

Die meisten Daten-Teams scheitern nicht daran, dass sie keine Daten erfassen können. Sie scheitern daran, dass Rohdaten unstrukturiert, dupliziert und inkonsistent ankommen und es keine disziplinierte Methode gibt, daraus etwas zu machen, dem Analysten und Modelle vertrauen können. Die Medallion-Architektur ist das Muster, das die meisten modernen Datenplattformen verwenden, um genau dieses Problem zu lösen: indem Daten durch drei zunehmend sauberere Schichten bewegt werden – Bronze, Silber und Gold.
Dieser Leitfaden erklärt das Muster so, wie ein Data Engineer es verstehen muss: wie sich jede Schicht verhält, wie Daten physisch zwischen ihnen bewegt werden und wo extern bezogene Web-Daten als roher Bronze-Input ins Bild kommen.
In diesem Artikel:
- Was die Medallion-Architektur ist und warum Databricks sie populär gemacht hat
- Was die Bronze-, Silber- und Goldschichten jeweils tun und wer sie nutzt
- Wie Daten durch die Schichten mit Tabellenformaten, ACID-Transaktionen und Change Data Capture fließen
- Wo externe Web-Daten als Bronze-Quelle in das Muster eintreten
- Best Practices, häufige Fallstricke und Anwendungsfälle, bei denen das Muster sich bewährt
Was ist die Medallion-Architektur?
Die Medallion-Architektur ist ein Entwurfsmuster zur Organisation von Daten in einem Lakehouse, sodass Struktur und Qualität in jeder Stufe verbessert werden, während die Daten von Bronze über Silber zu Gold fließen. Der Name entlehnt die Metapher von Medaillen: Daten kommen als minderwertiges rohes Bronze an und werden zu wertvolleren Silber, dann Gold verfeinert. Man bezeichnet es auch als Multi-Hop-Architektur, da jeder Datensatz mehrere Hops durchläuft, bevor er zur Nutzung bereit ist.
Das Muster wurde von Databricks zusammen mit dem Lakehouse-Paradigma und dem Delta-Lake-Tabellenformat popularisiert, das 2019 als Open Source veröffentlicht wurde. Ein Lakehouse kombiniert die niedrigen Speicherkosten eines Data Lakes mit den Zuverlässigkeitsfunktionen eines Data Warehouses, wie ACID-Transaktionen und Schema-Durchsetzung. Die Medallion-Architektur ist das Organisationsprinzip, das diesem Lakehouse einen klaren Vertrauensfluss verleiht. Es ist nun eine plattformübergreifende Konvention: dieselbe Bronze-, Silber- und Gold-Sprache findet sich in der Dokumentation von Databricks, Microsoft Fabric und Snowflake.
Die Kernidee ist einfach. Anstatt Daten in einem undurchsichtigen Schritt zu bereinigen, behalten Sie eine permanente Rohkopie und verfeinern sie stufenweise, wobei jede Stufe einen klaren Vertrag hat. Diese Trennung macht das Muster so dauerhaft und ist die Grundlage für alles Folgende.
Warum Daten-Teams es einsetzen
Die Medallion-Architektur verdient ihren Platz, weil sie mehrere Probleme gleichzeitig löst.
Inkrementelle, überprüfbare Datenqualität. Qualität wird stufenweise verbessert statt in einer einzelnen Transformation, die schwer nachzuvollziehen ist. Jeder Hop hat eine definierte Aufgabe, sodass Sie wissen, welche Schicht Sie prüfen müssen, wenn etwas nicht stimmt.
Neuverarbeitung aus Rohdaten. Da die Bronze-Schicht ein permanentes historisches Archiv ist, können Sie Silber- und Goldtabellen jederzeit neu aufbauen, ohne auf das Quellsystem zurückzugreifen. Wenn eine Transformation einen Fehler hat oder sich Geschäftslogik ändert, spielen Sie ab Bronze neu ab, statt Daten neu zu erfassen, die möglicherweise nicht mehr verfügbar sind.
Herkunft und Nachvollziehbarkeit. Bronze bewahrt die ursprüngliche Payload und liefert damit einen forensischen Nachweis. Compliance- und Audit-Teams können jede Zahl in einem Dashboard bis zum exakten Rohdatensatz zurückverfolgen, aus dem sie stammt.
Aufgabentrennung zwischen Konsumenten. Verschiedene Schichten bedienen verschiedene Zielgruppen. Data Engineers und Operations-Teams arbeiten auf Bronze und Silber. Analysten und Data Scientists arbeiten auf Silber. Business-Analysten, Führungskräfte und Anwendungen konsumieren Gold.
Multi-Consumer-Serving. Eine einzelne bereinigte Silber-Entität kann viele Goldtabellen speisen, sodass Finanzen, Operations und Marketing jeweils ihre eigenen konsumfertigen Ansichten aus derselben vertrauenswürdigen Quelle erstellen können.
Das ist auch der Grund, warum das Muster natürlich mit einem ELT-Ansatz harmoniert. Sie laden zuerst Rohdaten, dann transformieren Sie sie innerhalb der Plattform, anstatt alles vor der Landung zu transformieren. Wenn Sie einen Überblick über den breiteren Ingestion-Flow benötigen, passen der Leitfaden zu ETL-Pipelines und die Übersicht zur Datenpipeline-Architektur gut zum Medallion-Modell.
Die drei Schichten im Detail
Der Fluss ist konzeptionell linear: Rohdaten landen in Bronze, werden zu Silber verfeinert und für den Konsum in Gold geformt.
flowchart LR
S["Externe und Web-Quellen"] --> B["Bronze: roh, unveraendert, nur-append"]
B --> SI["Silber: bereinigt, konform, dedupliziert"]
SI --> G["Gold: aggregiert, Geschaeftsebene"]
G --> C["BI, Dashboards, ML, Anwendungen"]Daten werden progressiv verfeinert, wenn sie von Bronze über Silber zu Gold fließen.
Bronze-Schicht: roh und unveränderlich
Bronze ist die Landing-Zone für alles, was von externen Quellsystemen ankommt. Ihre Tabellen spiegeln die Struktur der Quelle unverändert wider, mit einigen zusätzlichen Metadatenspalten, die Details wie den Lade-Zeitstempel und den Prozess, der die Zeile geschrieben hat, aufzeichnen. Die Prioritäten hier sind Erfassungsgeschwindigkeit, ein dauerhaftes historisches Archiv der Quelle, saubere Herkunft und die Möglichkeit zur späteren Neuverarbeitung, ohne das Ursprungssystem erneut lesen zu müssen.
