

Exa ist eine semantische Suchmaschine. Bright Data ist eine Webdaten-Infrastruktur. Es handelt sich um grundlegend unterschiedliche Produkte, und die Frage, welches Sie verwenden sollten, hängt ganz davon ab, was Ihr KI-Agent tatsächlich leisten muss.
Dieser Vergleich beleuchtet beide Produkte in allen für Produktions-KI-Teams relevanten Dimensionen: Kosten, Ratenbegrenzungen, Abdeckung, Zugriff und historische Daten. Keine vagen Einschätzungen, nur Zahlen und Fakten.
TL;DR – Bright Data vs. Exa auf einen Blick
- Exa ist eine semantische Suchmaschine; Bright Data ist eine Webdaten-Infrastruktur.
- Die Bright Data SERP-API kostet 1,50 $ pro 1.000 Anfragen; Exa berechnet 7 $ pro 1.000.
- Das Standard-Ratenlimit für
/searchbei Exa beträgt 10 QPS. Bright Data hat kein Limit für gleichzeitige Anfragen. - Der Bright Data Web Unlocker kann gegen Bots geschützte Seiten crawlen. Exa kann das nicht.
- Bright Data verfügt über mehr als 50 PB historischer Webdaten. Exa ist nur live verfügbar.
- Die „Find Similar“-Funktion von Exa ist einzigartig und hat kein direktes Äquivalent bei Bright Data.
- Verwenden Sie Exa für semantische Erkundung. Verwenden Sie Bright Data für die Extraktion von Ground-Truth-Daten in großem Maßstab.
Bright Data vs. Exa: Direktvergleich
| Dimension | Bright Data | Exa |
|---|---|---|
| Produktkategorie | Webdaten-Infrastruktur (Proxy-Netzwerk + Scraping + Datensätze) | API für semantische Suchmaschinen |
| Suchansatz | Echtes Suchmaschinen-Scraping (Google, Bing, Yandex usw.) über SERP-API + Live-Erkennung über Discover-API | Benutzerdefinierter, auf Embeddings basierender neuronaler Index (eigener Index) |
| Ergebnisse pro Suchanfrage | Bis zu 1.000 (Discover-API) | Bis zu 100 (Standard); bis zu 1.000 bei Enterprise |
| Vollständiger Seiteninhalt | Ja, Live-Extraktion über Web Unlocker, als Markdown zurückgegeben | Ja, über den Endpunkt /contents (1 $ pro 1.000 Seiten zusätzlich) |
| Anti-Bot & CAPTCHA-Umgehung | Ja, in Web Unlocker integriert; über 150 Millionen Proxy-IPs | Nein, kann keine Inhalte hinter Login-Barrieren oder Anti-Bot-Schutz crawlen |
| Historische Daten | Ja, über 50 PB Webarchiv; vorgefertigte Datensätze | Nein, nur Live-Index |
| Ratenbegrenzungen | Keine Begrenzung der gleichzeitigen Anfragen (SERP-API) | Standardmäßig 10 QPS bei /search; benutzerdefiniert bei Enterprise |
| Preise (PAYG) | Ab 1,50 $/1.000 Anfragen (SERP-API) | 7 $ pro 1.000 Anfragen (Standardsuche, 1–10 Ergebnisse) |
| Unterstützte Suchmaschinen | Google, Bing, DuckDuckGo, Yandex, Baidu, Naver, Yahoo | Exas eigener proprietärer neuronaler Index |
| Compliance | DSGVO, CCPA, SOC 2, SOC 3, ISO 27701 | SOC 2 Typ II, ZDR-Option |
| MCP-Integration | Ja, Bright Data MCP Server (kostenlos, 5.000 kostenlose Anfragen/Monat) | Ja, Exa MCP Server |
| Framework-Integrationen | LangChain, LlamaIndex, CrewAI, Agno, Dify, n8n, Zapier, über 70 | LangChain, LlamaIndex, CrewAI, Vercel KI SDK, über 20 |
| Kostenlose Stufe | Ja, kostenlose Testversion | Ja, 1.000 Anfragen/Monat |
| Enterprise-SLA | Ja, 99,9 % SLA, persönlicher Account Manager | Ja, individuelles SLA, 1:1-Onboarding |
Was ist Exa?
