

Am Ende dieses Tutorials werden Sie verstehen:
- Warum PyTorch eine hervorragende Option für die Erstellung eines multimodalen Machine-Learning-Workflows ist.
- Die Notwendigkeit einer vertrauenswürdigen Quelle für zuverlässige Daten aus Datensätzen mit mehreren Millionen Datensätzen, wie sie beispielsweise von Bright Data bereitgestellt werden.
- Wie Sie die Datensätze von Bright Data in PyTorch nutzen können, um ein ML-Modell für die Klassifizierung von Produktbildern in einem multimodalen Prozess zu optimieren.
Lassen Sie uns loslegen!
Warum PyTorch für multimodales maschinelles Lernen verwenden?
Daten sind nur so wertvoll wie die Erkenntnisse, die sie ermöglichen. Für Unternehmen kann die richtige Nutzung von Daten zu intelligenteren Entscheidungen, verfeinerten Strategien und besseren Ergebnissen wie Kundenbindung und Marketingleistung führen.
Mit modernem maschinellem Lernen können Sie nicht nur strukturierte Daten wie Bewertungen oder Verkaufszahlen verarbeiten, sondern auch unstrukturierte Daten wie Bilder, Texte und sogar Videos. Das eröffnet Ihnen multimodale Erkenntnisse. Wenn Sie beispielsweise Bewertungsbilder mit Text kombinieren, können Sie ein umfassenderes Verständnis dafür gewinnen, was die Kundenbindung fördert.
Dieser Artikel basiert auf PyTorch, einem Python-Framework für maschinelles Lernen, das häufig für den Aufbau und das Training tiefer neuronaler Netze verwendet wird. Die Bibliothek unterstützt eine lange Liste von Aufgaben, darunter Bildklassifizierung, Verarbeitung natürlicher Sprache und kombinierte Workflows, bei denen mehrere Datentypen gemeinsam analysiert werden.
Zu den gängigen PyTorch-Anwendungen gehören:
- Bewertung der Produktbildqualität: Automatische Bestimmung, ob Bilder visuell ansprechend sind und Kunden ansprechen dürften.
- Analyse der Kundenstimmung: Gewinnung von Erkenntnissen aus Textbewertungen, um die Meinungen und die Zufriedenheit der Nutzer zu verstehen.
- Aufbau von Empfehlungssystemen: Kombinieren Sie Text- und Bildmerkmale, um genauere und personalisierte Produktvorschläge zu generieren.
- Prädiktive Modellierung mit multimodalen Daten: Verwenden Sie sowohl visuelle als auch textuelle Informationen, um Trends, Umsätze oder Kundenverhalten vorherzusagen.
So beschaffen Sie hochwertige multimodale Daten für Ihr Unternehmen
Unabhängig davon, welche Art von Machine Learning oder KI-Anwendung Sie entwickeln, müssen Sie bedenken, dass diese Systeme nur so effektiv sind wie die Daten, mit denen sie trainiert werden.
Bei multimodalen Anwendungen kann die Datenbeschaffung eine besondere Herausforderung darstellen, da Informationen sowohl in textueller als auch in visueller Form gesammelt werden müssen. Hier kommen vertrauenswürdige Datenanbieter wie Bright Data ins Spiel.
Bright Data bietet eine Reihe von KI- und maschinell lernfähigen Lösungen für Unternehmen jeder Größe, von Start-ups bis hin zu großen Konzernen:
- Web Scraper APIs: Bieten programmatischen Zugriff auf strukturierte Daten von Hunderten beliebter Websites und ermöglichen so die automatisierte Erfassung aktueller Webdaten in großem Umfang.
- Datensatz-Marktplatz: Bietet gebrauchsfertige, multimodale Datensätze mit Milliarden von Einträgen, darunter Bilder, Text und strukturierte Felder.
- Managed Data Acquisition Services: Vollständig verwaltete Lösungen der Enterprise-Klasse, mit denen Teams Daten erfassen und verwalten können, ohne Scraping-Pipelines aufbauen oder warten zu müssen.
- Datenannotationsdienste: Skalierbare und anpassbare Annotationslösungen für NLP-, Computer Vision- und Spracherkennungsaufgaben.
Diese Lösungen ermöglichen es Forschern, KMUs und großen Unternehmen, öffentliche Webdaten effizient zu sammeln und zu integrieren. Diese können genutzt werden, um multimodale Machine-Learning-Workflows zu unterstützen, ausgefeilte KI-Modelle zu trainieren, intelligente Agenten zu entwickeln und Analyse- und Business-Intelligence-Systeme aufzubauen.
So erstellen Sie eine multimodale Machine-Learning-Analyse-Pipeline mit PyTorch und einem Bright Data-Datensatz
In diesem Abschnitt erfahren Sie, wie Sie ein maschinelles Lernmodell auf dem Bright Data-Datensatz„Amazon-Produkte”trainieren, der sowohl Text- als auch Bilddaten enthält.
Wir gehen davon aus, dass Sie Online-Produkte verkaufen und wissen, wie wichtig es ist, diese mit geeigneten Bildern zu präsentieren. Das Ziel besteht darin, mit PyTorch ein maschinelles Lernmodell für E-Commerce-Produktbilder zusammen mit deren Bewertungsinformationen zu trainieren. Dieses Modell bewertet dann automatisch, ob ein Produktbild „gut” oder „schlecht” ist.
Dank dieses multimodalen ML-Workflows kann Ihr Unternehmen programmgesteuert bewerten, wie wahrscheinlich es ist, dass Ihre Produktbilder Kunden anziehen und das Engagement fördern.
Hinweis: Dies ist nur ein Beispiel. Durch die Verwendung von PyTorch in Verbindung mit Bright Data-Datensätzen und Datenfeeds können Sie viele andere Anwendungsfälle und Szenarien abdecken.
Befolgen Sie die nachstehenden Anweisungen!
Voraussetzungen
Um diesen Abschnitt nachvollziehen zu können, stellen Sie sicher, dass Sie über Folgendes verfügen:
- Python 3.9 oder höher lokal installiert ist.
- Ein Bright Data-Konto.
Außerdem sind Kenntnisse über das ResNet-18-Modell und die Funktionsweise von Fine-Tuning hilfreich, um die multimodale PyTorch-Bildklassifizierungslogik vollständig zu verstehen.
