
In diesem Blog-Beitrag werden Sie sehen:
- Was Ctush ist und warum es eine so beliebte CLI-Anwendung für KI-Codierungshilfe ist.
- Wie die Erweiterung um Webinteraktion und Datenextraktion die Effektivität erhöht.
- Wie Sie Crush CLI mit dem Bright Data Web MCP-Server verbinden, um einen erweiterten KI-Codierungsagenten zu erstellen.
Tauchen Sie ein!
Was ist Crush?
Crush ist ein Open-Source-KI-Codierungsagent für Ihr Terminal. Bei Crush CLI handelt es sich um eine Go-basierte CLI-Anwendung, die KI-Unterstützung direkt in Ihre Terminalumgebung bringt. Es bietet eine TUI(Terminal User Interface) für die Interaktion mit verschiedenen LLMs zur Unterstützung bei der Programmierung, Fehlersuche und anderen Entwicklungsaufgaben.
Genau das macht Crush so besonders:
- Plattformübergreifend: Funktioniert in allen wichtigen Terminals unter macOS, Linux, Windows (PowerShell und WSL), FreeBSD, OpenBSD und NetBSD.
- Unterstützung mehrerer Modelle: Wählen Sie aus einer breiten Palette von LLMs, integrieren Sie Ihre eigenen über OpenAI- oder Anthropic-kompatible APIs oder verbinden Sie sich mit lokalen Modellen.
- Sitzungsbasierte Erfahrung: Verwalten Sie mehrere Arbeitssitzungen und Kontexte pro Projekt.
- Hochgradig flexibel: Es ist möglich, zwischen LLMs mitten in der Sitzung zu wechseln und dabei den Kontext beizubehalten.
- LSP-fähig: Crush unterstützt LSP(Language Server Protocols) für zusätzlichen Kontext und Intelligenz, genau wie eine moderne IDE.
- Erweiterbar: Unterstützung der Integration von Drittanbieterfunktionen über MCPs(HTTP, stdio und SSE).
Das Projekt hat bereits über 10k Sterne auf GitHub erreicht und wird aktiv von einer lebendigen Entwicklergemeinschaft mit über 35 Mitwirkenden gepflegt.
Überwindung der LLM-Wissenslücke in Crush CLI mit dem Web MCP
Eine gemeinsame Herausforderung für alle LLMs besteht darin, eine Wissenslücke zu haben. Das LLM, das Sie in Crush CLI konfigurieren, ist nicht anders. Da diese Modelle auf einem festen Datensatz trainiert werden, ist ihr Wissen ein statischer Schnappschuss der Vergangenheit. Das heißt, sie kennen keine aktuellen Ereignisse oder Entwicklungen.
Dies ist ein großer Nachteil in der schnelllebigen Welt der Technologie. Ohne eine aktualisierte Wissensbasis könnte ein LLM veraltete Bibliotheken vorschlagen, veraltete Programmierpraktiken anwenden oder einfach keine Kenntnis von neuen Funktionen und Tools haben.
Was wäre, wenn Ihr Crush-KI-Programmierassistent mehr könnte, als nur alte Informationen abzurufen? Stellen Sie sich vor, er wäre in der Lage, das Internet nach den neuesten Dokumentationen, Artikeln und Anleitungen zu durchsuchen und dann diese Echtzeitdaten zu nutzen, um bessere und genauere Hilfe zu leisten.
Sie können dies erreichen, indem Sie Crush mit einer Lösung verbinden, die LLMs die Möglichkeit des Webzugriffs und der Datenabfrage bietet. Genau das ist es, was Sie mit dem Web MCP-Server von Bright Data erhalten. Dieser Open-Source-Server(jetzt mit einer kostenlosen Stufe!) stellt Ihnen mehr als 60 KI-fähige Tools für Webinteraktion und Datenerfassung zur Verfügung.
Bright Data Web MCP-Integration
Im Folgenden sind zwei der wichtigsten Tools aufgeführt, die Sie auf diesem MCP-Server finden:
search_engine: Stellt eine Verbindung zur SERP-API her, um Suchen in Google, Bing oder Yandex durchzuführen und die Daten der Suchmaschinenergebnisseite entweder im HTML- oder Markdown-Format zurückzugeben.scrape_as_markdown: Nutzt den Web Unlocker, um den Inhalt einer einzelnen Webseite zu extrahieren. Es unterstützt erweiterte Extraktionsoptionen, umgeht Bot-Erkennungssysteme und löst CAPTCHAs für Sie auf.
Darüber hinaus gibt es mehr als 55 spezialisierte Tools für die Interaktion mit Webseiten (z. B. scraping_browser_click) und das Sammeln von strukturierten Daten-Feeds aus einer Vielzahl von Domänen, darunter Amazon, LinkedIn und TikTok. Das Tool web_data_amazon_product kann zum Beispiel detaillierte, strukturierte Produktinformationen direkt von Amazon mithilfe einer Produkt-URL abrufen.
