

In diesem Leitfaden finden Sie die folgenden Informationen:
- Was Pica ist und warum es eine ausgezeichnete Wahl für die Entwicklung von KI-Agenten ist, die sich in externe Tools integrieren lassen.
- Warum KI-Agenten für den Datenabruf die Integration mit Lösungen von Drittanbietern benötigen.
- Wie Sie den integrierten Bright Data Connector in einem Pica-Agenten verwenden, um Webdaten für genauere Antworten zu erhalten.
Lasst uns eintauchen!
Was ist Pica?
Pica ist eine Open-Source-Plattform, die für den schnellen Aufbau von KI-Agenten und SaaS-Integrationen entwickelt wurde. Sie bietet einen vereinfachten Zugang zu über 125 APIs von Drittanbietern, ohne dass die Verwaltung von Schlüsseln oder komplexe Konfigurationen erforderlich sind.
Das Ziel von Pica ist es, KI-Modelle mühelos mit externen Tools und Diensten zu verbinden. Mit Pica können Sie Integrationen mit nur wenigen Klicks einrichten und sie dann problemlos in Ihrem Code verwenden. So können KI-Workflows Daten in Echtzeit abrufen, komplexe Automatisierungen durchführen und vieles mehr.
Das Projekt hat auf GitHub schnell an Popularität gewonnen und in nur wenigen Monaten über 1.300 Sterne gesammelt. Das zeigt das starke Wachstum und die Akzeptanz der Community.
Warum KI-Agenten Webdaten-Integrationen benötigen
Jedes KI-Agenten-Framework erbt zentrale Einschränkungen von den LLMs, auf denen es aufbaut. Da LLMs auf statischen Datensätzen vortrainiert sind, fehlt ihnen das Echtzeitbewusstsein und sie können nicht zuverlässig auf Live-Webinhalte zugreifen.
Dies führt oft zu veralteten Antworten oder sogar zu Halluzinationen. Um diese Einschränkungen zu überwinden, benötigen Agenten (und die LLMs, von denen sie abhängen) Zugang zu vertrauenswürdigen, aktuellen Webdaten. Warum gerade Webdaten? Weil das Internet nach wie vor die umfassendste und aktuellste verfügbare Informationsquelle ist.
Aus diesem Grund muss ein effektiver KI-Agent in der Lage sein, sich schnell und einfach mit KI-Webdatenanbietern von Drittanbietern zu integrieren. Und genau an dieser Stelle kommt Pica ins Spiel!
Auf der Pica-Plattform finden Sie über 125 verfügbare Integrationen, darunter eine für Bright Data:
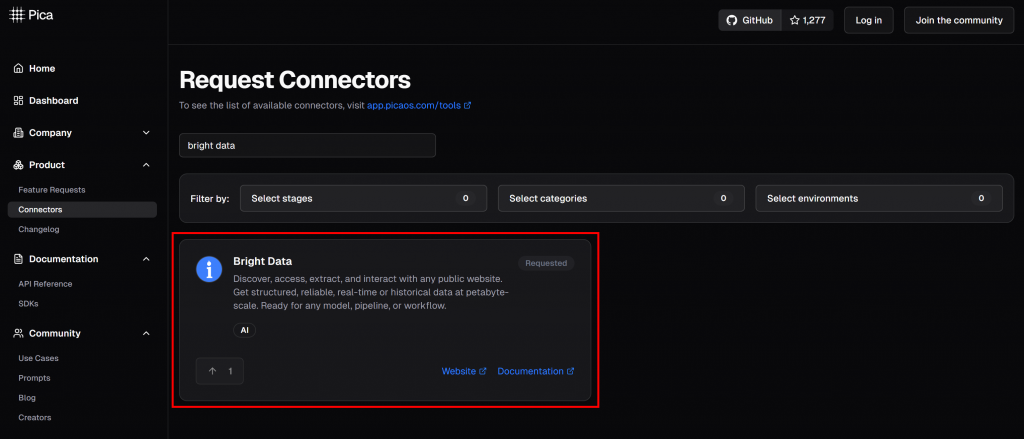
Die Bright Data-Integration ermöglicht Ihren KI-Agenten und -Workflows eine nahtlose Verbindung:
- Web Unlocker API: Eine fortschrittliche Scraping-API, die den Bot-Schutz umgeht und den Inhalt einer beliebigen Webseite im Markdown-Format liefert.
