
In diesem Artikel erfahren Sie:
- Wie Sie mit Google ADK und Vertex KI RAG Engine ein produktionsreifes RAG-System aufbauen
- Wie Sie eine hybride Suche mit semantischer und Stichwort-Suche implementieren
- Wie Sie durch richtige Grundierung und Zitierung Halluzinationen verhindern
- Wie Sie multimodale Inhalte wie Text, Bilder und Tabellen verarbeiten
- Wie Sie Ihr RAG mit Echtzeit-Webdaten mithilfe der Bright Data -Integration verbessern können (optional)
Los geht’s!
Die Herausforderung des modernen Wissensmanagements
Technische Dokumentationen werden in Wikis gespeichert, Produktspezifikationen finden sich in PDF-Dateien, Kundendaten in Datenbanken und institutionelles Wissen in E-Mails. Mitarbeiter verbringen Stunden mit der Suche nach Informationen und stoßen dabei oft auf veraltete oder unvollständige Antworten. Große Sprachmodelle, die auf allgemeinen Daten trainiert wurden, können nicht auf Ihr firmeneigenes Wissen zugreifen. Sie machen oft Fehler, wenn sie nach unternehmensspezifischen Informationen gefragt werden.
RAG-Agenten lösen dieses Problem, indemsie vor der Generierung von Antworten relevante Kontexte aus Ihrer Wissensdatenbank abrufen. Dadurch basiert die KI auf Fakten, Halluzinationen werden reduziert und transparente Quellenangaben zur Überprüfung bereitgestellt.
Was wir entwickeln: Intelligentes RAG-Agentensystem
Wir werden einen produktionsreifen RAG-Agenten entwickeln, der Dokumente aus verschiedenen Quellen aufnimmt, sie zu durchsuchbaren Teilen verarbeitet, sie in Vektordarstellungen umwandelt, relevante Kontexte mithilfe einer hybriden Suche abruft und korrekte Antworten mit korrekten Zitaten generiert, wodurch Ungenauigkeiten vermieden werden.
Das System verwaltet:
- Dokumenteneingabe aus Cloud-Speicher, Drive und lokalen Dateien
- Intelligentes Chunking mit Überlappung und Beibehaltung von Metadaten
- Hybride Abfrage, die semantische Ähnlichkeit und Keyword-Matching kombiniert
- Multimodale Inhalte, einschließlich Bildern und Tabellen
- Erstellung von Zitaten zur Überprüfung von Antworten
- Erkennung und Vermeidung von Fehlern
Voraussetzungen
Richten Sie Ihre Entwicklungsumgebung mit folgenden Komponenten ein:
- Python 3.10 oder höher – Erforderlich für die Kompatibilität mit Google ADK.
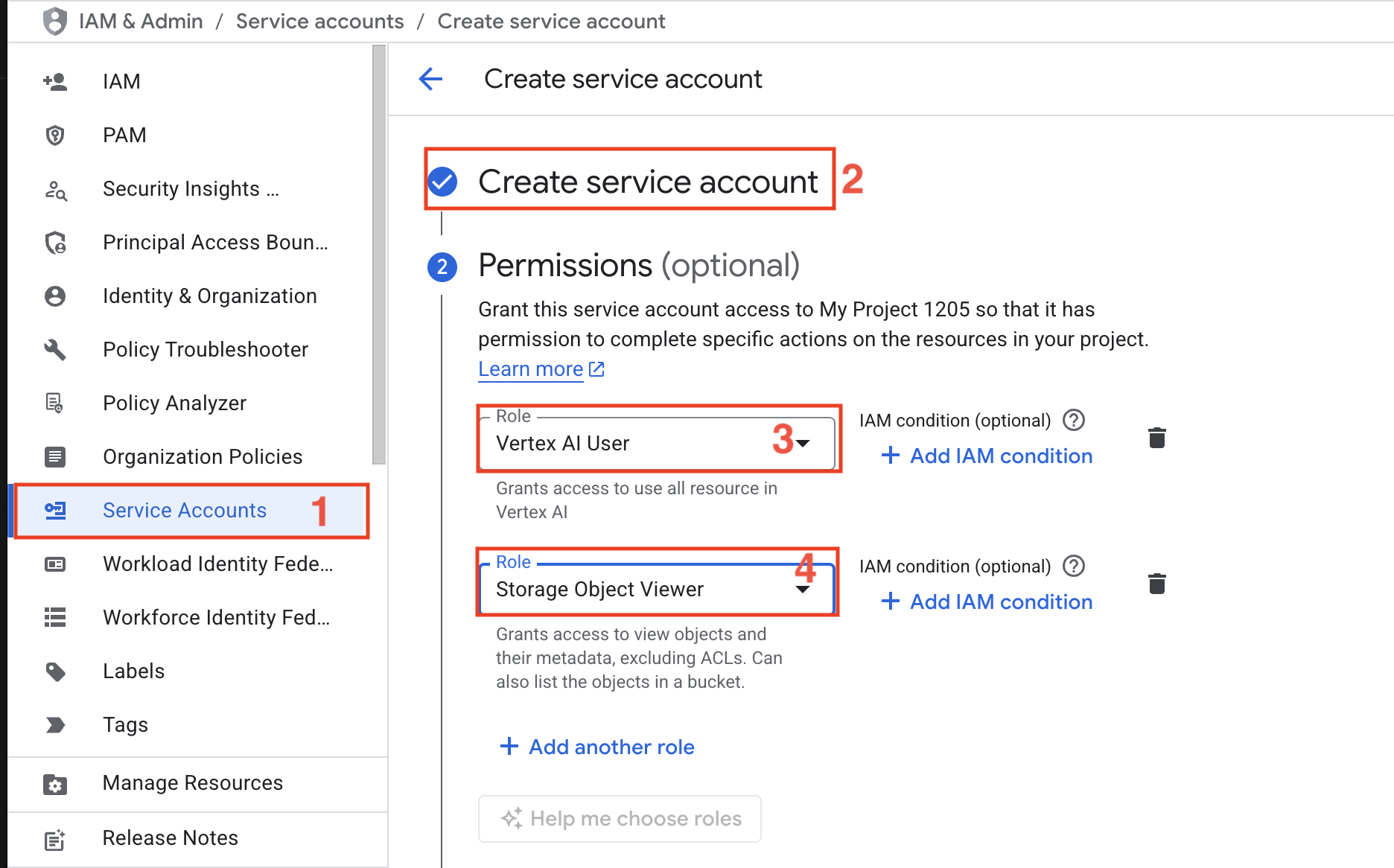
- Google Cloud-Projekt – Erstellen Sie ein Projekt in der Google Cloud Console mit aktivierter Abrechnung.
- Dienstkonto – Erstellen Sie ein Dienstkonto mit den Rollen „Vertex KI-Benutzer“ und „Speicherobjekt-Viewer“.
- Google ADK – Agent Development Kit zum Erstellen von KI-Agenten; siehe Dokumentation.
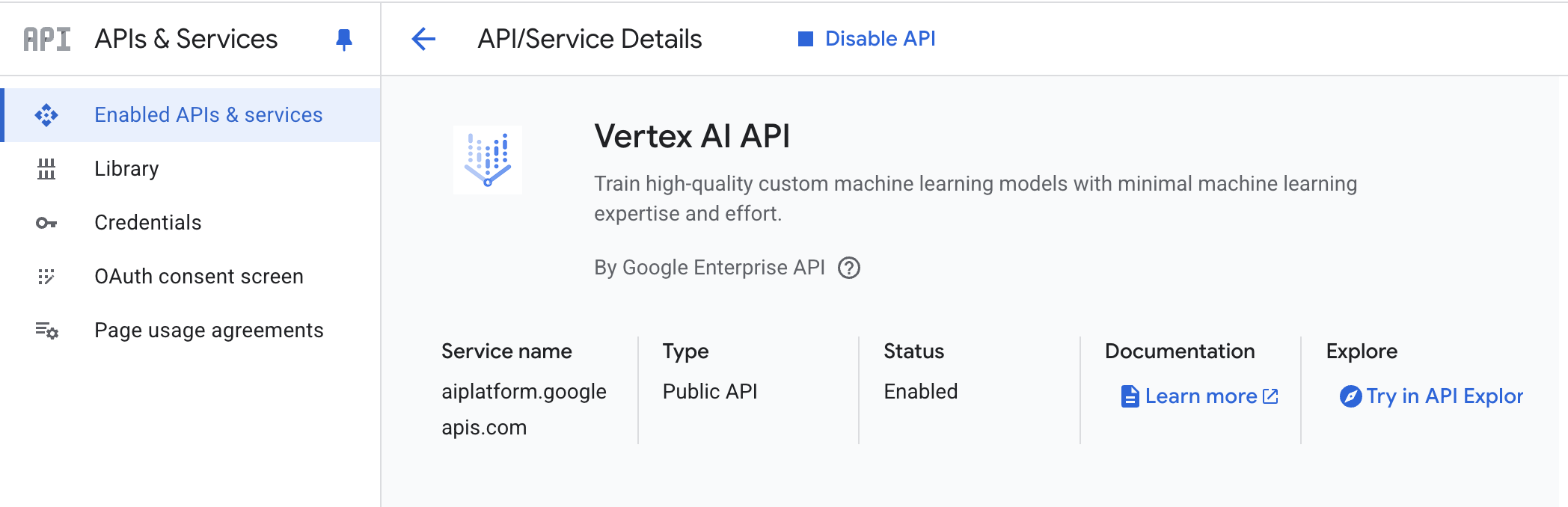
- Vertex KI API – Aktivieren Sie die Vertex KI API in Ihrem Google Cloud-Projekt.
