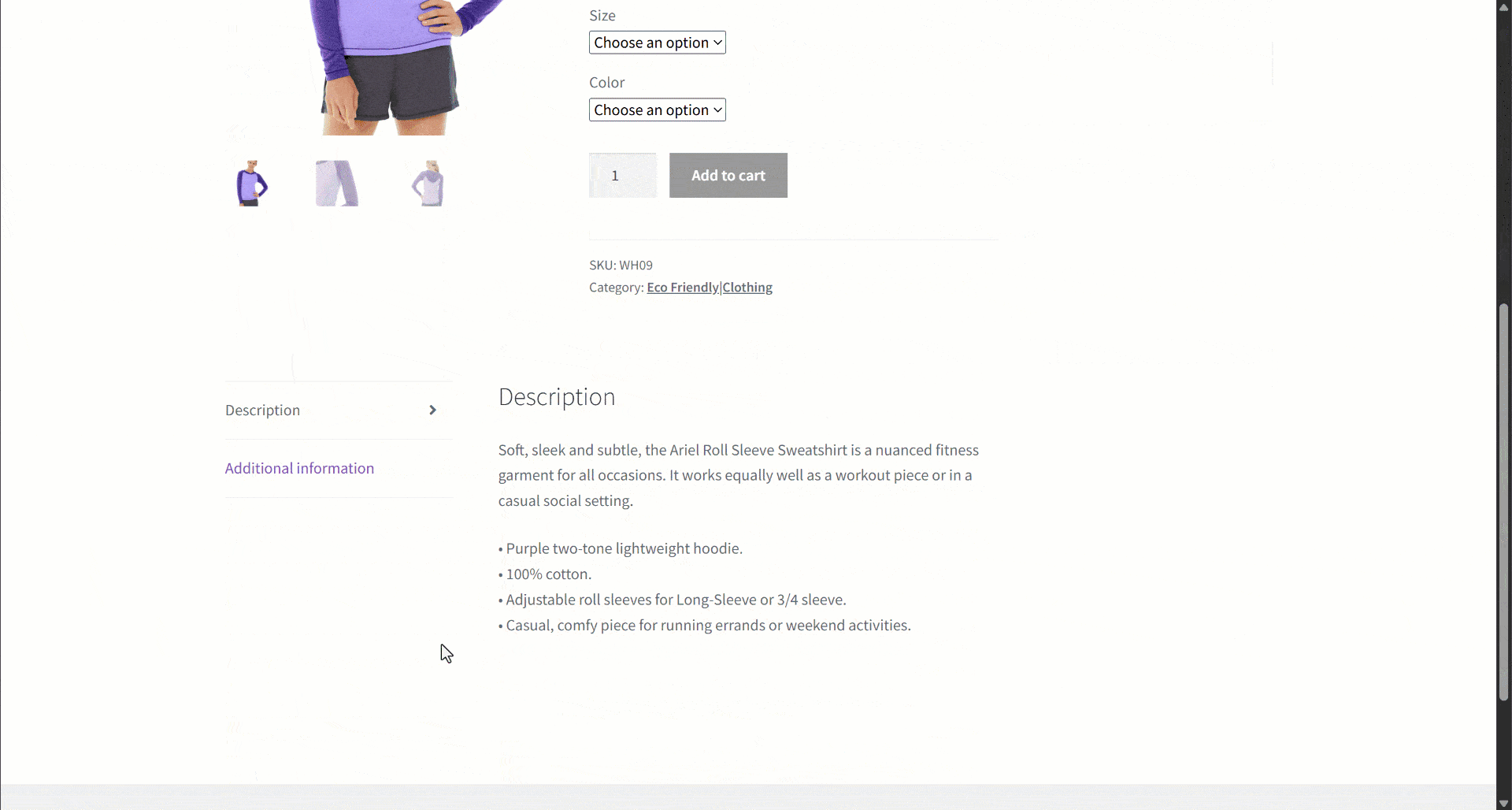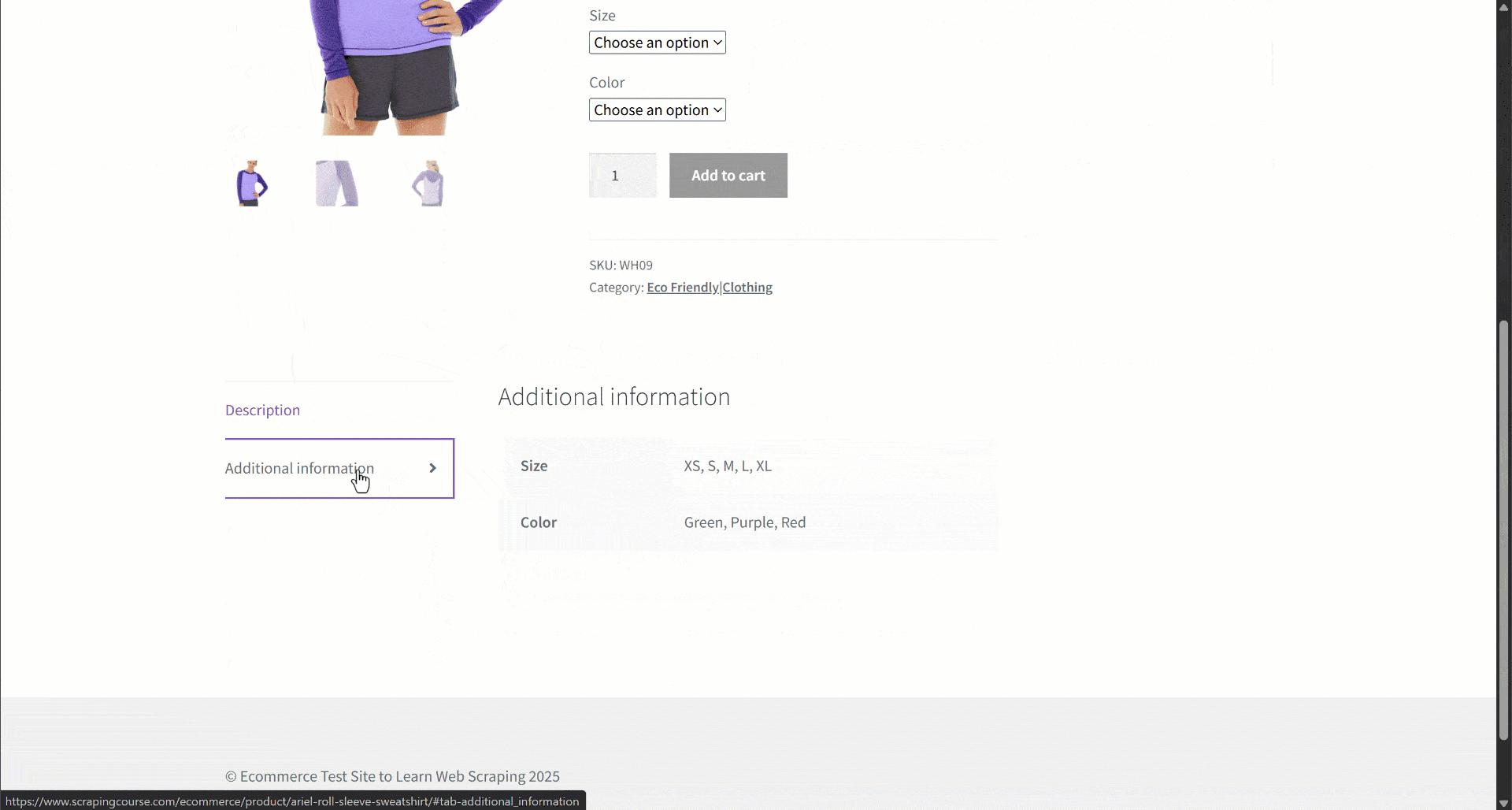
Während der Datenextraktion stellen Sie den Seiteninhalt einem LLM zur Verfügung, um das Parsing der Daten zu vereinfachen. LLMs können jedoch ungenau sein und erfundene, unzuverlässige oder unvollständige Daten liefern. Deshalb ist die Anwendung der Datenvalidierung so wichtig.
Der Einfachheit halber gehen wir davon aus, dass Sie bereits über ein Python-Projekt mit einer eingerichteten Entwicklungsumgebung verfügen.
Schritt 1: Definieren Sie das Zielschema und die Regeln
Beginnen Sie mit der Überprüfung der Zielseite und beachten Sie, dass die Produktseite die folgenden Felder enthält:
- Produkt-URL: Die URL der Produktseite.
- Produktname: Eine Zeichenfolge, die den Produktnamen enthält.
- Bilder: Eine Liste von Bild-URLs.
- Preis: Der Preis als Fließkommazahl.
- Währung: Ein einzelnes Zeichen, das die Währung angibt.
- SKU: Eine Zeichenfolge, die die Produkt-ID enthält.
- Kategorie: Ein Array, das eine oder mehrere Kategorien enthält.
- Beschreibung: Ein Textfeld mit der Produktbeschreibung.
- Ausführliche Beschreibung: Ein Textfeld mit der vollständigen Produktbeschreibung mit allen Details.
- Zusätzliche Informationen: Ein Objekt, das Folgendes enthält:
- Größenoptionen: Ein Array von Zeichenfolgen mit den verfügbaren Größen.
- Farboptionen: Ein Array von Zeichenfolgen mit den verfügbaren Farben.
Darstellen Sie dies dann in einem Pydantic-Modell wie unten gezeigt:
# pip install pip install pydantic
from typing import List, Optional, Annotated
from pydantic import BaseModel, ConfigDict, HttpUrl, PositiveFloat, StringConstraints, model_validator
