

Eine Amazon-Produktdatenpipeline auf Ihrem Laptop zum Laufen zu bringen, ist eine Sache. Sie in der Produktion mit Proxys, CAPTCHAs, Layoutänderungen und IP-Blocks am Laufen zu halten, ist eine andere. Selbst wenn Sie das Scraping selbst lösen, benötigen Sie noch Zeitplanung, Wiederholungsversuche, Fehlerbehandlung und eine Möglichkeit, tatsächlich zu sehen, was Sie gesammelt haben.
All das werden wir hier aufbauen. Wir verwenden die Web-Scraping-API von Bright Data und Mage AI, um eine Pipeline zu erstellen, die Amazon-Produkte und -Bewertungen sammelt, eine Gemini-Sentimentanalyse durchführt und alles an PostgreSQL und ein Streamlit-Dashboard weiterleitet. Die gesamte Pipeline läuft mit Docker und einem einzigen API-Schlüssel (plus einem optionalen Gemini-Schlüssel für die KI-Analyse).
TL;DR: Amazon-Produktinformationen ohne Aufbau einer Scraping-Infrastruktur.
- Was Sie erhalten: Eine Pipeline, die Produkte anhand von Schlüsselwörtern findet, Bewertungen mit KI analysiert und ein Live-Streamlit-Dashboard bereitstellt.
- Was es kostet: Pay-as-you-go, Abrechnung pro Datensatz (Preisseite), 5–8 Minuten von Anfang bis Ende.
- So funktioniert es: Bright Data kümmert sich um Proxys, CAPTCHAs und Parsing; Mage KI kümmert sich um die Planung, Wiederholungsversuche und Verzweigungen.
- So fangen Sie an:
docker compose up– der gesamte Code befindet sich im GitHub-Repo
Was wir entwickeln: eine Integrationspipeline für Bright Data + KI
Die Web-Scraping-API von Bright Data übernimmt die Scraping-Ebene. Sie senden ein Schlüsselwort oder eine Produkt-URL und erhalten strukturierte JSON-Daten (Titel, Preise, Bewertungen, Rezensionen, Verkäuferinformationen) zurück, die bereits geparst sind. Keine Proxy-Infrastruktur zu verwalten, kein HTML zu parsen. Wenn Amazon seine Website ändert, aktualisiert Bright Data in der Regel seine Parser. Ihr Code bleibt unverändert.
Falls Sie Mage KI noch nicht kennen: Es handelt sich um ein kostenloses Open-Source-Datenpipeline-Tool, ähnlich wie Airflow, aber ohne Boilerplate. Sie schreiben Python in einem Editor im Notebook-Stil, in dem jeder Block eine wiederverwendbare Einheit mit eigener Test- und Ausgabevorschau ist. Wichtig dabei: Mage KI unterstützt verzweigte Pipelines, im Grunde genommen ein DAG (gerichteter azyklischer Graph) mit parallelen Pfaden. Es verfügt außerdem über eine integrierte Wiederholungslogik pro Block und Pipeline-Variablen, die Sie über die Benutzeroberfläche ändern können, ohne dass Codeänderungen erforderlich sind.
Die Pipeline hat 6 Blöcke in zwei parallelen Zweigen:
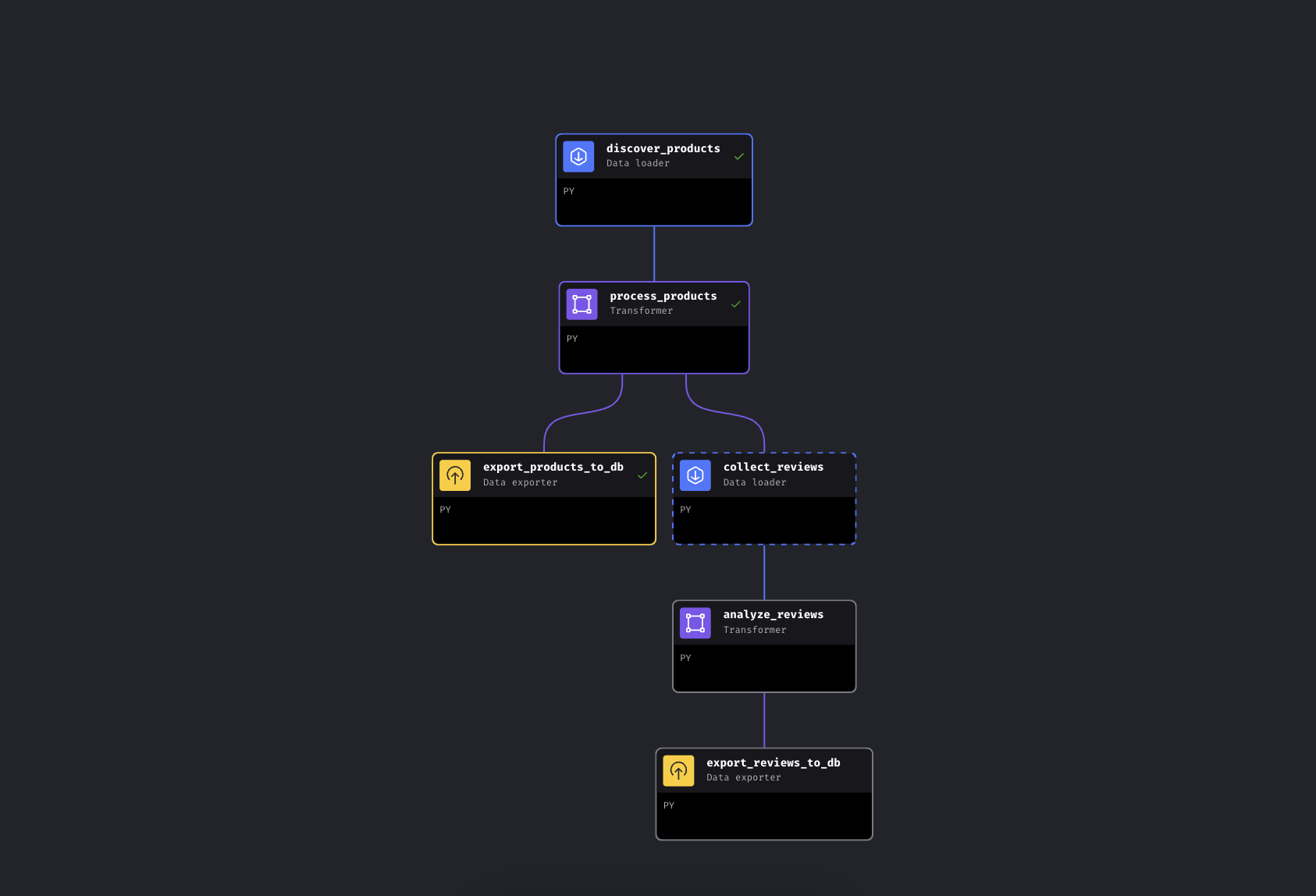
Die verzweigte Pipeline in Mage KI. Der linke Zweig exportiert Produkte sofort, der rechte Zweig sammelt und analysiert Bewertungen
Die Pipeline findet Produkte anhand von Schlüsselwörtern über Bright Data, ergänzt sie mit Preisstufen und Bewertungen und verzweigt sich dann. Ein Pfad exportiert Produkte sofort nach PostgreSQL, während der andere Bewertungen für die Top-Produkte sammelt, sie zur Sentimentanalyse durch Gemini laufen lässt und auch diese exportiert.