- Web Scraper APIs: Spezialisierte Lösungen für die ethische Extraktion von frischen, strukturierten Daten von beliebten Websites wie Amazon, LinkedIn, Instagram und 40 anderen.
Diese Tools geben Ihren KI-Agenten, Workflows oder Pipelines die Möglichkeit, ihre Antworten mit zuverlässigen Webdaten zu untermauern, die on the fly aus relevanten Seiten extrahiert werden. Im nächsten Kapitel sehen Sie diese Integration in Aktion!
Entwicklung eines KI-Agenten, der mit Pica und Bright Data Daten aus dem Internet abrufen kann
In diesem geführten Abschnitt erfahren Sie, wie Sie mit Pica einen Python-KI-Agenten erstellen, der sich mit der Bright Data-Integration verbindet. Auf diese Weise kann Ihr Agent strukturierte Webdaten von Websites wie Amazon abrufen.
Führen Sie die folgenden Schritte aus, um Ihren Bright Data-gestützten KI-Agenten mit Pica zu erstellen!
Voraussetzungen
Für dieses Tutorial benötigen Sie:
- Python 3.9 oder höher auf Ihrem Rechner installiert (wir empfehlen die neueste Version).
- Ein Pica-Konto.
- Ein Bright Data-API-Schlüssel.
- Ein OpenAI-API-Schlüssel.
Machen Sie sich keine Sorgen, wenn Sie noch keinen Bright Data-API-Schlüssel oder ein Pica-Konto haben. Wir zeigen Ihnen in den nächsten Schritten, wie Sie diese einrichten können.
Schritt #1: Initialisieren Sie Ihr Python-Projekt
Öffnen Sie ein Terminal und erstellen Sie ein neues Verzeichnis für Ihr Pica AI Agent Projekt:
mkdir pica-bright-data-agentDer Ordner pica-bright-data-agent enthält den Python-Code für Ihren Pica-Agenten. Dieser verwendet die Bright Data-Integration für den Abruf von Webdaten.
Navigieren Sie anschließend in das Projektverzeichnis und erstellen Sie darin eine virtuelle Umgebung:
cd pica-bright-data-agent
python -m venv venvÖffnen Sie nun das Projekt in Ihrer bevorzugten Python-IDE. Wir empfehlen Visual Studio Code mit der Python-Erweiterung oder PyCharm Community Edition.
Erstellen Sie innerhalb des Projektordners eine neue Datei namens agent.py. Ihre Verzeichnisstruktur sollte wie folgt aussehen:
pica-bright-data-agent/
├── venv/
└── agent.pyAktivieren Sie die virtuelle Umgebung in Ihrem Terminal. Unter Linux oder macOS führen Sie aus:
source venv/bin/activateUnter Windows können Sie auch diesen Befehl ausführen:
venv/Scripts/activateIn den nächsten Schritten werden Sie die erforderlichen Python-Pakete installieren. Wenn Sie es vorziehen, alles sofort zu installieren, während Ihre virtuelle Umgebung aktiviert ist, führen Sie einfach aus:
pip install langchain langchain-openai pica-langchain python-dotenvSie sind bereit! Sie verfügen nun über eine Python-Entwicklungsumgebung, um einen KI-Agenten mit Bright Data-Integration in Pica zu erstellen.
Schritt #2: Umgebungsvariablen einrichten Lesen
Ihr Agent stellt eine Verbindung zu Drittanbieterdiensten wie Pica, Bright Data und OpenAI her. Um diese Integrationen sicher zu halten, sollten Sie vermeiden, Ihre API-Schlüssel direkt in Ihrem Python-Code zu kodieren. Speichern Sie sie stattdessen als Umgebungsvariablen.
Um das Laden von Umgebungsvariablen zu erleichtern, verwenden Sie die Bibliothek python-dotenv. Installieren Sie sie in Ihrer aktivierten virtuellen Umgebung mit:
pip install python-dotenvAls nächstes importieren Sie die Bibliothek und rufen load_dotenv() am Anfang Ihrer agent.py-Datei auf, um Ihre Umgebungsvariablen zu laden:
import os
from dotenv import load_dotenv
load_dotenv()Diese Funktion ermöglicht es Ihrem Skript, Variablen aus einer lokalen .env-Datei zu lesen. Erstellen Sie diese .env-Datei im Stammverzeichnis Ihres Projekts. Ihre Ordnerstruktur wird wie folgt aussehen:
pica-bright-data-agent/
├── venv/
├── .env # <-----------
└── agent.pyGroßartig! Sie sind nun in der Lage, Ihre API-Schlüssel und andere Geheimnisse mithilfe von Umgebungsvariablen sicher zu verwalten.
