

Die Erstellung spezialisierter Modelle, die Ihr Fachgebiet verstehen, erfordert oft mehr als Prompt Engineering oder Retrieval-Augmented Generation (RAG). Die öffentlich verfügbaren Modelle sind zwar leistungsfähig, aber es fehlt ihnen an aktuellem Wissen oder an dem spezifischen Geschmack, den Ihr Anwendungsfall erfordert. Da wir über Webdaten verfügen, die von Artikeln, Dokumentationen, Produktlisten und Videotranskripten reichen, kann diese Lücke durch Feinabstimmung überbrückt werden.
In diesem Blogbeitrag erfahren Sie:
- Wie man domänenspezifische Webdaten mit den Scrapern und Datasets von Bright Data sammelt und aufbereitet.
- Wie Sie ein Open-Source-GPT-Modell mit den gesammelten Daten feinabstimmen
- Wie Sie Ihr fein abgestimmtes Modell für reale Aufgaben auswerten und einsetzen.
Tauchen wir ein!
Was ist Feinabstimmung?
Vereinfacht gesagt, ist die Feinabstimmung der Prozess, bei dem ein Modell, das bereits auf einem großen, allgemeinen Datensatz trainiert wurde, so angepasst wird, dass es auf einem neuen, oft spezifischeren Datensatz oder einer Aufgabe gut funktioniert. Bei der Feinabstimmung ändern Sie unter der Haube die Gewichte des Modells, anstatt es von Grund auf neu zu erstellen. Die Änderung der Gewichte bewirkt, dass sich das Modell anders oder in der von Ihnen gewünschten Weise verhält.
Webdaten sind für die Feinabstimmung nützlich, denn sie bieten Ihnen:
- Frische: Sie werden ständig aktualisiert, um die neuesten Trends, Ereignisse und Technologien zu erfassen.
- Vielfältigkeit: Zugang zu verschiedenen Schreibstilen, Quellen und Gedanken, was die Verzerrung durch enge Datensätze verringert.
Der Prozess der Feinabstimmung funktioniert wie hier dargestellt:
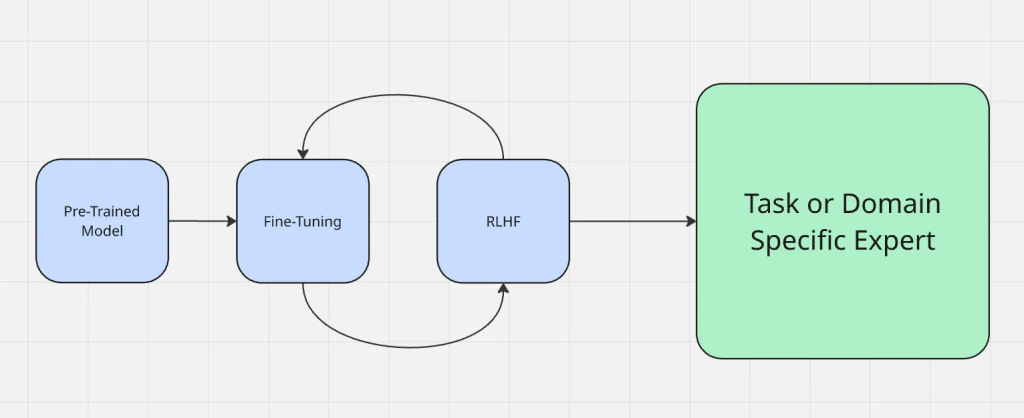
Die Feinabstimmung unterscheidet sich von anderen häufig verwendeten Anpassungsmethoden wie Prompt-Engineering und Retrieval-Augmented Generation. Beim Prompt-Engineering wird die Art und Weise, wie man einem Modell Fragen stellt, geändert, aber das Modell selbst wird nicht verändert. RAG fügt zur Laufzeit eine externe Wissensquelle hinzu, die z.B. den Kontext von etwas Neuem liefert. Bei der Feinabstimmung hingegen werden die Parameter des Modells direkt aktualisiert, was es zuverlässiger macht, ohne zusätzlichen Kontext jedes Mal eine domänengenaue Ausgabe zu erzeugen.
