
In diesem Tutorial werden Sie sehen:
- Was Opencode ist, welche Funktionen es bietet und warum es nicht mit Crush verwechselt werden sollte.
- Wie die Erweiterung um Webinteraktion und Datenextraktionsfunktionen das Programm noch einfallsreicher machen kann.
- Wie Sie opencode über die CLI mit dem Bright Data MCP-Server verbinden, um einen leistungsstarken KI-Codierungsagenten zu erstellen.
Tauchen wir ein!
Was ist opencode?
opencode ist ein Open-Source-KI-Codierungsagent, der für das Terminal entwickelt wurde. Er funktioniert insbesondere als:
- Ein TUI(Terminal User Interface) in Ihrem CLI.
- Eine IDE-Integration in Visual Studio Code, Cursor, etc.
- Eine GitHub-Erweiterung.
Mehr im Detail, opencode lässt Sie:
- Konfigurieren Sie eine ansprechende, thematisierbare Terminaloberfläche.
- Laden Sie die richtigen LSP(Language Server Protocols) für Ihren LLM.
- Mehrere Agenten parallel auf demselben Projekt laufen lassen.
- Links zu jeder Sitzung als Referenz oder zum Debuggen freigeben.
- Melden Sie sich bei Anthropic an, um Ihr Claude Pro- oder Max-Konto zu verwenden, und integrieren Sie sich über Models.dev mit anderen 75+ LLM-Anbietern (einschließlich lokaler Modelle).
Wie Sie sehen können, ist die CLI LLM-agnostisch. Es wurde hauptsächlich in Go und TypeScript entwickelt und hat bereits über 20k Sterne auf GitHub gesammelt, ein Beweis für seine Beliebtheit in der Community.
Hinweis: Diese Technologie sollte nicht mit Crush verwechselt werden, einem anderen Projekt, dessen ursprünglicher Name “opencode” war. Erfahren Sie mehr über den Namensstreit auf X. Wenn Sie stattdessen nach Crush suchen, lesen Sie unseren Leitfaden zur Integration von Crush mit dem Bright Data Web MCP.
Warum die Integration von Bright Data’s Web MCP in die opencode TUI wichtig ist
Unabhängig davon, welches LLM Sie in opencode konfigurieren, haben sie alle die gleiche Einschränkung: Ihr Wissen ist statisch. Die Daten, auf denen sie trainiert wurden, stellen eine Momentaufnahme in der Zeit dar, die schnell veraltet. Das gilt besonders in schnelllebigen Bereichen wie der Softwareentwicklung.
Stellen Sie sich nun vor, dass Ihr opencode CLI-Assistent in der Lage ist:
- Neue Tutorien und Dokumentationen einbeziehen.
- Live-Anleitungen zu konsultieren, während er Code schreibt.
- Dynamische Websites so einfach zu durchsuchen, wie er durch Ihre lokalen Dateien navigieren kann.
Das sind genau die Fähigkeiten, die Sie freischalten, indem Sie ihn mit dem Web MCP von Bright Data verbinden.
Die Bright Data Web MCP bietet Zugriff auf mehr als 60 KI-fähige Tools, die für Echtzeit-Webinteraktion und Datenerfassung entwickelt wurden und alle auf der KI-Infrastruktur von Bright Data basieren.
Die beiden meistgenutzten Tools(auch in der kostenlosen Version) auf der Bright Data Web MCP sind:
| Tool | Beschreibung |
|---|---|
scrape_as_markdown |
Scrape Content von einer einzelnen Webseite mit erweiterten Extraktionsoptionen und gibt die resultierenden Daten in Markdown zurück. Kann die Bot-Erkennung und CAPTCHA umgehen. |
