

In diesem Leitfaden erfahren Sie:
- Was AG2 ist und wie es die Entwicklung von Single-Agent- und Multi-Agent-Systemen unterstützt, sowie die Vorteile einer Erweiterung mit Bright Data.
- Die Voraussetzungen für den Einstieg in diese Integration.
- Wie Sie eine AG2-Multi-Agent-Architektur mit Bright Data über benutzerdefinierte Tools betreiben können.
- Wie Sie AG2 mit dem Web MCP von Bright Data verbinden.
Lassen Sie uns loslegen!
Eine Einführung in AG2 (ehemals AutoGen)
AG2 ist ein Open-Source-AgentOS-Framework zum Erstellen von KI-Agenten und Multi-Agent-Systemen, die autonom zusammenarbeiten können, um komplexe Aufgaben zu lösen. Damit können Sie Single-Agent-Workflows erstellen, mehrere spezialisierte Agenten orchestrieren und externe Tools in modulare, produktionsreife Pipelines integrieren.
AG2, ehemals AutoGen, ist eine Weiterentwicklung der Microfost AutoGen-Bibliothek. Es bewahrt die ursprüngliche Architektur und Abwärtskompatibilität und ermöglicht gleichzeitig Multi-Agent-Workflows, Tool-Integration und Human-in-the-Loop-KI. Es ist in Python geschrieben und hat über 4.000 GitHub-Stars.
(Wenn Sie eine Anleitung zur Integration von Bright Data mit AutoGen suchen, lesen Sie den entsprechenden Blogbeitrag.
AG2 bietet die Flexibilität und die fortschrittlichen Orchestrierungsmuster, die erforderlich sind, um agentenbasierte KI-Projekte von der Experimentierphase bis zur Produktion zu bringen.
Zu den Kernfunktionen gehören Multi-Agent-Konversationsmuster, Human-in-the-Loop-Unterstützung, Tool-Integration und strukturiertes Workflow-Management. Das Endziel besteht darin, Ihnen beim Aufbau anspruchsvoller KI-Systeme mit minimalem Aufwand zu helfen.
Trotz dieser wunderbaren Fähigkeiten sind AG2-Agenten immer noch mit den grundlegenden Einschränkungen von LLM konfrontiert: statisches Wissen aus Trainingsdaten und kein nativer Zugriff auf Live-Webinformationen!
Die Integration von AG2 mit einem Webdatenanbieter wie Bright Data behebt all diese Probleme. Durch die Verbindung von AG2-Agenten mit den APIs von Bright Data für Web-Scraping, Suche und Browser-Automatisierung werden strukturierte Webdaten in Echtzeit verfügbar, was ihre Intelligenz, Autonomie und praktische Nützlichkeit erhöht.
Voraussetzungen
Um dieser Anleitung folgen zu können, benötigen Sie:
- Python 3.10 oder höher auf Ihrem lokalen Rechnerinstalliert.
- Ein Bright Data-Konto mit der Web Unlocker API, der SERP-API und einem konfigurierten API-Schlüssel. (Dieses Tutorial führt Sie durch alle erforderlichen Einstellungen.)
- Einen OpenAI-API-Schlüssel (oder einen API-Schlüssel von einem anderen von AG2 unterstützten LLM).
Außerdem ist es hilfreich, wenn Sie mit den Produkten und Dienstleistungen von Bright Data vertraut sind und über grundlegende Kenntnisse der Funktionsweise des AG2-Tool-Systems verfügen.
So integrieren Sie Bright Data in einen AG2-Multi-Agent-Workflow
In diesem Schritt-für-Schritt-Abschnitt erstellen Sie einen Multi-Agent-AG2-Workflow auf Basis der Bright Data-Dienste. Insbesondere wird ein dedizierter Agent für die Abfrage von Webdaten über benutzerdefinierte AG2-Tool-Funktionen auf den Web Unlocker und die SERP-API von Bright Data zugreifen.
Dieses Multi-Agent-System identifiziert die wichtigsten Influencer auf Plattformen wie Twitch in der Lebensmittelbranche, um die Werbung für eine neue Art von Hamburger zu unterstützen. Dieses Beispiel zeigt, wie AG2 die Datenerfassung automatisieren, strukturierte Geschäftsberichte erstellen und fundierte Entscheidungen ermöglichen kann – ganz ohne manuellen Aufwand.
Sehen Sie sich an, wie Sie es implementieren können!
Schritt 1: Erstellen Sie ein AG2-Projekt
Öffnen Sie ein Terminal und erstellen Sie einen neuen Ordner für Ihr AG2-Projekt. Nennen Sie ihn beispielsweise ag2-bright-data-agent:
mkdir ag2-bright-data-agentag2-bright-data-agent/ enthält den Python-Code für die Implementierung und Orchestrierung von AG2-Agenten, die in Bright Data-Funktionen integriert sind.
Wechseln Sie als Nächstes in das Projektverzeichnis und erstellen Sie darin eine virtuelle Umgebung:
cd ag2-bright-data-agent
python -m venv .venvFügen Sie eine neue Datei namens agent.py zum Projektstamm hinzu. Ihre Projektstruktur sollte nun wie folgt aussehen:
ag2-bright-data-agent/
├── .venv/
└── agent.py # <----Die Datei agent.py enthält die AG2-Agentendefinition und die Orchestrierungslogik.
Öffnen Sie den Projektordner in Ihrer bevorzugten Python-IDE, z. B. Visual Studio Code mit der Python-Erweiterung oder PyCharm Community Edition.
Aktivieren Sie nun die soeben erstellte virtuelle Umgebung. Führen Sie unter Linux oder macOS folgenden Befehl aus:
source .venv/bin/activateUnter Windows führen Sie stattdessen folgenden Befehl aus:
.venv/Scripts/activateNachdem die virtuelle Umgebung aktiviert ist, installieren Sie die erforderlichen PyPI-Abhängigkeiten:
pip install ag2[openai] requests python-dotenvDiese Anwendung basiert auf den folgenden Bibliotheken:
ag2[openai]: Zum Erstellen und Orchestrieren von Multi-Agent-KI-Workflows, die auf OpenAI-Modellen basieren.requests: Für HTTP-Anfragen an Bright Data-Dienste über benutzerdefinierte Tools.python-dotenv: Zum Laden erforderlicher Geheimnisse aus Umgebungsvariablen, die in einer.env-Datei definiert sind
Gut gemacht! Sie verfügen nun über eine einsatzbereite Python-Umgebung für die Multi-Agenten-KI-Entwicklung mit AG2.
Schritt 2: Konfigurieren Sie die LLM-Integration
Die AG2-Agenten, die Sie in den nächsten Schritten erstellen werden, benötigen ein Gehirn, das von einem LLM bereitgestellt wird. Jeder Agent kann seine eigene LLM-Konfiguration verwenden, aber der Einfachheit halber verbinden wir alle Agenten mit demselben OpenAI-Modell.
AG2 enthält einen integrierten Mechanismus zum Laden von LLM-Einstellungen aus einer speziellen Konfigurationsdatei. Fügen Sie dazu den folgenden Code zu agent.py hinzu:
from autogen import LLMConfig
# LLM-Konfiguration aus der OpenAI-Konfigurationslistendatei laden
llm_config = LLMConfig.from_json(path="OAI_CONFIG_LIST")Dieser Code lädt die LLM-Konfiguration aus einer Datei namens OAI_CONFIG_LIST.json. Erstellen Sie diese Datei im Stammverzeichnis Ihres Projekts:
ag2-bright-data-agent/
├── .venv/
├── OAI_CONFIG_LIST.json # <----
└── agent.pyFüllen Sie nun OAI_CONFIG_LIST.json mit dem folgenden Inhalt:
[
{
"model": "gpt-5-mini",
"api_key": "<YOUR_OPENAI_API_KEY>"
}
]Ersetzen Sie den Platzhalter <YOUR_OPENAI_API_KEY> durch Ihren tatsächlichen OpenAI-API-Schlüssel. Diese Konfiguration versorgt Ihre AG2-Agenten mit dem GPT-5-Mini-Modell, aber Sie können bei Bedarf auch jedes andere unterstützte OpenAI-Modell verwenden.
Die Variable llm_config wird an Ihre Agenten und den Gruppenchat-Orchestrator weitergeleitet. Dadurch können diese mithilfe des konfigurierten LLM Schlussfolgerungen ziehen, kommunizieren und Aufgaben ausführen. Fantastisch!
Schritt 3: Verwalten des Lesens von Umgebungsvariablen
Ihre AG2-Agenten können nun eine Verbindung zu OpenAI herstellen, benötigen jedoch auch Zugriff auf einen weiteren Drittanbieter-Dienst: Bright Data. Genau wie OpenAI authentifiziert Bright Data Anfragen mithilfe eines externen API-Schlüssels.
Um Sicherheitsrisiken zu vermeiden, sollten Sie API-Schlüssel niemals direkt in Ihrem Code fest codieren. Stattdessen empfiehlt es sich, sie aus Umgebungsvariablen zu laden. Genau aus diesem Grund haben Sie zuvor python-dotenv installiert.
Importieren Sie zunächst python-dotenv in agent.py. Verwenden Sie es, um Umgebungsvariablen aus einer .env-Datei mit der Funktion load_dotenv() zu laden:
from dotenv import load_dotenv
import os
# Laden Sie Umgebungsvariablen aus der .env-Datei.
load_dotenv()Fügen Sie als Nächstes eine .env -Datei zum Stammverzeichnis Ihres Projekts hinzu, die Folgendes enthalten sollte:
ag2-bright-data-agent/
├── .venv/
├── OAI_CONFIG_LIST.json
├── .env # <----
└── agent.pyNachdem Sie Ihre geheimen Werte zur .env-Datei hinzugefügt haben, können Sie mit os.getenv() im Code darauf zugreifen:
ENV_VALUE = os.getenv("ENV_NAME")Cool! Ihr Skript kann nun sicher Geheimwerte von Drittanbieter-Integrationen aus Umgebungsvariablen laden.
Schritt 4: Einrichten der Bright Data-Dienste
Wie in der Einleitung angekündigt, verbindet sich der Webdaten-Agent mit der SERP-API und der Web Unlocker-API von Bright Data, um Websuchen und das Abrufen von Inhalten aus Webseiten zu verarbeiten. Zusammen ermöglichen diese Dienste dem Agenten, Live-Webdaten in einer agentenbasierten Datenabrufschicht im RAG-Stil abzurufen.
Um mit diesen beiden Diensten zu interagieren, müssen Sie später zwei benutzerdefinierte AG2-Tools definieren. Bevor Sie dies tun, müssen Sie alles in Ihrem Bright Data-Konto einrichten.
