

Tableau ist ein führendes Tool für die Datenvisualisierung, hat jedoch eine wesentliche Einschränkung: Es kann Live-Daten nicht eigenständig zuverlässig von Websites abrufen. Der alte Web Data Connector (WDC v2), der dieses Problem zuvor löste, wurde 2023 als veraltet eingestuft. Die letzte kompatible Version (Tableau 2022.4) hat inzwischen das Ende ihrer Lebensdauer erreicht, sodass Analysten nun ohne unterstützte Lösung dastehen.
Dieser Leitfaden vergleicht 6 Methoden für das Web-Scraping und die Anbindung von Live-Daten an Tableau. Er enthält außerdem eine Schritt-für-Schritt-Anleitung zum Aufbau einer API-zu-Tableau-Pipeline unter Verwendung der Web Scraper API von Bright Data.
TL;DR
Tableau kann Websites nicht nativ scrapen, und sein Web Data Connector (WDC v2) wurde 2023 als veraltet eingestuft. Sie benötigen eine externe Datenpipeline.
- WDC v2 ist veraltet; WDC v3 dient nur zum Extrahieren und ist komplex in der Erstellung
- Google Sheets, Excel und TabPy weisen jeweils erhebliche Einschränkungen bei der Skalierung auf
- Selbst erstellte Python-Skripte funktionieren zunächst, erfordern aber ständige Wartung
- Eine verwaltete Scraping-API kümmert sich automatisch um Proxys, CAPTCHAs und das Parsing der Daten
Befolgen Sie die Schritt-für-Schritt-Anleitung in diesem Leitfaden, um eine funktionierende Pipeline von Amazon → Bright Data → Tableau aufzubauen.
Warum Tableau eine externe Datenpipeline benötigt
Der moderne Datenstack erfordert Live-Webdaten: Preise von Mitbewerbern, Social-Media-Kennzahlen, Stellenanzeigen, Immobilienangebote und Finanz-Feeds. Tableau wurde nicht dafür entwickelt, diese Daten zu erfassen.
Die größten Herausforderungen sind:
- Websites ändern sich ständig – Layouts verschieben sich, Anti-Bot-Maßnahmen entwickeln sich weiter, die Anforderungen an das JavaScript-Rendering steigen
- Skalierbarkeit ist entscheidend – die tägliche Überwachung von 10.000 SKUs von Wettbewerbern erfordert Wiederholungslogik, Ratenbegrenzung und Fehlerbehandlung, die ein einseitiges Skript nicht benötigt
- Compliance ist zwingend erforderlich – DSGVO, CCPA und Plattformbedingungen erfordern sorgfältige Datenerfassungspraktiken
- Die Infrastruktur ist teuer – Rotierender Proxy, CAPTCHA-Lösung, Wiederholungslogik und IP-Management stellen fortlaufende technische Herausforderungen dar
Die folgenden Methoden schließen diese Lücke.
6 Methoden für Web-Scraping und die Anbindung von Live-Daten an Tableau
Jede Methode bietet ein unterschiedliches Gleichgewicht zwischen Skalierbarkeit, Wartungsaufwand und Zuverlässigkeit. Sie sind von der am wenigsten praktikablen bis zur produktionsreifsten Methode aufgelistet.
Methode 1: Tableau Web Data Connector v2 (veraltet)
Was es war: Mit WDC v2 konnten Sie JavaScript-basierte Konnektoren erstellen, die Daten aus Web-APIs direkt in Tableau abriefen.
Warum es nicht mehr funktioniert: In Tableau 2023.1 veraltet. WDC v2-Konnektoren werden in allen aktuellen Tableau-Versionen nicht mehr unterstützt, und Tableau wird sie möglicherweise in einer zukünftigen Version vollständig entfernen. Eine Migration zu WDC v3 ist erforderlich, aber v3 basiert auf einer grundlegend anderen Architektur.
Kritische Einschränkung: Der Support wurde eingestellt. Wenn Sie noch WDC v2-Konnektoren verwenden, migrieren Sie jetzt, da diese bei einem zukünftigen Tableau-Update möglicherweise nicht mehr funktionieren.
Methode 2: Google Sheets als Zwischenschicht
So funktioniert es: Importieren Sie Daten in Google Sheets (über Apps Script, IMPORTXML, IMPORTDATA oder Tools von Drittanbietern) und verbinden Sie Tableau dann mit Sheets als Live-Datenquelle.
Warum diese Methode verwenden: Sie ist kostenlos, erfordert keine Programmierung und Tableau verbindet sich über seinen Google Drive-Konnektor mit Google Sheets.
Wichtige Einschränkungen:
- Google Sheets hat eine Begrenzung auf 10 Millionen Zellen – große Datensätze erreichen diese Grenze schnell
- Die Formeln
IMPORTXMLundIMPORTHTMLversagen ständig aufgrund von Änderungen an der Website-Struktur - Der Aktualisierungszeitpunkt ist unzuverlässig. Google drosselt die Ausführung von Formeln auf unvorhersehbare Weise
- Es gibt keine JavaScript-Rendering-Unterstützung, sodass moderne Single-Page-Anwendungen (SPAs) leere Daten zurückgeben (hierfür ist ein Scraping-Browser erforderlich)
- Ratenbeschränkungen der Google Sheets-API führen zu Synchronisierungsfehlern bei geplanten Aktualisierungen
Fazit: Funktioniert für kleine Prototypen. Versagt bei jedem größeren Umfang. Gute Wahl für persönliche Dashboards, die weniger als 10.000 Zeilen selten wechselnder Daten verfolgen.
Methode 3: Excel + OneDrive / SharePoint
So funktioniert es: Verwenden Sie die Power Query- oder die „Daten aus dem Web abrufen“-Funktion von Excel, um Daten von URLs abzurufen und in OneDrive zu speichern. Verbinden Sie dann Tableau mit der in der Cloud gehosteten Excel-Datei.
Wesentliche Einschränkungen:
- Manuelle Aktualisierung erforderlich – Power Query aktualisiert sich im Hintergrund nicht zuverlässig automatisch
- Keine JavaScript-Rendering-Unterstützung, daher kann es keine React-, Angular- oder SPA-basierten Websites verarbeiten
- Eingeschränkte Parsing-Fähigkeiten. Komplexe HTML-Strukturen führen häufig zu Fehlern beim Import
- OneDrive-Synchronisierungskonflikte verursachen Probleme mit der Datenintegrität
- Keine Proxy-Rotation bedeutet IP-Sperren bei jedem nennenswerten Scraping-Volumen
Fazit: Geeignet für einen einzelnen Bericht von einer statischen Webseite. Keine Datenpipeline.
Methode 4: TabPy (Python + Tableau-Erweiterungen)
So funktioniert es: TabPy ist der offizielle Python-Server von Tableau. Er führt Python-Skripte innerhalb von berechneten Feldern in Tableau mithilfe von Funktionen wie SCRIPT_REAL und SCRIPT_STR aus. Theoretisch läuft die Logik des Web-Scraping über TabPy direkt in Tableau.
Warum es nutzen: Python verfügt über umfangreiche Scraping-Bibliotheken, und TabPy wird offiziell von Tableau unterstützt.
Wesentliche Einschränkungen:
- Erfordert einen laufenden TabPy-Server – zusätzliche Infrastruktur, die gewartet werden muss
- Das Scraping innerhalb von berechneten Feldern in Tableau ist ein Anti-Pattern. Es ist langsam, unzuverlässig und blockiert die Darstellung des Dashboards
- Keine Proxy-Rotation bedeutet, dass die IP-Adresse Ihres TabPy-Servers bei Zielen mit hohem Datenvolumen sofort gesperrt wird
- Keine CAPTCHA-Lösung, keine Wiederholungslogik, kein JavaScript-Rendering
- Berechnete Felder haben Ausführungszeitlimits, sodass komplexe Scraping-Aufträge zeitlich ablaufen
- Das Debugging ist extrem schwierig, da Fehler als unklare Tableau-Fehlermeldungen angezeigt werden
Fazit: TabPy eignet sich hervorragend für die Ausführung von ML-Modellen und statistischen Berechnungen innerhalb von Tableau. Für Web-Scraping ist es nicht geeignet.
Methode 5: DIY-Python-Skripte (requests, Scrapy, Selenium)
So funktioniert es: Schreiben Sie benutzerdefinierte Python-Skripte unter Verwendung von Bibliotheken wie requests, BeautifulSoup, Scrapy oder Selenium. Führen Sie diese nach einem Zeitplan aus (z. B. mit cron oder Airflow), geben Sie CSV-/JSON-Dateien aus und verbinden Sie Tableau mit diesen Dateien.
Warum man es nutzen sollte: Maximale Flexibilität. Sie haben die volle Kontrolle.
Wesentliche Einschränkungen:
- Hoher Wartungsaufwand – Websites ändern ihr Layout, fügen Anti-Bot-Maßnahmen hinzu und ändern HTML-Strukturen. Ihr Scraper fällt ohne Vorwarnung aus, und das Dashboard zeigt veraltete Daten an.
- IP-Blockierung in großem Umfang – ohne Proxy-Netzwerk blockieren die Ziele Ihren Server innerhalb weniger Stunden
- Keine CAPTCHA-Lösung – Cloudflare, reCAPTCHA und hCaptcha blockieren Ihren Scraper, ohne dass es eine integrierte Umgehungslösung gibt (Dienste wie Web Unlocker bewältigen dies automatisch)
- Infrastrukturkosten – Sie benötigen Server, Proxy-Abonnements, Überwachung und Benachrichtigungen
- Compliance-Risiko – ohne geeignete Infrastruktur verstoßen Sie möglicherweise gegen die DSGVO, den CCPA oder die Nutzungsbedingungen der Plattformen
- Nicht skalierbar – das Scrapen von 100 URLs ist etwas anderes als das Scrapen von 100.000. Die Architektur, die für das eine funktioniert, versagt beim anderen völlig.
Fazit: DIY ist anfangs praktikabel, aber langfristig nicht zuverlässig. Die meisten Teams fangen hier an, und viele sind zunächst erfolgreich. Aber der Wartungsaufwand steigt mit der Zeit.
Im ersten Monat funktioniert es gut, aber nach einigen Monaten verbringen Sie mehr Zeit damit, defekte Selektoren und IP-Sperren zu beheben, als Dashboards zu erstellen. Wenn Sie ein oder zwei Websites mit geringem Volumen scrapen, reichen DIY-Skripte möglicherweise aus.
Methode 6: Bright Data Web Scraper API (empfohlen)
So funktioniert es: Die Web Scraper API von Bright Data übernimmt die gesamte Datenerfassungsschicht: Rotierender Proxy, CAPTCHA-Lösung, JavaScript-Rendering, Anti-Bot-Umgehung und strukturierte Datenausgabe. Sie lösen einen Erfassungsauftrag über die API aus, erhalten bereinigte JSON-/CSV-Daten und laden diese in Tableau.
