

In diesem Blogbeitrag erfahren Sie:
- Was Convex ist, wie sein mentales Modell funktioniert und wie es sich im Vergleich zu anderen Datenbanken darstellt.
- Wie es im Detail funktioniert und auf welchen Kernkomponenten es aufbaut.
- Warum Convex bei der Speicherung von Echtzeit-Webdaten glänzt.
- Die größten Hindernisse und Herausforderungen bei der Beschaffung von Live-Daten aus dem Web.
- Wie Bright Data dabei hilft, diese Herausforderungen zu bewältigen, indem es strukturierte Echtzeit-Webdaten bereitstellt, die für die Speicherung in Convex geeignet sind.
- Wie Sie mit einer vollständigen Demo beginnen, die Bright Data für die Webdatenbeschaffung und Convex für die Datenspeicherung sowie nahtlose UI-Aktualisierungen kombiniert.
Lassen Sie uns loslegen!
Eine Einführung in Convex
Der erste Schritt besteht darin, Convex zu erkunden, um zu verstehen, was es ist, welche Vorteile es bietet und welches Kernkonzept dahintersteckt.
Was ist Convex?
Convex ist eine reaktive Open-Source-Backend-Plattform, die entwickelt wurde, um Ihre Web- und Mobil-Apps synchron zu halten.
Im Hintergrund vereint es eine Datenbank, serverlose Funktionen, Authentifizierung und Client-Bibliotheken in einem einzigen System. Ähnlich wie React-Komponenten, die auf Statusänderungen reagieren, reagieren Convex-Abfragen automatisch auf Datenbankaktualisierungen, was es ideal für Live-Anwendungen und dynamische Anwendungen macht.
Abfragen werden in TypeScript geschrieben und direkt in der Datenbank ausgeführt, was die Entwicklung vereinfacht und gleichzeitig schnelle, reaktive Anwendungen mit minimalem Infrastrukturaufwand ermöglicht. Die Lösung unterstützt zudem modulare Komponenten, Echtzeit-Datensynchronisation, Zeitplanung und KI-gestützte Codegenerierung. Sie lässt sich in Frameworks wie React, Next.js, Vue, Svelte und Nuxt integrieren und ist zudem mit Python-, Swift- (für iOS), Kotlin- (für Android) und Rust-Anwendungen kompatibel.
Dank ihrer Flexibilität ist sie bei Entwicklern sehr beliebt und hat über 10.900 Sterne auf GitHub sowie über 400.000 wöchentliche npm-Downloads erzielt.
Die Kernidee hinter Convex: Das mentale Modell verstehen
Im Gegensatz zu herkömmlichen Datenbanken behandelt Convex die Datenbank als ein lebendes, reaktives System und nicht nur als passiven Datenspeicher. Jedes Mal, wenn Daten hinzugefügt, aktualisiert oder gelöscht werden, wird die Änderung in einem unveränderlichen Transaktionsprotokoll aufgezeichnet. Das ist eine permanente, mit Zeitstempeln versehene Historie aller Vorgänge. Gleichzeitig rufen Abfragen nicht nur Daten ab. Sie verfolgen automatisch, welche Daten sie gelesen haben – bekannt als ihre „Read Sets“.
Dadurch kann Convex sofort erkennen, wenn sich Daten ändern, auf denen eine Abfrage basiert, sodass das System die Ergebnisse in Echtzeit aktualisieren kann. Diese Architektur unterstützt Echtzeit-Abonnements und gewährleistet starke Konsistenz durch deterministische Transaktionen und einen optimistischen Mechanismus zur Parallelitätskontrolle. Dank dieser Eigenschaften können mehrere Benutzer gleichzeitig und ohne Konflikte mit der Datenbank interagieren.
Convex im Vergleich zu anderen Datenbanken
Um besser zu verstehen, wie sich Convex im Vergleich zu anderen gängigen Datenbanken positioniert, sehen Sie sich die folgende Vergleichstabelle an:
| Funktion | Convex | Firebase | Supabase | Herkömmliche SQL-Datenbanken |
|---|---|---|---|---|
| Datenbanktyp | Transaktionaler Dokumentenspeicher | NoSQL / Firestore | PostgreSQL | Relationales SQL |
| Echtzeit | ✔️ (Integriert, automatische Abonnements) | ✔️ (Integriert) | ➖ (Optional, über separaten Server) | ❌ (Nicht nativ) |
| Transaktionen | Immer transaktional | Eingeschränkt | Unterstützt | Unterstützt |
| Schema | Optional, schrittweise, automatisch aus TypeScript generiert | Flexibel / schemalos | Erzwungen (Postgres) | Streng, manuell |
| SQL-Unterstützung | ❌ | ❌ | ✔️ | ✔️ |
| TypeScript-Integration | Vollständig | Eingeschränkt | Teilweise, serverseitig | Hängt vom ORM ab |
| Auth/OAuth | Standard + nativ | Standard + Firebase-Auth | Standard + nativ | Benutzerdefinierte Konfiguration |
| Verantwortung für die Datenbank | Wird vollständig von Convex übernommen | Gemeinsam | Geteilt | Vollständig vom Entwickler verwaltet |
So funktioniert Convex: Architektur, Komponenten und Datenfluss
Die Convex-Architektur basiert auf einer Full-Stack-Backend-Plattform mit drei Hauptkomponenten:
- Datenbank: Ein reaktiver, dokument-relationaler Speicher, in dem JSON-ähnliche Objekte in Tabellen organisiert sind. Die Convex-Datenbank wird für jedes Projekt automatisch in der Cloud bereitgestellt, sodass keine manuelle Verbindungskonfiguration oder Clusterverwaltung erforderlich ist.
- Serverfunktionen: Abfragen und Mutationen werden als TypeScript-Funktionen geschrieben, wodurch SQL oder ORMs überflüssig werden. Abfragen sind rein und schreibgeschützt, während Mutationen in vollständig verwalteten Transaktionen mit ACID-Garantien, serialisierbarer Isolation und optimistischer Parallelitätskontrolle ausgeführt werden.
- Client-Bibliotheken: Frameworkspezifische Bibliotheken (Next.js, React, Vue, Svelte usw.), die Serverfunktionen abonnieren, Ergebnisse automatisch synchronisieren und Mutationswarteschlangen verwalten. Sie gewährleisten konsistente UI-Aktualisierungen in Echtzeit ohne manuelles Abonnement oder Statusverwaltung.
Mit diesen drei Komponenten fließen Daten reaktiv von der Datenbank über Serverfunktionen zum Client. Abfragen verfolgen automatisch Abhängigkeiten, werden bei Datenänderungen erneut ausgeführt und übertragen Aktualisierungen in Echtzeit. Mutationen laufen als vollständig verwaltete Transaktionen, aktualisieren die Datenbank und abhängige Abfragen und stellen sicher, dass Clients stets den aktuellen Status sehen, ohne manuelle Synchronisation.
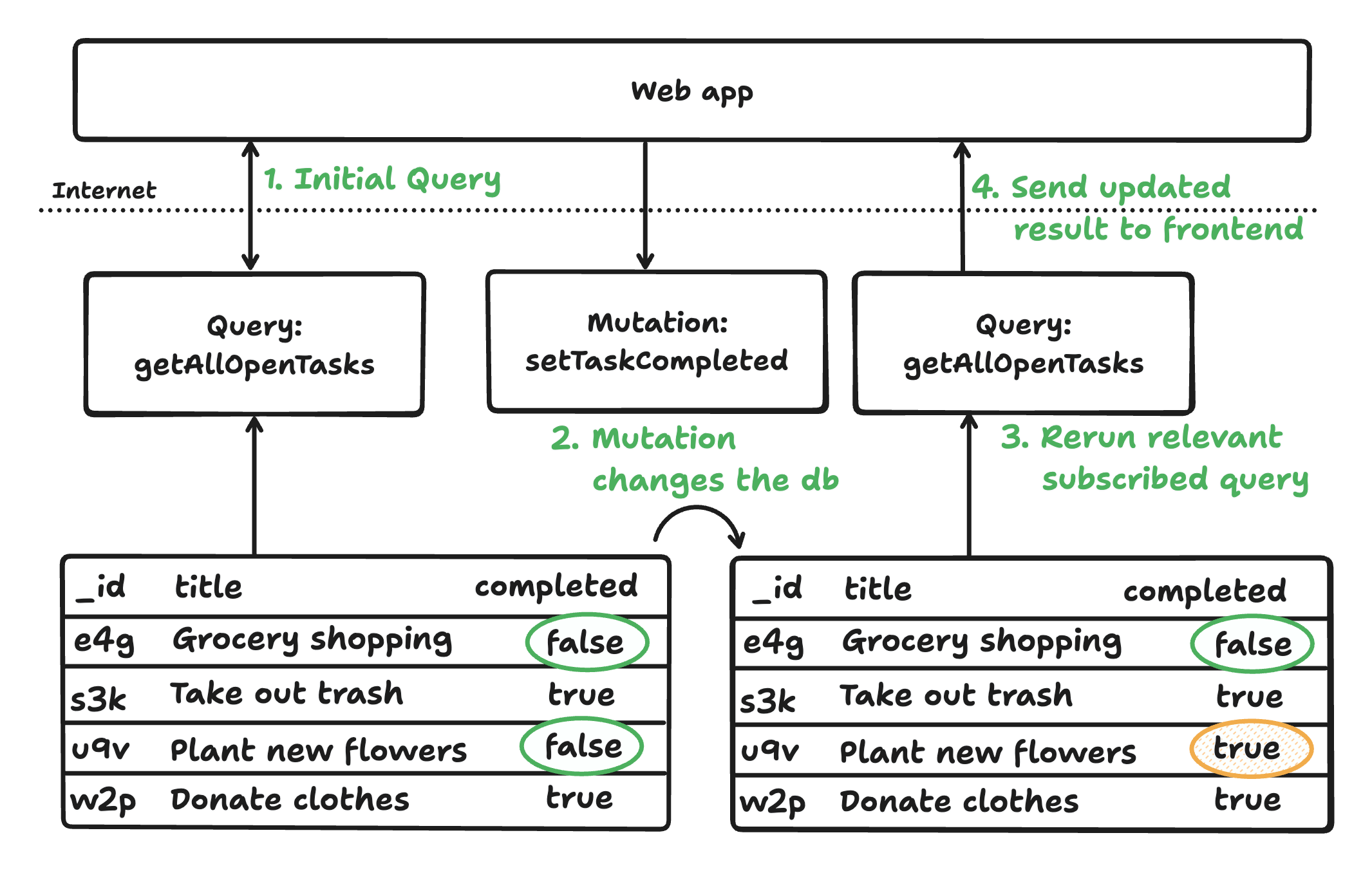
Die kohärente Architektur von Convex garantiert reaktive, konsistente und typsichere Anwendungen mit minimalem Boilerplate-Code. Sie unterstützt die schnelle Entwicklung sowohl von menschlich als auch von KI generiertem Code und abstrahiert Datenbankoptimierung und -synchronisation. Convex bietet außerdem Authentifizierung, Scheduling und mehr.