Erstellen Sie zunächst ein Bright Data-Konto, falls Sie noch keines haben. Andernfalls melden Sie sich an und rufen Sie Ihr Dashboard auf. Navigieren Sie von dort aus zur Seite „Proxies & Scraping“ und überprüfen Sie die Tabelle „My Zones“, in der die in Ihrem Profil konfigurierten Dienste aufgelistet sind: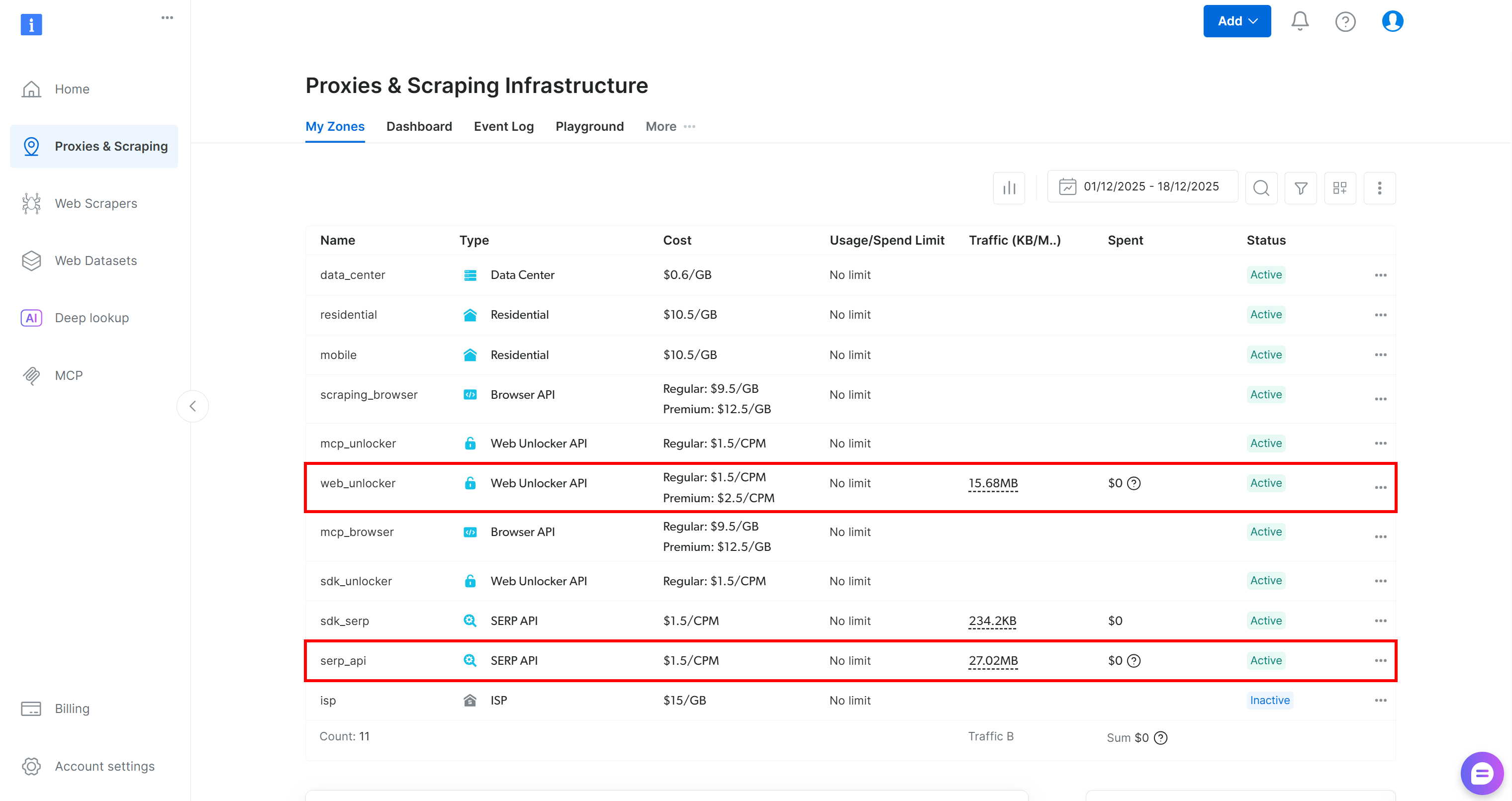
Wenn die Tabelle wie oben bereits eine Web Unlocker-API-Zone (in diesem Fall „web_unlocker” genannt) und eine SERP-API-Zone (in diesem Fall „serp_api” genannt) enthält, sind Sie startklar. Diese beiden Zonen werden von Ihren benutzerdefinierten AG2-Tools verwendet, um die erforderlichen Bright Data-Dienste aufzurufen.
Wenn eine oder beide Zonen fehlen, scrollen Sie nach unten zu den Karten „Unblocker API“ und „SERP-API“ und klicken Sie für jede einzelne auf „Zone erstellen“. Folgen Sie dem Einrichtungsassistenten, um beide Zonen zu erstellen: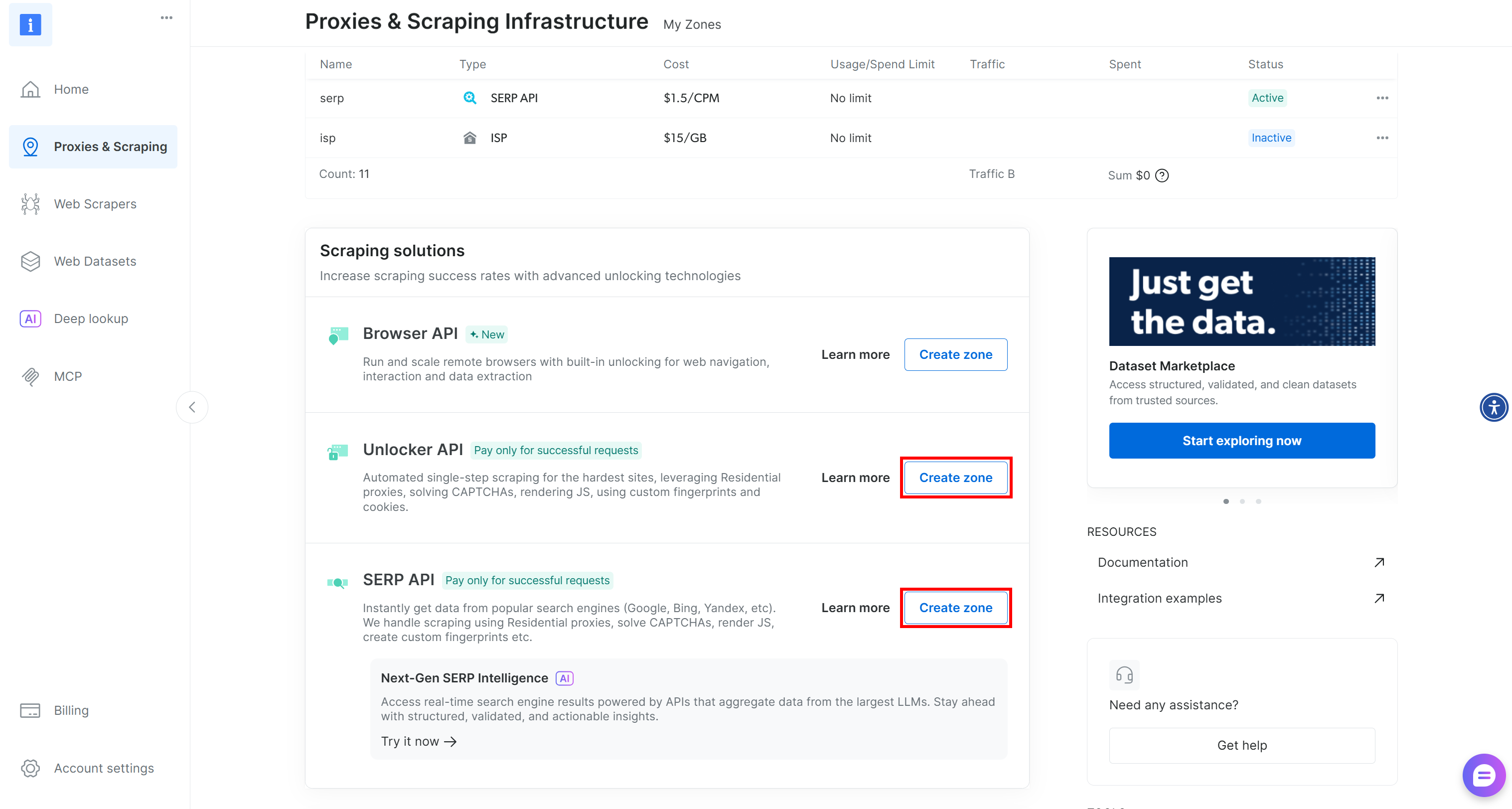
Ausführliche Schritt-für-Schritt-Anweisungen finden Sie in der offiziellen Dokumentation:
Wichtig: Von nun an gehen wir davon aus, dass Ihre Zonen serp_api bzw. web_unlocker heißen.
Sobald Ihre Zonen bereit sind, generieren Sie Ihren Bright Data API-Schlüssel. Speichern Sie ihn als Umgebungsvariable in .env:
BRIGHT_DATA_API_KEY="<IHR_BRIGHT_DATA_API_SCHLÜSSEL>"Laden Sie ihn dann wie unten gezeigt in agent.py:
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")Perfekt! Sie haben nun alle Bausteine, um Ihre AG2-Agenten über benutzerdefinierte Tools mit den SERP-API- und Web Unlocker-Diensten von Bright Data zu verbinden.
Schritt 5: Definieren Sie Bright Data-Tools für Ihre AG2-Agenten
In AG2 bieten Tools spezielle Funktionen, die Agenten aufrufen können, um Aktionen auszuführen und Entscheidungen zu treffen. Im Hintergrund sind Tools einfach benutzerdefinierte Python-Funktionen, die AG2 den Agenten in strukturierter Form zur Verfügung stellt.
In diesem Schritt implementieren Sie zwei Tool-Funktionen in agent.py:
serp_api_tool(): Stellt eine Verbindung zur Bright Data SERP-API her, um Google-Suchen durchzuführen.web_unlocker_api_tool(): Stellt eine Verbindung zur Bright Data Web Unlocker API her, um Webseiteninhalte abzurufen und dabei alle Anti-Bot-Systeme zu umgehen.
Beide Tools verwenden den Python-HTTP-Client „Requests“, um authentifizierte POST-Anfragen an Bright Data zu stellen, basierend auf der Dokumentation:
- Senden Sie Ihre erste Anfrage mit der SERP-API von Bright Data
- Senden Sie Ihre erste Anfrage mit der Web Unlocker API von Bright Data
Um die beiden Tool-Funktionen zu definieren, fügen Sie den folgenden Code zu agent.py hinzu:
from typing import Annotated
import requests
import urllib.parse
def serp_api_tool(
query: Annotated[str, "Die Google-Suchanfrage"],
) -> str:
payload = {
"zone": "serp_api", # Ersetzen Sie dies durch den Namen Ihrer Bright Data SERP-API-Zone
"url": f"https://www.google.com/search?q={urllib.parse.quote_plus(query)}&brd_json=1",
"format": "raw",
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json",
}
response = requests.post(
"https://api.brightdata.com/request",
json=payload,
headers=headers,
)
response.raise_for_status()
return response.text
def web_unlocker_api_tool(
url_to_fetch: Annotated[str, "URL der Zielseite, die abgerufen werden soll"],
data_format: Annotated[
str | None,
"Ausgabeformat der Seite (z. B. 'markdown' oder weglassen für rohen HTML-Code)"
] = "markdown",)
-> str:
payload = {
"zone": "web_unlocker", # Ersetzen Sie dies durch den Namen Ihrer Bright Data Web Unlocker-Zone.
"url": url_to_fetch,
"format": "raw",
"data_format": data_format,
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json",
}
response = requests.post(
"https://api.brightdata.com/request",
json=payload,
headers=headers
)
response.raise_for_status()
return response.textDie beiden Tools authentifizieren Anfragen mithilfe Ihres Bright Data API-Schlüssels und senden POST-Anfragen an den Bright Data API-Endpunkt:
serp_api_tool()fragt Google ab und ruft Suchergebnisse im strukturierten JSON-Format ab, indem es den Parameterbrd_json=1aktiviert.web_unlocker_api_tool()ruft beliebige Webseiten ab und gibt deren Inhalt in Markdown (oder auf Wunsch in rohem HTML) zurück.
Wichtig: Sowohl JSON als auch Markdown sind hervorragende Formate für die LLM-Erfassung in KI-Agenten.
