

In diesem Leitfaden zur Feinabstimmung von Llama 4 mit Webdaten erfahren Sie:
- Was Feinabstimmung ist
- Wie Sie die für die Feinabstimmung geeigneten Datensätze mithilfe einiger Scraping-APIs abrufen können
- Wie Sie die Cloud-Infrastruktur für den Feinabstimmungsprozess einrichten
- Wie Sie Llama 4 mit einer Schritt-für-Schritt-Anleitung feinabstimmen
Lassen Sie uns loslegen!
Was ist Feinabstimmung?
Fine-Tuning – auch als überwachtes Fine-Tuning (SFT)bekannt – ist ein Prozess, mit dem bestimmte Kenntnisse oder Fähigkeiten in einem vortrainierten LLM verbessert werden. Im Zusammenhang mit LLMs bezieht sich Vortraining auf das Training eines KI-Modells von Grund auf.
SFT wird verwendet, weil ein Modell seine Trainingsdaten nachahmt. Derzeit sind LLMs jedoch hauptsächlich generalistische Modelle. Das bedeutet, dass Sie ein Modell feinabstimmen müssen, wenn Sie möchten, dass es bestimmte Kenntnisse erlernt.
Wenn Sie mehr über SFT erfahren möchten, lesen Sie unseren Leitfaden zum überwachten Fine-Tuning in LLMs.
Scraping der Daten zur Feinabstimmung von LLama 4
Um ein LLM feinabzustimmen, benötigen Sie zunächst einen Feinabstimmungs-Datensatz. In diesem Abschnitt erfahren Sie, wie Sie mit den Web Scraper-APIsvon Bright Data Daten von einer Website abrufen können – dedizierte Endpunkte für über 100 Domains, die aktuelle Daten für Sie scrapen und im gewünschten Format abrufen.
Die Zielwebseite ist die Amazon-Bestsellerliste für Büroprodukte:
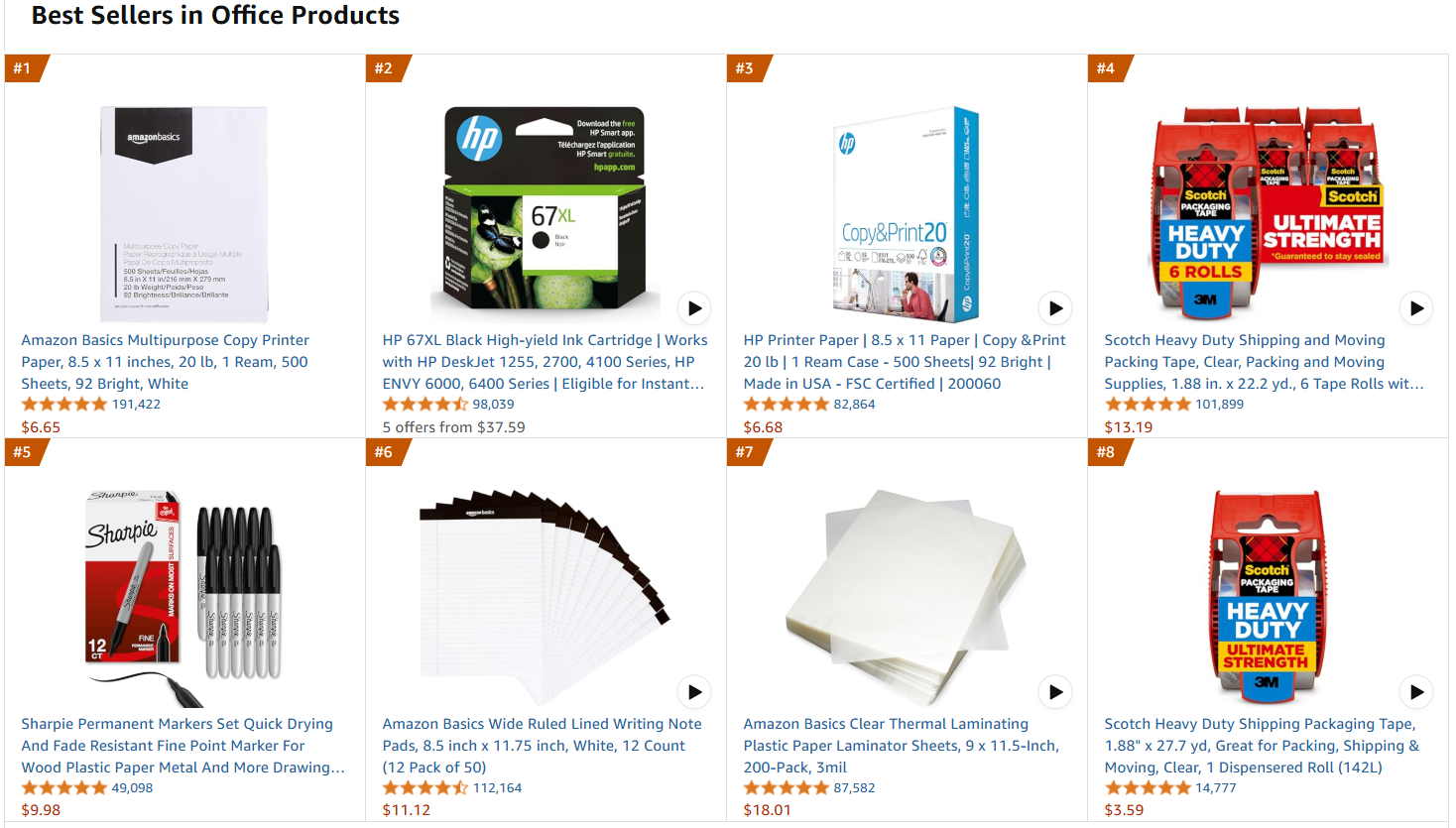
Befolgen Sie die folgenden Schritte, um die Feinabstimmungsdaten abzurufen!
Anforderungen
Um den Code zum Abrufen der Daten von Amazon zu verwenden, benötigen Sie:
- Python 3.10+ auf Ihrem Computer installiert.
- Einen gültigen Bright Data Scraper API-Schlüssel.
Befolgen Sie die Bright Data-Dokumentation, um Ihren API-Schlüssel abzurufen.
Projektstruktur und Abhängigkeiten
Angenommen, Sie nennen den Hauptordner Ihres Projekts amazon_scraper/. Am Ende dieses Schritts hat der Ordner die folgende Struktur:
amazon_scraper/
├── scraper.py
└── venv/Dabei gilt:
scraper.pydie Python-Datei ist, die die Codierungslogik enthält.venv/enthält die virtuelle Umgebung.
Sie können das Verzeichnis der virtuellen Umgebung venv/ wie folgt erstellen:
python -m venv venvUm sie zu aktivieren, führen Sie unter Windows Folgendes aus:
venvScriptsactivateEntsprechend führen Sie unter macOS und Linux Folgendes aus:
source venv/bin/activateInstallieren Sie in der aktivierten virtuellen Umgebung die Abhängigkeiten mit:
pip install requestsDabei handelt es sich bei requests um eine Bibliothek zum Erstellen von HTTP-Webanfragen.
Großartig! Sie sind nun bereit, die gewünschten Daten mithilfe der Scraper-APIs von Bright Data abzurufen.
Schritt 1: Definieren Sie die Scraping-Logik
Der folgende Ausschnitt definiert die gesamte Scraping-Logik:
import requests
import json
import time
def trigger_amazon_products_scraping(api_key, urls):
# Endpunkt zum Auslösen der Web Scraper API-Aufgabe
url = "https://api.brightdata.com/datensätze/v3/trigger"
params = {
"dataset_id": "gd_l7q7dkf244hwjntr0",
"include_errors": "true",
"type": "discover_new",
"discover_by": "best_sellers_url",
}
# Konvertieren Sie die Eingabedaten in das gewünschte Format, um die API aufzurufen.
data = [{"category_url": url} for url in urls]
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
response = requests.post(url, headers=headers, params=params, json=data)
if response.status_code == 200:
snapshot_id = response.json()["snapshot_id"]
print(f"Anfrage erfolgreich! Antwort: {snapshot_id}")
return response.json()["snapshot_id"]
else:
print(f"Anfrage fehlgeschlagen! Fehler: {response.status_code}")
print(response.text)
def poll_and_retrieve_snapshot(api_key, snapshot_id, output_file, polling_timeout=20):
snapshot_url = f"https://api.brightdata.com/Datensätze/v3/snapshot/{snapshot_id}?format=json"
headers = {
"Authorization": f"Bearer {api_key}"
}
print(f"Abfrage des Snapshots für ID: {snapshot_id}...")
while True:
response = requests.get(snapshot_url, headers=headers)
if response.status_code == 200:
print("Snapshot ist bereit. Herunterladen...")
snapshot_data = response.json()
# Snapshot in eine JSON-Ausgabedatei schreiben
with open(output_file, "w", encoding="utf-8") as file:
json.dump(snapshot_data, file, indent=4)
print(f"Snapshot in {output_file} gespeichert")
return
elif response.status_code == 202:
print(F"Snapshot ist noch nicht fertig. Wiederholung in {polling_timeout} Sekunden...")
time.sleep(polling_timeout)
else:
print(f"Anfrage fehlgeschlagen! Fehler: {response.status_code}")
print(response.text)
break
if __name__ == "__main__":
BRIGHT_DATA_API_KEY = "<IHR API-Schlüssel>" # Ersetzen Sie ihn durch Ihren Bright Data Web Scraper API-Schlüssel oder lesen Sie ihn aus den Umgebungsvariablen aus
# URLs der meistverkauften Produkte, von denen Daten abgerufen werden sollen
urls = [
"https://www.amazon.com/gp/bestsellers/office-products/ref=pd_zg_ts_office-products"
]
snapshot_id = trigger_amazon_products_scraping(BRIGHT_DATA_API_KEY, urls)
poll_and_retrieve_snapshot(BRIGHT_DATA_API_KEY, snapshot_id, "amazon-data.json")Dieser Code:
- Erstellt die Funktion
trigger_amazon_products_scraping(), die die Web-Scraping-Aufgabe initiiert, indem sie:- den zu triggernden Scraper-API-Endpunkt definiert.
