
Dieser Leitfaden zeigt Ihnen, wie Sie Bright Data Web MCP mit LangGraph verbinden können, um einen KI-Rechercheagenten zu erstellen, der Live-Webdaten suchen, scrapen und auswerten kann.
In diesem Leitfaden erfahren Sie, wie Sie:
- einen LangGraph-Agenten erstellen, der seine eigene Schlussfolgerungsschleife steuert
- Diesem Agenten mit Bright Data Web MCP Free Tier Live-Webzugriff gewähren
- Such- und Extraktionstools in einen funktionierenden Agenten einbinden
- Diesen Agenten mit Browser-Automatisierung mithilfe der Premium-Tools von Web MCP zu aktualisieren
Einführung in LangGraph
Mit LangGraph können Sie LLM-Anwendungen erstellen, bei denen der Kontrollfluss explizit und leicht überprüfbar ist und nicht in Eingabeaufforderungen oder Wiederholungsversuchen verborgen ist. Jeder Schritt wird zu einem Knoten. Jeder Übergang wird von Ihnen definiert.
Der Agent läuft als Schleife. Das LLM-Modell liest den aktuellen Status und antwortet entweder oder fragt nach einem Tool. Wenn es ein Tool (wie die Websuche) aufruft, wird das Ergebnis wieder zum Status hinzugefügt, und das Modell trifft erneut eine Entscheidung. Wenn es über genügend Informationen verfügt, endet die Schleife.
Dies ist der wesentliche Unterschied zwischen Workflows und Agenten. Ein Workflow folgt festen Schritten. Ein Agent wiederholt in einer Schleife: entscheiden, handeln, beobachten, erneut entscheiden. Diese Schleife ist die gleiche Grundlage, die auch in agentenbasierten RAG-Systemen verwendet wird, bei denen die Abfrage dynamisch statt an festen Punkten erfolgt.
LangGraph bietet Ihnen eine strukturierte Möglichkeit, diese Schleife mit Speicher, Toolaufruf und expliziten Stoppbedingungen aufzubauen. Sie können jede Entscheidung des Agenten sehen und steuern, wann er stoppt.
Warum Bright Data Web MCP mit LangGraph verwenden
LLMs denken gut, aber sie können nicht sehen, was gerade im Web passiert. Ihr Wissen endet zum Zeitpunkt des Trainings. Wenn ein Agent also aktuelle Daten benötigt, neigt das Modell dazu, die Lücke durch Vermutungen zu füllen.
Bright Data Web MCP bietet Ihrem Agenten direkten Zugriff auf Live-Webdaten über Such- und Extraktionstools. Anstatt zu raten, stützt das Modell seine Antworten auf reale, aktuelle Quellen.
LangGraph macht diesen Zugriff in einer Agentenumgebung nutzbar. Ein Agent muss entscheiden, wann er genug weiß und wann er weitere Daten abrufen muss.
Mit Web MCP kann der Agent bei der Beantwortung einer Frage auf die tatsächlich verwendeten Quellen verweisen, anstatt sich auf sein Gedächtnis zu verlassen. Dadurch sind die Ergebnisse vertrauenswürdiger und leichter zu debuggen.
So verbinden Sie Bright Data Web MCP mit einem LangGraph-Agenten
LangGraph steuert die Agentenschleife. Bright Data Web MCP ermöglicht dem Agenten den Zugriff auf Live-Webdaten. Nun müssen beide nur noch miteinander verbunden werden, ohne die Komplexität zu erhöhen.
In diesem Abschnitt richten Sie ein minimales Python-Projekt ein, stellen eine Verbindung zum Web MCP-Server her und machen dessen Tools für einen LangGraph-Agenten verfügbar.
Voraussetzungen
Um diesem Tutorial folgen zu können, benötigen Sie:
- Python-Versionen 3.11+
- Bright Data-Konto
- OpenAI Platform-Konto
Schritt 1: OpenAI-API-Schlüssel generieren
Der Agent benötigt einen LLM-API-Schlüssel, um zu entscheiden, wann Tools verwendet werden sollen. In dieser Konfiguration stammt dieser Schlüssel von OpenAI.
Erstellen Sie einen API-Schlüssel über das OpenAI-Plattform-Dashboard. Öffnen Sie die Seite „API-Schlüssel” und klicken Sie auf „Neuen geheimen Schlüssel erstellen”.