Beachten Sie, dass beide Funktionen Python-Typisierung zusammen mit Annotated verwenden, um ihre Argumente zu beschreiben. Die Typen sind erforderlich, um diese Funktionen in geeignete AG2-Tools umzuwandeln, während die Annotationsbeschreibungen dem LLM helfen, zu verstehen, wie jedes Argument beim Aufruf der Tools aus einem Agenten heraus ausgefüllt werden muss.
Großartig! Ihre AG2-Anwendung enthält nun zwei Bright Data-Tools, die von Ihren KI-Agenten konfiguriert und genutzt werden können.
Schritt 6: Implementieren Sie die AG2-Agenten
Nachdem Ihre Tools nun eingerichtet sind, ist es an der Zeit, die in der Einleitung beschriebene KI-Agentenstruktur aufzubauen. Diese Konfiguration besteht aus drei sich ergänzenden Agenten:
user_proxy: Dient als Ausführungsebene, führt Tool-Aufrufe sicher aus und koordiniert den Workflow ohne menschliches Zutun. Es handelt sich um eine Instanz desUserProxyAgent, einem speziellen AG2-Agenten, der als Proxy für den Benutzer fungiert, Code ausführt und bei Bedarf Feedback an andere Agenten gibt.web_data_agent: Verantwortlich für die Suche und den Abruf von Webdaten. Dieser Agent durchsucht das Web mithilfe der Bright Data SERP-API und ruft Seiteninhalte über die Web Unlocker API ab. AlsConversableAgentkann er mit anderen Agenten und Menschen kommunizieren, Informationen verarbeiten, in seiner Systemmeldung definierte Anweisungen befolgen und vieles mehr.reporting_agent: Analysiert die gesammelten Daten und wandelt sie in einen strukturierten, geschäftsfertigen Markdown-Bericht für Entscheidungsträger um.
Zusammen bilden diese Agenten eine vollständig autonome Multi-Agenten-Pipeline, die für die Identifizierung von Twitch-Streamern und die Werbung für ein bestimmtes Produkt entwickelt wurde.
Geben Sie in agent.py alle drei Agenten mit dem folgenden Code an:
from autogen import (
UserProxyAgent,
ConversableAgent,)
# Führt Tool-Aufrufe aus und koordiniert den Workflow ohne menschliches Eingreifen.
user_proxy = UserProxyAgent(
name="user_proxy",
code_execution_config=False,
human_input_mode="NEVER",
llm_config=llm_config,
)
# Verantwortlich für die Suche und das Abrufen von Webdaten
web_data_agent = ConversableAgent(
name="web_data_agent",
code_execution_config=False,
llm_config=llm_config,
system_message=(
"""
Sie sind ein Agent zum Abrufen von Webdaten.
Sie durchsuchen das Web mit dem Bright Data SERP-API-Tool
und rufen Seiteninhalte mit dem Web Unlocker-API-Tool ab.
"""
),
)
# Analysiert gesammelte Daten und erstellt einen strukturierten Bericht.
reporting_agent = ConversableAgent(
name="reporting_agent",
code_execution_config=False,
system_message=(
"""
Sie sind Marketinganalyst.
Sie erstellen strukturierte, geschäftsfertige Markdown-Berichte
für Entscheidungsträger.
"""
),
llm_config=llm_config,
# Beendet die Konversation automatisch, sobald das Wort „Bericht” erscheint.
is_termination_msg=lambda msg: „Bericht” in (msg.get(„content”, „”) oder „”).lower()
)Beachten Sie im obigen Code Folgendes:
- AG2-Agenten können in Nachrichten enthaltenenCode (z. B. Code-Blöcke)ausführen und die Ergebnisse an den nächsten Agenten weitergeben. In dieser Konfiguration ist die Codeausführung aus Sicherheitsgründen über
code_execution_config=Falsedeaktiviert. - Alle Agenten werden durch die in Schritt 2 geladene
llm_configunterstützt. - Der
reporting_agententhält eineis_termination_msg-Funktion, um den Workflow automatisch zu beenden, sobald die Nachricht das Wort „report” enthält, was signalisiert, dass die endgültige Ausgabe erstellt wurde.
Als Nächstes registrieren Sie die Bright Data-Tools beim web_data_agent, um das Abrufen von Webdaten zu ermöglichen!
Schritt 7: Registrieren Sie die AG2 Bright Data-Tools
Registrieren Sie die Bright Data-Funktionen als Tools und weisen Sie sie dem web_data_agent über register_function() zu. Der user_proxy-Agent fungiert als Ausführender für diese Tools, wie es die Architektur von AG2 erfordert:
from autogen import register_function
# SERP-Suchtool für den Webdaten-Agenten registrieren
register_function(
serp_api_tool,
caller=web_data_agent,
executor=user_proxy,
description="Verwenden Sie die SERP-API von Bright Data, um eine Google-Suche durchzuführen und Rohdaten zurückzugeben."
)
# Web Unlocker-Tool zum Abrufen geschützter Seiten registrieren
register_function(
web_unlocker_api_tool,
caller=web_data_agent,
executor=user_proxy,
description="Webseite mithilfe der Web Unlocker-API von Bright Data abrufen und dabei gängige Anti-Bot-Schutzmaßnahmen umgehen.",
)Beachten Sie, dass jede Funktion eine kurze Beschreibung enthält, damit das LLM ihren Zweck versteht und weiß, wann es sie aufrufen muss.
Nachdem diese Tools registriert wurden, kann der web_data_agent nun Websuchen und den Zugriff auf Webseiten planen, während der user_proxy die Ausführung übernimmt.
Ihre AG2-Multi-Agent-Pipeline ist nun vollständig in der Lage, mithilfe der APIs von Bright Data autonom Daten zu finden und zu scrapen. Mission erfüllt!
Schritt 8: Einführung der AG2-Multi-Agent-Orchestrierungslogik
AG2 unterstützt mehrere Möglichkeiten zur Orchestrierung und Verwaltung mehrerer Agenten. In diesem Beispiel sehen Sie das GroupChat- Muster.
Der Kern eines AG2-Gruppenchats besteht darin, dass alle Agenten zu einem einzigen Konversations-Thread beitragen und denselben Kontext teilen. Dieser Ansatz ist ideal für Aufgaben, die eine Zusammenarbeit zwischen mehreren Agenten erfordern, wie in unserer Pipeline.
Anschließend übernimmt ein GroupChatManager die Koordination der Agenten innerhalb des Gruppenchats. Er unterstützt verschiedene Strategien für die Auswahl des nächsten Agenten, der handeln soll. Hier konfigurieren Sie die standardmäßige Auto-Strategie, die das LLM des Managers nutzt, um zu entscheiden, welcher Agent als nächstes sprechen soll.
Kombinieren Sie alles für die Multi-Agenten-Orchestrierung wie folgt:
from autogen import (
GroupChat,
GroupChatManager,)
# Definieren Sie den Multi-Agenten-Gruppenchat
groupchat = GroupChat(
agents=[user_proxy, web_data_agent, reporting_agent],
speaker_selection_method="auto",
messages=[],
max_round=20
)
# Manager, der für die Koordination der Interaktionen zwischen den Agenten verantwortlich ist
manager = GroupChatManager(
name="group_manager",
groupchat=groupchat,
llm_config=llm_config
)Hinweis: Der Workflow wird beendet, wenn entweder der reporting_agent eine Nachricht erzeugt, die seine is_termination_msg-Logik auslöst, oder nach 20 Runden wechselseitiger Interaktionen zwischen den Agenten (aufgrund des Arguments max_round ), je nachdem, was zuerst eintritt.
Los geht’s! Die Agentendefinitionen und die Orchestrierungslogik sind fertig. Der letzte Schritt besteht darin, den Workflow zu starten und die Ergebnisse zu exportieren.
Schritt 9: Starten Sie den Agentic-Workflow und exportieren Sie das Ergebnis
Beschreiben Sie die Suchaufgabe für Twitch-Streamer-Influencer detailliert und übergeben Sie sie als Nachricht an den user_proxy- Agenten zur Ausführung:
prompt_message = """
Szenario:
---------
Eine Lebensmittel- und Getränkemarke möchte eine neue Art von Hamburger bewerben.
Ziel:
- Suche nach der Kategorie-Seite „Food & Drink“ auf TwitchMetrics
- Abrufen des Inhalts der TwitchMetrics-Kategorie-Seite aus der SERP und Auswählen der fünf besten Streamer
- Besuchen Sie die TwitchMetrics-Profilseite jedes Streamers und rufen Sie relevante Informationen ab
- Erstellen Sie einen strukturierten Markdown-Bericht mit folgenden Angaben:
- Kanalname
- Geschätzte Reichweite
- Inhaltsschwerpunkt
- Passung zum Publikum
- Machbarkeit der Markenreichweite
"""
# Starten Sie den Multi-Agent-Workflow
user_proxy.initiate_chat(recipient=manager, message=prompt_message)Sobald der Workflow abgeschlossen ist, speichern Sie die Ausgabe (d. h. den Markdown-Bericht) mit folgendem Befehl auf der Festplatte:
with open("report.md", "w", encoding="utf-8") as f:
f.write(user_proxy.last_message()["content"])Fantastisch! Ihr AG2 + Bright Data Multi-Agent-Workflow ist nun voll funktionsfähig und bereit, Twitch-Influencer-Daten zu sammeln, zu analysieren und zu berichten.
Schritt 10: Alles zusammenfügen
Der endgültige Code in Ihrer Datei agent.py lautet:
from autogen import (
LLMConfig,
UserProxyAgent,
ConversableAgent,
register_function,
GroupChat,
GroupChatManager,)
from dotenv import load_dotenv
import os
from typing import Annotated
import requests
import urllib.parse
# LLM-Konfiguration aus der OpenAI-Konfigurationslistendatei laden
llm_config = LLMConfig.from_json(path="OAI_CONFIG_LIST")
# Umgebungsvariablen aus der .env-Datei laden
load_dotenv()
# Den Bright Data API-Schlüssel aus den Umgebungsvariablen abrufen
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
# Funktionen zur Implementierung der Bright Data-Tools definieren
def serp_api_tool(
query: Annotated[str, "Die Google-Suchanfrage"],)
-> str:
payload = {
"zone": "serp_api", # Ersetzen Sie dies durch den Namen Ihrer Bright Data SERP-API-Zone
"url": f"https://www.google.com/search?q={urllib.parse.quote_plus(query)}&brd_json=1",
"format": "raw",
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json",
}
response = requests.post(
"https://api.brightdata.com/request",
json=payload,
headers=headers,
)
response.raise_for_status()
return response.text
def web_unlocker_api_tool(
url_to_fetch: Annotated[str, "URL der Zielseite, die abgerufen werden soll"],
data_format: Annotated[
str | None,
"Ausgabeformat der Seite (z. B. 'markdown' oder weglassen für rohen HTML-Code)"
] = "markdown",)
-> str:
payload = {
"zone": "web_unlocker", # Ersetzen Sie dies durch den Namen Ihrer Bright Data Web Unlocker-Zone.
"url": url_to_fetch,
"format": "raw",
"data_format": data_format,
}
headers = {
„Authorization”: f„Bearer {BRIGHT_DATA_API_KEY}”,
„Content-Type”: „application/json”,
}
response = requests.post(
„https://api.brightdata.com/request”,
json=payload,
headers=headers
)
response.raise_for_status()
return response.text
# Führt Tool-Aufrufe aus und koordiniert den Workflow ohne menschliches Eingreifen.
user_proxy = UserProxyAgent(
name="user_proxy",
code_execution_config=False,
human_input_mode="NEVER",
llm_config=llm_config,
)
# Verantwortlich für die Suche und das Abrufen von Webdaten
web_data_agent = ConversableAgent(
name="web_data_agent",
code_execution_config=False,
llm_config=llm_config,
system_message=(
"""
Sie sind ein Agent für das Abrufen von Webdaten.