Schritt #3: Pica konfigurieren
Falls Sie dies noch nicht getan haben, erstellen Sie ein kostenloses Pica-Konto. Standardmäßig wird Pica einen API-Schlüssel für Sie generieren. Sie können diesen API-Schlüssel mit LangChain oder jeder anderen unterstützten Integration verwenden.
Besuchen Sie die Seite “Schnellstart” und wählen Sie die Registerkarte “LangChain”:
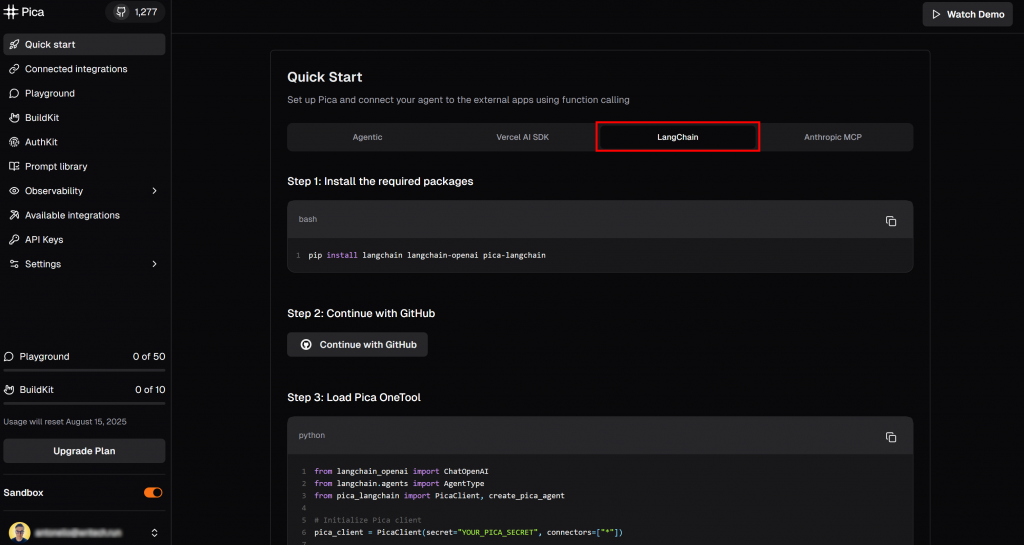
Hier finden Sie eine Anleitung, wie Sie mit Pica in LangChain beginnen können. Folgen Sie insbesondere dem dort gezeigten Installationsbefehl. Führen Sie in Ihrer aktivierten virtuellen Umgebung aus:
pip install langchain langchain-openai pica-langchainScrollen Sie nun nach unten, bis Sie den Abschnitt “API-Schlüssel” erreichen:

Klicken Sie auf die Schaltfläche “In die Zwischenablage kopieren”, um Ihren Pica-API-Schlüssel zu kopieren. Fügen Sie ihn dann in Ihre .env-Datei ein, indem Sie eine Umgebungsvariable wie die folgende definieren:
PICA_API_KEY="<YOUR_PICA_KEY>"Ersetzen Sie den Platzhalter durch den tatsächlichen API-Schlüssel, den Sie gerade kopiert haben.
Fantastisch! Ihr Pica-Konto ist nun vollständig konfiguriert und bereit für die Verwendung in Ihrem Code.
Schritt Nr. 4: Helle Daten in Pica integrieren
Bevor Sie beginnen, folgen Sie der offiziellen Anleitung zum Einrichten eines Bright Data-API-Schlüssels. Sie benötigen diesen Schlüssel, um Ihren Agenten über die integrierte Integration auf der Pica-Plattform mit Bright Data zu verbinden.
Da Sie nun Ihren API-Schlüssel haben, können Sie die Bright Data-Integration in Pica hinzufügen.
