

In diesem Leitfaden erfahren Sie:
- Was Selenium Wire ist
- Warum Sie Selenium Wire für das Web-Scraping verwenden sollten
- Die wichtigsten Funktionen von Selenium Wire
- Ein Anwendungsfall für Web-Scraping mit Selenium Wire und Rotierenden Proxies
- Bright Data-Proxy-Integration mit Selenium Wire
Lassen Sie uns eintauchen!
Was ist Selenium Wire?
Selenium Wireist eine Erweiterung für die Python-Bindings von Selenium, die die Kontrolle über Browser-Anfragen ermöglicht. Konkret können Sie damit sowohl Anfragen als auch Antworten in Echtzeit direkt aus Ihrem Python-Code heraus abfangen und ändern, während Sie Selenium verwenden.
Hinweis: Obwohl die Bibliothek nicht mehr gepflegt wird, basieren mehrere Scraping-Technologien und Skripte weiterhin darauf.
Warum Selenium Wire für das Web-Scraping verwenden?
Selenium ist ein beliebtes Browser-Automatisierungsframework, das beim Web-Scraping verwendet wird, um mit Websites so zu interagieren, wie es normale menschliche Benutzer tun würden. Weitere Informationen finden Sie in unseremSelenium-Web-Scraping-Leitfaden.
Das Problem ist, dass Browser bestimmte Einschränkungen haben, die das Web-Scraping erschweren können. Beispielsweise können Sie keine autorisierten Proxy-URLs festlegen oder Proxys spontan wechseln. Selenium Wire hilft Ihnen, diese Einschränkungen zu überwinden.
Hier sind drei gute Gründe, warum Sie Selenium Wire für das Web-Scraping verwenden sollten:
- Zugriff auf die Netzwerkschicht: Interpretieren, überprüfen und ändern Sie den AJAX-Netzwerk-Traffic für eine erweiterte Datenextraktion.
- Umgehen Sie Antibots:
ChromeDrivergibt eine erhebliche Menge an Informationen preis, die Anti-Bot-Systeme verwenden können, um Sie als Bot zu identifizieren. Selenium Wire wird von Technologien wieundetected-chromedriververwendet, um dies zu vermeiden und die meisten Anti-Bot-Lösungen zu umgehen. - Überwinden Sie die Einschränkungen von Browsern: Moderne Browser verwenden Flags, um das Verhalten beim Start zu konfigurieren, aber diese Einstellungen sind statisch und erfordern einen Neustart, um geändert zu werden. Selenium Wire überwindet diese Einschränkung, indem es dynamische Änderungen unterstützt. Auf diese Weise können Sie Request-Header oder Proxys während derselben Browsersitzung aktualisieren, was ideal für das Web-Scraping ist.
Wichtige Funktionen von Selenium Wire
Jetzt wissen Sie, was Selenium Wire ist und warum Sie es für das Web-Scraping verwenden sollten. Es ist an der Zeit, seine wichtigsten Funktionen zu erkunden!
Zugriff auf Anfragen und Antworten
Selenium Wire kann den HTTP/HTTPS-Traffic des Browsers erfassen und Ihnen Zugriff auf die folgenden Attribute gewähren:
| Attribut | Beschreibung |
|---|---|
driver.requests |
Es meldet die Liste der erfassten Anfragen in chronologischer Reihenfolge. |
driver.last_request |
Gibt die zuletzt erfasste Anfrage zurück (Dies ist effizienter als die Verwendung von driver.requests[-1]) |
driver.wait_for_request(pat, timeout=10) |
Diese Methode wartet – die Zeit wird durch den Parametertimeoutdefiniert – bis sie eine Anfrage sieht, die einem Muster entspricht, das durch den Parameterpatdefiniert ist – dies kann eine Teilzeichenfolge oder einregulärer Ausdruck sein. |
driver.har |