Im Gegensatz zur Retrieval-Augmented Generation (RAG), die ein Modell zur Laufzeit mit externem Kontext anreichert, passt die Feinabstimmung das Modell selbst an. Wenn Sie tiefer in die Kompromisse eintauchen möchten, lesen Sie RAG vs. Fine-Tuning.
Warum Webdaten für das Fine-Tuning verwenden?
Webdaten liegen in reichhaltigen und aktuellen Formaten vor (Artikel, Produktlisten, Forenbeiträge, Videotranskripte und sogar von Videos abgeleiteter Text), was einen Vorteil darstellt, den weder statische noch synthetische Datensätze bieten können. Diese Vielfalt hilft einem Modell, verschiedene Eingabearten effektiver zu verarbeiten.
Hier sind einige Beispiele für verschiedene Kontexte, in denen Webdaten glänzen:
- Daten aus sozialen Medien: Tokens von sozialen Plattformen helfen Modellen, informelle Sprache, Slang und Echtzeittrends zu verstehen, die für Anwendungen wie Stimmungsanalyse oder Chatbots unerlässlich sind.
- Strukturierte Datensätze: Token aus strukturierten Quellen wie Produktkatalogen oder Finanzberichten ermöglichen ein präzises, domänenspezifisches Verständnis, das für Empfehlungssysteme oder Finanzprognosen entscheidend ist.
- Nischenkontext: Startups und spezialisierte Anwendungen profitieren von Token aus relevanten Datensätzen, die auf ihre Anwendungsfälle zugeschnitten sind, z. B. juristische Dokumente für Legal Tech oder medizinische Fachzeitschriften für KI im Gesundheitswesen.
Webdaten sorgen für eine natürliche Vielfalt und einen natürlichen Kontext und verbessern die Realitätsnähe und Robustheit eines fein abgestimmten Modells.
Strategien der Datenerfassung
Groß angelegte Scraper und Datensatzanbieter wie Bright Data ermöglichen es, schnell und zuverlässig große Mengen an Webinhalten zu sammeln. So können Sie domänenspezifische Datensätze erstellen, ohne Monate für die manuelle Erfassung aufwenden zu müssen.
Bright Data hat die branchenweit vielfältigste und zuverlässigste Infrastruktur für die Sammlung von Webdaten aufgebaut, die sich aus mehreren verschiedenen Netzwerken und Quellen zusammensetzt. Dabei sind Webdaten nicht auf reinen Text beschränkt. Bright Data kann multimodale Eingaben wie Metadaten, Produktattribute und Videotranskripte erfassen, die einem Modell helfen, einen umfassenderen Kontext zu lernen.
Das Sammeln von Daten mithilfe von Rohdaten sollte vermieden werden, da diese fast immer Rauschen, irrelevante Inhalte oder Formatierungsartefakte enthalten. Filtern, Entfernen von Duplikaten und strukturierte Bereinigung sind wichtige Schritte, um sicherzustellen, dass der Trainingsdatensatz die Leistung verbessert, anstatt Verwirrung zu stiften.
Aufbereitung von Webdaten für die Feinabstimmung
- Konvertierung von rohen Scrapes in strukturierte Eingabe-/Ausgabepaare. Unverarbeitete Daten sind in den seltensten Fällen sofort für das Training geeignet. Der erste Schritt besteht in der Konvertierung der Daten in strukturierte Eingabe-/Ausgabepaare. Zum Beispiel kann eine Dokumentation über Feinabstimmung in eine Eingabeaufforderung wie “Was ist Feinabstimmung?” mit der ursprünglichen Antwort als Zielausgabe formatiert werden. Durch diese Art der Strukturierung wird sichergestellt, dass das Modell aus wohldefinierten Beispielen und nicht aus unstrukturiertem Text lernt.