- Virtuelle Python-Umgebung – Hält Abhängigkeiten isoliert; siehe
venv-Dokumentation.
Einrichten der Umgebung
Erstellen Sie Ihr Projektverzeichnis und installieren Sie Abhängigkeiten:
python -m venv venv
# macOS/Linux: source venv/bin/activate
# Windows: venvScriptsactivate
pip install google-genai google-cloud-aiplatform google-cloud-storage langchain-google-vertexai pypdf python-dotenv pandas pillowErstellen Sie eine neue Datei namens rag_agent.py und fügen Sie die folgenden Importe hinzu:
import os
import json
import PyPDF2
import fitz
import time
import vertexai
from google import genai
from vertexai.preview import rag
from pathlib import Path
from vertexai.preview.generative_models import GenerativeModel, Tool
from google.cloud import storage
from typing import List, Dict, Any, Optional
from datetime import datetime
from dotenv import load_dotenv
from google.api_core.exceptions import ResourceExhausted
from google.genai import types
load_dotenv()Erstellen Sie eine .env -Datei mit Ihren Anmeldedaten:
GOOGLE_CLOUD_PROJECT="Ihre-Projekt-ID"
GOOGLE_CLOUD_LOCATION="us-central1"
GOOGLE_APPLICATION_CREDENTIALS="Pfad/zu/service-account-key.json"
GENAI_API_KEY="Ihr-genai-API-Schlüssel"
GCS_BUCKET_NAME="Ihr-Bucket-Name"Sie benötigen:
- Projekt-ID: Ihre Google Cloud-Projekt-ID aus der Konsole
- Standort: Region für Vertex KI-Ressourcen (us-east1 empfohlen)
- Dienstkontoschlüssel: JSON-Schlüsseldatei, die von IAM & Admin heruntergeladen wurde
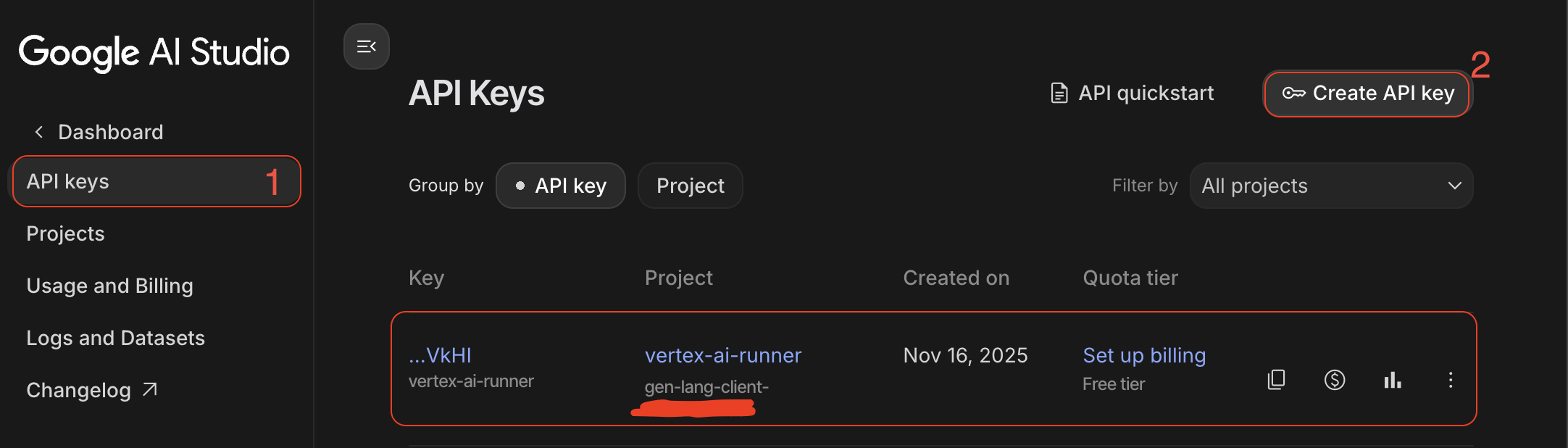
- GenAI-API-Schlüssel: Erstellen Sie diesen in Google AI Studio
- GCS-Bucket: Cloud Storage-Bucket für die Speicherung von Dokumenten
Aufbau des RAG-Agent-Systems
Schritt 1: Google ADK einrichten
Konfigurieren Sie den Google ADK-Client und initialisieren Sie Vertex AI mit der richtigen Authentifizierung. Der Client wickelt alle Interaktionen mit den generativen KI-Diensten von Google ab.
def initialize_adk():
"""Initialisieren Sie Vertex KI mit der richtigen Authentifizierung."""
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = os.getenv("GOOGLE_APPLICATION_CREDENTIALS")
vertexai.init(
project=os.getenv("GOOGLE_CLOUD_PROJECT"),
location=os.getenv("GOOGLE_CLOUD_LOCATION")
)
print(f"✓ Vertex KI initialisiert")
# Initialisieren Sie das System.
initialize_adk()Die Initialisierung stellt Verbindungen sowohl zum GenAI-Client für Agentenoperationen als auch zu Vertex AI für RAG-Funktionen her. Sie überprüft die Anmeldedaten und bestätigt die Projektkonfiguration, bevor sie fortfährt.
Schritt 2: Konfiguration der Vertex AI RAG-Engine
Erstellen Sie einen RAG-Korpus, der als Grundlage für Ihre Wissensdatenbank dient. Der Korpus speichert indizierte Dokumente, verwaltet Einbettungen und verarbeitet Abrufabfragen.
def create_rag_corpus(corpus_name: str, description: str) -> str:
"""Erstellen Sie einen neuen RAG-Korpus für die Speicherung und den Abruf von Dokumenten."""
try:
corpus = rag.create_corpus(
display_name=corpus_name,
description=description,
embedding_model_config=rag.EmbeddingModelConfig(
publisher_model="publishers/google/models/text-embedding-004"
)
)
corpus_id = corpus.name.split('/')[-1]
print(f"✓ RAG-Korpus erstellt: {corpus_name}")
print(f"✓ Korpus-ID: {corpus_id}")
print(f"✓ Einbettungsmodell: text-embedding-004")
return corpus_id
except Exception as e:
print(f"Fehler beim Erstellen des Korpus: {str(e)}")
raise
def configure_retrieval_parameters(corpus_id: str) -> Dict[str, Any]:
"""Konfigurieren Sie die Abrufparameter für eine optimale Suchleistung."""
retrieval_config = {
"corpus_id": corpus_id,
"similarity_top_k": 10,
"vector_distance_threshold": 0.5,
"filter": {},
"ranking_config": {
"rank_service": "default",
"alpha": 0.5
}
}
print(f"✓ Abrufparameter konfiguriert")
print(f" - Top-K-Ergebnisse: {retrieval_config['similarity_top_k']}")
print(f" - Entfernungsschwelle: {retrieval_config['vector_distance_threshold']}")
print(f" - Hybridsuche Alpha: {retrieval_config['ranking_config']['alpha']}")
return retrieval_configDie Korpus-Erstellung verwendet das Text-Embedding-004-Modell von Google für hochwertige semantische Einbettungen. Die Abrufkonfiguration gleicht semantische Ähnlichkeit und Keyword-Übereinstimmung durch den Alpha-Parameter aus, wobei 0,5 eine gleichmäßige Gewichtung ergibt.
