
In diesem Leitfaden erfahren Sie mehr:
- Was die agentengestützte Retrieval-Augmented Generation (RAG) ist und warum die Hinzufügung agentengestützter Fähigkeiten wichtig ist
- Wie Bright Data den autonomen und Live-Webdatenabruf für RAG-Systeme ermöglicht
- Verarbeitung und Bereinigung von Web-Scraping-Daten für die Erzeugung von Einbettungen
- Implementierung eines Agentencontrollers zur Orchestrierung zwischen Vektorsuche und LLM-Texterzeugung
- Entwicklung einer Feedback-Schleife zur Erfassung von Nutzereingaben und zur dynamischen Optimierung von Abruf und Erzeugung
Lasst uns eintauchen!
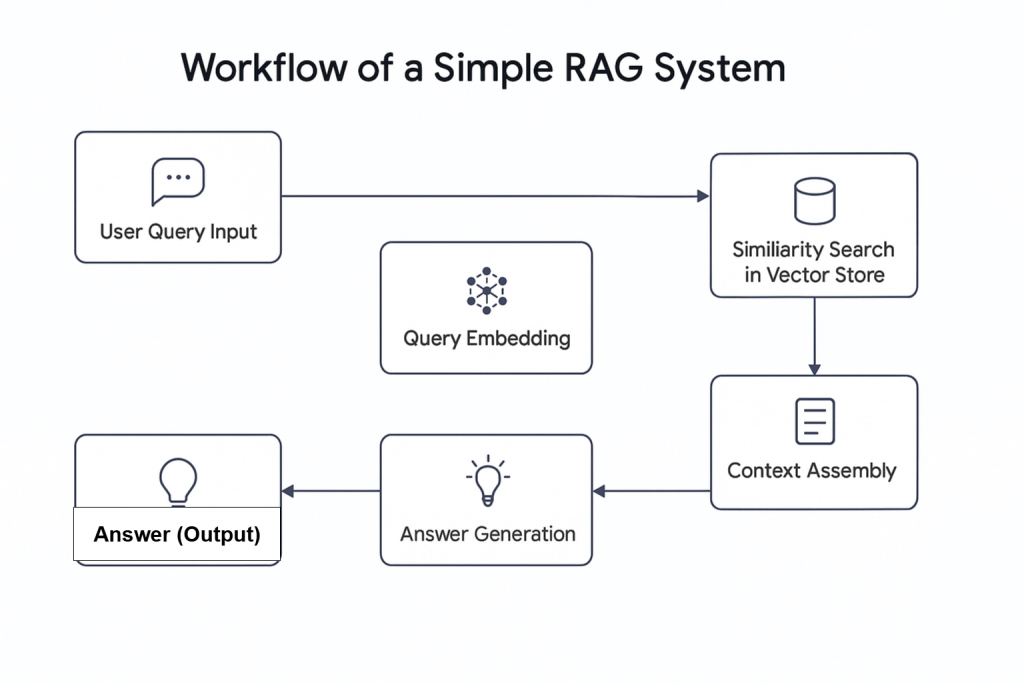
Mit dem Aufkommen der künstlichen Intelligenz (KI) wurden neue Konzepte eingeführt, darunter auch die agenturgestützte RAG. Einfach ausgedrückt, handelt es sich bei Agentic RAG um Retrieval Augmented Generation (RAG), das KI-Agenten integriert . Wie der Name schon sagt, handelt es sich bei RAG um ein Informationsabfragesystem, das einem linearen Prozess folgt: Es erhält eine Anfrage, ruft relevante Informationen ab und erzeugt eine Antwort.
Warum sollten KI-Agenten mit der RAG kombiniert werden?
Eine kürzlich durchgeführte Umfrage zeigt, dass fast zwei Drittel der Workflows, die KI-Agenten einsetzen, eine höhere Produktivität aufweisen. Darüber hinaus berichten fast 60 Prozent von Kosteneinsparungen. Dies macht die Kombination von KI-Agenten mit RAG zu einem potenziellen Game-Changer für moderne Retrieval-Workflows.
Agentic RAG bietet erweiterte Funktionen. Im Gegensatz zu herkömmlichen RAG-Systemen kann es nicht nur Daten abrufen, sondern auch Informationen aus externen Quellen, wie z. B. in eine Datenbank eingebettete Live-Webdaten, abrufen.
Dieser Artikel zeigt, wie man ein agentenbasiertes RAG-System aufbaut, das Nachrichteninformationen mit Hilfe von Bright Data für die Webdatenerfassung, Pinecone als Vektordatenbank, OpenAI für die Texterzeugung und Agno als Agentensteuerung abruft.
Überblick über Bright Data
Unabhängig davon, ob Sie Daten aus einem Live-Datenstrom beziehen oder aufbereitete Daten aus Ihrer Datenbank verwenden, hängt die Qualität des Outputs Ihres Agentic RAG-Systems von der Qualität der Daten ab, die es erhält. An dieser Stelle kommt Bright Data ins Spiel.