- Handhabung verschiedener Formate: JSON, CSV, Transkripte, Web-Seiten. Webdaten liegen in der Regel in verschiedenen Formaten vor, z. B. JSON von APIs, CSV-Exporte, Roh-HTML oder Transkripte von Videos. Die Standardisierung von Webdaten in einem einheitlichen Format wie JSONL vereinfacht die Verwaltung und die Einspeisung in Trainings-Pipelines.
- Packen von Datensätzen für effizientes Training. Um die Trainingsergebnisse und -prozesse zu verbessern, werden Datensätze oft “arrangiert”, d. h. mehrere kürzere Beispiele werden zu einer einzigen Sequenz zusammengefasst, um die Anzahl der vergeudeten Token zu reduzieren und die GPU-Speichernutzung während der Feinabstimmung zu optimieren.
- Abwägen zwischen domänenspezifischen und allgemeinen Webdaten. Es ist wichtig, ein Gleichgewicht zu finden. Ein Übermaß an domänenspezifischen Daten kann dazu führen, dass das Modell eng und oberflächlich ist, während zu viele allgemeine Daten das angestrebte Spezialwissen verwässern können. Die besten Ergebnisse erzielt man in der Regel, wenn man eine starke Basis von allgemeinen Webdaten mit domänenspezifischen Beispielen kombiniert.
Auswahl eines Basismodells
Die Wahl des richtigen Basismodells wirkt sich direkt darauf aus, wie gut Ihr fein abgestimmtes System funktioniert. Es gibt keine Einheitslösung, vor allem wenn man die Vielfalt der Angebote innerhalb jeder Modellfamilie bedenkt. Je nach Art Ihrer Daten, den gewünschten Ergebnissen und Ihrem Budget kann ein Modell Ihren Anforderungen besser entsprechen als ein anderes.
Befolgen Sie diese Checkliste, um das richtige Modell für den Einstieg auszuwählen:
- Welche Modalität oder Modalitäten benötigt Ihr Modell?
- Wie groß sind Ihre Eingabe- und Ausgabedaten?
- Wie komplex sind die Aufgaben, die Sie durchführen wollen?
- Wie wichtig ist die Leistung im Vergleich zum Budget?
- Wie wichtig ist die Sicherheit des KI-Assistenten für Ihren Anwendungsfall?
- Verfügt Ihr Unternehmen über eine bestehende Vereinbarung mit Azure oder GCP?
Wenn Sie beispielsweise mit extrem langen Videos oder Texten zu tun haben (stundenlang mit Hunderttausenden von Wörtern), könnte Gemini 1.5 pro eine optimale Wahl sein, da es ein Kontextfenster von bis zu 1 Million Token bietet.
Mehrere Open-Source-Modelle sind gute Kandidaten für die Feinabstimmung von Webdaten, darunter die Modelle Gemma 3, Llama 3.1, Mistral 7B oder Falcon. Die kleineren Versionen sind für die meisten Feinabstimmungsprojekte geeignet, während die größeren Modelle besonders gut geeignet sind, wenn Ihr Bereich eine hohe Abdeckung und Präzision erfordert. Sie können auch diesen Leitfaden zur Anpassung von Gemma 3 für die Feinabstimmung lesen.
Feinabstimmung mit Bright Data
Um zu demonstrieren, wie Webdaten die Feinabstimmung unterstützen, gehen wir ein Beispiel mit Bright Data als Quelle durch. In diesem Beispiel werden wir die Scraper-API von Bright Data verwenden, um Produktinformationen von Amazon zu sammeln und dann eine Feinabstimmung eines Llama 4-Modells auf Hugging Face vorzunehmen.
Schritt 1: Sammeln des Datensatzes
Mit der Web Scraper API von Bright Data können Sie strukturierte Produktdaten (Titel, Produkte, Beschreibungen, Bewertungen usw.) mit nur wenigen Zeilen Python abrufen.
