
In diesem Tutorial lernen Sie:
- Was MLflow ist und welche Tracking-Funktionen es bietet.
- Warum es sich lohnt, ML/KI-Experimente auf der Grundlage von aus dem Internet gescrapten Datensätzen zu erstellen.
- Wie Sie mit MLflow ein Experiment-Tracking anhand eines gescrapten Datensatzes durchführen.
Lassen Sie uns loslegen!
Was ist MLflow?
MLflow ist eine Open-Source-Plattform zur Verwaltung des gesamten Lebenszyklus des maschinellen Lernens. Sie bietet viele Funktionen und eine umfangreiche API, um Modelle effizient zu verfolgen, zu reproduzieren und bereitzustellen.
MLflow unterstützt sowohl traditionelle Machine-Learning- als auch Deep-Learning-Workflows und bietet Tools für Experimente, Versionierung, Bewertung und Bereitstellung. All dies auf reproduzierbare und kollaborative Weise.
MLflow ist sprachunabhängig, funktioniert mit Python, R und Java und unterstützt lokale, Cloud- und verwaltete Umgebungen. Das macht es herstellerneutral und äußerst flexibel. Außerdem bewahrt es seinen Open-Source-Charakter, denn sein GitHub-Repository kann sich über 24.000 Sterne rühmen.
Zu den wichtigsten Funktionen von MLflow gehören:
- Tracking: Protokollieren Sie Experimente, verfolgen Sie Parameter, Metriken, Codeversionen und Artefakte.
- Modelle: Standardisieren Sie die Paketierung von Modellen für die Bereitstellung auf verschiedenen Plattformen.
- Modellregistrierung: Zentrales Repository für Modellversionen, Stufenübergänge und Anmerkungen.
- Projekte: Verpacken Sie wiederverwendbaren Data-Science-Code für Konsistenz und Reproduzierbarkeit.
- KI/LLM-Bewertung: Verfolgen, vergleichen und bewerten Sie generative KI- oder LLM-Ausgaben.
- Integration und automatische Protokollierung: Funktioniert mit scikit-learn, TensorFlow, PyTorch, OpenAI und mehr und automatisiert die Protokollierung.
Weitere Informationen finden Sie in der offiziellen Dokumentation.
Warum Datensätze mit gescrapten Webdaten ideal für Experimente mit MLflow sind
Beim Aufbau von ML/KI-Pipelines entscheiden in der Regel die Qualität und Vielfalt Ihrer Datensätze über den Erfolg oder Misserfolg Ihrer Experimente. Scraped Webdaten bieten aufgrund ihrer Beschaffenheit sowohl Vielfalt als auch Umfang. Dies sind die beiden wichtigsten Zutaten für aussagekräftige Experimente.
Im Gegensatz zu kleinen oder synthetischen Datensätzen erfassen aus dem Web stammende Datensätze reale Verteilungen, Randfälle und natürliche Schwankungen. Diese Aspekte machen Ihre Modelle robuster und Ihre MLflow-Experimente aussagekräftiger. Aus diesem Grund gelten Webdaten allgemein als eine der besten Datenquellen.
Bright Data zeichnet sich als bester Anbieter von Datensätzen aus. Sein Marktplatz bietet ML- und KI-fähige strukturierte Datensätze aus über 150 Bereichen, von E-Commerce und Einzelhandel bis hin zu sozialen Medien und Reisen. Jeder Datensatz enthält Millionen von Datensätzen und gewährleistet so sowohl Breite als auch Tiefe.
Diese Datensätze werden regelmäßig aktualisiert und spiegeln so die Dynamik des Internets wider, sodass Ihre ML/KI-Workflows mit den aktuellsten Informationen trainiert und bewertet werden können. Diese Kombination aus Umfang, Aktualität und ML-fähiger Formatierung macht die Datensätze von Bright Data perfekt für solide, reproduzierbare und wirkungsvolle Experimente mit MLflow. Entdecken Sie die verfügbaren Datensätze auf dem Marktplatz!
So führen Sie Experiment-Tracking mit MLflow und einem Bright Data-Datensatz durch
In diesem Abschnitt erfahren Sie, wie Sie MLflow-Experimentverfolgung durchführen. Insbesondere erstellen Sie eine Machine-Learning-Pipeline unter Verwendung des Bright Data Amazon Best Product Seller- Datensatzes.
Das Ziel dieser Pipeline ist es, ein Modell zu trainieren, das den Endpreis eines Produkts auf der Grundlage seiner Bewertung, der Anzahl der Bewertungen und der Marke vorhersagt. Die zugrunde liegende Annahme ist, dass diese Merkmale Vorhersagesignale enthalten, die mit der Produktpreisgestaltung korrelieren.
Die Pipeline kombiniert die Vorverarbeitung mit einem Random-Forest-Modell und bewertet dessen Leistung. Während des gesamten Prozesses verfolgt MLflow Metriken, Artefakte, den Datensatz und die Nutzung der Systemressourcen.
Befolgen Sie die folgenden Schritte!
Voraussetzungen
Um dieses Tutorial durchzuarbeiten, benötigen Sie:
- Python 3.10 oder höher, lokal installiert.
- Ein Bright Data-Konto für den Zugriff auf gescrapte Datensätze.
- Grundkenntnisse im Training prädiktiver ML-Modelle mit scikit-learn.
Schritt 1: Projekt einrichten
Öffnen Sie zunächst Ihr Terminal und erstellen Sie einen neuen Ordner für Ihr MLflow-Experimentprojekt:
mkdir mlflow-experiment-trackingNavigieren Sie anschließend in das Projektverzeichnis und erstellen Sie darin eine virtuelle Python-Umgebung:
cd mlflow-experiment-tracking
python -m venv .venvLaden Sie nun den Projektordner in Ihre bevorzugte Python-IDE. Wir empfehlen Visual Studio Code mit der Python-Erweiterung oder PyCharm Community Edition.
Erstellen Sie eine neue Datei mit dem Namen experiment.py im Stammverzeichnis Ihres Projektverzeichnisses. Ihre Projektstruktur sollte wie folgt aussehen:
mlflow-experiment-tracking/
├── .venv/
└── experiment.pyAktivieren Sie die virtuelle Umgebung im Terminal. Führen Sie unter Linux oder macOS folgenden Befehl aus:
source venv/bin/activateUnter Windows führen Sie stattdessen folgenden Befehl aus:
venv/Scripts/activateInstallieren Sie nach Aktivierung der virtuellen Umgebung die Projektabhängigkeiten:
pip install mlflow pandas scikit-learn psutil nvidia-ml-pyDie erforderlichen Bibliotheken sind:
mlflow: Für die End-to-End-Experimentverfolgung, Beobachtbarkeit und Protokollierung von ML-Modellen und Metriken.pandas: Lädt, bereinigt und bearbeitet tabellarische Daten aus JSON/CSV für das Modelltraining.scikit-learn: Erstellt ML-Pipelines, übernimmt die Vorverarbeitung, trainiert Modelle und berechnet Bewertungsmetriken.psutil, nvidia-ml-py: Wird von MLflow benötigt, um CPU- und GPU-Ressourcen sowie andere Systemmetriken während der Experimente zu überwachen.
Als Nächstes importieren Sie in experiment.py alle erforderlichen Bibliotheken mit:
import json
import mlflow
import pandas as pd
import mlflow.sklearn
from mlflow.data.code_dataset_source import CodeDatasetSource
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import root_mean_squared_error, r2_score
from sklearn.impute import SimpleImputerGut gemacht! Ihre Python-Entwicklungsumgebung ist nun bereit, ML- und KI-Experimente in MLflow zu verfolgen.
Schritt 2: Machen Sie sich mit der MLflow-Benutzeroberfläche vertraut
Um zu überprüfen, ob MLflow funktioniert, öffnen Sie ein Terminal mit aktivierter virtueller Umgebung und starten Sie die MLflow-Benutzeroberfläche:
mlflow uiBeim ersten Start initialisiert MLflow eine lokale SQLite-Datenbank, um Experimentdaten zu speichern. Insbesondere werden Sie feststellen, dass eine Datei namens mlflow.db im Ordner Ihres Projekts erschienen ist. Das ist die lokale Datenbank, die von SQLite verwendet wird.
