

In diesem Artikel erfahren Sie:
- Warum das Scraping von LLMs wichtig ist und welche Szenarien es unterstützt.
- Warum es am besten ist, sich auf einen speziellen LLM-Chat-Scraper zu verlassen.
- Die wichtigsten Faktoren, die beim Vergleich von Lösungen zum Scrapen von LLMs zu berücksichtigen sind.
- Eine Liste der besten LLM-Scraper des Jahres.
Lassen Sie uns eintauchen!
TL;DR: Übersichtstabelle der besten LLM-Scraper
Wenn Sie es eilig haben, können Sie die besten LLM-Scraper in der folgenden Übersichtstabelle auf einen Blick vergleichen.
| LLM-Scraper | Typen | Unterstützte LLMs | APIs | No-Code | Infrastruktur | Parallelität | GDPR-Konformität | Kostenlose Testversion | Einstiegspreis |
|---|---|---|---|---|---|---|---|---|---|
| Bright Data | API Scraper + No-Code + Managed | ChatGPT, Perplexity, Gemini, Grok, Google KI Mode, Copilot | ✅ | ✅ | Unternehmens-Proxy-Netzwerk (über 150 Millionen IPs) mit automatischer Entsperrung | Unbegrenzt | ✅ | ✅ | 1,5 $/1.000 Datensätze |
| Ohne Scraping | API-Scraper | ChatGPT, Perplexity, Copilot, Gemini, Google KI Mode, Grok | ✅ | ❌ | Einheitliche API + Proxy-Netzwerk mit über 80 Millionen Servern | Hoch | ✅ | ✅ | 49 $/Monat |
| cloro | API-Scraper | ChatGPT, Perplexity, Copilot, Gemini, Grok, Google KI Mode | ✅ | ❌ | Einheitliche API mit Geo-Targeting | Begrenzt (10–100 gleichzeitige Aufträge) | ✅ | ✅ | 100 $/Monat |
| A-Parser | Desktop-Scraper + API | ChatGPT, Perplexity, Google KI Mode, Copilot, DeepAI, Kimi | ✅ (für die Verwaltung) | ✅ | Lokale Ausführung + Management-APIs | Begrenzt (~100–200 Abfragen/Minute) | — (nicht bekannt gegeben) | ❌ | 179 $ einmalig |
| Infatica | API-Scraper | ChatGPT, Gemini, Perplexity | ✅ | ❌ | Scraping der API mit Residential-Proxys | Hoch | ✅ | ❌ | Benutzerdefiniert |
| Apify | Fertige Scraper + API | ChatGPT, Gemini, Perplexity, Grok, andere (Akteursbasiert) | ✅ | ✅ | Serverlose Scraping-Plattform mit Proxy-Unterstützung | Begrenzt (25–256 gleichzeitige Ausführungen) | ✅ | ✅ | Akteursabhängig |
Eine Einführung in die Welt des Scrapings von LLMs
Bevor wir uns mit den besten LLM-Scrapers befassen, ist es hilfreich, sich einige Hintergrundinformationen und den Kontext zum Scraping von Daten aus LLMs anzueignen.
Was ist ein LLM-Scraper?
Ein LLM-Scraper, auch LLM-Chat-Scraper oder Scraping-LLM-Lösung genannt, ist ein Tool, das speziell dafür entwickelt wurde, strukturierte Daten aus LLMs zu extrahieren. Mit anderen Worten: Es sendet automatisch Eingabeaufforderungen und sammelt die generierten Antworten.
In den meisten Fällen ruft er nicht nur die direkten Antworten ab, sondern auch zusätzliche Ausgaben wie Zitate, Links und Metadaten. Zu den Zielplattformen gehören ChatGPT, Gemini, Perplexity, Grok und ähnliche Dienste.
Warum das Scraping von LLMs so wichtig ist
Das Scraping von Daten aus LLMs wird immer wichtiger, da KI-Forscher von einem wachsenden „Data Barrel”-Problem sprechen. Dahinter steht die Idee, dass hochwertige, von Menschen verfasste Online-Texte nicht mehr ausreichen, um neue Modelle zu trainieren, was Unternehmen dazu veranlasst, auf synthetische und KI-generierte Datenpipelines zurückzugreifen.
Infolgedessen werden LLM-generierte Inhalte mittlerweile in großem Umfang für das Training und die Feinabstimmung neuer Modelle verwendet. Dieser Ansatz wird für die Erstellung von Bewertungsdatensätzen und die Produktion kontinuierlich aktualisierter Wissensdatenbanken eingesetzt.
