

Google hat den num-Parameter im September 2025 ohne Vorwarnungabgeschafft. JavaScript-Rendering wurde obligatorisch und KI Overviews wurde in 200 Ländern und Gebieten eingeführt. Wenn Sie Google scrapen, geben Ihre rohen HTTP-Anfragen nun leere oder degradierte Antworten zurück, die num-basierte Paginierung ist defekt und KI-generierte Inhalte verdrängen organische Ergebnisse unter den Falz.
Jede Google-Such-URL enthält Parameter nach dem ? (wie q für Ihre Suchanfrage, gl für das Land, hl für die Sprache, tbs für Zeitfilter und Dutzende mehr). Wenn Sie diese falsch eingeben, gibt Ihr Scraper Daten aus dem falschen Land oder leere Ergebnisse zurück, die schwer zu debuggen sind.
Nachfolgend finden Sie alle wichtigen Parameter mit getestetem Code und praktischen Beispielen. Der gesamte Code wurde mit der Live-SERP-API von Bright Data ausgeführt.
TL;DR: Was Sie für 2026 wissen müssen:
- Rank-Tracking:
q=...&gl=us&hl=en&pws=0&udm=14&brd_json=1(nicht personalisiert, keine KI-Übersichten)- Paginierung:
start=10,start=20usw. (10 Ergebnisse pro Seite).numfunktioniert nicht mehr- Zeitfilter:
tbs=qdr:d(letzter Tag),tbs=sbd:1(nach Datum sortieren),tbs=li:1(wortwörtlich)- Neu:
udmerweiterttbmum Modi wieudm=14(nur Web, keine KI). Beide funktionieren heute. Unterstützen Sie beide.- Erforderlich: JavaScript-Rendering. Raw
requests.get()-Aufrufe liefern seit Januar 2025 leere Ergebnisse zurück
Minimales Arbeitsbeispiel:
curl -X POST "https://api.brightdata.com/request"
-H "Content-Type: application/json"
-H "Authorization: Bearer <API_TOKEN>"
-d '{"zone":"<ZONE_NAME>","url":"https://www.google.com/search?q=Web-Scraping+tools&gl=us&hl=en&brd_json=1","format":"raw"}'(brd_json=1 in der URL weist Bright Data an, den HTML-Code von Google in strukturiertes JSON zu parsen. format: raw im Request-Body gibt die Antwort unverändert aus der Infrastruktur von Bright Data zurück, in diesem Fall das von brd_json=1 geparste JSON.)
Schnellreferenz: Spickzettel für Google-Suchparameter
| Parameter | Funktion | Status |
|---|---|---|
q |
Suchanfrage | Aktiv |
hl |
Sprache der Benutzeroberfläche (en, fr, de) |
Aktiv |
gl |
Geolokalisierung/Land (us, gb, in) |
Aktiv |
lr |
Ergebnisse auf bestimmte Sprachen beschränken | Aktiv |
cr |
Ergebnisse auf Seiten beschränken, die in bestimmten Ländern gehostet werden | Aktiv |
num |
Ergebnisse pro Seite | Auslaufend (Sep 2025) |
Start |
Seitenumbruch-Offset | Aktiv |
tbm |
Suchtyp (isch, nws, shop, vid) |
Aktiv |
udm |
Inhaltsmodusfilter (14, 2, 39, 50) |
Aktiv (Neu) |
tbs |
Zeit- und erweiterte Filter (qdr:d, qdr:w) |
Aktiv |
sicher |
SafeSearch-Filterung | Aktiv |
Filter |
Filterung doppelter Ergebnisse | Aktiv |
nfpr |
Autokorrektur deaktivieren | Aktiv |
pws |
Personalisierte Ergebnisse deaktivieren (pws=0) |
Aktiv |
uule |
Kodierter Standort (Targeting auf Stadtebene) | Aktiv |
sclient |
Such-Client-Kennung | Aktiv (intern) |
kgmid |
Entitäts-ID des Wissensgraphen | Aktiv |
si |
Wissensgraphen-Registerkarten (undurchsichtige codierte Zeichenfolge; nicht vom Benutzer erstellbar) | Aktiv (intern) |
ibp |
Rendering-Steuerung (Aufträge, Unternehmenslisten) | Aktiv |
ei, ved, sxsrf |
Interne Tracking-/Sitzungstoken | Aktiv (intern) |
Google-Suchoperatoren (site:, filetype:, intitle: usw.) werden weiter unten im Abschnitt „Operatoren” behandelt.
Probieren Sie einfache Suchanfragen im SERP-API Playground aus – keine Anmeldung erforderlich. Für den vollständigen Parametersatz verwenden Sie bitte direkt die API.
Was sind Google-Suchparameter?
Google-Suchparameter steuern die Abfrage, den Standort, die Sprache und die Filterung der Ergebnisse. Sie sind wichtig für die Verfolgung von SEO-Rankings, die Analyse von Mitbewerbern, die Überwachung von Anzeigen und die Einspeisung von Suchergebnissen in LLM-Anwendungen.
Eine Änderung im Jahr 2025: Google kündigte im April 2025 an, dass ccTLDs (länderspezifische Top-Level-Domains wie google.co.uk, google.de, google.ca) zu google.com weiterleiten werden. Die Umstellung erfolgt schrittweise, und einige ccTLDs liefern weiterhin direkt Ergebnisse. Verwenden Sie in jedem Fall gl und hl für die Lokalisierung, nicht die Domain.
Kernsuchparameter
Dies sind die Parameter, die Sie bei fast jeder Anfrage festlegen: Suchanfrage, Sprache, Land und Paginierung.
q – Suchanfrage
Ihre Suchanfrage wird in q eingegeben.
https://www.google.com/search?q=bright+data+Web-ScrapingLeerzeichen in der Abfrage werden als + oder %20 kodiert. Der Parameter q unterstützt auch die Suchoperatoren von Google, zum Beispiel:
https://www.google.com/search?q=filetype:pdf+Web-Scraping+guide
https://www.google.com/search?q=site:github.com+SERP-API
https://www.google.com/search?q=intitle:proxy+rotation+tutorialKodieren Sie Ihre Abfragezeichenfolge ordnungsgemäß URL-kodieren, insbesondere nicht-lateinische Zeichen (Chinesisch, Arabisch, Japanisch, Koreanisch usw.) – wenn diese nicht kodiert werden, kommt es häufig zu unerwarteten oder leeren Ergebnissen. Wenn Sie die SERP-API von Bright Data verwenden, platzieren Sie den Parameter q immer an erster Stelle in Ihrer URL. Dies ist in der Dokumentation von Bright Data vorgeschrieben. Wenn Sie andere Parameter vor q platzieren, kann dies zu langsameren Antworten und geringeren Erfolgsraten führen.
Über die SERP-API -Proxy-Methode von Bright Data:
curl --proxy brd.superproxy.io:33335
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k
"https://www.google.com/search?q=Web-Scraping+tools&brd_json=1"Wenn Sie den Roh-HTML-Code innerhalb der JSON-Datei beibehalten möchten, verwenden Sie brd_json=html anstelle von brd_json=1. Die Direct API unterstützt zusätzliche Ausgabeformate, darunter Markdown, Screenshots und leichtgewichtige geparste Ausgaben.
Die JSON-Antwort sieht wie folgt aus (gekürzt):
{
"general": {
"search_engine": "google",
"results_cnt": 33500000,
"search_time": 0.21,
"language": "en",
"mobile": false,
"search_type": "text"
},
"input": {
"original_url": "https://www.google.com/search?q=Web-Scraping+tools&brd_json=1"
},
"organic": [
{
„link”: „https://www.reddit.com/r/automation/comments/1ncuv8k/best_web_scraping_tools_ive_tried_and_what_i/”,
„title”: „Die besten Web-Scraping-Tools, die ich ausprobiert habe (und was ich dabei gelernt habe ...”,
"description": "Playwright: Ideal für strukturierte Automatisierung und Tests, allerdings etwas code-lastig für leichtgewichtiges Scraping.",
"rank": 1,
"global_rank": 5
}
]
}Das JSON gruppiert alles nach SERP-Abschnitten. Organische Ergebnisse sind von top_ads und bottom_ads getrennt, Knowledge Panels sind von people_also_ask getrennt, lokale Ergebnisse befinden sich in snack_pack und neuere Funktionen wie ai_overview jeweils in ihren eigenen Feldern. Je nach Suchanfrage gibt es insgesamt über ein Dutzend Abschnitte.
hl – Host-Sprache
HL ist die Abkürzung für „Host Language“ (Hostsprache) und steuert die Sprache der Google-Oberfläche und wie Google Ihre Suchanfrage interpretiert.
https://www.google.com/search?q=coffee&hl=en
https://www.google.com/search?q=coffee&hl=es
https://www.google.com/search?q=coffee&hl=jaDie Werte sind ISO 639-1- Codes wie hl=en (Englisch), hl=fr (Französisch), hl=de (Deutsch) oder BCP 47 -Sprachcodes wie hl=en-gb (britisches Englisch), hl=pt-br (brasilianisches Portugiesisch), hl=es-419 (lateinamerikanisches Spanisch).
Über die SERP-API sieht dieselbe Suche wie folgt aus:
curl --proxy brd.superproxy.io:33335
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k
"https://www.google.com/search?q=meilleurs+outils+de+scraping&hl=fr&gl=fr&brd_json=1"Dadurch werden französischsprachige Ergebnisse für eine französischsprachige Suchanfrage abgerufen, als ob Sie von Frankreich aus suchen würden.
gl – Geolokalisierung
Ihr Suchort beeinflusst die Ergebnisse. Der Parameter gl simuliert Ihre Geolokalisierung (das Land, aus dem die Suche zu stammen scheint). Er verwendet zweistellige Ländercodes nach ISO 3166-1 alpha-2.
https://www.google.com/search?q=pizza+delivery&gl=us
https://www.google.com/search?q=pizza+delivery&gl=gb
https://www.google.com/search?q=pizza+delivery&gl=inVergleichen Sie dieselbe Suchanfrage in zwei Ländern:
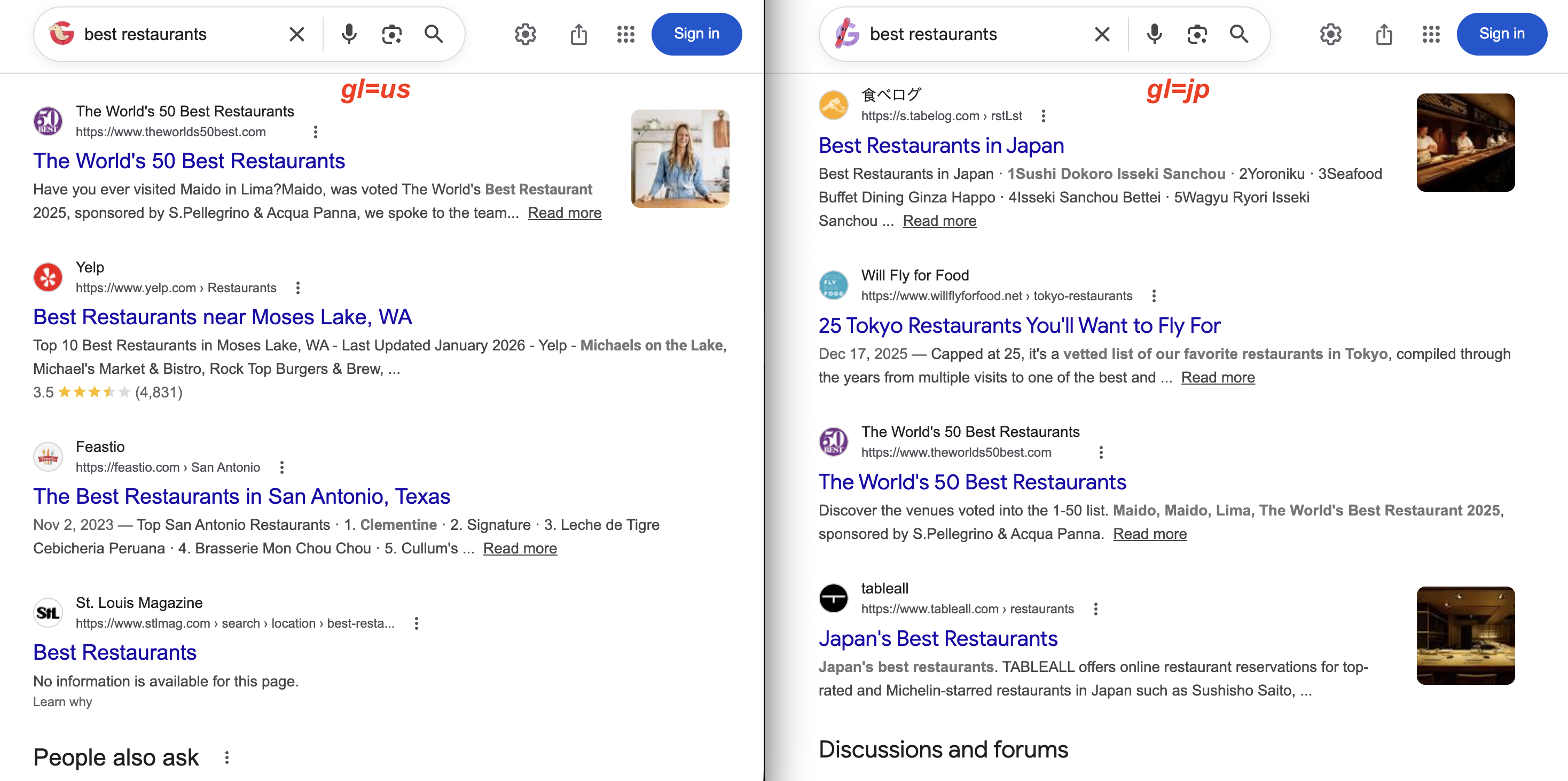
gl=us liefert Yelp und lokale US-Magazine. Mit gl=jp werden stattdessen 食べログ (Tabelog) und Restaurantführer für Tokio angezeigt. Gleiche Suchanfrage, sehr unterschiedliche Ergebnisse.
lr – Sprachbeschränkung
Die Suche nach „machine learning” mit hl=en liefert immer noch Artikel in Chinesisch, Japanisch oder Deutsch, wenn Google diese für relevant hält. Der Parameter lr löst dieses Problem. Er beschränkt die Ergebnisse auf Seiten, die tatsächlich in bestimmten Sprachen verfasst sind, nicht nur auf die Benutzeroberfläche.
https://www.google.com/search?q=machine+learning&lr=lang_en
https://www.google.com/search?q=machine+learning&lr=lang_en|lang_frStellen Sie dem Sprachcode „lang_“ voran (also „lang_en“ für Englisch und „lang_fr“ für Französisch). Verwenden Sie das Pipe-Zeichen „|“, um mehrere Sprachen zu kombinieren.
cr – Länderbeschränkung
Ähnlich wie lr, filtert jedoch nach dem Hosting-Land anstelle der Inhaltssprache. Verwenden Sie cr=countryUS für ein einzelnes Land und cr=countryUS|countryGB für mehrere Länder. Der wesentliche Unterschied zu gl: gl lokalisiert Ihre Suche so, als befänden Sie sich in diesem Land, cr filtert nach Seiten, die tatsächlich dort gehostet werden. Verwenden Sie beide zusammen, wenn Sie eine exakte Filterung benötigen.
num – Anzahl der Ergebnisse
Der Parameter num wurde verwendet, um zu steuern, wie viele Suchergebnisse pro Seite angezeigt wurden (z. B. num=20, num=50, num=100).