Ein JSON-formatiertesHAR-Archiv der stattgefundenen HTTP-Transaktionen. |
driver.iter_requests() |
Gibt einen Iterator über erfasste Anfragen zurück. |
Im Detail hat ein Selenium Wire Request -Objekt die folgenden Attribute:
| Attribut | Beschreibung |
|---|---|
body |
Die Anfrage des Hauptteils wird als Bytes dargestellt. Wenn die Anfrage keinen Hauptteil hat, ist der Wert von body leer (zum Beispiel: b''). |
cert |
Es enthält Informationen über das SSL-Zertifikat des Servers im Wörterbuchformat (bei Nicht-HTTPS-Anfragen ist es leer). |
date |
Zeigt das Datum und die Uhrzeit an, zu denen die Anfrage gestellt wurde. |
headers |
Es meldet ein Wörterbuch-ähnliches Objekt der Header der Anfrage (beachten Sie, dass in Selenium Wire Header nicht zwischen Groß- und Kleinschreibung unterscheiden und Duplikate zulässig sind). |
host |
Es gibt den Host der Anfrage an (z. B. https://brightdata.com/). |
Methode |
Gibt die HHTP-Methode an (GET, POST usw.). |
params |
Es meldet ein Wörterbuch der Parameter der Anfrage (beachten Sie, dass, wenn ein Parameter mit demselben Namen mehr als einmal in der Anfrage vorkommt, sein Wert im Wörterbuch eine Liste ist). |
Pfad |
Gibt den Pfad der Anfrage zurück. |
querystring |
Es meldet die Abfragezeichenfolge. |
Antwort |
Gibt das mit der Anfrage verbundene Antwortobjekt zurück (beachten Sie, dass der Wert None ist, wenn die Anfrage keine Antwort hat). |
url |
Gibt die vollständige Anfrage-URL mit Host, Pfad und Abfragezeichenfolge zurück. |
ws_messages |
Wenn es sich bei einer Anfrage um einen WebSocket handelt (in diesem Fall lautet die URL in der Regel wss://), enthält ws_messages alle gesendeten und empfangenen WebSocket-Nachrichten. |
Stattdessen gibt ein Response -Objekt folgende Attribute frei:
| Attribut | Beschreibung |
|---|---|
body |
Die Antwort des Hauptteils wird als Bytes dargestellt. Wenn die Antwort keinen Hauptteil hat, ist der Wert von body leer (zum Beispiel: b''). |
date |
Zeigt das Datum und die Uhrzeit an, zu denen die Antwort empfangen wurde. |
Kopf |
Es meldet ein dictionary-ähnliches Objekt der Header der Antwort (beachten Sie, dass in Selenium Wire die Header nicht zwischen Groß- und Kleinschreibung unterscheiden und Duplikate zulässig sind). |
reason |
Es gibt den Grund für die Antwort an, z. B. OK, Nicht gefunden usw. |
status_code |
Es meldet den Status der Antwort, z. B. 200, 404 usw. |
Um diese Funktion zu testen, können Sie ein Python-Skript wie das folgende erstellen:
from seleniumwire import webdriver
# Initialisieren Sie den WebDriver mit Selenium Wire.
driver = webdriver.Chrome()
try:
# Öffnen Sie die Zielwebsite.
driver.get("https://brightdata.com/")
# Greifen Sie auf alle erfassten Anfragen zu und drucken Sie sie aus.
for request in driver.requests:
print(f"URL: {request.url}")
print(f"Method: {request.method}")
print(f"Headers: {request.headers}")
print(f"Response Status Code: {request.response.status_code if request.response else 'No Response'}")
print("-" * 50)
finally:
# Schließen Sie den Browser.
driver.quit()
Der obige Code öffnet die Zielwebsite und erfasst Anfragen mithilfe von driver.requests. Anschließend werden in einer for-Schleife einige Anfrageattribute wie URL, Methode und Header abgefangen.
