In diesem Leitfaden erfahren Sie:
- Was es bedeutet, eine Website in Markdown zu scrapen und warum dies nützlich ist.
- Die wichtigsten Methoden zur Konvertierung des HTML einer Webseite in Markdown für statische und dynamische Websites.
- Wie man Python verwendet, um eine Webseite in Markdown zu scrapen.
- Die Grenzen dieser Lösung und wie man sie mit Bright Data überwinden kann.
Tauchen wir ein!
Was bedeutet es, eine Website in Markdown zu scrapen”?
Das “Scrapen einer Website in Markdown” bedeutet die Konvertierung des Inhalts in Markdown.
Genauer gesagt geht es darum, den HTML-Code einer Webseite in das Markdown-Datenformat umzuwandeln.
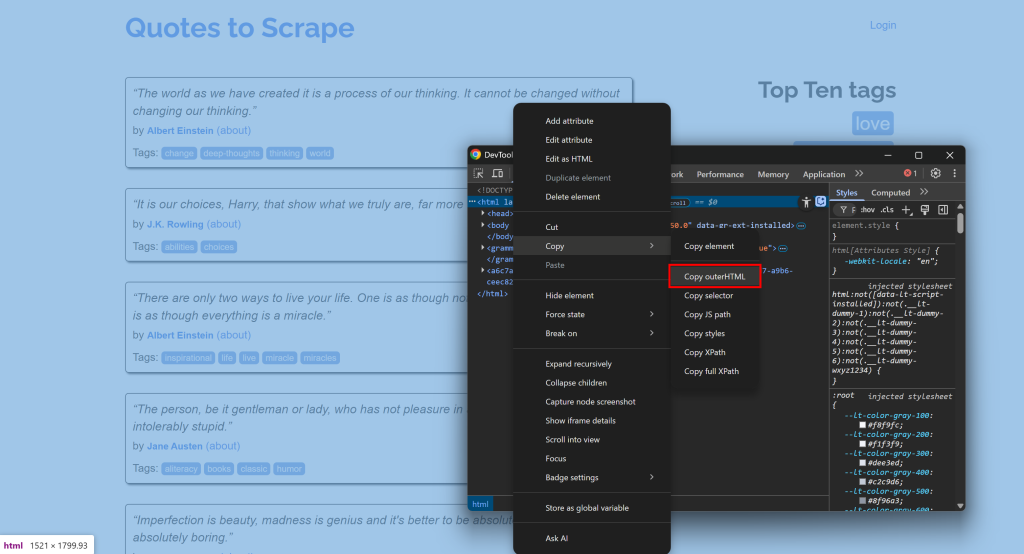
Verbinden Sie sich zum Beispiel mit einer Website, öffnen Sie die DevTools und kopieren Sie den HTML-Code:
Fügen Sie sie dann in einen HTML-zu-Markdown-Konverter ein:
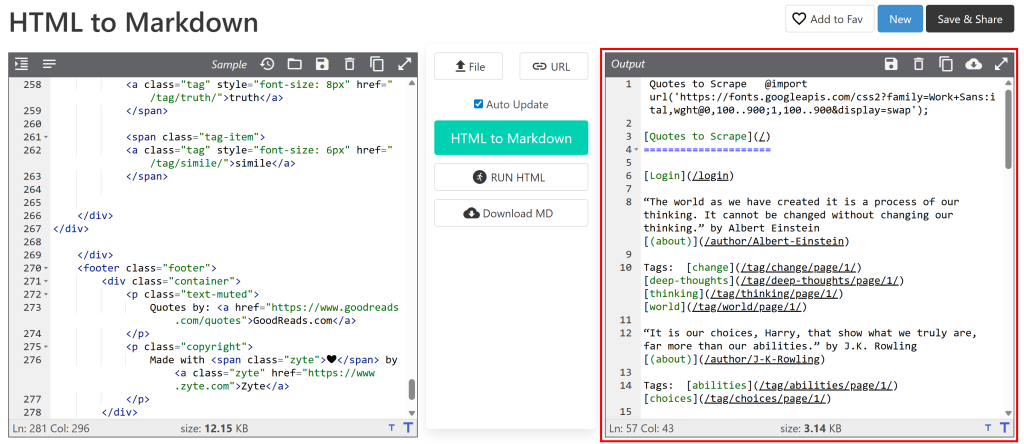
Die Ausgabe sieht dann ähnlich aus wie das Markdown-Dokument, das Sie durch Web-Scraping erhalten möchten. Das Ziel ist es nun, diesen Prozess zu automatisieren, und genau darum geht es in diesem Artikel!
[Extra] Warum Markdown?
Warum Markdown und nicht ein anderes Format (z. B. reiner Text)? Weil, wie unser Datenformat-Benchmark gezeigt hat, Markdown eines der besten Formate für die LLM-Ingestion ist. Die drei wichtigsten Gründe sind:
- Der größte Teil der Struktur und der Informationen einer Seite (z. B. Links, Bilder, Überschriften usw.) bleibt erhalten.