Schritt 3: Pipeline zur Dokumentenerfassung
Erstellen Sie eine robuste Pipeline zur Dokumenteneingabe, die mehrere Dateiformate verarbeitet, sauberen Text extrahiert und wichtige Metadaten für eine verbesserte Suche beibehält.
def extract_text_from_pdf(file_path: str) -> Dict[str, Any]:
"""Extrahieren Sie Text und Metadaten aus PDF-Dokumenten."""
with open(file_path, 'rb') as file:
pdf_reader = PyPDF2.PdfReader(file)
metadata = {
'source': file_path,
'num_pages': len(pdf_reader.pages),
'title': pdf_reader.metadata.get('/Title', ''),
'author': pdf_reader.metadata.get('/Author', ''),
'created_date': str(datetime.now())
}
text_content = []
for page_num, page in enumerate(pdf_reader.pages):
page_text = page.extract_text()
text_content.append({
'page': page_num + 1,
'text': page_text,
'char_count': len(page_text)
})
return {
'metadata': metadata,
'content': text_content,
'full_text': ' '.join([p['text'] for p in text_content])
}
def preprocess_document(text: str) -> str:
"""Dokumenttext bereinigen und normalisieren, um eine optimale Indizierung zu erzielen."""
text = ' '.join(text.split())
text = text.replace('x00', '')
text = text.replace('rn', 'n')
lines = text.split('n')
cleaned_lines = [
line for line in lines
if len(line.strip()) > 3
and not line.strip().isdigit()
]
return 'n'.join(cleaned_lines)Die Chunking-Strategie nutzt Satzgrenzen, um Unterbrechungen mitten im Gedankengang zu vermeiden, implementiert Überlappungen, um den Kontext über Chunks hinweg zu bewahren, und speichert Metadaten über die Positionen der Chunks für eine genaue Zitierbarkeit. Die Chunk-Größe von 1000 Zeichen sorgt für ein Gleichgewicht zwischen Suchgenauigkeit und Kontextvollständigkeit.
Schritt 4: Einbettung und Indizierung
Laden Sie Dokumente in den RAG-Korpus hoch und generieren Sie Vektor-Einbettungen für die semantische Suche. Das System übernimmt automatisch die Generierung der Einbettungen und die Indexoptimierung.
def chunk_document(text: str, chunk_size: int = 1000, overlap: int = 200) -> List[Dict[str, Any]]:
"""Teilen Sie das Dokument in überlappende Chunks auf, um eine optimale Suche zu erzielen."""
chunks = []
start = 0
text_length = len(text)
chunk_id = 0
while start < text_length:
end = start + chunk_size
if end < text_length:
last_period = text.rfind('.', start, end)
if last_period != -1 and last_period > start:
end = last_period + 1
chunk_text = text[start:end].strip()
if chunk_text:
chunks.append({
'chunk_id': chunk_id,
'text': chunk_text,
'start_char': start,
'end_char': end,
'char_count': len(chunk_text)
})
chunk_id += 1
start = end - overlap
print(f"✓ Created {len(chunks)} chunks with {overlap} char overlap")
return chunks
def upload_file_to_gcs(local_path: str, gcs_bucket: str) -> str:
"""Upload document to Google Cloud Storage for RAG ingestion."""
storage_client = storage.Client()
bucket = storage_client.bucket(gcs_bucket)
blob_name = f"rag-docs/{Path(local_path).name}"
blob = bucket.blob(blob_name)
blob.upload_from_filename(local_path)
gcs_uri = f"gs://{gcs_bucket}/{blob_name}"
print(f"✓ Hochgeladen zu GCS: {gcs_uri}")
return gcs_uri
def import_documents_to_corpus(corpus_id: str, file_uris: List[str]) -> str:
"""Importiere Dokumente in den RAG-Korpus und generiere Einbettungen."""
print(f"⚡ Import für {len(file_uris)} Dokumente wird gestartet...")
response = rag.import_files(
corpus_name=f"projects/{os.getenv('GOOGLE_CLOUD_PROJECT')}/locations/{os.getenv('GOOGLE_CLOUD_LOCATION')}/ragCorpora/{corpus_id}",
paths=file_uris,
chunk_size=1000,
chunk_overlap=200
)
try:
if hasattr(response, 'result'):
print("⏳ Warten auf Abschluss des Importvorgangs (dies kann eine Minute dauern)...")
response.result()
else:
print("✓ Importanforderung gesendet.")
except Exception as e:
print(f"⚠️ Hinweis zum Warten: {e}")
print(f"✓ Dokumente importiert und Indizierung ausgelöst.")
return getattr(response, 'name', 'unknown_operation')
def create_vector_index(corpus_id: str, index_config: Dict[str, Any]) -> str:
"""Erstellt einen optimierten Vektorindex für die schnelle Ähnlichkeitssuche."""
index_settings = {
'corpus_id': corpus_id,
'distance_measure': 'COSINE',
'algorithm': 'TREE_AH',
'leaf_node_embedding_count': 1000,
'leaf_nodes_to_search_percent': 10
}
print(f"✓ Vektorindex mit TREE_AH-Algorithmus erstellt")
print(f"✓ Distanzmaß: COSINE-Ähnlichkeit")
print(f"✓ Optimiert für {index_settings['leaf_nodes_to_search_percent']}% Suchabdeckung")
return corpus_idDer Importprozess übernimmt automatisch das Parsing und Chunking von Dokumenten sowie die Generierung von Einbettungen. Der TREE_AH-Algorithmus ermöglicht eine schnelle Suche nach annähernden nächsten Nachbarn bei gleichzeitig hoher Trefferquote. Die Kosinusähnlichkeit misst den Winkelabstand zwischen Einbettungsvektoren für die semantische Übereinstimmung.
Schritt 5: Agentenentwicklung mit ADK
Erstellen Sie die Kernarchitektur des Agenten, die den Kontext verwaltet, Benutzeranfragen bearbeitet und die Abfrage mit der Generierung von Antworten koordiniert.
class RAGAgent:
"""Intelligenter RAG-Agent mit Kontextverwaltung und Grounding."""
def __init__(self, corpus_id: str, model_name: str = "gemini-2.5-flash"):
self.corpus_id = corpus_id
self.model_name = model_name
self.conversation_history = []
self.rag_tool = Tool.from_retrieval(
retrieval=rag.Retrieval(
source=rag.VertexRagStore(
rag_corpora=[f"projects/{os.getenv('GOOGLE_CLOUD_PROJECT')}/locations/{os.getenv('GOOGLE_CLOUD_LOCATION')}/ragCorpora/{corpus_id}"],
similarity_top_k=5,
vector_distance_threshold=0.3
)
)
)
self.model = GenerativeModel(
model_name=model_name,
tools=[self.rag_tool]
)
print(f"✓ Initialized RAG agent with {model_name}")
print(f"✓ Mit Korpus verbunden: {corpus_id}")
def manage_context(self, query: str, max_history: int = 5) -> List[Dict[str, str]]:
"""Konversationskontext mit Kürzung der Historie verwalten."""
self.conversation_history.append({
'role': 'user',
'content': query,
'timestamp': datetime.now().isoformat()
})
if len(self.conversation_history) > max_history * 2:
self.conversation_history = self.conversation_history[-max_history * 2:]
formatted_history = []
for msg in self.conversation_history:
formatted_history.append({
'role': msg['role'],
'parts': [msg['content']]
})
return formatted_history
def build_grounded_prompt(self, query: str, retrieved_context: List[Dict[str, Any]]) -> str:
"""Erstelle eine Eingabeaufforderung mit expliziten Anweisungen zur Verankerung."""
context_text = "nn".join([
f"[Quelle {i+1}]: {ctx['text']}"
for i, ctx in enumerate(retrieved_context)
])
prompt = f"""Sie sind ein hilfreicher KI-Assistent mit Zugriff auf eine Wissensdatenbank.
Beantworten Sie die folgende Frage AUSSCHLIESSLICH anhand der im folgenden Kontext bereitgestellten Informationen.
WICHTIGE ANWEISUNGEN:
1. Stützen Sie Ihre Antwort ausschließlich auf den bereitgestellten Kontext.
2. Wenn der Kontext nicht genügend Informationen enthält, weisen Sie ausdrücklich darauf hin.
3. Zitieren Sie bestimmte Quellen unter Verwendung der Notation [Quelle X].
4. Fügen Sie keine Informationen aus Ihrem Allgemeinwissen hinzu.
5. Wenn Sie sich unsicher sind, geben Sie dies zu.
KONTEXT:
{context_text}
FRAGE:
{query}
ANTWORT:"""
return promptDer Agent speichert den Gesprächsverlauf für Interaktionen mit mehreren Runden, verwaltet die Größe des Kontextfensters, um Token-Beschränkungen zu vermeiden, und erstellt Eingabeaufforderungen mit expliziten Anweisungen, um Halluzinationen zu reduzieren. Die Integration des RAG-Tools ermöglicht die automatische Abfrage während der Generierung.
