

Der Google KI-Modus stellt einen grundlegenden Wandel in der Darstellung von Suchergebnissen dar und bietet KI-gestützte Antworten, die Informationen aus mehreren Quellen zusammenfassen. Für Unternehmen, die ihre digitale Präsenz verfolgen, für Competitive Intelligence-Teams und SEO-Experten bietet dieses neue Suchformat sowohl Chancen als auch Herausforderungen bei der Datenextraktion.
In diesem umfassenden Leitfaden erfahren Sie, was der Google KI-Modus ist, warum das Scrapen dieser Daten einen strategischen Geschäftswert darstellt, welche technischen Herausforderungen Sie zu bewältigen haben und welche manuellen und automatisierten Ansätze es gibt, um diese Informationen effizient und in großem Umfang zu extrahieren.
Was ist der Google AI-Modus?
Der Google KI-Modus ist die neuere Suchfunktion von Google, die synthetische, konversationelle Antworten am Anfang der Suchergebnisse liefert und es den Nutzern ermöglicht, natürliche Folgefragen zu stellen. Jede Antwort enthält prominente Quellenlinks, die es einfach machen, zu den zugrunde liegenden Inhalten zu springen.
Unter der Haube nutzt AI Mode Gemini zusammen mit den Google-Suchsystemen unter Verwendung eines “Query Fan-out”-Ansatzes. Bei dieser Technik werden Fragen in Unterthemen unterteilt und mehrere verwandte Suchvorgänge parallel ausgeführt, so dass mehr relevantes Material gefunden wird, als dies bei herkömmlichen Einzelanfragen möglich ist.
Hier sehen Sie ein Beispiel für die Beantwortung einer Suchanfrage durch den Google AI Mode mit zitierten Quellen (rechts), auf die Nutzer klicken können, um weitere Details zu erfahren:
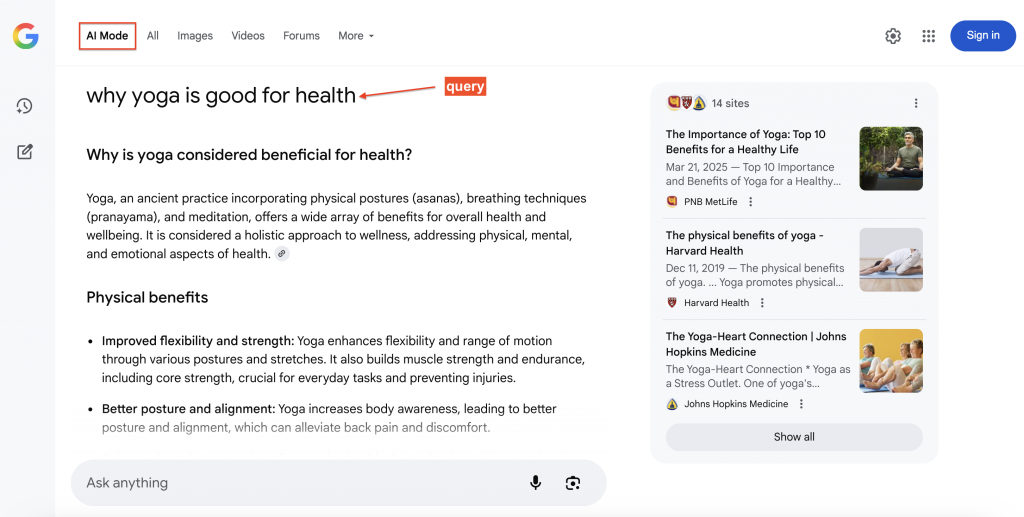
Warum Google AI Mode-Daten auslesen?
Die Daten von Google AI Mode bieten messbare Erkenntnisse, die sich erheblich auf SEO, Produktentwicklung und Wettbewerbsforschung auswirken.
- Verfolgung des Zitationsanteils. Überwachen Sie, auf welche Domains Google AI für Ihre Zielanfragen verweist, einschließlich der Rangfolge und Häufigkeit im Laufe der Zeit. Dies gibt Aufschluss über die thematische Autorität und hilft zu messen, ob inhaltliche Verbesserungen zu einer verstärkten Einbeziehung von KI-Antworten führen.
- Intelligente Konkurrenz. Erfassen Sie, welche Marken, Produkte oder Standorte in Empfehlungs- und Vergleichsanfragen auftauchen. Dies gibt Aufschluss über Marktpositionierung, Wettbewerbsdynamik und Attribute, die in KI-Antworten hervorgehoben werden.
- Analyse von Inhaltslücken. Vergleichen Sie die wichtigsten Fakten in KI-Modus-Antworten mit Ihren vorhandenen Inhalten, um Möglichkeiten für die Erstellung strukturierter Inhalte wie FAQs, Leitfäden oder Datentabellen zu ermitteln, die Zitate verdienen.