Im Terminal wird ein Protokoll wie das folgende angezeigt:
INFO: Uvicorn läuft unter http://127.0.0.1:5000 (Drücken Sie STRG+C, um das Programm zu beenden)Das bedeutet, dass die Benutzeroberfläche jetzt ausgeführt wird. Öffnen Sie Ihren Browser und rufen Sie http://127.0.0.1:5000/ auf. Sie sollten Folgendes sehen: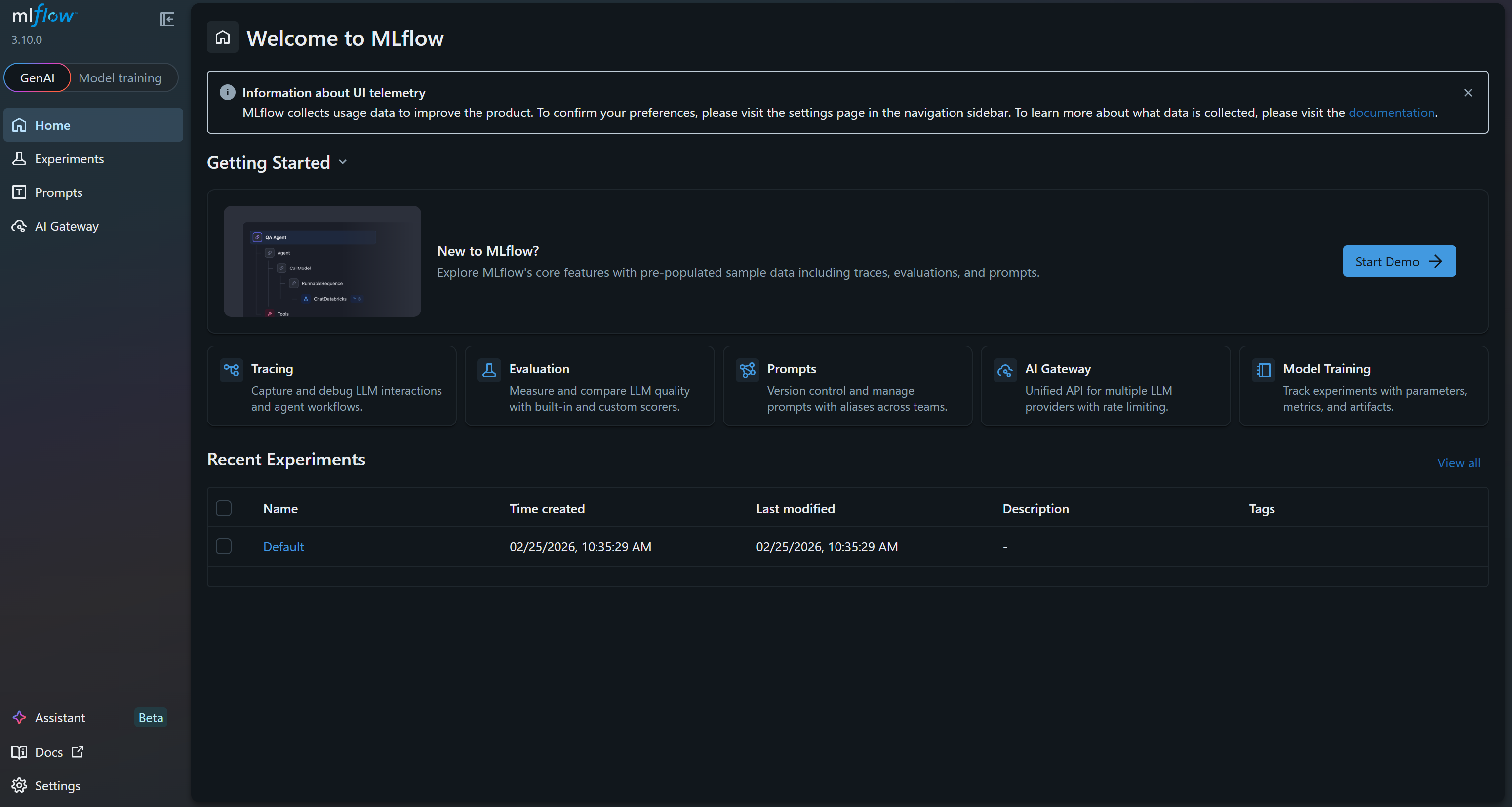
Dies ist die MLflow-Benutzeroberfläche, in der Sie Ihre Experimente beobachten und verfolgen können. Nehmen Sie sich ein paar Minuten Zeit, um sich mit den Menü-Links und den verfügbaren Funktionen vertraut zu machen. Hier können Sie während Ihrer ML-Projekte Metriken, Protokolle und Artefakte effektiv überwachen. Großartig!
Schritt 3: Aktivieren Sie die automatische Protokollierung und Systemverfolgung von MLflow
Aktivieren Sie in Ihrer Datei „experiment.ml“ die Protokollierung von MLflow-Systemmetriken, um die CPU-Auslastung, die Festplattenauslastung, die RAM-Auslastung und andere Metriken auf Systemebene während des Trainings zu verfolgen.
# Automatische Protokollierung von Systemmetriken (CPU, Speicher usw.) aktivieren
mlflow.enable_system_metrics_logging()
# Ereignisse für sklearn automatisch protokollieren
mlflow.sklearn.autolog()
# Konfigurieren Sie, wie oft Systemmetriken erfasst und protokolliert werden sollen.
mlflow.set_system_metrics_sampling_interval(1)
mlflow.set_system_metrics_samples_before_logging(1) Dieser Ausschnitt aktiviert auch die automatische Protokollierung, sodass MLflow automatisch scikit-learn-Ereignisse aufzeichnet. Anschließend wird das Abtastintervall für Systemmetriken auf 1 Sekunde festgelegt, um eine detaillierte und häufige Überwachung zu gewährleisten.
