

In diesem Leitfaden erfahren Sie mehr:
- Was Pipedream ist und warum Sie es verwenden sollten.
- Der Grund, warum Sie es mit einem eingebauten Scraping-Plugin integrieren sollten.
- Vorteile der Integration von Pipedream mit der Bright Data Scraping-Architektur.
- Ein Schritt-für-Schritt-Tutorial zur Erstellung eines Web-Scraping-Workflows mit Pipedream.
Lasst uns eintauchen!
Pipedream auf einen Blick: Automatisieren und Integrieren mit Leichtigkeit
Pipedream ist eine Plattform zur Erstellung und Ausführung von Workflows, die verschiedene Anwendungen und Drittanbieter miteinander verbinden. Im Einzelnen bietet sie sowohl No-Code- als auch Low-Code-Funktionen. Dank dieser Funktionen können Sie Prozesse automatisieren und Systeme durch vorgefertigte Komponenten oder benutzerdefinierten Code integrieren.
Nachstehend finden Sie eine Aufschlüsselung der wichtigsten Merkmale:
- Visueller Workflow-Builder: Definieren Sie Workflows über eine visuelle Schnittstelle und verbinden Sie vorgefertigte Komponenten für beliebte Anwendungen. Derzeit bietet es Integrationen für mehr als 2700 Anwendungen.
- Kein Code/wenig Code: Es sind keine technischen Kenntnisse erforderlich. Für komplexe Anforderungen können die Anwendungen von Pipedream jedoch benutzerdefinierte Codeknoten enthalten. Unterstützte Programmiersprachen sind Node.js, Python, Go und Bash.
- Ereignisgesteuerte Architektur: Workflows werden durch Ereignisse wie HTTP/Webhooks, geplante Zeiten, eingehende E-Mails und andere ausgelöst. So bleibt der Workflow inaktiv und verbraucht keine Ressourcen, bis ein bestimmtes Auslöseereignis eintritt.
- Serverlose Ausführung: Die Kernfunktionalität von Pipedream dreht sich um seine serverlose Laufzeit. Das bedeutet, dass Sie keine Server bereitstellen oder verwalten müssen. Pipedream führt Workflows in einer skalierbaren, bedarfsgesteuerten Umgebung aus.
- KI zur Erstellung von Arbeitsabläufen: Deal with String, eine KI, die auf das Schreiben von benutzerdefinierten Agenten spezialisiert ist, bei denen Sie nur Eingabeaufforderungen einfügen müssen. Sie können sie auch verwenden, wenn Sie nicht besonders vertraut mit Pipedream sind. Sie können einen Prompt schreiben und die KI einen Workflow für Sie erstellen lassen.
Warum nicht einfach programmieren? Die Vorteile einer gebrauchsfertigen Scraping-Integration
Pipedream unterstützt Code-Aktionen. Diese ermöglichen es Ihnen, komplette Skripte von Grund auf in Ihrer bevorzugten Sprache (unter den unterstützten Sprachen) zu schreiben. Technisch bedeutet dies, dass Sie mit diesen Knoten einen Scraping-Bot vollständig in Pipedream erstellen können.
Andererseits wird dadurch der Aufbau eines Scraping-Workflows nicht unbedingt vereinfacht. Sie würden immer noch mit den üblichen Herausforderungen und Hindernissen im Zusammenhang mit dem Schutz vor Scraping konfrontiert.
Daher ist es praktischer, effektiver und schneller, sich auf ein integriertes Scraping-Plugin zu verlassen, das diese komplexen Aufgaben für Sie übernimmt. Genau das ist die Erfahrung, die die Bright Data-Integration in Pipedream bietet.
Im Folgenden finden Sie eine Liste der wichtigsten Gründe, warum Sie sich auf das gebrauchsfertige Bright Data Scraping Plugin verlassen sollten:
- Einfache Authentifizierung: Pipedream speichert Ihren Bright Data-API-Schlüssel (der für die Authentifizierung erforderlich ist) sicher und bietet Ihnen eine einfache Benutzerfreundlichkeit. Sie müssen keinen benutzerdefinierten Code für die Authentifizierung schreiben und können sicher sein, dass Sie Ihren Schlüssel nicht preisgeben.
- Überwindung von Anti-Bot-Systemen: Unter der Haube bewältigen Bright Data-APIs alle Herausforderungen des Web-Scrapings, von der Proxy-Rotation und IP-Verwaltung bis zum Lösen von CAPTCHAs und dem Parsen von Daten. Auf diese Weise wird sichergestellt, dass Ihr Pipedream-Workflow konsistente und hochwertige Webdaten erhält.
- Strukturierte Daten: Nach dem Scraping erhalten Sie strukturierte, organisierte Daten, ohne eine Zeile Code schreiben zu müssen. Das Plugin übernimmt die Strukturierung der Daten für Sie.
Die wichtigsten Vorteile der Kombination von Pipedream mit dem Bright Data Plugin
Wenn Sie die Pipedream-Automatisierungsfunktionen mit Bright Data verbinden, können Sie:
- Zugang zu frischen Daten: Der Zweck von Web Scraping besteht darin, Daten aus dem Internet abzurufen, und Bright Data hilft Ihnen dabei. Doch Daten ändern sich mit der Zeit. Wenn Sie also nicht wollen, dass Ihre Analysen veraltet sind, müssen Sie ständig neue Daten extrahieren. Hier kommt die Leistung von Pipedream zum Tragen (z. B. über Planungsauslöser).
- Integrieren Sie AI in Ihre Scraping-Workflows: Pipedream ist mit mehreren LLMs wie ChatGPT und Gemini integriert. Dadurch können Sie verschiedene Aufgaben automatisieren, die sonst stundenlange manuelle Arbeit erfordern würden. Zum Beispiel könnten Sie einen RAG-Workflow erstellen, um eine Liste von Konkurrenzprodukten auf einer E-Commerce-Website zu überwachen.
- Vereinfachen Sie die technischen Aspekte: Websites verwenden ausgeklügelte Anti-Scraping-Blockierungstechniken, die fast jede Woche aktualisiert werden. Die Bright Data-Integration umgeht diese Sperren für Sie, da sie sich um alle Anti-Bot-Lösungen kümmert.
Es wird Zeit, die Bright Data-Integration in einem Pipedream-Scraping-Workflow in Aktion zu sehen!
