

Web-Scraping ist der Prozess des automatischen Sammelns von Daten aus Websites zur Datenanalyse oder zur Feinabstimmung von KI-Modellen.
Dank seiner umfangreichen Auswahl an Scraping-Bibliotheken, darunter lxml, das zum Parsen von XML- und HTML-Dokumenten eingesetzt wird, ist Python eine beliebte Wahl für Web-Scraping. lxml ergänzt den Funktionsumfang von Python um eine Python-API für den Zugriff auf die schnellen C-Bibliotheken libxml2 und libxslt. Darüber hinaus lässt es sich mit ElementTree integrieren, der hierarchischen Datenstruktur von Python für XML/HTML-Baumstrukturen, weshalb lxml ein bevorzugtes Tool für effizientes und zuverlässiges Web-Scraping darstellt.
In diesem Artikel lernen Sie, lxml für Web-Scraping zu verwenden.
Bright Data Lösungen – die ideale Alternative
Wenn es um Web-Scraping geht, ist die Verwendung von lxml mit Python zwar ein leistungsfähiger Ansatz, der jedoch zeit- und kostenaufwändig sein kann, insbesondere wenn es sich um komplexe Websites bzw. große Datenmengen handelt. Bright Data stellt mit seinen gebrauchsfertigen Datensätzen und Web-Scraper-APIs eine leistungsfähige Alternative dar. Mit diesen Lösungen lassen sich der Zeit- und Kostenaufwand für die Datenerfassung erheblich senken, da sie bereits gesammelte Daten von über 100 Domains und einfach zu integrierende Scraping-APIs bieten.
Mithilfe von Bright Data umgehen Sie die technischen Herausforderungen des manuellen Scraping, sodass Sie sich ganz der Analyse von Daten widmen können, anstatt diese abzurufen. Ob Sie nun auf Ihre spezifischen Anforderungen zugeschnittene Datensätze oder APIs zur Verwaltung von Proxys und zur Auflösung von CAPTCHAs benötigen, die Tools von Bright Data bilden eine rationalisierte, kosteneffiziente Lösung für jede Ihrer Web-Scraping-Anforderungen.
Verwendung von lxml für Web-Scraping in Python
Im Web können strukturierte und hierarchische Daten in zwei Formaten dargestellt werden – HTML und XML:
- XML ist eine Grundstruktur, die keine vorgefertigten Tags und Stile umfasst. Der Kodierer erstellt die Struktur, indem er seine eigenen Tags definiert. Hauptaufgabe der Tags ist die Erstellung einer Standard-Datenstruktur, die von verschiedenen Systemen gleichermaßen verstanden werden kann.
- HTML ist eine Web-Auszeichnungssprache mit vordefinierten Tags. Diese Tags verfügen über gewisse Styling-Eigenschaften wie etwa die
Schriftgrößebei<h1>- Tags oder dieAnzeigebei<img />-Tags. Die Hauptfunktion von HTML besteht in der effektiven Strukturierung von Websites.
lxml kann sowohl mit HTML- als auch mit XML-Dokumenten operieren.
Voraussetzungen
Ehe Sie das Web-Scraping mit lxml in Angriff nehmen können, sollten Sie einige Bibliotheken auf Ihrem Rechner installieren:
pip install lxml requests cssselect
Dieser Befehl installiert Folgendes:
- llxml zum Parsen von XML und HTML
- requests zum Abrufen von Webseiten
- cssselect, das CSS-Selektoren zur Extraktion von HTML-Elementen verwendet
Parsen von statischen HTML-Inhalten
Im Wesentlichen lassen sich zwei Arten von Webinhalten scrapen: statische und dynamische. Statische Inhalte sind in das HTML-Dokument eingebettet, wenn die Webseite zum ersten Mal geladen wird und lassen sich daher leicht scrapen. Dynamische Inhalte hingegen werden kontinuierlich geladen oder durch JavaScript nach dem erstmaligen Laden der Seite ausgelöst. Beim Scraping dynamischer Inhalte muss die Ausführung der Scraping-Funktion zeitlich so gesteuert werden, dass diese erst ausgeführt wird, nachdem der Inhalt im Browser verfügbar ist.
In diesem Artikel beginnen Sie mit dem Scraping der Website „ Books to Scrape“, die statische HTML-Inhalte zu Testzwecken enthält. Sie extrahieren Titel und Preise von Büchern und speichern diese Informationen in einer JSON-Datei.