Sie durchsuchen das Web mit dem Bright Data SERP-API-Tool
und rufen Seiteninhalte mit dem Web Unlocker API-Tool ab.
"""
),
)
# Analysiert gesammelte Daten und erstellt einen strukturierten Bericht.
reporting_agent = ConversableAgent(
name="reporting_agent",
code_execution_config=False,
system_message=(
"""
Sie sind Marketinganalyst.
Sie erstellen strukturierte, geschäftsfertige Markdown-Berichte
für Entscheidungsträger.
"""
),
llm_config=llm_config,
# Beendet die Konversation automatisch, sobald das Wort „Bericht” erscheint.
is_termination_msg=lambda msg: „Bericht” in (msg.get(„content”, „”) oder „”).lower()
)
# SERP-Suchtool für den Webdaten-Agenten registrieren
register_function(
serp_api_tool,
caller=web_data_agent,
executor=user_proxy,
description="Verwenden Sie die SERP-API von Bright Data, um eine Google-Suche durchzuführen und Rohdaten zurückzugeben.”
)
# Web Unlocker-Tool zum Abrufen geschützter Seiten registrieren
register_function(
web_unlocker_api_tool,
caller=web_data_agent,
executor=user_proxy,
description="Rufen Sie eine Webseite mit der Web Unlocker-API von Bright Data ab und umgehen Sie dabei gängige Anti-Bot-Schutzmaßnahmen.",
)
# Multi-Agent-Gruppenchat definieren
groupchat = GroupChat(
agents=[user_proxy, web_data_agent, reporting_agent],
speaker_selection_method="auto",
messages=[],
max_round=20
)
# Manager, der für die Koordination der Interaktionen zwischen den Agenten verantwortlich ist
manager = GroupChatManager(
name="group_manager",
groupchat=groupchat,
llm_config=llm_config)
prompt_message = """
Szenario:
---------
Eine Lebensmittel- und Getränkemarke möchte eine neue Art von Hamburger bewerben.
Ziel:
- Suche nach der Kategorie-Seite „Lebensmittel und Getränke” auf TwitchMetrics
- Abrufen des Inhalts der TwitchMetrics-Kategorie-Seite aus der SERP und Auswählen der fünf besten Streamer
- Besuchen Sie die TwitchMetrics-Profilseite jedes Streamers und rufen Sie relevante Informationen ab
- Erstellen Sie einen strukturierten Markdown-Bericht mit folgenden Angaben:
- Kanalname
- Geschätzte Reichweite
- Inhaltlicher Schwerpunkt
- Passung zum Publikum
- Machbarkeit der Markenreichweite
"""
# Starten Sie den Multi-Agent-Workflow
user_proxy.initiate_chat(recipient=manager, message=prompt_message)
# Speichern Sie den Abschlussbericht in einer Markdown-Datei
with open("report.md", "w", encoding="utf-8") as f:
f.write(user_proxy.last_message()["content"])Dank der leistungsstarken AG2-API haben Sie mit nur etwa 170 Zeilen Code einen komplexen, unternehmensgerechten Multi-Agent-Workflow auf Basis von Bright Data erstellt!
Schritt 11: Testen Sie das Multi-Agent-System
Überprüfen Sie in Ihrem Terminal, ob Ihre AG2-Agentenanwendung funktioniert, indem Sie Folgendes eingeben:
python agent.pyDie erwartete Ausgabe sieht wie folgt aus: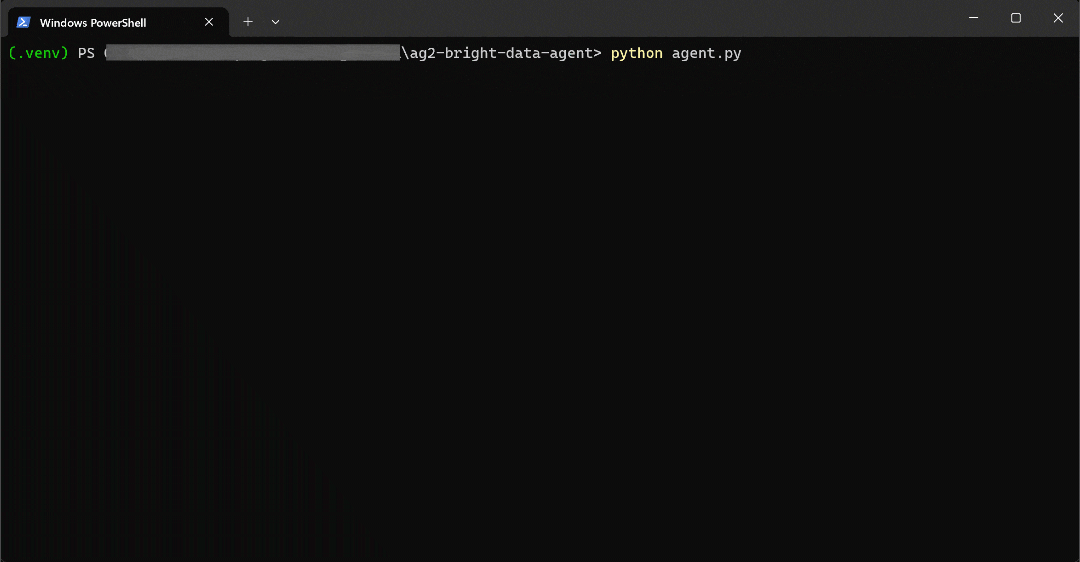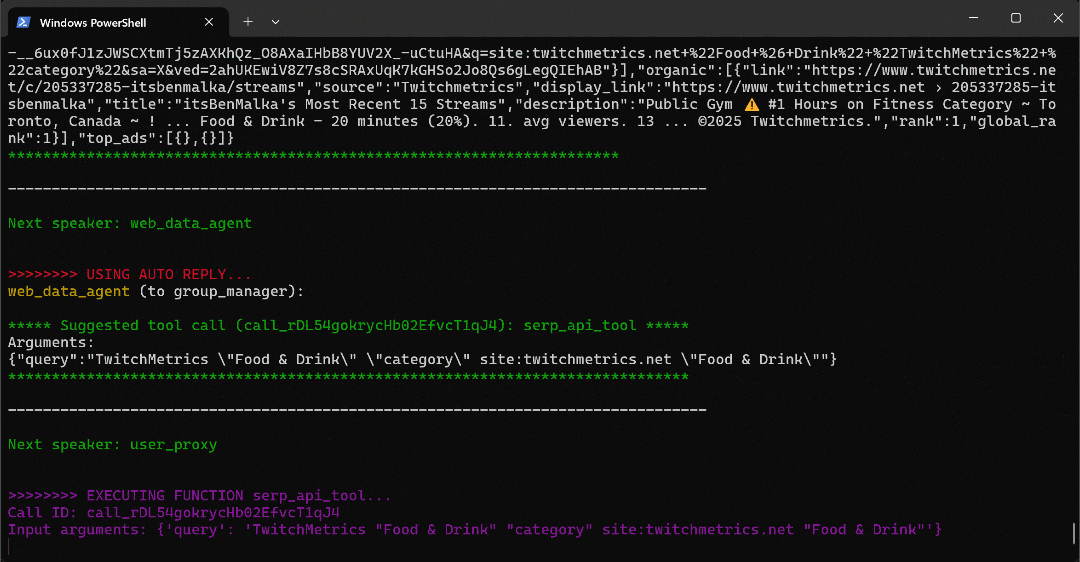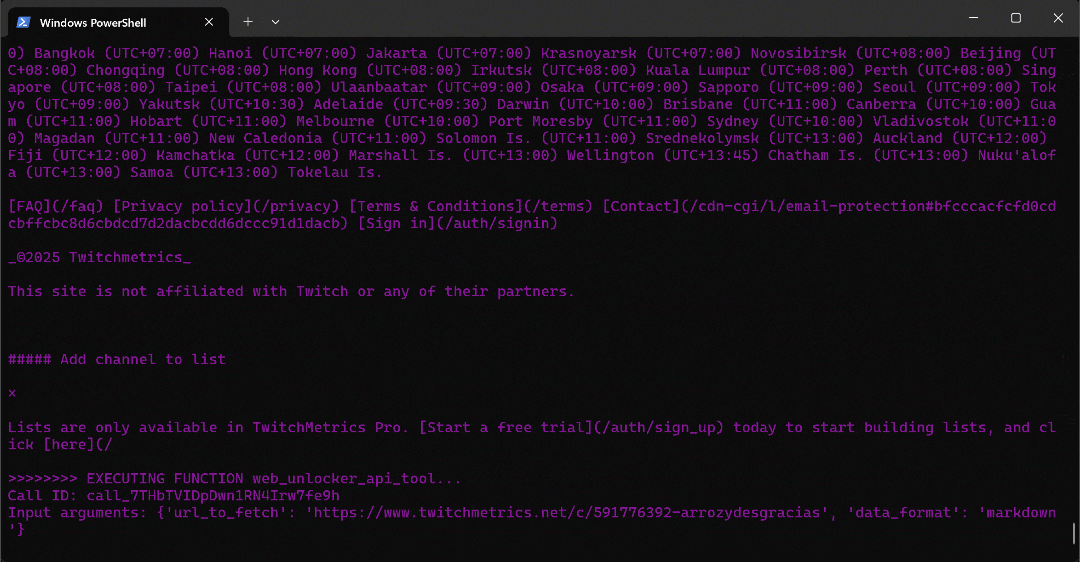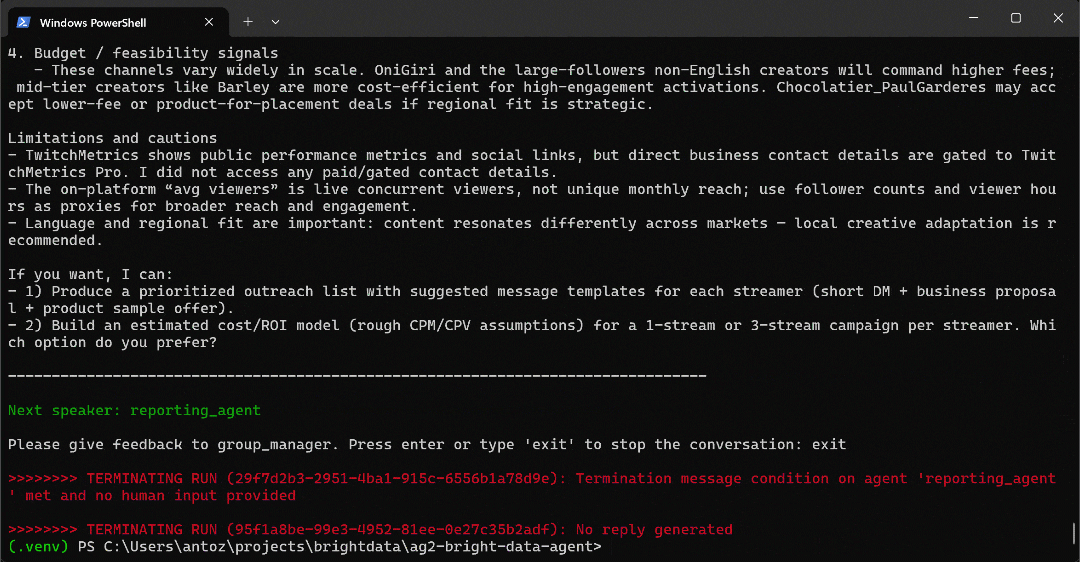
Beachten Sie im Detail, wie der Multi-Agent-Workflow Schritt für Schritt abläuft:
- Der
web_data_agentstellt fest, dass er dasserp_api_toolaufrufen muss, um die erforderliche TwitchMetrics-Kategorieseite „Food & Drink“ zu finden. - Über den
user_proxy-Agenten führt das Tool mehrere Suchanfragen aus. - Sobald die richtige TwitchMetrics-Kategorieseite identifiziert ist, ruft es das
web_unlocker_api_toolauf, um den Inhalt im Markdown-Format zu scrapen. - Aus der Markdown-Ausgabe extrahiert es die URLs der fünf einflussreichsten TwitchMetrics-Profile in der Kategorie „Food & Drink”.