Aufbau eines KI-gestützten Scraping-Workflows mit Pipedream und Bright Data: Schritt-für-Schritt-Anleitung
In diesem geführten Abschnitt erfahren Sie, wie Sie einen Pipedream-Workflow erstellen, der Bright Data zum Abrufen von Daten aus einem Amazon-Produkt verwendet. Insbesondere wird die Zielseite sein:
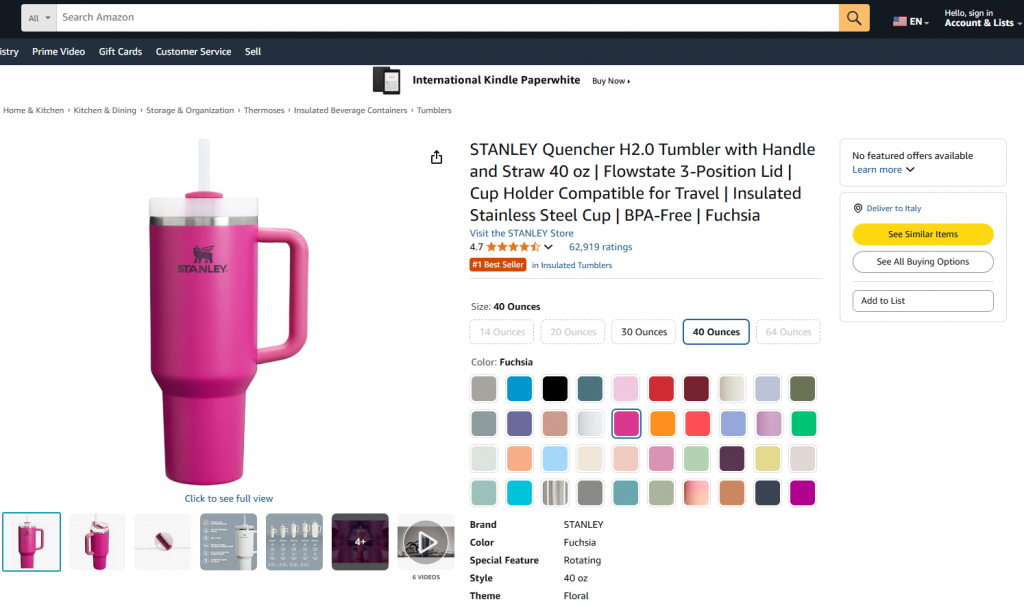
Ziel ist es, Ihnen zu zeigen, wie Sie einen Pipedream-Workflow erstellen können, der die folgenden Aufgaben erfüllt:
- Ruft die Daten von der Zielwebseite mithilfe der Bright Data-Integration ab.
- Nimmt die Daten in einen LLM auf.
- Er bittet den LLM, die Daten zu analysieren und daraus eine Produktzusammenfassung zu erstellen.
In den folgenden Schritten erfahren Sie, wie Sie einen solchen Workflow in Pipedream erstellen, testen und bereitstellen können.
Anforderungen
Zum Nachvollziehen dieses Tutorials benötigen Sie:
- Ein Pipedream-Konto (ein kostenloses Konto ist ausreichend).
- Ein Bright Data-API-Schlüssel.
- Ein OpenAI-API-Schlüssel.
Wenn Sie diese noch nicht haben, verwenden Sie die obigen Links und folgen Sie den Anweisungen, um alles einzurichten.
Es ist auch hilfreich, dieses Wissen zu haben, um dem Lernprogramm folgen zu können:
- Vertrautheit mit der Infrastruktur und den Produkten von Bright Data (insbesondere der Web Scraper API).
- Grundlegende Kenntnisse der KI-Verarbeitung (z. B. LLMs).
- Kenntnisse über die Funktionsweise von Triggern und API-Aufrufen über Webhooks.
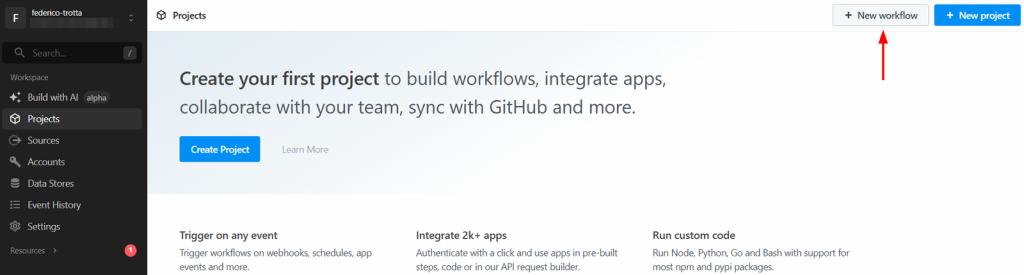
Schritt 1: Erstellen eines neuen Pipedream-Workflows
Melden Sie sich bei Ihrem Pipedream-Konto an und gehen Sie zu Ihrem Dashboard. Erstellen Sie dann einen neuen Workflow, indem Sie auf die Schaltfläche “Neuer Workflow” klicken:
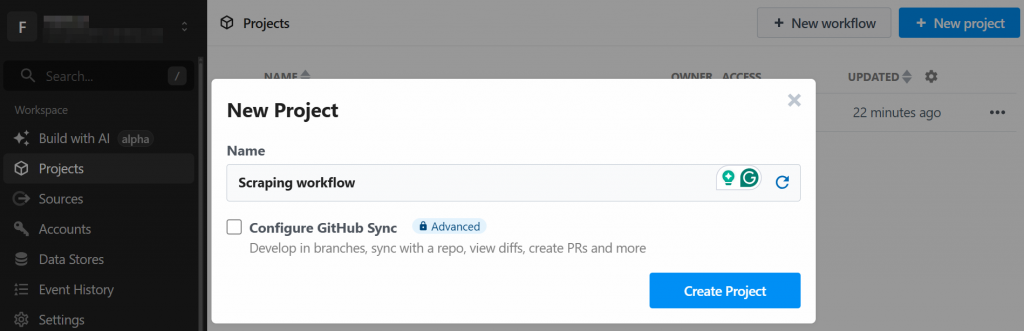
Das System wird Sie auffordern, ein neues Projekt zu erstellen. Geben Sie ihm einen Namen und klicken Sie anschließend auf die Schaltfläche “Projekt erstellen”:
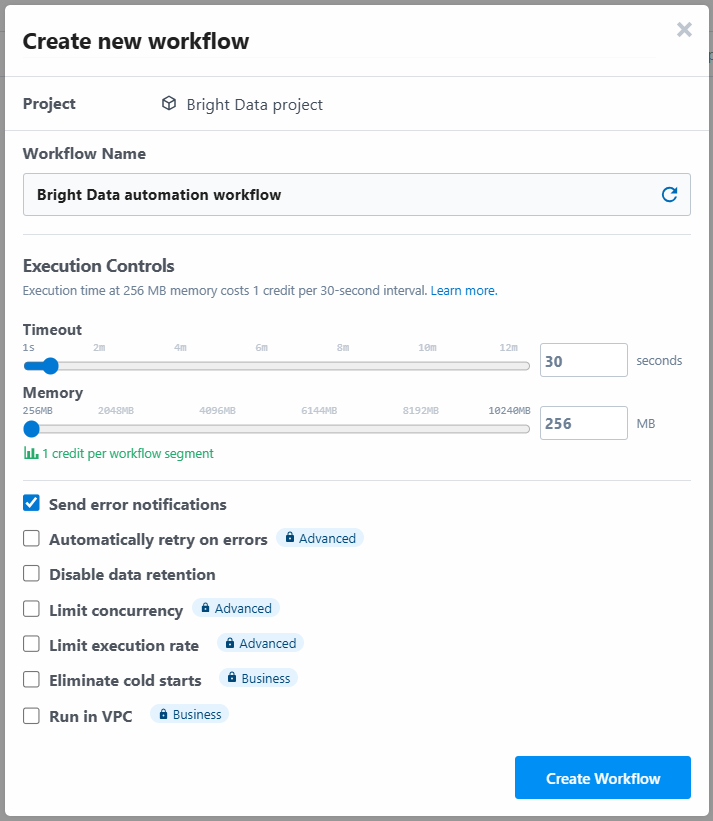
Das Tool fordert Sie auf, dem Workflow einen Namen zu geben und seine Einstellungen zu definieren. Sie können die Einstellungen so belassen, wie sie sind, und am Ende auf die Schaltfläche “Workflow erstellen” klicken:
Nachfolgend sehen Sie, wie die Benutzeroberfläche Ihres neuen Workflows aussieht:
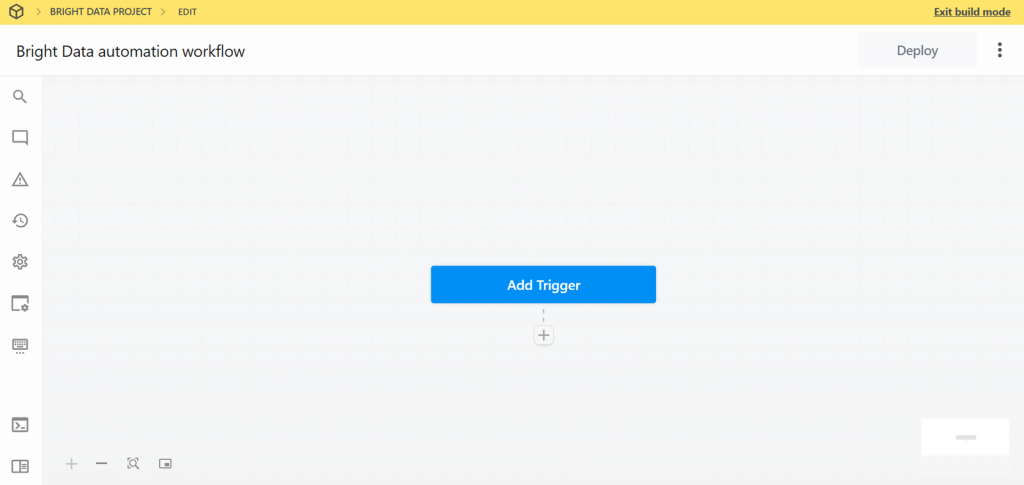
Sehr gut! Sie haben einen neuen Workflow in Pipedream erstellt. Sie können nun Plugin-Integrationen zu diesem Workflow hinzufügen.