Hier ist das erwartete Ergebnis:
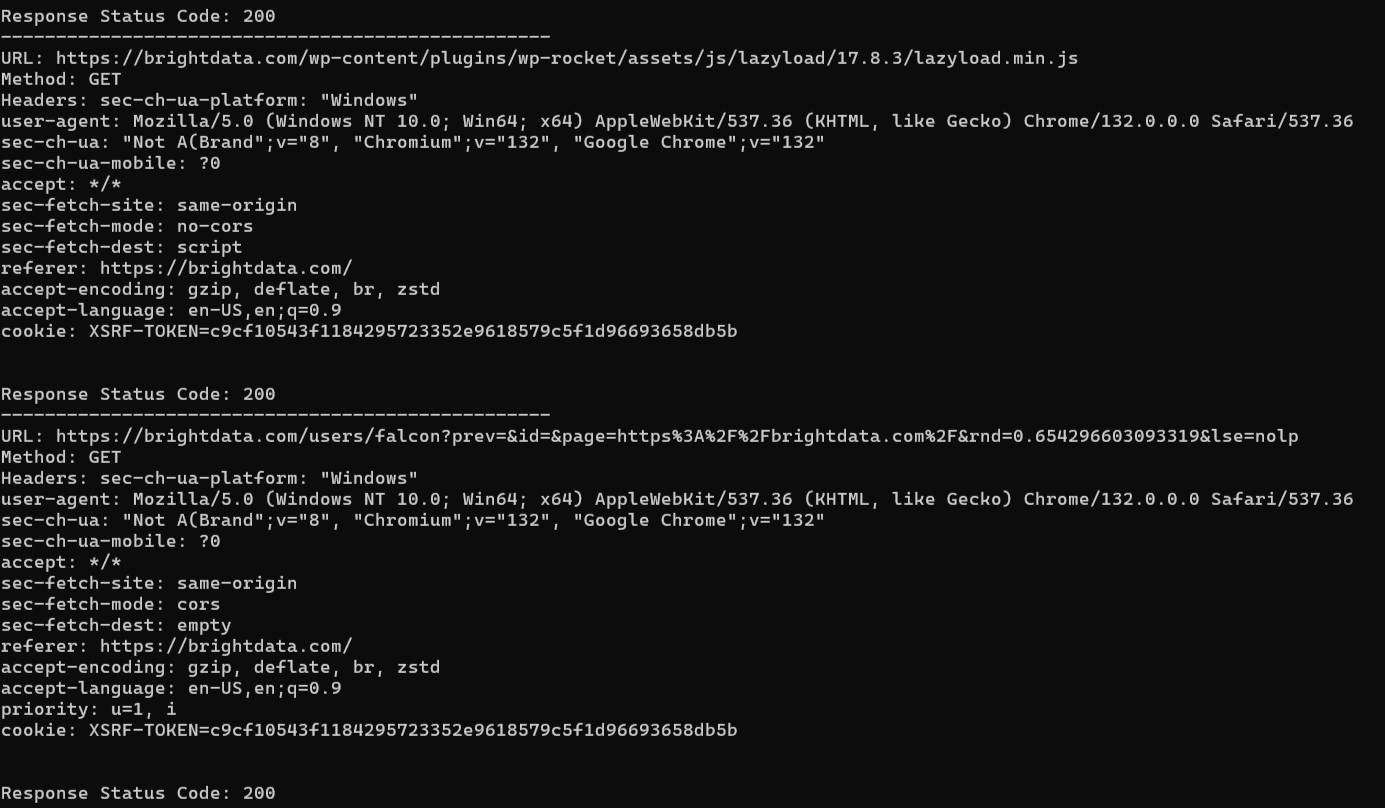
Die Zielseite sendet mehrere Anfragen, und das Skript verfolgt sie alle.
Anfragen und Antworten abfangen
Selenium Wire kann dank Interceptors Anfragen und Antworten abfangen und ändern. Ein Interceptor ist eine Funktion, die mit Anfragen und Antworten aufgerufen wird, wenn diese den Browser passieren.
Es gibt zwei separate Interceptors:
driver.request_interceptor: Er fängt Anfragen ab und akzeptiert ein einzelnes Argument.driver.response_interceptor: Er fängt die Antwort ab und akzeptiert zwei Argumente, eines für die ursprüngliche Anfrage und eines für die Antwort.
Hier ist ein Beispiel, das zeigt, wie ein Anfrage-Interceptor verwendet wird:
from seleniumwire import webdriver
# Definieren Sie die Anfrage-Interceptor-Funktion.
def interceptor(request):
# Fügen Sie allen Anfragen einen benutzerdefinierten Header hinzu.
request.headers["X-Test-Header"] = "MyCustomHeaderValue"
# Anfragen an eine bestimmte Domain blockieren
if "example.com" in request.url:
print(f"Anfrage an {request.url} blockieren")
request.abort() # Anfrage abbrechen
# WebDriver mit Selenium Wire initialisieren
driver = webdriver.Chrome()
# Interceptor-Funktion dem Treiber zuweisen
driver.request_interceptor = interceptor
try:
# Website öffnen, die mehrere Anfragen stellt
driver.get("https://brightdata.com/")
# Alle erfassten Anfragen ausgeben
for request in driver.requests:
print(f"URL: {request.url}")
print(f"Headers: {request.headers}")
print("-" * 50)
finally:
# Browser schließen
driver.quit()
Das macht dieser Ausschnitt:
- Interceptor-Funktion: Es wird eine Interceptor-Funktion erstellt, die bei jeder ausgehenden Anfrage aufgerufen wird. Diese fügt allen ausgehenden Anfragen mit
request.headers[]einen benutzerdefinierten Header hinzu. Außerdem blockiert sie Browseranfragen für die Domainexample.com. - Anfragen erfassen: Nachdem die Seite geladen wurde, werden alle erfassten Anfragen ausgegeben, einschließlich der geänderten Header.
