
In diesem Leitfaden erfahren Sie:
- Was Puppeteer Real Browser ist
- Wie es funktioniert, um Bot-Erkennung zu vermeiden und eine CAPTCHA-Lösung durchzuführen
- Wie es im Vergleich zu Vanilla Puppeteer abschneidet
- Wie man ihn gegen reale Bot-Erkennungssysteme einsetzt
- Die wichtigsten Alternativen
- Seine wichtigsten Einschränkungen
- Ein besserer Ansatz für die Anti-Bot-Browser-Automatisierung
Lassen Sie uns eintauchen!
Was ist Puppeteer Real Browser?
Puppeteer Real Browser ist eine JavaScript-Bibliothek, die den von Puppeteer gesteuerten Browser dazu bringt, sich eher wie ein echter Benutzer zu verhalten. Dadurch wird die Bot-Erkennung bei WAF-Diensten wie Cloudflare und ähnlichen Diensten reduziert. Außerdem unterstützt es die automatische CAPTCHA-Lösung, einschließlich Cloudflare Turnstile.
Die Bibliothek erweitert Puppeteer um benutzerdefinierte Konfigurationen und unterstützt gleichzeitig Proxys und alle anderen Funktionen von Vanilla Puppeteer. Sie ist Open Source – mit über 1.000 Sternen auf GitHub, ist auf npm als puppeteer-real-browser verfügbar und unterstützt Docker für die Bereitstellung.
Hinweis: Im Februar 2026 gab der Autor der Bibliothek, mdervisaygan, bekannt, dass das Projekt keine Updates mehr erhalten würde. Das bedeutet nicht, dass Puppeteer Real Browser zwangsläufig tot ist, da Community-Mitglieder die Entwicklung durch einen Fork fortsetzen können.
Wie funktioniert Puppeteer Real Browser?
Wenn Sie schon einmal mit Browser-Automatisierungstools wie Puppeteer, Playwright oder Selenium gearbeitet haben, wissen Sie, dass die von diesen Tools gesteuerten Browser von Anti-Bot-Systemen erkannt werden können. Dies gilt insbesondere für den Betrieb im Headless-Modus – selbst bei Verwendung der besten Headless-Browser.
Blockierungen treten auf, weil Automatisierungsbibliotheken Browser so konfigurieren, dass sie leichter zu steuern sind. Anti-Bot-Lösungen suchen nach diesen Konfigurationen und „Lecks“, um festzustellen, ob Anfragen von einem echten Menschen mit einem normalen Browser oder von einem automatisierten Bot stammen.
Puppeteer Real Browser behebt dieses Problem mit Rebrowser, einer Sammlung von Patches für Puppeteer und Playwright, die entwickelt wurden, um die Erkennung von Automatisierung zu verhindern.
Rebrowser modifiziert puppeteer-core direkt und patcht die Browser-Laufzeitumgebung, um botähnliche Spuren zu entfernen, die Puppeteer hinterlässt. Durch diese Änderungen sieht der Browser eher wie eine echte Benutzersitzung aus, wodurch die Wahrscheinlichkeit einer Blockierung durch Anti-Bot-Systeme verringert wird.
WAFs wie Cloudflare können jedoch weiterhin Ein-Klick-CAPTCHAs anzeigen:
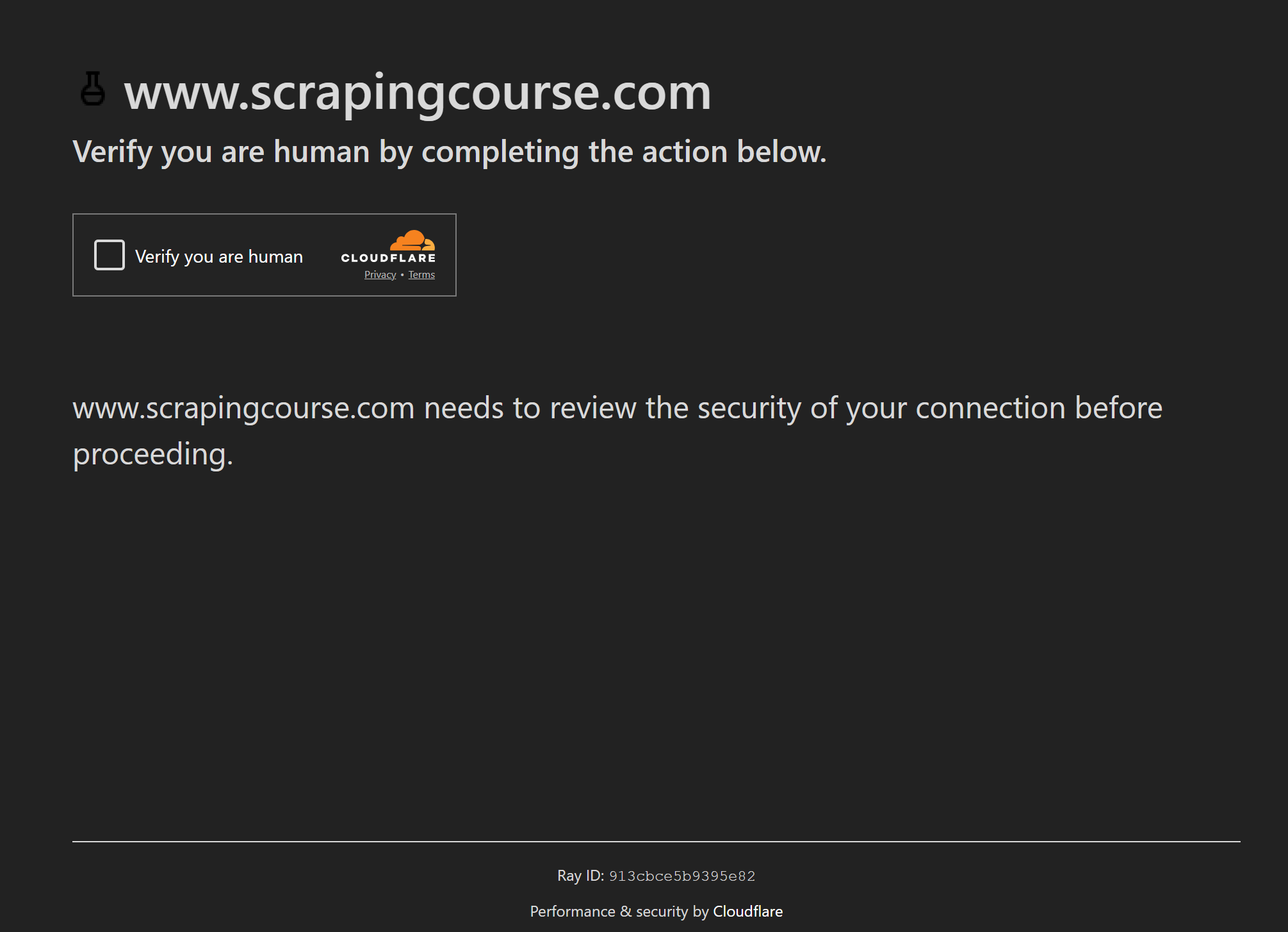
In diesem Fall nutzt Puppeteer Real Browser Ghost-Cursor, um mit CAPTCHAs zu interagieren, genau wie es ein echter Benutzer tun würde. Dabei handelt es sich um eine JavaScript-Bibliothek, die in Puppeteer oder jeder anderen 2D-Ebene menschenähnliche Mausbewegungen generiert.