Schritt #2: Auslöser hinzufügen
In Pipedream beginnt jeder Workflow mit einem Auslöser. Wenn Sie auf “Auslöser hinzufügen” klicken, werden Ihnen die Auslöser angezeigt, die Sie auswählen können:
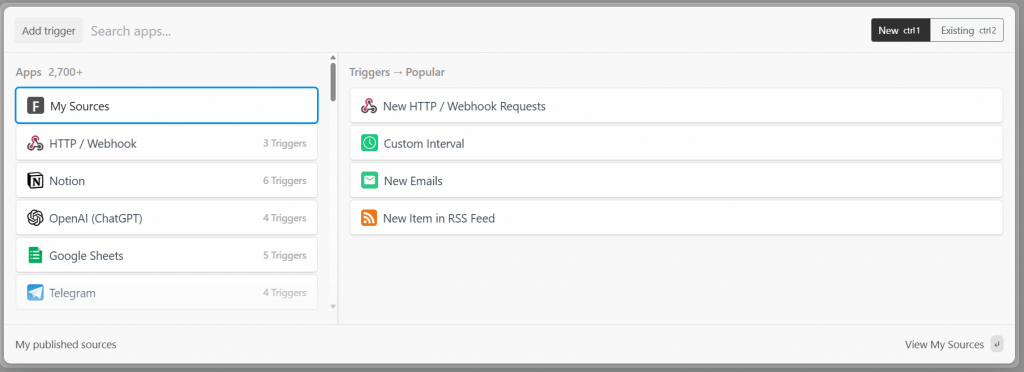
Wählen Sie in diesem Fall den Auslöser “Neue HTTP/Webhook-Anforderungen”, der für die Verbindung mit Bright Data erforderlich ist. Lassen Sie die Platzhalterdaten unverändert, und klicken Sie auf die Schaltfläche “Speichern und fortfahren”:
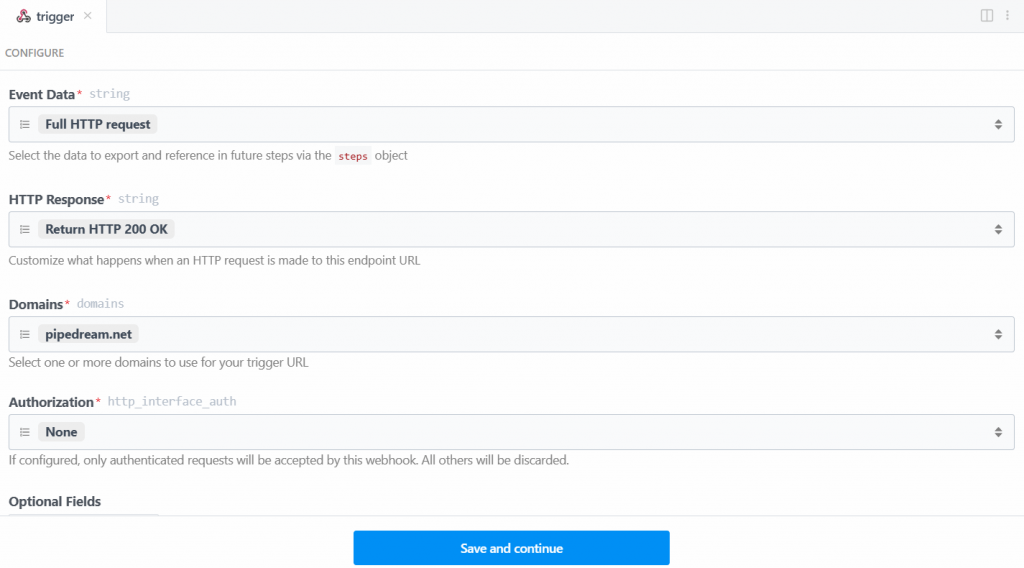
Damit der Auslöser funktioniert, müssen Sie ein Ereignis erzeugen. Klicken Sie also auf “Test-Ereignis generieren”:
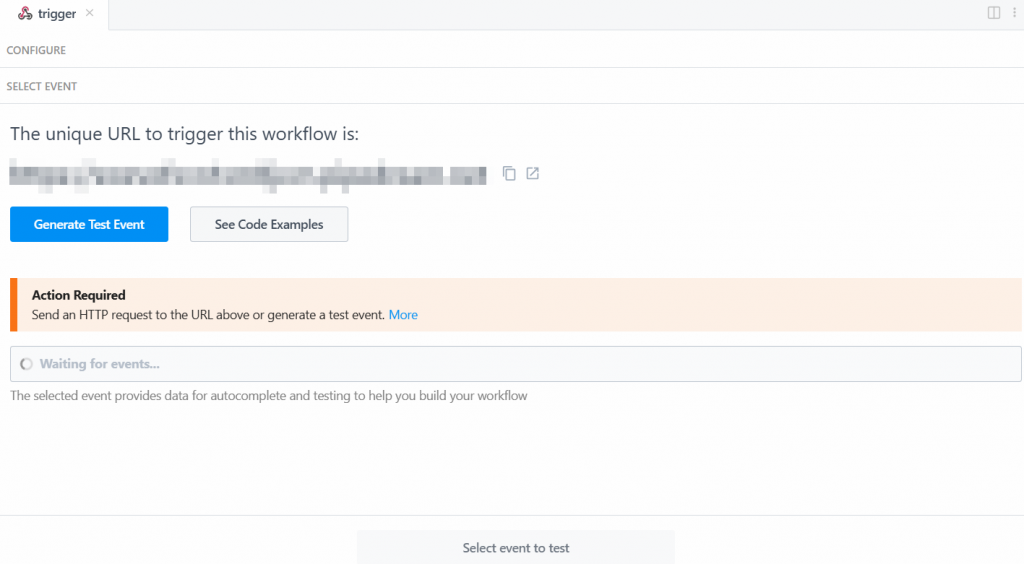
Das System stellt Ihnen einen vordefinierten Wert für ein Prüfereignis wie folgt zur Verfügung:
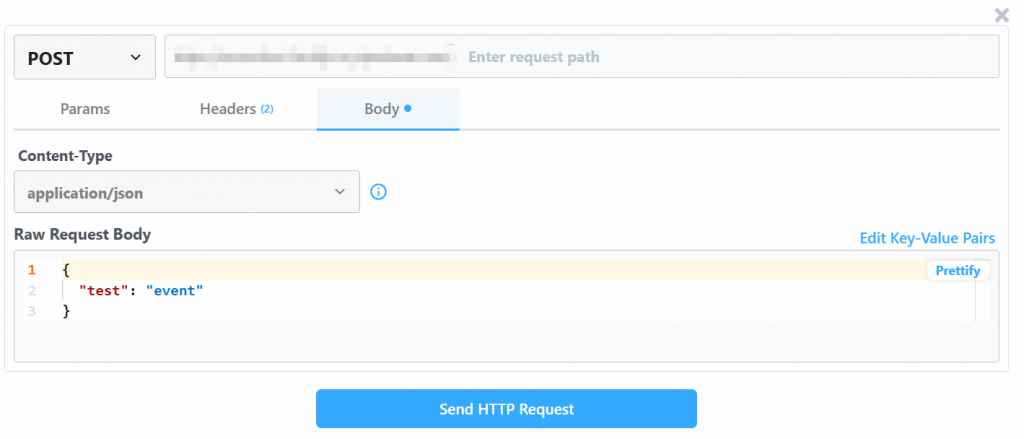
Ändern Sie den Wert “Raw Request Body” mit:
{
"url": "https://www.amazon.com/Quencher-FlowState-Stainless-Insulated-Smoothie/dp/B0CRMZHDG8",
"zipcode": "94107",
"language": ""
}Der Grund dafür ist, dass der von Pipedream generierte Auslöser den Aufruf der Amazon Scraper-API von Bright Data initiiert. Der Endpunkt (der später konfiguriert wird) erfordert Eingabedaten in diesem speziellen Payload-Format. Sie können dies überprüfen, indem Sie den Abschnitt “API Request Builder” des Scrapers “Collect by URL” in Bright Data’s Aamzon Web Scrapers überprüfen:
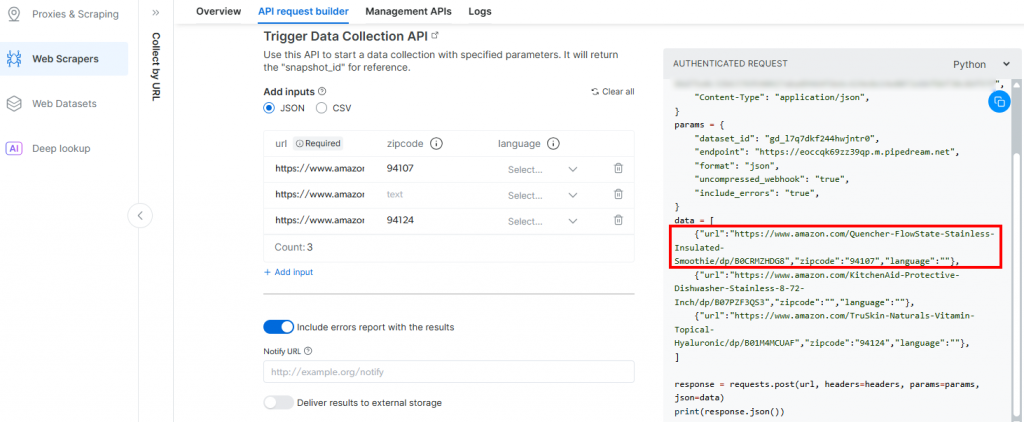
Kehren Sie zum Pipedream-Fenster zurück und klicken Sie anschließend auf die Schaltfläche “HTTP-Anfrage senden”. Wenn alles wie erwartet verläuft, wird im Ergebnisbereich eine Erfolgsmeldung angezeigt. Der Auslöser wird außerdem grün eingefärbt:
Perfekt! Der Auslöser für den Start der Bright Data-Integration im Pipedream-Scraping-Workflow wurde korrekt eingerichtet. Jetzt können Sie eine Aktion hinzufügen.
Schritt Nr. 3: Hinzufügen des Aktionsschritts “Helle Daten
Nach dem Auslöser können Sie einen Aktionsschritt in den Pipedream-Workflow einfügen. Jetzt müssen Sie den Schritt “Bright Data” mit dem Auslöser verbinden. Klicken Sie dazu auf das “+” unter dem Auslöser und suchen Sie nach “Bright Data”:
Pipedream bietet Ihnen mehrere Aktionen aus dem Bright Data Plugin. Wählen Sie sie aus, um sie alle zu sehen:
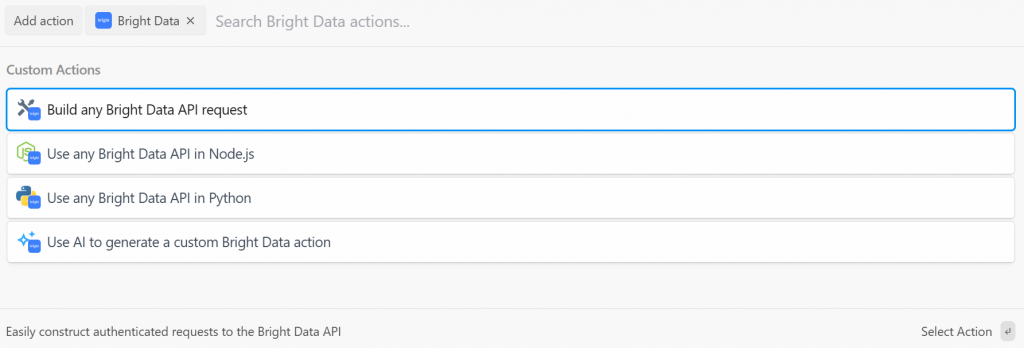
Sie haben die folgenden Möglichkeiten:
- Erstellen Sie beliebige Bright Data-API-Anfragen: Erstellen Sie authentifizierte Anforderungen an die APIs von Bright Data.
- Verwenden Sie jede Bright Data-API in Node.js/Python: Verbinden Sie Ihr Bright Data-Konto mit Pipedream und passen Sie die Anfragen in Node.js/Python an.
- Verwenden Sie AI, um eine benutzerdefinierte Bright Data-Aktion zu generieren: Bitten Sie AI, benutzerdefinierten Code für Bright Data zu generieren.
