

In diesem Lernprogramm lernen Sie:
- Wie ein Ansatz auf der Grundlage von Query Fan-out und Google AI Overview-Vergleich zur Verbesserung von GEO und SEO genutzt werden kann.
- Wie man diesen Workflow auf hohem Niveau mit sechs KI-Agenten aufbaut.
- Wie man diesen KI-Content-Optimierungsworkflow mit CrewAI, integriert mit Gemini und Bright Data, umsetzt.
- Einige Ideen und Ratschläge, um den Arbeitsablauf noch weiter zu verbessern.
Lasst uns eintauchen!
TL;DR
Möchten Sie direkt zu den einsatzbereiten Projektdateien springen? Sehen Sie sich das Projekt auf GitHub an.
Erläuterung von Query Fan-Out und AI-Übersichtsvergleich für besseres GEO und SEO
Wir alle wissen, dass SEO(Search Engine Optimization) die Kunst ist, die Sichtbarkeit einer Website in den organischen Suchergebnissen zu verbessern. Aber die Welt bewegt sich jetzt in Richtung GEO(Generative Engine Optimization).
Wenn Sie mit GEO nicht vertraut sind, handelt es sich um eine digitale Marketingstrategie, die sich darauf konzentriert, Inhalte in KI-gesteuerten Suchmaschinen wie Google AI Overviews, ChatGPT und anderen besser sichtbar zu machen.
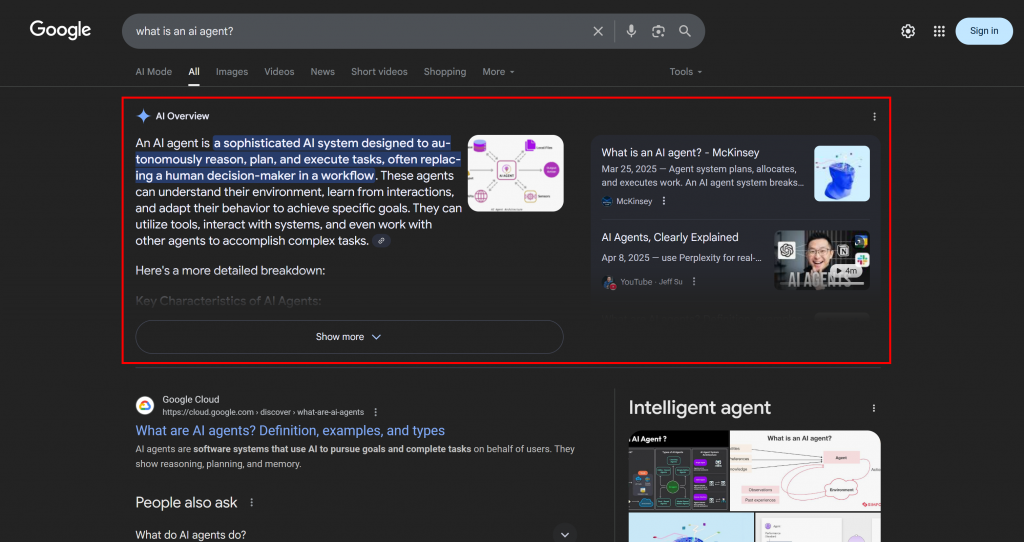
Da LLMs im Wesentlichen Black Boxes sind, gibt es keine einfache Möglichkeit, eine Webseite für GEO zu “optimieren” (ähnlich wie es SEO war, bevor es Suchtools für das Schlüsselwortvolumen gab).
Was Sie tun können, ist einen empirischen Ansatz zu verfolgen: Schauen Sie sich die KI-generierten Zusammenfassungen und Suchanfragen für Ihre Zielkeywords an. Wenn bei einem bestimmten Suchbegriff bestimmte Themen immer wieder in den KI-Ergebnissen auftauchen, sollten Sie Ihre Seiteninhalte auf diese Themen hin optimieren.
Im Zusammenhang mit der KI-gestützten Suche von Google ist ein Query Fan-Out eine Technik, die eine einzelne Nutzeranfrage in ein Netzwerk verwandelt, das aus verwandten Unteranfragen besteht. Anstatt einfach die ursprüngliche Anfrage mit der besten Antwort abzugleichen, geht der Google KI-Modus noch weiter, indem er mehrere verwandte Fragen auf einmal generiert und durchsucht.
Wie Sie im unten stehenden Beispiel sehen können, liefert der Google AI-Modus in der Regel etwa 10 verwandte Links mit kurzen Zusammenfassungen, die Ihnen helfen, das Thema zu vertiefen:
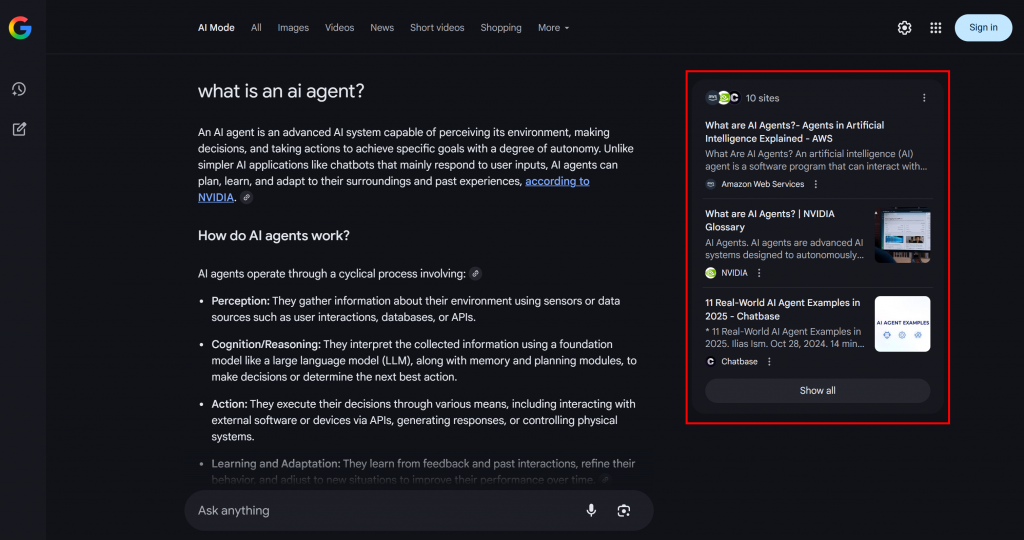
Genau das ist ein Google-Abfrage-Fan-Out, das einfacher definiert werden kann als eine Sammlung verwandter Unterabfragen, die aus einer einzigen KI-Suche generiert werden.