Das Ziel dieses Schritts ist es, ein kleines Projekt zu erstellen, das:
- Aktivieren einer virtuellen Python-Umgebung
- die Web Scraper API von Bright Data aufruft
- die Ergebnisse in amazon-data.json speichert
Voraussetzungen
- Python 3.10+
- Ein Bright Data-API-Token
- Eine Bright Data-Kollektor-ID (aus dem Bright Data-Dashboard) /cp/scrapers
- Ein OPENAI_API_KEY, da wir ein GPT-4-Modell feinabstimmen werden.
Erstellen Sie einen Projektordner
mkdir web-scraper u0026u0026 cd web-scrapper
Erstellen und aktivieren Sie eine virtuelle Umgebung
Aktivieren Sie eine virtuelle Umgebung, und Sie sollten (venv) am Anfang Ihrer Shell-Eingabeaufforderung sehen.
//macOS/Linux (bash or zsh):npython3 -m venv venvnsource venv/bin/activatennWindowsnpython -m venv venvn.venvScriptsActivate.ps1
Installieren Sie die Abhängigkeiten
Dies ist eine Bibliothek für HTTP-Webanfragen
pip install requests
Sobald dies abgeschlossen ist, sind Sie bereit, die gewünschten Daten mithilfe der Scraper-APIs von Bright Data abzurufen.
Definieren Sie die Scraping-Logik
Das folgende Snippet löst Ihren Bright Data-Collector aus (z. B. Amazon-Produkte), führt eine Abfrage durch, bis das Scrapen beendet ist, und speichert die Ergebnisse in einer lokalen JSON-Datei.
Ersetzen Sie hier Ihren API-Schlüssel in der API-Schlüsselzeichenfolge
import requestsnimport jsonnimport timenndef trigger_amazon_products_scraping(api_key, urls):n url = u0022https://api.brightdata.com/datasets/v3/triggeru0022nn params = {n u0022dataset_idu0022: u0022gd_l7q7dkf244hwjntr0u0022,n u0022include_errorsu0022: u0022trueu0022,n u0022typeu0022: u0022discover_newu0022,n u0022discover_byu0022: u0022best_sellers_urlu0022,n }n data = [{u0022category_urlu0022: url} for url in urls]nn headers = {n u0022Authorizationu0022: fu0022Bearer {api_key}u0022,n u0022Content-Typeu0022: u0022application/jsonu0022,n }nn response = requests.post(url, headers=headers, params=params, json=data)nn if response.status_code == 200:n snapshot_id = response.json()[u0022snapshot_idu0022]n print(fu0022Request successful! Response: {snapshot_id}u0022)n return response.json()[u0022snapshot_idu0022]n else:n print(fu0022Request failed! Error: {response.status_code}u0022)n print(response.text)nndef poll_and_retrieve_snapshot(api_key, snapshot_id, output_file, polling_timeout=20):n snapshot_url = fu0022https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=jsonu0022n headers = {n u0022Authorizationu0022: fu0022Bearer {api_key}u0022n }nn print(fu0022Polling snapshot for ID: {snapshot_id}...u0022)nn while True:n response = requests.get(snapshot_url, headers=headers)nn if response.status_code == 200:n print(u0022Snapshot is ready. Downloading...u0022)n snapshot_data = response.json()nn with open(output_file, u0022wu0022, encoding=u0022utf-8u0022) as file:n json.dump(snapshot_data, file, indent=4)nn print(fu0022Snapshot saved to {output_file}u0022)n returnn elif response.status_code == 202:n print(Fu0022Snapshot is not ready yet. Retrying in {polling_timeout} seconds...u0022)n time.sleep(polling_timeout)n else:n print(fu0022Request failed! Error: {response.status_code}u0022)n print(response.text)n breaknnif __name__ == u0022__main__u0022:n BRIGHT_DATA_API_KEY = u0022your_api_keyu0022n urls = [n u0022https://www.amazon.com/gp/bestsellers/office-products/ref=pd_zg_ts_office-productsu0022n ]n snapshot_id = trigger_amazon_products_scraping(BRIGHT_DATA_API_KEY, urls)n poll_and_retrieve_snapshot(BRIGHT_DATA_API_KEY, snapshot_id, u0022amazon-data.jsonu0022)
Führen Sie den Code aus
python3 web_scraper.py
Sie sollten sehen:
- Eine Snapshot-ID wird gedruckt
- Scrape abgeschlossen.
