

In diesem Leitfaden werden Sie sehen:
- Was Feinabstimmung ist.
- Wie man GPT-4o mit einer Web-Scraper-API über n8n feinabstimmen kann.
- Ein Vergleich von Feinabstimmungsansätzen.
- Warum qualitativ hochwertige Daten das Herzstück eines jeden Feinabstimmungsprozesses sind.
Lasst uns eintauchen!
Was ist Feinabstimmung?
Feinabstimmung – auch bekannt als überwachte Feinabstimmung (SFT)– ist ein Verfahren zur Verbesserung spezifischer Kenntnisse oder Fähigkeiten in einem vortrainierten LLM. Im Zusammenhang mit LLMs bezieht sich das Vortraining auf das Training eines KI-Modells von Grund auf.
Die Feinabstimmung ist wichtig, weil Modelle die Trainingsdaten nachahmen. Das bedeutet, dass, wenn Sie ein LLM nach dem Training testen, seine Ausgabe in gewisser Weise den Trainingsdaten folgen wird. Da es sich bei LLMs um generalistische Modelle handelt, muss man sie auf spezifische Daten abstimmen, wenn man möchte, dass sie spezifische Erkenntnisse gewinnen.
Wenn Sie mehr über SFT erfahren möchten, lesen Sie unseren Leitfaden zur überwachten Feinabstimmung in LLMs.
Feinabstimmung von GPT-4o mit der Bright Data n8n-Integration
Wie wir in einem kürzlich erschienenen Tutorial beschrieben haben, wissen Sie nun, wie Sie Llama 4 mit Hilfe der Cloud und mit Hilfe von Web Scraper APIs gescrapten Daten feinabstimmen können. In diesem geführten Abschnitt werden Sie das gleiche Ergebnis durch die Feinabstimmung von GPT-4o mithilfe von n8n, einer beliebten Plattform zur Workflow-Automatisierung, erzielen.
Im Einzelnen beziehen wir uns auf dieselbe Ziel-Webseite, nämlich die Seite mit den Amazon-Bestsellern für Büroartikel:
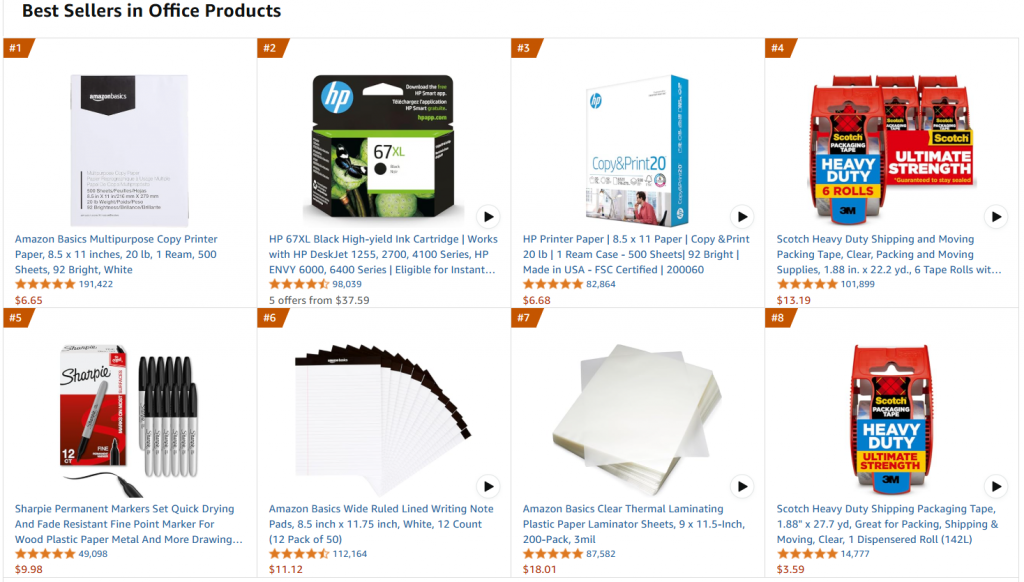
Das Ziel dieses Projekts ist es, GPT-4o-mini so zu optimieren, dass es büroähnliche Produktbeschreibungen erstellt, wenn einige Merkmale in einer Eingabeaufforderung eingegeben werden.
Führen Sie die folgenden Schritte aus, um zu erfahren, wie Sie GPT-4o-mini mit n8n und einem Trainingsdatensatz, der über die Lösungen von Bright Data gewonnen wurde, feinabstimmen können!
Anforderungen
Um diesen Feinabstimmungsprozess zu reproduzieren, benötigen Sie Folgendes:
- Ein aktives Bright Data-API-Token.
- Ein aktives n8n-Konto.
- Ein OpenAI API-Token.
Großartig! Sie sind bereit, mit der Feinabstimmung von GPT-4o zu beginnen.
Schritt 1: Erstellen Sie einen neuen n8n-Workflow und installieren Sie den Bright Data Node
Nach der Anmeldung bei n8n sieht das Dashboard wie in der folgenden Abbildung aus:
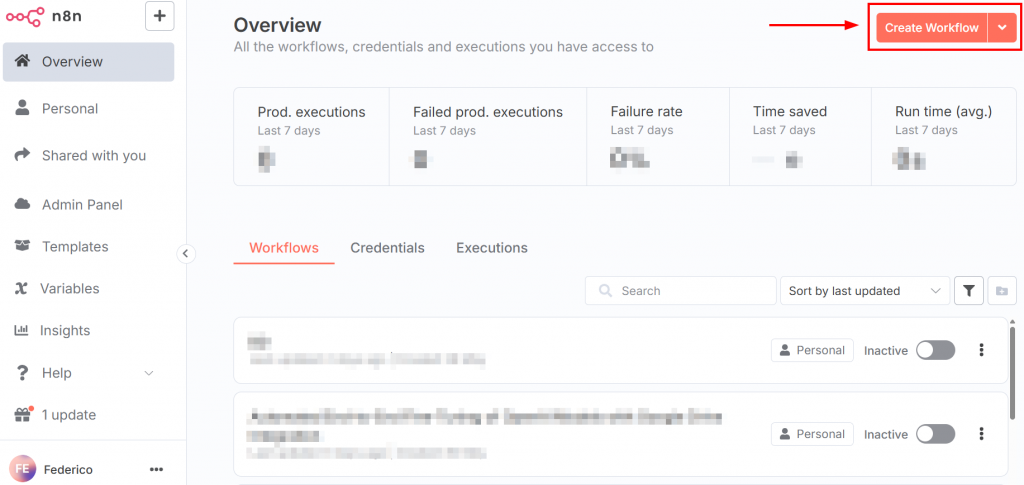
Um einen neuen Workflow zu erstellen, klicken Sie auf die Schaltfläche “Workflow erstellen”. Klicken Sie dann auf “Knotenpunkt-Panel öffnen”:
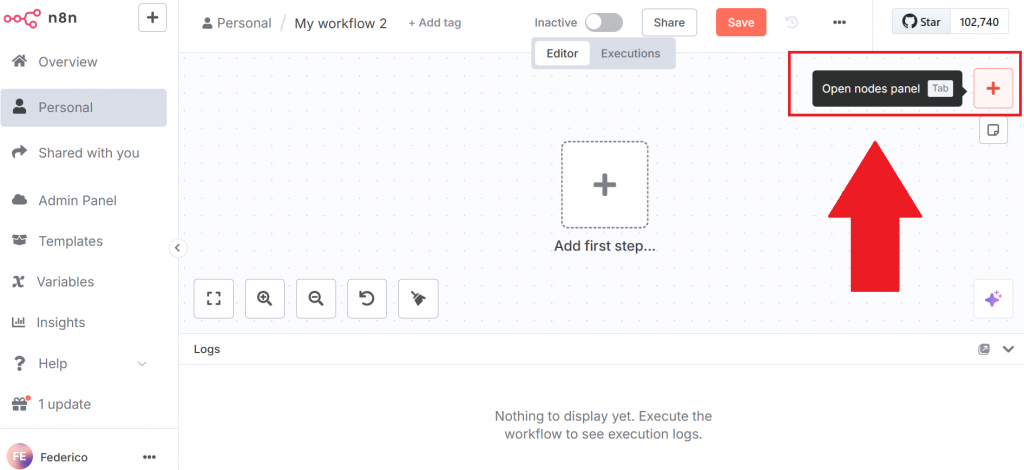
Suchen Sie im Knotenbedienfeld nach dem Knoten von Bright Data. In n8n ist ein “Knoten” ein Baustein eines automatisierten Workflows, der einen bestimmten Schritt oder eine Aktion in der Datenverarbeitungspipeline darstellt.
Klicken Sie auf den Knoten Bright Data n8n, um ihn zu installieren:

Weitere Informationen finden Sie auf der offiziellen Dokumentationsseite zur Einrichtung von Bright Data in n8n.
Sehr gut! Sie haben Ihren ersten n8n-Workflow initialisiert.
Schritt 2: Einrichten des Bright Data Node und Scrapen der Daten
Klicken Sie in der Benutzeroberfläche auf “Ersten Schritt hinzufügen”, und wählen Sie “Manuell auslösen”:
Mit diesem Knoten können Sie den gesamten Workflow manuell auslösen.
Klicken Sie auf das “+” auf der rechten Seite des Knotens für den manuellen Auslöser und suchen Sie nach Bright Data. Klicken Sie im Abschnitt “Web Scraper-Aktionen” auf “Daten synchron nach URL scrapen”:
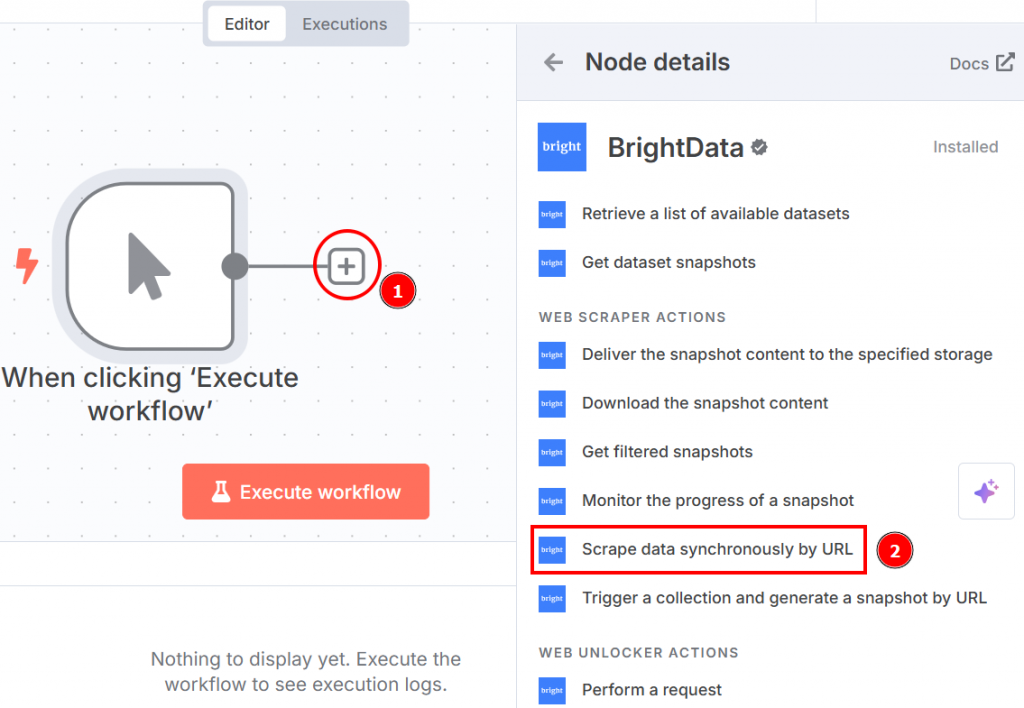
Nachfolgend sehen Sie, wie die Knoteneinstellungen aussehen, wenn Sie auf den Knoten klicken:

Richten Sie sie wie folgt ein:
- “Berechtigungsnachweis für die Verbindung mit”: Klicken Sie darauf, und fügen Sie Ihr Bright Data-API-Token hinzu. Die Anmeldeinformationen werden gespeichert.
- “Vorgang”: Wählen Sie die Option “Scrape by URL”. Damit können Sie eine Liste von URLs übergeben, die die Web Scraper API als Zielseiten zum Extrahieren der Daten verwenden wird.
- “Datensatz”: Wählen Sie die Option “Amazon-Bestseller-Produkte”. Das ist optimiert, um die Daten aus den meistverkauften Produkten von Amazon zu extrahieren.
- “URLs”: Gehen Sie auf die Seite mit den Amazon-Bestsellern für Büroprodukte und kopieren Sie eine Liste von mindestens 10 URLs. Sie benötigen mindestens 10 URLs, da der OpenAI-Chat-Knoten mindestens 10 benötigt. Wenn Sie weniger als 10 übergeben, gibt der OpenAI-Knoten bei der Feinabstimmung des Ziel-LLM einen Fehler zurück.
- “Format”: Wählen Sie das Datenformat “JSON”, da die Web Scraper API mehrere Ausgabeformate unterstützt.
Im Folgenden sehen Sie, wie Ihr Arbeitsablauf bisher aussah:

Wenn Sie auf die Schaltfläche “Workflow ausführen” klicken, werden die gescrapten Daten im Knoten Bright Data im Ausgabebereich verfügbar sein:
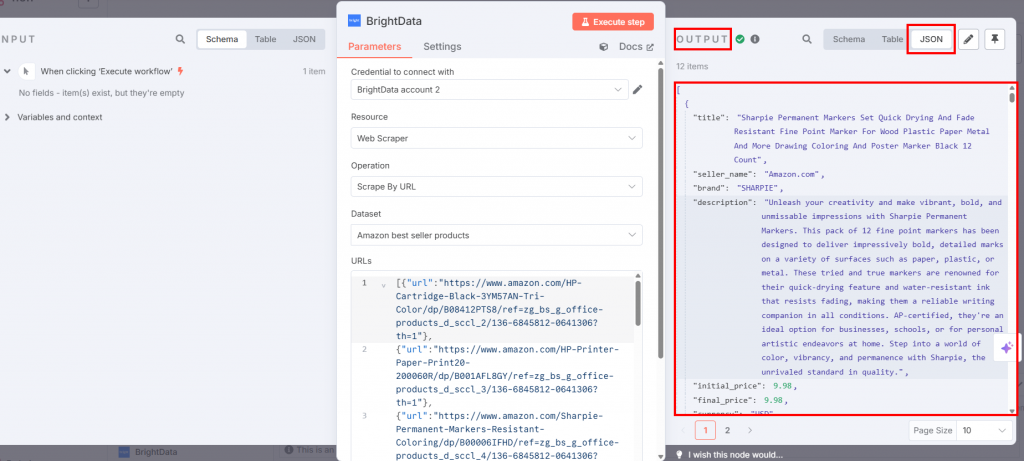
Fantastisch! Sie haben mit der Web Scraper-API von Bright Data die gewünschten Daten erfasst, ohne auch nur eine Zeile Code zu schreiben.
Schritt #3: Einrichten des Codeknotens
Verbinden Sie den Knoten “Code” des Knotens “Bright Data” und wählen Sie im Feld “Sprache” JavaScript aus:

Fügen Sie in das Feld “JavaScript” den folgenden Code ein:
// get all incoming items
const allInputItems = $input.all();
let jsonlString = "";
// define the training prompt
const systemMessage = "You are an expert marketing assistant specializing in writing compelling and informative product descriptions.";
// loop through each item retrieved from the input
for (const item of allInputItems) {
const product = item.json;
// validate if the product data exists and is an object
if (!product || typeof product !== 'object') {
console.warn('Skipping an item because product data is missing or not an object:', item);
continue;
}
// extract product data
const title = product.title || "N/A";
const brand = product.brand || "N/A";
let featuresString = "Not specified";
if (product.features && Array.isArray(product.features) && product.features.length > 0) {
featuresString = product.features.slice(0, 5).join(', ');
}
// create a snippet of the original product description for training
const originalDescSnippet = (product.description || "No original description available.").substring(0, 250) + "...";
// create prompt with specific details about the product
const userPrompt = `Generate a product description for the following item. Title: ${title}. Brand: ${brand}. Key Features: ${featuresString}. Original Description Snippet: ${originalDescSnippet}.`;
// create template for the kind of description the AI should generate
let idealDescription = `Discover the ${title} from ${brand}, a top-choice for discerning customers. `;
idealDescription += `Key highlights include: ${featuresString}. `;
if (product.rating) {
idealDescription += `Boasting an impressive customer rating of ${product.rating} out of 5 stars! `;
}
idealDescription += `This product, originally described as "${originalDescSnippet}", is perfect for anyone seeking quality and reliability. `;
idealDescription += `Don't miss out on the ${product.availability === "In Stock" ? "readily available" : "upcoming"} ${title} – enhance your collection today!`;
// create a training example object in the format expected by OpenAI
const trainingExample = {
messages: [
{ role: "system", content: systemMessage },
{ role: "user", content: userPrompt },
{ role: "assistant", content: idealDescription }
]
};
jsonlString += JSON.stringify(trainingExample) + "n";
}
// remove any leading or trailing whitespace
const fileContentString = jsonlString.trim();
// check if any product data was actually processed
if (fileContentString.length === 0) {
console.warn("No product data was processed, outputting empty file content.");
return [{
json: { error: "No products processed", fileNameToUse: "data.jsonl" },
binary: {}
}];
}
// convert the final JSONL string into a Buffer (raw binary data)
const buffer = Buffer.from(fileContentString, 'utf-8');
// define the filename that will be used when this data is sent to OpenAI
const actualFileNameForOpenAI = "data.jsonl";
// define the MIME type for the file
const mimeType = 'application/jsonl';
// prepare the binary data for output
const binaryData = await this.helpers.prepareBinaryData(buffer, actualFileNameForOpenAI, mimeType);
// return the processed data
return [{
json: {
processedFileName: actualFileNameForOpenAI
},
binary: {
// the "Input Data Field Name" in the OpenAI node
"data.jsonl": binaryData
}
}];Die Eingabe dieses Knotens ist die JSON-Datei mit den gescrapten Daten von Bright Data. Der OpenAI-Knoten benötigt jedoch eine JSONL-Datei. Dieser JavaScript-Code wandelt die JSON-Datei wie folgt in eine JSONL-Datei um:
- Mit der Methode
$input.all()werden alle Daten aus dem vorherigen Knoten abgerufen. - Es iteriert und verarbeitet Produkte. Insbesondere wird für jeden Produktposten:
- Extrahiert Produktdetails wie
Titel,Marke,Merkmale,Beschreibung,BewertungundVerfügbarkeit. Es enthält Fallback-Werte, wenn bestimmte Daten nicht vorhanden sind. - Konstruiert ein
userPromptdurch Formatierung dieser Details in eine Anfrage an den LLM zur Erstellung der Produktbeschreibung. - Erzeugt eine
idealDescriptionanhand einer Vorlage, die die Attribute des Produkts enthält. Diese dient als die gewünschte “Assistenten”-Antwort in den Trainingsdaten. - Kombiniert eine Systemnachricht, das
userPromptund dieidealDescriptionzu einem einzigentrainingExample-Objekt, formatiert für konversationelles LLM-Training. - Serialisiert dieses
trainingExamplein eine JSON-Zeichenfolge und hängt es an eine wachsende Zeichenfolge an, wobei jedes JSON-Objekt in einer neuen Zeile steht (JSONL-Format).
- Extrahiert Produktdetails wie
- Nach der Verarbeitung aller Elemente wird die gesammelte JSONL-Zeichenkette in einen
Puffermit Binärdaten umgewandelt. - Sie gibt die Datei
data.jsonlzurück.
Wenn Sie im Knoten “Code” auf “Schritt ausführen” klicken, wird die JSONL im Ausgabebereich verfügbar sein:
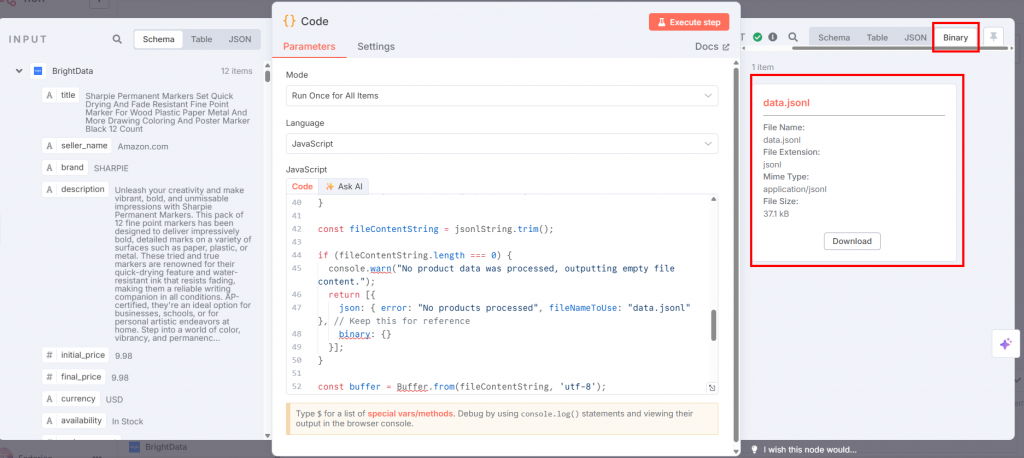
Im Folgenden sehen Sie, wie Ihr Arbeitsablauf bisher aussah:
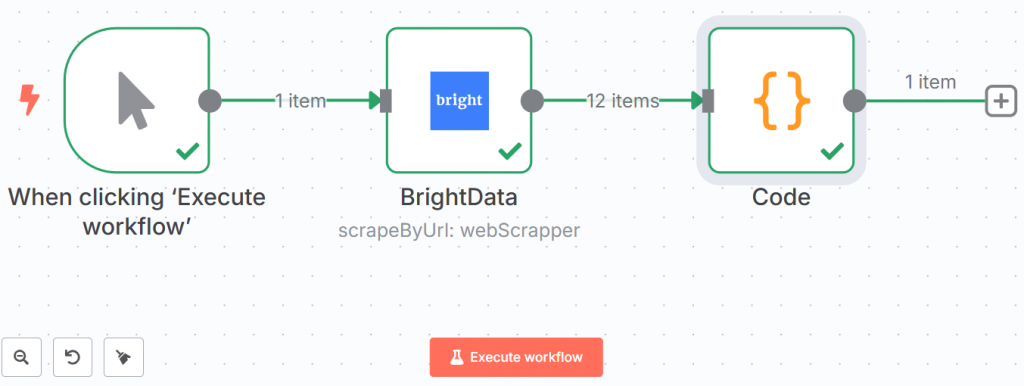
Die grünen Linien und Häkchen zeigen, dass jeder Schritt erfolgreich abgeschlossen wurde.
Hurra! Sie haben die Daten mit Bright Data abgerufen und sie im JSONL-Format gespeichert. Jetzt können Sie die Daten in den LLM übertragen.
Schritt 4: Schieben Sie die Feinabstimmungsdaten in den OpenAI-Chat-Knoten
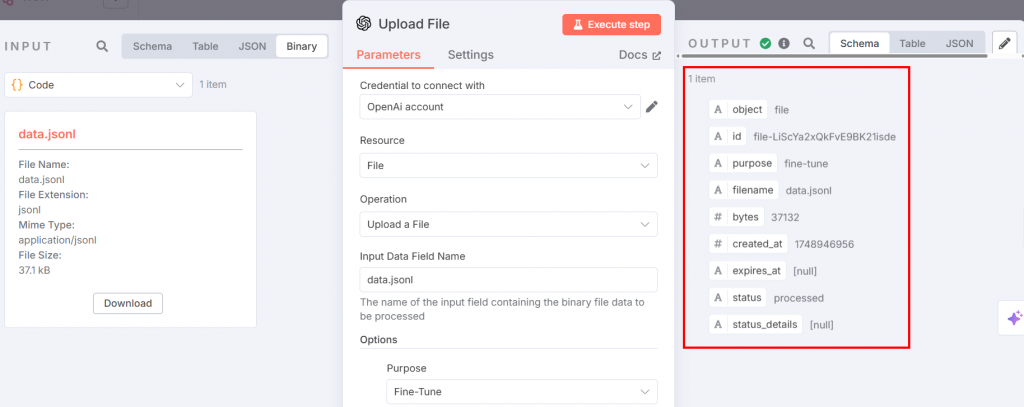
Die JSONL-Datei für die Feinabstimmung kann nun zur Feinabstimmung auf die OpenAI-Plattform hochgeladen werden. Fügen Sie dazu einen OpenAI-Knoten hinzu. Wählen Sie im Abschnitt “Datei-Aktionen” die Option “Eine Datei hochladen”:

Nachfolgend finden Sie die Einstellungen, die Sie vornehmen müssen:

Der obige Knoten gibt den Input für den Feinabstimmungsprozess. Stellen Sie die Parameter wie folgt ein:
- “Zugangsdaten für die Verbindung”: Fügen Sie Ihr OpenAI API-Token hinzu. Sobald Sie es festgelegt haben, werden die Anmeldeinformationen gespeichert.
- “Ressource”: Wählen Sie “Datei”. Dies liegt daran, dass Sie eine JSONL-Datei auf die Plattform hochladen werden.
- “Vorgang”: Wählen Sie “Eine Datei hochladen”.
- “Name des Feldes der Eingabedaten”: Der Name der Feinabstimmungsdatei lautet
data.jsonl. - Fügen Sie im Abschnitt “Optionen” “Zweck” hinzu und wählen Sie “Feinabstimmung”.
Nach Ausführung des Schrittes sieht die Ausgabe wie folgt aus:
Ihr Arbeitsablauf wird nun folgendermaßen aussehen:
Erstaunlich! Sie haben alles für den Feinabstimmungsprozess vorbereitet. Zeit, den eigentlichen Prozess zu durchlaufen.
Schritt #5: Feinabstimmung des LLM
Um die eigentliche Feinabstimmung vorzunehmen, verbinden Sie einen HTTP-Request-Knoten mit dem OpenAI-Knoten:

Die Einstellungen müssen wie folgt sein:
- Die “Methode” muss “POST” sein, da Sie die Trainingsdatendatei hochladen.
- Das Feld “URL” muss
https://api.openai.com/v1/fine_tuning/jobsendpoint lauten. Dies ist die Standard-URL für Feinabstimmungsaufträge auf der OpenAI-Plattform. - Wählen Sie für das Feld “Authentifizierung” die Option “Vordefinierter Berechtigungstyp”, damit Ihr OpenAI-API-Token verwendet wird.
- Wählen Sie für den “Credential Type” “OpenAi”, damit der Knoten eine Verbindung zu OpenAI herstellt.
- Wählen Sie im Feld “OpenAI” den Namen Ihres OpenAI-Kontos.
- Das Kontrollkästchen “Body senden” muss aktiviert sein. Wählen Sie “JSON” bzw. “JSON verwenden” für die Felder “Body Content Type” und “Specify Body”.
Das JSON-Feld muss Folgendes enthalten:
{
"training_file": "{{ $json.id }}",
"model": "gpt-4o-mini-2024-07-18"
} Dieses JSON:
- Gibt den Namen der Trainingsdaten mit
$json.idan. - Legt das für die Feinabstimmung zu verwendende Modell fest. In diesem Fall verwenden Sie GPT-4o-mini gemäß der am 2024-07-18 veröffentlichten Version.
Nachfolgend sehen Sie die Ausgabe, die Sie erhalten werden:
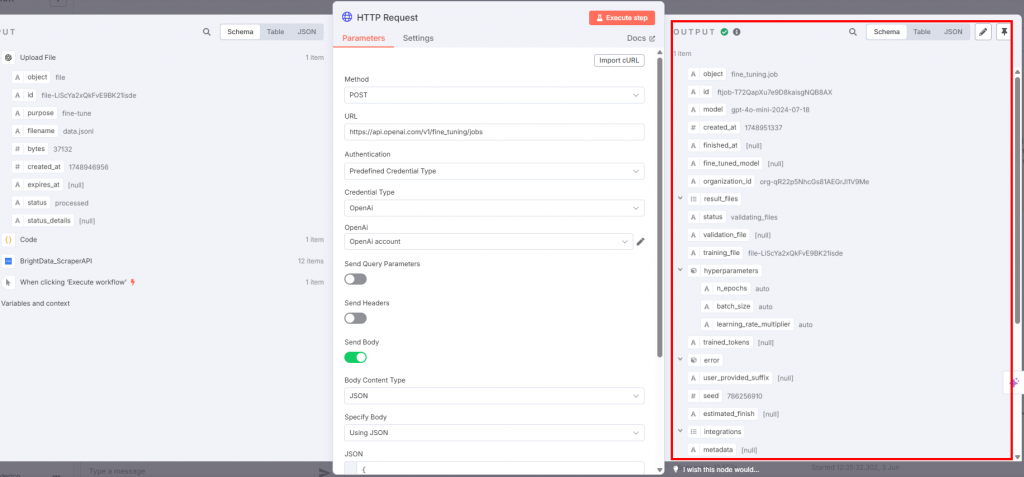
Wenn der HTTP-Anfrageknoten ausgelöst wird, beginnt der Feinabstimmungsprozess. Sie können seine Fortschritte im Feinabstimmungsabschnitt der OpenAI-Plattform sehen. Wenn der Feinabstimmungsprozess erfolgreich abgeschlossen ist, stellt OpenAI Ihnen das feinabgestimmte Modell zur Verfügung, das Sie in Schritt 7 verwenden werden:

Der Arbeitsablauf des n8n sollte nun wie folgt aussehen:

Herzlichen Glückwunsch! Sie haben Ihr erstes GPT-Modell mit Daten trainiert, die Sie mit der Scraper-API von Bright Data über n8n abgerufen haben.
Dies ist der letzte Knotenpunkt der ersten Hälfte des gesamten Arbeitsablaufs.
Schritt #6: Hinzufügen des Chat-Knotens
Die zweite Hälfte des gesamten Workflows muss mit einem Chat-Trigger-Knoten beginnen. Dort fügen Sie die Eingabeaufforderung zum Testen des fein abgestimmten LLM ein:

Nachfolgend finden Sie die Aufforderung, die Sie in den Chat einfügen können:
You are an expert marketing assistant specializing in writing compelling and informative product descriptions. Generate a product description for the following office item:
Title: ErgoComfort Pro Executive Chair.
Brand: OfficeSolutions.
Key Features: Adjustable lumbar support, Breathable mesh back, Memory foam seat cushion, 360-degree swivel, Smooth-rolling casters.Wie Sie sehen können, ist diese Aufforderung:
- Berichtet über den gleichen Satz, der in der Ausbildungsphase verwendet wurde, um ein fachkundiger Marketingassistent zu sein.
- Erfordert die Erstellung einer Produktbeschreibung anhand der Informationen über den benötigten Büroartikel, die durch definiert sind:
- Der Titel.
- Die Marke.
- Hauptmerkmale des Büroprodukts.
Es ist wichtig, dass die Struktur des Prompts so ist. Der Grund dafür ist, dass das Modell in dieser Phase die Trainingsdaten nachahmt. Sie müssen ihm also eine Aufforderung und Daten geben, die denen aus der Trainingsphase ähnlich sind. Dann wird das fein abgestimmte LLM die Produktbeschreibung auf der Grundlage dieser Faktoren verfassen.
Sie können die Eingabeaufforderung in den Chat-Bereich am unteren Rand der Benutzeroberfläche einfügen:
Dies ist Ihr aktueller n8n-Workflow:
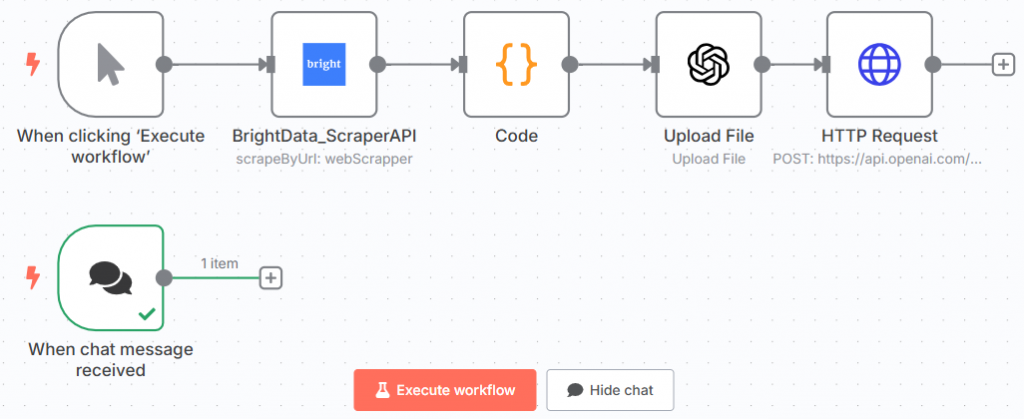
Großartig! Sie haben die Aufforderung zum Testen des Feinabstimmungsmodells definiert.
Schritt #7: Hinzufügen des KI-Agenten und der OpenAI-Chat-Knoten
Sie müssen nun einen KI-Agenten-Knoten mit dem Chat-Trigger verbinden:

Die Einstellungen müssen sein:
- “Agent”: Wählen Sie “Konversationsagent”. Damit können Sie über den Knoten “Chatauslöser” alles ändern, was Sie wollen, wie bei jedem anderen Gesprächsagenten.
- Legen Sie als “Quelle der Eingabeaufforderung (Benutzernachricht)” den “Verbundenen Chat-Trigger-Knoten” fest, damit er die Eingabeaufforderung direkt aus dem Chat übernehmen kann.
Verbinden Sie einen OpenAI-Chat-Modell-Knoten mit dem AI-Agenten über dessen Verbindungsoption “Chat-Modell”:

Das Bild unten zeigt die Einstellungen des OpenAI Chat Model Knotens:

Konfigurieren Sie den Knoten wie folgt:
- “Zugangsdaten zum Verbinden mit”: Wählen Sie Ihre gespeicherten OpenAI-Anmeldeinformationen.
- “Modell”: Fügen Sie das fein abgestimmte Ausgangsmodell aus dem Feinabstimmungsbereich der OpenAI-Plattform ein.
Kehren Sie zum Knoten AI Agent zurück und klicken Sie auf die Schaltfläche “Schritt ausführen”. Sie sehen die resultierende Beschreibung des Produkts:
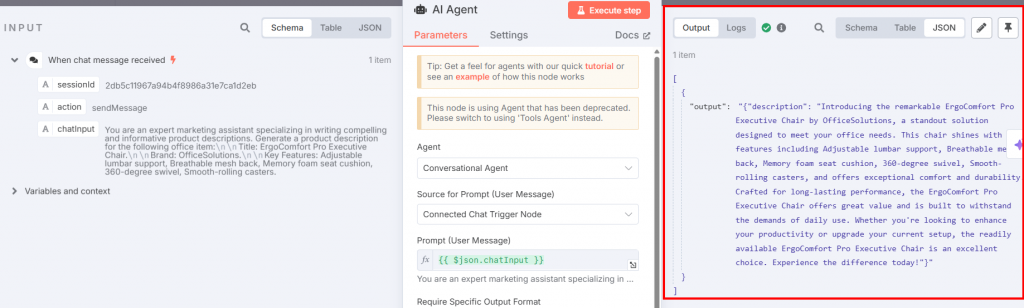
Nachfolgend finden Sie die resultierende Beschreibung im Klartext:
Introducing the remarkable ErgoComfort Pro Executive Chair by OfficeSolutions, a standout solution designed to meet your office needs. This chair shines with key features including Adjustable lumbar support, Breathable mesh back, Memory foam seat cushion, 360-degree swivel, Smooth-rolling casters, and offers exceptional comfort and durability. Crafted for long-lasting performance, the ErgoComfort Pro Executive Chair offers great value and is built to withstand the demands of daily use. Whether you're looking to enhance your productivity or upgrade your current setup, the readily available ErgoComfort Pro Executive Chair is an excellent choice. Experience the difference today!Wie Sie sehen können, nutzt die Beschreibung den Namen des Objekts (“ErgoComfort Pro Executive Chair”), seine Marke (“OfficeSolutions”) und alle seine Merkmale, um die Produktbeschreibung zu erstellen. Insbesondere listet die Beschreibung nicht nur die Eingabedaten auf, sondern nutzt sie, um eine ansprechende Beschreibung zu erstellen. Die letzten Sätze sind der Schlüssel:
- “Der ErgoComfort Pro Executive Chair ist für eine lange Lebensdauer ausgelegt, bietet ein gutes Preis-Leistungs-Verhältnis und ist für die Anforderungen des täglichen Gebrauchs ausgelegt.”
- “Egal, ob Sie Ihre Produktivität steigern oder Ihre derzeitige Einrichtung aufrüsten möchten, der sofort verfügbare ErgoComfort Pro Executive Chair ist eine ausgezeichnete Wahl. Erleben Sie den Unterschied noch heute!”
Et voilà! Sie haben Ihr fein abgestimmtes GPT-4o-mini-Modell getestet, das eine Produktbeschreibung als Antwort auf die vorgegebene Aufforderung (definiert in Schritt #6) erstellt hat.
Schritt #8: Alles zusammenfügen
Der endgültige Arbeitsablauf der GTP-4o n8n-Feinabstimmung sieht nun wie folgt aus:

Wenn Sie nun auf “Workflow ausführen” klicken, wird der Workflow erneut von Anfang an ausgeführt. Beachten Sie jedoch, dass die Ergebnisse bei jedem Schritt gespeichert werden. Wenn Sie also verschiedene Aufforderungen ausprobieren möchten, um das fein abgestimmte Modell zu testen, brauchen Sie diese nur in den Knoten “Chat-Auslöser” zu schreiben und diesen Knoten sowie den KI-Agenten-Knoten auszuführen.
Vergleich von Feinabstimmungsansätzen: Cloud-Infrastruktur vs. Workflow-Automatisierung
Dieser Leitfaden wurde aus zwei Gründen erstellt:
- Wir zeigen Ihnen, wie Sie ein LLM mithilfe eines Tools zur Automatisierung von Arbeitsabläufen wie n8n feinabstimmen können.
- Vergleichen Sie diese Art der Feinabstimmung von LLMs mit der in unserem Artikel “Feinabstimmung von Llama 4 mit frischen Webdaten für bessere Ergebnisse” verwendeten Methode
Zeit für einen Vergleich der beiden Ansätze!
Vergleich der Feinsteuerungsmethoden
Der Ansatz, den wir in unserem vorherigen Artikel zur Feinabstimmung von Llama 4 verfolgt haben, erfordert:
- Die Nutzung einer Cloud-Infrastruktur, deren Einrichtung Zeit und Kosten verursacht.
- Schreiben von Code zum Abrufen der Daten mithilfe der Scraper-APIs von Bright Data.
- Einrichten von Hugging Face.
- Die Notwendigkeit, ein Notizbuch mit dem Python-Code für die Feinabstimmung zu entwickeln, was Zeit und technische Fähigkeiten erfordert.
Sie können die erforderlichen technischen Fähigkeiten nicht abschätzen. Sie können jedoch die gesamte Zeit, die für die Einrichtung der gesamten Infrastruktur benötigt wird, und die Kosten abschätzen:
- Zeit: etwa ein ganzer Arbeitstag.
- Geld: $25. Nachdem Sie $25 für den Cloud-Service bezahlt haben, wird der Verbrauch pro Stunde berechnet. Gleichzeitig müssen Sie vor dem Start 25 $ bezahlen. Das ist also der Mindestpreis für die Nutzung der Cloud.
Die Vorgehensweise, die Sie in diesem Leitfaden gelernt haben, erfordert:
- n8n, das kostenlos ist und keine großen technischen Kenntnisse erfordert.
- Ein OpenAI API-Token für den Zugriff auf GPT-4o oder andere Modelle.
- Grundlegende Programmierkenntnisse, insbesondere zum Schreiben eines JavaScript-Snippets für den Code-Knoten.
In diesem Fall sind die technischen Fähigkeiten viel geringer. Das JavaScript-Snippet kann leicht von jedem LLM erstellt werden – wenn Sie es nicht selbst schreiben können. Abgesehen davon müssen Sie im gesamten Arbeitsablauf keine weiteren Codeschnipsel schreiben.
In diesem Fall können Sie die für die Einrichtung der Infrastruktur benötigte Zeit und die benötigten Mittel wie folgt schätzen:
- Zeit: etwa ein halber Arbeitstag.
- Geld: $10 für ein OpenAI API-Token. Auch in diesem Fall zahlen Sie für jede API-Anfrage. Dennoch können Sie mit nur $10 beginnen. Eine n8n-Lizenz kostet derzeit $25/Monat für den Basisplan oder völlig kostenlos, wenn Sie die selbst gehostete Version verwenden. Für den Anfang brauchen Sie also etwa 10 $.
Welchen Ansatz sollten Sie wählen?
| Aspekt | Cloud-Infrastruktur-Ansatz | Ansatz zur Workflow-Automatisierung |
|---|---|---|
| Technische Fähigkeiten | Hoch (erfordert Programmierkenntnisse in Python, Cloud und Datenabfrage) | Niedrig (grundlegendes JavaScript) |
| Zeit zum Einrichten | Etwa ein voller Arbeitstag | Etwa ein halber Arbeitstag |
| Anfängliche Kosten | ~25$ Minimum für Cloud-Service + stündliche Gebühren | ~$10 für OpenAI API Token + $24/Monat für n8n Lizenz oder kostenlos selbst gehostet |
| Flexibilität | Hoch (geeignet für erweiterte Anpassungen und verschiedene Anwendungsfälle) | Moderat (gut für die Automatisierung von Arbeitsabläufen und die Anpassung mit wenig Code) |
| Am besten für | Teams mit hohen technischen Fähigkeiten, die eine leistungsstarke, flexible Infrastruktur benötigen | Teams, die eine schnelle Einrichtung wünschen oder nur über begrenzte Programmierkenntnisse verfügen |
| Zusätzliche Vorteile | Volle Kontrolle über die Feinabstimmung von Umgebung und Prozess | Vorgefertigte Vorlagen, niedrige Einstiegshürde, Integration in andere Arbeitsabläufe |
Beide Ansätze erfordern eine ähnliche Anfangsinvestition, sowohl auf der Seite der Zeit als auch des Geldes. Wie entscheiden Sie sich also für die eine oder andere Variante? Hier sind einige Leitlinien:
- n8n: Wählen Sie n8n – oder ein ähnliches Tool zur Automatisierung von Arbeitsabläufen – für die Feinabstimmung von LLMs, wenn Sie andere Arbeitsabläufe automatisieren müssen und wenn Ihr Team technisch nicht sehr versiert ist. Dieser Low-Code-Ansatz hilft Ihnen bei der Automatisierung aller anderen Arbeitsabläufe. Sie müssen nur dann Code schreiben, wenn Sie Anpassungen benötigen. Außerdem bietet es vorgefertigte Vorlagen, die Sie kostenlos verwenden können, was die Einstiegshürde für die Nutzung des Tools senkt.
- Cloud-Dienste: Wählen Sie einen Cloud-Dienst für die Feinabstimmung von LLMs, wenn Sie ihn für mehrere Zwecke benötigen und über ein hochqualifiziertes Team verfügen. Die Einrichtung der Cloud-Umgebung und die Entwicklung des Feinabstimmungs-Notebooks erfordern fortgeschrittene technische Kenntnisse.
Das Herzstück des Feinabstimmungsprozesses: Qualitativ hochwertige Daten
Ganz gleich, für welchen Ansatz Sie sich entscheiden, Bright Data bleibt in beiden Fällen der wichtigste Vermittler. Der Grund dafür ist einfach: Hochwertige Daten sind die Grundlage für den Feinabstimmungsprozess!
Bright Data bietet Ihnen eine KI-Infrastruktur für Daten, die eine Reihe von Services und Lösungen zur Unterstützung Ihrer KI-Anwendungen bereitstellt:
- MCP-Server: Ein quelloffener Node.js-MCP-Server, der über 20 Tools für die Datenabfrage in KI-Agenten bereitstellt.
- Web Scraper APIs: Vorkonfigurierte APIs zum Extrahieren strukturierter Daten aus über 100 wichtigen Domains.
- Web Unlocker: Eine All-in-One-API, die die Freischaltung von Websites mit Anti-Bot-Schutz ermöglicht.
- SERP-API: Eine spezielle API, die Suchmaschinenergebnisse freischaltet und vollständige SERP-Daten extrahiert.
- Grundlegende Modelle: Greifen Sie auf konforme, webbasierte Datensätze zu, um LLM Pre-Training, Evaluierung und Feinabstimmung zu unterstützen.
- Datenanbieter: Verbinden Sie sich mit vertrauenswürdigen Anbietern, um hochwertige, KI-fähige Datensätze in großem Umfang zu beziehen.
- Datenpakete: Erhalten Sie kuratierte, gebrauchsfertige Datensätze – strukturiert, angereichert und mit Anmerkungen versehen.
Während Sie in dieser Anleitung gelernt haben, wie Sie GPT-4o-mini mit Hilfe der Web Scraper APIs feinabstimmen können, können Sie auch einen anderen Ansatz wählen und einen unserer Dienste nutzen.
Schlussfolgerung
In diesem Artikel haben Sie gelernt, wie Sie GPT-4o-mini mit von Amazon gescrapten Daten feinabstimmen können, indem Sie n8n verwenden, um den gesamten Arbeitsablauf zu automatisieren. Sie haben den gesamten Prozess durchlaufen, der aus zwei Zweigen besteht:
- Führt die Feinabstimmung nach dem Scannen der Daten durch.
- Testet das fein abgestimmte Modell, indem er die Eingabeaufforderung über einen Chat-Auslöser einfügt.
Sie haben auch einen Vergleich zwischen diesem Ansatz, bei dem ein Tool zur Workflow-Automatisierung zum Einsatz kommt, und einem anderen, der einen Cloud-Service nutzt, angestellt.
Unabhängig davon, welcher Ansatz am besten zu Ihren Bedürfnissen und Ihrem Team passt, sollten Sie nicht vergessen, dass qualitativ hochwertige Daten das Herzstück des Prozesses bleiben. In dieser Hinsicht bietet Bright Data mehrere Datenservices für KI an.
Erstellen Sie ein kostenloses Bright Data-Konto und testen Sie unsere KI-fähige Dateninfrastruktur!