Exa ist eine Suchmaschine, die speziell für KI-Anwendungen entwickelt wurde. Anstelle der herkömmlichen Keyword-Indizierung hat Exa einen eigenen neuronalen Index entwickelt, ein groß angelegtes Embedding-Modell, das im Web trainiert wurde. Wenn Sie eine Anfrage an Exa stellen, führt die Suchmaschine eine semantische Vektorsuche in diesem Index durch und liefert Ergebnisse, die nach konzeptioneller Relevanz und nicht nach Keyword-Übereinstimmung sortiert sind.
Diese architektonische Entscheidung ist das Hauptunterscheidungsmerkmal von Exa. Es beantwortet Fragen wie „Finde Artikel, die dieser arXiv-URL ähneln“ oder „Unternehmen, die das tun, was Nvidia im Bereich Halbleiter tut“ auf eine Weise, die ein keywordbasierter SERP-Scraper nicht leisten kann. Stand März 2026 umfasst der Index von Exa über 1 Milliarde Personenprofile und 70 Millionen Unternehmenseinträge, und es werden spezielle Suchmodi für Nachrichten, Code und Finanzberichte angeboten. Wenn Sie Alternativen zu Exa evaluieren, finden Sie unter den besten Exa-Alternativen für die KI-Websuche einen detaillierten Vergleich konkurrierender Tools, darunter Bright Data, Tavily und Firecrawl.
Was Exa gut macht
Semantische „Find Similar“-Suche. Keine andere API bietet die Funktion „Finde mir Seiten, die dieser URL konzeptionell ähnlich sind“. Dies ist eine echte Funktionslücke, die Bright Data nicht schließt.
Abruf mit geringer Latenz. Exa Instant liefert Antworten in weniger als 200 ms. Eine Standard-Suche dauert 100–1.200 ms. Für interaktive Chat-Oberflächen und Echtzeit-Agenten ist diese Geschwindigkeit ein echter Vorteil.
Entwicklererfahrung. SDKs in Python und TypeScript, native Integrationen mit LangChain, LlamaIndex und CrewAI, MCP-Server-Unterstützung sowie großzügige 1.000 kostenlose Anfragen pro Monat. Der Weg von Null zu einer funktionierenden Agentenintegration dauert nur wenige Minuten.
Spezialisierte Domänenindizes. Der Personenindex von Exa (über 1 Milliarde Profile, über 50 Millionen wöchentliche Aktualisierungen) und der Unternehmensindex (über 70 Millionen Unternehmen) wurden speziell für Rekrutierungsagenten, Sales-Intelligence-Pipelines und Workflows zur Unternehmensanreicherung entwickelt.
Hohe Benchmark-Genauigkeit. Bei der WebWalker-Multi-Hop-Abfrage erzielte Exa in einer Bewertung von Fortune-100-Unternehmen (Januar 2025) 81 % gegenüber 71 % bei Tavily. Im 100-Abfragen-Benchmark von AIMultiple über 8 APIs belegte Exa mit einem Agent Score von 14,39 den 3. Platz.
Die wesentlichen Einschränkungen von Exa bei hoher Auslastung
Exas Ratenbegrenzung schränkt Produktions-Workloads ein. Die Standardgrenze für /search liegt bei 10 QPS (600 Anfragen pro Minute). Dies wurde direkt in Exas offizieller Dokumentation zu Ratenbegrenzungen bestätigt. Bei Multi-Agent-Pipelines, die Tausende paralleler Rechercheaufgaben ausführen, zwingt diese Obergrenze Teams dazu, von Anfang an Wiederholungslogik und Anforderungswarteschlangen zu implementieren. Unternehmenskunden können höhere Limits aushandeln, dies erfordert jedoch ein separates Verkaufsgespräch.
Exa kann Anti-Bot-Schutzmaßnahmen nicht umgehen. Exa crawlt das offene Web nach seinem eigenen Zeitplan. Es kann keine Seiten hinter Cloudflare, Login-Barrieren, CAPTCHA-Systemen oder JavaScript-intensiver Bot-Erkennung abrufen. Für Wettbewerbsanalysen, Preisüberwachung oder jeden Anwendungsfall, bei dem die wertvollsten Seiten auch am stärksten geschützt sind, ist dies eine harte Einschränkung.
Keine historische Datenebene. Exa ist nur live verfügbar. Es gibt kein Archivprodukt, keinen historischen Datensatz und keine Möglichkeit, die heutigen Ergebnisse mit denen des letzten Quartals zu vergleichen. Für die Erkennung von Anomalien, Trendanalysen oder auf Basisdaten basierende Agentenausgaben ist dies eine strukturelle Lücke.