class AdditionalInformation(BaseModel):
size_options: Optional[List[str]] = None # nullable
color_options: Optional[List[str]] = None # nullable
class Product(BaseModel):
model_config = ConfigDict(strict=True, extra="forbid")
product_url: HttpUrl # erforderlich, muss eine gültige URL sein
product_name: str # erforderlich
images: Optional[List[HttpUrl]] = None # Liste gültiger URLs, nullbar
price: Optional[PositiveFloat] = None # nullbar, muss >= 0 sein
currency: Optional[Annotated[str, StringConstraints(min_length=1, max_length=1)]] = None # nullbar, einzelnes Zeichen
sku: str # erforderlich
category: Optional[List[str]] = None # nullbar
description: Optional[str] = None # nullbar
long_description: Optional[str] = None # nullbar
additional_information: Optional[AdditionalInformation] = None # nullbar
@model_validator(mode="after")
# Benutzerdefinierte Validierungsregel, um sicherzustellen, dass der Preis immer mit einer Währung verknüpft ist.
def check_currency_if_price(cls, values):
price = values.price
currency = values.currency
if price is not None and not currency:
raise ValueError("currency must be provided if price is set")
return valuesBeachten Sie, dass das Produktmodell nicht nur die Felder und ihre Typen (z. B. str, HttpUrl usw.) definiert, sondern auch Validierungsbeschränkungen enthält (z. B. muss die Währung ein einzelnes Zeichen sein). Außerdem enthält es strenge Validierungsregeln, um sicherzustellen, dass der Preis immer mit einer Währung verknüpft ist, und alle zusätzlichen Felder, die nicht direkt mit dem Modell übereinstimmen, sind verboten.