Verwenden Sie zunächst die Entwicklertools Ihres Browsers, um die relevanten HTML-Elemente zu identifizieren. Öffnen Sie dazu die Entwicklertools , indem Sie mit der rechten Maustaste auf die Webseite klicken und die Option Untersuchen aufrufen. In Chrome können Sie auch die Taste F12 betätigen, um dieses Menü aufzurufen:
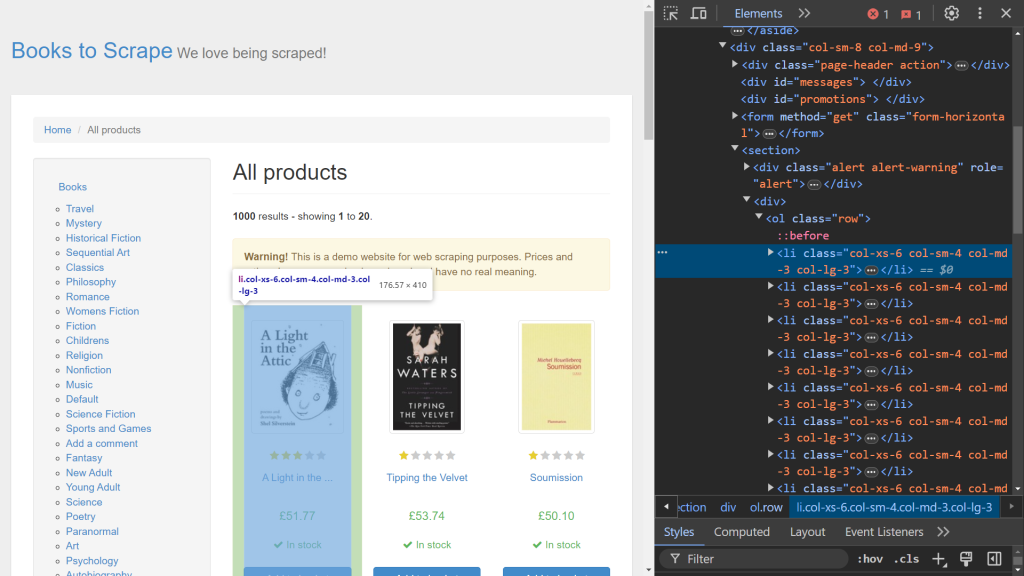
Auf der rechten Seite des Bildschirms wird der Code für die Darstellung der Seite eingeblendet. Um das spezifische HTML-Element zu lokalisieren, welches die Daten der einzelnen Bücher verarbeitet, durchsuchen Sie diesen Code mithilfe der Funktion „Auswahl durch Hovern“ (der Pfeil in der oberen linken Ecke des Bildschirms):
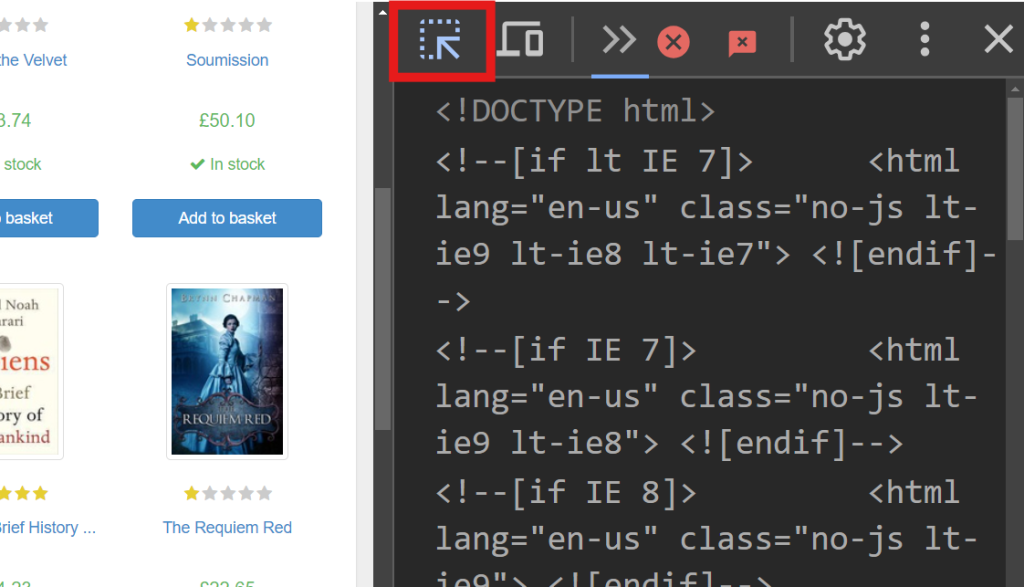
In den Entwicklertools sollten Sie folgenden Codeausschnitt sehen:
<article class="product_pod">
<!-- code omitted -->
<h3><a href="catalogue/a-light-in-the-attic_1000/index.html" title="A Light in the Attic">A Light in the ...</a></h3>
<div class="product_price">
<p class="price_color">£51.77</p>
<!-- code omitted -->
</div>
</article>
In diesem Ausschnitt ist das jeweilige Buch in einem <article> -Tag enthalten, das mit der Klasse product_pod gekennzeichnet ist. Dieses Element ist das Ziel für die Extraktion der Daten. Erstellen Sie eine neue Datei mit dem Namen static_scrape.py und geben Sie folgenden Code ein:
import requests
from lxml import html
import json
URL = "https://books.toscrape.com/"
content = requests.get(URL).text
Mit diesem Code werden die erforderlichen Bibliotheken importiert und eine URL -Variable definiert. Anhand von requests.get() ruft er den statischen HTML-Inhalt der Webseite ab, indem er eine GET-Anfrage an die angegebene URL sendet. Anschließend wird der HTML-Code über das Textattribut der Antwort abgerufen.
Sobald Sie den HTML-Inhalt erhalten haben, parsen Sie diesen mithilfe von lxml und extrahieren die erforderlichen Daten. Für die Extraktion bietet lxml zwei Methoden: XPath und CSS-Selektoren. Bei diesem Beispiel verwenden Sie XPath zum Abrufen des Buchtitels und CSS-Selektoren zum Abrufen des Buchpreises.