Hinweis: Das Blockieren von Anfragen ist hilfreich, wenn Seiten zusätzliche Ressourcen wie Anzeigen, Analyseskripte oder Widgets von Drittanbietern laden, die für Ihr Ziel irrelevant sind. Das Blockieren dieser Anfragen kann die Scraping-Geschwindigkeit erheblich verbessern und die Bandbreitennutzung des Browsers reduzieren.
Das erwartete Ergebnis sieht in etwa so aus:
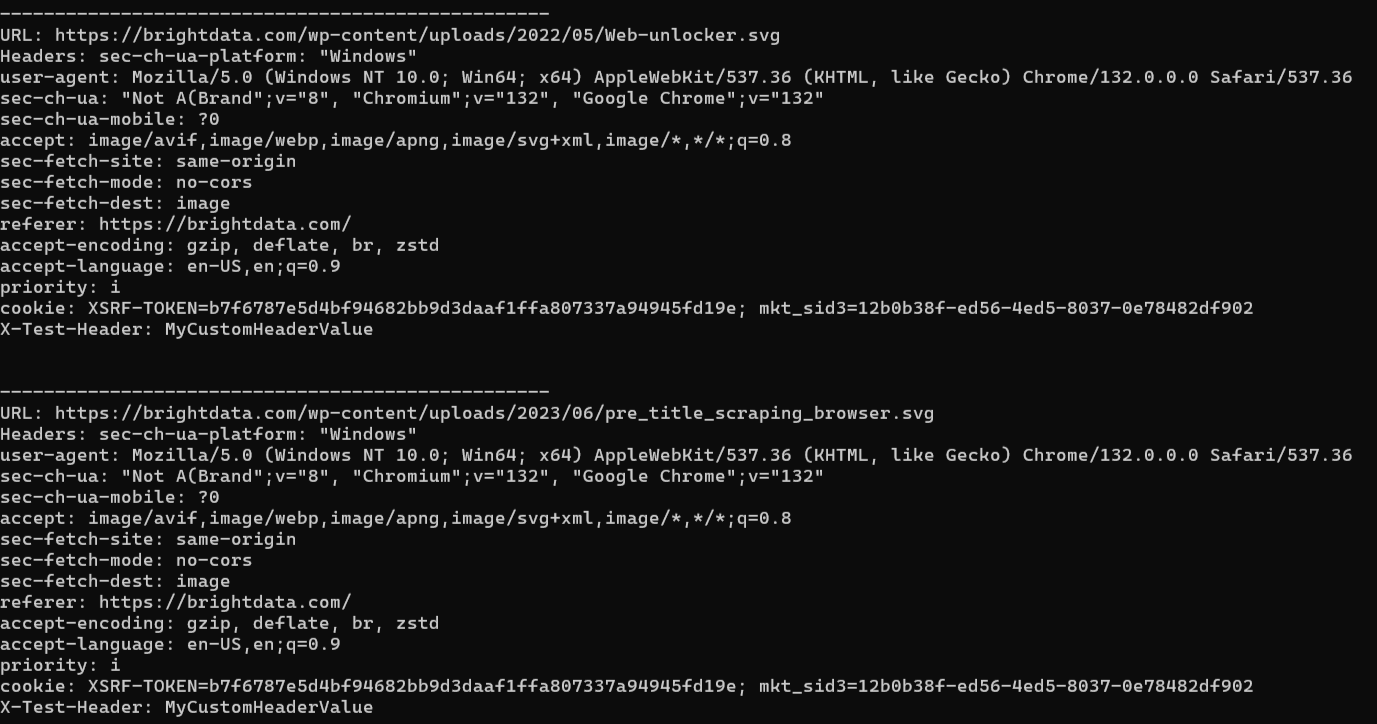
Sehen Sie, wie die vom Browser gestellte Anfrage abgefangen und der zusätzliche Header-Wert hinzugefügt wurde.
WebSocket-Überwachung
Viele moderne Webseiten verwendenWebSocketsfür die Echtzeitkommunikation mit Servern.WebSocketsstellen eine dauerhafte Verbindung zwischen dem Browser und dem Server her. Auf diese Weise können Daten kontinuierlich ausgetauscht werden, ohne den Overhead herkömmlicher HTTP-Anfragen.
