

Python ist weltweit die mit Abstand dominierende Sprache für Web-Scraping. Das war nicht immer so. In den späten 1990er und frühen 2000er Jahren wurde Web-Scraping fast ausschließlich in Perl und PHP durchgeführt.
Heute werden wir Python mit einem der Titanen der Webentwicklung aus der Vergangenheit, PHP, vergleichen. Wir werden einige Unterschiede zwischen den beiden Sprachen durchgehen und sehen, welche die bessere Erfahrung beim Web-Scraping bietet.
Voraussetzungen
Wenn Sie mitmachen möchten, müssen Sie Python und PHP installiert haben. Klicken Sie auf die jeweiligen Download-Links und folgen Sie den Anweisungen für Ihr Betriebssystem.
- Python
- PHP
Sie können die Installation beider Sprachen mit den folgenden Befehlen überprüfen.
Python
python --version
Sie sollten eine Ausgabe wie diese sehen.
Python 3.10.12
PHP
php --version
Hier ist die Ausgabe.
PHP 8.3.14 (cli) (built: Nov 25 2024 18:07:16) (NTS)
Copyright (c) The PHP Group
Zend Engine v4.3.14, Copyright (c) Zend Technologies
with Zend OPcache v8.3.14, Copyright (c), by Zend Technologies
Grundlegende Kenntnisse beider Sprachen wären hilfreich, sind aber keine Voraussetzung. Tatsächlich habe ich bis jetzt noch nie PHP geschrieben!
Vergleich zwischen Python und PHP für Web-Scraping
Bevor wir unser Projekt erstellen, müssen wir uns jede dieser Sprachen etwas genauer ansehen.
- Syntax: Python hat eine besser lesbare Syntax und ist weit verbreitet, insbesondere in der Daten-Community.
- Standardbibliothek: Beide Sprachen bieten umfangreiche Standardbibliotheken.
- Scraping-Frameworks: Python hat eine viel größere Auswahl an Scraping-Frameworks.
- Leistung: PHP bietet in der Regel höhere Geschwindigkeiten, da es für die Ausführung im Web entwickelt wurde.