Scrollen Sie auf der Registerkarte “LangChain” Ihres Pica-Dashboards nach unten zum Abschnitt “Aktuelle Integrationen” und klicken Sie auf die Schaltfläche “Integrationen durchsuchen”:
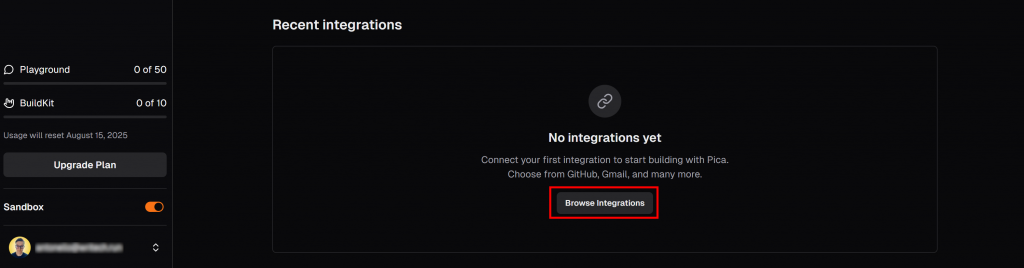
Daraufhin wird ein Modal geöffnet. Geben Sie in der Suchleiste “brightdata” ein und wählen Sie die “BrightData”-Integration aus:
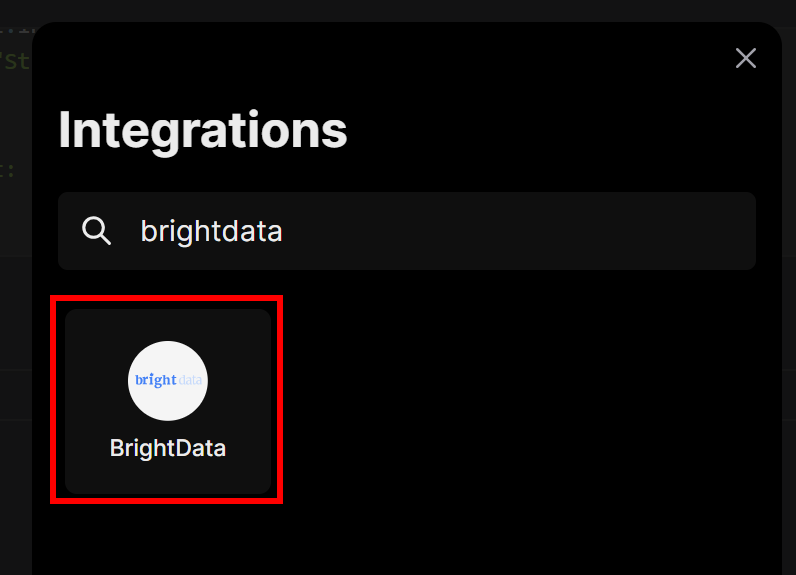
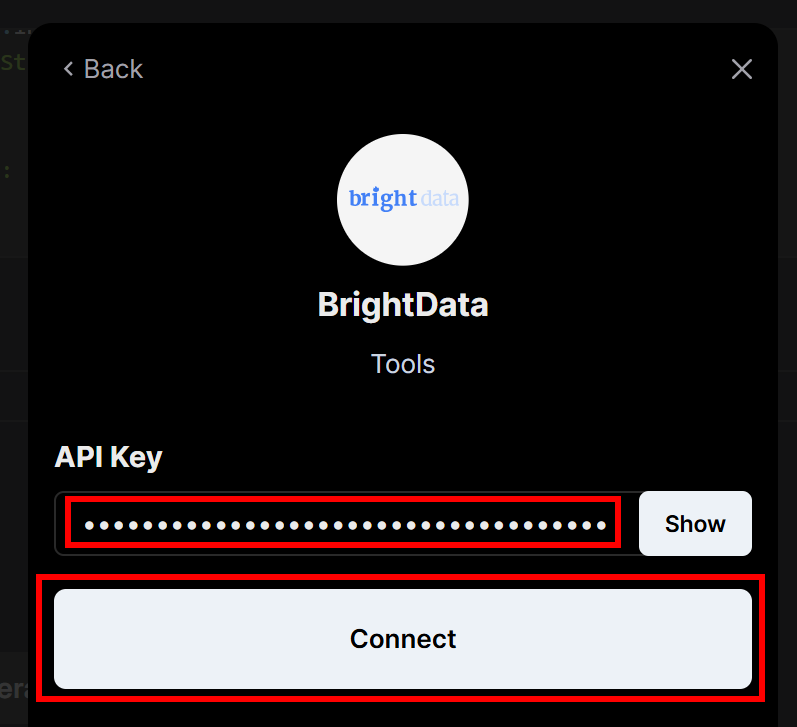
Sie werden aufgefordert, den zuvor erstellten Bright Data-API-Schlüssel einzugeben. Fügen Sie ihn ein und klicken Sie dann auf die Schaltfläche “Verbinden”:
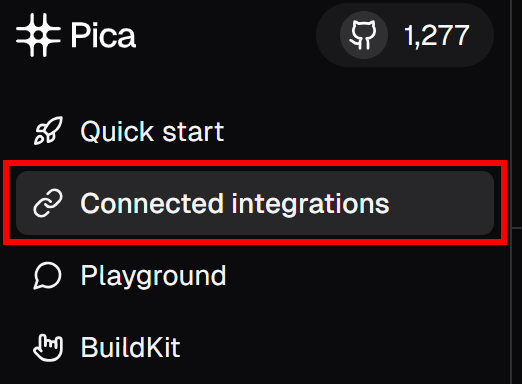
Klicken Sie anschließend im linken Menü auf den Menüpunkt “Verbundene Integrationen”:
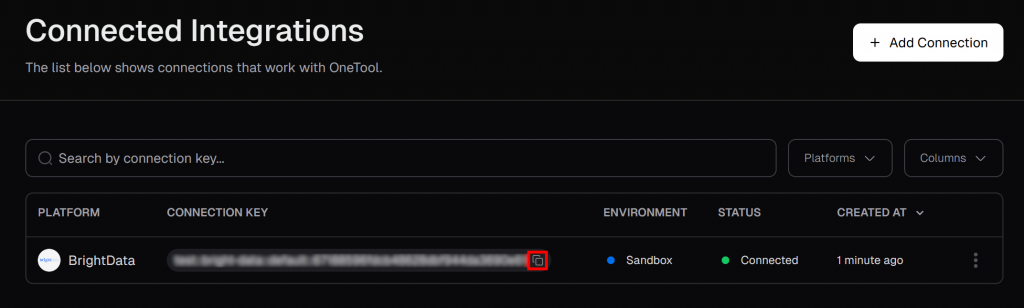
Auf der Seite “Verbundene Integrationen” sollte nun Bright Data als verbundene Integration aufgeführt sein. Klicken Sie in der Tabelle auf die Schaltfläche “In die Zwischenablage kopieren”, um Ihren Verbindungsschlüssel zu kopieren:
Fügen Sie sie dann in Ihre .env-Datei ein, indem Sie hinzufügen:
PICA_BRIGHT_DATA_CONNECTION_KEY="<YOUR_PICA_BRIGHT_DATA_CONNECTION_KEY>"Stellen Sie sicher, dass Sie den durch den tatsächlichen Verbindungsschlüssel, den Sie kopiert haben.
Sie benötigen diesen Wert, um Ihren Pica-Agenten im Code zu initialisieren, damit er weiß, dass er die konfigurierte Bright Data-Verbindung laden soll. Wie das geht, erfahren Sie im nächsten Schritt!
Schritt #5: Initialisieren Sie Ihren Pica-Agenten