Wir verwenden hier Mage KI, weil die Pipeline verzweigt ist (es handelt sich um ein DAG, kein lineares Skript – wenn die Sammlung von Bewertungen fehlschlägt, sind Ihre Produktdaten bereits sicher), aber die Bright Data API-Aufrufe sind nur HTTP-Anfragen. Sie funktionieren in Airflow, Prefect, Dagster oder einem einfachen Python-Skript auf die gleiche Weise.
Schnellstart
Klonen Sie das Repo, fügen Sie Ihre API-Schlüssel hinzu und führen Sie es aus. Alles läuft in Docker, sodass Sie Python nicht lokal installieren müssen.
Voraussetzungen
Sie benötigen:
- Docker und Docker Compose (Docker herunterladen)
- Ein Bright Data -Konto mit API-Token
- Einen Google Gemini API-Schlüssel (kostenlose Nutzung mit Einschränkungen verfügbar; siehe Abschnitt „Gemini“ weiter unten)
- Grundlegende Kenntnisse in Python und Docker. Keine Erfahrung im Scraping erforderlich; das ist der springende Punkt
Schritt 1: Klonen und Konfigurieren
Klonen Sie das Repo und erstellen Sie Ihre Konfigurationsdatei:
git clone https://github.com/triposat/mage-brightdata-demo.git
cd mage-brightdata-demo
cp .env.example .envFügen Sie nun Ihre API-Schlüssel zu .env hinzu:
BRIGHT_DATA_API_TOKEN=Ihr_API-Token_hier
GEMINI_API_KEY=Ihr_Gemini-API-Schlüssel_hierSo erhalten Sie Ihren Bright Data API-Token: Registrieren Sie sich bei [Bright Data]() (kostenlose Testversion, keine Kreditkarte erforderlich), gehen Sie dann zu „Kontoeinstellungen“ und erstellen Sie einen API-Schlüssel. Die Pipeline verwendet zwei Web-Scraping-API-Scraper (einen für die Produktsuche, einen für Bewertungen), die pro Datensatz abgerechnet werden und nach Verbrauch bezahlt werden. Die aktuellen Preise finden Sie auf der Preisseite.
So erhalten Sie Ihren Gemini-API-Schlüssel: Gehen Sie zu Google AI Studio, melden Sie sich an und klicken Sie auf „API-Schlüssel erstellen”. Kostenlos, keine Kreditkarte erforderlich. Die Pipeline funktioniert auch ohne diesen Schlüssel; sie greift dann auf die bewertungsbasierte Stimmung zurück.
Schritt 2: Starten Sie die Dienste
docker compose up -dWenn Sie überprüfen möchten, ob Ihre Schlüssel geladen sind:
docker compose exec mage python -c "import os; t=os.getenv('BRIGHT_DATA_API_TOKEN',''); assert t and t!='your_api_token_here', 'Token not set'; print('OK')"Dadurch werden drei Container gestartet:
| Dienst | URL | Zweck |
|---|---|---|
| Mage KI | http://localhost:6789 |
Pipeline-Editor und Scheduler |
| Streamlit-Dashboard | http://localhost:8501 |
Live-Datenvisualisierung + Chat |
| PostgreSQL | localhost:5432 |
Datenspeicherung |
Beim ersten Start werden Bilder abgerufen und Abhängigkeiten installiert, was je nach Verbindung etwa 3 bis 5 Minuten dauert. Der Neustart mit „docker compose stop/start“ dauert nur wenige Sekunden; „docker compose down/up“ installiert die Pip-Pakete neu und dauert etwa eine Minute.
Alle drei Dienste laufen
Schritt 3: Pipeline ausführen
Öffnen Sie http://localhost:6789, gehen Sie zu Pipelines, klicken Sie auf amazon_product_intelligence, klicken Sie dann in der linken Seitenleiste auf Triggers und klicken Sie auf Run@once.
Das Mage KI-Dashboard
Die Pipeline dauert insgesamt etwa 5–8 Minuten. Der größte Teil dieser Zeit wird von den Bright Data-APIs für das Sammeln von Daten von Amazon benötigt; die Anreicherung und der Export der Datenbank dauern nur wenige Sekunden, und die Gemini-Analyse hängt von der Batchgröße und den Ratenbeschränkungen ab. Wenn alle 6 Blöcke grün sind, öffnen Sie http://localhost:8501, um das Dashboard anzuzeigen.