- Wartung: Python ist aufgrund seiner klaren Syntax und der starken Unterstützung durch die Community in der Regel einfacher zu warten.
| Funktion | Python | PHP |
|---|---|---|
| Benutzerfreundlichkeit | Anfängerfreundlich und leicht zu erlernen | Für neue Entwickler schwieriger |
| Standardbibliothek | Umfangreich und voller Funktionen | Umfangreich und voller Funktionen |
| Scraping-Tools | Viele Scraping-Tools von Drittanbietern | Viel kleineres Ökosystem |
| Datenunterstützung | Auf Datenverarbeitung ausgelegt | Grundlegende Bibliotheken und Tools verfügbar |
| Community | Große Communities und Support | Kleinere Communities mit eingeschränktem Support |
| Wartung | Einfach zu warten, weit verbreitet | Schwierig, Programmierer sind schwer zu finden |
Was soll gescrapt werden?
Da es sich nur um eine Demonstration handelt und wir eine Website wollen, die für Benchmarking konsistent bleibt, verwenden wir quotes.toscrape.com. Diese Website bietet uns konsistente Inhalte und blockiert keine Scraper. Sie ist perfekt für Testfälle geeignet.
In der Abbildung unten sehen Sie eines der Zitat -Elemente auf der Seite. Es handelt sich um ein div-Element mit der Klasse „quote”. Zunächst müssen wir alle diese Elemente finden.
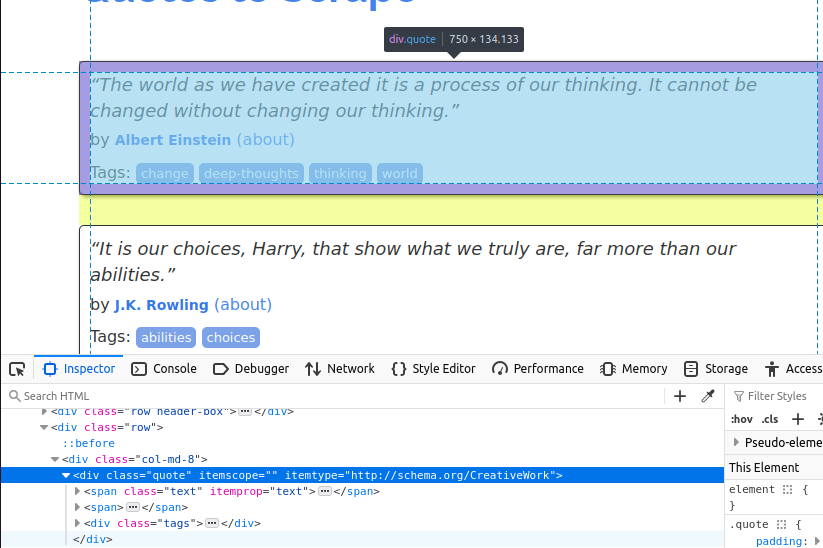
Sobald wir alle Zitat-Karten auf der Seite gefunden haben, müssen wir einzelne Elemente aus jeder Karte extrahieren.
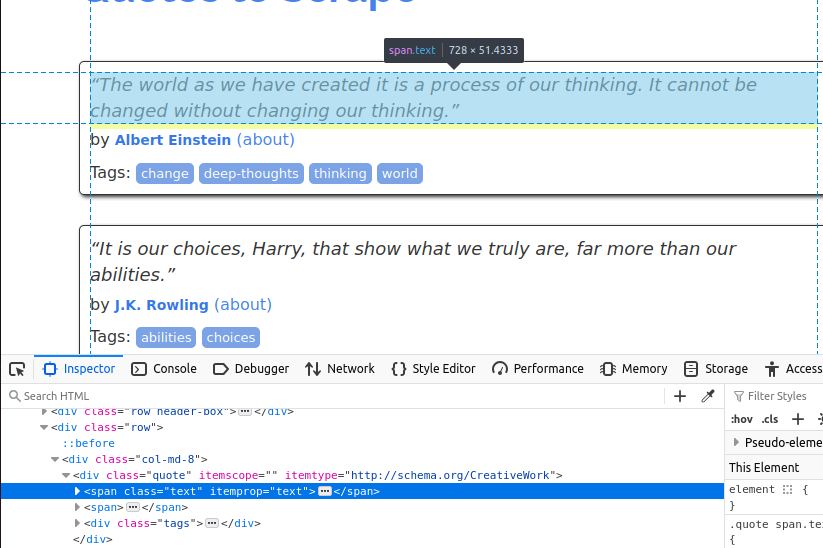
Der Text ist in einem span -Element mit der Klasse „text” eingebettet.
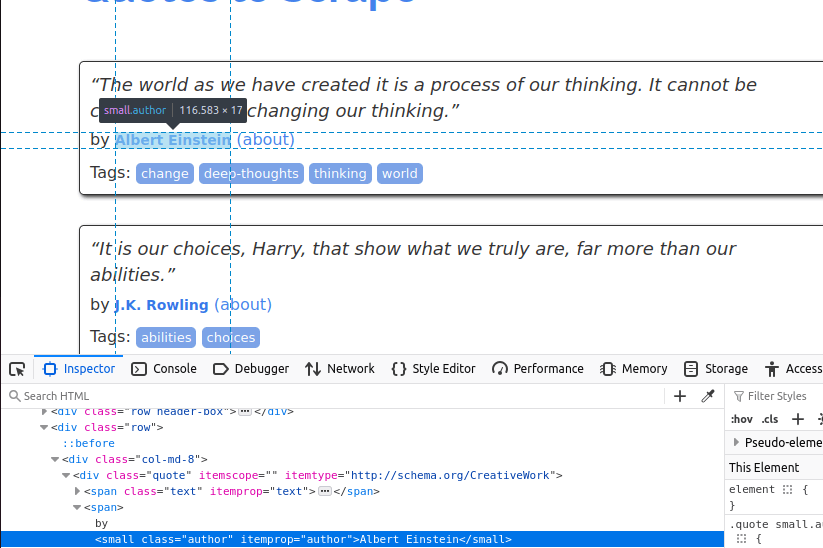
Jetzt müssen wir den Autor ermitteln. Dieser befindet sich in einem kleinen Element mit der Klasse „author”.
Zuletzt extrahieren wir die Tags. Diese befinden sich in einem Element mit der Klasse „tag ”.

