

In diesem Leitfaden erfahren Sie mehr:
- Was Agno ist und warum es eine ausgezeichnete Wahl für den Aufbau von agentenbasierten Arbeitsabläufen ist.
- Warum Web Scraping eine so wertvolle Rolle für KI-Agenten spielt.
- Wie man Agno mit den integrierten Bright Data-Tools integriert, um einen Web Scraping Agent zu erstellen.
Lasst uns eintauchen!
Was ist Agno?
Agno ist ein komplettes Python-Framework für den Aufbau von Multi-Agenten-Systemen, die Gedächtnis, Wissen und fortschrittliche Schlussfolgerungen nutzen. Es ermöglicht die Erstellung anspruchsvoller KI-Agenten für eine breite Palette von Anwendungsfällen. Diese reichen von einfachen Agenten, die Werkzeuge verwenden, bis hin zu kollaborativen Agententeams mit Zustand und Determinismus.
Agno ist modellunabhängig, hochleistungsfähig und stellt die Argumentation in den Mittelpunkt seines Designs. Es unterstützt multimodale Eingaben und Ausgaben, komplexe Multi-Agenten-Orchestrierung, integrierte Agentensuche mit Vektordatenbanken und vollständige Speicher-/Sitzungsverwaltung.
Zum Zeitpunkt der Erstellung dieses Artikels ist Agno eine der beliebtesten Open-Source-Bibliotheken für die Entwicklung von KI-Agenten und hat über 29.000 Sterne auf GitHub:
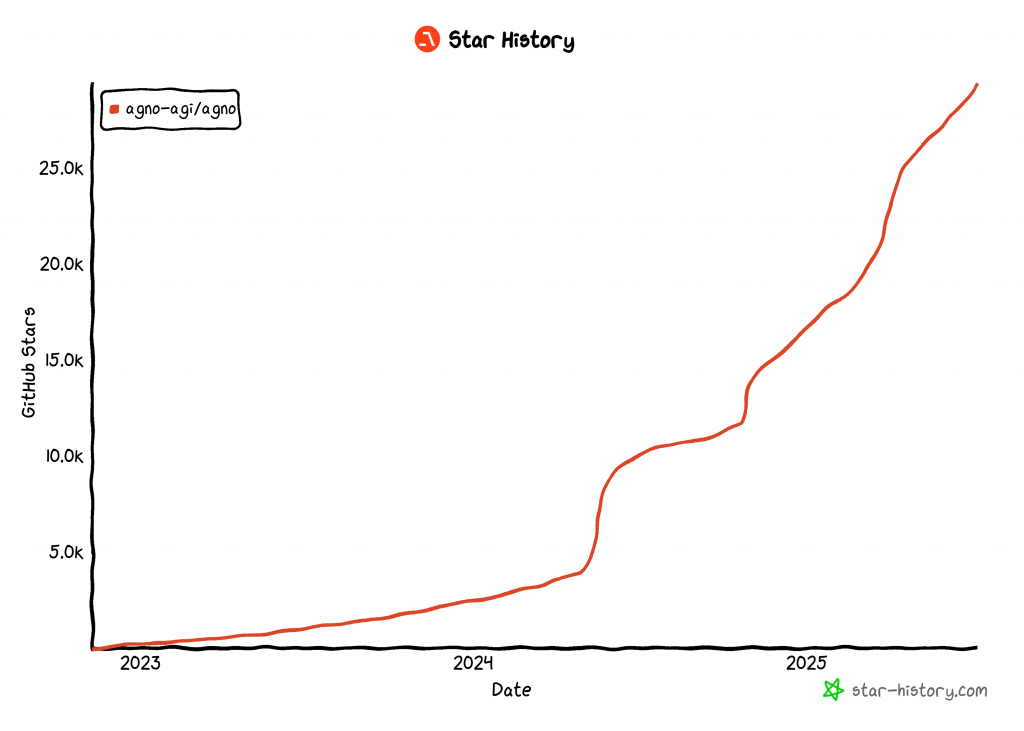
Sein rasanter Aufstieg zeigt, wie schnell Agno in der Entwickler- und KI-Gemeinschaft an Boden gewinnt.
Warum Agentic Web Scraping so nützlich ist
Beim herkömmlichen Web Scraping werden starre Regeln für die Datenanalyse geschrieben, um Daten aus bestimmten Webseiten zu extrahieren. Das Problem dabei? Websites ändern häufig ihre Struktur, was bedeutet, dass Sie Ihre Scraping-Logik ständig aktualisieren müssen. Das führt zu hohen Wartungskosten und anfälligen Pipelines.
Aus diesem Grund findet AI Web Scraping immer mehr Unterstützung. Anstatt benutzerdefinierte Parsing-Skripte zu erstellen, können Sie ein KI-Modell verwenden, um mit einer einfachen Eingabeaufforderung Daten direkt aus dem HTML-Code einer Webseite zu extrahieren. Dieser Ansatz ist so beliebt, dass in letzter Zeit viele KI-Scraping-Tools auf den Markt gekommen sind.
Dennoch wird KI-Web-Scraping noch leistungsfähiger, wenn es in eine agentenbasierte KI-Architektur eingebettet ist. Insbesondere können Sie einen speziellen Web-Scraping-Agenten erstellen, mit dem sich andere KI-Agenten verbinden können. Dies ist in Multi-Agenten-Workflows oder über KI-Protokolle wie A2A von Google möglich.