Angesichts dieser Tools gibt es einige Möglichkeiten, wie Sie Bright Data Web MCP mit Crush nutzen können:
- Rufen Sie aktuelle Informationen für Ihre Projekte ab, z. B. Aktienkurse von Yahoo Finance oder Produktdetails von E-Commerce-Websites. Speichern Sie diese Daten in lokalen Dateien für Analysen, Tests, Mocking und vieles mehr.
- Lassen Sie die KI die neueste Dokumentation für eine Bibliothek oder ein Framework abrufen, die Sie verwenden, und stellen Sie sicher, dass der vorgeschlagene Code aktuell und nicht veraltet ist.
- Sammeln Sie kontextabhängige Links und integrieren Sie diese Ressourcen in Markdown-Dateien, Dokumentationen oder andere Ausgaben – ohne Ihren Code-Editor zu verlassen.
Sehen Sie selbst, wie das Web MCP Ihren Crush-CLI-Agenten verbessern kann!
So stellen Sie eine Verbindung zwischen Crush und dem Web MCP von Bright Data her
In diesem geführten Lernprogramm erfahren Sie, wie Sie Crush lokal installieren und konfigurieren und mit dem Web MCP von Bright Data integrieren. Das Ergebnis ist ein verbesserter KI-Codierungsagent, der Folgendes kann
- Scraping einer Amazon-Produktseite im laufenden Betrieb.
- Speichern der Daten in einer lokalen JSON-Datei.
- Erstellen eines Node.js-Skripts zum Laden und Verarbeiten dieser Daten.
Befolgen Sie die unten stehenden Anweisungen!
Voraussetzungen
Bevor Sie beginnen, stellen Sie sicher, dass Sie Folgendes haben:
- Node.js ist lokal installiert (die neueste LTS-Version wird empfohlen).
- Einen API-Schlüssel von einem der unterstützten LLM-Anbieter (in dieser Anleitung wird Google Gemini verwendet).
- Ein Bright Data-Konto mit einem fertigen API-Schlüssel (keine Sorge, Sie werden durch die Erstellung eines Kontos geführt, falls Sie noch keines haben).
Außerdem ist optionales, aber hilfreiches Hintergrundwissen erforderlich:
- Ein allgemeines Verständnis für die Funktionsweise von MCP.
- Eine gewisse Vertrautheit mit dem Bright Data Web MCP-Server und seinen Tools.
- Kenntnisse über die Funktionsweise von CLI-Codierungsagenten und deren Interaktion mit Ihrem Dateisystem.
Schritt 1: Installieren und Konfigurieren von Crush
Installieren Sie die Crush-CLI global auf Ihrem System über das npm-Paket @charmland/crush:
npm install -g @charmland/crushWenn Sie die CLI nicht über npm installieren möchten, entdecken Sie die anderen Installationsoptionen.
Sie können Crush nun mit starten:
crushWas Sie sehen sollten, ist der LLM-Auswahlbildschirm unten:
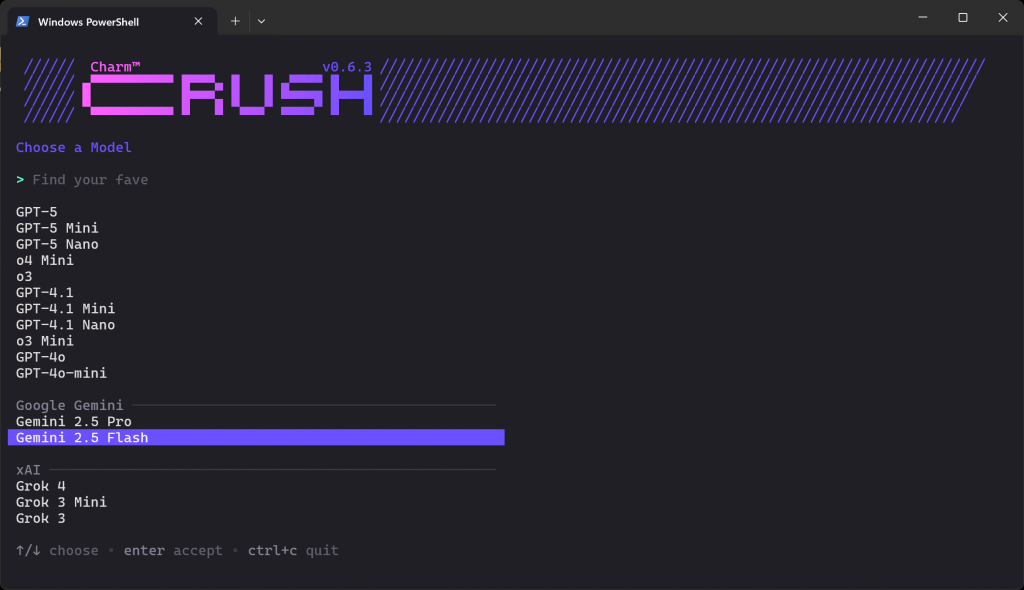
Es gibt Dutzende von Anbietern und Hunderte von Modellen, aus denen Sie wählen können. Navigieren Sie mit den Pfeiltasten, bis Sie das gewünschte Modell des Anbieters finden, für den Sie einen API-Schlüssel haben. In diesem Beispiel wählen wir “Gemini 2.5 Flash” (das im Wesentlichen kostenlos über die API genutzt werden kann).