- Sie ist prägnant, was zu einer begrenzten Verwendung von Token und einer schnelleren KI-Verarbeitung führt.
- LLMs neigen dazu, Markdown viel besser zu verstehen als einfaches HTML.
Aus diesem Grund arbeiten die besten KI-Scraping-Tools standardmäßig mit Markdown.
HTML-zu-Markdown-Ansätze
Sie wissen jetzt, dass das Scraping einer Website in Markdown einfach bedeutet, dass der HTML-Code der Seiten in Markdown konvertiert wird. Im Großen und Ganzen sieht der Prozess wie folgt aus:
- Verbinden Sie sich mit der Website.
- Abrufen des HTML als String.
- Verwendung einer HTML-zu-Markdown-Bibliothek, um die Markdown-Ausgabe zu erzeugen.
Die Herausforderung besteht darin, dass nicht alle Webseiten auf die gleiche Weise ausgeliefert werden. Die ersten beiden Schritte können sich erheblich unterscheiden, je nachdem , ob die Zielseite statisch oder dynamisch ist. Lassen Sie uns untersuchen, wie Sie beide Szenarien handhaben können, indem wir die erforderlichen Schritte erweitern!
Schritt #1: Verbindung zu einer Website
Bei einer statischen Webseite ist das vom Server zurückgegebene HTML-Dokument genau das, was Sie im Browser sehen. Mit anderen Worten, alles ist fixiert und in das vom Server erzeugte HTML eingebettet.
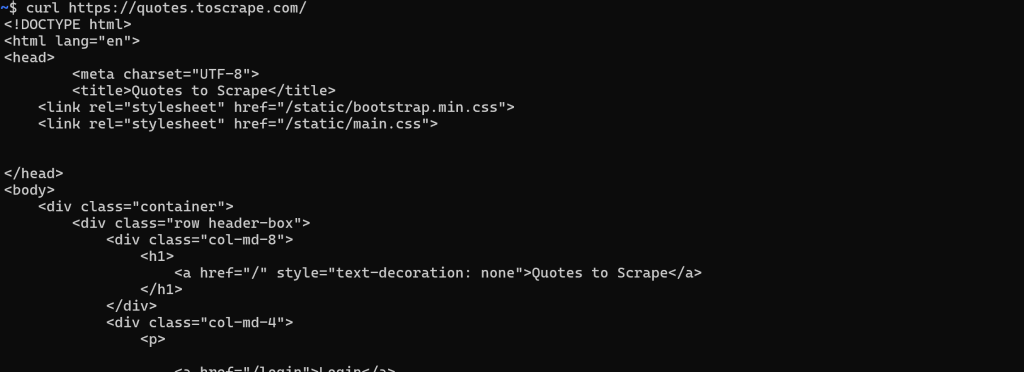
In diesem Fall ist das Abrufen des HTML-Dokuments einfach. Sie müssen nur eine GET-HTTP-Anfrage an die URL der Seite mit einem beliebigen HTTP-Client durchführen:
Im Gegensatz dazu wird bei einer dynamischen Website der Großteil (oder ein Teil) des Inhalts über AJAX abgerufen und im Browser über JavaScript gerendert. Das bedeutet, dass das ursprüngliche HTML-Dokument, das vom Webserver zurückgegeben wird, nur das Nötigste enthält. Erst wenn JavaScript auf der Client-Seite ausgeführt wird, wird die Seite mit dem vollständigen Inhalt gefüllt:

In solchen Fällen können Sie das HTML nicht einfach mit einem einfachen HTTP-Client abrufen. Stattdessen benötigen Sie ein Tool, das die Seite tatsächlich rendern kann, z. B. ein Browser-Automatisierungstool. Lösungen wie Playwright, Puppeteer oder Selenium ermöglichen es Ihnen, einen Browser programmatisch zu steuern, um die Zielseite zu laden und deren vollständig gerenderten HTML-Inhalt zu erhalten.
Schritt Nr. 2: Abrufen des HTML als String
Bei statischen Webseiten ist dieser Schritt sehr einfach. Die Antwort des Webservers auf Ihre GET-Anfrage enthält bereits das vollständige HTML-Dokument als String. Die meisten HTTP-Clients, wie Python’s Requests, bieten eine Methode oder ein Feld, um direkt darauf zuzugreifen:
url = "https://quotes.toscrape.com/"
response = requests.get(url)
# Zugriff auf den HTML-Inhalt der Seite als String
html = antwort.textBei dynamischen Websites sind die Dinge viel komplizierter. In diesem Fall sind Sie nicht an dem vom Server zurückgegebenen HTML-Rohdokument interessiert. Stattdessen müssen Sie warten, bis der Browser die Seite gerendert hat, das DOM sich stabilisiert hat, und dann auf den endgültigen HTML-Inhalt zugreifen.
