

In diesem Artikel erfahren Sie Schritt für Schritt, wie Sie mit Python Daten ausGoogle Scholarscrapen können. Bevor wir uns mit den Scraping-Schritten befassen, gehen wir zunächst auf die Voraussetzungen und die Einrichtung unserer Umgebung ein. Los geht’s!
Alternative zum manuellen Scraping von Google Scholar
Das manuelle Scraping von Google Scholar kann schwierig und zeitaufwändig sein. Als Alternative können Sie die Datensätze von Bright Data verwenden:
- Datensatz-Marktplatz: Greifen Sie auf vorab gesammelte Daten zu, die sofort einsatzbereit sind.
- Benutzerdefinierte Datensätze: Fordern Sie maßgeschneiderte Datensätze an oder erstellen Sie diese entsprechend Ihren Anforderungen.
Die Nutzung der Dienste von Bright Data spart Zeit und stellt sicher, dass Sie über genaue, aktuelle Informationen verfügen, ohne sich mit dem komplexen manuellen Scraping befassen zu müssen. Nun fahren wir fort!
Voraussetzungen
Bevor Sie mit diesem Tutorial beginnen, müssen Sie Folgendes installieren:
- Die neueste Version vonPython
- Einen Code-Editor Ihrer Wahl, z. B.Visual Studio Code
Bevor Sie mit einem Scraping-Projekt beginnen, sollten Sie außerdem sicherstellen, dass Ihre Skripte mit derrobots.txt-Dateider Website kompatibel sind, damit Sie keine eingeschränkten Bereiche scrapen. Der in diesem Artikel verwendete Code dient ausschließlich zu Lernzwecken und sollte verantwortungsbewusst verwendet werden.
Einrichten einer virtuellen Python-Umgebung
Bevor Sie Ihre virtuelle Python-Umgebung einrichten, navigieren Sie zum gewünschten Projektort und erstellen Sie einen neuen Ordner mit dem Namen google_scholar_scraper:
mkdir google_scholar_scraper
cd google_scholar_scraper
Nachdem Sie den Ordner google_scholar_scraper erstellt haben, erstellen Sie mit dem folgenden Befehl eine virtuelle Umgebung für das Projekt:
python -m venv google_scholar_env
Um Ihre virtuelle Umgebung zu aktivieren, verwenden Sie unter Linux/Mac den folgenden Befehl:
source google_scholar_env/bin/activate
Wenn Sie jedoch Windows verwenden, verwenden Sie Folgendes:
.google_scholar_envScriptsactivate
Installieren Sie die erforderlichen Pakete
Sobaldvenvaktiviert ist, müssen SieBeautiful Soupundpandas installieren:
pip install beautifulsoup4 pandas
Beautiful Soup hilft dabei, HTML-Strukturen auf Google Scholar-Seiten zu analysieren und bestimmte Datenelemente wie Artikel, Titel und Autoren zu extrahieren. pandas organisiert die extrahierten Daten in einem strukturierten Format und speichert sie als CSV-Datei.
Zusätzlich zu Beautiful Soup und pandas müssen Sie auchSelenium einrichten. Websites wie Google Scholar implementieren häufig Maßnahmen, um automatisierte Anfragen zu blockieren und eine Überlastung zu vermeiden. Selenium hilft Ihnen, diese Einschränkungen zu umgehen, indem es Browseraktionen automatisiert und das Benutzerverhalten nachahmt.
Verwenden Sie den folgenden Befehl, um Selenium zu installieren:
pip install selenium
Stellen Sie sicher, dass Sie die neueste Version von Selenium verwenden (zum Zeitpunkt der Erstellung dieses Artikels 4.6.0), damit SieChromeDriver nicht herunterladen müssen.
Erstellen Sie ein Python-Skript für den Zugriff auf Google Scholar
Sobald Ihre Umgebung aktiviert ist und Sie die erforderlichen Bibliotheken heruntergeladen haben, können Sie mit dem Scraping von Google Scholar beginnen.