- Einrichten der Parameter für die Scraping-Aktivität.
- Formatierung der
Eingabe-URLsin eine JSON-Struktur, die die API erwartet. - Senden einer
POST-Anfragean die Bright Data Scraper API mit dem angegebenen Endpunkt, den Headern, Parametern und Daten. - Verwaltung des Antwortstatus.
- Erstellen einer Funktion
poll_and_retrieve_snapshot(), die den Status der Scraping-Aufgabe (identifiziert durchsnapshot_id) überprüft und die Daten abruft, sobald sie bereit sind.
Beachten Sie, dass die Scraping-API nur mit einer einzigen URL aufgerufen wurde. Daher ruft der obige Code die Daten nur von einer einzigen Amazon-Zielseite ab. Für den Umfang dieses Tutorials ist dies ausreichend, aber Sie können beliebig viele Amazon-URLs zur Liste hinzufügen.
Bedenken Sie, dass der Datensatz umso größer wird, je mehr URLs Sie hinzufügen. Ein größerer Datensatz bedeutet – bei guter Kuratierung – eine bessere Feinabstimmung. Andererseits ist die Rechenzeit umso länger, je größer der Datensatz ist.
Perfekt! Ihre Scraping-Logik ist klar definiert und Sie können nun das Skript ausführen.
Schritt 2: Ausführen des Skripts
Um die Zielwebseite zu scrapen, führen Sie das Skript mit folgendem Befehl aus:
python Scraper.pySie erhalten folgendes Ergebnis:
Anfrage erfolgreich! Antwort: s_m9in0ojm4tu1v8h78
Polling-Snapshot für ID: s_m9in0ojm4tu1v8h78...
Snapshot ist noch nicht bereit. Wiederholung in 20 Sekunden...
# ...
Snapshot ist noch nicht bereit. Wiederholung in 20 Sekunden...
Snapshot ist bereit. Herunterladen...
Snapshot gespeichert in amazon-data.jsonAm Ende des Vorgangs enthält der Projektordner:
amazon_scraper/
├── scraper.py
├── amazon-data.json # <-- Beachten Sie den Feinabstimmungsdatensatz.
└── venv/Der Prozess hat automatisch die Datei amazon-data.json erstellt, die die gescrapten Daten enthält. Nachfolgend finden Sie die erwartete Struktur der JSON-Datei:
[
{
"title": "Amazon Basics Multipurpose Copy Printer Paper, 8,5 x 11 Zoll, 20 lb, 1 Ries, 500 Blatt, 92 Bright, White",
"seller_name": "Amazon.com",
"brand": "Amazon Basics",
"description": „Produktbeschreibung Amazon Basics Multifunktionskopierpapier, 8,5 x 11 Zoll, 20 lb Papier – 1 Ries (500 Blatt), 92 GE Bright White Vom Hersteller AmazonBasics”,
„initial_price”: 6,65,
„currency”: „USD”,
„availability”: „Auf Lager”,
„reviews_count”: 190989,
„categories”: [
„Büroartikel”,
„Büro- und Schulbedarf”,
„Papier”,
„Kopier- und Druckerpapier”,
„Kopier- und Mehrzweckpapier”
],
...
// der Kürze halber ausgelassen...
}Sehr gut! Sie haben erfolgreich Daten von Amazon gescrapt und in einer JSON-Datei gespeichert. Diese JSON-Datei ist der Feinabstimmungsdatensatz, den Sie später im Feinabstimmungsprozess verwenden werden.
Einrichten von Hugging Face für die Verwendung von Llama 4
Das Modell, das Sie verwenden werden, ist Llama-4-Scout-17B-16E-Instruct von Hugging Face.
Wenn Sie Hugging Face noch nie zuvor verwendet haben, werden Sie beim ersten Klicken auf den Link aufgefordert, ein Konto zu erstellen:
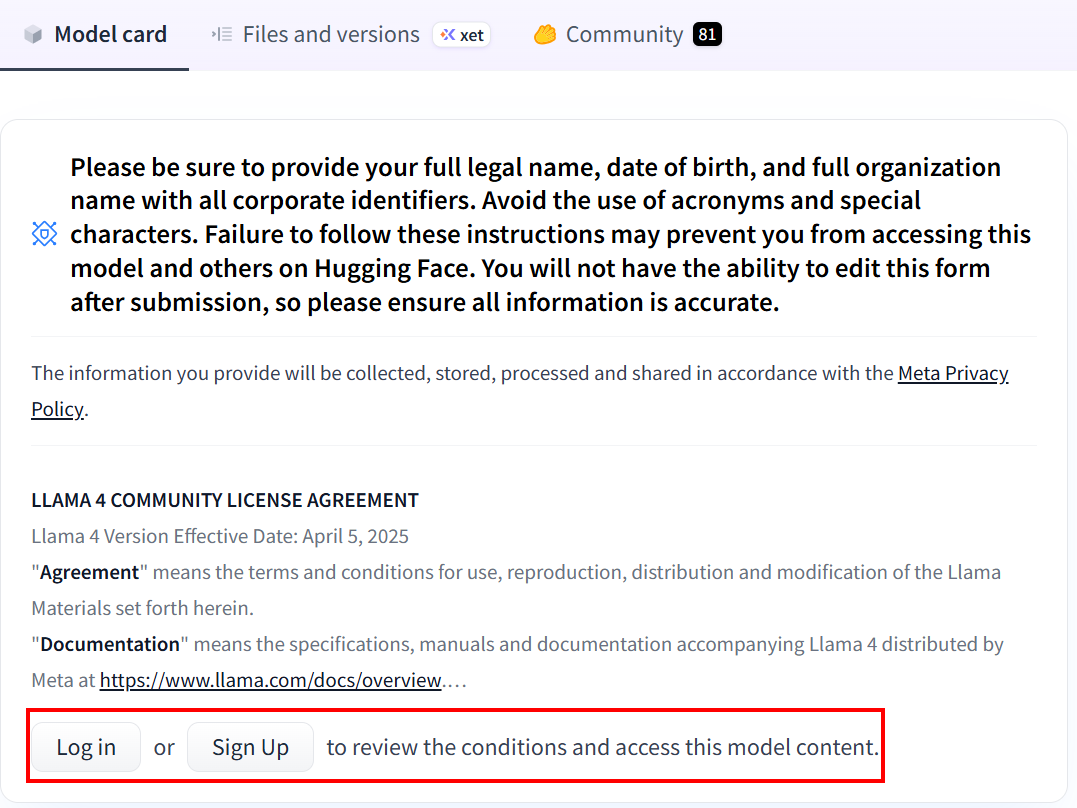
Nachdem Sie das Konto erstellt haben, müssen Sie, wenn Sie noch nie ein Llama 4-Modell verwendet haben, das Einverständnisformular ausfüllen. Klicken Sie auf „Expand to review and access” (Erweitern, um zu überprüfen und darauf zuzugreifen), um das Formular zu lesen und auszufüllen:
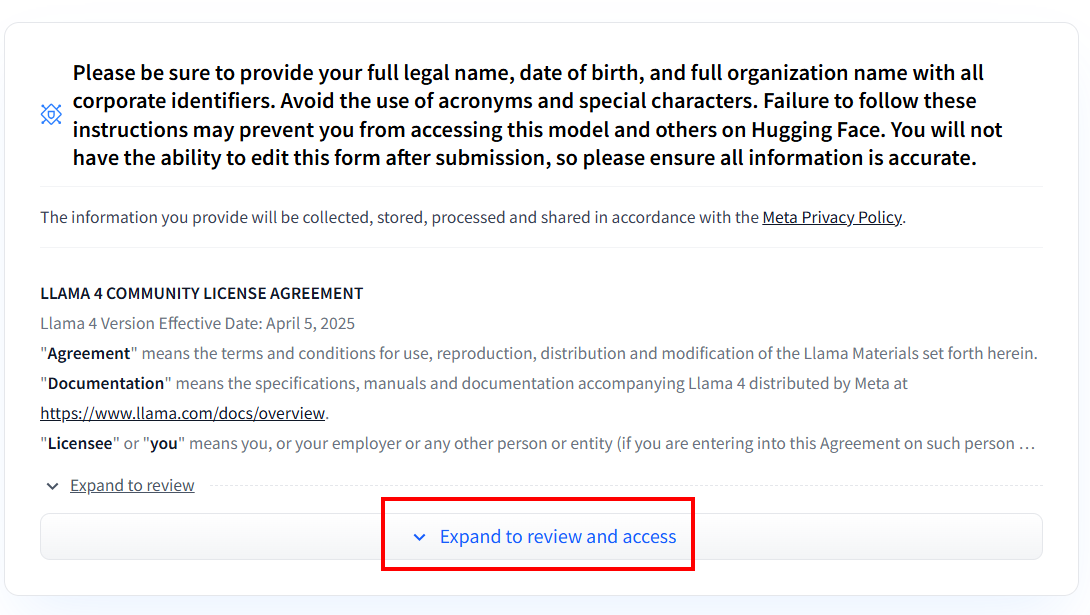
Nachdem Sie das Formular ausgefüllt haben, wird Ihre Anfrage geprüft:
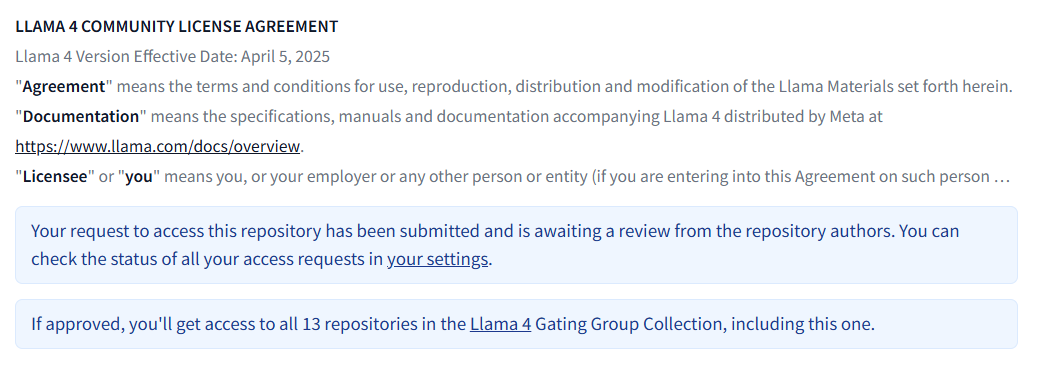
Überprüfen Sie den Status Ihrer Anfrage im Abschnitt„Gated Repositories”:
Sobald Ihre Anfrage angenommen wurde, können Sie ein neues Token erstellen. Gehen Sie zu„Access Tokens“ und erstellen Sie ein Token mit Schreibrechten. Kopieren Sie es anschließend und speichern Sie es an einem sicheren Ort, um es später zu verwenden:
Hurra! Sie haben alle notwendigen Schritte abgeschlossen, um ein Llama 4-Modell mit Hugging Face zu verwenden.