Dies entspricht dem, was Sie normalerweise manuell tun würden, indem Sie DevTools öffnen und den HTML-Code aus dem <html>-Knoten kopieren:
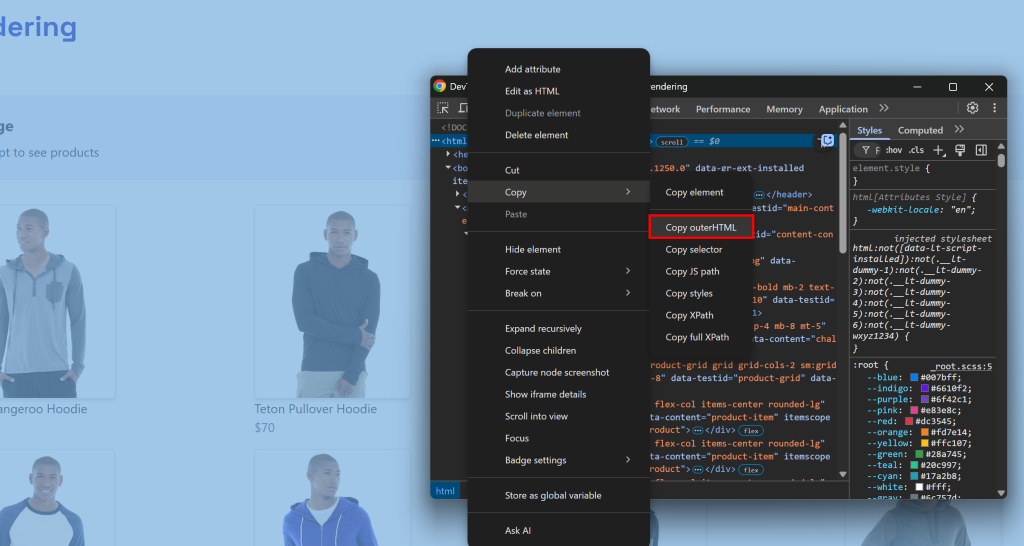
Die Herausforderung besteht darin, zu wissen, wann die Seite fertig gerendert ist. Übliche Strategien sind:
- Warten Sie auf das Ereignis
DOMContentLoaded: Wird ausgelöst, wenn das anfängliche HTML geparst wird und aufgeschobene<script>sgeladen und ausgeführt werden. Das Warten auf dieses Ereignis ist das Standardverhalten von Playwright. - Warten auf das
Load-Ereignis: Wird ausgelöst, wenn die gesamte Seite geladen wurde, einschließlich Stylesheets, Skripte, Iframes und Bilder (mit Ausnahme derjenigen, die nur langsam geladen werden). - Auf das Ereignis
networkidlewarten: Betrachtet das Rendering als abgeschlossen, wenn für eine bestimmte Dauer (z. B.500 msin Playwright) keine Netzwerkanfragen vorliegen. Dies ist nicht zuverlässig für Websites mit live-aktualisiertem Inhalt, da es nie ausgelöst wird. - Warten Sie auf bestimmte Elemente: Verwenden Sie benutzerdefinierte Warte-APIs, die von Browser-Automatisierungs-Frameworks bereitgestellt werden, um zu warten, bis bestimmte Elemente im DOM erscheinen.
Sobald die Seite vollständig gerendert ist, können Sie den HTML-Code mithilfe der vom Browser-Automatisierungstool bereitgestellten spezifischen Methode/Feld extrahieren. Zum Beispiel in Playwright:
html = await page.content()Schritt 3: Verwenden Sie eine HTML-to-Markdown-Bibliothek, um die Markdown-Ausgabe zu generieren
Sobald Sie den HTML-Code als String abgerufen haben, müssen Sie ihn nur noch in eine der vielen verfügbaren HTML-to-Markdown-Bibliotheken einspeisen. Die beliebtesten sind:
| Bibliothek | Programmiersprache | GitHub-Sterne |
|---|---|---|
markdownify |
Python | 1.8k+ |
Umkehrung |
JavaScript/Node.js | 10k+ |
Html2Markdown |
C# | 300+ |
commonmark-java |
Java | 2.5k+ |
html-zu-markdown |
Go | 3k+ |
html-zu-markdown |
PHP | 1.8k+ |
Scraping einer Website in Markdown: Praktische Python-Beispiele
In diesem Abschnitt sehen Sie komplette Python-Snippets zum Scrapen einer Website in Markdown. Die folgenden Skripte implementieren die zuvor erläuterten Schritte. Beachten Sie, dass Sie die Logik leicht in JavaScript oder eine andere Programmiersprache umwandeln können.
Die Eingabe ist die URL einer Webseite, und die Ausgabe ist der entsprechende Markdown-Inhalt!
Statische Seiten
In diesem Beispiel werden wir die folgenden zwei Bibliotheken verwenden:
requests: Um die GET-Anfrage zu stellen und den HTML-Code der Seite als String zu erhalten.markdownify: Um das HTML der Seite in Markdown zu konvertieren.
