

In diesem Leitfaden erfahren Sie mehr über:
- Was das NVIDIA NeMo Framework bietet, insbesondere für die Erstellung von KI-Agenten mit dem NVIDIA NeMo Agent Toolkit.
- Wie Sie Bright Data mithilfe benutzerdefinierter Tools über LangChain in einen NAT-KI-Agenten integrieren können.
- Wie Sie einen NVIDIA NeMo Agent Toolkit-Workflow mit Bright Data Web MCP verbinden.
Lassen Sie uns eintauchen!
Eine Einführung in das NVIDIA NeMo Framework
Das NVIDIA NeMo Framework ist eine umfassende, cloudnative KI-Entwicklungsplattform, die für die Erstellung, Anpassung und Bereitstellung generativer KI-Modelle, einschließlich LLMs und multimodaler Modelle, entwickelt wurde.
Es bietet End-to-End-Tools für den gesamten KI-Lebenszyklus – vom Training und der Feinabstimmung bis hin zur Bewertung und Bereitstellung. NeMo nutzt außerdem groß angelegtes verteiltes Training und enthält Komponenten für Aufgaben wie Datenkuratierung, Modellbewertung und die Implementierung von Sicherheitsvorkehrungen.
Es wird durch eine Open-Source-Python-Bibliothek mit über 16.000 GitHub-Stars und dedizierten Docker-Images unterstützt.
NVIDIA NeMo Agent Toolkit
Das NVIDIA NeMo Agent Toolkit (abgekürzt „NAT“) ist Teil des NVIDIA NeMo-Frameworks und ein Open-Source-Framework zum Erstellen, Optimieren und Verwalten komplexer KI-Agentensysteme.
Es hilft Ihnen, verschiedene Agenten und Tools zu einheitlichen Workflows mit umfassender Beobachtbarkeit, Profilerstellung und Kostenanalyse zu verbinden, fungiert als „Dirigent“ für Multi-Agent-Operationen und unterstützt die Skalierung von KI-Anwendungen.
NAT legt Wert auf Kombinierbarkeit und behandelt Agenten und Tools als modulare Funktionsaufrufe. Es bietet außerdem Funktionen zur Identifizierung von Engpässen, zur Automatisierung von Bewertungen und zur Verwaltung von agentenbasierten KI-Systemen auf Unternehmensebene.
Weitere Informationen finden Sie unter:
- Die offizielle NAT-Dokumentation.
- Die NAT-GitHub-Seite.
Verbindung von LLMs und Live-Daten mit Bright Data Tools
Das NVIDIA NeMo Agent Toolkit bietet die Flexibilität, Anpassbarkeit, Beobachtbarkeit und Skalierbarkeit, die für die Erstellung und Verwaltung von KI-Projekten auf Unternehmensebene erforderlich sind. Es gibt Unternehmen die Möglichkeit, komplexe KI-Workflows zu orchestrieren, mehrere Agenten zu verbinden und Leistung und Kosten zu überwachen.
Allerdings stoßen selbst die ausgefeiltesten NAT-Anwendungen an die Grenzen der LLMs. Dazu gehören veraltete Kenntnisse aufgrund statischer Trainingsdaten und der fehlende Zugriff auf Live-Webinformationen.
Die Lösung besteht darin, Ihren NVIDIA NeMo Agent Toolkit-Workflow mit einem Webdatenanbieter für KI, wie beispielsweise Bright Data, zu integrieren.
Bright Data bietet Tools für Web-Scraping, Suche, Browser-Automatisierung und mehr. Diese Lösungen ermöglichen es Ihrem KI-System, in Echtzeit verwertbare Daten abzurufen und sein volles Potenzial für Unternehmensanwendungen auszuschöpfen!
So verbinden Sie Bright Data mit einem NVIDIA NeMo KI-Agenten
Eine Möglichkeit, die Funktionen von Bright Data in einem NVIDIA NeMo KI Agent zu nutzen, besteht darin, benutzerdefinierte Tools über das NeMo Agent Toolkit zu erstellen.