Das Problem ist, dass Puppeteer-Mausereignisse aufgrund des unnatürlichen Cursorverhaltens oft als synthetisch erkannt werden. Puppeteer Real Browser behebt dieses Problem, indem es die Verarbeitung der Werte .screenX und .screenY verbessert, sodass die Mausbewegungen natürlicher erscheinen. Dies hilft dabei, Cloudflare Turnstile, reCAPTCHA und andere Ein-Klick-CAPTCHAs zu täuschen, sodass sie glauben, die Interaktion stamme von einem echten menschlichen Benutzer.
Die Bibliothek enthält außerdem:
- Puppeteer Extra: Zur Aktivierung von Erweiterungen über Plugins
- Xvfb: Zur Verarbeitung virtueller Browser-Anzeigen, ideal für Headless-Umgebungen.
Kurz gesagt, Puppeteer Real Browser kombiniert verschiedene Verbesserungen, um ein unauffälliges, hochpräzises Automatisierungstool zu schaffen, das menschliche Benutzer nachahmt und gleichzeitig eine Erkennung verhindert.
Puppeteer Real Browser vs. Puppeteer
Nachfolgend finden Sie eine Übersichtstabelle zum Vergleich der beiden Technologien Puppeteer und Puppeteer-Real-Browser:
| Puppeteer | Puppeteer Real Browser | |
|---|---|---|
| GitHub-Sterne | 1.000 Sterne | 89,7k Sterne |
| npm-Bibliothek | puppeteer |
puppeteer-real-browser |
| npm-Downloads | ~3,6 Millionen wöchentliche Downloads | ~10.000 wöchentliche Downloads |
puppeteer-core -Version |
Standard puppeteer-core |
Rebrowser-Puppeteer-Core gepatcht, um Automatisierungsspuren zu entfernen |
| Anti-Bot-Erkennung | Leicht zu erkennen durch fortschrittlichen Bot-Schutz | Entwickelt, um Bot-Erkennungssysteme (Cloudflare, Akamai usw.) zu umgehen |
| API | Standard | Gleiche Puppeteer-API mit zusätzlichen Erweiterungen |
| Proxy-Unterstützung | Unterstützt Proxys | Unterstützt Proxys |
| CAPTCHA-Verarbeitung | Keine integrierte CAPTCHA-Lösung | Unterstützt CAPTCHA-Lösung mit einem Klick (z. B. Cloudflare Turnstile, reCAPTCHA) |
| Plugin-Unterstützung | Keine native Plugin-Unterstützung | Integriert mit puppeteer-extra für Plugin-Unterstützung |
| Wartung und Updates | Wird aktiv von Google gewartet | Vom Autor eingestellt (Februar 2026), wird aber möglicherweise von der Community weitergeführt |
So verwenden Sie Puppeteer Real Browser, um CAPTCHAs zu umgehen
Um die Fähigkeiten von Puppeteer Real Browser zu demonstrieren, testen wir es anhand der Anti-Bot-Challenge-Seite von Scraping Course:
Diese durch Cloudflare geschützte Seite verfügt über ein Turnstile-Ein-Klick-CAPTCHA. In diesem Schritt-für-Schritt-Abschnitt zeigen wir Ihnen, wie Sie es mit Puppeteer Real Browser lösen können.
Eine alternative Vorgehensweise finden Sie in unserem Leitfaden zum Umgehen von CAPTCHAs in Puppeteer. Wichtig zu wissen ist, dass ein Standard-Puppeteer-Skript, das versucht, auf diese Seite zuzugreifen, immer auf das Turnstile-CAPTCHA stößt und blockiert wird.
Wie Sie gleich sehen werden, ist Puppeteer Real Browser eine effektive Lösung, um Cloudflare und ähnliche Anti-Bot-Schutzmaßnahmen zu umgehen!
Schritt 1: Installieren Sie puppeteer-real-browser
Wir gehen davon aus, dass Sie bereits ein Node.js-Projekt eingerichtet haben. Falls nicht, können Sie eines mit npm init erstellen.
Navigieren Sie nun zu Ihrem Projektordner und installieren Sie puppeteer-real-browser mit:
npm install puppeteer-real-browserUnter Linux müssen Sie außerdem xvfb als systemweite Abhängigkeit installieren. Für Debian-basierte Systeme installieren Sie es mit:
sudo apt-get install xvfbGroßartig! Sie können nun Puppeteer Real Browser verwenden, um CAPTCHAs zu umgehen.