Erstellen Sie eine neue Python-Datei mit dem Namen gscholar_scraper.py im Verzeichnis google_scholar_scraper und importieren Sie dann die erforderlichen Bibliotheken:
from bs4 import BeautifulSoup
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
Als Nächstes konfigurieren Sie denSelenium WebDriverso, dass er den Chrome-Browser im Headless-Modus (d. h.ohne grafische Benutzeroberfläche) steuert, da Sie so Daten scrapen können, ohne ein Browserfenster zu öffnen. Fügen Sie die folgende Funktion zum Skript hinzu, um den Selenium WebDriver zu initialisieren:
def init_selenium_driver():
chrome_options = Options()
chrome_options.add_argument("--headless")
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-dev-shm-usage")
driver = webdriver.Chrome(options=chrome_options)
return driver
Nachdem Sie WebDriver initialisiert haben, müssen Sie dem Skript eine weitere Funktion hinzufügen, die die Suchanfrage mithilfe von Selenium WebDriver an Google Scholar sendet:
def fetch_search_results(driver, query):
base_url = "https://scholar.google.com/scholar"
params = f"?q={query}"
driver.get(base_url + params)
driver.implicitly_wait(10) # Bis zu 10 Sekunden warten, bis die Seite geladen ist
# Die Seitenquelle (HTML-Inhalt) zurückgeben
return driver.page_source
In diesem Code weist driver.get(base_url + params) den Selenium WebDriver an, zu der erstellten URL zu navigieren. Der Code richtet den WebDriver außerdem so ein, dass er bis zu zehn Sekunden wartet, bis alle Elemente auf der Seite geladen sind, bevor er mit dem Parsen beginnt.
HTML-Inhalt analysieren
Sobald Sie den HTML-Inhalt der Suchergebnisseite haben, benötigen Sie eine Funktion, um ihn zu parsen und die erforderlichen Informationen zu extrahieren.
Um die richtigen CSS-Selektoren und Elemente für die Artikel zu erhalten, müssen Sie die Google Scholar-Seite manuell überprüfen. Verwenden Sie die Entwicklertools Ihres Browsers und suchen Sie nach eindeutigen Klassen oder IDs für die Elemente Autor, Titel und Snippet (z. B. gs_rt für den Titel, wie in der folgenden Abbildung gezeigt):
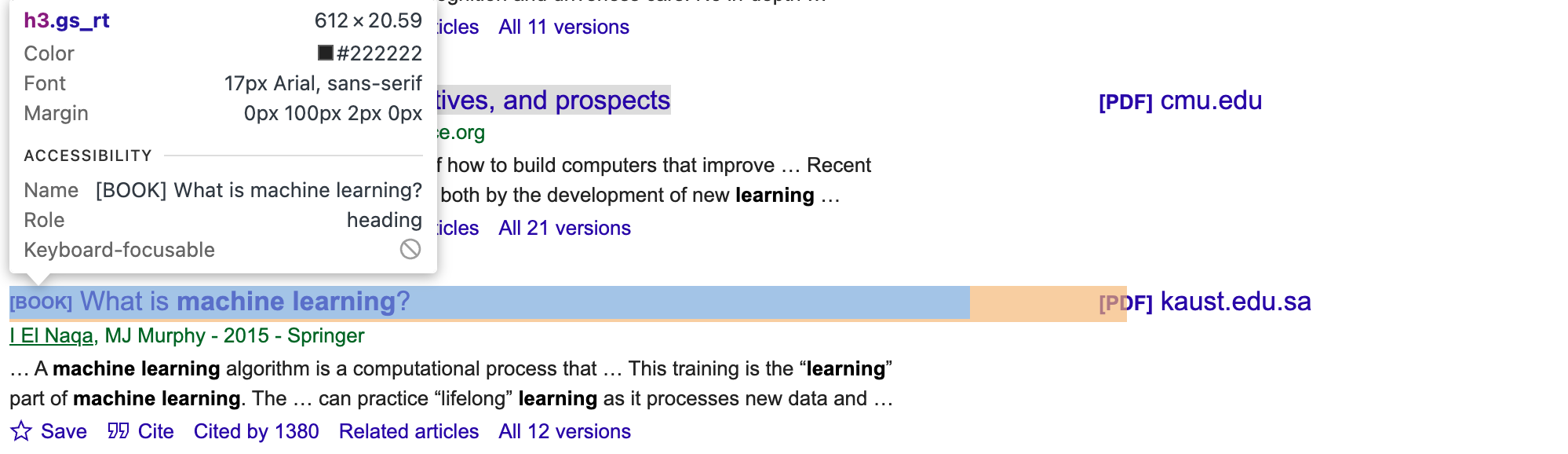
Aktualisieren Sie dann das Skript:
def parse_results(html):
soup = BeautifulSoup(html, 'html.parser')
articles = []
for item in soup.select('.gs_ri'):
title = item.select_one('.gs_rt').text
authors = item.select_one('.gs_a').text
snippet = item.select_one('.gs_rs').text
articles.append({'title': title, 'authors': authors, 'snippet': snippet})
return articles
Diese Funktion verwendet BeautifulSoup, um die HTML-Struktur zu navigieren, Elemente mit Artikelinformationen zu finden, die Titel, Autoren und Snippets für jeden Artikel zu extrahieren und sie dann zu einer Liste von Wörterbüchern zusammenzufassen.
