Das Trainieren eines KI-Modells umfasst das Lehren, Muster in Daten zu erkennen, um Entscheidungen zu treffen. Fine-Tuning (Feinabstimmung) ist eine Strategie, bei der Modelle, die anhand von großen Datensätzen wie OpenAIs GPT-4 trainiert wurden, auf kleinere und aufgabenspezifische Datensätze angepasst werden, wobei der Trainingsprozess fortgesetzt wird.
In den folgenden Abschnitten werden wir den Prozess der Anpassung eines benutzerdefinierten KI-Modells mithilfe des Fine-Tunings von OpenAI näher untersuchen und Sie durch jeden Schritt des Prozesses führen.
Verständnis von KI und Modelltraining
Künstliche Intelligenz (KI) umfasst die Entwicklung von Systemen, die Aufgaben ausführen können, die normalerweise menschliche Intelligenz erfordern, wie Lernen, Problemlösung und Entscheidungsfindung. Das Kernstück eines KI-Modells ist eine Menge an Algorithmen, die auf Basis von Eingabedaten Vorhersagen treffen. Maschinelles Lernen (ML), ein Teilbereich der KI, ermöglicht es Maschinen, aus Daten zu lernen und ihre Leistung automatisch zu verbessern.
KI-Modelle lernen ähnlich wie ein Kind, das Katzen und Hunde voneinander unterscheidet: Sie betrachten Merkmale, stellen Vermutungen an, korrigieren Fehler und versuchen es erneut. Dieser Prozess, als Modelltraining bekannt, beinhaltet das Verarbeiten von Eingabedaten, das Analysieren und Erkennen von Mustern sowie die Nutzung dieses Wissens zur Vorhersage. Die Leistung des Modells wird durch den Vergleich seiner Ausgabe mit dem erwarteten Ergebnis bewertet. Anschließend werden Anpassungen vorgenommen, um diese Leistung zu verbessern. Mit ausreichendem Training repräsentiert das Modell schließlich einen genauen mathematischen Prädiktor für eine bestimmte Situation und kann verschiedene Variationen der Eingabedaten handhaben.
Das Training eines Modells von Grund auf beinhaltet, einem Modell das Erlernen von Mustern in den Daten beizubringen, ohne jegliches Vorwissen. Dies erfordert eine große Menge an Daten und Rechenressourcen, und das Modell kann bei einer begrenzten Datenmenge möglicherweise nicht gut abschneiden.
Beim Fine-Tuning hingegen wird mit einem bereits vortrainierten Modell begonnen, das aus einem großen Datensatz allgemeine Muster gelernt hat. Anschließend wird dieses Modell mit einem kleineren, spezifischen Datensatz weiter trainiert. Auf diese Weise kann es sein zuvor erworbenes Wissen auf die neue Aufgabe anwenden, was oft zu einer besseren Leistung mit weniger Daten und Rechenressourcen führt. Fine-Tuning ist besonders dann nützlich, wenn der aufgabenspezifische Datensatz relativ klein ist.
Vorbereitung auf das Fine-Tuning
Auch wenn es verlockend erscheinen mag, ein existierendes Modell mithilfe eines kuratierten Datensatzes weiterzutrainieren, anstatt ein KI-Modell von Grund auf zu erstellen, hängt der Erfolg des Fine-Tuning-Prozesses von mehreren Schlüsselfaktoren ab.
Das richtige Modell auswählen
Bei der Auswahl eines Basismodells für das Fine-Tuning sollten Sie Folgendes berücksichtigen:
Aufgabenabstimmung: Es ist wichtig, den Problemumfang und die erwartete Funktionalität Ihres Modells klar zu definieren. Wählen Sie Modelle, die sich bei Aufgaben ähnlich der Ihren auszeichnen, da eine große Abweichung zwischen Ausgangs- und Zielaufgabe im Fine-Tuning-Prozess zu einer Leistungsminderung führen kann. Beispielsweise kann GPT-3 für Textgenerierungsaufgaben geeignet sein, während für Textklassifikationsaufgaben BERT oder RoBERTa besser geeignet sein können.