Bronze hat einige definierende Eigenschaften. Sie enthält den Rohzustand der Daten in ihrem ursprünglichen Format. Sie wird inkrementell ergänzt und wächst mit der Zeit. Sie dient als einzige Quelle der Wahrheit und bewahrt die Treue der Daten genau so, wie sie angekommen sind. Sie ist für die nachgelagerte Verarbeitung gedacht, nicht für den direkten Analysten-Zugriff.
Ein wichtiges Implementierungsdetail: Bei Bronze erzwingen Sie im Allgemeinen keine Typen. Databricks empfiehlt, die meisten Felder als String, VARIANT oder Binär zu speichern, um sich vor unerwarteten Schema-Änderungen aus dem Upstream zu schützen. Bronze ist im Wesentlichen Schema-on-Read. Sie erfassen zuerst und interpretieren später, was genau das ist, was Sie wollen, wenn das Quell-Schema außerhalb Ihrer Kontrolle liegt. Bronze-Quellen können eine beliebige Mischung aus Streaming- und Batch-Eingaben sein, einschließlich Cloud-Objektspeicher wie Amazon S3, Google Cloud Storage und Azure Data Lake Storage, Message-Busse wie Kafka und Kinesis sowie föderierte Systeme.
Silber-Schicht: bereinigt und konform
Silber ist der Ort, an dem Bronze-Datensätze abgeglichen, zusammengeführt, konform gemacht und bereinigt werden – genug, um dem Unternehmen eine einzige kohärente Sicht auf seine Kernentitäten, Konzepte und Transaktionen zu geben. Denken Sie an Master-Kundendatensätze, deduplizierte Transaktionen und Kreuzreferenztabellen. Durch die Abstimmung von Daten aus vielen Quellen in eine konsistente Form wird Silber zur Schicht, die Self-Service-Analysen, Ad-hoc-Berichte, erweiterte Analysen und maschinelles Lernen antreibt.
Die typischen Operationen hier sind konkret: Schema-Durchsetzung, Umgang mit Null- und fehlenden Werten, Deduplizierung, Auflösung von außer-der-Reihe und spät ankommenden Datensätzen, Datenqualitätsprüfungen, Schema-Evolution, Typ-Casting und Joins. Hier beginnt auch echtes Datenmodellieren, oft mit normalisierten, schreibperformanten Strukturen. Das Verfolgen von Datenqualitätsmetriken in dieser Phase ist das, was eine vertrauenswürdige Silber-Schicht von einer glorifizierten Kopie von Bronze unterscheidet.
Eine feste Best Practice: Schreiben Sie nicht direkt von der Ingestion in Silber. Wenn Sie Bronze überspringen und direkt in Silber schreiben, führen Sie Fehler durch Schema-Änderungen und korrupte Quelldatensätze ein und verlieren die Möglichkeit zum Replay. Silber sollte immer mindestens eine validierte, nicht aggregierte Darstellung jedes Datensatzes enthalten, damit detaillierte Analysen noch möglich sind, ohne auf rohes Bronze zurückzugreifen.
Gold-Schicht: geschäftsbereit
Gold enthält konsumfertige, projektspezifische Daten. Die Modelle hier sind stärker denormalisiert und auf schnelle Lesevorgänge mit weniger Joins optimiert, und hier landen die abschließenden Transformationen und Geschäftsregeln. Es ist der Heimatort der Präsentationsschicht-Arbeit: Kunden- und Inventaranalysen, Segmentierung, Vertriebsberichte und Ähnliches. In der Praxis finden sich in dieser Schicht oft Kimball-artige Sternschemas oder Inmon-artige Data Marts.
Gold repräsentiert hochverfeinerte Ansichten, die Dashboards, maschinelles Lernen und Anwendungen antreiben. Die Daten sind oft stark aggregiert und auf bestimmte Zeiträume oder Regionen gefiltert. Da eine einzelne Geschäftsdomäne selten in eine Form passt, erstellen viele Teams mehrere Gold-Tabellen, zum Beispiel separate Ansichten für Finanzen, Operations und HR, die alle aus demselben Silber-Fundament abgeleitet sind.
Die folgende Tabelle fasst zusammen, wie sich die drei Schichten unterscheiden.
| Schicht | Datenzustand | Typische Operationen | Primäre Konsumenten |
|---|---|---|---|
| Bronze | Roh, unveraendert, nur-append | Ingestion, Metadaten erfassen, Historie bewahren | Data Engineers, Audit- und Compliance-Teams |
| Silber | Bereinigt, konform, dedupliziert | Validierung, Dedup, Schema-Durchsetzung, Joins | Data Engineers, Analysten, Data Scientists |
| Gold | Aggregiert, Geschaeftsebene | Finale Aggregate, Geschaeftsregeln, Sternschemas | BI-Entwickler, Fuehrungskraefte, Anwendungen, ML |
Wie Daten durch die Schichten fließen
Die Medallion-Architektur ist ein logisches Muster, aber es basiert auf einem spezifischen Satz physischer Mechanismen. Das vollständige Bild sieht so aus: Viele Quellen speisen Bronze, die Daten verfeinern sich durch Silber und Gold innerhalb des Lakehouses, und viele Konsumenten lesen aus Gold.
flowchart LR
subgraph SRC["Quellen"]
WEB["Web-Daten via Bright Data"]
DB["Datenbanken und Apps"]
MB["Message-Busse: Kafka, Kinesis"]
end
subgraph LH["Lakehouse: Delta, Iceberg oder Hudi auf Parquet"]
BRONZE["Bronze: roh, nur-append"] --> SILVER["Silber: bereinigt, konform"] --> GOLD["Gold: Geschaeftsaggregate"]
end
subgraph CON["Konsumenten"]
BI["BI und Dashboards"]
ML["ML und KI"]
APP["Anwendungen"]
end
WEB --> BRONZE
DB --> BRONZE
MB --> BRONZE
GOLD --> BI
GOLD --> ML
GOLD --> APPEin Referenz-Medallion-Stack: Viele Quellen landen in Bronze, verfeinern sich durch Silber und Gold und bedienen viele Konsumenten.
Tabellen- und Dateiformate. Die Schichten werden in der Regel auf einem offenen Tabellenformat aufgebaut, das auf Parquet-Dateien in Cloud-Objektspeicher aufsetzt. Delta Lake ist das native Format auf Databricks und Microsoft Fabric: intern speichert es Daten als Parquet, fügt aber ein Transaktionsprotokoll und Statistiken hinzu, die Zuverlässigkeit und Leistung über einfaches Parquet hinaus bieten. Apache Iceberg ist eine ebenso leistungsfähige Alternative, wenn Multi-Engine-Interoperabilität wichtig ist, und Apache Hudi eignet sich gut für upsert-intensive Change-Data-Capture-Ingestion. Alle drei bieten die ACID-Garantien, auf die das Muster angewiesen ist.