Fantastisch! Ihre MLflow-Anwendung verfolgt nun nützliche Informationen über Ihr Trainingsexperiment für maschinelles Lernen.
Schritt 4: Abrufen des Quelldatensatzes mit gescrapten Daten von Bright Data
Sie haben nun eine MLflow-Konfiguration eingerichtet und können ML/KI-Experimente durchführen. Was noch fehlt, ist die Datenquelle für das Training Ihres Modells. Wie bereits erwähnt, werden wir den Amazon-Bestseller-Datensatz von Bright Data verwenden, um ein Preisvorhersagemodell auf Basis einer Random-Forest-Pipeline zu erstellen.
Zunächst müssen Sie den Quelldatensatz abrufen. In diesem Fall enthält er über 45 Datenfelder und umfasst mehr als 171 Millionen Amazon-Bestsellerprodukte.
Wenn Sie noch kein Bright Data-Konto haben, erstellen Sie eines. Andernfalls melden Sie sich an. Wählen Sie im Bright Data-Kontrollfeld die Menüoption „Web Datensätze“ (Web-Datensätze). Navigieren Sie dann zur Registerkarte „Dataset Marketplace“ (Datensatz-Marktplatz):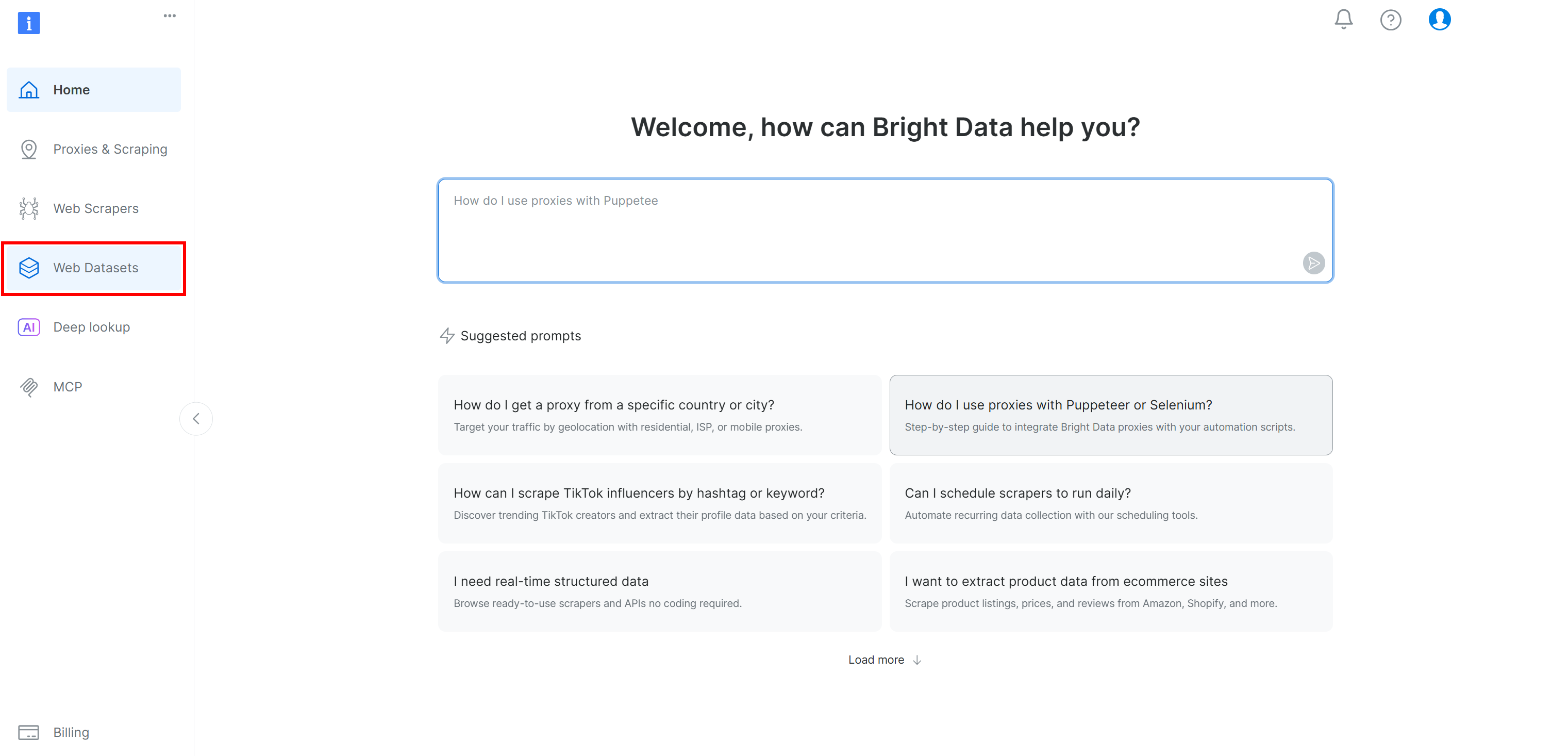
Wechseln Sie zur Registerkarte „Dataset Marketplace“: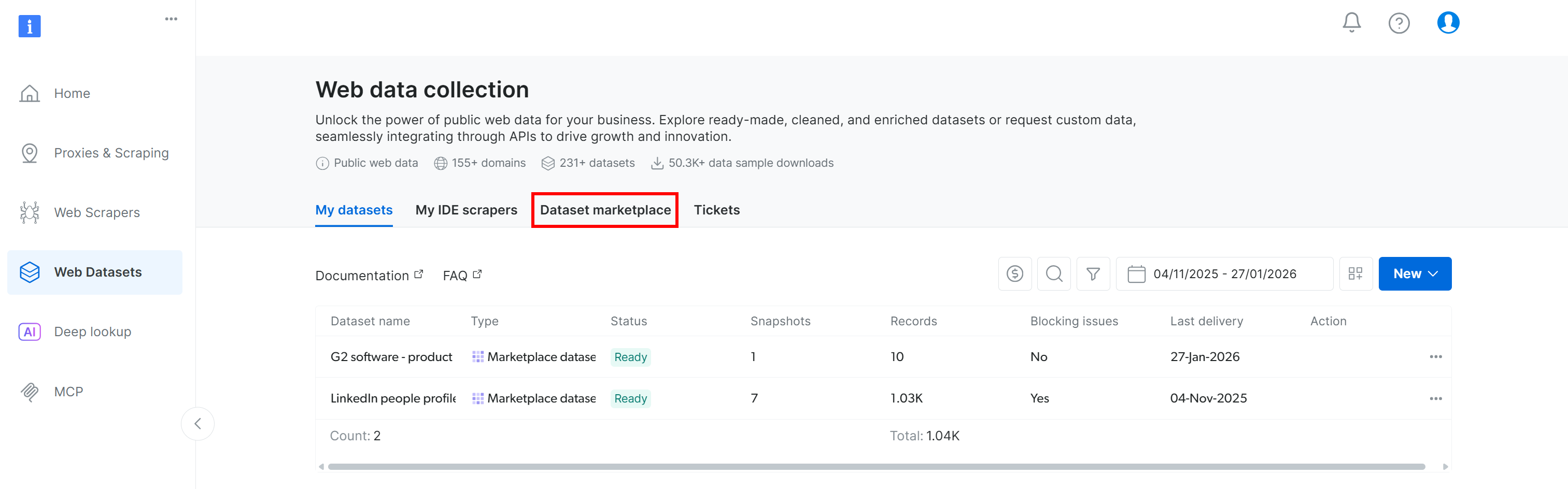
Sie gelangen zur Seite„Dataset Marketplace“: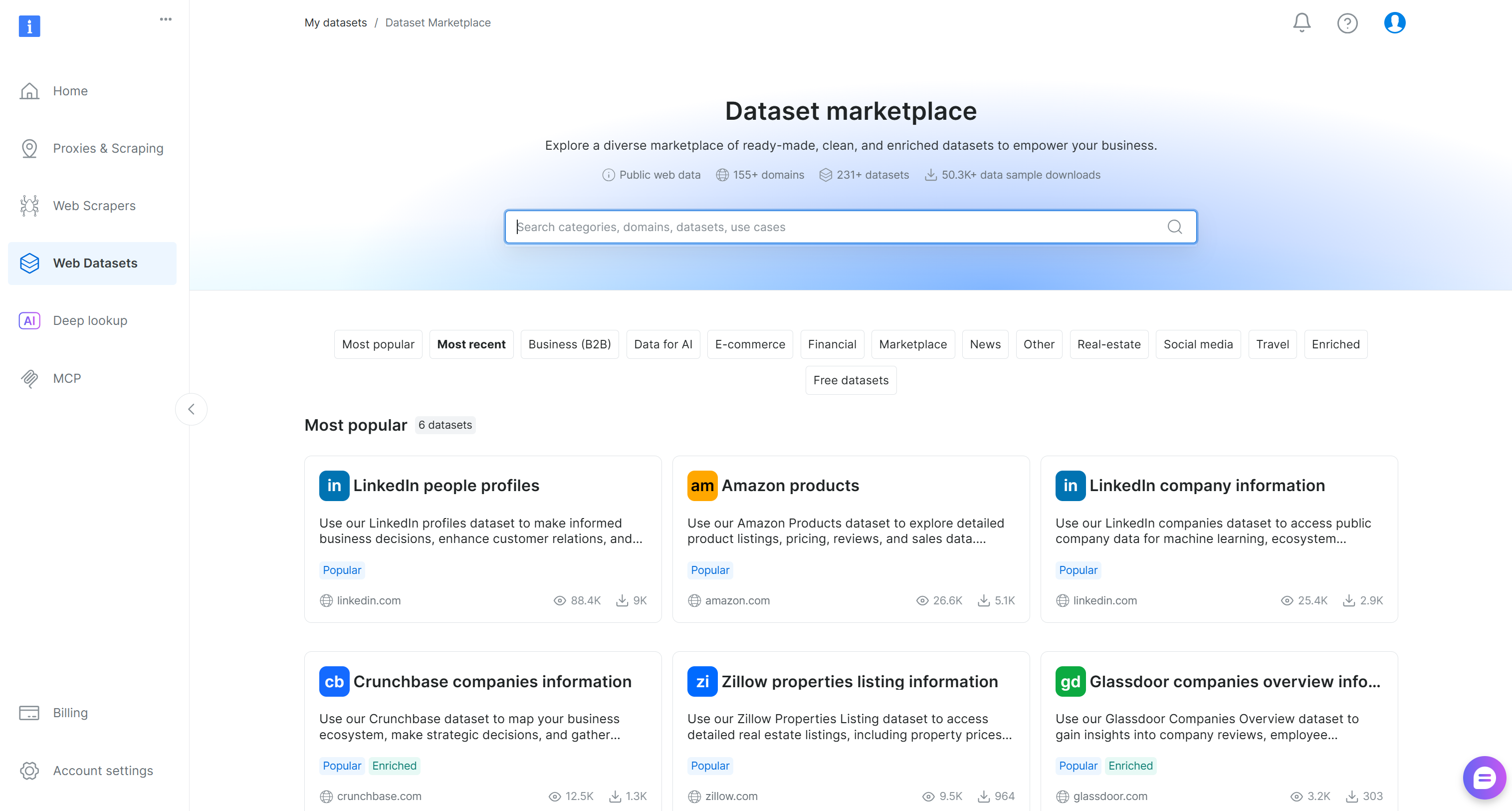
Hier können Sie über 200 gescrapte Datensätze aus über 155 Domains mit Milliarden von Datensätzen durchsuchen.
Suchen Sie nach „Amazon-Bestsellerprodukte“ und wählen Sie diese aus. Dadurch gelangen Sie zur Seite des Datensatzes: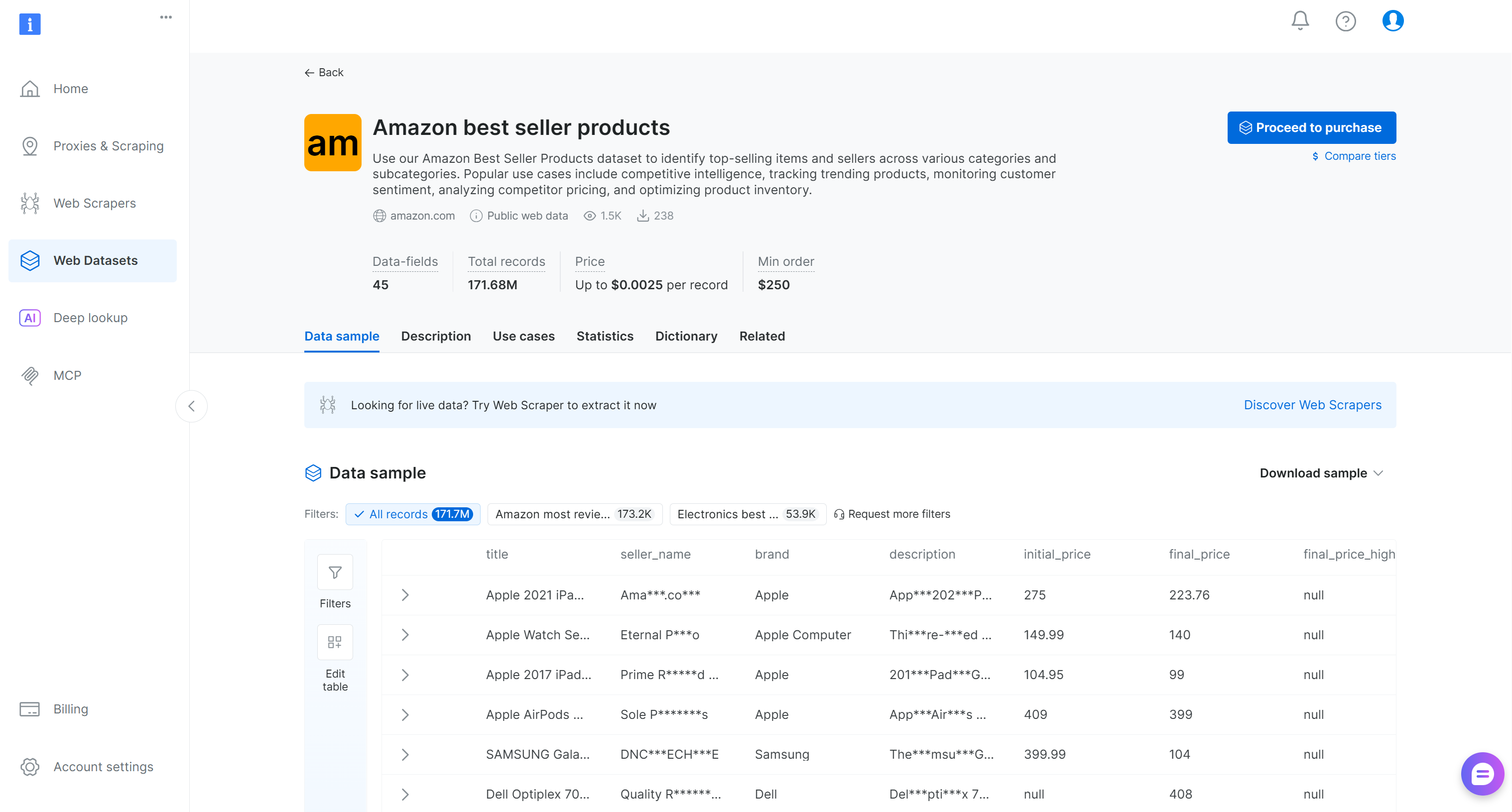
Sie können entweder eine gefilterte Teilmenge der Datensätze kaufen oder eine kostenlose Probe herunterladen. Da es sich hierbei nur um ein Beispiel handelt, verwenden wir die kostenlose Probe.