Wenn bestimmte Themen in den Suchergebnissen und KI-Übersichten immer wieder auftauchen, ist es sinnvoll, eine Inhaltsseite zu diesen Themen zu erstellen. Als positiver Nebeneffekt kann dieser Ansatz auch die traditionelle Suchmaschinenoptimierung verbessern, da Suchmaschinen wie Google wahrscheinlich Seiten in den SERPs aufwerten, die in ihren KI-gestützten Suchergebnissen bereits gut abschneiden.
Nachdem Sie nun die Grundlagen verstanden haben, sollten Sie sich mit den technischen Einzelheiten dieses GEO-Konzepts befassen!
Wie man ein Multi-Agenten-GEO-Optimierungssystem aufbaut
Wie Sie sich vorstellen können, ist die Implementierung eines KI-Agenten zur Unterstützung Ihres GEO-Content-Optimierungs-Workflows nicht einfach. Ein effektiver Ansatz ist der Einsatz eines Multi-Agenten-Systems, das auf sechs spezialisierten Agenten basiert:
- Titel Scraper: Extrahiert die Hauptüberschrift oder den Titel einer Webseite anhand ihrer URL.
- Google Query Fan-Out Researcher: Verwendet den extrahierten Titel, um das in Gemini verfügbare Google-Suchtool aufzurufen und einen Query-Fan-Out zu erstellen.
- Google Main Query Extractor: Analysiert das Query-Fan-out, um die primäre Google-ähnliche Suchanfrage zu identifizieren und zu extrahieren.
- Google AI Overview Retriever: Verwendet die Hauptabfrage, um eine Google-SERP-Suche durchzuführen und ruft den AI-Übersichtsabschnitt daraus ab.
- Abfrage-Fan-Out-Zusammenfassung: Komprimiert den Inhalt des Abfrage-Fan-Outs (der in der Regel recht lang ist) in eine optimierte Markdown-Zusammenfassung, die die wichtigsten Themen hervorhebt.
- KI-Inhaltsoptimierer: Vergleicht die Fan-Out-Zusammenfassung der Suchanfrage mit der Google AI-Übersicht, um Muster und wiederkehrende Themen zu erkennen. Es wird ein Markdown-Ausgabedokument erstellt, das verwertbare Erkenntnisse für die Optimierung von GEO-Inhalten enthält.
Einige der oben beschriebenen Agenten sind recht allgemein gehalten und können mit den meisten LLMs implementiert werden (z. B. Google Main Query Extractor, Query Fan-Out Summarizer und AI Content Optimizer). Andere Agenten erfordern jedoch speziellere Fähigkeiten und Zugang zu bestimmten Modellen oder Tools.
So benötigt der Google Main Query Extractor beispielsweise Zugriff auf das google_search-Tool, das nur in Gemini-Modellen verfügbar ist. In ähnlicher Weise muss der Title Scraper Agent auf den Inhalt der Webseite zugreifen, um den Titel zu extrahieren. Diese Aufgabe kann eine Herausforderung sein, da viele Websites Anti-AI-Maßnahmen einsetzen. Um Probleme zu vermeiden, können Sie Title Scraper mit Web Unlocker integrieren. Diese Bright Data Scraping-API ruft Inhalte im Roh-HTML- oder KI-optimierten Markdown-Format ab und umgeht alle Sperren für Sie.
Auf die gleiche Weise benötigt der Google AI Overview Retriever ein Tool wie Bright Data SERP API, um die Suchanfrage auszuführen und den AI Overview in Echtzeit zu scrapen.
Mit anderen Worten: Dank Gemini und der KI-Infrastruktur von Bright Data können Sie diesen GEO/SEO-Anwendungsfall umsetzen. Was Sie jetzt brauchen, ist ein System zur Erstellung von KI-Agenten, um diese Agenten zu orchestrieren, wie in diesem zusammenfassenden Diagramm dargestellt:
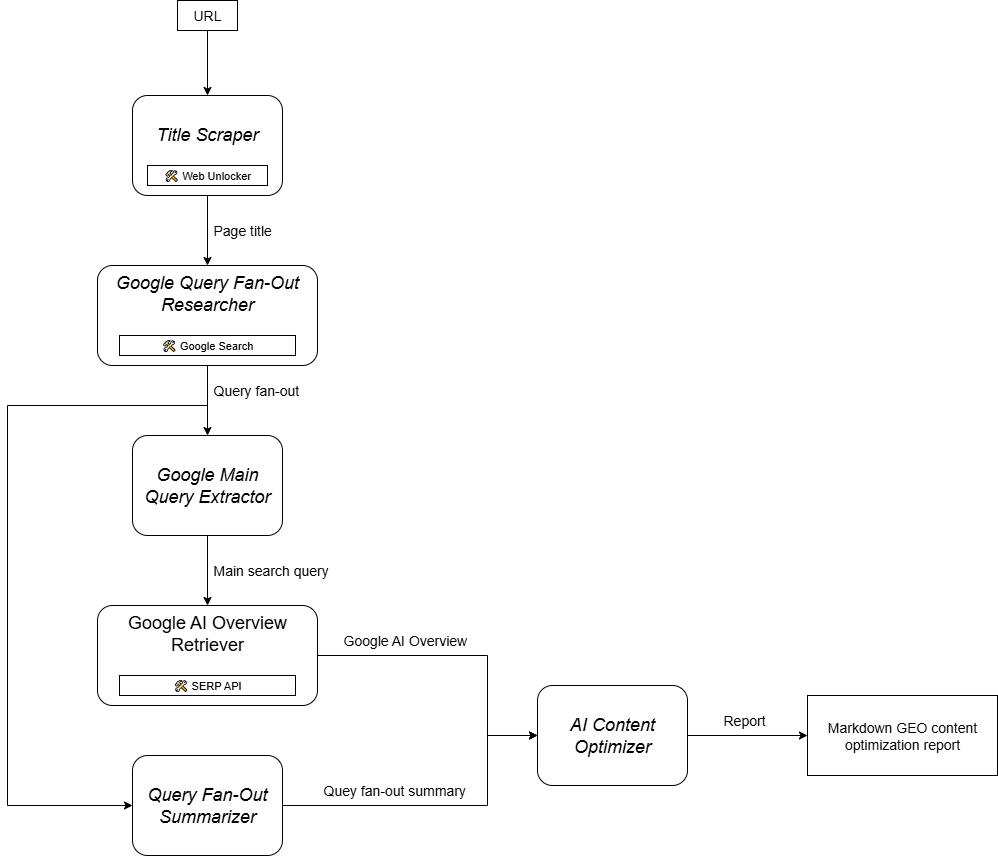
Da CrewAI speziell für die Orchestrierung von Multi-Agenten-Systemen entwickelt wurde, ist es der ideale Rahmen für den Aufbau und die Verwaltung dieses Workflows.