Modellgröße und Komplexität: Balancieren Sie Performance und Effizienz je nach Bedarf, da größere Modelle zwar komplexe Muster besser erfassen, jedoch auch mehr Ressourcen benötigen.
Bewertungsmetriken: Wählen Sie Bewertungsmetriken, die für Ihre Aufgabe relevant sind. Beispielsweise kann Genauigkeit (Accuracy) für Klassifikationsaufgaben wichtig sein, während BLEU oder ROUGE für Sprachgenerierungsaufgaben sinnvoll sein können.
Community und Ressourcen: Geben Sie Modellen mit einer großen Community und reichlich Ressourcen den Vorzug, da diese bei der Fehlersuche und Implementation hilfreich sind. Priorisieren Sie Modelle mit klaren Fine-Tuning-Richtlinien für Ihre Aufgabe und nutzen Sie vertrauenswürdige Quellen für vortrainierte Modell-Checkpoints.
Datensammlung und -aufbereitung
Beim Fine-Tuning kann die Qualität und Vielfalt Ihrer Daten die Modellleistung erheblich beeinflussen. Beachten Sie dabei Folgendes:
Arten benötigter Daten: Die Datentypen hängen von Ihrer spezifischen Aufgabe und den Daten ab, auf denen das Modell vortrainiert wurde. Für NLP-Aufgaben benötigen Sie in der Regel Textdaten aus Quellen wie Büchern, Artikeln, Social-Media-Beiträgen oder Transkriptionen gesprochener Sprache. Nutzen Sie Methoden wie Web-Scraping, Umfragen oder APIs von Social-Media-Plattformen, um Daten zu sammeln. Beispielsweise kann KI-gestütztes Web-Scraping besonders nützlich sein, wenn Sie eine große Menge unterschiedlicher und aktueller Daten benötigen.
Datenbereinigung und -annotation: Die Datenbereinigung umfasst das Entfernen irrelevanter Daten, den Umgang mit fehlenden oder inkonsistenten Daten und die Normalisierung. Annotation bedeutet, die Daten zu beschriften, damit das Modell daraus lernen kann. Die Verwendung automatisierter Tools wie Bright data kann diese Prozesse beschleunigen und effizienter gestalten.
Einbeziehung eines vielfältigen und repräsentativen Datensatzes: Beim Fine-Tuning eines Modells sorgt ein vielfältiger und repräsentativer Datensatz dafür, dass das Modell aus unterschiedlichen Perspektiven lernt und dadurch verlässlichere Vorhersagen trifft. Wenn Sie beispielsweise ein Sentiment-Analyse-Modell für Filmkritiken feinabstimmen, sollte Ihr Datensatz Rezensionen einer großen Bandbreite an Filmen, Genres und Stimmungen beinhalten, um die Klassenverteilung der realen Welt widerzuspiegeln.
Einrichtung der Trainingsumgebung
Stellen Sie sicher, dass Sie über die erforderliche Hardware und Software für das gewählte KI-Modell und Framework verfügen. Großsprachmodelle (LLMs) benötigen typischerweise erhebliche Rechenleistung, normalerweise bereitgestellt durch GPUs.
Frameworks wie TensorFlow oder PyTorch werden häufig für das Training von KI-Modellen verwendet. Das Installieren relevanter Bibliotheken und Tools sowie aller zusätzlichen Abhängigkeiten ist für eine nahtlose Einbindung in den Trainings-Workflow unerlässlich. Beispielsweise können Tools wie die OpenAI-API für das Fine-Tuning bestimmter Modelle von OpenAI erforderlich sein.
Der Fine-Tuning-Prozess
Nachdem wir nun die Grundlagen des Fine-Tunings verstanden haben, sehen wir uns eine Anwendung im Bereich der Verarbeitung natürlicher Sprache (NLP) an.