- Überwachung der Marke. Überprüfen Sie die von KI generierten Antworten zu Ihrer Marke oder Branche, um veraltete Informationen zu identifizieren und Ihre Inhalte entsprechend zu aktualisieren.
- Forschung und Entwicklung. Speichern Sie Antworten im KI-Modus mit Metadaten (Zeitstempel, Orte, Entitäten), um interne KI-Systeme zu unterstützen, Forschungsteams zu fördern und RAG-Anwendungen zu verbessern.
Methode 1 – manuelles Scraping mit Browser-Automatisierung
Das Scraping von Google AI Mode erfordert aufgrund der dynamischen, JavaScript-lastigen Natur von AI-generierten Inhalten eine ausgefeilte Browser-Automatisierung. Browser-Automatisierungs-Frameworks wie Playwright, Selenium oder Puppeteer verwenden echte Browser-Engines, um JavaScript auszuführen, auf das Laden von Inhalten zu warten und die menschliche Browser-Erfahrung zu replizieren – wichtig für die Erfassung von dynamisch generierten KI-Antworten.
So wird der Google AI-Modus in den Suchergebnissen angezeigt:
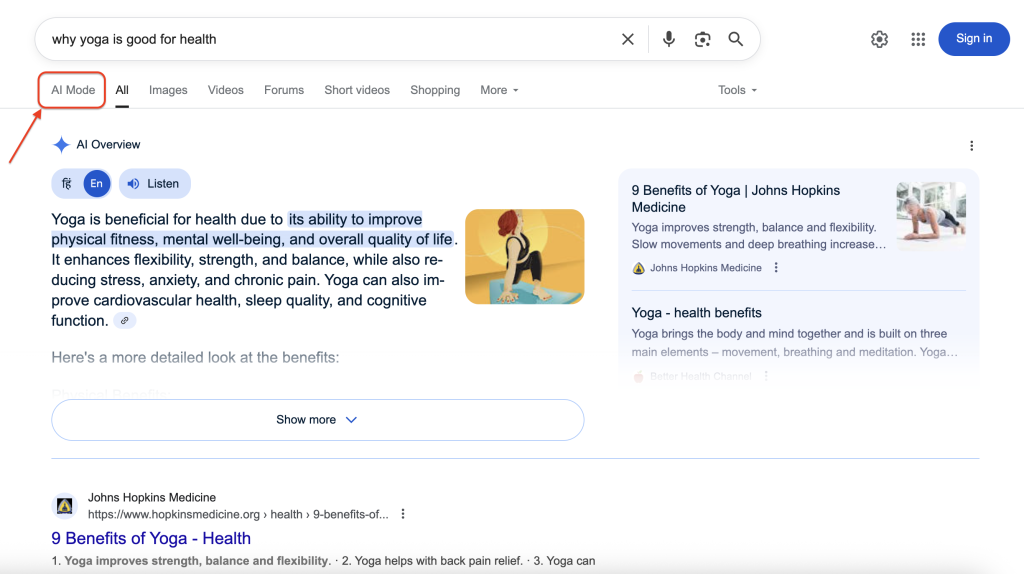
Wenn Sie auf den KI-Modus klicken, wird die vollständige Konversationsschnittstelle mit detaillierten Antworten und Quellennachweisen angezeigt. Unser Ziel ist es, programmatisch auf diese reichhaltigen, strukturierten Informationen zuzugreifen und sie zu extrahieren.
Schritt 1 – Einrichtung der Umgebung und Voraussetzungen
Installieren Sie die neueste Version von Python und dann die erforderlichen Abhängigkeiten. Für dieses Tutorial installieren Sie Playwright, indem Sie diese Befehle in Ihrem Terminal ausführen:
pip install playwright
playwright installierenDieser Befehl installiert Playwright und lädt die erforderlichen Browser-Binärdateien (für die Automatisierung benötigte Browser-Programme) herunter.
Schritt 2 – Abhängigkeiten importieren und einrichten
Importieren Sie die wesentlichen Bibliotheken für die Scraping-Aufgabe:
import asyncio
import urllib.parse
from playwright.async_api import async_playwrightAufschlüsselung der Bibliotheken:
- asyncio – ermöglicht asynchrone Programmierung für verbesserte Leistung und gleichzeitige Operationen.
- urllib.parse – behandelt die URL-Kodierung, um sicherzustellen, dass Abfragen für Webanfragen richtig formatiert sind.
- playwright – bietet Browser-Automatisierungsfunktionen, um mit Google wie ein menschlicher Benutzer zu interagieren.
Schritt 3 – Funktionsarchitektur und Parameter
Definieren Sie die wichtigste Scraping-Funktion mit klaren Parametern und Rückgabewerten:
async def scrape_google_ai_mode(query: str, output_path: str = "ai_response.txt") -> bool:Funktionsparameter:
- query – Suchbegriff, der an Google AI Mode übermittelt werden soll.