Vorteile:
| Fähigkeit | Bright Data | DIY-Skripte |
|---|---|---|
| Proxy-Netzwerk | Über 150 Millionen IPs in 195 Ländern | Kaufen Sie Ihre eigenen (teuren) |
| Fertige Scraper | Über 120 für die wichtigsten Plattformen | Von Grund auf neu erstellen |
| CAPTCHA-Lösung | Automatisch | Nicht enthalten |
| JavaScript-Rendering | Integriert | Erfordert Selenium/Playwright |
| Anti-Bot-Umgehung | Automatisch | Erfordert ständige manuelle Aktualisierungen |
| Verfügbarkeit | 99,99 % | Hängt von Ihrer Infrastruktur ab |
| Compliance | DSGVO, CCPA, ISO 27001 | Ihre Verantwortung |
| Wartung | Minimal – Bright Data kümmert sich um Scraper-Updates | Ständig |
| Skalierbarkeit | Millionen von Seiten/Tag | Begrenzt durch Ihre Server |
| Preise | Ab 1,50 $/1.000 Datensätze | Variabel (Server + Proxys + Wartung) |
Fazit: Sie konzentrieren sich auf Tableau-Dashboards; Bright Data kümmert sich um die Infrastruktur zur Datenerfassung.
Kompromiss: Bright Data ist ein kostenpflichtiger Drittanbieter-Dienst. Sie sind von dessen Infrastruktur und Preismodell abhängig. Für gelegentliches Scraping von ein oder zwei Websites mit geringem Datenvolumen kostet ein selbst erstelltes Skript (Methode 5) weniger und gibt Ihnen die volle Kontrolle.
Welche Tableau-Datenverbindungsmethode sollten Sie wählen?
Diese Tabelle vergleicht alle sechs Methoden hinsichtlich der Funktionen, die für Produktionspipelines am wichtigsten sind.
| Methode | JS-Rendering | Proxy-Rotation | CAPTCHA-Lösung | Automatische Aktualisierung | Skalierung | Wartung | Status |
|---|---|---|---|---|---|---|---|
| WDC v2 | Nein | Nein | Nein | Ja | Niedrig | k. A. | Veraltet |
| Google Tabellen | Nein | Nein | Nein | Unzuverlässig | Sehr gering | Niedrig | Zellenbegrenzungen |
| Excel + OneDrive | Nein | Nein | Nein | Manuell | Sehr gering | Mittel | Manueller Prozess |
| TabPy | Manuell/Selbstbau | Nein | Nein | Ja | Niedrig | Hoch | IP-Sperren |
| Python zum Selbermachen | Über Selenium | Selber machen | Nein | Über Cron | Mittel | Sehr hoch | Ausfälle bei hoher Auslastung |
| Bright Data API | Ja | Ja (über 150 Millionen IPs) | Ja | Ja | Hoch | Minimal | Produktionsbereit |
Tutorial: Verbinden einer Web-Scraping-API mit Tableau
In diesem Tutorial wird eine echte Pipeline erstellt: Amazon-Produktpreise → Bright Data API → CSV → Tableau-Dashboard unter Verwendung der Amazon Scraper API. Es behandelt den Anwendungsfall „Preisüberwachung“, den häufigsten Grund, warum Teams Webdaten mit Tableau verbinden.
Architektur
Die Pipeline folgt diesem Ablauf:
┌─────────────────┐ ┌──────────────────────┐ ┌─────────────┐ ┌─────────────┐
│ Ihr Skript │────▶│ Bright Data Scraper │────▶ │ CSV/JSON │────▶│ Tableau │
│ (Python/cron) │ │ API │ │ Ausgabe │ │ Dashboard │
└─────────────────┘ └──────────────────────┘ └─────────────┘ └─────────────┘
│ │ │
Auslösen mit Verarbeitet Proxys, Visualisiert Preise,
Schlüsselwörtern/URLs CAPTCHAs, rendert Bewertungen, TrendsVoraussetzungen
Bevor Sie beginnen, müssen folgende Komponenten installiert oder verfügbar sein:
- Python 3.8+
- Ein Bright Data-Konto (kostenlose Testversion verfügbar, keine Kreditkarte erforderlich)
- Ihr API-Token aus dem Bright Data-Dashboard (Anleitung in Schritt 0)
- Tableau Desktop (14-tägige kostenlose Testversion), Tableau Cloud oder Tableau Public (kostenlos, Dashboards sind öffentlich)
Sobald diese Tools bereitstehen, generieren Sie zunächst Ihren Bright Data-API-Token.
Schritt 0: Holen Sie sich Ihren Bright Data-API-Token
Befolgen Sie diese Schritte, um Ihren API-Token zu generieren:
- Registrieren Sie sich oder melden Sie sich unter brightdata.com/cp an
- Gehen Sie zu „Kontoeinstellungen“ → „Benutzer und API-Schlüssel“
- Wählen Sie „API-Schlüssel hinzufügen“ (oben rechts im Bereich „API-Schlüssel“)
- Legen Sie Berechtigungen und Ablaufdatum fest und wählen Sie dann „Speichern“
- Kopieren Sie den Token
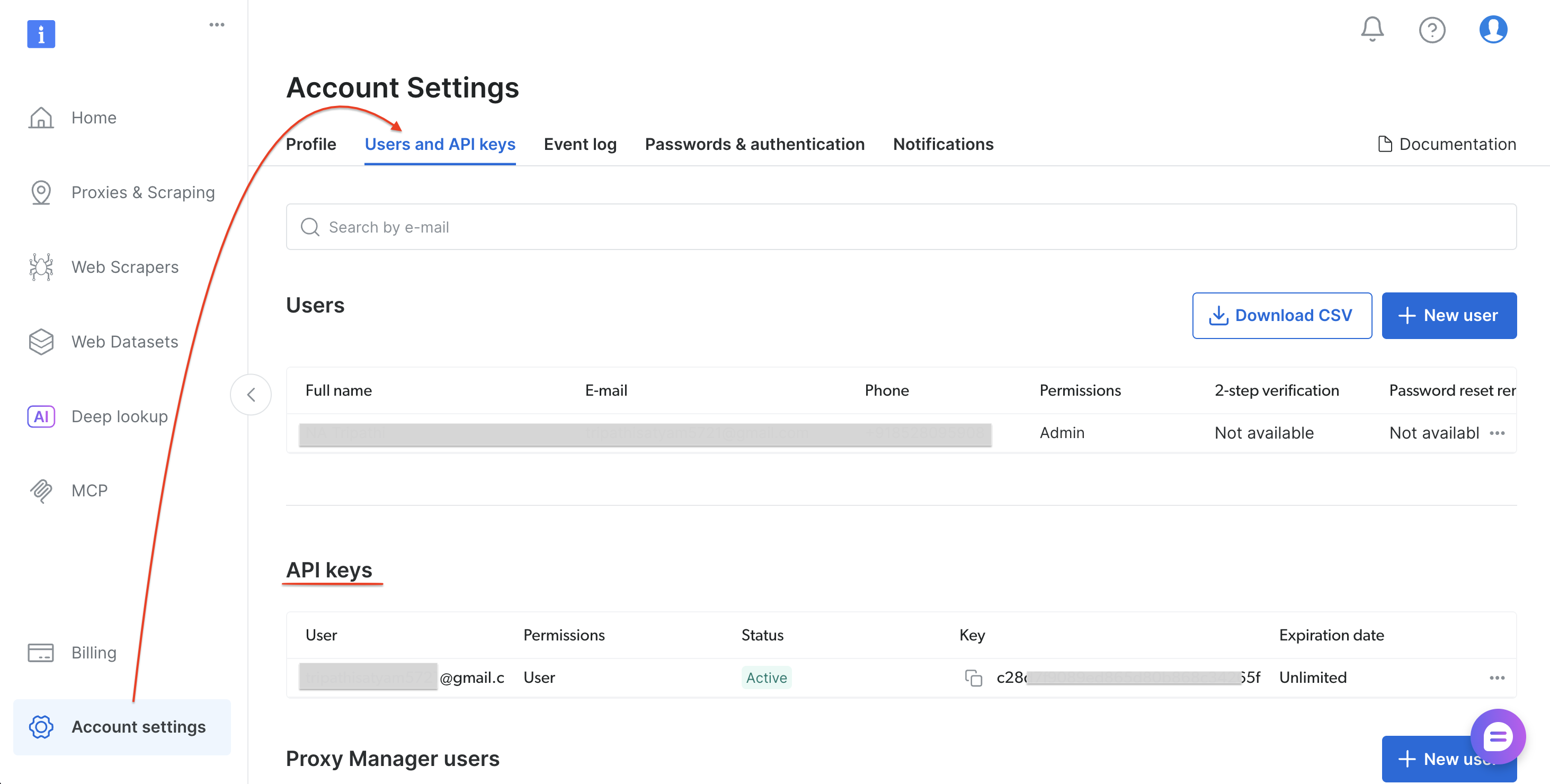
Nachdem Sie Ihren API-Token gespeichert haben, installieren Sie die Python-Abhängigkeiten.
Schritt 1: Abhängigkeiten installieren
Installieren Sie die erforderlichen Python-Pakete:
pip install requests pandasNachdem Sie requests und pandas installiert haben, erstellen Sie das Pipeline-Skript.
Schritt 2: Das Pipeline-Skript
Erstellen Sie eine Datei mit dem Namen bright_data_to_tableau.py:
"""
Bright Data → Tableau-Pipeline
Ruft Amazon-Produktdaten über die Web-Scraper-API von Bright Data ab
und gibt eine Tableau-fähige CSV-Datei aus.
