

Retrieval-Augmented Generation (RAG) und Fine-Tuning sind zwei sehr unterschiedliche Konzepte in der KI und dienen zwei sehr unterschiedlichen Zwecken. RAG ermöglicht es einem LLM, während der Laufzeit auf externe Informationen zuzugreifen. Fine-Tuning ermöglicht es dem LLM, sein internes Wissen für ein tieferes, dauerhaftes Lernen anzupassen.
Am Ende dieses Leitfadens werden Sie in der Lage sein, die folgenden Fragen zu beantworten.
- Was ist Fine-Tuning?
- Was ist RAG?
- Wann sollten Sie Fine-Tuning verwenden?
- Wann sollten Sie RAG verwenden?
- Wie ergänzen sich RAG und Fine-Tuning?
Was ist Fine-Tuning?
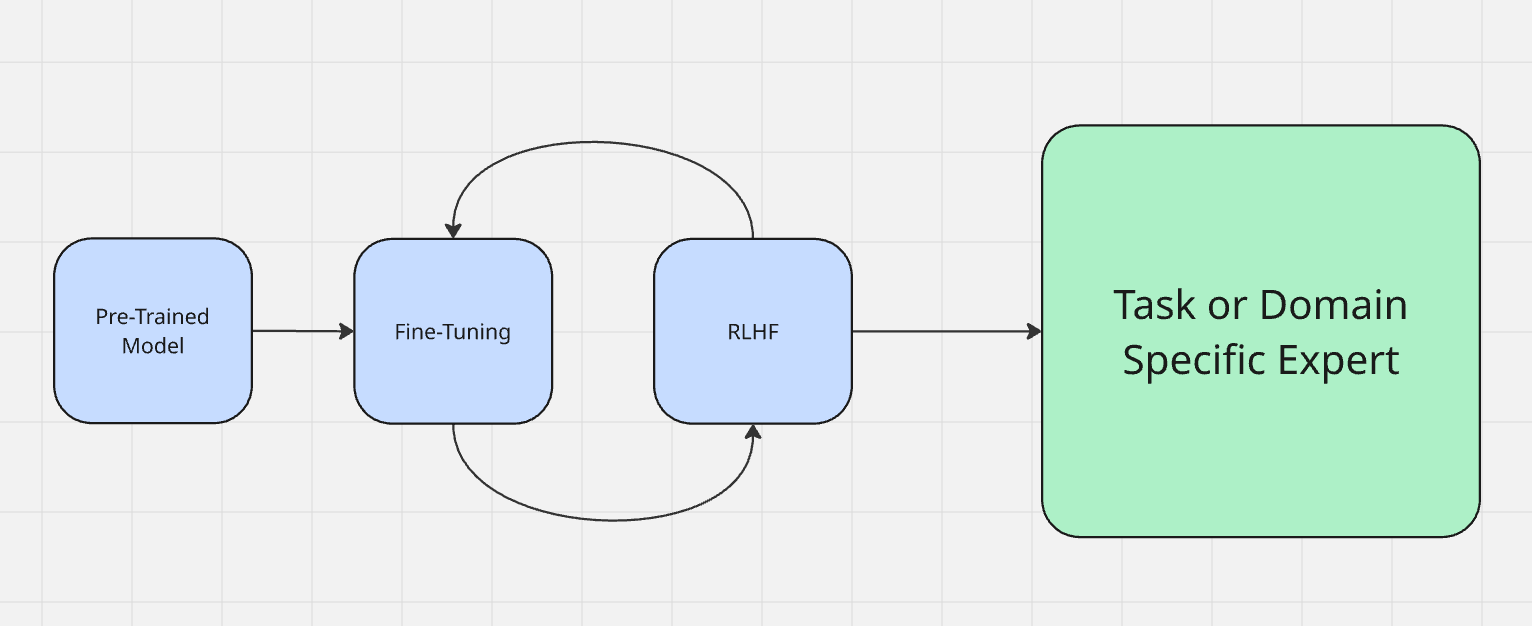
Fine-Tuning wird oft als Teil des eigentlichen Modelltrainingsprozesses betrachtet. Mehr darüber, wie Modelle trainiert werden, erfahren Sie hier. Modelle durchlaufen zunächst eine Phase, die als „Vortraining” bezeichnet wird. Einfach ausgedrückt lernen sie in dieser Phase, Eingaben zu verarbeiten und Ausgaben zu generieren. Nach Abschluss des Vortrainings verfügt das Modell über eine große Menge an Wissen, ist jedoch noch nicht vollständig für dessen Anwendung optimiert.