Agno macht all das möglich. Mit Agno können Sie eigenständige KI-Scraping-Agenten oder komplexe Multi-Agenten-Ökosysteme erstellen. Normale LLMs sind jedoch nicht für kompetentes Web Scraping ausgelegt. Sie schaffen es oft nicht, eine Verbindung zu Websites mit starker Bot-Abwehr herzustellen – oder schlimmer noch, sie “halluzinieren” und liefern gefälschte Daten.
Um diese Einschränkungen zu umgehen, ist Agno über spezielle Scraping-Tools nativ mit Bright Data integriert. Mit diesen Tools kann Ihr KI-Agent frische, strukturierte Daten von jeder beliebigen Website scrapen.
Um Blockaden und Unterbrechungen zu vermeiden, meistert Bright Data Herausforderungen wie TLS-Fingerprinting, Browser- und Geräte-Fingerprinting, CAPTCHAs, Cloudflare-Schutz und mehr für Sie. Sobald die Daten abgerufen sind, werden sie zur Interpretation und Analyse in das LLM eingespeist, wobei Ihre ursprünglichen Aufgabenanweisungen befolgt werden.
Erfahren Sie, wie Sie Bright Data-Tools in einen Agno-Agenten integrieren können, um Web-Scraping auf höchstem Niveau zu betreiben!
Wie man Bright Data Tools für Web Scraping in Agno integriert
In diesem Abschnitt erfahren Sie Schritt für Schritt, wie Sie mit Agno einen KI-Agenten für Web-Scraping erstellen. Durch die Integration der Bright Data-Tools geben Sie Ihrem Agno-Agenten die Möglichkeit, Daten von jeder beliebigen Webseite zu scrapen.
Befolgen Sie die nachstehenden Anweisungen, um Ihren von Bright Data betriebenen Scraping-Agenten in Agno zu erstellen!
Voraussetzungen
Um diesem Tutorial folgen zu können, müssen Sie folgende Voraussetzungen erfüllen:
- Python 3.7 oder höher lokal installiert (wir empfehlen die Verwendung der neuesten Version).
- Ein Bright Data-API-Schlüssel.
- Ein API-Schlüssel für einen unterstützten LLM-Anbieter (hier verwenden wir Gemini, da die Nutzung über die API kostenlos ist, aber jeder unterstützte LLM-Anbieter ist geeignet).
Machen Sie sich keine Sorgen, wenn Sie noch keinen Bright Data-API-Schlüssel oder Gemini-API-Schlüssel haben. Wir zeigen Ihnen in den nächsten Schritten, wie Sie diese erstellen können.
Schritt 1: Projekt einrichten
Öffnen Sie ein Terminal und erstellen Sie ein neues Verzeichnis für Ihr Agno AI-Agentenprojekt, das Bright Data für das Web-Scraping verwenden wird:
mkdir agno-web-scraperDer Ordner agno-web-scraper enthält den gesamten Python-Code für Ihren Agno-Agenten.
Navigieren Sie anschließend in das Projektverzeichnis und richten Sie darin eine virtuelle Umgebung ein:
cd agno-web-scraper
python -m venv venvLaden Sie nun das Projekt in Ihre bevorzugte Python-IDE. Wir empfehlen Visual Studio Code mit der Python-Erweiterung oder PyCharm Community Edition.
Erstellen Sie innerhalb des Projektordners eine neue Datei namens scraper.py. Ihre Verzeichnisstruktur sollte wie folgt aussehen:
agno-web-scraper/
├── venv/
└── scraper.pyAktivieren Sie die virtuelle Umgebung in Ihrem Terminal. Unter Linux oder macOS führen Sie aus:
source venv/bin/activateStarten Sie unter Windows entsprechend diesen Befehl:
venv/Scripts/activateIn den nächsten Schritten werden Sie durch die Installation der erforderlichen Python-Pakete geführt. Wenn Sie es vorziehen, alles jetzt in der aktivierten virtuellen Umgebung zu installieren, führen Sie aus:
pip install agno python-dotenv google-genai requestsHinweis: Wir installieren google-genai, weil dieses Tutorial Gemini als LLM-Anbieter verwendet. Wenn Sie einen anderen LLM verwenden möchten, müssen Sie die entsprechende Bibliothek für diesen Anbieter installieren.
Sie sind bereit! Sie verfügen nun über eine Python-Entwicklungsumgebung, die bereit ist, einen agentenbasierten Scraping-Workflow mit Agno und Bright Data zu erstellen.
Schritt #2: Umgebungsvariablen konfigurieren Lesen
Ihr Agno Scraping Agent stellt über API-Integrationen eine Verbindung zu Drittanbieterdiensten wie Bright Data und Gemini her. Um die Sicherheit zu gewährleisten, sollten Sie vermeiden, Ihre API-Schlüssel direkt in Ihren Python-Code zu kodieren. Speichern Sie sie stattdessen als Umgebungsvariablen.
Um das Laden von Umgebungsvariablen zu vereinfachen, verwenden Sie die Bibliothek python-dotenv. Wenn Ihre virtuelle Umgebung aktiviert ist, installieren Sie sie, indem Sie sie ausführen:
pip install python-dotenvAls nächstes importieren Sie in Ihrer scraper.py-Datei die Bibliothek und rufen load_dotenv() auf, um Ihre Umgebungsvariablen zu laden:
from dotenv import load_dotenv
load_dotenv()Diese Funktion ermöglicht es Ihrem Skript, Variablen aus einer lokalen .env-Datei zu lesen. Legen Sie eine .env-Datei im Stammverzeichnis Ihres Projekts an:
agno-web-scraper/
├── venv/
├── .env # <-----------
└── scraper.pyWunderbar! Sie sind nun in der Lage, Ihre Integrationsgeheimnisse mithilfe von Umgebungsvariablen sicher zu verwalten.