- output_path – Dateiziel zum Speichern der Antwort (Standardwert ist “ai_response.txt”).
- Gibt einen booleschen Wert zurück, der den Erfolg(True) oder Misserfolg(False) der Inhaltsextraktion angibt.
Schritt 4 – URL-Konstruktion und Aktivierung des AI-Modus
Konstruieren Sie die Such-URL, die die KI-Modus-Schnittstelle von Google auslöst:
url = f "https://www.google.com/search?q={urllib.parse.quote_plus(query)}&udm=50"Schlüsselkomponenten:
- urllib.parse.quote_plus(query) – kodiert die Suchanfrage sicher, indem Leerzeichen in “+” umgewandelt und Sonderzeichen umgangen werden.
- udm=50 – kritischer Parameter, der die KI-Modus-Schnittstelle von Google aktiviert.
Schritt 5 – Browser-Konfiguration und Anti-Erkennung
Starten Sie eine Browserinstanz, die so konfiguriert ist, dass sie eine Erkennung verhindert und gleichzeitig ein realistisches Verhalten beibehält:
async mit async_playwright() as pw:
browser = await pw.chromium.launch(
headless=False, args=["--disable-blink-features=AutomationControlled"]
)
Seite = await browser.new_page(
user_agent="Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
"AppleWebKit/537.36 (KHTML, wie Gecko) "
"Chrome/120.0.0.0 Safari/537.36"
)Einzelheiten zur Konfiguration:
- headless=False – zeigt das Browserfenster für die Fehlersuche an (für Produktionsumgebungen auf True setzen).
- -disable-blink-features=AutomationControlled – entfernt die Indikatoren für die Automatisierungserkennung.
- Benutzeragent – ahmt einen legitimen Chrome-Browser auf macOS nach, um die Wahrscheinlichkeit einer Bot-Erkennung zu verringern.
Diese Maßnahmen zum Schutz vor Erkennung lassen den Scraper als normalen Nutzer erscheinen, der in Google surft, und nicht als automatisiertes Skript.
Schritt 6 – Navigation und Laden von dynamischen Inhalten
Navigieren Sie zu der konstruierten URL und warten Sie, bis der dynamische Inhalt vollständig geladen ist:
await page.goto(url, wait_until="networkidle")
await page.wait_for_timeout(2000)Erklärung der Ladestrategie:
- wait_until=”networkidle ” – wartet, bis die Netzwerkaktivität aufhört, was bedeutet, dass die Seite vollständig geladen ist.
- wait_for_timeout – zusätzlicher Puffer für die Generierung von AI-Inhalten.
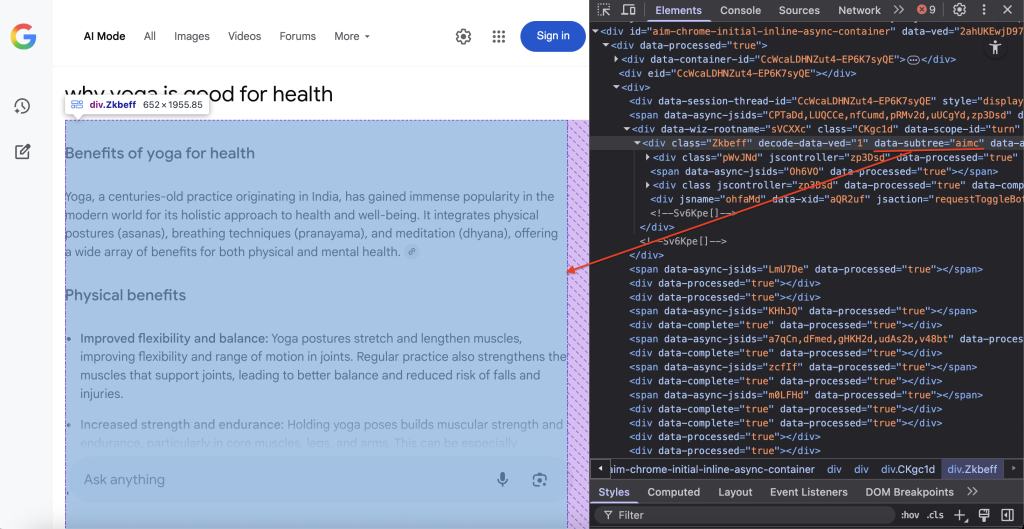
Schritt 7 – Auffinden von Inhalten und DOM-Extraktion
Ermitteln des spezifischen DOM-Containers, der den Inhalt des AI-Modus von Google enthält:
container = await page.query_selector('div[data-subtree="aimc"]')Der CSS-Selektor div[data-subtree=”aimc”] zielt auf den AIMC (AI Mode Container) von Google.