Diese Tools werden über benutzerdefinierte Funktionen, die von LangChain (oder einer anderen unterstützten Integration mit KI-Agent-Entwicklungsbibliotheken) bereitgestellt werden, mit Bright Data-Produkten verbunden.
Befolgen Sie die nachstehenden Anweisungen!
Voraussetzungen
Um dieses Tutorial durchzuführen, benötigen Sie:
- Python 3.11, 3.12 oder 3.13 lokal installiert.
- Ein Bright Data-Konto, das für die Integration mit den offiziellen LangChain-Tools eingerichtet ist.
- Ein NVIDIA NIM-Konto mit einem konfigurierten API-Schlüssel.
Machen Sie sich jetzt noch keine Gedanken über die Einrichtung der Bright Data- und NVIDIA NIM-Konten, da Sie in speziellen Kapiteln durch diesen Vorgang geführt werden.
Hinweis: Bei Problemen während der Installation oder beim Ausführen des Toolkits stellen Sie sicher, dass Sie eine der unterstützten Plattformen verwenden.
Schritt 1: Abrufen Ihres NVIDIA NIM-API-Schlüssels
Die meisten NVIDIA NeMo Agent-Workflows erfordern eine NVIDIA_API_KEY -Umgebungsvariable. Diese ist erforderlich, um die Verbindung zu den NVIDIA NIM LLMs hinter dem Workflow zu authentifizieren.
Um Ihren API-Schlüssel abzurufen, erstellen Sie zunächst ein NVIDIA NIM-Konto (falls Sie noch keines haben). Melden Sie sich an und klicken Sie auf Ihr Kontobild in der oberen rechten Ecke. Wählen Sie die Option „API-Schlüssel“:
Sie gelangen zur Seite „API-Schlüssel“. Klicken Sie auf die Schaltfläche „API-Schlüssel generieren“, um einen neuen Schlüssel zu erstellen: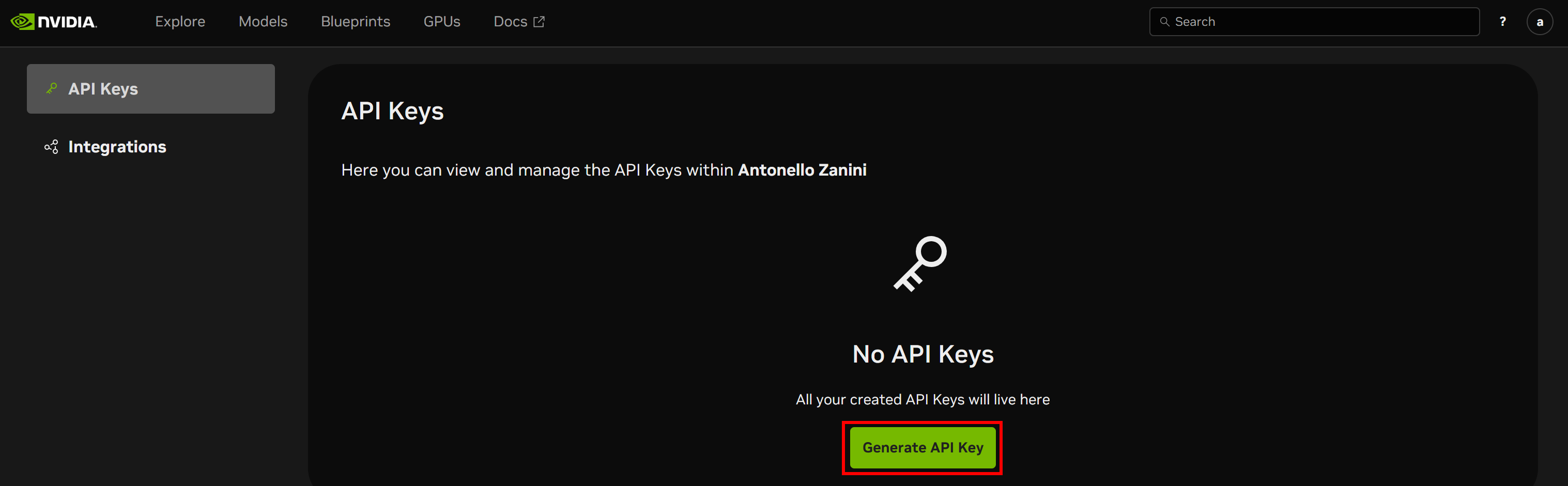
Geben Sie Ihrem API-Schlüssel einen Namen und klicken Sie auf „Generate Key“ (Schlüssel generieren):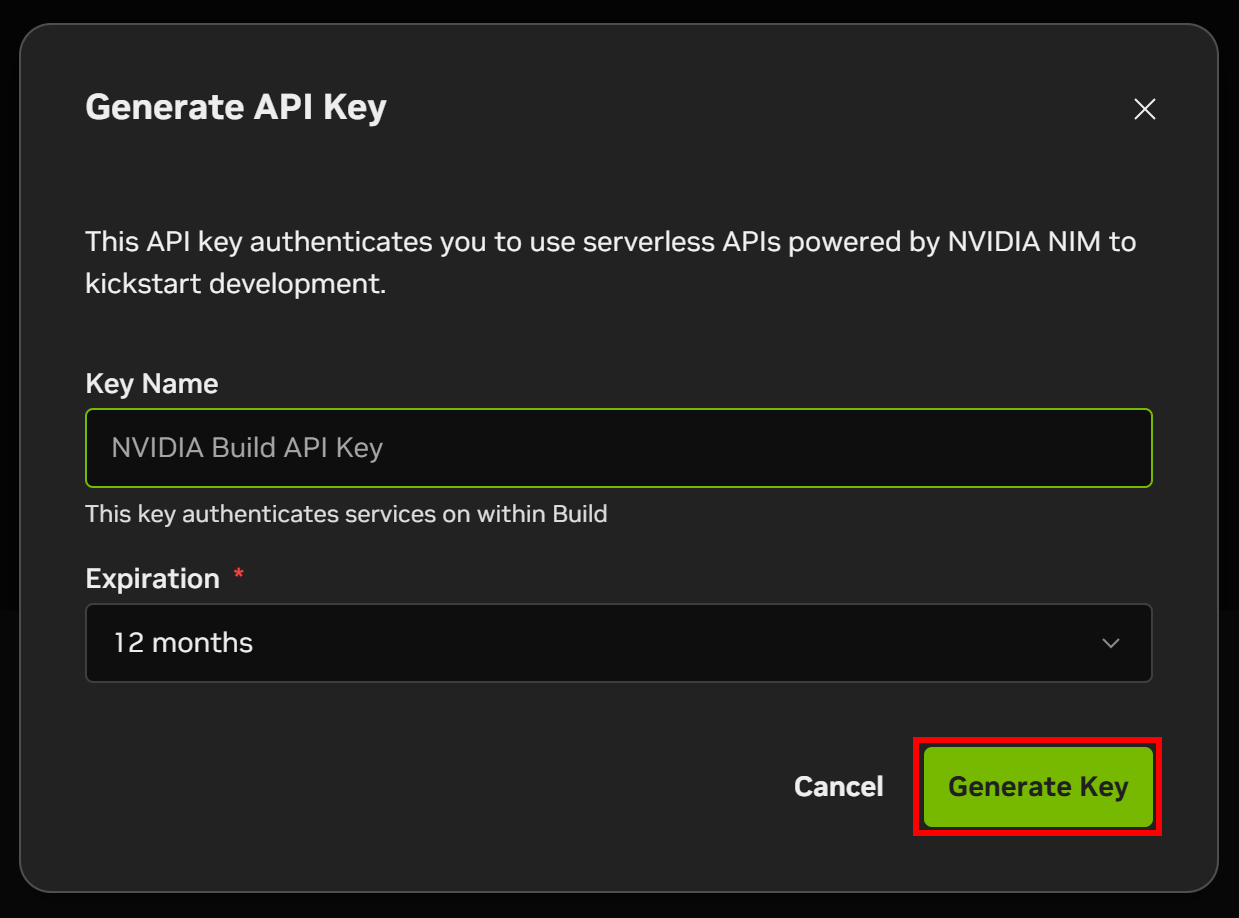
Ein Modalfenster zeigt Ihren API-Schlüssel an. Klicken Sie auf die Schaltfläche „API-Schlüssel kopieren“ und bewahren Sie den Schlüssel an einem sicheren Ort auf, da Sie ihn in Kürze benötigen werden.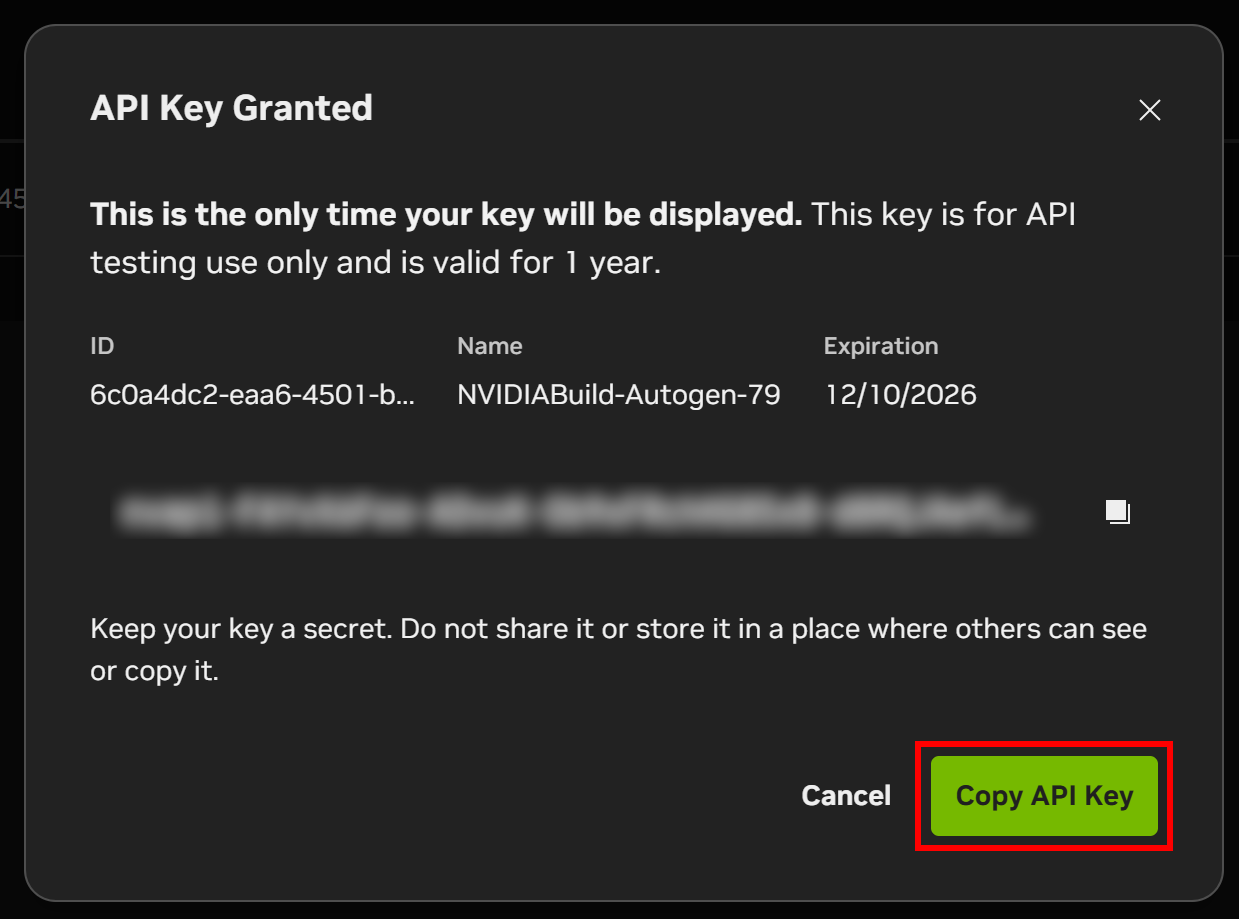
Gut gemacht! Sie können nun das NVIDIA NeMo Agent Toolkit installieren und loslegen.
Schritt 2: Einrichten eines NVIDIA NeMo-Projekts
Um die neueste stabile Version des NeMo Agent Toolkits zu installieren, führen Sie folgenden Befehl aus:
pip install nvidia-natDas NeMo Agent Toolkit hat viele optionale Abhängigkeiten, die zusammen mit dem Kernpaket installiert werden können. Diese optionalen Abhängigkeiten sind nach Frameworks gruppiert.
Nach der Installation sollten Sie Zugriff auf den Befehl „nat“ haben. Überprüfen Sie die Funktion, indem Sie Folgendes ausführen:
nat --versionSie sollten eine Ausgabe ähnlich der folgenden sehen:
nat, Version 1.3.1Erstellen Sie als Nächstes einen Stammordner für Ihre NVIDIA NeMo-Anwendung. Nennen Sie ihn beispielsweise „bright_data_nvidia_nemo“:
mkdir bright_data_nvidia_nemoErstellen Sie in diesem Ordner einen NeMo Agent-Workflow namens „web_data_workflow” mit folgendem Befehl:
nat workflow create --workflow-dir bright_data_nvidia_nemo web_data_workflow Hinweis: Wenn die Fehlermeldung „A required privilege is not held by the client” (Der Client verfügt nicht über die erforderlichen Berechtigungen) angezeigt wird, führen Sie den Befehl als Administrator aus.
Wenn dies erfolgreich war, sollten Sie Protokolle wie die folgenden sehen:
Installation des Workflows „web_data_workflow”...
Workflow „web_data_workflow” erfolgreich installiert.