Schritt 1: Erstellen Sie ein JupyterLab-Projekt
Bei der Arbeit mit multimodalen Daten ist es hilfreich, Ihre Datensätze zu visualisieren. Aus diesem Grund ist JupyterLab eine ausgezeichnete Wahl als Entwicklungsumgebung. Sobald Ihr Workflow entwickelt ist, kann der Code dann einfach in eine produktionsreife Machine-Learning-Pipeline umgewandelt werden.
Erstellen Sie zunächst einen eigenen Projektordner und navigieren Sie dorthin:
mkdir pytorch-brightdata-product-image-analysis
cd pytorch-brightdata-product-image-analysisInitialisieren Sie als Nächstes eine virtuelle Umgebung darin:
python -m venv .venvUnter macOS/Linux aktivieren Sie die virtuelle Umgebung mit:
source .venv/bin/activateUnter Windows führen Sie folgenden Befehl aus:
.venvScriptsactivateInstallieren Sie JupyterLab über das jupyterlab -Paket, während die virtuelle Umgebung aktiv ist:
pip install jupyterlabStarten Sie JupyterLab mit:
jupyter labDie JupyterLab-Oberfläche wird in Ihrem Browser unter http://localhost:8888/lab/ geöffnet. Erstellen Sie ein neues Notizbuch, indem Sie auf die Schaltfläche „Python 3 (ipykernel)” im Abschnitt „Notebook” klicken:
Sie sehen eine Datei mit dem Namen „Untitled.ipynb “:
Geben Sie Ihrem neuen Notebook einen Namen wie „Bright Data + PyTorch“ und speichern Sie es.
Fertig! Sie verfügen nun über eine vollständig eingerichtete Python-Umgebung, die für die Entwicklung multimodaler Machine-Learning-Workflows mit PyTorch bereit ist.
Schritt 2: Installieren und importieren Sie die erforderlichen Abhängigkeiten
Fügen Sie in Ihrem Notebook eine neue Codezelle mit dem folgenden pip -Befehl hinzu
!pip install pillow tqdm requests scikit-learn torch torchvision pandasFühren Sie diesen Block aus, um alle erforderlichen Bibliotheken zu installieren:
pillow: Zum Laden und Verarbeiten von Bildern.tqdm: Zum Anzeigen von Fortschrittsbalken für Schleifen, was für die Verfolgung des Datenladens und -trainings nützlich ist.requests: Zum Herunterladen von Bildern von URLs über HTTP-Anfragen.scikit-learn: Bietet Tools wietrain_test_splitzum Aufteilen von Datensätzen.torch: Die zentrale PyTorch-Bibliothek zum Erstellen und Trainieren von Modellen für maschinelles Lernen.torchvision: Bietet Datensätze, vortrainierte Modelle und Bildtransformationen.pandas: Verarbeitet strukturierte Daten wie CSV-Dateien und erleichtert die Datenbearbeitung.
Importieren Sie in einer anderen Codezelle alle erforderlichen Module:
import os
import io
import json
import requests
from PIL import Image, ImageStat
from tqdm import tqdm
from sklearn.model_selection import train_test_split
import pandas as pd
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, models
from tqdm import tqdm
from PIL import ImageGroßartig! Mit diesen beiden Zellen ist Ihr Notebook vollständig bereit, multimodale Datensätze von Bright Data zu verarbeiten und Bild- und Textverarbeitung mit PyTorch durchzuführen.
Schritt 3: Laden Sie den Bright Data-Datensatz herunter
Nachdem Ihr Notebook nun für die PyTorch-Entwicklung eingerichtet ist, ist es an der Zeit, die wichtigste Komponente dieses Workflows zu beschaffen: die Eingabedaten!
Für dieses Tutorial verwenden wir den Datensatz„Amazon-Produkte”, einen von vielen E-Commerce-Datensätzen, die auf Bright Data verfügbar sind. Zum Zeitpunkt der Erstellung dieses Artikels enthält dieser Datensatz über 311 Millionen Einträge mit jeweils 87 Datenfeldern. Für jedes Produkt listen diese Felder die Bild-URLs, Bewertungsnoten, Produkt-ASINs und viele weitere Informationen auf.
Hinweis: Mit dem Bright Data E-Commerce Scraper können Sie aktuelle strukturierte Daten von Plattformen wie Amazon, eBay, Walmart und vielen anderen sammeln.