Sie werden feststellen, dass das aktualisierte Skript .select(.gs_ri) enthält, den CSS-Selektor, der mit jedem Suchergebnis auf der Google Scholar-Seite übereinstimmt. Anschließend extrahiert der Code den Titel, die Autoren und den Ausschnitt (kurze Beschreibung) für jedes Ergebnis unter Verwendung spezifischerer Selektoren (.gs_rt, .gs_a und .gs_rs).
Ausführen des Skripts
Um das Scraper-Skript zu testen, fügen Sie den folgenden _main_-Code hinzu, um eine Suche nach „machine learning“ durchzuführen:
if __name__ == "__main__":
search_query = "machine learning"
# Initialisieren Sie den Selenium WebDriver.
driver = init_selenium_driver()
try:
html_content = fetch_search_results(driver, search_query)
articles = parse_results(html_content)
df = pd.DataFrame(articles)
print(df.head())
finally:
driver.quit()
Die Funktion fetch_search_results extrahiert den HTML-Inhalt der Suchergebnisseite. Anschließend extrahiert parse_results Daten aus dem HTML-Inhalt.
Das vollständige Skript sieht wie folgt aus:
from bs4 import BeautifulSoup
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
def init_selenium_driver():
chrome_options = Options()
chrome_options.add_argument("--headless")
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-dev-shm-usage")
driver = webdriver.Chrome(options=chrome_options)
return driver
def fetch_search_results(driver, query):
base_url = "https://scholar.google.com/scholar"
params = f"?q={query}"
# Verwende Selenium WebDriver, um die Seite abzurufen.
driver.get(base_url + params)
# Warten, bis die Seite geladen ist
driver.implicitly_wait(10) # Bis zu 10 Sekunden warten, bis die Seite geladen ist
# Die Seitenquelle (HTML-Inhalt) zurückgeben
return driver.page_source
def parse_results(html):
soup = BeautifulSoup(html, 'html.parser')
articles = []
for item in soup.select('.gs_ri'):
title = item.select_one('.gs_rt').text
authors = item.select_one('.gs_a').text
snippet = item.select_one('.gs_rs').text
articles.append({'title': title, 'authors': authors, 'snippet': snippet})
return articles
if __name__ == "__main__":
search_query = "machine learning"
# Initialisiere den Selenium WebDriver
driver = init_selenium_driver()
try:
html_content = fetch_search_results(driver, search_query)
articles = parse_results(html_content)
df = pd.DataFrame(articles)
print(df.head())
finally:
driver.quit()
Führen Sie python gscholar_scraper.py aus, um das Skript auszuführen. Ihre Ausgabe sollte wie folgt aussehen:
% python3 scrape_gscholar.py
title authors snippet
0 [PDF][PDF] Machine learning algorithms-a review B Mahesh - International Journal of Science an... … Hier ein kurzer Überblick über einige der häufig verwendeten ...
1 [BUCH][B] Maschinelles Lernen E Alpaydin – 2021 – books.google.com Das MIT präsentiert eine prägnante Einführung in maschinelles Lernen ...
2 Maschinelles Lernen: Trends, Perspektiven und ... MI Jordan, TM Mitchell – Science, 2015 – scien... … Maschinelles Lernen befasst sich mit der Frage, wie ...
3 [BUCH][B] Was ist maschinelles Lernen? I El Naqa, MJ Murphy – 2015 – Springer … Ein Algorithmus für maschinelles Lernen ist eine Berechnung...
4 [BUCH][B] Maschinelles Lernen
Die Suchanfrage als Parameter
Derzeit ist die Suchanfrage fest codiert. Um das Skript flexibler zu gestalten, müssen Sie es als Parameter übergeben, damit Sie den Suchbegriff leicht ändern können, ohne das Skript zu modifizieren.