Schritt 8 – Datenextraktion und -speicherung
Extrahieren Sie den Textinhalt und speichern Sie ihn in der angegebenen Datei:
if container:
text = (await container.inner_text()).strip()
if text:
with open(output_path, "w", encoding="utf-8") as f:
f.write(text)
print(f "Gespeicherte AI-Antwort an '{output_path}' ({len(text):,} Zeichen)")
await browser.close()
return True
else:
print("AI-Modus-Container gefunden, enthält aber keinen Inhalt.")
else:
print("Kein AI-Modus-Inhalt auf der Seite gefunden.")
await browser.close()
return FalseProzessablauf:
- Überprüfen, ob der AI-Container auf der Seite vorhanden ist, indem das DOM abgefragt wird.
- Extrahieren des reinen Textinhalts ohne HTML-Markup mit inner_text().
- Speichern des Inhalts in der angegebenen Datei mit UTF-8-Kodierung.
- Ordnungsgemäßes Schließen der Browser-Ressourcen, um Speicherlecks zu vermeiden.
Schritt 9 – Ausführen der Scraping-Funktion
Führen Sie den kompletten Scraping-Vorgang aus, indem Sie die Funktion mit Ihrer gewünschten Abfrage aufrufen:
if __name__ == "__main__":
asyncio.run(scrape_google_ai_mode("warum Yoga gut für die Gesundheit ist"))Vollständiger Code
Hier ist der vollständige Code, der alle Schritte kombiniert:
import asyncio
import urllib.parse
from playwright.async_api import async_playwright
async def scrape_google_ai_mode(
query: str, output_path: str = "ai_response.txt"
) -> bool:
url = f "https://www.google.com/search?q={urllib.parse.quote_plus(query)}&udm=50"
async mit async_playwright() as pw:
browser = await pw.chromium.launch(
headless=False, args=["--disable-blink-features=AutomationControlled"]
)
Seite = await browser.new_page(
user_agent="Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
"AppleWebKit/537.36 (KHTML, wie Gecko) "
"Chrome/139.0.0.0 Safari/537.36"
)
await page.goto(url, wait_until="networkidle")
await page.wait_for_timeout(1000)
container = await page.query_selector('div[data-subtree="aimc"]')
if container:
text = (await container.inner_text()).strip()
if text:
with open(output_path, "w", encoding="utf-8") as f:
f.write(text)
print(
f "Gespeicherte AI-Antwort an '{output_path}' ({len(text):,} Zeichen)"
)
await browser.close()
return True
else:
print("AI-Modus-Container gefunden, aber leer.")
else:
print("Kein AI-Modus-Inhalt gefunden.")
await browser.close()
return False
if __name__ == "__main__":
asyncio.run(scrape_google_ai_mode("warum yoga gut für die gesundheit ist"))Bei erfolgreicher Ausführung erstellt dieses Skript eine Textdatei, die die extrahierte KI-Antwort enthält:

Great job! Sie haben erfolgreich Inhalte aus dem Google AI-Modus extrahiert.
Herausforderungen und Einschränkungen beim manuellen Scraping
Manuelles Scraping ist mit erheblichen operativen Herausforderungen verbunden, die bei größerem Umfang noch deutlicher werden.
- Anti-Bot-Erkennung und CAPTCHA-Überprüfung. Google setzt ausgeklügelte Erkennungsmechanismen ein, die automatisierte Verkehrsmuster identifizieren. Nach einer begrenzten Anzahl von Anfragen löst das System eine CAPTCHA-Prüfung aus, wodurch die weitere Datenerfassung effektiv blockiert wird.
- Komplexität der Infrastruktur und Wartung. Erfolgreiche groß angelegte Operationen erfordern verschiedene Techniken, um zu vermeiden, dass sie blockiert werden, z. B. qualitativ hochwertige Proxy-Netzwerke, Rotation des Nutzeragenten, Umgehung des Browser-Fingerprints und ausgeklügelte Strategien zur Verteilung von Anfragen. Dies verursacht einen erheblichen technischen Aufwand und laufende Wartungskosten.
- Dynamische Inhalte und Layoutänderungen. Google aktualisiert häufig seine Schnittstellenstruktur, was bestehende Parser über Nacht zerstören kann und sofortige Aufmerksamkeit und Codeaktualisierungen zur Aufrechterhaltung der Funktionalität erfordert.
- Komplexität des Parsings. Antworten im AI-Modus enthalten verschachtelte Strukturen, dynamische Zitate und variable Formatierungen, die eine ausgeklügelte Parsing-Logik erfordern. Die Aufrechterhaltung der Genauigkeit über verschiedene Antworttypen hinweg erfordert umfangreiche Tests und Fehlerbehandlung.
- Einschränkungen bei der Skalierbarkeit. Manuelle Ansätze haben Probleme mit der Massenverarbeitung, der Verwaltung gleichzeitiger Anfragen und der konsistenten Leistung in verschiedenen geografischen Regionen und vertikalen Suchbereichen.