Schritt 2: Sammeln Sie die Daten
Angenommen, Sie rufen Daten über KI-Web-Scraping ab, wie in einem der folgenden Tutorials gezeigt:
- Web-Scraping mit ChatGPT: Schritt-für-Schritt-Tutorial
- Web-Scraping mit Gemini: Vollständiges Tutorial
- Web-Scraping mit Perplexity: Schritt-für-Schritt-Anleitung
- Web-Scraping mit Claude: KI-gestütztes Parsing in Python
Sie erhalten eine Datei „product.json“, die die gescrapten Daten enthält. Hier gehen wir davon aus, dass das LLM sie wie folgt gefüllt hat:
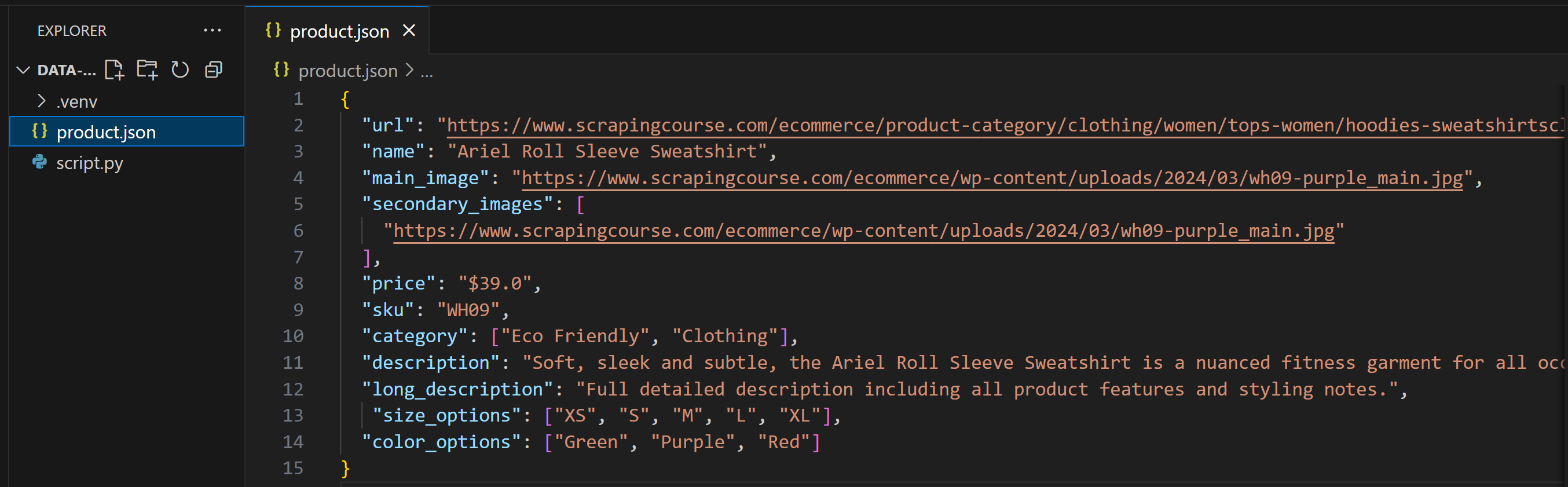
Wie Sie sehen können, stimmt diese Ausgabe nicht genau mit dem Pydantic-Modell überein. Dies ist häufig der Fall, wenn Sie in Ihrer Eingabeaufforderung keine Ausgabestruktur explizit angeben oder wenn die KI mit einer zu hohen Temperatur konfiguriert ist.
Schritt 3: Validierungsregeln anwenden
Laden Sie die Daten aus der Datei „product.json “:
import json
input_data_file_name = "product.json"
with open(input_data_file_name, "r", encoding="utf-8") as f:
product_data = json.load(f)Validieren Sie sie dann wie folgt mit Pydantic:
try:
# Validieren Sie die Daten über das Pydantic-Modell.
product = Product(**product_data)
print("Validierung erfolgreich!")
except ValidationError as e:
print("Validierung fehlgeschlagen:")
print(e)Führen Sie Ihr Skript aus, und Sie erhalten eine Fehlermeldung wie diese:
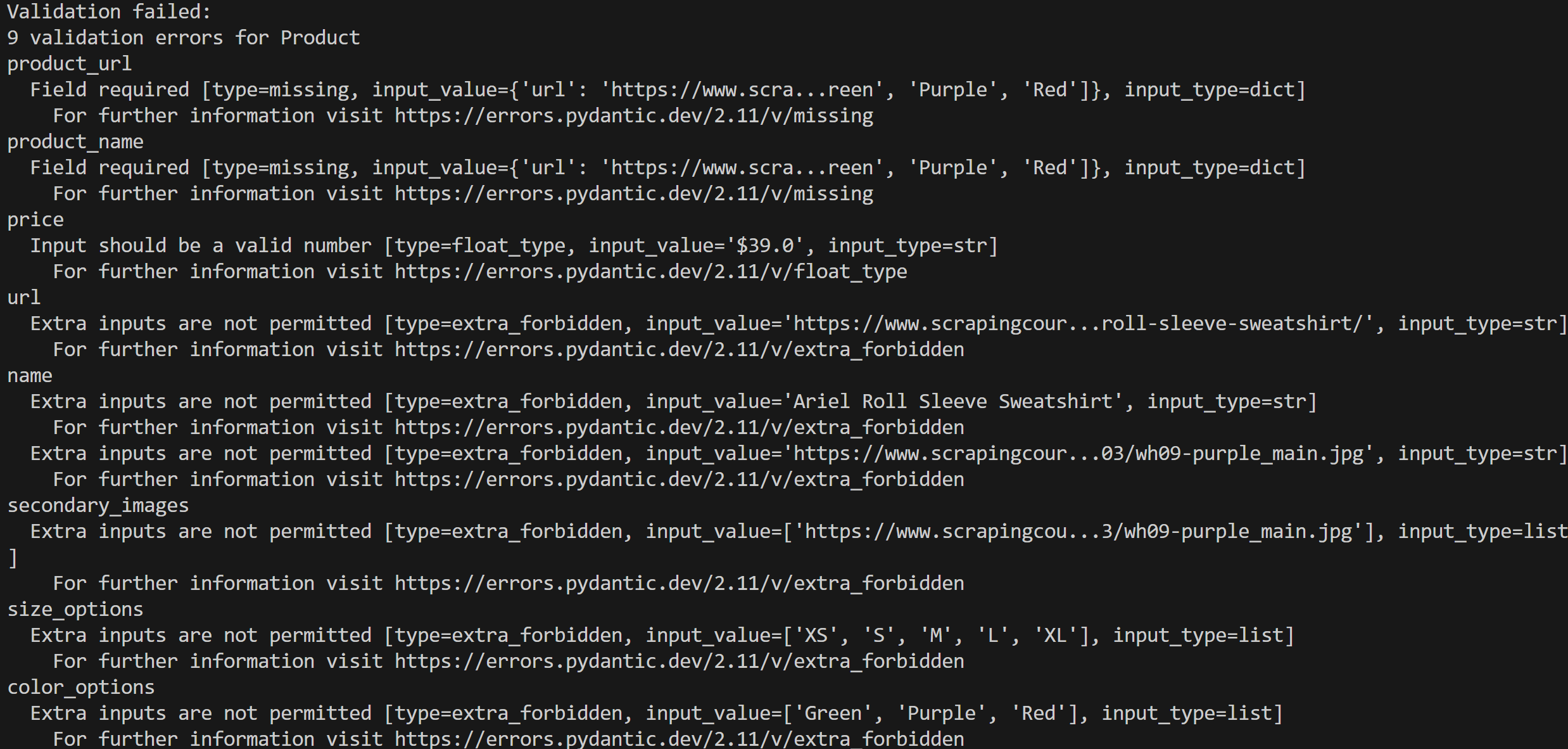
In diesem Fall wurden 9 Validierungsfehler erkannt, da die Eingabedaten nicht mit dem Produktmodell übereinstimmen.
