

Dieses System findet mithilfe von Echtzeit-Web-Intelligence neue Leads, erkennt automatisch Kaufsignale und generiert personalisierte Kontaktaufnahmen auf der Grundlage realer Geschäftsereignisse. Springen Sie direkt zur Aktion auf GitHub.
Sie lernen:
- Wie Sie mit CrewAI Multi-Agent-Systeme für spezielle Prospektierungsaufgaben aufbauen
- Wie Sie Bright Data MCP für Echtzeit-Unternehmens- und Kontaktinformationen nutzen
- Wie Sie Trigger-Ereignisse wie Einstellungen, Finanzierungen und Führungswechsel automatisch erkennen
- Wie Sie personalisierte Kontaktaufnahmen auf der Grundlage von Live-Business-Intelligence generieren
- Wie Sie eine automatisierte Pipeline von der Kundensuche bis zur CRM-Integration erstellen
Los geht’s!
Die Herausforderung der modernen Vertriebsentwicklung
Die traditionelle Vertriebsentwicklung basiert auf manueller Recherche, zu der unter anderem das Durchsuchen von LinkedIn-Profilen, Unternehmenswebsites und Nachrichtenartikeln gehört, um potenzielle Kunden zu identifizieren. Dieser Ansatz ist zeitaufwändig, fehleranfällig und führt oft zu veralteten Kontaktlisten und einer schlecht zielgerichteten Kommunikation.
Die Integration von CrewAI mit Bright Data automatisiert den gesamten Workflow der Interessentensuche und reduziert den manuellen Arbeitsaufwand von Stunden auf wenige Minuten.
Was wir entwickeln: ein intelligentes Vertriebsentwicklungssystem
Sie entwickeln ein Multi-Agenten-KI-System, das Unternehmen findet, die Ihrem idealen Kundenprofil entsprechen. Es verfolgt Trigger-Ereignisse, die Kaufabsichten anzeigen, sammelt verifizierte Informationen über Entscheidungsträger und erstellt personalisierte Kontaktnachrichten unter Verwendung tatsächlicher Business Intelligence. Das System ist direkt mit Ihrem CRM verbunden, um eine qualifizierte Pipeline zu gewährleisten.
Voraussetzungen
Richten Sie Ihre Entwicklungsumgebung mit den folgenden Anforderungen ein:
- Installation vonPython 3.11
- Bright Data-Konto mit MCP-Zugriff
- OpenAI-API-Schlüssel für die KI-Generierung
- HubSpot CRM-Anmeldedaten für die Pipeline-Integration
Einrichtung der Umgebung
Erstellen Sie Ihr Projektverzeichnis und installieren Sie die Abhängigkeiten. Beginnen Sie mit der Einrichtung einer sauberen virtuellen Umgebung, um Konflikte mit anderen Python-Projekten zu vermeiden.
python -m venv ai_bdr_env
source ai_bdr_env/bin/activate # Windows: ai_bdr_envScriptsactivate
pip install crewai "crewai-tools[mcp]" openai pandas python-dotenv streamlit requestsErstellen Sie die Umgebungskonfiguration:
BRIGHT_DATA_API_TOKEN="Ihr_Bright_Data_API-Token"
OPENAI_API_KEY="Ihr_OpenAI_API-Schlüssel"
HUBSPOT_API_KEY="Ihr_Hubspot_API-Schlüssel"Aufbau des KI-BDR-Systems
Beginnen wir nun mit der Erstellung der KI-Agenten für unser KI-BDR-System.
Schritt 1: Einrichtung von Bright Data MCP
Schaffen Sie die Grundlage für eine Web-Scraping-Infrastruktur, die Daten in Echtzeit aus mehreren Quellen sammelt. Der MCP-Client übernimmt die gesamte Kommunikation mit dem Scraping-Netzwerk von Bright Data.
Erstellen Sie eine Datei namens mcp_client.py in Ihrem Projektstammverzeichnis und fügen Sie den folgenden Code hinzu:
from crewai import Agent, Task
from crewai.tools import BaseTool
from typing import Any
from pydantic import BaseModel, Field
from .utils import validate_companies_input, safe_mcp_call, deduplicate_by_key, extract_domain_from_url
class CompanyDiscoveryInput(BaseModel):
industry: str = Field(description="Zielbranche für die Unternehmenssuche")
size_range: str = Field(description="Unternehmensgröße (Start-up, klein, mittel, groß)")
location: str = Field(default="", description="Geografischer Standort oder Region")
class CompanyDiscoveryTool(BaseTool):
name: str = "discover_companies"
description: str = "Unternehmen finden, die den ICP-Kriterien entsprechen, mithilfe von Web-Scraping"
args_schema: type[BaseModel] = CompanyDiscoveryInput
mcp: Any = None
def __init__(self, mcp_client):
super().__init__()
self.mcp = mcp_client
def _run(self, industry: str, size_range: str, location: str = "") -> list:
companies = []
search_terms = [
f"{industry} companies {size_range}",
f"{industry} startups {location}",
f"{industry} technology companies"
]
for term in search_terms:
results = self._search_companies(term)
for company in results:
enriched = self._enrich_company_data(company)
if self._matches_icp(enriched, industry, size_range):
companies.append(enriched)
return deduplicate_by_key(companies, lambda c: c.get('domain') or c['name'].lower())
def _search_companies(self, term):
"""Suche nach Unternehmen mithilfe einer echten Websuche über Bright Data."""
try:
companies = []
search_queries = [
f"{term} directory",
f"{term} list",
f"{term} news"
]
for query in search_queries:
try:
results = self._perform_company_search(query)
companies.extend(results)
if len(companies) >= 10:
break
except Exception as e:
print(f"Fehler in Suchanfrage '{query}': {str(e)}")
continue
return self._filter_unique_companies(companies)
except Exception as e:
print(f"Fehler bei der Suche nach Unternehmen für '{term}': {str(e)}")
return []
def _enrich_company_data(self, company):
linkedin_data = safe_mcp_call(self.mcp, 'scrape_company_linkedin', company['name'])
website_data = safe_mcp_call(self.mcp, 'scrape_company_website', company.get('domain', ''))
employee_count = linkedin_data.get('employee_count') or 150
return {
**company,
'linkedin_intelligence': linkedin_data,
'website_intelligence': website_data,
'employee_count': employee_count,
'icp_score': 0
}
def _matches_icp(self, company, industry, size_range):
score = 0
if industry.lower() in company.get('industry', '').lower():
score += 30
if self._check_size_range(company.get('employee_count', 0), size_range):
score += 25
if company.get('name') and company.get('domain'):
score += 20
company['icp_score'] = score
return score >= 20
def _check_size_range(self, count, size_range):
Bereiche = {'Startup': (1, 50), 'Klein': (51, 200), 'Mittel': (201, 1000)}
min_size, max_size = Bereiche.get(Größenbereich, (0, 999999))
return min_size <= Anzahl <= max_size
def _perform_company_search(self, query):
"""Perform company search using Bright Data MCP."""
search_result = safe_mcp_call(self.mcp, 'search_company_news', query)
if search_result and search_result.get('results'):
return self._extract_companies_from_mcp_results(search_result['results'], query)
else:
print(f"Keine MCP-Ergebnisse für: {query}")
return []
def _filter_unique_companies(self, companies):
"""Duplikate von Unternehmen herausfiltern."""
seen_names = set()
unique_companies = []
for company in companies:
name_key = company.get('name', '').lower()
if name_key and name_key not in seen_names:
seen_names.add(name_key)
unique_companies.append(company)
return unique_companies
def _extract_companies_from_mcp_results(self, mcp_results, original_query):
"""Extrahiert Unternehmensinformationen aus MCP-Suchergebnissen."""