Als nächstes werden Sie aufgefordert, Ihren API-Schlüssel einzugeben. Fügen Sie ihn ein und drücken Sie die Eingabetaste:
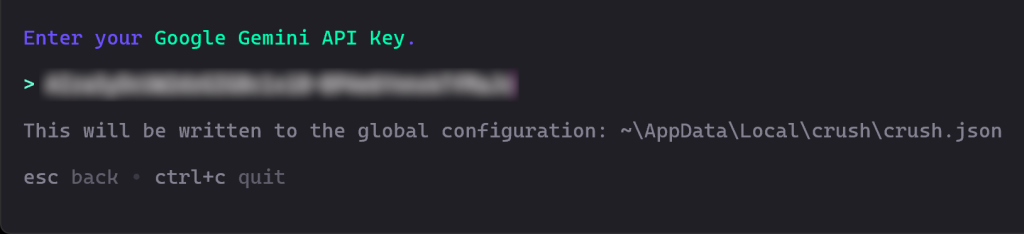
In diesem Fall fügen Sie Ihren Google Gemini-API-Schlüssel ein, den Sie kostenlos von Google Studio AI abrufen können.
Crush wird dann Ihren API-Schlüssel validieren, um zu bestätigen, dass er funktioniert.
Sobald die Validierung abgeschlossen ist, sollten Sie etwas Ähnliches sehen:
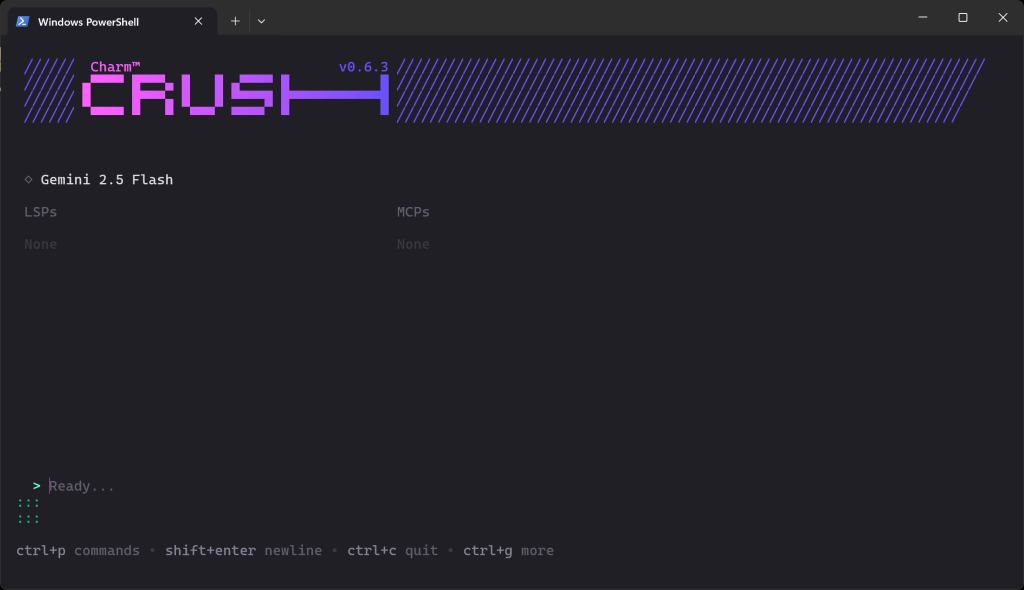
Im Abschnitt “Bereit…” können Sie nun Ihre Eingabeaufforderung eingeben.
Hinweis: Wenn Sie die Crush-Befehlszeilenschnittstelle erneut starten, werden Sie nicht erneut aufgefordert, eine LLM-Verbindung einzurichten. Das liegt daran, dass Ihr konfigurierter LLM-Schlüssel automatisch in der globalen Konfigurationsdatei $HOME/.config/crush/crush.json (oder unter Windows: %USERPROFILE%AppDataLocalcrushcrush.json) gespeichert wird.
