In diesem Leitfaden gehen wir auf die Verwendung und Architektur eines universellen LLM-Scrapers für die Verfolgung von LLM-Erwähnungen ein. Dieses Projekt wird die folgenden Scraper in einer einzigen einheitlichen Schnittstelle zusammenfassen:
Wenn Sie diesen Leitfaden durchgearbeitet haben, können Sie Folgendes tun.
- Scraper mithilfe der Bright Data Web-Scraping-API auslösen.
- Die Bereitschaft abfragen und Scraper-Ergebnisse herunterladen.
- Verwenden Sie das Ausgabeformat von Bright Data für eine mühelose Normalisierung.
- Prompts über mehrere LLMs hinweg gleichzeitig für Recherche und Validierung vergleichen.
Möchten Sie direkt mit dem Projekt beginnen? Schauen Sie sich das Projekt auf GitHub an.
Warum einen universellen LLM-Scraper entwickeln?
Das Suchverhalten hat sich verändert. Nutzer stellen KI-Chatbots Fragen und vertrauen den generierten Antworten, ohne weiterzusuchen. Dies verändert SEO- und Marktforschungsmaßnahmen drastisch: Wenn Ihre Marke nicht in den Chatbot-Ausgaben erwähnt wird, werden potenzielle Kunden Sie möglicherweise nie entdecken.
Unternehmen müssen nun nicht nur in den Suchergebnissen, sondern auch in den Model-Ausgaben erscheinen. Die vorgefertigten LLM-Scraper von Bright Data liefern normalisierte Ausgaben der beliebtesten Modelle auf dem Markt. Durch die Vereinheitlichung dieser APIs in einer einzigen Schnittstelle können Teams die Empfehlungsergebnisse aller wichtigen LLMs vergleichen.
Betrachten Sie die Eingabeaufforderung: Wer sind die besten Anbieter von Residential-Proxys?
Die manuelle Abfrage jedes LLM und das Lesen der Ergebnisse kann eine Stunde oder länger dauern. Mit vereinheitlichten Ergebnissen leiten Sie die Eingabeaufforderung gleichzeitig an mehrere LLMs weiter und verwenden Regex, um sofort festzustellen, ob Ihr Unternehmen in den Antworten erscheint.
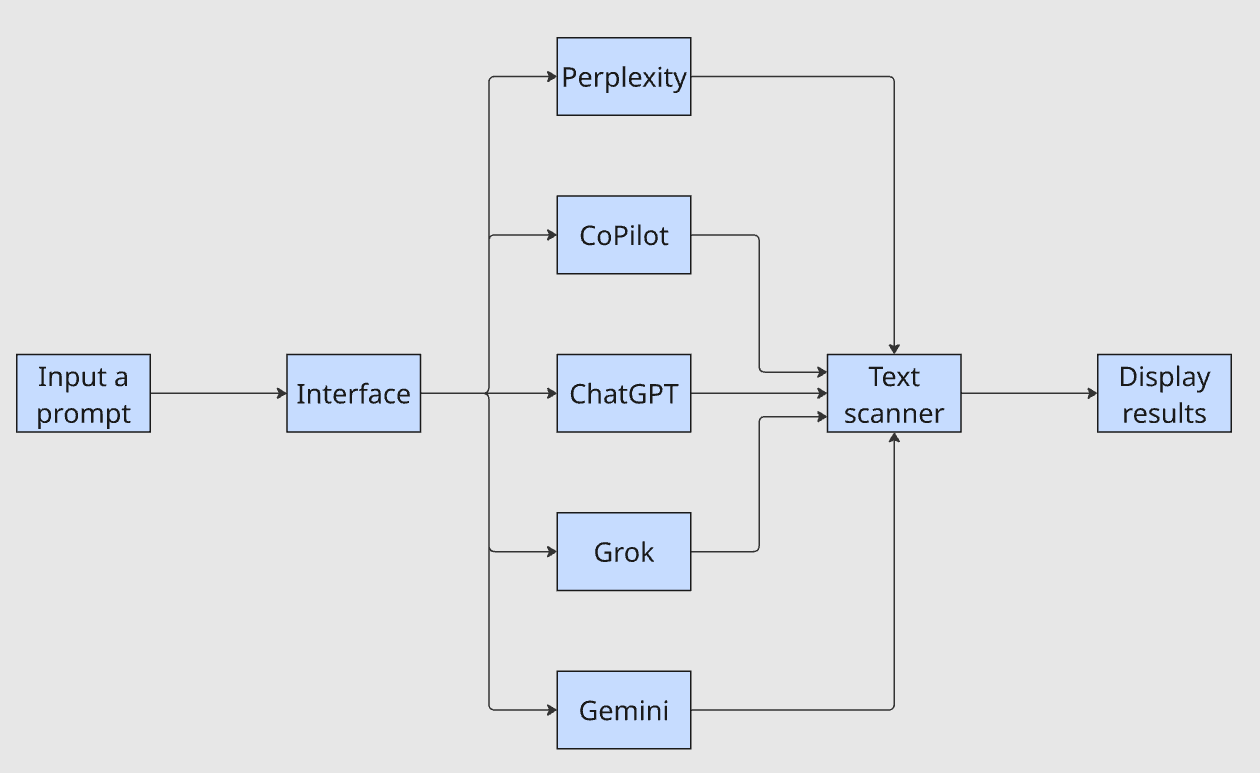
Die Schnittstelle nimmt eine einzige Eingabeaufforderung entgegen, leitet sie an jedes LLM weiter, leitet die Ausgaben durch einen Textscanner und zeigt die Ergebnisse an. Die Frage „Erscheint mein Unternehmen in den Ergebnissen?“ dauert nun nur noch Minuten statt einer Stunde.
Entwicklung der eigentlichen Software
Jetzt müssen wir die eigentliche Software erstellen. Wir erstellen unser grundlegendes Projektskelett. Dann füllen wir den Code nach und nach aus. Dieser Abschnitt enthält nicht den vollständigen Code. Es handelt sich um eine konzeptionelle Aufschlüsselung, nicht um eine Zeile-für-Zeile-Anleitung.
Erste Schritte
Wir können damit beginnen, einen neuen Projektordner zu erstellen.
mkdir universal-llm-scraper
cd universal-llm-scraperAls Nächstes erstellen wir eine virtuelle Umgebung, um Abhängigkeitskonflikte zu vermeiden.
python -m venv .venvAls Nächstes müssen Sie die virtuelle Umgebung aktivieren. Der erste Befehl kann unter Linux oder macOS aktiviert werden. Wenn Sie Windows verwenden, verwenden Sie den zweiten Befehl.
Linux/macOS
source .venv/bin/activateWindows
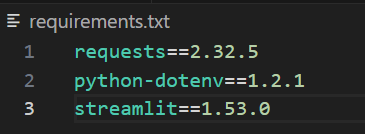
..venvScriptsActivate.ps1Erstellen Sie abschließend eine Datei namens requirements.txt und fügen Sie die unten aufgeführten Abhängigkeiten hinzu. Sie können die Versionsnummern anpassen. Diese haben jedoch beim Erstellen gut funktioniert, daher haben wir sie für ein reproduzierbares Verhalten festgehalten.
requests==2.32.5
python-dotenv==1.2.1
streamlit==1.53.0Wenn Sie fertig sind, sieht die Datei wie in der Abbildung unten aus.
Um diese Abhängigkeiten zu installieren, führen Sie einfach den folgenden pip-Befehl aus.
pip install -r requirements.txtKI-Modelle als Objekte
Als Nächstes müssen wir verstehen, dass alle unsere KI-Modelle als Objekte funktionieren. Jedes Modell hat die folgenden Attribute.
name: Eine für Menschen lesbare Bezeichnung für das Modell.dataset_id: Dies ist eine eindeutige Kennung für den Scraper.url: Die tatsächliche URL, über die wir auf das KI-Modell zugreifen.
In der folgenden Klasse erstellen wir dasselbe Modellobjekt. Diese Klasse benötigt keine Methoden oder Logik. Wenn Sie mit Informatik vertraut sind, ähnelt sie einer altmodischen Struktur.