companies = []
for result in mcp_results[:10]:
try:
title = result.get('title', '')
url = result.get('url', '')
snippet = result.get('snippet', '')
company_name = self._extract_company_name_from_result(title, url)
if company_name and len(company_name) > 2:
domain = self._extract_domain_from_url(url)
industry = self._extract_industry_from_query(original_query)
companies.append({
'name': company_name,
'domain': domain,
'industry': industry
})
except Exception as e:
print(f"Fehler beim Extrahieren des Unternehmens aus dem MCP-Ergebnis: {str(e)}")
continue
return companies
def _extract_company_name_from_result(self, title, url):
"""Extrahiert den Unternehmensnamen aus dem Titel oder der URL des Suchergebnisses."""
import re
if title:
title_clean = re.sub(r'[|-—–].*$', '', title).strip()
title_clean = re.sub(r's+(Inc|Corp|LLC|Ltd|Solutions|Systems|Technologies|Software|Platform|Company)$', '', title_clean, flags=re.IGNORECASE)
if len(title_clean) > 2 and len(title_clean) < 50:
return title_clean
if url:
domain_parts = url.split('/')[2].split('.')
if len(domain_parts) > 1:
return domain_parts[0].title()
return None
def _extract_domain_from_url(self, url):
"""Extrahiert die Domain aus der URL."""
return extract_domain_from_url(url)
def _extract_industry_from_query(self, query):
"""Extrahiert die Branche aus der Suchanfrage."""
query_lower = query.lower()
industry_mappings = {
'saas': 'SaaS',
'fintech': 'FinTech',
'ecommerce': 'E-Commerce',
'healthcare': 'Gesundheitswesen',
'ai': 'KI/ML',
'machine learning': 'KI/ML',
'artificial intelligence': 'KI/ML'
}
for keyword, industry in industry_mappings.items():
if keyword in query_lower:
return industry
return 'Technology'
def create_company_discovery_agent(mcp_client):
return Agent(
role='Company Discovery Specialist',
goal='Find high-quality prospects matching ICP criteria',
backstory='Expert at identifying potential customers using real-time web intelligence.',
tools=[CompanyDiscoveryTool(mcp_client)],
verbose=True
)Dieser MCP-Client verwaltet alle Web-Scraping-Aufgaben mithilfe der KI-Infrastruktur von Bright Data. Er bietet zuverlässigen Zugriff auf LinkedIn-Unternehmensseiten, Unternehmenswebsites, Finanzierungsdatenbanken und Nachrichtenquellen. Der Client kümmert sich um das Connection Pooling und umgeht automatisch Anti-Bot-Schutzmaßnahmen.
Schritt 2: Company Discovery Agent
Verwandeln Sie Ihre Kriterien für das ideale Kundenprofil in ein intelligentes Erkennungssystem, das Unternehmen findet, die Ihren spezifischen Anforderungen entsprechen. Der Agent durchsucht mehrere Quellen und verbessert Unternehmensdaten mit Business Intelligence.
Erstellen Sie zunächst einen Ordner „agents” in Ihrem Projektstammverzeichnis. Erstellen Sie dann eine Datei „agents/company_discovery.py” und fügen Sie den folgenden Code hinzu:
from crewai import Agent, Task
from crewai.tools import BaseTool
from typing import Any
from pydantic import BaseModel, Field
from .utils import validate_companies_input, safe_mcp_call, deduplicate_by_key, extract_domain_from_url
class CompanyDiscoveryInput(BaseModel):
industry: str = Field(description="Zielbranche für die Unternehmenssuche")
size_range: str = Field(description="Unternehmensgröße (Start-up, klein, mittel, groß)")
location: str = Field(default="", description="Geografischer Standort oder Region")
class CompanyDiscoveryTool(BaseTool):
name: str = "discover_companies"
description: str = "Unternehmen finden, die den ICP-Kriterien entsprechen, mithilfe von Web-Scraping"
args_schema: type[BaseModel] = CompanyDiscoveryInput
mcp: Any = None
def __init__(self, mcp_client):
super().__init__()
self.mcp = mcp_client
def _run(self, industry: str, size_range: str, location: str = "") -> list:
companies = []
search_terms = [
f"{industry} companies {size_range}",
f"{industry} startups {location}",
f"{industry} technology companies"
]
for term in search_terms:
results = self._search_companies(term)
for company in results:
enriched = self._enrich_company_data(company)
if self._matches_icp(enriched, industry, size_range):
companies.append(enriched)
return deduplicate_by_key(companies, lambda c: c.get('domain') or c['name'].lower())
def _search_companies(self, term):
"""Suche nach Unternehmen mithilfe einer echten Websuche über Bright Data."""
try:
companies = []
search_queries = [
f"{term} directory",
f"{term} list",
f"{term} news"
]
for query in search_queries:
try:
results = self._perform_company_search(query)
companies.extend(results)
if len(companies) >= 10:
break
except Exception as e:
print(f"Fehler in Suchanfrage '{query}': {str(e)}")
continue
return self._filter_unique_companies(companies)
except Exception as e:
print(f"Fehler bei der Suche nach Unternehmen für '{term}': {str(e)}")
return []
def _enrich_company_data(self, company):
linkedin_data = safe_mcp_call(self.mcp, 'scrape_company_linkedin', company['name'])
website_data = safe_mcp_call(self.mcp, 'scrape_company_website', company.get('domain', ''))
employee_count = linkedin_data.get('employee_count') or 150
return {
**company,
'linkedin_intelligence': linkedin_data,
'website_intelligence': website_data,
'employee_count': employee_count,
'icp_score': 0
}
def _matches_icp(self, company, industry, size_range):
score = 0
if industry.lower() in company.get('industry', '').lower():
score += 30
if self._check_size_range(company.get('employee_count', 0), size_range):
score += 25
if company.get('name') and company.get('domain'):
score += 20
company['icp_score'] = score
return score >= 20
def _check_size_range(self, count, size_range):
Bereiche = {'Startup': (1, 50), 'Klein': (51, 200), 'Mittel': (201, 1000)}
min_size, max_size = Bereiche.get(Größenbereich, (0, 999999))
return min_size <= Anzahl <= max_size
def create_company_discovery_agent(mcp_client):
return Agent(
role='Company Discovery Specialist',
goal='Find high-quality prospects matching ICP criteria',
backstory='Expert at identifying potential customers using real-time web intelligence.',
tools=[CompanyDiscoveryTool(mcp_client)],
verbose=True
)Der Discovery Agent durchsucht mehrere Datenquellen, um Unternehmen zu finden, die Ihrem idealen Kundenprofil entsprechen. Er fügt für jedes Unternehmen Geschäftsinformationen aus LinkedIn und Unternehmenswebsites hinzu. Anschließend filtert er die Ergebnisse anhand von Bewertungskriterien, die Sie festlegen können. Der Deduplizierungsprozess sorgt für saubere Interessentenlisten und vermeidet doppelte Einträge.
Schritt 3: Trigger-Erkennungsagent
Überwachen Sie Geschäftsereignisse, die Kaufabsichten und den besten Zeitpunkt für die Kontaktaufnahme anzeigen. Der Agent untersucht Einstellungsmuster, Finanzierungsankündigungen, Führungswechsel und Expansionssignale, um potenzielle Kunden zu priorisieren.
