

Google Trendsist ein kostenloses Tool, das Einblicke in die Online-Suchanfragen von Nutzern bietet. Durch die Analyse dieser Suchtrends können Unternehmen aufkommende Markttrends erkennen, das Verbraucherverhalten verstehen und datengestützte Entscheidungen treffen, um ihre Vertriebs- und Marketingbemühungen zu optimieren. Durch die Extraktion von Daten aus Google Trends können Unternehmen ihre Strategien individuell anpassen und so der Konkurrenz einen Schritt voraus sein.
In diesem Artikel erfahren Sie, wie Sie mit Python Daten aus Google Trends extrahieren und diese Daten effektiv speichern und analysieren können.
Warum Google Trends scrapen
Das Extrahieren und Analysieren von Google Trends-Daten kann in verschiedenen Szenarien wertvoll sein, darunter die folgenden:
- Keyword-Recherche:Content-Ersteller und SEO-Spezialisten müssen wissen, welche Keywords an Bedeutung gewinnen, damit sie mehr organischen Traffic auf ihre Websites lenken können. Google Trends hilft Ihnen dabei, trendige Suchbegriffe nach Region, Kategorie oder Zeit zu erkunden, sodass Sie Ihre Content-Strategie auf der Grundlage der sich entwickelnden Nutzerinteressen optimieren können.
- Marktforschung:Marketer müssen die Interessen der Kunden verstehen und Veränderungen in der Nachfrage antizipieren, um fundierte Entscheidungen treffen zu können. Das Scrapen und Analysieren von Google Trends-Daten ermöglicht es ihnen, die Suchmuster der Kunden zu verstehen und Trends im Laufe der Zeit zu beobachten.
- Gesellschaftsforschung:Verschiedene Faktoren, darunter lokale und globale Ereignisse, technologische Innovationen, wirtschaftliche Veränderungen und politische Entwicklungen, können das öffentliche Interesse und Suchtrends erheblich beeinflussen. Die Daten von Google Trends liefern wertvolle Einblicke in diese sich im Laufe der Zeit verändernden Trends und ermöglichen so umfassende Analysen und fundierte Zukunftsprognosen.
- Markenüberwachung:Unternehmen und Marketingteams müssen beobachten, wie ihre Marke auf dem Markt wahrgenommen wird. Wenn Sie Google Trends-Daten scrapen, können Sie die Sichtbarkeit Ihrer Marke mit der Ihrer Mitbewerber vergleichen und schnell auf Veränderungen in der öffentlichen Wahrnehmung reagieren.
Die Alternative von Bright Data zum Scraping von Google Trends – die SERP-API von Bright Data
Anstatt Google Trends manuell zu scrapen, können Sie die SERP-API von Bright Data verwenden, um die Echtzeit-Datenerfassung aus Suchmaschinen zu automatisieren. Die SERP-API bietet strukturierte Daten wie Suchergebnisse und Trends mit präzisem Geo-Targeting und ohne das Risiko von Blockierungen oder CAPTCHAs. Sie zahlen nur für erfolgreiche Anfragen, und die Daten werden zur einfachen Integration im JSON- oder HTML-Format geliefert.
Diese Lösung ist schneller, skalierbarer und macht komplexe Scraping-Skripte überflüssig. Gratis testen und Ihre Datenerfassung mit dem Google Trends-Scraper von Bright Data optimieren.
So scrapen Sie Daten aus Google Trends
Google Trends bietet keine offiziellen APIs zum Scraping von Trenddaten, aber Sie können mehrere APIs und Bibliotheken von Drittanbietern verwenden, um auf diese Informationen zuzugreifen, wie z. B.pytrends, eine Python-Bibliothek, die benutzerfreundliche APIs bereitstellt, mit denen Sie Berichte aus Google Trends automatisch herunterladen können. Pytrends ist zwar einfach zu verwenden, bietet jedoch nur begrenzte Daten, da es nicht auf Daten zugreifen kann, die dynamisch gerendert werden oder sich hinter interaktiven Elementen befinden. Um dieses Problem zu beheben, können SieSeleniummitBeautiful Soupnutzen, um Google Trends zu scrapen und Daten aus dynamisch gerenderten Webseiten zu extrahieren. Selenium ist ein Open-Source-Tool für die Interaktion mit und das Scraping von Websites, das JavaScript verwendet, um Inhalte dynamisch zu laden. Beautiful Soup hilft beim Parsing der gescrapten HTML-Inhalte, sodass Sie bestimmte Daten aus Webseiten extrahieren können.