Klicken Sie auf das Dropdown-Menü „Download sample“ und wählen Sie die Option „Download as JSON“: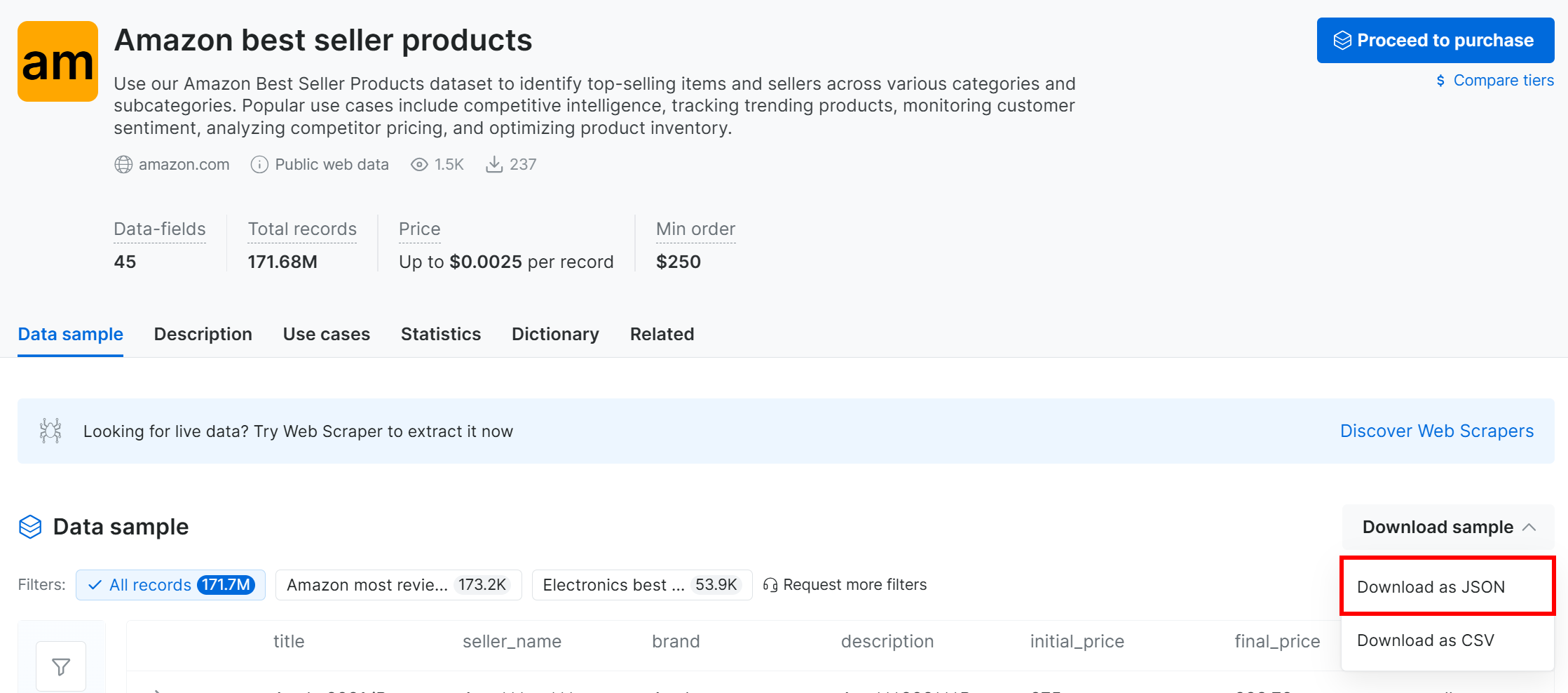
Sie erhalten einen Beispieldatensatz mit 1.000 Datensätzen zu den meistverkauften Produkten bei Amazon. Einige Felder sind aus Datenschutzgründen teilweise maskiert (mit „***“), aber der vollständige Datensatz ist nach der Bezahlung verfügbar. Dennoch reicht die Probe für einfache MLflow-Experimente aus.
Alternativ können Sie einen ähnlichen Beispieldatensatz aus einem speziellen GitHub-Repository herunterladen.
Benennen Sie die heruntergeladene Datensatzdatei in „products.json“ um und legen Sie sie in Ihrem Projektordner ab:
mlflow-experiment-tracking/
├── .venv/
├── experiment.py
├── mlflow.db
└── products.json # <--------Öffnen Sie die Datei, und Sie sehen Folgendes: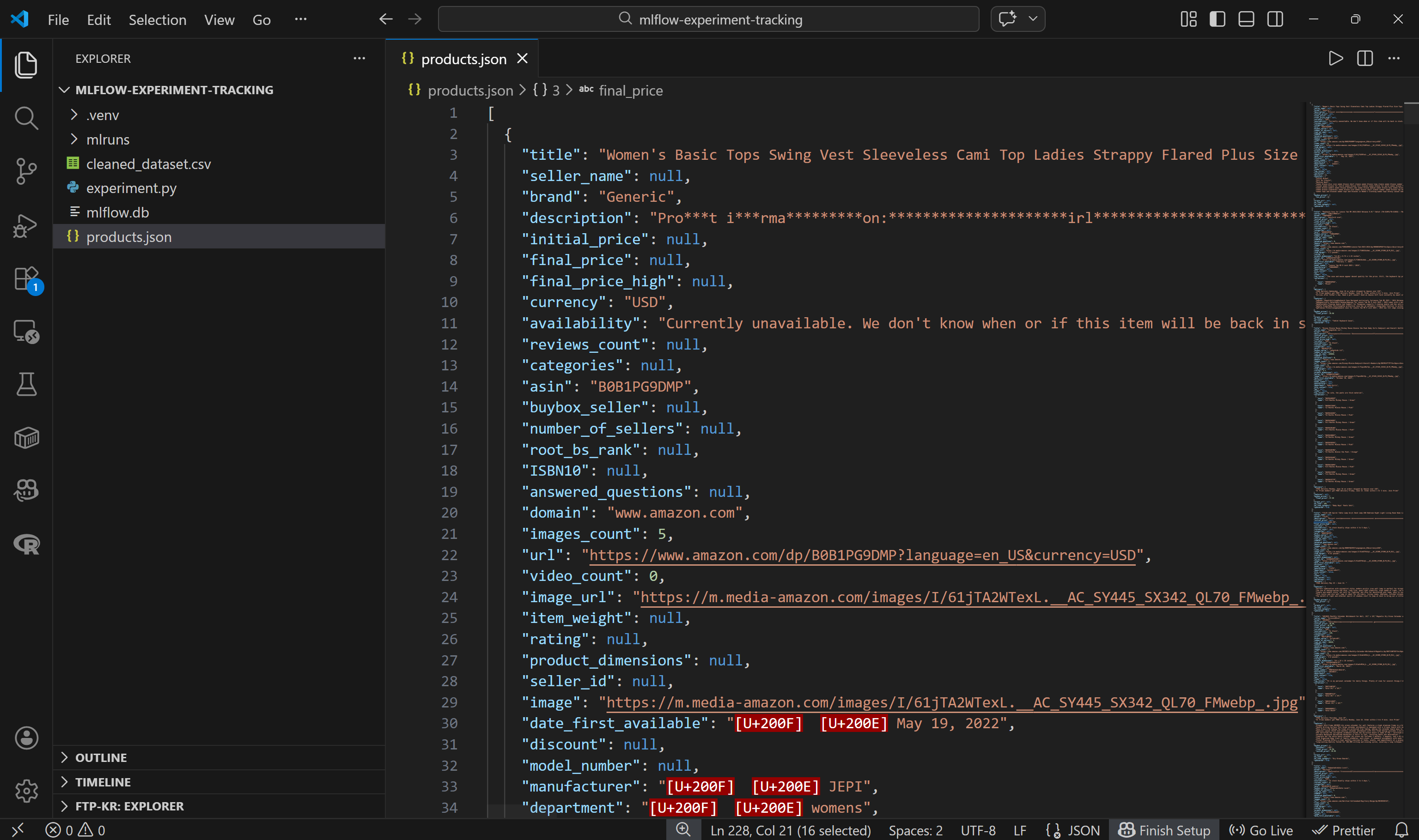
Beachten Sie, dass jedes Amazon-Produkt als JSON-Objekt mit etwa 45 Datenfeldern dargestellt wird. Dies bietet eine reichhaltige Grundlage für Experimente.
Perfekt! Sie können diesen Datensatz nun in Ihren Code laden und mit der Verarbeitung beginnen.