Branchenschätzungen zufolge stützen sich viele moderne Modelle bereits stark auf synthetische Inhalte für die spezialisierte Feinabstimmung. Prognosen zufolge könnten synthetische Daten bis 2030 das KI-Training dominieren.
Mehrere vielbeachtete Entwicklungen unterstreichen diesen Trend. NVIDIA hat mit seinem Minitron-Ansatz gezeigt, dass Modelle mit weniger als 3 % der Originaldaten durch Destillation aus größeren Modellen neu trainiert werden können. Dies zeigt, wie LLM-Ausgaben als effizientes Trainingsmaterial dienen können.
DeepSeek ist ein Beispiel für Leistungsverbesserungen, die durch das Training mit Outputs aus fortgeschritteneren Modellen erzielt werden. Das Scraping von LLMs unterstützt auch die dynamische Datenproduktion, z. B. die Überwachung, wie Modelle im Laufe der Zeit auf Eingaben reagieren, um Ihnen beim Aufbau von Datensätzen für Eingabe-Antwort-Kombinationen zu helfen.
Vorteile des LLM-Scrapings
Die wichtigsten Vorteile und Anwendungsfälle, die LLM-Scraping eröffnet, sind:
- Abfragen und Ergebnisse in einfacher Sprache: Rufen Sie Informationen über Eingaben in natürlicher Sprache ab, wodurch die Datenerfassung einfacher wird als beim herkömmlichen Scraping auf Basis von Parsing.
- Erstellung von Datensätzen für das Modelltraining: Sammeln Sie Eingabe-Antwort-Paare, um Datensätze für die Feinabstimmung, Bewertung, das Benchmarking oder das Training benutzerdefinierter KI-Modelle zu erstellen.
- Modellübergreifender Vergleich: Vergleichen Sie die Antworten mehrerer LLM-Anbieter, um Unterschiede, Übereinstimmungen und modellspezifisches Verhalten zu identifizieren.
- Strukturierte Wissensextraktion: Extrahieren Sie strukturierte Daten wie Links, Zitate, Entitäten und Metadaten aus ansonsten unstrukturierten Modellantworten.
- GEO (Generative Engine Optimization) und KI-Suchüberwachung: Verfolgen Sie, wie Marken, Produkte oder Themen im Laufe der Zeit in KI-generierten Antworten verschiedener Modelle erscheinen.
- Änderungserkennung im Zeitverlauf: Überwachen Sie, wie sich Modellantworten im Zuge von Modellaktualisierungen oder Änderungen der Informationen im Internet entwickeln.
Warum Sie sich auf einen dedizierten LLM-Scraper verlassen sollten
Das Abrufen von Daten aus LLMs ist an sich keine Herausforderung, da Sie über die API direkt Anweisungen an die Modelle senden können. Die eigentliche Schwierigkeit besteht darin, den Prozess zu standardisieren und in großem Maßstab auszuführen. Die meisten LLM-Anbieter legen API-Ratenbeschränkungen auf der Grundlage von Preisplänen fest, und die Antworten variieren stark zwischen den Anbietern.
Durch die Wahl eines spezialisierten LLM-Scrapers können Sie diese Herausforderungen vermeiden. Sie erhalten eine einheitliche Erfahrung für das Scraping von LLMs, in der Regel über APIs oder No-Code-Tools. Dies hilft, den Prozess des Abrufens von Daten aus KI-Modellen in einem strukturierten, stabilen und konsistenten Format zu standardisieren.
LLM-Scraper unterstützen auch Funktionen wie Geolokalisierung, Massenanfragen und andere Fähigkeiten, die die Datenextraktion einfacher machen als der direkte Aufruf der APIs. In vielen Fällen können sie dank der groß angelegten Infrastruktur und Caching-Mechanismen im Hintergrund auch schneller und kostengünstiger sein.
Aspekte, die bei der Bewertung von LLM-Scrapern zu berücksichtigen sind
Lösungen zum Web-Scraping mittels KI sind sehr beliebt, aber Tools, die speziell für das Scraping von Daten aus LLMs entwickelt wurden, sind noch relativ selten. Dennoch wächst der Markt schnell und es kommen regelmäßig neue Anbieter hinzu.