Diese Einschränkungen machen deutlich, warum viele Unternehmen spezialisierte Lösungen bevorzugen, die die Komplexität professionell handhaben. Dies bringt uns zur Erkundung der speziell entwickelten Google AI Mode Scraper-API von Bright Data.
Methode 2 – Google AI Mode Scraper-API
Die Google AI Mode Scraper-API von Bright Data bietet eine produktionsreife Lösung, die die Komplexität der Scraping-Infrastruktur eliminiert und gleichzeitig Zuverlässigkeit und Leistung auf Unternehmensniveau bietet. Die API extrahiert umfassende Datenpunkte, einschließlich Antwort-HTML, Antworttext, angehängte Links, Zitate und 12 zusätzliche Felder.
Wichtigste Merkmale
- Automatisierte Antibot- und Proxy-Verwaltung. Die API nutzt das umfangreiche Proxy-Netzwerk von Bright Data mit über 150 Millionen IP-Adressen in Kombination mit fortschrittlichen Techniken zur Umgehung von Anti-Bots. Durch diese Infrastruktur werden CAPTCHA-Begegnungen und IP-Sperren vermieden.
- Strukturierte Datenausgabe. Die API liefert konsistent formatierte Daten in mehreren Exportformaten, einschließlich JSON, NDJSON und CSV für flexible Integrationsoptionen.
- Skalierbarkeit auf Unternehmensebene. Die API wurde für hochvolumige Operationen entwickelt und verarbeitet effizient Tausende von Abfragen mit einer vorhersehbaren Kostenskalierung durch unser Preismodell “Pay-per-Success-Result”.
- Geografische Anpassung. Durch die Angabe von Zielländern für standortspezifische Ergebnisse können Sie nachvollziehen, wie KI-Antworten in verschiedenen Märkten und bei verschiedenen Nutzerdemografien variieren.
- Wartungsfreier Betrieb. Unser Team überwacht den Scraper kontinuierlich und passt ihn an die Änderungen von Google an. Wenn Google die Schnittstellen des AI-Modus ändert oder neue Anti-Bot-Maßnahmen einführt, werden die Updates automatisch bereitgestellt, ohne dass Ihr Entwicklungsteam eingreifen muss.
Das Ergebnis ist eine umfassende Google AI Mode-Datenextraktion mit der Zuverlässigkeit eines Unternehmens und ohne Infrastruktur-Overhead.
Erste Schritte mit der Google AI Mode Scraper API
Der Implementierungsprozess umfasst die Einrichtung eines Kontos und die Generierung eines API-Schlüssels für neue Bright Data-Benutzer, gefolgt von der Auswahl Ihrer bevorzugten Integrationsmethode. Erstellen Sie Ihr kostenloses Bright Data-Konto, und generieren Sie Ihr API-Authentifizierungstoken in 4 einfachen Schritten.
Navigieren Sie anschließend zur Bright Data Web Scrapers Library, und suchen Sie nach “google”, um die verfügbaren Scraper-Optionen zu finden. Klicken Sie auf “google.com”.
Wählen Sie dann in der Benutzeroberfläche die Option “Google AI Mode Search” aus.
Der Scraper bietet sowohl No-Code- als auch API-basierte Implementierungsmethoden, um unterschiedlichen technischen Anforderungen und Teamfähigkeiten gerecht zu werden.
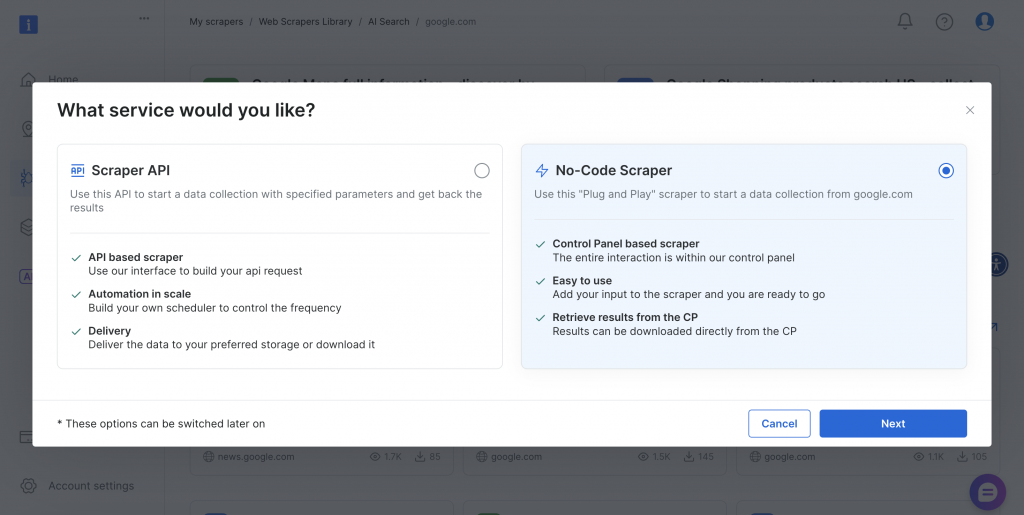
Schauen wir uns beide Ansätze an.