Bright Data bietet zuverlässige, strukturierte und aktuelle Webdaten für eine breite Palette von Anwendungsfällen. Mit der Web Scraper API von Bright Data, die Zugang zu mehr als 120 Domains hat, ist Web Scraping effizienter denn je. Sie bewältigt gängige Scraping-Herausforderungen wie IP-Sperren, CAPTCHA, Cookies und andere Formen der Bot-Erkennung.
Um loszulegen, melden Sie sich für eine kostenlose Testversion an und erhalten dann Ihren API-Schlüssel und die dataset_id für die Domain, die Sie abrufen möchten. Sobald Sie diese haben, können Sie beginnen.
Nachfolgend finden Sie die Schritte zum Abrufen frischer Daten von einer beliebten Domain wie BBC News:
- Erstellen Sie ein Bright Data-Konto, falls Sie dies noch nicht getan haben. Eine kostenlose Testversion ist verfügbar.
- Rufen Sie die Seite Web Scrapers auf. Unter Web Scrapers Library finden Sie die verfügbaren Scraper-Vorlagen.
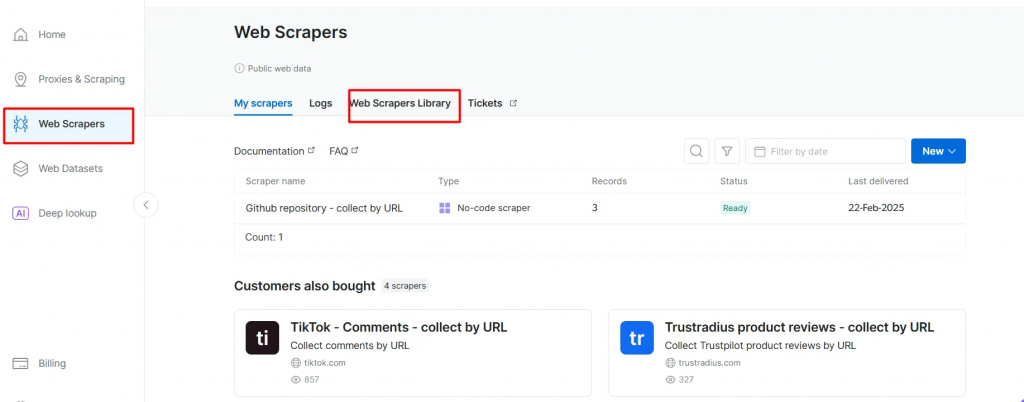
- Suchen Sie nach Ihrer Zieldomain, z. B. BBC News, und wählen Sie sie aus.
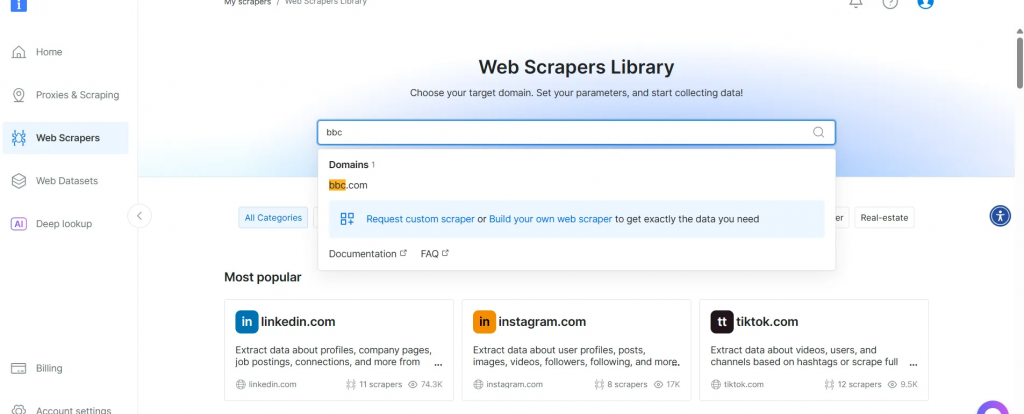
- Wählen Sie aus der Liste der BBC News Scraper BBC News – collect by URL. Mit diesem Scraper können Sie Daten abrufen, ohne sich bei der Domain anzumelden.
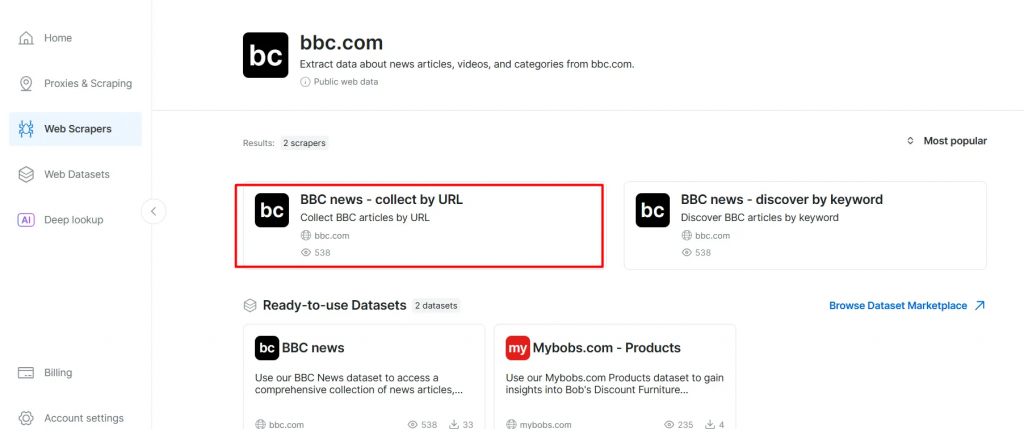
- Wählen Sie die Option Scraper API. Der No-Code Scraper hilft beim Abrufen von Datensätzen ohne Code.