In agent.py, initialisieren Sie Ihren Pica-Agenten mit:
pica_client = PicaClient(
secret=os.environ["PICA_API_KEY"],
options=PicaClientOptions(
connectors=[
os.environ["PICA_BRIGHT_DATA_CONNECTION_KEY"]
]
)
)
pica_client.initialize()Das obige Snippet initialisiert einen Pica-Client, der eine Verbindung zu Ihrem Pica-Konto herstellt und dabei das aus Ihrer Umgebung geladene PICA_API_KEY-Geheimnis verwendet. Außerdem wählt er die Bright Data-Integration, die Sie zuvor konfiguriert haben, aus allen verfügbaren Konnektoren aus.
Das bedeutet, dass alle KI-Agenten, die Sie mit diesem Client erstellen, in der Lage sind, die Echtzeit-Webdatenabfragefunktionen von Bright Data zu nutzen.
Vergessen Sie nicht, die erforderlichen Klassen zu importieren:
from pica_langchain import PicaClient
from pica_langchain.models import PicaClientOptionsGroßartig! Sie sind bereit, mit der Integration des LLM fortzufahren.
Schritt #6: OpenAI einbinden
Ihr Pica-Agent benötigt eine LLM-Engine, um die Eingabeaufforderungen zu verstehen und die gewünschten Aufgaben mithilfe der Funktionen von Bright Data auszuführen.
In diesem Tutorial wird die OpenAI-Integration verwendet, so dass Sie die LLM für Ihren Agenten in Ihrer agent.py-Datei wie folgt definieren:
llm = ChatOpenAI(
model="gpt-4o",
temperature=0,
)Beachten Sie, dass in allen Pica LangChain-Beispielen in der Dokumentation die Temperatur=0 verwendet wird. Dadurch wird sichergestellt, dass das Modell deterministisch ist und immer die gleiche Ausgabe für die gleiche Eingabe erzeugt.