Schritt 6: Abfrageverarbeitung und Abruf
Implementieren Sie eine hybride Suche, die semantisches Verständnis mit Keyword-Matching kombiniert, um eine optimale Abrufgenauigkeit zu erzielen.
def hybrid_search(
self,
corpus_id: str,
query: str,
semantic_weight: float = 0.7,
top_k: int = 10
) -> List[Dict[str, Any]]:
"""Führen Sie eine hybride Suche mit automatischer Wiederholung bei Quotenbeschränkungen durch."""
rag_resource = rag.RagResource(
rag_corpus=f"projects/{os.getenv('GOOGLE_CLOUD_PROJECT')}/locations/{os.getenv('GOOGLE_CLOUD_LOCATION')}/ragCorpora/{corpus_id}"
)
max_retries = 3
base_delay = 90
for attempt in range(max_retries):
try:
print(f"🔍 Suche im Korpus (Versuch {attempt + 1})...")
results = rag.retrieval_query(
rag_resources=[rag_resource],
text=query,
similarity_top_k=top_k,
vector_distance_threshold=0.5
)
# Bei Erfolg Ergebnisse verarbeiten und zurückgeben
abgerufene_Teile = []
für i, Kontext in enumerate(Ergebnisse.Kontexte.Kontexte):
retrieved_chunks.append({
'rank': i + 1,
'text': context.text,
'source': context.source_uri if hasattr(context, 'source_uri') else 'unknown',
'distance': context.distance if hasattr(context, 'distance') else 0.0
})
print(f"✓ {len(retrieved_chunks)} relevante Chunks abgerufen")
return retrieved_chunks
except ResourceExhausted:
wait_time = base_delay * (2 ** attempt)
print(f"⚠️ Kontingent erreicht (Limit: 5/min). Abkühlung für {wait_time}s...")
time.sleep(wait_time)
except Exception as e:
print(f"❌ Abruf-Fehler: {str(e)}")
raise
print("❌ Maximale Anzahl von Wiederholungsversuchen erreicht. Abruf fehlgeschlagen.")
return []
def rerank_results(
self,
results: List[Dict[str, Any]],
query: str,
model_name: str = "gemini-2.5-flash"
) -> List[Dict[str, Any]]:
"""Rerank abgerufen Ergebnisse basierend auf der Relevanz der Abfrage."""
if not results:
return []
rerank_prompt = f"""Bewerten Sie die Relevanz jedes Abschnitts für die Abfrage auf einer Skala von 0 bis 10.
Abfrage: {query}
Abschnitte:
{chr(10).join([f"{i+1}. {r['text'][:200]}..." for i, r in enumerate(results)])}
Geben Sie nur eine durch Kommas getrennte Liste der Bewertungen zurück (z. B. 8,6,9,3,7)."""
model = GenerativeModel(model_name)
response = model.generate_content(rerank_prompt)
if response.text:
try:
scores = [float(s.strip()) for s in response.text.strip().split(',')]
for i, score in enumerate(scores[:len(results)]):
results[i]['rerank_score'] = score
results.sort(key=lambda x: x.get('rerank_score', 0), reverse=True)
print(f"✓ Neu sortierte Ergebnisse unter Verwendung der LLM-Bewertung")
except Exception as e:
print(f"Warnung: Neusortierung fehlgeschlagen, Verwendung der ursprünglichen Reihenfolge: {str(e)}")
return resultsDie hybride Suche ruft Kandidaten anhand der Vektorsimilarität ab, anschließend wird mithilfe des LLM eine Neubewertung der Relevanz auf Grundlage des abfragespezifischen Kontexts vorgenommen. Dieser zweistufige Ansatz sorgt für ein ausgewogenes Verhältnis zwischen Effizienz und Genauigkeit.
Schritt 7: Generierung von Antworten und Grounding
Generieren Sie Antworten mit korrekten Zitaten und verhindern Sie Halluzinationen durch strenge Grounding-Überprüfung.
def generate_grounded_response(
self,
agent: 'RAGAgent',
query: str,
retrieved_context: List[Dict[str, Any]],
temperature: float = 0.2
) -> Dict[str, Any]:
"""Antwort mit Zitaten und Halluzinationsvermeidung generieren."""
grounded_prompt = agent.build_grounded_prompt(query, retrieved_context)
chat = agent.model.start_chat()
response = chat.send_message(
grounded_prompt,
generation_config={
'temperature': temperature,
'top_p': 0.8,
'top_k': 40,
'max_output_tokens': 1024
}
)
return {
'answer': response.text,
'sources': retrieved_context,
'query': query,
'timestamp': datetime.now().isoformat()
}
def verify_grounding(
self,
response: str,
sources: List[Dict[str, Any]],
model_name: str = "gemini-2.5-flash"
) -> Dict[str, Any]:
"""Überprüfen Sie, ob die Antworten auf dem Quellenmaterial basieren."""
verification_prompt = f"""Analysieren Sie, ob die folgende Antwort vollständig durch die angegebenen Quellen gestützt wird.
QUELLEN:
{chr(10).join([f"Quelle {i+1}: {s['text']}" for i, s in enumerate(sources)])}
ANTWORT:
{response}
Überprüfen Sie jede Behauptung in der Antwort. Antworten Sie mit JSON:
{{
"is_grounded": true/false,
"unsupported_claims": ["claim1", "claim2"],
"confidence_score": 0.0-1.0
}}"""
model = GenerativeModel(model_name)
verification_response = model.generate_content(verification_prompt)
try:
json_text = verification_response.text.strip()
if '```json' in json_text:
json_text = json_text.split('```json')[1].split('```')[0].strip()
verification_result = json.loads(json_text)
print(f"✓ Grounding-Verifizierung abgeschlossen")
print(f" - Grounded: {verification_result.get('is_grounded', False)}")
print(f" - Confidence: {verification_result.get('confidence_score', 0.0):.2f}")
return verification_result
except Exception as e:
print(f"Warnung: Überprüfung der Fundierung fehlgeschlagen: {str(e)}")
return {'is_grounded': True, 'confidence_score': 0.5}Die Überprüfung der Fundiertheit stellt sicher, dass jede Aussage in der Antwort auf Quelldokumente zurückgeführt werden kann. Eine niedrige Temperaturgenerierung (0,2) reduziert kreative Ausschmückungen und verbessert die sachliche Genauigkeit.
Schritt 8: Multimodale RAG-Implementierung
Erweitern Sie das RAG-System, um Bilder, Tabellen und andere Nicht-Text-Inhalte für eine umfassende Wissensgewinnung zu verarbeiten.
def extract_images_from_pdf(self, pdf_path: str, output_dir: str) -> List[Dict[str, Any]]:
"""Extrahieren Sie Bilder aus PDF-Dokumenten für die multimodale Indizierung."""
doc = fitz.open(pdf_path)
images = []
os.makedirs(output_dir, exist_ok=True)
for page_num in range(len(doc)):
page = doc[page_num]
image_list = page.get_images()
for img_index, img in enumerate(image_list):
xref = img[0]
base_image = doc.extract_image(xref)
image_bytes = base_image["image"]
# Bild speichern
image_filename = f"page{page_num + 1}_img{img_index + 1}.png"
image_path = os.path.join(output_dir, image_filename)
with open(image_path, "wb") as img_file:
img_file.write(image_bytes)
images.append({
'page': page_num + 1,
'image_path': image_path,
'format': base_image['ext'],
'size': len(image_bytes)
})
print(f"✓ {len(images)} Bilder aus PDF extrahiert")
return images
def process_table_content(self, table_text: str) -> Dict[str, Any]:
"""Tabellendaten für verbesserte Abfrage verarbeiten und strukturieren."""
lines = table_text.strip().split('n')
if not lines:
return {}
headers = [h.strip() for h in lines[0].split('|') if h.strip()]
rows = []
for line in lines[1:]:
cells = [c.strip() for c in line.split('|') if c.strip()]
if len(cells) == len(headers):
row_dict = dict(zip(headers, cells))
rows.append(row_dict)
return {
'headers': headers,
'rows': rows,
'row_count': len(rows),
'column_count': len(headers)
}
def create_multimodal_embedding(
self,
text: str,
image_path: Optional[str] = None,
table_data: Optional[Dict[str, Any]] = None
) -> Dict[str, Any]:
"""Erstellt eine einheitliche Einbettung für multimodale Inhalte."""
combined_text = text
if table_data and table_data.get('rows'):
table_desc = f"nTabelle mit {table_data['row_count']} Zeilen und Spalten: {', '.join(table_data['headers'])}n"
combined_text += table_desc
if image_path:
combined_text += f"n[Bild: {Path(image_path).name}]"
return {
'text': combined_text,
'has_image': image_path is not None,
'has_table': table_data is not None,
'modalities': sum([bool(text), bool(image_path), bool(table_data)])
}Bei der multimodalen Verarbeitung werden neben Text auch Bilder und Tabellen extrahiert und indexiert. Der einheitliche Einbettungsansatz kombiniert beschreibende Metadaten aus allen Modalitäten zu durchsuchbarem Text. Dadurch können Abfragen wie „Zeige mir die Preistabelle aus dem Bericht zum 3. Quartal” sowohl die Tabellendaten als auch den umgebenden Kontext abrufen.