Workflow „web_data_workflow” erfolgreich in <Ihr_Pfad> erstelltIhr Projektordner bright_data_nvidia_nemo/web_data_workflow enthält nun die folgende Struktur:
bright_data_nvidia_nemo/web_data_workflow/
├── configs -> src/web_data_workflow/configs
├── data -> src/text_file_ingest/data
├── pyproject.toml
└── src/
├── web_data_workflow.egg-info/
└── web_data_workflow/
├── __init__.py
├── configs/
│ └── config.yml
├── data/
├── __init__.py
├── register.py
└── web_data_workflow.pyDie einzelnen Dateien und Ordner haben folgende Bedeutung:
configs/→src/web_data_workflow/configs: Symlink für einfachen Zugriff auf die Workflow-Konfiguration.data/→src/text_file_ingest/data: Symlink zum Speichern von Beispieldaten oder Eingabedateien.pyproject.toml: Projekt-Metadaten und Abhängigkeitsdatei.src/: Verzeichnis mit dem Quellcode.web_data_workflow.egg-info/: Von Python-Paketierungstools erstellter Metadatenordner.web_data_workflow/: Hauptmodul des Workflows.__init__.py: Initialisiert das Modul.configs/config.yml: Workflow-Konfigurationsdatei, in der Sie das Laufzeitverhalten definieren (LLM-Konfiguration, Funktions-/Tool-Definitionen, Agententyp und -einstellungen, Workflow-Orchestrierung usw.).
data/: Verzeichnis zum Speichern von workflow-spezifischen Daten, Beispiel-Eingaben oder Testdateien.register.py: Registrierungsmodul zum Verbinden Ihrer benutzerdefinierten Funktionen mit NAT.web_data_workflow.py: Beispieldatei zur Definition benutzerdefinierter Tools.
Öffnen Sie das Projekt in Ihrer bevorzugten Python-IDE und machen Sie sich mit den generierten Dateien vertraut.
Sie werden sehen, dass sich die Workflow-Definition in der folgenden Datei befindet:
bright_data_nvidia_nemo/web_data_workflow/web_data_workflow/configs/config.ymlÖffnen Sie diese Datei, um die folgende YAML-Konfiguration anzuzeigen:
functions:
current_datetime:
_type: current_datetime
web_data_workflow:
_type: web_data_workflow
prefix: "Hello:"
llms:
nim_llm:
_type: nim
model_name: meta/llama-3.1-70b-instruct
temperature: 0.0
workflow:
_type: react_agent
llm_name: nim_llm
tool_names: [current_datetime, web_data_workflow]Dies definiert einen ReAct-Agent-Workflow, der auf dem Modell meta/llama-3.1-70b-instruct von NVIDIA NIM basiert und Zugriff auf Folgendes hat:
- Das integrierte
current_datetime-Tool. - Das benutzerdefinierte Tool
web_data_workflow.
Insbesondere das Tool web_data_workflow selbst ist definiert in:
bright_data_nvidia_nemo/web_data_workflow/web_data_workflow/web_data_workflow.pyDieses Beispiel-Tool nimmt eine Texteingabe entgegen und gibt sie mit einem vordefinierten Präfix (z. B. „Hallo:”) zurück.
Großartig! Sie haben nun einen Workflow mit dem NAT bereit.
Schritt 3: Testen Sie den aktuellen Workflow
Bevor Sie den generierten Workflow anpassen, sollten Sie sich zunächst mit ihm vertraut machen und seine Funktionsweise verstehen. So können Sie den Workflow leichter an Bright Data anpassen.
Navigieren Sie zunächst zum Workflow-Ordner in Ihrem Terminal:
cd ./bright_data_nvidia_nemo/web_data_workflowBevor Sie den Workflow ausführen, müssen Sie die Umgebungsvariable NVIDIA_API_KEY festlegen. Führen Sie unter Linux/macOS Folgendes aus:
export NVIDIA_API_KEY="<YOUR_NVIDIA_API_KEY>"Unter Windows PowerShell führen Sie entsprechend Folgendes aus:
$Env:NVIDIA_API_KEY="<IHR_NVIDIA_API_KEY>"Ersetzen Sie den Platzhalter <YOUR_NVIDIA_API_KEY> durch den zuvor abgerufenen NVIDIA NIM API-Schlüssel.
Testen Sie nun den Workflow mit dem Befehl nat run wie folgt:
nat run --config_file configs/config.yml --input "Hey! Wie geht's?"Dadurch wird die Datei config.yml (über den Symlink configs/ ) geladen und die Eingabeaufforderung „Hey! Wie geht's?“ gesendet.
Sie sollten eine Ausgabe wie diese sehen: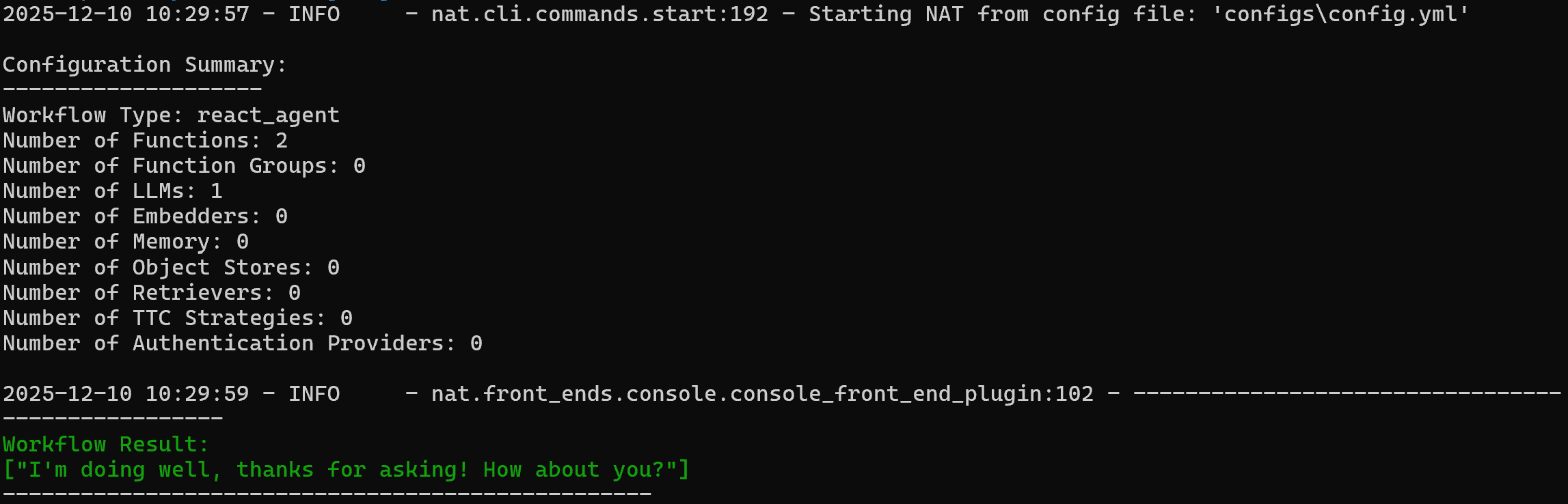
Beachten Sie, dass der Agent mit folgender Antwort reagiert hat:
Mir geht es gut, danke der Nachfrage! Und dir?Um zu überprüfen, ob das benutzerdefinierte Tool web_data_workflow funktioniert, versuchen Sie eine Eingabeaufforderung wie:
nat run --config_file configs/config.yml --input „Verwende das Tool web_data_workflow für ‚World!‘“Da das Tool „web_data_workflow“ mit dem Präfix „Hello:“ konfiguriert ist, lautet die erwartete Ausgabe:
Workflow-Ergebnis:
['Hello: World!']Beachten Sie, dass das Ergebnis dem erwarteten Verhalten entspricht: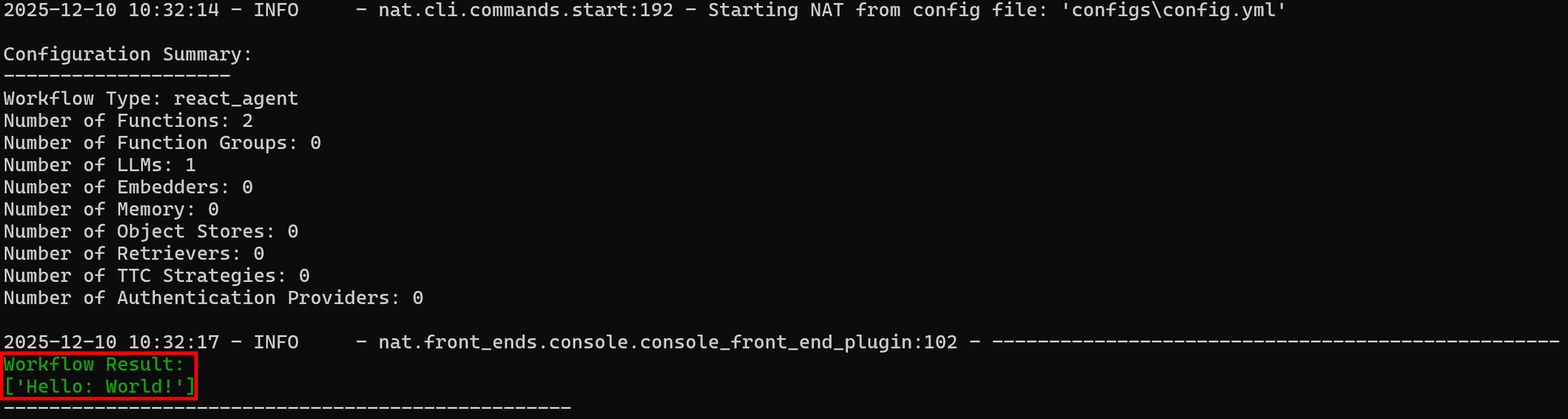
Fantastisch! Ihr NAT-Workflow funktioniert einwandfrei. Sie können ihn nun in Bright Data integrieren.