Erstellen Sie eine Datei namens agents/trigger_detection.py und fügen Sie den folgenden Code hinzu:
from crewai import Agent, Task
from crewai.tools import BaseTool
from datetime import datetime, timedelta
from typing import Any, List
from pydantic import BaseModel, Field
from .utils import validate_companies_input, safe_mcp_call
class TriggerDetectionInput(BaseModel):
companies: List[dict] = Field(description="Liste der Unternehmen, die auf Trigger-Ereignisse analysiert werden sollen")
class TriggerDetectionTool(BaseTool):
name: str = "detect_triggers"
description: str = "Signale für Neueinstellungen, Finanzierungsnachrichten, Führungswechsel finden"
args_schema: type[BaseModel] = TriggerDetectionInput
mcp: Any = None
def __init__(self, mcp_client):
super().__init__()
self.mcp = mcp_client
def _run(self, companies) -> list:
companies = validate_companies_input(companies)
if not companies:
return []
for company in companies:
triggers = []
hiring_signals = self._detect_hiring_triggers(company)
triggers.extend(hiring_signals)
funding_signals = self._detect_funding_triggers(company)
triggers.extend(funding_signals)
leadership_signals = self._detect_leadership_triggers(company)
triggers.extend(leadership_signals)
expansion_signals = self._detect_expansion_triggers(company)
triggers.extend(expansion_signals)
company['trigger_events'] = triggers
company['trigger_score'] = self._calculate_trigger_score(triggers)
return sorted(companies, key=lambda x: x.get('trigger_score', 0), reverse=True)
def _detect_hiring_triggers(self, company):
"""Erkenne Einstellungsauslöser mithilfe von LinkedIn-Daten."""
linkedin_data = safe_mcp_call(self.mcp, 'scrape_company_linkedin', company['name'])
triggers = []
if linkedin_data:
hiring_posts = linkedin_data.get('hiring_posts', [])
recent_activity = linkedin_data.get('recent_activity', [])
if hiring_posts:
triggers.append({
'type': 'hiring_spike',
'severity': 'high',
'description': f"Aktive Stellenausschreibungen bei {company['name']} entdeckt – {len(hiring_posts)} offene Stellen",
'date_detected': datetime.now().isoformat(),
'source': 'linkedin_api'
})
if recent_activity:
triggers.append({
'type': 'company_activity',
'severity': 'medium',
'description': f"Erhöhte LinkedIn-Aktivität bei {company['name']}",
'date_detected': datetime.now().isoformat(),
'source': 'linkedin_api'
})
return triggers
def _detect_funding_triggers(self, company):
"""Erkennen von Finanzierungstriggern mithilfe der Nachrichtensuche."""
funding_data = safe_mcp_call(self.mcp, 'search_funding_news', company['name'])
triggers = []
if funding_data and funding_data.get('results'):
triggers.append({
'type': 'funding_round',
'severity': 'high',
'description': f"Aktuelle Finanzierungsaktivitäten bei {company['name']} erkannt",
'date_detected': datetime.now().isoformat(),
'source': 'news_search'
})
return triggers
def _detect_leadership_triggers(self, company):
"""Erkenne Veränderungen in der Unternehmensführung mithilfe der Nachrichtensuche."""
return self._detect_keyword_triggers(
company, 'leadership_change', 'medium',
['ceo', 'cto', 'vp', 'hired', 'joins', 'appointed'],
f"Führungswechsel bei {company['name']} erkannt"
)
def _detect_expansion_triggers(self, company):
"""Erkennen von Geschäftserweiterungen mithilfe der Nachrichtensuche."""
return self._detect_keyword_triggers(
company, 'expansion', 'medium',
['expansion', 'new office', 'opening', 'market'],
f"Geschäftserweiterung bei {company['name']} erkannt"
)
def _detect_keyword_triggers(self, company, trigger_type, severity, keywords, description):
"""Generische Methode zum Erkennen von Auslösern anhand von Schlüsselwörtern in Nachrichten."""
news_data = safe_mcp_call(self.mcp, 'search_company_news', company['name'])
triggers = []
if news_data and news_data.get('results'):
for result in news_data['results']:
if any(keyword in str(result).lower() for keyword in keywords):
triggers.append({
'type': trigger_type,
'severity': severity,
'description': description,
'date_detected': datetime.now().isoformat(),
'source': 'news_search'
})
break
return triggers
def _calculate_trigger_score(self, triggers):
severity_weights = {'high': 15, 'medium': 10, 'low': 5}
return sum(severity_weights.get(t.get('severity', 'low'), 5) for t in triggers)
def create_trigger_detection_agent(mcp_client):
return Agent(
role='Trigger Event Analyst',
goal='Identify buying signals and optimal timing for outreach',
backstory='Expert at detecting business events that indicate readiness to buy.',
tools=[TriggerDetectionTool(mcp_client)],
verbose=True
)Das Triggererkennungssystem überwacht verschiedene Geschäftssignale, die Kaufabsichten und den besten Zeitpunkt für die Kontaktaufnahme anzeigen. Es untersucht Einstellungsmuster aus LinkedIn-Stellenanzeigen, verfolgt Finanzierungsankündigungen in Nachrichtenquellen, beobachtet Führungswechsel und identifiziert Expansionsaktivitäten. Jeder Trigger erhält eine Schweregradbewertung, die dabei hilft, potenzielle Kunden anhand der Dringlichkeit und der Größe der Verkaufschance zu priorisieren.
Schritt 4: Kontaktrecherche
Finden und überprüfen Sie die Kontaktinformationen von Entscheidungsträgern unter Berücksichtigung der Konfidenzwerte aus verschiedenen Datenquellen. Der Agent priorisiert Kontakte anhand ihrer Rolle und der Qualität der Daten.
Erstellen Sie eine Datei „agents/contact_research.py” und fügen Sie den folgenden Code hinzu:
from crewai import Agent, Task
from crewai.tools import BaseTool
from typing import Any, List
from pydantic import BaseModel, Field
import re
from .utils import validate_companies_input, safe_mcp_call, validate_email, deduplicate_by_key
class ContactResearchInput(BaseModel):
companies: List[dict] = Field(description="Liste der Unternehmen, für die Kontakte recherchiert werden sollen")
target_roles: List[str] = Field(description="Liste der Zielrollen, für die Kontakte gefunden werden sollen")
class ContactResearchTool(BaseTool):
name: str = "research_contacts"
description: str = "Kontaktinformationen von Entscheidungsträgern mithilfe von MCP finden und überprüfen"
args_schema: type[BaseModel] = ContactResearchInput
mcp: Any = None
def __init__(self, mcp_client):
super().__init__()
self.mcp = mcp_client
def _run(self, companies, target_roles) -> list:
companies = validate_companies_input(companies)
if not companies:
return []
if not isinstance(target_roles, list):
target_roles = [target_roles] if target_roles else []
for company in companies:
contacts = []
for role in target_roles:
role_contacts = self._search_contacts_by_role(company, role)
for contact in role_contacts:
enriched = self._enrich_contact_data(contact, company)
if self._validate_contact(enriched):
contacts.append(enriched)
company['contacts'] = self._deduplicate_contacts(contacts)
company['contact_score'] = self._calculate_contact_quality(contacts)
return companies
def _search_contacts_by_role(self, company, role):
"""Suche nach Kontakten nach Rolle mit MCP."""
contacts = []
search_query = f"{company['name']} {role} LinkedIn contact"
search_result = safe_mcp_call(self.mcp, 'search_company_news', search_query)
if search_result and search_result.get('results'):
contacts.extend(self._extract_contacts_from_mcp_results(search_result['results'], role))
if not contacts:
contact_query = f"{company['name']} {role} email contact"
contact_result = safe_mcp_call(self.mcp, 'search_company_news', contact_query)
if contact_result and contact_result.get('results'):
contacts.extend(self._extract_contacts_from_mcp_results(contact_result['results'], role))
return contacts[:3]
def _extract_contacts_from_mcp_results(self, results, role):
"""Extrahieren Sie Kontaktinformationen aus den MCP-Suchergebnissen."""