Fügen Sie Ihrem Skript folgenden Code hinzu:
parsed = html.fromstring(content)
all_books = parsed.xpath('//article[@class="product_pod"]')
books = []
Dieser Code initialisiert die geparste Variable unter Verwendung von html.fromstring(content), das den HTML-Inhalt in eine hierarchische Baumstruktur parst. DieVariable all_books verwendet einen XPath-Selektor, um sämtliche <article> -Tags der Klasse product_pod von der Website abzurufen. Diese Syntax ist insbesondere für XPath-Ausdrücke gültig.
Fügen Sie nun Folgendes zu Ihrem Skript hinzu, um jedes Buch in all_books zu durchlaufen und Daten daraus zu extrahieren:
for book in all_books:
book_title = book.xpath('.//h3/a/@title')
price = book.cssselect("p.price_color")[0].text_content()
books.append({"title": book_title, "price": price})
DieVariable book_title wird mit einem XPath-Selektor definiert, der das Attribut title aus einem <a> -Tag innerhalb eines <h3> -Tags abruft. Der Punkt (.) am Anfang des XPath-Ausdrucks gibt an, dass die Suche am <article> -Tag und nicht am Standardausgangspunkt ansetzen soll. Die nächste Zeile verwendet die Methode cssselect , um den Preis aus einem <p> -Tag der Klasse price_color zu extrahieren. Da cssselect eine Liste zurückgibt, greift indexing ([0]) auf das erste Element zu, und text_content() liest den Text in diesem Element aus. Jedes extrahierte Titel- und Preispaar wird dann als Wörterbuch an die Bücherliste angefügt, die problemlos in einer JSON-Datei gespeichert werden kann.
Nachdem Sie nun den Web-Scraping-Prozess abgeschlossen haben, ist es an der Zeit, diese Daten lokal zu speichern. Öffnen Sie Ihre Skriptdatei und geben Sie folgenden Code ein:
with open("books.json", "w", encoding="utf-8") as file:
json.dump(books ,file)
In diesem Code wird eine neue Datei mit dem Namen books.json erstellt. Diese Datei wird anhand der Methode json.dump gefüllt, welche die Bücherliste als Quelle und ein Dateiobjekt als Ziel nimmt.