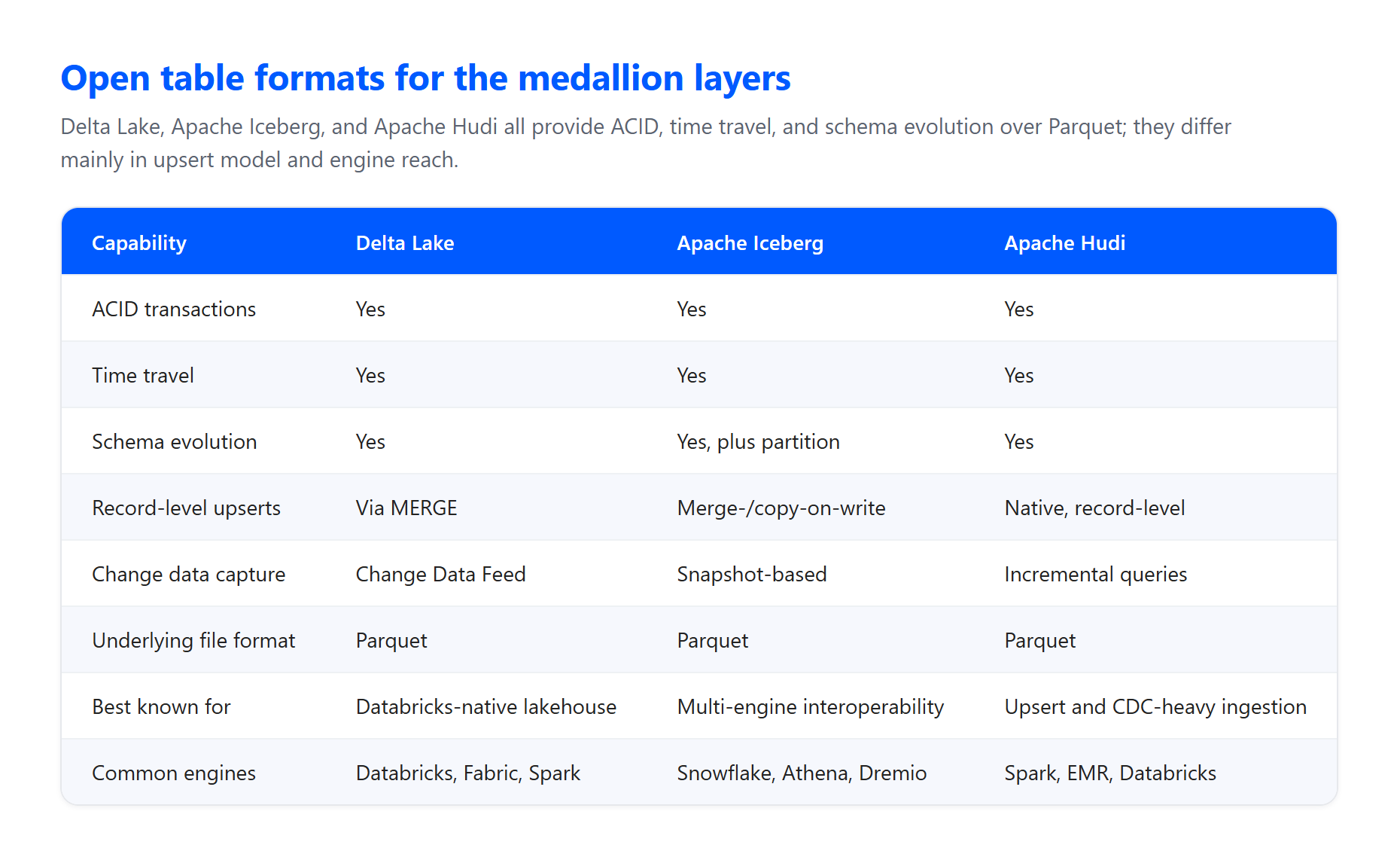
ACID-Transaktionen. Die Architektur garantiert Atomizität, Konsistenz, Isolation und Dauerhaftigkeit, wenn Daten Validierungen und Transformationen durchlaufen. Das verhindert, dass ein fehlgeschlagener Job eine Tabelle halb geschrieben und korrupt hinterlässt, was enorm wichtig ist, wenn viele Pipelines gleichzeitig lesen und schreiben.
Inkrementelle Ladevorgänge und Change Data Capture. Sie verarbeiten selten alles bei jedem Durchlauf neu. Delta Lakes Change Data Feed ermöglicht es nachgelagerten Schichten, nur das zu konsumieren, was sich geändert hat. Sie können zum Beispiel den Feed auf einer Silber-Tabelle aktivieren und ihn nutzen, um Gold-Aggregate inkrementell zu aktualisieren, ohne bei jedem Durchlauf eine vollständige Aktualisierung durchzuführen. Inkrementelle Ingestion bei Bronze ist ein Kosten- und Latenz-Kompromiss: Kontinuierliches Streaming hat die niedrigste Latenz und höchste Kosten, ausgelöste inkrementelle Ladevorgänge kosten weniger, fügen aber Latenz hinzu, und vollständige Batch-Ladevorgänge haben die höchste Latenz.
Idempotenz. Bronze-Ingestion sollte idempotent sein, sodass ein erneuter Ladevorgang keine Duplikate erzeugt oder Daten verliert. Nur-Append-Design plus Deduplizierung bei Silber macht sicheres Replay möglich.
Orchestrierung, Batch und Streaming. Tools wie Apache Spark führen die Bronze-zu-Silber- und Silber-zu-Gold-Transformationen durch, sowohl im Batch- als auch im Structured-Streaming-Modus. Deklarative Frameworks wie Spark Declarative Pipelines, Microsoft Fabric materialized lake views und Snowflake-Tasks reduzieren den Boilerplate-Code beim Bewegen von Daten zwischen Schichten. Orchestratoren wie Apache Airflow koordinieren die Läufe. Ein ausgearbeitetes Beispiel dieses Orchestrierungsmusters mit Airflow für die Planung und Spark für die Transformation finden Sie in diesem Airflow- und Spark-Pipeline-Walkthrough und eine Streaming-Variante in diesem Leitfaden zu Spark Structured Streaming.
Es ist erwähnenswert, dass das Medallion-Vokabular nicht universell ist. Das beliebte Transformations-Framework dbt strukturiert Projekte in Staging-, Intermediate- und Marts-Schichten. Die Anliegen entsprechen weitgehend Bronze, Silber und Gold, aber die Namen sind unterschiedlich, also nehmen Sie nicht an, dass die beiden Vokabulare austauschbar sind, wenn Sie Dokumentation lesen.