Wählen Sie für dieses Lernprogramm die Option “Use any Bright Data API in Python”. Sie werden Folgendes sehen:
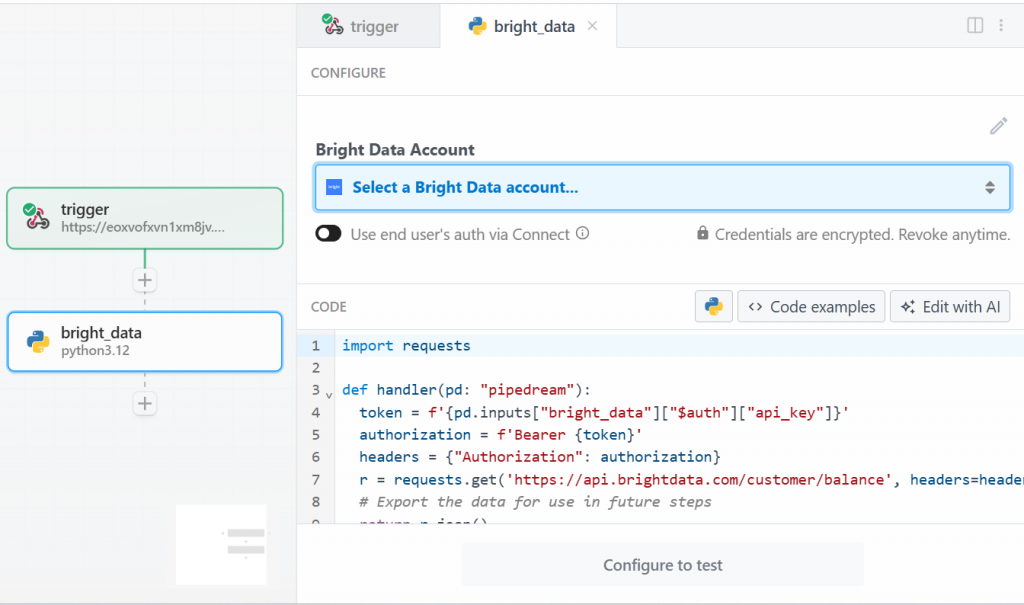
Klicken Sie zunächst unter “Bright Data-Konto” auf “Wählen Sie ein Bright Data-Konto aus”, und fügen Sie Ihren Bright Data-API-Schlüssel hinzu. Wenn Sie dies noch nicht getan haben, folgen Sie der offiziellen Anleitung zum Einrichten eines Bright Data-API-Schlüssels.
Löschen Sie dann den Code im Abschnitt “CODE” und schreiben Sie den folgenden Text:
import requests
import json
import time
def handler(pd: "pipedream"):
# Retrieve the Bright Data API key from Pipedream's authenticated accounts
api_key = pd.inputs["bright_data"]["$auth"]["api_key"]
# Get the target Amazon product URL from the trigger data
amazon_product_url = pd.steps["trigger"]["event"]["body"]["url"]
# Configure the Bright Data API request
brightdata_api_endpoint = "https://api.brightdata.com/datasets/v3/trigger"
params = { "dataset_id": "gd_l7q7dkf244hwjntr0", "include_errors": "true" }
payload_data = [{"url": amazon_product_url}]
headers = { "Authorization": f"Bearer {api_key}", "Content-Type": "application/json" }
# Initiate the data collection job
print(f"Triggering Bright Data dataset with URL: {amazon_product_url}")
trigger_response = requests.post(brightdata_api_endpoint, headers=headers, params=params, json=payload_data)
# Check if the trigger request was successful
if trigger_response.status_code == 200:
response_json = trigger_response.json()
# Extract the snapshot ID, which is needed to poll for results.
snapshot_id = response_json.get("snapshot_id")
# Handle cases where the trigger is successful but no snapshot ID is provided
if not snapshot_id:
print("Trigger successful, but no snapshot_id was returned.")
return {"error": "Trigger successful, but no snapshot_id was returned.", "response": response_json}
# Begin polling for the completed snapshot using its ID
print(f"Successfully triggered. Snapshot ID is {snapshot_id}. Now starting to poll for results.")
final_scraped_data = poll_and_retrieve_snapshot(api_key, snapshot_id)
# Return the final scraped data from the workflow
return final_scraped_data
else:
# If the trigger failed, log the error and exit the Pipedream workflow
print(f"Failed to trigger. Error: {trigger_response.status_code} - {trigger_response.text}")
pd.flow.exit(f"Error: Failed to trigger Bright Data scrape. Status: {trigger_response.status_code}")
def poll_and_retrieve_snapshot(api_key, snapshot_id, polling_timeout=20):
# Construct the URL for the specific snapshot
snapshot_url = f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json"
# Set the authorization header for the API request
headers = { "Authorization": f"Bearer {api_key}" }
print(f"Polling snapshot for ID: {snapshot_id}...")
# Loop until the snapshot is ready
while True:
response = requests.get(snapshot_url, headers=headers)
# If status is 200, the data is ready
if response.status_code == 200:
print("Snapshot is ready. Returning data...")
return response.json()
# If status is 202, the data is not ready yet. Wait and retry
elif response.status_code == 202:
print(f"Snapshot is not ready yet. Retrying in {polling_timeout} seconds...")
time.sleep(polling_timeout)
# If any other status code is received, an error occurred.
else:
print(f"Polling failed! Error: {response.status_code}")
print(response.text)
return {"error": "Polling failed", "status_code": response.status_code, "details": response.text}Dieser Code bewirkt Folgendes:
- Die Funktion
handler()verwaltet den Arbeitsablauf auf der Ebene von Pipedream. Sie:- Ruft den Bright Data-API-Schlüssel ab, nachdem Sie ihn in Pipedream gespeichert haben.
- Konfiguriert die Bright Data-API-Anforderung auf der Seite der Ziel-URL, der Datensatz-ID und aller dafür benötigten spezifischen Daten.
- Verwaltet die Antwort. Wenn etwas schief geht, sehen Sie die Fehler in den Protokollen von Pipedream.
- Die Funktion
poll_and_retrieve_snapshot()fragt die Bright Data API nach einem Snapshot ab, bis sie bereit ist. Wenn sie bereit ist, gibt sie die angeforderten Daten zurück. Wenn etwas schief geht, verwaltet sie Fehler und zeigt sie in den Protokollen an.