Öffnen Sie die globale Konfigurationsdatei crush.json in Visual Studio Code (oder Ihrer bevorzugten IDE), um sie zu überprüfen:
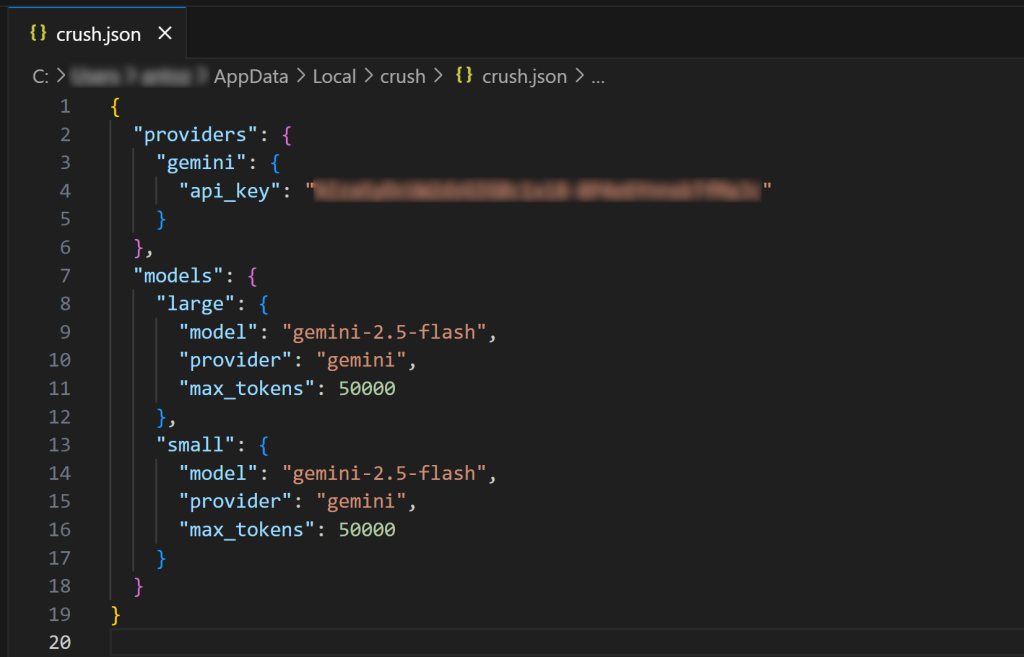
Wie Sie sehen können, enthält die Datei crush.json Ihren API-Schlüssel zusammen mit der Konfiguration für das gewählte Modell. Sie wurde von der Crush-Befehlszeilenschnittstelle ausgefüllt, als Sie ein LLM ausgewählt haben. Sie können diese Datei auch bearbeiten, um andere KI-Modelle(sogar lokale Modelle) zu konfigurieren.
Auf ähnliche Weise können Sie lokale crush.json oder .crush.json Dateien in Ihrem Projektverzeichnis erstellen, um die globale Konfiguration zu überschreiben. Weitere Einzelheiten finden Sie in der offiziellen Dokumentation.
Erstaunlich! Die Crush-CLI ist nun installiert und funktioniert auf Ihrem System.
Schritt 2: Testen Sie den Web-MCP von Bright Data
Wenn Sie noch kein Konto haben, erstellen Sie ein Bright Data-Konto. Andernfalls melden Sie sich einfach bei Ihrem bestehenden Konto an.
Folgen Sie anschließend den offiziellen Anweisungen, um Ihren Bright Data-API-Schlüssel zu generieren. Bewahren Sie ihn an einem sicheren Ort auf, da Sie ihn bald benötigen werden. Der Einfachheit halber gehen wir davon aus, dass Sie einen API-Schlüssel mit Admin-Berechtigungen verwenden.
Installieren Sie den Web MCP global mit dem Paket @brightdata/mcp mit:
npm install -g @brightdata/mcpÜberprüfen Sie dann mit diesem Bash-Befehl, ob der Server funktioniert:
API_TOKEN="<Ihre_BRIGHT_DATA_API>" npx -y @brightdata/mcpOder, äquivalent, auf Windows PowerShell:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; npx -y @brightdata/mcpErsetzen Sie den Platzhalter <YOUR_BRIGHT_DATA_API> durch das tatsächliche Bright Data-API-Token, das Sie zuvor generiert haben. Mit den obigen Befehlen wird die erforderliche Umgebungsvariable API_TOKEN festgelegt und der MCP-Server über das npm-Paket @brightdata/mcp gestartet.
Wenn alles ordnungsgemäß funktioniert, sollten Sie Protokolle wie das folgende sehen:

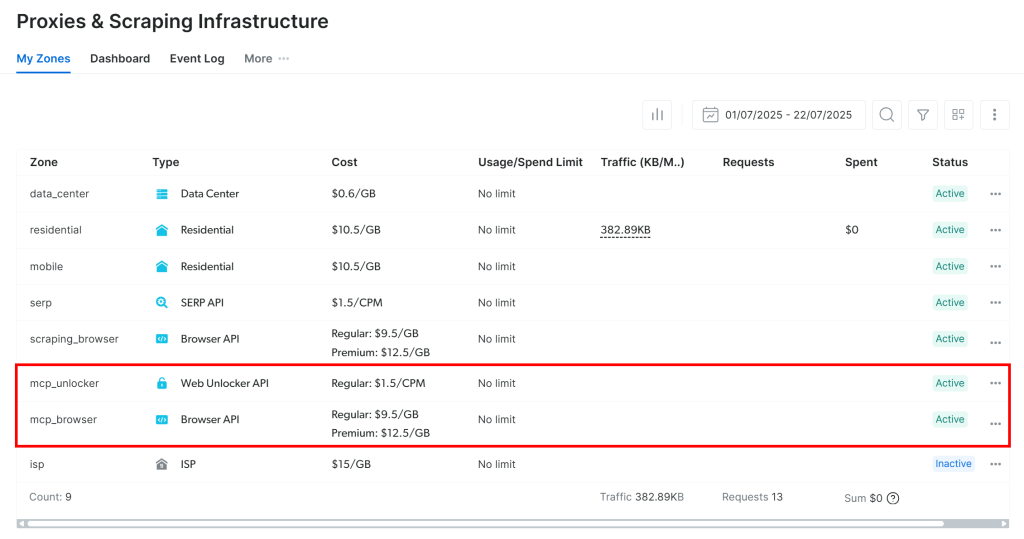
Beim ersten Start erstellt der MCP-Server automatisch zwei Zonen in Ihrem Bright Data-Konto:
mcp_unlocker: Eine Zone für Web Unlocker.mcp_browser: Eine Zone für die Browser-API.