- Das
web_unlocker_api_toolwird erneut aufgerufen, um den Seiteninhalt jedes Profils in Markdown abzurufen. - Alle gesammelten Daten werden an den
reporting_agentweitergeleitet, der sie analysiert und den Abschlussbericht erstellt.
Dieser Abschlussbericht wird wie im Code angegeben als report.md auf der Festplatte gespeichert: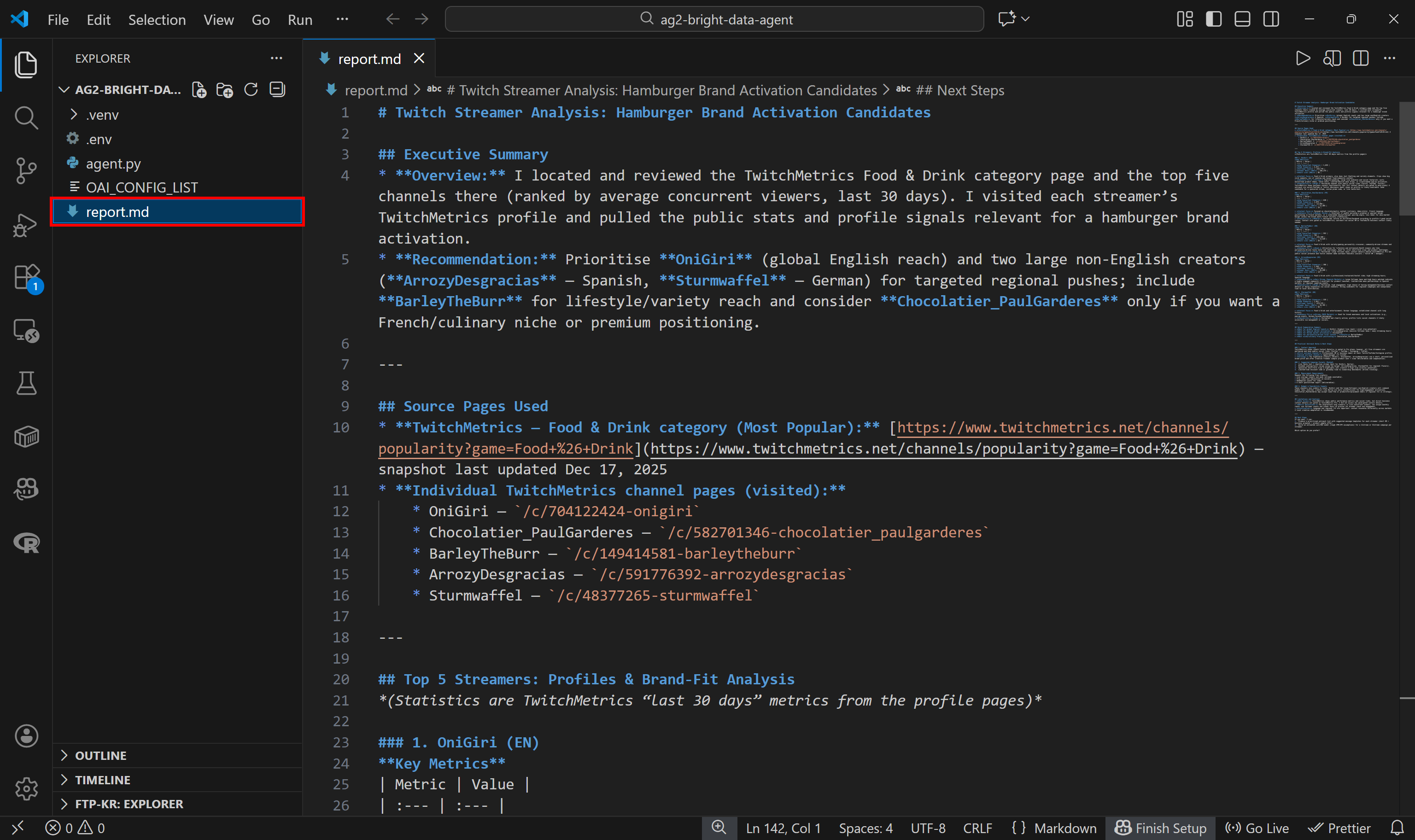
Sehen Sie sich den Bericht in VS Code mit der Markdown-Vorschau an, um zu sehen, wie detailliert und informativ er ist: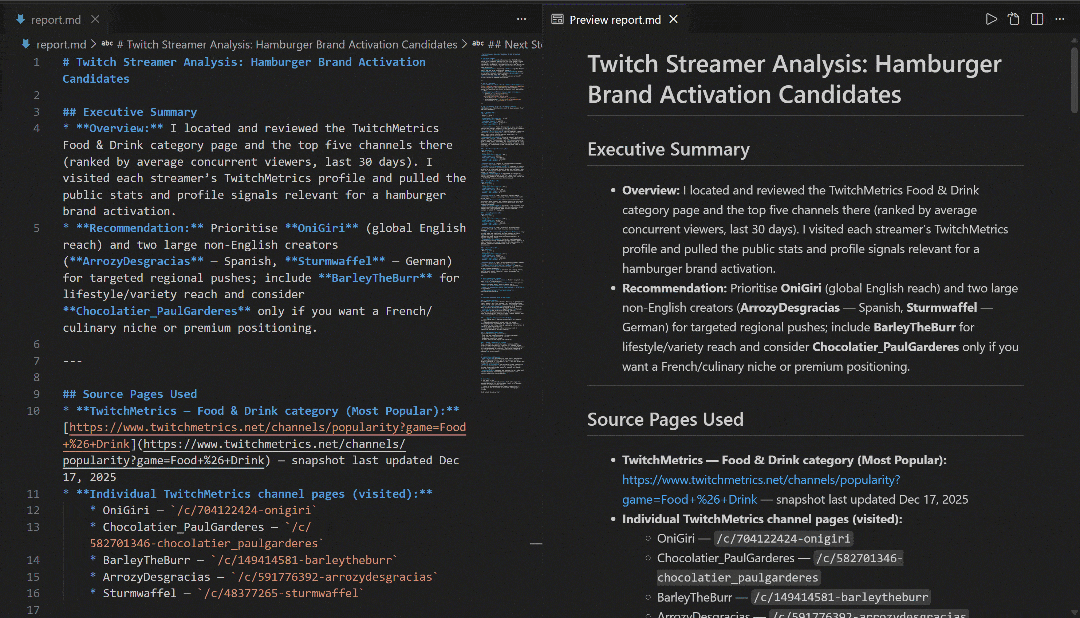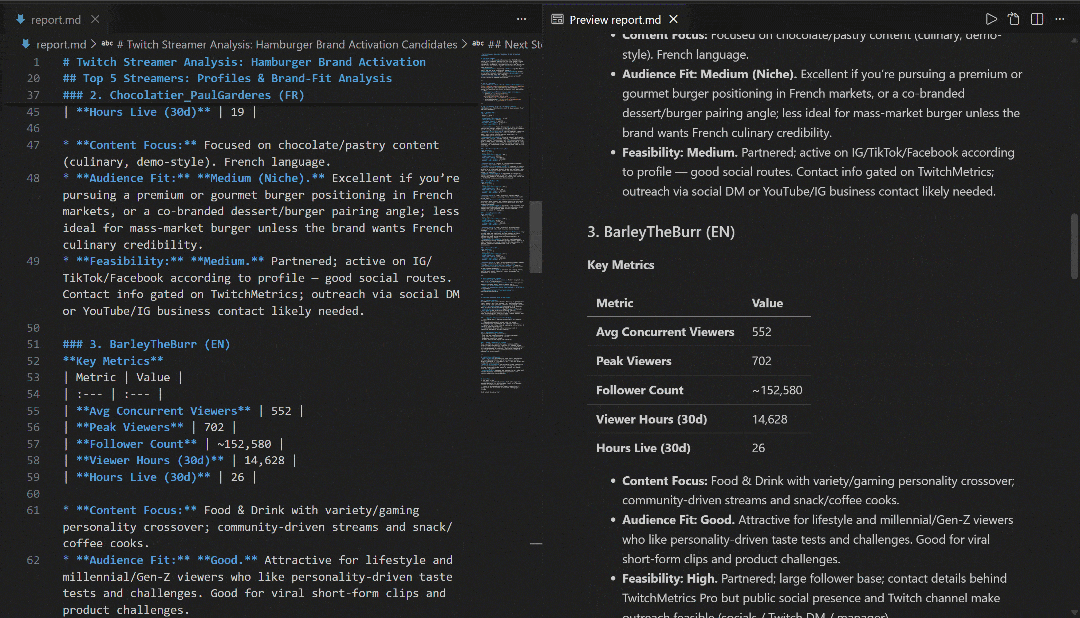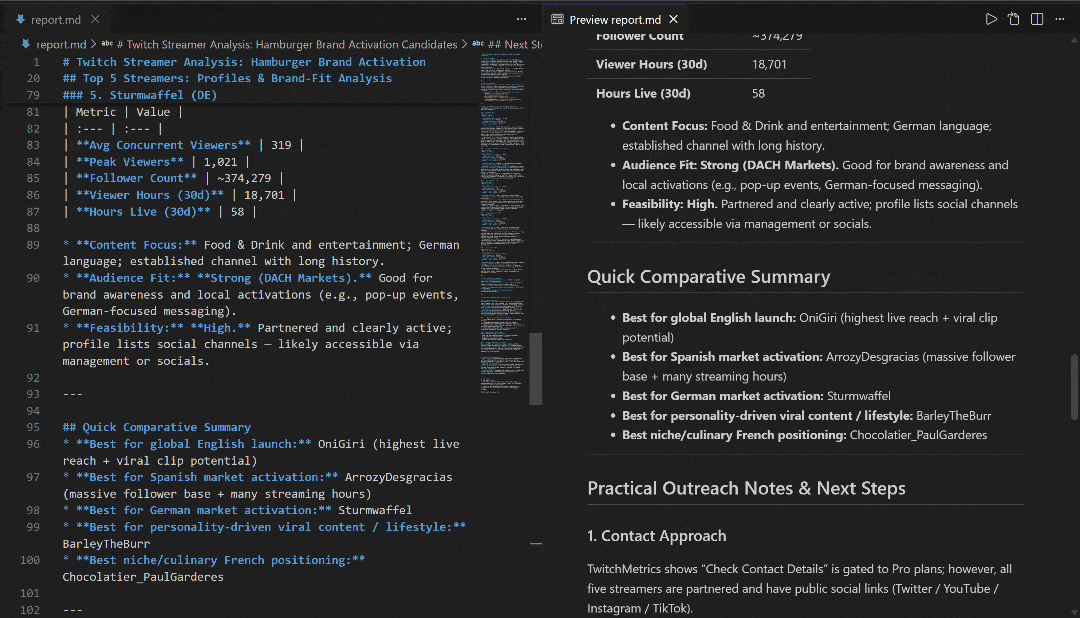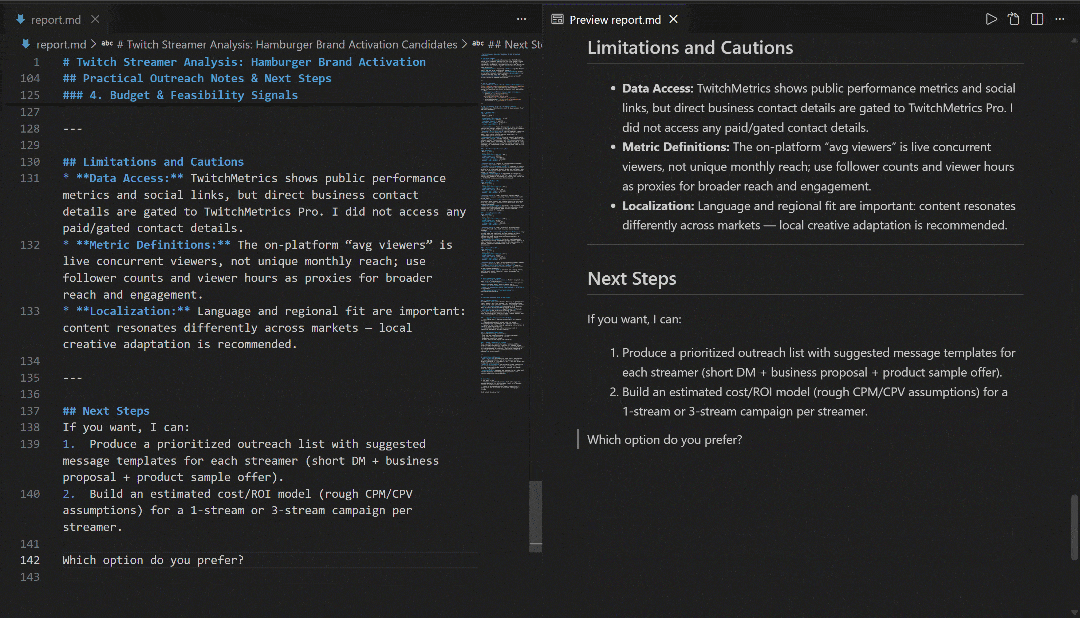
Wenn Sie sich fragen, woher die Quelldaten stammen, sehen Sie sich die Twitch-Stream-Kategorieseite „Food & Drink“ auf TwitchMetrics an: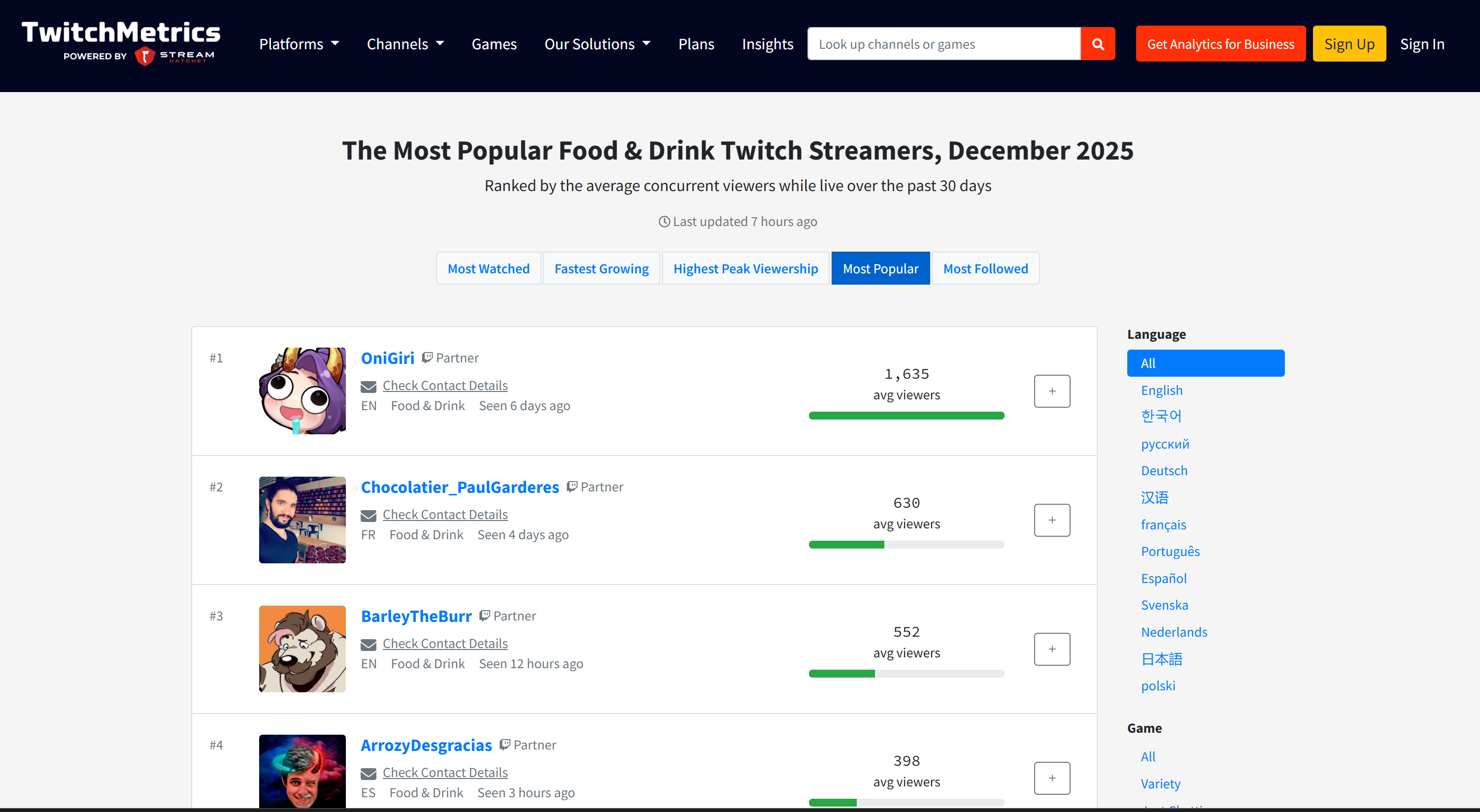
Beachten Sie, dass die Twitch-Streamer-Informationen im Bericht mit den dedizierten TwitchMetrics-Profilseiten für jedes der fünf besten Profile übereinstimmen: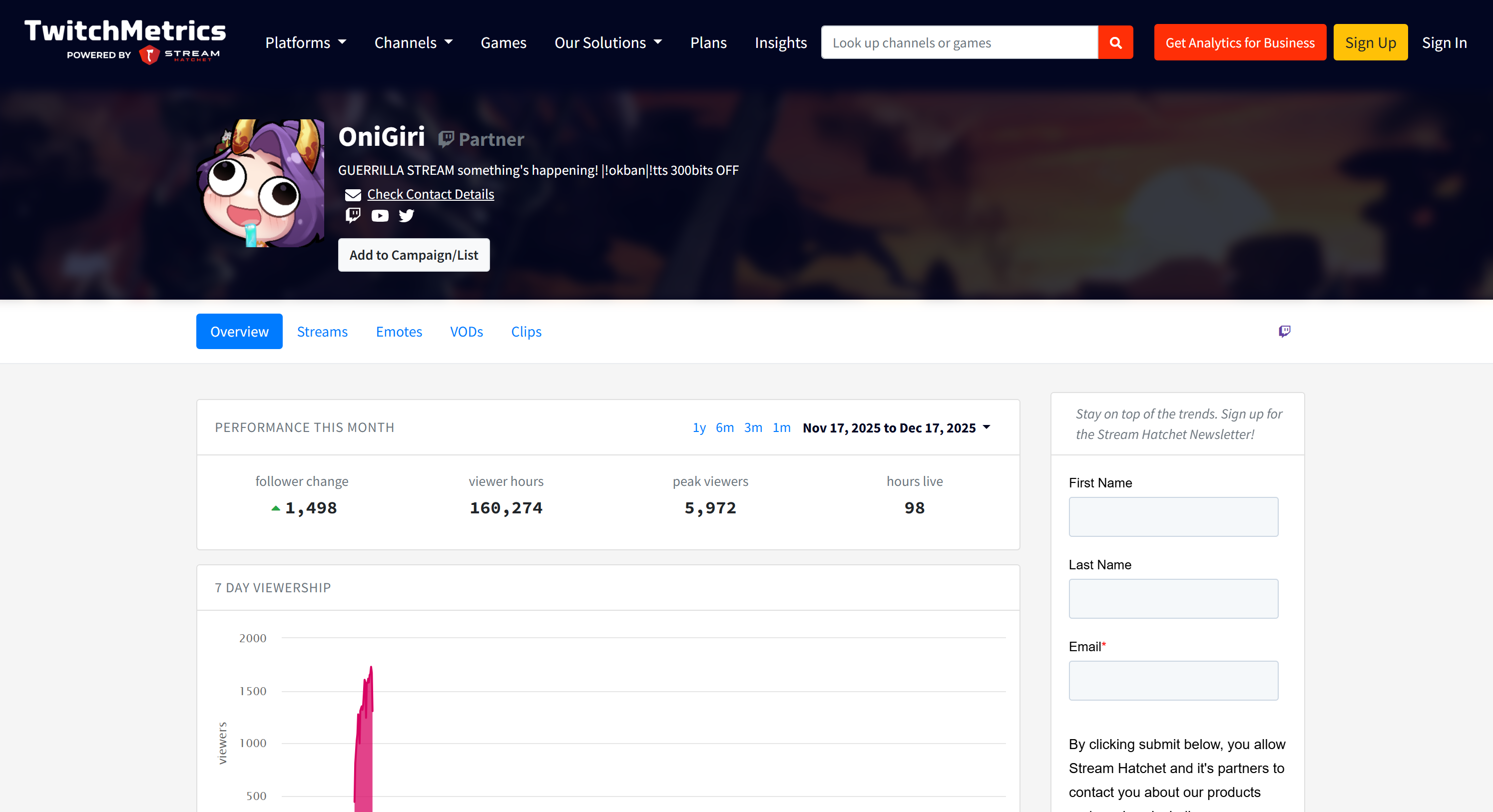
Alle diese Informationen wurden automatisch vom Multi-Agent-System abgerufen, was die Leistungsfähigkeit von AG2 und seine Integration mit Bright Data demonstriert.
Probieren Sie nun verschiedene Eingabeaufforderungen aus. Dank Bright Data kann Ihr AG2-Multi-Agent-Workflow eine Vielzahl von realen Aufgaben bewältigen.