Installieren Sie beide Bibliotheken mit:
pip install requests markdownifyDie Zielseite wird die statische Seite “Quotes to Scrape” sein. Sie können das Ziel mit folgendem Snippet erreichen:
import requests
von markdownify importieren markdownify als md
# Die URL der zu scrappenden Seite
url = "http://quotes.toscrape.com/"
# Abrufen des HTML-Inhalts mit requests
response = requests.get(url)
# Abrufen des HTML-Inhalts als String
html_content = response.text
# Konvertierung des HTML-Inhalts in Markdown
markdown_content = md(html_content)
# Drucken der Markdown-Ausgabe
print(markdown_content)Optional können Sie den Inhalt in eine .md-Datei exportieren mit:
with open("page.md", "w", encoding="utf-8") as f:
f.write(markdown_content)Das Ergebnis des Skripts wird sein:
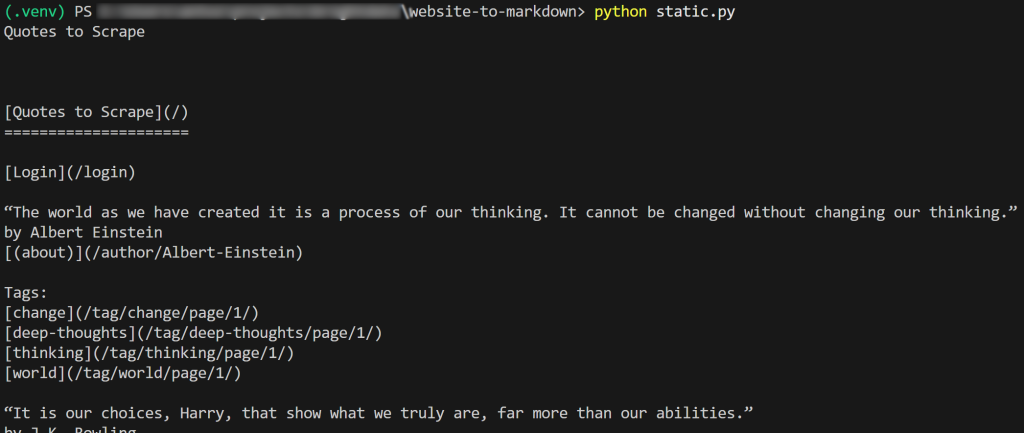
Wenn Sie die Markdown-Ausgabe kopieren und in einen Markdown-Renderer einfügen, sehen Sie das Ergebnis:
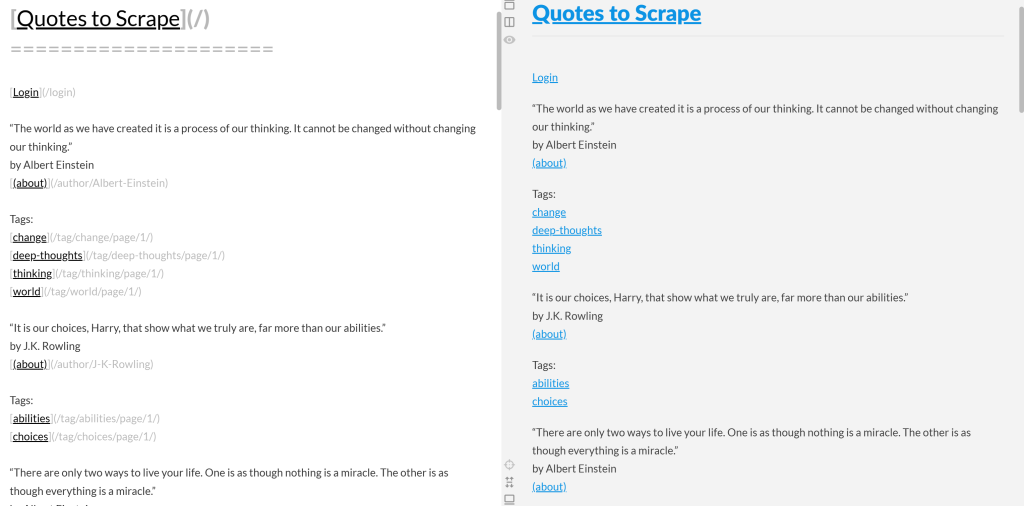
Beachten Sie, dass dies wie eine vereinfachte Version des ursprünglichen Inhalts der Seite “Quotes to Scrape” aussieht:
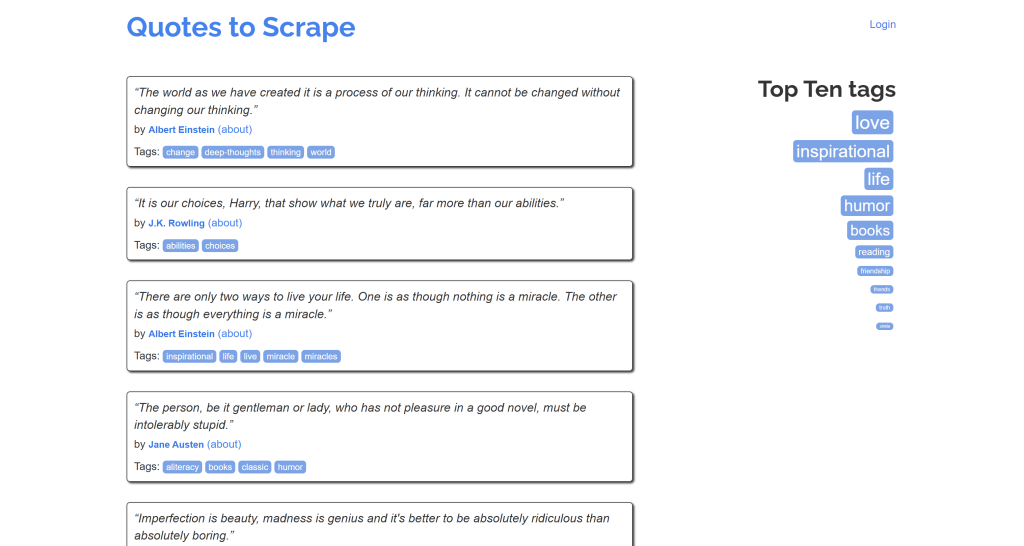
Auftrag erfüllt!