Implementierung eines Multi-Agenten-Systems zur Optimierung von GEO-Inhalten in CrewAI unter Verwendung von Gemini und Bright Data
In den folgenden Schritten erfahren Sie, wie Sie ein Multi-Agenten-System aufbauen, das einen wiederholbaren Workflow für die Optimierung von Webseiten für KI-gestützte Suchmaschinen bietet. Durch die systematische Analyse von Suchanfragen und KI-Übersichten hilft Ihnen dieser Ansatz, Themen mit hoher Priorität zu erkennen und Inhalte zu strukturieren, um höhere KI-gesteuerte Rankings zu erzielen.
Der nachstehende Code wurde in Python unter Verwendung von CrewAI geschrieben, wobei Bright Data und Gemini integriert wurden, um die Agenten mit den erforderlichen Tools und Fähigkeiten auszustatten.
Voraussetzungen
Um diesem Tutorial folgen zu können, benötigen Sie folgende Informationen:
- Python 3.10+ lokal installiert.
- Ein Gemini-API-Schlüssel (es ist kein Guthaben erforderlich).
- Ein Bright Data-Konto.
Machen Sie sich keine Sorgen, wenn Sie noch kein Bright Data-Konto haben. Sie werden durch die Einrichtung eines solchen Kontos geführt.
Außerdem ist es sehr wichtig, ein gewisses Verständnis dafür zu haben, wie CrewAI funktioniert. Bevor Sie loslegen, empfehlen wir Ihnen, die offiziellen Dokumente zu lesen.
Schritt #1: Einrichten Ihrer CrewAI-Anwendung
CrewAI benötigt uv für die Installation. Sie können es mit dem folgenden Befehl global installieren:
pip install uvAlternativ können Sie auch die offizielle Installationsanleitung für Ihr Betriebssystem verwenden.
Als nächstes installieren Sie CrewAI global auf Ihrem System:
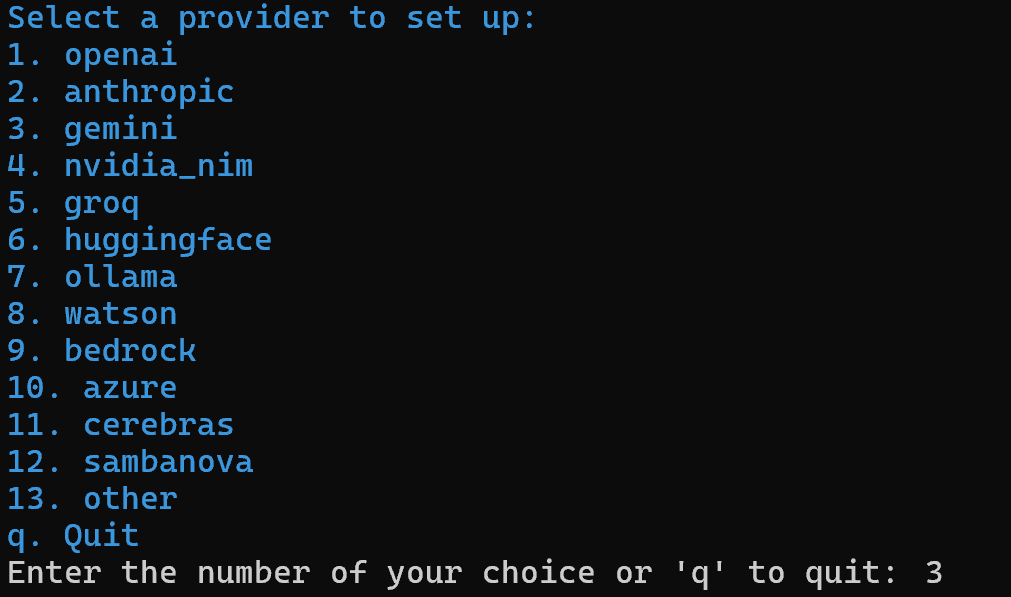
uv tool install crewai Erstellen Sie nun ein neues CrewAI-Projekt namens ai_content_optimization_agent:
crewai create crew ai_content_optimization_agentSie werden aufgefordert, einen KI-Anbieter auszuwählen. Da der aktuelle Workflow mit Gemini arbeitet, wählen Sie Option 3:
Wählen Sie dann ein Gemini-Modell aus:
Sie können eines der verfügbaren Modelle wählen, da Sie es später in diesem Artikel ersetzen werden. Also, es ist nicht wichtig.
Fahren Sie fort, indem Sie Ihren Gemini-API-Schlüssel einfügen:

Nach diesem Schritt sieht Ihr Projekt in der Ordnerstruktur ai_content_optimization_agent/ wie folgt aus:
ai_content_optimization_agent/
├── .gitignore
├── knowledge/
├── pyproject.toml
├── README.md
├── .env
└── src/
└── ai_content_optimization_agent/
├── __init__.py
├── main.py
├── crew.py
├── tools/
│ ├── custom_tool.py
│ └── __init__.py
└── config/
├── agents.yaml
└── tasks.yamlLaden Sie das Projekt in Ihrer bevorzugten Python-IDE und machen Sie sich mit ihm vertraut. Untersuchen Sie die aktuellen Dateien und beachten Sie, dass .env bereits das ausgewählte Gemini-Modell und Ihren Gemini-API-Schlüssel enthält:
MODEL=<SELECTED_GEMINI_MODEL>
GEMINI_API_KEY=<YOUR_GEMINI_API_KEY>Wenn Sie mit den Dateien in CrewAI nicht vertraut sind oder Probleme haben, lesen Sie bitte die offizielle Installationsanleitung.