Wo Web-Daten eintreten: die Bronze-Schicht
Hier ist der Teil, den die meisten Architekturdiagramme übergehen: Woher kommen externe Daten wirklich, und wie landen sie in einem nutzbaren Zustand in Bronze?
Die Bronze-Schicht ist definiert als die Landing-Zone für alle externen Quellsysteme, und Databricks listet explizit Cloud-Objektspeicher wie S3, GCS und ADLS als gültige Bronze-Quellen auf. Das ist die Nahtstelle, an der extern gesammelte Web-Daten passen. Konkurrenzpreise, Produktkataloge, öffentliche Unternehmensdaten, Suchergebnisse und Bewertungsdaten sind allesamt Roheingaben, die in Bronze in ihrer ursprünglichen Form gehören, mit ihren Eigenheiten und Inkonsistenzen, die für die Silber-Schicht zur Auflösung erhalten bleiben.
Genau hier operiert Bright Data. Bright Data ist eine Web-Datenplattform, die öffentliche Web-Daten im großen Maßstab erfasst und als rohe, strukturierte Dateien liefert, was sie zu einer natürlichen Bronze-Schicht-Quelle macht. Die Ausrichtung ist direkt: Die Ziele, an die Bright Data liefert, sind dieselben Cloud-Objektspeicher, die Lakehouse-Plattformen als Bronze-Eingaben behandeln.
flowchart LR
W["Oeffentliches Web: Sites, SERPs, Marktplaetze"] --> BD["Bright Data Ingestion: Web Scraper API, Datasets, Data Firehose"]
BD -->|"JSON, NDJSON, CSV, Parquet"| L["Cloud-Speicher: S3, GCS, Azure oder Snowflake"]
L --> BR["Bronze-Schicht: roh, als Quelle der Wahrheit bewahrt"]
BR --> SV["Silber: bereinigen und konformieren"]
SV --> GD["Gold: Analysen und ML bedienen"]Externe Web-Daten, die von Bright Data geliefert werden, landen in Cloud-Speicher als Bronze-Schicht und fließen dann durch Silber und Gold nach oben.
Es gibt mehrere Möglichkeiten, Bronze zu speisen, je nachdem, ob Sie einen Batch-, On-Demand- oder kontinuierlichen Datenstrom benötigen:
- Die Web Scraper API verwandelt jede Website in einen strukturierten Datenendpunkt mit 437+ vorgefertigten Scrapern und gibt Daten als JSON, NDJSON oder CSV zurück. Sie ist der On-Demand-Auslöser für frische Bronze-Datensätze.
- Gebrauchsfertige Datensätze bieten vorgesammelte Daten aus Hunderten populärer Domains, sofort herunterladbar oder nach einem Zeitplan aktualisiert. Dies ist der Batch-Pfad in Bronze.
- Der Data Firehose liefert einen kontinuierlichen Echtzeit-Stream von Web-Datensätzen direkt an Amazon S3, einen Webhook oder einen Stream, was einem Streaming-Bronze-Ingestion-Muster entspricht.
- Die SERP-API liefert strukturierte Suchmaschinenergebnisse, eine häufige Bronze-Eingabe für Wettbewerbsanalyse- und Generative-Engine-Monitoring-Pipelines.
- Der Scraping-Browser verarbeitet JavaScript-lastige Sites und liefert gerenderte Seitendaten, die statische Erfassung vermissen würde.
- Für zweckgebundene Feeds liefern die Company Data API und kuratierte KI- und LLM-Datensätze vertikale Daten, die sofort in eine Pipeline eingespeist werden können, während die Web Archive API historische Snapshots für Zeitreihen-Bronze-Tabellen liefert.
Die Liefergeschichte macht dies sauber. Bright Data-Datensätze werden als JSON, NDJSON, CSV, XLSX und, wichtig, Parquet exportiert – das spaltenorientierte Format, das Lakehouse-Tabellen nativ verwenden. Lieferziele umfassen Amazon S3, Google Cloud Storage, Microsoft Azure Blob Storage, Snowflake, Google Cloud Pub/Sub, SFTP, Webhook und direkten API-Download. In der Praxis bedeutet das, dass ein geplanter Datensatz in Ihrem S3-Bronze-Bucket als Parquet auf einer wiederkehrenden Basis landen kann, ohne Glue-Code schreiben zu müssen. Das No-Code-Scraper Studio erweitert dies weiter und ermöglicht es Ihnen, einen Scraper visuell zu erstellen und die Ausgabe direkt in S3, GCS, Azure, BigQuery oder Snowflake zu laden.
Zwei Prinzipien halten dies treu zum Medallion-Muster. Erstens: Bewahren Sie die rohe Payload. Landen Sie die Ausgabe des Anbieters in Bronze genau so, wie sie geliefert wurde, einschließlich Felder, die Sie noch nicht verwenden, damit Sie den vollständigen forensischen Nachweis behalten. Zweitens: Normalisieren Sie in Silber, nicht in Bronze. Datumsformate, Währungen, Feldzuordnungen und quellenübergreifende Deduplizierung gehören alle in den Silber-Hop, unabhängig davon, wie der externe Anbieter seine Daten strukturiert hat. Wenn Sie zwischen Batch- und On-Demand-Pfaden entscheiden, ist der Vergleich von Datensätzen versus Web-Scraping-APIs ein nützlicher Ausgangspunkt, ebenso wie die Einführung in strukturierte versus unstrukturierte Daten.
Zuverlässigkeit ist hier wichtiger als überall sonst, denn eine Bronze-Quelle, die still versagt, vergiftet jede darüber liegende Schicht. Bright Data meldet eine durchschnittliche Erfolgsrate von 98,44% in einem unabhängigen Benchmark von elf Anbietern, unterstützt durch ein ethisch bezogenes Residential-Proxy-Netzwerk mit über 400 Millionen IPs und einem Uptime-Ziel von 99,99%. Für Teams mit Governance-Anforderungen hält Bright Data die GDPR-, CCPA-, SOC-2-Typ-II- und ISO-27001-Konformität ein und erfasst nur öffentlich verfügbare Daten, was die Art von Provenienz ist, die ein Audit-Trail auf der Bronze-Schicht erfassen soll.
Ein ausgearbeitetes Beispiel: vom rohen Scrape zur Gold-Tabelle
Theorie ist leichter zu vertrauen, wenn man sie ausführen kann. Unten ist eine minimale Medallion-Pipeline auf einer kleinen, echten Stichprobe von Web-Produktdaten: zwölf Listings, die aus live Amazon US- und UK-Suchergebnissen in drei Kategorien erfasst wurden. Der Code ist bewusst einfach gehalten, damit das Muster – nicht das Tooling – im Vordergrund steht.