Verwendung:
1. Ersetzen Sie YOUR_API_TOKEN durch Ihren Bright Data-API-Token
2. Führen Sie folgenden Befehl aus: python bright_data_to_tableau.py
3. Öffnen Sie die ausgegebene CSV-Datei in Tableau Desktop
"""
import requests
import time
import json
import sys
import pandas as pd
from datetime import datetime
# ─── Konfiguration ───────────────────────────────────────────────────────────
API_TOKEN = "YOUR_API_TOKEN" # Durch Ihren Bright Data API-Token ersetzen
DATASET_ID = "gd_lwdb4vjm1ehb499uxs" # Amazon-Produktsuche (nach Stichwort)
OUTPUT_CSV = "amazon_products_tableau.csv"
POLL_INTERVAL = 10 # Sekunden zwischen Statusprüfungen
POLL_TIMEOUT = 300 # maximale Wartezeit in Sekunden
# ─── API-Endpunkte ───────────────────────────────────────────────────────────
TRIGGER_URL = (
f"https://api.brightdata.com/Datensätze/v3/trigger"
f"?dataset_id={DATASET_ID}&include_errors=true"
)
SNAPSHOT_URL = "https://api.brightdata.com/Datensätze/v3/snapshot"
HEADERS = {
"Authorization": f"Bearer {API_TOKEN}",
"Content-Type": "application/json",
}
def trigger_collection(keyword: str) -> str:
"""Löst einen Datenerfassungsauftrag bei Bright Data aus."""
payload = [{
"keyword": keyword,
"url": "https://www.amazon.com",
"pages_to_search": 1
}]
print(f"[1/3] Erfassung für das Stichwort '{keyword}' wird ausgelöst...")
response = requests.post(TRIGGER_URL, headers=HEADERS, data=json.dumps(payload))
if response.status_code != 200:
print(f" ERROR {response.status_code}: {response.text}")
sys.exit(1)
result = response.json()
snapshot_id = result.get("snapshot_id")
print(f" Snapshot-ID: {snapshot_id}")
return snapshot_id
def poll_snapshot(snapshot_id: str) -> list:
"""Den Snapshot-Endpunkt abfragen, bis die Daten bereitstehen."""
url = f"{SNAPSHOT_URL}/{snapshot_id}?format=json"
elapsed = 0
print(f"[2/3] Warten auf Ergebnisse...")
while elapsed < POLL_TIMEOUT:
response = requests.get(url, headers=HEADERS)
if response.status_code == 200:
data = response.json()
print(f" Bereit! {len(data)} Datensätze empfangen.")
return data
elif response.status_code == 202:
print(f" Wird verarbeitet... ({elapsed}s / {POLL_TIMEOUT}s)")
time.sleep(POLL_INTERVAL)
elapsed += POLL_INTERVAL
else:
print(f" FEHLER {response.status_code}: {response.text}")
sys.exit(1)
print(f" TIMEOUT: Snapshot nach {POLL_TIMEOUT}s noch nicht bereit.")
print(f" Versuchen Sie, POLL_TIMEOUT zu erhöhen, oder überprüfen Sie das Bright Data-Dashboard.")
sys.exit(1)
def to_tableau_csv(data: list, output_path: str) -> pd.DataFrame:
"""Wandelt rohe API-Daten in eine saubere, für Tableau optimierte CSV-Datei um."""
df = pd.DataFrame(data)
# Ordnet API-Feldnamen → Tableau-freundlichen Namen zu
column_mapping = {
"title": "Produktname",
"seller_name": "Verkäufer",
"brand": "Marke",
"initial_price": "Ursprünglicher Preis",
"final_price": "Aktueller Preis",
"currency": "Währung",
"rating": "Bewertung",
"reviews_count": "Anzahl der Bewertungen",
"availability": "Verfügbarkeit",
"url": "Produkt-URL",
"asin": "ASIN",
"categories": "Kategorien",
"delivery": "Lieferinformationen",
}
# Nur Spalten beibehalten, die in den Daten vorhanden sind
available = {k: v for k, v in column_mapping.items() if k in df.columns}
df = df.rename(columns=available)
df = df[list(available.values())]
# Metadaten für Tableau-Filterung und -Tracking hinzufügen
df["Scrape Date"] = datetime.now().strftime("%Y-%m-%d")
df["Scrape Timestamp"] = datetime.now().isoformat()
df["Data Source"] = "Bright Data API"
df.to_csv(output_path, index=False)
print(f"[3/3] {len(df)} Zeilen gespeichert → {output_path}")
return df
def print_summary(df: pd.DataFrame):
"""Drucke eine Zusammenfassung der gescrapten Daten."""
print(f"n{'─'*50}")
print(f" Zusammenfassung")
print(f"{'─'*50}")
print(f" Gesamtzahl der Produkte: {len(df)}")
if "Current Price" in df.columns:
prices = pd.to_numeric(df["Current Price"], errors="coerce")
print(f" Preisspanne : ${prices.min():.2f} – ${prices.max():.2f}")
print(f" Durchschnittspreis : ${prices.mean():.2f}")
if "Brand" in df.columns:
print(f" Einzigartige Marken : {df['Brand'].nunique()}")
if "Rating" in df.columns:
ratings = pd.to_numeric(df["Rating"], errors="coerce")
print(f" Durchschnittliche Bewertung : {ratings.mean():.1f} / 5.0")
print(f"{'─'*50}n")
def run_pipeline(keyword: str):
"""Führe die gesamte Pipeline aus: Trigger → Poll → CSV → Summary."""
print(f"n{'='*50}")
print(f" Bright Data → Tableau Pipeline")
print(f" Keyword: '{keyword}'")
print(f"{'='*50}n")
snapshot_id = trigger_collection(keyword)
data = poll_snapshot(snapshot_id)
df = to_tableau_csv(data, OUTPUT_CSV)
print_summary(df)
return df
if __name__ == "__main__":
# Standard-Schlüsselwort – ändern Sie dies oder übergeben Sie es als CLI-Argument
keyword = sys.argv[1] if len(sys.argv) > 1 else "wireless headphones"
run_pipeline(keyword)Schritt 3: Skript ausführen
Führen Sie das Pipeline-Skript aus:
python bright_data_to_tableau.pyErwartete Ausgabe:
==================================================
Bright Data → Tableau-Pipeline
Schlüsselwort: 'wireless headphones'
==================================================
[1/3] Erfassung für Schlüsselwort 'wireless headphones' wird ausgelöst...
Snapshot-ID: sd_mmlan9p51yycmmkd7d
[2/3] Warten auf Ergebnisse...
Wird verarbeitet... (0s / 300s)
Fertig! 43 Datensätze empfangen.
[3/3] 43 Zeilen gespeichert → amazon_products_tableau.csv
──────────────────────────────────────────────────
Zusammenfassung
──────────────────────────────────────────────────
Gesamtzahl der Produkte: 43
Preisspanne: 0,00 $ – 169,95 $
Durchschnittspreis: 45,98 $
Einzigartige Marken: 4
Durchschnittliche Bewertung: 4,4 / 5,0
──────────────────────────────────────────────────Die CSV-Datei ist fertig. Öffnen Sie sie in Tableau, um mit der Erstellung von Dashboards zu beginnen.
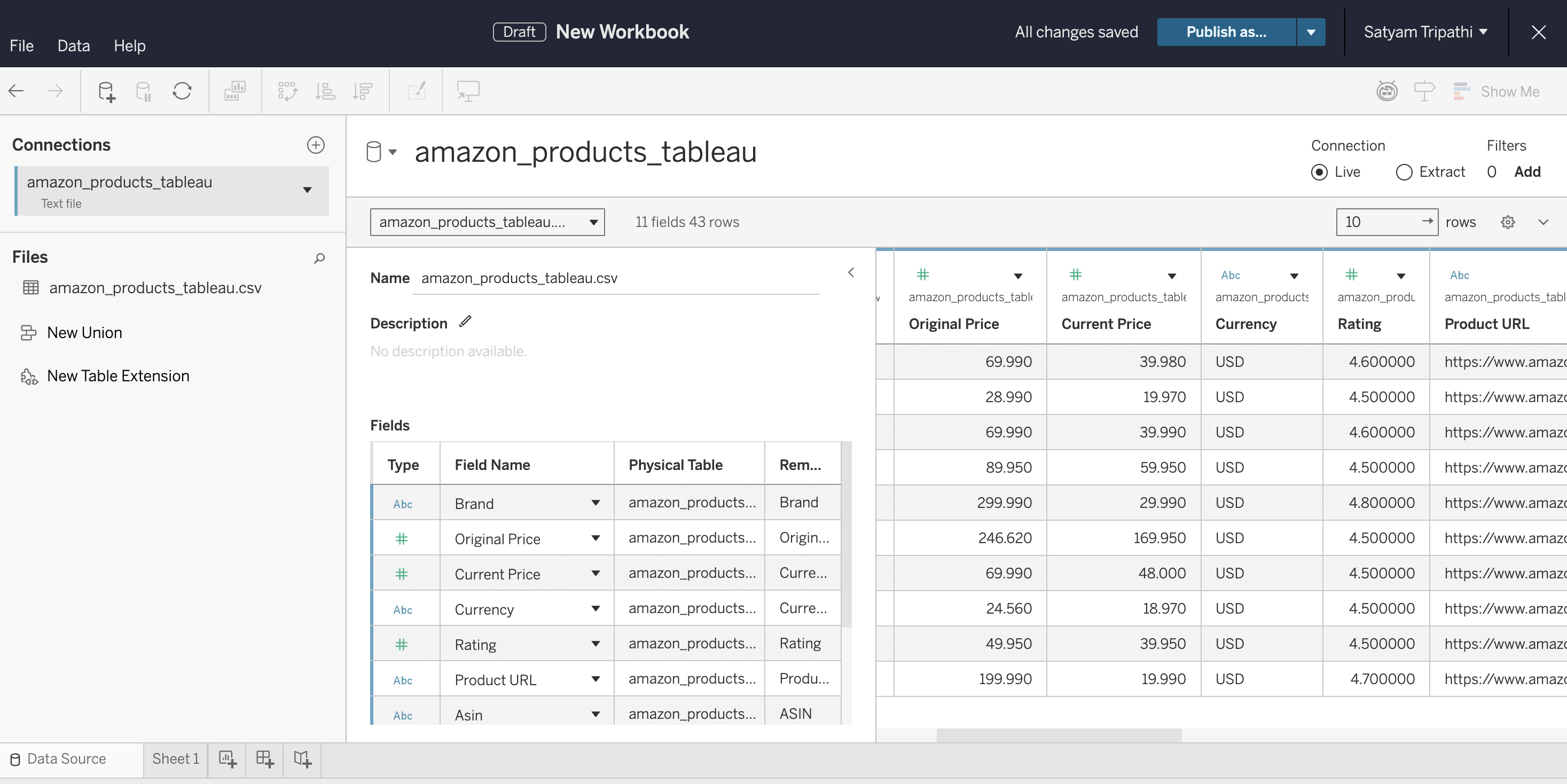
Schritt 4: Verbindung zu Tableau herstellen
Laden Sie die CSV-Datei in Tableau und überprüfen Sie die Datentypen:
- Öffnen Sie Tableau Desktop, Tableau Cloud oder Tableau Public
- Stellen Sie eine Verbindung zur CSV-Datei her: Wählen Sie in Desktop „Verbinden“ → „Textdatei“. Wählen Sie in Cloud „Neu“ → „Arbeitsmappe“ → Registerkarte „Dateien “ und laden Sie die Datei hoch
- Stellen Sie sicher, dass
„Current Price“und„Rating“als Zahlen und nicht als Zeichenfolgen erkannt werden - Wählen Sie „Blatt 1“ aus, um mit der Erstellung zu beginnen
Empfohlene Dashboard-Ansichten:
- Preisverteilung – Histogramm des
aktuellen Preiseszur Ermittlung der Marktposition - Preissenkungsanalyse – Nebeneinander angeordnetes Balkendiagramm von
Originalpreisvs.aktuellem Preiszur Ermittlung von Rabatten - Bewertung vs. Preis – Streudiagramm zur Ermittlung hochwertiger Produkte
- Markenvergleich – Balkendiagramm, das Produkte nach
Markengruppiert, um Preise und Bewertungen zu vergleichen
Schritt 5: Aktualisierung automatisieren
Um Ihr Dashboard aktuell zu halten, planen Sie das Skript mit cron (Linux/Mac) oder dem Taskplaner (Windows) ein:
# Alle 6 Stunden ausführen — crontab -e
0 */6 * * * cd /path/to/project && python bright_data_to_tableau.pyAktualisieren von Tableau, um die neuen Daten anzuzeigen:
- Tableau Desktop. Nachdem der Cron-Job die CSV-Datei aktualisiert hat, drücken Sie F5 (Windows) oder Befehlstaste+R (Mac), um die Seite neu zu laden. Alternativ können Sie die Datenquelle im Menü „Daten“ auswählen und „Aktualisieren“ wählen. Tableau Desktop aktualisiert dateibasierte Quellen nicht automatisch, daher müssen Sie die Daten manuell aktualisieren oder die Arbeitsmappe erneut öffnen.