Klasse AIModel:
def __init__(self, name: str, dataset_id: str, url: str):
self.name = name
self.dataset_id = dataset_id
self.url = url Schreiben eines Modell-Retrievers
Als Nächstes müssen wir einen Modell-Retriever schreiben. Diese Klasse übernimmt die schwerere Arbeit. Der Modell-Retriever bildet eine vereinheitlichende Orchestrierungsschicht zwischen Bright Data und dem Rest unseres Codes. Er verwendet Ihren Bright Data-API-Schlüssel zur Authentifizierung bei der API. Wir haben auch eine Vielzahl von Methoden: get_model_response(), trigger_prompt_collection(), collect_snapshot() und write_model_output(). Im weiteren Verlauf werden wir diese Methoden ausfüllen.
class AIModelRetriever:
def __init__(self, api_token: str):
self.api_token = api_token
def get_model_response(self, model: AIModel, prompt: str):
pass
def trigger_prompt_collection(self, model: AIModel, prompt: str, country: str = ""):
pass
def collect_snapshot(self, model: AIModel, snapshot_id: str):
pass
def write_model_output(self, model: AIModel, llm_response: dict):
passget_model_response()
Diese Methode wird in erster Linie für die Orchestrierung verwendet. Sie verwendet trigger_prompt_collection(), um einen Scraper zu initiieren und dessen snapshot_id zurückzugeben. Anschließend wird collect_snapshot() verwendet, um die API abzufragen und die Antwort zurückzugeben, sobald sie bereit ist. Schließlich schreiben wir die Antwort mit write_model_output() in eine Datei.
def get_model_response(self, model: AIModel, prompt: str):
snapshot_id = self.trigger_prompt_collection(model, prompt)
if not snapshot_id:
raise RuntimeError(f"{model.name}: failed to trigger snapshot. Bitte warten Sie und versuchen Sie es erneut.")
llm_response = self.collect_snapshot(model, snapshot_id)
if not llm_response:
raise RuntimeError(f"Failed to collect snapshot {snapshot_id} for {model.name}. Please wait and try again")
self.write_model_output(model, llm_response)trigger_prompt_collection()
Um eine Erfassung auszulösen, übergeben wir unseren API-Token an die HTTP-Header. Anschließend versuchen wir eine POST-Anfrage an die API. Wir erlauben bis zu drei Wiederholungsversuche, da Fehler in HTTP manchmal unvorhersehbar sein können und die Wiederholungsversuche dies berücksichtigen. Wenn die Antwort gut ist, geben wir die snapshot_id zurück. Wenn Fehler auftreten, versuchen wir es weiter, bis wir keine Wiederholungsversuche mehr haben. Wenn wir die Wiederholungsversuche überschreiten, beenden wir die Funktion.
def trigger_prompt_collection(self, model: AIModel, prompt: str, country: str = ""):
headers = {
"Authorization": f"Bearer {self.api_token}",
"Content-Type": "application/json",
}
data = json.dumps(
{"input":
[
{
"url": model.url,
"prompt": prompt,
"country":country,
}
],
})
tries = 3
while tries > 0:
response = None
try:
response = requests.post(
f"https://api.brightdata.com/Datensätze/v3/scrape?Datensatz-ID={model.Datensatz-ID}¬ify=false&include_errors=true",
headers=headers,
data=data,
timeout=POST_TIMEOUT
)
response.raise_for_status()
payload = response.json()
snapshot_id = payload["snapshot_id"]
return snapshot_id
except (ValueError, KeyError, TypeError, requests.RequestException) as e:
print(f"failed to trigger {model.name} snapshot: {e}")
tries -= 1
if response is not None and response.status_code >= 400:
print(f"Status: {response.status_code}")
print(response.text)
print("retries exceeded")
returncollect_snapshot()
Sobald wir unsere snapshot_id haben, überprüfen wir jede Minute, ob sie bereit ist. Die API gibt den Statuscode 202 zurück, wenn die Erfassung gerade läuft. Wenn der Snapshot bereit ist, gibt sie einen 200 zurück. Wenn wir einen anderen Statuscode erhalten, lösen wir einen Fehler aus und gehen zur Wiederholungslogik über. Wenn die Wiederholungsversuche überschritten sind, beenden wir die Methode.
def collect_snapshot(self, model: AIModel, snapshot_id: str):
url = f"https://api.brightdata.com/Datensätze/v3/snapshot/{snapshot_id}"
ready = False
llm_response = None
print(f"Warten auf {model.name} Snapshot {snapshot_id}")
max_errors = 3
while not ready and max_errors > 0:
headers = {"Authorization": f"Bearer {self.api_token}"}
try:
response = requests.get(url, headers=headers, timeout=GET_TIMEOUT)
except requests.RequestException as e:
max_errors -= 1
print(f"{model.name}: Abfragefehler ({e})")
continue
if response.status_code == 200:
print(f"{model.name} Snapshot {snapshot_id} ist bereit!")
bereit = True
llm_response = response.json()
return llm_response
elif response.status_code == 202:
sleep(60)
else:
max_errors-=1
print("Fehler bei der Kommunikation mit dem Server")
print(f"Maximale Fehlerzahl überschritten, Snapshot {snapshot_id} konnte nicht erfasst werden")
returnwrite_model_output()
Dieser ist sehr einfach. Wir verwenden ihn lediglich, um unsere Modellausgaben zu speichern. os.makedirs(OUTPUT_FOLDER, exist_ok=True) wird verwendet, um sicherzustellen, dass wir einen Ausgabeordner haben. Dann schreiben wir die Datei in den Ausgabeordner und verwenden model.name, um die Datei zu benennen.
def write_model_output(self, model: AIModel, llm_response: dict):
os.makedirs(OUTPUT_FOLDER, exist_ok=True)
path = os.path.join(OUTPUT_FOLDER, f"{model.name}-output.json")
with open(path, "w", encoding="utf-8") as file:
json.dump(llm_response, file, indent=4, ensure_ascii=False)
print(f"Finished generating report from {model.name} → {path}") Hauptdatei schreiben
Nun schreiben wir eine Hauptdatei. Mit dieser können wir die Backend-Prozesse ausführen, ohne die Benutzeroberfläche zu laden. Mit run_one() können wir den Prozess auf einem einzelnen Modell ausführen. Innerhalb von main() verwenden wir ThreadPoolExecutor(), um diese Funktion auf mehreren Threads gleichzeitig auszuführen. Anstatt jeweils eine Sammlung auszuführen, können wir eine Sammlung pro Thread ausführen, um unsere Ergebnisse drastisch zu beschleunigen.
import os
from concurrent.futures import ThreadPoolExecutor, as_completed
from dotenv import load_dotenv
from ai_models import chatgpt, perplexity, gemini, grok, copilot, AIModelRetriever
MAX_WORKERS = 5
def run_one(model, retriever, prompt):
retriever.get_model_response(model, prompt)
return model.name
def main():
load_dotenv()
api_token = os.environ["BRIGHTDATA_API_TOKEN"]
prompt = "Warum ist der Himmel blau?"
models = [chatgpt, perplexity, gemini, grok, copilot]
retriever = AIModelRetriever(api_token=api_token)
failures = 0
with ThreadPoolExecutor(max_workers=min(MAX_WORKERS, len(models))) as pool:
futures = {pool.submit(run_one, m, retriever, prompt): m for m in models}
for fut in as_completed(futures):
model = futures[fut]
try:
name = fut.result()
print(f"{name}: done")
except Exception as e:
failures += 1
print(f"{model.name}: failed ({e})")
if failures == len(models):
raise SystemExit(1)
if __name__ == "__main__":
main()Sie können die Hauptdatei mit dem folgenden Befehl ausführen.
python main.pyDie Streamlit-Benutzeroberfläche
Die Streamlit-Benutzeroberfläche ähnelt vom Konzept her stark unserer Hauptdatei. Wir verwenden weiterhin mehrere Threads, um jede Sammlung auszuführen. Unsere Funktionen write_output() und sanitize_filename() dienen lediglich dazu, Dateinamen zu bereinigen. Anstatt auf dem Terminal auszugeben, erstellen wir mit Streamlit Variablen, um die App in Ihrem lokalen Browser zu starten und anzuzeigen.
Schreiben der Benutzeroberfläche
import os
import json
import re
from concurrent.futures import ThreadPoolExecutor, as_completed
from pathlib import Path
import streamlit as st
from dotenv import load_dotenv
from ai_models import chatgpt, perplexity, gemini, grok, copilot, AIModelRetriever
OUTPUT_DIR = Path("output")
MAX_WORKERS = 5
def sanitize_filename(name: str) -> str:
return re.sub(r"[^A-Za-z0-9._-]+", "_", name).strip("_")
def write_output(model_name: str, payload: dict) -> Path:
OUTPUT_DIR.mkdir(parents=True, exist_ok=True)
path = OUTPUT_DIR / f"{sanitize_filename(model_name)}-output.json"
path.write_text(json.dumps(payload, indent=4, ensure_ascii=False), encoding="utf-8")
return path
def main():
st.set_page_config(page_title="Universal LLM Scraper", layout="wide")
st.title("Universal LLM Scraper")
load_dotenv()
api_token = os.getenv("BRIGHTDATA_API_TOKEN")
if not api_token:
st.error("Missing BRIGHTDATA_API_TOKEN. Add it to a .env file in the project root.")