Schritt #3: Helle Daten einrichten
Die in Agno integrierten Bright Data-Tools bieten Ihnen Zugang zu verschiedenen Lösungen für die Datenerfassung. In diesem Tutorial werden wir uns auf die Integration dieser beiden Scraping-spezifischen Produkte konzentrieren:
- Web Unlocker API: Eine fortschrittliche Scraping-API, die den Bot-Schutz überwindet und Zugang zu jeder Webseite im Markdown-Format bietet.
- Web Scraper APIs: Spezialisierte Endpunkte für die ethische Extraktion von frischen, strukturierten Daten aus beliebten Websites wie LinkedIn, Amazon und vielen anderen.
Um diese Tools zu nutzen, müssen Sie:
- Richten Sie die Web Unlocker-Lösung in Ihrem Bright Data-Konto ein.
- Holen Sie sich Ihr Bright Data-API-Token zur Authentifizierung von Anforderungen an Web Unlocker- und Web Scraper-APIs.
Befolgen Sie dazu die nachstehenden Anweisungen!
Wenn Sie noch kein Bright Data-Konto haben, melden Sie sich zunächst kostenlos an. Wenn Sie bereits ein Konto haben, melden Sie sich an und öffnen Sie Ihr Dashboard. Klicken Sie hier auf die Schaltfläche “Proxy-Produkte erhalten”:
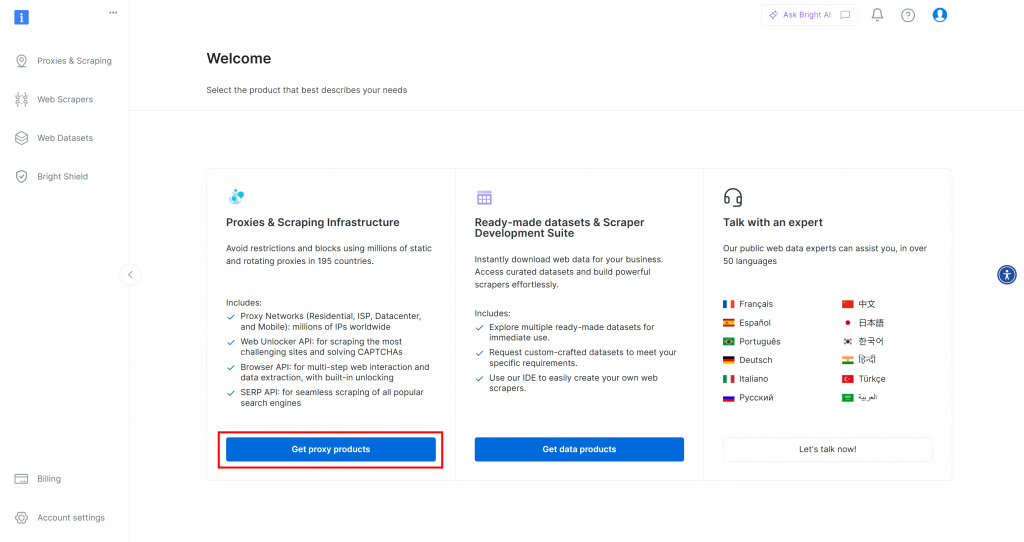
Sie werden auf die Seite “Proxies & Scraping-Infrastruktur” weitergeleitet:
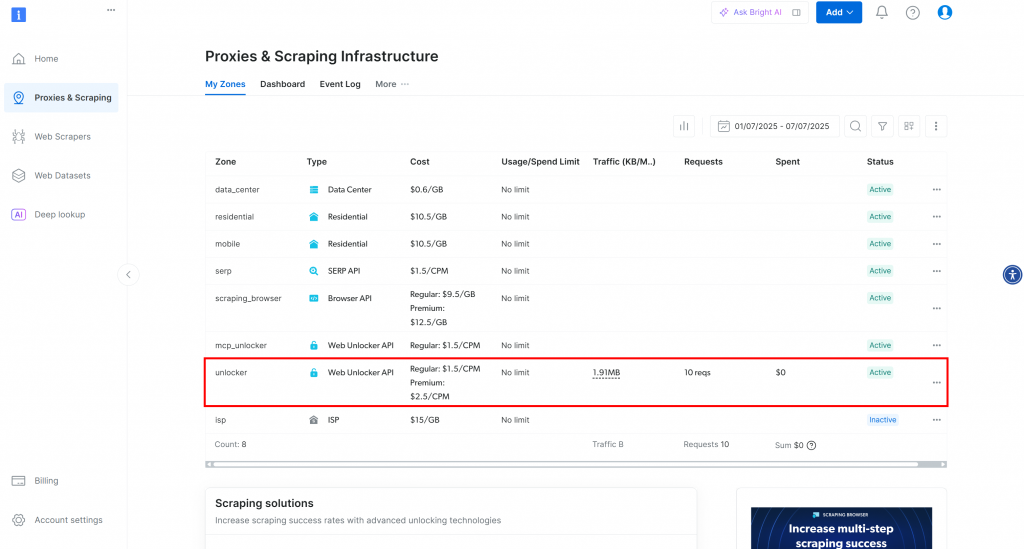
Auf dieser Seite sehen Sie bereits konfigurierte Bright Data-Lösungen. In diesem Beispiel ist eine Web Unloker-Zone aktiviert. Der Name dieser Zone lautet “unblocker” (diesen Namen benötigen Sie später, wenn Sie die Zone in Ihr Skript integrieren).