Schritt 4: Beheben Sie die Fehler
Es gibt keinen universellen Prozess, um Daten automatisch so zu korrigieren, dass sie den Validierungsschritt bestehen. Jede Datenpipeline oder jeder Workflow ist anders, und Sie müssen möglicherweise in verschiedene Aspekte eingreifen.
In diesem Fall ist die Lösung so einfach wie die klare Angabe des erwarteten Ausgabeformats in der LLM-Eingabeaufforderung, eine Funktion, die von den meisten LLMs wie OpenAI unterstützt wird.
Tipp: Sie können diese Funktion in unserem Leitfaden zum visuellen Web-Scraping mit GPT Vision in Aktion sehen.
Wenn die strukturierte Ausgabefunktion nicht verfügbar ist, können Sie das LLM jederzeit auffordern, das erwartete Pydantic-Modell in der Eingabeaufforderung abzugleichen, indem Sie es als JSON-Zeichenfolge ausgeben:
prompt = f"""
Extrahieren Sie Daten aus dem angegebenen Seiteninhalt und geben Sie sie mit der folgenden Struktur zurück:
{Product.model_json_schema()}
INHALT:
<Seiteninhalt>
"""In beiden Fällen sollte die Ausgabe des LLM dem erwarteten Format entsprechen.
Nach dieser Änderung enthält product.json Folgendes:
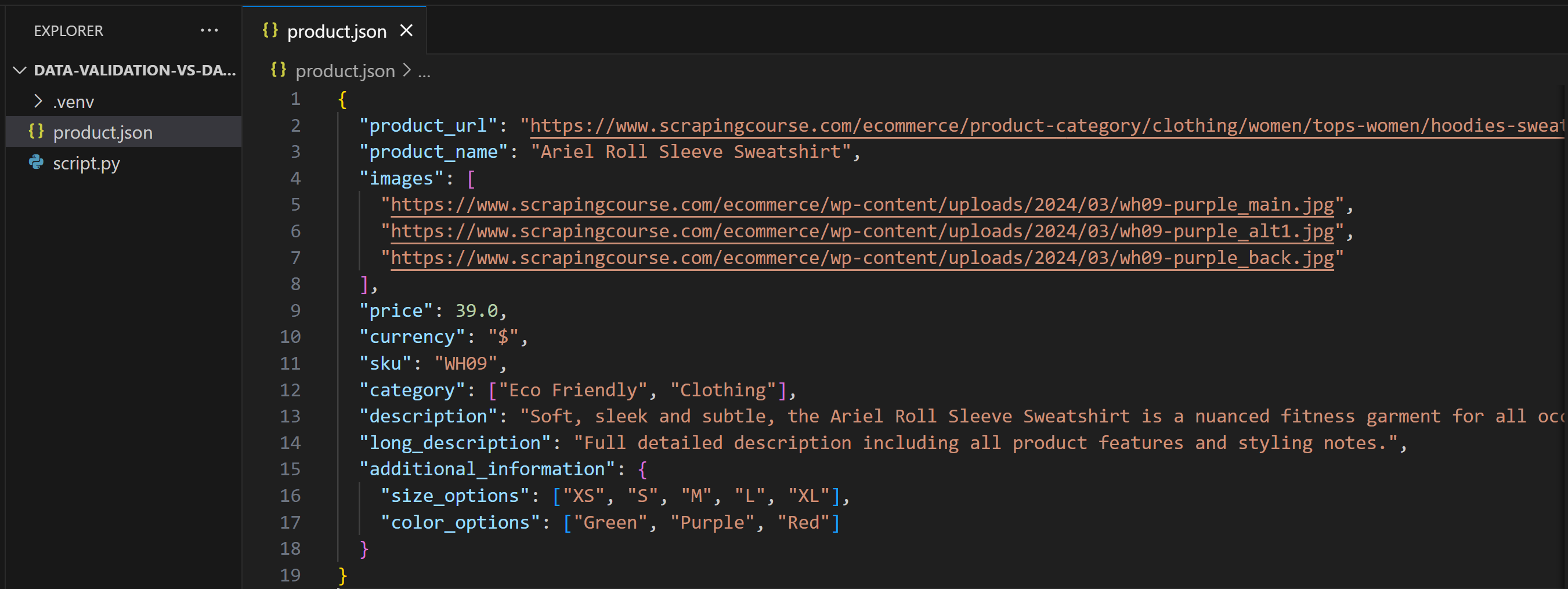
Wenn Sie das Skript diesmal ausführen, wird Folgendes ausgegeben:

Großartig! Die Datenvalidierung wurde erfolgreich durchgeführt. Sobald die Daten validiert wurden, können Sie mit der Verarbeitung fortfahren, sie in einer Datenbank speichern oder andere Vorgänge durchführen.