st.stop()
models = [chatgpt, perplexity, gemini, grok, copilot]
model_names = [m.name for m in models]
model_by_name = {m.name: m for m in models}
with st.sidebar:
st.header("Run settings")
prompt = st.text_area("Prompt", value="Who are the best Residential-Proxy providers?", height=120)
target_phrase = st.text_input("Target phrase to track", value="Bright Data")
selected = st.multiselect("Modelle", options=model_names, default=model_names)
country = st.text_input("Land (optional)", value="")
save_to_disk = st.checkbox("Ergebnisse speichern unter/", value=True)
redact_terms = st.text_area("Zu verborgende Markenbegriffe (einer pro Zeile)", value="")
redact_mode = st.selectbox("Verbergungsmodus", ["Maskieren", "Entfernen"], index=0)
run_clicked = st.button("Scrapes ausführen", type="primary", use_container_width=True)
if "results" not in st.session_state:
st.session_state.results = {} # model_name -> payload
if "errors" not in st.session_state:
st.session_state.errors = {} # model_name -> error str
if "paths" not in st.session_state:
st.session_state.paths = {} # model_name -> saved path
def apply_redaction(text: str) -> str:
terms = [t.strip() for t in redact_terms.splitlines() if t.strip()]
if not terms:
return text
pattern = re.compile(r"(" + "|".join(map(re.escape, terms)) + r")", flags=re.IGNORECASE)
if redact_mode == "Mask":
return pattern.sub("███", text)
return pattern.sub("", text)
def extract_answer_text(payload: dict) -> str | None:
if not isinstance(payload, dict):
return None
if isinstance(payload.get("answer_text"), str):
return payload["answer_text"]
if "data" in payload and isinstance(payload["data"], list) and payload["data"]:
first = payload["data"][0]
if isinstance(first, dict) and isinstance(first.get("answer_text"), str):
return first["answer_text"]
return None
def mentions_target(payload: dict) -> bool:
if not target_phrase:
return False
answer = extract_answer_text(payload)
if isinstance(answer, str):
return target_phrase.lower() in answer.lower()
# Fallback: Wenn wir answer_text nicht finden können, suchen wir einfach in der serialisierten Nutzlast.
try:
blob = json.dumps(payload, ensure_ascii=False)
return target_phrase.lower() in blob.lower()
except Exception:
return False
# Layout: Status + Ergebnisse
status_col, results_col = st.columns([1, 2], gap="large")
with status_col:
st.subheader("Status")
if run_clicked:
st.session_state.results = {}
st.session_state.errors = {}
st.session_state.paths = {}
if not selected:
st.warning("Wählen Sie mindestens ein Modell aus.")
st.stop()
retriever = AIModelRetriever(api_token=api_token)
status_boxes = {name: st.empty() for name in selected}
progress = st.progress(0)
done = 0
total = len(selected)
def run_one(model_name: str):
model = model_by_name[model_name]
payload = retriever.run(model, prompt, country=country)
return model_name, payload
with ThreadPoolExecutor(max_workers=min(MAX_WORKERS, total)) as pool:
futures = [pool.submit(run_one, name) for name in selected]
for fut in as_completed(futures):
try:
model_name, payload = fut.result()
st.session_state.results[model_name] = payload
status_boxes[model_name].success(f"{model_name}: done")
if save_to_disk:
path = write_output(model_name, payload)
st.session_state.paths[model_name] = str(path)
except Exception as e:
err = str(e)
st.session_state.errors[f"job-{done+1}"] = err
st.error(err)
done += 1
progress.progress(done / total)
st.success("Ausführung abgeschlossen.")
# Gespeicherte Dateien anzeigen (falls vorhanden)
if st.session_state.paths:
st.caption("Gespeicherte Dateien")
for k, v in st.session_state.paths.items():
st.write(f"- {k}: {v}")
if st.session_state.errors:
st.caption("Fehler")
for k, v in st.session_state.errors.items():
st.write(f"- {k}: {v}")
with results_col:
st.subheader("Ergebnisse")
if not st.session_state.results:
st.info("Klicken Sie auf 'Run scrapes', um die Ergebnisse zu sammeln.")
st.stop()
tabs = st.tabs(list(st.session_state.results.keys()))
for tab, model_name in zip(tabs, st.session_state.results.keys()):
payload = st.session_state.results[model_name]
with tab:
answer_text = extract_answer_text(payload)
mentioned = mentions_target(payload)
st.markdown(f"**Erwähnte Zielphrase:** {'✅' if mentioned else '❌'}")
if answer_text and isinstance(answer_text, str):
st.markdown("### Antwort")
st.text_area(
label="",
value=apply_redaction(answer_text),
height=260
)
else:
st.markdown("### Raw JSON")
st.json(payload)
if __name__ == "__main__":
main()Ja, app.py ist länger als unsere Hauptdatei. Es gibt jedoch nur wenige wesentliche Unterschiede zu main.py.
- Zustandsverwaltung: Mit Streamlit speichern wir unsere Ergebnisfehler und Dateipfade in
st.session_state. So können wir sie innerhalb der Benutzeroberfläche abrufen und anzeigen. - Orchestrierung: Anstatt unsere Eingabeaufforderungen und Modellsammlungen fest zu codieren, werden sie innerhalb der Benutzeroberfläche gesammelt und ausgelöst.
- Textprüfung: Wir überprüfen unseren Antworttext, um festzustellen, ob er die Zielphrase enthält. Ist die Zielphrase vorhanden, zeigen wir ein ✅ an. Ist dies nicht der Fall, zeigen wir stattdessen ein ❌ an.
Verwendung der Benutzeroberfläche
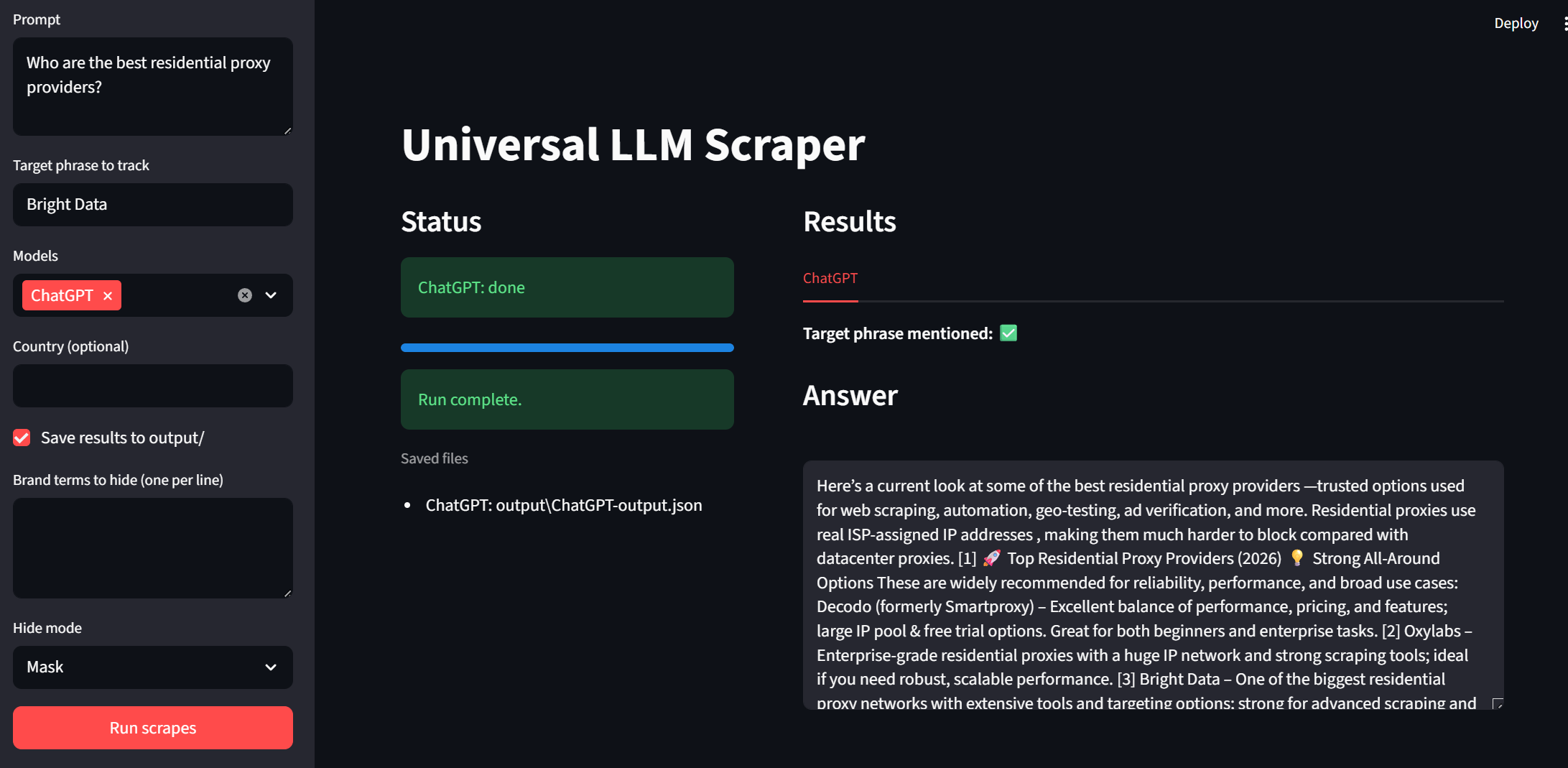
Jetzt ist es an der Zeit, unsere Benutzeroberfläche zu testen. Sie können die App mit dem folgenden Snippet ausführen.
streamlit run app.pyWerfen Sie einen Blick auf die Seitenleiste. Wir können Eingabeaufforderungen und Zielphrasen eingeben. Modelle können nun über ein Dropdown-Menü ausgewählt werden. „Land“ und „Ausgabe speichern“ sind optionale Anpassungen auf der Benutzerseite. Um das Programm auszuführen, klicken Sie einfach unten auf die Schaltfläche „Run scrapes“ (Scrapes ausführen).