Schritt 4: Installieren Sie die LangChain Bright Data Tools
Eine der Besonderheiten des NVIDIA NeMo Agent Toolkits ist, dass es mit anderen KI-Bibliotheken zusammenarbeitet, darunter LangChain, LlamaIndex, CrewAI, Agno, Microsoft Semantic Kernel, Google ADK und viele andere.
Um die Integration mit Bright Data zu vereinfachen, werden wir, anstatt das Rad neu zu erfinden, die offiziellen Bright Data-Tools für LangChain verwenden.
Weitere Informationen zu diesen Tools finden Sie in der offiziellen Dokumentation oder in diesen Blog-Beiträgen:
- Web-Scraping mit LangChain und Bright Data
- Verwendung von LangChain und Bright Data für die Websuche
Bereiten Sie die Verwendung von LangChain im NVIDIA NeMo Agent Toolkit vor, indem Sie die folgenden Bibliotheken installieren:
pip install „nvidia-nat[langchain]” langchain-brightdataDie erforderlichen Pakete sind:
„nvidia-nat[langchain]”: Ein Unterpaket zur Integration von LangChain (oder LangGraph) in das NeMo Agent Toolkit.langchain-brightdata: Bietet LangChain-Integrationen für die Suite von Webdatenerfassungstools von Bright Data. Damit können KI-Agenten Suchmaschinenergebnisse erfassen, auf geografisch eingeschränkte oder durch Anti-Bot-Maßnahmen geschützte Websites zugreifen und strukturierte Daten von beliebten Plattformen wie Amazon, LinkedIn und vielen anderen extrahieren.
Um Probleme bei der Bereitstellung zu vermeiden, stellen Sie sicher, dass die Datei pyproject.toml Ihres Projekts Folgendes enthält:
dependencies = [
"nvidia-nat[langchain]~=1.3",
"langchain-brightdata~=0.1.3",
]Hinweis: Passen Sie die Versionen dieser Pakete nach Bedarf für Ihr Projekt an.
Großartig! Ihr NVIDIA NeMo Agent-Workflow kann nun mit LangChain-Tools integriert werden, um Bright Data-Verbindungen zu vereinfachen.
Schritt 5: Vorbereitung der Bright Data-Integration
Die LangChain Bright Data-Tools funktionieren, indem sie eine Verbindung zu den in Ihrem Konto konfigurierten Bright Data-Diensten herstellen. Die beiden in diesem Artikel vorgestellten Tools sind:
BrightDataSERP: Ruft Suchmaschinenergebnisse ab, um relevante regulatorische Webseiten zu finden. Es stellt eine Verbindung zur SERP-API von Bright Data her.BrightDataUnblocker: Greift auf jede öffentliche Website zu, auch wenn diese geografisch beschränkt oder durch Anti-Bot-Maßnahmen geschützt ist. Dies hilft dem Agenten, Inhalte von einzelnen Webseiten zu scrapen und daraus zu lernen. Es stellt eine Verbindung zur Web Unblocker API von Bright Data her.
Um diese Tools nutzen zu können, benötigen Sie ein Bright Data-Konto, in dem sowohl eine SERP-API-Zone als auch eine Web Unblocker-API-Zone konfiguriert sind. Lassen Sie uns diese einrichten!
Wenn Sie noch kein Bright Data-Konto haben, erstellen Sie ein neues. Andernfalls melden Sie sich an und rufen Sie Ihr Dashboard auf. Navigieren Sie anschließend zur Seite „Proxies & Scraping“ und überprüfen Sie die Tabelle „My Zones“: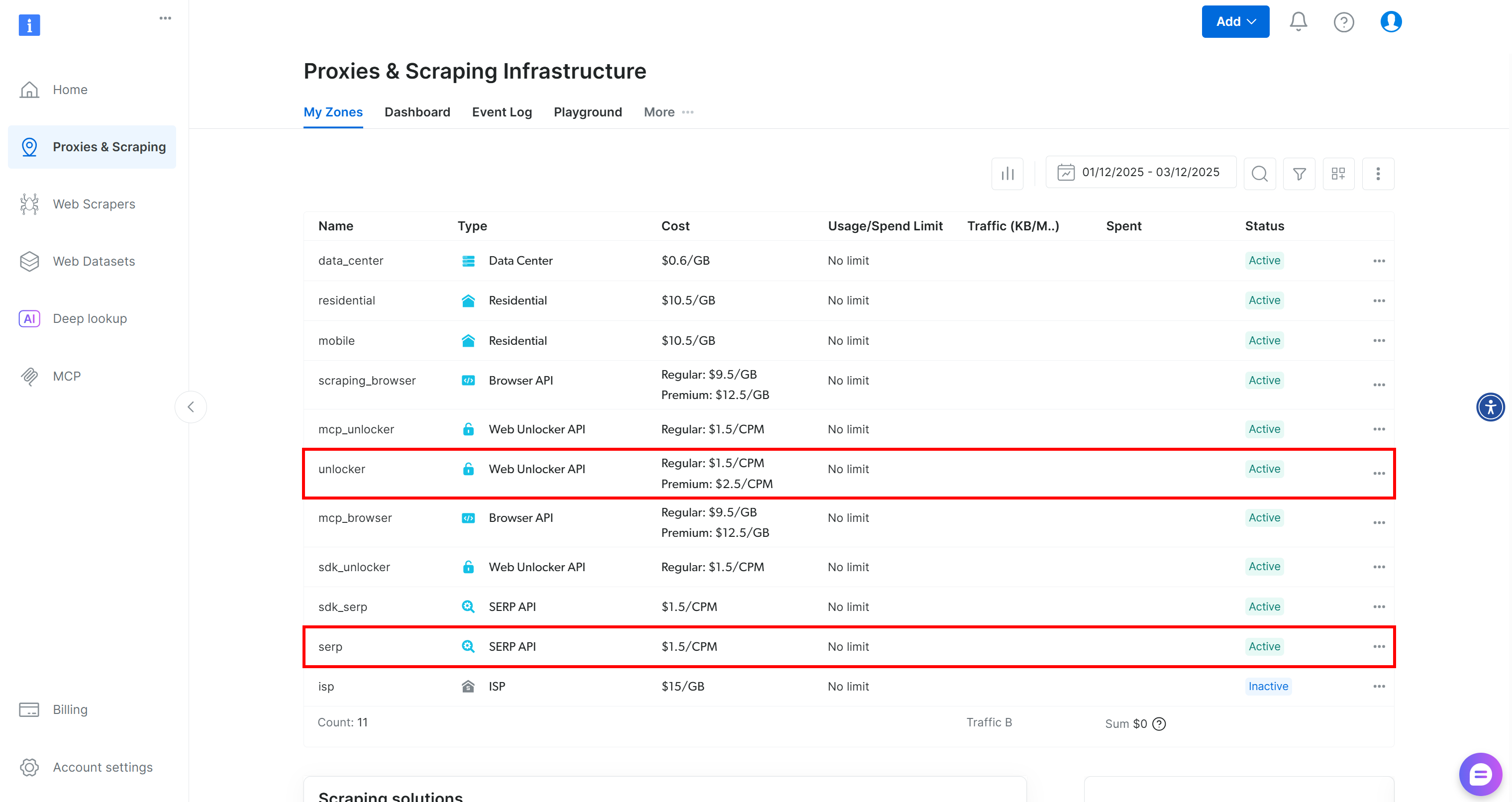
Wenn die Tabelle bereits eine Web Unlocker API-Zone namens „unlocker” und eine SERP-API-Zone namens „serp” enthält, sind Sie startklar. Der Grund dafür ist:
- Das
BrightDataSERPLangChain-Tool verbindet sich automatisch mit einer SERP-API-Zone namens„serp”. - Das
BrightDataUnblockerLangChain-Tool verbindet sich automatisch mit einer Web Unblocker API-Zone namens„web_unlocker”.