Datenüberprüfung: Die Grundlagen erklärt
Setzen wir diesen Leitfaden zum Thema Datenvalidierung vs. Datenüberprüfung fort und konzentrieren uns auf die zweite Technik: die Datenüberprüfung.
Was ist Datenüberprüfung und warum ist sie wichtig?
Bei der Datenüberprüfung wird überprüft, ob die Daten korrekt sind und die tatsächlichen Gegebenheiten widerspiegeln. Dazu werden die Informationen mit zuverlässigen Quellen abgeglichen.
Im Gegensatz zur Datenvalidierung, bei der nur überprüft wird, ob Daten vordefinierten Regeln entsprechen (z. B. ob eine E-Mail-Adresse korrekt formatiert ist), bestätigt die Verifizierung, dass die Daten wahrheitsgemäß sind und der Realität entsprechen (z. B. dass die E-Mail tatsächlich existiert und der vorgesehenen Person gehört).
Die Verifizierung von Daten ist entscheidend für die Durchsetzung der Datenqualität, insbesondere wenn es um die Bedeutung der Informationen geht. Schließlich können auch gut strukturierte, scheinbar saubere Daten falsche Informationen enthalten. Das Verlassen auf ungenaue Daten kann zu kostspieligen Fehlern, fehlerhaften Entscheidungen, schlechten Kundenerfahrungen und betrieblichen Ineffizienzen führen.
Beispiele für Datenüberprüfungen
Die Datenüberprüfung kann schwierig sein, und der richtige Ansatz hängt stark von den Eingabedaten und dem Bereich ab, in dem Sie tätig sind. Dennoch gibt es einige gängige Überprüfungsmethoden, darunter
- Automatisierte Überprüfung: Verwendung spezieller Software, Dienste von Drittanbietern oder agentenbasierter KI-Systeme, um Daten mit vertrauenswürdigen Quellen abzugleichen.
- Korrekturlesen: Manuelle Überprüfung von Dokumenten, Daten oder Datenfeldern, um sicherzustellen, dass sie präzise Informationen enthalten. Dies kann manuell durch Menschen unter Verwendung ihres Fachwissens zu einem Thema oder automatisch durch KI erfolgen.
- Doppelte Eingabe: Zwei separate Systeme (oder autonome KI-Agenten) geben unabhängig voneinander Daten zum gleichen Thema ein. Die Datensätze werden dann verglichen und etwaige Abweichungen zur Überprüfung oder Korrektur markiert.
- Überprüfung der Quelldaten: Vergleichen Sie die in einer Datenbank gespeicherten Daten mit den Originalquelldokumenten (z. B. Patientenakten), um sicherzustellen, dass sie übereinstimmen.
Wann sollte dies durchgeführt werden?
Eine Datenüberprüfung sollte immer dann durchgeführt werden, wenn Sie der Datenquelle nicht vollständig vertrauen. Ein gängiges Beispiel ist die Verwendung von KI zur Generierung oder Anreicherung von Daten, wodurch plausibel erscheinende, aber ungenaue Informationen entstehen können.
Ein weiteres Szenario, in dem die Datenüberprüfung wichtig ist, ist die Übertragung oder Speicherung von Daten, z. B. bei Migrationen oder Konsolidierungen. Nach solchen Aufgaben müssen Sie sicherstellen, dass die resultierenden Daten korrekt bleiben. Die Überprüfung von Daten ist auch im Rahmen der laufenden Datenqualitätspflege relevant.
Beachten Sie, dass die Datenüberprüfung in der Regel auf die Datenvalidierung folgt. Wenn die Struktur der Daten nicht dem erwarteten Format entspricht, ist eine Überprüfung sinnlos, da die Daten möglicherweise überhaupt nicht verwendbar sind. Erst nachdem die Daten die Validierung durchlaufen haben, ist es sinnvoll, mit der Überprüfung fortzufahren.
Die Überprüfung von Daten ist sicherlich komplexer als ihre Validierung, da Sie keine deterministischen Ergebnisse erhalten können (wie zuvor mit einem einfachen Python-Skript gezeigt). Das liegt daran, dass es sehr schwierig ist, mit absoluter Sicherheit festzustellen, ob die Informationen wahr sind.