Diese Zonen sind erforderlich, um die gesamte Palette der MCP-Server-Tools nutzen zu können.
Um zu bestätigen, dass sie erstellt wurden, melden Sie sich bei Ihrem Bright Data Dashboard an und gehen Sie zur Seite “Proxies & Scraping Infrastructure“. Dort sollten die beiden Zonen aufgeführt sein:
Hinweis: Wenn Ihr API-Token keine Admin-Berechtigungen hat, werden diese Zonen möglicherweise nicht für Sie erstellt. In diesem Fall können Sie sie manuell einrichten und ihre Namen mithilfe von Umgebungsvariablen festlegen, wie in den offiziellen Dokumenten beschrieben.
Denken Sie daran: Standardmäßig stellt der MCP-Server nur die Tools search_engine und scrape_as_markdown zur Verfügung.
Um erweiterte Tools für die Browser-Automatisierung und strukturierte Daten-Feeds freizuschalten, müssen Sie den Pro-Modus aktivieren. Dazu setzen Sie die Umgebungsvariable PRO_MODE=true, bevor Sie den MCP-Server starten:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcpOder, unter Windows:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; $Env:PRO_MODE="true"; npx -y @brightdata/mcpWichtig: Mit dem Pro-Modus erhalten Sie Zugang zu allen 60+ Werkzeugen. Die zusätzlichen Tools im Pro-Modus sind jedoch nicht in der kostenlosen Version enthalten, und es fallen Gebühren an.
Weitere Informationen über den Web MCP-Server von Bright Data finden Sie in den offiziellen Dokumenten.
Perfekt! Sie haben sich vergewissert, dass der Web MCP-Server auf Ihrem Computer korrekt ausgeführt wird. Stoppen Sie den Server, da der nächste Schritt darin besteht, Crush so zu konfigurieren, dass er beim Start gestartet und eine Verbindung zu ihm hergestellt wird.
Schritt 3: Konfigurieren Sie den Web MCP in Crush
Crush unterstützt die MCP-Integration über den Eintrag mcp in der lokalen oder globalen Konfigurationsdatei crush.json.
In diesem Beispiel gehen wir davon aus, dass Sie den Web-MCP von Bright Data global in Ihrer Crush-CLI-Umgebung konfigurieren möchten. Öffnen Sie also die globale Konfigurationsdatei:
- Unter Linux/macOS:
$HOME/.config/crush/crush.json. - Unter Windows:
%USERPROFILE%AppDataLocalcrushcrush.json.
Stellen Sie sicher, dass die Datei Folgendes enthält:
"mcp": {
"brightData": {
"type": "stdio",
"command": "npx",
"args": [
"-y",
"@brightdata/mcp"
],
"env": {
"API_TOKEN": "<IHR_BRIGHT_DATA_API_KEY>",
"PRO_MODE": "true"
}
}
}In dieser Konfiguration:
- Der
mcp-Eintragteilt Crush mit, wie externe MCP-Server gestartet werden sollen. - Der Eintrag
brightDatadefiniert den Befehl und die Umgebungsvariablen, die für die Ausführung des Web-MCPs erforderlich sind. (Zur Erinnerung: Die Angabe vonPRO_MODEist optional, wird aber empfohlen. Ersetzen Sie außerdem<YOUR_BRIGHT_DATA_API_KEY>durch Ihren Bright Data-API-Schlüssel).
Mit anderen Worten: Diese Konfiguration fügt einen benutzerdefinierten MCP-Server namens brightData hinzu. Crush verwendet die Umgebungsvariablen, die Sie in der Datei festgelegt haben, und startet den Server über den angegebenen npx-Befehl (der dem im vorherigen Schritt gezeigten Befehl entspricht). Einfacher ausgedrückt: Crush kann nun einen lokalen Web-MCP-Prozess starten und sich beim Start mit diesem verbinden.
Großartig! Jetzt können Sie die MCP-Integration in der Crush-CLI testen.