Um Zeit zu sparen und sich auf die relevantesten Tools zu konzentrieren, benötigen Sie ein Vergleichsrahmenwerk, um diese anhand einheitlicher Kriterien zu bewerten, wie z. B.:
- Typ: Handelt es sich bei der Lösung um eine API, eine No-Code-Plattform, eine Desktop-Anwendung oder ein anderes Tool?
- Abgedeckte LLMs: Die unterstützten LLM-Anbieter und -Plattformen (z. B. ChatGPT, Gemini, Grok usw.).
- Enthaltene Daten: Die Art der Daten, die Sie aus LLM-Antworten abrufen können, z. B. Klartext, Zitate, Hyperlinks und mehr.
- Infrastruktur: Die Fähigkeit des Anbieters, zu skalieren, die Verfügbarkeit aufrechtzuerhalten und große Anfragenvolumina zu bewältigen.
- Technische Anforderungen: Die Fähigkeiten oder die Infrastruktur, die für die Nutzung und Integration der LLM-Scraping-Lösung erforderlich sind.
- Compliance: Einhaltung von Datenschutzbestimmungen (wie DSGVO und CCPA) und bewährten Sicherheitsverfahren.
- Preise: Die Preisstruktur, einschließlich kostenloser Testversionen oder Gutschriften zur Evaluierung.
Die besten LLM-Scraper: Top-Tools und -Lösungen
Unter Berücksichtigung der zuvor genannten Kriterien wollen wir uns nun die sechs besten LLM-Scraper ansehen.
1. Bright Data
Bright Data begann als Proxy-Anbieter und hat seine Plattform zu einer führenden Webdatenlösung ausgebaut. Das umfangreiche Angebot umfasst spezielle Tools zum Sammeln von Daten aus KI-Systemen. Diese LLM-Scraper extrahieren strukturierte Antworten und Metadaten aus wichtigen KI-Modellen auf konsistente und skalierbare Weise, entweder über eine API oder über eine No-Code-Schnittstelle.
Im Einzelnen umfassen die wichtigsten Lösungen von Bright Data für das Scraping von LLMs:
- ChatGPT Scraper: Sammeln Sie strukturierte Antworten, Eingabeaufforderungen, Zitate, Links, Rankings und Konversationsmetadaten aus ChatGPT-Abfragen in Echtzeit.
- Perplexity Scraper: Rufen Sie KI-generierte Antworten zusammen mit Quellen, Zitaten und strukturierten Antwortdaten aus Perplexity-Suchen ab.
- Gemini Scraper: Extrahieren Sie Eingabeaufforderungen, generierte Antworten, Zitate, Links und Metadaten aus Gemini-Antworten in einem standardisierten Format.
- Grok Scraper: Sammeln Sie von Grok generierte Antworten zusammen mit strukturierten Metadaten wie Zitaten, Rohantworten und indizierten Ausgaben.
- Google AI Mode Scraper: Erfassen Sie KI-generierte Suchantworten aus dem Google AI Mode, einschließlich Eingabeaufforderungen, Antworten, Zitaten, Links und indizierten Ergebnissen.
- Copilot Scraper: Rufen Sie strukturierte Antworten, Quellen und Antwortabschnitte aus Copilot-Suchergebnissen ab.
Alle diese Lösungen laufen auf der unternehmensgerechten Infrastruktur von Bright Data, die von einem globalen Proxy-Netzwerk mit über 150 Millionen IPs, automatischen Entsperrungstechnologien und einer Verfügbarkeit von 99,99 % unterstützt wird. Diese Infrastruktur ermöglicht eine zuverlässige, groß angelegte LLM-Datenerfassung ohne zusätzlichen Betriebsaufwand.
Zusammengenommen machen diese Aspekte Bright Data zum umfassendsten und skalierbarsten Anbieter für LLM-Scraping.
🏆 Ideal für: Unternehmensgerechte, hoch skalierbare, gleichzeitige LLM-Scraping-Lösungen mit mehreren Anbietern über No-Code- oder API-Integrationen.
Typ:
- API-basierter LLM-Scraper.
- No-Code-LLM-Scraping-Optionen über ein Control Panel.
- Vollständig verwaltete LLM-Datenerfassungsoption verfügbar.
Abgedeckte LLMs:
- ChatGPT
- Perplexity
- Gemini
- Grok
- Google KI Mode (KI Overviews)
- Copilot
Enthaltene Daten:
- Modellantworten im Text-, HTML- oder Markdown-Format.
- Strukturierte Ausgabeformate wie JSON, NDJSON und CSV.