Et voilà! Sie haben gerade die Fähigkeiten eines mit Bright Data erweiterten AG2-Workflows gesehen.
AG2 mit Bright Data Web MCP verbinden: Eine Schritt-für-Schritt-Anleitung
Eine weitere Möglichkeit, Bright Data in AG2 zu integrieren, ist über den Bright Data Web MCP-Server.
Web MCP bietet Ihnen Zugriff auf über 60 Tools, die auf der Web-Automatisierungs- und Datenerfassungsplattform von Bright Data aufbauen. Selbst in der kostenlosen Version stehen Ihnen zwei leistungsstarke Tools zur Verfügung:
| Tool | Beschreibung |
|---|---|
search_engine |
Ruft Ergebnisse von Google, Bing oder Yandex im JSON- oder Markdown-Format ab. |
scrape_as_markdown |
Kratzen Sie jede Webseite in sauberes Markdown, während Sie Anti-Bot-Maßnahmen umgehen. |
Der Pro-Modus von Web MCP erweitert die Funktionalität noch weiter. Diese Premium-Option ermöglicht die Extraktion strukturierter Daten für wichtige Plattformen wie Amazon, LinkedIn, Instagram, Reddit, YouTube, TikTok, Google Maps und mehr. Außerdem enthält sie Tools für die erweiterte Browser-Automatisierung.
Hinweis: Informationen zur Projekteinrichtung finden Sie in Schritt 1 des vorherigen Kapitels.
Als Nächstes sehen wir uns an, wie Sie Bright Datas Web MCP in AG2 verwenden können!