Bronze. Die Zeilen werden genau so gelandet, wie sie erfasst wurden. Preise sind noch Strings, Währungen sind gemischt, und nichts wird bereinigt oder entfernt.
import pandas as pd
# Bronze: rohe gescrapte Zeilen, as-is gelandet mit Ingestion-Metadaten
bronze = pd.DataFrame(scraped_rows)
bronze["_ingested_at"] = "2026-06-23T00:00:00Z"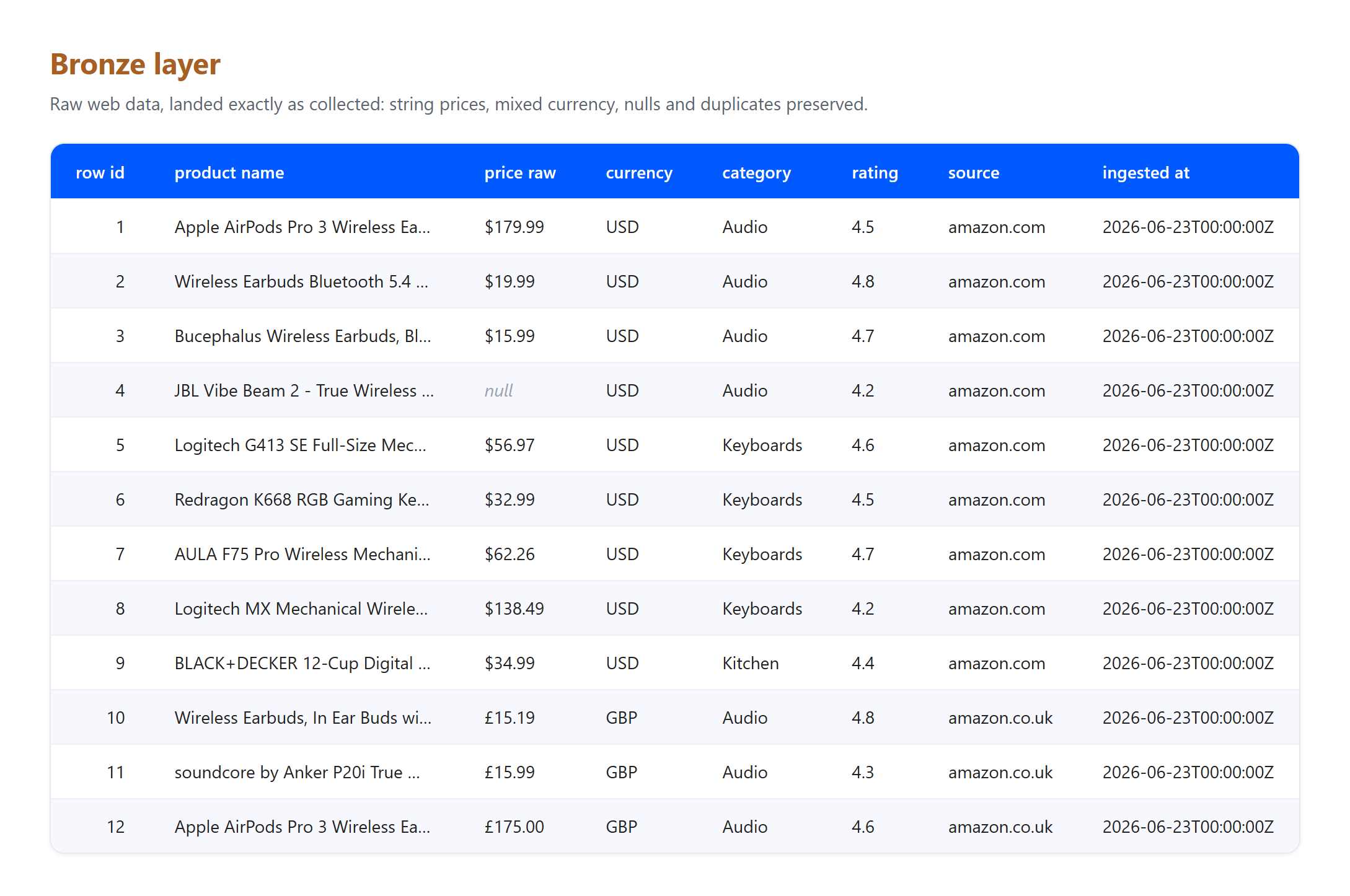
Silber. Preise in Zahlen parsen, alles auf USD normalisieren, HTML-Entities in Titeln dekodieren, Zeilen ohne verwendbaren Preis entfernen und dasselbe Produkt, das mehrfach erfasst wurde, deduplizieren.