Schritt 9: Integration von Google ADK Agent
Integrieren Sie das Agent Development Kit (ADK) von Google, um eine bessere Agentenschnittstelle zu erstellen, die mit Ihrem Vertex AI RAG Engine-Backend verbunden ist. Das ADK bietet verbesserte Agentenfunktionen, darunter Tool-Aufrufe, mehrteilige Konversationen und strukturierte Antworten.
class ADKRAGAgent:
"""Google ADK Agent-Wrapper, der Vertex KI RAG Engine als Backend verwendet."""
def __init__(self, corpus_id: str, project_id: str, location: str):
"""Initialisieren Sie den ADK-Agenten mit RAG-Funktionen."""
self.corpus_id = corpus_id
self.project_id = project_id
self.location = location
self.rag_agent = RAGAgent(corpus_id)
self.client = genai.Client(
vertexai=True,
project=project_id,
location=location
)
self.model_name = "gemini-2.0-flash-001"
print(f"✓ Google ADK Agent initialisiert")
print(f" - Framework: Google ADK (genai.Client)")
print(f" - Backend: Vertex KI RAG Engine")
print(f" - Projekt: {project_id}")
print(f" - Standort: {location}")
print(f" - RAG-Korpus: {corpus_id}")
def create_rag_search_tool(self) -> types.Tool:
"""RAG-Suchwerkzeug für ADK-Agent erstellen."""
def rag_search(query: str) -> str:
"""
RAG-Korpus durchsuchen und fundierte Antworten zurückgeben.
Argumente:
query: Die zu suchende Frage des Benutzers
Rückgabewerte:
Eine fundierte Antwort mit Zitaten aus der Wissensdatenbank
"""
try:
results = self.rag_agent.hybrid_search(
self.corpus_id,
query,
semantic_weight=0.7,
top_k=10)
if not results:
return "Keine relevanten Informationen in der Wissensdatenbank gefunden."
reranked = self.rag_agent.rerank_results(results, query)
response = self.rag_agent.generate_grounded_response(
self.rag_agent,
query,
reranked[:5]
)
verification = self.rag_agent.verify_grounding(
response['answer'],
response['sources']
)
answer = response['answer']
if not verification.get('is_grounded', True):
answer += f"nn[Confidence: {verification.get('confidence_score', 0):.0%}]"
return answer
except Exception as e:
return f"Error searching knowledge base: {str(e)}"
rag_tool = types.Tool(
function_declarations=[
types.FunctionDeclaration(
name="rag_search",
description="Durchsuchen Sie die Wissensdatenbank des Unternehmens mit RAG (Retrieval-Augmented Generation), um genaue, fundierte Antworten auf Fragen zu technischer Dokumentation, Produktspezifikationen und Benutzerhandbüchern zu finden.",
parameters={
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "Die Frage oder Suchanfrage des Benutzers"
}
},
"required": ["query"]
}
)
]
)
self.rag_search_function = rag_search
return rag_tool
def create_agent(self) -> Dict[str, Any]:
"""Erstellen Sie eine Google ADK Agent-Konfiguration mit dem RAG-Tool."""
rag_tool = self.create_rag_search_tool()
agent_instructions = """Sie sind ein intelligenter RAG-Agent (Retrieval-Augmented Generation) mit Zugriff auf eine Unternehmens-Wissensdatenbank.
Ihre Fähigkeiten:
- Durchsuchen Sie technische Dokumentationen, Produktspezifikationen und Benutzerhandbücher.
- Geben Sie genaue, fundierte Antworten mit Quellenangaben.
- Führen Sie mehrteilige Gespräche mit Kontextbewusstsein.
- Überprüfen Sie die Richtigkeit der Informationen, bevor Sie antworten.
Richtlinien:
1. Verwenden Sie vor der Beantwortung immer das rag_search-Tool, um Informationen zu finden.
2. Geben Sie spezifische, detaillierte Antworten auf der Grundlage der abgerufenen Dokumente.
3. Fügen Sie relevante Zitate und Quellen hinzu.
4. Wenn keine Informationen gefunden werden, geben Sie dies deutlich an.
5. Behalten Sie den Gesprächskontext über mehrere Abfragen hinweg bei.
Seien Sie in allen Antworten hilfsbereit, genau und professionell.“““
agent_config = {
'model': self.model_name,
'instructions': agent_instructions,
'tools': [rag_tool],
'display_name': 'RAG Agent mit Vertex KI (Google ADK + Vertex KI RAG Engine)'
}
print(f"✓ Google ADK-Agent-Konfiguration erstellt")
print(f" - Modell: {self.model_name}")
print(f" - Tools: RAG-Suche (Vertex KI RAG Engine)")
return agent_config
def chat(self, agent_config: Dict[str, Any], query: str, session_id: str = "default") -> str:
"""Senden Sie eine Nachricht an den ADK-Agenten und erhalten Sie eine Antwort mit Google GenAI."""
self.rag_agent.manage_context(query)
try:
response = self.client.models.generate_content(
model=agent_config['model'],
contents=query,
config=types.GenerateContentConfig(
system_instruction=agent_config['instructions'],
tools=agent_config['tools'],
temperature=0.2
)
)
if response.candidates and len(response.candidates) > 0:
candidate = response.candidates[0]
if candidate.content and candidate.content.parts:
for part in candidate.content.parts:
if hasattr(part, 'function_call') and part.function_call:
function_name = part.function_call.name
function_args = part.function_call.args
print(f" → ADK Agent calling tool: {function_name}")
if function_name == "rag_search":
query_arg = function_args.get("query", query)
tool_result = self.rag_search_function(query_arg)
response = self.client.models.generate_content(
model=agent_config['model'],
contents=[
types.Content(role="user", parts=[types.Part(text=query)]),
types.Content(role="model", parts=[part]),
types.Content(
role="function",
parts=[types.Part(
function_response=types.FunctionResponse(
name=function_name,
response={"result": tool_result}
)
)]
)
],
config=types.GenerateContentConfig(
system_instruction=agent_config['instructions'],
tools=agent_config['tools'],
temperature=0.2
)
)
elif hasattr(part, 'text') and part.text:
answer = part.text
self.rag_agent.conversation_history.append({
'role': 'assistant',
'content': answer,
'timestamp': datetime.now().isoformat()
})
return answer
if response.candidates and response.candidates[0].content.parts:
for part in response.candidates[0].content.parts:
if hasattr(part, 'text') and part.text:
answer = part.text
self.rag_agent.conversation_history.append({
'role': 'assistant',
'content': answer,
'timestamp': datetime.now().isoformat()
})
return answer
return "No response generated."
except Exception as e:
error_msg = f"Fehler im ADK-Agenten-Chat: {str(e)}"
print(f"❌ {error_msg}")
return error_msgDie ADK-Integration fügt das Agent-Framework von Google zu Ihrem bestehenden RAG-Agenten hinzu. Die ADKRAGAgent-Klasse richtet einen genai.Client für Agentenoperationen ein und verwendet Ihren RAGAgent für die Abfrage. Die Methode create_rag_search_tool definiert eine Funktion, die der Agent aufrufen kann, sodass er Ihre Wissensdatenbank mit der Vertex KI RAG Engine durchsuchen kann.
Der Tool-Aufrufmechanismus ermöglicht es dem Agenten, anhand von Benutzeranfragen automatisch zu bestimmen, wann die Wissensdatenbank durchsucht werden soll. Wenn eine Suche erforderlich ist, führt er die hybride Suchpipeline aus, ordnet die Ergebnisse neu, generiert fundierte Antworten und überprüft die Genauigkeit, bevor er Antworten liefert. Die Chat-Methode verwaltet den gesamten Gesprächsablauf, einschließlich der Tool-Ausführung und der Verwaltung des Mehrfachkontexts.
Schritt 10: Optimieren Sie Ihr RAG mit Echtzeit-Webdaten von Bright Data
Während Ihr RAG-System sich hervorragend für das Abrufen von Informationen aus Ihrer internen Wissensdatenbank eignet, benötigen KI-Anwendungen in Unternehmen häufig aktuelle Echtzeitdaten aus externen Quellen. Hier kommt die Webdatenplattform von Bright Data ins Spiel, die es Ihrem RAG-Agenten ermöglicht, auf Live-Informationen aus dem gesamten Web zuzugreifen und Ihre Wissensdatenbank aktuell und umfassend zu halten.
