

In diesem Tutorial lernen Sie:
- Warum es sinnvoll ist, Daten von Bilibili durch Web-Scraping abzurufen.
- Welche Arten von Daten Sie von Bilibili scrapen können.
- Wie Sie eine Bilibili-Scraping- und Download-Pipeline aufbauen, um Videodaten für das Training mit KI (und andere Anwendungsfälle) zu sammeln.
- Warum ein dedizierter Bilibili-Scraper die bessere Wahl für produktionsreife Anwendungen auf Unternehmensniveau ist.
Überspringen Sie die Komplexität:Der Bilibili-Scraper von Bright Dataliefert gebrauchsfertige Videodaten im Unternehmensmaßstab mit integrierter Anti-Bot-Umgehung und einer Verfügbarkeit von 99,99 %.
Lassen Sie uns eintauchen!
Warum Bilibili scrapen: Mögliche Anwendungsfälle
Bilibili ist eine in Shanghai ansässige Videoplattform, die oft als „YouTube Chinas” bezeichnet wird. Seit ihrer Gründung im Jahr 2009 hat sie sich zu einer Macht der Generation Z entwickelt, mit über 294 Millionen aktiven Nutzern pro Monat und mehr als 3 Milliarden Videoaufrufen pro Tag.
Ursprünglich auf ACG (Anime, Comics und Spiele) ausgerichtet, umfasst sie heute auch Technologie, Bildung, Lifestyle, Musik, E-Sport und Livestreaming. Bilibili ist bekannt für seine Echtzeit-„Danmu”-Kommentare und seine hoch engagierte Community. Es kombiniert nutzergenerierte Inhalte, Influencer-Kultur, Gaming und Werbung in einem digitalen Ökosystem.
Angesichts des rasanten Wachstums von Bilibili unterstützt der Zugriff auf Daten aus der Plattform viele Anwendungsfälle, darunter
- Video-KI-Training: Umfangreiche Bilibili-Videodatensätze können Computer Vision, Spracherkennung, multimodale LLMs, Empfehlungssysteme und Modelle zur Moderation von Inhalten unterstützen. Dies ist dank reichhaltiger Metadaten, Transkripte, Interaktionssignale und roher audiovisueller Inhalte möglich.
- Trend- und Content-Intelligence: Analysieren Sie Kategorien, Tags, Aufrufe und Interaktionsmetriken, um aufkommende Themen, schnell wachsende Creator und virale Formate innerhalb der Gen-Z-Zielgruppe und ACG-gesteuerten Communities zu identifizieren.
- Analyse von Creators und Influencern: Verfolgen Sie die Leistung von Uploadern, das Follower-Wachstum, die Engagement-Raten und die Veröffentlichungshäufigkeit, um die Wirkung von KOLs (Key Opinion Leaders) zu bewerten und Influencer-Marketingstrategien in China zu optimieren.
- Analyse der Zuschauerstimmung: Werten Sie Danmu (Bullet-Kommentare) und Standardkommentare aus, um die Reaktionen der Zuschauer, den emotionalen Ton, kulturelle Referenzen und Echtzeit-Feedback-Muster in großem Maßstab zu verstehen.
- Wettbewerbsbenchmarking: Vergleichen Sie Markenkanäle, gesponserte Kampagnen und Branchenführer, indem Sie Aufrufe, Interaktionen und Content-Strategien in ähnlichen Nischen überwachen.
- Markteintritts- und Lokalisierungsforschung: Bewerten Sie Inhaltspräferenzen, Sprachgebrauch und Trendthemen, um Produkte, Kampagnen und Botschaften auf das digital affine Publikum in China zuzuschneiden.
Daten, die Sie von Bilibili abrufen können
Beim Scraping von Bilibili gibt es mehrere Datenfelder, auf die Sie abzielen können. Diese hängen von den spezifischen Arten von Seiten, von denen Sie Daten sammeln, und Ihren Gesamtzielen ab. Es gibt also mehrere interessante Bilibili-Datenkategorien, die es wert sind, erkundet zu werden.
Video-Metadaten
Wenn Sie ein bestimmtes Bilibili-Video anvisieren, können Sie Folgendes erfassen:
- Grundlegende Informationen: Titel, Beschreibung, URL des Titelbildes, Video-ID, Videolänge usw.
- Details zum Hochladen: Zeitstempel der Veröffentlichung und Kategorie/Partition (z. B. „Anime“, „Tech“ oder „Musik“).
- Kategorisierung: Tags, Schlüsselwörter und ob das Video als Originalinhalt oder als Nachdruck gekennzeichnet ist.
- Interaktionsstatistiken: Gesamtanzahl der Aufrufe, Likes, Coins, Favoriten und Shares.
- Kommentare: Die direkt im Video angezeigten Kommentare. Dazu gehören der Kommentartext, der Zeitstempel, die Farbe, die Schriftgröße und der Anzeigemodus.
- Untertitel: KI-generierte oder vom Uploader bereitgestellte Transkripte.
Benutzer- und Creator-Profile
Wenn Sie sich auf eine Bilibili-Ersteller-Seite konzentrieren, können Sie Folgendes scrapen:
- Identitätsinformationen: Benutzername, Benutzer-ID, Geschlecht, Profilbild usw.
- Soziale Kennzahlen: Anzahl der Follower, Anzahl der Following und Gesamtzahl der Likes für alle Videos.
- Persönliche Angaben: Benutzerbiografie, Geburtstag und Kontostufe.
- Kontostatus: Verifizierungsabzeichen (z. B. „Offizieller Musiker”) und Mitgliedschaftsstufe (z. B. VIP/Big Member).
- Werkliste: Alle öffentlich hochgeladenen Videos eines bestimmten Creators.
Such- und Entdeckungsdaten
Sie können auch das Suchsystem von Bilibili nutzen, um Folgendes abzurufen:
- Suchergebnisse: Listen mit Videos, Benutzern oder Live-Streams, die bestimmten Schlüsselwörtern entsprechen.
- Trenddaten: Beliebte Suchbegriffe und tägliche/wöchentliche Ranglisten.
- Informationen zu Live-Streams: Raum-ID, Stream-Titel, Live-Status und Anzahl der gleichzeitigen Zuschauer (Beliebtheitsindex).
Erstellen eines Bilibili-Scrapers und einer Pipeline zum Herunterladen von Videos in Python: Eine Schritt-für-Schritt-Anleitung
In diesem Abschnitt erfahren Sie, wie Sie Bilibili-Videometadaten von der Kategorieseite „Tech“ scrapen können:
Beachten Sie, dass dies nur ein Beispiel ist. Die gleiche Logik kann auf jede andere Kategorieseite angewendet werden, einschließlich der Hauptstartseite.
Mit den aus dieser Seite extrahierten Video-URLs erstellen Sie dann ein zweites Skript, um sie nacheinander herunterzuladen. Mit den heruntergeladenen Videodateien können Sie diese schließlich direkt in Ihre KI/ML-Trainingspipelines einspeisen.
Befolgen Sie die nachstehenden Anweisungen!
Voraussetzungen
Um diesem Tutorial folgen zu können, stellen Sie sicher, dass Sie über Folgendes verfügen:
- Python 3.10 lokal installiert ist.
- FFmpeg ist lokal installiert.
- Vertrautheit mit der Funktionsweise der Browser-Automatisierung.
- Grundlegendes Verständnis der Funktionsweise von
yt-dlp.