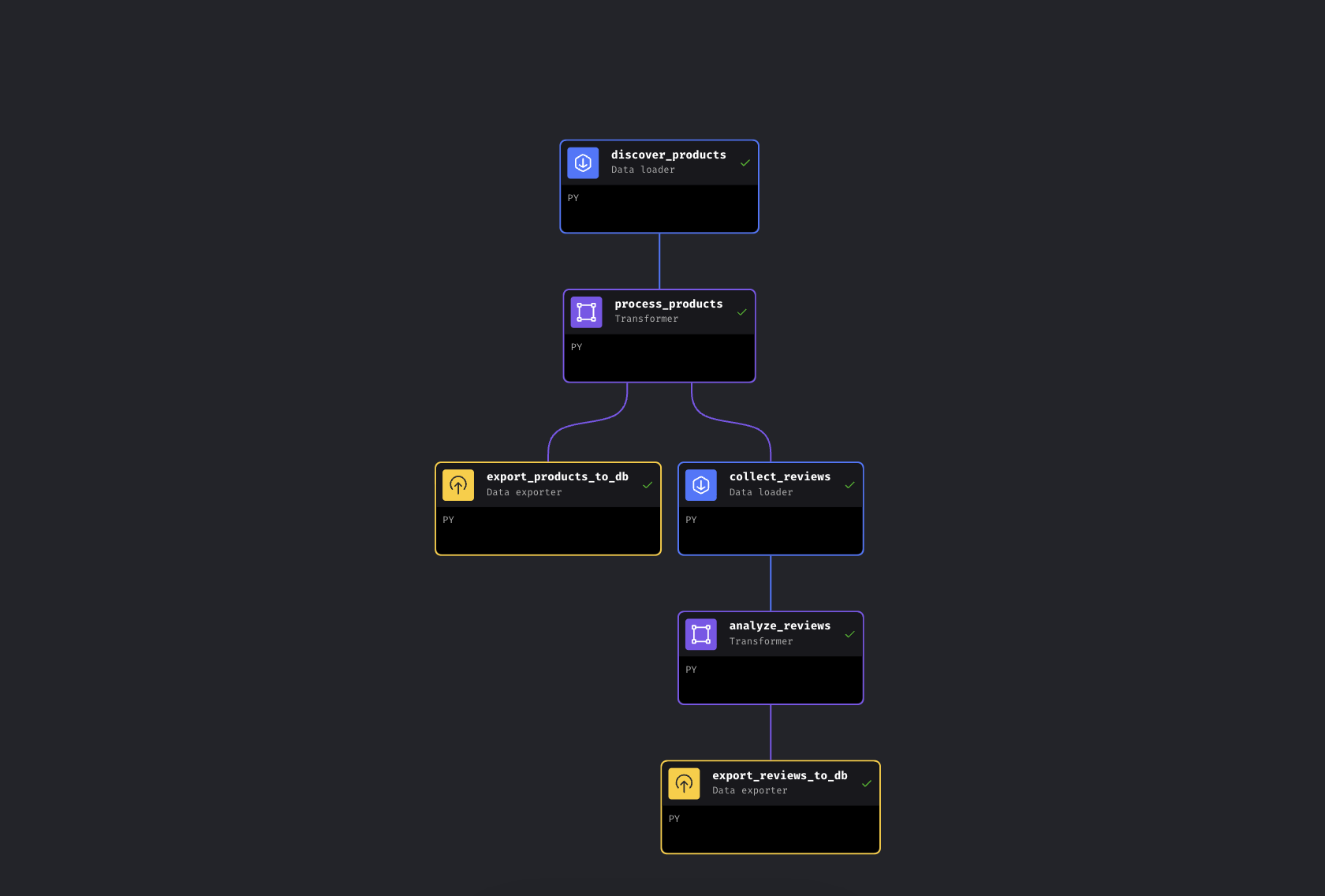
Alle 6 Blöcke grün. Pipeline abgeschlossen
So funktioniert die Mage KI-Datenpipeline
Sehen wir uns den Code einmal genauer an. Wir konzentrieren uns dabei auf die Bright Data-Integrationen und die Gemini-Analyse.
Verbindung der Web-Scraping-API von Bright Data mit Mage AI
Wir senden Schlüsselwörter an die Amazon Products API und erhalten strukturierte Daten zurück. Bright Data nennt dies einen „Discovery”-Scraper – er findet Produkte nach Schlüsselwort oder Kategorie. Der Bewertungsblock verwendet später einen separaten Bewertungs-Scraper, der Produkt-URLs als Eingabe verwendet. Die API verwendet ein asynchrones Muster: die Sammlung auslösen, eine Snapshot-ID abrufen, abfragen, bis die Ergebnisse bereit sind.
DATASET_ID = „gd_l7q7dkf244hwjntr0” # Amazon-Produkte (aktuelle IDs im Repo überprüfen)
API_BASE = „https://api.brightdata.com/datensätze/v3”
# Starten Sie die Erfassung (verwendet /scrape – wechselt automatisch zu asynchron, wenn >1 Min.; für die Produktion sollten Sie /trigger in Betracht ziehen)
response = requests.post(
f"{API_BASE}/scrape",
headers={"Authorization": f"Bearer {api_token}",
"Content-Type": "application/json"},
params={"dataset_id": DATASET_ID,
"type": "discover_new",
"discover_by": "keyword",
"limit_per_input": kwargs.get('limit_per_keyword', 5)},
json={"input": [{"keyword": kw} for kw in keywords]})
snapshot_id = response.json()["snapshot_id"]
# Abfragen, bis Ergebnisse vorliegen
data = requests.get(
f"{API_BASE}/snapshot/{snapshot_id}",
headers={"Authorization": f"Bearer {api_token}"},
params={"format": "json"}
).json()Hier ist die Antwort von Bright Data:
{
"title": "BESIGN LS03 Aluminium-Laptopständer",
"asin": "B07YFY5MM8", // Amazons eindeutige Produkt-ID
"url": "https://www.amazon.com/dp/B07YFY5MM8",
"initial_price": 19.99,
"final_price": 16.99,
"currency": "USD",
"rating": 4.8,
„reviews_count”: 22776,
„seller_name”: „BESIGN”,
„categories”: [„Office Products”, „Office & School Supplies”],
„image_url”: „https://m.media-amazon.com/images/I/...”