Ich werde die OpenAI-API zum Fine-Tuning eines vortrainierten Modells verwenden. Aktuell ist das Fine-Tuning für Modelle wie gpt-3.5-turbo-0125 (empfohlen), gpt-3.5-turbo-1106, gpt-3.5-turbo-0613, babbage-002, davinci-002 und das experimentelle gpt-4-0613 möglich. Das Fine-Tuning von GPT-4 befindet sich in einer experimentellen Phase, und berechtigte Nutzer können Zugriff über die Fine-Tuning-Oberfläche beantragen.
1. Datensatzvorbereitung
Laut einer Studie mangelt es GPT-3.5 an analytischem Denken. Daher versuchen wir, das Modell gpt-3.5-turbo zu verfeinern, um seine analytischen Fähigkeiten zu stärken. Dazu verwenden wir einen Datensatz mit analytischen Denkaufgaben des Law School Admission Test (AR-LSAT) aus dem Jahr 2022. Der öffentlich verfügbare Datensatz ist hier zu finden.
Die Qualität eines feingetunten Modells hängt direkt von den verwendeten Daten ab. Jedes Beispiel im Datensatz sollte gemäß der Chat Completions API von OpenAI als Konversation formatiert sein, bestehend aus einer Liste von Nachrichten, bei denen jede Nachricht eine Rolle (role), einen Inhalt (content) und optional einen Namen (name) hat. Diese Beispiele sollten als JSONL-Datei gespeichert werden.
Das erforderliche Chat-Format für das Fine-Tuning von gpt-3.5-turbo sieht folgendermaßen aus:
{"messages": [{"role": "system", "content": ""}, {"role": "user", "content": ""}, {"role": "assistant", "content": ""}]}
In diesem Format ist “messages” eine Liste von Nachrichten, die eine Unterhaltung zwischen drei Rollen bilden: system, user und assistant. Der “content” in der Rolle “system” sollte das Verhalten des feingetunten Systems spezifizieren.
Nachfolgend sehen Sie ein formatiertes Beispiel aus dem AR-LSAT-Datensatz, das wir in diesem Leitfaden verwenden:

Dies sind die wichtigsten Aspekte bei der Erstellung des Datensatzes:
- OpenAI-Preisseite
- Tokenzählungs-Notebooks
- Python-Skript
2. Generieren des API-Schlüssels und Installation der OpenAI-Bibliothek
Um ein OpenAI-Modell zu verfeinern (fine-tunen), benötigen Sie ein OpenAI-Entwicklerkonto mit ausreichendem Guthaben.
So generieren Sie den API-Schlüssel und installieren die OpenAI-Bibliothek:
1. Registrieren Sie sich auf der offiziellen Website von OpenAI.
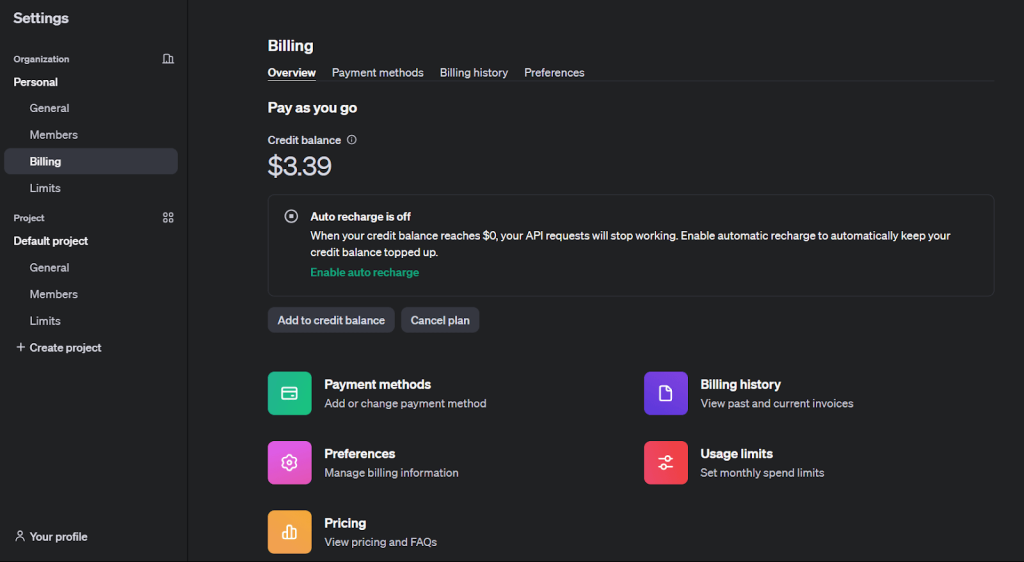
2. Laden Sie Ihr Guthaben auf, um das Fine-Tuning zu aktivieren. Dies erfolgt über den Tab „Billing“ unter „Settings“.
3. Klicken Sie oben links auf das Benutzerprofilsymbol und wählen Sie „API Keys“, um die Seite zum Erstellen von Schlüsseln aufzurufen.
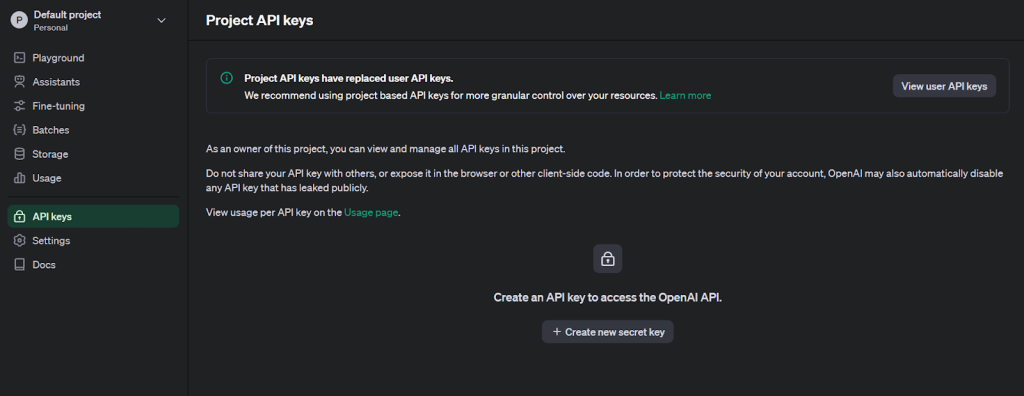
4. Erstellen Sie einen neuen geheimen Schlüssel, indem Sie einen Namen angeben.

5. Installieren Sie die Python-Bibliothek „openai“ für das Fine-Tuning.
pip install openai
6. Verwenden Sie die Python-Bibliothek „os“, um das Token als Umgebungsvariable zu setzen und die API-Kommunikation herzustellen.
import os
from openai import OpenAI
# Setzen der Umgebungsvariable OPENAI_API_KEY
os.environ['OPENAI_API_KEY'] = 'Ihr in Schritt 4 erstellter Schlüssel'
client = OpenAI(api_key=os.environ['OPENAI_API_KEY'])
3. Hochladen der Trainings- und Validierungsdateien
Nach der Validierung Ihrer Daten können Sie die Dateien über die Files API für Fine-Tuning-Aufgaben hochladen.
training_file_id = client.files.create(
file=open(training_file_name, "rb"),
purpose="fine-tune"
)
validation_file_id = client.files.create(
file=open(validation_file_name, "rb"),
purpose="fine-tune"
)
print(f"Training File ID: {training_file_id}")
print(f"Validation File ID: {validation_file_id}")
Nach erfolgreicher Ausführung werden die eindeutigen Bezeichner für die Trainings- und Validierungsdaten angezeigt.

4. Erstellen eines Fine-Tuning-Jobs
Nachdem Sie die Dateien hochgeladen haben, können Sie einen Fine-Tuning-Job über die Benutzeroberfläche oder programmgesteuert erstellen.