Bevor Sie mit diesem Tutorial beginnen, müssen SiePythonauf Ihrem Rechner installiert und eingerichtet haben. Außerdem müssen Sie ein leeres Projektverzeichnis für die Python-Skripte erstellen, die Sie in den nächsten Abschnitten erstellen werden.
Erstellen Sie eine virtuelle Umgebung
Eine virtuelle Umgebung ermöglicht es Ihnen, Python-Pakete in separaten Verzeichnissen zu isolieren, um Versionskonflikte zu vermeiden. Um eine neue virtuelle Umgebung zu erstellen, führen Sie den folgenden Befehl in Ihrem Terminal aus:
# Navigieren Sie zum Stammverzeichnis Ihres Projektverzeichnisses, bevor Sie den Befehl ausführen.
python -m venv myenv
Dieser Befehl erstellt einen Ordner namens myenv im Projektverzeichnis. Aktivieren Sie die virtuelle Umgebung, indem Sie den folgenden Befehl ausführen:
source myenv/bin/activate
Alle nachfolgenden Python- oder pip-Befehle werden ebenfalls in dieser Umgebung ausgeführt.
Installieren Sie Ihre Abhängigkeiten
Wie bereits erwähnt, benötigen Sie Selenium und Beautiful Soup, um Webseiten zu scrapen und zu parsen. Um die gescrapten Daten zu analysieren und zu visualisieren, müssen Sie zusätzlich die Python-ModulepandasundMatplotlibinstallieren. Verwenden Sie den folgenden Befehl, um diese Pakete zu installieren:
pip install beautifulsoup4 pandas matplotlib selenium
Abfrage von Google Trends-Suchdaten
Über dasGoogle Trends-Dashboardkönnen Sie Suchtrends nach Region, Datumsbereich und Kategorie untersuchen. Diese URL zeigt beispielsweise die Suchtrends für Kaffee in den Vereinigten Staaten für die letzten sieben Tage:
https://trends.google.com/trends/explore?date=now%207-d&geo=US&q=coffee
Wenn Sie diese Webseite in Ihrem Browser öffnen, werden Sie feststellen, dass die Daten mithilfe von JavaScript dynamisch geladen werden. Um dynamische Inhalte zu scrapen, können Sie denSelenium WebDriver verwenden, der Benutzerinteraktionen wie Klicken, Tippen oder Scrollen nachahmt.
Sie könnenWebDriverin Ihrem Python-Skript verwenden, um die Webseite in einem Browserfenster zu laden und den Quellcode der Seite zu extrahieren, sobald der Inhalt geladen ist. Um dynamische Inhalte zu verarbeiten, können Sie ein explizitestime.sleephinzufügen, um sicherzustellen, dass alle Inhalte geladen sind, bevor Sie den Quellcode der Seite abrufen. Wenn Sie mehr über Techniken zum Umgang mit dynamischen Inhalten erfahren möchten, lesen Siediesen Leitfaden.
Erstellen Sie eine Datei „main.py” im Stammverzeichnis des Projekts und fügen Sie den folgenden Codeausschnitt hinzu:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
def get_driver():
# aktualisieren Sie den Pfad zum Speicherort Ihrer Chrome-Binärdatei
CHROME_PATH = "/Applications/Google Chrome.app/Contents/MacOS/Google Chrome"
options = Options()
# options.add_argument("--headless=new")
options.binary_location = CHROME_PATH
driver = webdriver.Chrome(options=options)
return driver
def get_raw_trends_data(
driver: webdriver.Chrome, date_range: str, geo: str, query: str)
-> str:
url = f"https://trends.google.com/trends/explore?date={date_range}&geo={geo}&q={query}"
print(f"Daten von {url} abrufen")
driver.get(url)
# Workaround, um den Seitenquellcode nach dem anfänglichen 429-Fehler abzurufen
driver.get(url)
driver.maximize_window()
# Warten, bis die Seite geladen ist
time.sleep(5)
return driver.page_source
Die Methode get_raw_trends_data akzeptiert den Datumsbereich, die geografische Region und den Namen der Abfrage als Parameter und verwendet Chrome WebDriver, um den Seiteninhalt abzurufen. Beachten Sie, dass die Methode driver.get zweimal aufgerufen wird, um den anfänglichen 429-Fehler zu beheben, den Google beim ersten Laden der URL ausgibt.
Sie werden diese Methode in den folgenden Abschnitten zum Abrufen von Daten verwenden.