- Gespeichert in amazon-data.json (…items)
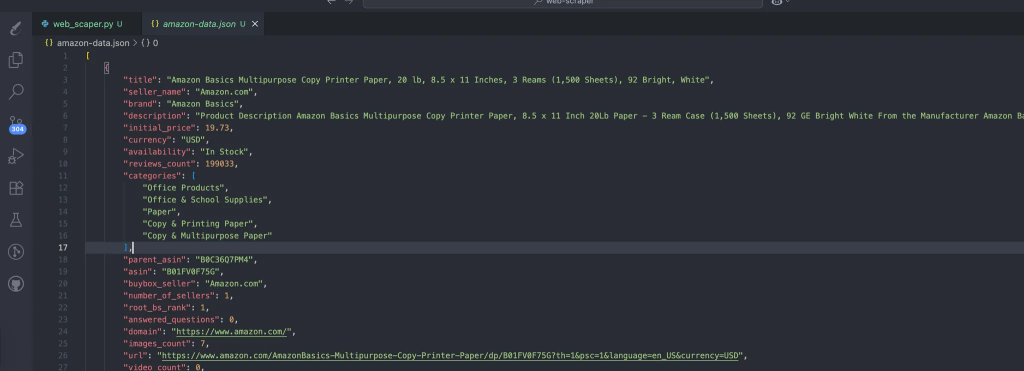
Der Prozess erstellt automatisch die Daten, die unsere gescrapten Daten enthalten. Dies ist die erwartete Struktur der Daten:
Schritt #2: JSON in Trainingspaare umwandeln
Erstellen Sie prepare_pair.py im Stammverzeichnis des Projekts mit dem folgenden Schnipsel, um unsere Daten im JSONL-Format zu strukturieren, damit sie für den Schritt der Feinabstimmung bereit sind.
import json, random, osnnINPUT = u0022amazon-data.jsonu0022nOUTPUT = u0022pairs.jsonlu0022nSYSTEM = u0022You are an expert copywriter. Generate concise, accurate product descriptions.u0022nndef make_example(item):n title = item.get(u0022titleu0022) or item.get(u0022nameu0022) or u0022Unknown productu0022n brand = item.get(u0022brandu0022) or u0022Unknown brandu0022n features = item.get(u0022featuresu0022) or item.get(u0022bulletsu0022) or []n features_str = u0022, u0022.join(features) if isinstance(features, list) else str(features)n target = item.get(u0022descriptionu0022) or item.get(u0022aboutu0022) or u0022u0022n user = fu0022Write a crisp product description.nTitle: {title}nBrand: {brand}nFeatures: {features_str}nDescription:u0022n assistant = target.strip()[:1200] # keep it tightn return {u0022systemu0022: SYSTEM, u0022useru0022: user, u0022assistantu0022: assistant}nndef main():n if not os.path.exists(INPUT):n raise SystemExit(fu0022Missing {INPUT}u0022)n data = json.load(open(INPUT, u0022ru0022, encoding=u0022utf-8u0022))n pairs = [make_example(x) for x in data if isinstance(x, dict)]n random.shuffle(pairs)n with open(OUTPUT, u0022wu0022, encoding=u0022utf-8u0022) as out:n for ex in pairs:n out.write(json.dumps(ex, ensure_ascii=False) + u0022nu0022)n print(fu0022Wrote {len(pairs)} examples to {OUTPUT}u0022)nnif __name__ == u0022__main__u0022:n main()