- Abfrageaufforderungen und URLs.
- Antwortinhalte und vollständige Nachrichten.
- Zitate und Quellen.
- Angehängte Links.
- Empfehlungen und Rankings.
- Zeitstempel und Metadaten.
- Rohantworten und Parsing von strukturierten Daten (je nach Anbieter).
- Metadaten auf Länderebene.
Infrastruktur:
- Integrierte Proxy- und Entsperrinfrastruktur mit automatischer IP-Rotation und CAPTCHA-Lösung.
- Zugriff auf über 150 Millionen IPs in 195 Ländern.
- Unterstützt Massenanfragen mit bis zu 5.000 Anfragen gleichzeitig.
- 99,95 % Erfolgsquote.
- Webhook-basierte oder API-basierte Datenübertragung.
- Ergebnisse können heruntergeladen oder an Speicherdienste wie Amazon S3 und Google Cloud Storage geliefert werden.
- Infrastruktur mit einer Verfügbarkeit von 99,99 %.
- Entwickelt für die Erfassung großer Datenmengen und skalierbare Workloads.
- Funktionen zum Parsing, zur Validierung und zur Strukturerkennung.
- Unbegrenzte Parallelität.
- Unterstützung für automatisierte, geplante Ausführungen.
- 27/4-Support durch ein Expertenteam.
- Über 70 KI-Integrationen verfügbar.
Technische Anforderungen:
- Grundlegende Programmierkenntnisse für die Verbindung mit den LLM-Scraping-APIs erforderlich.
- No-Code-Schnittstelle für nicht-technische Benutzer verfügbar.
- Technische Kenntnisse für die Integration in KI/ML-Workflows, Pipelines und Anwendungen erforderlich.
Compliance:
- Vollständig konform mit der DSGVO.
- CCPA-konform.
- SEC-konform.
- Zertifiziert nach den Standards ISO 27001, SOC 2 Typ II und CSA STAR Level 1.
Preise:
- Kostenlose Testversion ohne Kreditkarte verfügbar.
- Pay-as-you-go-Preise ab 1,5 $ pro 1.000 Datensätze ohne Vertragsbindung.
- Monatliche Tarife verfügbar:
- 510.000 Datensätze für 499 $/Monat (0,98 $/1.000 Datensätze).
- 1 Million Datensätze für 999 $/Monat (0,83 $/1.000 Datensätze).
- 2,5 Millionen Datensätze für 1.999 $/Monat (0,75 $/1.000 Datensätze).
- Unternehmenspläne mit individuellen Preisen verfügbar.
2. Scrapeless
Scrapeless ist ein Proxy- und Web-Scraping-Unternehmen, das sich auf die automatisierte Extraktion öffentlicher Daten spezialisiert hat, sogar aus LLMs. Insbesondere sein LLM Chat Scraper-Dienst bietet eine einheitliche API, um strukturierte Echtzeit-Einblicke aus ChatGPT, Gemini und anderen zu gewinnen. Durch die Erfassung von Zitaten und Rankings ermöglicht es eine präzise Überwachung der Markenpräsenz innerhalb generativer Suchökosysteme.
🏆 Ideal für: Die Erstellung von KI-gestützten Analyse-Dashboards mit Echtzeit-LLM-Antwortdaten und Zitaten.
Typ:
- API-basierter LLM-Scraper.
Abgedeckte LLMs:
- ChatGPT
- Perplexity
- Copilot
- Gemini
- Google KI Mode (KI Overviews)
- Grok
Enthaltene Daten:
- Modellantworten in Markdown oder Text.
- Je nach gewähltem Anbieter und Verfügbarkeit:
- Zitate und Inhaltsverweise.
- Extrahierte Links und URLs.
- Verwandte Eingabeaufforderungen und strukturierte Mediendaten (z. B. Karten, Bilder, Videos).
- Standortdaten (Koordinaten, Adressen, Kategorien).
- Roh-HTML (Google KI-Modus).
Infrastruktur:
- Einheitliche API zum Scraping mehrerer KI-Modelle.
- Webhook-Unterstützung für automatisierte Ergebnislieferung.
- Unterstützt Targeting auf Länderebene in über 195 Ländern und über 2.000 Städten über ein Proxy-Netzwerk mit über 80 Millionen Servern.
- Proxy-Netzwerk mit einer Erfolgsquote von 99,98 %, das die Scraping-API-Infrastruktur unterstützt.