Einrichten der Cloud-Infrastruktur zur Feinabstimmung von Llama 4
Die Llama 4-Modelle sind sehr groß – und ihr Name hilft Ihnen zu verstehen, wie groß sie sind. Llama-4-Scout-17B-16E-Instruct bedeutet beispielsweise, dass es 17 Milliarden Parameter mit 128 Experten hat.
Für den Feinabstimmungsprozess müssen Sie das Modell mit dem zuvor abgerufenen Feinabstimmungsdatensatz trainieren. Da das Modell 17 Milliarden Parameter hat, benötigen Sie dafür eine Menge Hardware. Insbesondere benötigen Sie mehr als eine GPU. Aus diesem Grund verwenden Sie einen Cloud-Dienst, um den Feinabstimmungsprozess durchzuführen.
Für dieses Tutorial verwenden Sie RunPod als Cloud-Dienst. Gehen Sie zu„RunPod“und erstellen Sie ein Konto. Gehen Sie dann zum Menü „Abrechnung“ und fügen Sie mit Ihrer Kreditkarte 25 $ hinzu:
Hinweis: Sie zahlen sofort 25 $ und RunPod schreibt Ihrem Konto ein Guthaben in Höhe von 25 $ gut. Sie verbrauchen stündlich Guthaben, je nachdem, wie viele Stunden Ihr Pod bei der Bereitstellung aktiv ist. Stellen Sie ihn daher nur bereit, wenn Sie sicher sind, dass Sie ihn auch nutzen können. Andernfalls verbrauchen Sie Guthaben, ohne es tatsächlich zu nutzen. Der tatsächliche stündliche Verbrauch hängt von der Art und Anzahl der GPUs ab, die Sie in den nächsten Schritten auswählen.
Navigieren Sie zum Menü „Pods“, um mit der Konfiguration Ihres Pods zu beginnen. Der Pod dient als virtueller Server, der Ihnen die für Ihre Aufgaben erforderlichen CPUs, GPUs, Arbeitsspeicher und Speicherplatz zur Verfügung stellt. Klicken Sie auf die Schaltfläche „Bereitstellen“:
Sie können zwischen verschiedenen Konfigurationen wählen:
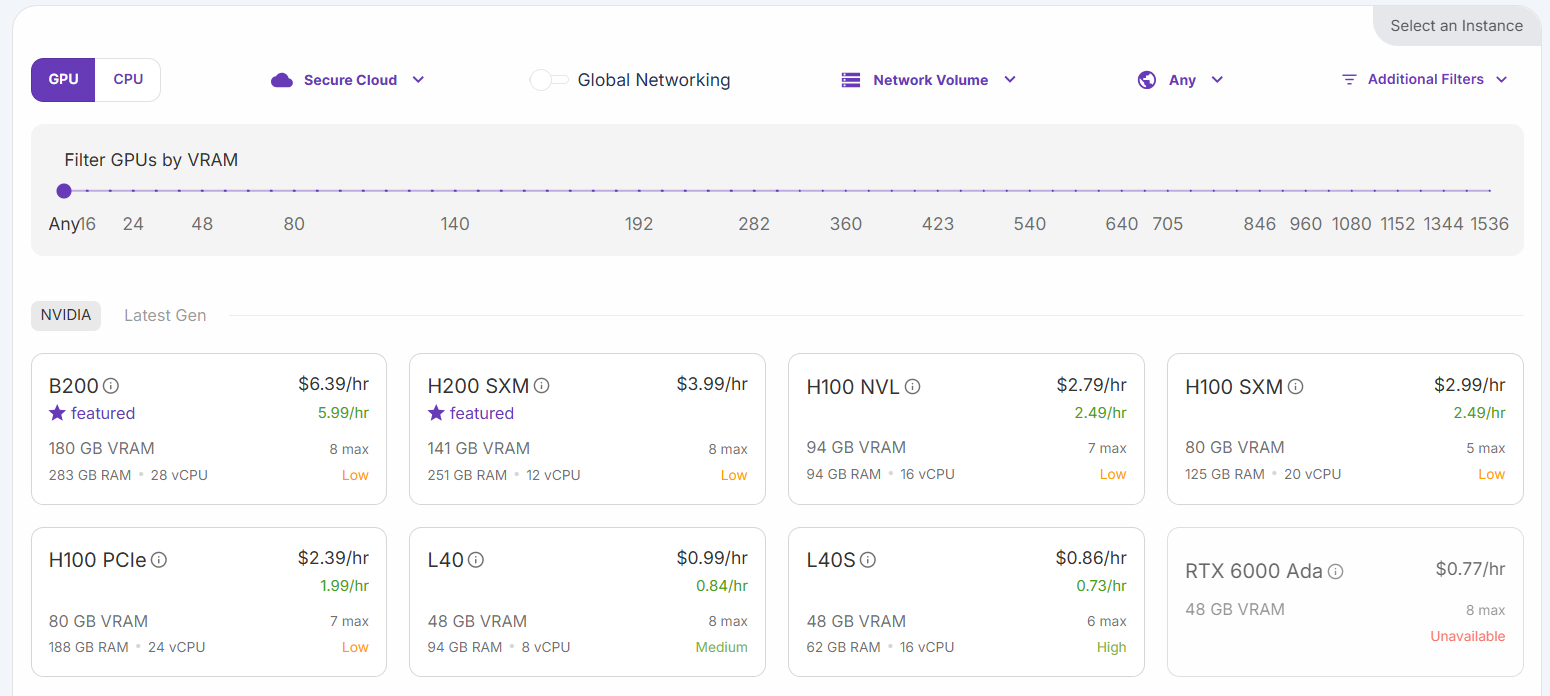
Wählen Sie die Option „H200 SXM GPU“. Geben Sie dem Pod einen Namen und wählen Sie die Anzahl der GPUs. Für dieses Tutorial sind 3 GPUs ausreichend:
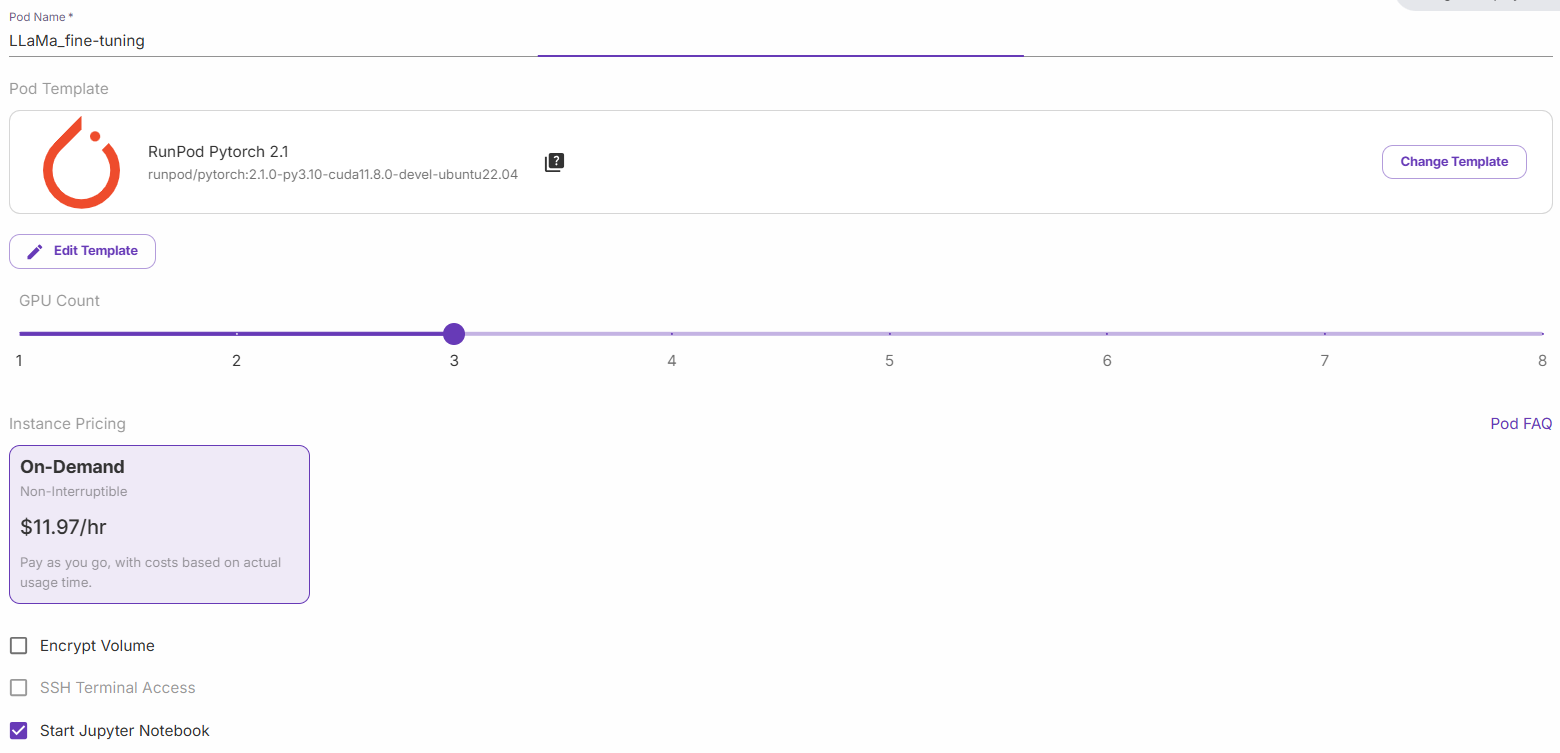
Wählen Sie „Start a Jupyter Notebook“ und klicken Sie auf „Deploy on Demand“. Gehen Sie nun zum Abschnitt „Pods“ und bearbeiten Sie Ihren Pod:
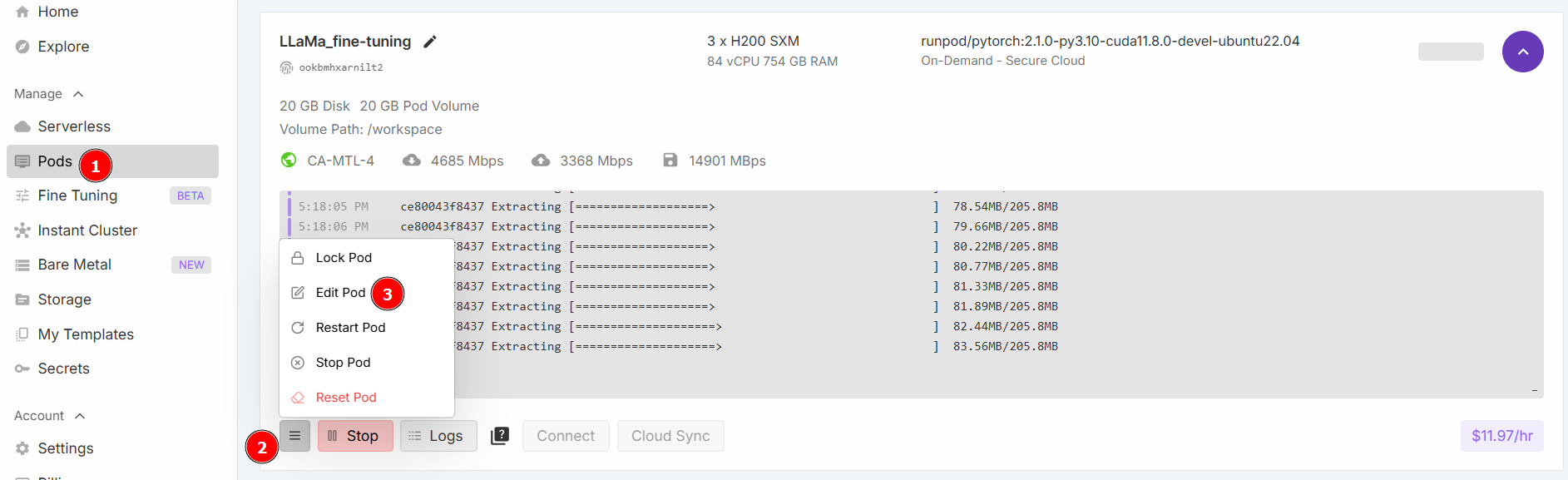
Ändern Sie die Werte für „Contained Disk“ und „Volume Disk“ wie unten angegeben und speichern Sie dann:
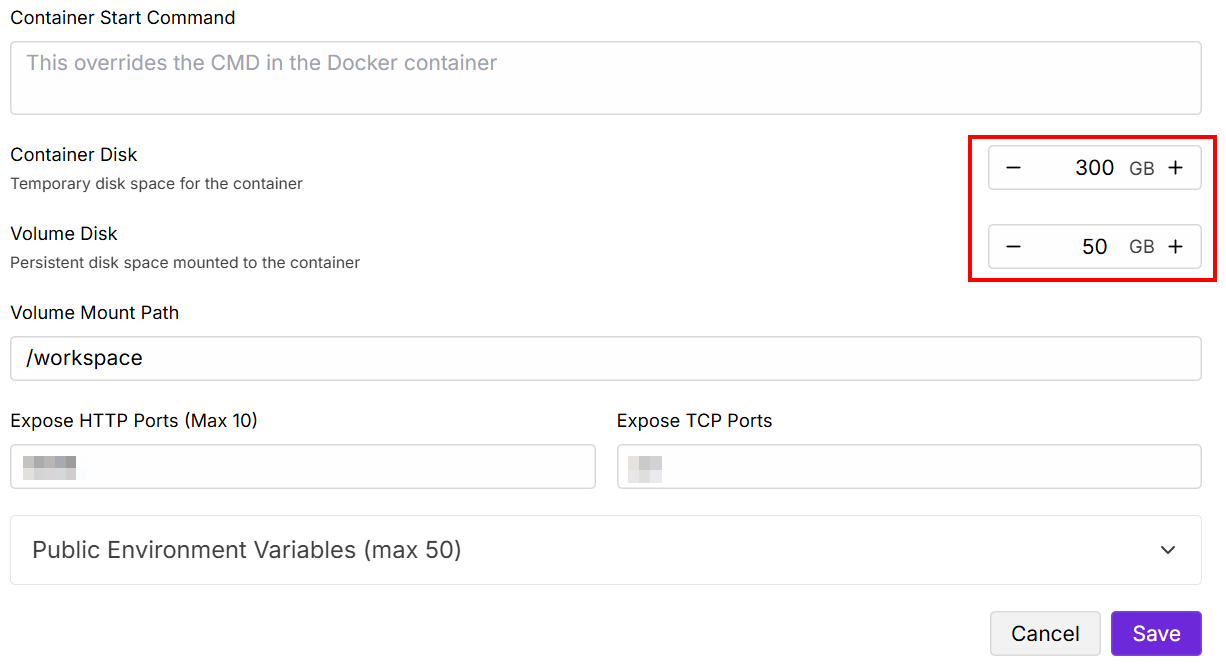
Wenn die Einrichtung abgeschlossen ist, klicken Sie auf die Schaltfläche „Verbinden“:
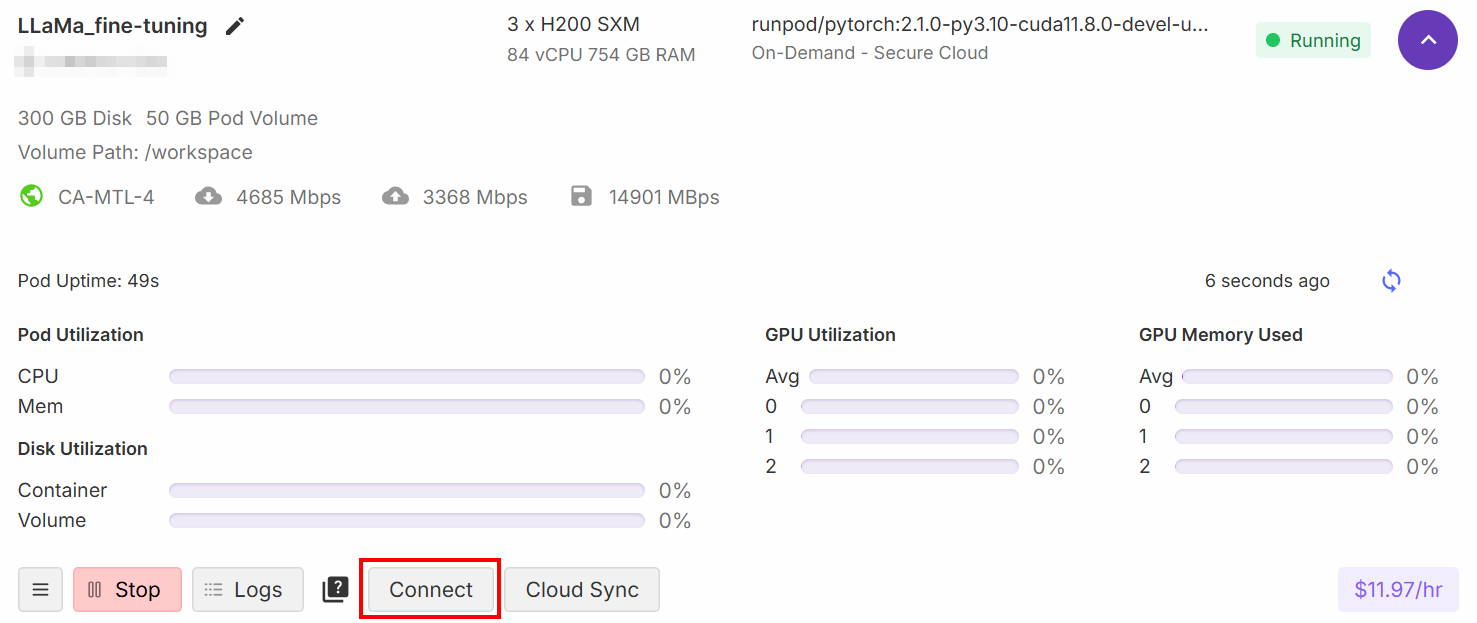
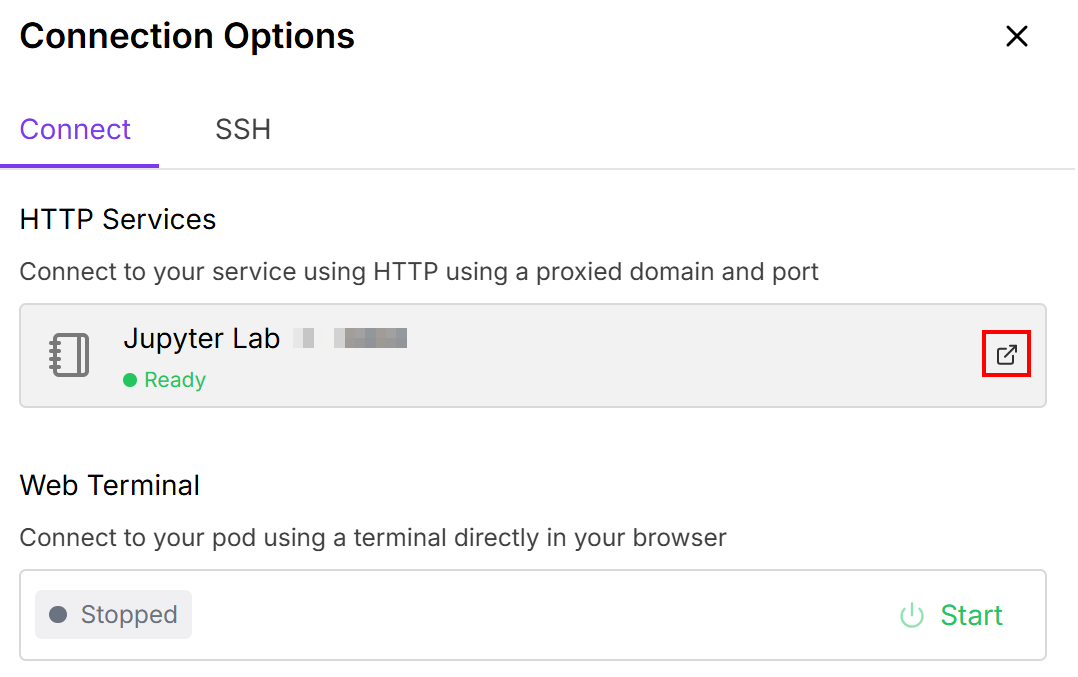
Dadurch können Sie den Pod mit einem Jupiter Lab -Notebook verbinden:
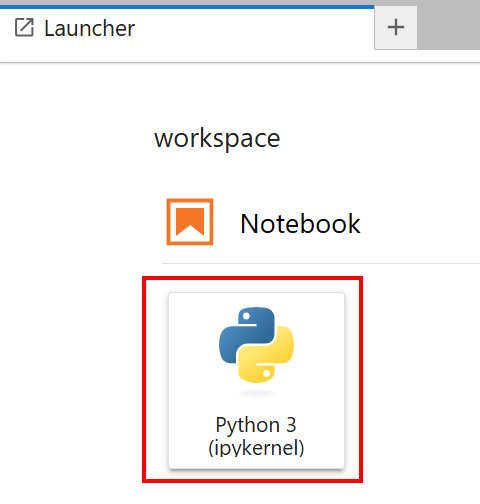
Wählen Sie das Notebook mit der Karte „Python 3 (ipykernel)“ aus:
Sehr gut! Sie verfügen nun über die richtige Infrastruktur, um das Llama 4-Modell zu trainieren.
Feinabstimmung von Llama 4 mit den gesammelten Daten
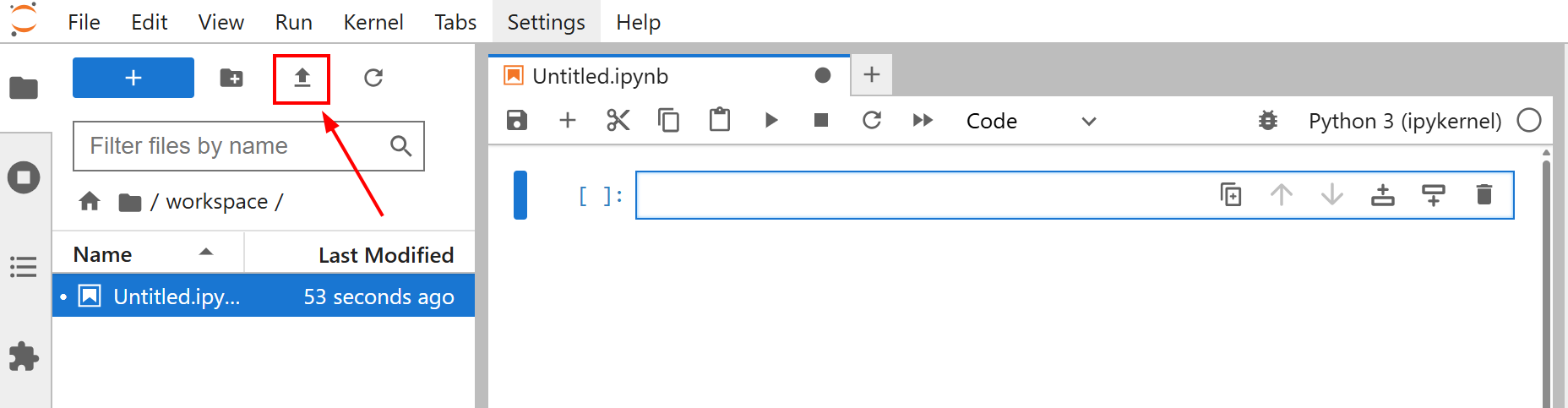
Bevor Sie mit der Feinabstimmung Ihres Modells beginnen, laden Sie die Datei amazon-data.json in Ihr Jupyter Lab-Notebook hoch. Klicken Sie dazu auf die Schaltfläche „Dateien hochladen“:
Das Ziel der Feinabstimmung für dieses Tutorial ist es, Llama 4 mit dem Datensatz amazon-data.json zu trainieren. Auf diese Weise bringen Sie Llama 4 bei, wie man Beschreibungen für Büroobjekte erstellt, wenn bestimmte Merkmale wie der Name des Objekts und einige Eigenschaften gegeben sind.