Überprüfen Sie mit diesem Befehl, ob FFmpeg auf Ihrem Rechner installiert ist:
ffmpeg -versionSie sollten eine ähnliche Ausgabe wie diese sehen: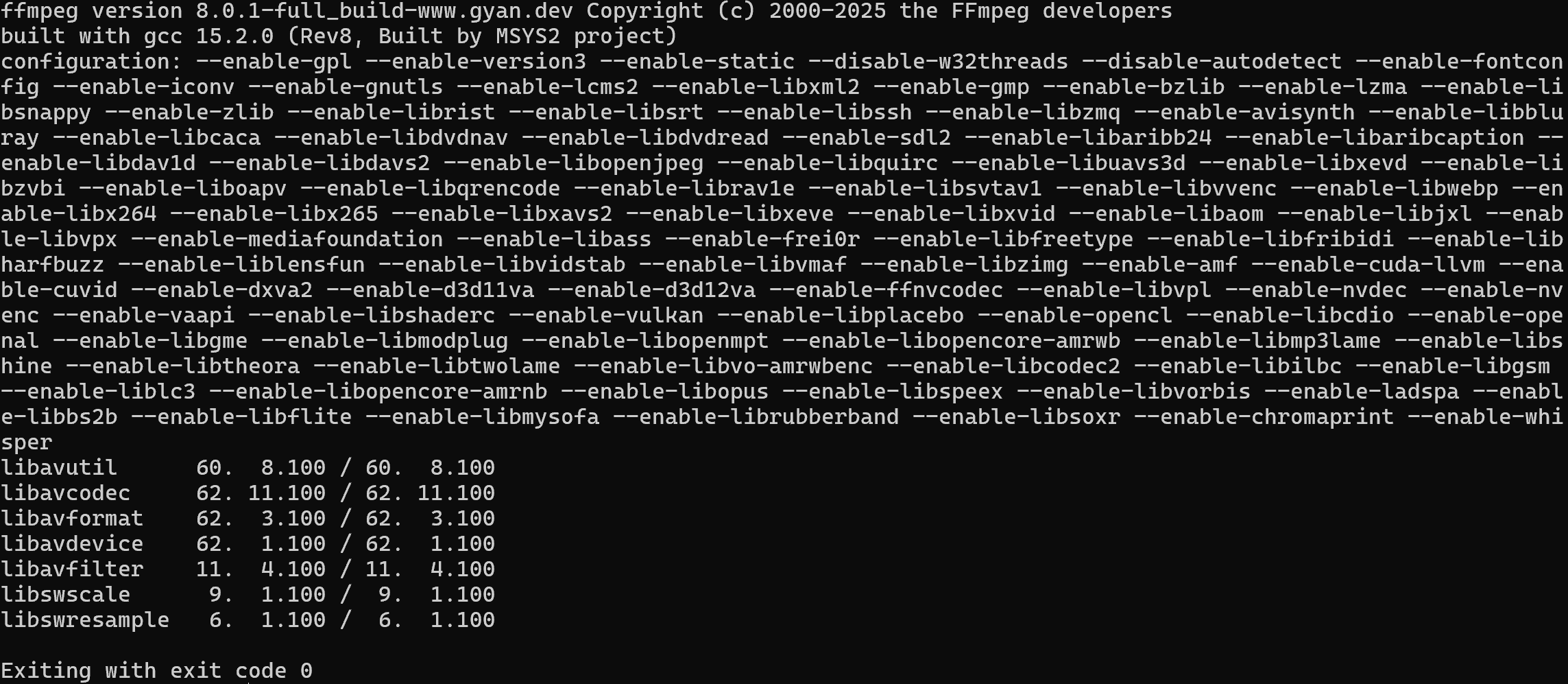
Wenn stattdessen eine Fehlermeldung angezeigt wird, installieren Sie FFmpeg gemäß der offiziellen Installationsanleitung für Ihr Betriebssystem.
Schritt 0: Machen Sie sich mit Bilibili vertraut
Bevor Sie Code schreiben, sollten Sie sich etwas Zeit nehmen, um die Zielwebsite zu erkunden. Sie müssen verstehen, ob es sich um eine statische oder dynamische Website handelt, da Ihre Web-Scraping-Roadmap davon abhängt.
Wenn die Website statisch ist, reicht möglicherweise ein einfacher HTTP-Client plus HTML-Parsing aus. Wenn sie dynamisch ist, benötigen Sie ein Browser-Automatisierungstool. Weitere Informationen finden Sie in unserem Leitfaden zu statischen und dynamischen Inhalten für das Web-Scraping.
Rufen Sie die Zielseite in Ihrem Browser auf und interagieren Sie mit ihr. Beachten Sie, dass die Seite ein UI-Muster mit unendlichem Scrollen verwendet:
Wenn Sie nach unten scrollen, werden automatisch neue Videokarten geladen. Dieses Verhalten ist ein Indikator dafür, dass die Website dynamisch ist. Genauer gesagt, nutzt sie JavaScript, um neue Daten basierend auf der Interaktion des Benutzers abzurufen und zu rendern.
Aus diesem Grund reicht eine einfache HTTP-Anfrage nicht aus. Sie benötigen ein Browser-Automatisierungstool, um den Inhalt korrekt zu rendern und zu scrapen. In diesem Tutorial verwenden wir Playwright, aber Tools wie Selenium, SeleniumBase oder NODRIVER würden ebenfalls funktionieren.
Schritt 1: Richten Sie Ihr Playwright-Projekt ein
Starten Sie zunächst Ihr Terminal und erstellen Sie ein neues Verzeichnis für Ihren Bilibili-Scraper:
mkdir bilibili-ScraperWechseln Sie in das Projektverzeichnis und erstellen Sie darin eine virtuelle Python-Umgebung:
cd bilibili-Scraper
python -m venv .venvLaden Sie anschließend den Projektordner in Ihre bevorzugte Python-IDE. Visual Studio Code mit der Python-Erweiterung und PyCharm Community Edition sind beide gute Optionen.
Erstellen Sie eine neue Datei mit dem Namen scraper.py im Stammverzeichnis des Projektverzeichnisses, die wie folgt aussehen sollte:
bilibili-Scraper/
├── .venv/
└── scraper.py # <-----------Aktivieren Sie die virtuelle Umgebung im integrierten Terminal Ihrer IDE. Unter Linux/macOS führen Sie folgenden Befehl aus:
source .venv/bin/activateUnter Windows führen Sie stattdessen folgenden Befehl aus:
.venv/Scripts/activateNachdem die virtuelle Umgebung aktiviert ist, installieren Sie Playwright mit:
pip install playwrightSchließen Sie die Installation ab, indem Sie die erforderlichen Browser-Binärdateien herunterladen:
python -m playwright installFügen Sie nun die folgende grundlegende Playwright-Konfiguration zu scraper.py hinzu:
import asyncio
from playwright.async_api import async_playwright
async def main():
async with async_playwright() as p:
# Starten Sie eine kontrollierte Chromium-Instanz im Headful-Modus.
browser = await p.chromium.launch(headless=False) # Setzen Sie in der Produktion auf True.
context = await browser.new_context()
page = await context.new_page()
# Scraping-Logik...
# Schließen Sie den Browser und geben Sie seine Ressourcen frei.
await browser.close()
if __name__ == "__main__":
asyncio.run(main())Dieser Ausschnitt initialisiert eine Chromium-Browserinstanz und lässt Playwright diese steuern.
Während der Entwicklung ist es hilfreich, headless=False beizubehalten, damit Sie visuell verfolgen können, was der Browser tut. In der Produktion sollten Sie headless=True einstellen, um den Ressourcenverbrauch zu reduzieren und die Ausführung durch Aktivieren des Headless-Modus zu beschleunigen.
Gut gemacht! Sie haben nun eine Python-Umgebung, die für das Web-Scraping von Bilibili über die Browser-Automatisierung bereit ist.
Schritt 2: Verbindung zur Zielwebsite herstellen
Verwenden Sie Playwright, um zur Zielwebseite zu navigieren, bei der es sich um die Bilibili-Seite der Kategorie „Tech” handelt:
# Die Zielseite „Technologie” von Bilibili
target_bilibili_page = „https://www.bilibili.com/c/tech/”
# Zur Zielseite navigieren
await page.goto(target_bilibili_page)Die Funktion goto() weist den gesteuerten Browser an, die angegebene URL aufzurufen und zu warten, bis die Seite geladen ist.