Warum Convex und Echtzeit-Webdaten perfekt zusammenpassen
Eine Echtzeit-Datenbank wie Convex entfaltet ihr volles Potenzial erst dann, wenn die Datenquelle selbst in Echtzeit arbeitet. Mit anderen Worten: Ihre reaktive Architektur eignet sich perfekt für Anwendungen, die Live-Bedingungen widerspiegeln müssen (z. B. Aktienkurse, Social-Media-Feeds, Nachrichten-Updates oder E-Commerce-Bestände).
Was ist nun die größte Quelle für dynamische, sich ständig ändernde Daten auf der Welt? Das Web! Webdaten fließen in Echtzeit aus Millionen von Quellen und sind damit die ideale Eingabe für eine auf Convex basierende reaktive Anwendung.
Durch die Anbindung von Convex an Echtzeit-Webdatenströme kann Ihre App sofort auf Aktualisierungen reagieren, ohne komplexes Polling, manuelle Synchronisation oder Statusverwaltung. Dies beseitigt die Latenz zwischen den Informationen und der Benutzeroberfläche und schafft ein nahtloses, stets aktuelles Benutzererlebnis.
Herausforderungen bei der Anbindung von Webdaten an eine Convex-Anwendung
Nun verstehen Sie, warum Echtzeit-Webdaten hervorragend zu einer Lösung wie Convex passen. Die nächste Frage lautet: Wie ruft man sie tatsächlich ab? Die Antwort lautet Web-Scraping, also der Prozess der programmgesteuerten Extraktion von Informationen aus Webseiten.
Web-Scraping ist ein leistungsstarker Ansatz, bringt jedoch einige Herausforderungen mit sich. Diese reichen von technischen Hürden bis hin zu operativer Komplexität, darunter:
- Dynamische Inhalte: Moderne Websites basieren auf JavaScript, AJAX sowie komplexen Navigations- und Interaktionsmustern, was die Extraktion strukturierter Daten erschwert.
- Anti-Bot-Maßnahmen: Viele Websites nutzen CAPTCHAs, Ratenbegrenzungen, Fingerabdrücke und andere Abwehrmechanismen, um automatisierten Zugriff zu erkennen und zu blockieren.
- Häufige Änderungen: Layouts, HTML-Strukturen und URLs ändern sich oft, was Scraper unbrauchbar macht und eine kontinuierliche Überwachung und Wartung erfordert.
- Skalierbarkeit: Die Datenerfassung in großem Maßstab erfordert eine solide Infrastruktur, die Integration mit einem vertrauenswürdigen Proxy-Anbieter für IP-Rotation sowie eine robuste Fehlerbehandlung.
- Datenkonsistenz: Die Gewährleistung von Genauigkeit, Vollständigkeit und Aktualität ist eine Herausforderung, insbesondere bei häufig aktualisierten Daten.
Daher ist die Entwicklung einer vollständig reaktiven Convex-Anwendung auf Basis von Webdaten eine gewaltige Aufgabe. Anstatt diese Hindernisse selbst zu bewältigen, ist es am besten, sich auf einen unternehmensfähigen Anbieter von Echtzeit-Webdaten wie Bright Data zu verlassen.
Bright Data + Convex für reaktive Apps auf Basis von Echtzeit-Webdaten
Bei der Entwicklung reaktiver Anwendungen, die auf Live-Webdaten basieren, sticht die Kombination aus Bright Data und Convex hervor. Zusammen sorgen sie für eine klare Aufgabenteilung: Bright Data konzentriert sich auf die groß angelegte Datenerfassung, während Convex die Live-Zustandssynchronisation und UI-Aktualisierungen übernimmt.
Mit Bright Data können Sie Informationen programmgesteuert in Echtzeit im Web suchen und extrahieren. Die gesammelten Daten werden als strukturiertes JSON zurückgegeben, das sich problemlos in Convex einlesen lässt. Convex sorgt dann dafür, dass diese Daten über reaktive Abfragen sofort an alle verbundenen Clients weitergeleitet werden.
Was Bright Data besonders attraktiv macht, ist seine Infrastruktur auf Unternehmensniveau. Das Unternehmen nutzt eines der größten Proxy-Netzwerke der Welt mit über 150 Millionen IP-Adressen in 195 Ländern und ermöglicht so eine unbegrenzte Anzahl gleichzeitiger Zugriffe. Diese Grundlage gewährleistet hohe Zuverlässigkeit mit einer Verfügbarkeit von 99,99 %, einer Erfolgsquote von 99,95 % und Support rund um die Uhr.
Alle Echtzeit-Datenabruf-Lösungen von Bright Data basieren auf dieser Infrastruktur. Zu den wichtigsten Angeboten gehören:
- Web-Scraper-APIs: Vorgefertigte API-Endpunkte zum Extrahieren strukturierter Live-Daten von beliebten Websites.
- Unlocker-API: Bewältigt automatisch CAPTCHAs, Blockierungsmechanismen und Anti-Bot-Systeme und ermöglicht Ihnen den Zugriff auf nicht gesperrte Seiteninhalte.
- SERP-API: Liefert Suchergebnisse in Echtzeit von mehreren Suchmaschinen mit Antwortzeiten von weniger als einer Sekunde.
- Crawl-API: Wandelt ganze Websites in strukturierte Datensätze um.
Die Konfiguration von Convex + Bright Data ermöglicht einen kontinuierlichen Fluss aktueller Daten aus dem Web zu Ihren Nutzern, ohne den typischen betrieblichen Aufwand des Web-Scrapings. Das Ergebnis ist ein skalierbares, wartungsfreundliches und vollständig reaktives System, das auf Echtzeit-Webdaten basiert.
Beispiel für eine Architektur
Nachfolgend finden Sie ein Beispiel für die Architektur einer reaktiven Web- oder Mobilanwendung, die mit Convex erstellt wurde und Echtzeit-Webdaten von Bright Data nutzt:
- Auslösen der Datenabfrage (Bright Data): Wenn ein Nutzer eine bestimmte Aktion ausführt (z. B. auf eine Schaltfläche klickt), sendet das Frontend eine Anfrage an Ihr Backend. Der Server ruft daraufhin eine Bright Data-API auf, um aktuelle Daten aus dem Web abzurufen. Bei den gescrapten Daten kann es sich um Produktpreise, Nachrichtenartikel, Stellenanzeigen usw. handeln.
- Backend-Verarbeitung (Convex): Sobald die strukturierten JSON-Daten empfangen wurden, werden sie über eine Mutation an Convex übergeben. In dieser Phase werden die Daten ingested, normalisiert, validiert und in der Convex-Datenbank gespeichert. Sie können die Daten hier auch basierend auf der Logik Ihrer Anwendung anreichern oder transformieren.
- Live-UI-Aktualisierungen (Convex Reactivity): Das Frontend abonniert Abfragen in Convex. Sobald die Datenbank aktualisiert wird, werden die entsprechenden Abfragen automatisch erneut ausgeführt. Die aktualisierten Ergebnisse werden sofort an den Client übermittelt, und die Benutzeroberfläche wird in Echtzeit ohne manuelles Eingreifen aktualisiert.