Wenn Ihr Scraper seit September 2025 nur noch 10 Ergebnisse zurückgibt, ist diese Parameteränderung der Grund dafür. Seit September 2025 hat Google den Parameter „num“ stillschweigend deaktiviert. Er wird nun vollständig ignoriert. Google gibt unabhängig vom übergebenen Wert für „num“ 10 Ergebnisse pro Seite zurück, ohne Fehlermeldung oder Weiterleitung. Dies hat SEO-Tools und SERP-Scraping-Workflows, die darauf basierten, unbrauchbar gemacht. Ein Google-Sprecher bestätigte: „Die Verwendung dieses URL-Parameters wird von uns nicht offiziell unterstützt.“ Der Abschnitt „Änderungen 2025–2026“ behandelt die Problemumgehung mithilfe des Endpunkts „Top 100 Results“ von Bright Data.
Sie können dies überprüfen. num=100 ist in der URL enthalten, aber es werden nur 10 Ergebnisse zurückgegeben:
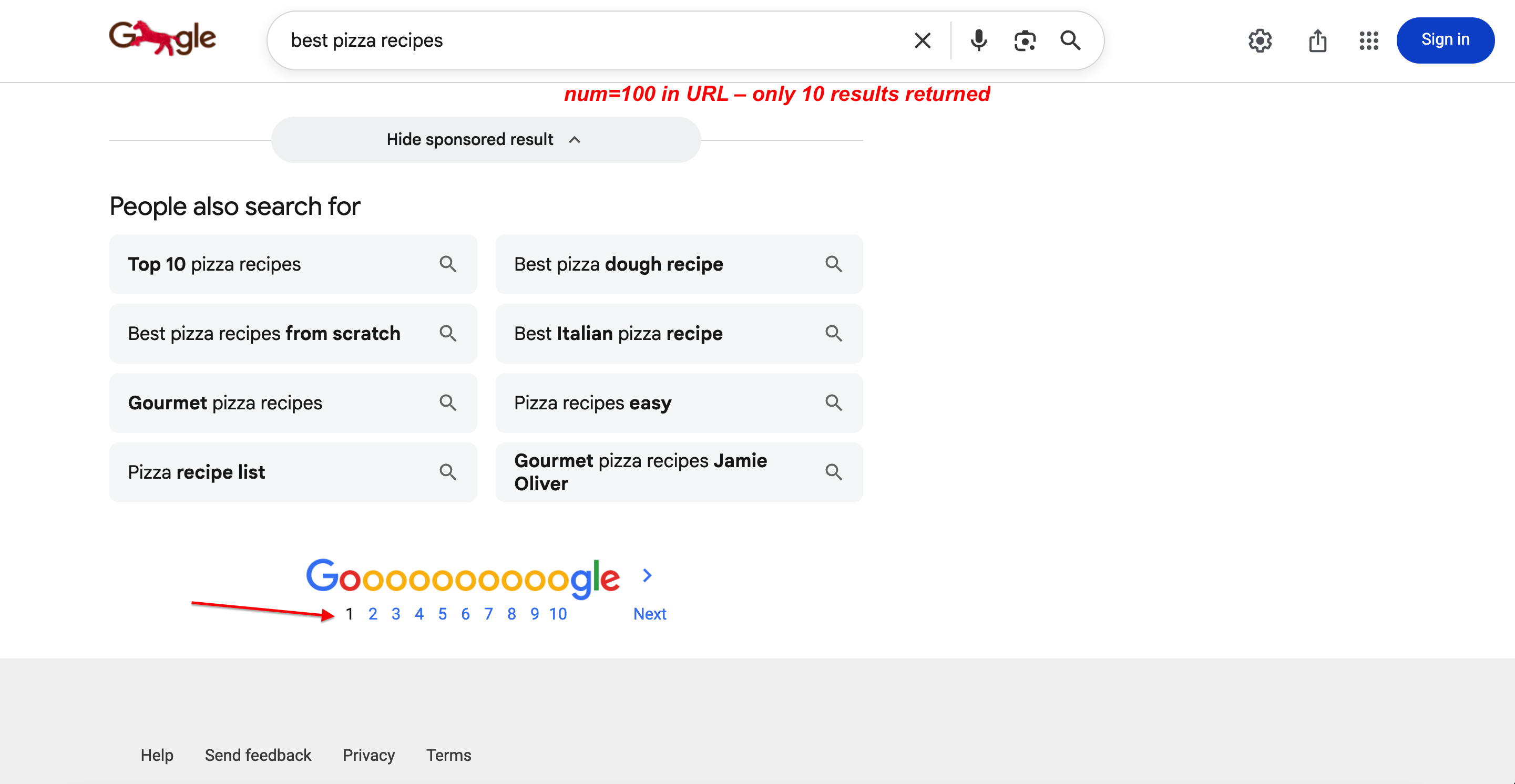
Suche mit num=100 in der URL. Google gibt weiterhin nur 10 Ergebnisse pro Seite mit vollständiger Paginierung zurück. Der Parameter wird vollständig ignoriert.
start – Ergebnis-Offset (Paginierung)
Da Google num abgeschafft hat, ist start Ihre einzige native Paginierungsoption. Es legt den Ergebnis-Offset fest und steuert, von welcher Ergebnisposition aus begonnen werden soll.
https://www.google.com/search?q=Web-Scraping&start=0
https://www.google.com/search?q=Web-Scraping&start=10
https://www.google.com/search?q=Web-Scraping&start=20start=0 ist Seite 1 (Standard), start=10 ist Seite 2, start=20 ist Seite 3.
Da Google 10 Ergebnisse pro Seite zurückgibt, erhalten Sie mit start=20 die Ergebnisse 21–30, mit start=30 die Ergebnisse 31–40 usw. Bei der Paginierung über mehrere Seiten hinweg kann es vorkommen, dass Google überlappende oder leicht umgeordnete Ergebnisse zwischen den Seiten zurückgibt. Entfernen Sie vor der Verarbeitung doppelte URLs.
Paginierung über die SERP-API:
# Seite 3 der Ergebnisse abrufen
curl --proxy brd.superproxy.io:33335
--Proxy-User brd-customer-<CUSTOMER_ID>-Zone-<ZONE_NAME>:<PASSWORD> -k
"https://www.google.com/search?q=serp+scraping&start=20&brd_json=1"Suchtyp-Parameter
Google verfügt über zwei Parameter zum Wechseln zwischen Suchvertikalen (Bilder, Nachrichten, Shopping, Videos): tbm und udm.
tbm – Inhaltstyp der Suche
Der Parameter tbm (allgemein als „to be matched” interpretiert, obwohl Google die Abkürzung nie bestätigt hat) teilt Google mit, welche Art von Suchergebnissen Sie wünschen. Ohne diesen Parameter verwendet Google standardmäßig die normale Websuche.
| Wert | Suchtyp | Beispiel |
|---|---|---|
| (leer) | Websuche | q=Kaffee |
isch |
Bildersuche | tbm=isch&q=coffee |
vid |
Videosuche | tbm=vid&q=coffee |
nws |
Nachrichtensuche | tbm=nws&q=coffee |
shop |
Shopping-Suche | tbm=shop&q=coffee |
bks |
Buchsuche | tbm=bks&q=coffee |
Dieselbe Suchanfrage in drei Suchtypen:
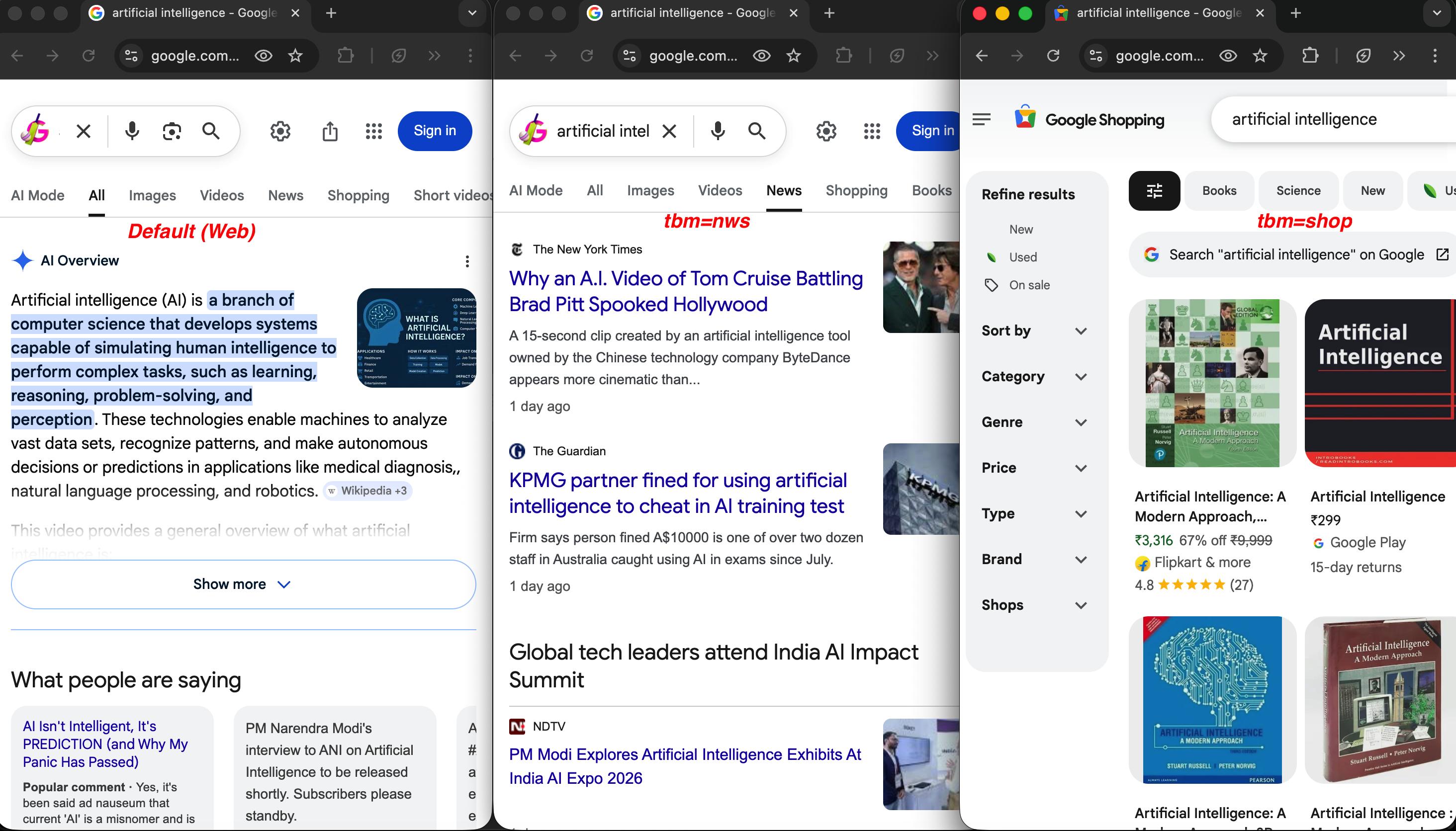
Gleiche Suchanfrage, unterschiedliche tbm-Werte: Die Standard-Websuche (links) zeigt eine KI-Übersicht, tbm=nws (Mitte) liefert Nachrichtenartikel aus der NYT und The Guardian, und tbm=shop (rechts) zeigt Produktlisten mit Preisen und Bewertungen.