Wenn Sie noch kein Bright Data-Konto haben, erstellen Sie zunächst eines. Andernfalls melden Sie sich an und gehen Sie zur Seite„Marktplatz für Datensätze“Ihres Kontos:
Wählen Sie unter den „Beliebtesten“ Datensätzen den Datensatz „Amazon-Produkte“ aus:
Sie gelangen zur Seite der Datensätze: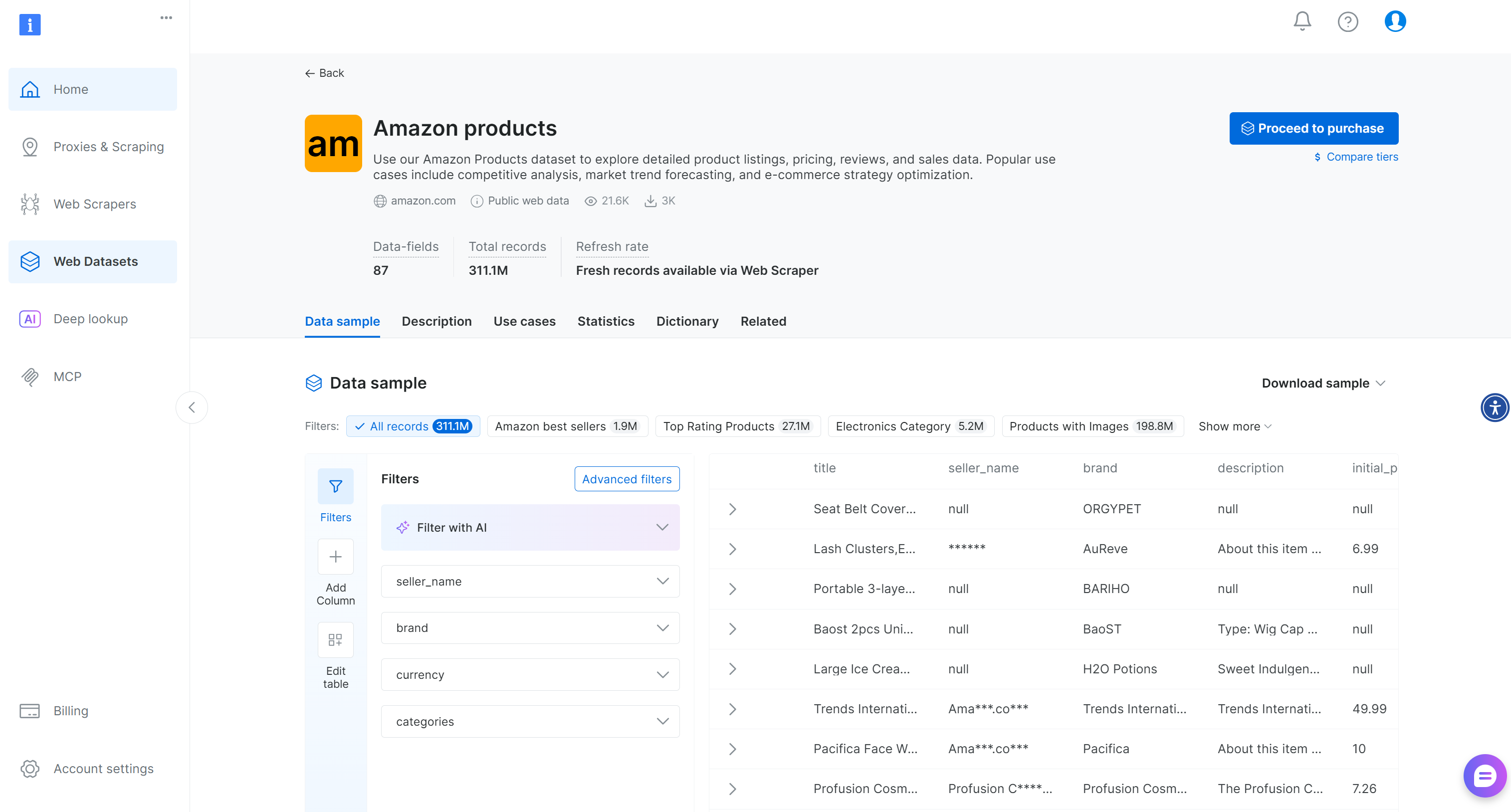
Hier können Sie Einträge manuell filtern oder KI-gestützte Filter verwenden, um auf Ihre Bedürfnisse zugeschnittene Teilmengen zu erstellen. Beachten Sie, dass diese Filter auch programmgesteuert über die Filter-API angewendet werden können, mit der Sie Datensatz-Snapshots basierend auf bestimmten Kriterien erstellen können.
Für dieses Tutorial benötigen wir nur einen kleinen Beispieldatensatz, um einen multimodalen ML-Workflow zu demonstrieren, sodass der kostenlose Beispieldatensatz ausreichend ist. Für einen produktions- oder unternehmensreifen Workflow müssen Sie einen vollständigen Datensatz herunterladen, der auf Ihre spezifischen Anforderungen zugeschnitten ist.
Um den Beispiel-Datensatz herunterzuladen, öffnen Sie das Dropdown-Menü „Datensatzbeispiel“ und wählen Sie „Als CSV herunterladen“: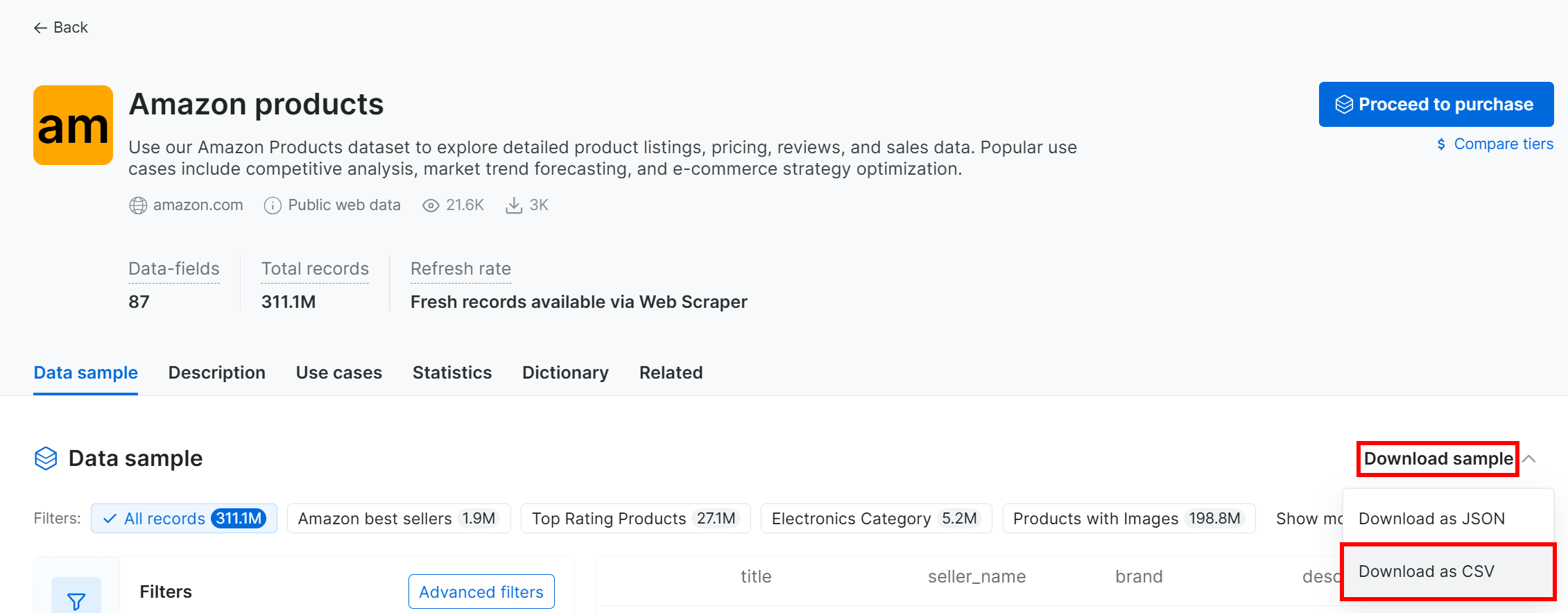
Sie erhalten eine Datei mit dem Namen „Amazon products.csv“, die 1.000 Produkte (~7,3 MB) enthält. Benennen Sie sie in „amazon_products.csv“ um und legen Sie sie in Ihrem Projektordner ab: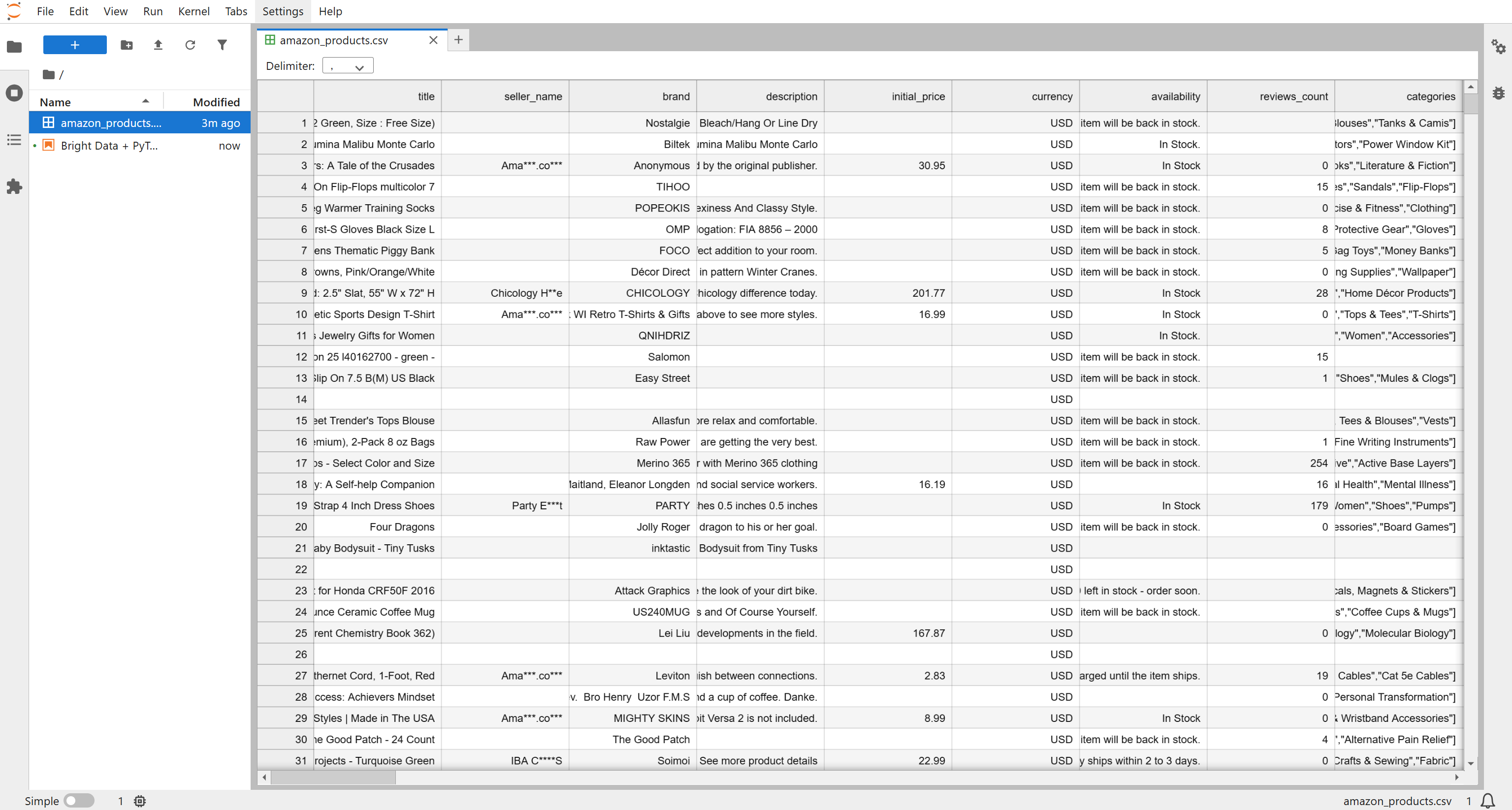