Dynamische Seiten
Hier werden wir diese beiden Bibliotheken verwenden:
playwright: Zum Rendern der Zielseite in einer kontrollierten Browserinstanz.markdownify: Um das gerenderte DOM der Seite in Markdown zu konvertieren.
Installieren Sie die beiden oben genannten Abhängigkeiten mit:
pip install playwright markdownifyVervollständigen Sie dann die Installation von Playwright mit:
python -m playwright installDas Ziel ist die dynamische “JavaScript Rendering“-Seite auf der ScrapingCourse.com-Website:
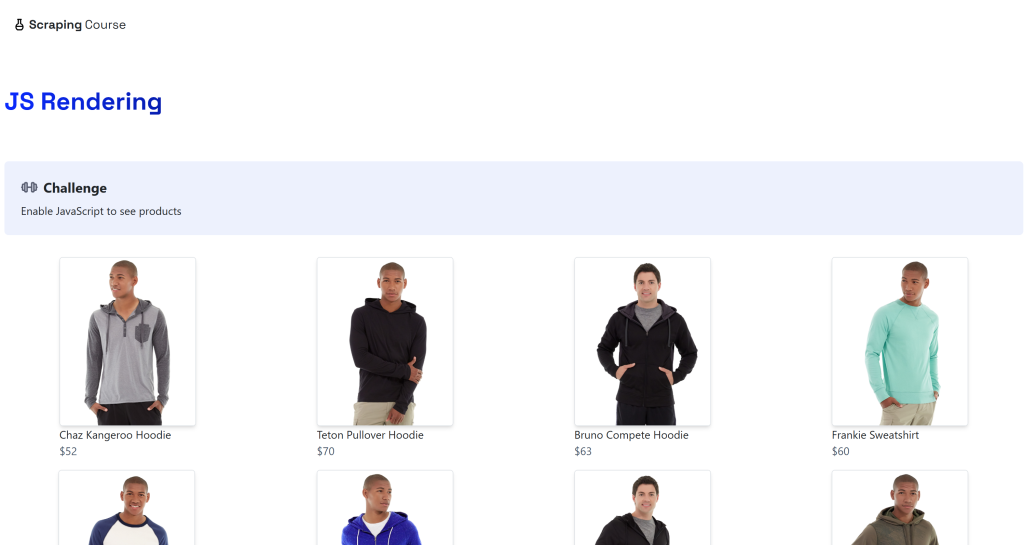
Diese Seite ruft Daten auf der Client-Seite über AJAX ab und rendert sie mit JavaScript:
Scraping einer dynamischen Website in Markdown wie unten:
from playwright.sync_api import sync_playwright
from markdownify import markdownify as md
with sync_playwright() as p:
# Starten eines Headless-Browsers
browser = p.chromium.launch()
Seite = browser.new_page()
# URL der dynamischen Seite
url = "https://scrapingcourse.com/javascript-rendering"
# Zur Seite navigieren
page.goto(url)
# Bis zu 5 Sekunden warten, bis das erste Produktlink-Element ausgefüllt ist
page.locator('.product-link:not([href=""])').first.wait_for(timeout=5000)
# Abrufen des vollständig gerenderten HTML
rendered_html = page.content()
# HTML in Markdown umwandeln
markdown_content = md(rendered_html)
# Drucken des resultierenden Markdown-Inhalts
print(markdown_content)