Wenn diese beiden Zonen fehlen, müssen Sie sie erstellen. Scrollen Sie auf den Karten „Unblocker API“ und „SERP-API“ nach unten und klicken Sie dann auf die Schaltflächen „Zone erstellen“. Folgen Sie den Anweisungen des Assistenten, um die beiden Zonen mit den erforderlichen Namen hinzuzufügen: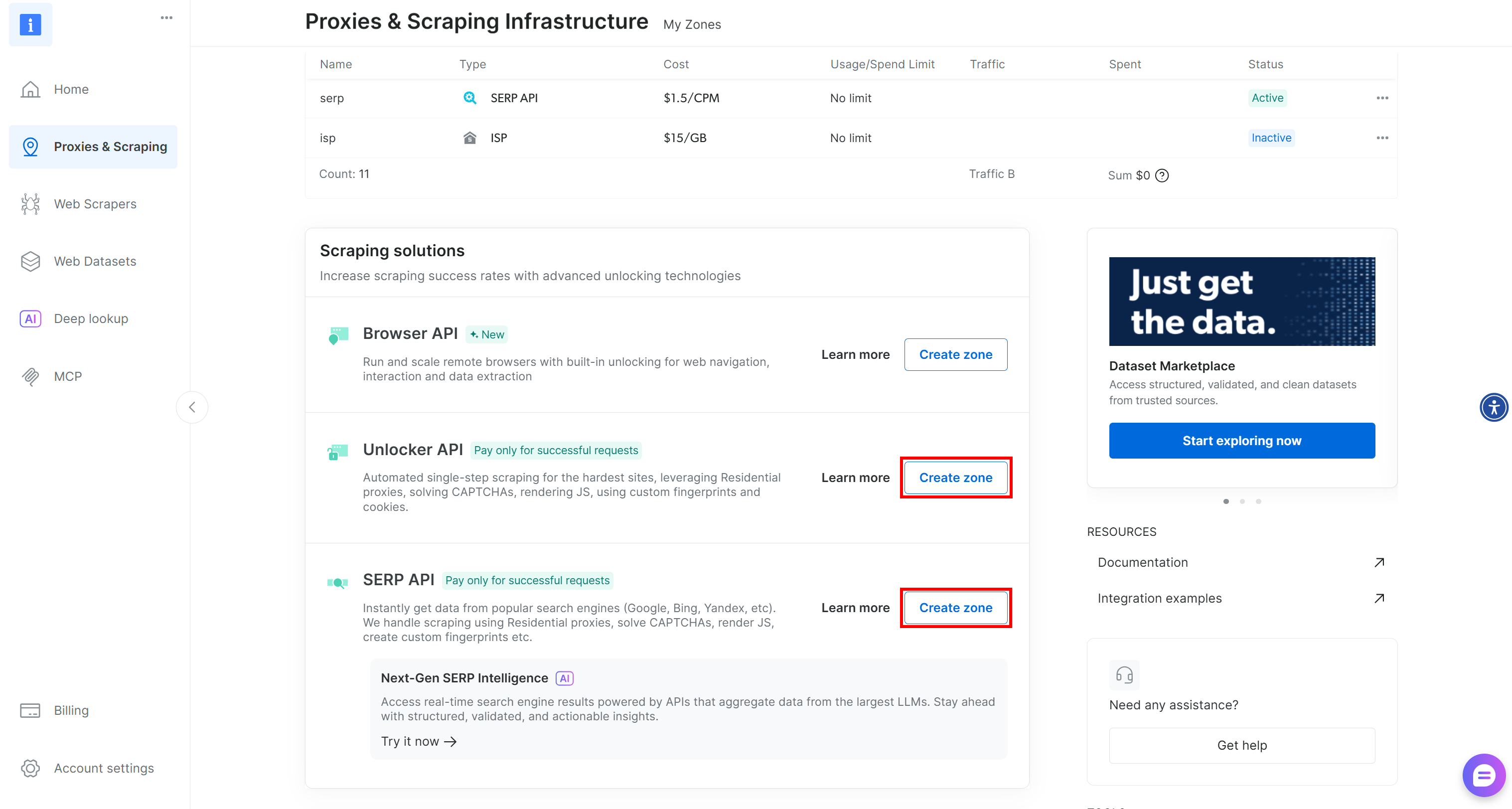
Eine Schritt-für-Schritt-Anleitung finden Sie auf diesen Dokumentationsseiten:
Zuletzt müssen Sie den LangChain Bright Data-Tools mitteilen, wie sie sich mit Ihrem Konto authentifizieren sollen. Generieren Sie Ihren Bright Data API-Schlüssel und speichern Sie ihn als Umgebungsvariable:
export BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"Oder in PowerShell:
$Env:BRIGHT_DATA_API_KEY="<IHR_BRIGHT_DATA_API_SCHLÜSSEL>"Großartig! Sie haben nun alle Voraussetzungen erfüllt, um Ihren NVIDIA NeMo-Agenten über die LangChain-Tools mit Bright Data zu verbinden.
Schritt 6: Definieren Sie die benutzerdefinierten Bright Data-Tools
Jetzt haben Sie alle Bausteine, um neue Tools in Ihrem NVIDIA NeMo Agent Toolkit-Workflow zu erstellen. Mit diesen Tools kann der Agent mit der SERP-API und der Web Unblocker-API von Bright Data interagieren und so das Internet durchsuchen und Daten von jeder öffentlichen Webseite scrapen.
Fügen Sie zunächst eine Datei „bright_data.py“ zum Ordner „src/“ Ihres Projekts hinzu: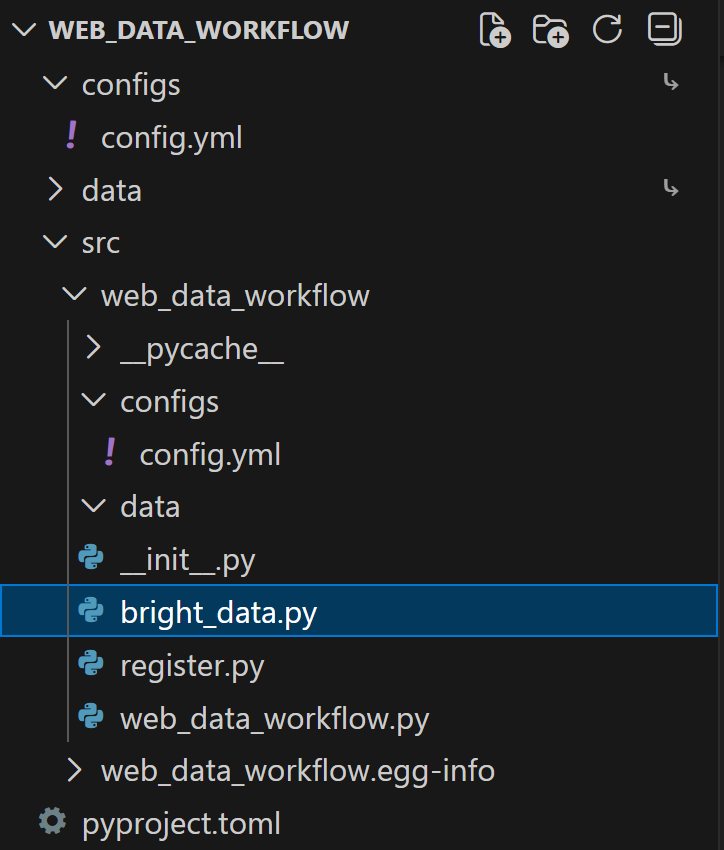
Definieren Sie ein benutzerdefiniertes Tool für die Interaktion mit der SERP-API wie folgt:
# bright_data_nvidia_nemo/web_data_workflow/src/web_data_workflow/bright_data.py
from pydantic import Field
from typing import Optional
from nat.builder.builder import Builder
from nat.builder.function_info import FunctionInfo
from nat.cli.register_workflow import register_function
from nat.data_models.function import FunctionBaseConfig
import json
class BrightDataSERPAPIToolConfig(FunctionBaseConfig, name="bright_data_serp_api"):
"""
Konfiguration für das Bright Data SERP-API-Tool.
Erfordert BRIGHT_DATA_API_KEY.
"""
api_key: str = Field(
default="",
description="Ihr Bright Data API-Schlüssel, der für SERP-Anfragen verwendet wird."
)
# Standard-SERP-Parameter (optionale Überschreibungen)
search_engine: str = Field(
default="google",
description="Suchmaschine für die Abfrage (Standard: google)."
)
country: str = Field(
default="us",
description="Zweistelliger Ländercode für lokalisierte Ergebnisse (Standard: us)."
)
language: str = Field(
default="en",
description="Zweistelliger Sprachcode (Standard: en)."
)
search_type: Optional[str] = Field(
default=None,
description="Art der Suche: None, 'shop', 'isch', 'nws', 'jobs'."
)
device_type: Optional[str] = Field(
default=None,
description="Gerätetyp: None, 'mobile', 'ios', 'android'."
)
parse_results: Optional[bool] = Field(
default=None,
description="Ob strukturiertes JSON anstelle von rohem HTML zurückgegeben werden soll."
)
@register_function(config_type=BrightDataSERPAPIToolConfig)
async def bright_data_serp_api_function(tool_config: BrightDataSERPAPIToolConfig, builder: Builder):
import os
from langchain_brightdata import BrightDataSERP
# API-Schlüssel festlegen, falls fehlend
if not os.environ.get("BRIGHT_DATA_API_KEY"):
if tool_config.api_key:
os.environ["BRIGHT_DATA_API_KEY"] = tool_config.api_key
async def _bright_data_serp_api(
query: str,
search_engine: Optional[str] = None,
country: Optional[str] = None,
language: Optional[str] = None,
search_type: Optional[str] = None,
device_type: Optional[str] = None,
parse_results: Optional[bool] = None,
) -> str:
"""
Führt eine Echtzeit-Suchanfrage mit der Bright Data SERP-API durch.
Argumente:
query (str): Der Text der Suchanfrage.
search_engine (str, optional): Zu verwendende Suchmaschine (Standard: google).
country (str, optional): Ländercode für lokalisierte Ergebnisse.
language (str, optional): Sprachcode für lokalisierte Ergebnisse.
search_type (str, optional): Suchtyp (z. B. None, 'isch', 'shop', 'nws').
device_type (str, optional): Gerätetyp (z. B. None, 'mobile', 'ios').
parse_results (bool, optional): Gibt an, ob strukturierte JSON-Daten zurückgegeben werden sollen.
Gibt zurück:
str: Suchergebnisse im JSON-Format.