So erstellen Sie ein Echtzeit-KI-Terminal für Marktforschung mit Convex und Bright Data
Um die Möglichkeiten zu veranschaulichen, die durch die Integration von Convex und Bright Data eröffnet werden, betrachten wir eine Demo aus der Praxis: das KI-Terminal für Marktforschung von Bright Data.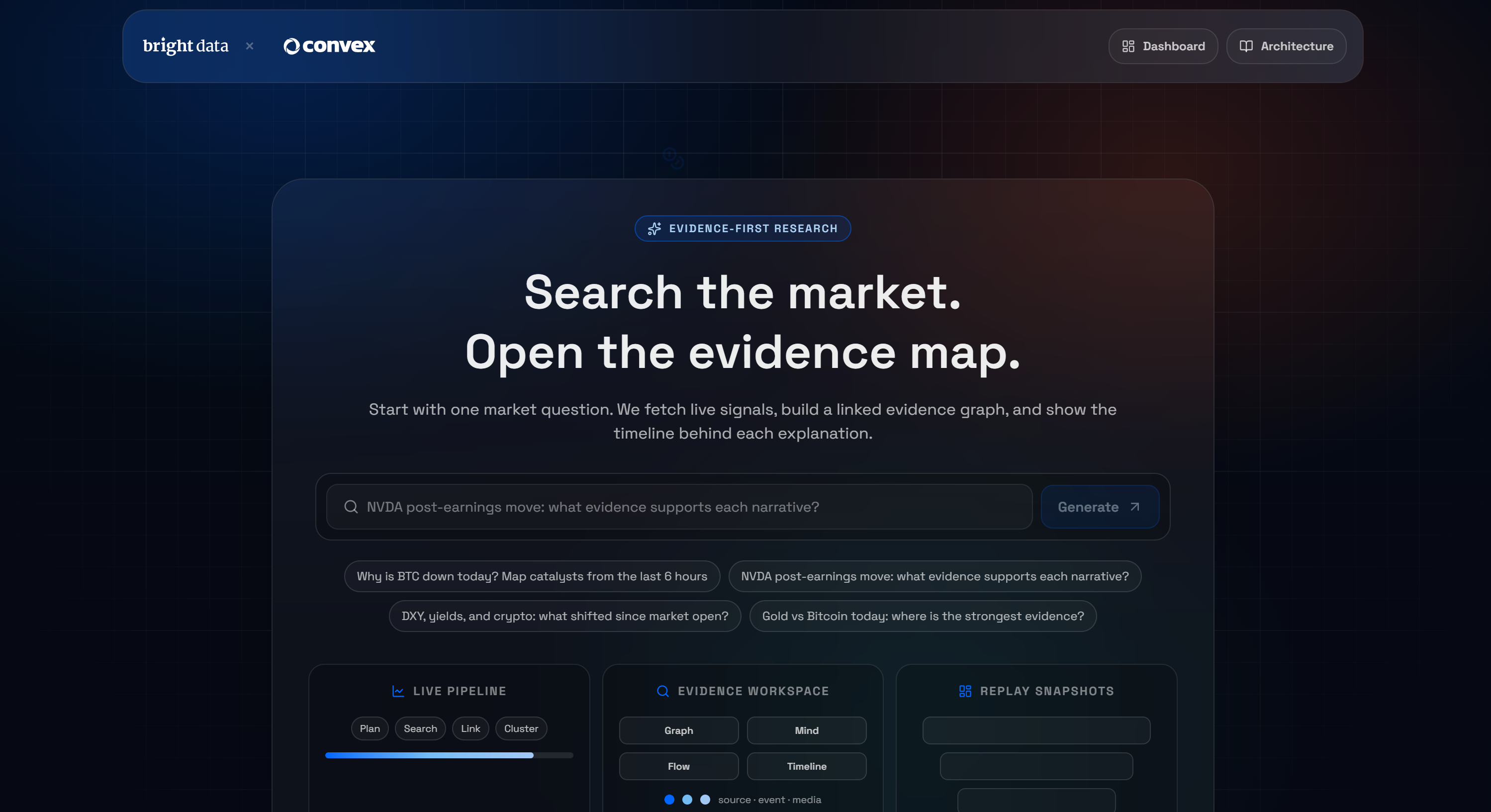
Dabei handelt es sich um eine auf Convex basierende Next.js-Anwendung, mit der Sie eine Frage stellen und einen live generierten, aus dem Web gesammelten Evidenzgraphen erhalten können. Falls Ihnen dieses Konzept nicht geläufig ist: Ein Evidenzgraph ist eine strukturierte Darstellung, die die Beziehungen zwischen Daten, Behauptungen und unterstützenden Belegen aufzeigt.
Im Hintergrund folgt die Anwendung einer Pipeline, die aus acht Schritten besteht:
- Plan: Ein LLM erstellt 4–6 gezielte Suchanfragen basierend auf Ihrem Thema.
- Suche: Sendet gleichzeitig 4–6 Bright Data SERP-API-Anfragen.
- Scrape: Extrahiert die wichtigsten URLs mithilfe der Bright Data Web Unlocker API in Markdown.
- Extrahieren: Kombiniert SERP-Snippets und Markdown zu strukturierten Evidenzelementen.
- Zusammenfassungen: Das LLM extrahiert für jedes Element wichtige Stichpunkte, Entitäten, Auslöser und die Stimmung.
- Artefakte: Erstellt Knoten und Kanten für den Wissensgraphen mit Konfidenzwerten.
- Link: Wendet heuristische Anreicherung an, einschließlich Korrekturen der Konnektivität, Domain-Tagging und Tape-Ereignissen.
- Render → Ready: Streamt die endgültigen Artefakte an den Client, während die Sitzung in Convex fortgesetzt wird.
Probieren Sie diese Demo aus und testen Sie sie lokal! Sehen Sie, wie eine reale Convex + Bright Data-Anwendung Live-Webdaten in einem reaktiven Workflow sammelt, verarbeitet und bereitstellt.
Voraussetzungen
Um diesem Abschnitt des Tutorials folgen zu können, stellen Sie sicher, dass Sie Folgendes haben:
- Node.js 20+ lokal installiert.
- Ein OpenRouter-API-Schlüssel.
- Ein Bright Data-Konto mit konfigurierten SERP- und Web Unlocker-Zonen.
- Ein eingerichtetes Convex-Projekt (die kostenlose Version reicht aus).
- Git lokal installiert.
Machen Sie sich vorerst keine Gedanken über die Einrichtung von Bright Data und Convex. Sie werden in zwei eigenen Unterkapiteln durch beide geführt.