Interaktives Scrapen (No-Code Scraper)
Die webbasierte Schnittstelle bietet einen benutzerfreundlichen Ansatz für diejenigen, die nicht mit Code arbeiten möchten. Sie können Suchabfragen direkt über das Dashboard eingeben oder CSV-Dateien mit mehreren Abfragen zur Stapelverarbeitung hochladen. Die Plattform verarbeitet alles automatisch und liefert die Ergebnisse als herunterladbare Dateien.
Erforderliche Parameter:
- URL – standardmäßig auf https://google.com/aimode eingestellt (dieser Wert bleibt konstant).
- Prompt – Ihre Suchanfrage oder Frage für die KI-Analyse von Google.
- Land – geografischer Standort für regionsspezifische Ergebnisse (optional).
Zusätzliche Konfiguration:
- Zustellungseinstellungen – wählen Sie Ihr bevorzugtes Ausgabeformat und Ihre Zustellungsmethode.
- Benutzerdefiniertes Schema – Wählen Sie, welche Datenfelder in Ihren Export aufgenommen werden sollen.
- Stapelverarbeitung – Verarbeiten Sie mehrere Abfragen gleichzeitig per CSV-Upload.
Lassen Sie uns eine einfache Suche mit der Eingabeaufforderung “Wie Meditation die psychische Gesundheit fördert” mit “Indien” als Zielland durchführen. Klicken Sie auf die Schaltfläche “Sammlung starten”, um den Prozess zu beginnen.
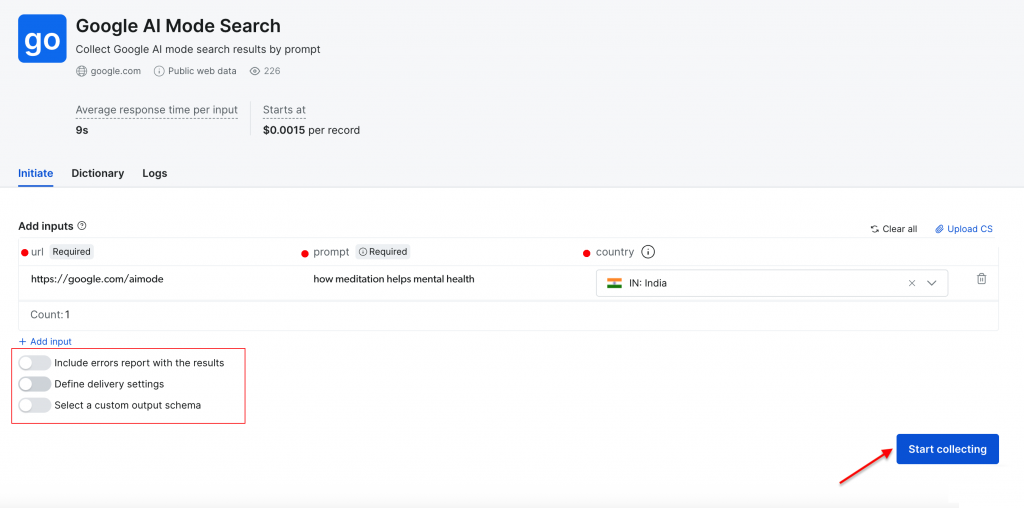
Auf dem Dashboard können Sie den Fortschritt in Echtzeit verfolgen(Fertig, läuft), und nach Abschluss können Sie Ihre Ergebnisse in Ihrem bevorzugten Format herunterladen.
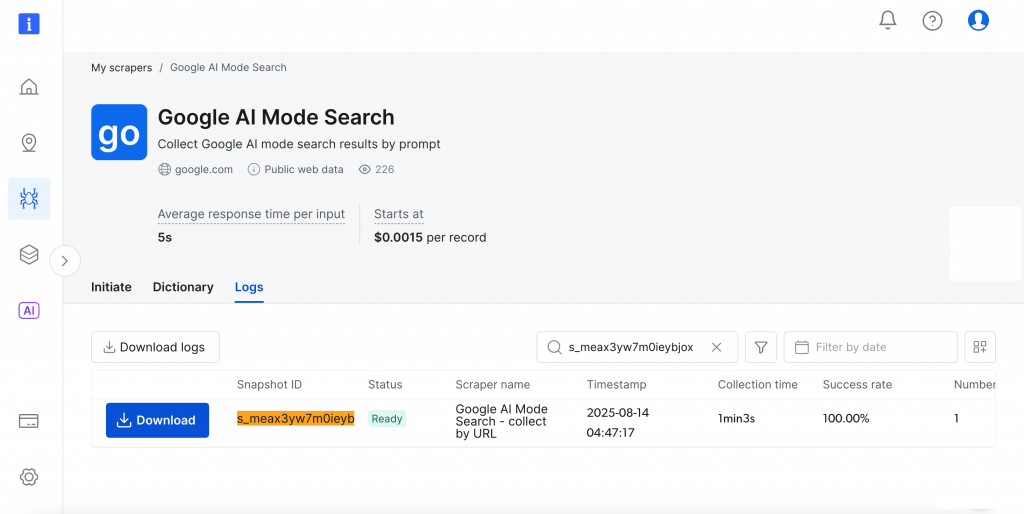
Ziemlich genial, oder?