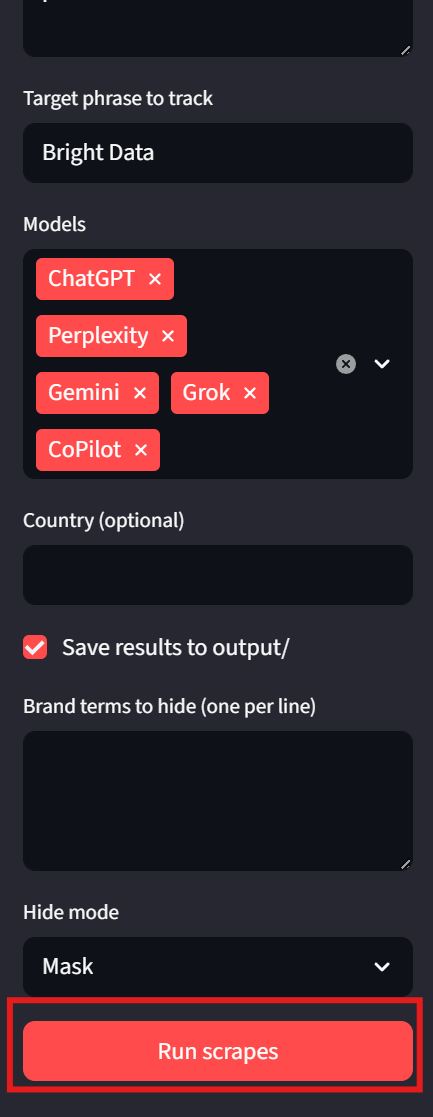
Die Ergebnisse
Jedes Modell wird in den Ergebnissen als eigene Registerkarte angezeigt. Auf diese Weise können wir die Ergebnisse schnell überprüfen. In den folgenden Bildern erhielt Bright Data für jede Modellausgabe ein grünes Häkchen. Beispiel:
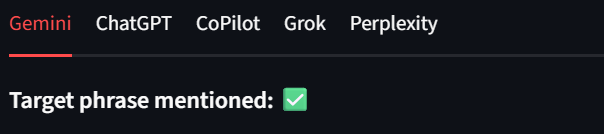
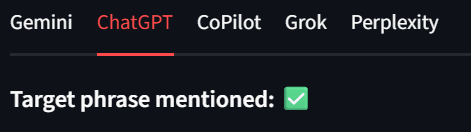
Benutzer sollten auch die untere linke Ecke der Benutzeroberfläche beachten. Hier zeigt die Benutzeroberfläche den Pfad zu jeder der Ergebnisdateien an. Dies erleichtert es den Benutzern, die Rohdaten zu überprüfen.
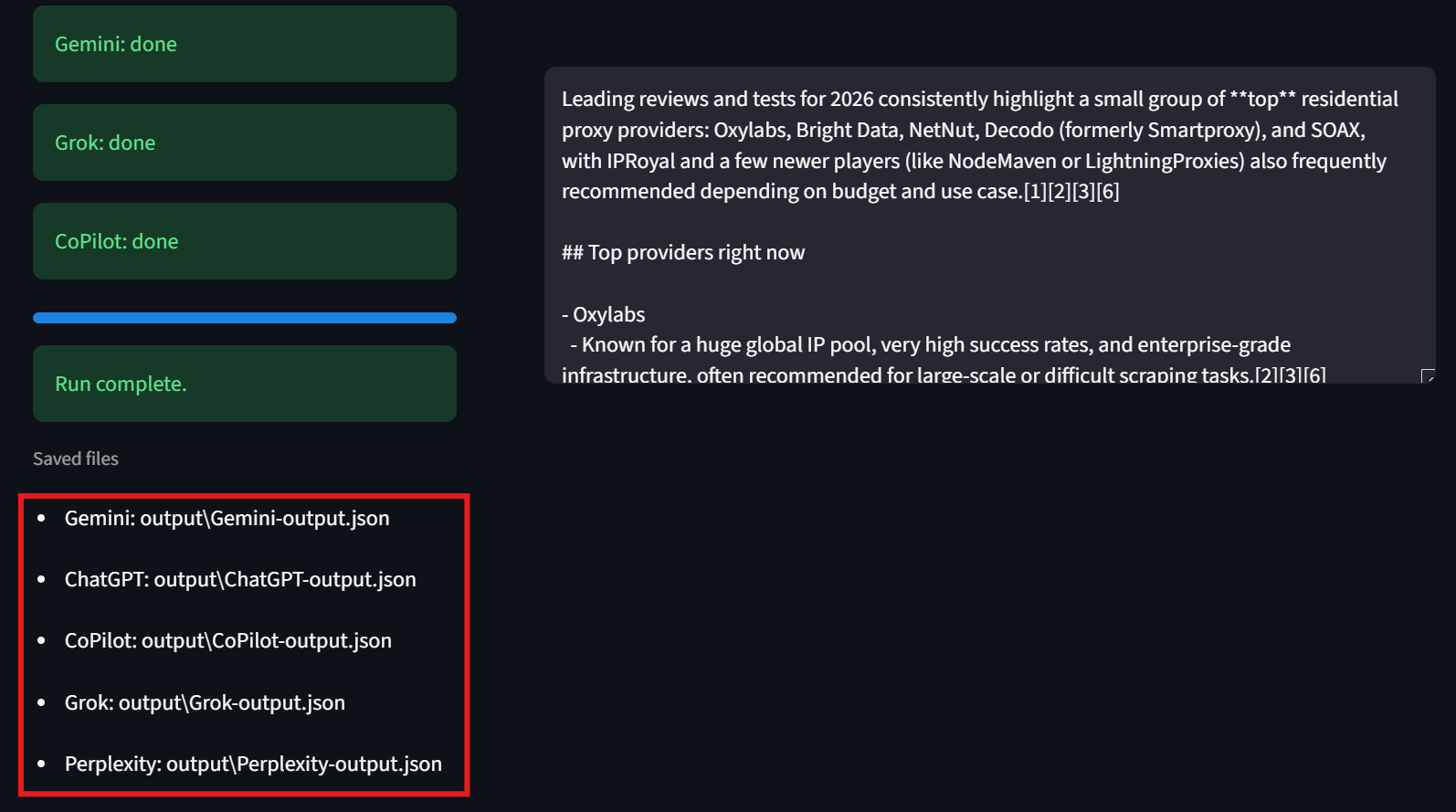
Der nächste Schritt
Zunächst benötigen wir ein Supabase-Konto. Gehen Sie dazu auf supabase.com und folgen Sie den Anweisungen. Supabase bietet verschiedene Preispläne, um Ihren Anforderungen gerecht zu werden. Für dieses Projekt reicht die kostenlose Version völlig aus. Wenn Ihre Datenbank jedoch wächst, müssen Sie möglicherweise ein Upgrade durchführen.
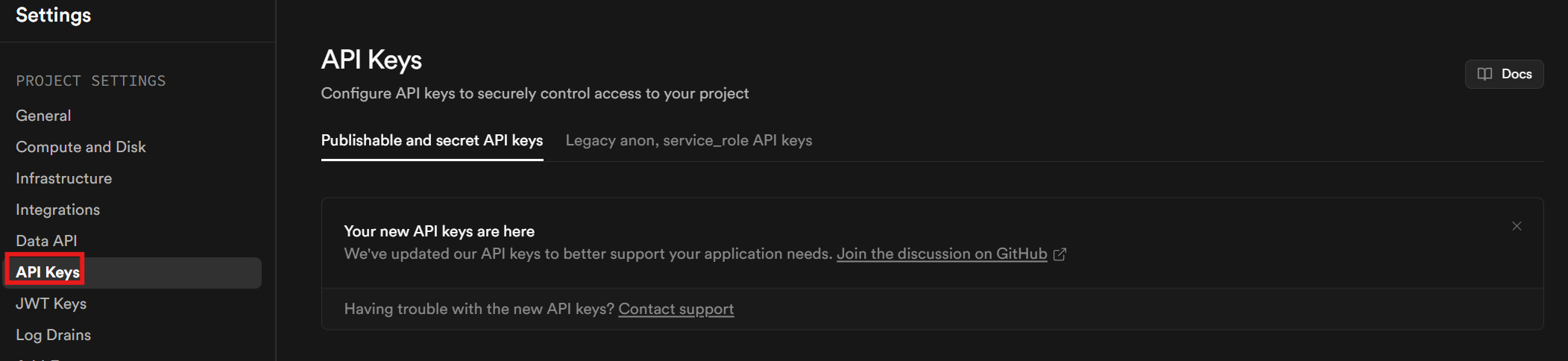
Sie benötigen einen API-Schlüssel. Nachdem Sie Ihr Konto und Ihr Projekt eingerichtet haben, klicken Sie in der Seitenleiste auf „Projekteinstellungen ”. Gehen Sie zur Registerkarte „API-Schlüssel”, um Ihren API-Schlüssel abzurufen.