Führen Sie den folgenden Befehl aus:
python3 prepare_pairs.py
Und sollte die folgende Ausgabe in der Datei ergeben:
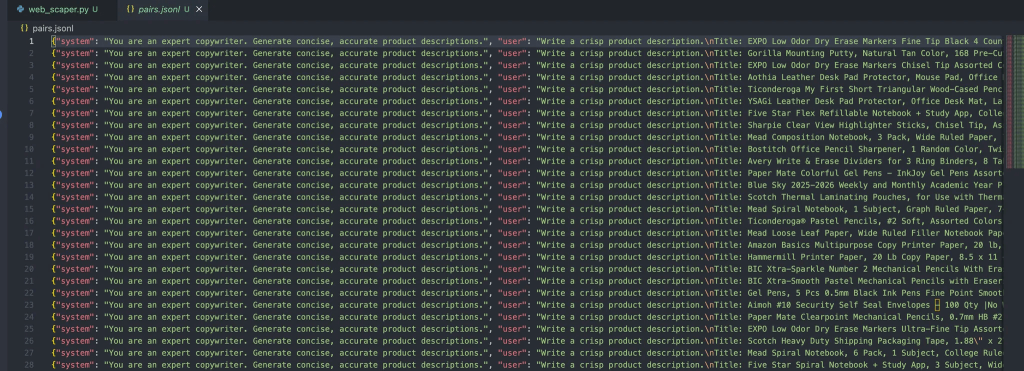
Jede Nachricht in diesen Objekten enthält drei Rollen:
- System: Stellt den anfänglichen Kontext für den Assistenten bereit.
- Benutzer: Die Eingabe des Benutzers.
- Assistent: Die Antwort des Assistenten.
Schritt Nr. 3: Hochladen der Datei zur Feinabstimmung
Sobald die Datei fertig ist, besteht der nächste Schritt nur noch darin, sie mit den folgenden Schritten in die OpenAI-Feinabstimmungspipelines einzubinden:
Installieren der OpenAI-Abhängigkeiten
pip install openai
Erstellen Sie eine upload.py zum Hochladen Ihres Datensatzes
Dieses Skript liest aus der Datei pairs.jsonl, die wir bereits haben
from openai import OpenAInclient = OpenAI(api_key=u0022your_api_key_hereu0022)nnwith open(u0022pairs.jsonlu0022, u0022rbu0022) as f:n uploaded = client.files.create(file=f, purpose=u0022fine-tuneu0022)nnprint(uploaded)
Führen Sie den folgenden Befehl aus:
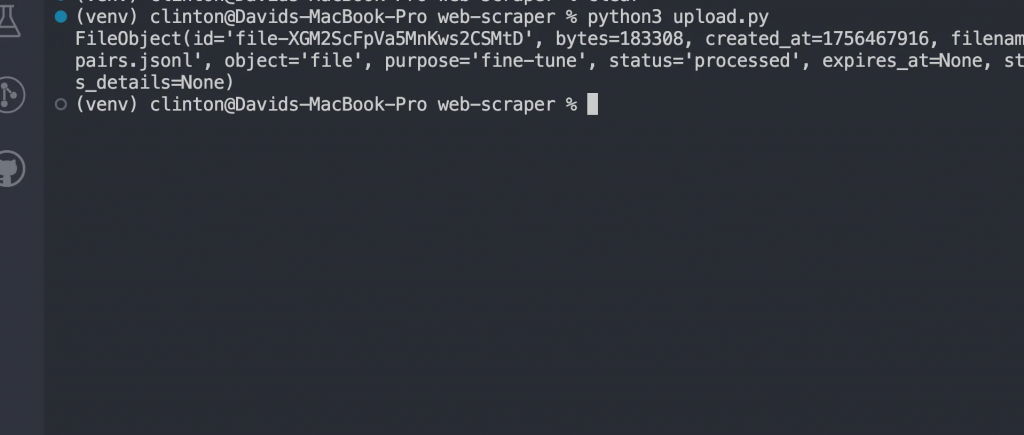
python3 upload.py
Sie sollten nun eine Antwort wie diese sehen:
Feinabstimmung des Modells
Erstellen Sie eine Datei fine-tune.py und ersetzen Sie die FILE_ID durch die hochgeladene Datei-ID, die wir aus unserer obigen Antwort erhalten haben, und führen Sie die Datei aus:
from openai import OpenAInclient = OpenAI()nn# replace with your uploaded file idnFILE_ID = u0022file-xxxxxxu0022nnjob = client.fine_tuning.jobs.create(n training_file=FILE_ID,n model=u0022gpt-4o-mini-2024-07-18u0022n)nnprint(job)
Dies sollte uns diese Antwort liefern:
Überwachen, bis das Training beendet ist
Sobald Sie die Feinabstimmung gestartet haben, braucht das Modell Zeit, um auf Ihrem Datensatz zu trainieren. Je nach Größe des Datensatzes kann dies ein paar Minuten bis Stunden dauern.