Eine Nachrichtensuche nach künstlicher Intelligenz:
https://www.google.com/search?q=artificial+intelligence&tbm=nws&hl=en&gl=usEine Shopping-Suche nach mechanischen Tastaturen:
https://www.google.com/search?q=mechanical+keyboard&tbm=shop&gl=usAlle diese Suchtypen funktionieren nativ. Beim Parsing der JSON-Antwort werden Anzeigen in die Felder „top_ads“ und „bottom_ads“ unterteilt, und Produktlisten erscheinen unter „popular_products“, allesamt getrennt von organischen Ergebnissen. Für die dedizierte Anzeigenüberwachung siehe den Google Ads-Scraper. Reise- und Hotelparameter (hotel_occupancy, hotel_dates, brd_dates, brd_occupancy, brd_currency usw.) sind Bright Data-spezifisch und in der SERP-API-Parameterreferenz dokumentiert.
udm – Benutzeranzeigemodus
Der neuere Inhaltsmodusfilter von Google ist udm, der tbm um zusätzliche Ergebnistypen erweitert. Er steuert, welchen „Modus“ der Suchergebnisse Sie sehen. Keiner der udm-Werte ist in der offiziellen Dokumentation von Google enthalten. Sie wurden alle von der Entwickler-Community durch Tests rückentwickelt. Die folgenden Werte sind stabil und weit verbreitet, aber Google könnte sie ohne Vorankündigung ändern.
| Wert | Ergebnismodus | Beschreibung |
|---|---|---|
udm=2 |
Bilder | Bilder Suchergebnisse |
udm=7 |
Videos | Videoresultate; neueres Äquivalent zu tbm=vid |
udm=12 |
Nachrichten | Nachrichtenergebnisse; neueres Äquivalent zu tbm=nws |
udm=14 |
Web | Klassische Web-Ergebnisse ohne KI-Funktionen |
udm=18 |
Foren | Diskussions- und Forenergebnisse |
udm=28 |
Einkaufen | Einkauf/Produktergebnisse |
udm=36 |
Bücher | Buch-Ergebnisse; neueres Äquivalent zu tbm=bks |
udm=39 |
Kurzvideos | Kurze Videoinhalte |
udm=50 |
KI-Modus | Googles KI-gestützte dialogorientierte Suche |
Der bemerkenswerteste Wert ist udm=14. Er zwingt Google dazu, traditionelle Web-Ergebnisse ohne KI-Übersichten oder andere KI-generierte Inhalte anzuzeigen:
https://www.google.com/search?q=Web-Scraping+tools&udm=14Der Unterschied zwischen der Standardeinstellung und udm=14 ist sofort sichtbar:
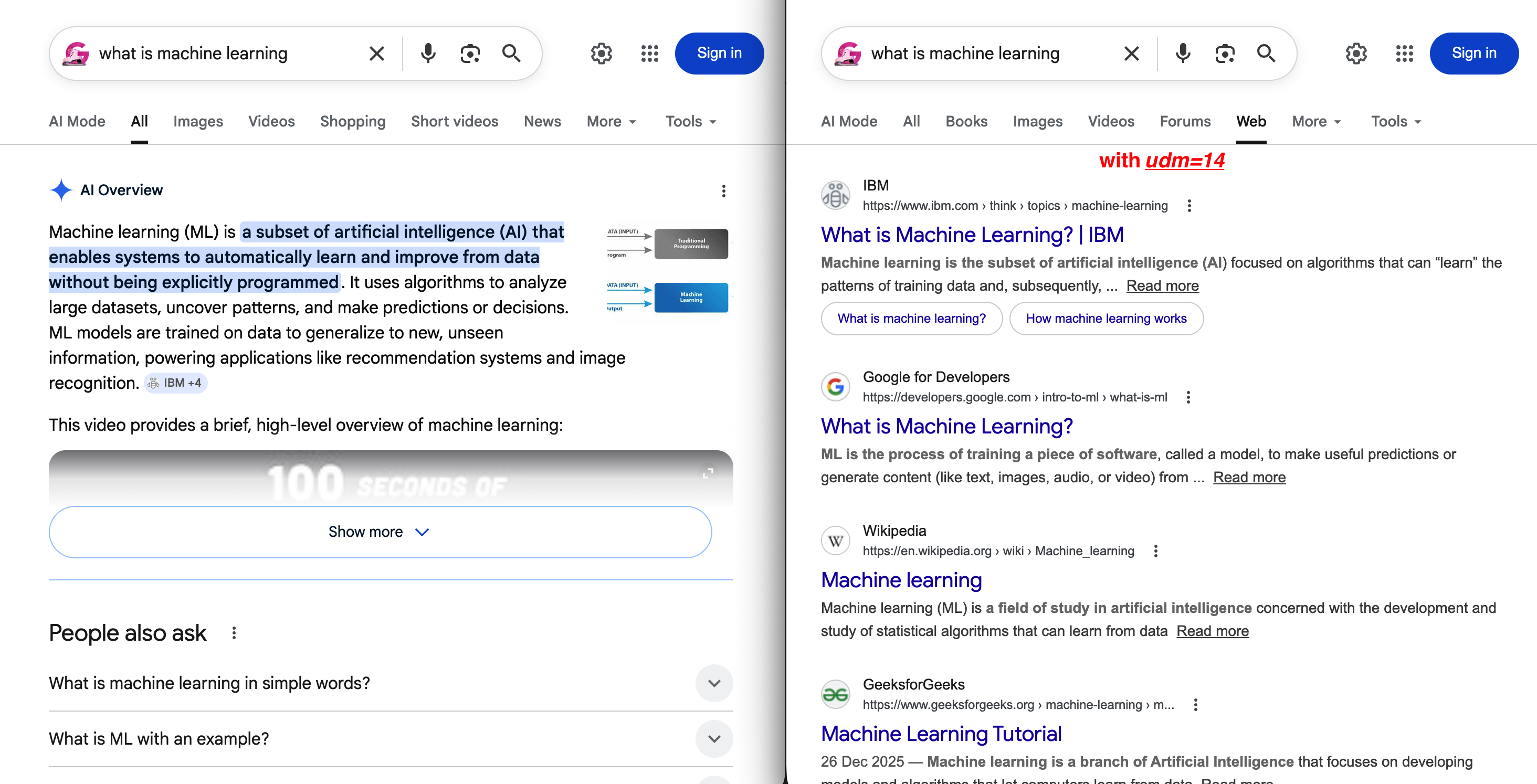
Links: die Standard-SERP mit einer KI-Übersicht, die organische Ergebnisse unter den Falz drückt. Rechts: udm=14 entfernt all das und zeigt eine übersichtliche Registerkarte „Web“ mit traditionellen blauen Links.
Für kurze Videoergebnisse verwenden Sie udm=39 (von Google nicht dokumentiert; Verhalten kann je nach Region variieren):
https://www.google.com/search?q=coffee+recipes&udm=39Der KI-Modus (udm=50) ist eine ganz andere Art der Suche:
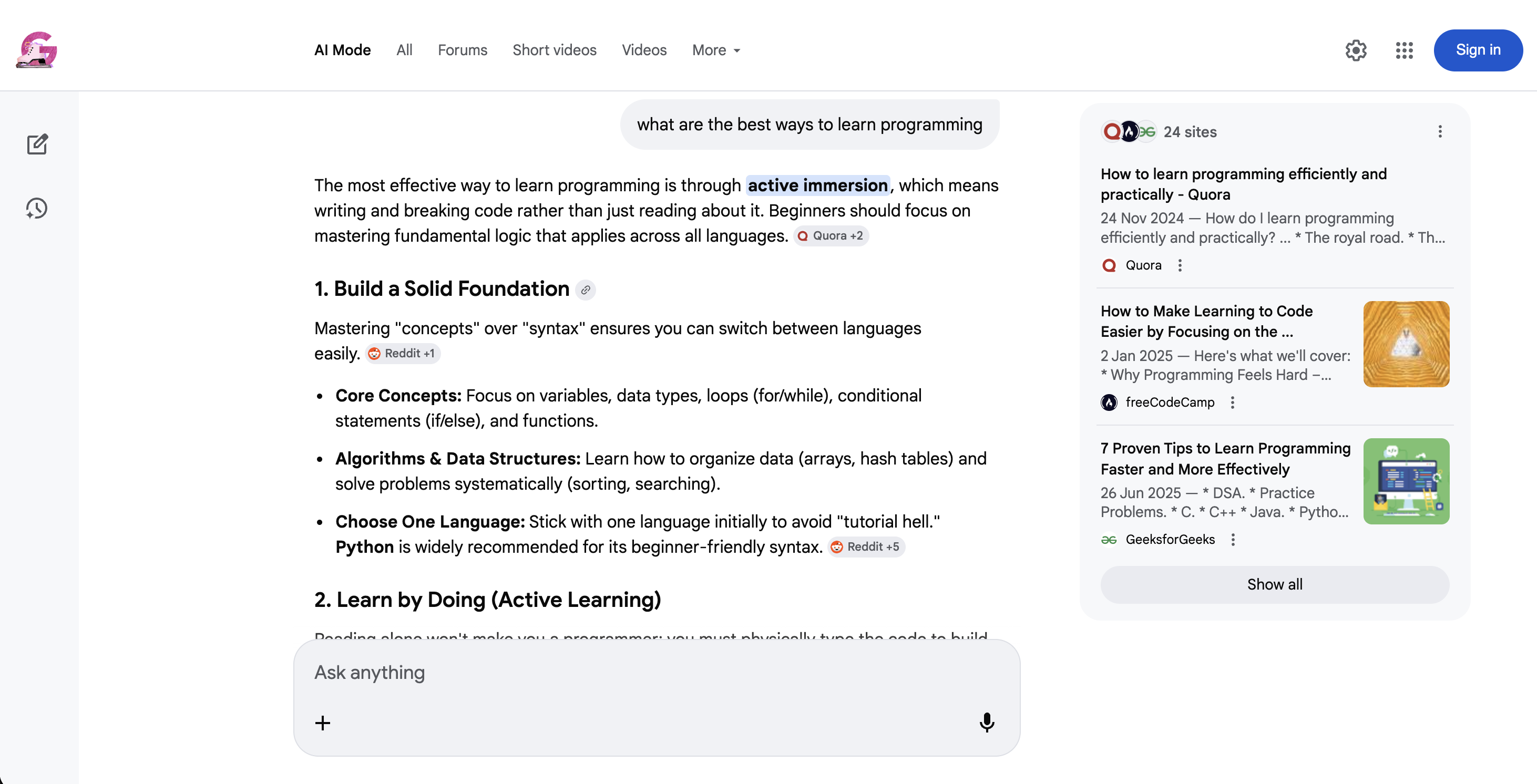
Google AI-Modus (udm=50): Anstelle der herkömmlichen Ergebnisse liefert Google eine dialogorientierte KI-Antwort mit Inline-Quellenangaben und vorgeschlagenen Folgefragen.
tbm und udm überschneiden sich bei Bildern, Nachrichten und Shopping, aber udm deckt auch Modi ab, die tbm nicht abdeckt (Foren, kurze Videos, KI-Modus, nur Web). Beide funktionieren heute. Wenn Sie neue Scraping-Workflows erstellen, unterstützen Sie beide Parameter für maximale Kompatibilität.
Filter- und Sortierparameter
tbs – zeitbasierte und erweiterte Filter
Der Parameter tbs (allgemein als „zu suchen” interpretiert, obwohl dies von keiner offiziellen Quelle bestätigt wird) steuert die Zeitfilterung, Datumsortierung und wortwörtliche Übereinstimmung.
Die häufigste Verwendung ist die Zeitfilterung mit qdr (query date range, Abfrage-Datumsbereich):
| Wert | Zeitbereich |
|---|---|
tbs=qdr:h |
Letzte Stunde |
tbs=qdr:d |
Letzte 24 Stunden |
tbs=qdr:w |
Letzte Woche |
tbs=qdr:m |
Letzter Monat |
tbs=qdr:y |
Vergangenes Jahr |
Sie können auch einen benutzerdefinierten Datumsbereich mit tbs=cdr:1,cd_min:01/01/2025,cd_max:12/31/2025 festlegen. Dies ist nützlich, um zu verfolgen, wie sich die Suchergebnisse über einen bestimmten Zeitraum ändern.
Neben der Zeitfilterung bietet tbs zwei weitere nützliche Modi. tbs=sbd:1 zwingt Google, die Ergebnisse nach Datum (neueste zuerst) statt nach Relevanz zu sortieren, was für die Überwachung aktueller Erwähnungen nützlich ist. Und tbs=li:1 ermöglicht die wortgetreue Suche. Google sucht genau nach dem, was Sie eingegeben haben, ohne Autokorrekturen, Synonyme oder verwandte Begriffe.