Sie können dieses Skript testen, indem Sie das Terminal öffnen und den folgenden Befehl ausführen:
python static_scrape.py
Dieser Befehl generiert eine neue Datei in Ihrem Verzeichnis mit folgender Ausgabe:
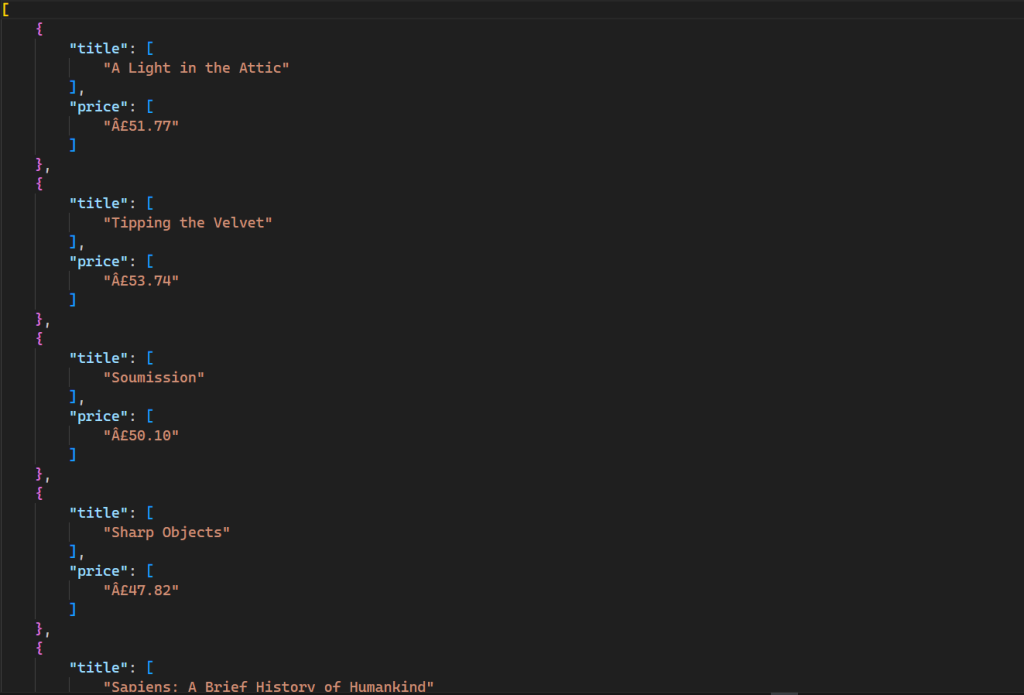
Der gesamte Code dieses Skripts ist auf GitHub verfügbar.
Parsen von dynamischen HTML-Inhalten
Das Scraping dynamischer Webinhalte ist etwas komplizierter als das Scraping statischer Inhalte, da JavaScript die Daten fortlaufend und nicht gleichzeitig rendert. Um dynamische Inhalte zu scrapen, nutzen Sie ein Tool zur Browser-Automatisierung wie Selenium, mit dem Sie eine Browser-Instanz erstellen sowie ausführen und diese programmgesteuert verwalten können.
Zur Installation von Selenium öffnen Sie das Terminal und führen folgenden Befehl aus:
pip install selenium
YouTube ist ein hervorragendes Beispiel für mit JavaScript gerenderte Inhalte. Beim Besuch eines beliebigen Kanals wird zunächst nur eine begrenzte Anzahl von Videos geladen, während beim Herunterscrollen weitere Videos angezeigt werden. Hier scrapen Sie Daten für die besten hundert Videos des freeCodeCamp.org YouTube-Kanals , indem Sie Tastatureingaben zum Scrollen der Seite emulieren.