Das war’s schon! Sie sind nun mit der Zielseite von Bilibili verbunden.
Der nächste Schritt besteht darin, die Scroll-Interaktion zu automatisieren, damit neue Videokarten dynamisch geladen werden. Sobald die zusätzlichen Inhalte angezeigt werden, können Sie die Daten aus diesen HTML-Elementen extrahieren.
Schritt 3: Neue Videokarten laden
Wie bereits erwähnt, basieren die Startseite und die Kategorieseiten von Bilibili auf dem UI-Muster des unendlichen Scrollens. Zunächst sind nur wenige Videokarten sichtbar. Wenn Sie nach unten scrollen, werden weitere Inhalte dynamisch über JavaScript geladen.
Konkret wird die Seite zunächst mit einer festen Anzahl von Videokartenelementen innerhalb eines .head-cards-HTML-Elements geladen: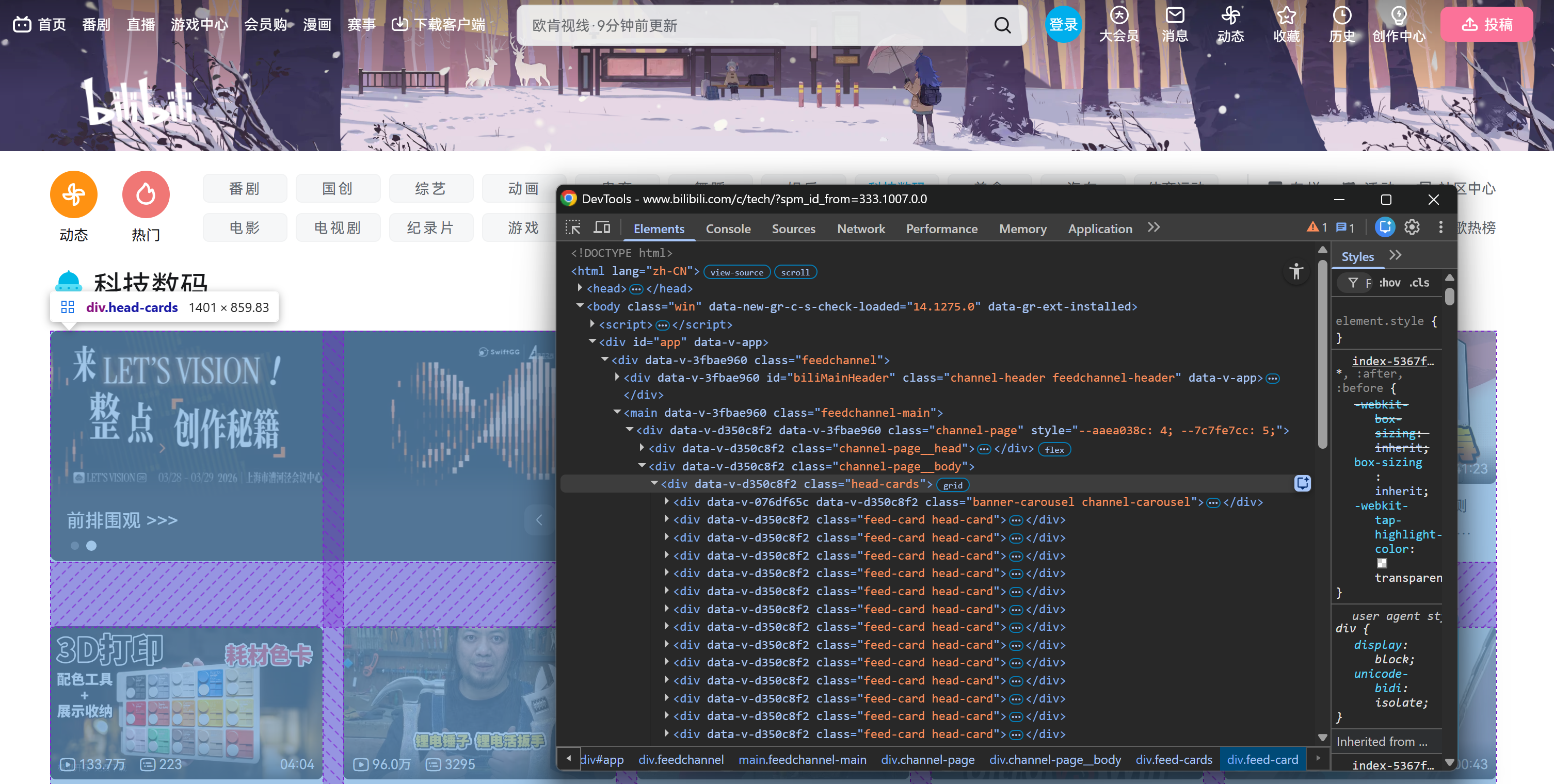
Nach dem Herunterscrollen wird der Seite ein .feed-cards-Container hinzugefügt. Dieser Abschnitt wird dynamisch mit neuen Videokarten gefüllt, während Sie weiter scrollen: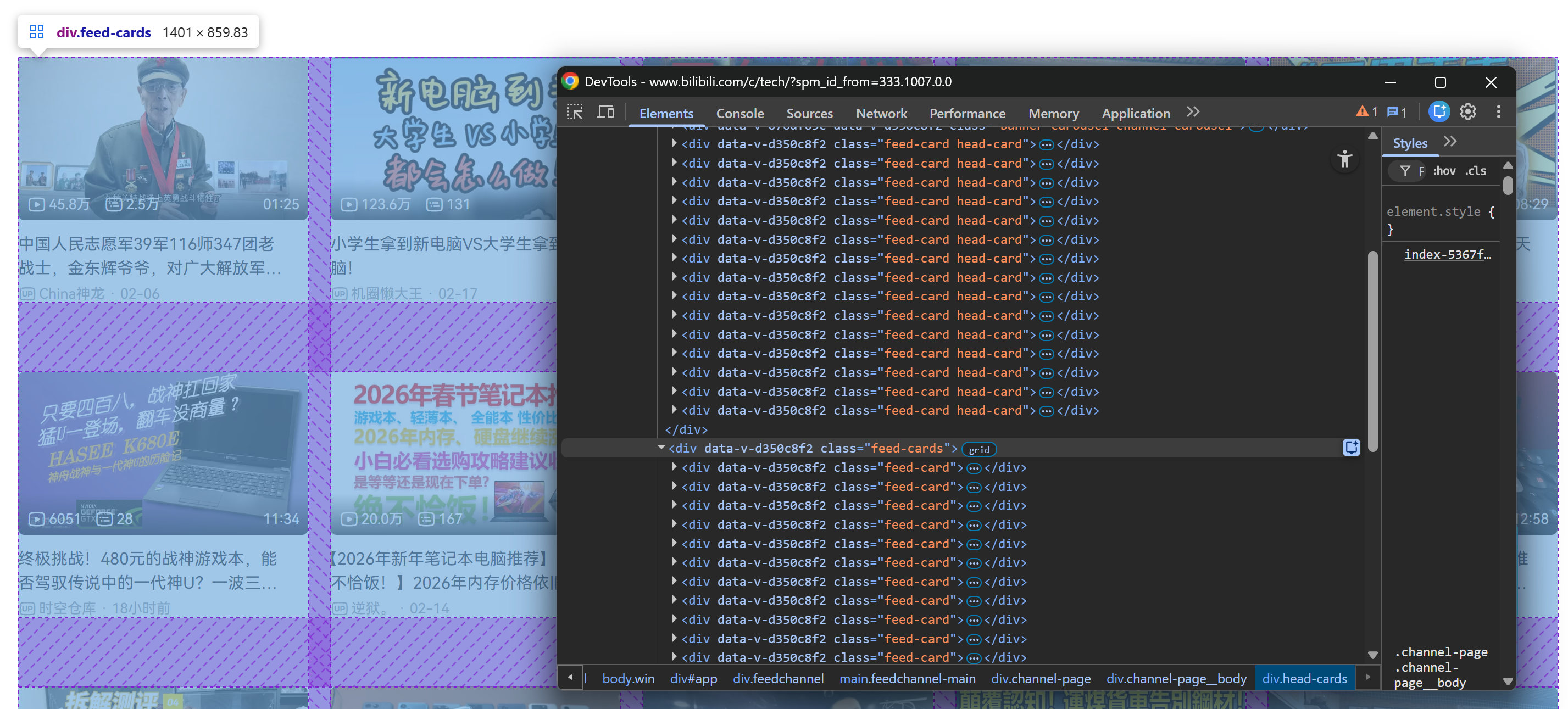
Wichtig ist hier, dass alle Videokarten (unabhängig davon, ob sie beim ersten Laden der Seite statisch vorhanden sind oder beim Scrollen dynamisch geladen werden) über diesen CSS-Selektor ausgewählt werden können:
.feed-cardIn diesem Bilibili-Scraping-Tutorial gehen wir davon aus, dass Sie mindestens 50 Videos abrufen möchten. Um dies zu erreichen, müssen Sie mehrere Scroll-Interaktionen simulieren. Playwright bietet keine spezifische API für das Scrollen, daher führen Sie ein einfaches JavaScript-Skript direkt im Seitenkontext aus:
for _ in range(3):
# Lazy Loading zulassen
await asyncio.sleep(1)
await page.evaluate("window.scrollTo(0, document.body.scrollHeight)")
# Lazy Loading zulassen
await asyncio.sleep(2) Diese Schleife führt window.scrollTo() dreimal aus und scrollt bei jeder Iteration vom oberen zum unteren Rand der Seite. Die Aufrufe von asyncio.sleep() sind wichtig, weil:
- Sie lassen das Scrollverhalten natürlicher erscheinen.