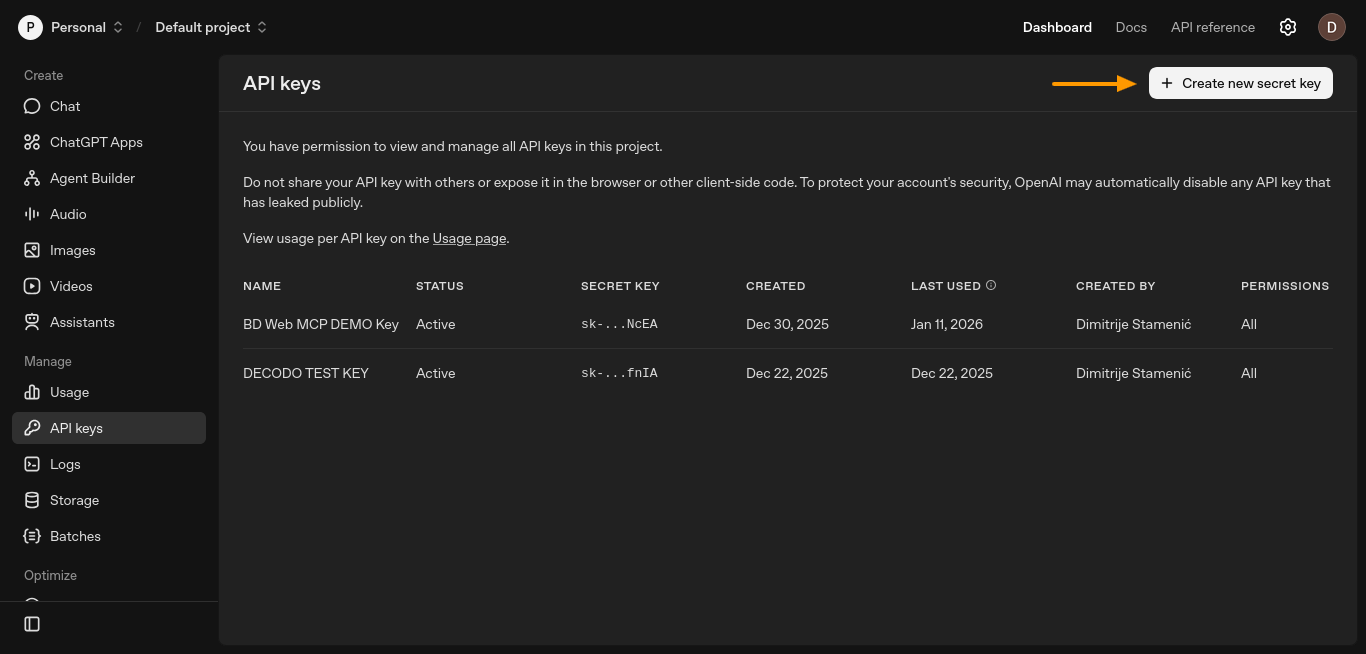
Dadurch wird ein neues Fenster geöffnet, in dem Sie Ihren Schlüssel einrichten können.
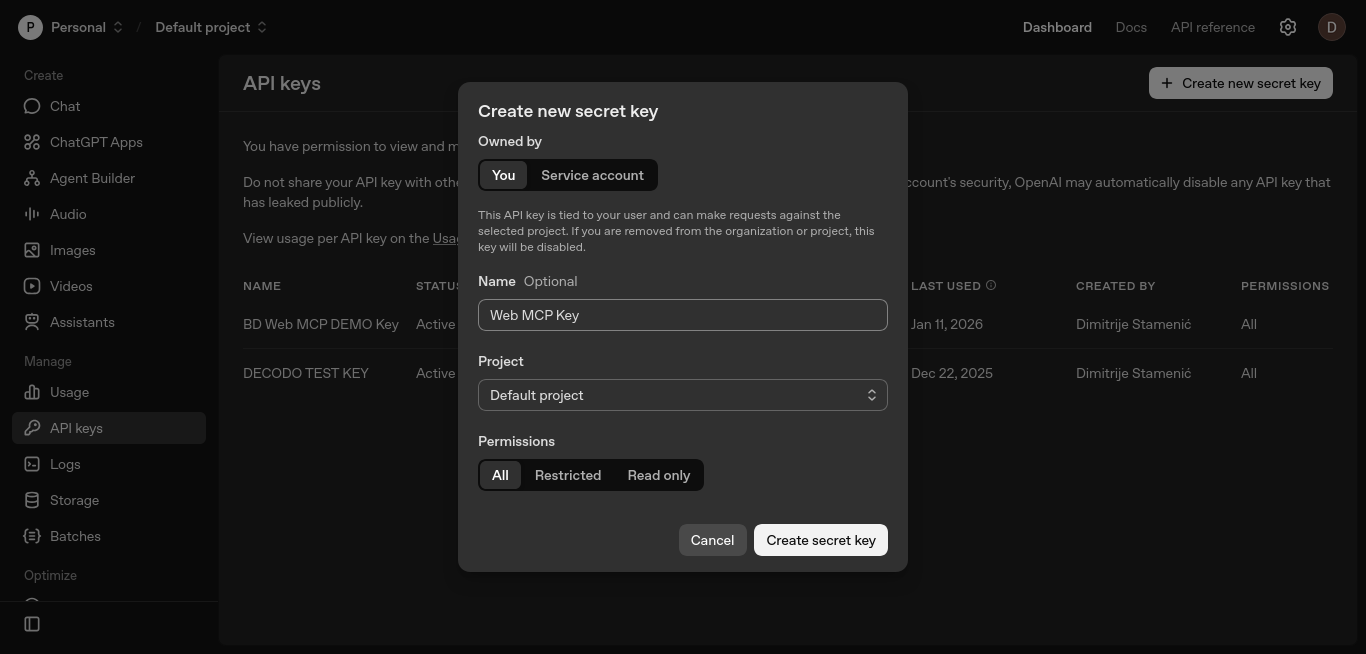
Behalten Sie die Standardeinstellungen bei, benennen Sie den Schlüssel optional und klicken Sie auf „Geheimen Schlüssel erstellen”.