Schritt 5: Laden und Vorverarbeiten des Datensatzes
Bevor Sie den Datensatz in Ihren Code laden, nehmen Sie sich etwas Zeit, um die verfügbaren Spalten zu erkunden. Wechseln Sie zur Registerkarte „Dictionary“, um detaillierte Informationen zu jeder Spalte anzuzeigen, einschließlich ihrer Beschreibung und ihres prozentualen Anteils: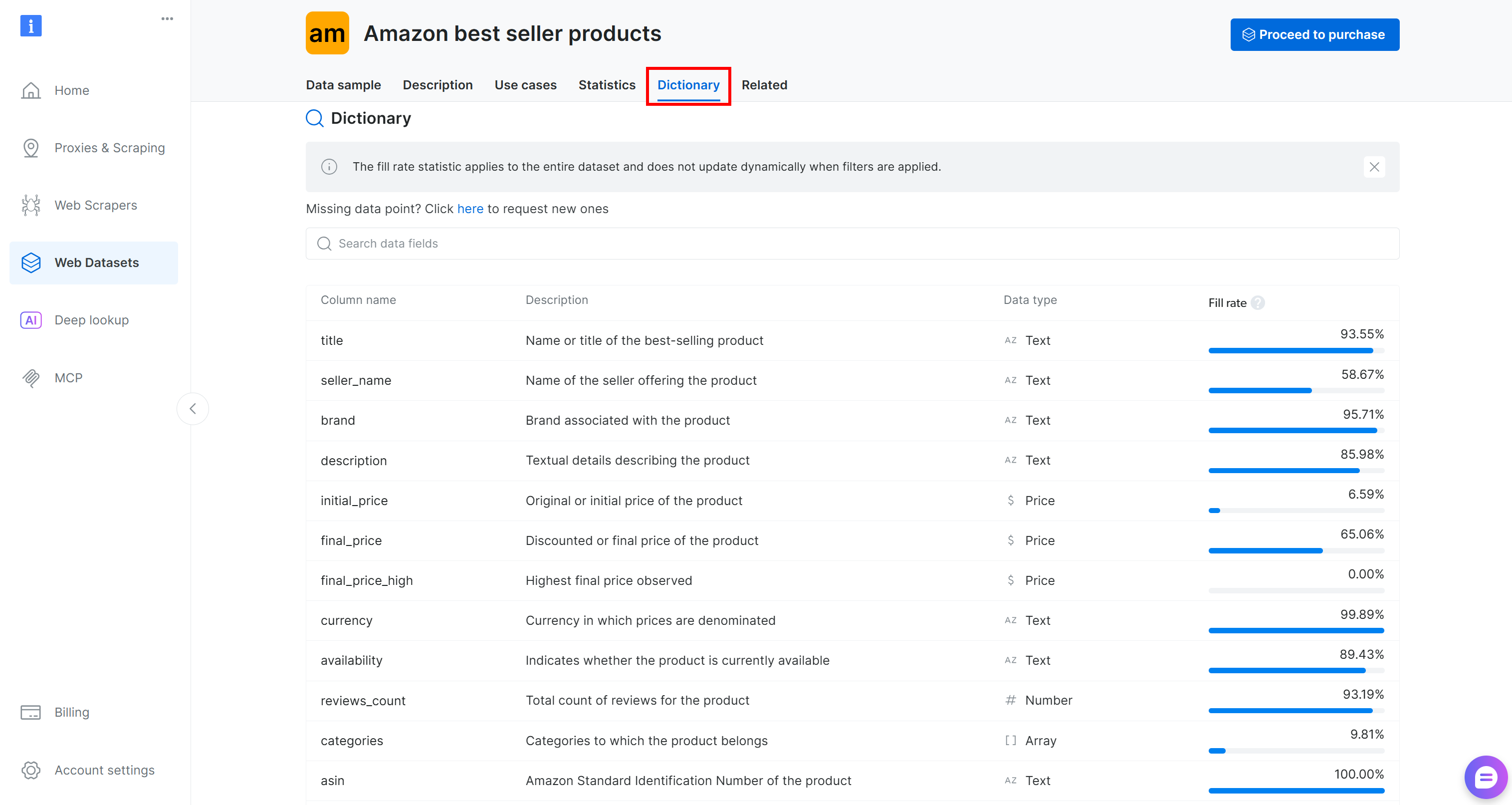
In diesem Fall sind die folgenden Spalten von Interesse:
brand(Text): Mit dem Produkt verbundene Marke.final_price(Preis): Der reduzierte oder Endpreis des Produkts.reviews_count(Zahl): Gesamtzahl der Bewertungen.rating(Zahl): Durchschnittliche Produktbewertung.
Laden Sie nun die JSON-Datei:
with open("products.json", "r", encoding="utf-8") as f:
data = json.load(f)Konvertieren Sie sie anschließend in einen Pandas-DataFrame:
df = pd.DataFrame(data)Wenn Sie die Spalte „final_price” überprüfen, werden Sie feststellen, dass sie manchmal nur numerische Werte (z. B. 1500) enthält, während sie in anderen Fällen formatierte Zeichenfolgen (z. B. 1.500 $) enthält.
Um eine konsistente Verarbeitung zu gewährleisten, konvertieren Sie alle Preise in das numerische Format und löschen Sie Zeilen, in denen final_price null ist:
df["final_price"] = pd.to_numeric(
df["final_price"].astype(str).str.replace(r"[$,]", "", regex=True),
errors="coerce")
df = df.dropna(subset=["final_price"])Registrieren Sie schließlich den Datensatz in MLflow:
# Definieren Sie Merkmals- und Zielspalten.
FEATURES = ["rating", "reviews_count", "brand"]
TARGET = "final_price"
# Definieren Sie die Datenquellen explizit.
dataset_source = CodeDatasetSource(tags="v1")
# Registrieren Sie den Datensatz in MLflow mit einigen Metadaten
mlflow_dataset = mlflow.data.from_pandas(
df[FEATURES + [TARGET]],
source=dataset_source,
name="brightdata_products",
targets=TARGET
)Dieser Code definiert die Eingabefunktionen (Bewertung, Anzahl der Bewertungen, Marke) und die Zielvariable (endgültiger Preis) für Ihre ML-Pipeline. Anschließend wird ein CodeDatasetSource-Objekt erstellt und der ausgewählte DataFrame mit Metadaten in MLflow registriert, um die Nachverfolgung und Reproduzierbarkeit des Experiments sicherzustellen.
Großartig! Sie können diese Daten nun in Ihrer Modelltrainings-Pipeline verwenden.
Schritt 6: Definieren Sie die Pipeline für das Vorhersagemodell
Bereiten Sie Ihre Daten für das ML-Modelltraining mit der folgenden Logik vor:
# Merkmale und Ziel trennen
X = df[FEATURES]
y = df[TARGET]
# Vorverarbeitungs-Pipeline:
# - Median-Imputation für numerische Spalten
# - Konstante Füllung + One-Hot-Kodierung für kategoriale Spalten
preprocessor = ColumnTransformer(
transformers=[
("num", SimpleImputer(strategy="median"), ["rating", "reviews_count"]),
("cat", Pipeline([
("imputer", SimpleImputer(strategy="constant", fill_value="unknown")),
("onehot", OneHotEncoder(handle_unknown="ignore"))
]), ["brand"]),
]
)
# Vollständige ML-Pipeline: Vorverarbeitung + RandomForest-Modell
pipeline = Pipeline(steps=[
("preprocessor", preprocessor),
("model", RandomForestRegressor(n_estimators=200, max_depth=None, random_state=42))
])
# Aufteilung der Datensätze in Trainings- und Testdatensätze
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)Dieser Ausschnitt bereitet die Daten vor und erstellt eine vollständige ML-Pipeline, indem er:
- Trennung der Eingabemerkmale (
Bewertung,Anzahl der Bewertungen,Marke) vom Ziel (Endpreis). - Behandlung fehlender Werte mit Median-Imputation für numerische Merkmale und konstanter Füllung für kategoriale Merkmale, anschließend One-Hot-Kodierung des
Markentextfeldesin ein numerisches Format. Diese Vorsichtsmaßnahmen stellen sicher, dass das Modell saubere, numerische Eingaben erhält. - Kombinieren der Vorverarbeitung mit einem Random-Forest-Modell und Aufteilen der Daten in Trainings- und Testsätze zur Auswertung.
Super! Jetzt ist es an der Zeit, Ihr MLflow-Experiment mit dem von Bright Data gescrapten Datensatz durchzuführen.
Schritt 7: Führen Sie das MLflow-Experiment aus
Sie verfügen nun über alle Bausteine, um Ihr MLflow-Experiment auszuführen. Führen Sie es mit folgendem Befehl aus:
# Starten Sie den MLflow-Lauf und aktivieren Sie die Verfolgung von Systemmetriken.
with mlflow.start_run(log_system_metrics=True) as run:
# Protokollieren Sie den Datensatz als Eingabe für den Lauf.
mlflow.log_input(mlflow_dataset, context="training")
# Trainieren Sie die Modellpipeline
pipeline.fit(X_train, y_train)
# Generieren Sie die Vorhersagen für den Testsatz
predictions = pipeline.predict(X_test)
# Protokollieren Sie die Bewertungsmetriken (RMSE und R2)
mlflow.log_metric("val_rmse", root_mean_squared_error(y_test, predictions))
mlflow.log_metric("r2_score", r2_score(y_test, predictions))
# Protokollieren Sie den CSV-Ausgabedatensatz in einer lokalen Datei und anschließend als Artefakt in MLflow.
csv_path = "cleaned_dataset.csv"
df.to_csv(csv_path, index=False, encoding="utf-8-sig", errors="replace")
mlflow.log_artifact(csv_path)
# Protokollieren Sie das trainierte Modell mit Signatur und Beispiel-Eingabe.
mlflow.sklearn.log_model(
sk_model=pipeline,
name="model",
signature=mlflow.models.infer_signature(X_train, predictions),
input_example=X_train.iloc[:3],
)
print(f"Ausführung abgeschlossen. Überprüfen Sie die Registerkarte „System Metrics“ in der MLflow-Benutzeroberfläche für die Ausführungs-ID: {run.info.run_id}")Das obenstehende Snippet bewirkt Folgendes:
- Starten Sie einen MLflow-Lauf mit aktivierter Systemmetrik-Verfolgung.
- Registriert
mlflow_datasetals Eingabe für das Experiment, um die Rückverfolgbarkeit und Reproduzierbarkeit zu gewährleisten. - Trainiert die Modellpipeline, indem die gesamte ML-Pipeline (Vorverarbeitung + Random Forest) an die Trainingsdaten angepasst wird.