So überwachen Sie aktuelle Nachrichten zu einem Thema:
curl --proxy brd.superproxy.io:33335
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k
"https://www.google.com/search?q=Web-Scraping+regulations&tbs=qdr:w&brd_json=1"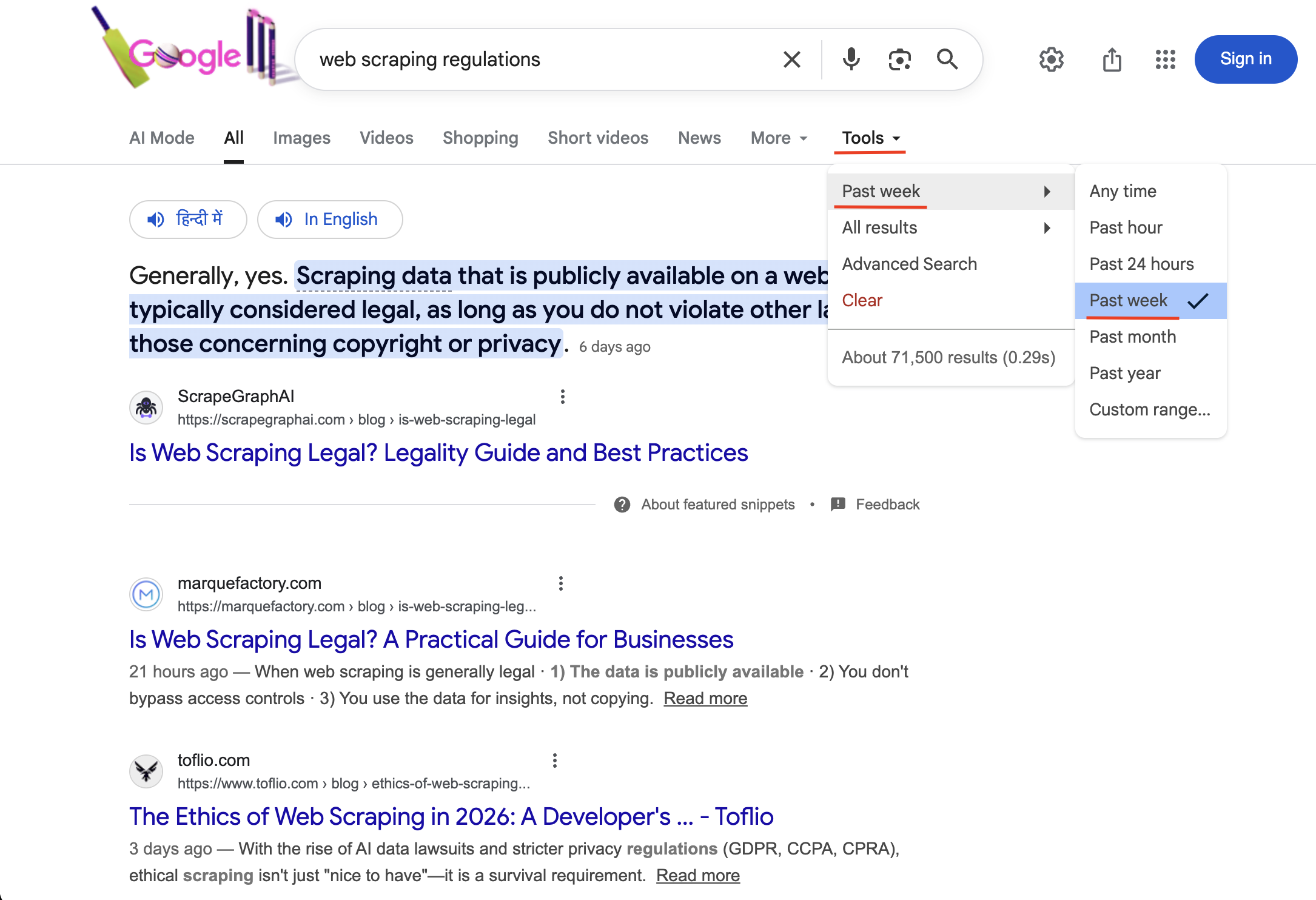
Die Suche mit tbs=qdr:w aktiviert den Zeitfilter „Letzte Woche” (sichtbar unter „Tools” mit einem Häkchen). Es werden nur Ergebnisse angezeigt, die innerhalb der letzten 7 Tage veröffentlicht wurden.
Tipp: Kombinieren Sie filter=0 mit einem beliebigen tbs-Zeitfilter, um alle Ergebnisse zu erhalten. Ohne diesen Filter gruppiert Google ähnliche Seiten und Sie könnten relevante Ergebnisse übersehen.
safe – SafeSearch-Filterung
safe=active filtert explizite Inhalte, safe=off deaktiviert die Filterung.
https://www.google.com/search?q=photography&safe=active
https://www.google.com/search?q=photography&safe=offfilter – Duplikatsfilterung
Der Filterparameter steuert, wie Google ähnliche oder doppelte Ergebnisse gruppiert.
https://www.google.com/search?q=Web-Scraping&filter=0
https://www.google.com/search?q=Web-Scraping&filter=1filter=0 zeigt alle Ergebnisse einschließlich Duplikaten an. filter=1 (Standard) gruppiert ähnliche Seiten. Am nützlichsten in Kombination mit Zeitfiltern (siehe den oben genannten TBS-Tipp ).
nfpr – keine Autokorrektur
Setzen Sie nfpr=1, um zu verhindern, dass Google Ihre Suchanfrage automatisch korrigiert.
https://www.google.com/search?q=scraping+brwser&nfpr=1Wenn dieser Wert auf 1 gesetzt ist, sucht Google genau nach dem, was Sie eingegeben haben, ohne Vorschläge wie „Meinten Sie: Scraping-Browser?“ zu machen. Dies ist nützlich, wenn Sie absichtlich nach falsch geschriebenen Begriffen, Markennamen, die Google für Rechtschreibfehler hält, oder Fachbegriffen suchen, die Google möglicherweise korrigieren möchte. Hinweis: nfpr=1 unterdrückt nur die Autokorrektur. tbs=li:1 (Verbatim-Modus) geht noch weiter und deaktiviert auch Synonyme, Stemming und verwandte Begriffe. Verwenden Sie beide zusammen für die strengste Übereinstimmung.
pws – personalisierte Websuche
Google personalisiert Suchergebnisse standardmäßig. pws steuert, ob diese Personalisierung aktiv ist.
https://www.google.com/search?q=Web-Scraping+tools&pws=0Das Deaktivieren der Personalisierung (pws=0) ist wichtig, da personalisierte Ergebnisse je nach Nutzer variieren und somit zu inkonsistenten Massendaten führen. Für jede seriöse SERP-Datenerfassung sollten Sie immer pws=0 hinzufügen, um die nicht personalisierten Basis-Rankings zu erhalten.
Standortparameter
Für die meisten Rankings ist eine Ausrichtung auf Länderebene mit gl ausreichend. Für lokale SEO benötigen Sie jedoch eine präzisere Ausrichtung.
uule – verschlüsselter Standort
uule bietet Ihnen Präzision auf Stadtebene, wenn gl nicht granular genug ist.
Der uule -Wert ist eine codierte Zeichenfolge, die auf den Geo-Zielen der Google Ads-API basiert. Er verwendet entweder eine kanonische Namenscodierung (aus der Geotargeting-Datenbank von Google) oder eine GPS-Koordinatencodierung (Breitengrad/Längengrad).
https://www.google.com/search?q=best+restaurants&uule=w+CAIQICIGUGFyaXMDie manuelle Generierung von uule-Werten ist kompliziert. Sie müssen den kanonischen Namen des Standorts in der Geo Targets-Dokumentation von Google nachschlagen und ihn dann in dem von Google erwarteten Format kodieren.
Mit der SERP-API von Bright Data können Sie die Kodierung komplett überspringen und den Ortsnamen einfach als lesbare Zeichenfolge übergeben:
https://www.google.com/search?q=best+restaurants&uule=New+York,New+York,United+StatesDie API übernimmt die Suche und Kodierung automatisch.
Verwenden Sie „gl” für die Ausrichtung auf Länderebene und „uule”, wenn Sie eine Genauigkeit auf Stadtebene benötigen. Für die meisten Rank-Tracking-Zwecke ist „gl” ausreichend. Reservieren Sie „uule” für lokale SEO-Audits, bei denen die Ergebnisse zwischen Städten desselben Landes variieren.
Geräte- und Client-Parameter
Google liefert unterschiedliche Ergebnisse für Mobilgeräte und Desktop-Computer. Diese Parameter steuern die Geräteemulation und die Browseridentifizierung.
sclient – Suchclient
sclient ist in fast jeder Google-Such-URL zu finden. Es identifiziert den Suchclient, der die Suche initiiert hat. Häufige Werte: gws-wiz (Websuche), gws-wiz-serp (SERP-initiiert), img (Bildersuche), psy-ab (verbunden mit der Sofort-/Vorhersagesuche von Google). Es wird für die interne Analyse von Google verwendet und hat keinen Einfluss auf Ihre Ergebnisse.
brd_mobile / brd_browser – Geräte- und Browseremulation
Die SERP-API bietet brd_mobile zur Simulation von Suchanfragen von bestimmten Geräten:
| Wert | Gerät | User-Agent-Typ |
|---|---|---|
0 oder weglassen |
Desktop | Desktop |
1 |
Mobil | Mobil |
iOS oder iPhone |
iPhone | iOS |
iPad oder iOS-Tablet |
iPad | iOS-Tablet |
Android |
Android | Android |
Android-Tablet |
Android-Tablet | Android-Tablet |
curl --proxy brd.superproxy.io:33335
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k
"https://www.google.com/search?q=best+apps&brd_mobile=ios&brd_json=1"Wenn bei der Verwendung
von brd_mobilemit der Proxy-Methodeexpect_body-Fehlerauftreten, versuchen Sie es stattdessen mit der Direct-API-Methode. Diese ist für die Geräteemulation in der Regel zuverlässiger. Die LangChain-Integration funktioniert hier ebenfalls gut, da siedevice_typeautomatisch über die Direct-API übergibt.
Sie können den Browsertyp auch mit brd_browser steuern:
brd_browser=chrome(Google Chrome)brd_browser=safari(Safari)brd_browser=firefox(Mozilla Firefox, nicht kompatibel mitbrd_mobile=1)
Wenn nichts angegeben ist, wählt die API einen zufälligen Browser aus. Kombinieren Sie beide Parameter, um die genaue Kombination aus Gerät und Browser festzulegen:
curl --proxy brd.superproxy.io:33335
--Proxy-User brd-customer-<CUSTOMER_ID>-Zone-<ZONE_NAME>:<PASSWORD> -k
"https://www.google.com/search?q=best+smartphones&brd_browser=safari&brd_mobile=ios&brd_json=1"Erweiterte und interne Parameter
Sie müssen keine dieser Einstellungen vornehmen. Es handelt sich um interne Parameter von Google. Wenn Sie jedoch wissen möchten, was ei, ved und sxsrf bedeuten, wenn Sie diese in einer Google-URL sehen, finden Sie in diesem Abschnitt eine Erklärung dazu.
kgmid – Knowledge Graph-Maschinen-ID
Der Parameter kgmid liefert Ergebnisse aus dem Knowledge Graph von Google und kann den Parameter q vollständig überschreiben.
https://www.google.com/search?kgmid=/m/07gyp7Dadurch wird das Knowledge Graph-Fenster für McDonald’s direkt geladen. Jede Entität hat eine eindeutige Maschinen-ID, und durch die Übergabe über kgmid wird das Fenster dieser Entität abgerufen.
Das von Google für diese ID zurückgegebene Panel:
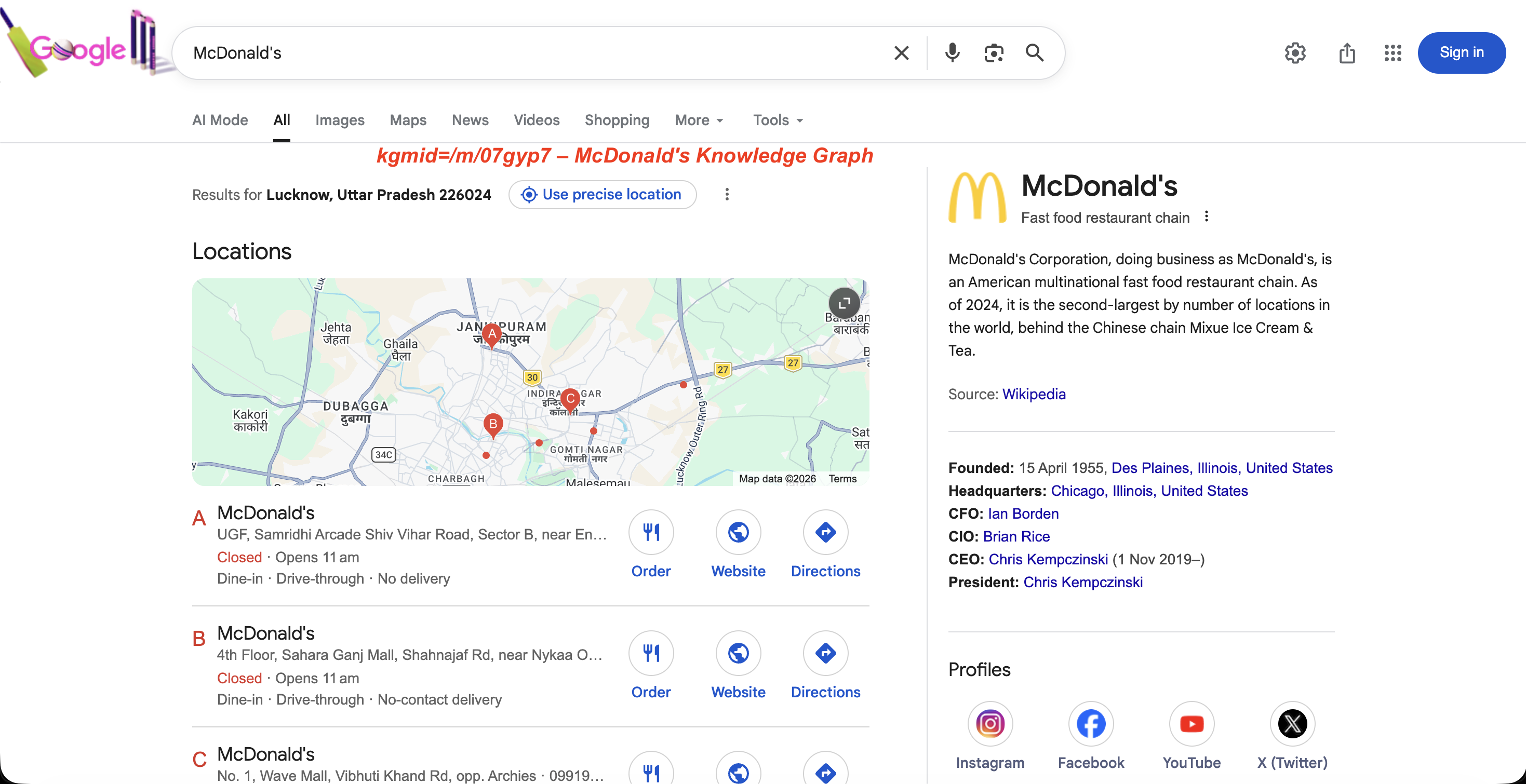
Das Knowledge Graph-Fenster für kgmid=/m/07gyp7: Beschreibung der Entität, Gründungsdatum, Führungspersonal und Social-Media-Profile.