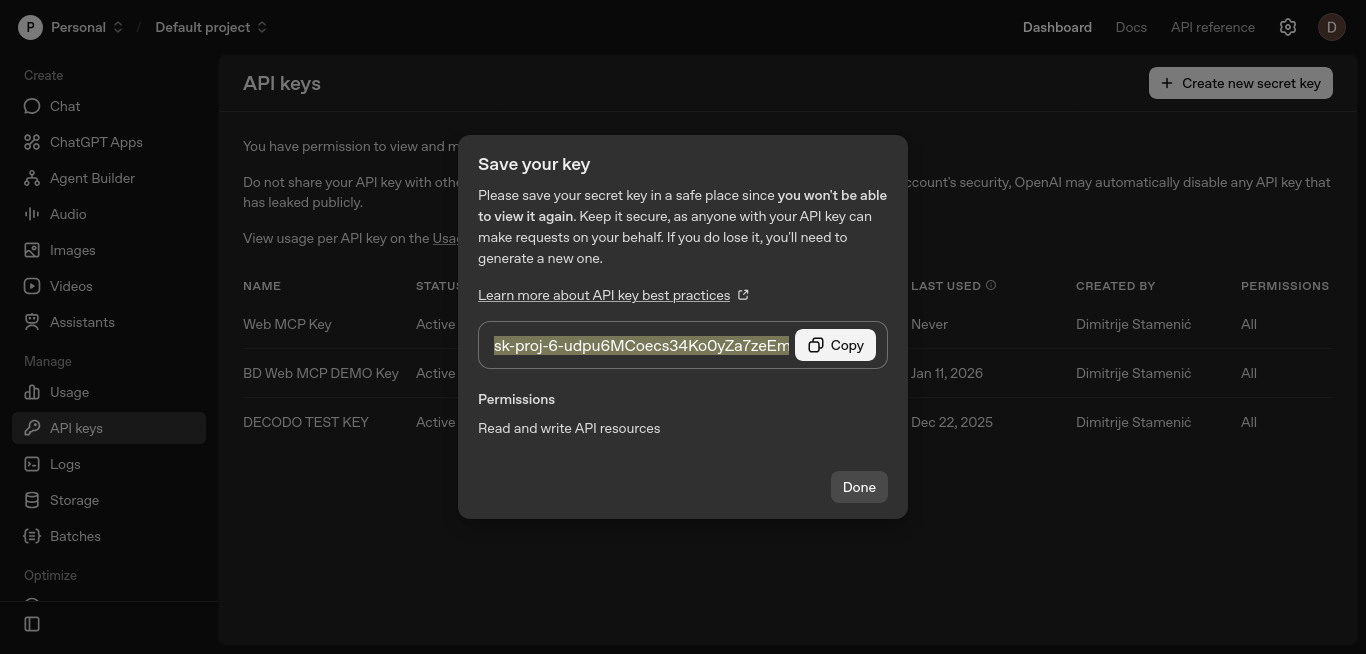
Kopieren Sie den Schlüssel und bewahren Sie ihn sicher auf. Sie fügen ihn in den nächsten Schritten zur Umgebungsvariablen OPENAI_API_KEY hinzu.
Mit diesem Schlüssel kann LangGraph das LLM-Modell aufrufen, das entscheidet, wann Web-MCP-Tools aufgerufen werden sollen.