Navigieren Sie in Ihrem Terminal zu Ihrem Projektordner:
cd ai_content_optimization_agentDann initialisieren Sie darin eine virtuelle Python-Umgebung:
python -m venv .venv Hinweis: Die virtuelle Umgebung muss den Namen .venv haben. Andernfalls schlägt der Befehl crewai run zum Starten des CrewAI Workflows fehl.
Unter Linux und macOS aktivieren Sie die virtuelle Umgebung mit:
source .venv/bin/activateAlternativ dazu können Sie unter Windows Folgendes ausführen:
.venvScriptsactivateErledigt! Sie haben nun ein leeres CrewAI-Projekt angelegt.
Schritt Nr. 2: Integration von Gemini
Wie bereits erwähnt, fügt CrewAI standardmäßig das ausgewählte Gemini-Modell in die .env-Datei ein. Um das neueste Modell zu konfigurieren, überschreiben Sie die Umgebungsvariable MODEL in der .env-Datei wie folgt:
MODEL=gemini/gemini-2.5-flashAuf diese Weise können sich Ihre KI-Agenten, die mit CrewAI orchestriert werden, mit Gemini-2.5-Flash verbinden. Zum Zeitpunkt der Erstellung dieses Artikels ist dies das neueste Gemini-Flash-Modell. Außerdem hat es sehr großzügige Ratenlimits, wenn es über die API abgefragt wird (wie bei dieser CrewAI-Integration).
In crew.py laden Sie den MODEL-Namen aus der Umgebung mit:
MODEL = os.getenv("MODEL")Diese Variable wird später verwendet, um die LLM in den Agenten festzulegen.
Vergessen Sie nicht, os aus der Python-Standardbibliothek zu importieren:
import osSuper! Das Gemini-Setup ist vorbei.
Schritt #3: Installieren und Konfigurieren der CrewAI Bright Data Tools
Die Extraktion des Titels aus einer Webseite mittels KI ist nicht einfach. Die meisten LLMs können nicht direkt auf Webseiteninhalte zugreifen. Und selbst wenn sie über integrierte Tools verfügen, die dies ermöglichen, scheitern diese oft an fortschrittlichen Anti-Scraping-Maßnahmen wie Browser-Fingerprinting und CAPTCHAs. Die gleichen Herausforderungen gelten für das Live-SERP-Scraping, da Google das automatisierte Scraping aktiv verhindert.
An dieser Stelle wird Bright Data grundlegend. Glücklicherweise wird dies offiziell durch die Bright-Data-Tools von CrewAI unterstützt.
Um loszulegen, melden Sie sich für ein Bright Data-Konto an (oder melden Sie sich an, wenn Sie bereits eines haben). Rufen Sie dann das Dashboard Ihres Profils auf und folgen Sie den offiziellen Anweisungen, um eine Web Unlocker-Zone einzurichten:

Stellen Sie sicher, dass die Zone auf “Aktiv” eingestellt ist:
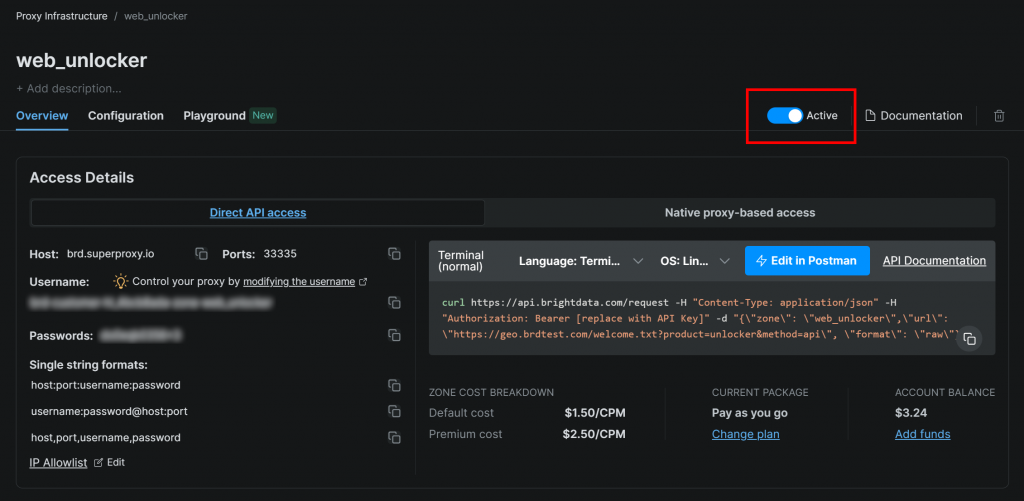
In diesem Fall lautet der Name der Web Unlocker-Zone "web_unlocker", aber Sie können sie benennen, wie Sie wollen. Merken Sie sich diesen Namen, denn Sie werden ihn bald brauchen.
Sobald Sie die Einrichtung abgeschlossen haben, folgen Sie der offiziellen Anleitung, um Ihren Bright Data-API-Schlüssel zu generieren. Bewahren Sie ihn sicher auf, da Sie ihn in Kürze benötigen werden.
Installieren Sie nun in Ihrer aktivierten virtuellen Umgebung die Anforderungen des CrewAI Bright Data Tools:
pip install crewai[tools] aiohttp requestsDamit die Integration funktioniert, fügen Sie Ihre Bright Data-Anmeldeinformationen über die folgenden zwei Umgebungsvariablen zur .env-Datei hinzu:
BRIGHT_DATA_API_KEY="<BRIGHT_DATA_API_KEY>"
BRIGHT_DATA_ZONE="<YOUR_BRIGHT_DATA_ZONE>"Ersetzen Sie die und durch Ihren tatsächlichen Bright Data-API-Schlüssel bzw. den Namen der Web Unlocker-Zone.
Als nächstes importieren Sie in crew.py die Bright Data-Tools:
from crewai_tools import BrightDataWebUnlockerTool, BrightDataSearchToolInitialisieren Sie sie wie unten beschrieben:
web_unlocker_tool = BrightDataWebUnlockerTool()
serp_search_tool = BrightDataSearchTool()Sie können Ihren Agenten jetzt Webfreigabe- und SERP-Abruffunktionen zur Verfügung stellen, indem Sie ihnen einfach diese Tools übergeben. Fantastisch!