"""
serp_client = BrightDataSERP(
bright_data_api_key=os.environ["BRIGHT_DATA_API_KEY"]
)
payload = {
"query": query,
"search_engine": search_engine oder tool_config.search_engine,
"country": country oder tool_config.country,
"language": language oder tool_config.language,
"search_type": search_type oder tool_config.search_type,
"device_type": device_type oder tool_config.device_type,
"parse_results": (
parse_results
wenn parse_results nicht None ist
sonst tool_config.parse_results
),
}
# Explizit auf None gesetzte Parameter entfernen
payload = {k: v for k, v in payload.items() if v is not None}
results = serp_client.invoke(payload)
return json.dumps(results)
yield FunctionInfo.from_fn(
_bright_data_serp_api,
description=_bright_data_serp_api.__doc__,
)
Dieser Ausschnitt definiert ein benutzerdefiniertes NVIDIA NeMo Agent-Tool namens bright_data_serp_api. Zunächst müssen Sie eine BrightDataSERPAPIToolConfig-Klasse definieren, die die erforderlichen Argumente und konfigurierbaren Parameter angibt, die von der SERP-API für Google unterstützt werden (z. B. API-Schlüssel, Suchmaschine, Land, Sprache, Gerätetyp, Suchtyp, ob Ergebnisse im JSON-Format geparst werden sollen usw.).
Als Nächstes wird eine benutzerdefinierte bright_data_serp_api_function() als NeMo-Workflow-Funktion registriert. Die Funktion überprüft, ob der Bright Data API-Schlüssel in der Umgebung festgelegt ist, und definiert dann eine asynchrone _bright_data_serp_api() -Funktion.
_bright_data_serp_api() erstellt eine Suchanfrage mit dem BrightDataSERP-Client von LangChain, ruft sie auf und gibt die Ergebnisse im JSON-Format zurück. Schließlich macht sie die Funktion über FunctionInfo für das NeMo Agent-Framework verfügbar, das alle Metadaten enthält, die der Agent zum Aufrufen der Funktion benötigt.
Hinweis: Die Rückgabe der Ergebnisse als JSON sorgt für eine standardisierte Zeichenfolgenausgabe. Dies ist ein hilfreicher Trick, da die SERP-API-Antworten je nach den konfigurierten Argumenten variieren können (parsiertes JSON, rohes HTML usw.).
Ebenso können Sie ein bright_data_web_unlocker_api- Tool in derselben Datei mit folgendem Befehl definieren:
class BrightDataWebUnlockerAPIToolConfig(FunctionBaseConfig, name="bright_data_web_unlocker_api"):
"""
Konfiguration für das Bright Data Web Unlocker Tool.
Ermöglicht den Zugriff auf geografisch eingeschränkte oder durch Anti-Bot-Maßnahmen geschützte Seiten mit
Bright Data Web Unlocker.
Erfordert BRIGHT_DATA_API_KEY.
"""
api_key: str = Field(
default="",
description="Bright Data API-Schlüssel für den Web Unlocker."
)
country: str = Field(
default="us",
description="Zweistelliger Ländercode, der für die Anfrage simuliert wird (Standard: us)."
)
data_format: str = Field(
default="html",
description="Ausgabeformat: 'html', 'markdown' oder 'screenshot'."
)
zone: str = Field(
default="unblocker",
description='Zu verwendende Bright Data-Zone (Standard: "unblocker").'
)
@register_function(config_type=BrightDataWebUnlockerAPIToolConfig)
async def bright_data_web_unlocker_api_function(tool_config: BrightDataWebUnlockerAPIToolConfig, builder: Builder):
import os
import json
from typing import Optional
from langchain_brightdata import BrightDataUnlocker
# Setze bei Bedarf die Umgebungsvariable
if not os.environ.get("BRIGHT_DATA_API_KEY") and tool_config.api_key:
os.environ["BRIGHT_DATA_API_KEY"] = tool_config.api_key
async def _bright_data_web_unlocker_api(
url: str,
country: Optional[str] = None,
data_format: Optional[str] = None,
) -> str:
"""
Greifen Sie mit Bright Data Web Unlocker auf eine geografisch eingeschränkte oder durch Anti-Bot-Schutz gesicherte URL zu.
Argumente:
url (str): Ziel-URL, die abgerufen werden soll.
country (str, optional): Überschreiben Sie das simulierte Land.
data_format (str, optional): Ausgabeformat des Inhalts („html”, „markdown”, „screenshot”).
Rückgabewerte:
str: Der von der Zielwebsite abgerufene Inhalt.
"""
unlocker = BrightDataUnlocker()
result = unlocker.invoke({
"url": url,
"country": country oder tool_config.country,
"data_format": data_format oder tool_config.data_format,
"zone": tool_config.zone,
})
return json.dumps(result)
yield FunctionInfo.from_fn(
_bright_data_web_unlocker_api,
description=_bright_data_web_unlocker_api.__doc__,
)
Passen Sie die Standardargumentwerte für beide Tools entsprechend Ihren Anforderungen an.
Beachten Sie, dass BrightDataSERP und BrightDataUnlocker versuchen, den API-Schlüssel aus der Umgebungsvariablen BRIGHT_DATA_API_KEY zu lesen (die Sie zuvor eingerichtet haben, sodass Sie startklar sind).
Importieren Sie anschließend diese beiden Tools, indem Sie die folgende Zeile zu register.py hinzufügen:
# bright_data_nvidia_nemo/web_data_workflow/src/web_data_workflow/register.py
# ...
from .bright_data import bright_data_serp_api_function, bright_data_web_unlocker_api_functionDie beiden Tools können nicht in der Datei config.yml verwendet werden. Der Grund dafür ist, dass die automatisch generierte Datei pyproject.toml Folgendes enthält:
[project.entry-points.'nat.components']
web_data_workflow = "web_data_workflow.register"Dies teilt dem Befehl nat mit: „Wenn du den Workflow web_data_workflow lädst, suche nach Komponenten im Modul web_data_workflow.register.“
Hinweis: Auf die gleiche Weise können Sie ein Tool für BrightDataWebScraperAPI erstellen, um es in die Web-Scraping-APIs von Bright Data zu integrieren. Damit kann der Agent strukturierte Datenfeeds von beliebten Websites wie Amazon, Instagram, LinkedIn, Yahoo Finance und vielen anderen abrufen.
Das war’s schon! Jetzt müssen Sie nur noch die Datei config.yml entsprechend aktualisieren, damit der Agent eine Verbindung zu diesen beiden neuen Tools herstellen kann.
Schritt 7: Konfigurieren Sie die Bright Data-Tools
Importieren Sie in config.yml die Bright Data-Tools und übergeben Sie sie mit folgendem Befehl an den Agenten:
# bright_data_nvidia_nemo/web_data_workflow/src/web_data_workflow/configs/config.yml
Funktionen:
# Definieren und Anpassen der benutzerdefinierten Bright Data-Tools
bright_data_serp_api:
_type: bright_data_serp_api
bright_data_web_unlocker_api:
_type: bright_data_web_unlocker_api
data_format: markdown
llms:
nim_llm:
_type: nim
model_name: meta/llama-3.1-70b-instruct # Ersetzen Sie es durch ein unternehmensfähiges KI-Modell.
temperature: 0.0
workflow:
_type: react_agent
llm_name: nim_llm
tool_names: [bright_data_serp_api, bright_data_web_unlocker_api] # Konfigurieren Sie die Bright Data-Tools
Um die zuvor definierten Tools zu verwenden:
- Fügen Sie sie unter dem Abschnitt
„functions”der Dateiconfig.ymlhinzu. Beachten Sie, dass Sie sie über die Argumente anpassen können, die von ihrenFunctionBaseConfig-Klassenbereitgestellt werden. Das Toolbright_data_web_unlocker_apiwurde beispielsweise so konfiguriert, dass es Daten im Markdown-Format zurückgibt, einemFormat, das sich hervorragendfür die Verarbeitung durch KI-Agenten eignet. - Listen Sie die Tools im Feld
„tool_names”imWorkflow-Blockauf, damit der Agent sie aufrufen kann.
Fantastisch! Ihr React-Agent, der auf meta/llama-3.1-70b-instruct basiert, hat nun Zugriff auf beide LangChain-basierten benutzerdefinierten Tools:
bright_data_serp_apibright_data_web_unlocker_api
Hinweis: In diesem Beispiel ist das LLM als NVIDIA NIM-Modell konfiguriert. Je nach Ihren Bereitstellungsanforderungen sollten Sie einen Wechsel zu einem eher unternehmensorientierten Modell in Betracht ziehen.
Schritt 8: Testen Sie den NVIDIA Nemo Agent Toolkit-Workflow
Um zu überprüfen, ob Ihr NVIDIA NeMo Agent Toolkit-Workflow nun mit den Bright Data-Tools interagieren kann, benötigen Sie eine Aufgabe, die sowohl die Websuche als auch die Webdatenextraktion auslöst.