Schritt 2: Ersteinrichtung
Importieren Sie in Ihrem JavaScript-Skript connect aus Puppeteer Real Browser:
const { connect } = require("puppeteer-real-browser");Mit der Funktion connect() können Sie innerhalb einer asynchronen Funktion eine Verbindung zur modifizierten Browser-Engine herstellen:
(async () => {
const { browser, page } = await connect({
headless: false,
turnstile: true,
});
// Scraping-Logik...
await browser.close();
})();Genau wie in Vanilla Puppeteer müssen Sie browser.close() aufrufen, um Ressourcen freizugeben.
Die Funktion connect() in Puppeteer Real Browser akzeptiert die folgenden Parameter:
headless: Der Standardwert istfalse. Andere Werte wie„new”,trueund„shell”können verwendet werden, aberfalseist am stabilsten.args: Zusätzliche Chromium-Flags können als String-Array übergeben werden. Siehe unterstützte Flags.customConfig: Puppeteer Real Browser wird mitchrome-launcherinitialisiert. Alle Optionen, die Sie hier übergeben, werden als direkte Initialisierungsargumente hinzugefügt. Sie können dies verwenden, umuserDataDiroder einen benutzerdefinierten Chrome-Pfad (chromePath) festzulegen.turnstile: Wenn„true“, klickt Puppeteer Real Browser automatisch auf Cloudflare Turnstile CAPTCHAs.connectOption: Optionen, die beim Herstellen einer Verbindung zu Chromium mitpuppeteer.connect()gesendet werden.disableXvfb: Unter Linux wird beiheadless: falseein virtuelles Display (xvfb) zum Ausführen des Browsers verwendet. Setzen Sie diesen Wert auf„true“, um diese Funktion zu deaktivieren und das tatsächliche Browserfenster anzuzeigen.ignoreAllFlags: Wenntrue, werden alle Standard-Initialisierungsargumente überschrieben, einschließlich der Seite „Let’s get started“, die beim ersten Laden angezeigt wird.plugins: Ein Array von Puppeteer Extra-Plugins. Weitere Informationen finden Sie in der offiziellen Dokumentation.