Sie sind nun bereit, mit dem Training des Modells zu beginnen. Befolgen Sie die folgenden Schritte, um Llama 4 mit neuen Webdaten zu optimieren!
Schritt 1: Installieren Sie die Bibliotheken
Installieren Sie in der ersten Zelle Ihres Notizbuchs die erforderlichen Bibliotheken:
%%capture
!pip install transformers==4.51.0
%pip install -U Datensätze
%pip install -U accelerate
%pip install -U peft
%pip install -U trl
%pip install -U bitsandbytes
%pip install huggingface_hub[hf_xet]Diese Bibliotheken sind:
transformers: Bietet Tausende von vortrainierten Modellen.Datensätze: Bietet Zugriff auf eine umfangreiche Sammlung von Datensätzen und effiziente Datenverarbeitungswerkzeuge.accelerate: Vereinfacht die Ausführung von PyTorch-Trainingsskripten über verschiedene verteilte Konfigurationen hinweg mit minimalen Codeänderungen.peft: Ermöglicht eine effizientere Feinabstimmung großer vortrainierter Modelle, indem nur eine kleine Teilmenge von Parametern aktualisiert wird.trl: Entwickelt für das Training von Transformer-Sprachmodellen unter Verwendung von Techniken des verstärkenden Lernens.scipy: Eine Bibliothek für wissenschaftliches und technisches Rechnen in Python.huggingface_hub: Bietet eine Python-Schnittstelle für die Interaktion mit dem Hugging Face Hub. Damit können Sie Modelle, Datensätze und Spaces herunterladen und hochladen.bitsandbytes: Bietet benutzerfreundliche 8-Bit-Optimierer und Quantisierungsfunktionen, wodurch der Speicherbedarf für das Training und die Inferenz großer Deep-Learning-Modelle reduziert wird.