- Generiert Vorhersagen, indem das trainierte Modell verwendet wird, um Zielwerte für den Testsatz vorherzusagen.
- Zeichnet RMSE und R² in MLflow auf, um die Modellleistung zu bewerten.
- Protokollieren Sie den bereinigten Datensatz als Artefakt, damit Sie ihn in MLflow als Referenz untersuchen können.
- Registriert die trainierte Pipeline in MLflow, einschließlich ihrer Eingabesignatur und einer Beispiel-Eingabe zur Reproduzierbarkeit.
Cool! Jetzt müssen Sie nur noch den endgültigen Code untersuchen und Ihr MLflow-Experiment ausführen.
Schritt 8: Alles zusammenfügen und das Experiment ausführen
Ihre Datei „experiment.py“ sollte Folgendes enthalten:
# pip install mlflow pandas scikit-learn psutil nvidia-ml-py
import json
import mlflow
import pandas as pd
import mlflow.sklearn
from mlflow.data.code_dataset_source import CodeDatasetSource
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import root_mean_squared_error, r2_score
from sklearn.impute import SimpleImputer
# Automatische Protokollierung von Systemmetriken (CPU, Speicher usw.) aktivieren
mlflow.enable_system_metrics_logging()
# Ereignisse für sklearn automatisch protokollieren
mlflow.sklearn.autolog()
# Konfigurieren, wie oft Systemmetriken erfasst und protokolliert werden (1 Sekunde)
mlflow.set_system_metrics_sampling_interval(1)
mlflow.set_system_metrics_samples_before_logging(1)
# Gelöschte Produktdaten aus der Eingabedatei des Bright Data-Datensatzes laden
# (Download unter: /cp/datasets/browse/gd_l1vijixj9g2vp7563)
with open("products.json", "r", encoding="utf-8") as f:
data = json.load(f)
# JSON in einen Pandas-DataFrame konvertieren
df = pd.DataFrame(data)
# Die Zielspalte „final_price” bereinigen:
# - Dollarzeichen und Kommas entfernen
# - In numerische Werte konvertieren
# - Ungültige Werte werden zu NaN
df["final_price"] = pd.to_numeric(
df["final_price"].astype(str).str.replace(r"[$,]", "", regex=True),
errors="coerce")
# Zeilen löschen, in denen der Zielwert fehlt
df = df.dropna(subset=["final_price"])
# Merkmals- und Zielspalten definieren
FEATURES = ["rating", "reviews_count", "brand"]
TARGET = "final_price"
# Datenquellenquelle explizit definieren
dataset_source = CodeDatasetSource(tags="v1")
# Datensatz mit einigen Metadaten in MLflow registrieren
mlflow_dataset = mlflow.data.from_pandas(
df[FEATURES + [TARGET]],
source=dataset_source,
name="brightdata_products",
targets=TARGET)
# Merkmale und Ziel trennen
X = df[FEATURES]
y = df[TARGET]
# Vorverarbeitungs-Pipeline:
# - Median-Imputation für numerische Spalten
# - Konstante Füllung + One-Hot-Kodierung für kategoriale Spalten
preprocessor = ColumnTransformer(
transformers=[
("num", SimpleImputer(strategy="median"), ["rating", "reviews_count"]),
("cat", Pipeline([
("imputer", SimpleImputer(strategy="constant", fill_value="unknown")),
("onehot", OneHotEncoder(handle_unknown="ignore"))
]), ["brand"]),
]
)
# Vollständige ML-Pipeline: Vorverarbeitung + RandomForest-Modell
pipeline = Pipeline(steps=[
("preprocessor", preprocessor),
("model", RandomForestRegressor(n_estimators=200, max_depth=None, random_state=42))
])
# Datensätze in Trainings- und Testdatensätze aufteilen
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# MLflow-Experiment festlegen