Wenn Sie bereit sind, klicken Sie auf die Schaltfläche “Testen”. Im Abschnitt “ERGEBNISSE” wird eine Erfolgsmeldung angezeigt, und der Aktionsschritt “Helle Daten” wird grün gefärbt:
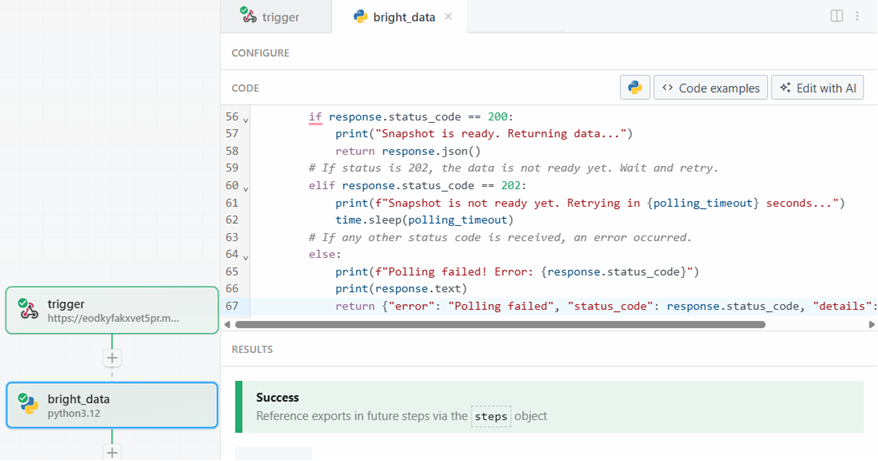
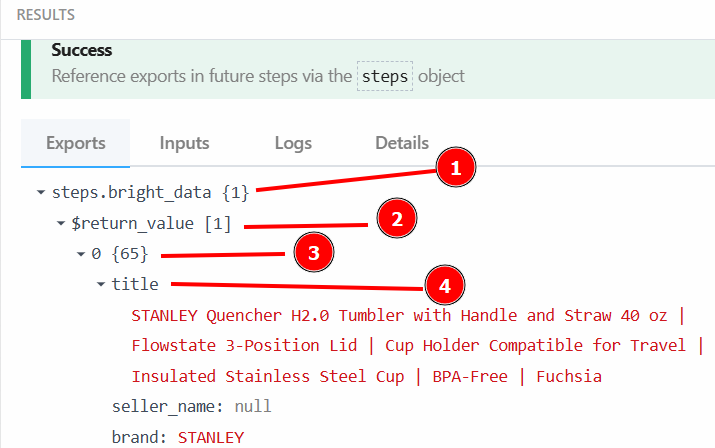
Im Abschnitt “Exporte” unter “ERGEBNISSE” können Sie die ausgewerteten Daten sehen:
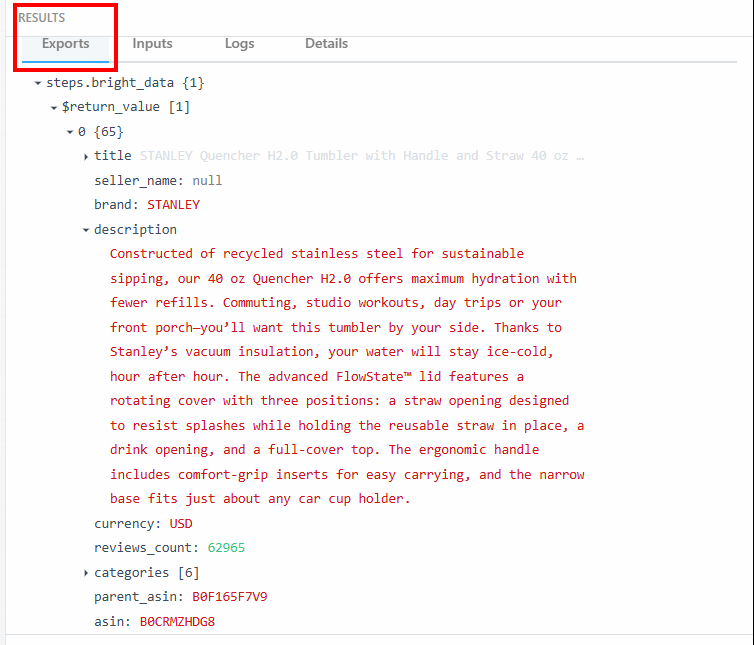
Nachfolgend finden Sie die ausgewerteten Daten als Text:
steps.bright_data{
$return_value{
0{
"title":"STANLEY Quencher H2.0 Tumbler with Handle and Straw 40 oz | Flowstate 3-Position Lid | Cup Holder Compatible for Travel | Insulated Stainless Steel Cup | BPA-Free | Fuchsia",
"seller_name":"null",
"brand":"STANLEY",
"description":"Constructed of recycled stainless steel for sustainable sipping, our 40 oz Quencher H2.0 offers maximum hydration with fewer refills. Commuting, studio workouts, day trips or your front porch—you’ll want this tumbler by your side. Thanks to Stanley’s vacuum insulation, your water will stay ice-cold, hour after hour. The advanced FlowState™ lid features a rotating cover with three positions: a straw opening designed to resist splashes while holding the reusable straw in place, a drink opening, and a full-cover top. The ergonomic handle includes comfort-grip inserts for easy carrying, and the narrow base fits just about any car cup holder.",
"currency":"USD",
"reviews_count":"62965",
..OMITTED FOR BREVITY...
}
}
}Diese Daten und ihre Struktur werden Sie im nächsten Schritt des Workflows verwenden.
Super! Dank der Aktion “Bright Data” in Pipedream haben Sie die Zieldaten korrekt abgefragt.
Schritt #4: Den OpenAI-Aktionsschritt hinzufügen
Die Amazon-Produktdaten wurden von der Beight Data-Integration erfolgreich abgefragt. Jetzt können Sie sie in ein LLM einspeisen. Fügen Sie dazu eine neue Aktion hinzu, indem Sie auf den “+”-Button klicken und nach “openai” suchen. Hier können Sie zwischen verschiedenen Optionen wählen:

Wählen Sie die Option “Build any OpenAI (ChatGPT) API request” und wählen Sie dann die Option “Chat”:
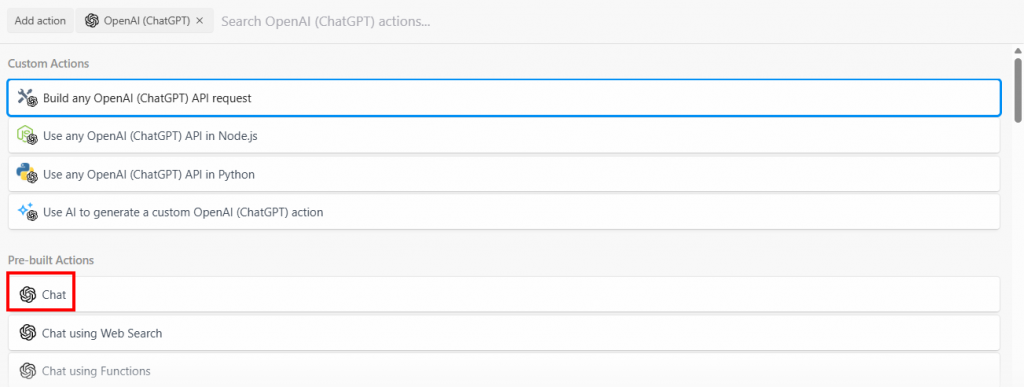
Nachfolgend finden Sie den Konfigurationsabschnitt dieses Aktionsschritts:
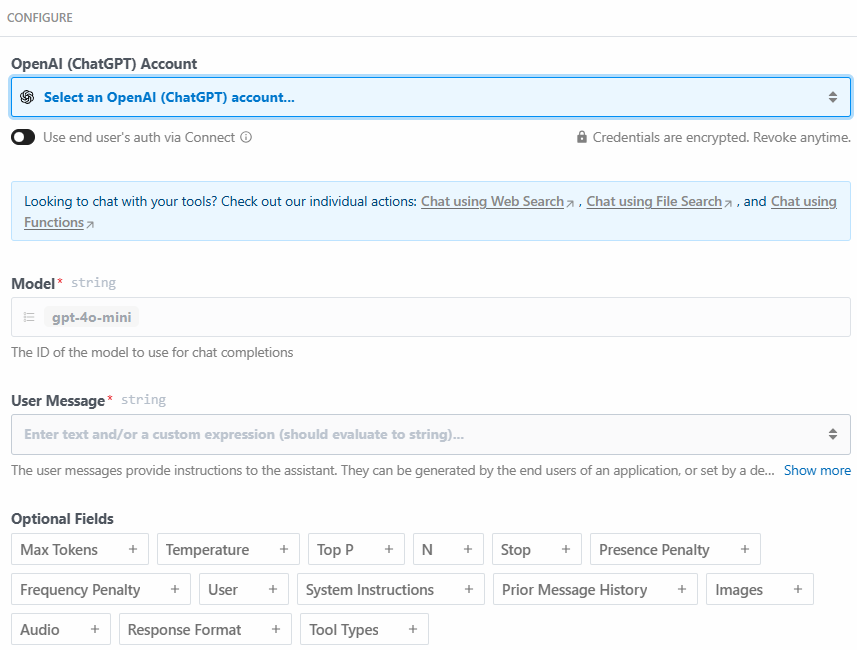
Klicken Sie auf “Wählen Sie ein OpenAI (ChatGPT) Konto…”, um Ihren OpenAI Plattform API Schlüssel hinzuzufügen. Schreiben Sie dann die folgende Aufforderung in den Abschnitt “User Message”:
Act as an expert product analyst. Consider the following data from an Amazon product page:
PRODUCT TITLE:
{{steps.bright_data.$return_value[0].title}}
BRAND:
{{steps.bright_data.$return_value[0].brand}}
DESCRIPTION:
{{steps.bright_data.$return_value[0].description}}
REVIEWS COUNT
{{steps.bright_data.$return_value[0].reviews_count}}
Based on this data, provide a concise summary of the product that should entice potential customers to buy it. The summary should include what the product is, and its most important features.Die Aufforderung fordert den LLM auf:
- Handeln Sie wie ein sachverständiger Produktanalytiker. Dies ist wichtig, da sich das LLM mit dieser Anweisung wie ein sachverständiger Produktanalyst verhalten wird. Dies trägt dazu bei, dass seine Antwort spezifisch für die Branche ist.