- Klicken Sie auf API Request Builder und kopieren Sie dann Ihren
API-Schlüssel, dieBBC Dataset URLund diedataset_id. Sie werden diese im nächsten Abschnitt bei der Erstellung des Agentic RAG-Workflows verwenden.
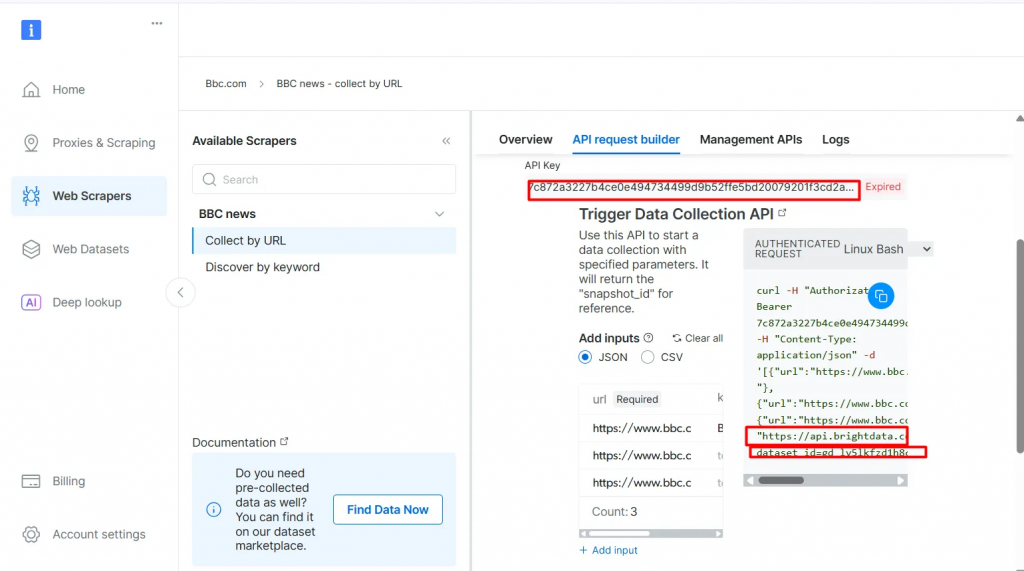
Der API-Schlüssel und die dataset_id sind erforderlich, um agentische Funktionen in Ihrem Arbeitsablauf zu aktivieren. Sie ermöglichen es Ihnen, Live-Daten in Ihre Vektordatenbank einzubetten und Echtzeit-Abfragen zu unterstützen, selbst wenn die Suchanfrage nicht direkt mit dem vorindizierten Inhalt übereinstimmt.
Voraussetzungen
Bevor Sie beginnen, vergewissern Sie sich, dass Sie die folgenden Informationen haben:
- Ein Bright Data-Konto
- Ein OpenAI API-Schlüssel Melden Sie sich bei OpenAI an, um Ihren API-Schlüssel zu erhalten:
- Ein Pinecone-API-Schlüssel Lesen Sie die Pinecone-Dokumentation und befolgen Sie die Anweisungen im Abschnitt API-Schlüssel anfordern.
- Ein grundlegendes Verständnis von Python Sie können Python von der offiziellen Website installieren
- Grundlegendes Verständnis von RAG- und Agentenkonzepten
Struktur der Agentischen RAG
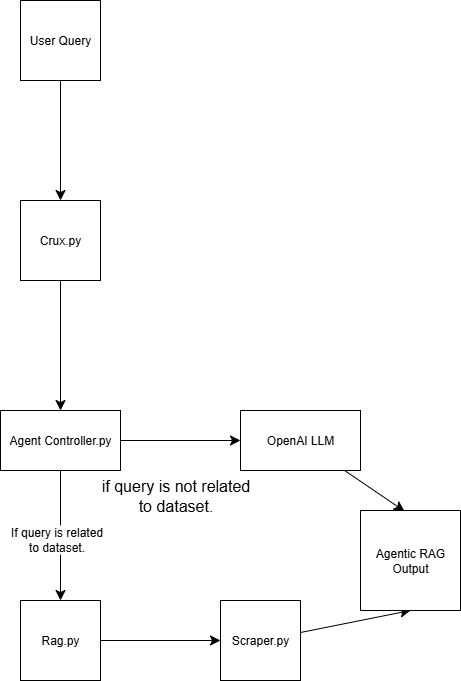
Dieses agentische RAG-System besteht aus vier Skripten:
scraper.py Ruft Webdaten über Bright Data ab
rag.py Bettet Daten in die Vektordatenbank (Pinecone) ein Hinweis: Eine Vektordatenbank (numerische Einbettung) wird verwendet, weil sie unstrukturierte Daten speichert, die typischerweise von einem maschinellen Lernmodell erzeugt werden. Dieses Format ist ideal für die Ähnlichkeitssuche bei Retrievalaufgaben.