Von den 87 verfügbaren Feldern sind die folgenden für diesen multimodalen Workflow relevant:
asin: Die eindeutige Produktkennung bei Amazon.image_url: Die URL des Hauptbildes für das Produkt.images: Ein Array im JSON-Format, das zusätzliche Bild-URLs für das Produkt enthält.rating: Die durchschnittliche Kundenbewertung auf einer Skala von 1 bis 5.
Mit diesen Feldern können Sie visuelle Daten (Bilder) mit strukturierten numerischen Daten (Bewertungen) in einem multimodalen PyTorch ML-Workflow kombinieren. Fantastisch! Sie haben nun den Eingabedatensatz.
Schritt 4: Definieren Sie die Logik zum Herunterladen und Beschriften von Produktbildern
Initialisieren Sie im Notizbuch die Kernlogik, indem Sie die Funktionen zum Herunterladen und Beschriften von Bildern hinzufügen. Diese beiden Funktionen bilden die Bausteine für die Implementierung des ML-Bildklassifizierungsprozesses, der folgende Schritte erfordert:
- Sammeln Sie Produktdaten einschließlich
image_url,imagesarray,ratingundasinaus dem Bright Data-Datensatz „Amazon products“. - Extrahieren und deduplizieren Sie die Bild-URLs für jeden Produkteintrag.
- Laden Sie Bilder von allen URLs herunter und speichern Sie sie lokal.
- Beschriften Sie die Bilder unter Kombination von visuellen Heuristiken (weißer Hintergrund, Auflösung) und Bewertungsnoten.
- Erstellen Sie einen PyTorch-Datensatz mit den beschrifteten Bildern, der für das Training eines CNN-Modells (Convolutional Neural Network) geeignet ist.