Schritt 2: Bright Data API-Token generieren
Als Nächstes benötigen Sie einen API-Token von Bright Data. Dieser Token authentifiziert Ihren Agenten beim Web-MCP-Server und ermöglicht ihm, Such- und Scraping-Tools aufzurufen.
Generieren Sie das Token im Bright Data-Dashboard. Öffnen Sie „Kontoeinstellungen“, gehen Sie zu „Benutzer und API-Schlüssel“ und klicken Sie auf „+ Schlüssel hinzufügen“.
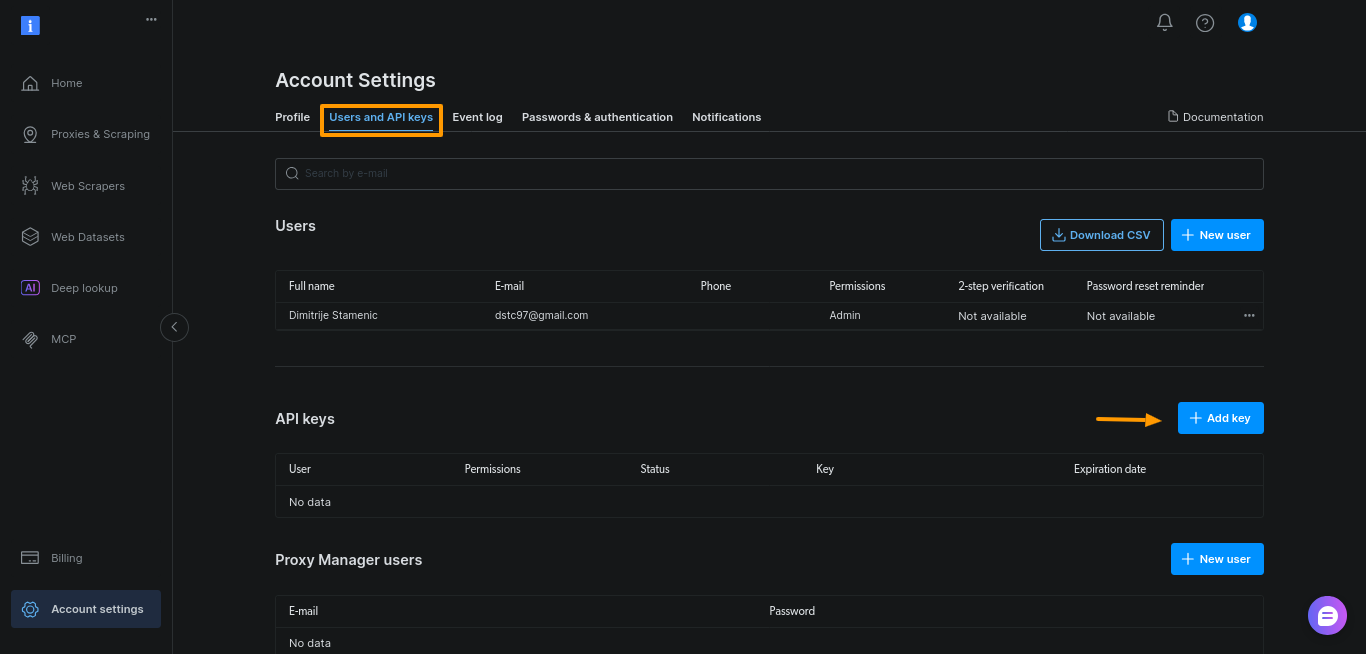
Behalten Sie für diese Anleitung einfach die Standardeinstellungen bei und klicken Sie auf „Speichern“:
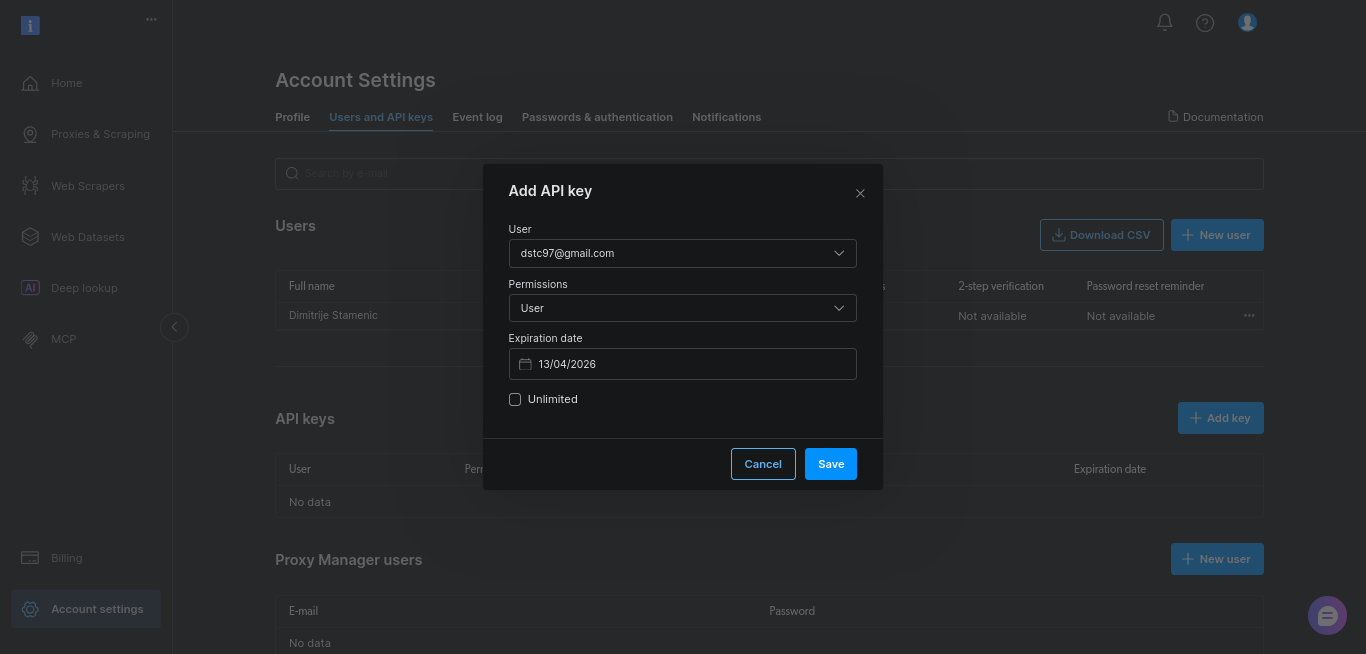
Kopieren Sie den Schlüssel und bewahren Sie ihn sicher auf. Sie fügen ihn in den nächsten Schritten zur Umgebungsvariablen BRIGHTDATA_TOKEN hinzu.
Dieser Token gibt Ihrem Agenten die Berechtigung, über Web MCP auf Live-Webdaten zuzugreifen.
Schritt 3: Einrichten eines einfachen Python-Projekts
Erstellen Sie ein neues Projektverzeichnis und eine virtuelle Umgebung:
mkdir webmcp-langgraph-demo
cd webmcp-langgraph-demo
python3 -m venv webmcp-langgraph-venv Aktivieren Sie die virtuelle Umgebung:
source webmcp-langgraph-venv/bin/activateDadurch bleiben Abhängigkeiten isoliert und Konflikte mit anderen Projekten werden vermieden. Installieren Sie bei aktiver Umgebung nur die erforderlichen Abhängigkeiten. Es handelt sich um dieselben MCP-Adapter, die auch in den LangChain- und LangGraph-Integrationen von Bright Data verwendet werden, sodass die Einrichtung auch bei Wachstum Ihres Agenten konsistent bleibt:
pip install
langgraph
langchain
langchain-openai
langchain-mcp-adapters
python-dotenvErstellen Sie eine .env -Datei, um Ihre API-Schlüssel zu speichern:
touch .envFügen Sie den OpenAI-API-Schlüssel und den Bright Data-Schlüssel in die .env -Datei ein:
OPENAI_API_KEY="Ihr-OpenAI-API-Schlüssel"
BRIGHTDATA_TOKEN="Ihr-BrightData-API-Schlüssel"Behalten Sie den Namen OPENAI_API_KEY unverändert bei. LangChain liest ihn automatisch, sodass Sie den Schlüssel nicht im Code übergeben müssen.
Erstellen Sie abschließend eine einzelne Python-Datei und definieren Sie die Systemaufforderung, die die Rolle, die Grenzen und die Regeln für die Verwendung des Tools durch den Agenten festlegt:
# webmcp-langgraph-demo.py-Datei
SYSTEM_PROMPT = """Sie sind ein Web-Rechercheassistent.
Aufgabe:
- Recherchieren Sie das Thema des Benutzers anhand der Google-Suchergebnisse und einiger Quellen.
- Geben Sie 6–10 einfache Stichpunkte zurück.
- Fügen Sie eine kurze Liste „Quellen:“ mit nur den von Ihnen verwendeten URLs hinzu.
Verwendung der Tools:
- Rufen Sie zunächst das Suchtool auf, um Google-Ergebnisse zu erhalten.
- Wählen Sie 3–5 seriöse Ergebnisse aus und scrapen Sie diese.
- Wenn das Scraping fehlschlägt, versuchen Sie es mit einem anderen Ergebnis.