agent_controller.py Enthält die Steuerungslogik. Sie entscheidet je nach Art der Abfrage, ob vorverarbeitete Daten aus der Vektordatenbank verwendet werden oder ob auf allgemeines Wissen aus GPT zurückgegriffen wird
crux.py fungiert als Kern des Agentic RAG-Systems. Es speichert die API-Schlüssel und initialisiert den Arbeitsablauf.
Am Ende der Demo wird die Struktur Ihrer Agentenlappen so aussehen:
Aufbau von Agentic RAG mit Bright Data
Schritt 1: Einrichten des Projekts
1.1 Erstellen Sie ein neues Projektverzeichnis
Erstellen Sie einen Ordner für Ihr Projekt und navigieren Sie dorthin:
mkdir agentic-rag
cd agentic-rag
1.2 Öffnen Sie das Projekt in Visual Studio Code
Starten Sie Visual Studio Code und öffnen Sie das neu erstellte Verzeichnis:
.../Desktop/agentic-rag> code .
1.3 Einrichten und Aktivieren einer virtuellen Umgebung
Um eine virtuelle Umgebung einzurichten, führen Sie aus:
python -m venv venv
Alternativ können Sie in Visual Studio Code den Anweisungen in der Anleitung zu Python-Umgebungen folgen, um eine virtuelle Umgebung zu erstellen.
So aktivieren Sie die Umgebung:
- Unter Windows:
.venv\\Scripts\\aktivieren - Unter macOS oder Linux:
Quelle venv/bin/activate
Schritt 2: Implementierung des Bright Data Retriever
2.1 Installieren Sie die Anfragen-Bibliothek in Ihrer scraper.py-Datei
pip install requests
2.2 Importieren Sie die folgenden Module
import requests
import json
import time
2.3 Einrichten der Anmeldeinformationen
Verwenden Sie den Bright Data-API-Schlüssel, die Dataset-URL und die Dataset_id, die Sie zuvor kopiert haben.
def trigger_bbc_news_articles_scraping(api_key, urls):
# Endpoint to trigger the Web Scraper API task
url = "<https://api.brightdata.com/datasets/v3/trigger>"
params = {
"dataset_id": "gd_ly5lkfzd1h8c85feyh", # ID of the BBC web scraper
"include_errors": "true",
}
# Convert the input data in the desired format to call the API
data = [{"url": url} for url in urls]
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
2.4 Einrichten der Antwortlogik
Geben Sie in Ihre Anfrage die URLs der Seiten ein, die Sie abrufen möchten. In diesem Fall konzentrieren Sie sich auf sportbezogene Artikel.
response = requests.post(url, headers=headers, params=params, json=data)
if response.status_code == 200:
snapshot_id = response.json()["snapshot_id"]
print(f"Request successful! Response: {snapshot_id}")
return response.json()["snapshot_id"]
else:
print(f"Request failed! Error: {response.status_code}")
print(response.text)
def poll_and_retrieve_snapshot(api_key, snapshot_id, output_file, polling_timeout=20):
snapshot_url = f"<https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json>"
headers = {
"Authorization": f"Bearer {api_key}"
}
print(f"Polling snapshot for ID: {snapshot_id}...")
while True:
response = requests.get(snapshot_url, headers=headers)
if response.status_code == 200:
print("Snapshot is ready. Downloading...")
snapshot_data = response.json()
# Write the snapshot to an output json file
with open(output_file, "w", encoding="utf-8") as file:
json.dump(snapshot_data, file, indent=4)
print(f"Snapshot saved to {output_file}")
return
elif response.status_code == 202:
print(F"Snapshot is not ready yet. Retrying in {polling_timeout} seconds...")