Denken Sie daran, dass die Klasse ChatOpenAI von diesem Import stammt:
from langchain_openai import ChatOpenAIInsbesondere erwartet ChatOpenAI, dass Ihr OpenAI API-Schlüssel in einer Umgebungsvariablen namens OPENAI_API_KEY definiert ist. Fügen Sie also in Ihrer .env-Datei Folgendes hinzu:
OPENAI_API_KEY=<YOUT_OPENai_API_KEY>Ersetzen Sie den Platzhalter durch Ihren tatsächlichen OpenAI-API-Schlüssel.
Erstaunlich! Sie haben nun alle Bausteine, um Ihren Pica AI-Agenten zu definieren.
Schritt #7: Definieren Sie Ihren Pica-Agenten
In Pica besteht ein KI-Agent aus drei Hauptbestandteilen:
- Eine Pica-Client-Instanz
- Ein LLM-Motor
- Ein Pica-Agent-Typ
In diesem Fall möchten Sie einen KI-Agenten erstellen, der OpenAI-Funktionen aufrufen kann (die wiederum über die Pica-Integration eine Verbindung zu den Webabfragefunktionen von Bright Data herstellen). Erstellen Sie also Ihren Pica-Agenten wie folgt:
agent = create_pica_agent(
client=pica_client,
llm=llm,
agent_type=AgentType.OPENAI_FUNCTIONS,
) Vergessen Sie nicht, die notwendigen Importe hinzuzufügen:
from pica_langchain import create_pica_agent
from langchain.agents import AgentTypeWunderbar! Jetzt müssen Sie Ihren Agenten nur noch mit einer Datenabrufaufgabe testen.
Schritt #8: Befragen Sie Ihren KI-Agenten
Um zu überprüfen, ob die Bright Data-Integration in Ihrem Pica-Agenten funktioniert, geben Sie ihm eine Aufgabe, die er normalerweise nicht selbst ausführen könnte. Bitten Sie ihn zum Beispiel, aktualisierte Daten von einer aktuellen Amazon-Produktseite abzurufen, wie z. B. die Nintendo Switch 2 (erhältlich unter https://www.amazon.com/dp/B0F3GWXLTS/).
Rufen Sie dazu Ihren Agenten mit dieser Eingabe auf:
agent_input = """
Use Bright Data to run a web scraping task and return the results from the following Amazon product URL:
https://www.amazon.com/dp/B0F3GWXLTS/
"""
result = agent.invoke({
"input": agent_input
})Hinweis: Die Aufforderung ist absichtlich explizit. Sie sagt dem Agenten genau, was zu tun ist, welche Seite er abrufen und welche Integration er verwenden soll. Dadurch wird sichergestellt, dass der LLM die über Pica konfigurierten Bright Data-Tools nutzt und die erwarteten Ergebnisse liefert.
Drucken Sie schließlich die Ausgabe des Agenten:
print(f"nAgent Result:n{result}")Und mit dieser letzten Zeile ist Ihr Pica AI-Agent fertig. Es ist an der Zeit, das Ganze in Aktion zu erleben!
Schritt #9: Alles zusammenfügen
Ihre agent.py-Datei sollte nun enthalten:
import os
from dotenv import load_dotenv
from pica_langchain import PicaClient, create_pica_agent
from pica_langchain.models import PicaClientOptions
from langchain_openai import ChatOpenAI
from langchain.agents import AgentType
# Load environment variables from .env file
load_dotenv()
# Initialize Pica client with the specific Bright Data connector
pica_client = PicaClient(
secret=os.environ["PICA_API_KEY"],
options=PicaClientOptions(
connectors=[
os.environ["PICA_BRIGHT_DATA_CONNECTION_KEY"] # Load the specific Bright Data connection
]
)
)
pica_client.initialize()
# Initialize the LLM
llm = ChatOpenAI(
model="gpt-4o",
temperature=0,
)
# Create your Pica agent
agent = create_pica_agent(
client=pica_client,
llm=llm,
agent_type=AgentType.OPENAI_FUNCTIONS,
)
# Execute a web data retrieval task in the agent
agent_input = """
Use Bright Data to run a web scraping task and return the results from the following Amazon product URL:
https://www.amazon.com/dp/B0F3GWXLTS/
"""
result = agent.invoke({
"input": agent_input
})
# Print the produced output
print(f"nAgent Result:n{result}")Wie Sie sehen, haben Sie in weniger als 50 Codezeilen einen Pica-Agenten mit leistungsstarken Datenabfragefunktionen erstellt. Dies ist dank der Bright Data-Integration möglich, die direkt auf der Pica-Plattform verfügbar ist.