Wenn Sie noch keine Web Unlocker Zone haben, scrollen Sie nach unten zur Karte “Web Unlocker API” und klicken Sie auf “Zone erstellen”:
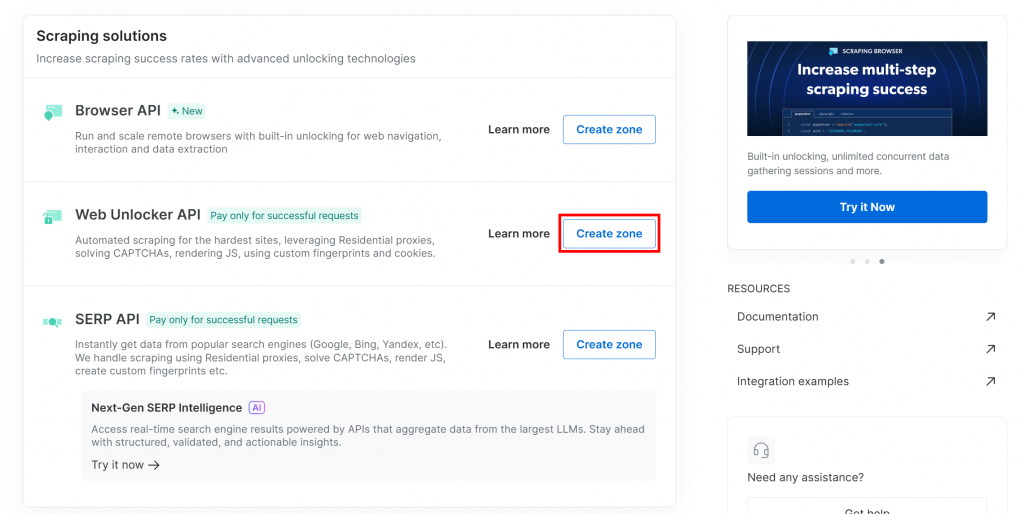
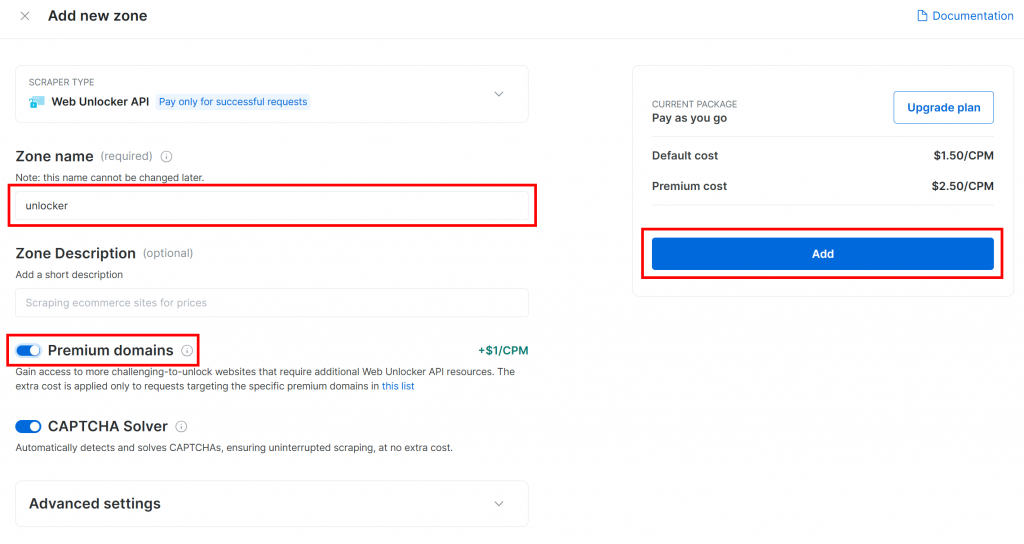
Geben Sie Ihrer Zone einen Namen (z. B. “unlocker”), aktivieren Sie die erweiterten Funktionen für eine optimale Leistung, und klicken Sie auf die Schaltfläche “Hinzufügen”:
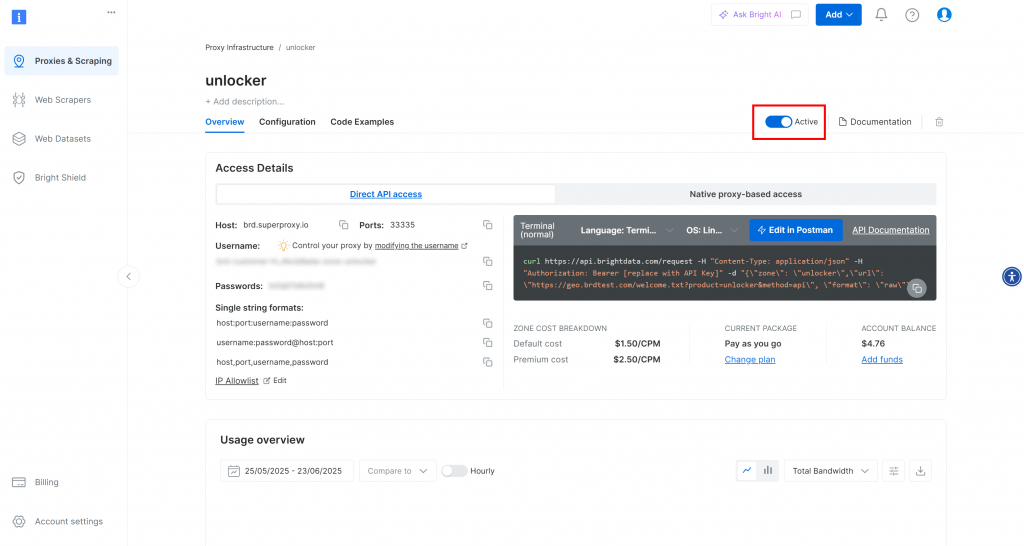
Sie werden auf die Seite Ihrer neuen Zone weitergeleitet. Vergewissern Sie sich, dass der Kippschalter auf den Status “Aktiv” gesetzt ist, der bestätigt, dass das Produkt einsatzbereit ist:
Folgen Sie nun der offiziellen Bright Data-Dokumentation, um Ihren API-Schlüssel zu generieren. Fügen Sie ihn anschließend wie folgt zu Ihrer .env-Datei hinzu:
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"Ersetzen Sie den Platzhalter durch Ihren tatsächlichen API-Schlüsselwert.