Schritt #4: Erstellen Sie den Titel Scraper Agent
Sie haben nun alles, um Ihren ersten Agenten zu erstellen. Beginnen Sie mit dem Agenten Title Scraper, der für die Extraktion des Titels aus einer Webseite zuständig ist.
Um den Seitentitel zu erhalten, gibt es zwei Hauptmöglichkeiten:
- Abrufen des Textinhalts aus dem HTML-Element
<h1>. - Wenn das
<h1>fehlt, bitten Sie die KI, den Seitentitel aus dem restlichen Inhalt der Seite abzuleiten.
Vergessen Sie nicht, dass dies die Integration des Web Unlocker Tools erfordert. Definieren Sie in crew.py den CrewAI-Agenten und die Aufgabe wie folgt:
@agent
def title_scraper_agent(self) -> Agent:
return Agent(
config=self.agents_config["title_scraper_agent"],
tools=[web_unlocker_tool], # <--- Web Unlocker tool integration
verbose=True,
llm=MODEL,
)
@task
def scrape_title_task(self) -> Task:
return Task(
config=self.tasks_config["scrape_title_task"],
agent=self.title_scraper_agent(),
max_retries=3,
)Da bei dieser Aufgabe ein Tool eines Drittanbieters aufgerufen wird, ist es sinnvoll, die Wiederholungslogik (bis zu 3 Mal) über die Option max_retries zu aktivieren. Dadurch wird verhindert, dass der gesamte Arbeitsablauf aufgrund von vorübergehenden Netzwerkproblemen oder Toolfehlern fehlschlägt. Die gleiche Logik sollte auf alle anderen Aufgaben angewandt werden, die auf Dienste von Drittanbietern (über Tools) angewiesen sind oder komplexe KI-Operationen beinhalten, die aufgrund von LLM-Verarbeitungsfehlern fehlschlagen können.
Als Nächstes definieren Sie in Ihrer Konfigurationsdatei agents.yaml den Agenten Title Scraper wie folgt:
title_scraper_agent:
role: "Title Scraper"
goal: "Extract the main H1 heading or title from a given web page URL."
backstory: "You are an expert scraper with a specialization in identifying and extracting the main heading (H1) or title of a webpage."Beschreiben Sie dann in tasks.yaml seine Hauptaufgabe wie folgt:
scrape_title_task:
description: |
1. Visit the URL: '{url}'.
2. Scrape the page's full content using the Bright Data Web Unlocker tool (using the Markdown data format).
3. Locate and extract only the text within the `<h1>` tag. If no `<h1>` tag is present, infer a title from the page content.
4. Output the extracted text as a plain string.
expected_output: "The plain string containing the extracted text from the specified URL."Beachten Sie, wie diese Aufgabe dank der {url}-Syntax die URL aus einer CrewAI-Eingabe liest. Sie werden in einem der nächsten Schritte sehen, wie Sie dieses Eingabeargument ausfüllen.
Großartig! Der Agent Title Scraper ist fertig. Sie werden nun eine ähnliche Logik anwenden, um alle übrigen Agenten zu definieren.
Schritt #5: Implementieren Sie den Google Query Fan-Out Researcher Agent
CrewAI bietet keine eingebaute Möglichkeit, auf das in den Gemini-Modellen verfügbare Google-Suchwerkzeug zuzugreifen. Stattdessen müssen Sie eine benutzerdefinierte Gemini-LLM-Integration definieren , wie im offiziellen Gemini CrewAI-Integrations-Repository gezeigt.
Im Wesentlichen müssen Sie eine Klasse erstellen, die die CrewAI LLM-Klasse erweitert. Diese wird sich mit Gemini verbinden und das google_search-Tool aktivieren. Sie können diese Klasse in einer Datei namens gemini_google_search_llm.py in einem benutzerdefinierten llms/-Unterordner ablegen (oder Sie können die Klasse direkt oben in crew.py einfügen).
Definieren Sie Ihre benutzerdefinierte Gemini LLM Integrationsklasse wie folgt:
# src/ai_content_optimization_agent/llms/gemini_google_search_llm.py
from crewai import LLM
import os
from typing import Any, Optional
# Define a custom Gemini LLM integration with Google Search grounding
class GeminiWithGoogleSearch(LLM):
"""
A Gemini-specific LLM that has the "google_search" tool enabled.
"""
def __init__(self, model: str | None = None, **kwargs):
if not model:
# Use a default Gemini model.
model = os.getenv("MODEL")
super().__init__(model, **kwargs)
def call(
self,
messages: str | list[dict[str, str]],
tools: list[dict] | None = None,
callbacks: list[Any] | None = None,
available_functions: dict[str, Any] | None = None,
from_task: Optional[Any] = None,
from_agent: Optional[Any] = None,
) -> str | Any:
if not tools:
tools = []
# LiteLLM will throw a warning if it sees `google_search`,
# so you must use camel case here
tools.insert(0, {"googleSearch": {}})
return super().call(
messages=messages,
tools=tools,
callbacks=callbacks,
available_functions=available_functions,
from_task=from_task,
from_agent=from_agent,
)Dies ermöglicht Ihnen den Zugriff auf die Google-Suche in Ihrem konfigurierten Gemini-Modell.
Hinweis: Das Google-Suchtool enthält ein gewisses Kontingent auf der kostenlosen Ebene der API, so dass Sie es in Ihrer App verwenden können, ohne einen Premium-Plan zu benötigen.
Dann importieren Sie in crew.py die Klasse GeminiWithGoogleSearch:
from .llms.gemini_google_search_llm import GeminiWithGoogleSearchVerwenden Sie es, um den Query Fan-Out Researcher-Agent wie folgt zu spezifizieren:
@agent
def query_fanout_researcher_agent(self) -> Agent:
return Agent(
config=self.agents_config["query_fanout_researcher_agent"],
verbose=True,
llm=GeminiWithGoogleSearch(MODEL), # <--- Gemini integration with the Google Search tool
)
@task
def google_search_task(self) -> Task:
return Task(
config=self.tasks_config["google_search_task"],
context=[self.scrape_title_task()],
agent=self.query_fanout_researcher_agent(),
max_retries=3,
markdown=True,
output_file="output/query_fanout.md",
)Beachten Sie, dass die in der Agentenklasse verwendete LLM eine Instanz der benutzerdefinierten Klasse GeminiWithGoogleSearch ist. Da die Abfrage-Fanout-Generierungsaufgabe eine wertvolle Ausgabe für die Fehlersuche und weitere Analysen erzeugt, sollten Sie sie in eine benutzerdefinierte Ausgabedatei exportieren. In diesem Fall wird die erzeugte Ausgabe in der Datei output/query_fanout.md gespeichert.