- Feinabstimmung eines CNN zur Vorhersage der Bildqualität („GOOD” vs. „BAD”) unter Verwendung der beschrifteten Datensätze.
- Bewerten Sie das Modell anhand eines Testsatzes.
- Verwenden Sie das Modell, um neue Produktbilder automatisch zu bewerten.
Schreiben Sie in einer neuen Codezelle in Ihrem Notizbuch die Funktionen zum Herunterladen und Beschriften von Produktbildern:
def download_image(url):
# Senden Sie eine GET-Anfrage an die URL des Bildes.
response = requests.get(url)
# Lesen Sie den Inhalt der Antwort in ein BytesIO-Objekt ein.
image_bytes = io.BytesIO(response.content)
# Öffnen Sie das Bild mit PIL und konvertieren Sie es in den RGB-Modus.
image = Image.open(image_bytes).convert("RGB")
return image
def label_image(image, rating):
# Ermitteln Sie die Breite und Höhe des Bildes.
w, h = image.size
# Die oberen 10 Pixel abschneiden, um den Rand auf Helligkeit zu analysieren
border = image.crop((0, 0, w, 10))
# Statistik (Mittelwert) für den Rand berechnen
stat = ImageStat.Stat(border)
# Durchschnittliche Helligkeit über RGB-Kanäle
brightness = sum(stat.mean) / 3
# Feststellen, ob das Bild einen weißen Hintergrund hat
is_white_bg = brightness > 240
# Feststellen, ob das Bild eine niedrige Auflösung hat (kleinste Seite < 400px)
is_low_res = min(image.size) < 400
# Heuristisches Label: 1=gut, wenn weißer Hintergrund und keine niedrige Auflösung, sonst 0=schlecht
heuristic_label = 1 if (is_white_bg and not is_low_res) else 0
# Wenn die Bewertung fehlt oder Null ist, nur auf die heuristische Bewertung zurückgreifen
if rating is None or rating == 0:
return heuristic_label
# Bewertung auf den Bereich 0-1 normalisieren
r = rating / 5
# Wende schwache Überwachung an, um das Label basierend auf extremen Bewertungen anzupassen
if heuristic_label == 1 and r < 0.5: # sehr niedrige Bewertung → als schlecht markieren
return 0
if heuristic_label == 0 and r > 0.9: # ausgezeichnete Bewertung → als gut markieren
return 1
# Andernfalls behalte das heuristische Label bei
return heuristic_labelDie Funktion download_image() lädt einfach ein Bild von einer bestimmten URL herunter und gibt es als PIL-Bildinstanz zurück. Die Funktion label_image() hingegen führt eine multimodale Bewertung von Produktbildern durch, wobei visuelle Hinweise und textuelle/numerische Daten wie Kundenbewertungen kombiniert werden.
label_image() wendet zunächst Heuristiken an – Überprüfung auf weißen Hintergrund und ausreichende Auflösung –, um eine erste Bewertung „gut” oder „schlecht” zu vergeben. Wenn eine Bewertung verfügbar ist, passt die Funktion die Bewertung wie folgt an:
- Sehr niedrige Bewertungen überschreiben ein visuell gutes Bild.
- Ausgezeichnete Bewertungen retten ein schlecht aussehendes Bild.
Diese Logik ist sinnvoll, denn selbst wenn ein Bild gut aussieht, deutet eine schlechte Bewertung darauf hin, dass es nicht vorteilhaft ist. Umgekehrt kann eine ausgezeichnete Bewertung ein erfolgreiches Bild trotz schlechter Bildqualität hervorheben. Somit werden sowohl visuelle als auch numerische Informationen bei der Vergabe der endgültigen Bewertung berücksichtigt.
Cool! Jetzt ist es an der Zeit, den Datensatz zu importieren und Ihre Produkteinträge vorzubereiten, um diese beiden Funktionen auf alle Bilder anzuwenden.
Schritt 5: Laden Sie den Datensatz und bereiten Sie sich darauf vor, alle Bilder herunterzuladen
Wenn Sie die Datei amazon_products.csv überprüfen, werden Sie feststellen, dass Produktbilder in zwei Datenfeldern gespeichert sind:
image_url: URL zum Hauptproduktbild.images: Eine JSON-formatierte Zeichenfolge, die ein Array aller zusätzlichen Produktbilder enthält.
Laden Sie in einem neuen Codeblock die CSV-Datei und rufen Sie alle Bilder für jedes Produkt mit einer Hilfsfunktion ab:
def extract_image_list(row):
image_urls = []
# Überprüfen Sie, ob eine einzelne image_url vorhanden ist, und fügen Sie sie hinzu, wenn sie existiert und nicht leer ist.
if isinstance(row.get("image_url"), str) and row["image_url"].strip():
image_urls.append(row["image_url"].strip())
# Überprüfen Sie das Feld „images”, das eine JSON-Zeichenkette oder eine Python-Liste sein kann.
images_field = row.get("images")
if isinstance(images_field, str):
# Dekodieren Sie die JSON-Zeichenkette in eine Python-Liste.
decoded = json.loads(images_field)
if isinstance(decoded, list):
# Füge alle Bilder aus der Liste zu image_urls hinzu
image_urls.extend(decoded)
# Entferne doppelte URLs, indem du sie in einen Satz und dann wieder in eine Liste konvertierst
return list(set(image_urls))
# Lade die Amazon-Produkte-CSV-Datei in einen DataFrame
df = pd.read_csv("amazon_products.csv")
# Zeilen löschen, in denen erforderliche Felder fehlen
df = df.dropna(subset=["asin", "image_url", "images", "rating"])
# Die Funktion extract_image_list auf jede Zeile anwenden, um eine Liste aller eindeutigen Bild-URLs zu erstellen
df["all_image_urls"] = df.apply(extract_image_list, axis=1)Der importierte Datensatz verfügt nun über eine neue Spalte namens „all_image_urls”. Diese enthält eine deduplizierte Liste aller Bild-URLs, wobei das Hauptbild und alle zusätzlichen Bilder zusammengefasst werden. Im nächsten Schritt greifen Sie auf dieses Feld zu, um alle Bilder für jedes Produkt herunterzuladen und zu verarbeiten!