Perfekt! Sie haben die für den Feinabstimmungsprozess erforderlichen Bibliotheken installiert.
Schritt 2: Verbindung zu Hugging Face herstellen
Schreiben Sie in die zweite Zelle Ihres Notizbuchs:
from huggingface_hub import notebook_login, login
# Interaktive Anmeldung
notebook_login()
print("Anmeldezelle ausgeführt. Bei Erfolg können Sie fortfahren.")Wenn Sie dies ausführen, wird Folgendes angezeigt:
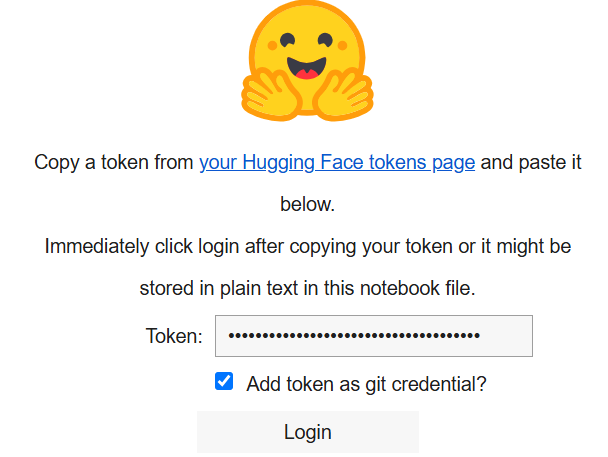
Fügen Sie in das Feld „Token“ den Token ein, den Sie in Ihrem Hugging Face-Konto erstellt haben.
Super! Jetzt können Sie das Llama 4-Modell von Hugging Face abrufen.
Schritt 3: Laden Sie das Llama 4-Modell
Schreiben Sie den folgenden Code in die dritte Zelle Ihres Notizbuchs:
import os
import torch
import json
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline, Llama4ForConditionalGeneration, BitsAndBytesConfig
from trl import SFTTrainer
# Modell laden
base_model_name = "meta-llama/Llama-4-Scout-17B-16E-Instruct"
# Konfiguration für BitsAndBytes-Quantisierung
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=False,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
# Laden Sie das Llama4-Modell mit den angegebenen Konfigurationen.
model = Llama4ForConditionalGeneration.from_pre-trained(
base_model_name,
device_map="auto",
torch_dtype=torch.bfloat16,
quantization_config=bnb_config,
trust_remote_code=True,
)
# Caching für das Modell deaktivieren
model.config.use_cache = False
# Tensor-Parallelität für das Vortraining auf 1 setzen
model.config.pre-training_tp = 1
# Pfad zur JSON-Datei für die Feinabstimmung.
fine_tuning_data_file_path = "amazon-data.json"
# Pfad zu den Ergebnissen
output_model_dir = "results_llama_office_items_finetuned/"
final_model_adapter_path = os.path.join(output_model_dir, "final_adapter")
max_seq_length_for_tokenization = 1024
# Ausgabeverzeichnis erstellen
os.makedirs(output_model_dir)Der obige Ausschnitt:
- Definiert den Namen des zu ladenden Modells mit
base_model_name. - Konfiguriert die Gewichte des Modells mit
bnb_configunter Verwendung der MethodeBitsAndBytesConfig(). - Lädt das Modell mit der Methode
from_pre-trained(), um es zu trainieren. - Lädt den Feinabstimmungsdatensatz mit
fine_tuning_data_file_path. - Definiert den Pfad des Ausgabeverzeichnisses für die Ergebnisse und erstellt es mit der Methode
makedirs().
Wenn die Zelle fertig ausgeführt ist, sollten Sie ein Ergebnis wie dieses sehen:

Fantastisch! Ihr Llama 4-Modell ist eingerichtet und in das Notebook geladen.
Schritt 4: Vorbereiten des Feinabstimmungsdatensatzes für den Trainingsprozess
Schreiben Sie den folgenden Code in die vierte Zelle Ihres Notebooks, um den Feinabstimmungsdatensatz für den Trainingsprozess vorzubereiten:
from Datensätze import Datensatz
# Feinabstimmungsdatensatz öffnen
with open(fine_tuning_data_file_path, "r") as f:
data_list = json.load(f)
# Die Liste der Datenelemente in ein Hugging Face Dataset-Objekt konvertieren
raw_fine_tuning_dataset = Dataset.from_list(data_list)
print(f"JSON-Daten in Hugging Face Datensatz konvertiert. Anzahl der Beispiele: {len(raw_fine_tuning_dataset)}")
def format_fine_tuning_entry(data_item):
system_message = "Sie sind ein erfahrener Texter. Erstellen Sie eine prägnante und ansprechende Produktbeschreibung auf der Grundlage der bereitgestellten Details."
# PASSE DIE FOLGENDEN ZEILEN an deine Fine-Tuning-Datei an.
item_title = data_item.get("title")
item_brand = data_item.get("brand")
item_category = data_item.get("categories")
item_name = data_item.get("name")
item_features_list = data_item.get("features")
item_features_str = ", ".join(item_features_list) if isinstance(item_features_list, list) else str(item_features_list)
target_description = data_item.get("description")
# Trainingsaufforderung
user_prompt = (
f"Erstellen Sie eine Produktbeschreibung für den folgenden Artikel:n"
f"Titel: {item_title}nMarke: {item_brand}nKategorie: {item_category}n"
f"Name: {item_name}nEigenschaften: {item_features_str}nBeschreibung:"
)
# Llama-Chat-Format
formatted_string = (
f"<|start_header_id|>system<|end_header_id|>nn{system_message}<|eot_id|>"
f"<|start_header_id|>user<|end_header_id|>nn{user_prompt}<|eot_id|>"
f"<|start_header_id|>assistant<|end_header_id|>nn{target_description}<|eot_id|>"
)
return {"text": formatted_string}
# Wende die Formatierungsfunktion auf jeden Eintrag im Rohdatensatz an, um ihn für die Feinabstimmung zu strukturieren.
text_formatted_dataset = raw_fine_tuning_dataset.map(format_fine_tuning_entry)
# Tokenizer-Einrichtung
tokenizer = AutoTokenizer.from_pre-trained(base_model_name, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
# Vorab-Tokenisierung der Datensätze
def tokenize_function_for_sft(examples):
# Tokenisierung des Feldes „text”, das die vollständige Zeichenfolge im Chat-Format enthält
tokenized_output = tokenizer(
examples["text"],
truncation=True,
padding="max_length",
max_length=max_seq_length_for_tokenization,
)
return tokenized_output
# Die Tokenisierungsfunktion auf den formatierten Datensatz anwenden
tokenized_train_dataset = text_formatted_dataset.map(
tokenize_function_for_sft,
batched=True,
remove_columns=["text"]
)Diese Zelle des Notizbuchs:
- Öffnet den Feinabstimmungsdatensatz und konvertiert ihn mit der Methode
Dataset.from_list()in ein Hugging FaceDataset-Objekt. - Definiert eine Funktion
format_fine_tuning_entry(). Ihr Zweck besteht darin, ein einzelnes Datenelement (die Details eines Produkts) in ein strukturiertes Textformat umzuwandeln, das für die Feinabstimmung eines Chat-Modells wie Llama geeignet ist. Beachten Sie, dass dies auf die Struktur Ihres Feinabstimmungsdatensatzes zugeschnitten sein muss. - Tokenisiert den Datensatz und wendet die Tokenisierung mit der Methode
map()an. Dies geschieht, weil Sprachmodelle Rohtext nicht verstehen. Sie arbeiten mit numerischen Darstellungen, die als Token bezeichnet werden.
Wenn die Zelle fertig ausgeführt ist, ist das erwartete Ergebnis wie folgt:

Beachten Sie, dass der Wert von „Num examples” von Ihrem Feinabstimmungsdatensatz abhängt.
Unglaublich! Ihr Feinabstimmungsdatensatz ist bereit für den Feinabstimmungsprozess.
Schritt 5: Konfigurieren Sie die Umgebung und Parameter für die parameter-effiziente Feinabstimmung (PEFT)
Schreiben Sie in einer neuen Zelle Ihres Notizbuchs den folgenden Code, um die Umgebung und die Parameter für PEFT festzulegen:
from transformers import BitsAndBytesConfig
from peft import LoraConfig
# QLoRA-Konfiguration
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,)
# LoRA-Konfiguration
lora_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],
)Dieser Code:
- Definiert die QLoRA-Konfiguration für die Quantisierung mit der Methode
BitsAndBytesConfig(), um festzulegen, wie ein vortrainiertes Sprachmodell beim Laden quantisiert werden soll. Quantisierung ist eine Technik zur Reduzierung von Rechen- und Speicherkosten. - Definiert die LoRA-Konfiguration, um das Modell für eine parameter-effiziente Feinabstimmung mit der Methode LoraConfig() einzurichten.
Sehr gut! Die Umgebung ist nun bereit für eine effiziente Feinabstimmung.