}Das kwargs.get('limit_per_keyword', 5) wird aus den Mage KI-Pipeline-Variablen abgerufen, sodass Sie es über die Benutzeroberfläche anpassen können.
Hinzufügen eines zweiten API-Aufrufs: Amazon-Bewertungssammlung
Der Bewertungs-Collector übernimmt die verarbeiteten Produkte aus dem vorgelagerten Block und sortiert sie nach der Anzahl der Bewertungen. Er wählt die besten N aus und gibt deren Amazon-URLs in eine zweite Bright Data API ein:
REVIEWS_DATASET_ID = "gd_le8e811kzy4ggddlq" # Amazon-Bewertungen
# Top-Produkte aus dem Upstream (automatisch von Mage KI übergeben)
top_products = data.sort_values('reviews_count', ascending=False).head(top_n)
product_urls = top_products['url'].dropna().tolist()
# URLs in die Reviews-API einspeisen (gleiches /scrape-Muster)
response = requests.post(
f"{API_BASE}/scrape",
headers={"Authorization": f"Bearer {api_token}",
"Content-Type": "application/json"},
params={"dataset_id": REVIEWS_DATASET_ID},
json={"input": [{"url": url} for url in product_urls]})
# Gleiches asynchrones Abfragemuster wie bei Produkten...Beide API-Blöcke verfügen über eine Wiederholungskonfiguration in der Datei metadata.yaml der Demo: Wenn ein Aufruf fehlschlägt, wiederholt die Pipeline den Versuch dreimal mit einer Verzögerung von 30 Sekunden. Jeder Block in dieser Demo verfügt außerdem über eine @test-Funktion, die nach der Ausführung ausgeführt wird. Wenn sie fehlschlägt, werden nachgelagerte Blöcke nicht ausgeführt, sodass keine fehlerhaften Daten in Ihrer Datenbank landen.
Hinzufügen einer KI-Analyse: Gemini-Sentiment-Pipeline-Block
Anstelle einer Keyword-Übereinstimmung (die „nicht billig, tolle Qualität!” aufgrund des Wortes „billig” als negativ kennzeichnen würde) verwenden wir Gemini, um den Kontext zu verstehen. Der Block verarbeitet Bewertungen in Stapeln mit einer Rotation von drei Modellen, um innerhalb der Grenzen der kostenlosen Stufe zu bleiben:
GEMINI_MODELS = ["gemini-2.5-flash-lite", "gemini-2.5-flash", "gemini-2.5-pro"] # aktuelle Modelle im Repository überprüfen
prompt = f"""Analysieren Sie diese Bewertungen. Geben Sie für JEDE Bewertung JSON mit folgenden Angaben zurück:
- „sentiment”: „Positiv”, „Neutral” oder „Negativ”
- „issues”: spezifische erwähnte Produktprobleme
- „themes”: 1–3 Themen-Tags
- „summary”: Zusammenfassung in einem Satz
Geben Sie NUR JSON zurück.nn{reviews_text}"""
for model in models:
try:
response = client.models.generate_content(model=model, contents=prompt)
return json.loads(response.text.strip())
except Exception as e:
if '429' in str(e):
continue # Rate limited -- rotate to next modelDie Rotation beginnt mit Flash-Lite (günstigstes und schnellstes Modell), weicht dann auf Flash und schließlich auf Pro aus. Sind alle drei Modelle ausgeschöpft, erhält die Bewertung stattdessen eine bewertungsbasierte Stimmung. Die Kontingente für die kostenlose Nutzung ändern sich regelmäßig, aber die Rotation der drei Modelle bewältigt die meisten Ratenbeschränkungen automatisch. Gemini gibt die Stimmung, spezifische Probleme (wie „wackelt auf unebenen Oberflächen” oder „Scharnier lockert sich mit der Zeit”) und 1–3 Themen-Tags pro Bewertung zurück. Jede Bewertung enthält außerdem eine einzeilige Zusammenfassung.
Die übrigen Blöcke (ein Transformator für Preisstufen und Rabattberechnungen sowie zwei Datenbank-Exporter mit Upsert-Logik) sind unkompliziert. Sie befinden sich im GitHub-Repo, falls Sie sich näher damit befassen möchten.
Pipeline-Ausgabe: Ergebnisse und Streamlit-Dashboard
Hier ist das Ergebnis, das die Pipeline in einem Durchlauf mit den Standard-Schlüsselwörtern „Laptopständer“ und „kabellose Ohrhörer“ erzeugt hat. Ihre Ergebnisse variieren je nach den aktuellen Angeboten bei Amazon.
In diesem Durchlauf: 10 Produkte gefunden, 20 Bewertungen von Gemini analysiert. In den Bewertungen zu den Ohrhörern tauchten Beschwerden auf, die sich nicht in der Durchschnittsbewertung von 4,3 Sternen widerspiegeln – Themen wie „Klangqualität”, „Akkulaufzeit” und „Konnektivität” mit konkreten Problemen.