- Tableau Server. Veröffentlichen Sie die Arbeitsmappe in Tableau Desktop über „Server“ → „Arbeitsmappe veröffentlichen“. Legen Sie im Veröffentlichungsdialog einen Zeitplan für die Aktualisierung des Extrakts fest (z. B. alle 6 Stunden, entsprechend Ihrem Cron-Job). Tableau Server aktualisiert den Extrakt automatisch nach diesem Zeitplan.
- Tableau Cloud. Über den Browser hochgeladene CSV-Dateien können nicht automatisch aktualisiert werden. Um Aktualisierungen zu automatisieren, installieren Sie Tableau Bridge auf dem Rechner, auf dem Ihr Cron-Job ausgeführt wird. Bridge verbindet Ihre lokale CSV-Datei mit Tableau Cloud und unterstützt geplante Extraktaktualisierungen. Ohne Bridge müssen Sie die CSV-Datei nach jedem Pipeline-Lauf manuell erneut hochladen.
- Tableau Public. Unterstützt keine geplanten Aktualisierungen für dateibasierte Quellen. Bei CSV-basierten Pipelines müssen Sie die Arbeitsmappe bei jeder Datenaktualisierung neu veröffentlichen.
Schritt 6: Verwenden Sie einen beliebigen Scraper (Ermitteln der IDs der Datensätze)
Das Tutorial verwendet den Datensatz „Amazon Products Search“ (gd_lwdb4vjm1ehb499uxs). Um eine andere Website zu scrapen, tauschen Sie die Datensatz-ID aus. So finden Sie sie:
- Melden Sie sich beim Bright Data-Kontrollpanel an
- Wählen Sie in der Seitenleiste „Scrapers“ aus, um die Scraper-Bibliothek zu öffnen