- Die Ergebnisse werden zur leichteren Auswertung vorübergehend gespeichert.
Technische Anforderungen:
- Grundlegende Programmierkenntnisse erforderlich, um Aufgaben zu erstellen und Ergebnisse über die API abzurufen.
Konformität:
- Vollständige GDPR-Konformität.
Preise:
- Kostenlose Testversion verfügbar.
- Benutzerbasierte Preisgestaltung:
- Wachstum: 49 $/Monat
- Scale: 199 $/Monat
- Business: 399 $/Monat
- Individuell: Individuelle Preisgestaltung.
- Preise für Unternehmen:
- Unternehmen: 699 $/Monat
- Enterprise Plus: 999 $/Monat
- Kundenspezifisch: Individuelle Preisgestaltung.
3. cloro
cloro ist eine API-gesteuerte Plattform zur Überwachung von SEO- und KI-Suchökosystemen. Die LLM-Scraping-Lösung sammelt strukturierte Antworten direkt von KI-Schnittstellen wie ChatGPT, Gemini und Perplexity über eine einheitliche API. Sie gibt Text, Zitate und strukturierte Objekte zurück und unterstützt gleichzeitig geografisches Targeting.
🏆 Ideal für: SEO- und GEO-Teams, die die Sichtbarkeit von KI-Suchen über mehrere LLM-Anbieter und Suchmaschinen hinweg analysieren.
Typ:
- API-basierte LLM-Scraping-Lösung.
Abgedeckte LLMs:
- ChatGPT
- Perplexity
- Copilot
- Gemini
- Grok
- Google KI-Modus
- Google KI Übersicht
Enthaltene Daten:
- Modellantworten im Text-, HTML- oder Markdown-Format.
- Abhängig vom Ziel-LLM und den verfügbaren Informationen:
- Strukturierte Quellen und Zitate.
- Extrahierte Entitäten und strukturierte Objekte.
- Suchanfragen und Sucherweiterungen.
- Strukturierte Daten zum Thema Einkaufen (z. B. Produktkarten).
- Quell-URLs und Metadaten.
Infrastruktur:
- Einheitliche API für die Extraktion strukturierter Daten über mehrere KI-Modelle hinweg.
- Unterstützt mehr als 300 Millionen API-Aufrufe pro Monat.
- 99,99 % Verfügbarkeit.
- Unterstützt geografisches Targeting nach Ländern.
- Unterstützt gleichzeitige Scraping-Aufträge, je nach Preisplan zwischen 10 und 100.
Technische Anforderungen:
- Erfordert API-Integration über HTTP-Anfragen.
- Grundlegende Programmierkenntnisse für die schnelle Übermittlung und Bearbeitung von Antworten erforderlich.
Konformität:
- DSGVO-konform für europäische Nutzer.
Preise:
- Kostenlose Testversion mit 500 Credits verfügbar.
- Guthabenbasiertes Preismodell mit monatlichen Tarifen:
- Hobby: 100 $/Monat für 250.000 Credits.
- Starter: 250 $/Monat für 694.444 Credits.
- Wachstum: 500 $/Monat für 1.562.500 Credits.
- Business: 1.000 $/Monat für 3.333.333 Credits.
- Unternehmen: Individuelle Preisgestaltung.
4. A-Parser
A-Parser ist eine webbasierte und Desktop-Anwendung für Web-Scraping und Automatisierung. Sie bietet Ihnen Dutzende integrierter Parser zum Abrufen von Daten aus verschiedenen Plattformen. Im Einzelnen umfasst sie Dienste wie ChatGPT, Perplexity, Google und andere KI-Systeme.
🏆 Ideal für: Eine Desktop-basierte LLM-Scraping-Erfahrung.
Typ:
- Desktop-Scraping-Software verfügbar für Windows, Linux und macOS (über Docker) + eine Webschnittstelle.
- Unterstützt Automatisierung über API.
Abgedeckte LLMs:
- ChatGPT
- Perplexity
- Google AI (Gemini-basierter KI-Modus)
- Copilot
- DeepAI
- Kimi
Enthaltene Daten:
- Modellantworten in Markdown/Text.
- Je nach Antwort und Ziel-LLM-Anbieter:
- Quelllinks, Anker und Snippets.
- Bilder und Bildmetadaten (sofern vorhanden).
- Strukturierte Exporte (z. B. JSON, CSV, SQL).
Infrastruktur:
- Unterstützt 100/200 Abfragen pro Minute, je nach Ziel-LLM-Anbieter.