Aber Sie wollen nicht raten, wann es fertig ist. Schreiben Sie stattdessen diesen Code in monitor.py und führen Sie ihn aus
from openai import OpenAInclient = OpenAI()nnjobs = client.fine_tuning.jobs.list(limit=1)nprint(jobs)
Führen Sie dann die Datei mit Python3 [manage.py](http://manage.py) im Terminal aus, und es sollten Details angezeigt werden wie:
- Ob das Training erfolgreich war oder nicht.
- Wie viele Token trainiert wurden
- Die ID des neuen feinabgestimmten Modells.
In diesem Abschnitt sollten Sie nur weitermachen, wenn im Statusfeld steht
u0022succeededu0022
Chatten Sie mit Ihrem feinabgestimmten Modell
Sobald die Arbeit beendet ist, haben Sie nun Ihr eigenes GPT-Modell. Um es zu verwenden, öffnen Sie chat.py, aktualisieren Sie die MODEL_ID mit der von Ihrem Feinabstimmungsauftrag zurückgegebenen und führen Sie die Datei aus:
from openai import OpenAInclient = OpenAI()nn# replace with your fine-tuned model idnMODEL_ID = u0022ft:gpt-4o-mini-2024-07-18:your-org::custom123u0022nnwhile True:n user_input = input(u0022User: u0022)n if user_input.lower() in [u0022quitu0022, u0022qu0022]:n breaknn response = client.chat.completions.create(n model=MODEL_ID,n messages=[n {u0022roleu0022: u0022systemu0022, u0022contentu0022: u0022You are a helpful assistant fine-tuned on domain data.u0022},n {u0022roleu0022: u0022useru0022, u0022contentu0022: user_input}n ]n )n print(u0022Assistant:u0022, response.choices[0].message.content)
Dieser Schritt beweist, dass die Feinabstimmung funktioniert hat. Anstatt das allgemeine Basismodell zu verwenden, sprechen Sie nun mit einem Modell, das speziell für Ihre Daten trainiert wurde.
Jetzt werden Sie sehen, wie Ihre Ergebnisse lebendig werden.