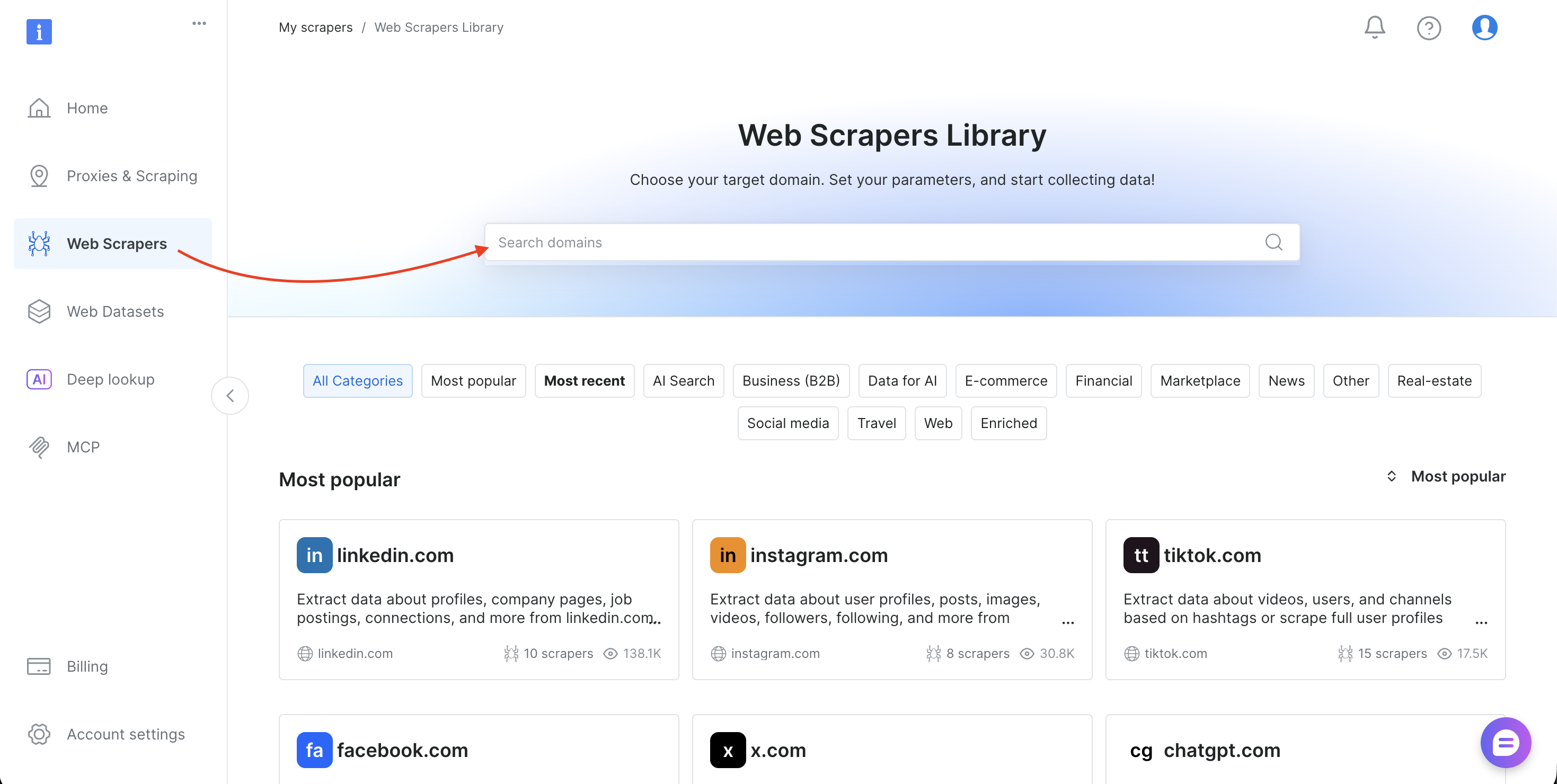
- Suchen Sie nach Ihrer Ziel-Domain (z. B. amazon.com, zillow.com oder linkedin.com) und wählen Sie sie aus
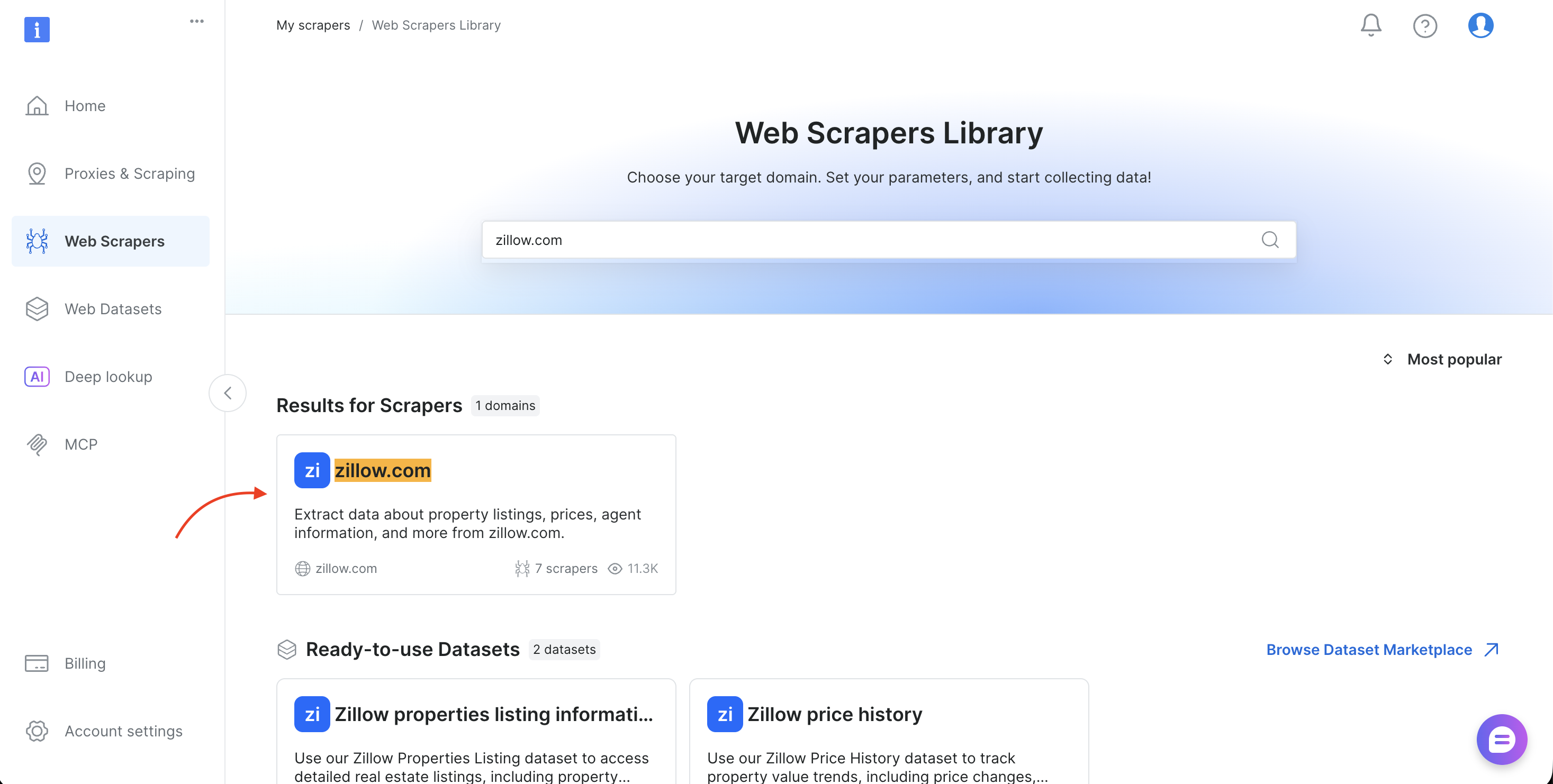
- Wählen Sie die Erfassungsmethode (Nach URL erfassen oder Nach Stichwort suchen)
- Kopieren Sie die
dataset_idaus der URL-Leiste des Browsers (z. B.brightdata.com/cp/scrapers/gd_lfqkr8wm13ixtbd8f5) oder aus dem Bereich „Code examples“
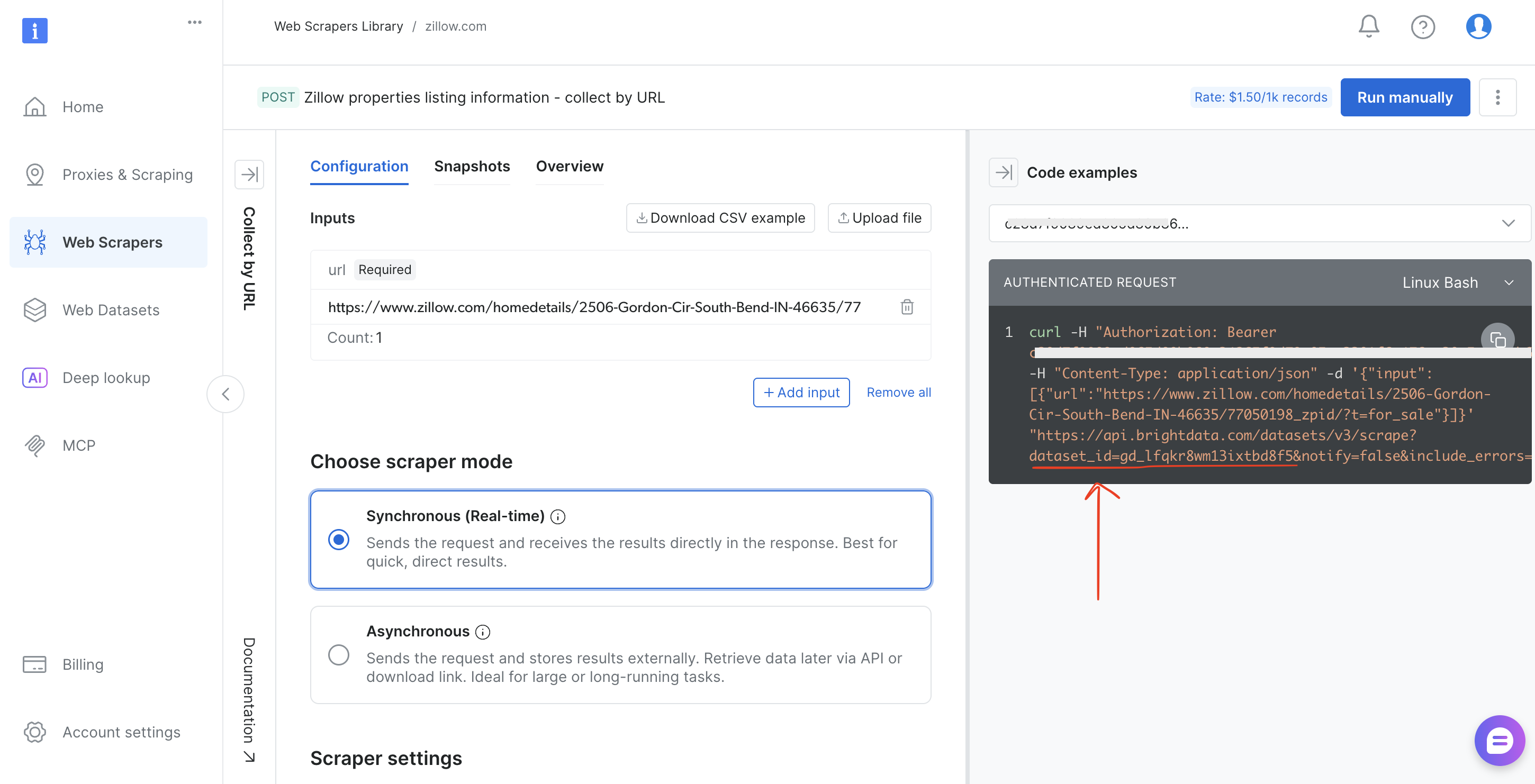
Ersetzen Sie DATASET_ID im Skript, passen Sie die Nutzlast an, und dieselbe Pipeline funktioniert für jeden der über 120 Scraper von Bright Data.
Echte Ergebnisse: So sehen die gescrapten Daten aus
Der folgende Screenshot zeigt die rohe CSV-Ausgabe der Pipeline – genau das, was die API von Bright Data für das Stichwort „wireless headphones“ zurückgegeben hat:
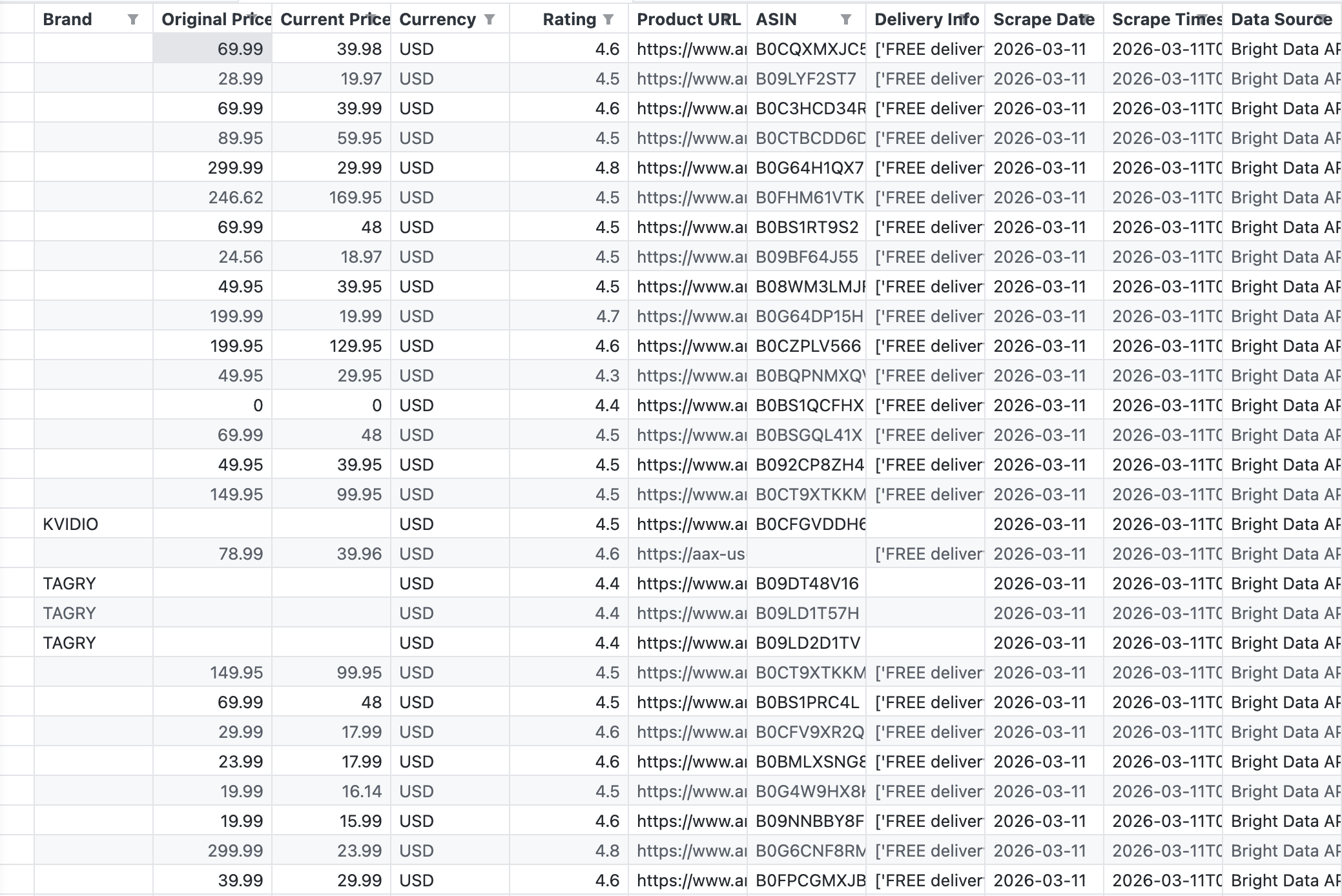
Die API lieferte 43 Datensätze mit Feldern wie Marke, Originalpreis, Aktueller Preis, Bewertung, ASIN, Produkt-URL und Lieferinformationen.
Die API lieferte 43 Produkte in einem einzigen Aufruf. Die Daten sind strukturiert und Tableau-kompatibel. Kein HTML-Parsing, keine fehlerhaften Selektoren, keine CAPTCHA-Herausforderungen. Weitere Informationen zu den Scraping-Optionen für Amazon finden Sie unter „So scrapen Sie Amazon-Produktdaten“.