Der Index von Exa ist nicht Google. Exa liefert Ergebnisse aus seinem eigenen proprietären neuronalen Index, nicht von Google, Bing oder Yandex. Für jeden Anwendungsfall, bei dem man genau wissen muss, was ein echter Nutzer gerade in Google sieht (SEO-Überwachung, Anzeigenanalyse, Rank-Tracking, Markenschutz), ist der Index von Exa die falsche Datenquelle.
Die Preisgestaltung skaliert bei hohem Volumen schlecht. Bei 1 Million Anfragen pro Monat kostet die Standardsuche von Exa über 7.000 $. Mit vollständigen Seiteninhalten steigt dieser Betrag auf über 8.000 $. Exa hat seine Preise im März 2026 aktualisiert, wobei die Standardsuche von 5 $/1.000 auf 7 $/1.000 angehoben und eine „Agentic“-Stufe für 12 $/1.000 eingeführt wurde.
Was ist Bright Data?
Bright Data ist eine Webdaten-Infrastruktur. Es verfügt über keinen eigenen Suchindex, sondern greift über eine Reihe von Produkten, die für verschiedene Datenerfassungsmuster entwickelt wurden, in großem Umfang auf das tatsächliche Live-Web zu.
Die SERP-API erfasst echte Ergebnisse von Google, Bing, Yandex, Baidu, DuckDuckGo, Yahoo und Naver in Echtzeit aus jedem der 195 Länder mit Geo-Targeting auf Stadtebene. Sie liefert das, was ein echter Nutzer an diesem Standort gerade sehen würde, und nicht das, was ein Index für richtig hält.
Die Discover-API wurde speziell für Agenten-Workloads entwickelt, die umfassendere und tiefere Erkenntnisse aus dem Live-Web benötigen, anstatt einer oberflächlichen Liste von SEO-gerankten Links. Sie findet Live-URLs mit bis zu 1.000 Ergebnissen pro Anfrage, die nach der spezifischen Absicht des Agenten und nicht nach der SEO-Position gerankt sind, mit optional bereinigten Markdown-Inhalten für RAG-Grounding und Verifizierung. Im Gegensatz zu Suchmaschinen oder zwischengespeicherten Indizes wird jede Discover-Anfrage zum Zeitpunkt der Abfrage im Live-Web ausgeführt, wodurch sie sich besonders gut für Wettbewerbsanalysen, Risikoüberwachung und Due-Diligence-Workflows eignet.
Der Web Unlocker ruft jede Webseite ab, einschließlich solcher hinter Cloudflare, CAPTCHAs, Login-Wänden oder JavaScript-Rendering, und liefert bereinigte Markdown-Inhalte. Er leitet Anfragen über ein Netzwerk von mehr als 150 Millionen Residential-IPs in 195 Ländern weiter und umgeht Erkennungsmechanismen automatisch.
Die Datensätze -Ebene bietet vorgefertigte strukturierte Daten aus über 100 Domains. Die Web Archive API stellt über 50 PB historischer Webdaten aus den vergangenen Jahren bereit und ist damit die perfekte Lösung für historische Einordnungen.
Wie Bright Data Webdaten für KI nutzt
Die Architektur von Bright Data basiert auf einer zentralen Prämisse: Die Ground Truth ist das tatsächliche Live-Web, nicht die Annäherung eines Indexes daran. Für KI-Teams in Unternehmen, die Produktionssysteme entwickeln, ist dies in folgenden Fällen von Bedeutung:
- Ihr Agent die Preisseite eines Mitbewerbers abrufen muss und diese Seite Scraper blockiert
- Ihr Agent muss wissen, was Google tatsächlich für ein Keyword anzeigt, und nicht, was ein neuronaler Index schätzt
- Ihr Agent 10.000 Abfragen parallel ausführen muss, ohne an eine Ratenbegrenzung zu stoßen
- Ihr Agent muss erkennen, ob die heutigen Ergebnisse im Vergleich zu denen vor sechs Monaten anomal sind
Bright Data genießt das Vertrauen von über 20.000 Kunden, darunter Fortune-500-Unternehmen, und wird in Gartners Wettbewerbslandschaft für Web-Datenerfassungslösungen erwähnt. Das Unternehmen verfügt über Zertifizierungen nach DSGVO, CCPA, SOC 2, SOC 3 und ISO 27701.