time.sleep(polling_timeout)
else:
print(f"Request failed! Error: {response.status_code}")
print(response.text)
break
if __name__ == "__main__":
BRIGHT_DATA_API_KEY = "BRIGHT DATA KEY" # Replace it with your Bright Data's Web Scraper API key
# URLs of BBC articles to retrieve data from
urls = [
"<https://www.bbc.com/sport/formula1/articles/c9dj0elnexyo>",
"<https://www.bbc.com/sport/formula1/articles/cgenqvv9309o>",
"<https://www.bbc.com/sport/formula1/articles/c78jng0q2dxo>",
"<https://www.bbc.com/sport/formula1/articles/cdrgdm4ye53o>",
"<https://www.bbc.com/sport/formula1/articles/czed4jk7eeeo>",
"<https://www.bbc.com/sport/football/articles/c807p94r41do>",
"<https://www.bbc.com/sport/football/articles/crgglxwge10o>",
"<https://www.bbc.com/sport/tennis/articles/cy700xne614o>",
"<https://www.bbc.com/sport/tennis/articles/c787dk9923ro>",
"<https://www.bbc.com/sport/golf/articles/ce3vjjq4dqzo>"
]
snapshot_id = trigger_bbc_news_articles_scraping(BRIGHT_DATA_API_KEY, urls)
poll_and_retrieve_snapshot(BRIGHT_DATA_API_KEY, snapshot_id, "news-data.json")
2.5 Ausführen des Codes
Nachdem Sie das Skript ausgeführt haben, erscheint in Ihrem Projektordner eine Datei namens news-data.json. Sie enthält die gescrapten Artikeldaten im strukturierten JSON-Format.
Hier ist ein Beispiel für den Inhalt der JSON-Datei:
[
{
"id": "c9dj0elnexyo",
"url": "<https://www.bbc.com/sport/formula1/articles/c9dj0elnexyo>",
"author": "BBC",
"headline": "Max Verstappen: Red Bull adviser Helmut Marko has 'great concern' about world champion's future with team",
"topics": [
"Formula 1"
],
"publication_date": "2026-04-14T13:42:08.154Z",
"content": "Saudi Arabian Grand PrixVenue: Jeddah Dates: 18-20 April Race start: 18:00 BST on SundayCoverage: Live radio commentary of practice, qualifying and race online and BBC 5 Sports Extra; live text updates on the BBC Sport website and app; Red Bull motorsport adviser Helmut Marko says he has \\"great concern\\" about Max Verstappen's future with the team in the context of their current struggles.AdvertisementThe four-time champion finished sixth in the Bahrain Grand Prix on Sunday, while Oscar Piastri scored McLaren's third win in four races so far this year.Dutchman Verstappen is third in the drivers' championship, eight points behind leader Lando Norris of McLaren.Marko told Sky Germany: \\"The concern is great. Improvements have to come in the near future so that he has a car with which he can win again.\\"We have to create a basis with a car so that he can fight for the world championship.\\"Verstappen has a contract with Red Bull until 2028. But Marko told BBC Sport this month that it contains a performance clause that could allow him to leave the team.; The wording of this clause is not known publicly but it effectively says that Red Bull have to provide Verstappen with a winning car.Verstappen won the Japanese Grand Prix a week before Bahrain but that victory was founded on a pole position lap that many F1 observers regarded as one of the greatest of all time.Because overtaking was next to impossible at Suzuka, Verstappen was able to hold back the McLarens of Norris and Piastri and take his first win of the year.Verstappen has qualified third, fourth and seventh for the other three races in Australia, China and Bahrain.The Red Bull is on average over all qualifying sessions this year the second fastest car but 0.214 seconds a lap slower than the McLaren.Verstappen has complained all year about balance problems with the Red Bull, which is unpredictable on corner entry and has mid-corner understeer.Red Bull team principal Christian Horner admitted after the race in Bahrain that the car's balance problems were fundamentally similar to the ones that made the second half of last year a struggle for Verstappen.He won just twice in the final 13 races of last season, but managed to win his fourth world title because of the huge lead he built up when Red Bull were in dominant form in the first five races of the season.Horner also said the team were having difficulties with correlation between their wind tunnel and on-track performance. Essentially, the car performs differently on track than the team's simulation tools say it should.; Verstappen had a difficult race in Bahrain including delays at both pit stops, one with the pit-lane traffic light system and one with fitting a front wheel.At one stage he was running last, and he managed to snatch sixth place from Alpine's Pierre Gasly only on the last lap.Verstappen said that the hot weather and rough track surface had accentuated Red Bull's problems.He said: \\"Here you just get punished a bit harder when you have big balance issues because the Tarmac is so aggressive.\\"The wind is also quite high and the track has quite low grip, so everything is highlighted more.\\"Just the whole weekend struggling a bit with brake feeling and stopping power, and besides that also very poor grip. We tried a lot on the set-up and basically all of it didn't work, didn't give us a clear direction to work in.\\"Verstappen has said this year that he is \\"relaxed\\" about his future.Any decision about moving teams for 2026 is complicated by the fact that F1 is introducing new chassis and engine rules that amount to the biggest regulation change in the sport's history, and it is impossible to know which team will be in the best shape.But it is widely accepted in the paddock that Mercedes are looking the best in terms of engine performance for 2026.Mercedes F1 boss Toto Wolff has made no secret of his desire to sign Verstappen.The two parties had talks last season but have yet to have any discussions this season about the future.",
"videos": [],
"images": [
{
"image_url": "<https://ichef.bbci.co.uk/ace/branded_sport/1200/cpsprodpb/bfc4/live/d3cc7850-1931-11f0-869a-33b652e8958c.jpg>",
"image_description": "Main image"
},
Nun, da Sie die Daten haben, müssen Sie sie einbetten.