Alle anderen von der oben genannten Funktion unterstützten Optionen stammen aus der Puppeteer-Methode connect().
Da wir Cloudflare umgehen möchten, ist die wichtigste Einstellung in diesem Beispiel „turnstile ” auf „true”.
Schritt 3: Verbindung zur Zielseite herstellen
Verwenden Sie die Funktion goto() aus der Puppeteer-API, um zur Zielseite zu navigieren:
await page.goto("https://www.scrapingcourse.com/antibot-challenge");Da turnstile auf true gesetzt ist, wartet Puppeteer Real Browser automatisch darauf, dass das Cloudflare Turnstile CAPTCHA geladen wird, und versucht, es zu lösen.
Schritt 4: Auf die CAPTCHA-Lösung warten
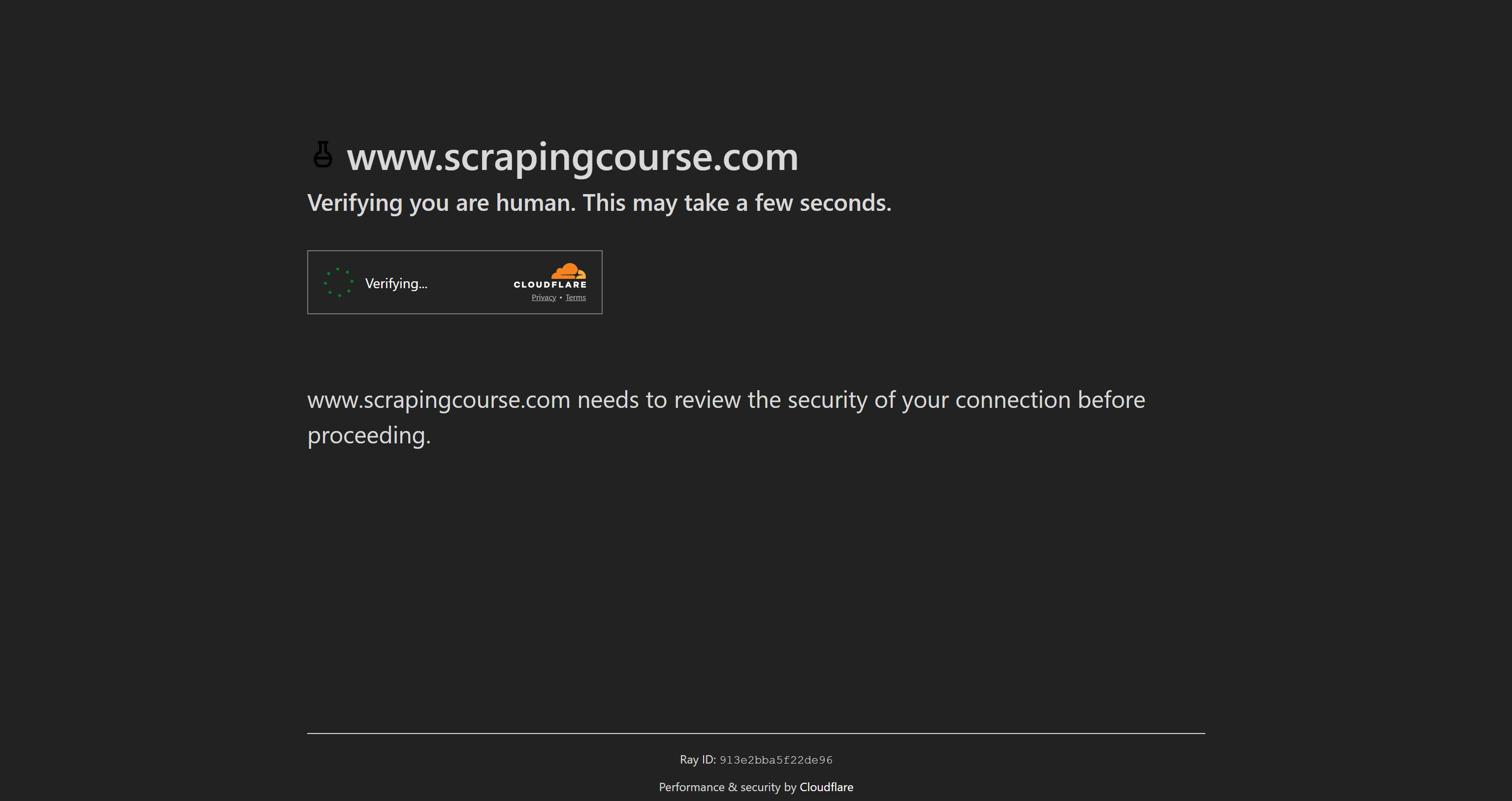
Wenn Sie die Zielseite im Inkognito-Modus öffnen und die CAPTCHA-Lösung manuell durchführen, erhalten Sie das folgende Ergebnis:

Untersuchen Sie die Meldung mit DevTools, und Sie sehen Folgendes:
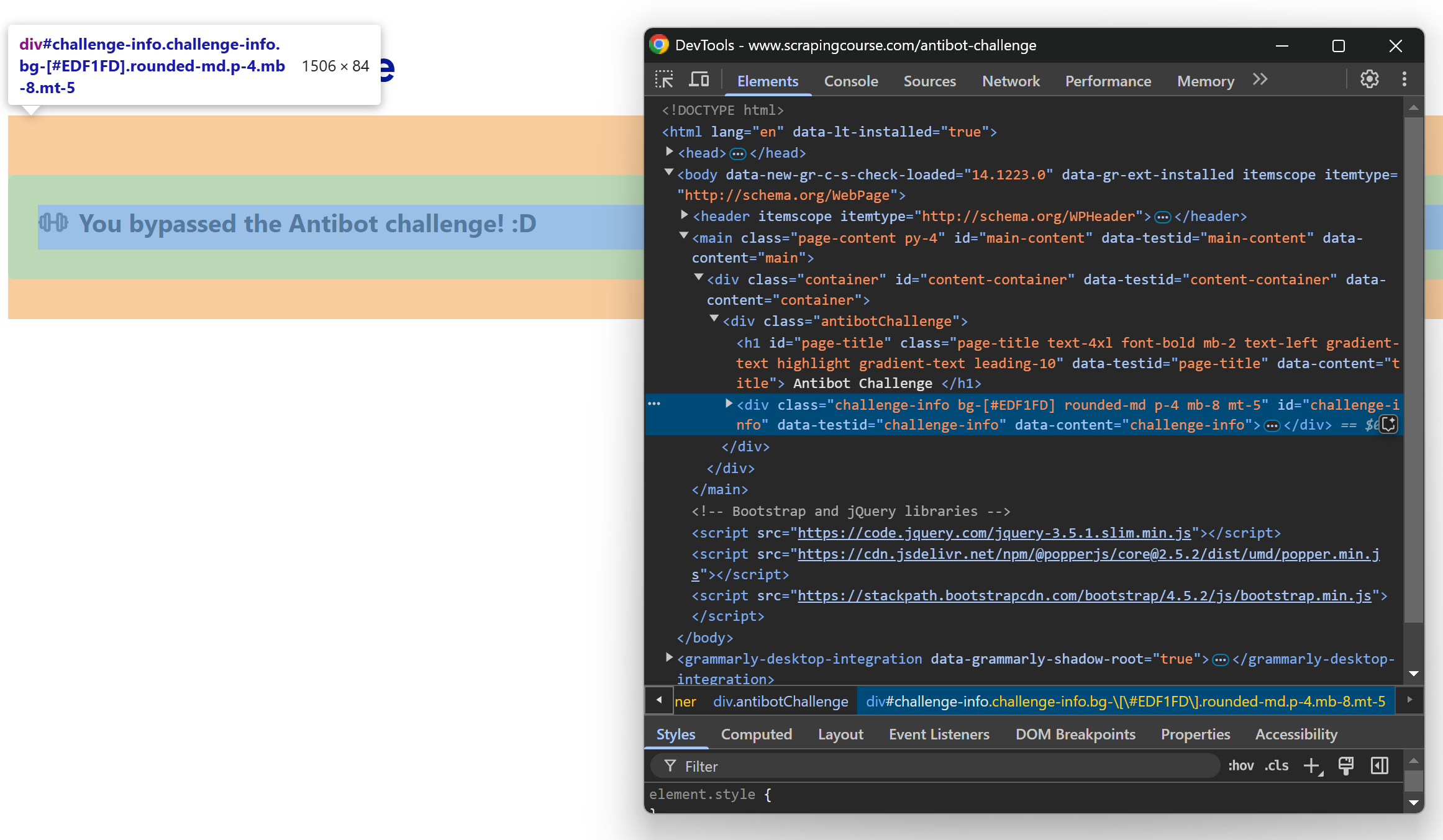
Beachten Sie, dass das Nachrichtenelement mit dem CSS-Selektor #challenge-info ausgewählt werden kann.
Definieren Sie nun eine benutzerdefinierte Funktion, um auf die Änderung des Seiten-DOM zu warten:
function delay(timeout) {
return new Promise((resolve) => {
setTimeout(resolve, timeout);
});
}Diese Funktion ist notwendig, da puppeteer-real-browser keinen integrierten Callback für die CAPTCHA-Lösung bietet. Da wir davon ausgehen, dass Puppeteer Real Browser das CAPTCHA erfolgreich umgeht, wird das DOM der Seite entsprechend aktualisiert, und Sie müssen auf diese Änderungen warten.