Da wir nun wissen, welche Daten wir benötigen, können wir loslegen.
Erste Schritte
Jetzt ist es an der Zeit, alles einzurichten. Wir benötigen einige Abhängigkeiten sowohl für Python als auch für PHP.
Python
Für Python müssen wir Requests und BeautifulSoup installieren.
Beide können wir mit pip installieren.
pip install requests
pip install beautifulsoup4
PHP
Anscheinend sollten alle diese Abhängigkeiten bereits mit PHP vorinstalliert sein. Als ich sie jedoch verwenden wollte, waren sie nicht vorhanden.
sudo apt install php-curl
sudo apt install php-xml
Nachdem wir unsere Abhängigkeiten installiert haben, können wir mit dem Codieren beginnen.
Scraping der Daten
Ich begann damit, den folgenden Scraper in Python zu schreiben. Der folgende Code sendet eine Reihe von Anfragen an quotes.toscrape.com. Er extrahiert den Text, den Namen und den Autor aus jedem Zitat. Sobald alle Zitate abgerufen wurden, schreiben wir sie in eine JSON-Datei. Sie können den Code gerne kopieren und in Ihre eigene Python-Datei einfügen.
Python
import requests
from bs4 import BeautifulSoup
import json
page_number = 1
output_json = []
while page_number <= 5:
response = requests.get(f"https://quotes.toscrape.com/page/{page_number}")
soup = BeautifulSoup(response.text, "html.parser")
divs = soup.select("div[class='quote']")
for div in divs:
tags = []
quote_text = div.select_one("span[class='text']").text
author = div.select_one("small[class='author']").text
tag_holders = div.select("a[class='tag']")
for tag_holder in tag_holders:
tags.append(tag_holder.text)
quote_dict = {
"author": author,
"quote": quote_text.strip(),
"tags": tags
}
output_json.append(quote_dict)
page_number+=1
with open("quotes.json", "w") as file:
json.dump(output_json, file, indent=4)
print("Scraping complete. Quotes saved to quotes.json.")
- Zunächst legen wir Variablen für
page_numberundoutput_jsonfest. Während page_number <= 5den Scraper anweist, seine Arbeit fortzusetzen, bis wir 5 Seiten gescrapt haben.response = requests.get(f"https://quotes.toscrape.com/page/{page_number}")sendet eine Anfrage an die Seite, auf der wir uns befinden.- Wir finden alle unsere Ziel
-Div-Elemente mitdivs = soup.select("div[class='quote']"). - Wir durchlaufen die
divsund extrahieren ihre Daten:quote_text:div.select_one("span[class='text']").textauthor:div.select_one("small[class='author']").texttags: Wir finden alletag_holder-Elementeund extrahieren dann ihren Text einzeln.
- Sobald wir damit fertig sind, speichern wir das
output_json-Array in einer Datei undgebeneine Meldung an das Terminalaus (print()).
Hier sind Screenshots von einigen unserer Durchläufe. Wir haben mehr Durchläufe durchgeführt, aber der Kürze halber verwenden wir hier eine Stichprobengröße von 3 Durchläufen.
Durchlauf 1 dauerte 11,642 Sekunden.