contacts = []
for result in results:
try:
title = result.get('title', '')
snippet = result.get('snippet', '')
url = result.get('url', '')
names = self._extract_names_from_text(title + ' ' + snippet)
for name_parts in names:
if len(name_parts) >= 2:
first_name, last_name = name_parts[0], ' '.join(name_parts[1:])
contacts.append({
'first_name': first_name,
'last_name': last_name,
'title': role,
'linkedin_url': url if 'linkedin' in url else '',
'data_sources': 1,
'source': 'mcp_search'
})
if len(contacts) >= 2:
break
except Exception as e:
print(f"Fehler beim Extrahieren des Kontakts aus dem Ergebnis: {str(e)}")
continue
return contacts
def _extract_names_from_text(self, text):
"""Extrahiert wahrscheinliche Namen aus dem Text."""
import re
name_patterns = [
r'b([A-Z][a-z]+)s+([A-Z][a-z]+)b',
r'b([A-Z][a-z]+)s+([A-Z].?s*[A-Z][a-z]+)b',
r'b([A-Z][a-z]+)s+([A-Z][a-z]+)s+([A-Z][a-z]+)b'
]
names = []
for pattern in name_patterns:
matches = re.findall(pattern, text)
for match in matches:
if isinstance(match, tuple):
names.append(list(match))
return names[:3]
def _enrich_contact_data(self, contact, company):
if not contact.get('email'):
contact['email'] = self._generate_email(
contact['first_name'],
contact['last_name'],
company.get('domain', '')
)
contact['email_valid'] = validate_email(contact.get('email', ''))
contact['confidence_score'] = self._calculate_confidence(contact)
return contact
def _generate_email(self, first, last, domain):
if not all([first, last, domain]):
return ""
return f"{first.lower()}.{last.lower()}@{domain}"
def _calculate_confidence(self, contact):
score = 0
if contact.get('linkedin_url'): score += 30
if contact.get('email_valid'): score += 25
if contact.get('data_sources', 0) > 1: score += 20
if all(contact.get(f) for f in ['first_name', 'last_name', 'title']): score += 25
return score
def _validate_contact(self, contact):
required = ['first_name', 'last_name', 'title']
return (all(contact.get(f) for f in required) and
contact.get('confidence_score', 0) >= 50)
def _deduplicate_contacts(self, contacts):
unique = deduplicate_by_key(
contacts,
lambda c: c.get('email', '') or f"{c.get('first_name', '')}_{c.get('last_name', '')}"
)
return sorted(unique, key=lambda x: x.get('confidence_score', 0), reverse=True)
def _calculate_contact_quality(self, contacts):
if not contacts:
return 0
avg_confidence = sum(c.get('confidence_score', 0) for c in contacts) / len(contacts)
high_quality = sum(1 for c in contacts if c.get('confidence_score', 0) >= 75)
return min(avg_confidence + (high_quality * 5), 100)
def create_contact_research_agent(mcp_client):
return Agent(
role='Contact Intelligence Specialist',
goal='Find accurate contact information for decision-makers using MCP',
backstory='Expert at finding and verifying contact information using advanced MCP search tools.',
tools=[ContactResearchTool(mcp_client)],
verbose=True
)Das Kontaktrecherchesystem identifiziert Entscheidungsträger, indem es Rollen auf LinkedIn und Unternehmenswebsites durchsucht. Es generiert E-Mail-Adressen anhand typischer Unternehmensmuster und überprüft Kontaktinformationen mithilfe verschiedener Verifizierungsmethoden. Das System vergibt Vertrauenswürdigkeitsscores basierend auf der Qualität der Datenquellen. Der Deduplizierungsprozess sorgt für saubere Kontaktlisten und priorisiert diese nach ihrer Verifizierungsvertrauenswürdigkeit.
Schritt 5: Intelligente Nachrichtenerstellung
Verwandeln Sie Business Intelligence in personalisierte Outreach-Nachrichten, die bestimmte Auslöserereignisse erwähnen und Recherchen zeigen. Der Generator erstellt mehrere Nachrichtenformate für verschiedene Kanäle.
Erstellen Sie eine Datei „agents/message_generation.py” und fügen Sie den folgenden Code hinzu:
from crewai import Agent, Task
from crewai.tools import BaseTool
from typing import Any, List
from pydantic import BaseModel, Field
import openai
import os
class MessageGenerationInput(BaseModel):
companies: List[dict] = Field(description="Liste der Unternehmen mit Kontakten, für die Nachrichten generiert werden sollen")
message_type: str = Field(default="cold_email", description="Art der zu generierenden Nachricht (cold_email, linkedin_message, follow_up)")
class MessageGenerationTool(BaseTool):
name: str = "generate_messages"
description: str = "Erstellen Sie personalisierte Kontaktaufnahmen auf der Grundlage von Unternehmensinformationen"
args_schema: type[BaseModel] = MessageGenerationInput
client: Any = None
def __init__(self):
super().__init__()
self.client = openai.OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
def _run(self, companies, message_type="cold_email") -> list:
# Sicherstellen, dass companies eine Liste ist
if not isinstance(companies, list):
print(f"Warnung: Erwartete Liste von Unternehmen, erhielt {type(companies)}")
return []
if not companies:
print("Keine Unternehmen für die Nachrichtenerstellung angegeben")
return []
for company in companies:
if not isinstance(company, dict):
print(f"Warnung: Erwartet wurde ein Unternehmens-Dict, erhalten wurde {type(company)}")
continue
for contact in company.get('contacts', []):
if not isinstance(contact, dict):
continue
message = self._generate_personalized_message(contact, company, message_type)
contact['generated_message'] = message
contact['message_quality_score'] = self._calculate_message_quality(message, company)
return companies
def _generate_personalized_message(self, contact, company, message_type):
context = self._build_message_context(contact, company)
if message_type == "cold_email":
return self._generate_cold_email(context)
elif message_type == "linkedin_message":
return self._generate_linkedin_message(context)
else:
return self._generate_cold_email(context)
def _build_message_context(self, contact, company):
triggers = company.get('trigger_events', [])
primary_trigger = triggers[0] if triggers else None
return {
'contact_name': contact.get('first_name', ''),
'contact_title': contact.get('title', ''),
'company_name': company.get('name', ''),
'industry': company.get('industry', ''),
'primary_trigger': primary_trigger,
'trigger_count': len(triggers)
}
def _generate_cold_email(self, context):
trigger_text = ""
if context['primary_trigger']:
trigger_text = f"Ich habe bemerkt, dass {context['company_name']} {context['primary_trigger']['description'].lower()}."
prompt = f"""Schreiben Sie eine personalisierte Kaltakquise-E-Mail:
Kontakt: {context['contact_name']}, {context['contact_title']} bei {context['company_name']}
Branche: {context['industry']}
Kontext: {trigger_text}
Anforderungen:
- Betreffzeile, die sich auf das auslösende Ereignis bezieht
- Persönliche Anrede mit Vornamen
- Einleitung, die Recherche zeigt
- Kurze Wertversprechung
- Klare Handlungsaufforderung
- Maximal 120 Wörter
Formatieren Sie wie folgt:
BETREFF: [Betreffzeile]
TEXT: [E-Mail-Text]"""
response = self.client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}],
temperature=0.7,
max_tokens=300
)
return self._parse_email_response(response.choices[0].message.content)
def _generate_linkedin_message(self, context):
prompt = f"""Schreiben Sie eine LinkedIn-Verbindungsanfrage (max. 300 Zeichen):
Kontakt: {context['contact_name']} bei {context['company_name']}
Kontext: {context.get('primary_trigger', {}).get('description', '')}
Seien Sie professionell, beziehen Sie sich auf die Aktivitäten des Unternehmens, keine direkten Verkaufsargumente."""