Beachten Sie auch, dass der Hauptaufgabenkontext des Agenten genau die Ausgabe der Hauptaufgabe des vorherigen Agenten im Workflow ist. Auf diese Weise hat der aktuelle Agent Zugriff auf die vom Title Scraper-Agenten erzeugte Ausgabe. Insbesondere wird er diese als Eingabe verwenden, wenn er den Fan-Out-Abruf über das Google-Suchwerkzeug durchführt.
Als nächstes fügen Sie in agents.yaml hinzu:
query_fanout_researcher_agent:
role: "Google Query Fan-Out Researcher"
goal: "Given a title, perform a comprehensive web search to get the query fan-out."
backstory: "You are an AI research assistant, powered by the Google Search tool from Gemini."Und in tasks.yaml:
google_search_task:
description: |
1. Use the title from the previous task as your search query.
2. Perform a web search using the Google Search tool.
3. Return the results from the Google Search tool.
expected_output: "The output from the Google Search tool in Markdown format."Wenn Sie sich fragen, wie ein Abfrage-Fan-Out aussieht, finden Sie unten einen kurzen Ausschnitt aus einer realen Ausgabe des google_search-Tools:
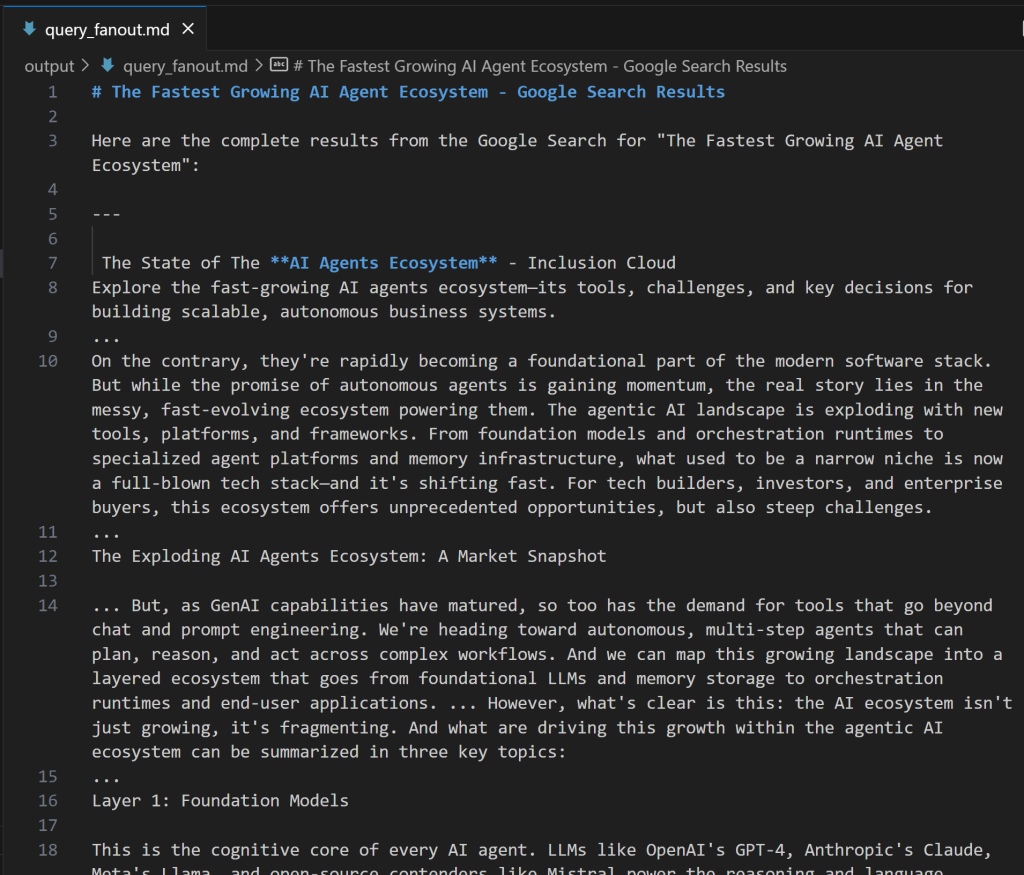
Perfekt! Der Google Query Fan-Out Researcher Agent ist bereit.
Schritt #6: Definieren Sie die verbleibenden Agenten
Fahren Sie wie zuvor mit der Definition der übrigen Agenten in crew.py fort:
@agent
def main_query_extractor_agent(self) -> Agent:
return Agent(
config=self.agents_config["main_query_extractor_agent"],
verbose=True,
llm=MODEL,
)
@task
def main_query_extraction_task(self) -> Task:
return Task(
config=self.tasks_config["main_query_extraction_task"],
context=[self.google_search_task()],
agent=self.main_query_extractor_agent(),
)
@agent
def ai_overview_retriever_agent(self) -> Agent:
return Agent(
config=self.agents_config["ai_overview_retriever_agent"],
tools=[serp_search_tool], # <--- SERP API tool integration
verbose=True,
llm=MODEL,
)
@task
def ai_overview_extraction_task(self) -> Task:
return Task(
config=self.tasks_config["ai_overview_extraction_task"],
context=[self.main_query_extraction_task()],
agent=self.ai_overview_retriever_agent(),
max_retries=3,
markdown=True,
output_file="output/ai_overview.md",
)
@agent
def query_fanout_summarizer_agent(self) -> Agent:
return Agent(
config=self.agents_config["query_fanout_summarizer_agent"],
verbose=True,
llm=MODEL,
)
@task
def query_fanout_summarization_task(self) -> Task:
return Task(
config=self.tasks_config["query_fanout_summarization_task"],
context=[self.google_search_task()],
agent=self.query_fanout_summarizer_agent(),
markdown=True,
output_file="output/query_fanout_summary.md",
)
@agent
def ai_content_optimizer_agent(self) -> Agent:
return Agent(
config=self.agents_config["ai_content_optimizer_agent"],
verbose=True,
llm=MODEL,
)
@task
def compare_ai_overview_task(self) -> Task:
return Task(
config=self.tasks_config["compare_ai_overview_task"],
context=[self.query_fanout_summarization_task(), self.ai_overview_extraction_task()],
agent=self.ai_content_optimizer_agent(),
max_retries=3,
markdown=True,
output_file="output/report.md",
)Dementsprechend gibt der obige Code an:
- Der Google Main Query Extractor Agent und seine Hauptaufgabe.