Perfekt! Es ist an der Zeit, Bright Data-Tools in Ihr Agno-Agentenskript zu integrieren, um Web-Scraping zu betreiben.
Schritt #4: Integrieren Sie die Agno Bright Data Tools für Web Scraping
Installieren Sie Agno in Ihrem Projektordner bei aktivierter virtueller Umgebung, indem Sie Agno ausführen:
pip install agnoBeachten Sie, dass das agno-Paket bereits integrierte Unterstützung für Bright Data-Tools enthält. Sie benötigen also keine zusätzlichen integrationsspezifischen Pakete.
Das einzige zusätzlich benötigte Paket ist die Python Requests-Bibliothek, mit der die Bright Data-Tools die zuvor konfigurierten Produkte über die API aufrufen können. Installieren Sie Requests mit:
pip install requestsImportieren Sie in Ihrer Datei scraper.py die Bright Data Scraping Tools von agno:
from agno.tools.brightdata import BrightDataToolsDann initialisieren Sie die Werkzeuge wie folgt:
bright_data_tools = BrightDataTools(
web_unlocker_zone="unlocker", # Replace with your Web Unlocker API zone name
search_engine=False,
)Ersetzen Sie "unlocker" durch den tatsächlichen Namen Ihrer Bright Data Web Unlocker-Zone.
Beachten Sie auch, dass search_engine auf False gesetzt ist, da wir in diesem Beispiel nicht das SERP-API-Tool verwenden, das sich ausschließlich auf Web Scraping konzentriert.
Tipp: Anstatt die Zonennamen fest zu kodieren, können Sie sie auch aus Ihrer .env-Datei laden. Fügen Sie dazu diese Zeile zu Ihrer .env-Datei hinzu:
BRIGHT_DATA_WEB_UNLOCKER_ZONE="<YOUR_BRIGHT_DATA_WEB_UNLOCKER_ZONE>"Ersetzen Sie den Platzhalter durch den Namen Ihrer echten Web Unlocker-Zone. Anschließend können Sie das Argument web_unlocker_zone aus BrightDataTools entfernen. Die Klasse übernimmt automatisch den Zonennamen aus Ihrer Umgebung.
Hinweis: Um eine Verbindung zu Bright Data herzustellen, sucht BrightDataTools nach Ihrem API-Schlüssel in der Umgebungsvariablen BRIGHT_DATA_API_KEY. Aus diesem Grund haben wir sie im vorherigen Schritt zu Ihrer .env-Datei hinzugefügt.
Erstaunlich! Integrieren Sie Gemini, um Ihren Agno-Web-Scraping-Workflow zu unterstützen.
Schritt #5: Konfigurieren Sie das LLM-Modell von Gemini
Es ist an der Zeit, sich mit Gemini zu verbinden, dem LLM-Anbieter, der in diesem Tutorial ausgewählt wurde. Installieren Sie zunächst das Paket google-genai:
pip install google-genaiDann importieren Sie die Gemini-Integrationsklasse von Agno:
from agno.models.google import GeminiInitialisieren Sie nun Ihr LLM-Modell wie folgt:
llm_model = Gemini(id="gemini-2.5-flash")In dem obigen Ausschnitt ist gemini-2.5-flash der Name des Gemini-Modells, das Ihr Agent verwenden soll. Sie können es durch jedes andere unterstützte Gemini-Modell ersetzen (denken Sie nur daran, dass einige von ihnen nicht frei über die API verwendet werden können).
Unter der Haube erwartet die google-genai-Bibliothek, dass Ihr Gemini-API-Schlüssel in einer Umgebungsvariablen namens GOOGLE_API_KEY gespeichert ist. Um dies einzurichten, fügen Sie die folgende Zeile in Ihre .env-Datei ein:
GOOGLE_API_KEY="<YOUR_GOOGLE_API_KEY>"Ersetzen Sie den Platzhalter durch Ihren tatsächlichen API-Schlüssel. Wenn Sie noch keinen haben, folgen Sie der offiziellen Anleitung, um einen Gemini-API-Schlüssel zu generieren.
Hinweis: Wenn Sie eine Verbindung zu einem anderen LLM-Anbieter herstellen möchten, finden Sie in der offiziellen Dokumentation Anweisungen zur Einrichtung.
Fantastisch! Sie haben nun alle Kernkomponenten, die Sie für den Aufbau Ihres Agno Scraping Agent benötigen.