response = self.client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}],
temperature=0.7,
max_tokens=100
)
return {
'subject': 'LinkedIn Connection Request',
'body': response.choices[0].message.content.strip()
}
def _parse_email_response(self, response):
lines = response.strip().split('n')
subject = ""
body_lines = []
for line in lines:
if line.startswith('SUBJECT:'):
subject = line.replace('SUBJECT:', '').strip()
elif line.startswith('BODY:'):
body_lines.append(line.replace('BODY:', '').strip())
elif body_lines:
body_lines.append(line)
return {
'subject': subject,
'body': 'n'.join(body_lines).strip()
}
def _calculate_message_quality(self, message, company):
score = 0
body = message.get('body', '').lower()
if company.get('name', '').lower() in message.get('subject', '').lower():
score += 25
if company.get('trigger_events') and any(t.get('type', '') in body for t in company['trigger_events']):
score += 30
if len(body.split()) <= 120:
score += 20
if any(word in body for word in ['call', 'meeting', 'discuss', 'connect']):
score += 25
return score
def create_message_generation_agent():
return Agent(
role='Personalization Specialist',
goal='Create compelling personalized outreach that gets responses',
backstory='Expert at crafting messages that demonstrate research and provide value.',
tools=[MessageGenerationTool()],
verbose=True
)Das System zur Nachrichtenerstellung wandelt Business Intelligence in personalisierte Kontaktaufnahmen um. Es bezieht sich auf bestimmte auslösende Ereignisse und zeigt detaillierte Recherchen. Es erstellt Betreffzeilen, die zum Kontext passen, personalisierte Begrüßungen und Wertversprechen, die zur Situation jedes potenziellen Kunden passen. Das System generiert verschiedene Nachrichtenformate, die für unterschiedliche Kanäle gut geeignet sind. Es sorgt für eine gleichbleibende Qualität der Personalisierung.
Schritt 6: Lead-Bewertung und Pipeline-Manager
Bewerten Sie potenzielle Kunden anhand verschiedener Informationsfaktoren und exportieren Sie qualifizierte Leads automatisch in Ihr CRM-System. Der Manager priorisiert Leads anhand von Eignung, Zeitpunkt und Datenqualität.
Erstellen Sie eine Datei namens agents/pipeline_manager.py und fügen Sie den folgenden Code hinzu:
from crewai import Agent, Task
from crewai.tools import BaseTool
from datetime import datetime
from typing import List
from pydantic import BaseModel, Field
import requests
import os
from .utils import validate_companies_input
class LeadScoringInput(BaseModel):
companies: List[dict] = Field(description="Liste der zu bewertenden Unternehmen")
class LeadScoringTool(BaseTool):
name: str = "score_leads"
description: str = "Leads basierend auf mehreren Informationsfaktoren bewerten"
args_schema: type[BaseModel] = LeadScoringInput
def _run(self, companies) -> list:
companies = validate_companies_input(companies)
if not companies:
return []
for company in companies:
score_breakdown = self._calculate_lead_score(company)
company['lead_score'] = score_breakdown['total_score']
company['score_breakdown'] = score_breakdown
company['lead_grade'] = self._assign_grade(score_breakdown['total_score'])
return sorted(companies, key=lambda x: x.get('lead_score', 0), reverse=True)
def _calculate_lead_score(self, company):
breakdown = {
'icp_score': min(company.get('icp_score', 0) * 0.3, 25),
'trigger_score': min(company.get('trigger_score', 0) * 2, 30),
'contact_score': min(company.get('contact_score', 0) * 0.2, 20),
'timing_score': self._assess_timing(company),
'company_health': self._assess_health(company)
}
breakdown['total_score'] = sum(breakdown.values())
return breakdown
def _assess_timing(self, company):
triggers = company.get('trigger_events', [])
if not triggers:
return 0
recent_triggers = sum(1 for t in triggers if 'high' in t.get('severity', ''))
return min(recent_triggers * 8, 15)
def _assess_health(self, company):
score = 0
if company.get('trigger_events'):
score += 5
if company.get('employee_count', 0) > 50:
score += 5
return score
def _assign_grade(self, score):
if score >= 80: return 'A'
elif score >= 65: return 'B'
elif score >= 50: return 'C'
else: return 'D'
class CRMIntegrationInput(BaseModel):
companies: List[dict] = Field(description="Liste der Unternehmen, die in das CRM exportiert werden sollen")
min_grade: str = Field(default="B", description="Mindestnote für den Export (A, B, C, D)")
Klasse CRMIntegrationTool(BaseTool):
name: str = "crm_integration"
description: str = "Qualifizierte Leads in HubSpot CRM exportieren"
args_schema: type[BaseModel] = CRMIntegrationInput
def _run(self, companies, min_grade='B') -> dict:
companies = validate_companies_input(companies)
if not companies:
return {"message": "Keine Unternehmen für CRM-Export angegeben", "success": 0, "errors": 0}
qualified = [c for c in companies if isinstance(c, dict) and c.get('lead_grade', 'D') in ['A', 'B']]
if not os.getenv("HUBSPOT_API_KEY"):
return {"error": "HubSpot API-Schlüssel nicht konfiguriert", "success": 0, "errors": 0}
results = {"success": 0, "errors": 0, "details": []}
for company in qualified:
for contact in company.get('contacts', []):
if not isinstance(contact, dict):
continue
result = self._create_hubspot_contact(contact, company)
if result.get('success'):
results['success'] += 1
else:
results['errors'] += 1
results['details'].append(result)
return results
def _create_hubspot_contact(self, contact, company):
api_key = os.getenv("HUBSPOT_API_KEY")
if not api_key:
return {"success": False, "error": "HubSpot API key not configured"}
url = "https://api.hubapi.com/crm/v3/objects/contacts"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
trigger_summary = "; ".join([
f"{t.get('type', '')}: {t.get('description', '')}"
for t in company.get('trigger_events', [])
])
email = contact.get('email', '').strip()
if not email:
return {"success": False, "error": "Kontakt-E-Mail ist erforderlich", "contact": contact.get('first_name', 'Unbekannt')}
properties = {
"email": email,
"firstname": contact.get('first_name', ''),
"lastname": contact.get('last_name', ''),
"jobtitle": contact.get('title', ''),
"company": company.get('name', ''),
"website": f"https://{company.get('domain', '')}" if company.get('domain') else "",
"hs_lead_status": "NEW",
"lifecyclestage": "lead"
}
if company.get('lead_score'):
properties["lead_score"] = str(company.get('lead_score', 0))
if company.get('lead_grade'):
properties["lead_grade"] = company.get('lead_grade', 'D')
if trigger_summary:
properties["trigger_events"] = trigger_summary[:1000]
if contact.get('confidence_score'):
properties["contact_confidence"] = str(contact.get('confidence_score', 0))
properties["ai_discovery_date"] = datetime.now().isoformat()
try:
response = requests.post(url, json={"properties": properties}, headers=headers, timeout=30)
if response.status_code == 201:
return {
"success": True,
"contact": contact.get('first_name', ''),
"company": company.get('name', ''),
"hubspot_id": response.json().get('id')
}
elif response.status_code == 409:
existing_contact = response.json()
return {
"success": True,
"contact": contact.get('first_name', ''),
"company": company.get('name', ''),
"hubspot_id": existing_contact.get('id'),
"note": "Contact already exists"
}
else:
error_detail = response.text if response.text else f"HTTP {response.status_code}"
return {
"success": False,
"contact": contact.get('first_name', ''),
"company": company.get('name', ''),
"error": f"API Error: {error_detail}"
}
except requests.exceptions.RequestException as e:
return {
"success": False,
"contact": contact.get('first_name', ''),
"company": company.get('name', ''),
"error": f"Netzwerkfehler: {str(e)}"
}
except Exception as e:
return {
"success": False,
"contact": contact.get('first_name', ''),
"company": company.get('name', ''),
"error": f"Unexpected error: {str(e)}"
}
def create_pipeline_manager_agent():
return Agent(
role='Pipeline Manager',
goal='Score leads and manage CRM integration for qualified prospects',
backstory='Expert at evaluating prospect quality and managing sales pipeline.',
tools=[LeadScoringTool(), CRMIntegrationTool()],
verbose=True
)Das Lead-Bewertungssystem bewertet potenzielle Kunden in mehreren Bereichen, darunter die Übereinstimmung mit dem idealen Kundenprofil, die Dringlichkeit von Auslöseereignissen, die Qualität der Kontaktdaten und zeitliche Faktoren. Es liefert detaillierte Bewertungsaufschlüsselungen, die eine datengestützte Priorisierung ermöglichen, und vergibt automatisch Buchstaben-Noten für eine schnelle Qualifizierung. Das CRM-Integrationstool exportiert qualifizierte Leads direkt nach HubSpot und stellt so sicher, dass alle Informationsdaten für die Nachverfolgung durch das Vertriebsteam richtig formatiert sind.