- Der Google AI Overview Retriever Agent und seine Hauptaufgabe.
- Der Agent “Query Fan-Out Summarizer” und seine Hauptaufgabe.
- Der AI Content Optimizer Agent und seine Hauptaufgabe.
Vervollständigen Sie die Agentendefinitionen, indem Sie diese Zeilen in agents.yaml einfügen:
main_query_extractor_agent:
role: "Google Main Query Extractor"
goal: "Extract the main Google-like search query from a provided query fan-out."
backstory: "You are an AI assistant specialized in parsing query fan-outs and identifying the main, concise search query suitable for Google searches."
ai_overview_retriever_agent:
role: "Google AI Overview Retriever"
goal: "Given a query fan-out, extract the main search query and use it to perform a SERP search on Google to retrieve the AI Overview section."
backstory: "You are an AI SERP search assistant with the ability to retrieve SERPs from Google."
query_fanout_summarizer_agent:
role: "Query Fan-Out Summarizer"
goal: "Generate a concise and structured summary from the provided query fan-out."
backstory: "You are an AI summarization expert focused on condensing query fan-outs into clear, actionable summaries in Markdown format."
ai_content_optimizer_agent:
role: "AI Content Optimizer"
goal: "Compare a summary generated from a query fan-out with the Google AI Overview, identify patterns and similarities, and generate a list of action items based on common topics."
backstory: "You are an AI assistant that analyzes content summaries and AI overviews to find recurring themes, patterns, and actionable insights to optimize content strategies."Und diese Zeilen in tasks.yaml:
main_query_extraction_task:
description: |
1. From the provided query fan-out, extract the main search query.
2. Transform the search query into a concise, Google-like keyphrase that users would type into Google.
expected_output: "A short, clear, Google-style search query."
ai_overview_extraction_task:
description: |
1. Use the search query from the previous task to perform a SERP search on Google via the Bright Data SERP Search tool by setting the `brd_ai_overview` argument to 2.
2. Retrieve and return an aggregated Markdown version of the AI Overview section from the search results.
3. After all attempts, if none of the responses contain a Google AI Overview, generate one based on the results from the SERP API, and include a note indicating it was generated.
expected_output: "The AI Overview section Markdown format (either retrieved from the SERP API or generated if unavailable)."
query_fanout_summarization_task:
description: |
1. Generate a summary from the query fan-out received as input.
expected_output: "A Markdown summary containing the main information from the query fan-out."
compare_ai_overview_task:
description: |
1. Compare the previously generated summary with the Google AI Overview provided as input.
2. Identify patterns and similarities (such as sub-topics or recurring themes), as well as differences between the two sources.
3. Generate a list of action items based on the comparison, focusing on topics that appear in both the Google AI Overview and the initial summary.
4. Produce a summary table to compare the patterns, similarities, and differences, containing these columns: Aspect, Query Fan-Out Summary, Google AI Overview, Similarities/Patterns, Differences.
expected_output: |
A comparison report in Markdown that highlights patterns, similarities, and a list of action items derived from the query fan-out.
The document must with a summary table presenting the main similarities and differences, and then all remaining content.Sehen Sie, wie die Aufgabe ai_overview_extraction_task technische Spezifikationen enthält, um die AI-Übersicht in der SERP-API-Antwort abzurufen. Erfahren Sie mehr in den offiziellen Dokumenten.
Wunderbar! Alle Ihre KI-Agenten im GEO-Content-Optimierungs-Workflow sind nun erstellt worden. Nun ist es an der Zeit, eine Crew hinzuzufügen, die sie orchestriert.
Schritt #7: Alle Agenten in einer Crew zusammenfassen
Definieren Sie in crew.py eine neue Funktion Crew, um die Agenten nacheinander auszuführen:
@crew
def crew(self) -> Crew:
return Crew(
agents=self.agents,
tasks=self.tasks,
process=Process.sequential,
verbose=True,
)Erstaunlich! Die Klasse AiContentOptimizationAgent in der Datei crew.py ist vollständig. Sie müssen nur noch ihre crew() -Methode in der Datei main.py ausführen, um den Arbeitsablauf zu starten.
Schritt Nr. 8: Definieren des Ablaufs
Überschreiben Sie die Datei main.py zu:
- Lesen Sie die Eingabe-URL aus dem Terminal mit der Python-Funktion
input(). - Verwenden Sie die angegebene URL, um den erforderlichen Agenteninput zu erstellen.
- Initialisieren Sie eine
AiContentOptimizationAgent-Instanzund rufen Sie ihrecrew()-Methode auf, wobei Sie ein Eingabeobjekt mit dem erforderlichen{url}-Feldübergeben. - Führen Sie den AI-Workflow aus.
Implementieren Sie die gesamte obige Logik in main.py wie folgt:
#!/usr/bin/env python
import warnings
from ai_content_optimization_agent.crew import AiContentOptimizationAgent
warnings.filterwarnings("ignore", category=SyntaxWarning, module="pysbd")
def run():
# Read URL from the terminal
url = input("Please enter the URL to process: ").strip()
if not url:
raise ValueError("No URL provided. Exiting.")
# Build the required agent input
inputs = {
"url": url,
}
try:
print(f"Analyzing '${url}' for AI content optimization...")