Schritt 4: Überprüfen der MCP-Verbindung
Schließen Sie alle laufenden Crush-Instanzen und starten Sie Crush erneut:
crush Wenn die MCP-Verbindung wie erwartet funktioniert, sollten Sie den brightData-Eintrag im Abschnitt “MCPs” sehen:
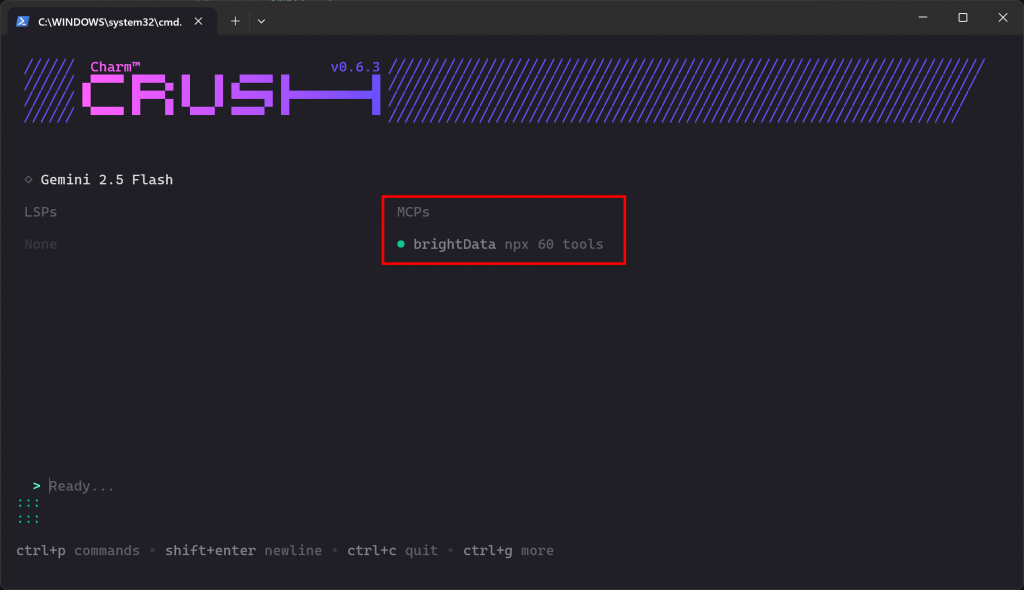
Die CLI zeigt an, dass 60 Tools verfügbar sind. Das liegt daran, dass wir das Programm so konfiguriert haben, dass es im Pro-Modus läuft. Ansonsten hätten Sie nur Zugriff auf 2 Tools(scrape_as_markdown und search_engine). Gut gemacht!
Schritt #5: Führen Sie eine Aufgabe in Crush aus
Um die neuen Möglichkeiten in Ihrer Crush-CLI-Einrichtung zu überprüfen, versuchen Sie, eine Eingabeaufforderung wie die folgende auszuführen:
Scrape Daten von "https://www.amazon.com/Microfiber-Cleaning-Cloth-Performance-Washes/dp/B08BRJHJF9/", speichere sie in einer lokalen "product.json"-Datei, und definiere ein Node.js-Skript "script.js", um die Datei zu laden und ihren Inhalt im Terminal auszugeben.Dies ist ein hervorragender Testfall, da er den Abruf frischer Produktdaten erfordert, was mit den von Bright Data’s Web MCP bereitgestellten Tools erreicht werden sollte. Außerdem demonstriert er einen realistischen Arbeitsablauf, den Sie beim Mocking oder Einrichten eines Datenanalyseprojekts verwenden könnten.
Fügen Sie die Eingabeaufforderung in Crush ein und drücken Sie die Eingabetaste, um sie auszuführen. Sie sollten etwa so etwas sehen:
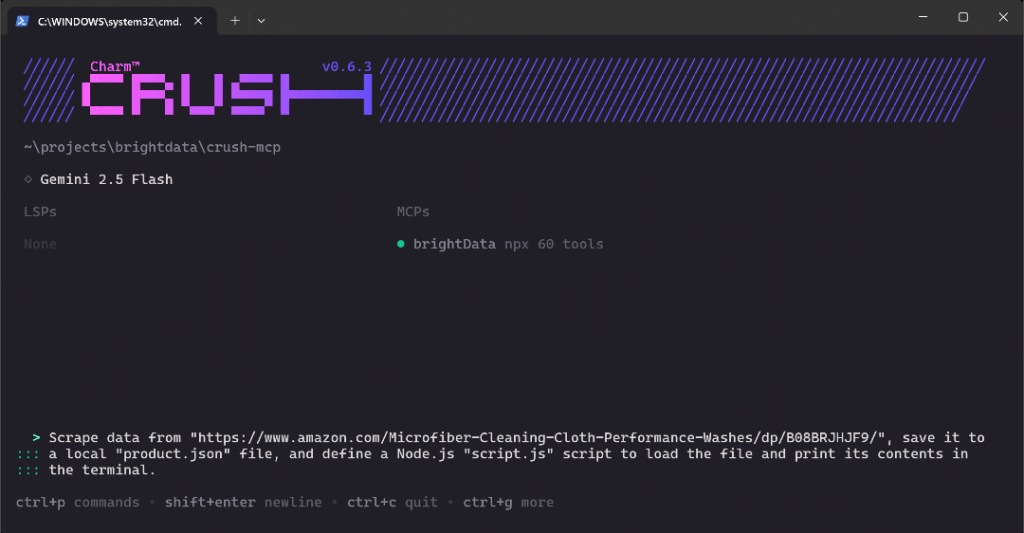
Das obige GIF wurde beschleunigt, aber so sieht es Schritt für Schritt aus:
- Crush erkennt das Tool
web_data_amazon_product(das in der Befehlszeilenschnittstelle alsmcp_brightData_web_data_amazon_productbezeichnet wird) als das richtige Tool für die Aufgabe und bittet Sie um Ihre Genehmigung, es auszuführen. - Sobald die Genehmigung erteilt wurde, wird die Scraping-Aufgabe über die MCP-Integration ausgeführt.