API-basiertes Scraping (Scraper API)
Der programmatische Ansatz bietet mehr Flexibilität und Automatisierungsmöglichkeiten durch RESTful-API-Endpunkte. Die umfassende API-Anfrageerstellungs- und -Verwaltungsschnittstelle bietet volle Kontrolle über Ihre Scraping-Vorgänge:
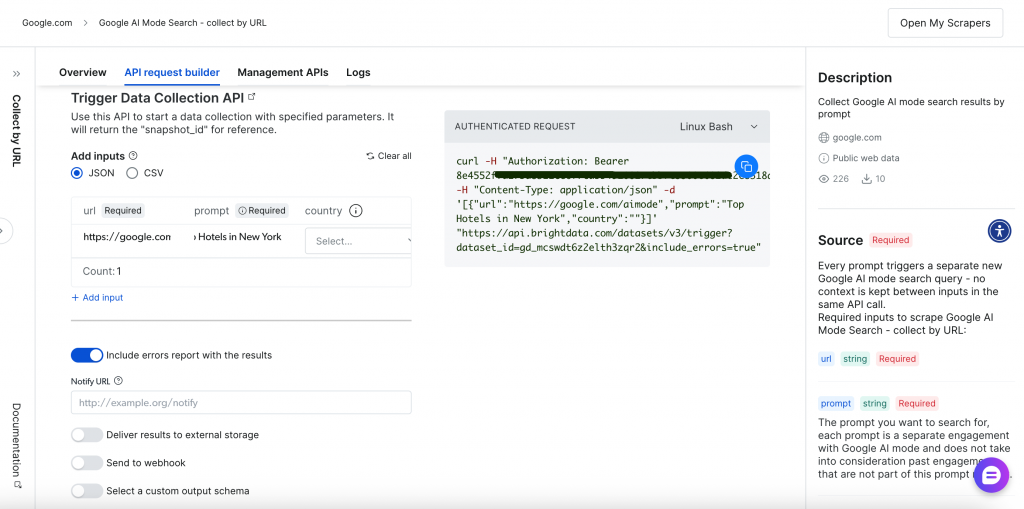
Lassen Sie uns den API-basierten Scraping-Prozess durchgehen.
Schritt 1 – Datenerfassung auslösen
Lösen Sie zunächst die Datenerfassung mit einer der folgenden Methoden aus:
Einzelne Abfrageausführung:
curl -H "Authorization: Bearer <YOUR_API_TOKEN>"
-H "Content-Type: application/json"
-d '[
{
"url": "https://google.com/aimode",
"prompt": "Gesundheitstipps für Computernutzer",
"Land": "US"
}
]'
"https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_mcswdt6z2elth3zqr2&include_errors=true"Stapelverarbeitung mit CSV-Upload:
curl -H "Authorization: Bearer <YOUR_API_TOKEN>"
-F 'data=@/path/to/your/queries.csv'
"https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_mcswdt6z2elth3zqr2&include_errors=true"Anforderungskomponenten:
- Authentifizierung – Überbringer-Token im Header für sicheren Zugriff.
- Dataset ID – spezifischer Bezeichner für Google AI Mode Scraper.
- Eingabeformat – JSON-Array oder CSV-Datei mit Abfrageparametern.
- Fehlerbehandlung – fügen Sie den Fehlerparameter für umfassendes Feedback ein.
Sie können auch Ihre Übermittlungsmethode über Webhook für die automatische Ergebnisbehandlung auswählen.
Schritt 2 – Auftragsfortschritt überwachen
Verwenden Sie die zurückgegebene Snapshot-ID, um den Fortschritt der Sammlung zu verfolgen:
curl -H "Authorization: Bearer <YOUR_API_TOKEN>"
"https://api.brightdata.com/datasets/v3/progress/<snapshot_id>"Die Antwort zeigt an, dass die Datenerfassung läuft und dass die Ergebnisse zum Herunterladen bereitstehen.