# Schließen Sie den Browser und geben Sie seine Ressourcen frei.
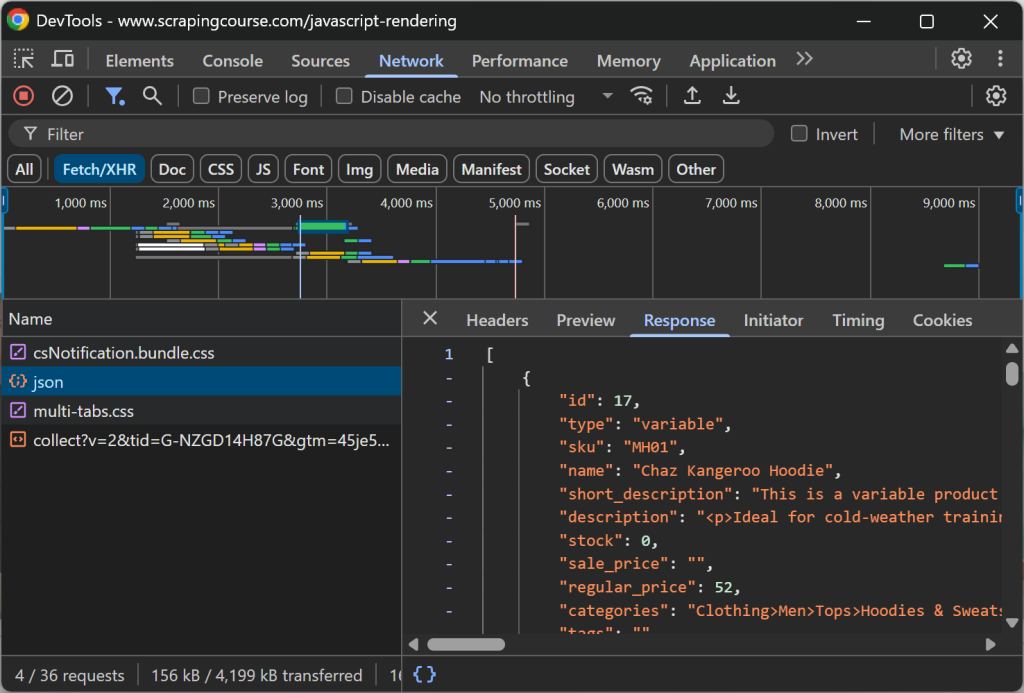
browser.close()Im obigen Schnipsel haben wir uns für Option 4 (“Auf bestimmte Elemente warten”) entschieden, weil sie am zuverlässigsten ist. Schauen Sie sich diese Code-Zeile im Detail an:
page.locator('.product-link:not([href=""])').first.wait_for(timeout=5000)Damit wird bis zu 5000 Millisekunden (5 Sekunden) gewartet, bis das Element .product-link (ein <a>-Tag ) ein nicht leeres href-Attribut hat. Dies reicht aus, um anzuzeigen, dass das erste Produktelement auf der Seite gerendert wurde, was bedeutet, dass die Daten abgerufen wurden und das DOM nun stabil ist.
Das Ergebnis wird sein:
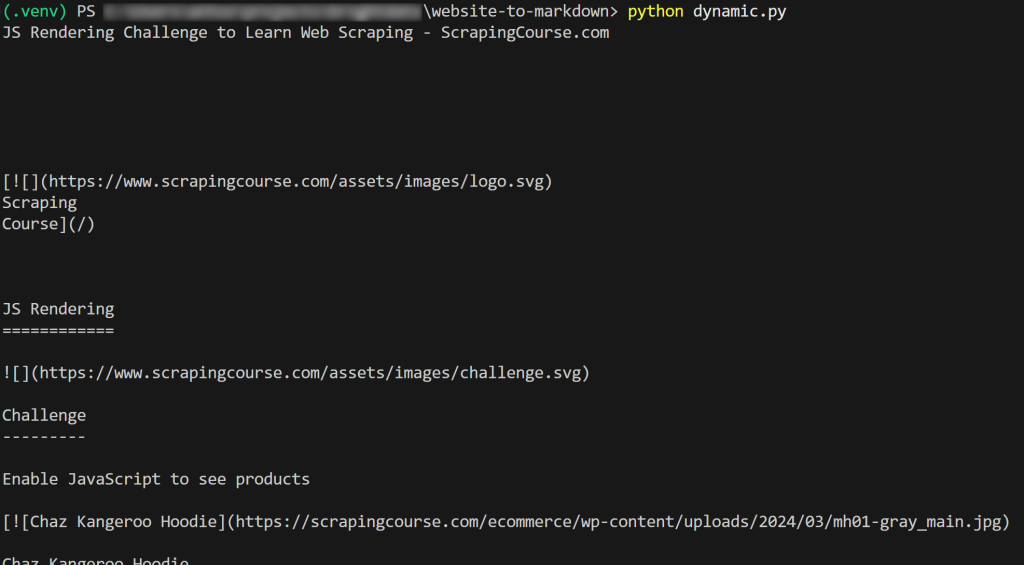
Et voilà! Sie haben soeben gelernt, wie man eine Website in Markdown scrappt.
Beschränkungen dieser Ansätze und die Lösung
Alle Beispiele in diesem Blog-Beitrag haben einen grundlegenden Aspekt gemeinsam: Sie beziehen sich auf Seiten, die so gestaltet wurden, dass sie leicht zu scrapen sind!