- Die resultierenden JSON-Produktdaten werden im Terminal angezeigt.
- Crush fragt, ob es diese Daten in einer lokalen Datei mit dem Namen
product.jsonspeichern kann. - Nach Genehmigung wird die Datei erstellt und mit den gescrapten Daten gefüllt.
- Crush CLI generiert dann die JavaScript-Logik für
script.js, die den JSON-Inhalt lädt und ausgibt. - Sobald Sie zustimmen, wird die Datei
script.jserstellt. - Sie werden um die Erlaubnis gebeten, das Node.js-Skript auszuführen.
- Nachdem Sie die Erlaubnis erteilt haben, wird
script.jsausgeführt und die Produktdaten werden im Terminal ausgegeben.
Beachten Sie, dass die Befehlszeilenschnittstelle die Ausführung des erstellten Node.js-Skripts anfordert, auch wenn Sie dies nicht explizit angefordert haben. Dieses Verhalten war beabsichtigt, da es das Testen (und damit die Fehlerbehebung) erleichtert und einen Mehrwert für den Arbeitsablauf darstellt.
Am Ende sollte Ihr Arbeitsverzeichnis diese beiden Dateien enthalten:
├── prodcut.json
└── script.jsÖffnen Sie product.json in VS Code, und Sie sollten sehen:
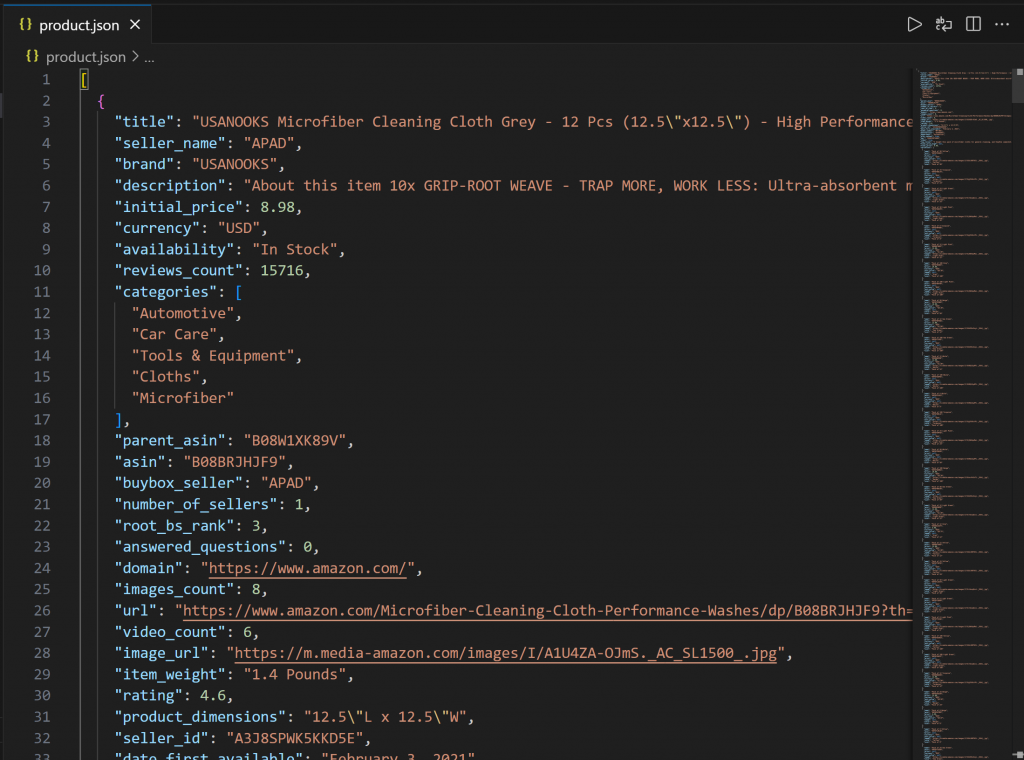
Diese Datei enthält echte Produktdaten, die über den Web MCP von Bright Data von Amazon abgerufen wurden.