Oft fließen kritische Daten über diese Kanäle, und der direkte Zugriff darauf kann für die Datenabfrage von unschätzbarem Wert sein. Durch das Abfangen der WebSocket-Kommunikation können Sie die vom Server gesendeten Rohdaten extrahieren, ohne darauf warten zu müssen, dass der Browser sie umwandelt oder die Seite sie rendert.
Sie haben bereits gelernt, dass Anfrageobjekte über das Attribut ws_messages verfügen, um WebSockets zu verwalten. Dies sind die Attribute eines Selenium Wire WebSocket-Objekts:
| Attribut | Beschreibung |
|---|---|
content |
Es meldet den Inhalt der Nachricht, der entweder ein str oder im Byte-Format sein kann. |
date |
Zeigt das Datum und die Uhrzeit der Nachricht an. |
Kopfzeilen |
Es meldet ein dictionary-ähnliches Objekt der Header der Antwort (beachten Sie, dass in Selenium Wire Header nicht zwischen Groß- und Kleinschreibung unterscheiden und Duplikate zulässig sind). |
from_client |
Dies ist ein boolescher Wert, der „True“ zurückgibt, wenn die Nachricht vom Client gesendet wurde, und „False“, wenn sie vom Server gesendet wurde. |
Proxys verwalten
Proxy-Serverfungieren als Vermittler zwischen Ihrem Gerät und den Zielseiten und maskieren dabei Ihre IP-Adresse. Sie sind für das Web-Scraping unerlässlich, da sie:
- IP-basierte Einschränkungen umgehen
- Blockierungen im Falle von Ratenbegrenzern verhindern
- das Scraping von Inhalten aus geografisch eingeschränkten Websites ermöglichen
Im Folgenden erfahren Sie, wie Sie einen Proxy in Selenium Wire konfigurieren können:
# Selenium Wire-Optionen einrichten
options = {
"proxy": {
"http": "<YOUR_HTTP_PROXY_URL>",
"https": "<YOUR_HTTPS_PROXY_URL>"
}
}
# Initialisieren Sie den WebDriver mit Selenium Wire
driver = webdriver.Chrome(seleniumwire_options=options)
Diese Einrichtung unterscheidet sich von der Konfiguration einesProxys in Vanilla Selenium, wo Sie sich auf das Flag--proxy-servervon Chrome verlassen müssen. Das bedeutet, dass die Proxy-Konfiguration in Vanilla Selenium statisch ist.
Sobald Sie einen Proxy festgelegt haben, gilt dieser für die gesamte Browsersitzung und kann ohne Neustart des Browsers nicht geändert werden. Diese Einschränkung kann besonders in Szenarien, in denen Sie Proxys dynamisch wechseln müssen, hinderlich sein.
Im Gegensatz dazu bietet Selenium Wire die Flexibilität, Proxys innerhalb derselben Browserinstanz dynamisch zu ändern. Dies ist dank des Proxy-Attributs möglich:
# Proxy dynamisch ändern
driver.proxy = {
"http": "<NEW_HTTP_PROXY_URL>",
"https": "<NEW_HTTPS_PROXY_URL>"
}
Außerdem unterstützt das Flag „--proxy-server“ von Chrome keine Proxys mit Authentifizierungsdaten in der URL:
protocol://username:password@host:port
Selenium Wire hingegen unterstützt authentifizierte Proxys vollständig und ist daher die bessere Wahl für das Web-Scraping.
Da die Proxy-Konfiguration einer der wichtigsten Vorteile von Selenium Wire ist, werden wir dieses Thema im nächsten Kapitel weiter vertiefen.
Anwendungsfall für Web-Scraping: Rotierender Proxy in Selenium Wire
Wie bereits erwähnt, ist der Hauptgrund für die Verwendung von Selenium Wire für das Web-Scraping seine fortschrittlichen Proxy-Verwaltungsfunktionen.
In diesem Abschnitt erfahren Sie, wie Sie ein Selenium Wire-Projekt für die Rotation der Proxys einrichten. Auf diese Weise können Sie Ihre Exit-IP bei jeder Anfrage ändern.
Voraussetzungen
Um dieses Tutorial nachzuvollziehen, muss Ihr System die folgenden Voraussetzungen erfüllen:
- Python 3.7 oder höher: Jede Python-Version höher als 3.7 ist geeignet. Konkret werden wir die Abhängigkeiten über pip installieren, das bereits mit jeder Python-Version höher als 3.4 installiert ist.
- Ein unterstützter Webbrowser: Selenium Wire erweitert Selenium, daher benötigen Sie einenunterstützten Browser.