Sie können Ergebnisse wie diese erwarten:
u002du002d- Generating Descriptions with Fine-Tuned Model using Synthetic Test Data u002du002d-nnPROMPT for item: ErgoPro-EL100nGENERATED (Fine-tuned):n**Introducing the ErgoPro-EL100: The Ultimate Executive Ergonomic Office Chair**nnExperience the pinnacle of comfort and support with the ComfortLuxe ErgoPro-EL100, designed to elevate your work experience. This premium office chair boasts a high-back design that cradles your upper body, providing unparalleled lumbar support and promoting a healthy posture.nnThe breathable mesh fabric ensures a cool and comfortable seating experience, while the synchronized tilt mechanism allows for seamless adjustments to your preferred working position. The padded armrests provide additional support and comfort, reducing strain on your shoulders and wrists.nnBuilt to last, the ErgoPro-EL100 features a heavy-duty nylon base that ensures stability and durability. Whether you're working long hours or simplynu002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002dnnPROMPT for item: HeightRise-FD20nGENERATED (Fine-tuned):n**Elevate Your Productivity with FlexiDesk's HeightRise-FD20 Adjustable Standing Desk Converter**nnTake your work to new heights with FlexiDesk's HeightRise-FD20, the ultimate adjustable standing desk converter. Designed to revolutionize your workspace, this innovative converter transforms any desk into a comfortable and ergonomic standing station.nn**Experience the Benefits of Standing**nnThe HeightRise-FD20 features a spacious dual-tier surface, perfect for holding your laptop, monitor, and other essential work tools. The smooth gas spring lift allows for effortless height adjustments, ranging from 6 to 17 inches, ensuring a comfortable standing position that suits your needs.nn**Durable and Reliable**nnWith a sturdy construction and non-slip rubber feetnu002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002du002d
Schlussfolgerung
Bei der Arbeit mit der Feinabstimmung im Web-Maßstab ist es wichtig, die Einschränkungen und Arbeitsabläufe realistisch einzuschätzen:
- Ressourcenanforderungen: Das Training mit großen, vielfältigen Datensätzen erfordert Rechenleistung und Speicherplatz. Wenn Sie experimentieren, sollten Sie vor der Skalierung mit kleineren Datenausschnitten beginnen.
- Iterieren Sie schrittweise: Anstatt beim ersten Versuch Millionen von Datensätzen zu verarbeiten, sollten Sie mit einem kleineren Datensatz beginnen. Nutzen Sie die Ergebnisse, um Lücken oder Fehler in Ihrer Vorverarbeitungspipeline zu erkennen.
- Arbeitsabläufe für die Bereitstellung: Behandeln Sie feinabgestimmte Modelle wie jedes andere Software-Artefakt. Versionieren Sie sie, integrieren Sie sie nach Möglichkeit in CI/CD, und halten Sie Rollback-Optionen für den Fall bereit, dass ein neues Modell nicht die gewünschte Leistung erbringt.
Glücklicherweise bietet Bright Data zahlreiche KI-fähige Services für die Erfassung oder Erstellung von Datensätzen:
- Scraping Browser: Ein Playwright-, Selenium- und Puppeter-kompatibler Browser mit integrierten Freischaltfunktionen.
- Web Scraper APIs: Vorkonfigurierte APIs zum Extrahieren strukturierter Daten aus über 100 wichtigen Domains.
- Web-Entsperrer: Eine All-in-One-API, die die Freischaltung von Websites mit Anti-Bot-Schutz ermöglicht.
- SERP-API: Eine spezielle API, die Suchmaschinenergebnisse freischaltet und vollständige SERP-Daten extrahiert.
- Daten für Gründungsmodelle: Greifen Sie auf konforme, webbasierte Datensätze zu, um Pre-Training, Bewertung und Feinabstimmung zu unterstützen.
- Datenanbieter: Verbinden Sie sich mit vertrauenswürdigen Anbietern, um hochwertige, KI-fähige Datensätze in großem Umfang zu beziehen.
- Datenpakete: Erhalten Sie kuratierte, gebrauchsfertige Datensätze – strukturiert, angereichert und mit Anmerkungen versehen.
Die Feinabstimmung großer Sprachmodelle mit Webdaten ermöglicht eine leistungsstarke Domänenspezialisierung. Das Web bietet frische, vielfältige und multimodale Inhalte, von Artikeln und Rezensionen bis hin zu Transkripten und strukturierten Metadaten, die mit kuratierten Datensätzen allein nicht erreicht werden können.
Erstellen Sie ein kostenloses Bright Data-Konto, um unsere KI-fähige Dateninfrastruktur zu testen!