So starten Sie einen Fine-Tuning-Job mit dem OpenAI-SDK:
response = client.fine_tuning.jobs.create(
training_file=training_file_id.id,
validation_file=validation_file_id.id,
model="gpt-3.5-turbo",
hyperparameters={
"n_epochs": 10,
"batch_size": 3,
"learning_rate_multiplier": 0.3
}
)
job_id = response.id
status = response.status
print(f'Fine-tunning model with jobID: {job_id}.')
print(f"Training Response: {response}")
print(f"Training Status: {status}")
model: der Name des zu verfeinernden Modells (gpt-3.5-turbo,babbage-002,davinci-002oder ein bereits feingetuntes Modell).training_fileundvalidation_file: die Dateibezeichner, die beim Hochladen der Dateien zurückgegeben wurden.n_epochs,batch_sizeundlearning_rate_multiplier: Hyperparameter, die angepasst werden können.
Um weitere Fine-Tuning-Parameter festzulegen, konsultieren Sie die API-Spezifikation für Fine-Tuning.
Der obige Code erzeugt folgende Informationen für die Job-ID (ftjob-0EVPunnseZ6Xnd0oGcnWBZA7):

Ein Fine-Tuning-Job kann einige Zeit in Anspruch nehmen. Er kann in einer Warteschlange hinter anderen Jobs stehen, und die Trainingsdauer kann je nach Modell und Datensatzgröße von Minuten bis zu Stunden variieren.
Sobald das Training abgeschlossen ist, erhält der Nutzer, der den Fine-Tuning-Job initiiert hat, eine Bestätigungs-E-Mail.
Den Status Ihres Fine-Tuning-Jobs können Sie in der Fine-Tuning-Oberfläche einsehen:
5. Analyse des feingetunten Modells
OpenAI berechnet während des Trainings folgende Metriken:
- Training loss
- Training token accuracy
- Validation loss
- Validation token accuracy
Validation loss und Validation token accuracy werden auf zwei Arten berechnet: an einem kleinen Datenbatch bei jedem Schritt und am kompletten Validierungsset am Ende jeder Epoche. Die vollständige Validation loss und Validation token accuracy sind die genauesten Kenngrößen zur Überwachung der Modellleistung und dienen als Plausibilitätsprüfung, um sicherzustellen, dass das Training reibungslos verläuft (loss sollte sinken, token accuracy sollte steigen).
Solange ein Fine-Tuning-Job aktiv ist, können Sie diese Metriken auf folgende Weise einsehen:
1. In der Benutzeroberfläche:

2. Über die API:
import os
from openai import OpenAI
client = OpenAI(api_key=os.environ['OPENAI_API_KEY'],)
jobid = 'Job-ID, die Sie überwachen möchten'
print(f"Streaming events for the fine-tuning job: {jobid}")
# signal.signal(signal.SIGINT, signal_handler)
events = client.fine_tuning.jobs.list_events(fine_tuning_job_id=jobid)
try:
for event in events:
print(f'{event.data}')
except Exception:
print("Stream interrupted (client disconnected).")
Der obige Code gibt die Streaming-Ereignisse für den Fine-Tuning-Job aus, einschließlich Schrittzahl, training loss, validation loss, Gesamtanzahl an Schritten sowie mean token accuracy für das Training und die Validierung:
Streaming events for the fine-tuning job: ftjob-0EVPunnseZ6Xnd0oGcnWBZA7
{'step': 67, 'train_loss': 0.30375099182128906, 'valid_loss': 0.49169286092122394, 'total_steps': 67, 'train_mean_token_accuracy': 0.8333333134651184, 'valid_mean_token_accuracy': 0.8888888888888888}
6. Anpassen der Parameter und des Datensatzes zur Leistungsverbesserung
Wenn die Ergebnisse eines Fine-Tuning-Jobs nicht Ihren Erwartungen entsprechen, sollten Sie folgende Möglichkeiten in Betracht ziehen, um die Leistung zu steigern:
1. Anpassen des Trainingsdatensatzes:
- Erweitern Sie Ihren Trainingsdatensatz um Beispiele, die die Schwächen des Modells adressieren, und achten Sie darauf, dass die Verteilungsstruktur der erwarteten entspricht.
- Prüfen Sie zudem, ob das Modell potenzielle Probleme in den Daten reproduziert, und stellen Sie sicher, dass alle notwendigen Informationen für die Ausgabe in den Beispielen enthalten sind.