Bevor Sie Selenium Wire installieren, können Sie ein Verzeichnisfür die virtuelle Umgebungwie folgt erstellen:
python -m venv venv
Um es zu aktivieren, führen Sie unter Windows Folgendes aus:
venvScriptsactivate
Unter macOS/Linux führen Sie stattdessen folgenden Befehl aus:
source venv/bin/activate
Jetzt können Sie Selenium Wire mit folgendem Befehl installieren:
pip install selenium-wire
Hinweis: Sie müssen Selenium nicht installieren. Die Installation erfolgt mit Selenium Wire, da es eine seiner Abhängigkeiten ist.
Angenommen, Sie nennen Ihren Hauptordner selenium_wire/. Am Ende dieses Schritts hat der Ordner die folgende Struktur:
selenium_wire/
├── selenium_wire.py
└── venv/
Dabei ist selenium_wire.py die Python-Datei, die alle Logiken enthält, die Sie in den nächsten Schritten implementieren werden.
Schritt 1: Proxys randomisieren
Zunächst benötigen Sie eine Liste gültiger Proxy-URLs. Wenn Sie nicht wissen, wo Sie diese finden können, sehen Sie sich unsere Listekostenloser Proxys an. Fügen Sie sie zu einer Liste hinzu und verwendenSie random.choice(), um ein zufälliges Element daraus auszuwählen:
def get_random_Proxy():
proxies = [
"http://PROXY_1:PORT_NUMBER_X",
"http://PROXY_2:PORT_NUMBER_Y",
"http://PROXY_3:PORT_NUMBER_Z",
# ...
]
# Liste randomisieren
return random.choice(Proxies)
Nach dem Aufruf gibt diese Funktion eine zufällige Proxy-URL aus der Liste zurück.
Damit dies funktioniert, vergessen Sie nicht, random zu importieren:
mport random
Schritt 2: Proxy einrichten
Rufen Sie die Funktion get_random_proxy() auf, um eine Proxy-URL zu erhalten:
Proxy = get_random_Proxy()
Initialisieren Sie dann die Browser-Instanz und legen Sie den ausgewählten Proxy fest:
# Selenium Wire-Konfiguration mit dem Proxy
seleniumwire_options = {
"proxy": {
"http": proxy,
"https": proxy
}
}
# Browserkonfiguration
chrome_options = Options()
chrome_options.add_argument("--headless") # Den Browser im Headless-Modus ausführen
# Eine Browserinstanz mit den angegebenen Konfigurationen initialisieren
driver = webdriver.Chrome(service=Service(), options=chrome_options, seleniumwire_options=seleniumwire_options)
Der obige Ausschnitt erfordert die folgenden Importe:
from seleniumwire import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
Um den Proxy während der Browsersitzung dynamisch zu ändern, würden Sie stattdessen diesen Code verwenden:
driver.proxy = {
"http": Proxy,
"https": Proxy
}
Erstaunlich, die kontrollierte Chrome-Instanz leitet nun Anfragen über den angegebenen Proxy weiter.
Schritt 3: Besuchen Sie die Zielseite
Besuchen Sie die Zielwebsite, extrahieren Sie die Ausgabe und schließen Sie den Browser:
try:
# Besuchen Sie die Zielseite
driver.get("https://httpbin.io/ip")
# Extrahieren Sie die Seitenausgabe
body = driver.find_element(By.TAG_NAME, "body").text
print(body)
except Exception as e:
# Behandeln Sie alle Fehler, die mit dem Browser oder dem Proxy auftreten
print(f"Fehler mit Proxy {proxy}: {e}")
finally:
# Schließen Sie den Browser
driver.quit()
Damit dies funktioniert, importieren Sie By aus Selenium:
from selenium.webdriver.common.by import By
In diesem Beispiel ist die Zielseite der Endpunkt/ipaus dem HTTPBin-Projekt. Dies war eine bewusste Entscheidung, da die Seite die IP-Adresse des Aufrufers zurückgibt. Wenn alles wie erwartet funktioniert, sollte das Skript bei jedem Durchlauf eine andere IP-Adresse aus der Liste der Proxys ausgeben.
Zeit, das zu überprüfen!