Beginnen Sie mit der Überprüfung des HTML-Codes der Webseite. Wenn Sie die Entwicklertools öffnen, sehen Sie Folgendes:
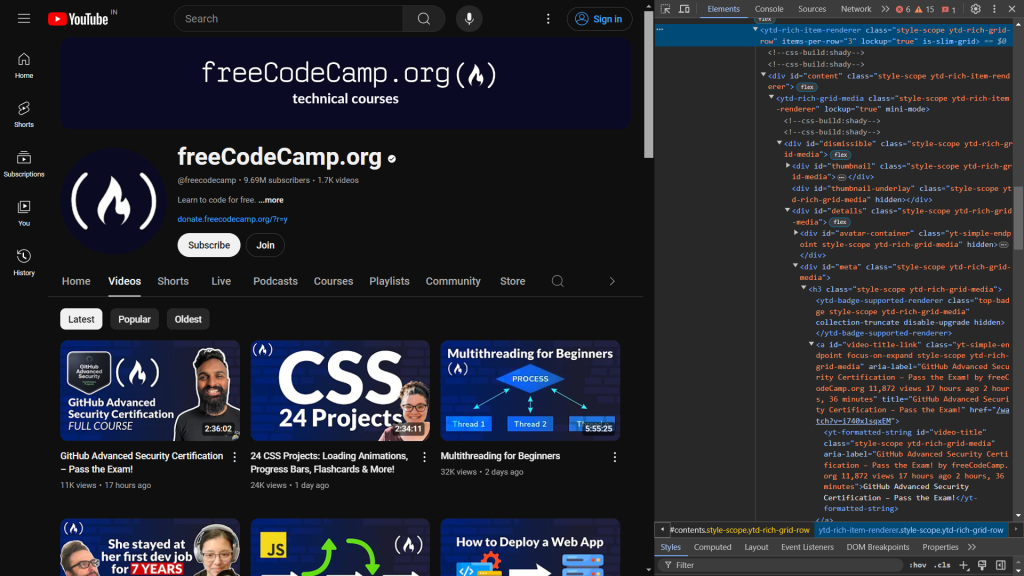
Der folgende Code identifiziert die für die Anzeige des Videotitels und des Links verantwortlichen Elemente:
<a id="video-title-link" class="yt-simple-endpoint focus-on-expand style-scope ytd-rich-grid-media" href="/watch?v=i740xlsqxEM">
<yt-formatted-string id="video-title" class="style-scope ytd-rich-grid-media">GitHub Advanced Security Certification – Pass the Exam!
</yt-formatted-string></a>
Der Videotitel befindet sich im yt-formatted-string -Tag mit der Kennung video-title, während der Videolink im href- Attribut des a -Tags mit der Kennung video-title-link zu finden ist.
Sobald Sie die zum Scrapen vorgesehenen Inhalte identifiziert haben, erstellen Sie eine neue Datei mit dem Namen dynamic_scrape.py und fügen folgenden Code ein, der alle für das Skript erforderlichen Module importiert:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from lxml import html
from time import sleep
import json
Zunächst importieren Sie Webdriver von Selenium, das eine Browser-Instanz generiert, die Sie programmgesteuert verwalten können. Die nächsten Zeilen importieren By und Keys, die ein Web-Element auswählen und einige Tastenanschläge daran ausführen. Die Funktion sleep wird importiert, um die Programmausführung zu unterbrechen und auf das Rendern von Inhalten auf der Seite durch JavaScript zu warten.
Nachdem alle Importvorgänge vorgenommen wurden, können Sie die Treiberinstanz für einen Browser Ihrer Wahl definieren. In diesem Tutorial wird Chrome verwendet, doch Selenium unterstützt auch Edge, Firefox und Safari.
Um die Treiberinstanz für den Browser zu definieren, fügen Sie dem Skript folgenden Code hinzu:
URL = "https://www.youtube.com/@freecodecamp/videos"
videos = []
driver = webdriver.Chrome()
driver.get(URL)
sleep(3)
Ähnlich wie im vorherigen Skript deklarieren Sie eine URL- Variable, in der die auszulesende Web-URL enthalten ist, und eine Video- Variable, die alle Daten als Liste speichert. Als Nächstes wird eine Treibervariable deklariert (d. h. eine Chrome- Instanz), die Sie bei der Interaktion mit dem Browser verwenden. Die Funktion get() öffnet die Browser-Instanz und stellt eine Anfrage an die angegebene URL. Danach rufen Sie die sleep- Funktion auf und warten drei Sekunden, bevor Sie auf ein Element der Webseite zugreifen, um sicherzustellen, dass der gesamte HTML-Code in den Browser geladen wird.