Markenüberwachungsteams verwenden dies, um zu verfolgen, wie sich das Knowledge Graph-Panel von Google im Laufe der Zeit für ihr Unternehmen oder ihre Konkurrenten verändert.
ibp – Rendering-Steuerung
Google verwendet ibp nicht für reguläre Suchergebnisse. Es steuert, wie bestimmte Elemente auf der SERP gerendert werden, insbesondere Google Business-Einträge und Google Jobs.
https://www.google.com/search?ibp=gwp%3B0,7&ludocid=1663467585083384531In Verbindung mit dem Parameter ludocid (der eindeutigen ID für einen Google Business-Eintrag) kann ibp die Vollbildanzeige des Business-Eintrags auslösen.
Bei der Jobsuche löst ibp=htl;jobs (URL-codiert als ibp=htl%3Bjobs) das Google Jobs-Fenster mit vollständigen Jobangeboten aus:
curl --proxy brd.superproxy.io:33335
--Proxy-User brd-customer-<CUSTOMER_ID>-Zone-<ZONE_NAME>:<PASSWORD> -k
"https://www.google.com/search?q=technical+copywriter&ibp=htl%3Bjobs&brd_json=1"Das Job-Panel, das ibp=htl%3Bjobs auslöst:
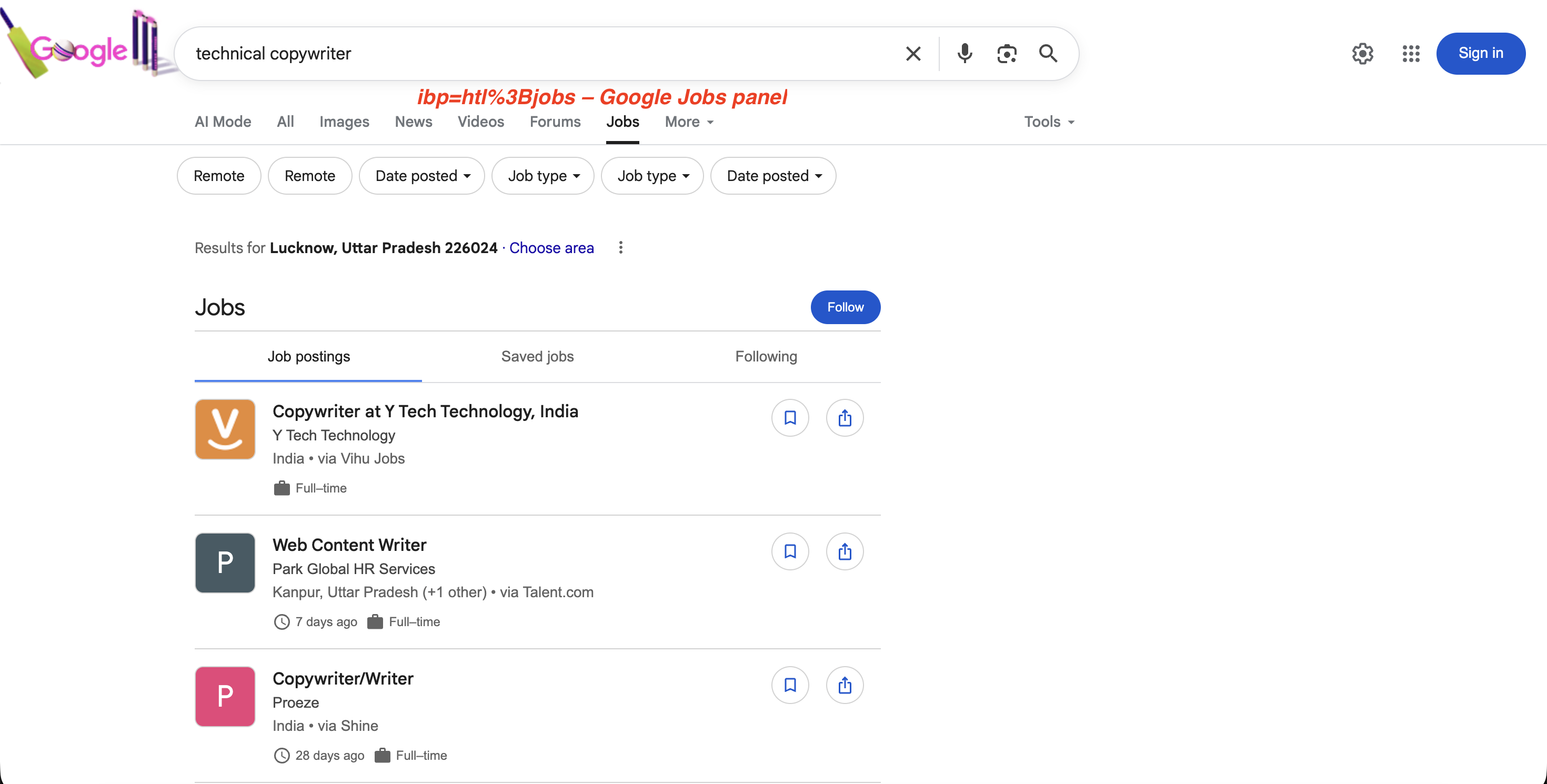
Der Parameter ibp=htl%3Bjobs löst das spezielle Jobs-Panel von Google mit Stellenanzeigen, Filtern und einer „Follow”-Option aus, die alle über die SERP-API extrahierbar sind.
Das Semikolon in
htl;jobsmuss als%3B(d. h.ibp=htl%3Bjobs) URL-codiert werden, wenn es in curl oder einem HTTP-Client verwendet wird. Ohne ordnungsgemäße Codierung kann die Anfrage leere Ergebnisse zurückgeben.
ei, ved, sxsrf, oq, gs_lp – interne Tracking-Parameter
Keiner dieser Parameter beeinflusst die zurückgegebenen Ergebnisse. Sie können bedenkenlos aus Ihren URLs entfernt werden. Hier ist die jeweilige Funktion:
| Parameter | Zweck |
|---|---|
ei |
Sitzungskennung mit einem Unix-Zeitstempel und undurchsichtigen Werten |
ved |
Klick-Tracking: Kodiert, welches SERP-Element angeklickt wurde, seinen Index und Typ |
sxsrf |
CSRF-Token mit einem verschlüsselten Unix-Zeitstempel |
oq |
Die ursprüngliche Suchanfrage, wie sie vor der Änderung durch die Autovervollständigung eingegeben wurde (z. B. oq=web+scrap, wenn q=web+Web-Scraping+API) |
gs_lp |
Interne Sitzungsdaten zum Status des Suchclients |
ie / oe |
Zeichenkodierung für Eingabe/Ausgabe (fast immer UTF-8; kann ignoriert werden) |
client |
Suchclient-Typ (z. B. firefox-b-d, safari); identifiziert den Browser oder die App |
Quelle |
Suchquellenkennung (z. B. hp für Homepage, lnms für Modusumschaltung) |
biw / bih |
Innere Breite/Höhe des Browsers in Pixeln; kann Einfluss darauf haben, welche SERP-Layoutvariante Google anzeigt |
Google-Suchoperatoren
Suchoperatoren sind spezielle Befehle innerhalb des q-Parameters, die Ergebnisse nach Domain, Dateityp, Titel, URL oder exakter Phrase filtern. Google dokumentiert einige davon auf seiner Hilfeseite zur Suchverfeinerung.
Sie unterscheiden sich von URL-Parametern: Operatoren werden in den q-Wert eingefügt, während Parameter separate Schlüssel-Wert-Paare in der URL sind. Hier sind die nützlichsten für das Scraping und die Datenerfassung:
| Operator | Funktion | Beispiel |
|---|---|---|
site: |
Auf eine bestimmte Domain beschränken | site:github.com python Scraper |
filetype: |
Auf Dateityp beschränken | filetype:pdf Web-Scraping-Anleitung |
intitle: |
Suche innerhalb von Seitentiteln | intitle:SERP-API comparison |
inurl: |
Suche innerhalb von URLs | inurl:API documentation |
intext: |
Suche innerhalb des Seiteninhalts | intext:Proxy-Rotation |
allintitle: |
Alle Wörter im Titel | allintitle:Web-Scraping Python |
allinurl: |
Alle Wörter in der URL | allinurl:API docs scraping |
related: |
Ähnliche Websites finden | related:brightdata.com |
ODER |
Entspricht einem der Begriffe | Web-Scraping ODER Web-Crawling |
„genaue Wortgruppe” |
Exakte Übereinstimmung | „SERP-API für Python“ |
- |
Begriff ausschließen | Web-Scraping – Selenium |
vor: / nach: |
Datumsbereich | KI-Übersicht nach: 2025-01-01 |
AROUND(n) |
Umkreissuche | Scraping AROUND(3) Python |
definieren: |
Wörterbuchdefinition | definieren:Web-Scraping |
* |
Platzhalter | „best * for Web-Scraping” |
All dies funktioniert auch in API-Anfragen. Zum Beispiel:
curl --proxy brd.superproxy.io:33335
--Proxy-User brd-customer-<CUSTOMER_ID>-Zone-<ZONE_NAME>:<PASSWORD> -k
"https://www.google.com/search?q=site:reddit.com+Web-Scraping+tools+2026&brd_json=1"Sucht in Reddit speziell nach Diskussionen über Web-Scraping-Tools im Jahr 2026, mit strukturierter JSON-Ausgabe.
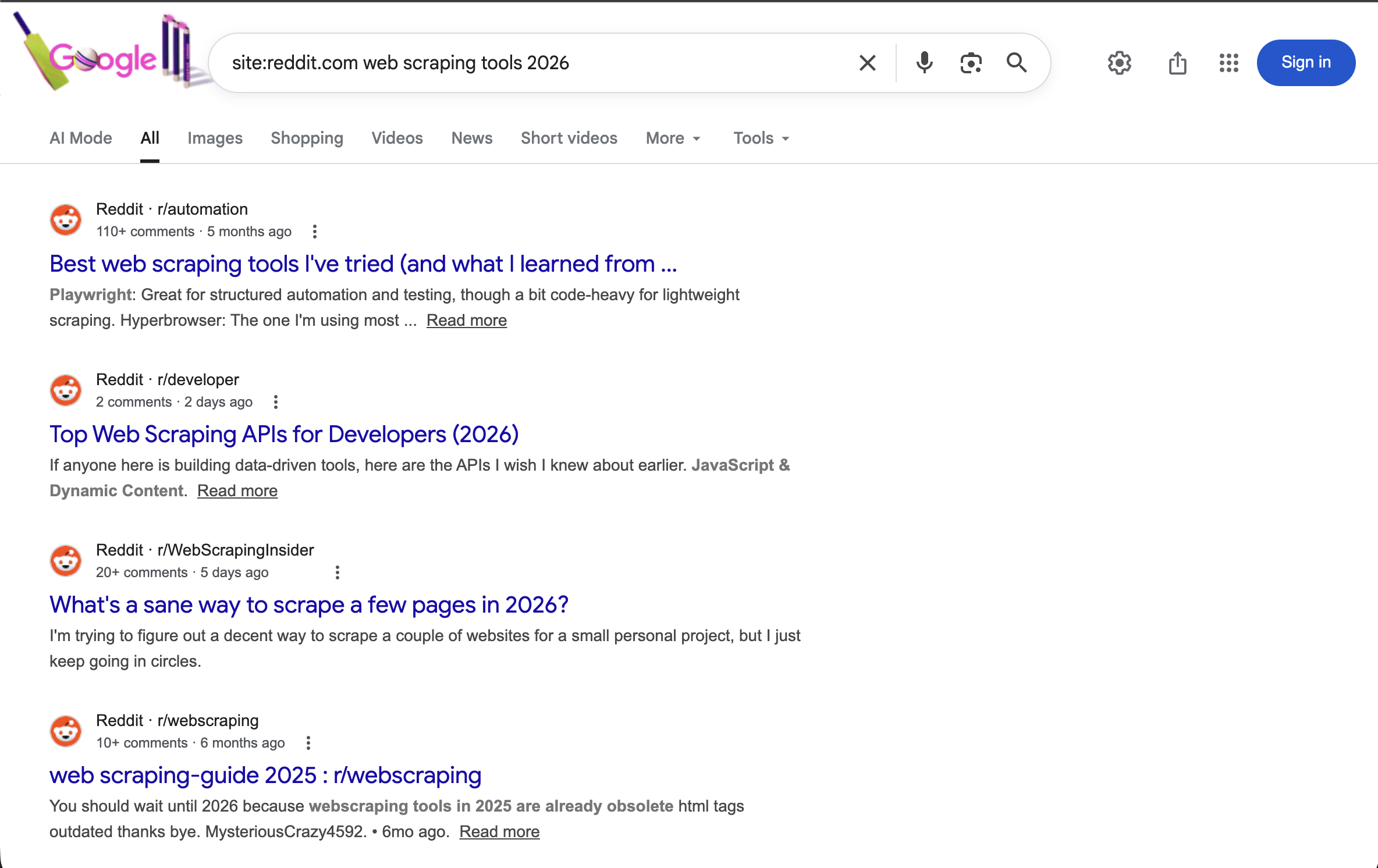
Der Operator site:reddit.com beschränkt alle Ergebnisse auf Reddit. In Kombination mit einem Jahresbegriff werden aktuelle Community-Diskussionen über Web-Scraping-Tools angezeigt.