Stellen Sie sich beispielsweise vor, Ihr Unternehmen möchte die neuen Produkte und Preise Ihrer Mitbewerber überwachen, um die Business Intelligence zu unterstützen. Wenn Ihr Mitbewerber Nike ist, könnten Sie eine Eingabeaufforderung wie die folgende schreiben:
Durchsuche das Web, um die neuesten Nike-Schuhe zu finden. Wähle aus den gefundenen Suchergebnissen bis zu drei der relevantesten Webseiten aus, wobei die offiziellen Nike-Webseiten Vorrang haben. Rufe diese Seiten auf und rufe ihren Inhalt im Markdown-Format ab. Gib für das gefundene Schuhmodell den Namen, den Veröffentlichungsstatus, den Preis, wichtige Informationen und einen Link zur offiziellen Nike-Seite (falls verfügbar) an.Stellen Sie sicher, dass die Umgebungsvariablen NVIDIA_API_KEY und BRIGHT_DATA_API_KEY definiert sind, und führen Sie dann Ihren Agenten mit folgendem Befehl aus:
nat run --config_file configs/config.yml --input "Durchsuche das Internet, um die neuesten Nike-Schuhe zu finden. Wähle aus den Suchergebnissen bis zu drei der relevantesten Webseiten aus, wobei die offiziellen Nike-Webseiten Vorrang haben. Rufen Sie diese Seiten auf und laden Sie deren Inhalt im Markdown-Format herunter. Geben Sie für die gefundenen Schuhmodelle den Namen, den Veröffentlichungsstatus, den Preis, wichtige Informationen und einen Link zur offiziellen Nike-Seite (falls verfügbar) an.“Die erste Ausgabe sieht in etwa so aus: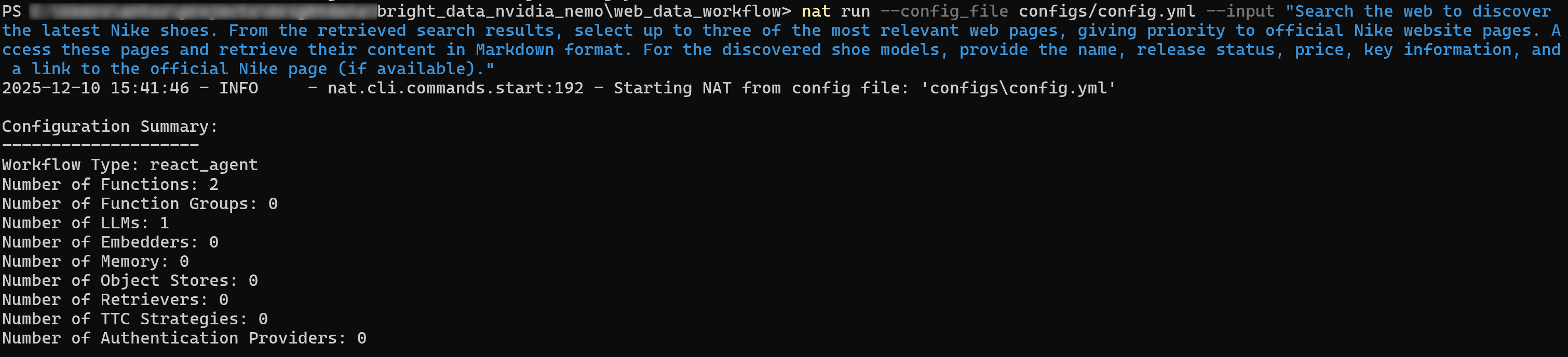
Wenn Sie den Verbose- Modus aktivieren ( verbose: true im Workflow-Block festlegen), sehen Sie, wie der Agent die folgenden Schritte ausführt:
- Aufruf der SERP-API mit Suchanfragen wie „neueste Nike-Schuhe“ und „neue Nike-Schuhe“.
- Wählen Sie die relevantesten Seiten aus, wobei Sie der offiziellen Nike-Seite„Neue Schuhe“Vorrang einräumen.
- Verwenden Sie das Web Unlocker API-Tool, um auf die ausgewählte Seite zuzugreifen und deren Inhalt im Markdown-Format zu scrapen.
- Verarbeiten Sie die extrahierten Daten und erstellen Sie eine strukturierte Liste mit Ergebnissen:
[Air Jordan 11 Retro „Gamma“ – Herrenschuhe](https://www.nike.com/t/air-jordan-11-retro-gamma-mens-shoes-DYkD1oXL/CT8012-047)
Veröffentlichungsstatus: Demnächst erhältlich
Farben: 1
Preis: 235 $
[Air Jordan 11 Retro „Gamma“ – Schuhe für größere Kinder](https://www.nike.com/t/air-jordan-11-retro-gamma-big-kids-shoes-LJyljnZt/378038-047)
Veröffentlichungsstatus: Demnächst erhältlich
Farben: 1
Preis: 190 $
# Der Kürze halber weggelassen...Diese Ergebnisse stimmen genau mit denen überein, die Sie auf der Seite „Neue Schuhe” von Nike finden würden: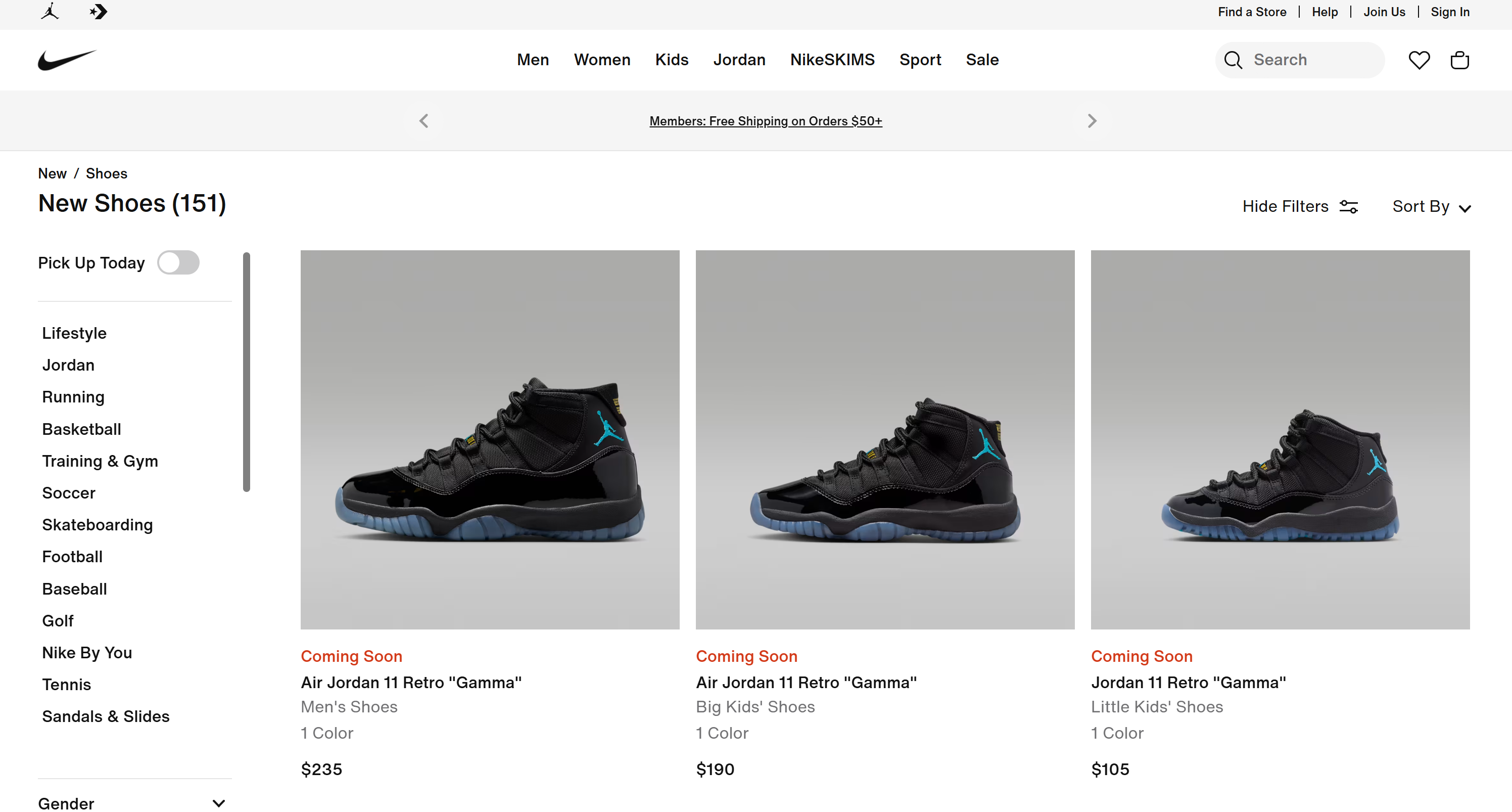
Mission erfüllt! Der KI-Agent hat selbstständig das Internet durchsucht, die richtigen Seiten ausgewählt, sie gecrawlt und strukturierte Produktinformationen extrahiert. All dies wäre ohne die Integration der Bright Data-Tools in Ihren NAT-Workflow nicht möglich gewesen!
Denken Sie daran, dass agentenbasierte Business Intelligence nur einer von vielen Anwendungsfällen ist, die durch Bright Data-Lösungen in Kombination mit dem NVIDIA NeMo Agent Toolkit ermöglicht werden. Probieren Sie verschiedene Tool-Konfigurationen aus, integrieren Sie zusätzliche Tools oder ändern Sie die Eingabeaufforderung, um weitere Szenarien zu erkunden!