- Sie verringern das Risiko, Anti-Bot-Mechanismen auszulösen.
- Sie geben lazy-geladenen Inhalten Zeit, sich vollständig zu rendern, bevor zum nächsten Bildlauf übergegangen wird.
Da Videokarten dynamisch geladen werden, kann man nicht davon ausgehen, dass sie unmittelbar nach dem Scrollen verfügbar sind. Stattdessen muss man explizit warten, bis die 50. Karte an das DOM angehängt ist. In Playwright geschieht dies mit:
fiftieth_card = page.locator(".feed-card").nth(49)
await fiftieth_card.wait_for(state="attached")Dieser Code erstellt einen Playwright-Locator für das 50. .feed-card-Element (nth(49), da die Indizierung bei 0 beginnt). Dann wartet er mit wait_for(), bis dieses Element an das DOM angehängt ist.
Wenn Sie das Skript nun im Headful-Modus (headless=False) ausführen, sehen Sie, wie der Browser dreimal selbstständig scrollt:
Wie beabsichtigt, werden nach jedem Scrollen neue Videokarten geladen.
Nach diesem Schritt können Sie sicher sein, dass mindestens 50 Grafikkarten auf der Seite vorhanden sind. Fantastisch!
Schritt 4: Machen Sie sich mit der Struktur der Grafikkarte vertraut
Um die richtigen Daten zu extrahieren, müssen Sie zunächst verstehen, wie jede Grafikkarte im DOM strukturiert ist.
Klicken Sie zunächst mit der rechten Maustaste auf eine der Grafikkarten im Abschnitt .head-cards und überprüfen Sie diese in den Entwicklertools des Browsers: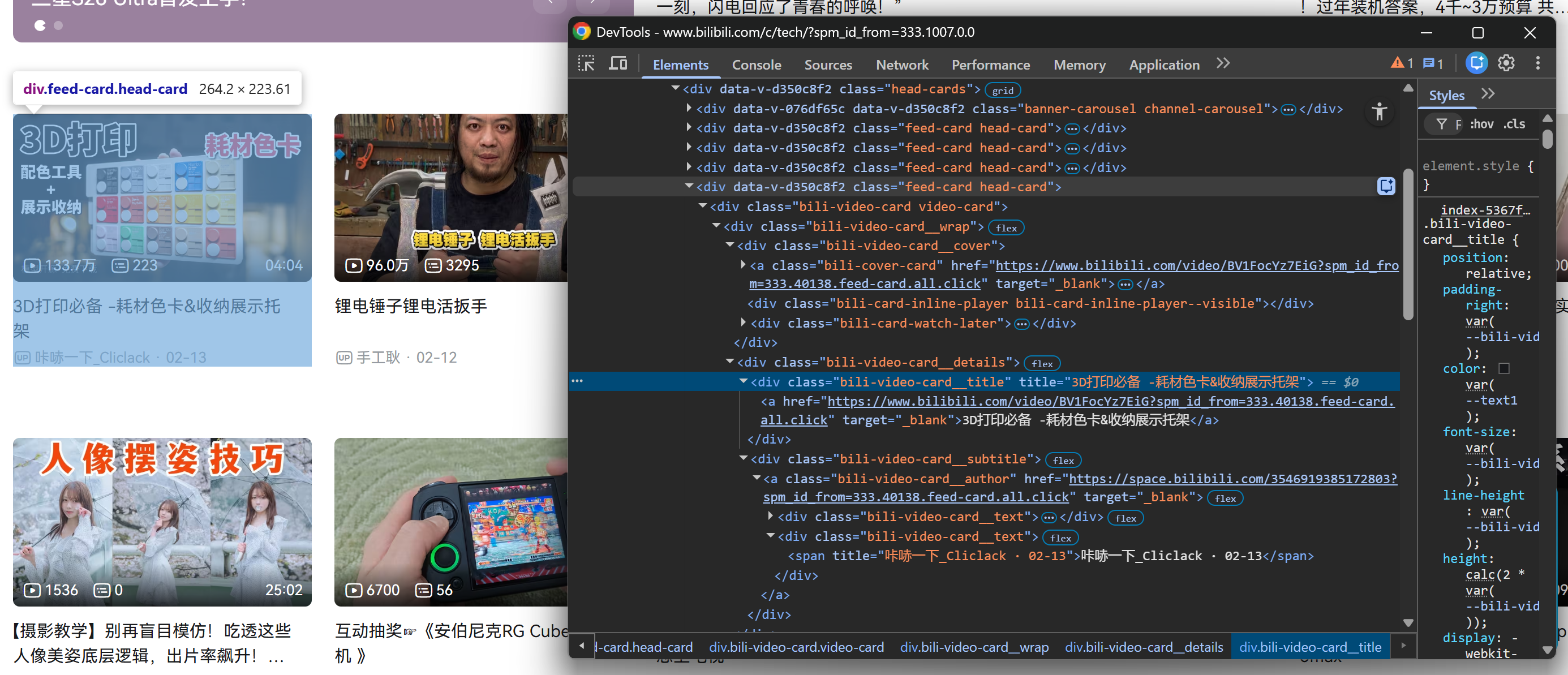
Wiederholen Sie dann denselben Vorgang für eine Grafikkarte im geladenen Abschnitt .feed-cards: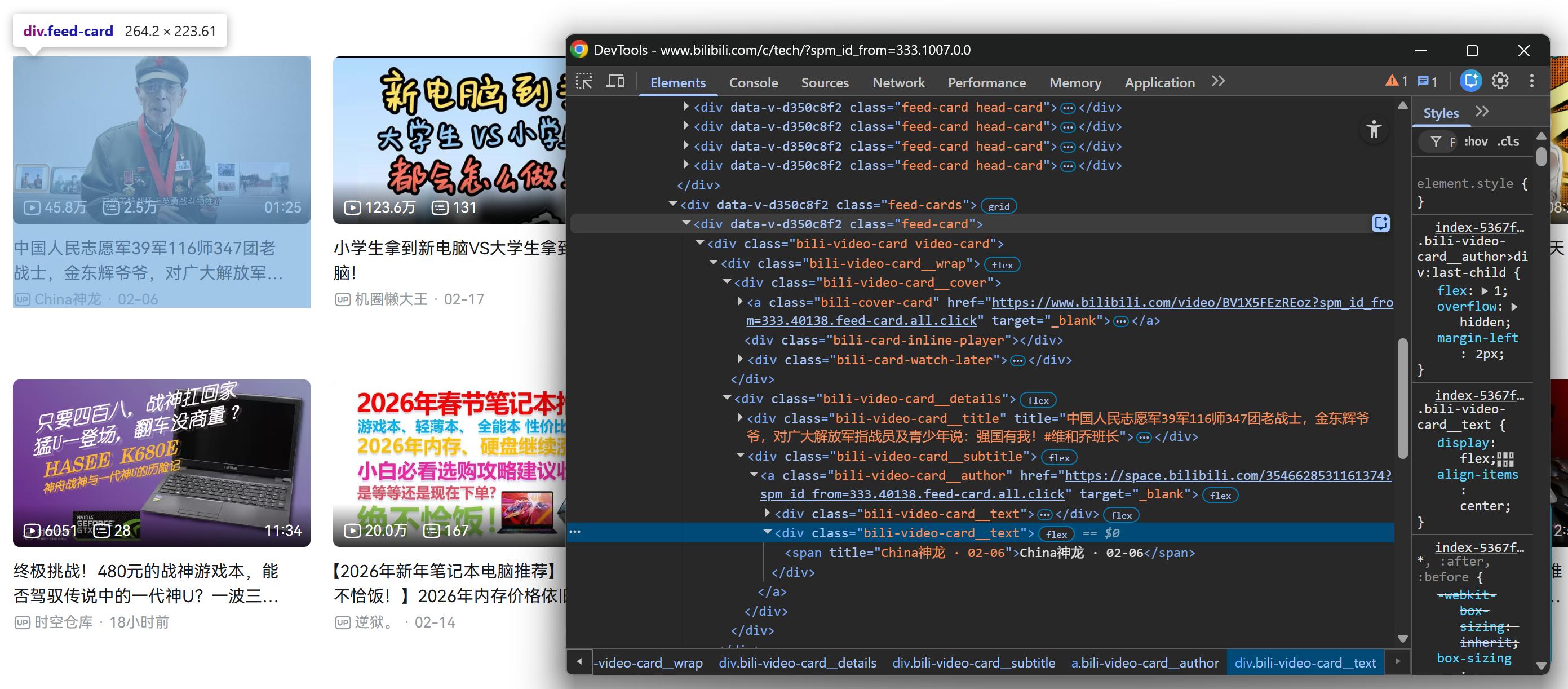
Glücklicherweise haben alle .feed-card-Elemente die gleiche interne Struktur. Das bedeutet, dass Sie nicht zwischen Grafikkarten unterscheiden müssen, die beim ersten Rendern der Seite geladen werden, und Grafikkarten, die nach dem Scrollen dynamisch geladen werden. Sie können sie alle mit denselben Selektoren ansprechen!
Beachten Sie, wie Sie aus jeder Videokarte Folgendes erfassen können:
- Den Videotitel aus dem Element
.bili-video-card__title a. - Die Video-URL aus dem
href-Attribut desselben Titel-Knotens<a>. - Den Rohuntertitel (der den Namen des Autors und das Veröffentlichungsdatum enthält) aus