Die wichtigsten Produkte: SERP-API, Discover API, Web Unlocker, Datensätze
| Produkt | Funktionsumfang | Preise |
|---|---|---|
| SERP-API | Echtzeit-Scraping von 7 Suchmaschinen, 195 Ländern, strukturierte JSON/Markdown-Ausgabe | Ab 1,50 $/1.000 Ergebnisse (PAYG); ab 1,00 $/1.000 bei 2 Mio./Monat |
| Discover-API | Live-URL-Erkennung mit bis zu 1.000 Ergebnissen pro Anfrage, nach Absicht sortiert, optionaler Markdown-Inhalt | Kostenlos (Beta) |
| Web Unlocker | Ruft jede Seite hinter Anti-Bot-Schutz ab, gibt sauberes Markdown zurück | Ab 1 $ pro 1.000 Anfragen |
| Datensätze | Vorgefertigte strukturierte Daten aus über 100 Domains | Ab 250 $/100.000 Datensätze |
| Webarchiv-API | Über 50 PB historische Webdaten | Ab 0,20 $/1.000 HTML-Seiten |
| MCP-Server | Verbinden Sie KI-Agenten direkt mit der gesamten Produktpalette von Bright Data | Kostenlos, 5.000 Anfragen/Monat |
Preisvergleich: Bright Data vs. Exa
Exa-Preise (März 2026)
| Produkt | Preis |
|---|---|
| Standard-Suche (1–10 Ergebnisse) | 7 $ / 1.000 Anfragen |
| Zusätzliche Ergebnisse über 10 hinaus | +1 $ / 1.000 Ergebnisse |
| Agentische / Tiefensuche | 12 $ / 1.000 Anfragen |
| Deep Search mit Schlussfolgerungen | 15 $ / 1.000 Anfragen |
| Inhalt (vollständiger Seitentext) | 1 $ / 1.000 Seiten |
| Antwort-API | 5 $ / 1.000 Antworten |
| Kostenlose Stufe | 1.000 Anfragen/Monat |
| Enterprise | Individuell |
Wichtiger Hinweis: Die Preise von Exa sind additiv. Wenn Ihr Agent 10 Ergebnisse plus den vollständigen Seiteninhalt benötigt, zahlen Sie für die Suche (7 $) plus den Inhalt (1 $) pro 1.000 Anfragen. Die effektiven Mindestkosten für Agenten, die den vollständigen Text inline benötigen, betragen 8 $/1.000.
Preise von Bright Data
| Produkt | Preis |
|---|---|
| SERP-API (PAYG) | 1,50 $ / 1.000 Ergebnisse |
| SERP-API (380.000 Ergebnisse/Monat) | 1,30 $ / 1.000 Ergebnisse |
| SERP-API (900.000 Ergebnisse/Monat) | 1,10 $ / 1.000 Ergebnisse |
| SERP-API (2 Mio. Ergebnisse/Monat) | 1,00 $ / 1.000 Ergebnisse |
| Web Unlocker | Ab 1 $ / 1.000 Anfragen |
| Datensätze | Ab 250 $ / 100.000 Datensätze |
| Web-Archiv | Ab 0,20 $ / 1.000 HTML-Seiten |
| Discover-API | Kostenlos (Beta) |
| MCP-Server | Kostenlos (5.000 Anfragen/Monat) |
Kosten bei Skalierung: Die Zahlen sprechen eine deutliche Sprache
| Volumen | Exa (nur Standardsuche) | Exa (Suche + Inhalt) | Bright Data SERP-API |
|---|---|---|---|
| 10.000 Anfragen | 70 | 80 | 15 |
| 100.000 Anfragen | 700 | 800 | 130–150 $ |
| 1.000.000 Anfragen | 7.000 $+ | 8.000 $+ | 1.000–1.500 |
Bei 1 Million Anfragen pro Monat ist Bright Data allein bei der Suche 5-7-mal günstiger als Exa. Einen vollständigen Vergleich von SERP- und Web-Such-APIs in großem Maßstab finden Sie unter den besten SERP-APIs und Web-Such-APIs des Jahres 2026. Für Agenten, die den gesamten Seiteninhalt benötigen, vergrößert sich der Preisunterschied weiter: Exa berechnet zusätzlich 1 $ pro 1.000; Bright Data Web Unlocker beginnt bei 1 $ pro 1.000 (All-inclusive).
Bright Data hat keine Begrenzung für gleichzeitige Anfragen
Dies ist kein subtiler Unterschied. Das Standard-Ratenlimit von Exa für /search beträgt 10 QPS, 10 Abfragen pro Sekunde, 600 pro Minute. Dies wird in der offiziellen Dokumentation zu den Ratenlimits von Exa bestätigt.