Wie zuvor erwähnt, verwendet YouTube JavaScript, um beim Scrollen weitere Videos zu laden. Um Daten von hundert Videos zu scrapen, müssen Sie nach dem Öffnen des Browsers programmgesteuert zum Ende der Seite scrollen. Fügen Sie hierzu Ihrem Skript folgenden Code hinzu:
parent = driver.find_element(By.TAG_NAME, 'html')
for i in range(4):
parent.send_keys(Keys.END)
sleep(3)
Bei diesem Code wird das <html> -Tag mit der Funktion find_element ausgewählt. Die Funktion gibt das erste Element zurück, das den angegebenen Kriterien genügt, was in diesem Fall das html -Tag ist. Die Methode send_keys simuliert das Betätigen der END -Taste, um zum unteren Ende der Seite zu scrollen, womit das Laden weiterer Videos ausgelöst wird. Dieser Vorgang wird viermal innerhalb einer for -Schleife wiederholt, um das Laden einer ausreichenden Anzahl von Videos zu gewährleisten. Die sleep- Funktion pausiert nach jedem Scrollen drei Sekunden lang, um vor dem erneuten Scrollen das Laden der Videos zu ermöglichen.
Nachdem Sie nun alle für den Scraping-Prozess benötigten Daten zur Verfügung haben, ist es an der Zeit, lxml mit cssselect zu verwenden, um die zu extrahierenden Elemente auszuwählen:
html_data = html.fromstring(driver.page_source)
videos_html = html_data.cssselect("a#video-title-link")
for video in videos_html:
title = video.text_content()
link = "https://www.youtube.com" + video.get("href")
videos.append( {"title": title, "link": link} )
In diesem Code übergeben Sie den HTML-Inhalt aus dem page_source- Attribut des Treibers an die fromstring- Methode, die eine hierarchische Baumstruktur des HTML aufbaut. Wählen Sie danach alle <a> -Tags mit der Kennung video-title-link mithilfe von CSS-Selektoren aus, wobei das Zeichen # die Auswahl anhand der Kennung des Tags angibt. Diese Auswahl gibt eine Liste von Elementen zurück, die die angegebenen Kriterien erfüllen. Der Code durchläuft nun jedes Element, um den Titel und den Link zu extrahieren. Die text_content- Methode ruft den inneren Text ab (den Videotitel), während die get- Methode den Wert des href- Attributs abruft (den Videolink). Schließlich werden die Daten in einer Liste mit dem Namen videos gespeichert.
Hier angelangt, haben Sie den Scraping-Prozess abgeschlossen. Der nächste Schritt umfasst die lokale Speicherung der gescrapten Daten auf Ihrem System. Zur Speicherung der Daten fügen Sie folgenden Code in das Skript ein:
with open('videos.json', 'w') as file:
json.dump(videos, file)
driver.close()
Sie erstellen hierbei die Datei videos.json und verwenden die Methode json.dump , um die Liste der Videos im JSON-Format zu serialisieren und in das Dateiobjekt zu kopieren. Abschließend rufen Sie die close-Methode für das Treiberobjekt auf, um die Browser-Instanz sicher zu schließen und zu löschen.
Jetzt können Sie Ihr Skript testen, indem Sie das Terminal öffnen und folgenden Befehl ausführen:
python dynamic_scrape.py
Nach Ausführung des Skriptswird eine neue Datei mit dem Namen videos.json in Ihrem Verzeichnis erstellt:
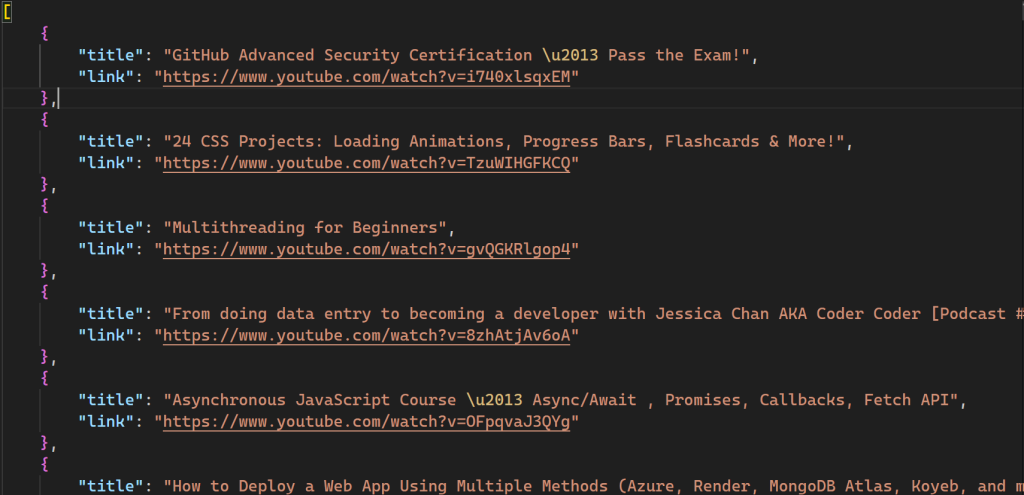
Der gesamte Code für dieses Skript ist ebenfalls auf GitHub verfügbar.