mlflow.set_experiment("brightdata_product_price_prediction")
# MLflow-Ausführung starten und Verfolgung von Systemmetriken aktivieren
with mlflow.start_run(log_system_metrics=True) as run:
# Datensatz als Eingabe für die Ausführung protokollieren
mlflow.log_input(mlflow_dataset, context="training")
# Trainieren der Modell-Pipeline
pipeline.fit(X_train, y_train)
# Generieren der Vorhersagen für den Testsatz
predictions = pipeline.predict(X_test)
# Protokollieren Sie die Bewertungsmetriken (RMSE und R2)
mlflow.log_metric("val_rmse", root_mean_squared_error(y_test, predictions))
mlflow.log_metric("r2_score", r2_score(y_test, predictions))
# Protokollieren Sie den CSV-Ausgabedatensatz in einer lokalen Datei und anschließend als Artefakt in MLflow.
csv_path = "cleaned_dataset.csv"
df.to_csv(csv_path, index=False, encoding="utf-8-sig", errors="replace")
mlflow.log_artifact(csv_path)
# Protokollieren Sie das trainierte Modell mit Signatur und Beispiel-Eingabe.
mlflow.sklearn.log_model(
sk_model=pipeline,
name="model",
signature=mlflow.models.infer_signature(X_train, predictions),
input_example=X_train.iloc[:3],
)
print(f"Ausführung abgeschlossen. Überprüfen Sie die Registerkarte „System Metrics“ in der MLflow-Benutzeroberfläche für die Ausführungs-ID: {run.info.run_id}")Führen Sie Ihr MLflow-Experiment mit aktivierter Python-Umgebung aus:
python experiment.pyDie Ausführung dauert einige Sekunden, haben Sie also etwas Geduld.
Mission abgeschlossen! Sie haben soeben eine MLflow-Experiment-Tracking-Pipeline mit einem von Bright Data gescrapten Datensatz implementiert.
Schritt 9: Erkunden Sie die MLflow-Tracking-Ergebnisse
Rufen Sie die MLflow-Benutzeroberfläche unter http://127.0.0.1:5000/ auf. Dort sollten Sie einen Eintrag mit dem Namen „brightdata_product_price_prediction“ sehen (dies ist der Name, der dem MLflow-Experiment im Code gegeben wurde). Klicken Sie darauf:
Wechseln Sie zum Abschnitt „Training runs“, um weitere Details anzuzeigen:
Sie sollten den letzten Lauf sehen, den Sie gerade ausgeführt haben: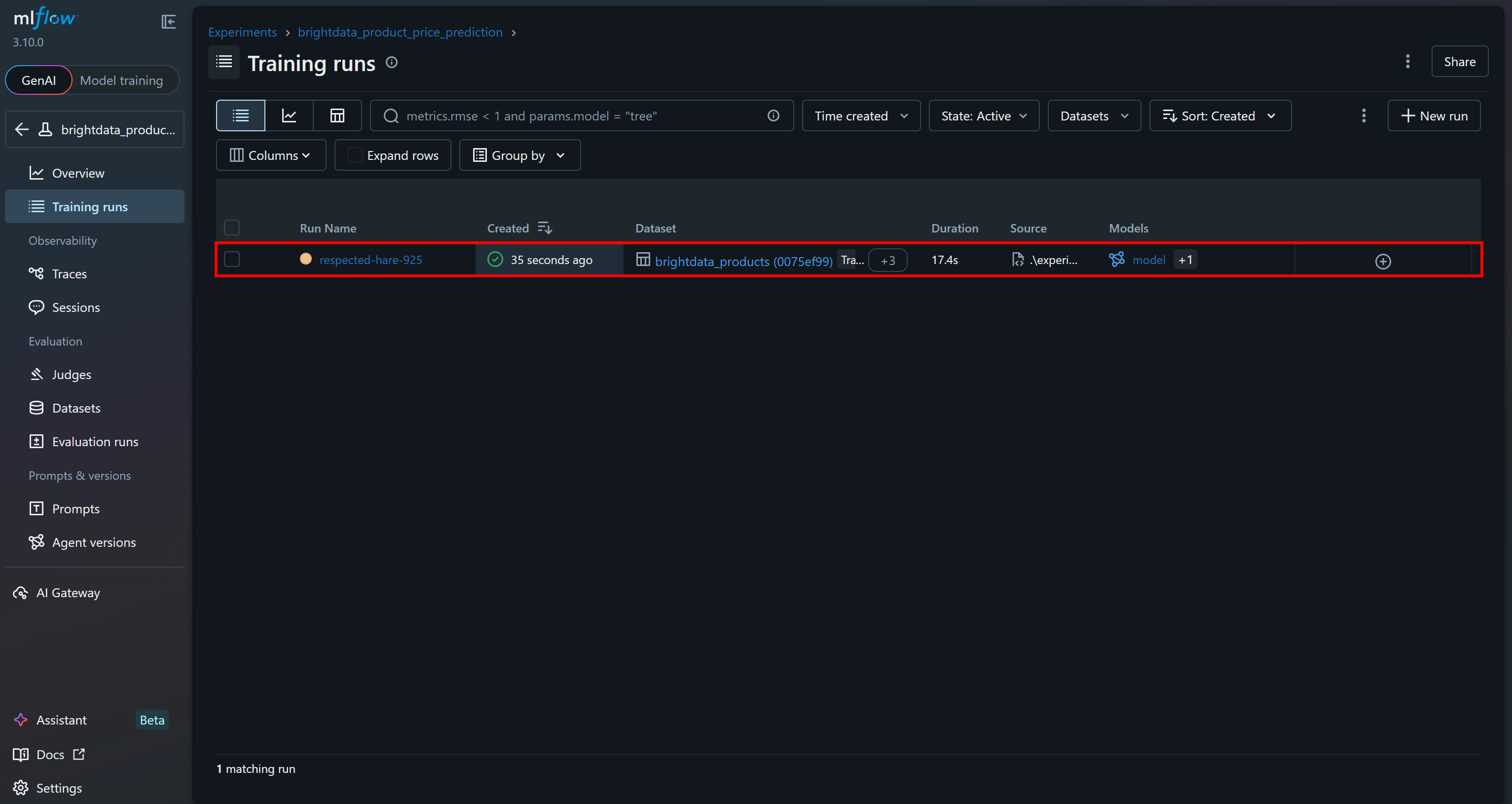
Klicken Sie darauf, um sofort auf über 15 Metriken zuzugreifen: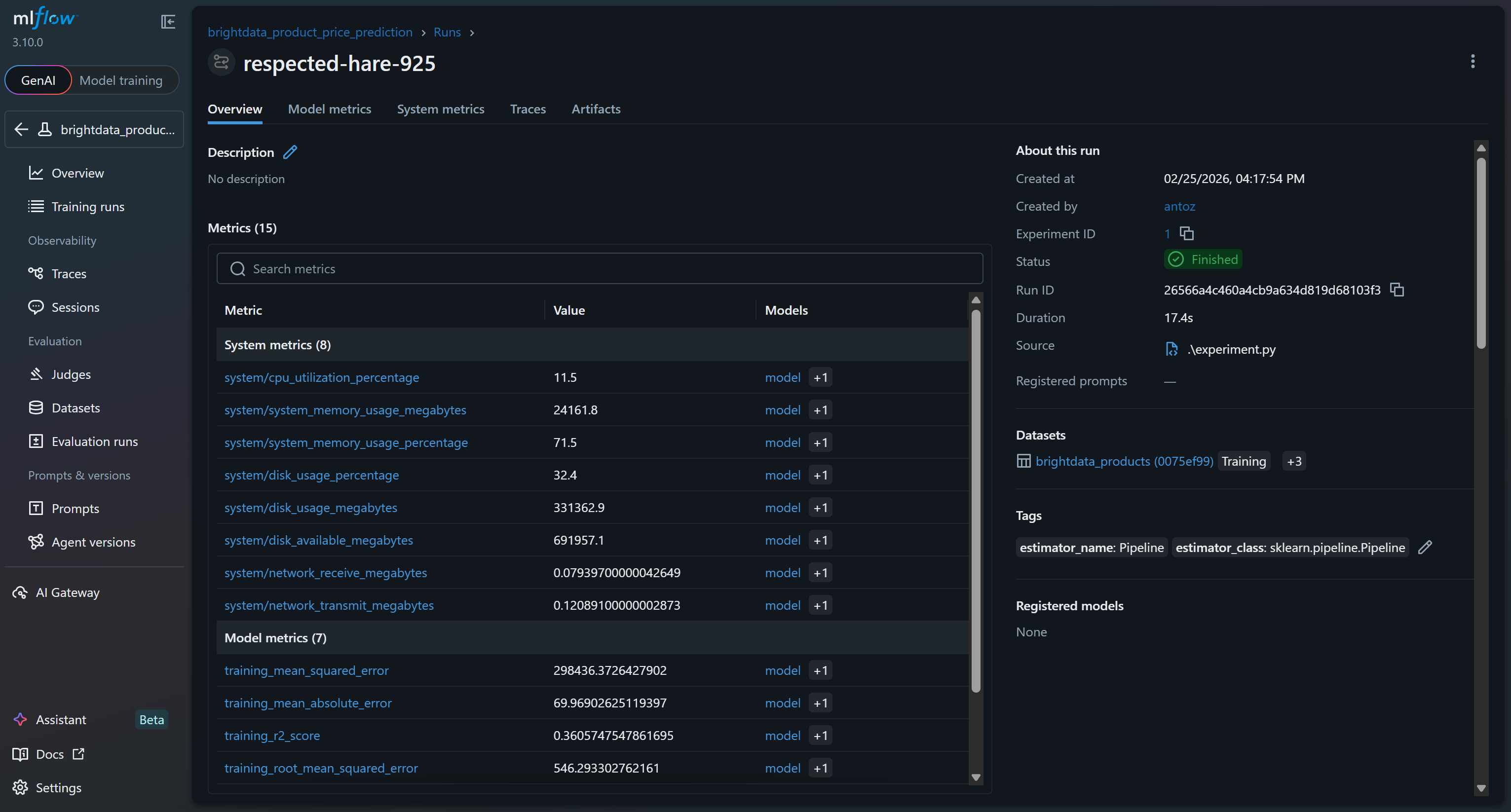
Dazu gehören System- und Modellmetriken, die automatisch von den Tracing-Funktionen von MLflow erfasst werden, sowie Modellmetriken, die während Ihres Laufs protokolliert wurden (z. B. val_rmse, r2_score).
Um die Modellmetriken zu untersuchen, rufen Sie die entsprechende Registerkarte auf: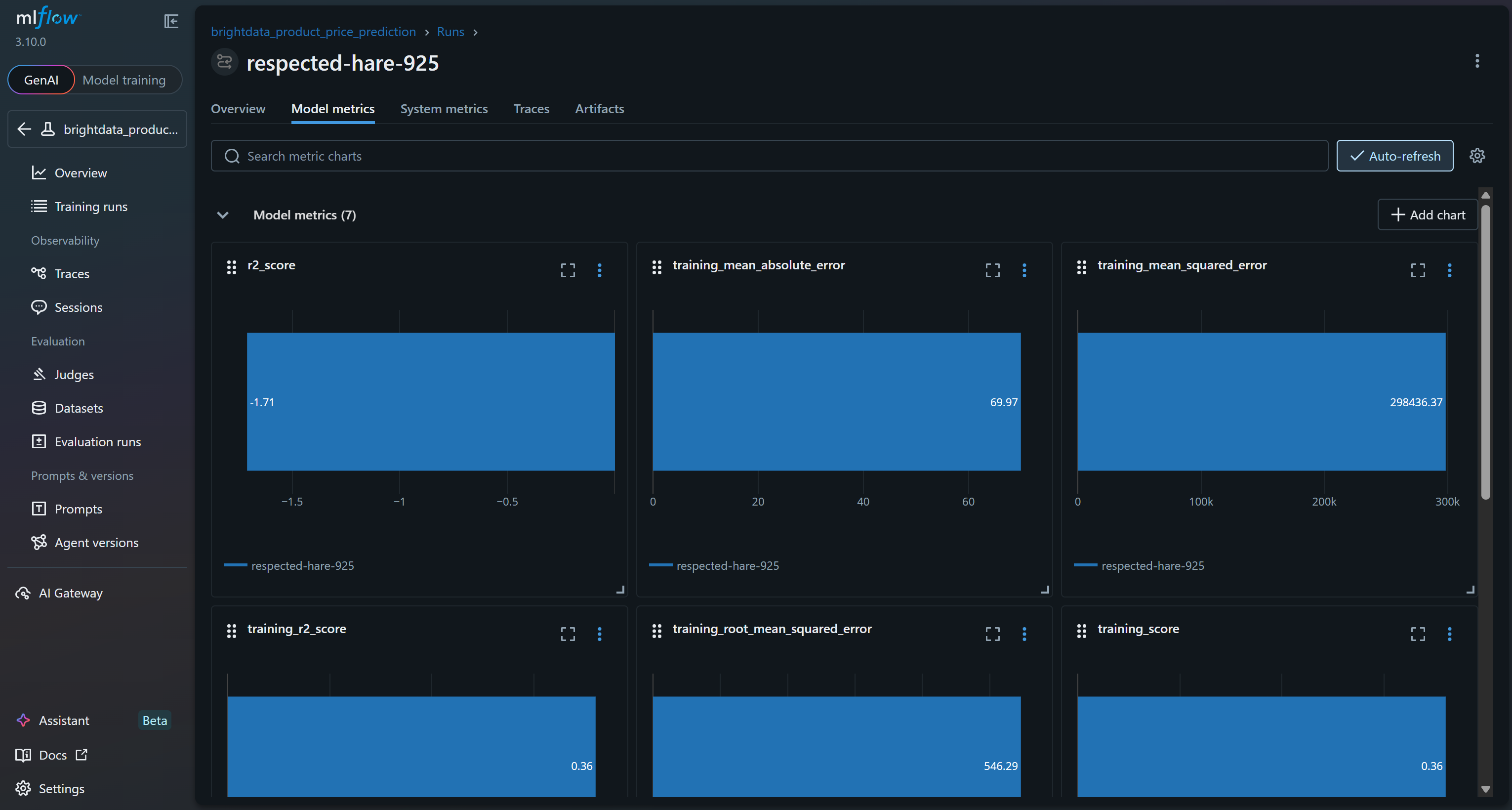
Oder sehen Sie sich die Systemmetrik-Diagramme auf der Registerkarte „Systemmetriken“ an:
Außerdem werden im Abschnitt „Artefakte” Ausgabedateien angezeigt (z. B. die Datei cleaned_dataset.csv, wie in Ihrem Code protokolliert):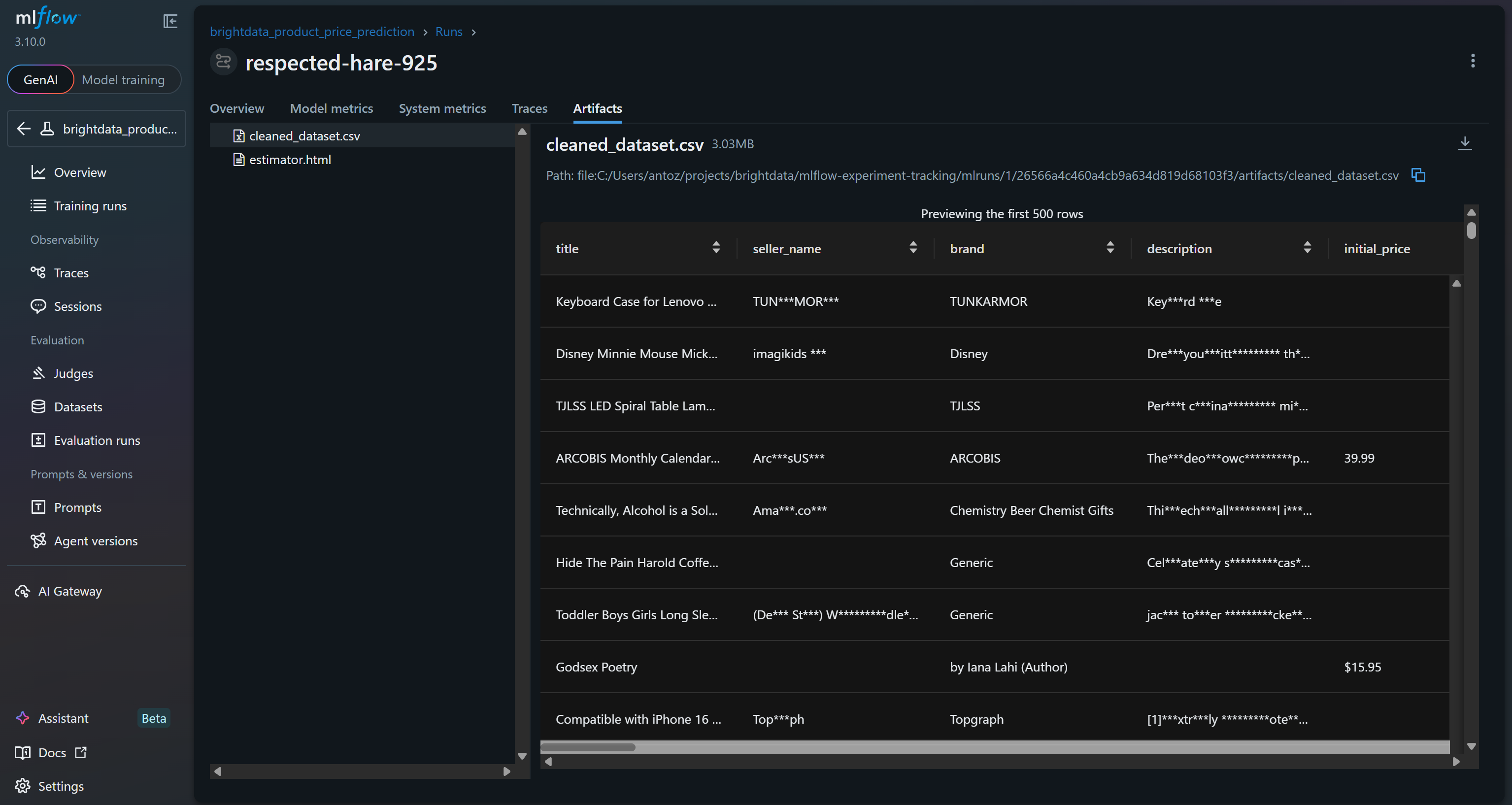
Dies sind nur einige der Metriken und Ausgaben, die Sie dank eines MLflow-Experiments verfolgen können, das auf einem von Bright Data gescrapten Datensatz basiert!
Schritt 10: Kommentieren Sie die Ergebnisse
Um zu überprüfen, ob der Modelltrainingsprozess funktioniert hat, konzentrieren Sie sich auf die Modellmetriken: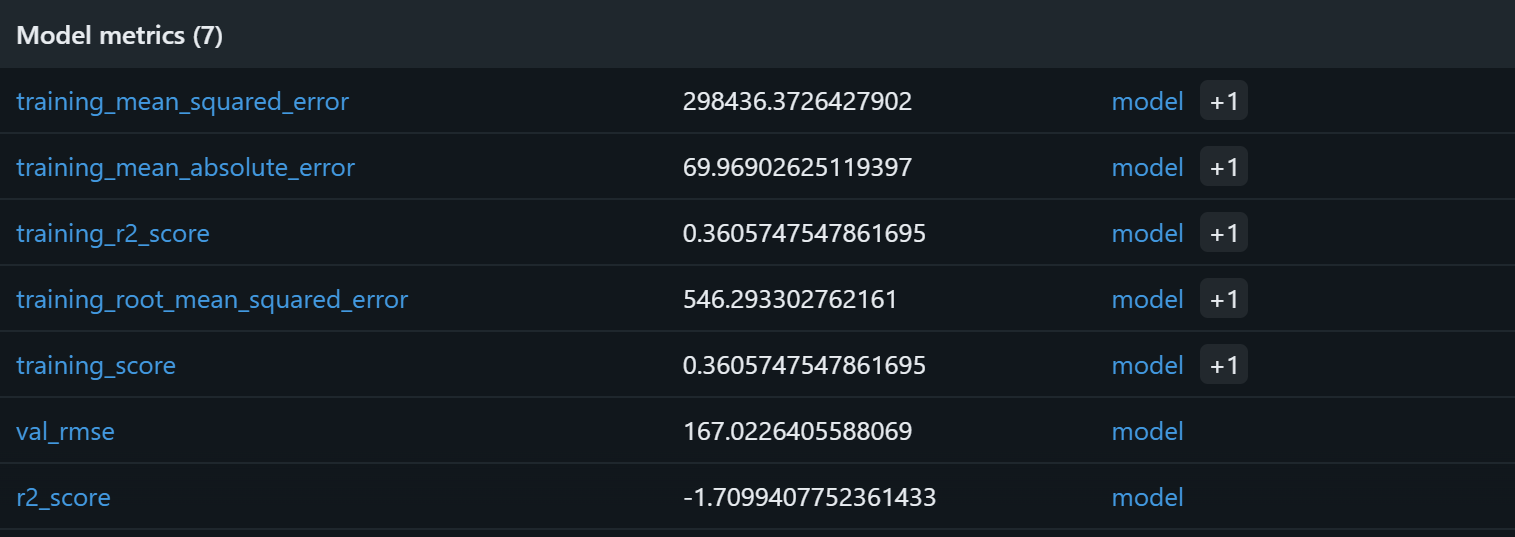