Operatoren können kombiniert werden:
site:github.com filetype:pdf machine learninggibt nur PDF-Dateien zurück, die auf GitHub gehostet werden und mit „machine learning” übereinstimmen.
as_* – erweiterte Suchparameter
Das erweiterte Suchformular von Google generiert Parameter mit dem Präfix as_ (as_q, as_epq, as_sitesearch, as_filetype usw.), die den oben genannten Operatoren zugeordnet sind. Die meisten Ingenieure verwenden stattdessen die Operatoren direkt in q. Diese sind vor allem nützlich, wenn Sie eine Suchformular-Benutzeroberfläche erstellen und Formularfelder URL-Parametern zuordnen möchten, ohne Operatorzeichenfolgen zu verknüpfen.
Änderungen 2025–2026, die Sie kennen sollten
Google hat 2025–2026 drei Änderungen vorgenommen, die bestehende Scraping-Konfigurationen unbrauchbar gemacht haben: obligatorisches JavaScript-Rendering (Januar 2025), Entfernung des Parameters „num“ (September 2025) und Ausweitung der KI-Übersichten auf über 200 Länder.
Google erfordert jetzt JavaScript-Rendering
Seit Januar 2025 liefert Google keine Suchergebnisse mehr ohne JavaScript-Rendering. Wenn Sie einen Requests + BeautifulSoup-Scraper verwenden, ist diese Änderung der Grund dafür. Jedes requests.get('https://google.com/search?q=...') liefert nun eine leere oder beeinträchtigte Antwort. Sie benötigen ein vollständiges Browser-Rendering oder eine SERP-API, die dies für Sie übernimmt.
Die JavaScript-Rendering erfolgt automatisch mit der SERP-API, sodass Ihre API-Aufrufe unverändert bleiben.
Der Parameter „num” funktioniert nicht mehr
Zwischen dem 12. und 14. September 2025 hat Google num stillschweigend deaktiviert. Die Auswirkungen waren weitreichend: Laut einer Studie, die 319 Websites umfasste, verzeichneten 87,7 % der untersuchten Websites einen Rückgang der Impressionen in der Google Search Console.
Um mehr als 10 Ergebnisse abzurufen, verfügt die SERP-API von Bright Data über einen Endpunkt für die Top-100-Ergebnisse, der die Positionen 1 bis 100 in einer einzigen Anfrage zurückgibt. Sie verwendet eine andere API-Oberfläche (/datasets/v3/trigger mit der Datensatz-ID gd_mfz5x93lmsjjjylob) und bietet Ihnen die Parameter start_page und end_page, um die Tiefe der Paginierung zu steuern:
curl -X POST "https://api.brightdata.com/Datensätze/v3/trigger?dataset_id=gd_mfz5x93lmsjjjylob&include_errors=true"
-H "Authorization: Bearer <API_TOKEN>"
-H "Content-Type: application/json"
-d '[{
"url": "https://www.google.com/",
"keyword": "Web-Scraping tools",
"language": "en",
"country": "US",
"start_page": 1,
"end_page": 10
}]'Seitenbereiche: 1..2 = Top 20, 1..5 = Top 50, 1..10 = Top 100 (10 Ergebnisse pro Seite). Die Antwort enthält einen KI-Übersichtstext (im Feld „aio_text“ ), wenn Google einen anzeigt. Sie können „include_paginated_html“: true hinzufügen , um neben den geparsten Daten auch den rohen HTML-Code zu erfassen. Batching wird ebenfalls unterstützt. Übergeben Sie ein Array von Abfrageobjekten, um mehrere Schlüsselwörter in einer einzigen Anfrage zu suchen.
KI-Übersichten in Suchergebnissen
Die KI-Übersichten von Google (die KI-generierten Zusammenfassungen oben in den Suchergebnissen) sind jetzt in über 200 Ländern und über 40 Sprachen verfügbar. Im Januar 2026 hat Google die KI-Übersichten auf Gemini 3 aktualisiert. Google hat außerdem Übergänge von KI-Übersichten zu KI-Modus-Konversationen (udm=50) hinzugefügt. Um diese Inhalte zu erfassen, sind JavaScript-Rendering und eine spezielle Extraktionslogik erforderlich. Eine KI-Übersicht auf einer Live-SERP:
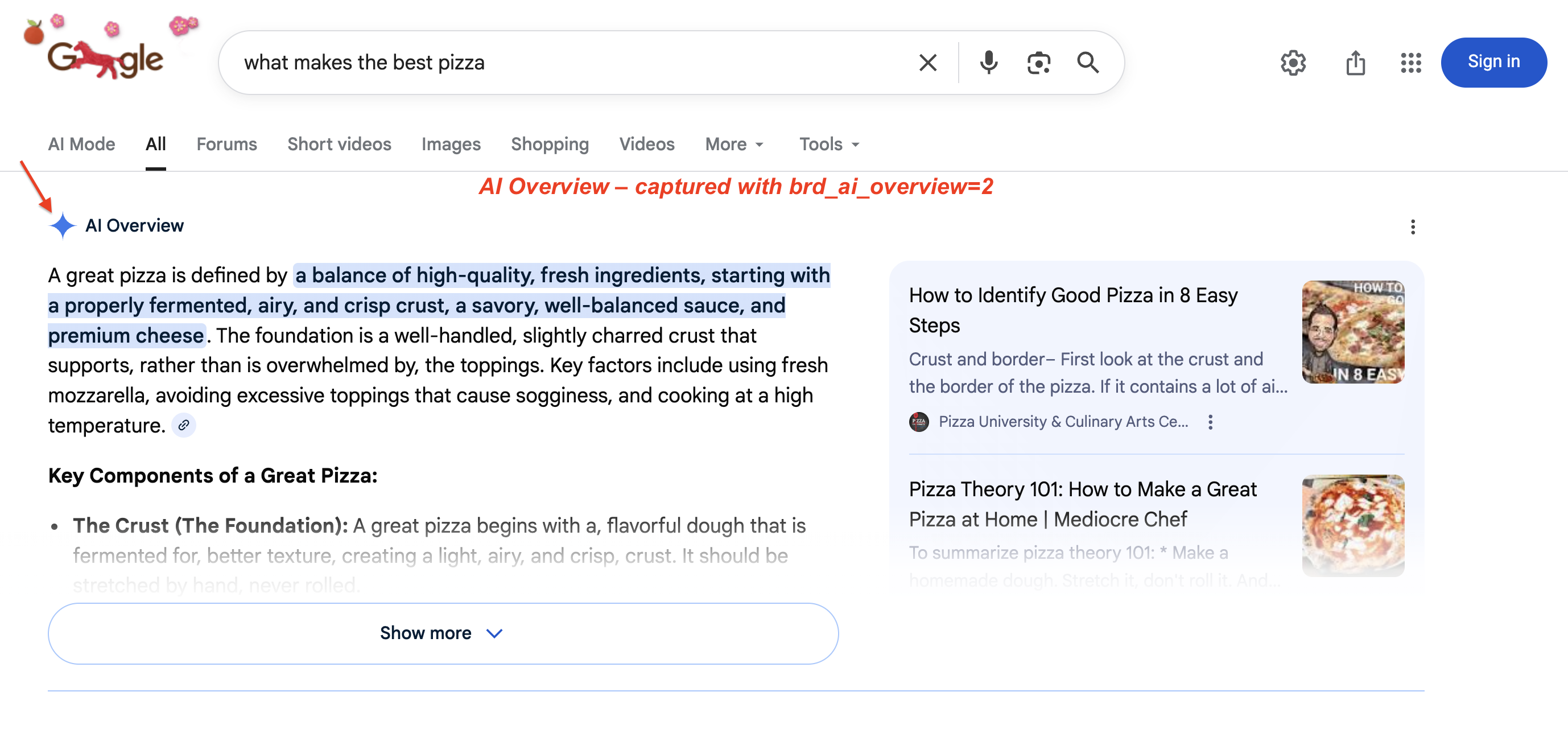
Eine typische KI-Übersicht: Google generiert eine mehrteilige Zusammenfassung mit hervorgehobenen Schlüsselbegriffen und Quellenkarten auf der rechten Seite. Dieser Block verschiebt organische Ergebnisse unter den Falz. Verwenden Sie brd_ai_overview=2, um ihn über die SERP-API zu erfassen.
Der KI-Übersichts-Scraper funktioniert über den Parameter brd_ai_overview. Setzen Sie brd_ai_overview=2, um die Wahrscheinlichkeit zu erhöhen, dass Sie KI-generierte Übersichten in Ihren Ergebnissen erhalten:
curl --proxy brd.superproxy.io:33335
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k
"https://www.google.com/search?q=what+makes+the+best+pizza&brd_ai_overview=2&brd_json=1"In unseren Tests (US-Abfragen) verlängerte die Aktivierung der KI-Übersicht die Antwortzeit um 5 bis 10 Sekunden. Die zusätzliche Latenzzeit entsteht durch das Warten auf die Fertigstellung der Darstellung der dynamisch geladenen KI-Inhalte von Google in einem Headless-Browser.
So verwenden Sie Google-Suchparameter mit einer SERP-API
Wenn Sie in großem Umfang Scraping betreiben, werden Sie auf CAPTCHAs, IP-Blocks, obligatorisches JavaScript-Rendering und Änderungen an der Google-Infrastruktur stoßen, die Parser stillschweigend außer Kraft setzen. Wir haben alle unten aufgeführten Methoden mit der Live-API getestet, um sicherzustellen, dass sie wie dokumentiert funktionieren.
Vier Möglichkeiten, diese Parameter mit der SERP-API von Bright Data zu verwenden, von der einfachsten bis zur fortgeschrittensten. Wenn Sie sich erst einmal umsehen möchten, beginnen Sie mit Methode 1 (Direkte API). Wenn Sie die API in eine bestehende Codebasis mit benutzerdefinierten Headern integrieren möchten, wählen Sie Methode 2 (Proxy). Für AI-Agent-Workflows springen Sie zu Methode 4 (LangChain). Die Einführungsanleitung führt Sie durch die Einrichtung.
| Methode | Am besten geeignet für | Antwort | Komplexität |
|---|---|---|---|
| Direkte API | Erste Schritte, einzelne Abfragen | Synchron | Niedrig |
| Proxy-Routing | Bestehende HTTP-Workflows, benutzerdefinierte Anfrage-Header | Synchron | Niedrig |
| Asynchron Batch | Hohe Volumen (1.000+ Abfragen), Paginierungssweeps | In Warteschlange | Mittel |
| LangChain | KI-Agenten, RAG-Pipelines, Multi-Tool-Workflows | Synchron | Niedrig |
Methode 1: Direkte API-Anfrage
Die einfachste Methode. Senden Sie eine POST-Anfrage mit Ihrer Such-URL und erhalten Sie strukturierte Daten zurück:
import requests
import json
from urllib.parse import urlencode
# Erstellen Sie die Google-Such-URL mit der richtigen Kodierung (verarbeitet nicht-lateinische Zeichen und Sonderzeichen)
params = urlencode({"q": "Web-Scraping API", "gl": "us", "hl": "en", "brd_json": "1"})
search_url = f"https://www.google.com/search?{params}"
url = "https://api.brightdata.com/request"
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer <API_TOKEN>"
}
payload = {
"Zone": "<ZONE_NAME>",
"url": search_url,
"format": "raw"
}
response = requests.post(url, headers=headers, json=payload, timeout=30)
response.raise_for_status()
data = response.json()
# Antwort vor der Verarbeitung validieren
if "organic" not in data or len(data.get("organic", [])) == 0:
print("Warnung: keine organischen Ergebnisse zurückgegeben (mögliche Soft-Blockierung oder leere SERP)")
print(json.dumps(data, indent=2))Der Standardname der Zone lautet in der Regel „serp”. Die geparste Antwort sieht wie folgt aus:
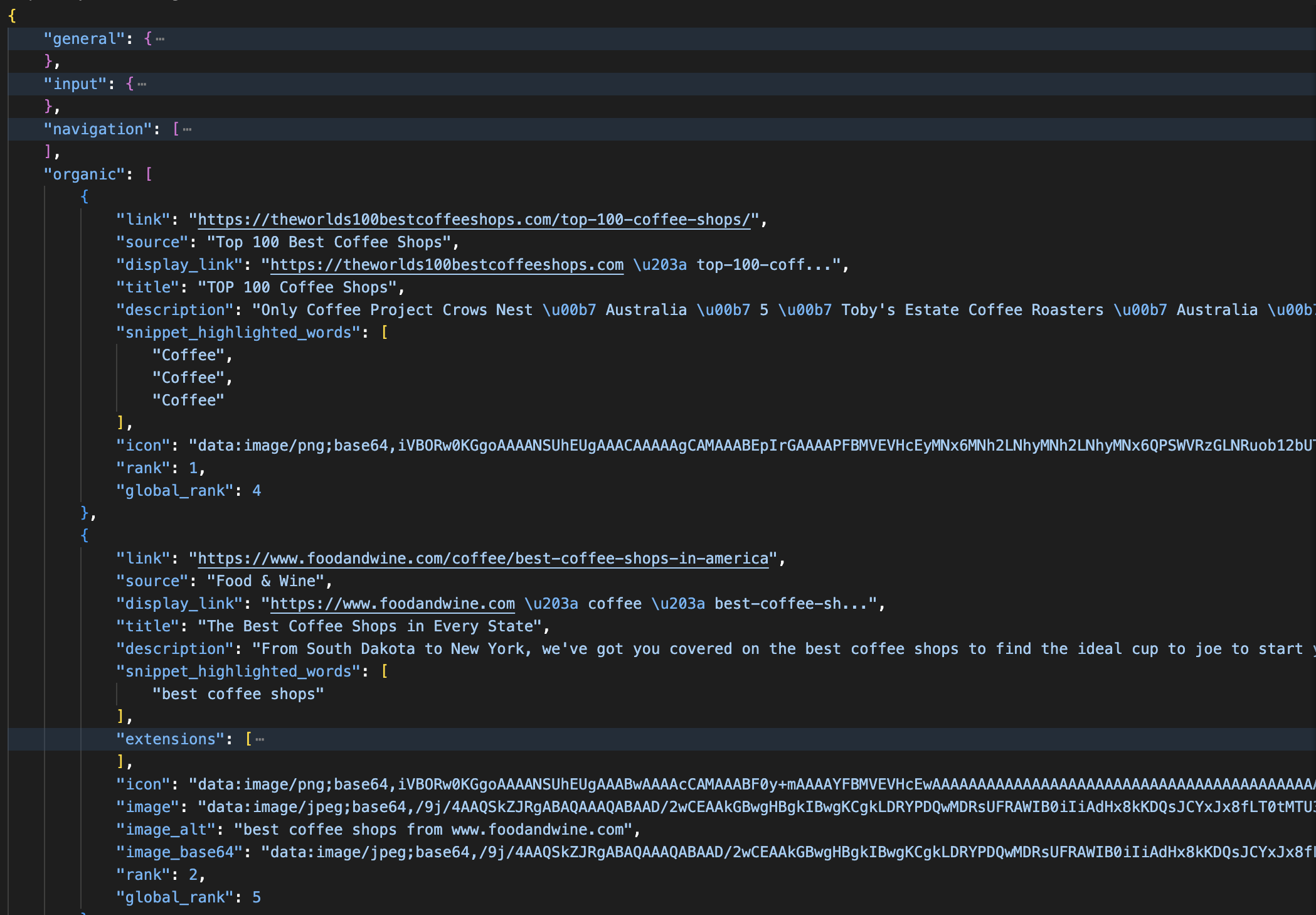
Eine geparste JSON-Antwort aus der SERP-API: Jedes organische Ergebnis enthält die Felder „title”, „link”, „description”, „rank” und „global_rank ”. Die Antwort trennt außerdem Anzeigen, Knowledge Panels und KI-Übersichten in benannte Abschnitte.