Daher können Sie delay() verwenden, um eine bestimmte Zeit zu warten, damit die Seite vollständig aktualisiert werden kann, wie unten gezeigt:
await delay(10000);Warten Sie dann, bis das Zielnachrichtenelement auf der Seite angezeigt wird:
await page.waitForSelector("#challenge-info", { timeout: 5000 });Rufen Sie dann dessen Inhalt ab und drucken Sie ihn aus:
const challengeInfo = await page.$eval(
"#challenge-info",
(el) => el.textContent.trim()
);
console.log(`Page message: "${challengeInfo}"`);Wenn alles wie erwartet funktioniert, sollte das Skript Folgendes ausgeben:
Seitenmeldung: „Sie haben die Antibot-Herausforderung umgangen! :D”Schritt 5: Alles zusammenfügen
Nachfolgend finden Sie Ihr endgültiges Puppeteer Real Browser-Skript:
const { connect } = require("puppeteer-real-browser");
// benutzerdefinierte Funktion zur Implementierung einer harten Wartezeit
function delay(timeout) {
return new Promise((resolve) => {
setTimeout(resolve, timeout);
});
}
(async () => {
// Verbindung zum kontrollierten Browser herstellen
const { browser, page } = await connect({
headless: false,
turnstile: true, // Turnstile CAPTCHA-Verarbeitung aktivieren
connectOption: {
defaultViewport: null, // Viewport so groß wie das Browserfenster machen
},
args: ["--start-maximized"], // Browser in maximiertem Fenster starten
});
// Zur Challenge-Seite navigieren
await page.goto("https://www.scrapingcourse.com/antibot-challenge", {
waitUntil: "networkidle2", // Warten, bis die Seite vollständig geladen und inaktiv ist
});
// bis zu 10 Sekunden warten, bis die CAPTCHA-Lösung erfolgt
await delay(10000);
// bis zu 5 Sekunden warten, bis das Challenge-Info-Element angezeigt wird
await page.waitForSelector("#challenge-info", { timeout: 5000 });
// den Challenge-Info-Text abrufen und ausgeben
const challengeInfo = await page.$eval(
"#challenge-info",
(el) => el.textContent.trim()
);
console.log(`Seitenmeldung: "${challengeInfo}"`);
// Browser schließen und Ressourcen freigeben
await browser.close();
})();Starten Sie den obigen Code, woraufhin sich ein Browser mit folgendem Verhalten öffnet:
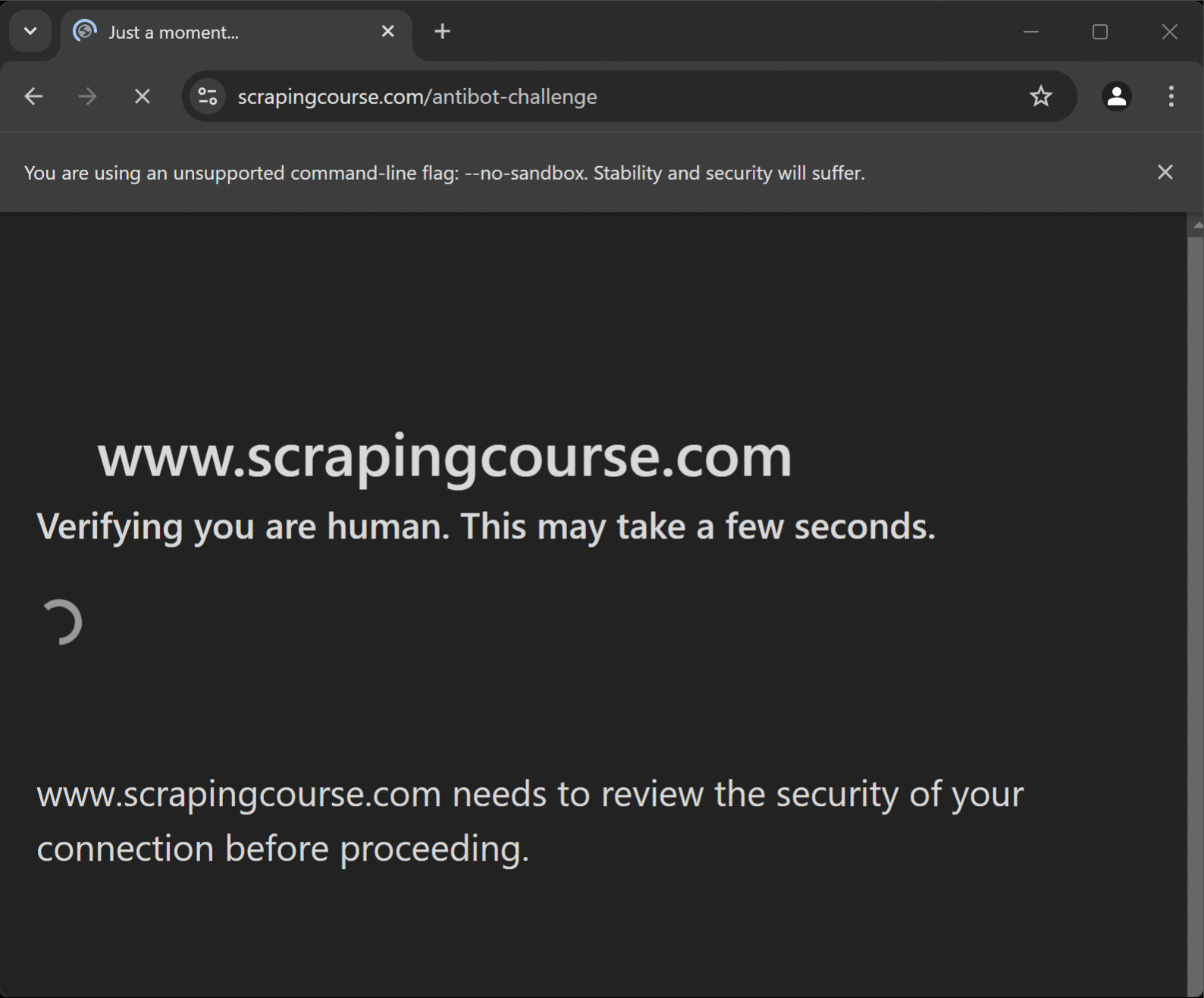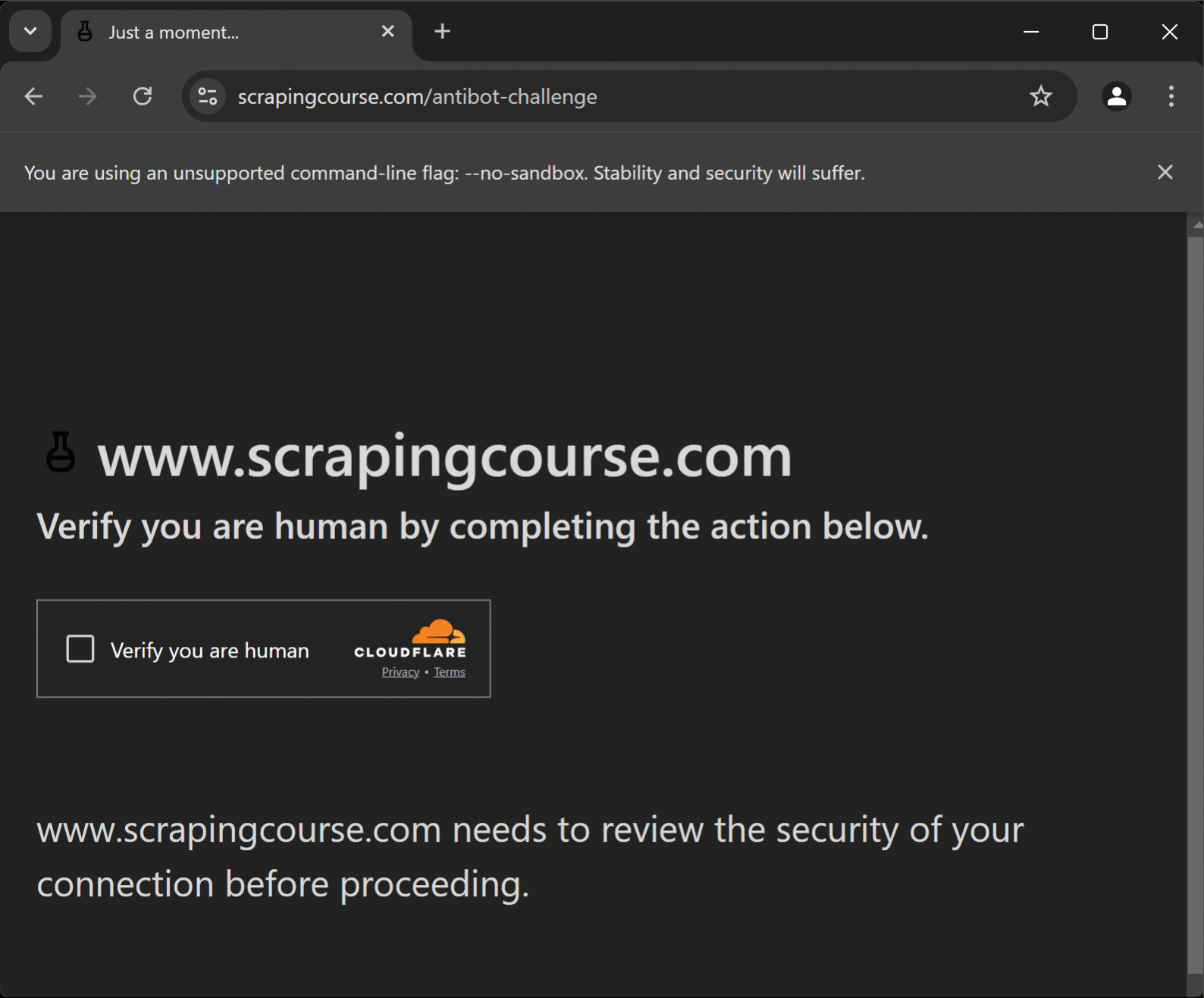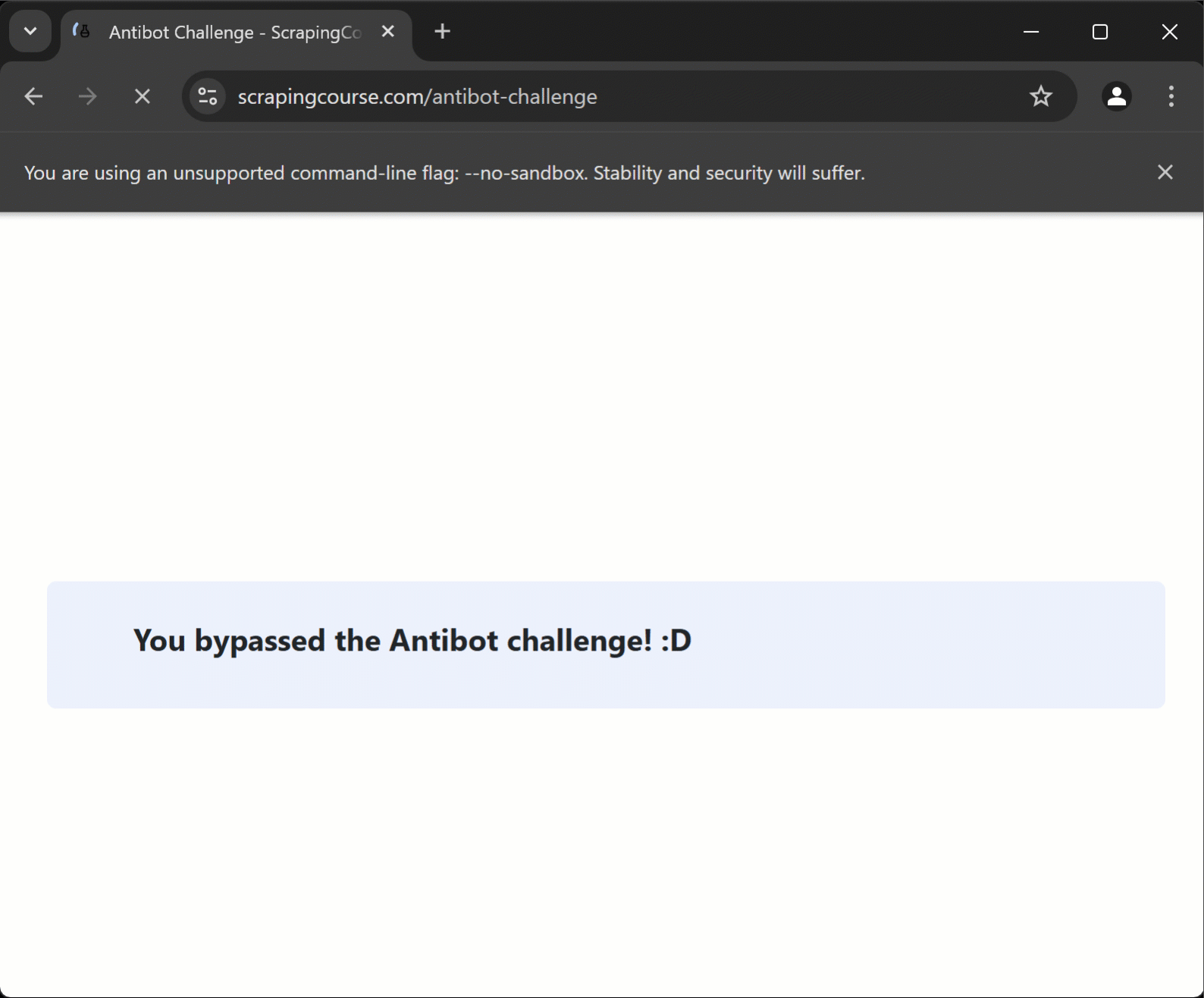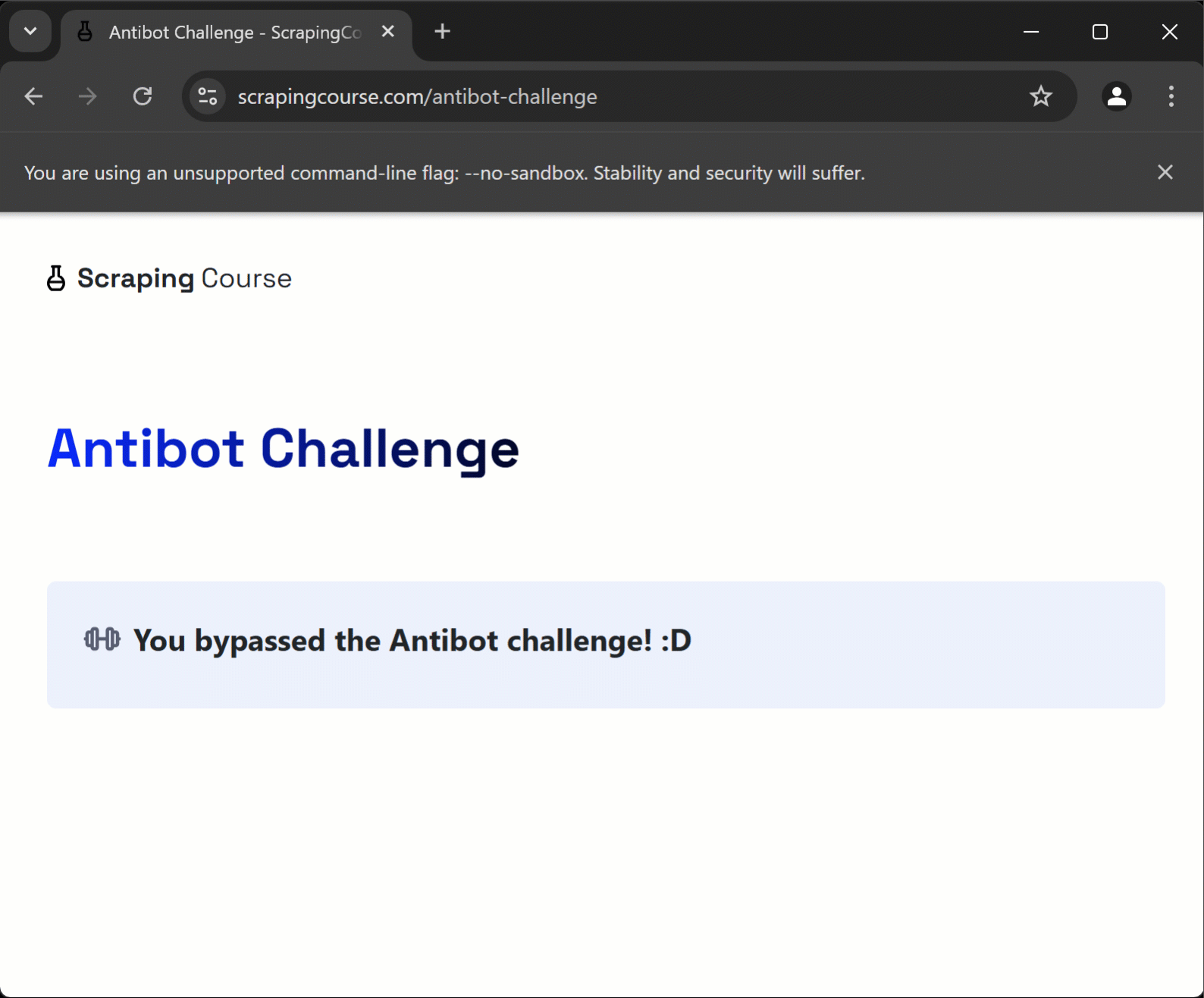