Warum sollten Sie Bright Data in Ihr RAG-System integrieren?
1. Halten Sie Ihre Wissensdatenbank auf dem neuesten Stand
- Aktualisieren Sie Ihren RAG-Korpus automatisch mit den neuesten Produktinformationen, Preisdaten, Wettbewerbsinformationen und Markttrends.
- Beseitigen Sie veraltete Daten, die zu überholten KI-Antworten führen.
- Planen Sie regelmäßige Datenaktualisierungen, um die Genauigkeit zu gewährleisten.
2. Gehen Sie über interne Dokumente hinaus
- Greifen Sie auf Echtzeitdaten von über 120 beliebten Websites zu, darunter E-Commerce-Plattformen, Nachrichtenseiten, soziale Medien und branchenspezifische Quellen.
- Ergänzen Sie Ihre technische Dokumentation mit Live-API-Dokumentation, Community-Diskussionen und aktualisierten Spezifikationen.
- Beziehen Sie Kundenbewertungen, Feedback und Stimmungsdaten ein, um Ihre Produkt-Wissensdatenbank zu verbessern
3. Dynamische Abfrageverbesserung aktivieren
- Wenn Ihr RAG-Agent eine Abfrage erkennt, die aktuelle Informationen erfordert (Preise, Verfügbarkeit, aktuelle Nachrichten), ruft er automatisch neue Daten ab
- Kombinieren Sie internes Wissen mit externen Webdaten, um umfassende Antworten zu erhalten.
- Stellen Sie den Benutzern sowohl historischen Kontext als auch aktuelle Informationen zur Verfügung
4. Skalieren Sie die Datenerfassung mühelos
- Sie müssen keine Proxys verwalten, CAPTCHAs bearbeiten oder sich mit Anti-Bot-Systemen auseinandersetzen.
- Bright Data kümmert sich um die gesamte Infrastruktur, die Entsperrung und die Datenqualität.
- Konzentrieren Sie sich auf die KI-Entwicklung, während Bright Data die Datenbeschaffung übernimmt
Implementierung: Hinzufügen von Bright Data zu Ihrer RAG-Pipeline
Erweitern Sie Ihr RAG-System mit den Funktionen von Bright Data. Wir fügen drei Integrationsmuster hinzu: Datensatzintegration für vorab gesammelte Daten, Web-Scraper-API für Echtzeit-Scraping und KI-Scraper für angereicherte, KI-generierte Erkenntnisse.
Muster 1: Datensatzintegration für historische Daten
Nutzen Sie den Marktplatz für Datensätze von Bright Data, um Ihren RAG-Korpus schnell mit hochwertigen, strukturierten Daten zu füllen.
import requests
from typing import List, Dict
import json
class BrightDataRAGEnhancer:
"""Verbessern Sie das RAG-System mit den Webdatenfunktionen von Bright Data."""
def __init__(self, api_key: str, rag_agent: RAGAgent):
self.api_key = api_key
self.rag_agent = rag_agent
self.base_url = "https://api.brightdata.com"
def fetch_dataset_data(
self,
dataset_id: str,
filters: Dict[str, Any] = None,
limit: int = 1000
) -> List[Dict[str, Any]]:
"""Daten aus dem Bright Data Dataset Marketplace abrufen."""
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
endpoint = f"{self.base_url}/Datensätze/v3/snapshot/{dataset_id}"
params = {
"format": "json",
"limit": limit
}
if filters:
params["filter"] = json.dumps(filters)
response = requests.get(endpoint, headers=headers, params=params)
response.raise_for_status()
print(f"✓ {len(response.json())} Datensätze aus dem Datensatz {dataset_id} abgerufen")
return response.json()
def ingest_dataset_to_rag(
self,
corpus_id: str,
dataset_records: List[Dict[str, Any]],
text_fields: List[str]
) -> None:
"""Datensatzdatensätze verarbeiten und zum RAG-Korpus hinzufügen."""
processed_chunks = []
for record in dataset_records:
# Kombinieren Sie bestimmte Textfelder zu durchsuchbaren Inhalten.
combined_text = " ".join([
str(record.get(field, ""))
for field in text_fields
if record.get(field)
])
if combined_text.strip():
# Fügen Sie Metadaten für eine bessere Suche hinzu.
metadata = {
"source": "bright_data_dataset",
"record_id": record.get("id", "unknown"),
"ingestion_date": datetime.now().isoformat(),
"data_type": "external_web_data"
}
# Inhalt in Blöcke aufteilen
chunks = chunk_document(combined_text, chunk_size=1000, overlap=200)
for chunk in chunks:
chunk['metadata'] = metadata
processed_chunks.append(chunk)
print(f"✓ {len(processed_chunks)} Blöcke aus den Datensätzen verarbeitet")
# Temporäre Datei zum Hochladen erstellen
temp_file = "temp_dataset_content.txt"
with open(temp_file, 'w') as f:
for chunk in processed_chunks:
f.write(chunk['text'] + "nn")
# In GCS hochladen und in Korpus importieren
gcs_uri = upload_file_to_gcs(temp_file, os.getenv('GCS_BUCKET_NAME'))
import_documents_to_corpus(corpus_id, [gcs_uri])
os.remove(temp_file)
print(f"✓ Datensatzinhalt zum RAG-Korpus hinzugefügt")Anwendungsbeispiel: Füllen Sie Ihr E-Commerce-RAG mit Produktdaten
# Zuerst einen RAG-Korpus erstellen
corpus_id = create_rag_corpus(
corpus_name="bright_data_corpus",
description="Korpus für Bright Data Enhanced RAG")
# RAG-Agent mit Korpus initialisieren
rag_agent = RAGAgent(corpus_id=corpus_id)
# Enhancer initialisieren
enhancer = BrightDataRAGEnhancer(
api_key=os.getenv("BRIGHT_DATA_API_KEY"),
rag_agent=rag_agent)
print("✓ BrightDataRAGEnhancer erfolgreich initialisiert!")
# Amazon-Produktdaten abrufen
amazon_data = enhancer.fetch_dataset_data(
dataset_id="gd_l7q7dkf244hwxr90h", # Amazon-Produktdatensatz
filters={"category": "Electronics"},
limit=5000
)
# In RAG-Korpus aufnehmen
enhancer.ingest_dataset_to_rag(
corpus_id=corpus_id,
dataset_records=amazon_data,
text_fields=["title", "description", "features", "reviews"]
)Muster 2: Echtzeit-Web-Scraper-API-Integration
Für dynamische, aktuelle Informationen integrieren Sie die Web Scraper API von Bright Data direkt in die Abfrage-Pipeline Ihres RAG-Agenten.
def scrape_real_time_data(
self,
scraper_id: str,
inputs: List[Dict[str, Any]],
wait_for_completion: bool = True)
-> List[Dict[str, Any]]:
"""Führen Sie Echtzeit-Web-Scraping mit Bright Data-Scrapern durch."""
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
# Scraper auslösen
trigger_url = f"{self.base_url}/dca/trigger"
params = {
"Scraper": Scraper_id,
"queue_next": 1
}
response = requests.post(
trigger_url,
headers=headers,
params=params,
json=inputs
)
response.raise_for_status()
snapshot_id = response.json().get("snapshot_id")
print(f"✓ Scraper ausgelöst. Snapshot-ID: {snapshot_id}")
if not wait_for_completion:
return {"snapshot_id": snapshot_id, "status": "processing"}
# Ergebnisse abfragen
results_url = f"{self.base_url}/dca/dataset"
params = {"id": snapshot_id}
max_retries = 30
for i in range(max_retries):
time.sleep(10) # 10 Sekunden zwischen den Abfragen warten
results_response = requests.get(results_url, headers=headers, params=params)
if results_response.status_code == 200:
data = results_response.json()
print(f"✓ Scraping abgeschlossen. {len(data)} Datensätze abgerufen")
return data
elif results_response.status_code == 202:
print(f"⏳ Wird noch verarbeitet... ({i+1}/{max_retries})")
continue
else:
print(f"❌ Fehler beim Abrufen der Ergebnisse: {results_response.status_code}")
break
return []
def create_dynamic_rag_tool(self) -> types.Tool:
"""RAG-Tool mit Echtzeit-Webdatenanreicherung erstellen."""
def augmented_rag_search(query: str, include_live_data: bool = False) -> str:
"""
Wissensdatenbank mit optionaler Echtzeit-Webdatenanreicherung durchsuchen.