Die SERP-API von Bright Data hat keine Begrenzung für gleichzeitige Anfragen. Aus den eigenen FAQ: „Es gibt keine Begrenzung für die Anzahl gleichzeitiger Anfragen. Die SERP-API ist auf Skalierbarkeit ausgelegt.“
Für Workloads mit einem einzigen Agenten und jeweils nur einer Abfrage spielt dies keine Rolle. Für Produktions-KI-Pipelines, die Dutzende oder Hunderte paralleler Rechercheaufgaben ausführen, für Systeme der Wettbewerbsanalyse, Multi-Agenten-Recherche-Frameworks und Echtzeit-Überwachungsstacks ist der Unterschied jedoch grundlegend. Bei Exa müssen Sie vom ersten Tag an mit einer Obergrenze arbeiten.
Bright Data kann Seiten erreichen, die Exa nicht erreichen kann
Exa crawlt das offene Web. Es kann nicht auf folgende Seiten zugreifen:
- Seiten, die durch Cloudflare geschützt sind
- Websites mit Login-Barrieren oder Authentifizierungsanforderungen
- Seiten mit CAPTCHA-Anforderungen
- JavaScript-lastige Websites, die bei reinen HTTP-Anfragen keine Inhalte ausliefern
- Geografisch eingeschränkte Inhalte, die lokale IP-Adressen erfordern
Dies ist keine Kritik, sondern liegt einfach außerhalb des Produktumfangs von Exa.
Der Web Unlocker von Bright Data wurde speziell für dieses Problem entwickelt. Er leitet Anfragen über mehr als 150 Millionen Residential-IPs weiter, bewältigt Browser-Fingerprinting, bietet eine CAPTCHA-Lösung und gibt den vollständig gerenderten Seiteninhalt als sauberes Markdown zurück. Für Teams, die den vollen Umfang dessen verstehen müssen, was die Umgehung von Anti-Bot-Maßnahmen beinhaltet, behandelt der Leitfaden zur Umgehung von Cloudflare für Web-Scraping die relevanten Techniken ausführlich. Für wettbewerbsorientierte Preisinformationen, bei denen die wertvollsten Daten oft auf den am besten geschützten Seiten zu finden sind, ist dies eine entscheidende Funktion.
Hier ist ein einfaches Beispiel dafür, wie ein Produktionsagent die Bright Data SERP-API im Vergleich zu Exa für dieselbe Aufgabe nutzen würde:
# Bright Data SERP-API – echte Google-Ergebnisse, keine Obergrenze für die Abrufrate
import requests
response = requests.get(
"https://api.brightdata.com/serp/req",
headers={"Authorization": "Bearer YOUR_API_KEY"},
params={
"q": "competitor pricing enterprise 2026",
"gl": "us",
"num": 10,
"data_format": "markdown" # LLM-fähige Ausgabe
}
)
results = response.json()
# Exa – semantische Suche, 10 QPS-Limit
from exa_py import Exa
exa = Exa(api_key="YOUR_EXA_KEY")
results = exa.search_and_contents(
"competitor pricing enterprise 2026",
num_results=10,
text=True
)
# 7 $/1.000 (Suche) + 1 $/1.000 (Inhalte) = 8 $/1.000 effektive KostenDie funktionale Ausgabe ist bei einfachen Abfragen ähnlich. Unterschiede treten auf, wenn Sie dies parallel für 1.000 Wettbewerber ausführen müssen oder wenn die Zielseite die Crawler von Exa blockiert. Sehen Sie sich dieses Beispiel an:
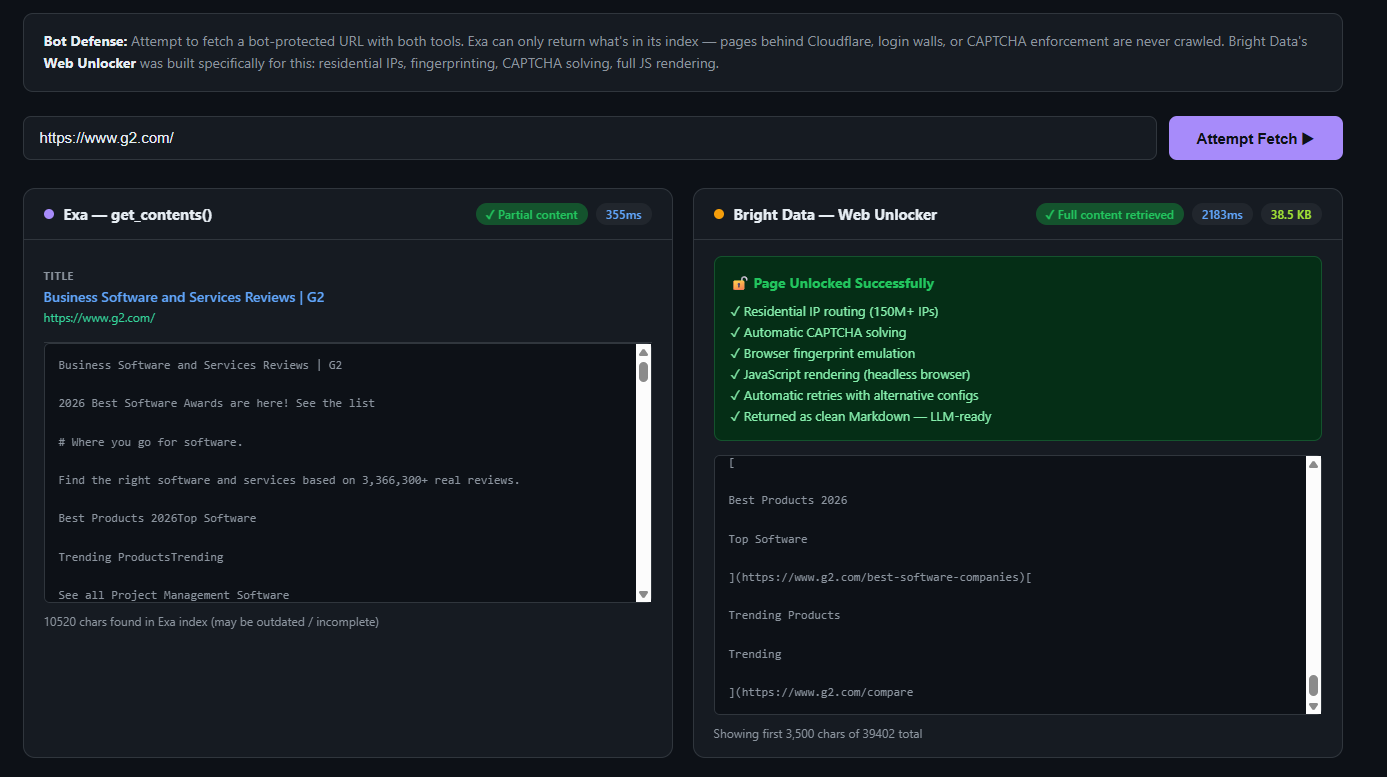
Wenn Sie es selbst ausprobieren möchten, sehen Sie sich diese Demo auf GitHub an.
Exa verfügt über keine historische Datenschicht
KI-Agenten, die Preisänderungen, Richtlinienänderungen oder Marktbewegungen erkennen, benötigen eine Basis, von der aus sie arbeiten können. Man kann etwas nicht als Anomalie kennzeichnen, ohne zu wissen, wie der Normalzustand aussieht.
Exa ist nur live verfügbar. Es gibt kein Archivprodukt, keinen historischen Datensatz und keine Zeitreihenfunktion.
Die Web-Archiv-API von Bright Data enthält über 50 PB an historischen Webdaten, die täglich wachsen. Vorgefertigte strukturierte Datensätze decken über 100 Domänen ab und bieten historische Basiswerte für E-Commerce, soziale Medien, Immobilien und mehr. Für langfristige Analysen – etwa die Beobachtung, wie sich die Preisseite eines Mitbewerbers über 12 Monate verändert hat, die Verfolgung von behördlichen Einreichungen im Zeitverlauf oder die Erkennung von Verschiebungen in der öffentlichen Stimmung – verfügt Bright Data über die Infrastruktur, Exa hingegen nicht.