Die besten Ansätze zur Datenüberprüfung
Bei von Benutzern eingereichten Inhalten ist die beste Methode zur Überprüfung die manuelle Überprüfung durch einen Menschen. Beispiele hierfür sind:
- E-Mail-Verifizierung: Nachdem ein Benutzer bei der Registrierung eine E-Mail-Adresse eingegeben hat, wird eine automatische E-Mail mit einem Bestätigungslink oder -code gesendet, um sicherzustellen, dass die Adresse gültig und zugänglich ist.
- Telefonnummernüberprüfung: Ein Einmalpasswort (OTP) wird per SMS oder Telefonanruf gesendet, um zu bestätigen, dass die Nummer gültig und aktiv ist und dem Benutzer gehört.
Ebenso können Sie Benutzer auffordern, Dokumente oder Rechnungen zur Identitäts- oder Adressüberprüfung einzureichen. Diese Dokumente können mit OCR-Systemen verarbeitet werden, um zu überprüfen, ob die vom Benutzer eingegebenen Daten mit den Informationen auf den hochgeladenen Dokumenten übereinstimmen. Dieser Ansatz ist zwar immer noch anfällig für Betrug, aber sehr nützlich, um die Zuverlässigkeit der Daten zu erhöhen.
Die eigentliche Herausforderung besteht darin, öffentliche Daten aus dem Internet abzurufen, der größten und unstrukturiertesten Informationsquelle. In diesem Fall ist es schwierig zu bestimmen, ob die Informationen korrekt sind. Der allgemeine Ansatz besteht darin, vertrauenswürdigen Quellen (z. B. Dokumentationen, offiziellen Erklärungen) Vorrang einzuräumen und bei bestimmten Eingaben deren Herkunft zurückzuverfolgen, sie online mit zuverlässigen Quellen abzugleichen und die Ergebnisse zu vergleichen.
Dies manuell zu tun, ist äußerst zeitaufwändig, weshalb viele dieser Aufgaben heute mithilfe von KI-Agenten automatisiert werden, die mit Tools für die Suche und das Web-Scraping von Webdaten ausgestattet sind.
So überprüfen Sie Daten: Python-Beispiel
In diesem Abschnitt finden Sie ein Schritt-für-Schritt-Beispiel für die Erstellung eines KI-Agenten zur Datenüberprüfung. Der Agent wird:
- Nimmt einen Beispieltext als Eingabe entgegen.
- Die Informationen an ein LLM weiterleiten, das um Tools für die Websuche und das Web-Scraping erweitert wurde.
- Bittet die KI, die Hauptthemen im Quelltext zu identifizieren und bei Google nach relevanten, vertrauenswürdigen Seiten zu suchen, um die Richtigkeit zu überprüfen.
- Informationen von diesen Seiten scrapen und mit dem Quelltext vergleichen.
- Erstellt einen Bericht, der angibt, ob die Daten korrekt sind, und schlägt gegebenenfalls Korrekturen vor.
Ein solcher Arbeitsablauf wäre ohne eine KI-fähige Infrastruktur, die das Abrufen von Webdaten, die Suche, die Interaktion und vieles mehr unterstützt, nicht möglich – wie beispielsweise die KI-Infrastruktur von Bright Data.
Für eine einfachere Integration verwenden wir Bright Data Web MCP, das über 60 Tools bietet. Insbesondere umfasst die kostenlose Version diese beiden Tools:
search_engine: Ruft Suchergebnisse von Google, Bing oder Yandex in JSON oder Markdown ab.scrape_as_markdown: Scrapen Sie beliebige Webseiten in ein sauberes Markdown-Format und umgehen Sie dabei Bot-Erkennung und CAPTCHA.
Diese beiden Tools reichen aus, um den Datenüberprüfungsagenten zu betreiben und das Ziel zu erreichen!
Szenariobeschreibung
Angenommen, Sie haben einige Eingabedaten in einer Datei summary.txt, deren Richtigkeit Sie überprüfen möchten. Diese enthält beispielsweise eine kurze Zusammenfassung des Super Bowl LIX:

Sie erstellen einen Datenüberprüfungsagenten mit LangChain, das in Web MCP integriert ist. Dazu benötigen Sie:
- Python lokal installiert.
- Ein eingerichtetes LangChain-Projekt.
- Einen Bright Data API-Schlüssel zur Authentifizierung Ihrer Verbindung zu Web MCP.
- Einen OpenAI-API-Schlüssel.
Bevor Sie beginnen, lesen Sie unser Tutorial zur Verwendung des LangChain MCP-Adapters für die Integration mit Bright Data’s Web MCP. Wenn Sie andere Frameworks oder Tools bevorzugen, lesen Sie diese Anleitungen:
- Erstellen von Web-Scraping-Agenten mit CrewAI und dem Model Context Protocol (MCP) von Bright Data
- Erstellen eines CLI-Chatbots mit LlamaIndex und Bright Data MCP
- Integration von Claude Code mit Bright Data Web MCP
- So erstellen Sie einen RAG-Chatbot mit GPT-4o unter Verwendung von SERP-Daten
Erstellen eines KI-Agenten zur Datenüberprüfung
So können Sie den Datenüberprüfungsagenten mit LangChain und Bright Data’s Web MCP erstellen:
# pip install langchain["openai"] langchain-mcp-adapters langgraph
import asyncio
import os
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_API_KEY>" # Ersetzen Sie dies durch Ihren OpenAI-API-Schlüssel
from langchain_openai import ChatOpenAI
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from langchain_mcp_adapters.tools import load_mcp_tools
from langgraph.prebuilt import create_react_agent
async def main():
# Lade die Eingabedaten zur Überprüfung
input_file_name = "summary.txt"
with open(input_file_name, "r", encoding="utf-8") as f:
summary_data_to_verify = f.read()