Schritt #6: Definieren Sie den Scraping Agent
Richten Sie in Ihrer scraper.py-Datei Ihren Agno-Scraping-Agenten wie folgt ein:
agent = Agent(
tools=[bright_data_tools],
model=llm_model,
)Dadurch wird ein Agno-Agent-Objekt erstellt, das Ihren konfigurierten LLM zur Verarbeitung von Prompts verwendet und die Bright Data-Tools für das Web-Scraping nutzt.
Vergessen Sie nicht, diesen Import an den Anfang Ihrer Datei zu stellen:
from agno.agent import AgentGroßartig! Jetzt müssen Sie nur noch eine Anfrage an Ihren Agenten schicken und die gesammelten Daten exportieren.
Schritt #7: Abfrage des Agno Scraping Agent
Lesen Sie die Eingabeaufforderung von der CLI und übergeben Sie sie an Ihren Agno Scraping Agent zur Ausführung:
# Read the agent request from the CLI
request = input("Request -> ")
# Run a task in the AI agent
response = agent.run(request)Die erste Zeile verwendet die in Python eingebaute Funktion input(), um eine vom Benutzer eingegebene Eingabeaufforderung zu lesen. Die Eingabeaufforderung sollte die Scraping-Aufgabe oder Frage beschreiben, die Ihr Agent bearbeiten soll. Die zweite Zeile [ruft run()] im Agenten auf, um die Eingabeaufforderung zu verarbeiten und die Aufgabe auszuführen](https://docs.agno.com/agents/run#running-your-agent).
Um die Antwort schön formatiert in Ihrem Terminal anzuzeigen, verwenden Sie:
pprint_run_response(response)Importieren Sie diese Hilfsfunktion von Agno wie folgt:
from agno.utils.pprint import pprint_run_responsepprint_run_response gibt die Antwort des KI-Agenten aus. Wahrscheinlich möchten Sie aber auch die vom Bright Data-Tool zurückgegebenen Rohdaten extrahieren und speichern. Das erledigen wir im nächsten Schritt!
Schritt #8: Exportieren Sie die gescrapten Daten
Bei der Ausführung einer Scraping-Aufgabe ruft Ihr Agno Web Scraping Agent die konfigurierten Bright Data-Tools im Hintergrund auf. Wenn Sie sicherstellen, dass Ihr Skript auch die von diesen Tools zurückgegebenen Rohdaten exportiert, ist das für Ihren Arbeitsablauf von großem Nutzen. Der Grund dafür ist, dass Sie diese Daten für andere Szenarien (z. B. Datenanalyse) oder zusätzliche agentische Anwendungsfälle wiederverwenden können.
Derzeit hat Ihr Scraping Agent Zugriff auf diese beiden Toolmethoden von BrightDataTools:
scrape_as_markdown(): Scraped eine beliebige Webseite und gibt den Inhalt im Markdown-Format zurück.web_data_feed(): Ruft strukturierte JSON-Daten von beliebten Websites wie LinkedIn, Amazon, Instagram und anderen ab.
Je nach Aufgabe kann die Ausgabe der gescrapten Daten also entweder im Markdown- oder im JSON-Format erfolgen. Um beide Fälle zu behandeln, können Sie die Rohausgabe aus dem Toolergebnis unter response.tools[0].result lesen. Versuchen Sie dann, sie als JSON zu parsen. Gelingt dies nicht, werden die ausgewerteten Daten als Markdown behandelt.
Implementieren Sie die obige Logik mit diesen Codezeilen:
if (len(response.tools) > 0):
# Access the scraped data from the Bright Data tool
scraping_data = response.tools[0].result
try:
# Check if the scraped data is in JSON format
parsed_json = json.loads(scraping_data)
output_extension = "json"
except json.JSONDecodeError:
output_extension = "md"
# Write the scraped data to an output file
with open(f"output.{output_extension}", "w", encoding="utf-8") as file:
file.write(scraping_data) Vergessen Sie nicht, json aus der Python-Standardbibliothek zu importieren:
import jsonGroßartig! Ihr Agno-Web-Scraping-Agent-Workflow ist nun vollständig.
Schritt #9: Alles zusammenfügen
Dies ist der endgültige Code der Datei scraper.py:
from dotenv import load_dotenv
from agno.tools.brightdata import BrightDataTools
from agno.models.google import Gemini
from agno.agent import Agent
from agno.utils.pprint import pprint_run_response
import json
# Load the environment variables from the .env file
load_dotenv()
# Configure the Bright Data tools for Agno integration
bright_data_tools = BrightDataTools(
web_unlocker_zone="web_unlocker", # Replace with your Web Unlocker API zone name
search_engine=False, # As the SERP API tool is not required in this use case
)
# The LLM that will be used by the AI scraping agent
llm_model = Gemini(id="gemini-2.5-flash")
# Define your Agno agent with Bright Data tools
agent = Agent(
tools=[bright_data_tools],
model=llm_model,
)
# Read the agent request from the CLI
request = input("Request -> ")
# Run a task in the AI agent
response = agent.run(request)
# Print the agent response in the terminal
pprint_run_response(response)
# Export the scraped data
if (len(response.tools) > 0):
# Access the scraped data from the Bright Data tool
scraping_data = response.tools[0].result
try:
# Check if the scraped data is in JSON format
parsed_json = json.loads(scraping_data)
output_extension = "json"
except json.JSONDecodeError:
output_extension = "md"
# Write the scraped data to an output file
with open(f"output.{output_extension}", "w", encoding="utf-8") as file:
file.write(scraping_data)In weniger als 50 Codezeilen haben Sie einen KI-gesteuerten Scraping-Workflow erstellt, der Daten von jeder beliebigen Webseite abrufen kann. Das ist die Stärke der Kombination von Bright Data mit Agno für die Agentenentwicklung!