Daten mit Beautiful Soup analysieren
Die Trends-Seite für einen Suchbegriff enthält ein Widget „Interesse nach Teilregion“, das paginierte Datensätze mit Werten zwischen 0 und 100 enthält, die die Beliebtheit des Suchbegriffs basierend auf dem Standort angeben. Verwenden Sie den folgenden Codeausschnitt, um diese Daten mit Beautiful Soup zu analysieren:
# Import hinzufügen
from bs4 import BeautifulSoup
def extract_interest_by_sub_region(content: str) -> dict:
soup = BeautifulSoup(content, "html.parser")
interest_by_subregion = soup.find("div", class_="geo-widget-wrapper geo-resolution-subregion")
related_queries = interest_by_subregion.find_all("div", class_="fe-atoms-generic-content-container")
# Wörterbuch zum Speichern der extrahierten Daten
interest_data = {}
# Extrahieren Sie den Namen der Region und den Prozentsatz des Interesses
for query in related_queries:
items = query.find_all("div", class_="item")
for item in items:
region = item.find("div", class_="label-text").text.strip()
interest = item.find("div", class_="progress-value").text.strip()
interest_data[region] = interest
return interest_data
Dieser Codeausschnitt findet anhand des Klassennamens das passende div für die Daten der Unterregion und durchläuft das Ergebnis, um ein interest_data-Wörterbuch zu erstellen.
Beachten Sie, dass sich der Klassenname in Zukunft ändern könnte und Sie möglicherweise dieChrome DevTools-Funktion „Elementuntersuchen”verwenden müssen, um den richtigen Namen zu finden.
Nachdem Sie nun die Hilfsmethoden definiert haben, verwenden Sie den folgenden Codeausschnitt, um Daten für „Kaffee“ abzufragen:
# Parameter
date_range = "now 7-d"
geo = "US"
query = "coffee"
# Rohdaten abrufen
driver = get_driver()
raw_data = get_raw_trends_data(driver, "now 7-d", "US", "coffee")
# Interesse nach Region extrahieren
interest_data = extract_interest_by_sub_region(raw_data)
# Extrahierte Daten ausgeben
for region, interest in interest_data.items():
print(f"{region}: {interest}")
Ihre Ausgabe sieht wie folgt aus:
Hawaii: 100
Montana: 96
Oregon: 90
Washington: 86
Kalifornien: 84
Datenpagination verwalten
Da die Daten im Widget paginiert sind, gibt der Codeausschnitt im vorherigen Abschnitt nur die Daten von der ersten Seite des Widgets zurück. Um weitere Daten abzurufen, können Sie den Selenium WebDriver verwenden, um die Schaltfläche „Weiter“ zu finden und anzuklicken. Zusätzlich muss Ihr Skript den Cookie-Zustimmungsbanner verarbeiten, indem es auf die Schaltfläche „Akzeptieren“ klickt, um sicherzustellen, dass der Banner andere Elemente auf der Seite nicht behindert.
Um Cookies und Paginierung zu verarbeiten, fügen Sie diesen Codeausschnitt am Ende von main.py hinzu:
# Import hinzufügen
from selenium.webdriver.common.by import By
all_data = {}
# Cookies akzeptieren
driver.find_element(By.CLASS_NAME, "cookieBarConsentButton").click()
# Paginierte Interessensdaten abrufen
while True:
# Klicken Sie auf die Schaltfläche „md“, um weitere Daten zu laden, sofern verfügbar.
try:
geo_widget = driver.find_element(
By.CSS_SELECTOR, "div.geo-widget-wrapper.geo-resolution-subregion"
)
# Finde die Schaltfläche „Mehr laden” mit dem Klassennamen „md-button” und der Aria-Bezeichnung „Weiter”
load_more_button = geo_widget.find_element(
By.CSS_SELECTOR, "button.md-button[aria-label='Next']"
)
icon = load_more_button.find_element(By.CSS_SELECTOR, ".material-icons")
# Überprüfen Sie, ob die Schaltfläche deaktiviert ist, indem Sie überprüfen, ob der Klassenname „arrow-right-disabled” enthält.
if "arrow-right-disabled" in icon.get_attribute("class"):
print("Keine weiteren Daten zum Laden vorhanden")
break
load_more_button.click()
time.sleep(2)
extracted_data = extract_interest_by_sub_region(driver.page_source)
all_data.update(extracted_data)
except Exception as e:
print("Keine weiteren Daten zum Laden", e)
break
driver.quit()
Dieser Ausschnitt verwendet die vorhandene Treiberinstanz, um die Schaltfläche „Weiter“ zu finden und anzuklicken, indem er sie mit ihrem Klassennamen abgleicht. Er überprüft, ob die Klasse „arrow-right-disabled“ im Element vorhanden ist, um festzustellen, ob die Schaltfläche deaktiviert ist, was bedeutet, dass Sie die letzte Seite des Widgets erreicht haben. Wenn diese Bedingung erfüllt ist, wird die Schleife verlassen.