Argumente:
query: Die Frage des Benutzers
include_live_data: Ob aktuelle Webdaten abgerufen werden sollen
Rückgabewerte:
Fundierte Antwort, die interne und externe Daten kombiniert
"""
# Zuerst interne Wissensdatenbank durchsuchen
internal_results = self.rag_agent.hybrid_search(
corpus_id=self.rag_agent.corpus_id,
query=query,
top_k=5
)
combined_results = internal_results
# Wenn die Abfrage aktuelle Informationen erfordert, Live-Daten abrufen
if include_live_data or self._requires_fresh_data(query):
print("🌐 Abrufen von Echtzeit-Webdaten...")
# Beispiel: Preisinformationen scrapen
if "price" in query.lower() or "cost" in query.lower():
live_data = self.scrape_real_time_data(
scraper_id="your_product_scraper_id",
inputs=[{"url": "https://example.com/products"}],
wait_for_completion=True
)
# Live-Daten in durchsuchbare Blöcke konvertieren
for record in live_data[:3]: # Top 3 Ergebnisse
combined_results.append({
'rank': len(combined_results) + 1,
'text': f"{record.get('title', '')}: {record.get('price', '')} - {record.get('description', '')}",
'source': f"Live-Webdaten: {record.get('url', 'unknown')}",
'distance': 0.3 # Hohe Relevanz für aktuelle Daten
})
# Antwort mit allen verfügbaren Kontextinformationen generieren
response = self.rag_agent.generate_grounded_response(
self.rag_agent,
query,
combined_results
)
return response['answer']
return types.Tool(
function_declarations=[
types.FunctionDeclaration(
name="augmented_rag_search",
description="Durchsuchen der internen Wissensdatenbank und optional Abrufen von Echtzeit-Webdaten für aktuelle Informationen",
parameters={
"type": "object",
"properties": {
"query": {"type": "string", "description": "Frage des Benutzers"},
"include_live_data": {"type": "boolean", "description": "Aktuelle Webdaten abrufen"}
},
"required": ["query"]
}
)
]
)
def _requires_fresh_data(self, query: str) -> bool:
"""Bestimmen Sie, ob die Abfrage Echtzeitdaten erfordert."""
fresh_data_keywords = [
„latest“, „current“, „today“, „now“, „recent“,
„price“, „cost“, „available“, „in stock“
]
return any(keyword in query.lower() for keyword in fresh_data_keywords)Muster 3: Integration von KI-Scrapern für erweiterte Intelligenz
Nutzen Sie die KI-Scraper von Bright Data (ChatGPT, Perplexity, Gemini), um Ihr RAG mit KI-generierten Erkenntnissen und umfassendem Webkontext zu erweitern.
def query_ai_scraper(
self,
scraper_type: str,
prompt: str,
country_code: str = "us"
) -> Dict[str, Any]:
"""Fragen Sie KI-Scraper (ChatGPT, Perplexity usw.) nach erweitertem Kontext."""
scraper_ids = {
"chatgpt": "chatgpt_scraper_id",
"perplexity": "perplexity_scraper_id",
"gemini": "gemini_scraper_id"
}
inputs = [{
"prompt": prompt,
"country": country_code
}]
results = self.scrape_real_time_data(
scraper_id=scraper_ids.get(scraper_type),
inputs=inputs,
wait_for_completion=True
)
if results:
return {
"answer": results[0].get("answer", ""),
"sources": results[0].get("sources", []),
"citations": results[0].get("citations", [])
}
return {}
def create_hybrid_intelligence_agent(self) -> Dict[str, Any]:
"""Erstellen Sie einen Agenten, der RAG mit KI-Scraper-Intelligenz kombiniert."""
def hybrid_search(query: str) -> str:
"""
Kombinieren Sie interne RAG mit externer KI-Scraper-Intelligenz.
Dies bietet:
1. Internen Wissensdatenbankkontext
2. Echtzeit-Erkenntnisse aus dem Internet, die von KI generiert werden
3. Umfassende, gut recherchierte Antworten
"""
# Internes Wissen abrufen
internal_answer = self.rag_agent.hybrid_search(
corpus_id=self.rag_agent.corpus_id,
query=query,
top_k=3
)
internal_context = "n".join([r['text'][:200] for r in internal_answer])
# KI-Scraper-Anreicherung abrufen
print("🤖 Abrufen von KI-erweiterter Web-Intelligenz...")
ai_insight = self.query_ai_scraper(
scraper_type="perplexity", # Bekannt für gut recherchierte Antworten
prompt=query
)
# Beide Quellen synthetisieren
synthesis_prompt = f"""Synthetisieren Sie eine umfassende Antwort unter Verwendung sowohl interner Kenntnisse als auch externer KI-Erkenntnisse.
INTERNE WISSENSBASE:
{internal_context}
EXTERNE KI-ERKENNTNISSE:
{ai_insight.get('answer', 'Keine externen Erkenntnisse verfügbar')}
QUELLEN:
{json.dumps(ai_insight.get('citations', []), indent=2)}
FRAGE: {query}
Geben Sie eine vollständige Antwort, die:
1. internes Wissen für unternehmensspezifische Informationen priorisiert
2. externe Erkenntnisse für einen breiteren Kontext und aktuelle Entwicklungen nutzt
3. alle Quellen klar angibt
4. angibt, wann Informationen aus externen bzw. internen Quellen stammen"""
model = GenerativeModel("gemini-2.0-flash-001")
response = model.generate_content(synthesis_prompt)
return response.text
return {
'search_function': hybrid_search,
'description': 'Hybrid RAG + KI Scraper Intelligence System'
}Ausführen Ihres RAG-Agent-Systems
Führen Sie alle Komponenten zu einem vollständigen Workflow zusammen, der Dokumente verarbeitet, Anfragen bearbeitet und fundierte Antworten generiert. Laden Sie außerdem die PDF-Dokumente, die Sie verarbeiten möchten, herunter und legen Sie sie im Ordner „docs/“ ab, damit die KI einen Kontext zu Ihrem Produkt aufbauen kann.
def main():
"""Hauptablauf für das RAG-Agentensystem."""
print("=" * 60)
print("RAG-Agentensystem – Initialisierung")
print("=" * 60)
initialize_adk()
corpus_id = create_rag_corpus(
corpus_name="enterprise-knowledge-base-3",
description="Multimodale Unternehmensdokumentation und Wissensspeicher"
)
retrieval_config = configure_retrieval_parameters(corpus_id)
print(f"n✓ Verwendung der Abrufkonfiguration mit top_k={retrieval_config['similarity_top_k']}")
print("n" + "=" * 60)
print("Dokumenteneingabe-Pipeline")
print("=" * 60)
document_paths = [
"docs/technical_manual.pdf",
"docs/product_specs.pdf",
"docs/user_guide.pdf"
]
gcs_uris = []
all_chunks = []
extracted_images = []
for doc_path in document_paths:
if os.path.exists(doc_path):
extracted = extract_text_from_pdf(doc_path)
print(f"n✓ Extracted {extracted['metadata']['num_pages']} pages from {Path(doc_path).name}")
cleaned_text = preprocess_document(extracted['full_text'])
print(f"✓ Vorverarbeiteter Text: {len(cleaned_text)} Zeichen")
chunks = chunk_document(cleaned_text, chunk_size=1000, overlap=200)
all_chunks.extend(chunks)
print(f"✓ Dokument in {len(chunks)} Segmente unterteilt")
gcs_uri = upload_file_to_gcs(doc_path, os.getenv('GCS_BUCKET_NAME'))
gcs_uris.append(gcs_uri)
print(f"n✓ Insgesamt erstellte Segmente: {len(all_chunks)}")
print(f"✓ Insgesamt extrahierte Bilder: {len(extracted_images)}")
if gcs_uris:
import_documents_to_corpus(corpus_id, gcs_uris)
index_config = {"distance_measure": "COSINE", "algorithm": "TREE_AH"}
create_vector_index(corpus_id, index_config)
time.sleep(180)
# ========================================================================
# Initialisieren Sie Google ADK Agent mit Vertex KI RAG Engine.
# ========================================================================
print("n" + "=" * 60)
print("Google ADK Agent Initialisierung")
print("=" * 60)
adk_agent = ADKRAGAgent(
corpus_id=corpus_id,
project_id=os.getenv("GOOGLE_CLOUD_PROJECT"),
location=os.getenv("GOOGLE_CLOUD_LOCATION")
)
agent = adk_agent.create_agent()
for doc_path in document_paths:
if os.path.exists(doc_path):
try:
images = adk_agent.rag_agent.extract_images_from_pdf(doc_path, "extracted_images")
extracted_images.extend(images)
if images:
print(f"✓ {len(images)} Bilder für multimodale Verarbeitung extrahiert")
except Exception as e:
print(f"⚠️ Bildextraktion übersprungen: {str(e)}")
queries = [
"Was sind die Systemanforderungen für die Installation?",
"Wie konfiguriere ich die Authentifizierungseinstellungen?",
„Wie sehen die Preisstufen und ihre Funktionen aus?”