.bili-video-card__subtitle span[title]. - Die URL des Autorenprofils aus dem Element
.bili-video-card__author.
Perfekt! Nachdem Sie nun die DOM-Struktur verstanden haben, besteht der nächste Schritt darin, dieses Wissen in eine programmatische Logik zum Scraping von Bilibili-Daten umzusetzen.
Schritt 5: Scrapen der Videodaten
Denken Sie daran, dass die Zielseite mehrere Videokarten enthält. Daher benötigen Sie zunächst eine Datenstruktur, um die gescraped Ergebnisse zu speichern. Eine Liste ist dafür perfekt geeignet:
videos = []Als Nächstes durchlaufen Sie alle Videokarten und wenden die zuvor beschriebene Extraktionslogik an:
for i in range(feed_card_count):
# Die aktuelle Videokarte abrufen, aus der Daten extrahiert werden sollen
card = feed_cards.nth(i)
title_locator = card.locator(".bili-video-card__title a")
title = await title_locator.inner_text() if await title_locator.count() else None
video_url = await title_locator.get_attribute("href") if await title_locator.count() else None
subtitle_locator = card.locator(".bili-video-card__subtitle span[title]")
subtitle = await subtitle_locator.inner_text() if await subtitle_locator.count() else None
author_locator = card.locator(".bili-video-card__author")
author_url = await author_locator.get_attribute("href") if await author_locator.count() else None
author_name = None
date = None
if subtitle and "·" in subtitle:
parts = [p.strip() for p in subtitle.split("·")]
if len(parts) >= 2:
author_name = parts[0]
date = parts[1]
# Speichern der gescrapten Daten
video = {
"title": title,
"video_url": video_url,
"subtitle": subtitle,
"author": {
"name": author_name,
"url": author_url
},
"date": date
}
videos.append(video)Der obige Ausschnitt durchläuft jede Videokarte und:
- Extrahiert den Titel, die Video-URL, den Roh-Untertitel und die URL des Autorenprofils.
- Das Parsing der Untertitelzeichenfolge (die dem Format
„<AUTOR_NAME> · <DATUM>”folgt) führt zu der Extraktion des Namens des Autors und des Datums des Videos. - Erstellt ein strukturiertes
Video-Wörterbuch und hängt es an die Videolistean.
Am Ende der for -Schleife enthält die Vide oliste mehr als 50 strukturierte Bilibili-Videoobjekte. Großartig!