Visualisierung der Daten: vom CSV-Dateiformat zu Erkenntnissen
Diese vier Visualisierungen zeigen, was die Pipeline erzeugt. Jede Ansicht basiert auf genau der CSV-Datei, die das Skript generiert hat:
Preisverteilung über die Produkte
Dieses Diagramm listet 31 Produkte (solche mit auswertbaren Namen aus ihren Amazon-URLs) nach dem aktuellen Preis auf, vom niedrigsten zum höchsten:
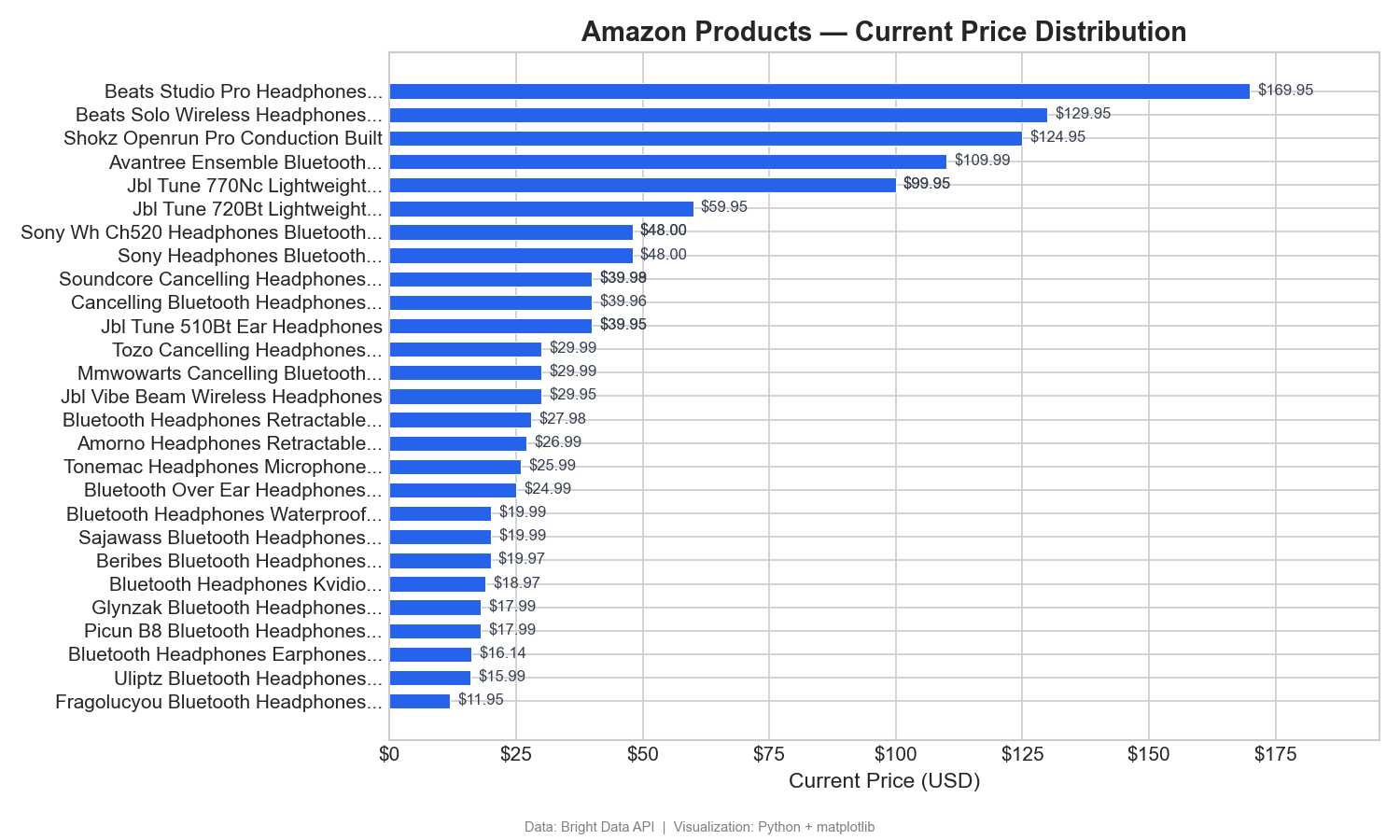
Dieses horizontale Balkendiagramm zeigt die Preisspanne deutlich: Beats dominiert das Premium-Segment (125–170 $), während sich die meisten kabellosen Kopfhörer im Bereich von 12–60 $ ansiedeln. In Tableau würden Sie dies als sortiertes Balkendiagramm erstellen, mit „Aktueller Preis“ in den Spalten und „Produktname“ in den Zeilen.
Preissenkungen: Originalpreis vs. aktueller Preis
Dieses gruppierte Balkendiagramm vergleicht die Listen- und aktuellen Preise der 10 meistdiskontierten Produkte:
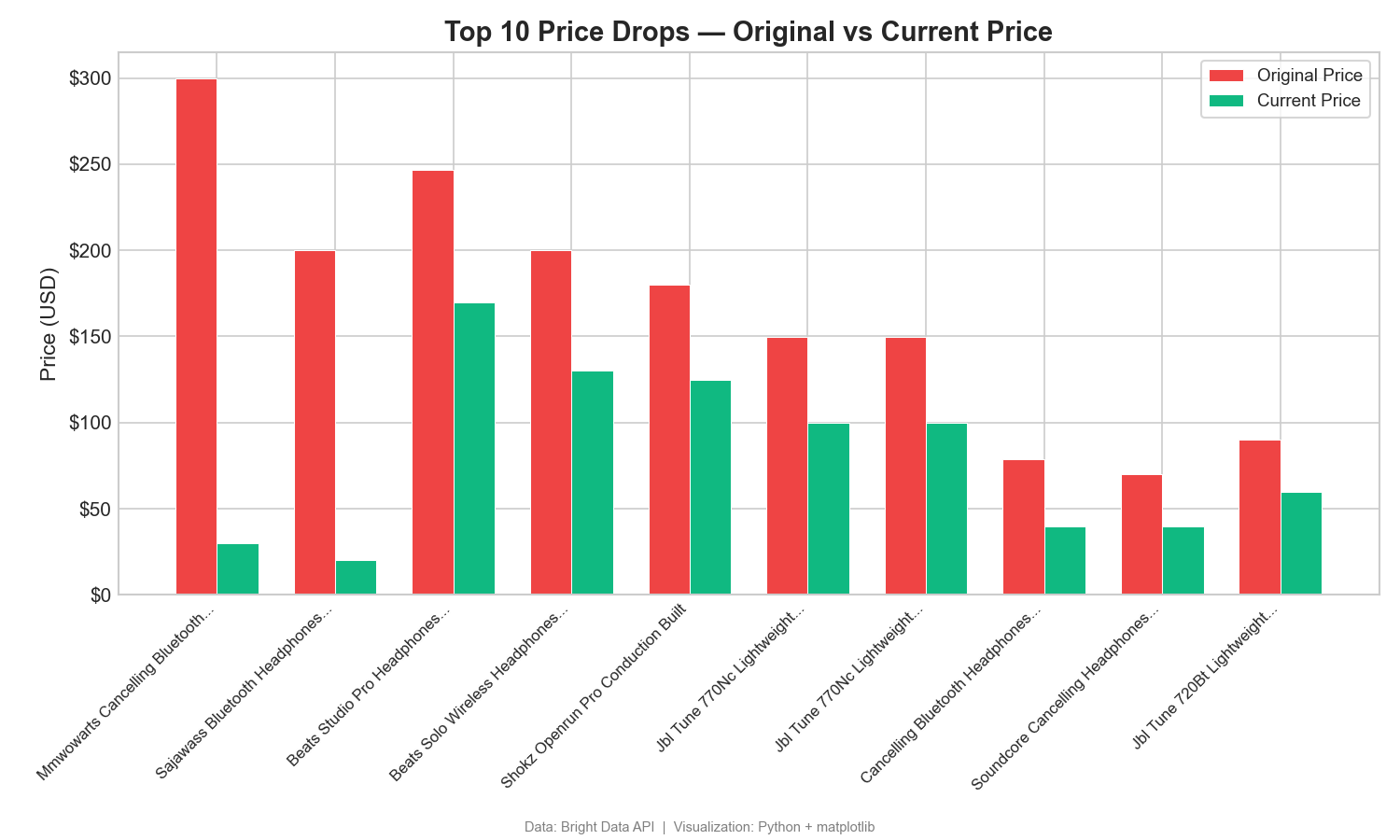
Die Differenz zwischen Original- und aktuellem Preis zeigt große Rabatte. Bei einem Produkt ist ein Preisrückgang von 270 $ gegenüber dem ursprünglichen Listenpreis zu verzeichnen (299,99 $ → 29,99 $). Solche Unterschiede verdeutlichen Werbe- und Preisstrategien. Verwenden Sie in Tableau ein nebeneinander angeordnetes Balkendiagramm mit „Maßnamen“ in der Farbe.
Bewertung vs. Preis: Wert ermitteln
Dieses Streudiagramm stellt Kundenbewertungen dem Preis gegenüber, um Produkte mit hohem Wert zu identifizieren:
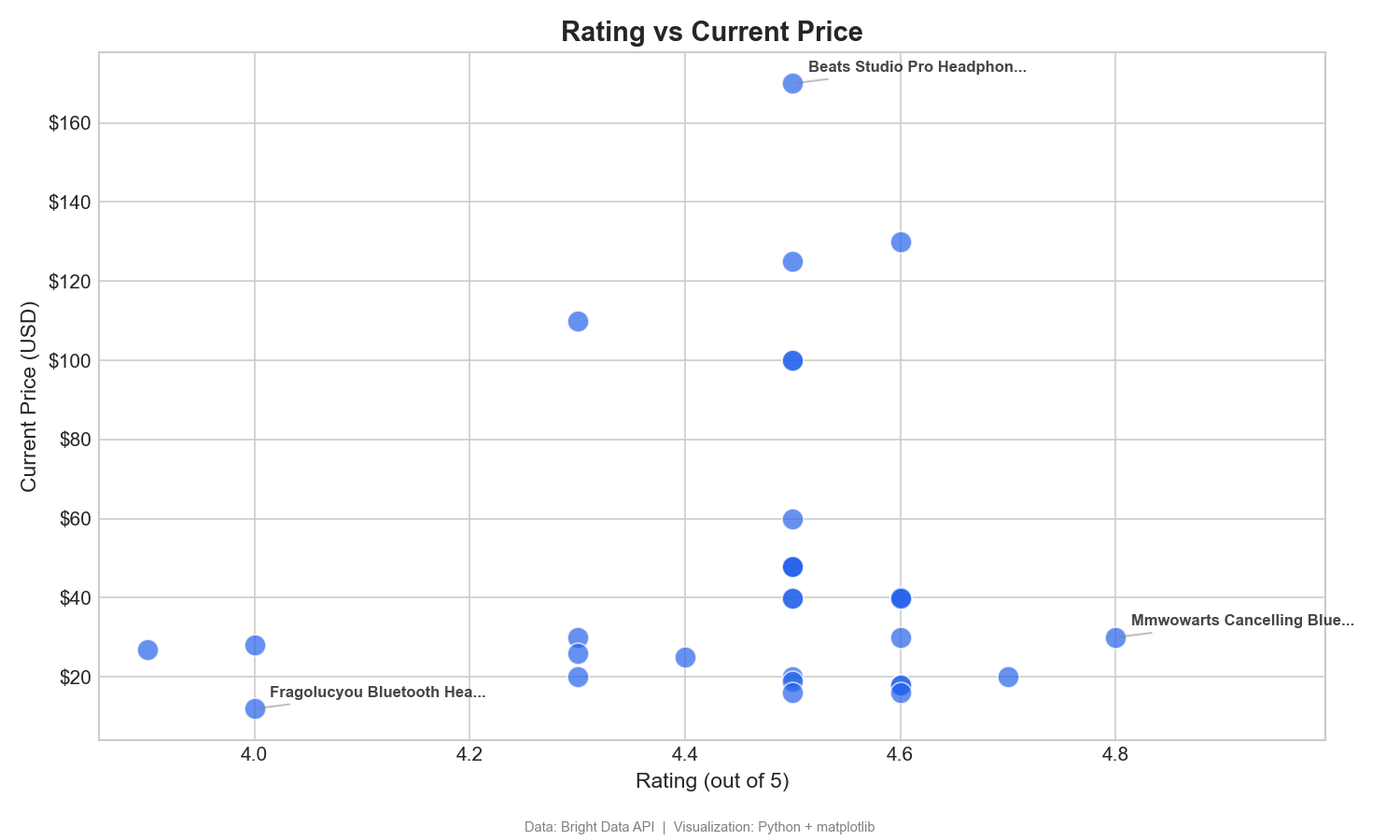
Dieses Streudiagramm hilft dabei, hochwertige Produkte zu identifizieren, also solche mit hohen Bewertungen und niedrigen Preisen (unterer rechter Quadrant). Die MMWOWARTS-Kopfhörer für 29,99 $ mit einer Bewertung von 4,8 sind ein klares Beispiel dafür. Ziehen Sie in Tableau „Bewertung“ in die Spalten, „Aktueller Preis“ in die Zeilen und „Produktname“ in die Details.