# Run the multi-agent workflow
AiContentOptimizationAgent().crew().kickoff(inputs=inputs)
except Exception as e:
raise Exception(f"An error occurred while running the crew: {e}")Schritt #9: Testen Sie Ihren Agenten
Installieren Sie in Ihrer aktivierten virtuellen Umgebung vor dem Start Ihres Agenten die erforderlichen Abhängigkeiten mit:
crewai installDann starten Sie Ihr Multi-Agenten-GEO-Optimierungssystem:
crewai runSie werden aufgefordert, die Eingabe-URL einzugeben:

In diesem Beispiel verwenden wir eine Seite von der CrewAI-Website selbst als Eingabe:
https://www.crewai.com/ecosystem
Auf dieser Seite werden die wichtigsten Akteure im Ökosystem der KI-Agenten vorgestellt.
Führen Sie den Agenten auf dieser Seite aus, und Sie werden eine Ausgabe wie diese sehen:
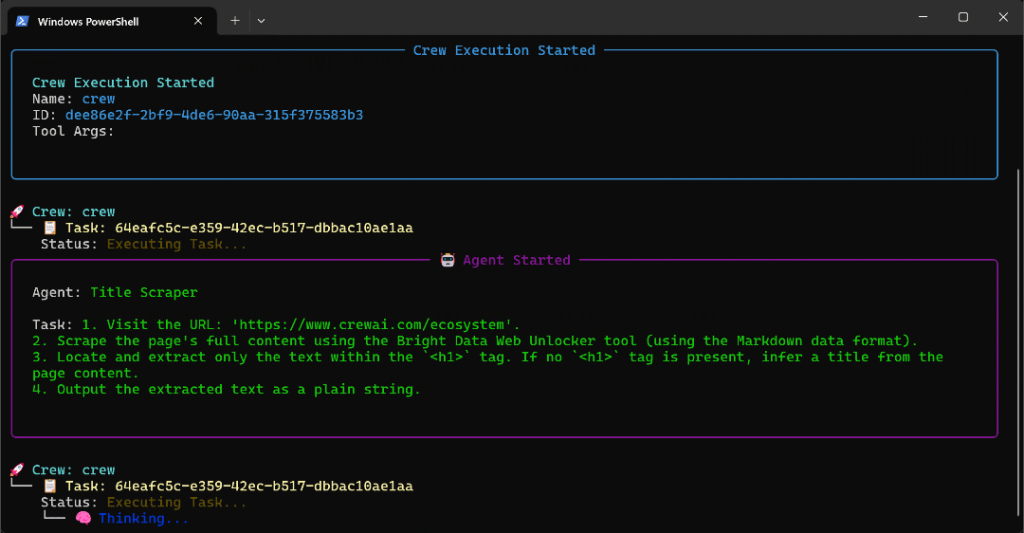
Das obige GIF wurde beschleunigt, aber dies ist der Ablauf der einzelnen Schritte:
- Der Title Scraper Agent sammelt den Seitentitel über das Bright Data Web Unlocker Tool. Das Ergebnis ist
"Das am schnellsten wachsende KI-Agenten-Ökosystem"(genau wie im Screenshot der Seite dargestellt). - Google Query Fan-Out Researcher generiert die Query Fan-Out-Ausgabe aus dem
google_search-Tool. Dabei entsteht die Dateiquery_fanout.mdim Ordneroutput/. - Google Main Query Extractor identifiziert die primäre Google-ähnliche Suchanfrage aus dem Query Fan-out. Das Ergebnis ist
"AI agent ecosystem growth". - Google AI Overview Retriever ruft die AI-Übersicht für die Suchanfrage über die Bright Data SERP API ab. Die Ausgabe wird in
ai_overview.mdgespeichert. - Der Agent Query Fan-Out Summarizer fasst den Inhalt des Query Fan-Out in einer detaillierten Markdown-Zusammenfassung in
query_fanout_summary.mdzusammen. - AI Content Optimizer vergleicht die Zusammenfassung des Query Fan-Out mit der Google AI Overview, um die endgültige
report.md-Dateizu erstellen.
Am Ende der Ausführung sollte der Ordner output/ die folgenden vier Dateien enthalten:
Öffnen Sie die Datei report.md im Vorschaumodus von Visual Studio Code und blättern Sie sie durch:

Wie Sie sehen können, enthält es einen detaillierten Markdown-Bericht, der Ihnen hilft, den Inhalt der angegebenen Eingabeseite für GEO (und SEO) zu optimieren!
Verwenden Sie nun diesen Agenten für die URLs der Webseiten, die Sie für das AI-Ranking verbessern möchten, und Sie werden Ihre GEO- und SEO-Positionierung verbessern.
Et voilà! Mission erfüllt.
Nächste Schritte
Der oben beschriebene KI-Agent für die Optimierung von Inhalten ist bereits recht leistungsfähig, aber er kann immer noch verbessert werden. Eine Idee ist, am Anfang des Workflows einen weiteren Agenten hinzuzufügen, der eine Sitemap als Input nimmt (optional mit einem Regex, um URLs zu filtern, z. B. um nur Blogbeiträge auszuwählen). Dieser Agent könnte dann die URLs an den bestehenden Workflow weiterleiten, möglicherweise parallel, so dass Sie mehrere Seiten gleichzeitig für die KI-Inhaltsoptimierung analysieren können.
Denken Sie daran, dass Sie mit den Anweisungen in agents.yaml und tasks.yaml experimentieren können, um das Verhalten jedes der sechs Agenten an Ihren speziellen Anwendungsfall anzupassen. Es sind keine fortgeschrittenen technischen Kenntnisse erforderlich, um diese Anpassungen vorzunehmen!
Schlussfolgerung
In diesem Artikel erfahren Sie, wie Sie die KI-Integrationsfunktionen von Bright Data nutzen können, um einen komplexen Multi-Agenten-Workflow für die GEO/SEO-Optimierung in CrewAI aufzubauen.
Der hier vorgestellte KI-Workflow ist ideal für alle, die nach einer programmatischen Möglichkeit suchen, Webseiteninhalte sowohl für herkömmliche Suchmaschinen als auch für KI-gestützte Suchen zu verbessern.
Um ähnliche fortschrittliche Workflows zu erstellen, können Sie die gesamte Bandbreite an Lösungen zum Abrufen, Validieren und Transformieren von Live-Webdaten in der Bright Data AI-Infrastruktur nutzen.
Erstellen Sie noch heute ein kostenloses Bright Data-Konto und experimentieren Sie mit unseren KI-fähigen Webtools!