# Initialisieren Sie die LLM-Engine.
llm = ChatOpenAI(
model="gpt-5-nano",
)
# Konfiguration für die Verbindung mit einer lokalen Bright Data Web MCP-Serverinstanz
server_params = StdioServerParameters(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": "<YOUR_BRIGHT_DATA_API_KEY>", # Durch Ihren Bright Data API-Schlüssel ersetzen
}
)
# Verbindung zum MCP-Server herstellen
async with stdio_client(server_params) as (read, write):
async with ClientSession(read, write) as session:
# MCP-Client-Sitzung initialisieren
await session.initialize()
# MCP-Tools abrufen
tools = await load_mcp_tools(session)
# Erstellen Sie den ReAct-Agenten.
agent = create_react_agent(llm, tools)
# Beschreibung der Agentenaufgabe.
input_prompt = f"""
Führen Sie anhand der folgenden Eingabe die folgenden Schritte aus:
1. Identifizieren Sie das Hauptthema als eine Google-ähnliche Suchanfrage und verwenden Sie es, um eine Websuche durchzuführen und Informationen darüber zu sammeln.
2. Wählen Sie aus den Suchergebnissen die 2/3 besten zuverlässigen Quellen aus (z. B. vertrauenswürdige Nachrichtenseiten, Zeitschriften, offizielle Veröffentlichungen).
3. Scrape den Inhalt der ausgewählten Seiten.
4. Vergleiche die gescrapten Informationen mit dem Eingabeinhalt, um festzustellen, ob sie korrekt sind.
5. Wenn sie nicht korrekt sind, erstelle einen Bericht, in dem alle im Eingabeinhalt gefundenen Fehler zusammen mit den korrigierten Informationen und Links zu den unterstützenden Quellen aufgeführt sind.
Eingabeinhalt:
{summary_data_to_verify}
"""
# Die Antwort des Agenten streamen
async for step in agent.astream({"messages": [input_prompt]}, stream_mode="values"):
step["messages"][-1].pretty_print()
if __name__ == "__main__":
asyncio.run(main())Konzentrieren Sie sich auf die Eingabeaufforderung selbst, da sie der wichtigste Teil des obigen Skripts ist.
Agent ausführen
Starten Sie Ihren Agenten, und Sie werden sehen, dass er das Hauptthema korrekt als „Super Bowl LIX“ identifiziert. Anschließend führt er eine Google-Suche mit dem Toolsearch_engine von Web MCP durch:

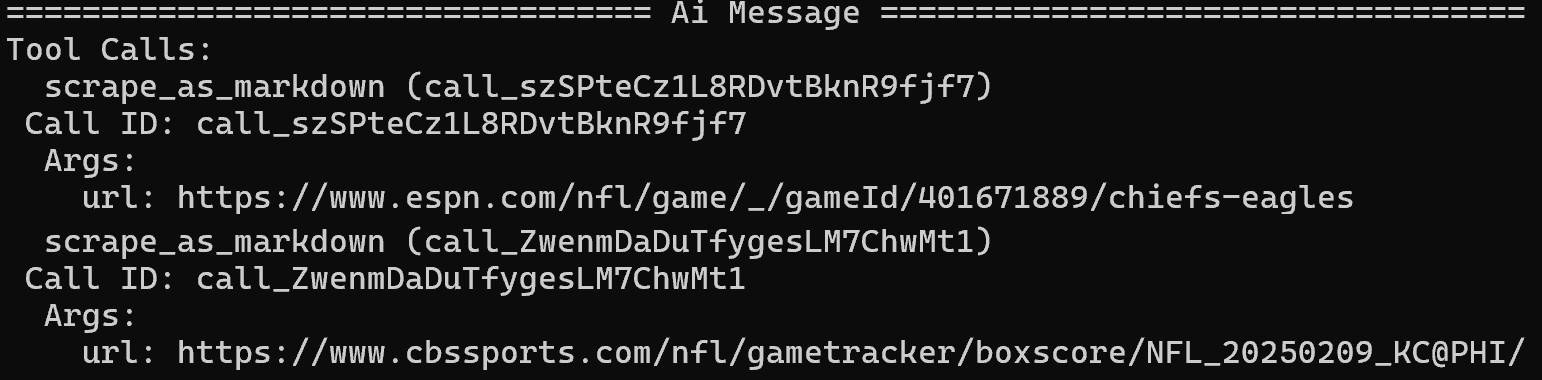
Aus den SERP-Ergebnissen identifiziert er Artikel von ESPN und CBS Sports als primäre Quellen und scrapt sie mit dem Tool scrape_as_markdown:
Nach dem Extrahieren der Inhalte aus den drei Nachrichtenquellen erstellt er den folgenden Markdown-Bericht:
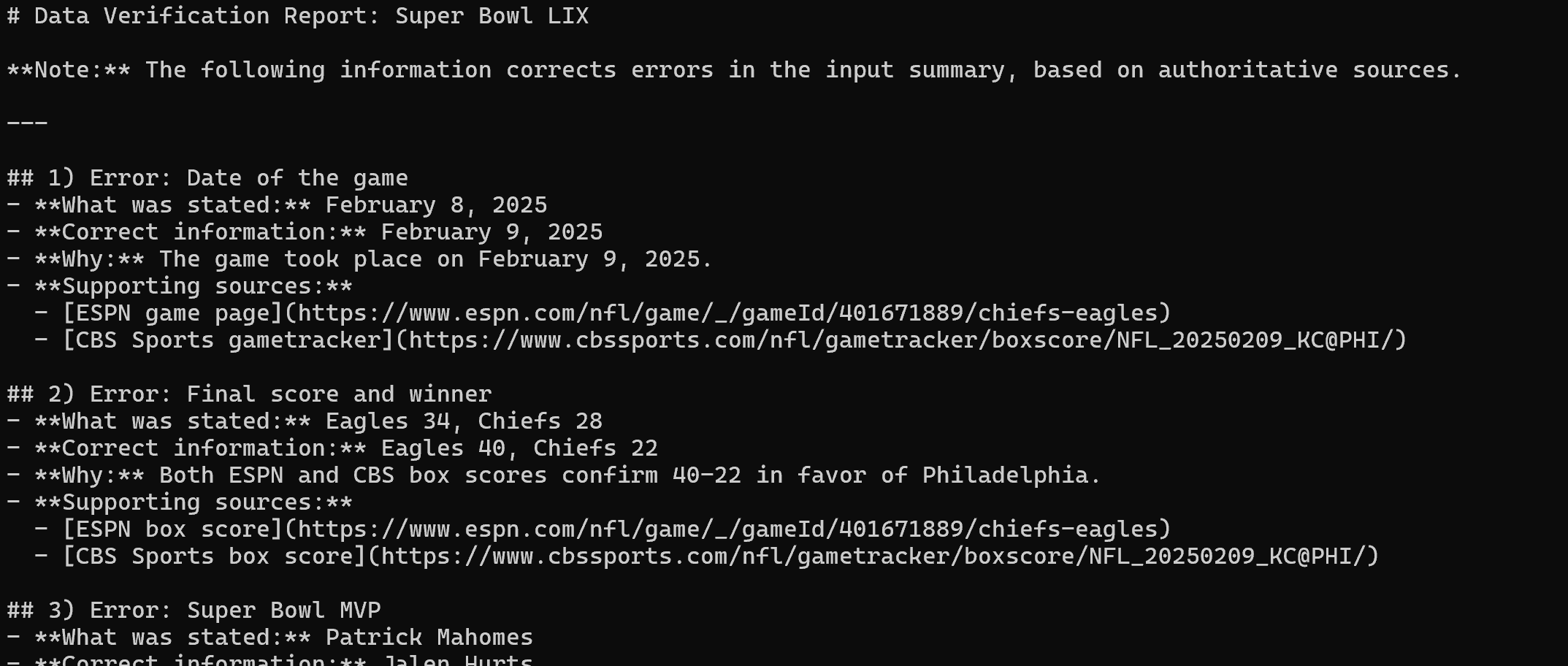
Rendern Sie ihn in Visual Studio Code, um den endgültigen Bericht anzuzeigen.
Wie Sie sehen können, konnte der LangChain-Agent dank der Web-Such- und Web-Scraping-Funktionen von Web MCP alle Fehler im ursprünglichen fehlerhaften Text identifizieren. Mission erfüllt!