import html, re
def to_usd(price_raw, gbp_rate=1.27): # 1.27 ist ein illustrativer fester Kurs
if not price_raw:
return None # kein Preis, die Zeile kann nicht vertraut werden
is_gbp = "£" in price_raw
value = float(re.sub(r"[^0-9.]", "", price_raw.replace(",", "")))
return round(value * gbp_rate, 2) if is_gbp else round(value, 2)
silver = bronze.copy()
silver["price_usd"] = silver["price_raw"].map(to_usd)
silver["rating"] = silver["rating"].astype(float) # Text-Rating zu Zahl
silver["product_name"] = silver["product_name"].map(html.unescape) # & wird zu &
silver = silver[silver["price_usd"].notna()] # Zeilen ohne Preis entfernen
silver = silver.sort_values("price_usd").drop_duplicates("product_name") # Dedup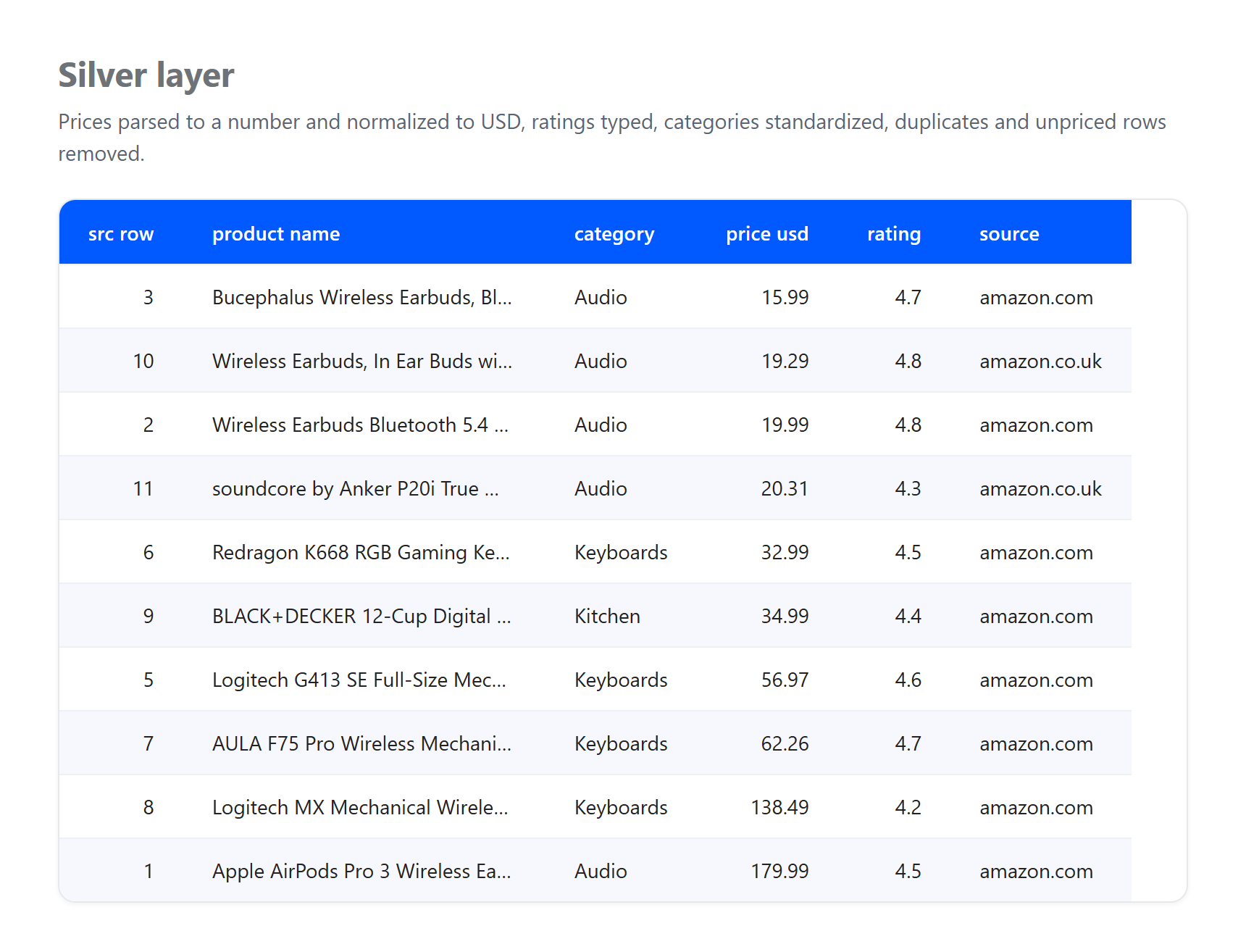
Gold. Die bereinigten Datensätze in die Geschäftsansicht aggregieren, die ein Dashboard oder Modell tatsächlich abfragt.
gold = (
silver.groupby("category")
.agg(
products=("product_name", "count"),
avg_price_usd=("price_usd", "mean"),
min_price_usd=("price_usd", "min"),
max_price_usd=("price_usd", "max"),
avg_rating=("rating", "mean"),
)
.round(2)
.reset_index()
)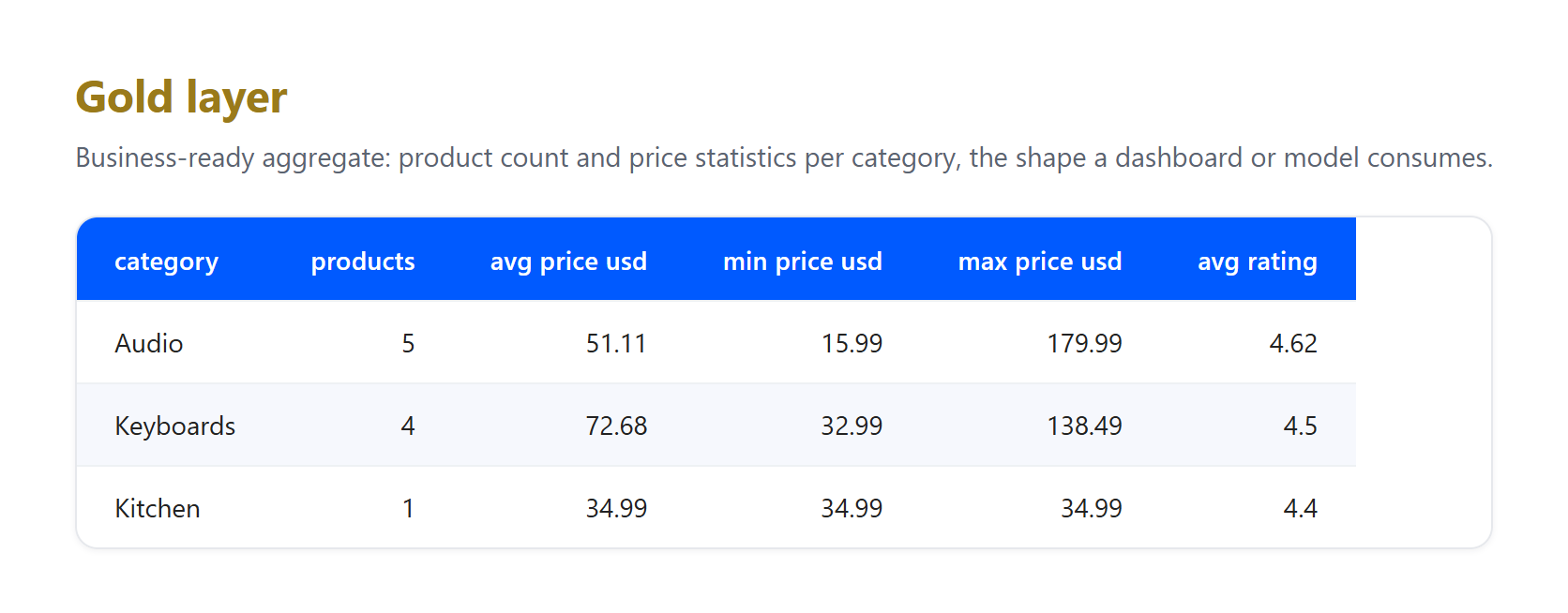
Beachten Sie, was die Schichten absorbiert haben, denn das ist genau das, womit eine echte Pipeline umgehen muss. Dies ist eine kleine echte Stichprobe, die am 23. Juni 2026 erfasst wurde, und der GBP-zu-USD-Wert ist ein illustrativer fester Kurs, keine Live-Konvertierung. Drei echte Artefakte kamen bei Bronze an und wurden bei Silber aufgelöst: Ein Listing kam ohne Preis an und wurde entfernt, dasselbe Apple AirPods Pro 3-Produkt wurde sowohl von der US- als auch der UK-Seite erfasst und auf einen einzelnen Datensatz dedupliziert, und Titel mit rohen HTML-Entities wie & wurden in Klartext dekodiert. Nichts davon gehört in Bronze, dessen einzige Aufgabe es ist, zu bewahren, was angekommen ist. Diese Aufgabentrennung ist der eigentliche Sinn des Musters.