- Halten Sie Daten, die von verschiedenen Personen erstellt wurden, einheitlich und standardisieren Sie das Format aller Trainingsbeispiele, um die Erwartungen bei der Inferenz zu erfüllen.
- Im Allgemeinen sind qualitativ hochwertige Daten effektiver als eine größere Menge minderwertiger Daten.
2. Anpassen der Hyperparameter:
- OpenAI ermöglicht das Festlegen von drei Hyperparametern: epochs, learning rate multiplier und batch size.
- Beginnen Sie mit den Standardwerten, die basierend auf der Datensatzgröße von den integrierten Funktionen gewählt werden, und passen Sie sie bei Bedarf an.
- Wenn das Modell den Trainingsdaten nicht wie erwartet folgt, erhöhen Sie die Anzahl der Epochen.
- Wenn das Modell weniger vielseitig erscheint, als erwartet, verringern Sie die Anzahl der Epochen um 1 oder 2.
- Wenn das Modell nicht zu konvergieren scheint, erhöhen Sie den learning rate multiplier.
7. Verwendung eines Checkpoint-Modells
Derzeit stellt OpenAI die Checkpoints der letzten drei Epochen eines Fine-Tuning-Jobs zur Verfügung. Diese Checkpoints sind vollständige Modelle, die für Inferenz und weiteres Fine-Tuning verwendet werden können.
Um diese Checkpoints abzurufen, warten Sie, bis ein Job erfolgreich abgeschlossen ist, und fragen Sie dann den Checkpoints-Endpunkt mit der ID Ihres Fine-Tuning-Jobs ab. Jedes Checkpoint-Objekt enthält das Feld fine_tuned_model_checkpoint mit dem Namen des Modell-Checkpoints. Sie können den Namen des Checkpoint-Modells auch in der Fine-Tuning-Oberfläche einsehen.
Sie können die Ergebnisse des Checkpoint-Modells validieren, indem Sie Abfragen mit einem Prompt und dem Modellnamen über die Funktion openai.chat.completions.create() starten:
completion = client.chat.completions.create(
model="ft:gpt-3.5-turbo-0125:personal::9PWZuZo5",
messages=[
{"role": "system", "content": "Instructions: You will be presented with a passage and a question about that passage. There are four options to be chosen from, you need to choose the only correct option to answer that question. If the first option is right, you generate the answer 'A', if the second option is right, you generate the answer 'B', if the third option is right, you generate the answer 'C', if the fourth option is right, you generate the answer 'D', if the fifth option is right, you generate the answer 'E'. Read the question and options thoroughly and select the correct answer from the four answer labels. Read the passage thoroughly to ensure you know what the passage entails"},