Leider sind die meisten realen Webseiten nicht so offen für Web-Scraping-Bots. Ganz im Gegenteil, viele Websites setzen Schutzmaßnahmen gegen Scraping ein , wie CAPTCHAs, IP-Sperren, Browser-Fingerprinting und mehr.
Mit anderen Worten: Sie können nicht erwarten, dass eine einfache HTTP-Anfrage oder eine Playwright goto()-Anweisung wie vorgesehen funktioniert. Bei den meisten realen Websites können Sie auf 403 Forbidden-Fehler stoßen:

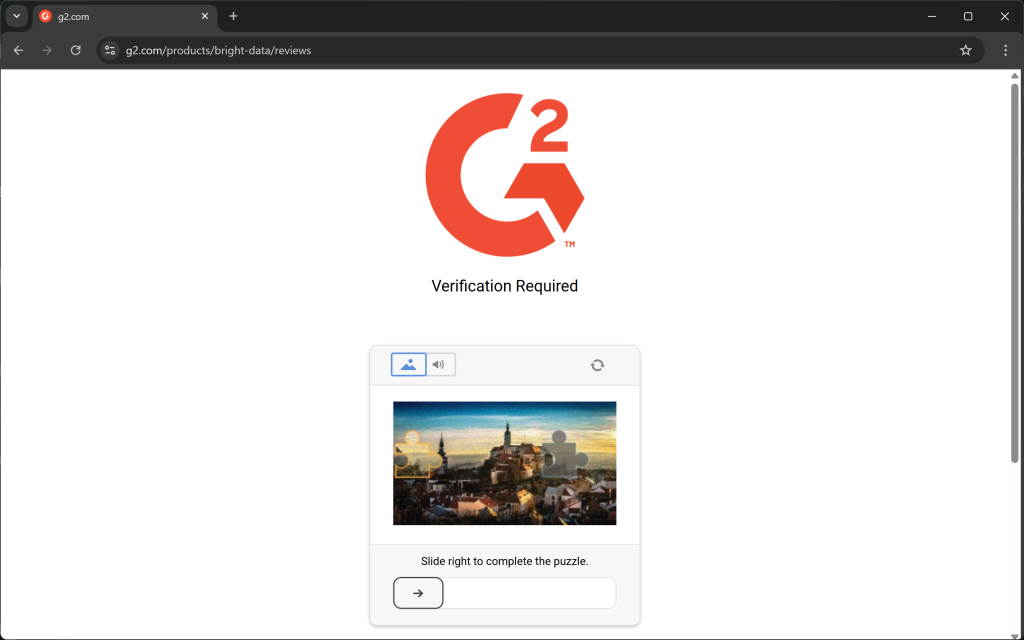
Oder Fehler- bzw. menschliche Überprüfungsseiten:
Ein weiterer wichtiger Aspekt ist, dass die meisten HTML-zu-Markdown-Bibliotheken eine Rohdatenkonvertierung durchführen. Dies kann zu unerwünschten Ergebnissen führen. Wenn eine Seite beispielsweise <style>- oder <script>-Elemente enthält, die direkt in den HTML-Code eingebettet sind, wird deren Inhalt (d. h. CSS- bzw. JavaScript-Code) in die Markdown-Ausgabe aufgenommen:

Dies ist in der Regel unerwünscht, insbesondere wenn Sie die Markdown-Ausgabe zur Datenverarbeitung an einen LLM weiterleiten wollen. Schließlich fügen diese Textelemente nur Rauschen hinzu.
Die Lösung? Verlassen Sie sich auf eine spezielle Web Unlocker API, die auf jede beliebige Website zugreifen kann, unabhängig von ihrem Schutz, und die LLM-geeignete Markdown-Dateien erzeugt. Dadurch wird sichergestellt, dass der extrahierte Inhalt sauber, strukturiert und für nachgelagerte KI-Aufgaben bereit ist.
Scraping zu Markdown mit Web Unlocker
Web Unlocker von Bright Data ist eine Cloud-basierte Web-Scraping API, die den HTML-Code jeder Webseite zurückgeben kann. Dies gilt unabhängig von den vorhandenen Anti-Scraping- oder Anti-Bot-Schutzmaßnahmen und unabhängig davon, ob es sich um eine statische oder dynamische Seite handelt.
Die API wird von einem Proxy-Netzwerk mit über 150 Millionen IPs unterstützt, so dass Sie sich auf Ihre Datenerfassung konzentrieren können, während Bright Data die gesamte Infrastruktur für die Freigabe, das JavaScript-Rendering, die CAPTCHA-Lösung, die Skalierung und die Wartungsupdates übernimmt.
Die Verwendung ist einfach. Stellen Sie eine POST-HTTP-Anfrage an Web Unlocker mit den richtigen Argumenten, und Sie erhalten die vollständig entsperrte Webseite zurück. Sie können die API auch so konfigurieren, dass Inhalte im LLM-optimierten Markdown-Format zurückgegeben werden.