Das Lakehouse-Tooling-Ökosystem
Das Medallion-Muster wird über eine vertraute Reihe von Tools implementiert. Keines davon ist mit den anderen austauschbar, aber eine funktionierende Architektur kombiniert normalerweise mehrere davon.
- Databricks ist die kommerzielle Lakehouse-Plattform, die sowohl das Lakehouse-Paradigma als auch die Medallion-Architektur geprägt hat, mit nativem Delta-Lake-Support und deklarativem Pipeline-Tooling.
- Delta Lake ist das Open-Source-Tabellenformat, das ACID-Transaktionen, Schema-Durchsetzung, Time Travel und Change Data Capture auf Parquet aufbaut.
- Apache Spark ist die verteilte Compute-Engine, die die Bronze-zu-Silber- und Silber-zu-Gold-Transformationen im Batch- oder Streaming-Modus ausführt.
- Apache Iceberg ist ein offenes Tabellenformat, das bevorzugt wird, wenn mehrere Engines dieselben Tabellen lesen müssen.
- Apache Hudi ist ein offenes Tabellenformat mit starker Unterstützung für Upserts auf Datensatzebene und inkrementelles Pullen, häufig bei änderungsintensiven Bronze-Schichten.
- Snowflake unterstützt das Muster nativ, einschließlich verwalteter Iceberg-Tabellen für die Gold-Schicht.
- dbt ist das SQL-first-Transformations-Framework, das viele Teams verwenden, um die Silber- und Gold-Schichten aufzubauen.
- Microsoft Fabric implementiert die Medallion-Architektur nativ auf OneLake und standardisiert auf Delta Lake.
Wenn Ihre Plattform Snowflake oder Google Cloud ist, zeigen die Integrationsleitfäden für Bright Data mit Snowflake Cortex und den Vertex AI plus SERP-API-Workflow den Bronze-Übergabe im Kontext.
Best Practices
Eine Handvoll Konventionen trennt eine saubere Implementierung von einer fragilen.
- Schreiben Sie nicht von der Ingestion in Silber. Landen Sie Rohdaten immer zuerst in Bronze, damit Schema-Änderungen und korrupte Datensätze Ihre verfeinerten Tabellen nicht beschädigen können.
- Halten Sie Bronze lose typisiert. Speichern Sie die meisten Felder als String, VARIANT oder Binär, damit Schema-Drift aus dem Upstream keine Daten verliert.
- Lesen Sie Bronze wo möglich als Stream. Für Nur-Append-Quellen halten Streaming-Lesevorgänge die Latenz niedrig; reservieren Sie Batch-Lesevorgänge für kleine Datensätze.
- Behalten Sie immer einen nicht aggregierten Datensatz in Silber. Aggregation gehört in Gold, damit Silber für viele Konsumenten wiederverwendbar bleibt.
- Erzwingen Sie nicht, dass Gold Echtzeit ist. Gold ist für häufig abgefragte, batch-aktualisierte Aggregate optimiert. Das Nachrüsten für Niedriglatenz-Workloads neigt dazu, fragile, teure Pipelines zu erzeugen.
- Benennen Sie Tabellen nach Schicht. Ein Namensraum wie catalog.bronze.table, catalog.silver.table, catalog.gold.table kommuniziert das Vertrauensniveau jeder Tabelle auf einen Blick.
Häufige Fallstricke und Kritik
Das Muster ist robust, wird aber häufig genug falsch angewendet, dass die Fehlermodi gut dokumentiert sind.
Bronze überspringen. Es ist verlockend, wenn externe Daten bereits sauber aussehen, aber das Überspringen von Bronze entfernt den Audit-Trail und die Möglichkeit zur Neuverarbeitung. Die Semantik Ihrer Silber-Schicht ändert sich still, wenn kein Rohdatensatz dahinter steht.
Silber als Gold behandeln. Wenn Teams Geschäfts-KPIs und schwere Aggregationen direkt in Silber aufbauen, definieren verschiedene Teams Metriken unterschiedlich und es gibt keine einzige autoritative Version. Halten Sie Aggregate in Gold.
Rohes Bronze als Produktionsdaten lesen. Bronze ist ungeprüft und oft unordentlich. Ein Dashboard darauf zu richten führt zu doppelten Zählungen und inkonsistenten Ergebnissen. Bronze ist ein historischer Nachweis, keine Quelle der Wahrheit für Analysen.
Schichtenübergreifende Verflechtung. Wenn Pipelines Verantwortlichkeiten über Schichten hinweg verlieren, zum Beispiel rohe Events direkt in Gold aufnehmen, kann eine einzelne Schema-Änderung den gesamten Stack kaskadieren.
Es gibt auch eine legitime Kritik an der starren Anwendung des Musters. Wie eine Analyse es formulierte, führt die Anwendung einer starren Drei-Schicht-Struktur auf alle Quellen zu Ineffizienzen, wenn bestimmte Datensätze keine umfangreiche Bereinigung benötigen, und die sequentielle Schichtung fügt Latenz hinzu, die Echtzeit-Anwendungsfälle möglicherweise nicht tolerieren können. Die Praktiker-Community hat darauf reagiert, indem sie in einigen Designs zusätzliche Schichten vorschlägt, wie eine Pre-Bronze-Landing-Zone oder eine Platin-Schicht über Gold für operationale und maschinelles-Lernen-Serving.
Der gesunde Weg, all dies zu lesen, ist, dass die Medallion-Architektur ein flexibles Framework ist, kein Mandat. Databricks selbst stellt fest, dass das Befolgen der Medallion-Architektur eine empfohlene Best Practice ist, aber keine Anforderung, und das Delta-Lake-Projekt beschreibt es als optionales, flexibles Framework. Verwenden Sie die Schichtenanzahl und die Benennung, die zu Ihren Abfragemustern und Ihren Konsumenten passen.
Häufige Anwendungsfälle
Das Muster zahlt sich am deutlichsten aus, wenn Roheingaben unordentlich sind und viele Konsumenten vertrauenswürdige Ausgaben benötigen.
- Wettbewerbspreise und E-Commerce-Intelligence. Produkt- und Preisdaten, die von vielen Einzelhändlern erfasst wurden, landen as-is in Bronze, werden in Silber normalisiert und dedupliziert und speisen Gold-Preisverfolgung und Sortiment-Dashboards.