Einschränkungen:
- Verwenden Sie maximal 5 Quellen.
- Bevorzugen Sie offizielle Dokumente oder Primärquellen.
- Arbeiten Sie zügig: kein tiefes Crawling.
"""Schritt 4: LangGraph-Knoten einrichten
Dies ist der Kern des Agenten. Sobald Sie diesen Kreislauf verstanden haben, ist alles andere nur noch eine Frage der Umsetzung.
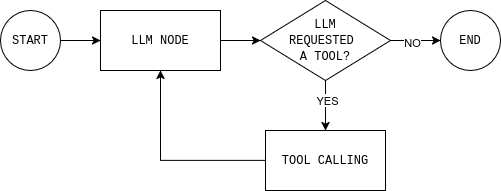
Bevor Sie Code schreiben, ist es hilfreich, die Agentenschleife zu verstehen, die Sie erstellen möchten. Das Diagramm zeigt eine einfache LangGraph-Agentenschleife: Das Modell liest den aktuellen Zustand, entscheidet, ob es externe Daten benötigt, ruft bei Bedarf ein Tool auf, beobachtet das Ergebnis und wiederholt dies, bis es eine Antwort geben kann.
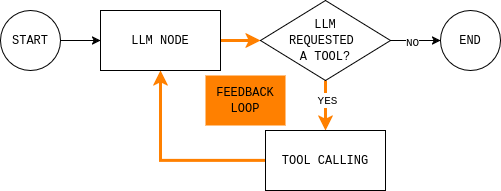
Um diese Schleife zu implementieren, benötigen Sie zwei Knoten (einen LLM-Knoten und einen Tool-Ausführungsknoten) sowie eine Routing-Funktion, die entscheidet, ob fortgefahren oder beendet und eine endgültige Antwort gegeben wird.
Der LLM-Knoten sendet den aktuellen Konversationsstatus und die Systemregeln an das Modell und gibt entweder eine Antwort oder Tool-Aufrufe zurück. Der entscheidende Punkt ist, dass jede Modellantwort an MessagesState angehängt wird, sodass spätere Schritte sehen können, was das Modell entschieden hat und warum.
def make_llm_call_node(llm_with_tools):
async def llm_call(state: MessagesState):
messages = [SystemMessage(content=SYSTEM_PROMPT)] + state["messages"]
ai_message = await llm_with_tools.ainvoke(messages)
return {"messages": [ai_message]}
return llm_callDer Tool-Ausführungsknoten führt alle vom Modell angeforderten Tools aus und zeichnet die Ausgaben als Beobachtungen auf. Durch diese Trennung bleibt das Schlussfolgern im Modell und die Ausführung im Code.
def make_tool_node(tools_by_name: dict):
async def tool_node(state: MessagesState):
last_ai_msg = state["messages"][-1]
tool_results = []
for tool_call in last_ai_msg.tool_calls:
tool = tools_by_name.get(tool_call["name"])
if not tool:
tool_results.append(
ToolMessage(
content=f"Tool not found: {tool_call['name']}",
tool_call_id=tool_call["id"],
)
)
continue
# MCP-Tools sind in der Regel asynchron.
observation = (
await tool.ainvoke(tool_call["args"])
if hasattr(tool, "ainvoke")
else tool.invoke(tool_call["args"])
)
tool_results.append(
ToolMessage(
content=str(observation),
tool_call_id=tool_call["id"],
)
)
return {"messages": tool_results}
return tool_nodeSchließlich entscheidet die Routing-Regel, ob der Graph weiterlaufen oder stoppen soll. In der Praxis beantwortet sie eine einzige Frage: Hat das Modell Tools angefordert?
def should_continue(state: MessagesState) -> Literal["tool_node", END]:
last_message = state["messages"][-1]
if getattr(last_message, "tool_calls", None):
return "tool_node"
return ENDSchritt 5: Alles miteinander verbinden
Alles in diesem Schritt befindet sich innerhalb der Funktion main(). Hier konfigurieren Sie Anmeldedaten, stellen eine Verbindung zu Web MCP her, binden Tools, erstellen den Graphen und führen eine Abfrage aus.
Beginnen Sie damit, die Umgebungsvariablen zu laden und BRIGHTDATA_TOKEN zu lesen. Dadurch bleiben die Anmeldedaten aus dem Quellcode heraus und es kommt zu einem schnellen Fehler, wenn das Token fehlt.
# Umgebungsvariablen aus .env laden
load_dotenv()
# Bright Data-Token lesen
bd_token = os.getenv("BRIGHTDATA_TOKEN")
if not bd_token:
raise ValueError("Missing BRIGHTDATA_TOKEN")Erstellen Sie als Nächstes einen MultiServerMCPClient und verweisen Sie ihn auf den Web-MCP-Endpunkt. Dieser Client verbindet den Agenten mit Live-Webdaten.