Schritt 1: Richten Sie Ihr Bright Data-Konto ein
Wie in der Einleitung erwähnt, stützt sich die Demo-Anwendung auf zwei Bright Data-Produkte:
- SERP-API
- Web Unlocker API
Im Folgenden werden Sie durch die Einrichtung dieser Produkte in Ihrem Konto geführt. Ausführlichere Anweisungen finden Sie auch in der offiziellen Dokumentation von Bright Data:
Wenn Sie noch kein Konto haben, erstellen Sie eines. Andernfalls melden Sie sich an. Nach der Anmeldung navigieren Sie im Kontrollpanel zur Seite „Proxies & Scraping“. Suchen Sie im Abschnitt „Meine Zonen“ nach einer Zeile mit der Bezeichnung „SERP-API“ und einer weiteren mit „Web Unlocker API“: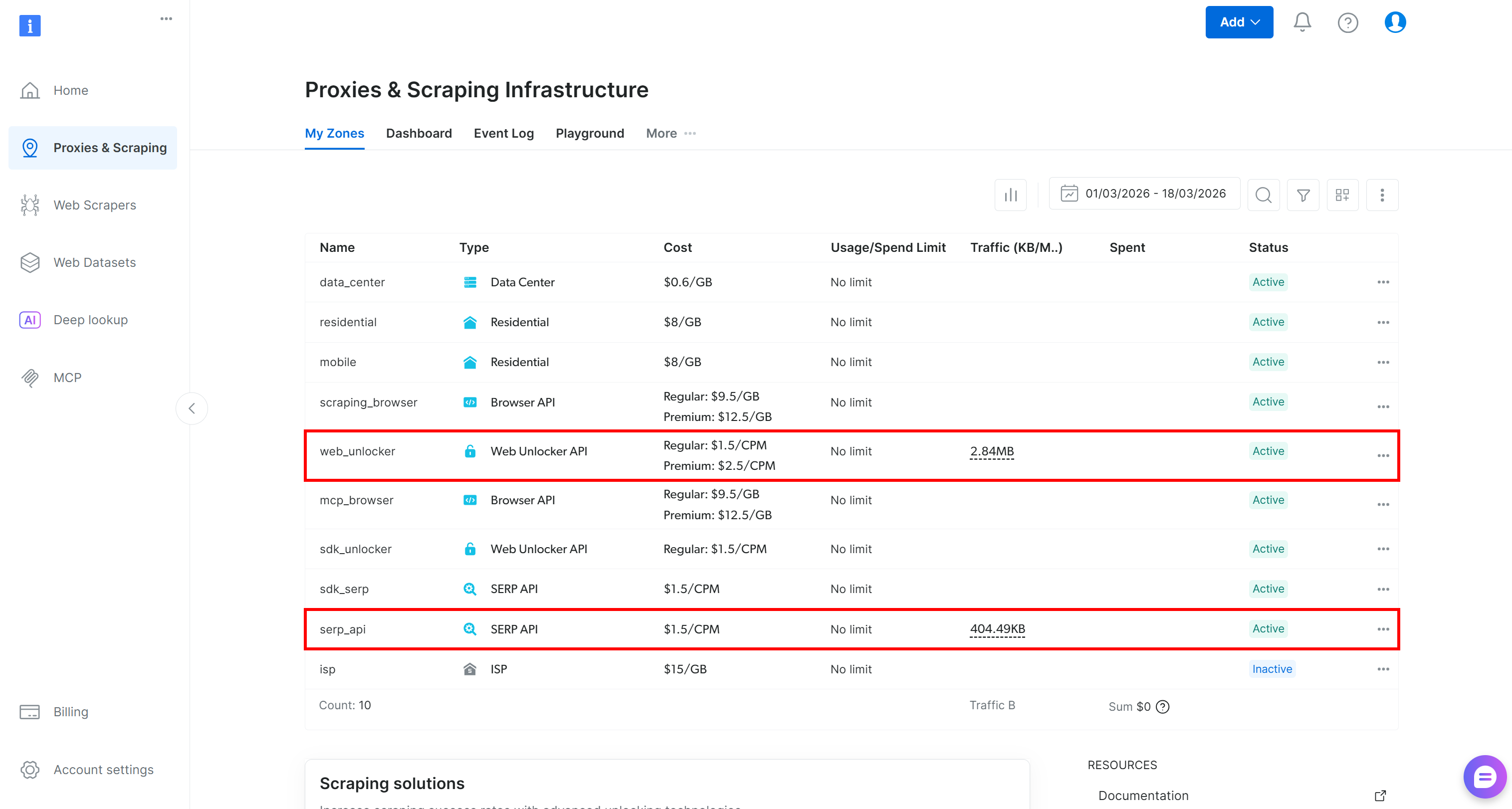
Fehlt eine der beiden Zeilen, bedeutet dies, dass die entsprechende Zone noch nicht eingerichtet wurde. Um beispielsweise eine SERP-API-Zone zu erstellen, scrollen Sie nach unten zum Abschnitt „SERP-API“ und klicken Sie auf „Zone erstellen“: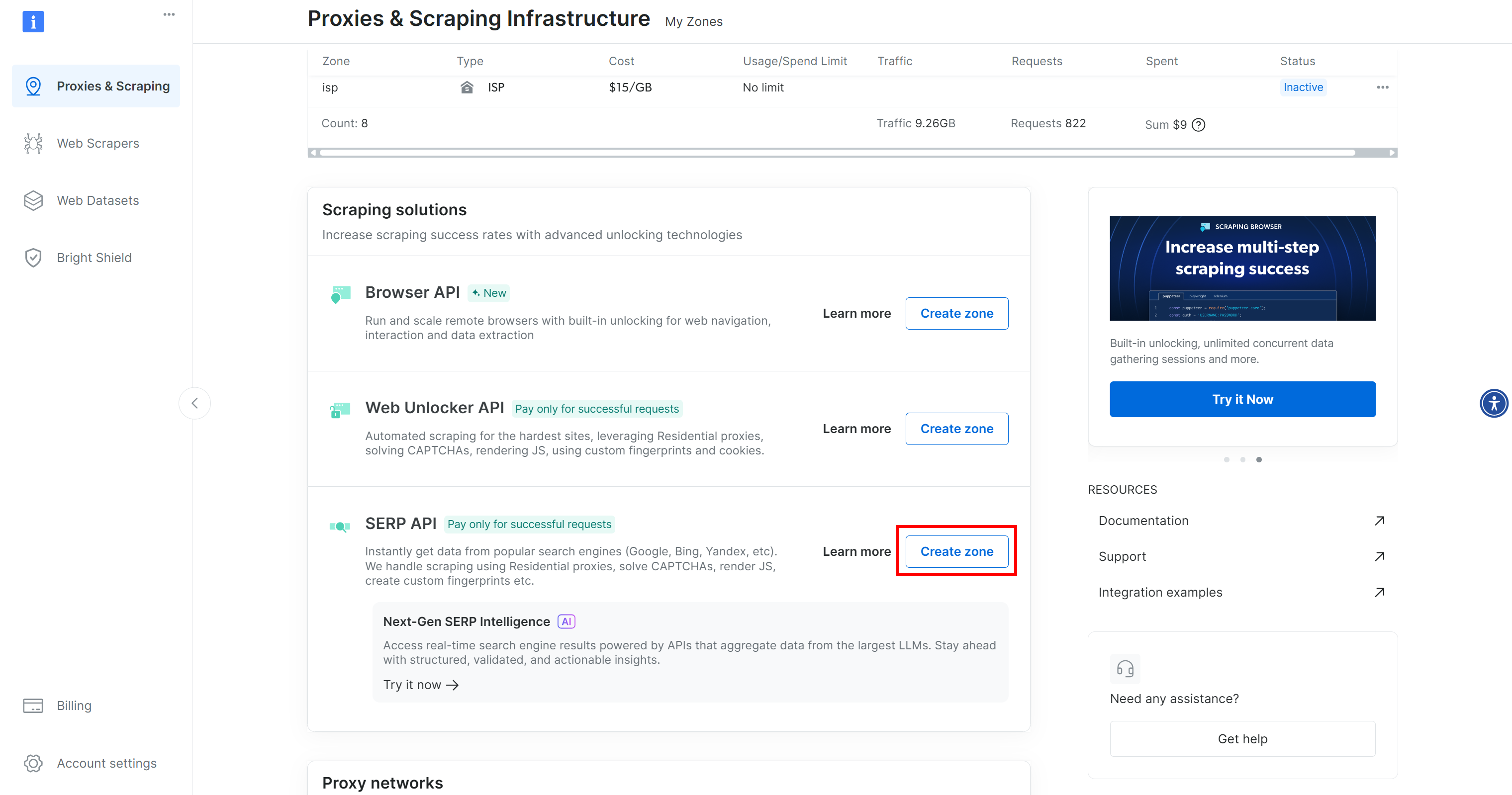
Erstellen Sie eine SERP-API-Zone und geben Sie ihr einen Namen, z. B. serp_api (oder einen beliebigen anderen Namen). Notieren Sie sich den Zonennamen, da Sie ihn später benötigen.
Wiederholen Sie denselben Vorgang für die Web Unlocker API. Für dieses Tutorial gehen wir davon aus, dass Ihre Web Unlocker-Zone den Namen web_unlocker trägt.
Befolgen Sie abschließend das offizielle Tutorial, um Ihren Bright Data API-Schlüssel zu generieren. Bewahren Sie ihn sicher auf, da er zur Authentifizierung von API-Anfragen der Convex-basierten Next.js-App an die SERP-API und den Web Unlocker benötigt wird.
Großartig! Ihr Bright Data-Konto ist nun vollständig konfiguriert und bereit für die Integration in die Demo des KI-Marktforschungs-Terminals.
Schritt 2: Richten Sie Ihr Convex-Konto ein
Melden Sie sich zunächst bei Convex an oder erstellen Sie ein neues Konto, falls Sie dies noch nicht getan haben. Sie gelangen auf Ihr Convex-Dashboard: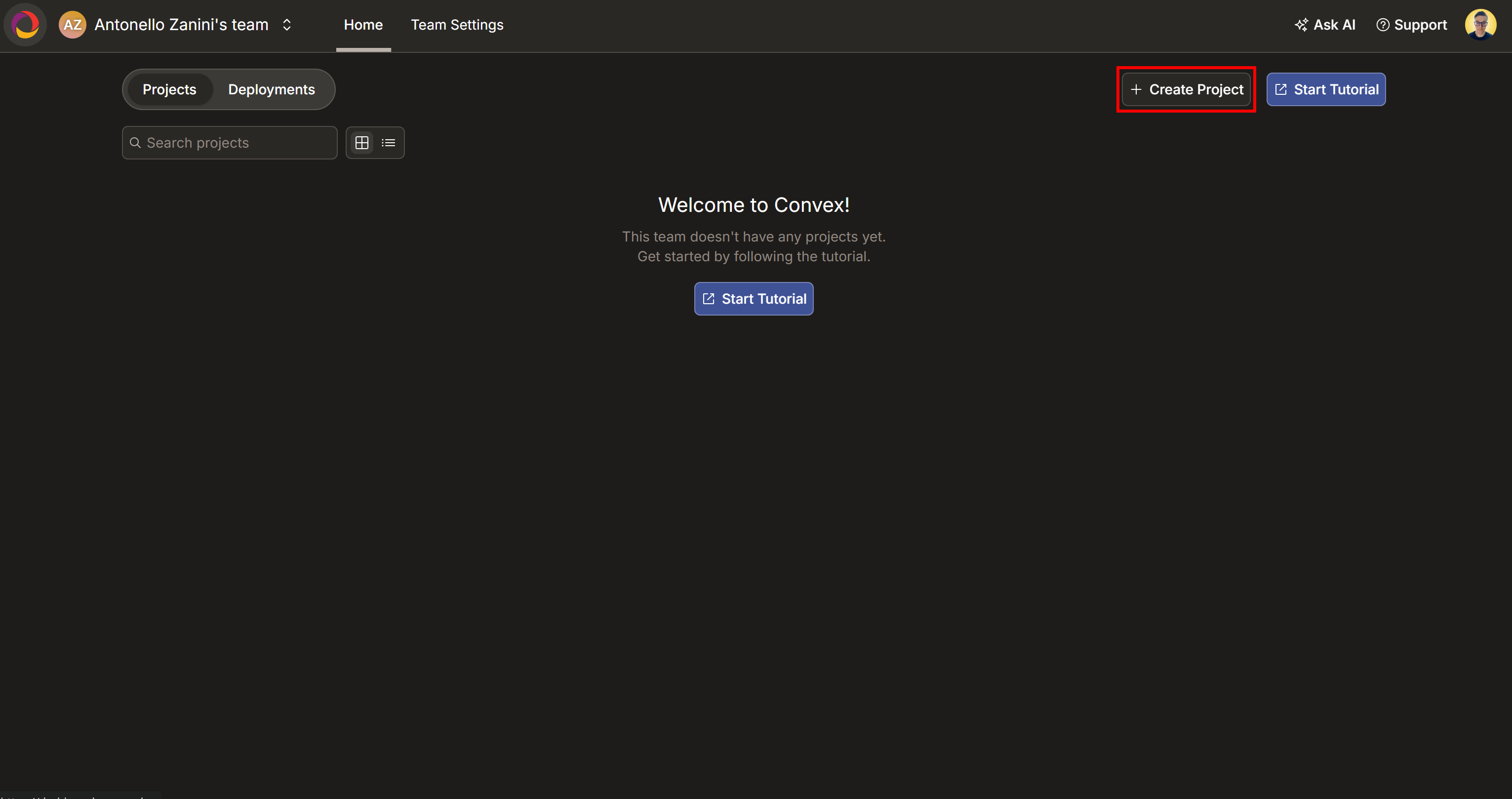
Klicken Sie hier auf die Schaltfläche „Create Project“. Benennen Sie Ihr Projekt „KI-Marktforschung-Terminal“ (oder einen beliebigen anderen Namen) und klicken Sie dann auf „Create“: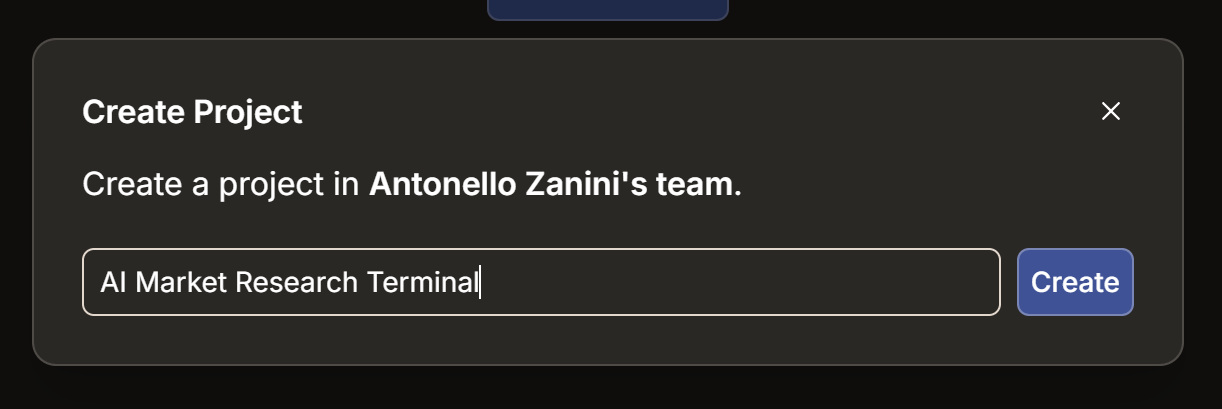