Anwendungsfall-Entscheidungshilfe
| Anwendungsfall | Beste Wahl | Grund |
|---|---|---|
| RAG-Prototyping / Hackathon | Exa | Schnell, kostenlose Stufe, natives LangChain, minimale Einrichtung |
| Semantische Ähnlichkeitssuche („Finde Seiten wie diese URL“) | Exa | Der Endpunkt „Find Similar“ hat in Bright Data keine Entsprechung |
| Anreicherung von Personen- und Unternehmensdaten (Personalvermittler, Vertriebsinformationen) | Exa | Über 1 Milliarde indizierte Profile, strukturierter Unternehmensindex |
| Wettbewerbsanalyse (Live-Seiteninhalte) | Bright Data | Web Unlocker umgeht Anti-Bot-Maßnahmen; Exa kann geschützte Seiten nicht erreichen |
| Produktionsagent mit über 1.000 gleichzeitigen Abfragen | Bright Data | Keine Obergrenze für die Abfragefrequenz; SERP-API für parallele Workloads |
| Echte Google-SERP-Daten (SEO, Anzeigenüberwachung, Rank-Tracking) | Bright Data | Die SERP-API scrapt das tatsächliche Google, Exa verwendet einen eigenen Index |
| Historische Basiswerte / Anomalieerkennung | Bright Data | Webarchiv mit über 50 PB, Datensätze, Zeitreihen-Fähigkeit |
| Seiten hinter Cloudflare / Login-Barrieren | Bright Data | Web Unlocker; Exa kann nicht auf geschützte Inhalte zugreifen |
| Multi-Engine-Suche (Google + Bing + Yandex) | Bright Data | Die SERP-API deckt 7 große Suchmaschinen in 195 Ländern ab |
| Interaktive Chat-UX mit geringer Latenz | Exa | Exa Instant liefert Ergebnisse in unter 200 ms |
| Kostenoptimiert bei hohem Volumen (über 100.000 Abfragen/Monat) | Bright Data | 1–1,50 $/1.000 gegenüber 7–15 $/1.000 bei Exa |
Wann sollte man sich für Exa entscheiden?
Exa ist das richtige Tool, wenn:
- Sie einen Prototyp entwickeln oder sich in der frühen Forschungsphase befinden. Die 1.000 kostenlosen Anfragen pro Monat, die native Unterstützung von LangChain/LlamaIndex und die einfache SDK-Einbindung machen Exa zur reibungslosesten Möglichkeit, einem KI-Agenten eine Websuche hinzuzufügen.
- Ihr Hauptanwendungsfall die semantische Ähnlichkeit ist. „Finde mir Seiten wie diese URL“ ist eine Exklusivität von Exa. Wenn das Ihr primäres Suchmuster ist, wählen Sie Exa.
- Sie strukturierte Personen- oder Unternehmensdaten benötigen. Exas Index mit über 1 Milliarde Profilen und über 70 Millionen Unternehmen ist speziell für Vertriebs- und Recruiting-Intelligence-Agenten konzipiert.
- Latenz ist die wichtigste Einschränkung. Mit weniger als 200 ms über Exa Instant übertrifft Exa jede Live-Scraping-Lösung für interaktive Echtzeitanwendungen.
- Ihr Abfragevolumen liegt unter 50.000–100.000 Anfragen/Monat und Sie benötigen keine echten Google-Daten oder Zugriff auf geschützte Seiten.
Wann Sie sich für Bright Data entscheiden sollten
Bright Data ist das richtige Tool, wenn:
- Sie im Produktionsmaßstab arbeiten. Unbegrenzte gleichzeitige Anfragen und eine SLA mit 99,9 % Verfügbarkeit bedeuten, dass keine technischen Workarounds für Ratenbeschränkungen erforderlich sind.
- Sie echte Google-Ergebnisse benötigen. Die SERP-API scrapt echtes Google (sowie Bing, Yandex, Baidu, Yahoo, Naver und DuckDuckGo) in Echtzeit und in jedem Land und zeigt, was echte Nutzer sehen, nicht was ein neuronaler Index schätzt.
- Ihr Agent muss auf geschützte Seiten zugreifen können. Web Unlocker bewältigt Cloudflare, CAPTCHA-Barrieren, Anmeldeseiten und JavaScript-Rendering. Exa kann das nicht.
- Sie benötigen historische Daten. Die Web Archive API stellt über 50 PB an historischen Daten für die Basisermittlung und Längsschnittanalyse bereit.
- Die Kosten bei großem Umfang sind ein Faktor. Bei über 100.000 Anfragen pro Monat ist Bright Data 5- bis 7-mal günstiger als Exa.
- Sie bauen Systeme auf Unternehmensniveau. Mit über 20.000 Kunden, der Nutzung durch Fortune-500-Unternehmen, der Anerkennung durch Gartner und über 70 KI-Framework-Integrationen passt Bright Data in bestehende Unternehmensdatenstacks.
Fazit: Zwei verschiedene Tools für zwei verschiedene Aufgaben
Exa und Bright Data konkurrieren nicht um denselben Einsatzbereich.