- Aufgabenwarteschlange und Automatisierung über API.
- Unterstützung von Drittanbieter-Proxys (HTTP, SOCKS4/5).
- Unterstützung für die Integration von CAPTCHA-Lösungen von Drittanbietern.
Technische Anforderungen:
- Installation und lokale Einrichtung für die No-Code-Desktop-Software erforderlich.
- Programmierkenntnisse für die Verwaltung über API erforderlich.
Compliance:
- Nicht bekannt gegeben.
Preise:
- Einmalige Lizenzgebühr:
- Lite: 179 $
- Pro: 299 $
- Enterprise: 479 $
- Kostenpflichtige Updates sind separat erhältlich.
5. Infatica
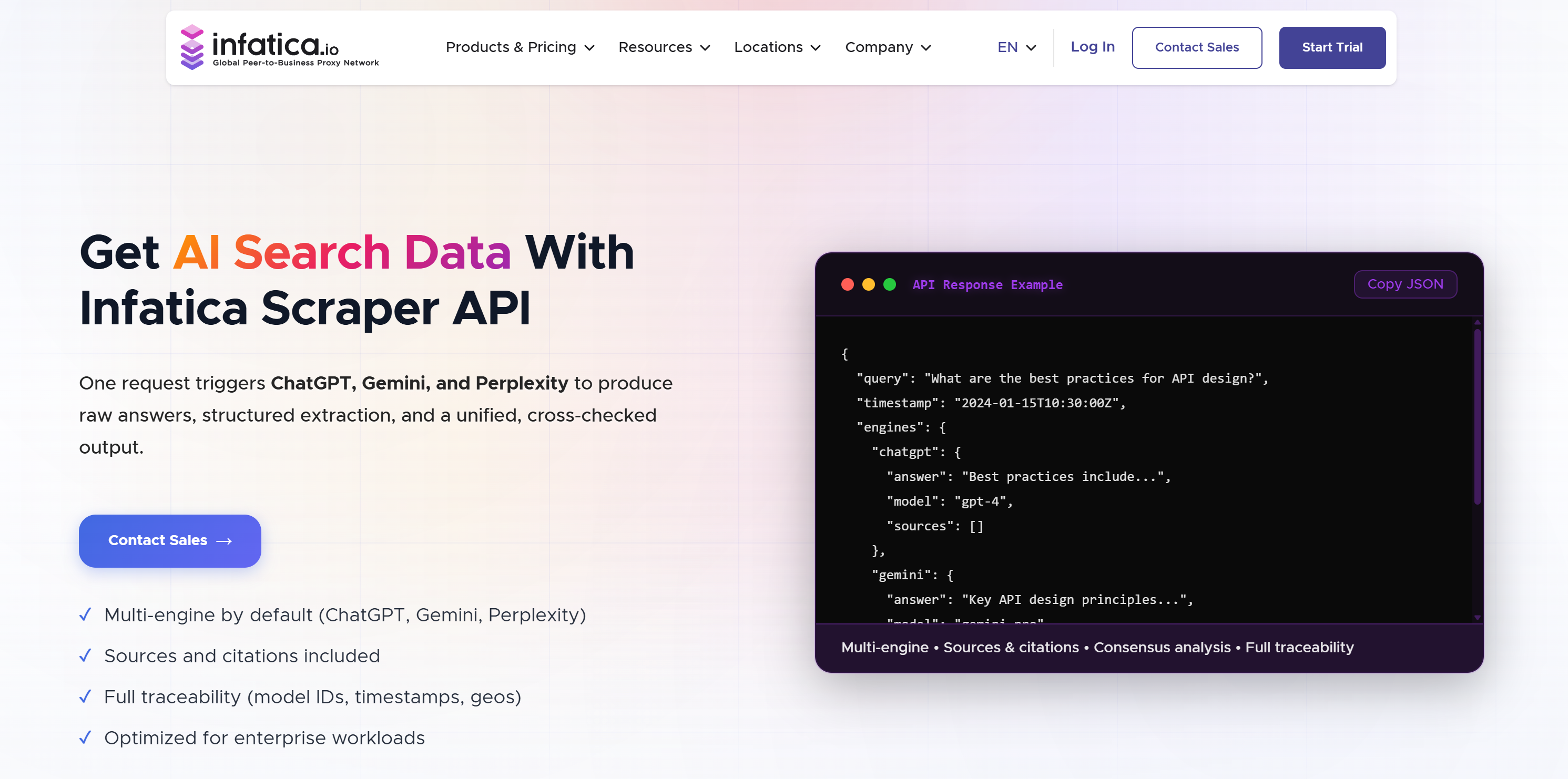
Infatica ist ein Anbieter von Datenerfassungsdiensten, der Proxy-Netzwerke und Scraping-APIs anbietet. Zu seinen zahlreichen Scraping-APIs gehört auch eine KI-Suchdaten-API. Diese unterstützt LLM-Scraping, indem sie mehrere Modelle in einer einzigen Anfrage abfragt. Sie gibt normalisierte Ausgaben mit Antworten, Quellen und Metadaten zurück und ermöglicht so eine strukturierte Analyse und einen modellübergreifenden Vergleich. Erfahren Sie mehr im Vergleich zwischen Infatica und Bright Data.