Was die Pipeline zu Ihren Rohdaten hinzufügt:
| Feld | Beispiel | Hinzugefügt von |
|---|---|---|
best_price |
16,99 | Transformator (berechnet) |
Rabattprozentsatz |
15,0 | Transformator (berechnet) |
Preisstufe |
Budget (<25 $) | Transformator (angereichert) |
Bewertungskategorie |
Ausgezeichnet (4,5–5) | Transformer (angereichert) |
Stimmung |
Negativ | Gemini KI |
Probleme |
[„Bluetooth-Verbindung bricht häufig ab“] | Gemini KI |
Themen |
[„Konnektivität“, „Akkulaufzeit“] | Gemini KI |
ai_summary |
„Der Akku hält trotz der Angabe von 8 Stunden nur 2 Stunden.“ | Gemini KI |
So sieht das in der Praxis aus – alle 10 Produkte mit angereicherten Feldern sind sichtbar:
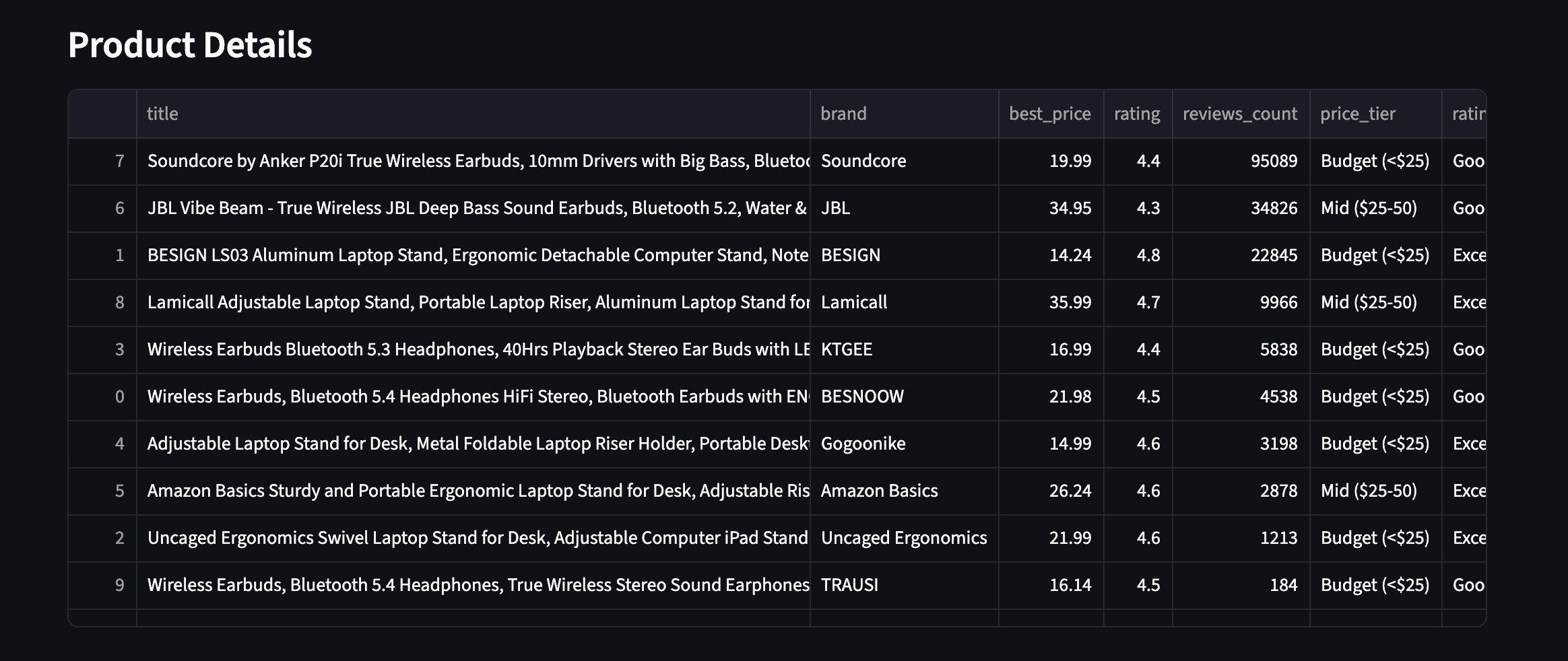
Alle 10 Produkte mit angereicherten Feldern. Preisstufen, Bewertungen und Anzahl der Rezensionen aus zwei verschiedenen Produktkategorien
Das Dashboard
Öffnen Sie http://localhost:8501 für das Streamlit-Dashboard. Klicken Sie in der Seitenleiste auf „Daten aktualisieren“, um die neuesten Ergebnisse aus PostgreSQL abzurufen.