Exa ist hervorragend in dem, wofür es entwickelt wurde: semantische neuronale Suche, schnelle Entwickler-Onboarding und spezialisierte Indizes für Personen und Unternehmen. Wenn Sie konzeptionell ähnliche Seiten finden, eine semantische Nachbarschaft erkunden oder 1 Milliarde LinkedIn-Profile durchsuchen müssen, ist die Architektur von Exa für diese Aufgaben bestens geeignet.
Bright Data wurde für eine andere Problemstellung entwickelt: den Zugriff auf die „Ground Truth“ des Live-Webs im Produktionsmaßstab, einschließlich der Teile des Webs, die Crawler blockieren. Die SERP-API liefert echte Google-Ergebnisse für 1,50 $ pro 1.000 Ergebnisse ohne Begrenzung der gleichzeitigen Anfragen. Der Web Unlocker erreicht Seiten, an die Exas Crawler nicht herankommen. Das Web-Archiv bietet die historische Basis, die reine Live-APIs nicht bieten können.
Hier ist das Entscheidungsschema:
- Wenn Ihr Agent semantisch ähnliche Seiten finden, über 1 Milliarde Profile durchsuchen oder Antworten in weniger als 200 ms liefern muss, ist Exa genau dafür ausgelegt.
- Wenn Ihr Agent Produktionsskalierbarkeit, echte Google-Daten, Anti-Bot-Zugriff, historische Basisdaten oder Kosteneffizienz bei mehr als 100.000 Abfragen pro Monat benötigt, ist Bright Data die richtige Infrastruktur.
Viele Produktions-KI-Teams nutzen beide: Exa für die semantische Erkennung in den frühen Phasen einer Pipeline und Bright Data für die Live-Verifizierung, die Vollseitenextraktion und SERP-Intelligenz im großen Maßstab. Sie schließen sich nicht gegenseitig aus. Sie haben lediglich unterschiedliche Obergrenzen, und im Unternehmensmaßstab stößt Exa schnell an seine Grenzen. Für Teams, die die gesamte Palette der führenden MCP-Server für KI-Workflows evaluieren, rangiert der MCP-Server von Bright Data durchweg als die führende Option, um Agenten in Echtzeit-Webdaten zu verankern.
Häufig gestellte Fragen
Was ist der Unterschied zwischen Bright Data und Exa?
Exa ist eine semantische Suchmaschinen-API, die Ergebnisse aus ihrem eigenen neuronalen Index liefert. Bright Data ist eine Webdaten-Infrastruktur, die echte Suchmaschinen scrapt, Seiten hinter Anti-Bot-Schutz extrahiert und historische Datensätze bereitstellt. Sie lösen unterschiedliche Probleme in unterschiedlichem Umfang.
Ist Bright Data günstiger als Exa?
Ja. Die SERP-API von Bright Data kostet ab 1,50 $ pro 1.000 Anfragen auf Pay-as-you-go-Basis. Die Standard-Suche von Exa kostet 7 $ pro 1.000 Anfragen. Bei 1 Million Anfragen pro Monat ist Bright Data etwa 5- bis 7-mal günstiger.
Kann Exa Websites hinter Cloudflare crawlen?
Nein. Exa kann keine Seiten crawlen, die durch Cloudflare, Login-Barrieren oder CAPTCHA-Systeme geschützt sind. Der Web Unlocker von Bright Data wurde speziell entwickelt, um Anti-Bot-Schutz zu umgehen, und nutzt ein Netzwerk von über 150 Millionen Residential-IPs.
Gibt es bei Exa eine Ratenbegrenzung?
Ja. Die Standard-Anfragerate für Suchanfragen bei Exa beträgt 10 QPS (600 Anfragen pro Minute). Unternehmenskunden können höhere Limits aushandeln. Die SERP-API von Bright Data hat kein Limit für gleichzeitige Anfragen.
Was ist die beste Exa-Alternative für KI-Agenten in Unternehmen?
Bright Data ist die führende Exa-Alternative für Unternehmen. Es bietet unbegrenzte gleichzeitige Anfragen, Echtzeit-Scraping von Google/Bing/Yandex, Umgehung von Anti-Bot-Schutz durch Web Unlocker, historische Datenarchive und Unterstützung für MCP-basierte KI-Agenten-Workflows – alles zu einem Pay-per-Success-Preis.
Verfügt Exa über historische Daten?
Nein. Exa ist nur live verfügbar und bietet keine Archiv- oder Datensatzprodukte. Die Web Archive API von Bright Data enthält über 50 PB an historischen Webdaten, die täglich wachsen.