Datenvalidierung vs. Datenverifizierung: Übersichtstabelle
Vergleichen Sie die beiden Techniken in der folgenden Übersichtstabelle zur Datenvalidierung vs. Datenverifizierung:
| Aspekt | Datenvalidierung | Datenverifizierung |
|---|---|---|
| Definition | Überprüft die Genauigkeit, Qualität und Integrität von Daten anhand vordefinierter Regeln und Standards vor der Verwendung oder Speicherung. | Bestätigt, dass die Daten die tatsächlichen Fakten korrekt widerspiegeln, indem sie mit maßgeblichen Quellen verglichen werden. |
| Zweck | Stellt sicher, dass Daten den erwarteten Formaten, Typen, Bereichen und Regeln entsprechen; verhindert, dass fehlerhafte Daten in Systeme gelangen. | Stellt sicher, dass die Daten wahrheitsgemäß, genau und vertrauenswürdig für die Entscheidungsfindung sind. |
| Zeitpunkt | Wird zum Zeitpunkt der Eingabe, nach der Extraktion, nach der Transformation oder in regelmäßigen Abständen durchgeführt. | Wird nach der Validierung oder immer dann durchgeführt, wenn die Zuverlässigkeit der Datenquelle ungewiss ist; in der Regel nach der Datenerfassung oder -übertragung. |
| Komplexität | Relativ einfach; deterministische Überprüfungen auf der Grundlage definierter Regeln. | Komplexer; kann Unsicherheiten, externe Quellen und manuelle Überprüfungen beinhalten; nicht deterministische Ergebnisse möglich. |
| Beispiel | Der Preis muss ≥ 0 sein. |
Überprüfen Sie, ob der Preis mit dem offiziellen Ladenangebot übereinstimmt. |
Abschließender Kommentar
Wie Sie in diesem Blogbeitrag zum Thema Datenvalidierung vs. Datenverifizierung erfahren haben, befassen sich Datenvalidierung und Datenverifizierung mit zwei unterschiedlichen, aber sich ergänzenden Aufgaben. Insbesondere tragen beide dazu bei, eine hohe Datenqualität zu erreichen. Ein weiterer ähnlicher Punkt ist, dass das Übersehen einer der beiden Aufgaben zu erheblichen Problemen bei datengesteuerten Prozessen führen kann, die die meisten Geschäftsabläufe unterstützen.
Aus diesem Grund ist es unverzichtbar, einen vertrauenswürdigen, zuverlässigen Datenanbieter zu wählen, der mehrere Lösungen für eine ordnungsgemäße Datenvalidierung anbietet und die Tools für den Aufbau eines effektiven Datenverifizierungssystems bereitstellt.
Bright Data ist ein hervorragendes Beispiel dafür. Das Unternehmen bietet eine breite Palette von Produkten, darunter gebrauchsfertige, validierte Datensätze und eine umfassende Auswahl an KI-fähigen Web-Scraping-Lösungen, um genaue Informationen aus dem Internet zu sammeln und sowohl Validierungs- als auch Verifizierungsworkflows zu unterstützen.
Registrieren Sie sich noch heute für ein kostenloses Bright Data-Konto und entdecken Sie unsere Datendienste!