Das Skript besucht eine durch Cloudflare geschützte Seite, löst automatisch die CAPTCHA-Lösung und gelangt dann zur Zielseite, aus der es Daten extrahiert.
Wie gewünscht, gibt das Skript dieses Ergebnis im Terminal aus:
Seitenmeldung: „Sie haben die Antibot-Herausforderung umgangen! :D“Fantastisch! Die Cloudflare-CAPTCHA-Lösung wurde automatisch durchgeführt.
Alternativen zu puppeteer-real-browser
Da puppeteer-real-browser nicht mehr gepflegt wird, lohnt es sich, nach Alternativen zu suchen, die ähnliche Funktionen bieten, wie zum Beispiel:
- Puppeteer Stealth: Ein Plugin für Puppeteer Extra, das verschiedene Umgehungsmaßnahmen anwendet, um die Automatisierung weniger erkennbar zu machen. Es modifiziert Browser-Fingerabdrücke, deaktiviert WebRTC-Lecks und ahmt menschliches Verhalten nach, um Anti-Bot-Maßnahmen zu umgehen.
- Playwright Stealth: Ein Playwright Extra-Plugin, das ähnliche Stealth-Techniken wie Puppeteer Stealth integriert. Es patcht Browser-APIs, um Fingerprinting-Lecks zu verhindern.