Schritt 4: Alles zusammenfügen
Dies ist die gesamte Selenium Wire-Proxy-Rotationslogik, die in Ihrer Datei selenium_wire.py enthalten sein sollte:
import random
from seleniumwire import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
def get_random_proxy():
proxies = [
"http://PROXY_1:PORT_NUMBER_X",
"http://PROXY_2:PORT_NUMBER_Y",
"http://PROXY_3:PORT_NUMBER_Z",
# Fügen Sie hier weitere Proxys hinzu...
]
# Zufällige Auswahl eines Proxys
return random.choice(proxies)
# Auswahl einer zufälligen Proxy-URL
proxy = get_random_proxy()
# Selenium Wire-Konfiguration mit dem Proxy
seleniumwire_options = {
"proxy": {
"http": proxy,
"https": proxy
}
}
# Browserkonfiguration
chrome_options = Options()
chrome_options.add_argument("--headless") # Browser im Headless-Modus ausführen
# Browserinstanz mit den angegebenen Konfigurationen initialisieren
driver = webdriver.Chrome(service=Service(), options=chrome_options, seleniumwire_options=seleniumwire_options)
try:
# Zielseite aufrufen
driver.get("https://httpbin.io/ip")
# Extrahieren der Seitenausgabe
body = driver.find_element(By.TAG_NAME, "body").text
print(body)
except Exception as e:
# Behandeln aller Fehler, die mit dem Browser oder dem Proxy auftreten
print(f"Fehler mit Proxy {proxy}: {e}")
finally:
# Schließen des Browsers
driver.quit()
Um die Datei auszuführen, starten Sie:
python3 selenium_wire.py
Bei jeder Ausführung sollte die Ausgabe wie folgt lauten:
{
"origin": "PROXY_1:XXXX"
}
Oder:
{
"origin": "PROXY_2:YYYY"
}
Und so weiter…
Führen Sie das Skript mehrmals aus, und Sie werden jedes Mal eine andere IP-Adresse sehen. Die Proxy-Rotation funktioniert!
Ein besserer Ansatz für die Proxy-Rotation: Bright Data Proxies
Wie wir gerade gesehen haben, erfordert die manuelle Proxy-Rotation in Selenium Wire viel Boilerplate-Code und die Pflege einer Liste gültiger Proxy-URLs.
Glücklicherweise sinddie rotierenden Proxys von Bright Dataeine effizientere Lösung!
Unsere rotierenden Proxys übernehmen automatisch die Änderung der IP-Adressen, sodass keine manuelle Proxy-Verwaltung mehr erforderlich ist. Mit einer Abdeckung in 195 Ländern garantieren wir eine außergewöhnliche Netzwerkverfügbarkeit und eine Erfolgsquote von 99,9 %. Unser weltweites Proxy-Netzwerk umfasst:
- Datacenter-Proxys– Über 770.000 Rechenzentrums-IPs.
- Residential-Proxys– Über 72 Millionen Residential-IPs in mehr als 195 Ländern.
- ISP-Proxys– Über 700.000 ISP-IPs.
- Mobile-Proxy– Über 7 Millionen mobile IPs.
Befolgen Sie die folgenden Schritte und erfahren Sie, wie Sie die Proxys von Bright Data in Selenium Wire verwenden können.
Wenn Sie bereits ein Konto haben, melden Sie sich bei Bright Data an. Andernfalls erstellen Sie kostenlos ein Konto. Sie erhalten Zugriff auf das folgende Benutzer-Dashboard:
Klicken Sie auf die Schaltfläche „Proxy-Produkte anzeigen“:
Sie werden zur Seite „Proxys & Scraping-Infrastruktur“ weitergeleitet:
Scrollen Sie nach unten, suchen Sie die Karte„Residential-Proxys“und klicken Sie auf die Schaltfläche „Get started“:
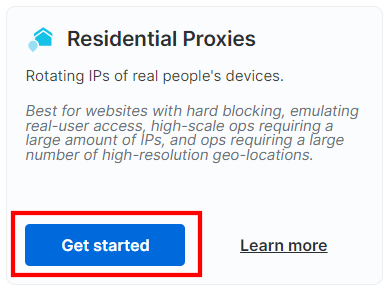
Sie gelangen zum Dashboard für die Konfiguration von Residential-Proxys. Folgen Sie den Anweisungen des Assistenten und richten Sie den Proxy-Dienst entsprechend Ihren Anforderungen ein. Wenn Sie Fragen zur Konfiguration des Proxys haben,wenden Sie sich bittean den 24/7-Support:
Gehen Sie zur Registerkarte „Zugriffsparameter“ und rufen Sie den Host, den Port, den Benutzernamen und das Passwort Ihres Proxys wie folgt ab:
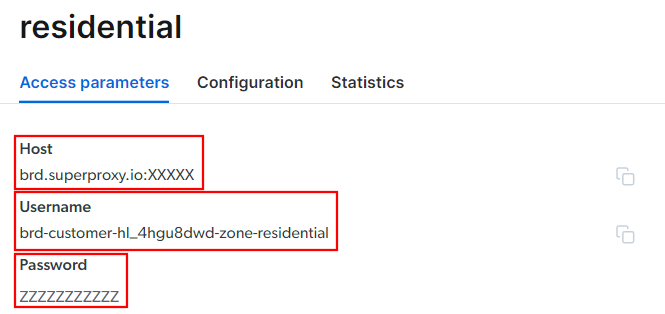
Beachten Sie, dass das Feld „Host“ bereits den Port enthält.