Marktsegmentierung nach Preisklasse
Dieses Ringdiagramm schlüsselt die Produkte nach Preisklassen auf:
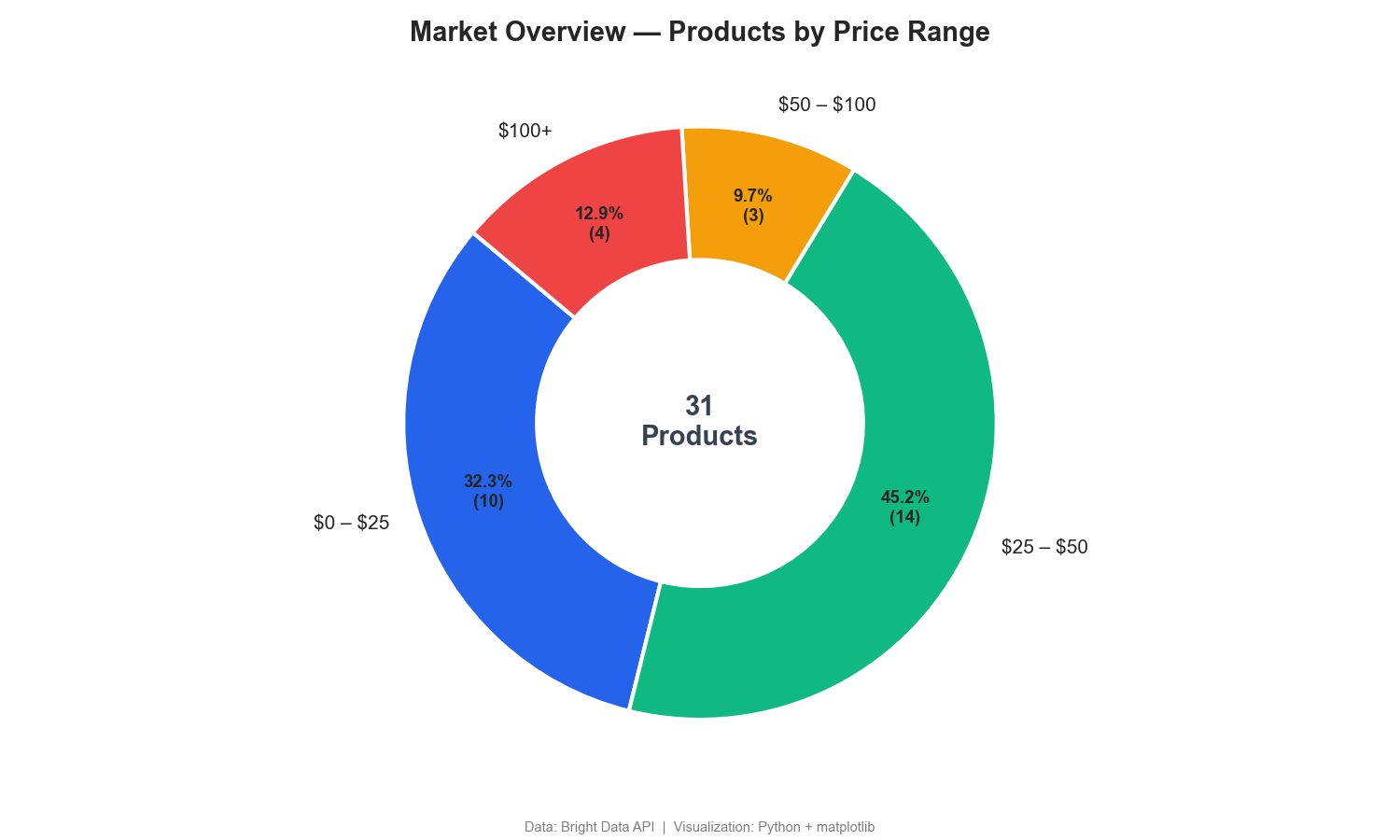
Das Ringdiagramm zeigt, dass 77 % der kabellosen Kopfhörer für unter 50 $ verkauft werden, während nur 13 % im Premium-Segment über 100 $ liegen. Dashboards zur Preisüberwachung von Wettbewerbern enthalten oft eine ähnliche Segmentierung.
Bonus: Immobilien-Pipeline mit Zillow
Das gleiche Pipeline-Muster funktioniert mit jedem der über 120 Scraper von Bright Data. Das folgende Beispiel verwendet die Zillow Scraper API (GitHub-Repo). Aktualisieren Sie zwei Variablen in „bright_data_to_tableau.py“, der Rest der Pipeline läuft unverändert weiter:
# Ersetzen Sie die Amazon-Datensatz-ID durch die Zillow-Datensatz-ID
DATASET_ID = "gd_lfqkr8wm13ixtbd8f5" # Zillow-ImmobilienAktualisieren Sie anschließend die Nutzlast in trigger_collection(), um anstelle eines Schlüsselworts eine Standort-URL zu verwenden:
payload = [{
"url": "https://www.zillow.com/new-york-ny/"
}]Führen Sie das Skript auf die gleiche Weise aus. Die Abfrage- und CSV-Exportlogik funktioniert ohne Änderungen.
Zu den Zillow-Feldern gehören: Adresse der Immobilie, Preis, Schlafzimmer, Badezimmer, Wohnfläche, Grundstücksgröße, Baujahr, Immobilientyp, Listing-Status und Zestimate.
Ideen für Tableau-Dashboards:
- Heatmap zum Preis pro Quadratfuß nach Postleitzahl
- Analyse der Differenz zwischen Angebotspreis und Zestimate
- Verteilung der Immobilientypen nach Stadt oder Postleitzahl
- Streudiagramm: Baujahr vs. Preis für Renovierungsmöglichkeiten
Der entscheidende Vorteil: Sie lernen das Muster einmal und wenden es dann auf jede beliebige Datenquelle an. Amazon, Zillow, LinkedIn-Stellenanzeigen – alle nutzen dieselbe Bright Data-Infrastruktur, um Daten an Tableau-Dashboards zu senden.
Die 6 wichtigsten Anwendungsfälle für Live-Webdaten in Tableau
Dies sind die häufigsten Gründe, warum Teams Webdaten-Pipelines in Tableau integrieren.
1. Preisüberwachung der Wettbewerber
Verfolgen Sie die Preise der Wettbewerber auf Amazon, Walmart, Target oder jeder anderen E-Commerce-Plattform. Erstellen Sie Tableau-Dashboards, die tägliche Preisbewegungen, historische Trends und die Preispositionierung in Ihrem Markt anzeigen. Richten Sie Benachrichtigungen ein, wenn Wettbewerber unter Ihren Mindestpreis fallen.
Überwachen Sie Tausende von SKUs auf mehreren Marktplätzen mit den über 120 vorgefertigten Scrapern von Bright Data. Es sind keine benutzerdefinierten Scraper erforderlich.
Tableau-Ansichten: Preis-Wasserfall-Diagramme, Zeitreihentrends nach SKU, Heatmaps zu den Preisen der Wettbewerber.
2. Marken-Tracking in sozialen Medien
Rufen Sie Erwähnungen, Interaktionskennzahlen, Followerzahlen und Kommentardaten von Instagram, Twitter/X, TikTok und LinkedIn ab. Erstellen Sie Dashboards, die die Markensichtbarkeit plattformübergreifend verfolgen und die Kampagnenleistung im Zeitverlauf messen. Der Scraping-Browser bewältigt JavaScript-intensive soziale Plattformen, die mit Standard-HTTP-Anfragen nicht gerendert werden können.
Tableau-Ansichten: Trends bei der Interaktionsrate, Erwähnungsvolumen im Zeitverlauf, Balkendiagramme zum Plattformvergleich.
3. Arbeitsmarktanalysen
Aggregieren Sie Stellenanzeigen von Indeed, Glassdoor, LinkedIn (GitHub-Repo) und Nischen-Jobbörsen. Analysieren Sie Einstellungstrends, Gehaltsbenchmarks, erforderliche Fähigkeiten und Verschiebungen der Nachfrage über Branchen und Regionen hinweg. HR-Teams und Personalvermittler nutzen diese Dashboards, um Vergütungen zu vergleichen und Veränderungen auf dem Talentmarkt vor der Konkurrenz zu erkennen.
Tableau-Ansichten: Geografische Bubble-Maps offener Stellen, Histogramme zur Gehaltsverteilung, Treemaps zur Qualifikationsnachfrage.
4. Immobilien-Dashboards
Überwachen Sie Immobilienangebote, Preisänderungen, Bestandsniveaus und Nachbarschaftstrends von Zillow, Realtor.com, Redfin und Airbnb. Immobilieninvestoren und -analysten erstellen in Tableau geografische Heatmaps, um unterbewertete Märkte zu identifizieren und Trends bei den Mietrenditen in verschiedenen Städten zu verfolgen.
Tableau-Ansichten: Postleitzahlen-Heatmaps, Streudiagramme zu Quadratmeterpreisen, Zeitreihen zum Angebotsvolumen.
5. Finanzdaten-Feeds
Sammeln Sie Aktienkurse, Gewinnberichte, Analystenbewertungen, Insiderhandelsdaten und Finanznachrichten von Yahoo Finance, Bloomberg und anderen Finanzplattformen. Quantitative Analysten und Portfoliomanager erstellen Finanz-Dashboards mit automatischer Datenaktualisierung, um die Portfolio-Performance und Marktsignale zu verfolgen.
Tableau-Ansichten: Kurscharts im Candlestick-Stil, Balkendiagramme zu Gewinnüberraschungen, Dashboards zur Sektorrotation.
6. Überwachung der Lieferkette
Verfolgen Sie Produktverfügbarkeit, voraussichtliche Lieferzeiten, Lagerbestände der Verkäufer und Preise auf globalen Marktplätzen. Betriebsteams erstellen Tableau-Dashboards, die Versorgungsunterbrechungen wie plötzliche Lagerengpässe oder sprunghafte Anstiege der Lieferzeiten erkennen, bevor sie sich auf den Rest der Lieferkette auswirken.