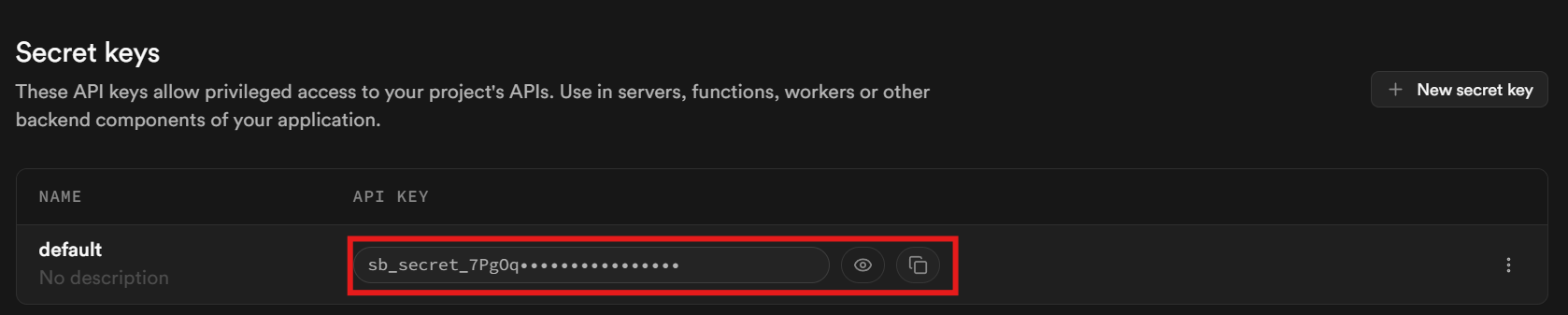
Scrollen Sie zum Ende der Seite. Ihr Schlüssel befindet sich im Abschnitt „Geheime Schlüssel”.
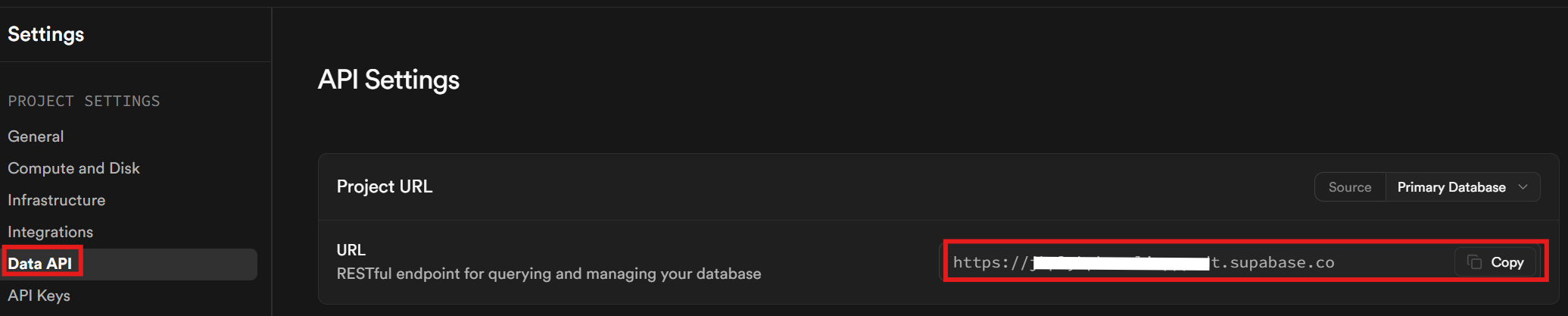
Rufen Sie schließlich auf der Registerkarte „Daten-API“ Ihre Supabase-URL ab. Dies ist die URL, die Sie für die Kommunikation mit Ihrer Datenbank verwenden.
Sobald wir unsere Schlüssel haben, müssen wir unsere Umgebungsdatei und unsere Anforderungsdatei aktualisieren. Ihre neue Umgebungsdatei sollte nun wie folgt aussehen.
BRIGHTDATA_API_TOKEN=<IHR-Bright-Data-API-Schlüssel>
SUPABASE_URL=<IHRE-Supabase-Projekt-URL>
SUPABASE_API_TOKEN=<IHR-Supabase-API-Schlüssel>Unsere Anforderungsdatei sieht nun wie folgt aus.
requests==2.32.5
python-dotenv==1.2.1
streamlit==1.53.0
supabase==2.27.2Erstellen der Tabellen
Nun müssen wir unsere Tabellen in der Datenbank erstellen. Öffnen Sie den SQL-Editor über die Seitenleiste.
LLM-Läufe
Fügen Sie den folgenden SQL-Code in ein Skript ein und führen Sie es aus. Dadurch wird eine Tabelle namens llm_runs erstellt. Jedes Mal, wenn wir eine Sammlung ausführen, werden die Ergebnisse hier gespeichert.
create table public.llm_runs (
id bigint generated by default as identity primary key,
created_at_ts bigint not null, -- unix seconds
model_name text not null,
prompt text not null,
country text null,
target_phrase text null,
mentioned boolean not null default false,
payload jsonb not null
);
create index if not exists llm_runs_created_at_ts_idx
on public.llm_runs (created_at_ts);
create index if not exists llm_runs_model_idx
on public.llm_runs (model_name);
create index if not exists llm_runs_target_idx
on public.llm_runs (target_phrase);Eingabeaufforderungen
Wir benötigen außerdem die Möglichkeit, Eingabeaufforderungen zu speichern. Der folgende Code erstellt eine Tabelle für Eingabeaufforderungen.
create table public.prompts (
id bigint generated by default as identity primary key,
created_at_ts bigint not null,
prompt text not null,
is_active boolean not null default true
);
create index if not exists prompts_created_at_ts_idx
on public.prompts (created_at_ts desc);
create index if not exists prompts_active_idx
on public.prompts (is_active);Zeitpläne
Zuletzt benötigen wir eine Tabelle, in der geplante Jobs gespeichert werden.
create table public.schedules (
id bigint generated by default as identity primary key,
name text not null,
is_enabled boolean not null default true,
next_run_ts bigint not null,
last_run_ts bigint null,
models jsonb not null default '[]'::jsonb,
country text null,
target_phrase text null,
only_active_prompts boolean not null default true,
locked_until_ts bigint null,
lock_owner text null,
repeat_every_seconds bigint not null default 86400
);
create index if not exists schedules_due_idx
on public.schedules (is_enabled, next_run_ts);
create index if not exists schedules_lock_idx
on public.schedules (locked_until_ts);Aktualisierte Architektur
Der endgültige Code ist nun so umfangreich, dass er nicht mehr in ein Tutorial passt. Anstatt hier alle Dateien aufzulisten, gehen wir auf einige der Kernpunkte der Datenbankverbindung, des Headless Runners und der Streamlit-Benutzeroberfläche ein.
Datenbankinteraktionen
Wir haben eine Vielzahl von Datenbank-Helfern, aber alles basiert in erster Linie auf dem Lesen und Erstellen innerhalb der Datenbank. Der folgende Code ermöglicht es uns, eine Verbindung zur gesamten Datenbank herzustellen.
def get_db() -> Client:
url = os.getenv("SUPABASE_URL")
key = os.getenv("SUPABASE_API_TOKEN") # Halten Sie die Konsistenz mit Ihrer .env ein
if not url or not key:
raise RuntimeError("Missing SUPABASE_URL or SUPABASE_API_TOKEN in environment.")
return create_client(url, key)Um tatsächlich mit der Datenbank zu interagieren, rufen wir zusätzlich zu get_db() weitere Methoden auf. Im nächsten Ausschnitt ruft get_db() die Datenbank ab. Anschließend verwenden wir db.table("llm_runs").insert(row).execute(), um neue Zeilen in unsere Tabelle llm_runs einzufügen. Die Eingabeaufforderungen und Planungshilfen folgen derselben grundlegenden Logik.