🏆 Ideal für: Vergleich von Antworten über mehrere LLMs hinweg mittels normalisierter Ausgaben und Konsensanalyse.
Typ:
- API-basierter LLM-Scraper.
Abgedeckte LLMs:
- ChatGPT
- Gemini
- Perplexity
Enthaltene Daten:
- Rohdaten der Modellantworten.
- Strukturierte Extraktion in den Formaten JSON oder Markdown.
- Konsensanalyse über Modelle hinweg (Übereinstimmungsgrad und Unterschiede).
- Metadaten zur Rückverfolgbarkeit (z. B. Modell-IDs, Zeitstempel, geografische Informationen, Versionen).
- Sofern verfügbar und basierend auf dem Zielmodell:
- Quellen und Zitate.
- Links und referenzierte Entitäten.
Infrastruktur:
- Aufgebaut auf einer Scraping-Engine mit Browser-Automatisierung und Rendering.
- Kann bis zu Millionen von Anfragen verarbeiten.
- Unterstützt Batch-Jobs und kontinuierliche Überwachung.
- Integrierte Integration eines Residential-Proxy-Netzwerks mit geografischer Ausrichtung.
- Unterstützt Webhooks und Batch-Pipelines.
- Strukturierte Ausgabestandardisierung über Modelle hinweg.
Technische Anforderungen:
- Erfordert Programmierkenntnisse, um Anfragen zu senden und Ergebnisse über die API zu verarbeiten.
- SDKs in Python und Node.js für vereinfachte Integration verfügbar.
Konformität:
- DSGVO-konform.
- ISO-zertifiziert
- Unterstützt den BYOK-Modus für verbesserte Compliance und Überwachung.
Preise:
- Individuelle Preisgestaltung (Kontakt Vertrieb).
6. Apify
Apify ist eine Full-Stack-Plattform für Web-Scraping, Browser-Automatisierung und KI-Integrationen. Sie bietet Tausende von vorgefertigten serverlosen Anwendungen, die sowohl von der Community als auch vom Unternehmen entwickelt wurden und als „Actors” bezeichnet werden. Für das Scraping von LLMs gibt es spezielle Actors für KI-Plattformen wie ChatGPT, Gemini und andere. Sehen Sie sich an, wie Apify im Vergleich zu Bright Data abschneidet.
🏆 Ideal für: Teams, die nach vielen vorgefertigten LLM-Scraping-Optionen mit optionaler API-Integration suchen.
Typ:
- Vorkonfigurierter LLM-Scraper mit No-Code- und API-Schnittstellen.
Abgedeckte LLMs:
- ChatGPT
- Gemini
- Perplexity
- Grok
- Andere, je nach ausgewähltem Akteur
Enthaltene Daten:
- Hängt vom ausgewählten Akteur ab, reicht von einfachen Antworten bis hin zu Antworten, die mit Metadaten angereichert sind.
Infrastruktur:
- Skalierbare Infrastruktur, die mehrere gleichzeitige Anfragen (von 25 bis 256) unterstützt.
- Unterstützung für integrierte und Drittanbieter-Proxy-Integrationen.
- Integrierte Speicherlösungen für verschiedene Datentypen.
Technische Anforderungen:
- Technische Kenntnisse, die für die Integration von Actors in benutzerdefinierte Skripte erforderlich sind.
- Grundlegende Programmierkenntnisse, die zum Aufrufen von Actors über die API erforderlich sind.
- Keine technischen Kenntnisse erforderlich, um LLM-Scraping-Actors über die Weboberfläche zu verwalten und zu starten.