Schritt 6: Exportieren der gescrapten Daten
Um die Verarbeitung der gescrapten Daten zu vereinfachen, exportieren Sie diese in eine Datei namens „videos.json “:
import json
with open("videos.json", "w", encoding="utf-8") as f:
json.dump(videos, f, ensure_ascii=False, indent=2)Wenn Sie jetzt scraper.py ausführen, sollte eine Datei „videos.json” mit strukturierten Bilibili-Videodaten wie folgt generiert werden: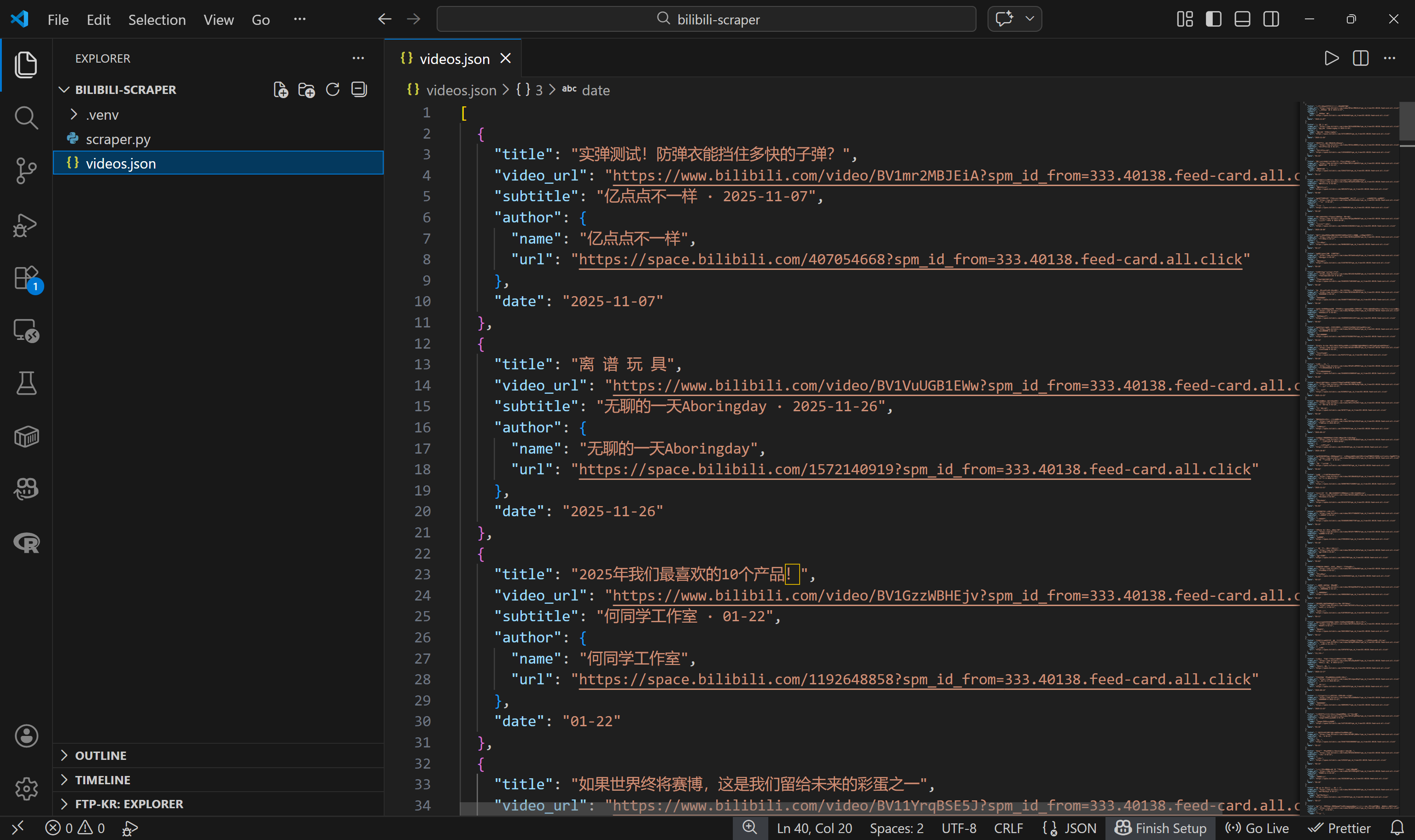
Mission erfüllt! Sie haben mit einer Seite begonnen, die viele Videokarten enthält, und haben nun deren Metadaten in einer strukturierten JSON-Datei gespeichert.
Wenn Ihr Ziel lediglich darin besteht, Bilibili zu scrapen, könnte das Tutorial hier enden (sehen Sie sich nur den letzten Schritt für das vollständige Skript an). Wenn Sie noch einen Schritt weiter gehen und die Videos selbst herunterladen möchten, lesen Sie weiter…
Schritt 7: Bereiten Sie sich auf den Download der Bilibili-Videos vor
Der einfachste Weg, Bilibili-Videos von den zuvor gescrapten URLs herunterzuladen, ist die Verwendung von yt-dlp.
yt-dlp ist ein funktionsreicher Audio-/Video-Downloader, der Hunderte von Websites unterstützt, darunter auch Bilibili. Es kann sowohl über die Befehlszeile als auch über eine programmatische Python-API verwendet werden. Hier werden wir es programmgesteuert über seine Python-API nutzen.
Installieren Sie yt-dlp, nachdem Sie Ihre virtuelle Umgebung aktiviert haben:
pip install yt-dlpFügen Sie dann eine neue Datei namens video-downloader.py zum Stammverzeichnis Ihres Projekts hinzu:
bilibili-Scraper/
├── .venv/
├── scraper.py
└── video-downloader.py # <-----------Diese Datei enthält die yt-dlp-basierte Logik zum Herunterladen von Bilibili-Videos.
Das Skript video-downloader.py muss:
- Die Datei
videos.jsonlesen. - Die
video_urlfür jedes Video extrahieren. - Die
YoutubeDL-Klasse ausyt_dlpverwenden, um die Videodateien herunterzuladen.
Nachfolgend finden Sie die Implementierung:
import os
import json
from yt_dlp import YoutubeDL
INPUT_FILE = "videos.json"
OUTPUT_DIR = "./videos"
# Laden der Videodaten aus der Eingabe-JSON-Datei
with open(INPUT_FILE, "r", encoding="utf-8") as f:
videos = json.load(f)
print(f"{len(videos)} Videos aus {INPUT_FILE} geladenn")
# Sicherstellen, dass der Ausgabeordner existiert
os.makedirs(OUTPUT_DIR, exist_ok=True)
ydl_opts = {
"format": "bestvideo+bestaudio/best",
"outtmpl": f"{OUTPUT_DIR}/%(title)s.%(ext)s",