Normalerweise optimieren wir ein Modell mithilfe von Reinforcement Learning from Human Feedback (RLHF). Bei der Feinabstimmung sprechen Sie tatsächlich mit dem Modell, um dessen Ausgabe zu testen. Wenn ein Modell beispielsweise sagt „der Himmel ist grün”, muss es korrigiert werden, damit es „der Himmel ist blau” sagt. Bei der Feinabstimmung beurteilen Sie die Ausgabe der Maschine und verstärken das gewünschte Verhalten – ähnlich wie wenn Sie Ihrem Hund für gutes Verhalten „Guter Junge!“ sagen oder ihn für schlechtes Verhalten mit einer Zeitung schlagen.
Wenn Sie ein LLM feinabstimmen, bereiten Sie es auf seine tatsächliche Aufgabe in der realen Welt vor. Es gibt zwei Hauptarten der Feinabstimmung.
- Domänenanpassung: Stellen Sie sich vor, Sie möchten mit einem Basismodell wie DeepSeek einen Programmier-Experten erstellen. Sie haben ein starkes Modell mit einer soliden Grundlage, aber es ist noch kein echter Experte in irgendeinem Bereich. Sicher, es versteht Shell-Befehle und den meisten Python-Code, aber es braucht Fachwissen. Hier würden Sie ihm die Feinheiten der Informatik und des Programmierens mit Dingen wie StackOverflow und LeetCode beibringen. Sobald die Feinabstimmung abgeschlossen ist, haben Sie ein Modell, das schneller und besser Code schreiben kann als jeder Mensch.
- Aufgabenanpassung: Beider Aufgabenanpassung geht es darum, sich an die jeweilige Aufgabe anzupassen. In heutigen LLMs sehen wir dies am häufigsten in tatsächlichen Chats. Anfang 2026 wurde ChatGPT-4o einer sehr intensiven Feinabstimmung unterzogen, um sich an die Stimmung der Person anzupassen, die mit ihm spricht. In diesem Fall wurde RLHF verwendet, um den Bot dazu anzuregen, die Stimmung des Benutzers widerzuspiegeln. Wenn der Benutzer technisch spricht, tut GPT dies ebenfalls. Wenn der Benutzer über Recht spricht, spricht GPT in Juristensprache. Wenn der Benutzer religiös klingt, wird GPT religiös (ja, wirklich).
Die Feinabstimmung wird verwendet, um die tatsächlichen Entscheidungen und Schlussfolgerungen des Modells zu beeinflussen.
Was ist RAG?