Tableau-Ansichten: Verfügbarkeitsstatus-Matrizen, Trendlinien für Lieferzeiten, Risikoscorecards für Lieferanten.
Jeder dieser Anwendungsfälle folgt derselben Architektur: Bright Data API → Strukturierte Daten → Tableau-Dashboard. Die einzigen Dinge, die sich ändern, sind die Datensatz-ID und die von Ihnen erstellten Tableau-Visualisierungen.
So funktioniert die Bright Data API-Pipeline
Das Tutorial-Skript übernimmt das Auslösen und Abfragen. Hier sehen Sie, was in der gesamten Pipeline passiert, vom API-Aufruf bis zum Tableau-Dashboard.
Schritt-für-Schritt-Datenfluss
- Trigger. Ihr Python-Skript sendet eine POST-Anfrage an den Endpunkt
/triggervon Bright Data. Fügen Sie entweder ein Schlüsselwort (für die Erkennung) oder eine Liste von URLs (für die gezielte Erfassung) hinzu. Die API gibt sofort einesnapshot_idzurück. - Erfassung. Die Infrastruktur von Bright Data leitet Anfragen über mehr als 150 Millionen Residential-Proxys weiter. Sie bewältigt CAPTCHA-Herausforderungen automatisch, rendert JavaScript bei Bedarf und wiederholt fehlgeschlagene Anfragen.
- Parsing. Bright Data parst rohen HTML-Code in strukturierte Datenfelder. Bei Amazon-Produkten können dies Titel, Preis, Bewertung, Rezensionen, Verkäuferinformationen und Verfügbarkeit sein – wobei die genau zurückgegebenen Felder von den Datensätzen und der Suchart abhängen.
- Snapshot. Sobald die Erfassung und das Parsing abgeschlossen sind, speichert Bright Data die Daten als Snapshot. Ihr Skript fragt den Endpunkt
/snapshotab, bis sich der Status von202 (in Bearbeitung)auf200 (bereit)ändert. - Lieferung. Sie rufen den Snapshot als JSON oder CSV ab. Alternativ können Sie die Lieferung an Amazon S3, Google Cloud Storage, Azure Blob, Snowflake, SFTP oder Webhook konfigurieren. Die automatische Lieferung ist nützlich für Produktionspipelines, die Daten in einem Data Warehouse speichern.
- Transformation. Ihr Skript (oder ein Tool wie pandas) benennt Spalten um, filtert Felder und formatiert die Daten so, dass Tableau sie lesen kann. Hier fügen Sie Metadaten-Spalten wie das Erfassungsdatum und die Datenquelle hinzu.
- Visualisierung. Tableau liest die Ausgabedatei (oder stellt eine Verbindung zu einer Datenbank her, falls Sie die Daten dort geladen haben) und rendert Ihr Dashboard mit den aktuellsten Daten.
Skalierung der Pipeline
Für den produktiven Einsatz sollten Sie folgende Erweiterungen in Betracht ziehen:
- Mehrere Schlüsselwörter. Durchlaufen Sie in Ihrem Skript eine Liste von Schlüsselwörtern oder Produktkategorien, um umfassende Datensätze zu erstellen.
- Datenbankspeicherung. Schreiben Sie statt in CSV-Dateien in PostgreSQL oder MySQL. Tableau stellt nativ eine Verbindung zu beiden her, und im Laufe der Zeit sammeln sich historische Daten für Trendanalysen an.
- Orchestrierung. Verwenden Sie Apache Airflow, Prefect oder einen Cron-Job, um Ausführungen in der von Ihrem Unternehmen benötigten Häufigkeit (stündlich, täglich, wöchentlich) zu planen.
- Webhook-Übermittlung. Verzichten Sie vollständig auf Polling, indem Sie Bright Data so konfigurieren, dass Ergebnisse an Ihren Server gesendet werden, sobald sie bereitstehen.
Checkliste für die Produktion
Bevor Sie die Pipeline in einem Produktionsplan bereitstellen, sollten Sie folgende operative Aspekte berücksichtigen:
- Fehlerbehandlung. Umschließen Sie API-Aufrufe mit try/except-Blöcken und einer Wiederholungslogik. Protokollieren Sie Fehler in einer Datei oder einem Überwachungsdienst, damit veraltete Daten frühzeitig erkannt werden.
- Datendeduplizierung. Fügen Sie einen eindeutigen Schlüssel (z. B. ASIN + Erfassungsdatum) hinzu und deduplizieren Sie die Daten vor dem Laden in Tableau. Doppelte Zeilen verfälschen Aggregationen.
- Schema-Validierung. Überprüfen Sie, ob die API-Antwort die erwarteten Felder enthält, bevor Sie in CSV schreiben. Änderungen an der Website können die Datenstruktur ohne Vorwarnung verändern.
- Überwachung und Benachrichtigung. Richten Sie Benachrichtigungen (E-Mail, Slack oder PagerDuty) für fehlgeschlagene Durchläufe, leere Datensätze oder unerwartete Rückgänge der Zeilenanzahl ein.
- Datensicherungen. Archivieren Sie jeden CSV-Snapshot mit einem Zeitstempel. Falls ein fehlerhafter Scrape Ihre Arbeitsdatei beschädigt, rollen Sie auf die vorherige Version zurück.
Warum Bright Data für Tableau-Pipelines
Für Tableau-Workflows in der Produktion sind folgende Faktoren entscheidend:
- Flexible Bereitstellung. Erhalten Sie Ergebnisse als JSON, CSV oder NDJSON über API, Webhook, Amazon S3, Google Cloud, Azure oder SFTP. Laden Sie Daten in Ihr Tableau-Data-Warehouse.
- Maßgeschneidert oder vorgefertigt. Verwenden Sie Serverless Functions, um benutzerdefinierte Scraper zu erstellen, Scraper Studio, um KI-gestützte und generierte Scraper zu erstellen, oder nutzen Sie vorgefertigte Datensätze für sofortigen Zugriff ohne Programmieraufwand.
- Kostengünstig. Zahlen Sie 1,50 $ pro 1.000 Datensätze im Pay-as-you-go-Modell, mit Mengenrabatten bis zu 0,75 $/1.000 bei höheren Stufen.
Erstellen Sie Ihre Live-Webdaten-Pipeline
Die Kluft zwischen verfügbaren und benötigten Daten wird immer größer, insbesondere wenn diese Daten im offenen Web ohne API oder Konnektor vorliegen.
WDC v2 ist veraltet und wird nicht mehr unterstützt. Google Sheets stößt an Zellgrenzen. Excel erfordert manuelle Arbeit. TabPy bietet keinen Rotierenden Proxy. DIY-Skripte versagen bei Skalierung.
Die Web Scraper API von Bright Data bietet die Infrastruktur, die diesen Ansätzen fehlt. Die API umfasst über 120 vorgefertigte Scraper, mehr als 150 Millionen Proxys in 195 Ländern, automatische CAPTCHA-Lösung und strukturierte Datenausgabe in Formaten, die Tableau nativ unterstützt. Die Preise beginnen bei 1,50 $ pro 1.000 Datensätze, bei einer Verfügbarkeit von 99,99 % und vollständiger GDPR-Konformität, CCPA und ISO 27001.
Konzentrieren Sie sich auf die Erstellung von Dashboards, anstatt eine Infrastruktur zur Datenerfassung aufzubauen.
Starten Sie die Gratis-Testversion →
Häufig gestellte Fragen
Ist Tableau WDC veraltet?
Ja. Der Tableau Web Data Connector v2 wurde mit der Version 2023.1 offiziell als veraltet eingestuft. Tableau 2022.4, die letzte Version, die WDC v2 unterstützt, hat das Ende ihrer Lebensdauer erreicht. WDC v2-Konnektoren werden in allen aktuellen Tableau-Versionen nicht mehr unterstützt und könnten in zukünftigen Updates entfernt werden.
Was hat Tableau WDC ersetzt?
Tableau hat WDC v3 veröffentlicht, aber es ist nur für Extrakte gedacht und wird von Tableau Bridge nicht unterstützt. Für Live-Webdaten ist eine Scraping-API-Pipeline (Bright Data → CSV/JSON → Tableau) eine praktische Alternative. Das Tutorial in diesem Leitfaden erstellt diese Pipeline.
Kann Tableau eine direkte Verbindung zu einer API für Web-Scraping herstellen?
Nicht nativ. Tableau verbindet sich mit Datenbanken, Dateien und bestimmten Cloud-Diensten. Um eine Scraping-API zu nutzen, benötigen Sie ein leichtgewichtiges Skript in Python oder Node.js, das die API aufruft und die Daten empfängt. Das Skript gibt dann ein Format aus, das Tableau lesen kann: CSV, JSON oder einen Datenbank-Eintrag.
Wie halte ich meine Tableau-Dashboard-Daten auf dem neuesten Stand?
Planen Sie Ihr Datenerfassungsskript mit cron (Linux/Mac), dem Task Scheduler (Windows) oder einem Workflow-Orchestrator wie Apache Airflow. Das Skript ruft die neuesten Daten aus der API von Bright Data ab und überschreibt die CSV-Datei. Tableau lädt die aktualisierten Daten beim nächsten Aktualisierungszyklus.
Wie viel kostet es, Webdaten in Tableau zu laden?
Die Web-Scraper-API von Bright Data kostet ab 1,50 $ pro 1.000 Datensätze im Pay-as-you-go-Modell, mit Mengenrabatten bis zu 0,75 $/1.000. Für ein typisches Dashboard zur Wettbewerbsbeobachtung, das täglich 5.000 Produkte verfolgt, sind das etwa 7,50 $/Tag oder ~225 $/Monat.
Welche Datenformate liefert Bright Data für Tableau?
Bright Data liefert Daten über die API als JSON, CSV oder NDJSON. Für Tableau ist CSV die direkteste Option. Tableau liest diese Daten nativ, ohne dass eine Transformation erforderlich ist. Alternativ können Sie die automatische Bereitstellung an Amazon S3, Google Cloud Storage, Azure Blob, Snowflake, SFTP oder Webhook für Produktionspipelines konfigurieren.
Kann ich Bright Data mit Tableau Public verwenden?
Ja. Bright Data gibt Standard-CSV-Dateien aus, die Tableau Public nativ liest. Die Einschränkung liegt auf Seiten von Tableau Public: Es unterstützt keine geplanten Aktualisierungen für dateibasierte Quellen. Sie müssen Ihr Datenerfassungsskript jedes Mal neu ausführen und die Arbeitsmappe neu veröffentlichen, wenn die Daten aktualisiert werden.