Führen Sie Ihren Agenten mit aus:
python agent.pyIn Ihrem Terminal sollten Sie ähnliche Protokolle wie die folgenden sehen:
# Omitted for brevity...
2026-07-15 17:06:03,286 - pica_langchain - INFO - Successfully fetched 1 connections
# Omitted for brevity...
2026-07-15 17:06:05,546 - pica_langchain - INFO - Getting available actions for platform: bright-data
2026-07-15 17:06:05,546 - pica_langchain - INFO - Fetching available actions for platform: bright-data
2026-07-15 17:06:05,789 - pica_langchain - INFO - Found 54 available actions for bright-data
2026-07-15 17:06:07,332 - pica_langchain - INFO - Getting knowledge for action ID: XXXXXXXXXXXXXXXXXXXX on platform: bright-data
# Omitted for brevity...
2026-07-15 17:06:12,447 - pica_langchain - INFO - Executing action ID: XXXXXXXXXXXXXXXXXXXX on platform: bright-data with method: GET
2026-07-15 17:06:12,447 - pica_langchain - INFO - Executing action for platform: bright-data, method: GET
2026-07-15 17:06:12,975 - pica_langchain - INFO - Successfully executed Get Dataset List via bright-data
2026-07-15 17:06:12,976 - pica_langchain - INFO - Successfully executed action: Get Dataset List on platform: bright-data
2026-07-15 17:06:16,491 - pica_langchain - INFO - Executing action ID: XXXXXXXXXXXXXXXXXXXX on platform: bright-data with method: POST
2026-07-15 17:06:16,492 - pica_langchain - INFO - Executing action for platform: bright-data, method: POST
2026-07-15 17:06:22,265 - pica_langchain - INFO - Successfully executed Trigger Synchronous Web Scraping and Retrieve Results via bright-data
2026-07-15 17:06:22,267 - pica_langchain - INFO - Successfully executed action: Trigger Synchronous Web Scraping and Retrieve Results on platform: bright-dataVereinfacht ausgedrückt, ist es das, was Ihr Pica-Agent getan hat:
- Verbindung zu Pica hergestellt und die konfigurierte Bright Data-Integration abgerufen.
- Er entdeckte, dass 54 Tools auf der Bright Data-Plattform verfügbar waren.
- Ruft eine Liste aller Datensätze von Bright Data ab.
- Auf Ihre Aufforderung hin wählte es das Tool “Synchrones Web Scraping auslösen und Ergebnisse abrufen” aus und nutzte es, um frische Daten von der angegebenen Amazon-Produktseite abzurufen. Hinter den Kulissen wird dadurch ein Aufruf an den Bright Data Amazon Scraper ausgelöst, wobei die URL des Amazon-Produkts übergeben wird. Der Scraper ruft die Produktdaten ab und gibt sie zurück.
- Die Scraping-Aktion wurde erfolgreich ausgeführt und die Daten zurückgegeben.