Öffnen Sie nun script.js:
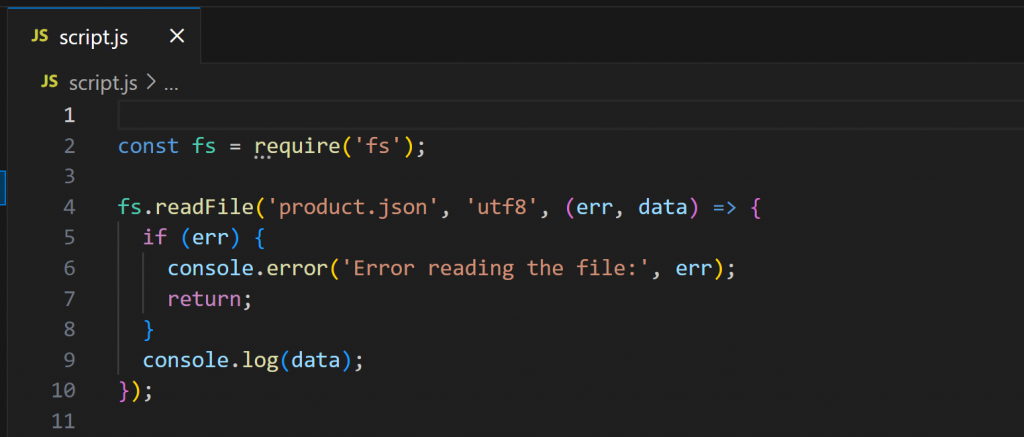
Dieses Skript verwendet Node.js zum Laden und Anzeigen des Inhalts von product.json. Führen Sie es mit aus:
node script.jsDie Ausgabe sollte sein:
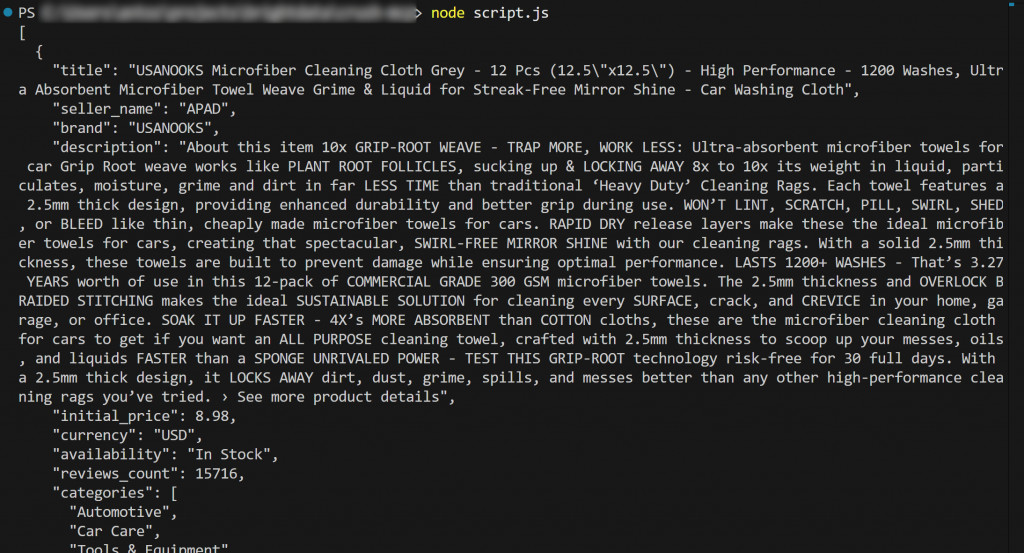
Et voilà! Der Arbeitsablauf war erfolgreich.
Der aus der Datei product.json geladene und im Terminal ausgegebene Inhalt stimmt mit den tatsächlichen Daten überein, die Sie auf der ursprünglichen Amazon-Produktseite finden können.
Wichtig: Die Datei product.json enthält echte gescrapte Daten und keine halluzinierten oder von der KI erfundenen Inhalte. Dies ist von grundlegender Bedeutung, denn das Scraping von Amazon ist aufgrund des fortschrittlichen Anti-Bot-Schutzes (z. B. wegen des Amazon CAPTCHA) bekanntermaßen schwierig. Ein normales LLM allein könnte dieses Ziel also nicht erreichen!
Dieses Beispiel zeigt die wahre Stärke der Kombination von Crush mit dem MCP-Server von Bright Data. Experimentieren Sie jetzt mit neuen Prompts und erforschen Sie fortgeschrittenere, LLM-gesteuerte Daten-Workflows direkt in der CLI!
Schlussfolgerung
In diesem Lernprogramm haben Sie gesehen, wie Sie Crush mit dem Web-MCP von Bright Data(der jetzt eine kostenlose Stufe anbietet!) verbinden können. Das Ergebnis ist ein leistungsstarker CLI-Coding-Agent, der auf das Web zugreifen und mit ihm interagieren kann. Diese Integration ist dank der in Crush CLI integrierten Unterstützung für MCP-Server möglich.
Die Beispielaufgabe in diesem Leitfaden wurde absichtlich einfach gehalten. Vergessen Sie jedoch nicht, dass Sie mit dieser Integration auch viel komplexere Anwendungsfälle bewältigen können. Schließlich unterstützen die Bright Data Web MCP-Tools eine Vielzahl von Agentenszenarien.
Um fortschrittlichere Agenten zu erstellen, erkunden Sie die gesamte Palette der in der Bright Data AI-Infrastruktur verfügbaren Services.
Melden Sie sich für ein kostenloses Bright Data-Konto an und experimentieren Sie noch heute mit KI-fähigen Webtools!