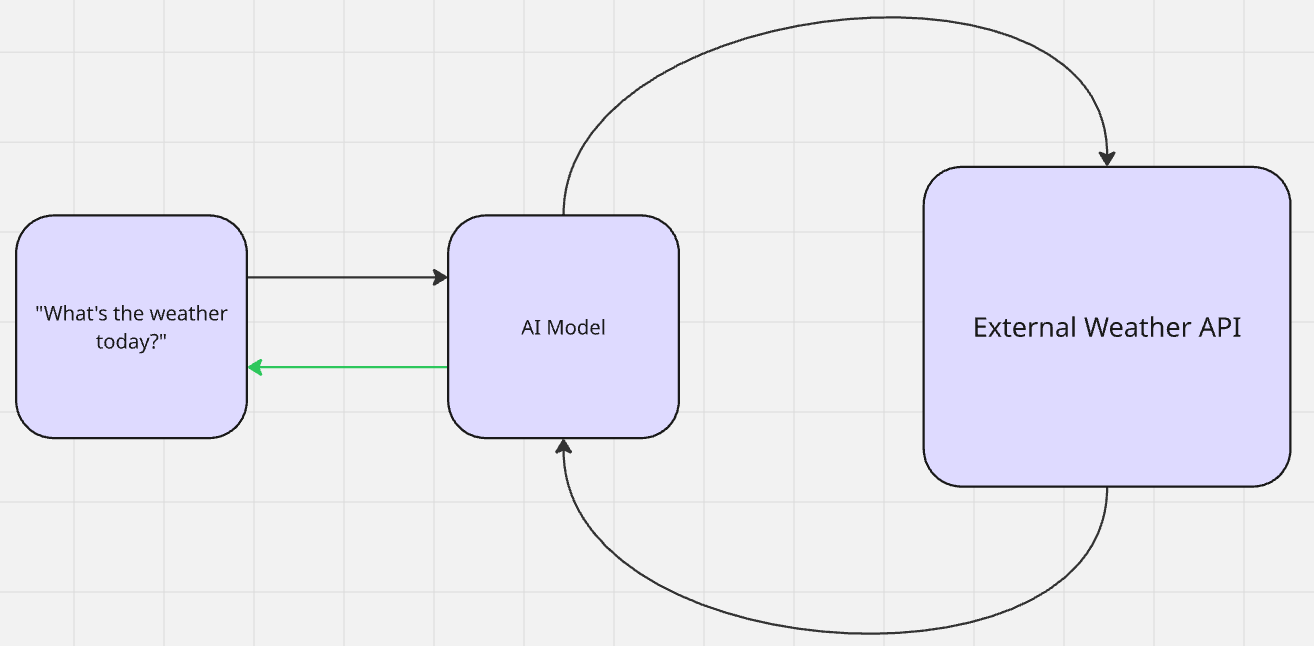
Mit RAG findet kein echtes Lernen statt. Eine KI ruft zusätzliche Daten für die kontextuelle Relevanz ab und generiert eine Ausgabe. Sobald die Ausgabe erstellt ist, kehrt das Modell in seinen Zustand vor dem Abruf zurück. Dies ist eine Form des Zero-Shot-Lernens. Das Modell referenziert die Informationen ohne vorherigen Kontext. Dann nutzt es sein Vortraining, um Schlussfolgerungen zu ziehen und eine Ausgabe zu generieren.
Wenn Sie Gemini fragen: „Wie ist das Wetter heute?“, sucht es das Wetter (erweitert sein Wissen) und teilt Ihnen dann die Ausgabe mit (generiert sie).
Es gibt zwei Haupttypen von RAG: passiv und aktiv. Dies lässt sich am besten anhand der neuesten Generation von Chat-Modellen mit gespeicherten Erinnerungen veranschaulichen.
- Passives RAG: „Erinnerungen“ werden in einer Vektordatenbank gespeichert und später für den Kontext herangezogen. Wenn ein LLM Ihren Namen oder Ihre Vorlieben kennt, handelt es sich um passives RAG. Die herangezogenen Informationen sollen statisch und dauerhaft sein. Die einzige Möglichkeit, „Erinnerungen“ zu entfernen, ist die manuelle Löschung.
- Aktives RAG: Denken Sie an unser Wetterbeispiel von vorhin zurück. Das Wetter ändert sich jeden Tag. Das Modell führt eine aktive Suche (wahrscheinlich über eine API) nach dem Wetter durch. Sobald es sicher ist, dass es das Wetter versteht, gibt es Ihnen die Informationen in seiner eigenen „Persönlichkeit” zurück.
RAG-Pipelines folgen genau diesem Arbeitsablauf: Daten abrufen -> Schlussfolgerung ergänzen -> Ausgabe generieren.
Wann sollten Sie eine Feinabstimmung vornehmen?
Fine-Tuning eignet sich am besten, wenn Sie definieren möchten, wie Ihr Modell tatsächlich denkt. Wenn Sie möchten, dass Wissen und Inferenz dauerhaft sind, sollten Sie ein Fine-Tuning durchführen. Wenn Ihr LLM die Daten wirklich verstehen muss, sollten Sie ein Fine-Tuning durchführen.