Verbinden Sie das NVIDIA NeMo Agent Toolkit über Web MCP mit Bright Data
Eine weitere Möglichkeit, das NVIDIA NeMo Agent Toolkit in Bright Data-Produkte zu integrieren, besteht darin, es mit Web MCP zu verbinden. Weitere Informationen finden Sie in der offiziellen Dokumentation.
Web MCP bietet Zugriff auf über 60 Tools, die auf der Web-Automatisierungs- und Datenerfassungsplattform von Bright Data aufbauen. Selbst in der kostenlosen Version haben Sie bereits Zugriff auf zwei leistungsstarke Tools:
| Tool | Beschreibung |
|---|---|
search_engine |
Ruft Ergebnisse von Google, Bing oder Yandex im JSON- oder Markdown-Format ab. |
scrape_as_markdown |
Kratzen Sie jede Webseite in sauberes Markdown, während Sie Anti-Bot-Maßnahmen umgehen. |
Aber Web MCP glänzt erst richtig im Pro-Modus. Diese Premium-Stufe ist nicht kostenlos, ermöglicht jedoch die strukturierte Datenextraktion für große Plattformen wie Amazon, Zillow, LinkedIn, YouTube, TikTok, Google Maps und mehr – sowie zusätzliche Tools für automatisierte Browser-Aktionen.
Hinweis: Informationen zur Projekteinrichtung und zu den Voraussetzungen finden Sie im vorherigen Kapitel.
Lassen Sie uns nun gemeinsam durchgehen, wie Sie Bright Datas Web MCP innerhalb des NVIDIA NeMo Agent Toolkits verwenden können!
Schritt 1: Installieren Sie das NVIDIA NAT MCP-Paket
Wie bereits erwähnt, ist das NVIDIA NeMo Agent Toolkit modular aufgebaut. Das Kernpaket bildet die Grundlage, und zusätzliche Funktionen werden durch optionale Erweiterungen hinzugefügt.
Für die MCP-Unterstützung ist das erforderliche Paket nvidia-nat[mcp]. Installieren Sie es mit:
pip install nvidia-nat[mcp]Ihr NVIDIA NeMo Agent Toolkit-Agent kann nun eine Verbindung zu MCP-Servern herstellen. Um insbesondere eine Leistung und Zuverlässigkeit auf Unternehmensniveau zu gewährleisten, stellen Sie über den verwalteten Remote-Server eine Verbindung zum Web-MCP von Bright Data her, indem Sie die Remote-Streamable-HTTP-Kommunikation verwenden.
Schritt 2: Konfigurieren Sie die Remote-Web-MCP-Verbindung
Konfigurieren Sie in Ihrer config.yml die Verbindung zum Remote-Web-MCP-Server von Bright Data mithilfe des Streamable-HTTP-Protokolls:
# bright_data_nvidia_nemo/web_data_workflow/src/web_data_workflow/configs/config.yml
function_groups:
bright_data_web_mcp:
_type: mcp_client
server:
transport: streamable-http
url: "https://mcp.brightdata.com/mcp?token=<YOUR_BRIGHT_DATA_API_KEY>&pro=1" tool_call_timeout: 600
auth_flow_timeout: 300
reconnect_enabled: true
reconnect_max_attempts: 3
llms:
nim_llm:
_type: nim
model_name: meta/llama-3.1-70b-instruct # Ersetzen Sie dies durch ein unternehmensfähiges KI-Modell.
temperature: 0.0
workflow:
_type: react_agent
llm_name: nim_llm
tool_names: [bright_data_web_mcp]
Dieses Mal definieren Sie die Tools nicht unter dem Funktionsblock, sondern verwenden function_groups. Dadurch wird die Web-MCP-Verbindung konfiguriert und der gesamte Satz von MCP-Tools vom Remote-Server abgerufen. Die Gruppe wird dann über das Feld tool_names an den Agenten weitergeleitet, genau wie einzelne Tools.
Die Web-MCP-URL enthält den Abfrageparameter &pro=1. Dadurch wird der Pro-Modus aktiviert, der optional ist, aber für den Einsatz in Unternehmen dringend empfohlen wird, da er die gesamte Palette der Tools zur Extraktion strukturierter Daten freischaltet – nicht nur die grundlegenden.
Schritt 3: Überprüfen Sie die Web-MCP-Verbindung
Führen Sie Ihren NVIDIA NeMo Agent mit einer neuen Eingabeaufforderung aus. In den ersten Protokollen sollten Sie sehen, dass der Agent alle von Web MCP bereitgestellten Tools lädt: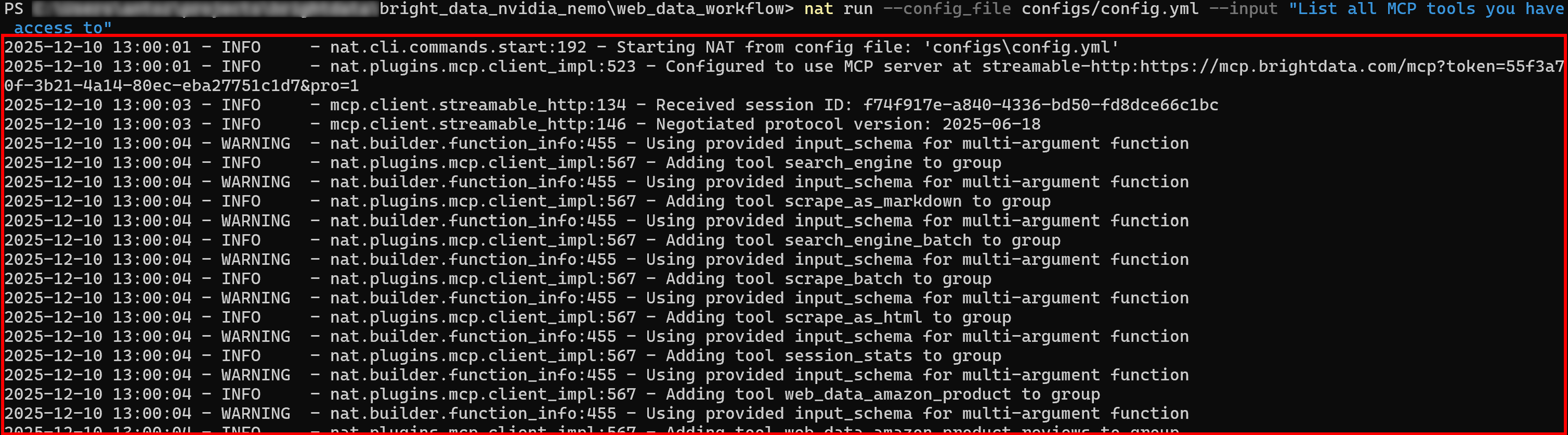
Wenn der Pro-Modus aktiviert ist, werden zunächst alle über 60 Tools geladen.
Anschließend zeigen die Konfigurationszusammenfassungsprotokolle wie erwartet eine einzige Funktionsgruppe an: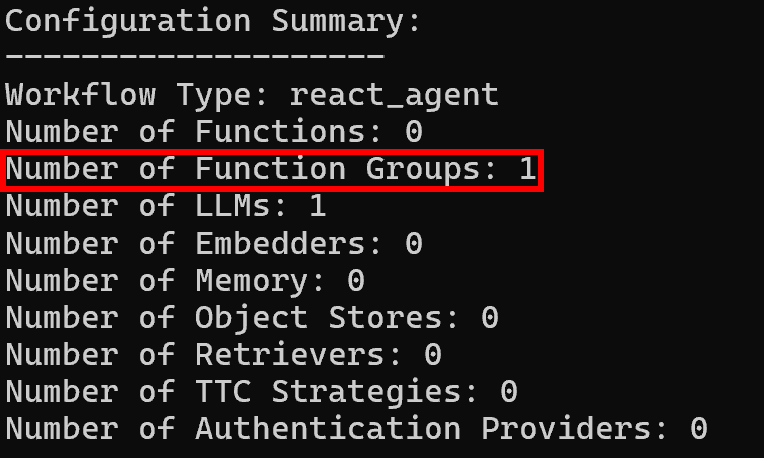
Et voilà! Ihr NVIDIA NeMo Agent Toolkit-Workflow hat nun vollen Zugriff auf alle Funktionen von Bright Data Web MCP.
Fazit
In diesem Blogbeitrag haben Sie gelernt, wie Sie Bright Data in das NVIDIA NeMo Agent Toolkit integrieren können, entweder über benutzerdefinierte Tools, die von LangChain unterstützt werden, oder über Web MCP.
Diese Konfigurationen eröffnen Ihnen die Möglichkeit zu Echtzeit-Websuchen, strukturierter Datenextraktion, Live-Webfeed-Zugriff und automatisierten Webinteraktionen innerhalb von NAT-Workflows. Dabei wird die gesamte Palette der Bright Data-Dienste für KI genutzt, wodurch das volle Potenzial Ihrer KI-Agenten ausgeschöpft wird!
Melden Sie sich noch heute bei Bright Data an und beginnen Sie mit der Integration unserer KI-fähigen Webdaten-Tools!