Voraussetzungen
Um diesem Abschnitt des Tutorials folgen zu können, müssen Sie Node.js lokal installiert haben, da es für die Ausführung von Web MCP auf Ihrem Rechner erforderlich ist.
Außerdem müssen Sie das MCP-Paket für AG2 installieren mit:
pip install ag2[mcp]Dadurch kann AG2 als MCP-Client fungieren.
Schritt 1: Erste Schritte mit Bright Data’s Web MCP
Bevor Sie AG2 mit Bright Data’s Web MCP verbinden, stellen Sie sicher, dass Ihr lokaler Computer den MCP-Server ausführen kann. Dies ist wichtig, da Ihnen gezeigt wird, wie Sie sich lokal mit dem Web MCP-Server verbinden können.
Hinweis: Web MCP ist auch als Remote-Server über Streamable HTTP verfügbar, der sich dank seiner unbegrenzten Skalierbarkeit besser für Anwendungsfälle in Unternehmen eignet.
Stellen Sie zunächst sicher, dass Sie über ein Bright Data-Konto verfügen. Wenn Sie bereits ein Konto haben, melden Sie sich einfach an. Für eine schnelle Einrichtung folgen Sie den Anweisungen im Abschnitt„MCP“Ihres Dashboards:
Weitere Anleitungen finden Sie in den folgenden Schritten.
Beginnen Sie mit der Generierung Ihres Bright Data API-Schlüssels. Bewahren Sie ihn an einem sicheren Ort auf, da Sie ihn in Kürze zur Authentifizierung Ihrer lokalen Web-MCP-Instanz verwenden werden.
Installieren Sie anschließend Web MCP global auf Ihrem Rechner mit dem Paket @brightdata/mcp:
npm install -g @brightdata/mcpStarten Sie den MCP-Server, indem Sie Folgendes ausführen:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcpOder alternativ in PowerShell:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; npx -y @brightdata/mcpErsetzen Sie <YOUR_BRIGHT_DATA_API> durch Ihren Bright Data API-Token. Diese Befehle legen die erforderliche Umgebungsvariable API_TOKEN fest und starten den Web-MCP-Server lokal.
Bei erfolgreicher Ausführung sollte eine Ausgabe ähnlich der folgenden angezeigt werden:
Standardmäßig erstellt Web MCP beim ersten Start zwei Zonen in Ihrem Bright Data-Konto:
mcp_unlocker: Eine Zone für Web Unlocker.mcp_browser: Eine Zone für die Browser-API.
Diese Zonen unterstützen die über 60 in Web MCP verfügbaren Tools.
Sie können überprüfen, ob die Zonen erstellt wurden, indem Sie in Ihrem Bright Data-Dashboard „Proxies & Scraping-Infrastruktur“ aufrufen: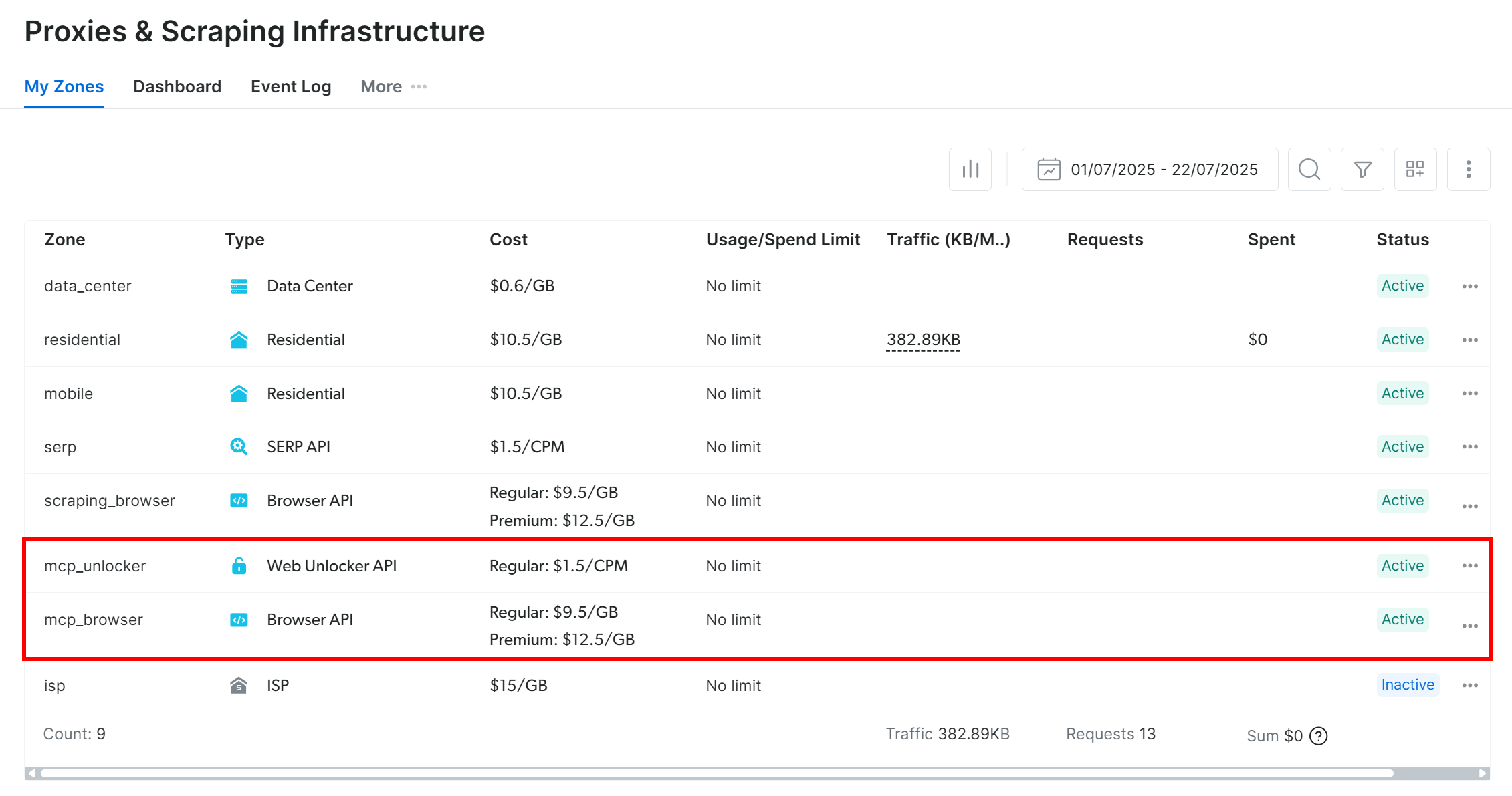
In der kostenlosen Version von Web MCP sind nur die Tools „search_engine“ und „scrape_as_markdown“ (sowie deren Batch-Versionen) verfügbar.
Um alle Tools freizuschalten, aktivieren Sie den Pro-Modus, indem Sie die Umgebungsvariable PRO_MODE="true" setzen:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcpOder unter Windows:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; $Env:PRO_MODE="true"; npx -y @brightdata/mcpDer Pro-Modus schaltet alle über 60 Tools frei, ist jedoch nicht in der kostenlosen Version enthalten und kann zusätzliche Kosten verursachen.
Fertig! Sie haben nun überprüft, dass der Web-MCP-Server lokal ausgeführt wird. Beenden Sie den MCP-Prozess vorerst, da der nächste Schritt darin besteht, AG2 so zu konfigurieren, dass der Server lokal gestartet und eine Verbindung zu ihm hergestellt wird.
Schritt 2: Integration von Web MCP in AG2
Verwenden Sie den AG2 MCP-Client, um über STDIO eine Verbindung zu einer lokalen Web-MCP-Instanz herzustellen und die verfügbaren Tools abzurufen:
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from autogen.mcp import create_toolkit
# Anweisungen zum Herstellen einer Verbindung zu einer lokalen Web-MCP-Instanz
server_params = StdioServerParameters(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": BRIGHT_DATA_API_KEY,
"PRO_MODE": "true" # Optional
},)
async with stdio_client(server_params) as (read, write), ClientSession(read, write) as session:
# Erstellen Sie eine MCP-Verbindungssitzung und rufen Sie die Tools ab.
await session.initialize()
web_mcp_toolkit = await create_toolkit(session, use_mcp_resources=False)Das StdioServerParameters -Objekt spiegelt den zuvor ausgeführten npx -Befehl wider, einschließlich Umgebungsvariablen für Anmeldedaten und Einstellungen:
API_TOKEN: Erforderlich. Setzen Sie diesen Wert auf Ihren Bright Data API-Schlüssel.PRO_MODE: Optional. Entfernen Sie diese Option, wenn Sie die kostenlose Stufe beibehalten möchten (nursearch_engineundscrape_as_markdownsowie deren Batch-Versionen).
Die Sitzung wird verwendet, um eine Verbindung zu Web MCP herzustellen und mit create_toolkit ein AG2 MCP-Toolkit zu erstellen.
Hinweis: Wie in einem speziellen GitHub-Issue betont, ist die Option use_mcp_resources=False erforderlich, um den Fehler mcp.shared.exceptions.McpError: Method not found zu vermeiden.
Nach der Erstellung enthält das Objekt web_mcp_toolkit alle Web-MCP-Tools. Überprüfen Sie dies mit:
for tool in web_mcp_toolkit.tools:
print(tool.name)
print(tool.description)
print("---n")Die Ausgabe lautet: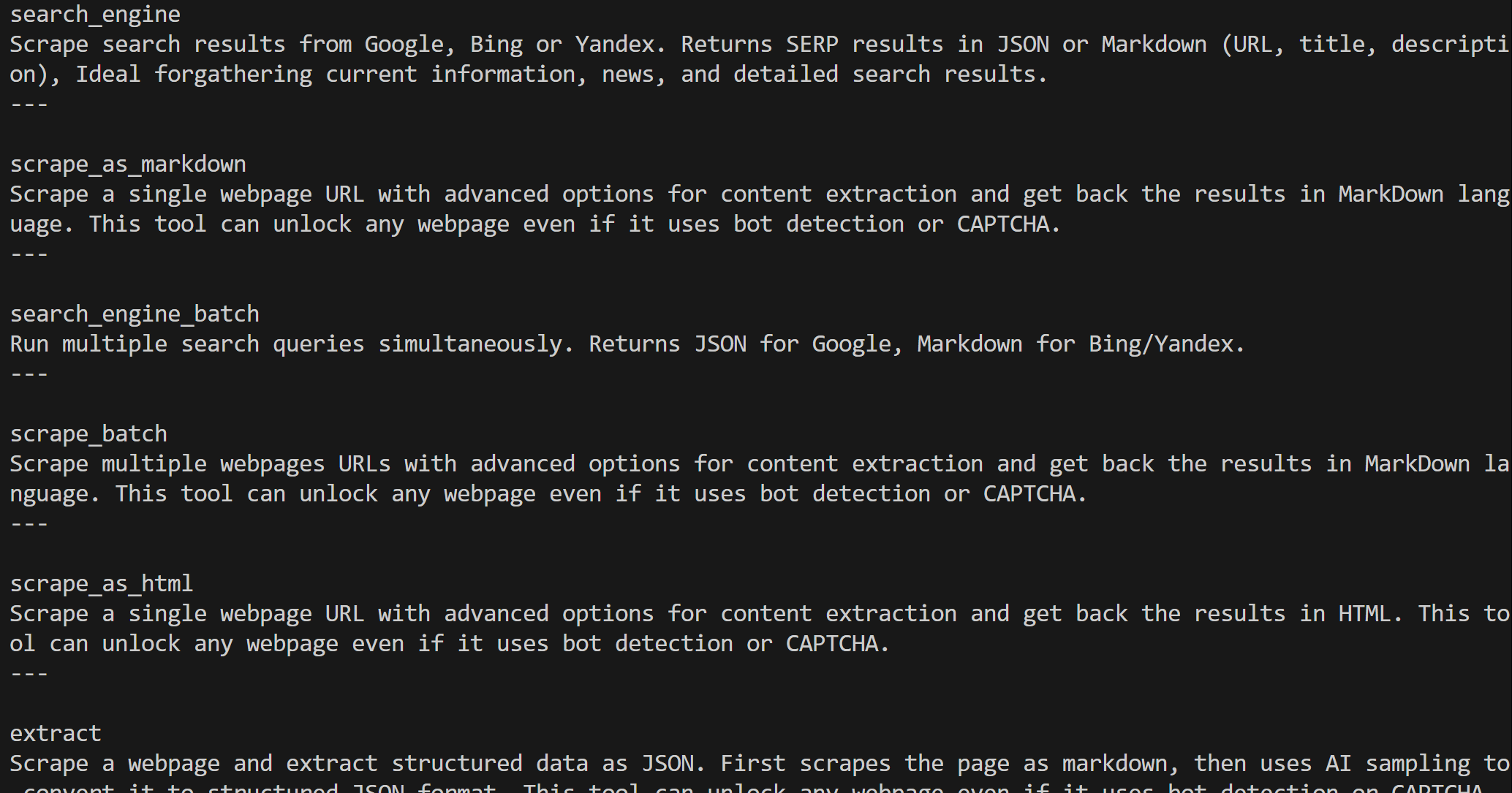
Je nach konfigurierter Stufe stehen Ihnen entweder alle über 60 Web-MCP-Tools (Pro-Modus) oder nur die Tools der kostenlosen Stufe zur Verfügung.