Wenn die von Ihrem Modell erzeugte Ausgabe nicht ganz richtig ist, wenn sein Denkprozess auch nur geringfügig daneben liegt, müssen Sie eine Feinabstimmung vornehmen.
- Tonfall und Persönlichkeit: Wenn Sie eine bestimmte Haltung oder Intonation für Ihr Modell im Sinn haben, sollten Sie eine Feinabstimmung vornehmen. Dies ist besonders nützlich bei maßgeschneiderten Chatbots. Als Grok 3 die Welt mit benutzerdefinierten Persönlichkeiten schockierte, war dies zum Teil auf die Feinabstimmung zurückzuführen.
- Randfälle und Genauigkeit: Wenn Ihr Modell Probleme mit Randfällen hat oder seine Trainingsdaten nicht richtig darstellt, ist eine Feinabstimmung erforderlich. Dies gilt insbesondere für Modelle, die in der medizinischen Diagnose eingesetzt werden. Ein Modell, das Gesetze halluziniert, könnte zu Gerichtsverfahren führen. Ein Modell, das eine Krankheit halluziniert, ist für den Patienten gefährlich.
- Modellgröße und Kostensenkung: Durch Feinabstimmung können Sie die Größe und die Betriebskosten Ihres Modells erheblich reduzieren. So gelang es dem Llama-Team beispielsweise, die Ergebnisse von GPT-4 in GPT-3.5 zu destillieren. Weitere Informationen hierzu finden Sie in der Dokumentation zur Feinabstimmung hier.
- Neue Aufgaben und Fähigkeiten: Wenn Sie echte Fähigkeiten hinzufügen möchten, die in einem vortrainierten Modell noch nicht vorhanden sind, müssen Sie es feinabstimmen. Stellen Sie sich vor, Sie haben ein Modell, das nur für die Verwendung von Englisch trainiert wurde, aber Sie benötigen Ergebnisse auf Spanisch – kein Prompt Engineering und kein RAG können dieses Problem lösen, Sie müssen eine Feinabstimmung vornehmen.
Wann sollten Sie RAG verwenden?
RAG eignet sich am besten für Modelle, die bereits korrekt denken. Wenn Ihr Modell nach der Feinabstimmung die richtigen Ergebnisse liefert, ist es wahrscheinlich an der Zeit, RAG für den Zugriff auf externe Daten hinzuzufügen. Ohne den richtigen Kontext sind Modelle für viele Aufgaben oft unbrauchbar – egal wie intelligent sie sind.
Denken Sie an unser Wetterbeispiel von vorhin zurück. Sie könnten das intelligenteste Modell der Welt haben, aber ohne Zugriff auf Live-Daten kann Ihr Modell Ihnen weder das Wetter noch andere Echtzeitinformationen liefern. RAG ist für die folgenden Datenanforderungen sinnvoll.
- Echtzeitdaten: Dies haben wir bereits am Beispiel des Wetters erläutert. Dazu gehören Nachrichten, Finanzprognosen, Systemüberwachung und andere schnelllebige Datenströme.
- Forschungs- oder Bibliotheksassistenten: Manchmal müssen Menschen einfach nur auf die richtige Quelle hingewiesen werden. Wenn Sie eine Frage mit Gemini oder Brave Search stellen, erhalten Sie eine direkte Antwort. Das Modell durchforstet die Dokumentation und verweist Sie auf relevante Quellen.
- Kundensupport: Wenn Sie ein LLM benötigen, um den Helpdesk zu besetzen und allgemeine Fragen zu beantworten, ist RAG schnell und effektiv. KI-Modelle wissen bereits, wie man Fragen beantwortet und Dokumentationen liest, sie benötigen lediglich Zugriff auf die richtigen Inhalte.