def save_run(
*,
model_name: str,
prompt: str,
country: str,
target_phrase: str,
mentioned: bool,
payload: dict,)
-> dict:
db = get_db()
row = {
"created_at_ts": int(time.time()),
"model_name": model_name,
"prompt": prompt,
"country": country or None,
"target_phrase": target_phrase or None,
„mentioned”: bool(mentioned),
„payload”: payload, # JSONB
}
res = db.table("llm_runs").insert(row).execute()
if not getattr(res, "data", None):
row["payload"] = {"ERROR": "FAILED RUN"}
res = db.table("llm_runs").insert(row).execute()
raise RuntimeError(f"Insert failed: {res}")
return res.data[0]Headless Runner
Nach der Erstellung der Streamlit-Benutzeroberfläche haben wir main.py in headless_runner.py umbenannt, da sich der Umfang des Projekts erweitert hat. Es gibt nicht mehr nur ein Hauptprogramm, sondern zwei Skripte, die gleichzeitig ausgeführt werden.
persist_run() überprüft, ob die API eine leere Nutzlast enthält. Ist dies der Fall, geben wir False zurück und drucken eine Meldung über die fehlgeschlagene Einfügung auf dem Terminal aus. Enthält die Nutzlast Informationen, fügen wir die Ergebnisse mit save_run() in die Datenbank ein.
def persist_run(*, model_name: str, prompt: str, payload, target_phrase: str, country: str = "") -> bool:
if payload is None:
print(f"{model_name}: skipping DB insert (payload is None).")
return False
# Wenn Sie leere Listen/Dicts als „nicht speichern” behandeln möchten, behalten Sie dies bei:
if payload == {} or payload == []:
print(f"{model_name}: DB-Einfügung überspringen (leere Nutzlast). type={type(payload).__name__}")
return False
try:
json.dumps(payload, ensure_ascii=False)
except TypeError as e:
print(f"{model_name}: payload nicht JSON-serialisierbar ({e}). Stringifizierung.")
payload = {"raw": json.dumps(payload, default=str, ensure_ascii=False)}
mentioned = mentions_target(payload if isinstance(payload, dict) else {"data": payload}, target_phrase)
try:
save_run(
model_name=model_name,
prompt=prompt,
country=country,
target_phrase=target_phrase,
mentioned=mentioned,
payload=payload,
)
except Exception as db_err:
print(f"{model_name}: DB-Einfügung fehlgeschlagen: {db_err}")
return mentionedBevor wir fortfahren, gibt es noch einen weiteren wichtigen Teil unseres Headless Runners, den Sie sich ansehen sollten. Wir haben eine Reihe von optionalen Umgebungsvariablen, die Sie zur Konfigurationsanpassung verwenden können. Unsere eigentliche Programmlaufzeit wird in einer einfachen while-Schleife gehalten. Innerhalb der Laufzeitschleife überprüfen wir kontinuierlich, ob neue Jobs im Zeitplan vorhanden sind. Immer wenn ein geplanter Job fällig ist, ruft er run_schedule_once() auf, um den Lauf zu starten.