Ausgezeichnet! Ihre Web-MCP-Verbindung ist nun in AG2 voll funktionsfähig.
Schritt 3: Verbinden Sie die Web-MCP-Tools mit einem Agenten
Der einfachste Weg, die Web-MCP-Integration in AG2 zu testen, ist über einen AssistantAgent, eine Unterklasse von ConversableAgent, die entwickelt wurde, um Aufgaben mit Hilfe des LLM schnell zu lösen. Definieren Sie zunächst den Agenten und registrieren Sie das Web-MCP-Toolkit bei ihm:
from autogen import AssistantAgent
# Definieren Sie einen Agenten, der Webdaten suchen und abrufen kann.
assistant_agent = AssistantAgent(
name="assistant",
code_execution_config=False,
llm_config=llm_config,
system_message="""
Sie haben Zugriff auf alle Tools, die von Web MCP bereitgestellt werden, darunter:
- Websuche
- Web-Scraping und Seitenabruf
- Web-Datenfeeds
- Browser-basierte Benutzersimulation
Verwenden Sie diese Tools bei Bedarf.
""")
# Registrieren Sie die Web-MCP-Tools beim Agenten.
web_mcp_toolkit.register_for_llm(assistant_agent)Nach der Registrierung können Sie den Agenten mit der Funktion a_run() starten und direkt die zu verwendenden Tools angeben. Hier sehen Sie beispielsweise, wie Sie den Agenten bei einer Amazon-Web-Scraping-Aufgabe testen können:
prompt = """
Rufen Sie Daten aus dem folgenden Amazon-Produkt ab und erstellen Sie eine kurze Zusammenfassung mit den wichtigsten Informationen:
"""
# Den Web MCP-erweiterten Agenten asynchron ausführen
result = await assistant_agent.a_run(
message=prompt,
tools=web_mcp_toolkit.tools,
user_input=False,)
await result.process()Wichtig: Beachten Sie, dass dies nur eine Demo ist, um die Integration zu veranschaulichen. Dank aller Web-MCP-Tools kann der Agent viel komplexere, mehrstufige Aufgaben über verschiedene Webplattformen und Datenquellen hinweg bewältigen.
Schritt 4: Endgültiger Code + Ausführung
Nachfolgend finden Sie den endgültigen Code für Ihre AG2 + Bright Data Web MCP-Integration:
import asyncio
from autogen import (
LLMConfig,
AssistantAgent,)
from dotenv import load_dotenv
import os
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from autogen.mcp import create_toolkit
# Laden Sie die Umgebungsvariablen aus der .env-Datei.
load_dotenv()
# Rufen Sie den Bright Data API-Schlüssel aus den Umgebungsvariablen ab.
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
# Definieren Sie das MCP-Toolkit, das alle Web-MCP-Tools enthält
async def launch_mcp_agent():
# Laden Sie die LLM-Konfiguration aus der OpenAI-Konfigurationslistendatei
llm_config = LLMConfig.from_json(path="OAI_CONFIG_LIST")
# Anweisungen zum Herstellen einer Verbindung mit einer lokalen Web-MCP-Instanz
server_params = StdioServerParameters(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": BRIGHT_DATA_API_KEY,
"PRO_MODE": "true" # Optional
},
)
async with stdio_client(server_params) as (read, write), ClientSession(read, write) as session:
# Erstellen einer MCP-Verbindungssitzung und Abrufen der Tools
await session.initialize()
web_mcp_toolkit = await create_toolkit(session, use_mcp_resources=False)
# Einen Agenten definieren, der Webdaten suchen und abrufen kann
assistant_agent = AssistantAgent(
name="assistant",
code_execution_config=False,
llm_config=llm_config,
system_message="""
Sie haben Zugriff auf alle vom Web-MCP bereitgestellten Tools, darunter:
- Websuche
- Web-Scraping und Seitenabruf
- Web-Daten-Feeds
- Browser-basierte Benutzersimulation
Verwenden Sie diese Tools bei Bedarf.
"""
)
# Registrieren Sie die Web-MCP-Tools beim Agenten.
web_mcp_toolkit.register_for_llm(assistant_agent)
# Die an den Agenten zu übergebende Eingabeaufforderung
prompt = """
Rufen Sie Daten aus dem folgenden Amazon-Produkt ab und erstellen Sie eine kurze Zusammenfassung mit den wichtigsten Informationen:
"""
# Den Web-MCP-erweiterten Agenten asynchron ausführen
result = await assistant_agent.a_run(
message=prompt,
tools=web_mcp_toolkit.tools,
user_input=False,
)
await result.process()
asyncio.run(launch_mcp_agent())Führen Sie dies aus, und das Ergebnis lautet: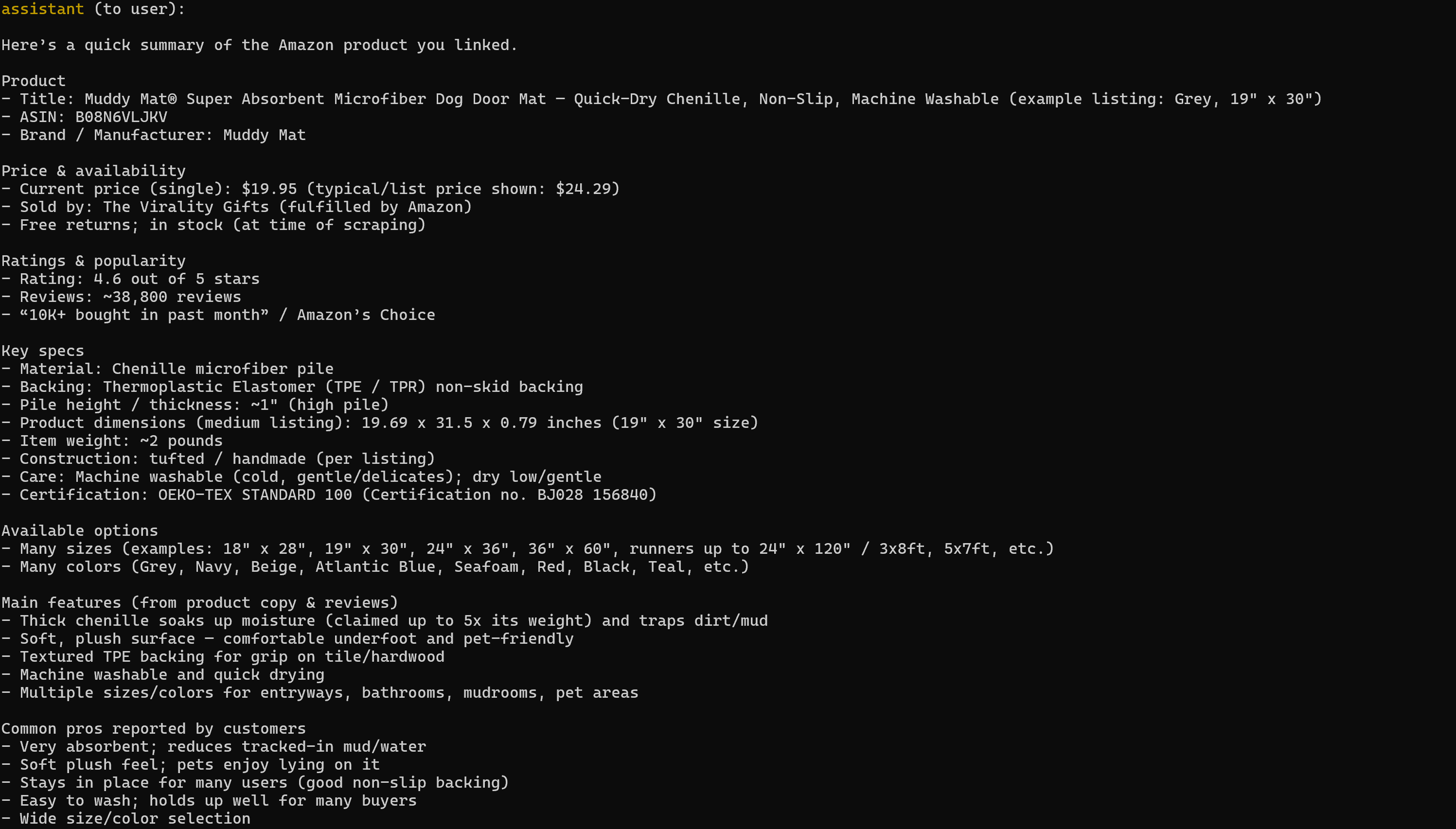
Beachten Sie, dass der generierte Bericht alle relevanten Daten von der Zielseite des Amazon-Produkts enthält:
Wenn Sie schon einmal versucht haben, Amazon-Produktdaten in Python zu scrapen, wissen Sie, dass das kein Kinderspiel ist. Amazon verwendet das bekanntermaßen schwierige Amazon CAPTCHA sowie andere Anti-Bot-Maßnahmen. Außerdem ändern sich Produktseiten ständig und haben unterschiedliche Strukturen.
Bright Data’s Web MCP übernimmt all das für Sie. In der kostenlosen Version ruft es im Hintergrund das Tool scrape_as_markdown auf, um die Seitenstruktur in sauberem Markdown über Web Unlocker abzurufen. Im Pro-Modus nutzt es das Produkt web_data_amazon_product, das Bright Data’s Amazon Scraper aufruft, um vollständig strukturierte Produktdaten zu sammeln.
Das war’s! Jetzt wissen Sie, wie Sie AG2 mit Bright Data Web MCP erweitern können.
Fazit
In diesem Tutorial haben Sie gelernt, wie Sie Bright Data mit AG2 integrieren können, entweder über benutzerdefinierte Funktionen oder über Web MCP.
Diese Integration ermöglicht es AG2-Agenten, Websuchen durchzuführen, strukturierte Daten zu extrahieren, auf Live-Web-Feeds zuzugreifen und Web-Interaktionen zu automatisieren. All dies wird durch die Suite von Bright Data-Diensten für KI ermöglicht.
Erstellen Sie kostenlos ein Bright Data-Konto und entdecken Sie noch heute unsere KI-fähigen Webdaten-Tools!