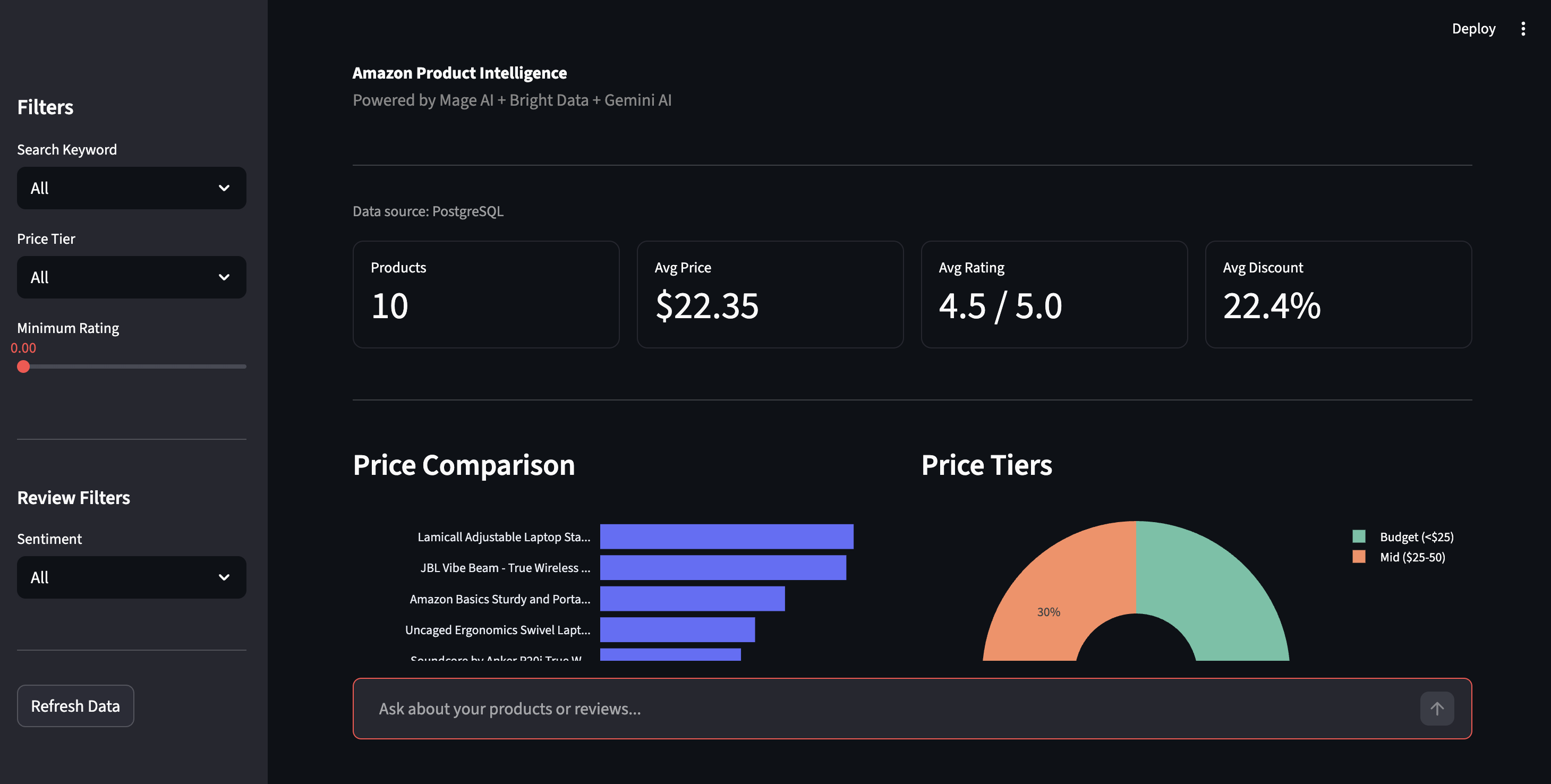
Produktinformations-Dashboard – Preisvergleich, Preisstufen und Filtersteuerung
In der Seitenleiste können Sie nach Preisstufe, Bewertung oder Stimmung filtern. Die Stimmungsansicht zeigt die Aufschlüsselung nach positiv/negativ für alle Bewertungen mit den spezifischen Problemen, die Gemini herausgefiltert hat: „Bluetooth-Verbindung bricht ab“, „Scharnier lockert sich mit der Zeit“ – Details, die in Sternbewertungen untergehen.

Aufschlüsselung der Stimmung und von KI erkannte Produktprobleme. Echte Beschwerden, die von Gemini extrahiert wurden, keine Keyword-Übereinstimmungen
Das Dashboard verfügt auch über eine Funktion „Chat with Your Data“ (Chatten Sie mit Ihren Daten). Stellen Sie Fragen in einfachem Englisch, und Gemini antwortet unter Verwendung Ihrer tatsächlich gesammelten Daten als Kontext. Hier ist ein Beispiel aus einem separaten Durchlauf mit mehr Produkten:
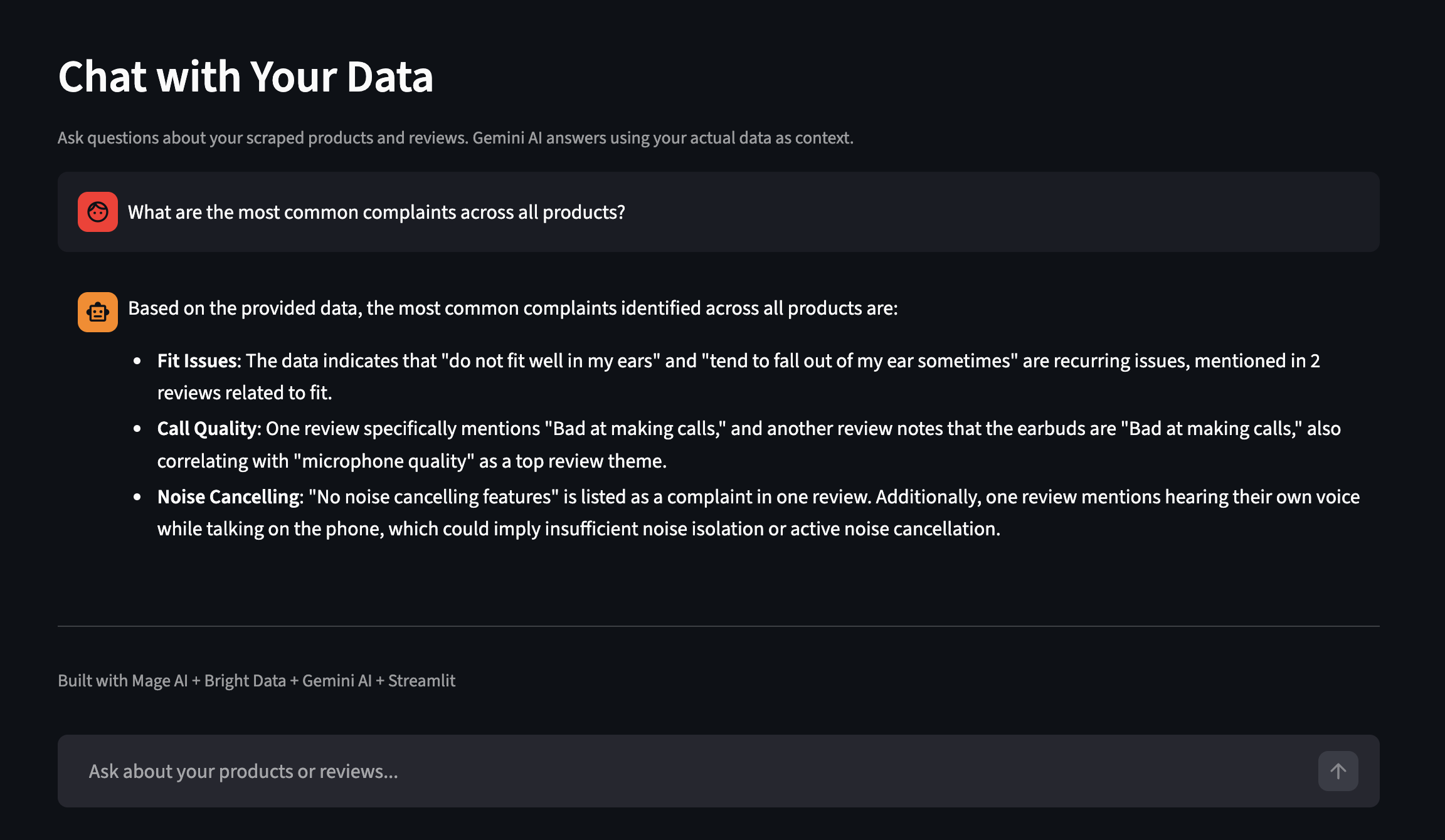
Stellen Sie Fragen zu Ihren gesammelten Daten in einfachem Englisch
Skalierung der Pipeline
Die Demo läuft mit zwei Schlüsselwörtern und 10 Produkten.