# diese ohne DB-Änderungen anpassen
tick_every_seconds = int(os.getenv("SCHED_TICK_SECONDS", "15")) # wie oft aufwachen
lock_seconds = int(os.getenv("SCHED_LOCK_SECONDS", "1800")) # Sperrdauer während eines Auftrags läuft
drain_all_due = os.getenv("SCHED_DRAIN_ALL_DUE", "1") == "1" # alle fälligen Aufträge bei jedem Tick ausführen
save_to_disk = os.getenv("SCHED_SAVE_TO_DISK", "0") == "1"
while True:
now_ts = int(time.time())
ran_any = False
# einen Zeitplan beanspruchen und ausführen oder alle fälligen Zeitpläne abarbeiten
while True:
try:
due = claim_due_schedule(now_ts=now_ts, lock_owner=lock_owner, lock_seconds=lock_seconds)
except Exception as e:
print(f"Failed to claim due schedule: {e}")
due = None
if not due:
break
ran_any = True
try:
run_schedule_once(
schedule_row=due,
retriever=retriever,
available_models=available_models,
model_by_name=model_by_name,
save_to_disk=save_to_disk,
)
except Exception as e:
# Wenn während der Ausführung ein Fehler auftritt, wird der Zeitplan NICHT fortgesetzt.
# Die Sperre läuft ab und der Zeitplan wird später wieder aufgenommen.
print(f"Zeitplanausführung abgestürzt: {e}")
if not drain_all_due:
break
# Zeit für nächsten Anspruch aktualisieren
now_ts = int(time.time())
if not ran_any:
# optional: leisere Protokolle
print(f"[{int(time.time())}] Keine fälligen Zeitpläne.")
time.sleep(tick_every_seconds)Um den Headless Runner zu starten, öffnen Sie einfach ein neues Terminal und führen Sie python headless_runner.py aus.
Die Streamlit-Anwendung
Unsere Streamlit-Anwendung ist massiv gewachsen. Sie können sie weiterhin mit streamlit run app.py aufrufen. Sie verfügt nun über fünf separate Registerkarten. Die ursprüngliche Seite „Run Scrapes“ wird weiterhin sofort auf unserem Dashboard angezeigt.
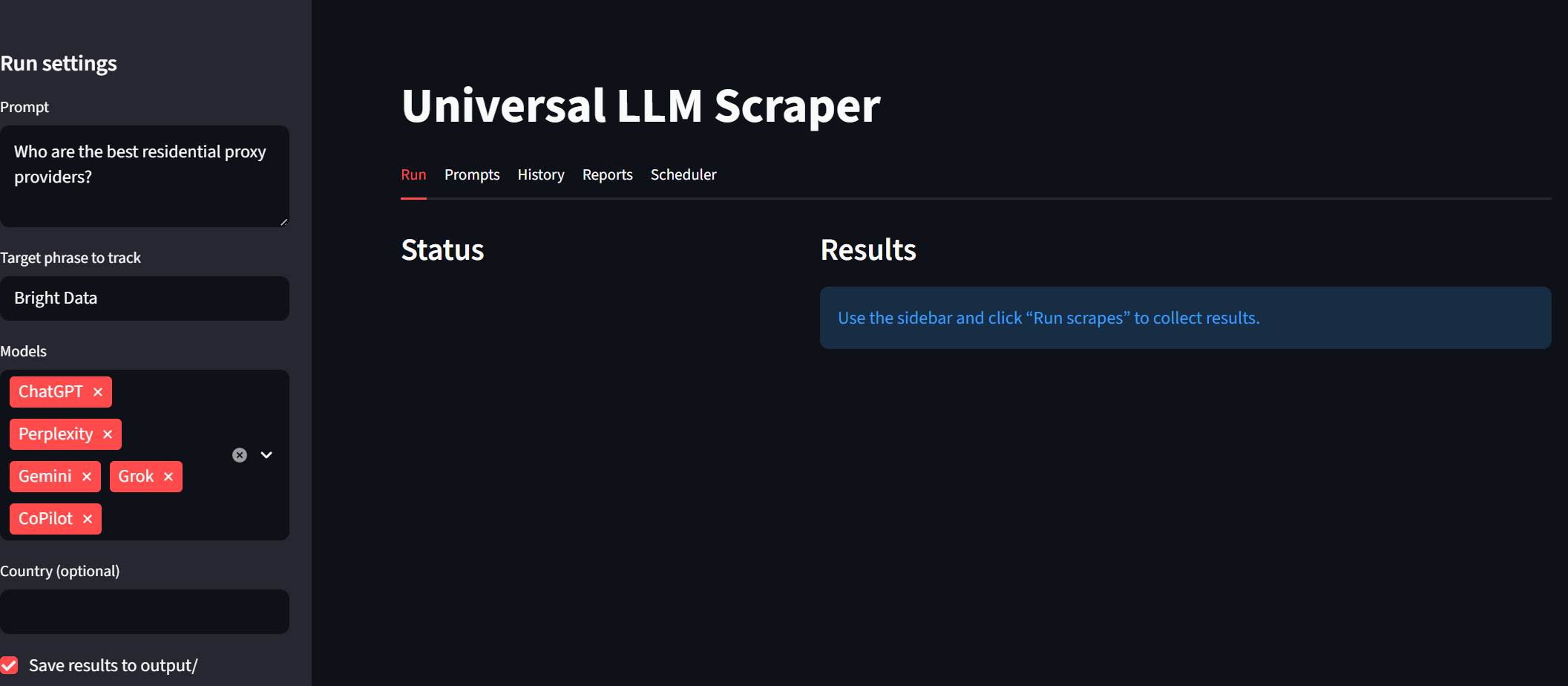
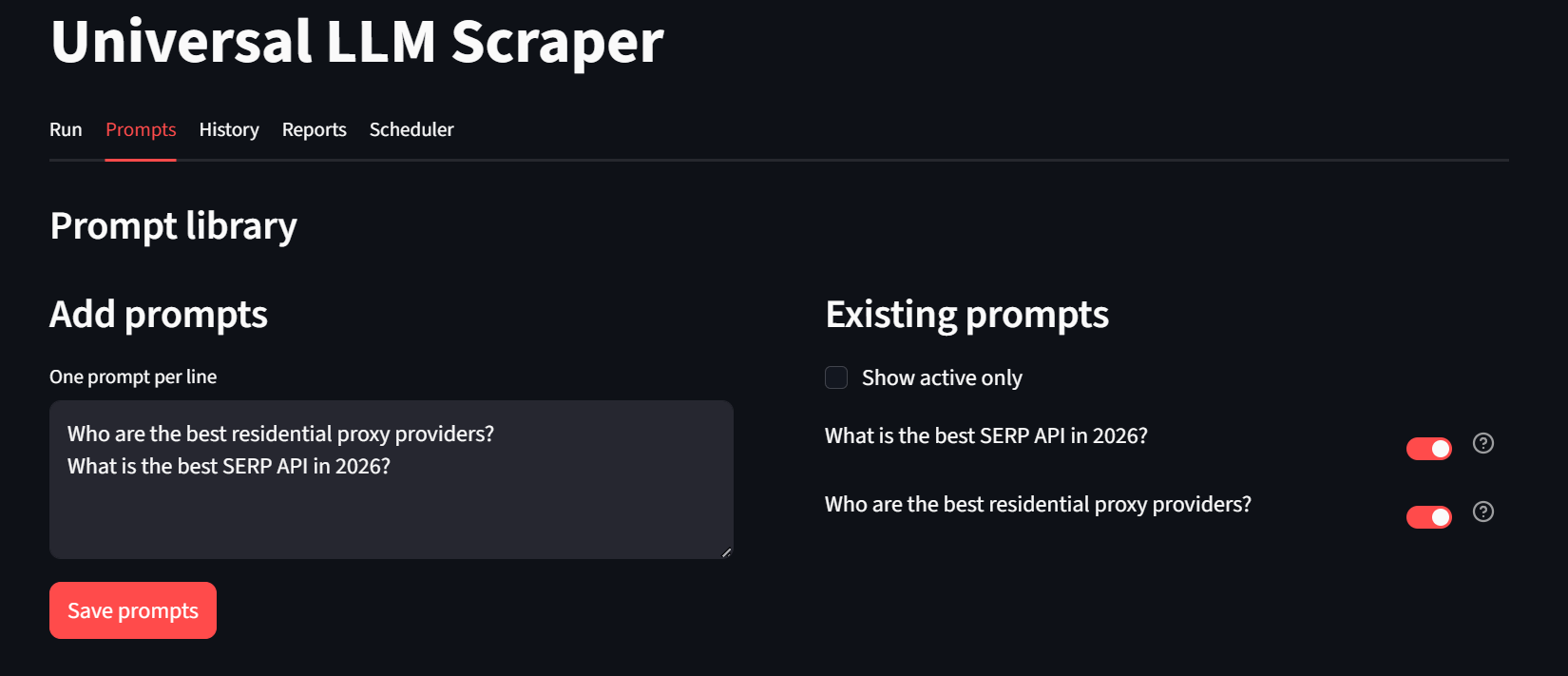
Auf unserer Registerkarte „Prompts“ können Benutzer neue Eingabeaufforderungen erstellen und diese optional für die spätere Verwendung speichern. Am unteren Rand dieser Seite können Benutzer Massenausführungen konfigurieren und durchführen.
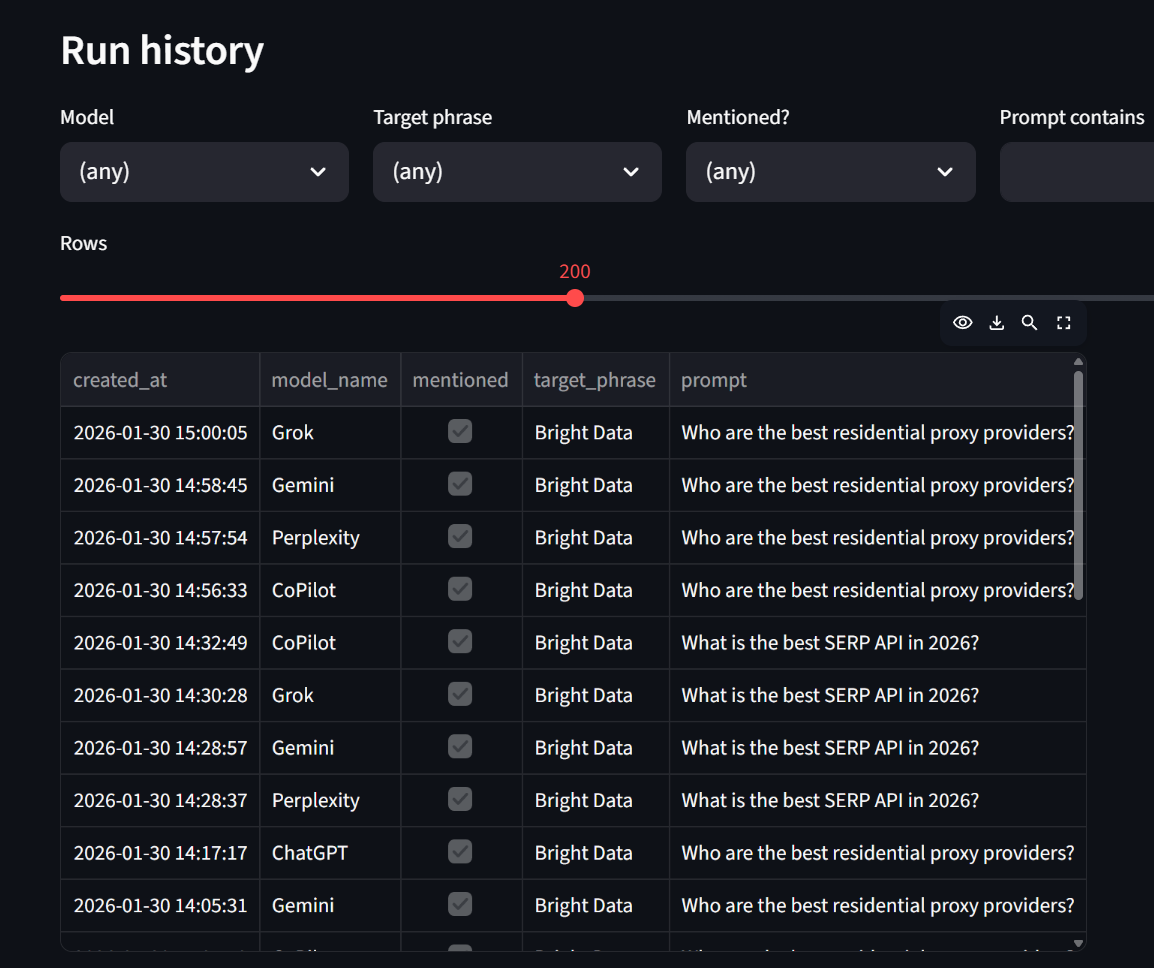
Über die Registerkarte „History“ können Benutzer den detaillierten Ausführungsverlauf einsehen. Am Ende dieser Seite haben Benutzer außerdem die Möglichkeit, bei Bedarf die rohen JSON-Nutzdaten zu überprüfen.