Schritt 6: Alle Bilder herunterladen und kennzeichnen
Implementieren Sie in einer Zelle die Logik, um alle Produktbilder in einen lokalen Ordner „images/“ herunterzuladen und zu kennzeichnen:
# Erstellen Sie den Ordner „images”, falls er noch nicht vorhanden ist.
os.makedirs("images", exist_ok=True)
# Initialisieren Sie eine Liste, um Metadaten für jedes heruntergeladene und beschriftete Bild zu speichern.
records = []
# Durchlaufen Sie jede Produktzeile im DataFrame mit einem Fortschrittsbalken.
for idx, row in tqdm(df.iterrows(), total=len(df)):
# Greifen Sie auf die erforderlichen Produktdatenfelder zu.
url_list = row["all_image_urls"]
rating = float(row["rating"])
asin = row.get("asin")
# Durchlaufen Sie jede Bild-URL für dieses Produkt, um es herunterzuladen und zu kennzeichnen.
for i, url in enumerate(url_list):
# Bild herunterladen
image = download_image(url)
if image is None:
continue
# Dateinamen unter Verwendung von ASIN und Bildindex erstellen
filename = f"{asin}_{i}.jpg"
path = os.path.join("images", filename)
# Heruntergeladenes Bild auf Festplatte speichern
image.save(path)
# Bild anhand der multimodalen Informationen kennzeichnen
label = label_image(image, rating)
# Relevante Metadaten für dieses Bild speichern
records.append({
"asin": asin,
"image_path": path,
"image_url": url,
"label": label
})
# Konvertieren Sie die Datensatzliste in einen DataFrame und exportieren Sie sie in eine CSV-Datei.
labeled_df = pd.DataFrame(records)
labeled_df.to_csv("labeled_images.csv", index=False)Wenn Sie diesen Codeblock in Ihrem Notizbuch ausführen, wird der Downloadvorgang gestartet. Dabei müssen über 2.500 Bilder heruntergeladen werden, haben Sie also bitte einige Minuten Geduld.
Nach Abschluss des Vorgangs sollte die Ausgabe in Ihrer Codezelle einen Fortschrittsbalken bis 100 % anzeigen:
Nun enthält der Ordner „images/“ in Ihrem Projektverzeichnis alle aus den Datensätzen heruntergeladenen Produktbilder:
Zusätzlich wird die Datei „labeled_images.csv“ lokal erstellt und mit den Beschriftungsinformationen für jedes Bild gefüllt:
Großartig! Sie verfügen nun über alle lokalen Bilder und Beschriftungsinformationen, die für das Training des maschinellen Lernmodells in einem multimodalen Prozess erforderlich sind.
Schritt 7: Vorbereiten der Trainings- und Test-Datensätze
Fügen Sie einen neuen Block hinzu, um die Beschriftungsinformationen aus der Datei „labeled_images.csv“ zu lesen und daraus Trainings- und Testdatensätze zu erstellen, die Sie für die Feinabstimmung des ML-Modells verwenden werden:
# Definieren Sie eine benutzerdefinierte PyTorch-Datensatzklasse für Produktbilder.
class ProductImageDataset(Dataset):
def __init__(self, df, transform=None):
self.df = df
self.transform = transform
def __len__(self):
# Gibt die Gesamtzahl der Samples im Datensatz zurück.
return len(self.df)
def __getitem__(self, idx):
# Bildpfad und Beschriftung für einen bestimmten Index abrufen
path, label = self.df.iloc[idx]["image_path"], self.df.iloc[idx]["label"]
# Bild laden und in RGB konvertieren
image = Image.open(path).convert("RGB")
# Wende Transformationen an, falls vorhanden (z. B. Größenänderung, Tensor-Konvertierung)
if self.transform:
image = self.transform(image)
# Gib den Bildtensor und die Beschriftung als Torch-Tensor zurück
return image, torch.tensor(label, dtype=torch.long)
# Die CSV-Datei mit den beschrifteten Bildern laden
labeled_df = pd.read_csv("labeled_images.csv")
# Den Datensatz in Trainings- und Testdatensätze aufteilen, dabei die Verteilung der Beschriftungen ausgeglichen halten
train_df, test_df = train_test_split(
labeled_df,
test_size=0.2,
stratify=labeled_df["label"]
)
# Transformationen definieren, um die Bilder auf 224x224 zu verkleinern und in Tensoren zu konvertieren
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
])
# Datensatzobjekte initialisieren
train_ds = ProductImageDataset(train_df, transform)
test_ds = ProductImageDataset(test_df, transform)
# Datensätze in DataLoaders einbinden, um sie zu batchweise zu verarbeiten und zu mischen
train_dl = DataLoader(train_ds, batch_size=32, shuffle=True)
test_dl = DataLoader(test_ds, batch_size=32)Dieser Ausschnitt bereitet die beschrifteten Produktbilder für das Training eines PyTorch-CNN vor. Dazu wird ein benutzerdefinierter Datensatz definiert und folgende Bildtransformationen angewendet:
transforms.Resize((224, 224)): Verkleinert Bilder auf224×224. Dies ist wichtig, da die Bilder im Datensatz unterschiedliche Auflösungen und Seitenverhältnisse haben, während CNNs erwarten, dass alle Eingaben die gleiche feste Größe haben.transforms.ToTensor(): PyTorch-Modelle arbeiten mit Tensoren statt mit rohen PIL-Bildern. Dadurch wird jedes Bild in einen normalisierten Tensor der Form(C, H, W)(Kanäle, Höhe, Breite) umgewandelt, wodurch es mit dem CNN kompatibel wird.
Zusammen standardisieren die Transformationen jedes Bild in Bezug auf Größe und Format, sodass sich das Modell auf das Lernen visueller Muster konzentrieren kann, anstatt inkonsistente Eingaben zu verarbeiten. Die Datensätze werden dann unter Beibehaltung der Label-Verteilungen in Trainings- und Testsätze aufgeteilt und in DataLoader-Objekte verpackt, um Datenbatches mit Bildern und Labels zu generieren.
Insgesamt garantiert dieser Schritt, dass das CNN ordnungsgemäß formatierte Daten erhält, und legt damit den Grundstein für ein effektives multimodales Machine-Learning-Training. Großartig!