Warten Sie, bis das Projekt initialisiert ist, und wählen Sie dann eine Bereitstellungsregion aus: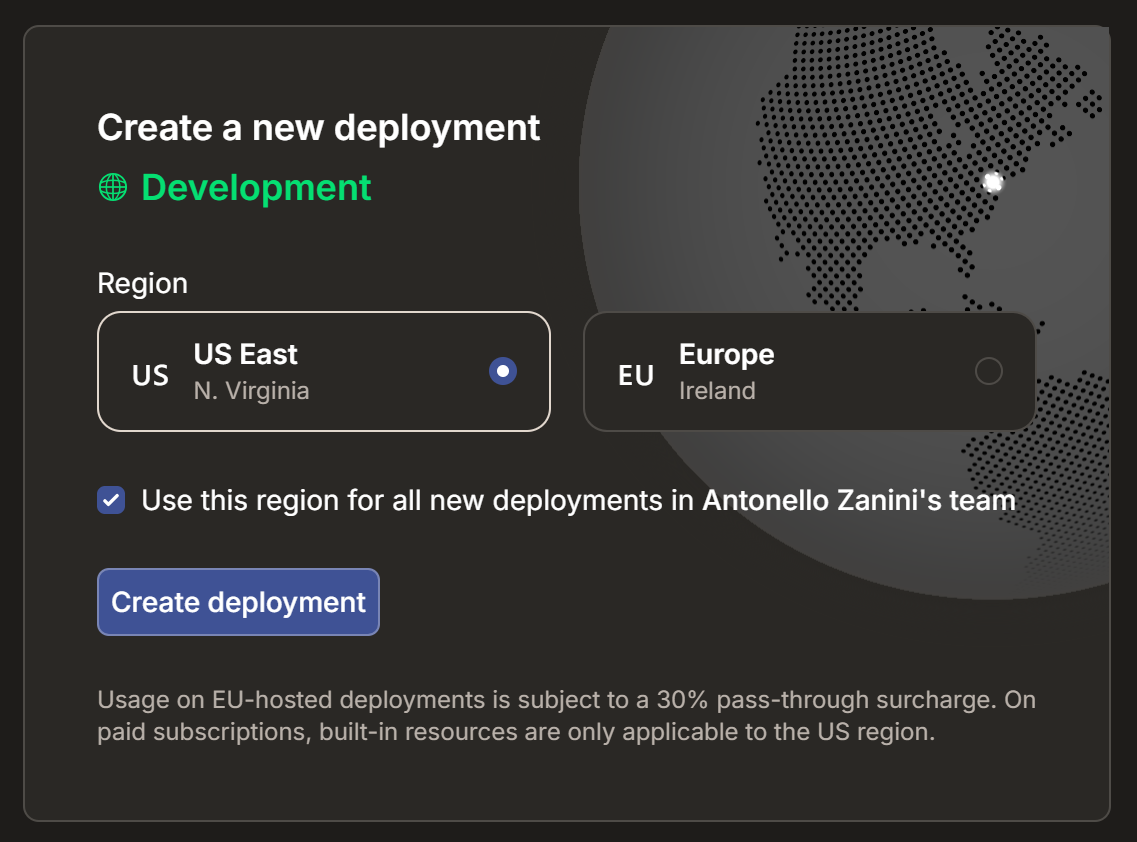
Bestätigen Sie durch Klicken auf „Bereitstellung konfigurieren“. Nach wenigen Sekunden sollte Ihr Projekt bereit sein:
Großartig! Sie verfügen nun über alle erforderlichen Bausteine, um das Projekt zu klonen und lokal auszuführen.
Schritt 3: Projekt einrichten
Beginnen Sie damit, das Demo-Repository in einen lokalen Ordner namens ai-marktforschung-terminal/ zu klonen:
git clone https://github.com/brightdata/market-terminal KI-Marktforschung-TerminalIhr Projektordner ai-Marktforschung-Terminal/ sollte nun alle Dateien enthalten, die im offiziellen Repository aufgeführt sind.
Wechseln Sie in das Projektverzeichnis:
cd KI-Marktforschung-TerminalInstallieren Sie anschließend die Projektabhängigkeiten:
npm installGroßartig! Sie können das Projekt nun in Ihrer bevorzugten JavaScript-IDE, wie beispielsweise Visual Studio Code, öffnen. Erkunden Sie es und machen Sie sich damit vertraut, um zu sehen, wie es funktioniert. Weitere Informationen und Details hinter den Kulissen finden Sie im entsprechenden ausführlichen Artikel auf DEV.
Schritt 4: Konfigurieren Sie die Anwendung
Die Anwendung liest ihre gesamte Konfiguration aus einer .env.local-Datei. Das Repository enthält eine Beispieldatei namens .env.local.example. Kopieren Sie diese, um Ihre eigene .env.local-Datei zu erstellen:
cp .env.local.example .env.local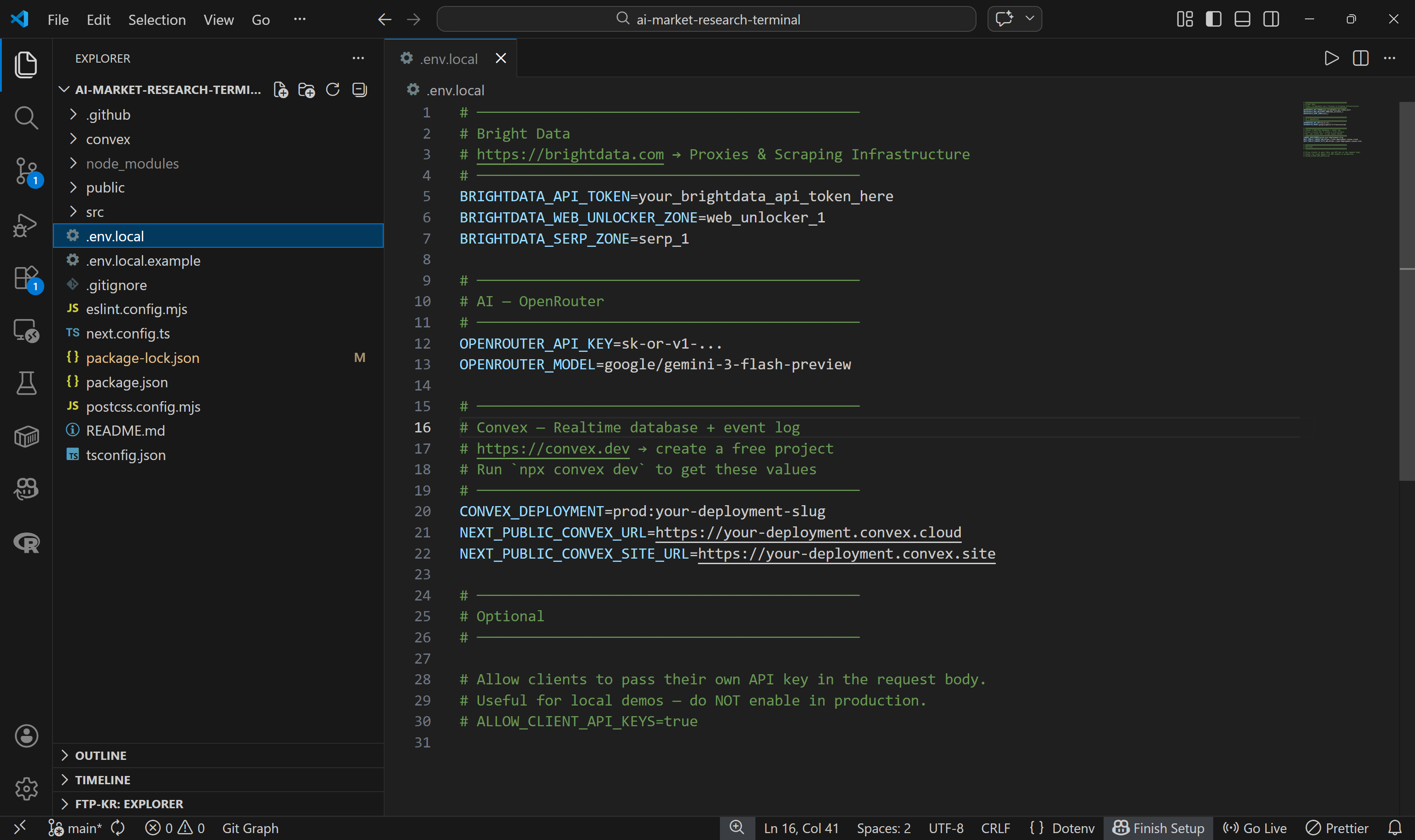
Richten Sie anschließend den Convex-Konnektor ein, indem Sie den folgenden Befehl im Stammverzeichnis Ihres Projekts ausführen:
npx convex devBefolgen Sie die Anweisungen und verbinden Sie Ihr Gerät im Browser mit Ihrem Convex-Konto. Wählen Sie dann das vorhandene Projekt „KI-Marktforschung Terminal“ aus, das Sie in Schritt 2 erstellt haben. Convex aktualisiert Ihre .env.local-Datei automatisch mit den erforderlichen Umgebungsvariablen. In diesem Fall werden folgende Einträge hinzugefügt:
CONVEX_DEPLOYMENT=dev:deafening-bloodhound-209
NEXT_PUBLIC_CONVEX_URL=https://deafening-bloodhound-209.convex.cloud
NEXT_PUBLIC_CONVEX_SITE_URL=https://deafening-bloodhound-209.convex.siteDiese Werte ermöglichen es Ihrer Anwendung, eine Verbindung zu Ihrem Convex-Projekt herzustellen.