Durchlauf 2 dauerte 11,413 Sekunden.

Durchlauf 3 dauerte 10,258 Sekunden.

Unsere durchschnittliche Laufzeit mit Python beträgt 11,104 Sekunden.
PHP
Nachdem ich den Python-Code geschrieben hatte, bat ich ChatGPT, ihn für mich in PHP umzuschreiben. Zunächst funktionierte der Code nicht, aber nach einigen kleinen Änderungen war er einsatzfähig.
<?php
$pageNumber = 1;
$outputJson = [];
while ($pageNumber <= 5) {
$url = "https://quotes.toscrape.com/page/$pageNumber";
$ch = curl_init($url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
$response = curl_exec($ch);
curl_close($ch);
if ($response === false) {
echo "Fehler beim Abrufen der Seite $pageNumbern";
break;
}
$dom = new DOMDocument();
@$dom->loadHTML($response);
$xpath = new DOMXPath($dom);
$quoteDivs = $xpath->query("//div[@class='quote']");
foreach ($quoteDivs as $div) {
$quoteText = $xpath->query(".//span[@class='text']", $div)->item(0)->textContent ?? "";
$author = $xpath->query(".//small[@class='author']", $div)->item(0)->textContent ?? "";
$tagElements = $xpath->query(".//a[@class='tag']", $div);
$tags = [];
foreach ($tagElements as $tagElement) {
$tags[] = $tagElement->textContent;
}
$outputJson[] = [
"author" => trim($author),
"quote" => trim($quoteText),
"tags" => $tags
];
}
$pageNumber++;
}
$jsonData = json_encode($outputJson, JSON_PRETTY_PRINT | JSON_UNESCAPED_UNICODE);
file_put_contents("quotes.json", $jsonData);
echo "Scraping abgeschlossen. Zitate in quotes.json.n gespeichert";
- Ähnlich wie beim Python-Code beginnen wir mit den Variablen
pageNumberundoutputJson. - Wir verwenden eine
while-Schleife, um die Laufzeit des eigentlichen Scrapings festzuhalten:while ($pageNumber <= 5). $ch = curl_init($url);richtet unsere HTTP-Anfrage ein. Wir verwendencurl_setopt(), um Weiterleitungen zu verfolgen.$response = curl_exec($ch);führt die HTTP-Anfrage aus.$dom = new DOMDocument();richtet ein neuesDOM-Objekt ein, das wir verwenden können. Dies ähnelt der früheren Verwendung vonBeautifulSoup().- Wir erhalten unsere
Divs, indem wir ihren Xpath anstelle ihres CSS-Selektors verwenden:$quoteDivs = $xpath->query("//div[@class='quote']"); $quoteText = $xpath->query(".//span[@class='text']", $div)->item(0)->textContent ?? "";liefert den Text aus jedem Zitat.$author = $xpath->query(".//small[@class='author']", $div)->item(0)->textContent ?? "";gibt uns den Autor.- Wir erhalten unsere
Tags, indem wir erneut alle Tag-Elemente suchen und sie mit einer Schleife durchlaufen, um ihren Text zu extrahieren. - Schließlich speichern wir unsere Ausgabe in einer JSON-Datei und geben eine Meldung auf dem Bildschirm aus.
Hier sind unsere Ausführungsergebnisse mit PHP.
Lauf 1 dauerte 11,351 Sekunden.

Lauf 2 dauerte 9,846 Sekunden.

Durchlauf 3 dauerte 9,795 Sekunden.

Unser PHP-Durchschnitt lag bei 10,33 Sekunden.
Bei weiteren Tests lieferte PHP weiterhin schnellere Ergebnisse … manchmal sogar nur 7 Sekunden!
Erwägen Sie die Verwendung von Bright Data
Wenn Ihnen die obigen Abschnitte gefallen haben, schreiben Sie Web-Scraper! Wenn Sie Ihren Lebensunterhalt mit dem Extrahieren von Daten verdienen, sind Dinge wie die oben genannten genau die Art von Code, die Sie ständig schreiben werden!
Wir bieten eine Vielzahl von Produkten, mit denen Sie Ihre Scraper robuster machen können.Der Scraping-Browserbietet Ihnen einen Remote-Browser mit integrierter Proxy-Integration und JavaScript-Rendering. Wenn Sie nur Proxys und CAPTCHA-Lösungen ohne Browser wünschen, verwenden SieWeb Unlocker.
Scraper sind nicht für jeden geeignet.
Wenn Sie nur Ihre Daten abrufen und mit Ihrem Tag weitermachen möchten, schauen Sie sich unsere Datensätze an.Wir übernehmen das Scraping, damit Sie es nicht tun müssen.Schauen Sie sich unseregebrauchsfertigen Datensätze an. Unsere beliebtesten Datensätze sind LinkedIn, Amazon, Crunchbase, Zillow und Glassdoor. Sie können sich kostenlos Beispieldaten ansehen und Berichte im CSV- oder JSON-Format herunterladen.
Fazit
Mit einer durchschnittlichen Geschwindigkeit von 11,104 Sekunden in Python und 10,33 Sekunden in PHP war unser PHP-Scraper durchweg schneller als der Python-Scraper. Ein Teil davon könnte auf die Latenz des Servers zurückzuführen sein, aber in weiteren Tests schlug PHP Python weiterhin bei fast jedem einzelnen Durchlauf.
Während es Python in puncto Geschwindigkeit definitiv übertrifft, gilt dies nicht unbedingt für die Syntax. Nicht viele Entwickler fühlen sich heute mit der Syntax von Sprachen wie PHP oder Perl wohl. Es handelt sich dabei um Skriptsprachen von gestern. Hinzu kommt, dass Ihr Team möglicherweise nicht mit PHP vertraut ist. Es erfordert einen besonderen Programmierer, um diese Art von Code ständig zu schreiben und Legacy-Anwendungen am Laufen zu halten.
Bringen Sie Ihre Scrape-Ops mit Bright Data auf die nächste Stufe. Melden Sie sich jetzt an und testen Sie gratis!