Schritt 3: Einbettungen und Vektorspeicher einrichten
3.1 Installieren Sie die erforderlichen Bibliotheken in Ihrer rag.py-Datei
pip install openai pinecone pandas
3.2 Importieren der benötigten Bibliotheken
import json
import time
import re
import openai
import pandas as pd
from pinecone import Pinecone, ServerlessSpec
3.3 Konfigurieren Sie Ihren OpenAI-Schlüssel
Verwenden Sie OpenAI, um Einbettungen aus dem Feld text_for_embedding zu erzeugen.
# Configure your OpenAI API key here or pass to functions
OPENAI_API_KEY = "OPENAI_API_KEY" # Replace with your OpenAI API key
3.4 Konfigurieren Sie Ihren Pinecone-API-Schlüssel und Ihre Indexeinstellungen
Richten Sie die Pinecone-Umgebung ein und definieren Sie Ihre Indexkonfiguration.
pinecone_api_key = "PINECONE_API_KEY" # Replace with your Pinecone API key
index_name = "news-articles"
dimension = 1536 # OpenAI embedding dimension for text-embedding-ada-002 (adjust if needed)
namespace = "default"
3.5 Initialisierung des Pinecone-Clients und des Index
Stellen Sie sicher, dass der Client und der Index für die Speicherung und den Abruf von Daten ordnungsgemäß initialisiert sind.
# Initialize Pinecone client and index
pc = Pinecone(api_key=pinecone_api_key)
# Check if index exists
if index_name not in pc.list_indexes().names():
pc.create_index(
name=index_name,
dimension=dimension,
metric="cosine",
spec=ServerlessSpec(cloud="aws", region="us-east-1")
)
while not pc.describe_index(index_name).status["ready"]:
time.sleep(1)
pinecone_index = pc.Index(index_name)
print(pinecone_index)
3.6 Daten bereinigen, laden und vorverarbeiten
# Text cleaning helper
def clean_text(text):
text = re.sub(r"\\s+", " ", text)
return text.strip()
# Load and preprocess `news-data.json`
def load_and_prepare_data(json_path="news-data.json"):
with open(json_path, "r", encoding="utf-8") as f:
news_data = json.load(f)
df = pd.DataFrame(news_data)
df["text_for_embedding"] = df["headline"].map(clean_text) + ". " + df["content"].map(clean_text)
df["id"] = df["id"].astype(str)
return df
Hinweis: Sie können
scraper.pyerneut ausführen, um sicherzustellen, dass Ihre Daten aktuell sind.
3.7 Erzeugen von Einbettungen mit OpenAI
Erstellen Sie Einbettungen aus Ihrem vorverarbeiteten Text mit dem Einbettungsmodell von OpenAI.
# New embedding generation via OpenAI API
def openai_generate_embeddings(texts, model="text-embedding-ada-002"):
openai.api_key = OPENAI_API_KEY
# OpenAI endpoint accepts a list of strings and returns list of embeddings
response = openai.embeddings.create(
input=texts,
model=model
)
embeddings = [datum.embedding for datum in response.data]
return embeddings
3.8 Pinecone mit Einbettungen aktualisieren
Übertragen Sie die generierten Einbettungen an Pinecone, um die Vektordatenbank auf dem neuesten Stand zu halten.
# Embed and upsert to Pinecone
def embed_and_upsert(json_path="news-data.json", namespace=namespace):
df = load_and_prepare_data(json_path)
texts = df["text_for_embedding"].tolist()
print(f"Generating embeddings for {len(texts)} texts using OpenAI...")
embeddings = openai_generate_embeddings(texts)
df["embedding"] = embeddings
records = []
for row in df.itertuples():
records.append((
row.id,
row.embedding,
{
"url": getattr(row, "url", ""), # safe get url if present
"text": row.text_for_embedding
}
))
pinecone_index.upsert(vectors=records, namespace=namespace)
print(f"Upserted {len(records)} records to Pinecone index '{index_name}'.")
Hinweis: Sie müssen diesen Schritt nur einmal ausführen, um die Datenbank aufzufüllen. Danach können Sie diesen Teil des Codes auskommentieren.
3.9 Initialisierung der Pinecone-Suchfunktion
def pinecone_search(index, query, namespace=namespace, top_k=3, score_threshold=0.8, embedding_model=None):
# OpenAI embedding here
query_embedding = openai_generate_embeddings([query])[0]
results = index.query(
vector=query_embedding,
top_k=top_k,
namespace=namespace,
include_metadata=True,
)
filtered = []
for match in results.matches:
if match.score >= score_threshold:
filtered.append({
"score": match.score,
"url": match.metadata.get("url", ""),
"text": match.metadata.get("text", ""),
})
return filtered
Anmerkung:
Der Schwellenwert legt fest, ab welchem Ähnlichkeitsgrad ein Ergebnis als relevant angesehen wird. Sie können diesen Wert an Ihre Bedürfnisse anpassen. Je höher die Punktzahl, desto genauer das Ergebnis.