{"role": "user", "content": "Passage: For the school paper, five studentsu2014Jiang, Kramer, Lopez, Megregian, and O'Neillu2014each review one or more of exactly three plays: Sunset, Tamerlane, and Undulation, but do not review any other plays. The following conditions must apply: Kramer and Lopez each review fewer of the plays than Megregian. Neither Lopez nor Megregian reviews any play Jiang reviews. Kramer and O'Neill both review Tamerlane. Exactly two of the students review exactly the same play or plays as each other.Question: Which one of the following could be an accurate and complete list of the students who review only Sunset?nA. LopeznB. O'NeillnC. Jiang, LopeznD. Kramer, O'NeillnE. Lopez, MegregiannAnswer:"}
]
)
print(completion.choices[0].message)
Das aus dem Antwortwörterbuch abgerufene Ergebnis lautet:

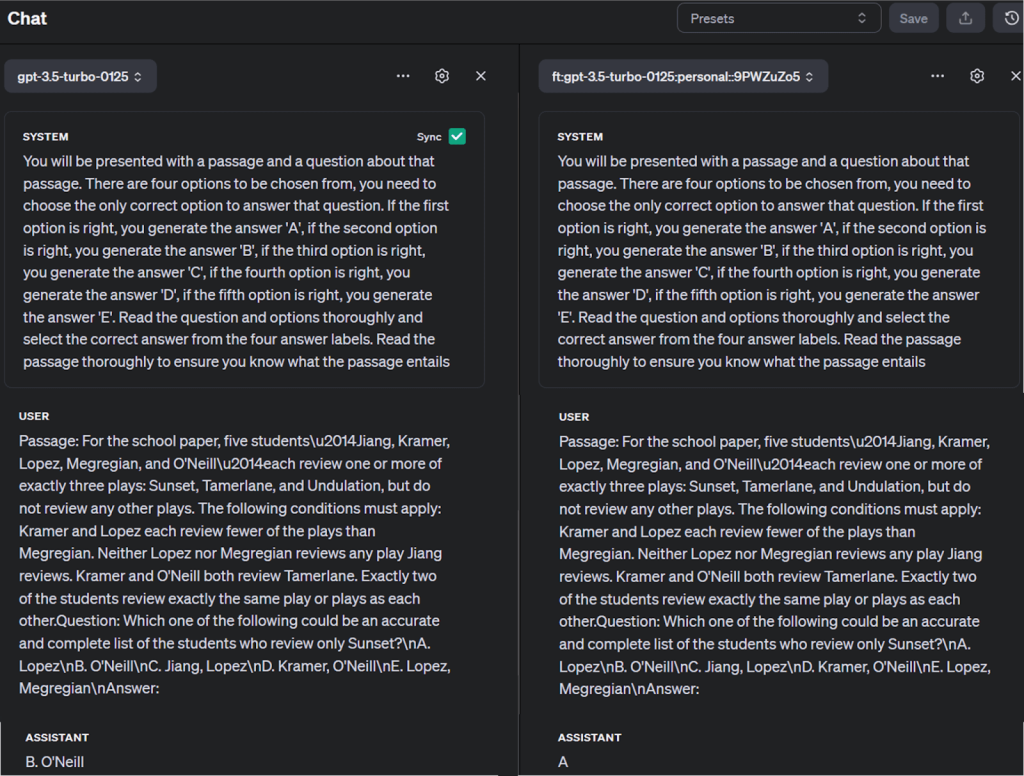
Sie können auch das feingetunte Modell mit anderen Modellen im OpenAI Playground vergleichen, wie unten gezeigt:
Tipps und Best Practices
Für erfolgreiches Fine-Tuning sollten Sie Folgendes beachten:
Datenqualität: Achten Sie darauf, dass Ihre aufgabenspezifischen Daten sauber, vielfältig und repräsentativ sind, um Overfitting zu vermeiden, bei dem das Modell zwar bei Trainingsdaten gut abschneidet, jedoch bei unbekannten Daten versagt.
Hyperparameterwahl: Wählen Sie geeignete Hyperparameter, um langsame Konvergenz oder unbefriedigende Ergebnisse zu vermeiden. Dies kann komplex und zeitaufwändig sein, ist jedoch entscheidend für effektives Training.
Ressourcenverwaltung: Beachten Sie, dass das Fine-Tuning großer Modelle erhebliche Rechenressourcen und Zeit erfordert.
Vermeidung von Fallstricken
Overfitting und Underfitting: Balancieren Sie die Komplexität Ihres Modells und den Trainingsumfang, um Overfitting (hohe Varianz) und Underfitting (hohe Verzerrung) zu vermeiden.
Katastrophales Vergessen: Während des Fine-Tunings kann das Modell zuvor erlerntes Allgemeinwissen „vergessen“. Bewerten Sie regelmäßig die Leistung Ihres Modells anhand verschiedener Aufgaben, um dem entgegenzuwirken.
Empfindlichkeit für Domain-Shift: Wenn Ihr Fine-Tuning-Datensatz stark von den Pretraining-Daten abweicht, können Probleme mit Domain-Shift auftreten. Wenden Sie Domain-Adaptionstechniken an, um diese Unterschiede zu überbrücken.
Speichern und Wiederverwenden von Modellen
Nach dem Training sollten Sie den Zustand Ihres Modells speichern, um ihn später wiederverwenden zu können. Dazu zählen die Modellparameter sowie der Zustand des verwendeten Optimierers. So können Sie das Training zu einem späteren Zeitpunkt vom selben Stand aus fortsetzen.