- Berücksichtigen Sie die durch den Schritt Bright Data extrahierten Daten, wie z. B. den Produkttitel und die Beschreibung. Dies hilft dem LLM, sich auf spezifische Daten zu konzentrieren, die Sie benötigen.
- Erstellen Sie eine Zusammenfassung des Produkts auf der Grundlage der ausgewerteten Daten. In der Aufforderung wird auch genau angegeben, was die Zusammenfassung enthalten muss. Hier zeigt sich die Stärke der KI-Automatisierung bei der Produktzusammenfassung. Der LLM erstellt auf der Grundlage der gescrapten Daten eine Zusammenfassung des Produkts und fungiert als Produktspezialist.
Sie können den Produkttitel mit {{steps.bright_data.$return_value[0].title}} abrufen, da die Struktur der Ausgabedaten des Aktionsschritts Bright Data wie im vorherigen Schritt angegeben ist:
Nachdem Sie auf “Test” geklickt haben, finden Sie die Ausgabe des LLM im Abschnitt “ERGEBNISSE” des OpenAI-Chat-Aktionsschritts unter “Generierte Nachricht” > “Inhalt”:
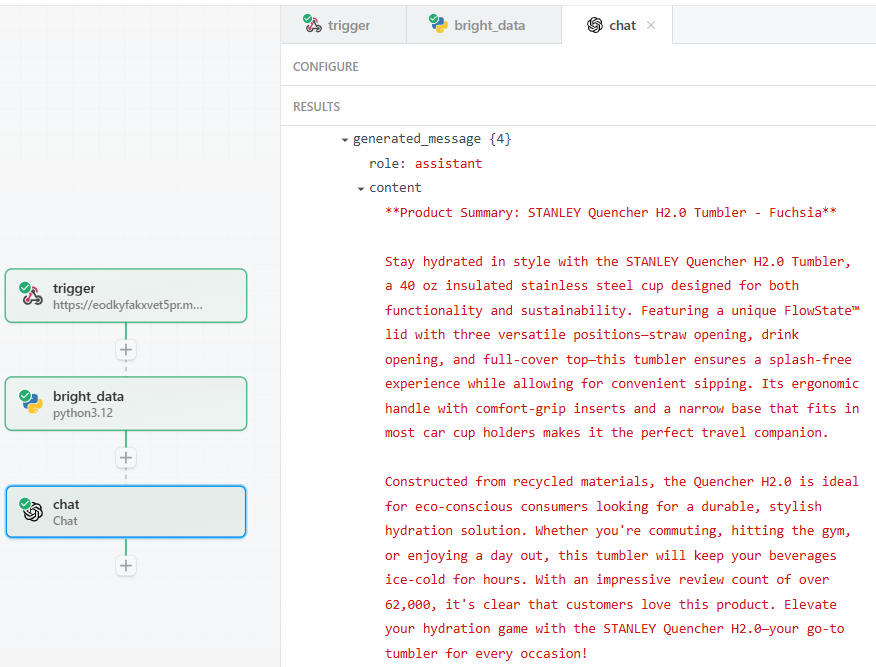
Nachstehend finden Sie ein mögliches Ergebnis in Textform:
**Product Summary: STANLEY Quencher H2.0 Tumbler - Fuchsia**
Stay hydrated in style with the STANLEY Quencher H2.0 Tumbler, a 40 oz insulated stainless steel cup designed for both functionality and sustainability. Featuring a unique FlowState™ lid with three versatile positions—straw opening, drink opening, and full-cover top—this tumbler ensures a splash-free experience while allowing for convenient sipping. Its ergonomic handle with comfort-grip inserts and a narrow base that fits in most car cup holders makes it the perfect travel companion.
Constructed from recycled materials, the Quencher H2.0 is ideal for eco-conscious consumers looking for a durable, stylish hydration solution. Whether you're commuting, hitting the gym, or enjoying a day out, this tumbler will keep your beverages ice-cold for hours. With an impressive review count of over 62,000, it's clear that customers love this product. Elevate your hydration game with the STANLEY Quencher H2.0—your go-to tumbler for every occasion!Wie Sie sehen, hat der LLM als Produktspezialist die Zusammenfassung des Produkts erstellt. Die Zusammenfassung gibt genau das wieder, was in der Aufforderung verlangt wird:
- Was das Produkt ist.
- Einige der wichtigsten Merkmale.
Der Grund, warum Sie genaue Daten wie die Anzahl der Bewertungen extrahieren wollen, ist, dass Sie sicher sein wollen, dass der LLM nicht halluziniert. In der Zusammenfassung steht, dass die Bewertungen über 62.000 betragen. Wenn Sie die genaue Zahl sehen wollen, können Sie sie unter dem Feld “Inhalt” in den Ergebnissen überprüfen:
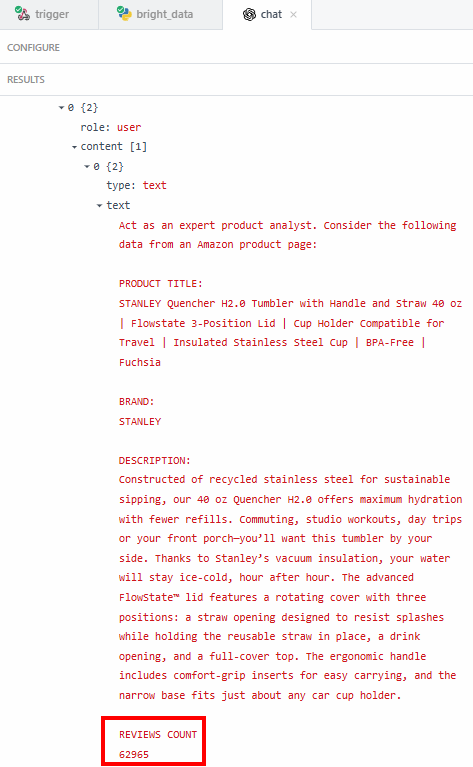
Dann müssen Sie überprüfen, ob diese Nummer mit der auf der Amazon-Produktseite angegebenen übereinstimmt.