Schritt 8: Trainieren Sie das multimodale ML-Modell
Nachdem die Trainings- und Testdatensätze bereitstehen, optimieren Sie ein CNN in PyTorch für die Bildklassifizierung mit diesem Code:
# Wählen Sie das Gerät für das Training aus (GPU, falls verfügbar, andernfalls CPU)
device = "cuda" if torch.cuda.is_available() else "cpu"
# Laden Sie ein vortrainiertes ResNet-18-Modell aus torchvision
model = models.resnet18(weights=models.ResNet18_Weights.IMAGENET1K_V1)
# Ersetzen Sie die letzte vollständig verbundene Schicht, um 2 Klassen (GOOD/BAD) auszugeben.
model.fc = nn.Linear(model.fc.in_features, 2)
# Verschieben Sie das Modell auf das ausgewählte Gerät.
model = model.to(device)
# Definieren Sie die Verlustfunktion für die Klassifizierung.
criterion = nn.CrossEntropyLoss()
# Definieren Sie den Optimierer mit einer kleinen Lernrate.
opt = torch.optim.Adam(model.parameters(), lr=1e-4)
# Trainingsschleife für 3 Epochen.
for epoch in range(3):
model.train()
total_loss = 0
# Durchlaufen der Batches von Bildern und Labels
for images, labels in tqdm(train_dl, desc=f"Epoch {epoch+1}"):
images, labels = images.to(device), labels.to(device)
opt.zero_grad()
out = model(images)
loss = criterion(out, labels)
loss.backward()
opt.step()
total_loss += loss.item()
# Durchschnittlichen Verlust für die Epoche ausgeben
print(f"Epoch {epoch+1}: Average Loss={total_loss/len(train_dl):.4f}")Die obige Zelle optimiert ein vortrainiertes ResNet-18-CNN, ein konvolutionelles neuronales Netzwerk mit 18 Schichten, das in erster Linie zur Klassifizierung von Bildern in verschiedene Kategorien verwendet wird.
In diesem Fall klassifiziert das ML-Modell Produktbilder als gut oder schlecht. Die Verwendung von ImageNet -Gewichten beschleunigt die Konvergenz und nutzt Merkmale, die bereits aus Millionen von natürlichen Bildern gelernt wurden. Anschließend wird die letzte vollständig verbundene Schicht ersetzt, um zwei Klassen auszugeben („GOOD” vs. „BAD”, wie beabsichtigt).
In der Schleife misst die CrossEntropyLoss-Instanz den Klassifizierungsfehler, während der Adam-Optimierer die Modellgewichte aktualisiert. Jede Epoche durchläuft Batches, führt einen Vorwärtsdurchlauf durch, berechnet den Verlust, die Rückpropagierung und die Gewichtsaktualisierungen.
Führen Sie den Codeblock aus, und Sie erhalten eine Ausgabe wie diese: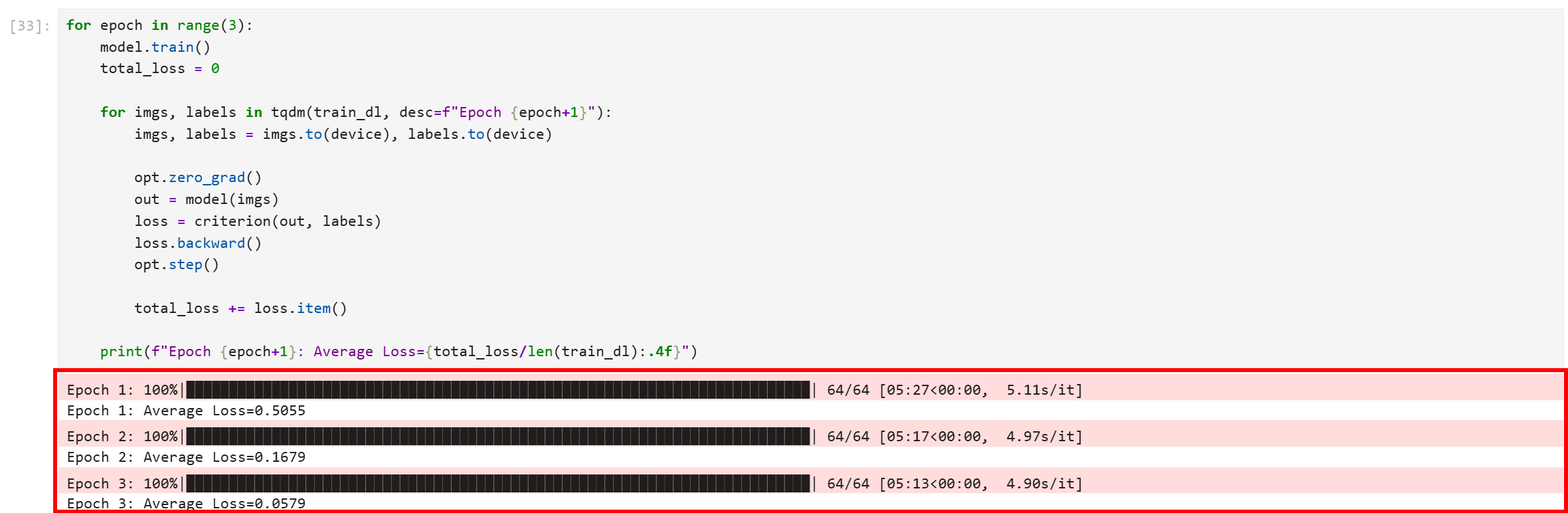
Beachten Sie, dass alle drei Epochen erfolgreich abgeschlossen wurden. Der endgültige durchschnittliche Verlust beträgt 0,0579, was recht niedrig ist und darauf hindeutet, dass das Modell gut konvergiert ist und gelernt hat, mit hoher Sicherheit zwischen den Trainingsbildern zu unterscheiden.
Das war’s schon! Sie haben gerade ein CNN für die Unterscheidung der Bildqualität im E-Commerce feinabgestimmt.