]
print("n" + "=" * 60)
print("Google ADK Agent – Abfrageverarbeitung")
print("=" * 60)
print("Verwendung: Google ADK + Vertex KI RAG Engine")
print("=" * 60)
session_id = f"session_{datetime.now().strftime('%Y%m%d_%H%M%S')}"
for idx, query in enumerate(queries):
print(f"n📝 Abfrage {idx + 1}: {query}")
print("-" * 60)
try:
answer = adk_agent.chat(agent, query, session_id)
print(f"n💬 ADK Agent Response:n{answer}n")
print(f"✓ Conversation history: {len(adk_agent.rag_agent.conversation_history)} messages")
except Exception as e:
print(f"❌ Fehler: {str(e)}")
import traceback
traceback.print_exc()
print("-" * 60)
if idx < len(queries) - 1:
time.sleep(90)
if extracted_images:
print("n" + "=" * 60)
print("Multi-Modal Processing Demo")
print("=" * 60)
sample_table = """Feature | Basic | Pro | Enterprise
Speicherplatz | 10 GB | 100 GB | Unbegrenzt
Benutzer | 1 | 10 | Unbegrenzt
Preis | 10 $ | 50 $ | Individuell"""
table_data = adk_agent.rag_agent.process_table_content(sample_table)
print(f"n✓ Tabelle mit {table_data.get('row_count', 0)} Zeilen verarbeitet")
if all_chunks and extracted_images:
multimodal_embed = adk_agent.rag_agent.create_multimodal_embedding(
text=all_chunks[0]['text'][:500],
image_path=extracted_images[0]['image_path'] if extracted_images else None,
table_data=table_data
)
print(f"✓ Multimodale Einbettung mit {multimodal_embed['modalities']} Modalitäten erstellt")
print(f" - Hat Bild: {multimodal_embed['has_image']}")
print(f" - Hat Tabelle: {multimodal_embed['has_table']}")
print("n" + "=" * 60)
print(f"Google ADK RAG Agent System – Fertiggestellt")
print(f"✓ Architektur: Google ADK + Vertex KI RAG Engine")
print(f"✓ Gesamtzahl der Gesprächsrunden: {len(adk_agent.rag_agent.conversation_history)}")
print("=" * 60)
if __name__ == "__main__":
try:
main()
except Exception as e:
print(f"n❌ Fehler: {str(e)}")
import traceback
traceback.print_exc()Führen Sie das RAG-Agentensystem aus:
python3 rag_agent.pySie sehen die Verarbeitungs-Pipeline des Agenten in der Konsole, während er:
- den Google ADK-Client und die KI-Verbindung initialisiert.
- Erstellt den RAG-Korpus mit eingebetteter Modellkonfiguration.
- Dokumente werden durch Extrahieren, Bereinigen und Chunking verarbeitet.
- Dateien in Cloud Storage hochlädt und in den Korpus importiert.
- Vektor-Einbettungen generiert und den Suchindex erstellt.
- Führt Abfragen mit Erweiterung, Abruf und Neuanordnung durch.
- Erstellt fundierte Antworten mit Zitaten und Verifizierungen.
- Bewertet die Qualität der Antworten anhand von Relevanz, Vollständigkeit, Genauigkeit und Klarheit.
Die Konsolenausgabe zeigt den detaillierten Fortschritt für jeden Schritt an.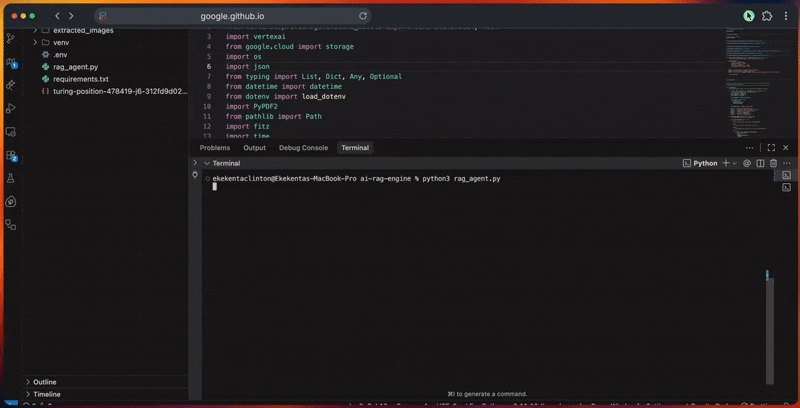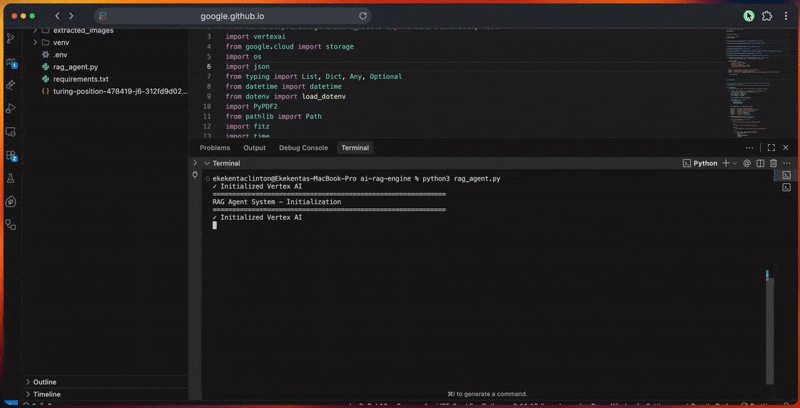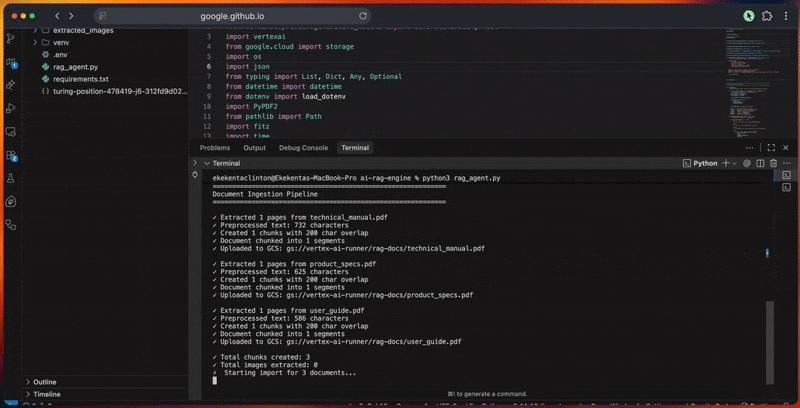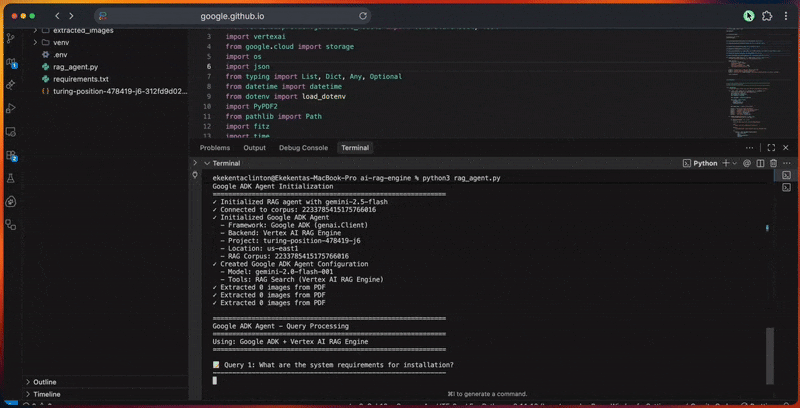
Abschließende Gedanken
Sie verfügen nun über ein produktionsreifes RAG-Agentensystem, das das Agent Development Kit von Google mit Vertex KI kombiniert. Das System nimmt Dokumente auf, ruft relevante Kontexte über eine hybride Suche ab und generiert präzise Antworten mit Zitaten.
Verbessern Sie es, indem Sie die Chunking-Strategien optimieren, Feedback-Schleifen hinzufügen, zusätzliche Datenquellen integrieren oder Echtzeitüberwachung aktivieren. Das modulare Design ermöglicht eine einfache Anpassung.
Entdecken Sie erweiterte KI-Workflows und die KI-Infrastruktur von Bright Data für weitere Funktionen.
Erstellen Sie ein kostenloses Konto, um mit dem Aufbau zu beginnen.