# Mit dem Bright Data Web MCP-Server verbinden
client = MultiServerMCPClient({
"bright_data": {
"url": f"https://mcp.brightdata.com/mcp?token={bd_token}",
"transport": "streamable_http",
}
})Hinweis: Web MCP verwendet Streamable HTTP als Standardtransport, was das Streaming und die Wiederholungsversuche von Tools im Vergleich zu älteren SSE-basierten Setups vereinfacht. Aus diesem Grund standardisieren die meisten neueren MCP-Integrationen diesen Transport.
Rufen Sie dann die verfügbaren MCP-Tools ab und indizieren Sie sie nach Namen. Der Tool-Ausführungsknoten verwendet diese Zuordnung, um Aufrufe weiterzuleiten.
# Alle verfügbaren MCP-Tools abrufen (Suchen, Scrapen usw.)
tools = await client.get_tools()
tools_by_name = {tool.name: tool for tool in tools}Initialisieren Sie das LLM und binden Sie die MCP-Tools daran. Dadurch wird der Aufruf von Tools ermöglicht.
# Initialisieren Sie das LLM und erlauben Sie ihm, MCP-Tools aufzurufen.
llm = ChatOpenAI(model="gpt-4.1-mini", temperature=0)
llm_with_tools = llm.bind_tools(tools)Erstellen Sie nun den zuvor gezeigten LangGraph-Agenten. Erstellen Sie einen StateGraph(MessagesState), fügen Sie die LLM- und Tool-Knoten hinzu und verbinden Sie die Kanten so, dass sie der Schleife entsprechen.
# Erstellen Sie den LangGraph-Agenten.
graph = StateGraph(MessagesState)
graph.add_node("llm_call", make_llm_call_node(llm_with_tools))
graph.add_node("tool_node", make_tool_node(tools_by_name))
# Graph-Ablauf:
# START → LLM → (tools?) → LLM → END
graph.add_edge(START, "llm_call")
graph.add_conditional_edges("llm_call", should_continue, ["tool_node", END])
graph.add_edge("tool_node", "llm_call")
agent = graph.compile()Führen Sie den Agenten schließlich mit einer echten Eingabeaufforderung aus. Legen Sie ein recursion_limit fest, um Endlosschleifen zu verhindern.
# Beispiel für eine Rechercheanfrage
topic = "Was ist Bright Data Web MCP?"
# Starten Sie den Agenten
result = await agent.ainvoke(
{
"messages": [
HumanMessage(content=f"Recherchieren Sie dieses Thema:n{topic}")
]
},
# Endlosschleifen verhindern
config={"recursion_limit": 12})
# Die endgültige Antwort ausgeben
print(result["messages"][-1].content)So sieht das in main() aus:
async def main():
# Umgebungsvariablen aus .env laden
load_dotenv()
# Bright Data-Token lesen
bd_token = os.getenv("BRIGHTDATA_TOKEN")
if not bd_token:
raise ValueError("Missing BRIGHTDATA_TOKEN")
# Mit dem Bright Data Web MCP-Server verbinden
client = MultiServerMCPClient({
"bright_data": {
"url": f"https://mcp.brightdata.com/mcp?token={bd_token}",
"transport": "streamable_http",
}
})
# Alle verfügbaren MCP-Tools abrufen (suchen, scrapen usw.)
tools = await client.get_tools()
tools_by_name = {tool.name: tool for tool in tools}
# Initialisiere das LLM und erlaube ihm, MCP-Tools aufzurufen.
llm = ChatOpenAI(model="gpt-4.1-mini", temperature=0)
llm_with_tools = llm.bind_tools(tools)
# LangGraph-Agent erstellen
graph = StateGraph(MessagesState)
graph.add_node("llm_call", make_llm_call_node(llm_with_tools))
graph.add_node("tool_node", make_tool_node(tools_by_name))
# Graph-Ablauf:
# START → LLM → (tools?) → LLM → END
graph.add_edge(START, "llm_call")
graph.add_conditional_edges("llm_call", should_continue, ["tool_node", END])
graph.add_edge("tool_node", "llm_call")
agent = graph.compile()
# Beispiel für eine Rechercheanfrage
topic = "Was ist das Model Context Protocol (MCP) und wie wird es mit LangGraph verwendet?"