Compliance:
- SOC 2 Typ II-konform.
- Vollständig konform mit den Bestimmungen der DSGVO und des CCPA.
Preise:
- Hängt vom gewählten Actor ab.
Fazit
In diesem Artikel haben Sie erfahren, was LLM-Scraper sind und wie Sie damit Daten aus gängigen KI-Modellen abrufen können. Außerdem haben Sie die wachsende Bedeutung von synthetischen Daten und LLM-Datenextraktion für das Modelltraining, die Überwachung, GEO und viele andere Anwendungsfälle kennengelernt.
Unter den besten verfügbaren LLM-Scrapern sticht Bright Data als führende Option hervor. Seine Datenerfassungsinfrastruktur auf Unternehmensniveau wird durch ein Proxy-Netzwerk mit über 150 Millionen IPs unterstützt, bietet eine Verfügbarkeit von 99,99 % und erreicht eine Erfolgsquote von 99,99 %.
Bright Data unterstützt mehrere dedizierte LLM-Scraping-APIs, darunter:
- ChatGPT Scraper
- Perplexity Scraper
- Gemini-Scraper
- Grok Scraper
- Google KI Mode Scraper
- Copilot-Scraper
Melden Sie sich noch heute kostenlos bei Bright Data an und beginnen Sie mit der Integration unserer Lösungen für das Scraping von LLMs!
FAQ
Was ist der Unterschied zwischen einem LLM-Scraper und einem LLM-basierten Scraper?
Ein LLM-Scraper sammelt Antworten oder Daten direkt von LLM-Anbietern mithilfe von Prompts. Ein LLM-basierter Scraper hingegen nutzt LLMs, um strukturierte Daten aus Webseiten oder Dokumenten zu extrahieren. Kurz gesagt: LLM-Scraper zielen auf KI-Dienste ab, während LLM-basierte Scraper KI einsetzen , um das traditionelle Web-Scraping zu verbessern.
Auf welche LLM-Anbieter zielen Scraper in der Regel ab?
LLM-Scraper zielen auf weit verbreitete KI-Plattformen ab, die strukturierte Antworten generieren. Zu den am häufigsten unterstützten Anbietern gehören ChatGPT, Gemini, Perplexity und Copilot. Einige Tools unterstützen auch Grok und KI-Suchfunktionen, wie z. B. Google AI Overviews.
Was ist die llm-Scraper-Bibliothek?
llm-scraper ist eine Open-Source-TypeScript-Bibliothek, die LLMs verwendet, um strukturierte Daten aus Webseiten zu extrahieren. Anstatt eine benutzerdefinierte Parsing-Logik zu schreiben, definieren Sie ein Schema, das vom LLM durch Analyse des Seiteninhalts ausgefüllt wird. Es handelt sich also nicht um ein Scraping-Tool zum Sammeln von Daten aus LLMs, sondern um eine KI-gestützte Web-Scraping-Lösung zum Extrahieren von Daten aus Webseiten mithilfe von LLMs. Sehen Sie sich die Funktionsweise in unserem speziellen llm-scraper-Leitfaden an.
Wie unterscheidet sich KI-Scraping vom herkömmlichen SERP-Scraping?
In diesem Zusammenhang bezieht sich KI-Scraping auf das Sammeln strukturierter Antworten direkt von LLM-Anbietern. Sie senden eine Eingabeaufforderung an den Scraper und erhalten eine Antwort, die Zitate und angereicherte Inhalte enthalten kann. Im Gegensatz dazu umfasst herkömmliches SERP-Scraping das Extrahieren von rohem HTML aus Suchergebnisseiten auf der Grundlage einer Suchanfrage. KI-Scraping konzentriert sich auf das Abrufen modellgenerierter Erkenntnisse, während SERP-Scraping auf der manuellen Analyse von Suchmaschinenlisten basiert. Erfahren Sie mehr über die beiden Ansätze.
Wie verwendet man LLMs für das Web-Scraping?
Wenn Sie lieber LLMs zum Extrahieren und Verarbeiten von Daten aus Websites verwenden möchten, anstatt LLMs selbst zu scrapen, folgen Sie diesen Tutorials:
- Web-Scraping mit ChatGPT: Schritt-für-Schritt-Anleitung
- Web-Scraping mit Perplexity: Schritt-für-Schritt-Anleitung
- Wie man den Google KI-Modus scrapt: Vollständige Anleitung
- Wie man Google KI-Übersichten scrapt