Schritt 3 – Ergebnisse herunterladen
Laden Sie den Inhalt des Snapshots herunter oder liefern Sie ihn an den angegebenen Speicherort. Rufen Sie die fertigen Ergebnisse in Ihrem bevorzugten Format ab:
curl -H "Authorization: Bearer <YOUR_API_TOKEN>"
"https://api.brightdata.com/datasets/v3/snapshot/<snapshot_id>?format=json"Die API gibt für jede Abfrage umfassende strukturierte Daten zurück:
{
"url": "https://www.google.co.in/search?q=health+tips+for+computer+users&hl=de&udm=50&aep=11&...",
"prompt": "Gesundheitstipps für Computernutzer",
"answer_html": "<html>...vollständige HTML-Antwort...</html>",
"answer_text": "Gesundheitstipps für Computernutzernn Längere Zeit vor einem Computer zu verbringen, kann zu verschiedenen gesundheitlichen Problemen führen, einschließlich Überanstrengung der Augen, Muskel-Skelett-Schmerzen und verminderter körperlicher Aktivität...",
"links_attached": [
{
"url": "https://www.aao.org/eye-health/tips-prevention/computer-usage",
"text": null,
"position": 1
},
{
"url": "https://uhs.princeton.edu/health-resources/ergonomics-computer-use",
"text": null,
"position": 2
}
],
"Zitate": [
{
"url": "https://www.ramsayhealth.co.uk/blog/lifestyle/five-healthy-tips-for-working-at-a-computer",
"title": null,
"description": "Ramsay Health Care",
"icon": "https://...icon-url...",
"domain": "https://www.ramsayhealth.co.uk",
"zitiert": false
},
{
"url": "https://my.clevelandclinic.org/health/diseases/24802-computer-vision-syndrome",
"title": null,
"description": "Cleveland Clinic",
"icon": "https://...icon-url...",
"domain": "https://my.clevelandclinic.org",
"zitiert": false
}
],
"Land": "IN",
"answer_text_markdown": "Gesundheitstipps für Computernutzer...",
"timestamp": "2026-08-07T05:02:56.887Z",
"input": {
"url": "https://google.com/aimode",
"prompt": "Gesundheitstipps für Computernutzer",
"Land": "IN"
}
}So einfach und effektiv!
Dieser unkomplizierte API-Workflow lässt sich nahtlos in jede Anwendung und jedes Projekt integrieren. Der Bright Data API Request Builder bietet außerdem Codebeispiele in mehreren Programmiersprachen für eine einfache Implementierung.
Fazit
Wir haben zwei Ansätze untersucht: eine Do-it-yourself-Lösung mit Python und Playwright und die schlüsselfertige Google AI Mode Scraper-API von Bright Data.
In der sich schnell entwickelnden Suchlandschaft, in der sich Algorithmen und Schnittstellen häufig ändern, ist eine robuste und gut gewartete Scraping-Infrastruktur von unschätzbarem Wert. Mit der API entfällt die Notwendigkeit, die Parsing-Logik ständig zu aktualisieren oder IP-Beschränkungen zu verwalten. So können Sie sich ganz auf die Analyse der umfangreichen KI-generierten Erkenntnisse aus den Google-Suchergebnissen konzentrieren und den maximalen Wert aus den Daten ziehen.
Das sollten Sie als nächstes tun
- Erweitern Sie Ihre Google-Datenerfassung. Da Sie bereits mit dem Google KI-Modus arbeiten, sollten Sie weitere Google-Datenquellen erforschen. Wir haben auch einen umfassenden Leitfaden zum Scraping von Google AI-Übersichten für eine breitere Abdeckung. Sie können auf spezielle Funktionen für Google News, Maps, Suche, Trends, Bewertungen, Hotels, Videos und Flüge zugreifen.
- Testen Sie ohne Risiko. Für alle Hauptprodukte gibt es kostenlose Testoptionen, und wir erstatten die ersten Einzahlungen mit bis zu 500 $. So haben Sie die Möglichkeit, erweiterte Funktionen auszuprobieren, bevor Sie eine Verpflichtung eingehen.
- Skalieren Sie mit integrierten Lösungen. Wenn Ihr Bedarf wächst, sollten Sie den Web MCP Server in Betracht ziehen, der KI-Anwendungen direkt mit Webdaten verbindet, ohne dass für jede Website eine eigene Entwicklung erforderlich ist. Beginnen Sie jetzt mit einem kostenlosen Plan mit 5.000 monatlichen Anfragen!
- Unternehmensinfrastruktur, wenn Sie bereit sind. Viele Teams beginnen mit einzelnen Projekten wie dem Ihren und benötigen später eine robuste Infrastruktur für einen größeren Betrieb. Die vollständige Plattform bietet die zugrunde liegende Infrastruktur, wenn Sie bereit sind, zu expandieren.
Sie sind sich nicht sicher, wie Sie vorgehen sollen? Sprechen Sie mit unserem Team – wir werden ihn für Sie planen.