# Agent ausführen
result = await agent.ainvoke(
{
"messages": [
HumanMessage(content=f"Recherchiere dieses Thema:n{topic}")
]
},
# Endlosschleifen verhindern
config={"recursion_limit": 12}
)
# Die endgültige Antwort ausgeben
print(result["messages"][-1].content)Hinweis: Eine vollständige, ausführbare Version dieses Agenten finden Sie in diesem GitHub-Repository. Klonen Sie das Repo, fügen Sie Ihre API-Schlüssel zu einer
.env-Dateihinzu und führen Sie das Skript aus, um die vollständige LangGraph + Web MCP-Schleife in Aktion zu sehen.
Verwendung von kostenpflichtigen Web-MCP-Tools zur Überwindung von Herausforderungen beim Web-Scraping mit Browser-Automatisierung
Statisches Scraping funktioniert nicht mehr, sobald Sie über servergerenderte Seiten hinausgehen und zu JavaScript-lastigen oder interaktionsgesteuerten Websites gelangen. Dies ist dieselbe Unterscheidung zwischen statisch und dynamisch, die darüber entscheidet, wann Sie einen echten Browser anstelle von rohem HTML benötigen.
Es versagt auch auf Seiten, die echte Benutzerinteraktion erfordern (unendliches Scrollen, buttongesteuerte Paginierung), wo die Browser-Automatisierung die einzige zuverlässige Option ist.
Web MCP bietet Browser-Automatisierung und erweitertes Scraping-Browser als MCP-Tools an. Für den Agenten sind dies lediglich zusätzliche Optionen, wenn einfachere Tools nicht ausreichen.
Browser-Automatisierungstools in Web MCP aktivieren
Da die Browser-Automatisierungstools von Web MCP nicht in der kostenlosen Version enthalten sind, müssen Sie zunächst im Menü „Abrechnung” in der linken Seitenleiste Guthaben auf Ihr Bright Data-Konto laden.
Aktivieren Sie anschließend die Browser-Automatisierungstools-Gruppe für Ihre MCP-Einrichtung. Öffnen Sie den Abschnitt „MCP” und klicken Sie auf „Bearbeiten”:
Aktivieren Sie nun einfach „Browser-Automatisierung“ und klicken Sie auf „Weiter zur Konfiguration“:
Behalten Sie die Standardeinstellungen bei und klicken Sie auf „Kopieren & Schließen“:
Nach der Aktivierung werden diese Tools neben den Such- und Scrape-Tools angezeigt, wenn der Agent client.get_tools() aufruft.
Erweitern Sie den vorhandenen LangGraph-Agenten für Browser-Automatisierungstools
Der entscheidende Punkt hierbei ist einfach: Sie ändern Ihre LangGraph-Architektur nicht.
Ihr Agent kann bereits:
- Entdeckt Tools dynamisch
- bindet sie an das Modell
- leitet die Ausführung über dieselbe
LLM -> Tool ->Beobachtungsschleife
Durch das Hinzufügen von Browser-Automatisierungstools ändert sich lediglich, welche Tools verfügbar sind.
In der Praxis ändert sich lediglich die MCP-Verbindungs-URL. Anstatt eine Verbindung zum Basis-Endpunkt herzustellen, fordern Sie die erweiterten Scraping- und Browser-Automatisierungstool-Gruppen an:
# Erweiterte Scraping- und Browser-Automatisierung aktivieren
"url": f"https://mcp.brightdata.com/mcp?token={bd_token}&groups=advanced_scraping,browser"Wenn Sie das Skript erneut ausführen, gibt client.get_tools() zusätzliche browserbasierte Tools zurück. Das Modell kann diese auswählen, wenn das statische Scraping dünne oder unvollständige Ergebnisse liefert.
Fazit
LangGraph bietet Ihnen eine klare, überprüfbare Agentenschleife mit Status-, Routing- und Stoppbedingungen, die Sie selbst steuern können. Web MCP ermöglicht dieser Schleife einen zuverlässigen Zugriff auf echte Webdaten, ohne die Scraping-Logik in Prompts oder Code zu verschieben.
Das Ergebnis ist eine klare Trennung der Aufgabenbereiche. Das Modell entscheidet, was zu tun ist. LangGraph entscheidet, wie die Schleife abläuft. Bright Data kümmert sich um die Suche, Extraktion und Blockierung. Wenn etwas fehlschlägt, können Sie sehen, wo und warum es fehlgeschlagen ist.
Ebenso wichtig ist, dass diese Konfiguration Sie nicht in eine Sackgasse führt. Sie können mit einfachen Web-MCP-Tools für schnelle Recherchen beginnen und zu kostenpflichtigen Web-MCP-Tools wechseln, wenn das statische Web-Scraping nicht mehr funktioniert. Die Agent-Architektur bleibt unverändert. Nur die Reichweite des Agenten wird erweitert.