Visualisieren Sie die Daten
Um einfach auf die gesammelten Daten zugreifen und sie weiter analysieren zu können, können Sie die extrahierten Daten der Unterregionen mit einem csv.DictWriter in einer CSV-Datei speichern.
Beginnen Sie damit, save_interest_by_sub_region in main.py zu definieren, um das Wörterbuch all_data in einer CSV-Datei zu speichern:
# Import hinzufügen
import csv
def save_interest_by_sub_region(interest_data: dict):
interest_data = [{"Region": region, "Interest": interest} for region, interest in interest_data.items()]
csv_file = "interest_by_region.csv"
# CSV-Datei zum Schreiben öffnen
with open(csv_file, mode='w', newline='') as file:
writer = csv.DictWriter(file, fieldnames=["Region", "Interest"])
writer.writeheader() # Kopfzeile schreiben
writer.writerows(interest_data) # Daten schreiben
print(f"Daten gespeichert in {csv_file}")
return csv_file
Anschließend können Siepandasverwenden, um die CSV-Datei alsDataFramezu öffnen und Analysen durchzuführen, z. B. Daten nach bestimmten Bedingungen filtern, Daten mitGruppierungsoperationenaggregieren oder Trends mit Diagrammen visualisieren.
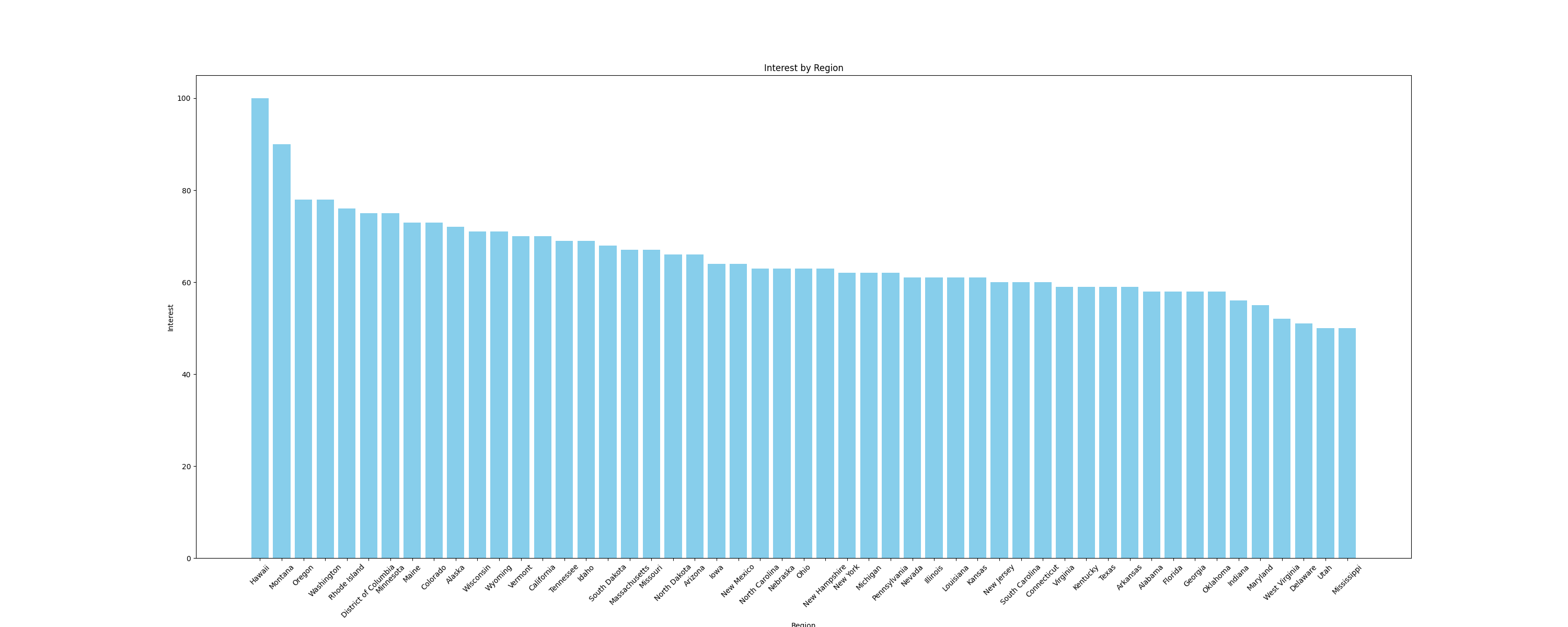
Visualisieren wir beispielsweise die Daten alsBalkendiagramm, um die Zinsen nach Teilregionen zu vergleichen. Verwenden Sie zum Erstellen von Diagrammen die Python-Bibliothekmatplotlib, die nahtlos mit DataFrames zusammenarbeitet. Fügen Sie die folgende Funktion zur Dateimain.pyhinzu, um ein Balkendiagramm zu erstellen und es als Bild zu speichern:
# Importe hinzufügen
import pandas as pd
import matplotlib.pyplot as plt
def plot_sub_region_data(csv_file_path, output_file_path):