Die Direct-API akzeptiert auch ein „data_format”- Body-Feld (separat von „format”): „markdown” für LLM/RAG-Pipelines (Retrieval-Augmented Generation), „screenshot” für eine PNG-Erfassung oder „parsed_light” nur für die 10 besten organischen Ergebnisse. Verwenden Sie brd_json=html in der URL, wenn Sie möchten, dass roher HTML-Code innerhalb der JSON beibehalten wird.
„country”im Body ist nicht dasselbe wie„gl”in der URL.„country”: „us”steuert den Proxy-Ausgangsknoten (den IP-Standort der Anfrage).„gl=us”teilt Google mit, welche Ländernergebnisse angezeigt werden sollen. Für genaue geografisch ausgerichtete Ergebnisse sollten Sie beide festlegen.
Methode 2: Proxy-Routing
Leiten Sie Ihre Anfragen über die Proxy-Infrastruktur von Bright Data. Der Proxy übernimmt das JavaScript-Rendering auf seiner Seite, sodass Ihr Code, obwohl er eine Standard-HTTP-Anfrage stellt, vollständig gerenderte Ergebnisse zurückerhält. Dies funktioniert mit jedem HTTP-Client und ermöglicht es Ihnen, benutzerdefinierte Header, Cookies und Optionen auf Anfrageebene festzulegen, die die Direct API nicht bereitstellt. Mit dem Proxy-Ansatz steuern Sie das Ausgabeformat über URL-Parameter: Fügen Sie brd_json=1 hinzu, um geparstes JSON anstelle von rohem HTML zurückzuerhalten:
import requests
# Verwenden Sie eine Sitzung für Connection Pooling (wiederverwendet TCP-Verbindungen über Anfragen hinweg)
session = requests.Session()
session.proxies = {
"http": "http://brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD>@brd.superproxy.io:33335",
"https": "http://brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD>@brd.superproxy.io:33335"
}
session.verify = False # zum Testen; laden Sie das TLS/SSL-Zertifikat von Bright Data in der Produktion
url = "https://www.google.com/search?q=SERP-API+comparison&gl=us&hl=en&tbs=qdr:m&brd_json=1"
response = session.get(url, timeout=30)
response.raise_for_status()
print(response.json())Die Anmeldedaten finden Sie in Ihrem Dashboard auf der Registerkarte „Zugriffsdaten“ der SERP-API-Zone. Überprüfen Sie die Antwort immer vor der Verarbeitung. Eine Soft-Blockierung von Google kann gültige JSON-Daten mit leeren oder reduzierten Ergebnismengen zurückgeben. Wenn general.results_cnt Millionen von geschätzten Ergebnissen anzeigt, aber das organische Array leer ist oder nur 1–2 Einträge enthält, deutet dies in der Regel auf eine Soft-Blockierung hin und nicht auf eine echte leere SERP.
Das Flag
verify=False(oder-kin curl) überspringt die TLS/SSL-Überprüfung, was für Tests in Ordnung ist. Laden Sie für die Produktion stattdessen das SSL-Zertifikat von Bright Data.
Methode 3: Asynchrone Stapelverarbeitung
Verwenden Sie für Operationen mit hohem Volumen (1.000+ Abfragen) den asynchronen Modus. Async ist sinnvoll, wenn Sie Hunderte von Keyword- + Standortkombinationen mit den Parametern start, gl und hl paginieren (z. B. 500 Keywords in 10 Ländern verfolgen). Ihnen werden nur die Kosten für das Senden der Anfrage berechnet; das Sammeln der Antwort ist kostenlos. Die Rückrufzeiten variieren je nach Volumen und Spitzenauslastung.
Aktivieren Sie zunächst die Option „Asynchrone Anfragen “ in den erweiterten Einstellungen Ihrer Zone. Verwenden Sie dann den Endpunkt /unblocker/req:
import requests
import json
import time
url = "https://api.brightdata.com/unblocker/req"
params = {"customer": "<CUSTOMER_ID>", "Zone": "<ZONE_NAME>"}
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer <API_TOKEN>"
}
payload = {
"url": "https://www.google.com/search?q=Web-Scraping+tools&gl=us&hl=en&brd_json=1",
"country": "us"
}
response = requests.post(url, params=params, headers=headers, json=payload, timeout=30)
response.raise_for_status()
response_id = response.headers.get("x-response-id")
print(f"Queued. Response ID: {response_id}")
# Ergebnisse abfragen (für die Produktion konfigurieren Sie stattdessen eine Webhook-URL in Ihren Zone-Einstellungen)
# Gesamtabfragefenster: 30 Versuche × 10 s = 300 s. Erhöhen Sie range() für große Stapel.
for attempt in range(30):
time.sleep(10) # vor der Überprüfung warten – Ergebnisse sind nie sofort verfügbar
result = requests.get(
"https://api.brightdata.com/unblocker/get_result",
params={"customer": "<CUSTOMER_ID>", "zone": "<ZONE_NAME>", "response_id": response_id},
headers={"Authorization": "Bearer <API_TOKEN>"},
timeout=30
)
if result.status_code == 200:
data = result.json()
if "organic" in data and len(data["organic"]) > 0:
print(json.dumps(data, indent=2))
else:
print("Warnung: Antwort zurückgegeben, enthält jedoch keine organischen Ergebnisse")
break
elif result.status_code == 202:
continue # Ergebnisse noch nicht bereit
else:
print(f"Zeitüberschreitung nach 300 Sekunden Wartezeit auf response_id={response_id}")Anstelle von Polling können Sie eine Webhook-URL konfigurieren (entweder als Standard in Ihren Zoneneinstellungen oder pro Anfrage mit dem Parameter webhook_url ). Bright Data sendet eine Benachrichtigung an Ihren Endpunkt, wenn die Ergebnisse bereitstehen (mit der response_id und dem Status), sodass Sie den Endpunkt /get_result nicht manuell abfragen müssen. Die Antworten werden bis zu 48 Stunden lang gespeichert.
Beachten Sie auch bei einer verwalteten API die Ratenbeschränkungen Ihrer Zone. Die Standardkonfiguration ist für einen hohen Durchsatz ausgelegt, aber wenn Tausende von gleichzeitigen Synchronisierungsanfragen ohne Pacing gesendet werden, kann dies zu HTTP-429-Antworten führen. Der Async-Modus vermeidet dies, da die API die Anfragen intern in eine Warteschlange stellt und das Pacing übernimmt.
Methode 4: LangChain-Integration für KI-Workflows
Wenn Sie KI-Agenten entwickeln, die Live-Suchdaten benötigen, gibt es eine offizielle LangChain-Integration (langchain-brightdata), mit der Sie die Live-Suche als Tool in Agenten-Workflows verwenden können:
pip install langchain-brightdatafrom langchain_brightdata import BrightDataSERP
serp_tool = BrightDataSERP(
bright_data_api_key="<API_TOKEN>",
zone="<ZONE_NAME>", # muss mit dem Zonennamen in Ihrem Bright Data-Dashboard übereinstimmen
search_engine="google",
country="us",
language="en",
results_count=10,
parse_results=True)
# Überschreiben Sie die Konstruktor-Standardeinstellungen für diese spezifische Anfrage:
results = serp_tool.invoke({
"query": "best web scraping tools 2026",
"country": "de",
"language": "de",
"search_type": "shop",
"device_type": "mobile",
})Einige Dinge, die bei dieser Integration zu beachten sind:
results_countwird intern auf Googlesnumabgebildet. Danumnicht mehr funktioniert (siehe Abschnitt „num”), haben Werte über 10 keine Auswirkung.countryundlanguagewerdenglundhlzugeordnet (Ergebnisse aus welchem Land und in welcher Sprache). Im Gegensatz zur Direct API, bei der„country“den Proxy-Ausgangsknoten steuert, übernimmt LangChain das Proxy-Routing automatisch.Zoneist standardmäßig auf„serp“eingestellt. Wenn Ihr Zonenname anders lautet (z. B.„serp_api1“), legen Sie ihn explizit fest, da Sie sonst die Fehlermeldung „zone not found“ erhalten.
Über LangChain hinaus finden Sie Integrationsanleitungen für CrewAI, AWS Bedrock und Google Vertex AI. Für die Erfassung von Nicht-Suchdaten siehe die KI-Webzugriffstools von Bright Data.
Die vollständige Parameterliste finden Sie in der SERP-API-Dokumentation.
Warum eine verwaltete SERP-API verwenden?
Die SERP-API übernimmt das Rendern von JavaScript, die Rotation von Proxies, die CAPTCHA-Lösung und das Geo-Targeting:
Sie könnten dies selbst mit Playwright, Selenium oder der Browser-API von Bright Data erstellen. Die Wartung eines Google-Scrapers bedeutet jedoch, dass Sie sich mit CAPTCHAs, IP-Blocks, Residential-Proxys, JavaScript-Rendering und HTML-Parsing befassen müssen, was bei jeder Aktualisierung des Markups durch Google zu Problemen führt. Einen Vergleich beider Ansätze finden Sie unter Managed vs. API-basiertes Scraping.
Mit der SERP-API senden Sie eine Such-URL und erhalten strukturierte JSON-Daten zurück. Sie funktioniert mit Google, Bing, DuckDuckGo, Yandex und anderen. Die aktuellen Preise finden Sie auf der Preisseite.
Mit dem SERP-API-Playground können Sie grundlegende Suchen ohne Code durchführen, und der Postman-Arbeitsbereich enthält vorgefertigte Anfragen. Hier ist der Playground:
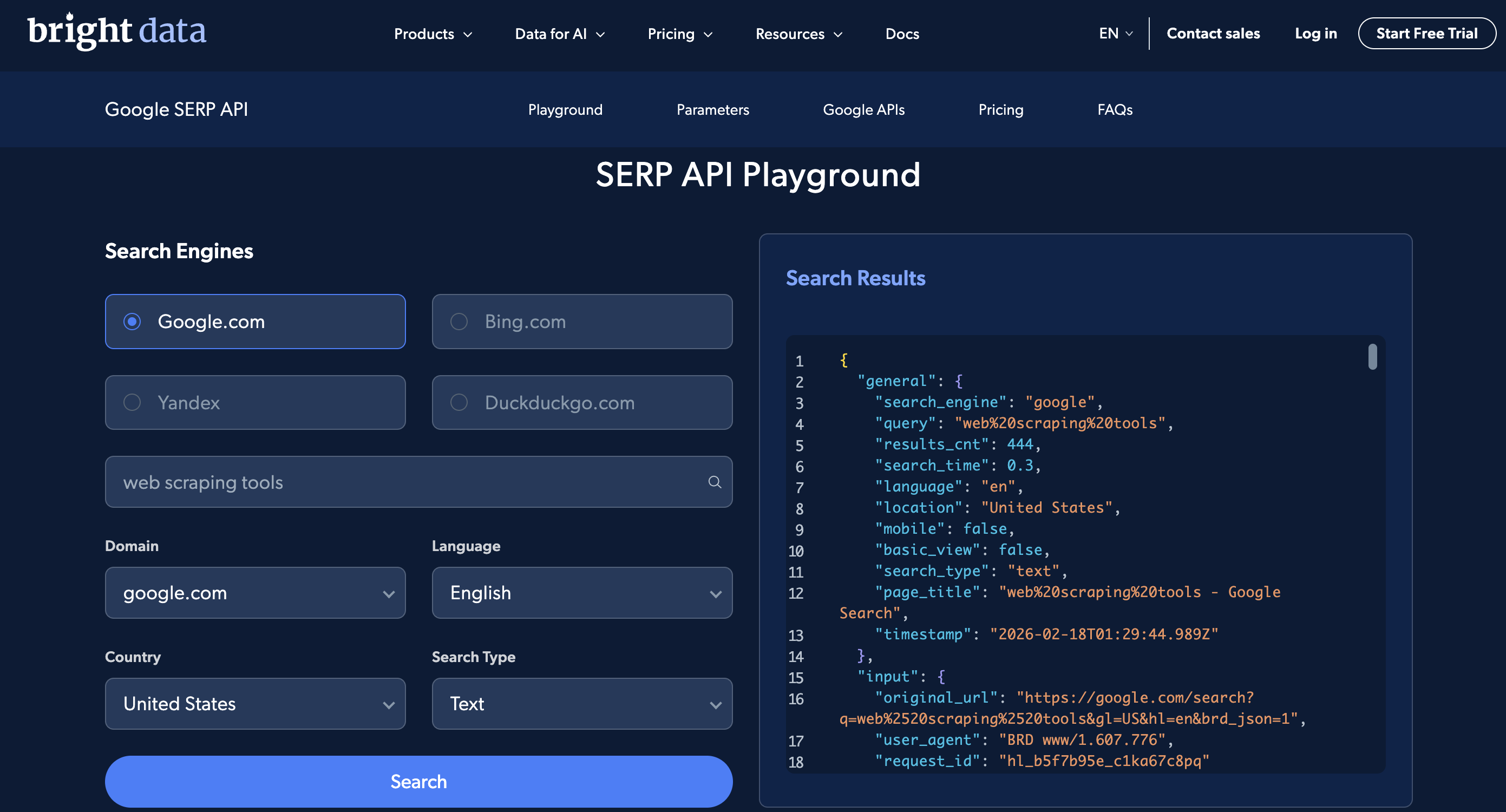
Die Benutzeroberfläche des Playgrounds: Wählen Sie eine Suchmaschine, ein Land und eine Sprache aus, geben Sie eine Suchanfrage ein und sehen Sie sich die geparste JSON-Antwort auf der rechten Seite an.