Schritt 9: Bewerten Sie die Modellleistung
Um die Leistung des Modells zu überprüfen, führen Sie einen Bewertungsschritt durch:
# Laden Sie die Bewertungsversion des Modells.
model.eval()
# Um die verarbeiteten Bilder zu verfolgen.
correct = 0
total = 0
# Bewerten Sie das Modell anhand des Trainingsdatensatzes.
with torch.no_grad():
for images, labels in test_dl:
images, labels = images.to(device), labels.to(device)
out = model(images)
prediction = out.argmax(dim=1)
correct += (prediction == labels).sum().item()
total += len(labels)
# Ausgabe der Ergebnisse
print("Testgenauigkeit:", correct / total)Dies misst, wie gut das fein abgestimmte Modell auf Daten generalisiert, die es noch nie gesehen hat (der Testdatensatz). Konkret führt es eine Modellbewertung mittels Inferenz durch.
Die Codezelle schaltet das Modell zunächst in den Bewertungsmodus und deaktiviert die Gradientenverfolgung, um die Geschwindigkeit zu optimieren und ein konsistentes Verhalten sicherzustellen. Als Nächstes durchläuft die Schleife den Testdatensatz und vergleicht die Vorhersagen des Modells mit den tatsächlichen Labels. Schließlich berechnet sie die Gesamtgenauigkeit und liefert so eine klare Metrik für die Fähigkeit des Modells, über den Trainingssatz hinaus zu generalisieren.
Das Ergebnis sollte in etwa so aussehen:

Ein Testgenauigkeitswert von 0,924XXX bedeutet, dass Ihr fein abgestimmtes ResNet-18-Modell 92,4+ % der Produktbilder in Ihrem unbekannten Testdatensatz korrekt als „GOOD” oder „BAD” klassifiziert hat.
Dies kann als hervorragendes Ergebnis für die binäre Klassifizierung von realen Daten wie E-Commerce-Produktbildern angesehen werden. Es deutet stark darauf hin, dass das Modell den Unterschied zwischen guten und schlechten Bildqualitätsmerkmalen erfolgreich gelernt hat und nicht nur die Trainingsdaten auswendig lernt.
Gut gemacht! Wenden wir nun das fein abgestimmte Modell auf einige neue Bilder an, um zu sehen, ob es wie erwartet funktioniert.
Schritt 10: Verwenden Sie das ML-Modell zur Vorhersage der Bildqualität
Um wirklich zu überprüfen, ob das fein abgestimmte Modell wie erwartet funktioniert, müssen Sie seine Leistung anhand von Bildern testen, die es noch nie gesehen hat. Da das Modell für die Arbeit mit beliebigen E-Commerce-Produktbildern trainiert wurde, können Sie es mit Bildern von Plattformen wie eBay, Walmart, Alibaba oder Ihren eigenen internen Produktdatenbanken testen.
In dieser Demonstration testen wir das Modell anhand der folgenden zwei Produktbilder, die von eBay stammen:
Fügen Sie dazu den folgenden Code in einen speziellen Block ein:
def predict_image_quality(img: Image.Image) -> str:
# Modell in den Bewertungsmodus versetzen
model.eval()
# Transformationen anwenden und eine Batch-Dimension hinzufügen
x = transform(img).unsqueeze(0).to(device)
with torch.no_grad():
# Vorwärtsdurchlauf, den vorhergesagten Klassenindex abrufen und als Skalar extrahieren
prediction = model(x).argmax().item()
# Die Ergebniszeichenfolge zurückgeben
return "GOOD" if prediction == 1 else "BAD"
# Testbilder
image_urls = ["https://i.ebayimg.com/images/g/N5kAAOSwTlplqFTa/s-l500.webp", "https://i.ebayimg.com/images/g/yUsAAOSweMJd67Jd/s-l1600.webp"]
# Durchlaufen der Bild-URLs, Herunterladen, Vorhersagen und Anzeigen
for image_url in image_urls:
# Herunterladen des Bildinhalts mithilfe einer HTTP-Anfrage
response = requests.get(image_url)
image = Image.open(io.BytesIO(response.content)).convert("RGB")
# Vorhersagefunktion aufrufen
quality = predict_image_quality(image)
# Bild zusammen mit den Modellergebnissen im Notizbuch anzeigen
display(image)
print(image_url, "→", quality)Nach Ausführung der Zelle werden Sie die folgenden Klassifizierungen sehen:
Beachten Sie, dass das Modell das Bild als „BAD” klassifiziert hat. Dies ist ein korrektes Ergebnis, da das Bild sichtbar von geringer Qualität und unscharf ist und der Hintergrund keinen scharfen Kontrast aufweist, sodass das Produkt nicht richtig hervorgehoben wird.
Beim zweiten Bild hingegen ergibt sich folgendes Ergebnis:
Diesmal lautet die Klassifizierung „GOOD”, was ein überzeugendes Ergebnis ist, wenn man bedenkt, dass das Bild optisch ansprechend, scharf und gut ausgeleuchtet ist. Außerdem zeigt es das Produkt deutlich.
Et voilà! Dank der umfangreichen Datensätze von Bright Data haben Sie E-Commerce-Produktdaten (in diesem Fall von Amazon) abgerufen. Anschließend haben Sie PyTorch zur Feinabstimmung eines CNN für die Bilderkennung angewendet, indem Sie einen multimodalen ML-Datenanalyseansatz verfolgt haben.
Fazit
In diesem Blogbeitrag haben Sie gesehen, wie Sie ein multimodales Machine-Learning-System implementieren können. Wir haben Produktdatensätze verwendet, die Hunderte Millionen von Amazon-Produkten und die dazugehörigen Bilder enthalten.
Durch die Eingabe dieser Daten in einen PyTorch-Workflow innerhalb eines Python-Notebooks haben Sie erfolgreich ein CNN (Convolutional Neural Network) zur Klassifizierung von E-Commerce-Produktbildern als gut oder schlecht feinabgestimmt.
Dieses Projekt richtet sich direkt an kleine und mittlere Unternehmen oder größere Konzerne, die nach Möglichkeiten suchen, die Bildqualität für die Produktdarstellung schnell zu bewerten, insbesondere für E-Commerce-Zwecke.
All dies wäre ohne die Unternehmensdatendienste von Bright Data nicht möglich, mit denen Sie Daten aus über 100 Domänen sammeln können, darunter Amazon, Walmart, LinkedIn, Zillow, Airbnb, Yahoo Finance und viele andere.
Registrieren Sie sich noch heute für ein Bright Data-Konto, um unsere Datenlösungen kostenlos zu testen!