Schritt #10: Starten Sie Ihren Agno Scraping Agent
Starten Sie in Ihrem Terminal den Agno Web Scraping Agent, indem Sie ihn ausführen:
python scraper.pySie werden dann aufgefordert, eine Anfrage einzugeben. Versuchen Sie etwas wie:
Give me a short summary from "https://www.reuters.com/sports/formula1/hulkenberg-rids-himself-unwanted-record-239th-attempt-2025-07-06/"Sie sollten eine ähnliche Ausgabe wie die folgende erhalten:
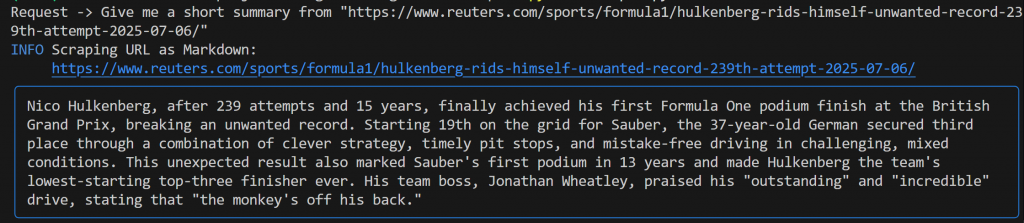
Diese Ausgabe umfasst:
- Die ursprüngliche Aufforderung, die Sie eingereicht haben.
- Ein Protokoll, aus dem hervorgeht, welches Bright Data-Tool für das Scrapen verwendet wurde. In diesem Fall bestätigt es, dass
scrape_as_markdown()aufgerufen wurde. - Eine von Gemini erstellte Zusammenfassung im Markdown-Format, hervorgehoben durch ein blaues Rechteck.
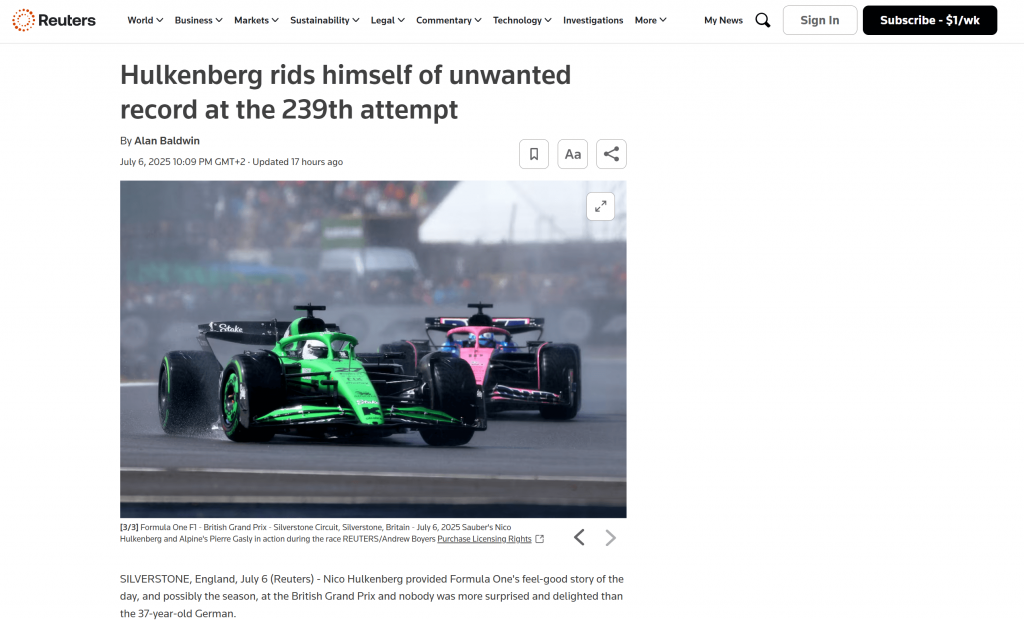
Im Stammordner Ihres Projekts finden Sie eine neue Datei namens output.md. Öffnen Sie sie in einem beliebigen Markdown-Viewer, und Sie erhalten eine Markdown-Version des gescrapten Seiteninhalts:

Wie Sie sehen können, gibt die Markdown-Ausgabe von Bright Data den Inhalt der Original-Webseite genau wieder:
Versuchen Sie nun, Ihren Scraping-Agenten erneut mit einer anderen, spezifischeren Anfrage zu starten:
Summarize the main features of the product on this Amazon page: "https://www.amazon.com/PlayStation%C2%AE5-console-slim-PlayStation-5/dp/B0CL61F39H/" Diesmal könnte Ihre Ausgabe wie folgt aussehen:
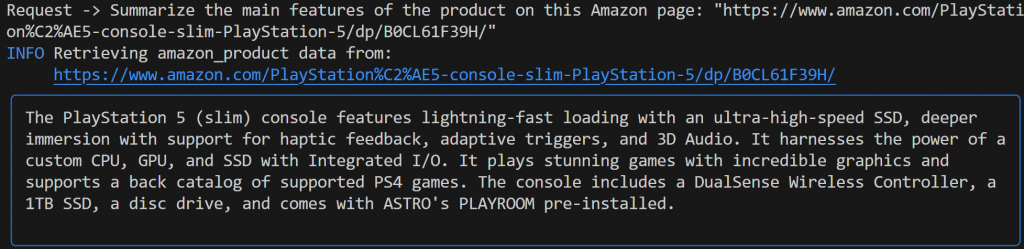
Beachten Sie, dass der von Gemini betriebene Agno-Agent automatisch das web_data_feed-Tool ausgewählt hat, das korrekt für das strukturierte Scraping von Amazon-Produktseiten konfiguriert ist.