Schritt 6.1: Gemeinsame Dienstprogramme
Bevor Sie die Hauptanwendung erstellen, erstellen Sie eine Datei agents/utils.py mit gemeinsam genutzten Dienstprogrammen, die von allen Agenten verwendet werden:
"""
Gemeinsam genutzte Hilfsfunktionen für alle Agentenmodule.
"""
from typing import List, Dict, Any
import re
def validate_companies_input(companies: Any) -> List[Dict]:
"""Validieren und normalisieren Sie die Unternehmenseingaben für alle Agenten."""
if isinstance(companies, dict) and 'companies' in companies:
companies = companies['companies']
if not isinstance(companies, list):
print(f"Warnung: Erwartete Liste von Unternehmen, erhalten {type(companies)}")
return []
if not companies:
print("Keine Unternehmen angegeben")
return []
valid_companies = []
for company in companies:
if isinstance(company, dict):
valid_companies.append(company)
else:
print(f"Warnung: Erwartet wurde ein Unternehmens-Dict, erhalten wurde {type(company)}")
return gültige_unternehmen
def safe_mcp_call(mcp_client, method_name: str, *args, **kwargs) -> Dict:
"""Sicheres Aufrufen von MCP-Methoden mit konsistenter Fehlerbehandlung."""
try:
method = getattr(mcp_client, method_name)
result = method(*args, **kwargs)
return result if result and not result.get('error') else {}
except Exception as e:
print(f"Fehler beim Aufruf von MCP {method_name}: {str(e)}")
return {}
def validate_email(email: str) -> bool:
"""E-Mail-Format validieren."""
pattern = r'^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}$'
return bool(re.match(pattern, email))
def deduplicate_by_key(items: List[Dict], key_func) -> List[Dict]:
"""Entferne Duplikate aus der Liste der Dicts mithilfe einer Schlüsselfunktion."""
seen = set()
unique_items = []
for item in items:
key = key_func(item)
if key and key not in seen:
seen.add(key)
unique_items.append(item)
return unique_items
def extract_domain_from_url(url: str) -> str:
"""Extrahiert die Domain aus der URL mit Fallback-Parsing."""
if not url:
return ""
try:
from urllib.parse import urlparse
parsed = urlparse(url)
return parsed.netloc
except:
if '//' in url:
return url.split('//')[1].split('/')[0]
return ""Sie müssen außerdem eine leere Datei agents/__init__.py erstellen, um den Ordner agents zu einem Python-Paket zu machen.
Schritt 7: Systemorchestrierung
Erstellen Sie die Hauptanwendung Streamlit, die alle Agenten in einem intelligenten Workflow koordiniert. Die Schnittstelle gibt Echtzeit-Feedback und ermöglicht es Benutzern, Parameter für verschiedene Prospektierungsszenarien anzupassen.
Erstellen Sie eine Datei „ai_bdr_system.py” in Ihrem Projektstammverzeichnis und fügen Sie den folgenden Code hinzu:
import streamlit as st
import os
from dotenv import load_dotenv
from crewai import Crew, Process, Task
import pandas as pd
from datetime import datetime
import json
from mcp_client import Bright DataMCP
from agents.company_discovery import create_company_discovery_agent
from agents.trigger_detection import create_trigger_detection_agent
from agents.contact_research import create_contact_research_agent
from agents.message_generation import create_message_generation_agent
from agents.pipeline_manager import create_pipeline_manager_agent
load_dotenv()
st.set_page_config(
page_title="KI BDR/SDR System",
page_icon="🤖",
layout="wide")
st.title("🤖 KI BDR/SDR Agent System")
st.markdown("**Echtzeit-Prospektion mit Multi-Agent-Intelligenz und triggerbasierter Personalisierung**")
if 'workflow_results' not in st.session_state:
st.session_state.workflow_results = None
with st.sidebar:
try:
st.image("bright-data-logo.png", width=200)
st.markdown("---")
except:
st.markdown("**🌐 Powered by Bright Data**")
st.markdown("---")
st.header("⚙️ Konfiguration")
st.subheader("Ideales Kundenprofil")
industry = st.selectbox("Branche", ["SaaS", "FinTech", "E-Commerce", "Gesundheitswesen", "KI/ML"])
size_range = st.selectbox("Unternehmensgröße", ["Start-up", "klein", "mittel", "Großunternehmen"])
location = st.text_input("Standort (optional)", placeholder="San Francisco, NY, etc.")
max_companies = st.slider("Max. Anzahl Unternehmen", 5, 50, 20)
st.subheader("Zielgruppe: Entscheidungsträger")
all_roles = ["CEO", "CTO", "VP Engineering", "Head of Product", "VP Sales", "CMO", "CFO"]
target_roles = st.multiselect("Rollen", all_roles, default=["CEO", "CTO", "VP Engineering"])
st.subheader("Outreach-Konfiguration")
message_types = st.multiselect(
"Nachrichtentypen",
["cold_email", "linkedin_message", "follow_up"],
default=["cold_email"]
)
with st.expander("Erweiterte Wettbewerbsanalyse"):
enable_wettbewerbsanalyse = st.checkbox("Wettbewerbsanalyse", value=True)
enable_validation = st.checkbox("Multi-source Validation", value=True)
min_lead_grade = st.selectbox("Min CRM Export Grade", ["A", "B", "C"], index=1)
st.divider()
st.subheader("🔗 API Status")
apis = [
("Bright Data", "BRIGHT_DATA_API_TOKEN", "🌐"),
("OpenAI", "OPENAI_API_KEY", "🧠"),
("HubSpot CRM", "HUBSPOT_API_KEY", "📊")
]
for name, env_var, icon in API:
if os.getenv(env_var):
st.success(f"{icon} {name} Connected")
else:
if name == "HubSpot CRM":
st.warning(f"⚠️ {name} Required for CRM export")
elif name == "Bright Data":
st.error(f"❌ {name} Fehlt")
if st.button("🔧 Konfigurationshilfe", key="bright_data_help"):
st.info("""
**Bright Data-Einrichtung erforderlich:**
1. Abrufen der Anmeldedaten aus dem Bright Data-Dashboard
2. Aktualisieren der .env-Datei mit:
```
BRIGHT_DATA_API_TOKEN=Ihr_Passwort
WEB_UNLOCKER_ZONE=lum-Kunden-Benutzername-Zone-Zonenname
```
3. Eine detaillierte Anleitung finden Sie unter BRIGHT_DATA_SETUP.md.
**Aktueller Fehler**: 407 Ungültige Authentifizierung = Falsche Anmeldedaten
""")
else:
st.error(f"❌ {name} fehlt")
col1, col2 = st.columns([3, 1])
with col1:
st.subheader("🚀 KI Prospecting Workflow")
if st.button("Start Multi-Agent Prospecting", type="primary", use_container_width=True):
required_keys = ["BRIGHT_DATA_API_TOKEN", "OPENAI_API_KEY"]
missing_keys = [key for key in required_keys if not os.getenv(key)]
if missing_keys:
st.error(f"Fehlende erforderliche API-Schlüssel: {', '.join(missing_keys)}")
st.stop()
progress_bar = st.progress(0)
status_text = st.empty()
try:
mcp_client = Bright DataMCP()
discovery_agent = create_company_discovery_agent(mcp_client)
trigger_agent = create_trigger_detection_agent(mcp_client)
contact_agent = create_contact_research_agent(mcp_client)
message_agent = create_message_generation_agent()
pipeline_agent = create_pipeline_manager_agent()
status_text.text("🔍 Suche nach Unternehmen, die dem ICP entsprechen...")