Basierend auf diesen Modellmetriken wird die aktuelle Pipeline wahrscheinlich bedeutungslose Vorhersagen für den Validierungssatz liefern. Der Trainings-R²-Wert von 0,36 zeigt an, dass das Modell etwa 36 % der Varianz in den Trainingsdaten erklärt, was eher bescheiden ist. Der Trainings-RMSE-Wert (546) und der MAE-Wert (~70) deuten darauf hin, dass die Fehler im Vergleich zu typischen Produktpreisen recht hoch sind, was möglicherweise auf verrauschte Daten oder schwache Korrelationen zwischen den Merkmalen und dem Ziel zurückzuführen ist.
Noch besorgniserregender ist die Validierungsleistung: Das R² ist negativ (-1,71) und der Validierungs-RMSE (167) bleibt signifikant. Ein negatives R² bedeutet, dass das Modell schlechter abschneidet als eine einfache Vorhersage des Durchschnittspreises für alle Stichproben. Das deutet darauf hin, dass die angenommene Beziehung zwischen Bewertung, Anzahl der Bewertungen, Marke und Endpreis möglicherweise nicht stark oder ausreichend linear ist, um von einem Random Forest effektiv erfasst zu werden!
Mögliche Verbesserungen sind die Erweiterung des Merkmalsatzes, die Durchführung von Feature Engineering (z. B. Log-Transformation der Bewertungsanzahl, Kodierung der Markenbeliebtheit), der Versuch alternativer Modelle wie Gradient Boosting oder XGBoost und die Vergrößerung des Datensatzes über die Teilmenge von 1.000 Stichproben hinaus. Mit einem größeren Bright Data-Datensatz hätten Sie mehr Daten und Vielfalt, was tiefere und relevantere Experimente ermöglichen würde.
Kurz gesagt: Die aktuelle Pipeline funktioniert technisch, kann jedoch die zugrunde liegenden Preismuster nicht angemessen erfassen. Dank der Experimentverfolgung von MLflow konnten Sie feststellen, dass die dieser Machine-Learning-Pipeline zugrunde liegenden Annahmen wahrscheinlich fehlerhaft sind.
Nächste Schritte
Wenn Sie MLflow zur Verfolgung von KI-Pipelines mit Bright Data-Datensätzen für die Feinabstimmung oder RAG verwenden möchten, denken Sie daran, dass MLflow-Tracing vollständig mit OpenTelemetry kompatibel ist. Insbesondere bietet MLflow eine LLM-Observability-Lösung, die Eingaben, Ausgaben und Metadaten für jeden Zwischenschritt einer Anfrage erfasst.
Bei der Integration mit OpenAI können Sie dies ganz einfach aktivieren mit:
import mlflow
mlflow.openai.autolog() Weitere Informationen finden Sie in der offiziellen MLflow-Dokumentation.
Fazit
In diesem Tutorial haben Sie gesehen, was MLflow für die Erstellung und Verfolgung von Machine-Learning- und KI-Pipelines zu bieten hat. Sie haben auch verstanden, warum gescrapte Datensätze hervorragende Quellen für das Training oder die Feinabstimmung von Modellen sind.
Wie gezeigt, bietet Bright Data einen umfangreichen Marktplatz für Datensätze, der Hunderte von Domänen und Milliarden von Webdaten-Datensätzen umfasst. Diese Datensätze werden durch Web-Scraping kontinuierlich aktualisiert, um Machine-Learning- und KI-Workflows zu unterstützen. Im Detail sind sie, wie hier gezeigt, perfekt mit MLflow-Tracking kompatibel.
Erstellen Sie ein kostenloses Bright Data-Konto und entdecken Sie noch heute unsere Webdatenlösungen!