Als Ergebnis finden Sie nun eine output.json-Datei in Ihrem Projektordner. Öffnen Sie sie und fügen Sie ihren Inhalt in einen beliebigen JSON-Viewer ein:
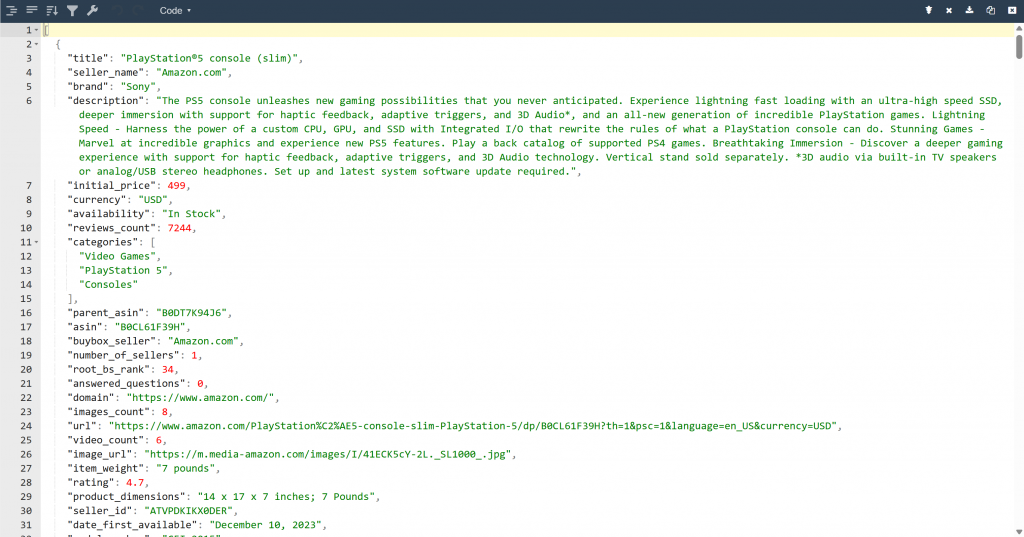
Sehen Sie sich an, wie sauber das Bright Data-Tool strukturierte JSON-Daten aus dieser Amazon-Seite extrahiert hat:
Diese beiden Beispiele zeigen, wie Ihr Agent jetzt Daten von praktisch jeder Webseite abrufen kann. Das gilt sogar für komplexe Websites wie Amazon, die für ihre strengen Abwehrmaßnahmen gegen Scraping bekannt sind (z. B. das berüchtigte Amazon CAPTCHA).
Et voilà! Sie haben soeben nahtloses Web-Scraping in Ihrem KI-Agenten erlebt, unterstützt von Bright Data-Tools und Agno.
Nächste Schritte
Der Web Scraping Agent, den Sie gerade mit Agno erstellt haben, ist nur der Anfang. Von hier aus können Sie verschiedene Möglichkeiten zur Erweiterung und Verbesserung Ihres Projekts erkunden:
- Integrieren Sie eine Speicherebene: Verwenden Sie die native Vektordatenbank von Agno, um die Daten zu speichern, die Ihr Agent über Bright Data sammelt. Dies verleiht Ihrem Agenten ein Langzeitgedächtnis und ebnet den Weg für fortgeschrittene Anwendungsfälle wie agentenbasiertes RAG.
- Erstellen Sie eine benutzerfreundliche Oberfläche: Erstellen Sie eine einfache Web- oder Desktop-Benutzeroberfläche, damit die Benutzer mit Ihrem Agenten auf natürliche Weise chatten können (ähnlich wie bei der Interaktion mit ChatGPT oder Gemini). Das macht Ihr Scraping-Tool viel zugänglicher.
- Erforschen Sie umfassendere Integrationen: Agno bietet eine Vielzahl von Tools und Funktionen, die die Fähigkeiten Ihres Agenten weit über das Scraping hinaus erweitern können. In der Agno-Dokumentation finden Sie Anregungen, wie Sie weitere Datenquellen anbinden, verschiedene LLMs verwenden oder mehrstufige Agenten-Workflows orchestrieren können.
Schlussfolgerung
In diesem Artikel haben Sie gelernt, wie Sie mit Agno einen KI-Agenten für Web-Scraping erstellen können. Dies wurde durch die integrierte Integration von Agno mit Bright Data-Tools ermöglicht. Diese statten das gewählte LLM mit der Fähigkeit aus, Daten von jeder beliebigen Website zu extrahieren.
Denken Sie daran, dass dies nur ein einfaches Beispiel war. Wenn Sie fortgeschrittenere Agenten entwickeln möchten, benötigen Sie Lösungen zum Abrufen, Validieren und Umwandeln von Live-Webdaten. Genau das können Sie in der Bright Data AI-Infrastruktur finden.
Erstellen Sie ein kostenloses Bright Data-Konto und experimentieren Sie mit unseren KI-fähigen Scraping-Tools!