progress_bar.progress(15)
discovery_task = Task(
description=f"Finde {max_companies} Unternehmen in {industry} (Größe {size_range}) in {location}",
expected_output="Liste von Unternehmen mit ICP-Bewertungen und Informationen",
agent=discovery_agent
)
discovery_crew = Crew(
agents=[discovery_agent],
tasks=[discovery_task],
process=Process.sequential
)
companies = discovery_agent.tools[0]._run(industry, size_range, location)
st.success(f"✅ {len(companies)} Unternehmen gefunden")
status_text.text("🎯 Analyse von Auslöseereignissen und Kaufsignalen...")
progress_bar.progress(30)
trigger_task = Task(
description="Erkennung von Einstellungshochs, Finanzierungsrunden, Führungswechseln und Expansionssignalen",
expected_output="Unternehmen mit Trigger-Ereignissen und Bewertungen",
agent=trigger_agent
)
trigger_crew = Crew(
agents=[trigger_agent],
tasks=[trigger_task],
process=Process.sequential
)
companies_with_triggers = trigger_agent.tools[0]._run(Unternehmen)
total_triggers = sum(len(c.get('trigger_events', [])) for c in Unternehmen_mit_Auslösern)
st.success(f"✅ {total_triggers} Auslöserereignisse erkannt")
progress_bar.progress(45)
status_text.text("👥 Suche nach Entscheidungsträgern...")
contact_task = Task(
description=f"Verifizierte Kontakte für Rollen finden: {', '.join(target_roles)}",
expected_output="Unternehmen mit Kontaktinformationen von Entscheidungsträgern",
agent=contact_agent
)
contact_crew = Crew(
agents=[contact_agent],
tasks=[contact_task],
process=Process.sequential
)
companies_with_contacts = contact_agent.tools[0]._run(companies_with_triggers, target_roles)
total_contacts = sum(len(c.get('contacts', [])) for c in companies_with_contacts)
st.success(f"✅ {total_contacts} verifizierte Kontakte gefunden")
progress_bar.progress(60)
status_text.text("✍️ Generierung personalisierter Kontaktnachrichten...")
message_task = Task(
description=f"Generierung von {', '.join(message_types)} für jeden Kontakt unter Verwendung von Trigger-Intelligenz",
expected_output="Unternehmen mit personalisierten Nachrichten",
agent=message_agent
)
message_crew = Crew(
agents=[message_agent],
tasks=[message_task],
process=Process.sequential
)
companies_with_messages = message_agent.tools[0]._run(companies_with_contacts, message_types[0])
total_messages = sum(len(c.get('contacts', [])) for c in companies_with_messages)
st.success(f"✅ Generated {total_messages} personalized messages")
progress_bar.progress(75)
status_text.text("📊 Scoring leads and updating CRM...")
pipeline_task = Task(
description=f"Leads bewerten und mit der Note {min_lead_grade}+ in HubSpot CRM exportieren",
expected_output="Bewertete Leads mit CRM-Integrationsergebnissen",
agent=pipeline_agent
)
pipeline_crew = Crew(
agents=[pipeline_agent],
tasks=[pipeline_task],
process=Process.sequential
)
final_companies = pipeline_agent.tools[0]._run(companies_with_messages)
qualified_leads = [c for c in final_companies if c.get('lead_grade', 'D') in ['A', 'B']]
crm_results = {"success": 0, "errors": 0}
if os.getenv("HUBSPOT_API_KEY"):
crm_results = pipeline_agent.tools[1]._run(final_companies, min_lead_grade)
progress_bar.progress(100)
status_text.text("✅ Workflow erfolgreich abgeschlossen!")
st.session_state.workflow_results = {
'companies': final_companies,
'total_companies': len(final_companies),
'total_triggers': total_triggers,
'total_contacts': total_contacts,
'qualified_leads': len(qualified_leads),
'crm_results': crm_results,
'timestamp': datetime.now()
}
except Exception as e:
st.error(f"❌ Workflow fehlgeschlagen: {str(e)}")
st.write("Bitte überprüfen Sie Ihre API-Konfigurationen und versuchen Sie es erneut.")
if st.session_state.workflow_results:
results = st.session_state.workflow_results
st.markdown("---")
st.subheader("📊 Workflow-Ergebnisse")
col1, col2, col3, col4 = st.columns(4)
with col1:
st.metric("Analysierte Unternehmen", results['total_companies'])
with col2:
st.metric("Auslösende Ereignisse", results['total_triggers'])
with col3:
st.metric("Gefundene Kontakte", results['total_contacts'])
with col4:
st.metric("Qualifizierte Leads", results['qualified_leads'])
if results['crm_results']['success'] > 0 or results['crm_results']['errors'] > 0:
st.subheader("🔄 HubSpot CRM-Integration")
col1, col2 = st.columns(2)
mit col1:
st.metric("In CRM exportiert", Ergebnisse['crm_results']['success'], delta="contacts")
mit col2:
if results['crm_results']['errors'] > 0:
st.metric("Exportfehler", results['crm_results']['errors'], delta_color="inverse")
st.subheader("🏢 Unternehmensinformationen")
for company in results['companies'][:10]:
mit st.expander(f"📋 {company.get('name', 'Unknown')} - Note {company.get('lead_grade', 'D')} (Punktzahl: {company.get('lead_score', 0):.0f})"):
col1, col2 = st.columns(2)
with col1:
st.write(f"**Branche:** {company.get('industry', 'Unknown')}")
st.write(f"**Domäne:** {company.get('domain', 'Unknown')}")
st.write(f"**ICP-Punktzahl:** {company.get('icp_score', 0)}")
triggers = company.get('trigger_events', [])
if triggers:
st.write("**🎯 Trigger-Ereignisse:**")
for trigger in triggers:
severity_emoji = {"high": "🔥", "medium": "⚡", "low": "💡"}.get(trigger.get('severity', 'low'), '💡')
st.write(f"{severity_emoji} {trigger.get('description', 'Unbekannter Auslöser')}")
with col2:
contacts = company.get('contacts', [])
if contacts:
st.write("**👥 Entscheidungsträger:**")
for contact in contacts:
confidence = contact.get('confidence_score', 0)
confidence_color = "🟢" if confidence >= 75 else "🟡" if confidence >= 50 else "🔴"
st.write(f"{confidence_color} **{contact.get('first_name', '')} {contact.get('last_name', '')}**")
st.write(f" {contact.get('title', 'Unbekannter Titel')}")
st.write(f" 📧 {contact.get('email', 'Keine E-Mail')}")
st.write(f" Konfidenz: {confidence}%")
message = contact.get('generated_message', {})
if message.get('subject'):
st.write(f" **Betreff:** {message['subject']}")
if message.get('body'):
preview = message['body'][:100] + "..." if len(message['body']) > 100 else message['body']
st.write(f" **Vorschau:** {preview}")
st.write("---")
st.subheader("📥 Export & Aktionen")
col1, col2, col3 = st.columns(3)
with col1:
export_data = []
for company in results['companies']:
for contact in company.get('contacts', []):
export_data.append({
'Unternehmen': company.get('name', ''),
'Branche': company.get('industry', ''),
'Lead-Bewertung': company.get('lead_grade', ''),
'Lead-Punktzahl': company.get('lead_score', 0),
'Trigger-Anzahl': len(company.get('trigger_events', [])),
'Contact Name': f"{contact.get('first_name', '')} {contact.get('last_name', '')}",
'Title': contact.get('title', ''),
'Email': contact.get('email', ''),
'Confidence': contact.get('confidence_score', 0),
'Subject Line': contact.get('generated_message', {}).get('subject', ''),
'Message': contact.get('generated_message', {}).get('body', '')
})
if export_data:
df = pd.DataFrame(export_data)
csv = df.to_csv(index=False)
st.download_button(
label="📄 Vollständigen Bericht herunterladen (CSV)",
data=csv,
file_name=f"ai_bdr_prospects_{datetime.now().strftime('%Y%m%d_%H%M')}.csv",
mime="text/csv",
use_container_width=True
)
with col2:
if st.button("🔄 Mit HubSpot CRM synchronisieren", use_container_width=True):
if not os.getenv("HUBSPOT_API_KEY"):
st.warning("HubSpot-API-Schlüssel für CRM-Export erforderlich")
else:
with st.spinner("Synchronisierung mit HubSpot..."):
pipeline_agent = create_pipeline_manager_agent()
new_crm_results = pipeline_agent.tools[1]._run(results['companies'], min_lead_grade)
st.session_state.workflow_results['crm_results'] = new_crm_results
st.rerun()
mit col3:
wenn st.button("🗑️ Ergebnisse löschen", use_container_width=True):
st.session_state.workflow_results = None
st.rerun()
wenn __name__ == "__main__":
passDas Streamlit-Orchestrierungssystem koordiniert alle Agenten in einem effizienten Workflow mit Echtzeit-Fortschrittsverfolgung und anpassbaren Einstellungen. Es bietet eine übersichtliche Ergebnisanzeige mit Metriken, detaillierten Unternehmensinformationen und Exportoptionen. Die Benutzeroberfläche erleichtert die Verwaltung komplexer Multi-Agent-Vorgänge durch ein intuitives Dashboard, das Vertriebsteams ohne technische Kenntnisse nutzen können.