Folgen Sie der Anleitung für die Ersteinrichtung und verwenden Sie dann Web Unlocker, um eine Website mit nur wenigen Zeilen Code in Markdown zu scrapen:
# pip install requests
Anfragen importieren
# Ersetzen Sie diese durch die richtigen Werte aus Ihrem Bright Data-Konto
BRIGHT_DATA_API_KEY= "<IHR_BRIGHT_DATA_API_KEY>"
WEB_UNLOCKER_ZONE = "<IHR_WEB_UNLOCKER_ZONE_NAME>"
# Ersetzen Sie durch Ihre Ziel-URL
url_to_scrape = "https://www.g2.com/products/bright-data/reviews"
# Bereiten Sie die erforderlichen Header vor
headers = {
"Authorization": f "Bearer {BRIGHT_DATA_API_KEY}", # Für die Authentifizierung
"Content-Type": "application/json"
}
# Bereiten Sie die Web Unlocker POST-Nutzdaten vor
payload = {
"url": url_to_scrape,
"zone": WEB_UNLOCKER_ZONE,
"format": "raw",
"data_format": "markdown" # Um die Antwort als Markdown-Inhalt zu erhalten
}
# Stellen Sie eine POST-Anforderung an die Bright Data Web Unlocker API
response = requests.post(
"https://api.brightdata.com/request",
json=payload,
headers=Kopfzeilen
)
# Die Markdown-Antwort abrufen und ausdrucken
markdown_content = response.text
print(markdown_content)Führen Sie das Skript aus und Sie erhalten:
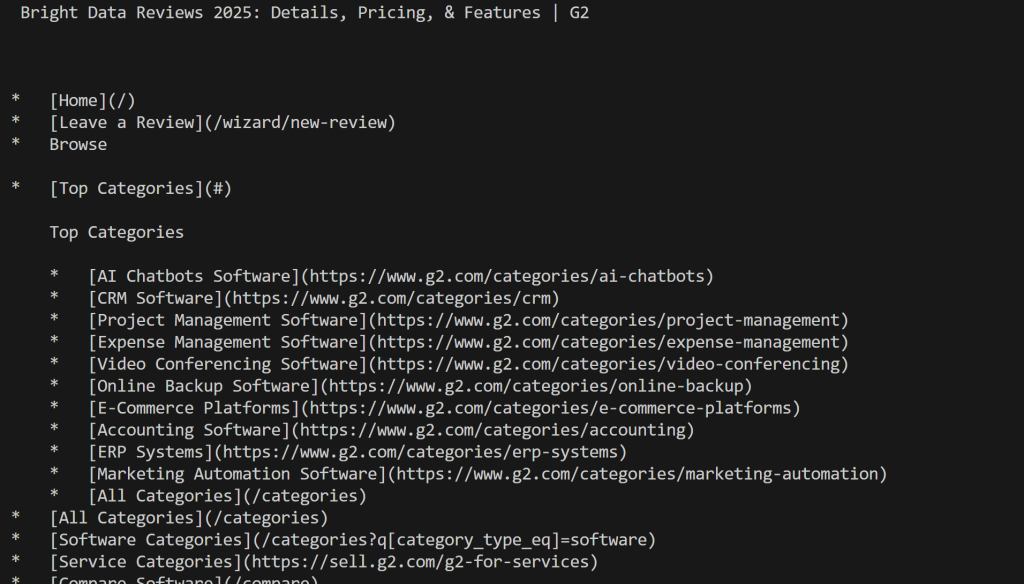
Beachten Sie, dass Sie dieses Mal nicht von G2 blockiert wurden. Stattdessen erhalten Sie den eigentlichen Mardkwon-Inhalt, wie gewünscht.
Perfekt! Die Konvertierung einer Website in Markdown war noch nie so einfach.
Hinweis: Diese Lösung ist über 75+ Integrationen mit KI-Agententools wie CrawlAI, Agno, LlamaIndex und LangChain verfügbar. Außerdem kann sie direkt über das Tool scrape_as_markdown auf dem Bright Data Web MCP-Server verwendet werden.
Schlussfolgerung
In diesem Blogbeitrag haben Sie erfahren, warum und wie Sie eine Webseite in Markdown konvertieren können. Wie bereits erwähnt, ist die Konvertierung von HTML in Markdown aufgrund von Herausforderungen wie Anti-Scraping-Schutz und suboptimalen Markdown-Ergebnissen nicht immer ganz einfach.
Bright Data unterstützt Sie mit Web Unlocker, einer Cloud-basierten Web-Scraping API, die jede beliebige Webseite in LLM-optimiertes Markdown konvertieren kann. Sie können diese API manuell aufrufen oder sie direkt in KI-Lösungen zur Erstellung von Agenten oder über die Web MCP-Integration integrieren.
Denken Sie daran: Web Unlocker ist nur eines von vielen Webdaten- und Scraping-Tools, die in der KI-Infrastruktur von Bright Data zur Verfügung stehen.
Melden Sie sich noch heute für ein kostenloses Bright Data-Konto an und lernen Sie unsere KI-fähigen Webdatenlösungen kennen!