Ihre Ausgabe sollte in etwa so aussehen:

Fügen Sie diese Ausgabe in einen Markdown-Editor ein, und Sie werden einen gut formatierten Produktbericht wie diesen sehen:
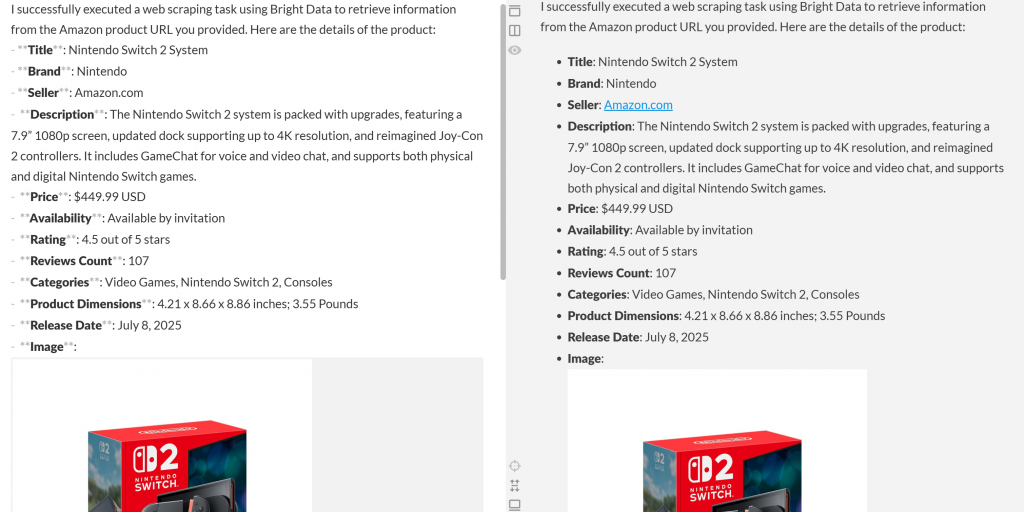
Wie Sie sehen können, war der Agent in der Lage, einen Markdown-Bericht mit aussagekräftigen, aktuellen Daten von der Amazon-Produktseite zu erstellen. Sie können die Genauigkeit überprüfen, indem Sie die Zielproduktseite in Ihrem Browser besuchen:
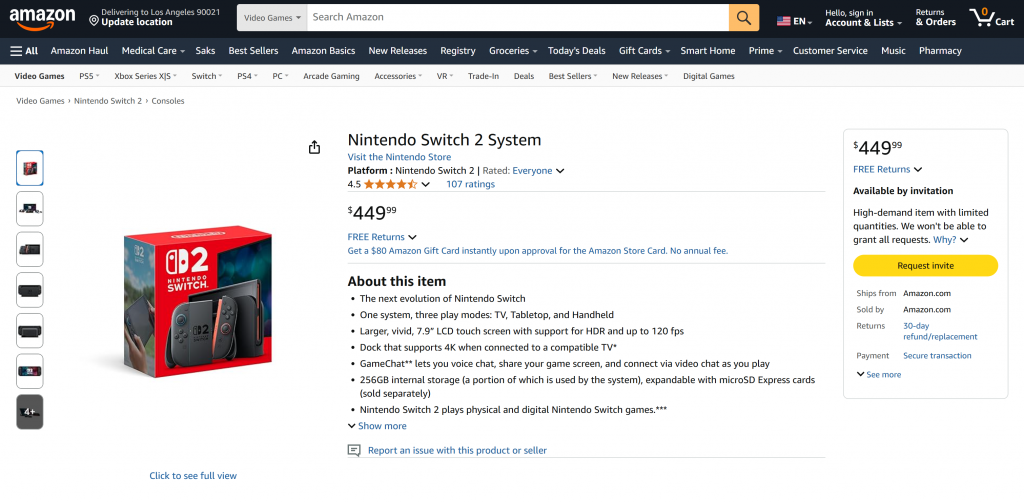
Beachten Sie, dass es sich bei den erzeugten Daten um echte Daten von der Amazon-Seite handelt, die nicht vom LLM erdacht wurden. Das ist ein Beweis für das Scraping, das mit den Tools von Bright Data durchgeführt wurde. Und das ist erst der Anfang!
Mit der breiten Palette an Bright Data-Aktionen, die in Pica verfügbar sind, kann Ihr Agent jetzt Daten von praktisch jeder Website abrufen. Das schließt komplexe Ziele wie Amazon ein, die für strenge Anti-Scraping-Maßnahmen bekannt sind (wie das berüchtigte Amazon CAPTCHA).
Et voilà! Sie haben soeben nahtloses Web-Scraping erlebt, das von der Bright Data-Integration in Ihrem Pica AI-Agenten unterstützt wird.
Schlussfolgerung
In diesem Artikel haben Sie gesehen, wie Sie mit Pica einen KI-Agenten erstellen können, der seine Antworten mit frischen Webdaten untermauern kann. Dies wurde dank der integrierten Integration von Pica mit Bright Data möglich. Der Pica Bright Data Connector gibt der KI die Möglichkeit, Daten von jeder beliebigen Webseite abzurufen.
Bedenken Sie, dass dies nur ein einfaches Beispiel war. Wenn Sie fortschrittlichere Agenten erstellen möchten, benötigen Sie robuste Lösungen zum Abrufen, Validieren und Umwandeln von Live-Webdaten. Genau das finden Sie in der KI-Infrastruktur von Bright Data.
Erstellen Sie ein kostenloses Bright Data-Konto und erkunden Sie unsere KI-fähigen Tools zur Extraktion von Webdaten!