Wenn Sie schon einmal versucht haben, große E-Commerce-Websites wie Amazon zu scrapen, wissen Sie, wie schwierig es ist, dies selbst zu tun. Sie könnten zum Beispiel auf das berüchtigte Amazon CAPTCHA stoßen, das die meisten Scraper blockieren kann:
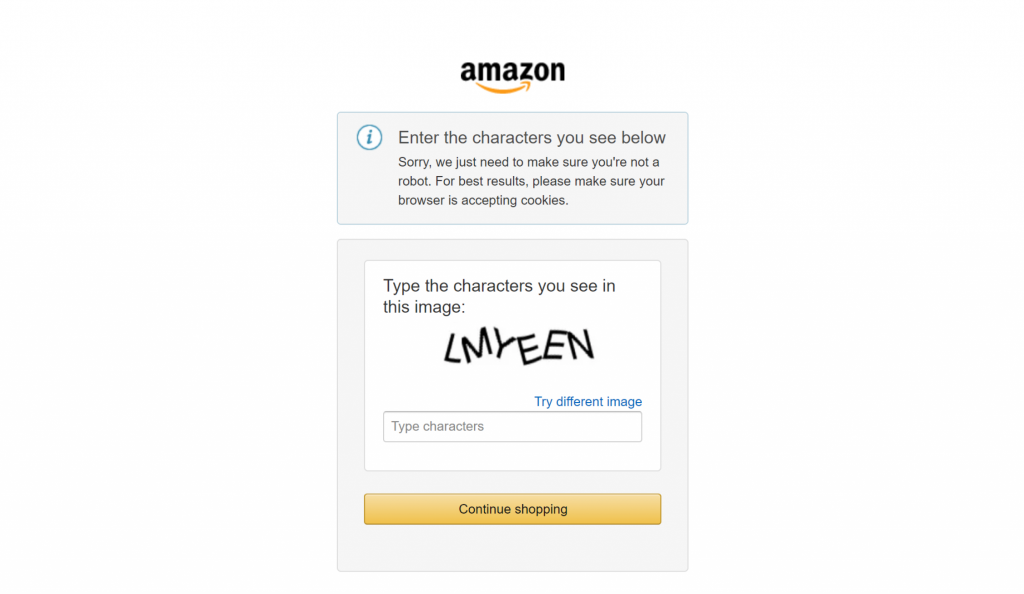
Hier macht die Bright Data-Integration den entscheidenden Unterschied in Ihren Scraping-Workflows aus. Sie verwaltet alle Anti-Scraping-Maßnahmen im Hintergrund und sorgt dafür, dass der Datenabruf reibungslos funktioniert.
Großartig! Sie haben den LLM-Schritt erfolgreich getestet. Sie sind nun bereit, den Workflow einzusetzen.
Schritt Nr. 5: Einsatz des Workflows
Um Ihren Workflow bereitzustellen, klicken Sie auf eine der Schaltflächen “Bereitstellen”:
Nachstehend sehen Sie, was Sie nach der Bereitstellung sehen werden:
Um den gesamten Workflow auszuführen, klicken Sie auf “Ereignis generieren”:
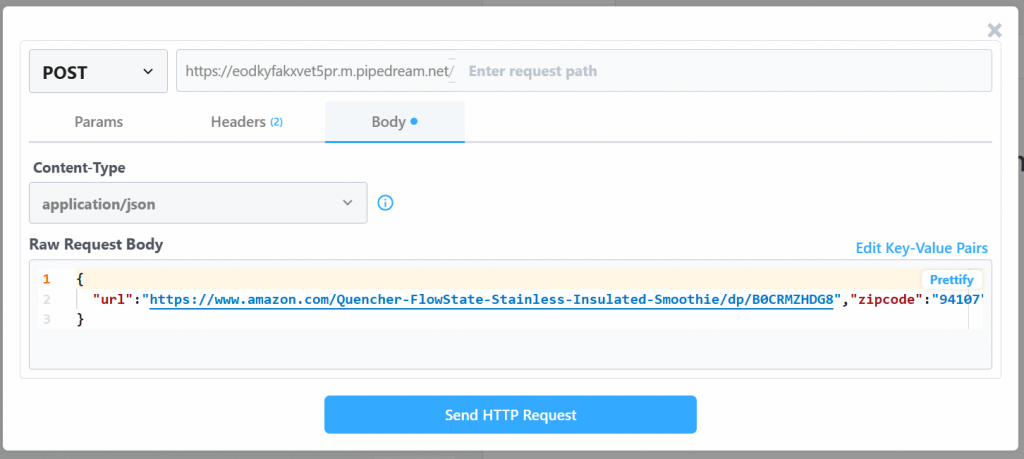
Klicken Sie auf “HTTP-Anfrage senden”, um den Workflow auszulösen, und er wird vollständig ausgeführt. Um die Ergebnisse der ausgeführten Workflows zu sehen, gehen Sie auf der Startseite auf “Ereignisverlauf”. Wählen Sie den gewünschten Workflow aus und sehen Sie die Ergebnisse unter “Exporte”:
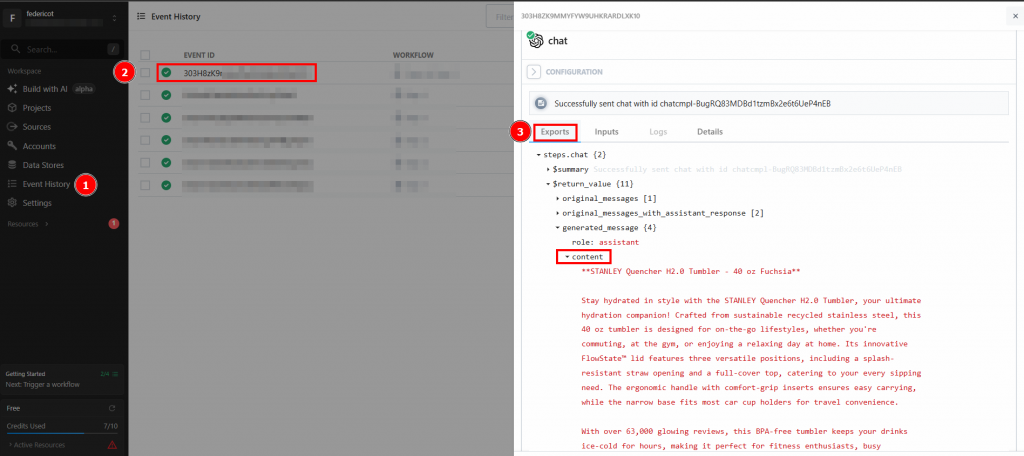
Et voilà! Sie haben Ihren ersten Scraping-Workflow in Pipedream unter Verwendung von Bright Data erstellt und implementiert.
Schlussfolgerung
In diesem Leitfaden haben Sie gelernt, wie Sie mit Pipedream einen automatisierten Web-Scraping-Workflow aufbauen können. Sie haben aus erster Hand erfahren, wie die intuitive Benutzeroberfläche der Plattform in Kombination mit der Scraping-Integration von Bright Data den Aufbau anspruchsvoller Scraping-Pipelines in wenigen Minuten ermöglicht.
Die größte Herausforderung bei jeder datengesteuerten Automatisierung ist die Gewährleistung eines konsistenten Flusses sauberer, zuverlässiger Daten. Pipedream stellt die Automatisierungs- und Planungs-Engine bereit, während die KI-Infrastruktur von Bright Data die Komplexität des Web-Scrapings bewältigt und gebrauchsfertige Daten liefert. Dank dieser Synergie können Sie sich auf die Wertschöpfung aus Daten konzentrieren, anstatt sich mit den technischen Hürden der Datenerfassung zu befassen.
Erstellen Sie ein kostenloses Bright Data-Konto und experimentieren Sie noch heute mit unseren KI-fähigen Datentools!