- SeleniumBase: Ein voll ausgestattetes Selenium-basiertes Automatisierungsframework mit integrierten Anti-Bot-Erkennungsfunktionen. Es umfasst Bot-Umgehungstechniken, User-Agent-Spoofing, CAPTCHA-Handling und andere Tools, die Selenium-Skripten helfen, den Bot-Schutz zu umgehen.
- undetected-chromedriver: Eine modifizierte ChromeDriver-Version, die Selenium-Skripten hilft, die Bot-Erkennung zu umgehen. Sie entfernt Automatisierungsflags, verschleiert WebDriver-Eigenschaften und sorgt dafür, dass sich der Browser eher wie eine von Menschen betriebene Sitzung verhält.
Einschränkungen von Puppeteer Real Browser
Puppeteer Real Browser ist ein leistungsstarkes Anti-Bot-Browser-Automatisierungstool, das jedoch einige Nachteile mit sich bringt. Der Autor geht offen mit diesen Einschränkungen um und gibt klare Einblicke in die Grenzen des Tools.
Die wichtigsten Einschränkungen sind:
- Keine weitere Pflege: Im Februar 2026 gab der ursprüngliche Autor bekannt, dass die Bibliothek keine Updates mehr erhalten wird. Zukünftige Verbesserungen werden eher von Beiträgen der Community als von aktiver Entwicklung abhängen.
- Nicht zu 100 % unauffindbar: Obwohl es die Bot-Erkennung reduziert, können fortschrittliche Anti-Bot-Systeme automatisierten Traffic dennoch erkennen.
- Erfordert zusätzliche Konfiguration: Benutzer müssen möglicherweise Proxys, Header und andere Einstellungen optimieren, um eine optimale Tarnung und Funktionalität zu erreichen.
- Kein Zugriff auf Funktionen im Fensterobjekt: Dies liegt daran, dass die Browser-Laufzeitumgebung von Rebrowser geschlossen wird. Eine Umgehungslösung besteht darin, JavaScript mit puppeteer-intercept-and-modify-requests in die Seite einzufügen oder Chrome-Plugins zu verwenden.
- Abhängig von externen Bibliotheken: Die Bibliothek stützt sich auf Projekte von Drittanbietern wie Rebrowser, Puppeteer Extra und ghost-cursor, die sich ändern oder eingestellt werden könnten.
- Probleme mit reCAPTCHA: reCAPTCHA v3 erfordert eine aktive Google-Sitzung. Selbst mit einem nicht erkennbaren Browser werden Automatisierungsversuche ohne gültige Sitzung wahrscheinlich markiert.
Nahtlose Anti-Bot-Browser-Automatisierung
Die oben genannten Nachteile könnten Sie davon abhalten, Puppeteer Real Browser überhaupt in Betracht zu ziehen. Sie könnten zwar eine der Alternativen ausprobieren, würden aber wahrscheinlich auf ähnliche Herausforderungen stoßen.
Entscheidend ist, dass sich die meisten Anti-Bot-Browser-Automatisierungsbibliotheken auf das Patchen von Browsern konzentrieren und nicht auf die Browser-Automatisierungsbibliothek selbst. Obwohl geringfügige Änderungen am Kern dieser Bibliotheken erforderlich sein können, wird der größte Teil der Arbeit in das Patchen von Browser-Engines investiert, um Erkennungslecks zu vermeiden.
Stellen Sie sich nun vor, Sie könnten Vanilla-Browser-Automatisierungsbibliotheken wie Playwright, Puppeteer und Selenium nutzen – und sich dabei auf deren Updates und stabile APIs verlassen –, um einen cloudbasierten, skalierbaren Browser zu steuern, der speziell für das Web-Scraping entwickelt wurde. Genau das bietet Ihnen der Scraping-Browser von Bright Data!
Der Scraping-Browser verfügt über eine integrierte Funktion zum Entsperren von Websites, die Blockierungen automatisch für Sie übernimmt. Er lässt sich nahtlos in ein Proxy-Netzwerk mit 400M+ monthly IPs integrieren, arbeitet effizient in der Cloud und verfügt über einen integrierten CAPTCHA-Löser.
Optimierte Scraping-Browser sind die echte Lösung für eine Anti-Bot-Browser-Automatisierung!
Fazit
In diesem Artikel haben Sie gelernt, wie Sie mit Puppeteer Real Browser mit der Bot-Erkennung in Puppeteer umgehen können. Diese Bibliothek bietet eine gepatchte Version von puppeteer-core für das Web-Scraping, ohne blockiert zu werden.
Das Problem ist, dass puppeteer-real-browser nicht mehr gepflegt wird. Auch wenn es heute noch funktioniert, könnte es morgen schon nicht mehr funktionieren, da sich Anti-Bot-Lösungen ständig weiterentwickeln.
Das Problem liegt nicht bei der API von Puppeteer zur Steuerung des Browsers, sondern bei den Browsern selbst. Die Lösung ist ein cloudbasierter, stets aktualisierter, skalierbarer Browser mit integrierter Anti-Bot-Bypass-Funktionalität, wie beispielsweise der Scraping-Browser!
Der Scraping-Browser von Bright Data ist ein hoch skalierbarer Cloud-Browser, der mit Puppeteer, Selenium, Playwright und anderen zusammenarbeitet. Er übernimmt für Sie das Browser-Fingerprinting, die CAPTCHA-Lösung und automatische Wiederholungsversuche.
Außerdem wechselt er dank eines globalen Proxy-Netzwerks, das Folgendes umfasst, bei jeder Anfrage automatisch die Exit-IP:
- Datacenter-Proxys – Über 770.000 Rechenzentrums-IPs.
- Residential-Proxys – Über 150 Millionen Residential-IPs in mehr als 195 Ländern.
- ISP-Proxys – Über 700.000 ISP-IPs.
- Mobile-Proxy – Über 7 Millionen mobile IPs.
Erstellen Sie noch heute ein kostenloses Bright Data-Konto, um unseren Scraping-Browser auszuprobieren oder unsere Proxys zu testen.