Verwendung von lxml mit Bright Data-Proxy
Obwohl Web-Scraping eine hervorragende Methode zur automatisierten Datenerfassung aus unterschiedlichen Quellen ist, birgt der Prozess auch seine Tücken. Sie müssen mit Anti-Scraping-Tools zurechtkommen, die von Websites mit Ratenbeschränkungen, Geoblocking und mangelnder Anonymität eingesetzt werden. Proxy-Server können bei der Lösung dieser Probleme durchaus nützlich sein, denn sie fungieren als Vermittler, wobei sie die IP-Adresse des Benutzers maskieren. Auf diese Weise können Scraper die Beschränkungen umgehen und unerkannt auf die gewünschten Daten zugreifen. Bright Data ist die erste Anlaufstelle wenn es um zuverlässige Proxy-Dienste geht.
BIm folgenden Beispiel wird verdeutlicht, wie einfach es ist, mit Bright Data-Proxys zu arbeiten. Dazu müssen Sie einige Änderungen an der Datei script_scrape.py vornehmen, um die Books to Scrape-Website zu scrapen.
Als Erstes benötigen Sie Proxys von Bright Data, für die Sie sich für eine kostenlose Testversion anmelden müssen, die Proxy-Ressourcen im Wert von 5 US-Dollar enthält. Nachdem Sie ein Bright Data-Konto eingerichtet haben, erscheint das folgende Dashboard:
Öffnen Sie die Option „ Meine Zonen “ und erstellen Sie eine neue Residential-Proxy- Zone. Bei der Erstellung einer neuen Zone werden Ihr Proxy-Benutzername, -Passwort und -Host angezeigt, die Sie im nächsten Schritt benötigen.
Öffnen Sie die Datei static_scrape.py und fügen Sie folgenden Code unterhalb der URL-Variable ein:
URL = "https://books.toscrape.com/"
# new
username = ""
password = ""
hostname = ""
proxies = {
"http": f"https://{username}:{password}@{hostname}",
"https": f"https://{username}:{password}@{hostname}",
}
content = requests.get(URL, proxies=proxies).text
Ersetzen Sie die Platzhalter für den Benutzernamen, das Passwort und den Hostnamen durch Ihre Proxy-Anmeldedaten. Dieser Code weist die Anfragebibliothek an, den angegebenen Proxy zu verwenden. Der Rest Ihres Skripts bleibt unverändert.
Testen Sie Ihr Skript, indem Sie folgenden Befehl ausführen:
python static_scrape.py
Nachdem Sie dieses Skript ausgeführt haben, erscheint eine ähnliche Ausgabe wie in dem vorherigen Beispiel.
Sie können das gesamte Skript auf GitHub einsehen.
Fazit
lxml ist ein robustes und benutzerfreundliches Tool zur Extraktion von Daten aus HTML-Dokumenten. lxml ist auf Geschwindigkeit optimiert und unterstützt XPath- und CSS-Selektoren, was ein effizientes Parsen großer XML- und HTML-Dokumente gewährleistet.
In diesem Tutorial haben Sie alles über Web-Scraping mit lxml sowie über das Scraping dynamischer und statischer Inhalte gelernt. Außerdem haben Sie erfahren, wie Sie mithilfe von Bright Data Proxy- Servern die von Websites auferlegten Beschränkungen für Scraper umgehen können.
Bright Data ist eine Komplettlösung für Ihre gesamten Web-Scraping-Projekte. Es bietet Funktionen wie Proxys, Scraping-Browser und reCAPTCHAs, mit denen Nutzer Web-Scraping-Hürden effektiv überwinden können. Bright Data stellt auch einen ausführlichen Blog mit Anleitungen und Best Practices zum Thema Web-Scraping zur Verfügung.
Möchten Sie loslegen? Melden Sie sich jetzt an und testen Sie unsere Produkte kostenlos!