Ethische Überlegungen
Verstärkung von Bias: Vortrainierte Modelle können Verzerrungen enthalten, die sich während des Fine-Tunings verstärken können. Wenn Sie unvoreingenommene Vorhersagen benötigen, sollten Sie bevorzugt bereits auf Bias und Fairness getestete vortrainierte Modelle einsetzen.
Unerwünschte Ausgaben: Feingetunte Modelle können plausibel wirkende, aber falsche Ausgaben liefern. Implementieren Sie robuste Nachverarbeitungs- und Validierungsmechanismen, um dies abzufedern.
Modell-Drift: Die Leistung eines Modells kann sich im Laufe der Zeit aufgrund von Veränderungen in Umgebung oder Datenverteilung verschlechtern. Überwachen Sie daher regelmäßig die Leistung Ihres Modells und führen Sie bei Bedarf ein erneutes Fine-Tuning durch.
Fortgeschrittene Techniken und weiteres Lernen
Fortgeschrittene Fine-Tuning-Techniken für LLMs umfassen Low Ranking Adaptation (LoRA) und Quantized LoRA (QLoRA), die die Rechen- und Kostenbelastung reduzieren und gleichzeitig die Leistung aufrechterhalten. Parameter Efficient Fine Tuning (PEFT) passt Modelle effizient an, indem nur wenige trainierbare Parameter verwendet werden. DeepSpeed und ZeRO optimieren die Speichernutzung für groß angelegtes Training. Diese Methoden adressieren Herausforderungen wie Overfitting, katastrophales Vergessen und Domain-Shift-Empfindlichkeit und erhöhen die Effizienz und Effektivität des Fine-Tunings großer Sprachmodelle.
Über das Fine-Tuning hinaus gibt es weitere fortgeschrittene Trainingsmethoden wie Transfer Learning und Reinforcement Learning. Transfer Learning beinhaltet das Anwenden von Wissen aus einem Problem auf ein anderes verwandtes Problem, während Reinforcement Learning eine Form des maschinellen Lernens ist, bei der ein Agent Entscheidungen trifft, um eine Belohnung in seiner Umgebung zu maximieren.
Folgende Ressourcen können für ein tieferes Verständnis hilfreich sein:
- Attention is all you need von Ashish Vaswani et al.
- Das Buch „Deep Learning“ von Ian Goodfellow, Yoshua Bengio und Aaron Courville
- Das Buch „Speech and Language Processing“ von Daniel Jurafsky und James H. Martin
- Verschiedene Methoden zum Training von LLMs
- Mastering LLM Techniques: Training
- NLP-Kurs von Hugging Face
Fazit
Das Trainieren eines KI-Modells erfordert eine beträchtliche Menge hochwertiger Daten. Zwar sind die Definition des Problems, die Auswahl eines Modells und dessen Verfeinerung durch Iterationen wichtige Schritte, doch der wahre Unterschied liegt in der Qualität und dem Umfang der verwendeten Daten. Anstatt Web-Scraper selbst zu erstellen und zu warten, können Sie die Datenerfassung vereinfachen, indem Sie vorgefertigte oder benutzerdefinierte Datensätze verwenden, die auf der Plattform von Bright Data verfügbar sind.
Mit dem Dataset Marketplace können Sie geprüfte, einsatzbereite Datensätze von beliebten Websites abrufen oder maßgeschneiderte Datensätze erstellen, die Ihre spezifischen Anforderungen mithilfe der automatisierten Plattform erfüllen. So können Sie sich darauf konzentrieren, Ihre Modelle effizient mit präzisen und konformen Daten zu trainieren, was in verschiedenen Branchen schnellere und zuverlässigere Ergebnisse ermöglicht.
Entdecken Sie die Datensatzlösungen von Bright Data und integrieren Sie sie problemlos in Ihren Workflow für die Datenerfassung.
Melden Sie sich jetzt an und starten Sie Ihre kostenlose Testphase für die Scraping-Infrastruktur von Bright Data, einschließlich kostenloser Datensatzproben.