Erstellen Sie ein Konto, um die oben genannten Beispiele auszuführen (neue Konten erhalten ein kostenloses Guthaben zum Testen).
Anwendungsfälle aus der Praxis
Diese Parameterkombinationen kommen in Produktions-Scraping-Workflows immer wieder vor.
SEO-Rank-Tracking
Verfolgen Sie Keyword-Rankings an verschiedenen Standorten, indem Sie q, gl, hl, pws=0, udm=14 und start kombinieren:
# Überprüfen Sie das Ranking von „Web-Scraping-Tools” in den USA, Großbritannien und Deutschland.
curl --proxy brd.superproxy.io:33335
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k
„https://www.google.com/search?q=Web-Scraping+Tools&gl=us&hl=en&pws=0&udm=14&brd_json=1”
# Wiederholen Sie den Vorgang dann mit gl=gb und gl=de.
# Verwenden Sie start=10, start=20, um Positionen jenseits von Seite 1 zu überprüfen.Eine vollständige Anleitung finden Sie unter „So erstellen Sie einen SEO-Rank-Tracker mit v0 und SERP-API “.
Überwachung von Anzeigen der Konkurrenz
Die Anzeigenplatzierungen Ihrer Wettbewerber ändern sich täglich. Kombinieren Sie Markenbegriffe mit tbs=qdr:d, um aktuelle Änderungen zu finden:
https://www.google.com/search?q=competitor+brand+name&gl=us&hl=en&tbs=qdr:d&brd_json=1Die JSON-Antwort trennt top_ads, bottom_ads und popular_products (Produktanzeigen) von den organischen Ergebnissen.
Preisvergleich und E-Commerce-Informationen
Für einen Preisvergleich über verschiedene Märkte hinweg ändern Sie den gl- Wert, während Sie tbm=shop beibehalten:
https://www.google.com/search?q=sony+wh-1000xm5&tbm=shop&gl=us&brd_json=1
https://www.google.com/search?q=sony+wh-1000xm5&tbm=shop&gl=gb&brd_json=1
https://www.google.com/search?q=sony+wh-1000xm5&tbm=shop&gl=de&brd_json=1Nachrichtenüberwachung und Stimmungsanalyse
https://www.google.com/search?q=openai&tbm=nws&tbs=qdr:h&filter=0&brd_json=1. Verwenden Sie tbm=nws für Nachrichten, tbs=qdr:h für die letzte Stunde und filter=0, um zu verhindern, dass Google ähnliche Artikel zusammenfasst. Führen Sie dies als Cron-Job aus, um stündlich die Berichterstattung zu überwachen.
KI-gestützte Suche und RAG-Anwendungen
Grundlegende LLM-Anwendungen in Live-Suchdaten unter Verwendung der SERP-API als Abrufschicht. Die LangChain-Integration (Methode 4 oben), der MCP-Server und direkte API-Aufrufe funktionieren alle. Ein funktionierendes Beispiel finden Sie unter „So erstellen Sie einen RAG-Chatbot mit der SERP-API “.
Lokale SEO und Überwachung mehrerer Standorte
Lokale Rankings können sich zwischen Städten erheblich unterscheiden. Verwenden Sie uule mit gl und pws=0 zum Vergleich:
# Überprüfen Sie die Rankings für „Klempner in meiner Nähe” in 3 Städten.
curl --proxy brd.superproxy.io:33335
--proxy-user brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>:<PASSWORD> -k
„https://www.google.com/search?q=plumber+near+me&uule=Chicago,Illinois,United+States&gl=us&pws=0&brd_json=1”
# Wiederholen Sie dies mit uule=Miami,Florida,United+States und uule=Seattle,Washington,United+StatesVergleichen Sie die Ergebnisse für Snack-Packs (lokale 3er-Packs) und Bio-Produkte an verschiedenen Standorten, um festzustellen, wo Ihre Einträge verbessert werden müssen.
Akademische Forschung und Marktforschung
https://www.google.com/search?q=site:arxiv.org+large+language+models&lr=lang_en&tbs=cdr:1,cd_min:01/01/2025,cd_max:12/31/2025&brd_json=1Kombinieren Sie site: mit lr- und Datumsbereich -tbs-Filtern, um fokussierte Forschungsdatensätze zu erstellen. Ersetzen Sie arxiv.org durch scholar.google.com, pubmed.ncbi.nlm.nih.gov oder eine beliebige andere Domain.
Fazit
Was aus all dem oben Genannten tatsächlich wichtig ist:
- Verwenden Sie
gl+hl+pws=0+udm=14für eine konsistente, nicht personalisierte Rangverfolgung über alle Märkte hinweg. numist nicht mehr verfügbar. Verwenden Siestartfür die Paginierung oder den Top-100-Endpunkt von Bright Data für Massenresultate.udm=14entfernt KI-Übersichten und liefert klassische organische Ergebnisse.udmerweiterttbmum zusätzliche Moditbsübernimmt die Zeitfilterung, Datumsortierung (sbd:1) und die wortgetreue Suche (li:1).- Sonderzeichen müssen URL-kodiert werden. Das Semikolon in
ibp=htl%3Bjobsist neben nicht-lateinischen Abfragen der häufigste Kodierungsfehler
Google ändert diese Parameter ständig. Sie haben num ohne Vorwarnung entfernt und könnten dasselbe mit start tun oder tbm zugunsten von udm abschaffen. Wenn Sie in nennenswertem Umfang scrapen, übernimmt die SERP-API von Bright Data das Rendern, Rotieren und Parsing. Probieren Sie es mit den obigen Beispielen aus.
Nächste Schritte
Empfohlene Lektüre, basierend auf Ihrem Anwendungsfall:
Wenn Sie jetzt mit dem Scraping von Google beginnen möchten:
- Wie man Google-Suchergebnisse mit Python scrapt: vollständiges Python-Tutorial mit funktionierendem Code
- Wie man Google KI scrapt – Übersicht: Extrahieren von KI-generierten Zusammenfassungen
- Wie man den Google AI-Modus scrapt: Scrapen der dialogorientierten KI-Suche von Google
Wenn Sie KI-Anwendungen entwickeln:
- Erstellen Sie einen RAG-Chatbot mit SERP-API: LLM-Antworten in Live-Suchdaten verankern
- Erstellen Sie einen SEO-Rank-Tracker mit v0 und SERP-API: Schritt-für-Schritt-Anleitung
- GEO & SEO AI Agent: Optimieren Sie Inhalte für KI-gestützte Suchmaschinen
- CrewAI mit SERP-API: Multi-Agent-KI-Workflows
Wenn Sie SERP-API-Anbieter evaluieren:
- Die besten SERP-APIs und Web-Such-APIs von 2026: Vergleich der führenden Anbieter
- Managed vs. API-basiertes Scraping: Vergleich von Managed Services und API-basierten Ansätzen
Andere Google-Datenquellen:
- So scrapen Sie Google Trends-Daten
- Die besten Hotel-Datenanbieter: Vergleich von Hotel-Datenerfassungsdiensten
- Die besten Flugdatenanbieter: Vergleich von Flugdatenerfassungsdiensten
Externe Referenzen:
- Google-Suchen verfeinern: Offizieller Leitfaden von Google zum Verfeinern von Suchanfragen
Referenzen
- Bright Data Google Search API (GitHub)
- Bright Data SERP-API (GitHub)
- Bright Data SERP-API-Dokumentation
Häufig gestellte Fragen
Was sind Google-Suchparameter?
Google-Suchparameter sind Schlüssel-Wert-Paare, die an die URL https://www.google.com/search? angehängt werden und steuern, wie Suchergebnisse generiert und angezeigt werden. Beispielsweise legt q=pizza die Suchanfrage fest, gl=us zielt auf die Vereinigten Staaten ab und hl=en legt die Sprache der Benutzeroberfläche auf Englisch fest. Sie werden durch & getrennt und folgen auf das ? in der URL.
Was ist der Unterschied zwischen gl und hl in der Google-Suche?
Der Parameter „gl“ steuert die Geolokalisierung (das Land, aus dem die Suche zu stammen scheint) und beeinflusst, welche Ergebnisse angezeigt werden. Der Parameter „hl“ steuert die Hostsprache (die Sprache der Google-Benutzeroberfläche). Beispielsweise liefert „gl=de&hl=en“ Ergebnisse, die für Deutschland relevant sind, wobei die Benutzeroberfläche jedoch in Englisch angezeigt wird.
Ist der Google-Parameter „num” veraltet?
Er ist nicht nur veraltet, sondern funktioniert überhaupt nicht mehr. Google hat ihn zwischen dem 12. und 14. September 2025 stillschweigend deaktiviert. Die Übergabe von num=100 hat keine Wirkung, und Google gibt unabhängig davon immer 10 Ergebnisse zurück. Verwenden Sie start für die Paginierung oder den Top-100-Endpunkt der Web Scraper API von Bright Data, um die Positionen 1–100 in einer einzigen Anfrage zu erhalten.
Was ist der Google-Parameter „udm“?
udm steht wahrscheinlich für User Display Mode (basierend auf Reverse Engineering der Community; Google hat die Abkürzung nicht bestätigt). Meistens werden Sie udm=14 verwenden, wodurch KI-Übersichten entfernt und klassische organische Ergebnisse zurückgegeben werden. Weitere Werte sind udm=2 (Bilder), udm=39 (kurze Videos) und udm=50 (KI-Modus). udm erweitert tbm um zusätzliche Modi, wobei beide weiterhin funktionieren. Alle Werte sind im Abschnitt udm aufgeführt.
Was ist der Unterschied zwischen tbm und udm?
tbm ist der ältere Parameter, udm ist die neuere Erweiterung. Sie überschneiden sich bei Bildern, Nachrichten und Shopping (tbm=isch ≈ udm=2), aber udm enthält auch Funktionen, die tbm nicht unterstützt: KI-Modus (udm=50), Foren (udm=18), kurze Videos (udm=39). Beide funktionieren heute. Erstellen Sie neuen Code für udm und behalten Sie tbm als Fallback.
Wie kann ich Google-Ergebnisse paginieren, jetzt wo num nicht mehr existiert?
Verwenden Sie den Startparameter. start=0 (oder weggelassen) liefert Ihnen die Ergebnisse 1–10, start=10 liefert die Ergebnisse 11–20 und so weiter. Jede Seite liefert 10 Ergebnisse. Für die Positionen 1–100 in einer einzigen Anfrage verwenden Sie den Top-100-Endpunkt von Bright Data mit den Parametern start_page und end_page.
Wie filtere ich Google-Ergebnisse nach Datum?
Verwenden Sie den Parameter „tbs “. tbs=qdr:h = letzte Stunde, tbs=qdr:d = letzter Tag, tbs=qdr:w = letzte Woche, tbs=qdr:m = letzter Monat, tbs=qdr:y = letztes Jahr. Für einen benutzerdefinierten Datumsbereich: tbs=cdr:1,cd_min:MM/DD/YYYY,cd_max:MM/DD/YYYY. Fügen Sie tbs=sbd:1 hinzu, um nach Datum statt nach Relevanz zu sortieren.
Wie kann ich Google-Suchergebnisse scrapen, ohne blockiert zu werden?
Die Wartung eines Google-Scrapers in großem Maßstab erfordert seit Januar 2025 die Aktualisierung von HTML-Parsern, wann immer Google seine Markups ändert, die CAPTCHA-Lösung, das Rotieren von IPs und das Rendern von JavaScript für jede Anfrage. Eine verwaltete SERP-API übernimmt diese Infrastruktur. Sie senden eine URL, erhalten strukturiertes JSON zurück und müssen den Parser nicht warten.