such_engine |
Extrahiert Suchergebnisse von Google, Bing oder Yandex. Gibt SERP-Daten im JSON- oder Markdown-Format zurück. |
Zusätzlich zu diesen beiden gibt es mehr als 55 spezialisierte Tools, die mit Webseiten interagieren (z. B. scraping_browser_click) und strukturierte Daten aus verschiedenen Domänen sammeln, wie z. B. LinkedIn, Amazon, Yahoo Finance, TikTok und andere. ool ruft strukturierte Profilinformationen von einer öffentlichen LinkedIn-Seite ab, wenn die URL einer Fachkraft angegeben wird.
Schauen wir uns an, wie Web MCP in opencode funktioniert!
Wie man opencode mit dem Web MCP von Bright Data verbindet
Erfahren Sie, wie Sie opencode lokal installieren und konfigurieren und mit dem Bright Data Web MCP Server verbinden. Das Ergebnis ist ein erweiterter Coding Agent mit Zugriff auf über 60 Web Tools. Dieser CLI-Agent wird dann in einer Beispielaufgabe verwendet, um:
- Scrapen einer LinkedIn-Produktseite im laufenden Betrieb, um reale Profildaten zu sammeln.
- Speichern Sie die Daten lokal in einer JSON-Datei.
- Erstellen eines Node.js-Skripts zum Laden und Verarbeiten der Daten.
Führen Sie die folgenden Schritte aus!
Hinweis: Dieser Abschnitt des Tutorials konzentriert sich auf die Verwendung von opencode über die CLI. Sie können jedoch ein ähnliches Setup verwenden, um es direkt in Ihre IDE zu integrieren, wie in der Dokumentation beschrieben.
Voraussetzungen
Bevor Sie beginnen, stellen Sie sicher, dass Sie über die folgenden Voraussetzungen verfügen:
- Eine macOS- oder Linux-Umgebung (Windows-Benutzer müssen die WSL verwenden).
- Ein Claude Pro- oder Max-Abonnement oder ein Anthropic-Konto mit einem gewissen Guthaben und einem API-Schlüssel (in diesem Tutorial werden wir einen Anthropic-API-Schlüssel verwenden, aber Sie können auch andere unterstützte LLMs konfigurieren).
- Lokal installiertes Node.js (wir empfehlen die neueste LTS-Version).
- Ein Bright Data-Konto mit einem fertigen API-Schlüssel.
Machen Sie sich vorerst keine Gedanken über die Bright Data-Einrichtung, da Sie durch die folgenden Schritte geführt werden.
Als Nächstes sollten Sie über einige optionale, aber nützliche Hintergrundkenntnisse verfügen:
- Ein allgemeines Verständnis für die Funktionsweise von MCP.
- Eine gewisse Vertrautheit mit dem Web-MCP von Bright Data und seinen Tools.
Schritt 1: Installieren Sie opencode
Installieren Sie opencode auf Ihrem Unix-basierten System mit dem folgenden Befehl:
curl -fsSL https://opencode.ai/install | bashDadurch wird das Installationsprogramm von https://opencode.ai/install heruntergeladen und ausgeführt, um opencode auf Ihrem Rechner einzurichten. Probieren Sie die anderen möglichen Installationsoptionen aus.
Überprüfen Sie, dass opencode mit funktioniert:
opencodeWenn Sie eine Fehlermeldung wie “fehlende ausführbare Datei” oder “nicht erkannter Befehl” erhalten, starten Sie Ihren Rechner neu und versuchen Sie es erneut.
Wenn alles wie erwartet funktioniert, sollten Sie etwas wie dieses sehen:

Großartig! opencode ist jetzt einsatzbereit.
Schritt #2: Konfigurieren Sie den LLM
opencode kann sich mit vielen LLMs verbinden, aber die empfohlenen Modelle sind von Anthropic. Stellen Sie sicher, dass Sie ein Claude Max- oder Pro-Abonnement oder ein Anthropic-Konto mit etwas Geld und einem API-Schlüssel haben.
Die folgenden Schritte zeigen Ihnen, wie Sie opencode über einen API-Schlüssel mit Ihrem Anthropic-Konto verbinden, aber jede andere unterstützte LLM-Integration funktioniert ebenfalls.
Schließen Sie Ihr opencode-Fenster mit dem Befehl /exit und starten Sie dann die Authentifizierung mit einem LLM-Anbieter mit:
opencode auth login Sie werden aufgefordert, einen KI-Modellanbieter auszuwählen:

Wählen Sie “Anthropic”, indem Sie die Eingabetaste drücken, und wählen Sie dann die Option “Manuelle Eingabe des API-Schlüssels”:

Fügen Sie Ihren Anthropic-API-Schlüssel ein und drücken Sie die Eingabetaste:

Die LLM-Konfiguration ist nun abgeschlossen. Starten Sie opencode neu, rufen Sie den Befehl /models auf, und Sie können ein Anthropic-Modell auswählen. Wählen Sie zum Beispiel “Claude Opus 4.1”:
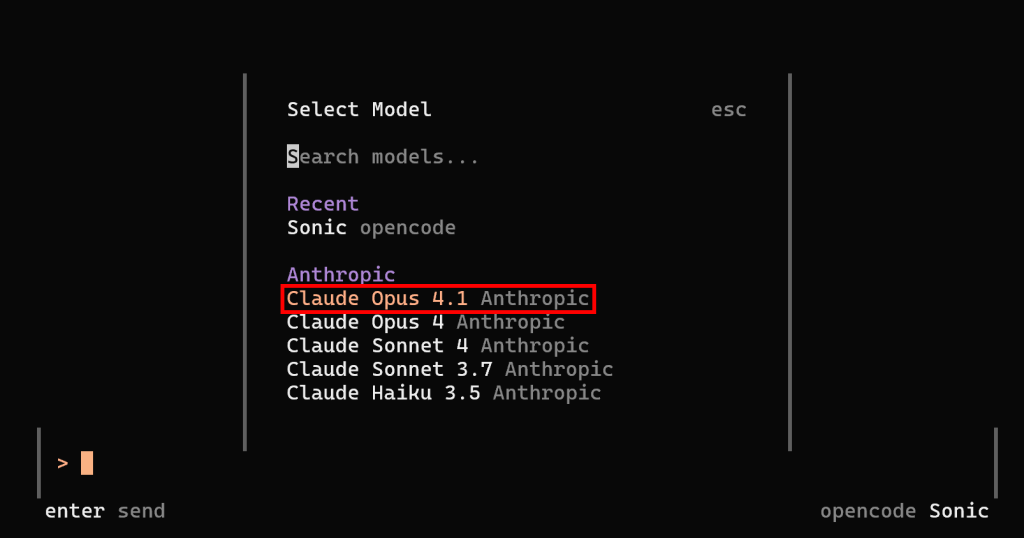
Drücken Sie die Eingabetaste, und Sie sollten nun sehen:

Beachten Sie, dass opencode jetzt mit dem konfigurierten Anthropic-Modell Claude Opus 4.1 arbeitet. Gut gemacht!
Schritt #3: Initialisieren Sie Ihr opencode Projekt
Wechseln Sie mit dem cd-Befehl in Ihr Projektverzeichnis und starten Sie opencode dort:
cd <Pfad_zu_Ihrem_Projekt_Ordner>
opencodeFühren Sie den Befehl /init aus, um ein opencode-Projekt zu initialisieren. Die Ausgabe sollte in etwa so aussehen:

Mit dem Befehl /init wird eine Datei AGENTS.md erstellt. Ähnlich wie CLAUDE.md oder die Regeln von Cursor enthält sie benutzerdefinierte Anweisungen für opencode. Diese Anweisungen werden in den Kontext des LLM aufgenommen, um sein Verhalten an Ihr spezifisches Projekt anzupassen.
Öffnen Sie die Datei AGENTS.md in Ihrer IDE (z. B. Visual Studio Code), und Sie sollten sie sehen:

Passen Sie die Datei an Ihre Bedürfnisse an, um den KI-Codierungsagenten zu instruieren, wie er in Ihrem Projektverzeichnis arbeiten soll.
Tipp: Die Datei AGENTS.md sollte in das Git-Repository Ihres Projektordners übertragen werden.
Schritt Nr. 4: Testen Sie Bright Data’s Web MCP
Bevor Sie versuchen, Ihren Opencode-Agenten in den Bright Data Web MCP-Server zu integrieren, müssen Sie wissen, wie dieser Server funktioniert und ob Ihr Computer ihn ausführen kann.
Falls Sie dies noch nicht getan haben, erstellen Sie zunächst ein Bright Data-Konto. Wenn Sie bereits eines haben, melden Sie sich einfach an. Für eine schnelle Einrichtung werfen Sie einen Blick auf die Seite “MCP” in Ihrem Konto:

Andernfalls folgen Sie den nachstehenden Anweisungen.
Generieren Sie nun Ihren Bright Data-API-Schlüssel. Bewahren Sie ihn an einem sicheren Ort auf, da Sie ihn bald benötigen werden. Wir gehen hier davon aus, dass Sie einen API-Schlüssel mit Admin-Berechtigungen verwenden, da dies die Integration erleichtert.
Installieren Sie im Terminal das Web MCP global über das Paket @brightdata/mcp:
npm install -g @brightdata/mcpPrüfen Sie mit diesem Bash-Befehl, ob der lokale MCP-Server funktioniert:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcpErsetzen Sie den Platzhalter <YOUR_BRIGHT_DATA_API> durch das tatsächliche Bright Data-API-Token. Der Befehl setzt die erforderliche Umgebungsvariable API_TOKEN und feuert dann den Web MCP über das Paket @brightdata/mcp.
Im Erfolgsfall sollten Sie ähnliche Protokolle wie das folgende sehen:

Beim ersten Start richtet das Paket automatisch zwei Standardzonen in Ihrem Bright Data-Konto ein:
mcp_unlocker: Eine Zone für Web Unlocker.mcp_browser: Eine Zone für die Browser-API.
Diese beiden Zonen werden von der Web MCP benötigt, um alle Tools zu betreiben, die sie zur Verfügung stellt.
Um zu bestätigen, dass die beiden oben genannten Zonen erstellt wurden, melden Sie sich bei Ihrem Bright Data-Konto an. Navigieren Sie im Dashboard zur Seite“Proxies & Scraping Infrastructure“. Dort sollten Sie die beiden Zonen in der Tabelle sehen:

Hinweis: Wenn Ihr API-Token nicht über Admin-Berechtigungen verfügt, werden diese Zonen möglicherweise nicht automatisch erstellt. In diesem Fall können Sie sie manuell im Dashboard einrichten und ihre Namen über Umgebungsvariablen angeben, wie auf der GitHub-Seite des Pakets erläutert.
Standardmäßig stellt der MCP-Server nur die Tools search_engine und scrape_as_markdown zur Verfügung(die kostenlos genutzt werden können!).
Um erweiterte Funktionen wie die Browser-Automatisierung und den Abruf von strukturierten Daten-Feeds freizuschalten, müssen Sie den Pro-Modus aktivieren. Dazu setzen Sie die Umgebungsvariable PRO_MODE=true, bevor Sie den MCP-Server starten:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcpWichtig! Sobald der Pro-Modus aktiviert ist, erhalten Sie Zugriff auf alle 60+ Werkzeuge. Auf der anderen Seite ist der Pro-Modus nicht in der kostenlosen Version enthalten und verursacht zusätzliche Kosten.
Perfekt! Sie haben soeben überprüft, dass der Web MCP-Server auf Ihrem Rechner funktioniert. Beenden Sie den Serverprozess, da Sie nun opencode so konfigurieren werden, dass es den Server für Sie startet und sich mit ihm verbindet.
Schritt #5: Integrieren Sie den Web MCP in opencode
opencode unterstützt die MCP-Integration über den mcp-Eintrag in der Konfigurationsdatei. Beachten Sie bitte, dass es zwei unterstützte Konfigurationsansätze gibt:
- Global: Über die Datei unter
~/.config/opencode/opencode.json. Die globale Konfiguration ist nützlich für Einstellungen wie Themes, Provider oder Keybinds. - Pro Projekt: Über eine lokale
opencode.json-Dateiim Verzeichnis Ihres Projekts.
Angenommen, Sie möchten die MCP-Integration lokal konfigurieren. Fügen Sie zunächst eine opencode.json-Datei in Ihrem Arbeitsverzeichnis hinzu.
Öffnen Sie dann die Datei und stellen Sie sicher, dass sie die folgenden Zeilen enthält:
{
"$schema": "https://opencode.ai/config.json",
"mcp": {
"brightData": {
"type": "lokal",
"aktiviert": wahr,
"command": [
"npx",
"-y",
"@brightdata/mcp"
],
"Umgebung": {
"API_TOKEN": "<IHR_BRIGHT_DATA_API_KEY>",
"PRO_MODE": "true"
}
}
}
}Ersetzen Sie <YOUR_BRIGHT_DATA_API_KEY> durch den Bright Data-API-Schlüssel, den Sie zuvor erstellt und getestet haben.
In dieser Konfiguration:
- Das
mcp-Objektteilt opencode mit, wie externe MCP-Server gestartet werden sollen. - Der
brightData-Eintraggibt den Befehl(npx) und die Umgebungsvariablen an, die zum Starten des Web-MCPs erforderlich sind.(PRO_MODEist optional, aber wenn Sie es aktivieren, können Sie alle verfügbaren Werkzeuge nutzen).
Mit anderen Worten: Die obige opencode.json-Konfiguration weist die CLI an, denselben npx-Befehl mit den zuvor definierten Umgebungsvariablen auszuführen. Dadurch wird opencode in die Lage versetzt, den Bright Data Web MCP-Server zu starten und eine Verbindung zu ihm herzustellen.
Zum jetzigen Zeitpunkt gibt es keinen speziellen Befehl zur Überprüfung von MCP-Serververbindungen oder verfügbaren Tools. Lassen Sie uns also direkt mit dem Testen beginnen!
Schritt 6: Ausführen eines Tasks in opencode
Um die Webfähigkeiten Ihres erweiterten opencode Coding Agents zu überprüfen, starten Sie eine Eingabeaufforderung wie die folgende:
Scrape "https://it.linkedin.com/in/antonello-zanini" und speichere die resultierenden Daten in einer lokalen "profile.json" Datei. Richten Sie dann ein einfaches Node.js-Skript ein, das die JSON-Datei liest und ihren Inhalt zurückgibtDies stellt einen realen Anwendungsfall dar, da es tatsächliche Daten sammelt und sie dann in einem Node.js-Skript verwendet.
Starten Sie opencode, geben Sie die Eingabeaufforderung ein und drücken Sie Enter, um sie auszuführen. Sie sollten ein ähnliches Verhalten wie hier sehen:

Das GIF wurde beschleunigt, aber dies ist der Ablauf Schritt für Schritt:
- Das Claude-Opus-Modell definiert einen Plan.
- Der erste Schritt des Plans besteht darin, die LinkedIn-Daten abzurufen. Dazu wählt der LLM das entsprechende MCP-Tool
(web_data_linkedin_person_profile, in der CLI referenziert alsBrightdata_web_data_linkedin_person_profile) mit den richtigen Argumenten, die der Eingabeaufforderung entnommen werden(https://it.linkedin.com/in/antonello-zanini). - Der LLM sammelt die Zieldaten über das LinkedIn-Scraping-Tool und aktualisiert den Plan.
- Die Daten werden in einer lokalen
profile.json-Dateigespeichert. - Ein Node.js-Skript (namens
readProfile.js) wird erstellt, um die Daten ausprofile.jsonzu lesen und zu drucken. - Es wird eine Zusammenfassung der ausgeführten Schritte mit Anweisungen zur Ausführung des erstellten Node.js-Skripts angezeigt.
In diesem Beispiel sieht die von der Aufgabe erzeugte Endausgabe wie folgt aus:

Am Ende der Interaktion sollte Ihr Arbeitsverzeichnis diese Dateien enthalten:
├── AGENTS.md
├─── opencode.json
├── profile.json # <-- erstellt von der CLI
└── readProfile.js # <-- erstellt von der CLIWunderbar! Lassen Sie uns nun überprüfen, ob die erzeugten Dateien die beabsichtigten Daten und die Logik enthalten.
Schritt #7: Erkunden und Testen der Ausgabe
Öffnen Sie das Projektverzeichnis in Visual Studio Code und untersuchen Sie zunächst die Datei profile.json:

Wichtig: Bei den Daten in profile.json handelt es sich um echte LinkedIn-Daten, die vom Bright Data LinkedIn Scraper über das spezielle web_data_linkedin_person_profile MCP-Tool gesammelt wurden. Es handelt sich nicht um halluzinierte oder erfundene Inhalte, die vom Claude-Modell generiert wurden!
Die LinkedIn-Daten wurden erfolgreich abgerufen, wie Sie überprüfen können, indem Sie die in der Eingabeaufforderung erwähnte öffentliche LinkedIn-Profilseite untersuchen:

Hinweis: Das Scraping von LinkedIn ist aufgrund des ausgefeilten Anti-Bot-Schutzes bekanntermaßen schwierig. Ein normaler LLM kann diese Aufgabe nicht zuverlässig ausführen, was zeigt, wie leistungsfähig Ihr Coding Agent dank der Bright Data Web MCP-Integration geworden ist.
Werfen Sie als Nächstes einen Blick auf die Datei readProfile.js:
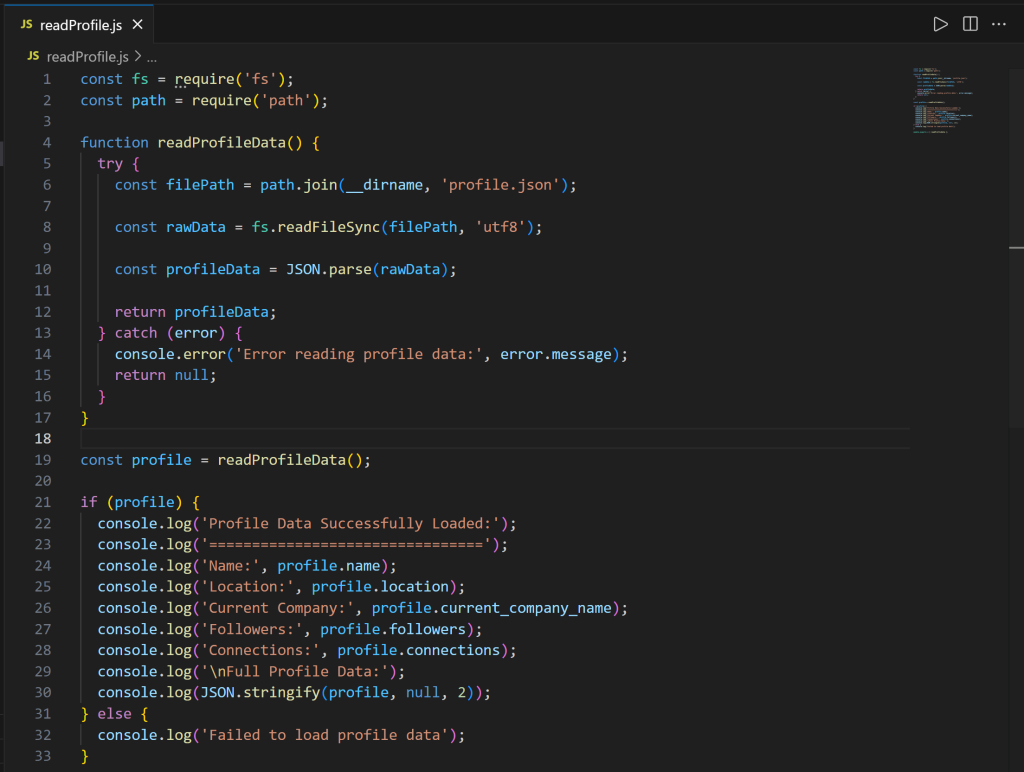
Beachten Sie, dass der Code eine readProfileData() -Funktion zum Lesen der LinkedIn-Profildaten aus profile.json definiert. Diese Funktion wird dann aufgerufen, um die Profildaten mit allen Details zu drucken.
Testen Sie das Skript mit:
node readProfile.jsDie Ausgabe sollte so aussehen:

Sehen Sie, wie das erstellte Skript die von LinkedIn gescrapten Daten wie geplant ausgibt.
Auftrag erfüllt! Probieren Sie verschiedene Prompts aus und testen Sie erweiterte LLM-gesteuerte Daten-Workflows direkt in der CLI.
Fazit
In diesem Artikel haben Sie gesehen, wie Sie opencode mit dem Web MCP von Bright Data verbinden können(das jetzt eine kostenlose Stufe anbietet!). Das Ergebnis ist ein werkzeugreicher KI-Codieragent, der Daten aus dem Web extrahieren und mit ihnen interagieren kann.
Um komplexere KI-Agenten zu erstellen, können Sie die gesamte Palette der in der KI-Infrastruktur von Bright Data verfügbaren Services und Produkte nutzen. Diese Lösungen unterstützen eine Vielzahl von Agentenszenarien, einschließlich mehrerer CLI-Integrationen.
Melden Sie sich kostenlos bei Bright Data an und experimentieren Sie mit unseren KI-fähigen Webtools!