Pipeline-Variablen
Alle können über die Mage KI-Benutzeroberfläche oder metadata.yaml konfiguriert werden:
| Variable | Was sie steuert | Standard |
|---|---|---|
Schlüsselwörter |
Amazon-Suchbegriffe | ["Laptopständer", "kabellose Ohrhörer"] |
limit_per_keyword |
Produkte pro Schlüsselwort von Bright Data | 5 |
top_n_products |
Wie viele Top-Produkte erhalten gesammelte Bewertungen | 2 |
reviews_per_product |
Maximale Anzahl an Bewertungen pro Produkt | 10 |
sortieren_nach |
Wie Produkte für die Auswahl von Bewertungen bewertet werden | reviews_count |
Ändern Sie die Schlüsselwörter zu „Handyhülle“, „USB-C-Hub“ und Sie erhalten einen völlig anderen Datensatz. Keine Codeänderungen erforderlich.
Pipeline-Variablen in der Mage KI-Benutzeroberfläche
Zeitplanung
Um dies nach einem Zeitplan auszuführen, gehen Sie zu „Triggers“ in der Mage KI-Seitenleiste, klicken Sie auf „+ New trigger“, wählen Sie „Schedule“ und legen Sie eine Häufigkeit fest (einmal, stündlich, täglich, wöchentlich, monatlich oder benutzerdefinierter Cron).
Jeder Durchlauf wird nach ASIN aktualisiert – dabei werden die Daten für dieselben Produkte ersetzt, während die Ergebnisse für andere Schlüsselwörter beibehalten werden. Eine CSV-Sicherung mit Zeitstempel wird ebenfalls gespeichert, um einen historischen Vergleich zu ermöglichen.
Sobald Sie einige Datenläufe haben, können Sie PostgreSQL direkt abfragen, um Beschwerden anzuzeigen, die in den Sternebewertungen nicht berücksichtigt werden:
-- Produkte mit hoher negativer Bewertung finden
SELECT asin, product_name,
AVG(CASE WHEN sentiment = 'Negative' THEN 1 ELSE 0 END) as negative_rate
FROM amazon_reviews
GROUP BY asin, product_name
HAVING AVG(CASE WHEN sentiment = 'Negative' THEN 1 ELSE 0 END) > 0.2;Um Ihre eigenen Produkte anstelle von Suchbegriffen zu überwachen, entfernen Sie die Parameter „type”, „discover_by” und „limit_per_input” und übergeben Sie Ihre Produkt-URLs direkt als [{"url": "https://www.amazon.com/dp/YOUR_ASIN"}].
Wenn Sie Dashboards und Benachrichtigungen benötigen, ohne diese selbst erstellen zu müssen, bietet Bright Insights diese Funktion ohne zusätzliche Einrichtung für Einzelhandelsdaten.
Skalierung. Diese Demo läuft in Docker auf einem einzelnen Rechner, aber Mage KI unterstützt einen Kubernetes-Executor für die Produktion, und die APIs von Bright Data verarbeiten die Parallelität auf ihrer Seite (mit Ratenbeschränkungen für Batch-Anfragen). Bei der Skalierung geht es darum, die Kapazität von Mage KI zu erhöhen, nicht darum, Ihren Datenerfassungscode zu ändern.
Integration anderer Bright Data-Scraper
Das gleiche Pipeline-Muster funktioniert mit allen vorgefertigten Scrapern von Bright Data für über 100 Websites. Siehe beispielsweise die Repositorys Google Maps Scraper, LinkedIn Scraper und Crunchbase Scraper. Um von Amazon zu einer anderen Plattform zu wechseln, tauschen Sie die DATASET_ID in den Datenladeblöcken aus und passen Sie die Eingabeparameter an das Schema des neuen Scrapers an.
Um die richtigen ID- und Eingabefelder zu finden, durchsuchen Sie die Scraper-Bibliothek in Ihrem Dashboard oder rufen Sie den Endpunkt /datasets/list auf – der API Request Builder im Dashboard zeigt Ihnen genau, was jeder Scraper erwartet. Die Gemini-Analyse und die Pipeline-Struktur bleiben unverändert; die Anreicherungs- und Exportblöcke müssen möglicherweise in Bezug auf die Spaltennamen angepasst werden, wenn sich die Antwortfelder des neuen Scrapers von denen von Amazon unterscheiden.