Standardmäßig werden Ihrem Convex-Projekt zwei neue Tabellen (sessionEnvts und session) hinzugefügt: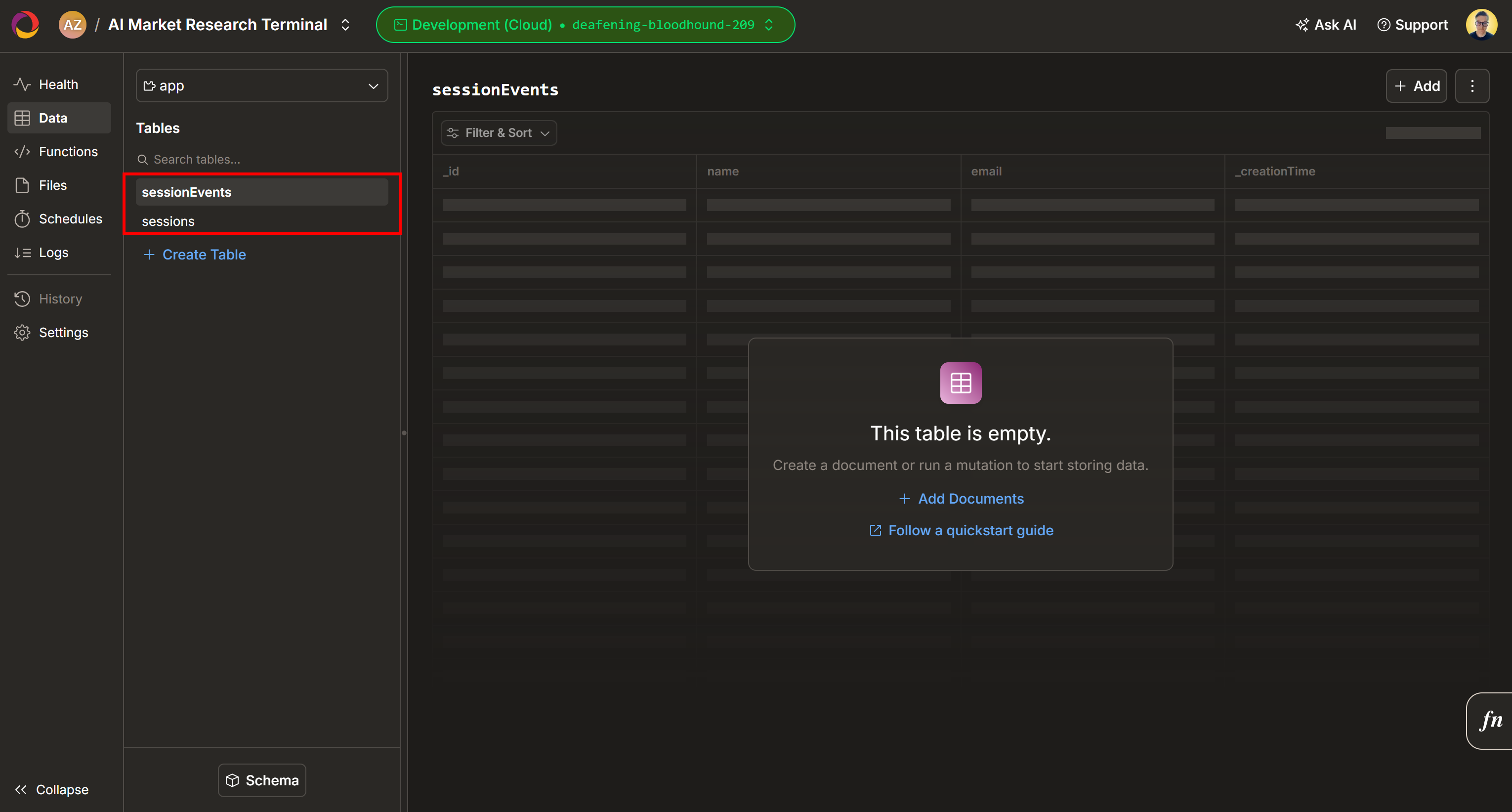
Füllen Sie anschließend die restlichen Umgebungsvariablen in .env.local aus:
BRIGHTDATA_API_TOKEN=<YOUR_BRIGHTDATA_API_KEY>
BRIGHTDATA_WEB_UNLOCKER_ZONE=<YOUR_BRIGHTDATA_WEB_ULOCKER_API_NAME> # z. B. „web_unlocker“
BRIGHTDATA_SERP_ZONE=<IHR_BRIGHTDATA_SERP_API_NAME> # z. B. „serp_api“
OPENROUTER_API_KEY=<IHR_OPENROUTER_API_KEY>
OPENROUTER_MODEL=google/gemini-3-flash-previewErsetzen Sie die Platzhalter durch Ihren Bright Data API-Token, den Web Unlocker-Zonennamen, die SERP-API-Zone und den OpenRouter API-Schlüssel. Beachten Sie, dass das Standard-LLM „Gemini 3 Flash“ ist, Sie jedoch jedes andere unterstützte Modell verwenden können, wenn Sie dies bevorzugen.
Super! Ihre Demo ist nun vollständig konfiguriert und bereit für die lokale Ausführung.
Schritt 5: Starten Sie die Anwendung lokal
Starten Sie die Demo lokal mit:
npm run devÖffnen Sie http://localhost/market-terminal in Ihrem Browser, um auf die lokale KI-Marktforschung-Terminal-App zuzugreifen. Sie sollten Folgendes sehen: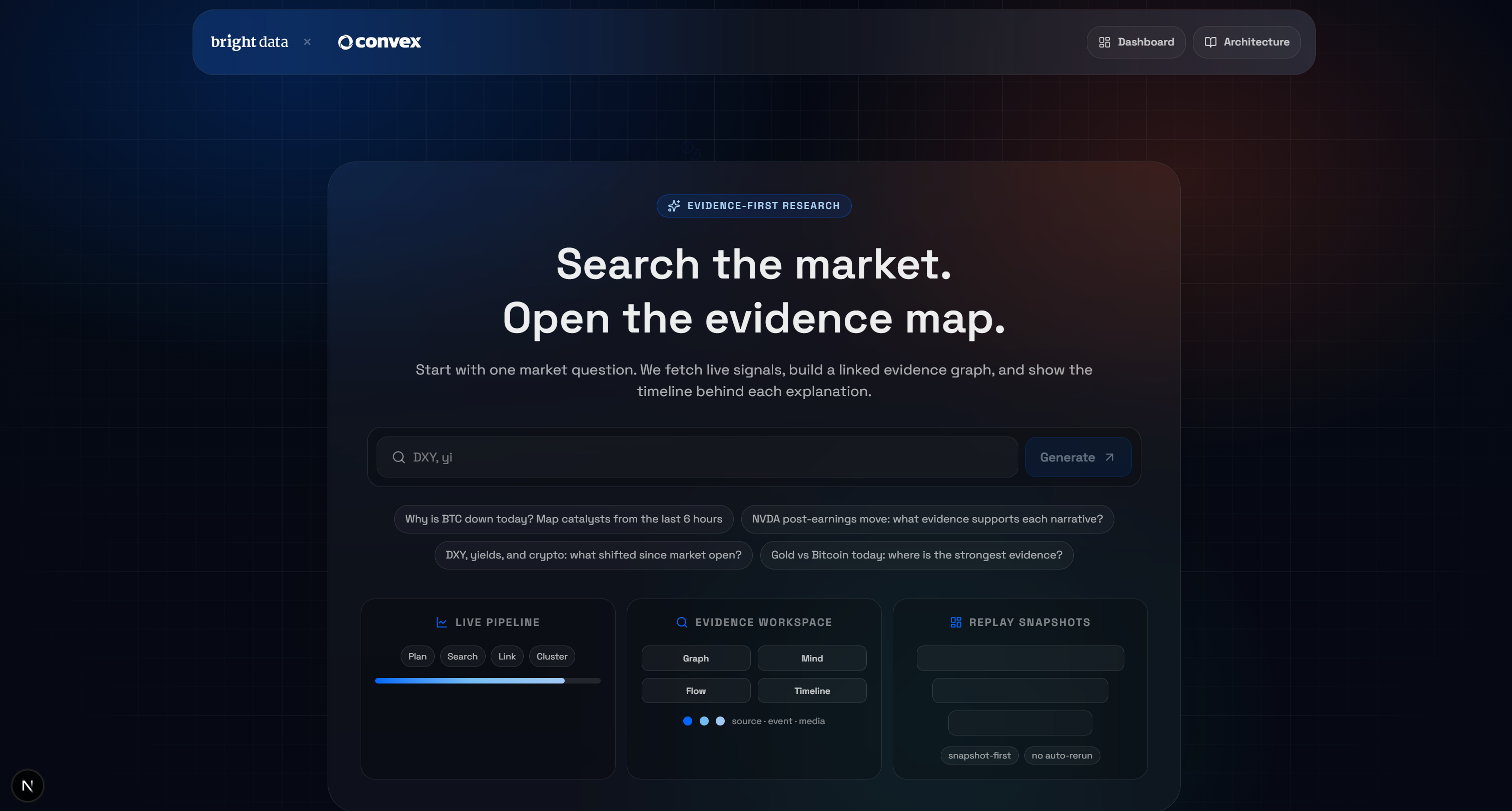
Testen Sie die Anwendung, indem Sie eine Suchanfrage eingeben, zum Beispiel:
Warum ist der BTC-Kurs heute gefallen?Klicken Sie auf die Schaltfläche „Generate“, und Sie erhalten ein Ergebnis wie dieses: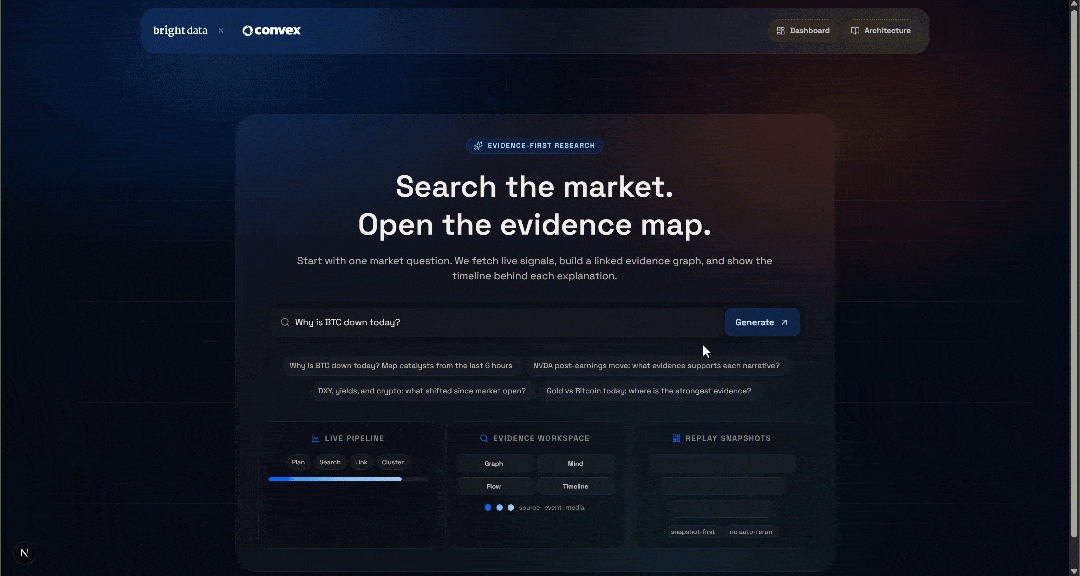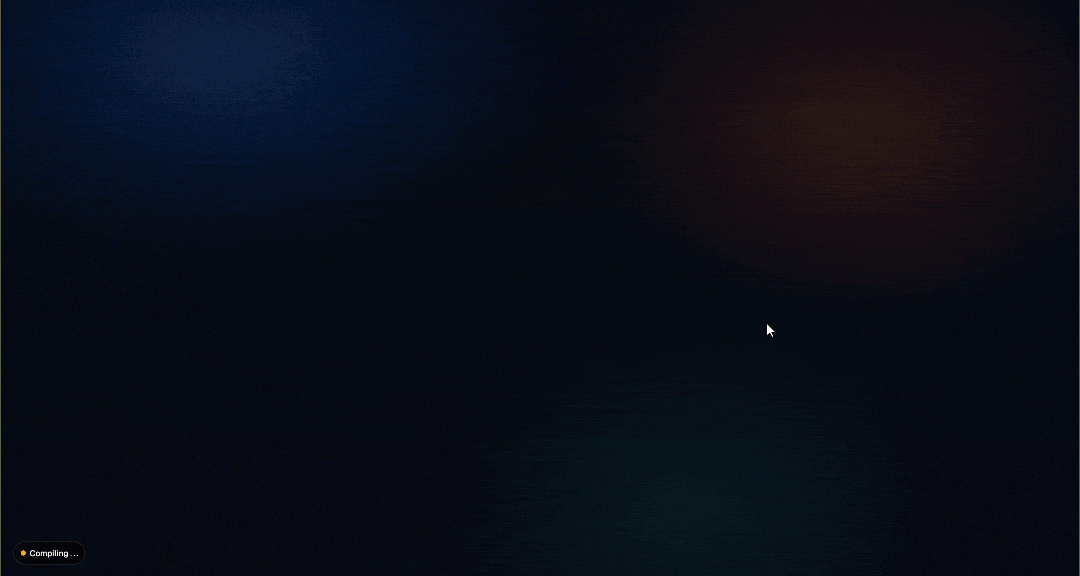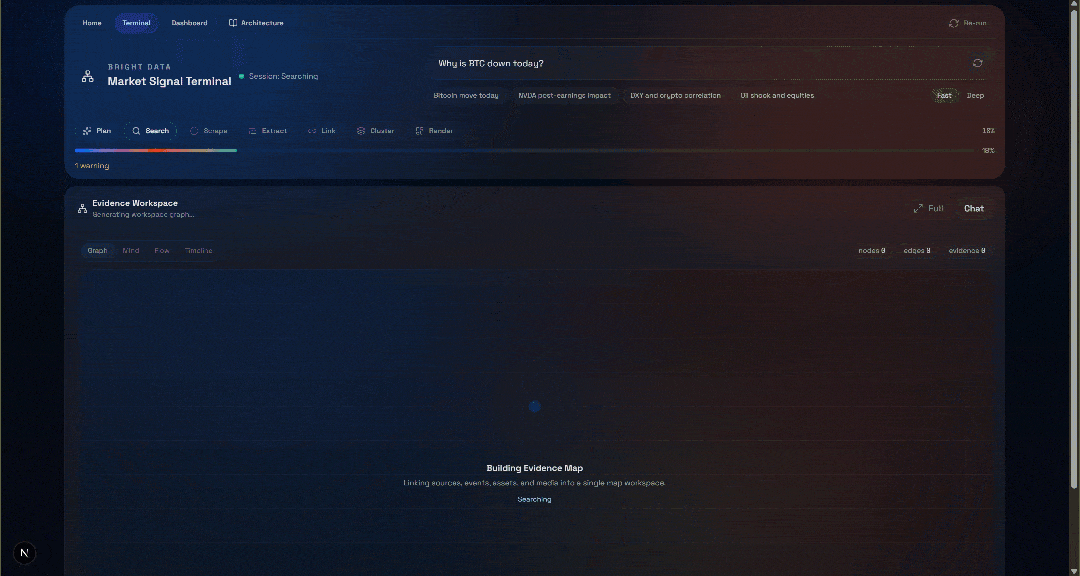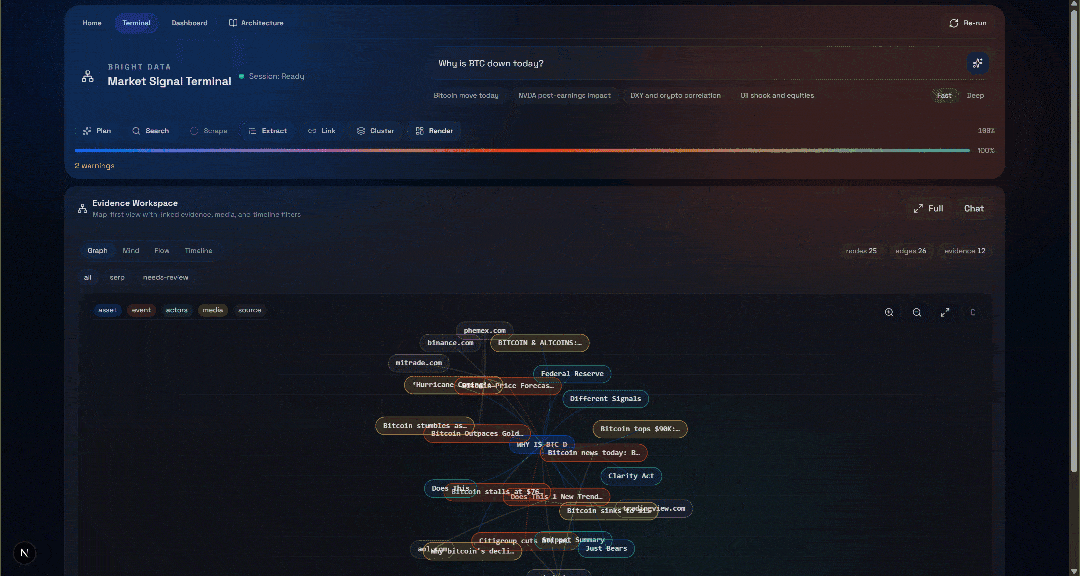
Sehen Sie sich nun den Abschnitt „Evidence Workspace“ an. Diese Ansicht enthält alle Daten, die in Echtzeit per Web-Scraping abgerufen, aggregiert, verarbeitet und in Convex gespeichert wurden. Ihre Convex-Datenbank enthält nun Daten für diesen Durchlauf: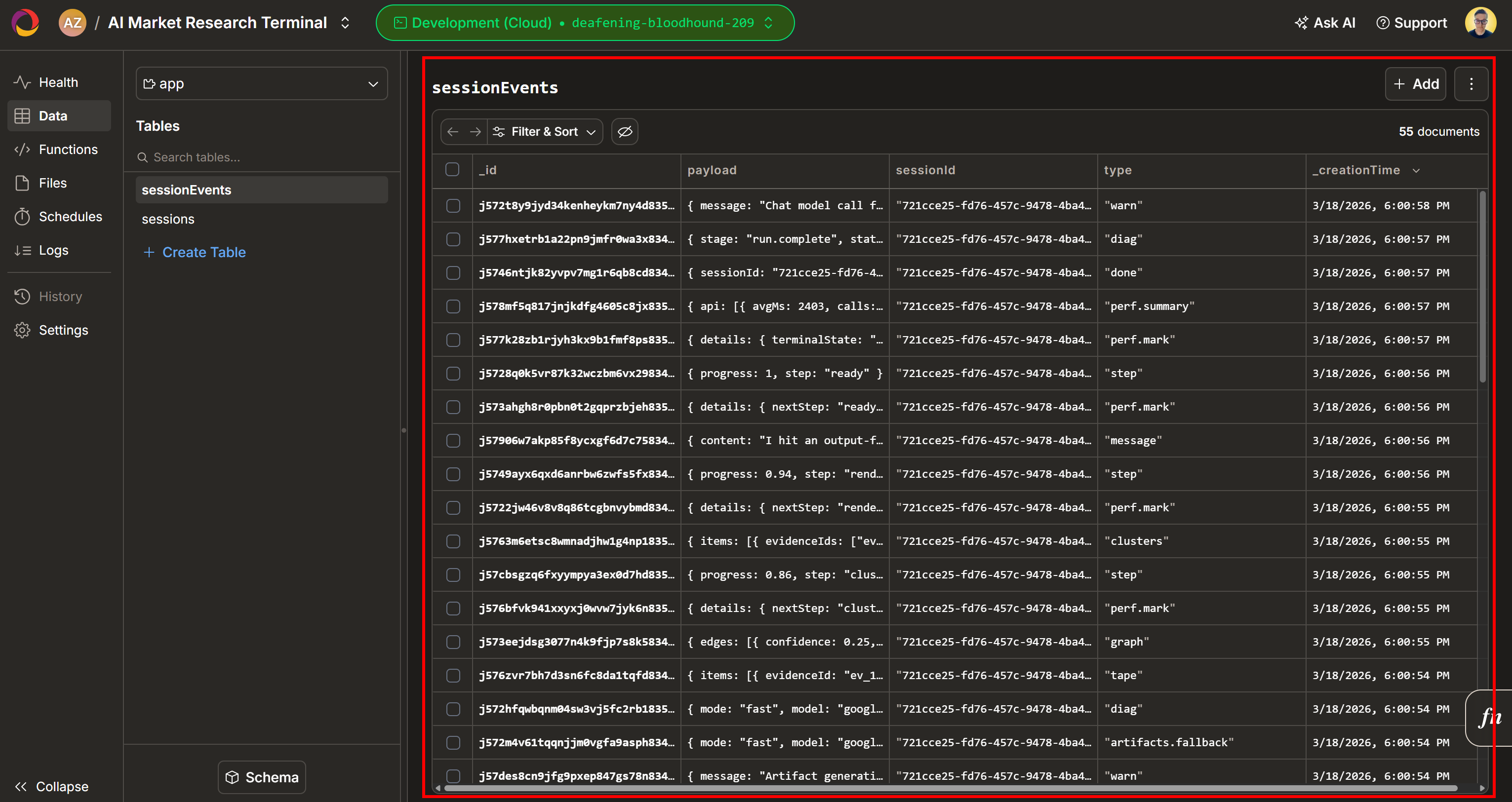
Erkunden Sie als Nächstes die Ansichten „Graph“, „Mind“, „Flow“ und „Timeline“: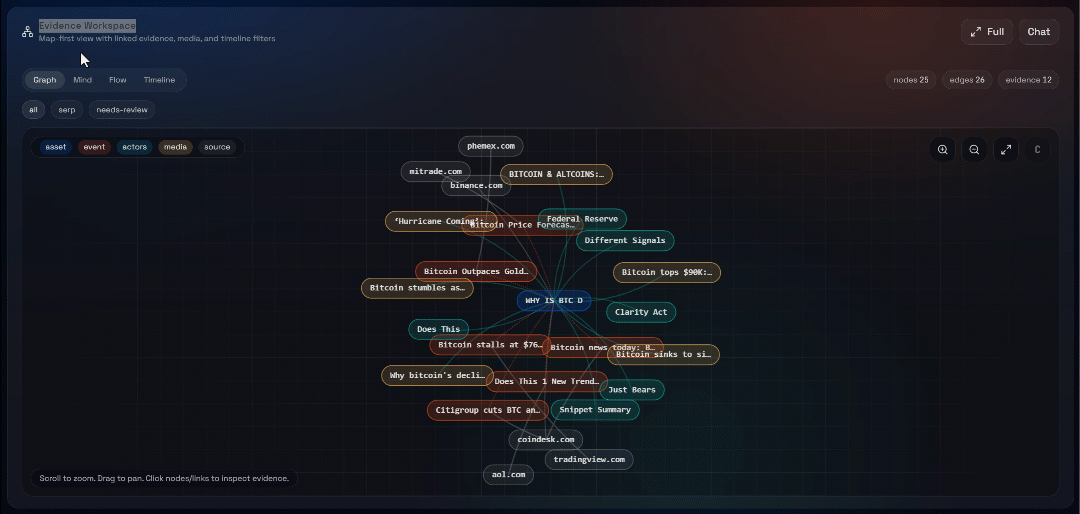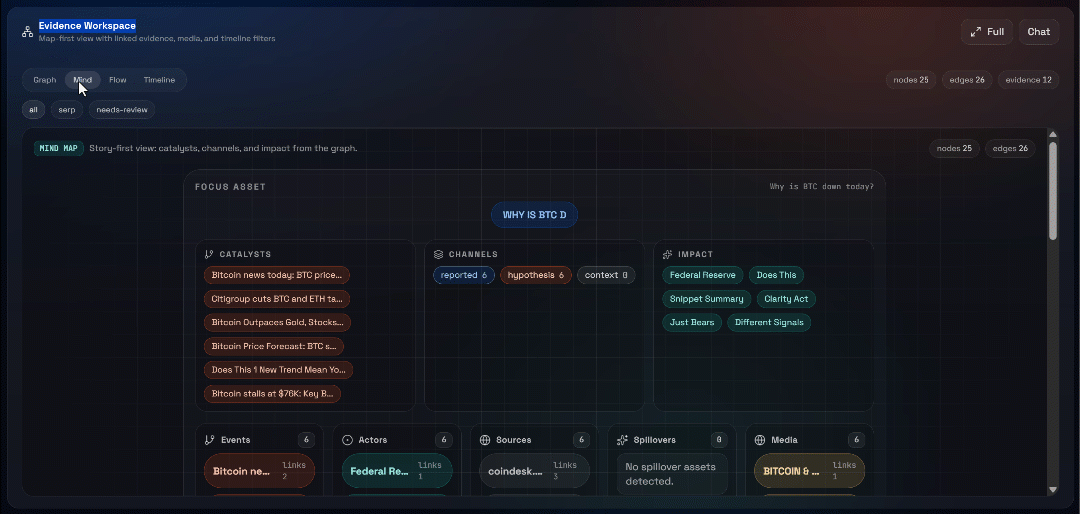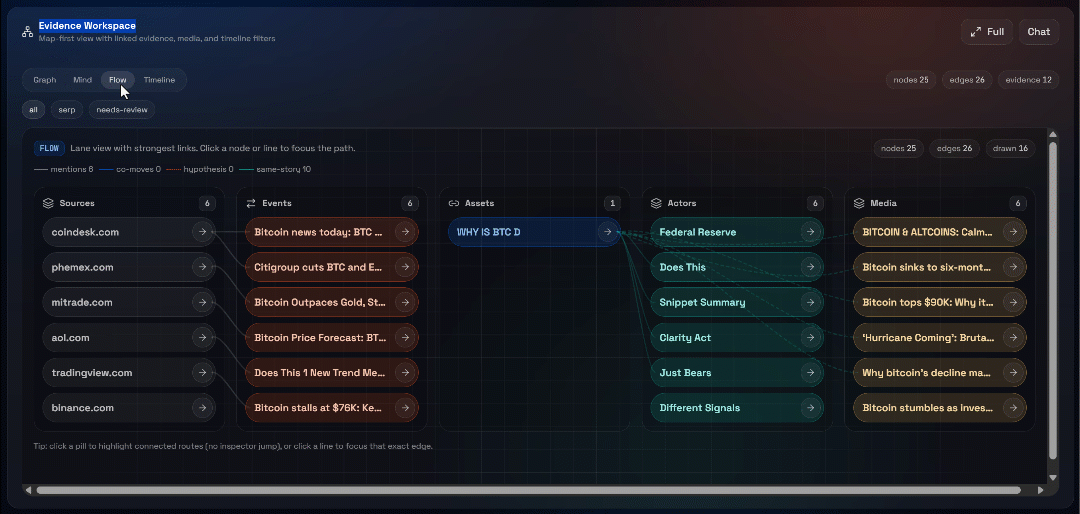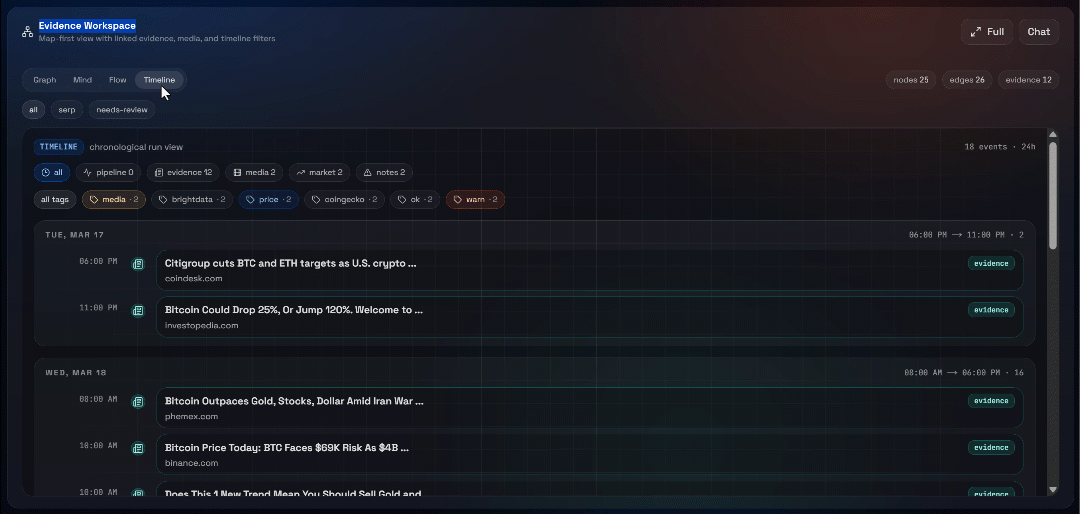
Hier können Sie die wiederhergestellten Quellen einsehen, filtern und die Daten weiter untersuchen, um tiefere Einblicke zu gewinnen.
Et voilà! Sie verfügen nun über eine voll funktionsfähige KI-Marktforschung-Terminal-App, die von Bright Data betrieben wird und Convex als Backend-Datenbank nutzt. Es handelt sich um eine live arbeitende, reaktive Anwendung, die Echtzeit-Webdaten direkt in Ihren Arbeitsbereich liefert.
Fazit
In diesem Artikel haben Sie erfahren, was Convex ist, wie es funktioniert und wie es reaktive Anwendungen unterstützt. Diese Lösung wird noch leistungsfähiger, wenn sie zum Speichern von aktuellen Daten verwendet wird, die live aus dem Web gescrapt werden.
Bright Data ermöglicht Web-Scraping in Echtzeit über eine Infrastruktur auf Unternehmensniveau. Dies dient als Grundlage für eine breite Palette von Web-Scraping-Diensten, mit denen Sie Daten schnell und zuverlässig aus dem Web sammeln können, ohne blockiert zu werden.
Melden Sie sich noch heute kostenlos bei Bright Data an und entdecken Sie unsere Lösungen zur Echtzeit-Webdatenerfassung!