"merge_output_format": "mp4",
}
with YoutubeDL(ydl_opts) as ydl:
for index, video in enumerate(videos, start=1):
video_url = video.get("video_url")
print(f"[{index}/{len(videos)}] Downloading: {video.get('title')}")
try:
ydl.download([video_url])
print(f"Video #{index} heruntergeladenn")
except Exception as e:
print(f"Video #{index} Download fehlgeschlagen: {e}n")Wow! Weniger als 35 Zeilen Code reichten aus, um das Ziel zu erreichen.
Schritt 8: Herunterladen der Videodateien
Stellen Sie sicher, dass ffmpeg lokal installiert ist, und führen Sie dann das Skript video-downloader.py aus. Im Terminal sollte etwa Folgendes angezeigt werden: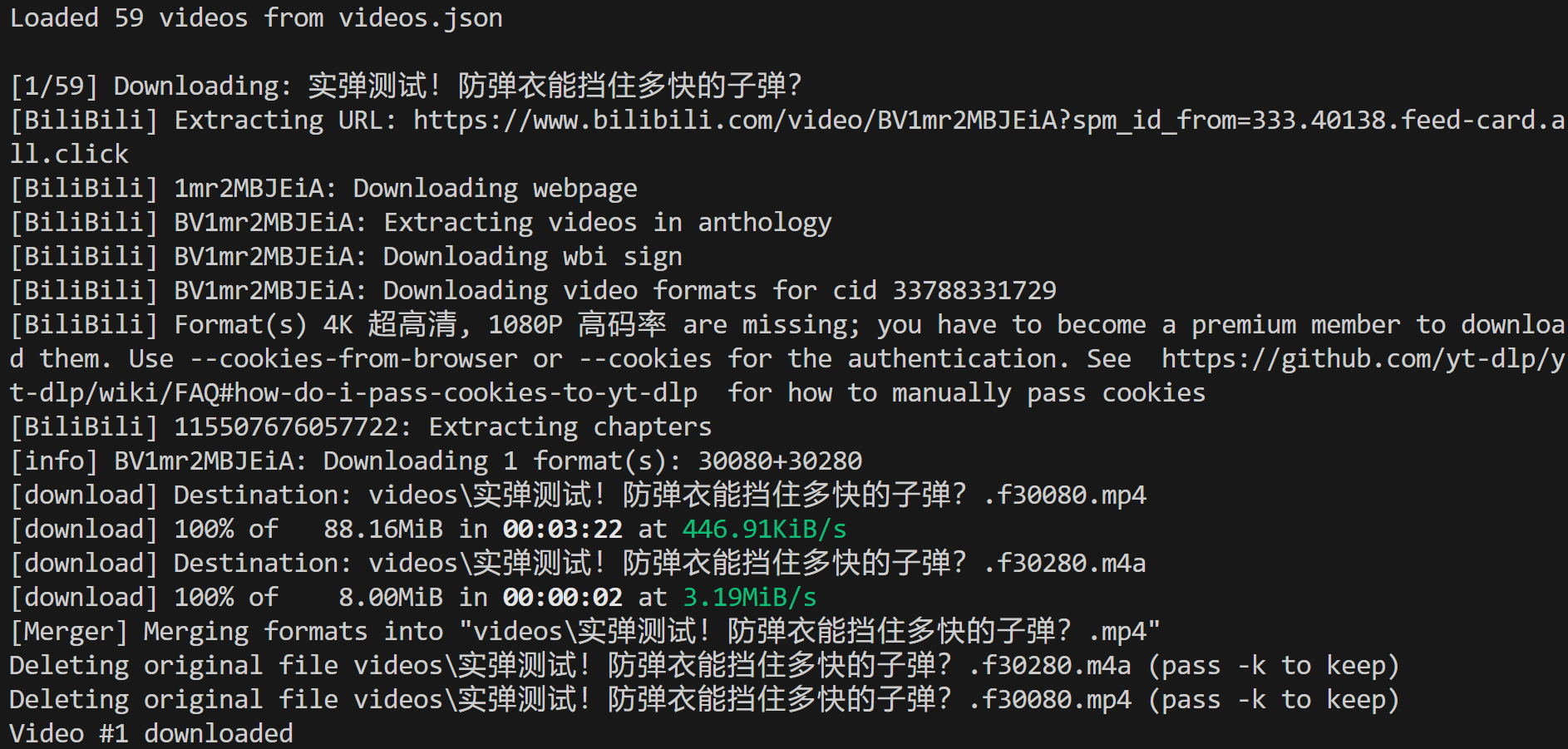
Dies zeigt, dass 59 Videos aus der Eingabedatei videos.json geladen wurden und das erste erfolgreich in den lokalen Pfad heruntergeladen wurde:
./videos/实弹测试!防弹衣能挡住多快的子弹?.mp4In Visual Studio Code sehen Sie die MP4-Videodatei genau in diesem Pfad: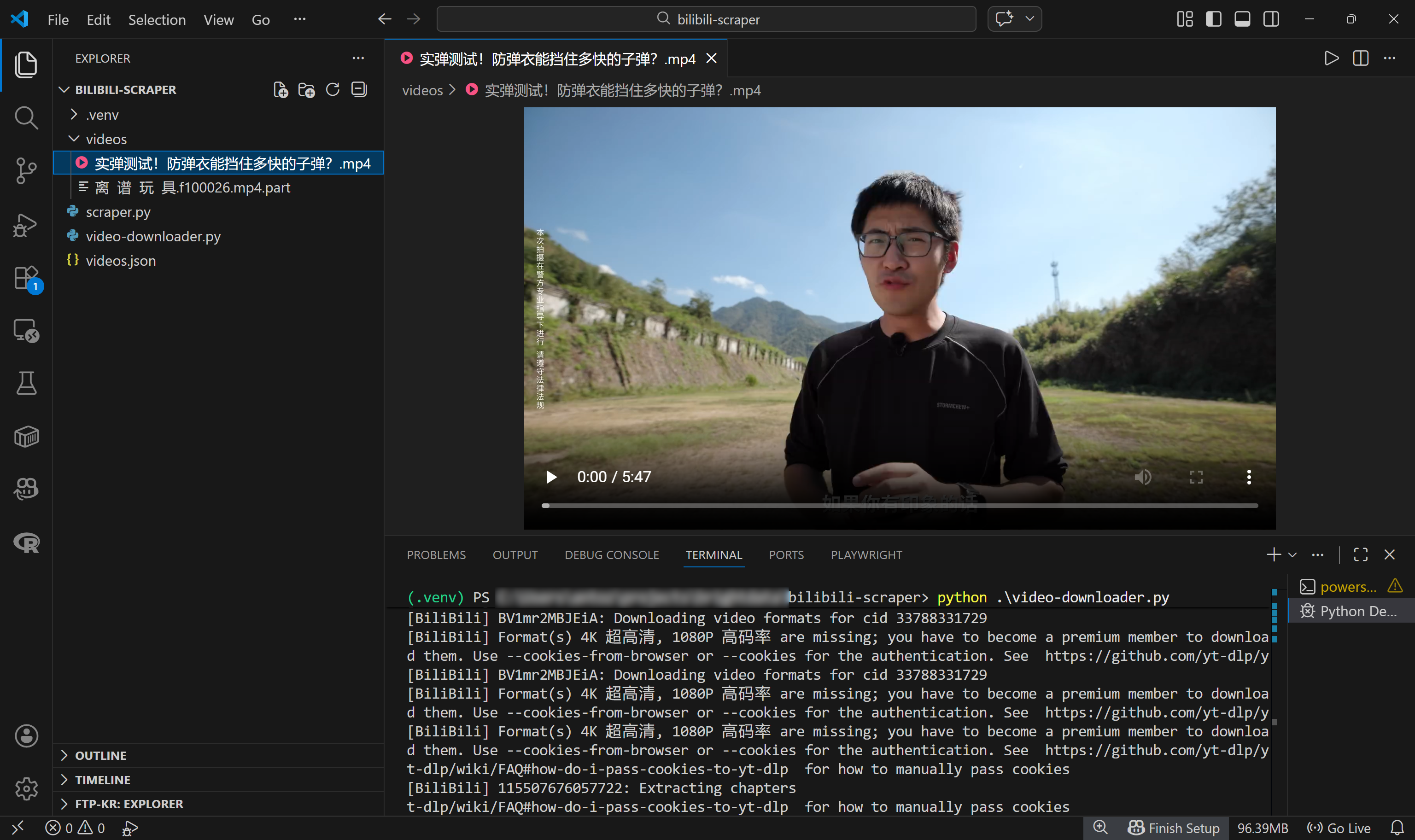
Erstaunlich! Sie verfügen nun über ein vollständig automatisiertes Bilibili-System, das nicht nur neue Videos entdeckt, sondern diese auch herunterlädt. Mit diesen Dateien können Sie sogar KI-Modelle über eine multimodale ML-Pipeline trainieren.
Schritt 9: Endgültiger Code
Die Datei scraper.py enthält den folgenden Code:
# scraper.py
# pip install playwright
# python -m playwright install
import asyncio
from playwright.async_api import async_playwright
import json
async def main():
async with async_playwright() as p:
# Starten Sie eine kontrollierte Chromium-Instanz im Headful-Modus.
browser = await p.chromium.launch()
context = await browser.new_context()
page = await context.new_page()
# Die Zielseite „Tech” von Bilibili
target_bilibili_page = „https://www.bilibili.com/c/tech/”
# Zur Zielseite navigieren
await page.goto(target_bilibili_page)
# Dreimal die gesamte Seite nach unten scrollen
for _ in range(3):
# Lazy Loading zulassen
await asyncio.sleep(1)
await page.evaluate("window.scrollTo(0, document.body.scrollHeight)")
# Lazy Loading zulassen
await asyncio.sleep(2)
# Warten, bis das 50. Videokartenelement an das DOM angehängt ist
fiftieth_card = page.locator(".feed-card").nth(49)
await fiftieth_card.wait_for(state="visible")
# Alle Feed-Karten über Locator auswählen
feed_cards = page.locator(".feed-card")
feed_card_count = await feed_cards.count()
print(f"{feed_card_count} Feed-Karten geladen.")