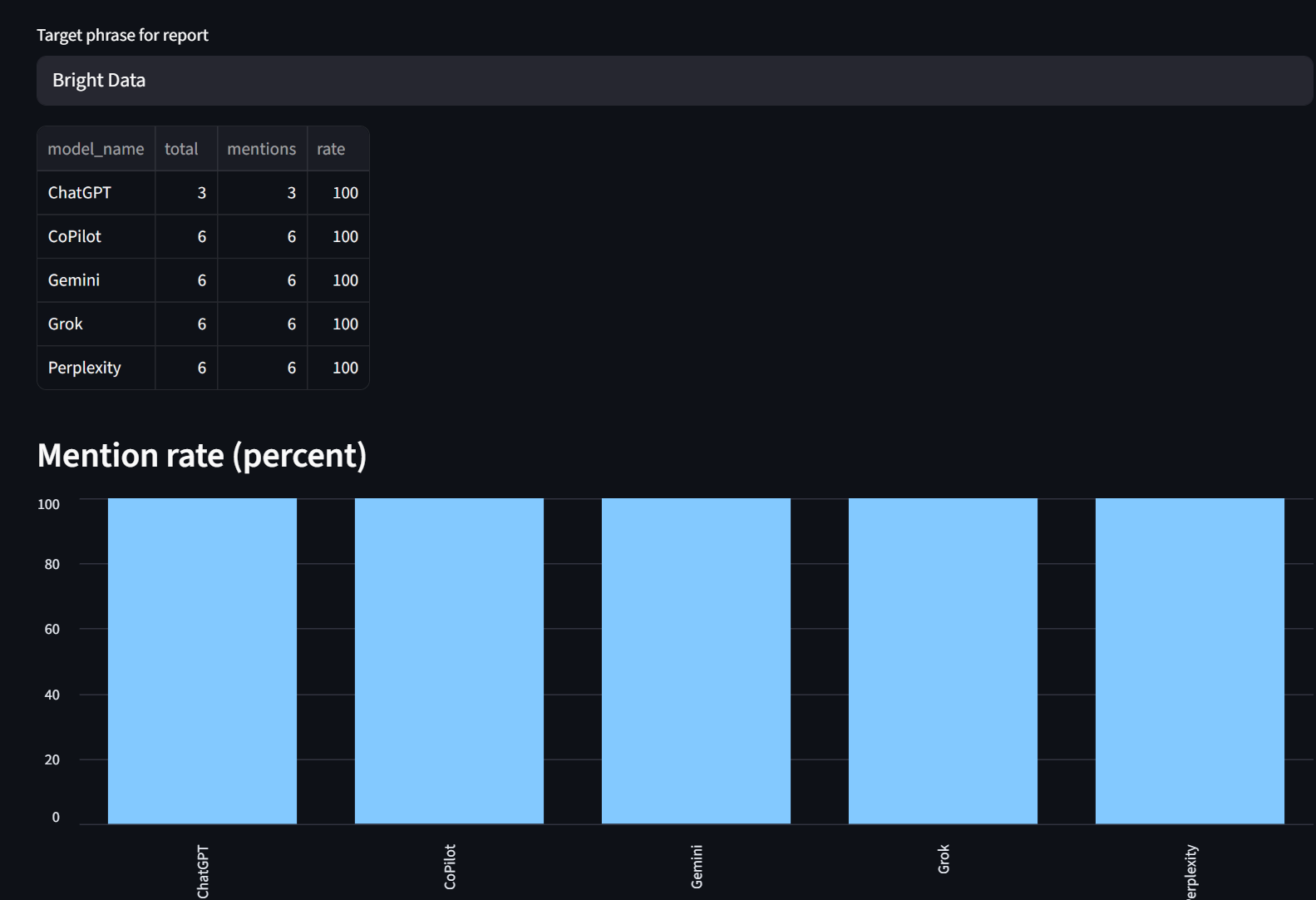
Auf unserer Registerkarte „Reports“ können Sie die Erwähnungsraten nach Modell aufgeschlüsselt einsehen. Wie Sie sehen können, wurde Bright Data hier von jedem Modell zu 100 % erwähnt.
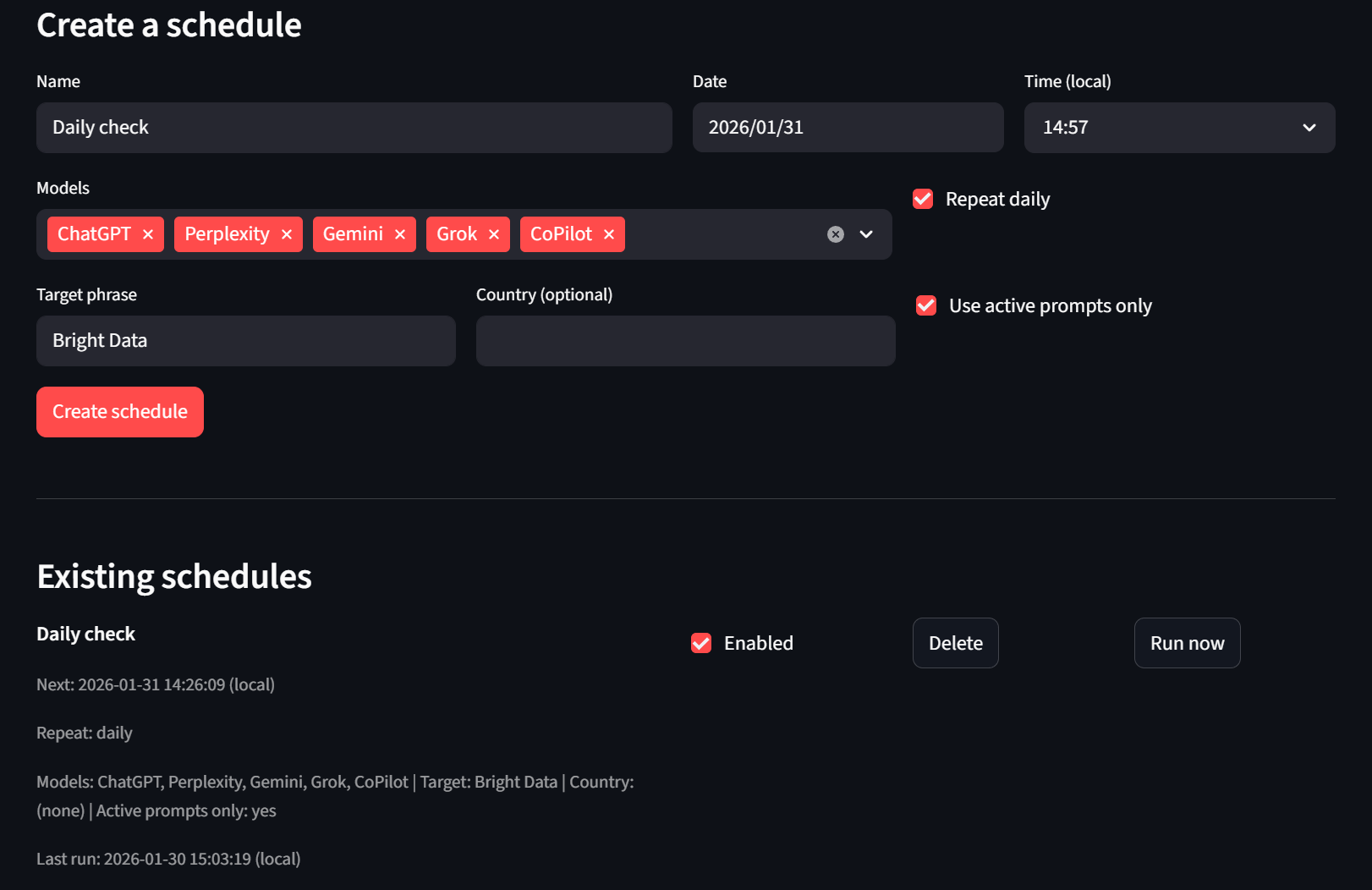
Schließlich gibt es noch die Registerkarte „Scheduler“. Benutzer können Zeitpläne erstellen und löschen. Wenn sie nicht warten möchten, können sie auch die Schaltfläche „Jetzt ausführen“ verwenden, und der Headless Runner übernimmt den Auftrag beim nächsten Tick.
Fazit
Wenn Sie den Prototyp am Anfang dieses Artikels erstellt haben, verstehen Sie bereits die Konzepte, die erforderlich sind, um Tools wie dieses in die nächste Phase zu bringen.
Die in diesem Leitfaden vorgestellte Architektur unterstützt:
- Persistenter Speicher und historische Nachverfolgung: Speichern Sie Ergebnisse über einen längeren Zeitraum, um Trends zu erkennen, wie KI-Modelle Ihre Marke erwähnen, Ranking-Änderungen zu verfolgen und aufstrebende Wettbewerber zu identifizieren.
- Hunderte von täglich überwachten Eingabeaufforderungen: Automatisieren Sie geplante Erfassungen über Tausende von Keyword-Variationen, Produktkategorien und Wettbewerbsvergleiche hinweg.
- Automatisierte Berichterstellung und Analyse: Erstellen Sie Berichte, die die Erwähnungshäufigkeit Ihrer Marke, Stimmungsanalysen, Zitierhäufigkeit und Wettbewerbspositionierung in allen wichtigen LLMs zeigen.
- Warnsysteme: Lösen Sie Benachrichtigungen aus, wenn Ihre Marke aus Empfehlungen herausfällt oder wenn Wettbewerber an Sichtbarkeit gewinnen.
- Überwachung mehrerer Regionen: Verfolgen Sie, wie sich KI-Antworten je nach Region unterscheiden, um lokalisierte Marketingstrategien zu entwickeln.
Für Unternehmensteams, die die Markenreputation in großem Maßstab verwalten, ist die Fähigkeit, die Frage „Wird mein Unternehmen von KI empfohlen?“ für jedes wichtige Modell, für jede relevante Anfrage und jeden Tag zu beantworten, nicht mehr optional. Es handelt sich um eine unverzichtbare Infrastruktur.
Die Web Scraper-APIs von Bright Data liefern die normalisierten, zuverlässigen Datenfeeds, die diese Art der Überwachung ermöglichen. Ganz gleich, ob Sie ChatGPT, Perplexity, Gemini, Grok oder Microsoft Copilot verfolgen – das einheitliche Schema beseitigt Reibungsverluste bei der Integration und ermöglicht es Ihrem Team, sich auf Erkenntnisse statt auf die Datenaufbereitung zu konzentrieren.
Sind Sie bereit, Ihr eigenes KI-Sichtbarkeitsüberwachungssystem aufzubauen? Testen Sie es gratis und sehen Sie selbst, wie Bright Data Ihre SEO-Strategie der nächsten Generation voranbringen kann.