3.10 Antworten mit OpenAI generieren
Verwenden Sie OpenAI, um Antworten aus dem über Pinecone abgerufenen Kontext zu generieren.
# OpenAI answer generation
def openai_generate_answer(openai_api_key, query, context=None):
import openai
openai.api_key = openai_api_key
prompt_context = ""
if context:
prompt_context = "\\n\\nContext:\\n" + "\\n\\n".join(context)
prompt = f"Answer the following question: {query}" + prompt_context
response = openai.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}],
max_tokens=256,
temperature=0.7,
)
answer = response.choices[0].message.content.strip()
return answer
3.11 (Optional) Führen Sie einen einfachen Test zur Abfrage und zum Ausdrucken der Ergebnisse durch.
Fügen Sie CLI-freundlichen Code ein, mit dem Sie einen einfachen Test durchführen können. Mit diesem Test können Sie überprüfen, ob Ihre Implementierung funktioniert und eine Vorschau der in der Datenbank gespeicherten Daten anzeigen.
def search_news_and_answer(openai_api_key, query):
results = pinecone_search(pinecone_index, query)
if results:
print(f"Found {len(results)} relevant documents.")
print("Top documents:")
for doc in results:
print(f"Score: {doc['score']:.4f}")
print(f"URL: {doc['url']}")
print(f"Text (excerpt): {doc['text'][:250]}...\\n")
answer = openai_generate_answer(openai_api_key, query, [r["text"] for r in results])
print("\\nGenerated answer:\\n", answer)
if __name__ == "__main__":
OPENAI_API_KEY = "OPENAI_API_KEY" # Replace with your OpenAI key here or pass via arguments/env var
test_query = "What is wrong with Man City?"
search_news_and_answer(OPENAI_API_KEY, test_query)
Tipp: Sie können die Menge des angezeigten Textes steuern, indem Sie das Ergebnis in Scheiben schneiden, zum Beispiel:
[:250].
Jetzt sind Ihre Daten in der Vektordatenbank gespeichert. Das bedeutet, dass Sie zwei Abfrageoptionen haben:
- Abruf aus der Datenbank
- Verwenden Sie eine von OpenAI erzeugte generische Antwort
Schritt 4: Aufbau des Agent Controllers
4.1 In agent_controller.py
Importieren Sie die erforderlichen Funktionen aus rag.py.
from rag import openai_generate_answer, pinecone_search
4.2 Pinecone-Abruf implementieren
Hinzufügen von Logik zum Abrufen relevanter Daten aus dem Pinecone-Vektorspeicher.
def agent_controller_decide_and_act(
pinecone_api_key,
openai_api_key,
pinecone_index,
query,
namespace="default"
):
print(f"Agent received query: {query}")
try:
print("Trying Pinecone retrieval...")
results = pinecone_search(pinecone_index, query, namespace=namespace)
if results:
print(f"Found {len(results)} matching documents in Pinecone.")
context_texts = [r["text"] for r in results]
answer = openai_generate_answer(openai_api_key, query, context_texts)
return answer
else:
print("No good matches found in Pinecone. Falling back to OpenAI generator.")
except Exception as e:
print(f"Pinecone retrieval failed: {e}")
4.3 Implementierung einer Fallback-OpenAI-Antwort
Erstellen Sie eine Logik, um eine Antwort mit OpenAI zu generieren, wenn kein relevanter Kontext abgerufen wird.
try:
print("Generating answer from OpenAI without retrieval context...")
answer = openai_generate_answer(openai_api_key, query)
return answer
except Exception as e:
print(f"OpenAI generation failed: {e}")
return "Sorry, I am currently unable to answer your query."
Schritt 5: Alles zusammenfügen
5.1 In crux.py
Importieren Sie alle notwendigen Funktionen aus agent_controller.py.
from rag import pinecone_index # Import Pinecone index & embedding model
from rag import openai_generate_answer, pinecone_search # Import helper functions if needed
from agent_controller import agent_controller_decide_and_act # Your orchestration function
5.2 Geben Sie Ihre API-Schlüssel an
Stellen Sie sicher, dass Ihre OpenAI- und Pinecone-API-Schlüssel richtig eingestellt sind.
# Your actual API keys here - replace with your real keys
PINECONE_API_KEY = "PINECONE_API_KEY"
OPENAI_API_KEY = "OPENAI_API_KEY"
5.3 Geben Sie Ihre Eingabeaufforderung in die Funktion main() ein
Definieren Sie die Eingabeaufforderung innerhalb der Funktion main().
def main():
query = "What is the problem with Man City?"
answer = agent_controller_decide_and_act(
pinecone_api_key=PINECONE_API_KEY,
openai_api_key=OPENAI_API_KEY,
pinecone_index=pinecone_index,
query=query,
namespace="default"
)
print("\\nAgent's answer:\\n", answer)
if __name__ == "__main__":
main()
5.4 Aufruf der Agentic RAG
Führen Sie die Agentic RAG-Logik aus. Sie werden sehen, wie sie eine Abfrage verarbeitet, indem sie zunächst ihre Relevanz prüft, bevor sie die Vektordatenbank abfragt.