# Speicherort für die gescrapten Daten
videos = []
# Bilili-Datenscraping-Logik auf jede Videokarte anwenden
for i in range(feed_card_count):
# Aktuelle Videokarte zum Extrahieren von Daten abrufen
card = feed_cards.nth(i)
title_locator = card.locator(".bili-video-card__title a")
title = await title_locator.inner_text() if await title_locator.count() else None
video_url = await title_locator.get_attribute("href") if await title_locator.count() else None
subtitle_locator = card.locator(".bili-video-card__subtitle span[title]")
subtitle = await subtitle_locator.inner_text() if await subtitle_locator.count() else None
author_locator = card.locator(".bili-video-card__author")
author_url = await author_locator.get_attribute("href") if await author_locator.count() else None
author_name = None
date = None
if subtitle and "·" in subtitle:
parts = [p.strip() for p in subtitle.split("·")]
if len(parts) >= 2:
author_name = parts[0]
date = parts[1]
# Speichern der gescrapten Daten
video = {
"title": title,
"video_url": video_url,
"subtitle": subtitle,
"author": {
"name": author_name,
"url": author_url
},
"date": date
}
videos.append(video)
# Schließen des Browsers und Freigabe seiner Ressourcen
await browser.close()
# Exportieren der gesammelten Daten in eine JSON-Datei
with open("videos.json", "w", encoding="utf-8") as f:
json.dump(videos, f, ensure_ascii=False, indent=2)
print(f"{len(videos)} gescrapte Bilibili-Videos in videos.json exportiert")
if __name__ == "__main__":
asyncio.run(main())Starten Sie es mit:
python Scraper.pyDadurch wird eine Datei videos.json erstellt, die die gescrapten Bilibili-Videodaten enthält. Sie können diese Videos dann mit diesem Skript video-downloader.py herunterladen:
# video-downloader.py
# pip install yt-dlp
import os
import json
from yt_dlp import YoutubeDL
INPUT_FILE = "videos.json"
OUTPUT_DIR = "./videos"
# Laden Sie die Videodaten aus der Eingabe-JSON-Datei
with open(INPUT_FILE, "r", encoding="utf-8") as f:
videos = json.load(f)
print(f"{len(videos)} Videos aus {INPUT_FILE} geladenn")
# Sicherstellen, dass der Ausgabeordner existiert
os.makedirs(OUTPUT_DIR, exist_ok=True)
ydl_opts = {
"format": "bestvideo+bestaudio/best",
"outtmpl": f"{OUTPUT_DIR}/%(title)s.%(ext)s",
"merge_output_format": "mp4",
}
with YoutubeDL(ydl_opts) as ydl:
for index, video in enumerate(videos, start=1):
video_url = video.get("video_url")
print(f"[{index}/{len(videos)}] Herunterladen: {video.get('title')}")
try:
ydl.download([video_url])
print(f"Video #{index} heruntergeladenn")
except Exception as e:
print(f"Video #{index} Download fehlgeschlagen: {e}n")Führen Sie es aus mit:
python video-downloader.pyDas Ergebnis ist ein Ordner „./videos”, der die MP4-Dateien für jedes gefundene Bilibili-Video enthält.
Et voilà! Sie haben gerade gelernt, wie Sie einen Bilibili-Scraper erstellen und damit die gescrapten Videodaten in einen Downloader einspeisen können. Dieser Prozess hilft Ihnen, die eigentlichen Videodateien für das Training mit KI oder andere Anwendungsfälle abzurufen.
Nächste Schritte
Nachdem Sie nun sowohl strukturierte Metadaten als auch die eigentlichen Videodateien haben, können Sie diese Daten an eine KI-Trainingspipeline weiterleiten. Sie könnten beispielsweise Frames für Computer-Vision-Aufgaben extrahieren, Transkripte für die Feinabstimmung von NLP-Modellen erstellen, Audiosignale analysieren oder Empfehlungssysteme auf der Grundlage von Videoinhalten und Metadaten erstellen. Die Kombination aus Titeln, Autoren, Daten und Rohvideodateien liefert Ihnen einen reichhaltigen multimodalen Datensatz, der für Experimente bereit ist.
Um die Download-Phase zu beschleunigen, sollten Sie außerdem eine Parallelisierung des Prozesses in Betracht ziehen, sodass mehrere Videos gleichzeitig heruntergeladen werden. Dieser Ansatz hilft Ihnen, Ihre verfügbare Bandbreite voll auszuschöpfen, was zu schnelleren Download-Zeiten führt.
Eine produktionsreife Lösung für das Scraping von Bilibili: Video-Daten für KI abrufen
Wenn Sie das Download-Skript für eine große Anzahl von Videos ausführen, können irgendwann Fehler wie die folgenden auftreten:
Webseite kann nicht heruntergeladen werden: HTTP-Fehler 412: Vorbedingung nicht erfüllt (verursacht durch <HTTPError 412: Precondition Failed>)Dies geschieht, weil Bilibili über einen Anti-Bot-Schutz verfügt. Wenn die Plattform verdächtigen Traffic feststellt (z. B. zu viele automatisierte Anfragen von derselben IP-Adresse), gibt sie eine 412 -Fehlermeldung ( „Voraussetzung nicht erfüllt“ ) zurück.
Die Fehlerseite sieht wie folgt aus:
Dies ist nur eine der Herausforderungen, denen Sie beim Scraping von Bilibili begegnen. Weitere häufige Probleme sind strukturelle Änderungen an den Zielseiten, die Erkennung anhand von Fingerabdrücken und vieles mehr. Eine benutzerdefinierte Playwright + yt-dlp-Konfiguration eignet sich zwar gut für kleine Projekte, aber die langfristige Wartung kann komplex und anfällig sein.
Um Bilibili zuverlässig in großem Umfang zu scrapen, benötigen Sie eine robustere Infrastruktur, die IP-Rotation, Browser-Fingerprinting, CAPTCHA-Lösung und automatische Wiederholungsversuche unterstützt. Genau das bietet der Bilibili Scraper von Bright Data.
Diese Web-Scraping-API, die auch als No-Code-Scraper verfügbar ist, ruft Videotitel, Upload-Daten, Aufrufe, Likes, Kommentare, Favoriten, Dauer, Namen der Uploader, Beschreibungen, URLs und mehr ab. Dabei umgeht sie automatisch Anti-Bot-Mechanismen für Sie.
Was den Bilibili Scraper so einzigartig macht, ist, dass er auf einer Proxy-Infrastruktur mit über 150 Millionen IPs in 195 Ländern läuft, eine Verfügbarkeit von 99,99 % und eine Erfolgsquote von 99,95 % erreicht und unbegrenzte Parallelität unterstützt. Dies ermöglicht groß angelegte Scraping-Szenarien auf Unternehmensebene, was angesichts der Tatsache, dass multimodales KI-Training riesige Mengen an Videodaten erfordert, von grundlegender Bedeutung ist.
Nachdem Sie die Video-URLs abgerufen haben, integrieren Sie die Web Unlocker API von Bright Data in automatisierte yt-dlp-Workflows, um 412-Fehler zu vermeiden und Videos ohne Blockierungen herunterzuladen. Dank Bright Data können Sie Rate Limits, Blockierungen oder yt-dlp-Fehler vergessen und mehr Videos für das Training Ihrer KI-/ML-Modelle erhalten.
Fazit
In diesem Blogbeitrag haben Sie gesehen, welche Art von Daten Sie von Bilibili scrapen können und welche Anwendungsfälle damit unterstützt werden. Eines der interessantesten Szenarien ist das KI-Training mit Videodaten. Mit Hunderten Millionen Videos, die auf der Plattform verfügbar sind, stellt Bilibili eine riesige Quelle öffentlich zugänglicher Multimedia-Inhalte dar.
Der Prozess beginnt mit einem Bilibili-Scraper, dessen Erstellung Sie Schritt für Schritt gelernt haben. Dieser sammelt strukturierte Videometadaten, einschließlich Video-URLs. Anschließend können Sie diese URLs an einen yt-dlp-basierten Workflow übergeben, um die eigentlichen Videodateien herunterzuladen, wie in dieser Anleitung gezeigt.
Bright Data unterstützt das Scraping von Bilibili durch einen dedizierten Scraper und direkte yt-dlp-Integrationsoptionen für zuverlässige, unterbrechungsfreie Downloads. Weitere Informationen finden Sie in unseren Lösungen für den Zugriff auf große Videodatenmengen für das LLM-Training.
Melden Sie sich noch heute bei Bright Data an und entdecken Sie unsere Lösungen zur Erfassung von Videodaten!