- Individuelle Ausgabe: Erinnern Sie sich, wie wir zuvor den benutzerorientierten Tonfall von GPT erwähnt haben? Das ist keine mittelalterliche Zauberei. Das Modell greift auf gespeicherte Fakten in einer Datenbank zurück. Wenn OpenAI Modelle für jeden Benutzer neu trainieren müsste, würde es nicht existieren.
Wie Sie sich zwischen ihnen entscheiden
Wenn Ihr Modell besser denken muss, sollten Sie es feinabstimmen. Wenn Ihr Modell externe Informationen benötigt, verwenden Sie RAG. In der Realität bewegen wir uns in Richtung hybrider Systeme. Sobald Sie Ihr Modell in die Welt hinauslassen, muss es klar denken und auf die richtigen Daten zugreifen können. Die folgende Tabelle hilft Ihnen bei der Entscheidung, wann Sie welches Modell für Ihr Projekt verwenden sollten.
| Situation | Beste Wahl | Warum? |
|---|---|---|
| Die Ausgabe klingt falsch oder passt nicht zusammen | Feinabstimmung | Sie korrigieren die Argumentation, den Tonfall oder das Verhalten |
| Die Ausgabe ist korrekt, aber es fehlen Details | RAG | Ihnen fehlen externe oder domänenspezifische Fakten |
| Sie benötigen aktualisierte Fakten oder Echtzeitdaten | RAG | Statische Modelle können nach dem Training nicht weiter lernen |
| Sie möchten eine starke Leistung in einem neuen Bereich | Feinabstimmung | Sie fügen tiefgreifendes, verinnerlichtes Fachwissen hinzu |
| Sie benötigen sowohl Genauigkeit als auch Aktualität | Beides | Feinabstimmung für Logik, RAG für externes Wissen |
Bright Data Tools für RAG und Feinabstimmung
Hier bei Bright Data bieten wir Ihnen robuste Toolsets, die sowohl Ihre Feinabstimmungs- als auch Ihre RAG-Anforderungen erfüllen. Ob Sie Datensätze für die Feinabstimmung oder Echtzeit-Pipelines benötigen, unsere Systeme bieten Ihnen alles, was Sie brauchen.
Feinabstimmung
- Datensätze: Erhalten Sie historische Daten aus dem gesamten Internet – täglich aktualisiert. Ob Sie nach sozialen Medien, Produktlisten oder sogar Wikipedia suchen, wir haben alles – bereit für das Training.
- Archiv-API: Trainieren Sie mit multimodalen und anderen Quellen, zu denen täglich Petabytes an Daten hinzugefügt werden.
- Annotation: Beschleunigen Sie Ihr Training mit einem flexiblen Annotationsdienst, bei dem Sie zwischen KI-gestützter und von Menschen überwachter Beschriftung wählen können.
RAG
- Such-API: Führen Sie Websuchen in Echtzeit mit jeder gängigen Suchmaschine und benutzerdefinierten Parametern wie Bildern oder Einkaufen durch.
- Unlocker-API: Nutzen Sie unsere verwalteten Proxy-Dienste, um fast jede Website im Internet zu scrapen.
- Agent Browser: Vollständige Browser-Automatisierung für Ihren KI-Agenten.
- MCP-Server: Integrieren Sie Ihren KI-Agenten nahtlos in unsere Tools.
Fazit
Durch Fine-Tuning lernt Ihr Modell, wie es denken soll. RAG ermöglicht Ihrem Modell den Zugriff auf externe Daten, ohne dass es neu trainiert oder aufgebläht werden muss. In der Praxis sollten Sie beides verwenden – nur in unterschiedlichen Entwicklungsphasen.
Wenn Sie verstehen, wann und warum Sie Fine-Tuning und RAG einsetzen sollten, können Sie fundierte Entscheidungen mit Ihren eigenen KI-Modellen treffen. Ganz gleich, ob Sie einen domänenspezifischen Experten erstellen oder ihm Zugriff auf Echtzeitdaten gewähren möchten, unsere Tools stehen Ihnen zur Verfügung, ebenso wie wir.
Melden Sie sich für die Gratis-Testversion an und legen Sie noch heute los!