- Trainingsdaten für KI und maschinelles Lernen. Web-skaliger Text und strukturierte Daten landen roh in Bronze, werden in Silber bereinigt und dedupliziert und in Gold zu modellbereiten Features geformt. Die praktischen Schritte werden in diesem Leitfaden zum Web-Scraping für maschinelles Lernen behandelt, und die breitere Strategie im KI-Datenschwungrad-Artikel.
- Marktforschung und Alternative-Data-Research. Externe Signale aus vielen Quellen werden in Silber zu einer einzigen Forschungsansicht konformiert und dann in Gold-Indikatoren aggregiert.
- Such- und SERP-Monitoring. Ein kontinuierlicher Stream von Suchergebnissen fließt in Bronze, wird in Silber strukturiert und fasst sich in Gold-Sichtbarkeits- und Share-of-Voice-Metriken zusammen.
- Firmografische und Kunden-Anreicherung. Unternehmens-Daten-Feeds reichern interne Datensätze auf der Silber-Schicht an und produzieren Gold-Tabellen für Vertrieb und Marketing.
Für das Engineering-Plumbing dahinter zeigen die Walkthroughs zu AWS Glue ETL, AWS Step Functions, Kubeflow-Pipelines, der Mage-KI-Pipeline und dem Verbinden von Live-Web-Daten mit Tableau jeweils einen echten Bronze-zu-Serving-Pfad. Die Grundlagen des Extraktionsschritts selbst werden in diesem Primer zur Datenextraktion behandelt.
Fazit
Die Medallion-Architektur besteht, weil sie Teams eine gemeinsame Sprache gibt, um Rohdaten in vertrauenswürdige Daten zu verwandeln – einen disziplinierten Hop nach dem anderen. Bronze bewahrt die Wahrheit, Silber macht sie konsistent und Gold macht sie nützlich. Das Muster funktioniert nur so gut wie die Rohdaten, die es speisen, weshalb eine zuverlässige, gut strukturierte Bronze-Quelle kein Detail, sondern ein Fundament ist.
Für externe Web-Daten ist das Fundament der Ort, an dem Bright Data passt: produktionsreife Erfassung, geliefert als JSON, CSV oder Parquet direkt in den Cloud-Speicher, den Ihr Lakehouse bereits als Bronze behandelt. Bereit, Ihre Bronze-Schicht mit zuverlässigen Web-Daten zu speisen? Gratis testen und sehen Sie, wie schnell rohe Web-Daten in Ihre Pipeline fließen können.
Häufig gestellte Fragen
F: Was ist die Medallion-Architektur in einfachen Worten?
Es ist eine Methode zur Organisation von Daten in einem Lakehouse, sodass sie sauberer und nützlicher werden, wenn sie durch drei Schichten fließen. Rohdaten landen in der Bronze-Schicht, werden in der Silber-Schicht bereinigt und standardisiert und in der Gold-Schicht in geschäftsbereite Tabellen aggregiert. Jede Schicht hat eine klare Aufgabe, was das Datenqualitätsmanagement und die Prüfung erleichtert.
F: Was ist der Unterschied zwischen den Bronze-, Silber- und Gold-Schichten?
Bronze enthält Rohdaten genau so, wie sie ankamen, nur-append und untransformiert, als permanente Quelle der Wahrheit. Silber enthält bereinigte und konforme Daten mit angewendeter Deduplizierung, Schema-Durchsetzung und Joins, sodass die Daten vertrauenswürdig und konsistent sind. Gold enthält aggregierte, geschäftliche Daten, die für spezifische Berichte, Dashboards, maschinelles Lernen und Anwendungen modelliert wurden.
F: Ist die Medallion-Architektur dasselbe wie ETL?
Nein, aber sie sind verwandt. ETL beschreibt das Extrahieren, Transformieren und Laden von Daten. Die Medallion-Architektur ist ein Schichtungsmuster, das organisiert, wo diese Transformationen stattfinden. In einem Lakehouse folgt es normalerweise einem ELT-Stil, bei dem Rohdaten zuerst in Bronze geladen und stufenweise in Silber und Gold innerhalb der Plattform transformiert werden.
F: Benötige ich immer alle drei Schichten?
Nein. Databricks beschreibt die Medallion-Architektur als empfohlene Best Practice, nicht als Anforderung. Einige Datensätze, die sauber ankommen, benötigen möglicherweise keinen umfangreichen Silber-Schritt, und einige Echtzeit-Anwendungsfälle umgehen bewusst Teile des Flusses. Die Anzahl der Schichten und die Benennung sollten zu Ihren Abfragemustern und Konsumenten passen. Die Hauptwarnung ist, dass das Überspringen von Bronze Ihren rohen Audit-Trail und die Möglichkeit zur Neuverarbeitung entfernt.
F: Welches Dateiformat sollte ich für Medallion-Tabellen verwenden?
Die meisten Implementierungen verwenden ein offenes Tabellenformat wie Delta Lake, Apache Iceberg oder Apache Hudi, die alle auf Parquet-Dateien in Cloud-Objektspeicher aufsetzen. Diese Formate fügen ACID-Transaktionen, Schema-Durchsetzung und Time Travel hinzu, auf die das Muster angewiesen ist. Delta Lake ist das native Format auf Databricks und Microsoft Fabric, während Iceberg häufig verwendet wird, wenn mehrere Engines dieselben Tabellen lesen.
F: Wie passen externe oder Web-Daten in eine Medallion-Architektur?
Externe und Web-Daten sind Bronze-Schicht-Eingaben. Sie landen die rohen gesammelten Daten, zum Beispiel Produkt-, Preis-, Such- oder Unternehmensdaten, in ihrer ursprünglichen Form in Bronze und normalisieren und deduplizieren sie dann in Silber. Da Lakehouse-Plattformen Cloud-Objektspeicher wie S3, GCS und Azure als gültige Bronze-Quellen behandeln, kann ein Anbieter wie Bright Data Web-Daten als JSON, CSV oder Parquet direkt in diese Speicher liefern, wo sie zur Bronze-Schicht werden.
F: Ist die Medallion-Architektur an Databricks gebunden?
Databricks hat den Begriff zusammen mit dem Lakehouse-Paradigma und Delta Lake popularisiert, aber das Muster ist nicht exklusiv daran gebunden. Dieselbe Bronze-, Silber- und Gold-Sprache wird in der Dokumentation von Microsoft Fabric und Snowflake verwendet, und die zugrunde liegenden offenen Tabellenformate laufen auf vielen Engines. Das Muster ist eine allgemeine Konvention, kein Produkt eines einzelnen Anbieters.