Fehlerbehebung
Wenn während der Einrichtung oder Ausführung ein Fehler auftritt, finden Sie hier die gängigsten Lösungen:
- Port 6789 oder 8501 wird bereits verwendet. Ein anderer Dienst belegt den Port. Beenden Sie diesen Dienst oder bearbeiten Sie
die Datei docker-compose.yml, um die Ports neu zuzuordnen (ändern Sie beispielsweise6789:6789in6790:6789). - Die Bright Data API gibt 401 Unauthorized zurück. Ihr API-Token fehlt oder ist fehlerhaft. Gehen Sie zu den Kontoeinstellungen, kopieren Sie den vollständigen Token und stellen Sie sicher, dass Ihre
.env-Dateikeine nachgestellten Leerzeichen enthält. Der Token ist eine lange Hexadezimalzeichenfolge (64 Zeichen). Wenn das, was Sie kopiert haben, kurz ist oder Bindestriche wie eine UUID enthält, haben Sie möglicherweise das falsche Feld kopiert. - Gemini gibt für jedes Modell 429 (Rate Limit) zurück. Die kostenlose Stufe hat Minutenlimits, die sich regelmäßig ändern. Die Pipeline bewältigt dies, indem sie zwischen drei Modellen wechselt. Wenn jedoch alle drei erschöpft sind, greifen die Bewertungen auf die bewertungsbasierte Stimmung zurück. Um dies zu vermeiden, reduzieren Sie
reviews_per_productin den Pipeline-Variablen, fügen Sie eintime.sleep(60)zwischen den Batches im Gemini-Block hinzu oder aktivieren Sie die Abrechnung in Ihrem Google KI-Projekt für höhere Kontingente. Die aktuellen Kontingente finden Sie auf der Seite mit den Ratenbegrenzungen von Google. - Ein Pipeline-Block wird rot angezeigt (fehlgeschlagen). Rufen Sie die Seite „Logs“ für Ihre Pipeline auf (zugänglich über die linke Seitenleiste), um den Fehler anzuzeigen. Sie können nach Blockname und Protokollebene filtern. Häufige Ursachen: abgelaufener API-Token, Netzwerk-Timeout bei der Bright Data API (erhöhen Sie
max_wait_secondsim Block) oder eine Gemini-Antwort, die kein gültiges JSON ist (die@test-Funktiondes Blocks fängt dies ab). - Docker Compose ist langsam oder schlägt auf Apple Silicon fehl. Das Mage KI-Image ist multiarch und funktioniert auf ARM, aber der erste Pull kann länger dauern. Wenn der Build mit einem Speicherfehler fehlschlägt, erhöhen Sie die Speicherzuweisung von Docker Desktop in den Einstellungen → Ressourcen auf mindestens 4 GB.
Nächste Schritte
Sie haben nun eine funktionierende Pipeline, die Amazon-Produktdaten sammelt, KI-gestützte Bewertungsanalysen durchführt und alles in PostgreSQL speichert – ohne Proxys, Parser oder Cron-Jobs, vor denen Sie sich fürchten müssen.
Wenn Sie alles mitgemacht haben, machen Sie es sich zu eigen. Tauschen Sie die Keyword-Liste in metadata.yaml gegen eine andere Produktkategorie aus – ohne dass Sie den Code ändern müssen. Für eine tiefere Anpassung verweisen Sie auf bestimmte ASINs oder wechseln Sie komplett zu einem anderen Bright Data-Scraper.
Neu hier? [Starten Sie mit einer kostenlosen Bright Data-Testversion]() (keine Kreditkarte erforderlich), klonen Sie das Demo-Repo und führen Sie „docker compose up“ aus.
FAQ
Häufige Fragen zu dieser Konfiguration:
Wie kann ich Amazon-Produktdaten mit Python scrapen?
Sie können Ihren eigenen Scraper mit Requests und BeautifulSoup erstellen (der jedoch nicht mehr funktioniert, wenn Amazon das Layout ändert) oder den Amazon-Scraper von Bright Data verwenden, der strukturierte JSON-Daten aus einem einzigen API-Aufruf zurückgibt. Ein eigenständiges Python-Beispiel finden Sie im Amazon Scraper-Repo. Ausführliche Informationen finden Sie im vollständigen Amazon-Scraping-Leitfaden von Bright Data.
Wie viel kostet das Scraping von Amazon mit Bright Data?
Die Web-Scraping-API verwendet eine Pay-as-you-go-Preisgestaltung, die pro 1.000 gesammelten Datensätzen abgerechnet wird. Die kostenlose Stufe von Gemini deckt die KI-Analyse ab. Neue Konten erhalten eine kostenlose Testversion. Die aktuellen Preise finden Sie auf der Preisseite.
Kann ich mit dieser Pipeline Walmart, eBay oder andere E-Commerce-Websites scrapen?
Tauschen Sie die DATASET_ID in den Datenlader-Blöcken aus und passen Sie die Eingabeparameter an das Schema des neuen Scrapers an. Die Gemini-Analyse und die Pipeline-Struktur bleiben unverändert; die Anreicherungs- und Exportblöcke müssen möglicherweise in Bezug auf die Spaltennamen angepasst werden.
Was passiert, wenn Amazon sein Seitenlayout ändert?
Für Sie ändert sich nichts. Bright Data wartet die Parser, sodass Ihre API-Aufrufe und das Antwortformat in der Regel unverändert bleiben, wenn Amazon sein HTML aktualisiert.
Benötige ich Gemini oder kann ich ein anderes LLM verwenden?
Die Pipeline funktioniert auch ohne Gemini; sie greift dann auf eine bewertungsbasierte Stimmungsanalyse zurück. Um ein anderes LLM (OpenAI, Claude, Llama) zu verwenden, ändern Sie die Funktion „analyze_reviews” im Gemini-Block. Das Prompt-Format bleibt unverändert, Sie ändern lediglich den API-Aufruf.