Agent received query: What exactly is the problem with Man City Women Team?
Trying Pinecone retrieval...
Found 1 matching documents in Pinecone.
Agent's answer:
The problems with the Man City Women Team this season include a significant injury crisis, managerial upheaval, and poor performances in key games. Key players such as Vivianne Miedema, Khadija Shaw, Lauren Hemp, and Alex Greenwood have been sidelined due to injuries, which has severely impacted the team's performance and highlighted a lack of squad depth. Interim manager Nick Cushing suggests that the number of injuries is not solely down to bad luck or bad practice and calls for an examination of the situation.
Testen Sie es mit einer Abfrage, die nicht mit Ihrer Datenbank übereinstimmt, z. B:
def main():
query = "Why Sleep?"
Der Agent stellt fest, dass in Pinecone keine guten Übereinstimmungen gefunden werden, und greift auf die Generierung einer generischen Antwort mit OpenAI zurück.

Agent received query: Why Sleep?
Trying Pinecone retrieval...
No good matches found in Pinecone. Falling back to OpenAI generator.
as a car crash), or it can harm you over time.
For example, ongoing sleep deficiency can raise your risk for some chronic health problems. It also can affect how well you think, react, work, learn, and get along with as a car crash), or it can harm you over time.
Tipp: Sie können die Relevanzbewertung (score_threshold) für jede Eingabeaufforderung ausdrucken, um das Vertrauensniveau des Agenten zu ermitteln.
Das war’s! Sie haben Ihre Agentic RAG erfolgreich aufgebaut.
Schritt 6 (optional): Rückkopplungsschleife und Optimierung
Sie können Ihr System verbessern, indem Sie eine Feedback-Schleife einrichten, um das Training und die Indexierung im Laufe der Zeit zu verbessern.
6.1 Hinzufügen einer Feedback-Funktion
Erstellen Sie in agent_controller.py eine Funktion, die den Benutzer nach der Anzeige einer Antwort um Feedback bittet. Sie können diese Funktion am Ende des Hauptlaufs in crux.py aufrufen.
def collect_user_feedback():
feedback = input("Was the answer helpful? (yes/no): ").strip().lower()
comments = input("Any comments or corrections? (optional): ").strip()
return feedback, comments
6.2 Implementierung der Rückkopplungslogik
Erstellen Sie eine neue Funktion in agent_controller.py, die den Abrufprozess erneut aufruft, wenn das Feedback negativ ist. Rufen Sie diese Funktion dann in crux.py auf :
def agent_controller_handle_feedback(
feedback,
comments,
openai_api_key,
pinecone_index,
query,
namespace="default"
):
if feedback == "no":
print("Feedback: answer not helpful. Retrying with relaxed retrieval parameters...")
# Relaxed retrieval - increase number of docs and lower score threshold
results = pinecone_search(
pinecone_index,
query,
namespace=namespace,
top_k=5,
score_threshold=0.3
)
if results:
print(f"Found {len(results)} documents after retry.")
context_texts = [r["text"] for r in results]
answer = openai_generate_answer(openai_api_key, query, context_texts)
print("\\nNew answer based on feedback:\\n", answer)
return answer
else:
print("No documents found even after retry. Generating answer without retrieval context...")
answer = openai_generate_answer(openai_api_key, query)
print("\\nAnswer generated without retrieval:\\n", answer)
return answer
else:
print("Thank you for your positive feedback!")
return None
Schlussfolgerung und nächste Schritte
In diesem Artikel haben Sie ein autonomes agentenbasiertes RAG-System aufgebaut, das Bright Data für Web-Scraping, Pinecone als Vektordatenbank und OpenAI für die Texterstellung kombiniert. Dieses System bietet eine Grundlage, die erweitert werden kann, um eine Vielzahl von zusätzlichen Funktionen zu unterstützen, wie z. B.:
- Integration von Vektordatenbanken mit relationalen oder nicht-relationalen Datenbanken
- Erstellen einer Benutzeroberfläche mit Streamlit
- Automatisierter Abruf von Webdaten, um die Schulungsdaten auf dem neuesten Stand zu halten
- Verbesserung der Abfragelogik und der Argumentation von Agenten
Wie gezeigt, hängt die Qualität der Ausgabe des Agentic RAG-Systems stark von der Qualität der Eingabedaten ab. Bright Data spielte eine Schlüsselrolle bei der Bereitstellung zuverlässiger und frischer Webdaten, die für eine effektive Abfrage und Generierung unerlässlich sind.
Ziehen Sie weitere Verbesserungen dieses Arbeitsablaufs und die Verwendung von Bright Data in Ihren zukünftigen Projekten in Betracht, um konsistente, hochwertige Eingabedaten zu erhalten.