# Laden Sie die Daten aus der CSV-Datei.
df = pd.read_csv(csv_file_path)
# Erstellen Sie ein Balkendiagramm zum Vergleich nach Region
plt.figure(figsize=(30, 12))
plt.bar(df["Region"], df["Interest"], color="skyblue")
# Titel und Beschriftungen hinzufügen
plt.title('Interesse nach Region')
plt.xlabel('Region')
plt.ylabel('Interesse')
# Bei Bedarf die Beschriftungen der x-Achse drehen
plt.xticks(rotation=45)
# Die Grafik anzeigen
plt.savefig(output_file_path)
Fügen Sie den folgenden Codeausschnitt am Ende der Datei main.py hinzu, um die zuvor definierten Funktionen aufzurufen:
csv_file_path = save_interest_by_sub_region(all_data)
output_file_path = "interest_by_region.png"
plot_sub_region_data(csv_file_path, output_file_path)
Dieser Ausschnitt erstellt ein Diagramm, das wie folgt aussieht:
Der gesamte Code für dieses Tutorial ist indiesem GitHub-Repo verfügbar.
Herausforderungen beim Scraping
In diesem Tutorial haben Sie eine kleine Datenmenge aus Google Trends gescrapt, aber wenn Ihre Scraping-Skripte an Umfang und Komplexität zunehmen, werden Sie wahrscheinlich auf Herausforderungen wie IP-Sperren und CAPTCHAs stoßen.
Wenn Sie beispielsweise mit diesem Skript häufiger Traffic an eine Website senden, könnten Sie mit IP-Sperren konfrontiert werden, da viele Websites über Schutzmaßnahmen verfügen, um Bot-Traffic zu erkennen und zu blockieren. Um dies zu vermeiden, können Sie manuelle IP-Rotation oder einen der besten Proxy-Dienste verwenden. Wenn Sie sich nicht sicher sind, welchen Proxy-Typ Sie verwenden sollten, lesen Sie unseren Artikel über die besten Proxy-Typen für das Web-Scraping.
Das Auftreten von CAPTCHA oder reCAPTCHA ist eine weitere häufige Herausforderung, die Websites nutzen, wenn sie Bot-Traffic oder Anomalien erkennen oder vermuten. Um dies zu vermeiden, können Sie die Anfragehäufigkeit reduzieren, geeignete Anfrage-Header verwenden oder Dienste von Drittanbietern nutzen, die diese Herausforderungen lösen können.
Fazit
In diesem Artikel haben Sie gelernt, wie Sie mit Python unter Verwendung von Selenium und Beautiful Soup Daten aus Google Trends scrapen können.
Im Laufe Ihrer Web-Scraping-Aktivitäten können Sie auf Herausforderungen wie IP-Sperren und CAPTCHAs stoßen. Anstatt komplexe Scraping-Skripte zu verwalten, sollten Sie die Verwendung der SERP-API von Bright Data in Betracht ziehen, die den Prozess der Erfassung genauer Suchmaschinendaten in Echtzeit, einschließlich Google Trends, automatisiert. Die SERP-API verarbeitet dynamische Inhalte, standortbasiertes Targeting und gewährleistet hohe Erfolgsraten, wodurch Sie Zeit und Aufwand sparen.
Melden Sie sich jetzt an und starten Sie Ihre kostenlose Testversion der SERP-API!