Das ist alles, was Sie benötigen, um die Proxy-URL zu erstellen und in Selenium Wire festzulegen. Fügen Sie alle Informationen zusammen und erstellen Sie eine URL mit der folgenden Syntax:
<Benutzername>:<Passwort>@<Host>
In diesem Fall wäre das beispielsweise:
brd-customer-hl_4hgu8dwd-Zone-residential:[email protected]:XXXXX
Aktivieren Sie „Active proxy“ (Aktiver Proxy), befolgen Sie die letzten Anweisungen, und schon können Sie loslegen!

Ihr Selenium Wire-Proxy-Snippet für die Bright Data-Integration sieht dann wie folgt aus:
# Bright Data-Proxy-URL
proxy = "brd-customer-hl_4hgu8dwd-Zone-residential:[email protected]:XXXXX"
# Selenium Wire-Optionen einrichten
options = {
"proxy": {
"http": proxy,
"https": proxy
}
}
# Initialisieren Sie den WebDriver mit Selenium Wire
driver = webdriver.Chrome(seleniumwire_options=options)
Mit diesem Ansatz ist die Proxy-Rotation viel einfacher!
Selenium vs. Selenium Wire für Web-Scraping
Als Zusammenfassung sehen Sie sich die folgende Übersichtstabelle zu Selenium vs. Selenium Wire an:
| Selenium | Selenium Wire | |
|---|---|---|
| Zweck | Ein Tool zur Automatisierung von Webbrowsern für UI-Tests und Webinteraktionen | Erweitert Selenium um zusätzliche Funktionen zur Überprüfung und Änderung von HTTP/HTTPS-Anfragen und -Antworten |
| HTTP/HTTPS-Anfragen | Bietet keinen direkten Zugriff auf HTTP/HTTPS-Anfragen oder -Antworten | Ermöglicht die Überprüfung, Änderung und Erfassung von HTTP/HTTPS-Anfragen und -Antworten |
| Proxy-Unterstützung | Eingeschränkte Unterstützung für Proxies (manuelle Konfiguration erforderlich) | Erweiterte Proxy-Verwaltung mit Unterstützung für dynamische Einstellungen |
| Leistung | Leichtgewichtig und schnell | Etwas langsamer aufgrund des Overheads für die Erfassung und Verarbeitung des Netzwerktraffics |
| Anwendungsfälle | Wird in erster Linie für Funktionstests von Webanwendungen verwendet, ist aber auch für einfache Web-Scraping-Anwendungen nützlich | Nützlich für das Testen von APIs, das Debuggen von Netzwerk-Traffic und Web-Scraping |
Fazit
In diesem Blogbeitrag haben Sie erfahren, was Selenium Wire ist und wie es für das Web-Scraping verwendet werden kann. Dabei haben wir uns insbesondere auf die Proxy-Integration und Rotierende Proxys konzentriert. Beachten Sie, dass Selenium Wire zwar nützlich ist, aber keine Einheitslösung darstellt. Außerdem wird es nicht mehr aktiv weiterentwickelt.
Der bessere Ansatz besteht nicht darin, Selenium Wire zu erweitern, sondern Vanilla Selenium oder ein anderes Browser-Automatisierungstool zusammen mit einem dedizierten Scraping-Browser zu verwenden.
Der Scraping-Browser von Bright Dataist ein skalierbarer Cloud-Browser, der mit Playwright, Puppeteer, Selenium und anderen zusammenarbeitet. Er rotiert automatisch die Exit-IPs bei jeder Anfrage und kann Browser-Fingerprinting, Wiederholungsversuche,CAPTCHA-Auflösung und vieles mehr verarbeiten. Vergessen Sie Blockierungen und optimieren Sie Ihren Scraping-Vorgang.
Melden Sie sich jetzt an und testen Sie gratis!