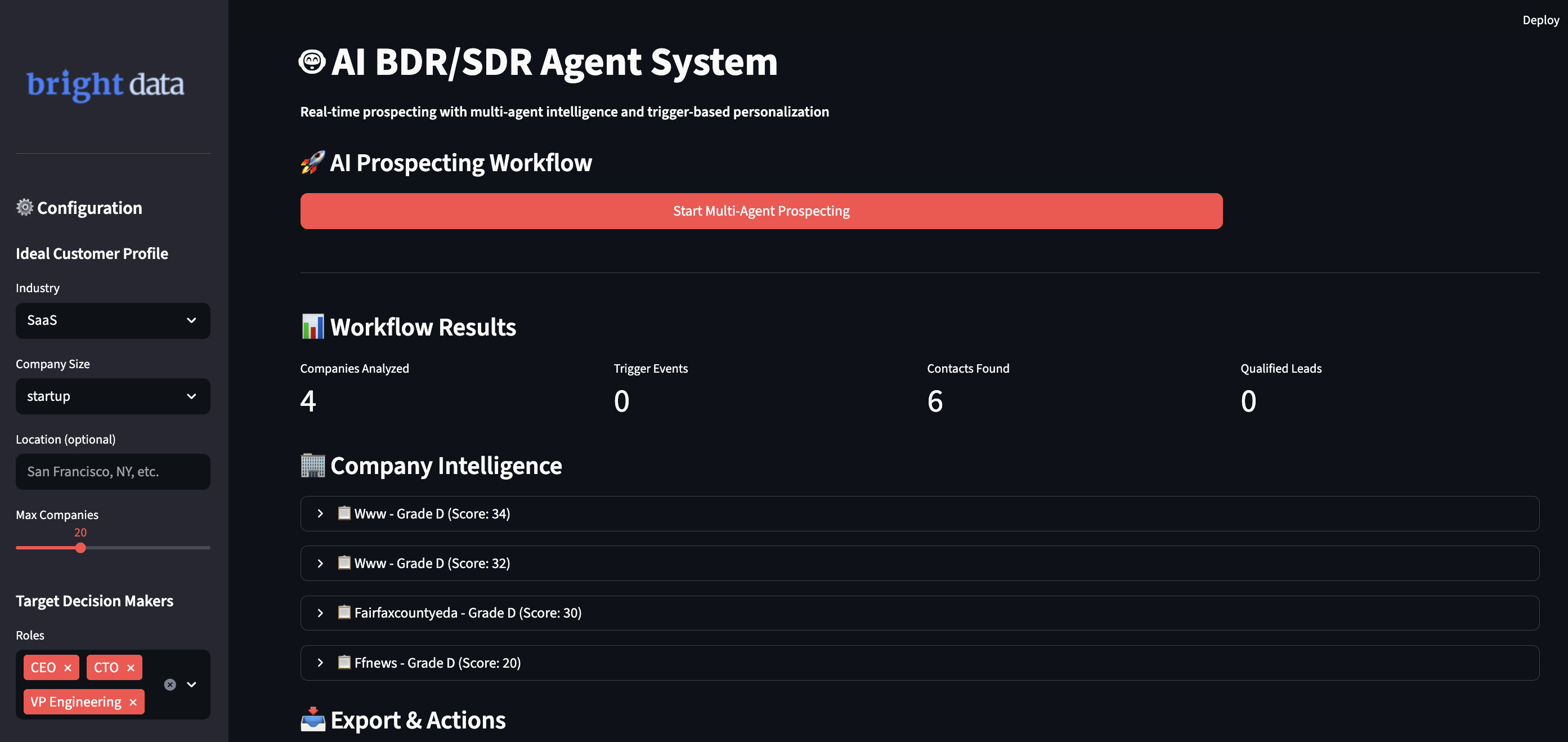
Ausführen Ihres KI-BDR-Systems
Führen Sie die Anwendung aus, um intelligente Prospektierungs-Workflows zu starten. Öffnen Sie Ihr Terminal und wechseln Sie in Ihr Projektverzeichnis.
streamlit run ai_bdr_system.py
Sie sehen den intelligenten Workflow des Systems, während es Ihre Anforderungen verarbeitet:
- Es findet Unternehmen, die Ihrem idealen Kundenprofil entsprechen, mithilfe von Echtzeit-Datenprüfungen.
- Es verfolgt Trigger-Ereignisse aus verschiedenen Quellen, um den besten Zeitpunkt zu finden.
- Es sucht anhand mehrerer Quellen nach Kontakten zu Entscheidungsträgern und bewertet diese hinsichtlich ihrer Zuverlässigkeit.
- Es erstellt personalisierte Nachrichten, die spezifische Geschäftseinblicke enthalten.
- Es bewertet Leads automatisch und fügt qualifizierte Interessenten zu Ihrer CRM-Pipeline hinzu.
Abschließende Gedanken
Dieses KI-BDR-System zeigt, wie Automatisierung die Akquise und Lead-Qualifizierung optimieren kann. Um Ihre Vertriebspipeline weiter zu verbessern, sollten Sie Bright Data-Produkte wie unseren LinkedIn-Datensatz für genaue Kontakt- und Unternehmensdaten sowie andere Datensätze und Automatisierungstools für BDR- und Vertriebsteams in Betracht ziehen.
Entdecken Sie weitere Lösungen in der Bright Data-Dokumentation.
Erstellen Sie ein kostenloses Bright Data-Konto, um mit dem Aufbau Ihrer automatisierten BDR-Workflows zu beginnen.