Schritt 6: Initialisieren Sie den Trainingsprozess
Schreiben Sie in einer neuen Zelle den folgenden Code, um den Trainingsprozess zu initialisieren:
from peft import get_peft_model, prepare_model_for_kbit_training
from transformers import TrainingArguments
# Bereiten Sie das Modell für das k-Bit-Training vor.
model = prepare_model_for_kbit_training(
model,
gradient_checkpointing_kwargs={"use_reentrant": False}
)
# PEFT-Konfiguration (LoRA) auf das Modell anwenden.
model = get_peft_model(model, lora_config)
# Caching in der Modellkonfiguration deaktivieren.
model.config.use_cache = False
# Anzahl der trainierbaren Parameter im Modell ausgeben.
model.print_trainable_parameters()
# Trainingsargumente definieren
training_args = TrainingArguments(
output_dir=output_model_dir,
num_train_epochs=3,
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
learning_rate=2e-4,
logging_steps=25,
save_steps=50,
fp16=True,
optim="paged_adamw_8bit",
lr_scheduler_type="cosine",
warmup_ratio=0.03,
report_to="none",
max_grad_norm=0.3,
save_total_limit=2,)
# SFTTrainer initialisieren
trainer = SFTTrainer(
model=model,
args=training_args,
train_dataset=tokenized_train_dataset,
peft_config=lora_config,
)Der Code in dieser Zelle:
- Die Methode
prepare_model_for_kbit_training()bereitet das vorinstallierteModellfür das Training mit Quantisierung vor. - Die Methode
get_peft_model()nimmt das quantisierte und vorbereiteteBasismodellund wendet dielora_configan. - Definiert die Trainingsargumente durch Aufruf der Klasse
TrainingArguments(). - Initialisiert den Trainer mit
SFTTrainer().
Nachfolgend das erwartete Ergebnis:

Schritt 7: Trainieren des Modells
Der Prozess ist nun bereit, das Llama 4-Modell mit der Methode train() zu trainieren:
# Modell trainieren
trainer.train()
# Feinabgestimmtes Modell speichern
trainer.save_model(final_model_adapter_path) # Speichert den LoRA-Adapter
tokenizer.save_pre-trained(final_model_adapter_path) # Speichert den Tokenizer mit dem AdapterDas Ergebnis ist wie folgt:

Beachten Sie, dass Sie aufgrund der stochastischen Natur der KI möglicherweise andere Zahlen erhalten.
Schritt 8: Modell für die Inferenz vorbereiten
Um das Modell für die Inferenz vorzubereiten, schreiben Sie den folgenden Code in eine neue Zelle:
# Laden Sie das Modell mit Quantisierung für die Inferenz.
base_model_for_inference = AutoModelForCausalLM.from_pre-trained(
base_model_name,
quantization_config=bnb_config,
device_map="auto",
trust_remote_code=True
)
# Laden Sie den fein abgestimmten LoRA-Adapter und fügen Sie ihn dem Modell hinzu.
fine_tuned_model_for_testing = PeftModel.from_pre-trained(
base_model_for_inference,
final_model_adapter_path
)
# LoRA-Adapter in das Basismodell einbinden
fine_tuned_model_for_testing = fine_tuned_model_for_testing.merge_and_unload()
# Laden Sie den Tokenizer.
fine_tuned_tokenizer_for_testing = AutoTokenizer.from_pre-trained(
final_model_adapter_path,
trust_remote_code=True)
# Konfigurieren Sie den Tokenizer für die Inferenz.
fine_tuned_tokenizer_for_testing.pad_token = fine_tuned_tokenizer_for_testing.eos_token
fine_tuned_tokenizer_for_testing.padding_side = "left"
# Das fein abgestimmte Modell in den Bewertungsmodus versetzen
fine_tuned_model_for_testing.eval()Der Code in dieser Zelle:
- Lädt das Modell mit der Methode
from_pre-trained()zur Inferenz. - Lädt, wendet und führt den LoRA-Adapter mit dem Basismodell für die Inferenz zusammen.
- Lädt den fein abgestimmten Tokenizer und konfiguriert ihn für die Inferenz.
- Setzt das Modell mit der Methode
eval()in den Evaluierungsmodus. Dadurch werden trainingsspezifische Verhaltensweisen deaktiviert, wodurch konsistente und deterministische Ausgaben während der Inferenz gewährleistet werden.
Das war’s schon! Jetzt ist alles für die Inferenz eingerichtet.
Schritt 9: Inferenz des Modells
In diesem letzten Schritt führen Sie die Inferenz durch. Zuvor haben Sie Llama 4 mit von Amazon gescrapten Produkten trainiert. Nun möchten Sie anhand einiger Daten, die den Namen und die Eigenschaften von Büroartikeln enthalten, überprüfen, ob das Modell in der Lage ist, deren Beschreibung zu generieren.
Mit dem folgenden Code können Sie den Inferenzprozess verwalten:
# Definieren Sie eine Liste synthetischer Produktdatenelemente zum Testen des fein abgestimmten Modells.
synthetic_test_items = [
{
"title": "Executive Ergonomic Office Chair", "brand": "ComfortLuxe", "category": "Office Chairs", "name": "ErgoPro-EL100",
„features”: [„Hochlehner-Design”, „Verstellbare Lendenwirbelstütze”, „Atmungsaktives Netzgewebe”, „Synchronisierter Neigungsmechanismus”, „Gepolsterte Armlehnen”, „Robuste Nylonbasis”]
},
{
"title": "Verstellbarer Stehtisch-Konverter", "brand": "FlexiDesk", "category": "Schreibtische & Arbeitsplätze", "name": "HeightRise-FD20",
„Features“: [„Geräumige zweistufige Oberfläche“, „Leichtgängiger Gasfederlift“, „Einstellbarer Höhenbereich 6–17 Zoll“, „Tragkraft bis zu 35 lbs“, „Tastaturablage inklusive“, „Rutschfeste Gummifüße“]
},
{
„title“: „Kombination aus kabelloser Tastatur und Maus“, „brand“: „TechGear“, „category“: „Computerperipheriegeräte“, „name“: „SilentType-KM850“,
„Features“: [„Vollwertige Tastatur mit Ziffernblock“, „Leise Tasten“, „Ergonomische Maus mit einstellbarer DPI“, „2,4-GHz-Funkverbindung“, „Lange Akkulaufzeit“, „Plug-and-Play-USB-Empfänger“]
},
{
„title“: „Schreibtisch-Organizer mit Schubladen“, „brand“: „NeatOffice“, „category“: „Schreibtischzubehör“, „name“: „SpaceSaver-DO3“,
„Features“: [„Design mit mehreren Fächern“, „Zwei ausziehbare Schubladen“, „Stabile Holzkonstruktion“, „Kompakte Stellfläche“, „Ideal für Stifte, Notizen und kleine Utensilien“]
},
{
„title“: „LED-Schreibtischlampe mit USB-Ladeanschluss“, „brand“: „BrightSpark“, „category“: „Bürobeleuchtung“, „name“: „LumiCharge-LS50“,
„Features“: [„Einstellbare Helligkeitsstufen (5)“, „Farbtemperaturmodi (3)“, „Flexibles Schwanenhalsdesign“, „Integrierter USB-Ladeanschluss“, „Augenschonendes, flimmerfreies Licht“, „Energieeffiziente LED“]
},
]
# Systemmeldung und Eingabeaufforderungsstruktur für die Inferenz
system_message_inference = „Sie sind ein erfahrener Texter. Erstellen Sie anhand der bereitgestellten Details eine prägnante und ansprechende Produktbeschreibung.“
print("n--- Generieren von Beschreibungen mit einem fein abgestimmten Modell unter Verwendung synthetischer Testdaten ---")
# Durchlaufen Sie alle Elemente in der Liste „synthetic_test_items“
for item_data in synthetic_test_items:
# Erstellen Sie den Benutzeraufforderungsabschnitt basierend auf der Struktur des synthetischen Elements
user_prompt_inference = (
f"Generieren Sie eine Produktbeschreibung für das folgende Büroartikel:n"
f"Titel: {item_data["title"]}n"
f"Marke: {item_data["brand"]}n"
f"Kategorie: {item_data["category"]}n"
f"Name: {item_data["name"]}n"
f"Eigenschaften: {", ".join(item_data["features"])}n"
f"Beschreibung:" # Das Modell generiert nach diesem Punkt Text.
)
full_prompt_for_inference = (
f"<|start_header_id|>system<|end_header_id|>nn{system_message_inference}<|eot_id|>"
f"<|start_header_id|>user<|end_header_id|>nn{user_prompt_inference}<|eot_id|>"
f"<|start_header_id|>assistant<|end_header_id|>nn"
)
print(f"nPROMPT for item: {item_data["name"]}")
# Tokenisieren Sie die vollständige Eingabeaufforderungszeichenfolge mit dem fein abgestimmten Tokenizer.
inputs = fine_tuned_tokenizer_for_testing(
full_prompt_for_inference,
return_tensors="pt",
padding=False,
truncation=True,
max_length=max_seq_length_for_tokenization - 150
).to(fine_tuned_model_for_testing.device)
# Inferenz durchführen
with torch.no_grad():
outputs = fine_tuned_model_for_testing.generate(
**inputs,
max_new_tokens=150,
num_return_sequences=1,
do_sample=True,
temperature=0.6,
top_k=50,
top_p=0.9,
pad_token_id=fine_tuned_tokenizer_for_testing.eos_token_id,
eos_token_id=[
fine_tuned_tokenizer_for_testing.eos_token_id,
fine_tuned_tokenizer_for_testing.convert_tokens_to_ids("<|eot_id|>")
]
)
# Dekodieren Sie die generierten Token-IDs zurück in eine für Menschen lesbare Textzeichenfolge
generated_text_full = fine_tuned_tokenizer_for_testing.decode(outputs[0], skip_special_tokens=False)
# Den Marker definieren, der den Beginn der Antwort des Assistenten im Llama-Chat-Format anzeigt.
assistant_marker = "<|start_header_id|>assistant<|end_header_id|>nn"
# Suche nach dem letzten Vorkommen des Assistentenmarkers im generierten Text
assistant_response_start_index = generated_text_full.rfind(assistant_marker)
# Extrahieren der tatsächlich generierten Beschreibung aus der vollständigen Modellausgabe
if assistant_response_start_index != -1:
# Wenn der Assistentenmarker gefunden wird, extrahiere den Text, der danach kommt
generated_description = generated_text_full[assistant_response_start_index + len(assistant_marker):]
# Definiere das End-of-Turn-Token für Llama
eot_token = "<|eot_id|>"
# Überprüfe, ob die extrahierte Beschreibung mit dem Llama-End-of-Turn-Token endet, und entferne es.
if generated_description.endswith(eot_token):
generated_description = generated_description[:-len(eot_token)]
# Überprüfen Sie auch, ob sie mit dem Standard-Token für das Ende der Sequenz des Tokenizers endet, und entfernen Sie diesen.
if generated_description.endswith(fine_tuned_tokenizer_for_testing.eos_token):
generated_description = generated_description[:-len(fine_tuned_tokenizer_for_testing.eos_token)]
# Entfernen Sie alle führenden oder nachfolgenden Leerzeichen aus der bereinigten Beschreibung.
generated_description = generated_description.strip()
else:
# Fallback: Wenn der Assistentenmarker nicht gefunden wird, versuchen Sie, den generierten Teil zu extrahieren, indem Sie davon ausgehen, dass es sich um alles nach der ursprünglichen Eingabeaufforderung handelt.
input_prompt_decoded_len = len(fine_tuned_tokenizer_for_testing.decode(inputs["input_ids"][0], skip_special_tokens=False))
# Dekodieren Sie die Eingabeaufforderungstoken, um ihre Länge als Zeichenfolge zu erhalten.
generated_description = generated_text_full[input_prompt_decoded_len:].strip()
# Bereinigen Sie alle nachgestellten Llama-End-of-Turn-Token aus dieser Fallback-Extraktion.
if generated_description.endswith("<|eot_id|>"):
generated_description = generated_description[:-len("<|eot_id|>")]
generated_description = generated_description.strip()
# Die extrahierte und bereinigte generierte Beschreibung ausgeben.
print(f"GENERATED (Fine-tuned):n{generated_description}")
# Eine Trennlinie ausgeben, um die Lesbarkeit zwischen den Elementen zu verbessern.
print("-" * 50)Diese letzte Jupyter Notebook-Zelle verwaltet den Inferenzprozess. Dieser Prozess ist nützlich, um zu sehen, wie gut das Training während des Feinabstimmungsprozesses war.
Insbesondere der obige Code:
- Testdaten als Liste namens
synthetic_test_itemsdefiniert. Jedes Element in dieser Liste ist ein Wörterbuch, das ein Produkt darstellt und Details wie Titel, Marke, Kategorie, Name und eine Liste von Merkmalen enthält. Diese Daten dienen als Eingabe für das Modell und ihre Struktur muss mit der des Feinabstimmungsdatensatzes übereinstimmen. - Richtet die Referenz-Prompt-Struktur mit
system_message_inferenceein. Diese muss mit dem während des Trainingsprozesses verwendeten Prompt übereinstimmen. - Die Schleife
„for item_data in synthetic_test_items“erstellt eine Benutzeraufforderung für jedesitem_data. Die Struktur jedesitem_datamuss mit der im Trainingsprozess verwendeten übereinstimmen. - Tokenisiert und steuert, wie das Modell den Ausgabetext erzeugt. Die eigentliche Inferenz erfolgt unter der
with-Anweisung. Insbesondere dank der Methodegenerate(), die den Kernschritt der Inferenz darstellt. - Dekodiert die Rohausgabe des Modells (eine Folge von Token-IDs) mithilfe des Tokenizers zurück in eine für Menschen lesbare Zeichenfolge (
generated_text_full). - Verwendet einen
if-else-Block, um die Rohausgabe des Sprachmodells zu bereinigen und nur die vom Assistenten generierte Produktbeschreibung zu extrahieren. Die Rohausgabe (generated_text_full) enthält in der Regel die gesamte Eingabeaufforderung, gefolgt von der Antwort des Modells, die alle mit den speziellen Chat-Tokens von Llama formatiert sind. - Gibt die Ergebnisse aus.
Sie können folgendes Ergebnis erwarten:
--- Generieren von Beschreibungen mit einem fein abgestimmten Modell unter Verwendung synthetischer Testdaten ---
PROMPT für Artikel: ErgoPro-EL100
GENERATED (fein abgestimmt):
**Wir stellen vor: ErgoPro-EL100 – der ultimative ergonomische Bürostuhl für Führungskräfte**
Erleben Sie höchsten Komfort und beste Unterstützung mit dem ComfortLuxe ErgoPro-EL100, der entwickelt wurde, um Ihr Arbeitserlebnis zu verbessern. Dieser hochwertige Bürostuhl verfügt über eine hohe Rückenlehne, die Ihren Oberkörper stützt, eine unvergleichliche Lendenwirbelstütze bietet und eine gesunde Körperhaltung fördert.
Das atmungsaktive Netzgewebe sorgt für ein kühles und bequemes Sitzerlebnis, während der synchronisierte Neigungsmechanismus eine nahtlose Anpassung an Ihre bevorzugte Arbeitsposition ermöglicht. Die gepolsterten Armlehnen bieten zusätzlichen Halt und Komfort und entlasten Ihre Schultern und Handgelenke.
Der ErgoPro-EL100 ist auf Langlebigkeit ausgelegt und verfügt über ein robustes Nylon-Fußkreuz, das Stabilität und Haltbarkeit gewährleistet. Egal, ob Sie lange arbeiten oder einfach nur
--------------------------------------------------
PROMPT für Artikel: HeightRise-FD20
GENERATED (Feinabstimmung):
**Steigern Sie Ihre Produktivität mit dem verstellbaren Stehpult-Konverter HeightRise-FD20 von FlexiDesk**
Bringen Sie Ihre Arbeit auf ein neues Niveau mit dem HeightRise-FD20 von FlexiDesk, dem ultimativen verstellbaren Stehpult-Konverter. Dieser innovative Konverter wurde entwickelt, um Ihren Arbeitsplatz zu revolutionieren, und verwandelt jeden Schreibtisch in einen bequemen und ergonomischen Steharbeitsplatz.
**Erleben Sie die Vorteile des Stehens**
Der HeightRise-FD20 verfügt über eine geräumige zweistufige Oberfläche, die sich perfekt für Ihren Laptop, Monitor und andere wichtige Arbeitsgeräte eignet. Der leichtgängige Gasfederlift ermöglicht eine mühelose Höhenverstellung von 15 bis 43 cm und sorgt so für eine bequeme Stehposition, die Ihren Bedürfnissen entspricht.
**Langlebig und zuverlässig**
Mit einer robusten Konstruktion und rutschfesten Gummifüßen
--------------------------------------------------Et voilà! Sie haben Llama 4 mit einem neuen Datensatz, der mit den Bright Data Scraper-APIs abgerufen wurde, fein abgestimmt.
Fazit
In diesem Artikel haben Sie gelernt, wie Sie Llama 4 mit einem Datensatz optimieren können, der mit den Bright Data Scraper-APIs von Amazon gesammelt wurde. Sie haben den gesamten Prozess durchlaufen, der aus folgenden Schritten besteht:
- Abrufen der Daten aus dem Internet.
- Einrichten eines Hugging Face-Kontos mit einem Token.
- Einrichten der erforderlichen Cloud-Infrastruktur.
- Training und Testen (Inferenz) von Llama 4.
Der Kern des Feinabstimmungsprozesses basiert auf hochwertigen Datensätzen. Glücklicherweise bietet Bright Data Ihnen zahlreiche KI-fähige Dienste für die Erfassung oder Erstellung von Datensätzen:
- Scraping-Browser: Ein mit Playwright, Selenium und Puppeter kompatibler Browser mit integrierten Entsperrungsfunktionen.
- Web Scraper APIs: Vorkonfigurierte APIs zum Extrahieren strukturierter Daten aus über 100 großen Domains.
- Web Unlocker: Eine All-in-One-API, die die Entsperrung von Websites mit Anti-Bot-Schutz übernimmt.
- SERP-API: Eine spezielle API, die Suchmaschinenergebnisse entsperrt und vollständige SERP-Daten extrahiert.
- Grundlagenmodelle: Zugriff auf konforme, webbasierte Datensätze für Vorab-Training, Bewertung und Feinabstimmung.
- Datenanbieter: Verbinden Sie sich mit vertrauenswürdigen Anbietern, um hochwertige, KI-fähige Datensätze in großem Umfang zu beziehen.
- Datenpakete: Erhalten Sie kuratierte, gebrauchsfertige Datensätze – strukturiert, angereichert und mit Anmerkungen versehen.
Erstellen Sie kostenlos ein Bright Data-Konto, um unsere KI-fähige Dateninfrastruktur zu testen!