Beginnen Sie mit dem Importieren von sys, um auf die an das Skript übergebenen Befehlszeilenargumente zuzugreifen:
import sys
Aktualisieren Sie dann das Skript im Block __main__, um die Abfrage als Parameter zu verwenden:
if __name__ == "__main__":
if len(sys.argv) != 2:
print("Verwendung: python gscholar_scraper.py '<search_query>'")
sys.exit(1)
search_query = sys.argv[1]
# Initialisieren Sie den Selenium WebDriver
driver = init_selenium_driver()
try:
html_content = fetch_search_results(driver, search_query)
articles = parse_results(html_content)
df = pd.DataFrame(articles)
print(df.head())
finally:
driver.quit()
Führen Sie den folgenden Befehl zusammen mit einer bestimmten Suchanfrage aus:
python gscholar_scraper.py <search_query>
An dieser Stelle können Sie alle Arten von Suchanfragen über das Terminal ausführen (z. B. „künstliche Intelligenz“, „agentenbasierte Modellierung“ oder „affektives Lernen“).
Paginierung aktivieren
In der Regel zeigt Google Scholar nur wenige Suchergebnisse pro Seite an (etwa zehn), was möglicherweise nicht ausreicht. Um mehr Ergebnisse zu erhalten, müssen Sie mehrere Suchseiten durchsuchen, was bedeutet, dass Sie das Skript so ändern müssen, dass zusätzliche Seiten angefordert und analysiert werden.
Sie können die Funktion fetch_search_results so ändern, dass sie einen Startparameter enthält, der die Anzahl der abzurufenden Seiten steuert. Das Paginierungssystem von Google Scholar erhöht diesen Parameter für jede nachfolgende Seite um zehn.
Wenn Sie die erste Seite eines typischen Google Scholar-Seitenlinks wie https://scholar.google.ca/scholar?start=10&q=machine+learning&hl=en&as_sdt=0,5 durchgehen, bestimmt der Startparameter in der URL, welche Ergebnisse angezeigt werden. Beispielsweise ruft start=0 die erste Seite ab, start=10 die zweite Seite, start=20 die dritte Seite usw.
Aktualisieren wir das Skript, um dies zu berücksichtigen:
def fetch_search_results(driver, query, start=0):
base_url = "https://scholar.google.com/scholar"
params = f"?q={query}&start={start}"
# Verwenden Sie Selenium WebDriver, um die Seite abzurufen.
driver.get(base_url + params)
# Warten, bis die Seite geladen ist
driver.implicitly_wait(10) # Bis zu 10 Sekunden warten, bis die Seite geladen ist
# Die Seitenquelle (HTML-Inhalt) zurückgeben
return driver.page_source
Als Nächstes müssen Sie eine Funktion erstellen, um das Scraping mehrerer Seiten zu verarbeiten:
def scrape_multiple_pages(driver, query, num_pages):
all_articles = []
for i in range(num_pages):
start = i * 10 # jede Seite enthält 10 Ergebnisse
html_content = fetch_search_results(driver, query, start=start)
articles = parse_results(html_content)
all_articles.extend(articles)
return all_articles
Diese Funktion durchläuft die angegebene Anzahl von Seiten (num_pages), analysiert den HTML-Inhalt jeder Seite und sammelt alle Artikel in einer einzigen Liste.
Vergessen Sie nicht, das Hauptskript zu aktualisieren, um die neue Funktion zu verwenden:
if __name__ == "__main__":
if len(sys.argv) < 2 or len(sys.argv) > 3:
print("Usage: python gscholar_scraper.py '<search_query>' [<num_pages>]")
sys.exit(1)
search_query = sys.argv[1]
num_pages = int(sys.argv[2]) if len(sys.argv) == 3 else 1
# Initialize the Selenium WebDriver
driver = init_selenium_driver()
try:
all_articles = scrape_multiple_pages(driver, search_query, num_pages)
df = pd.DataFrame(all_articles)
df.to_csv('results.csv', index=False)
finally:
driver.quit()
Dieses Skript enthält auch eine Zeile (df.to_csv('results.csv', index=False)), um alle aggregierten Daten zu speichern und nicht nur an das Terminal auszugeben.
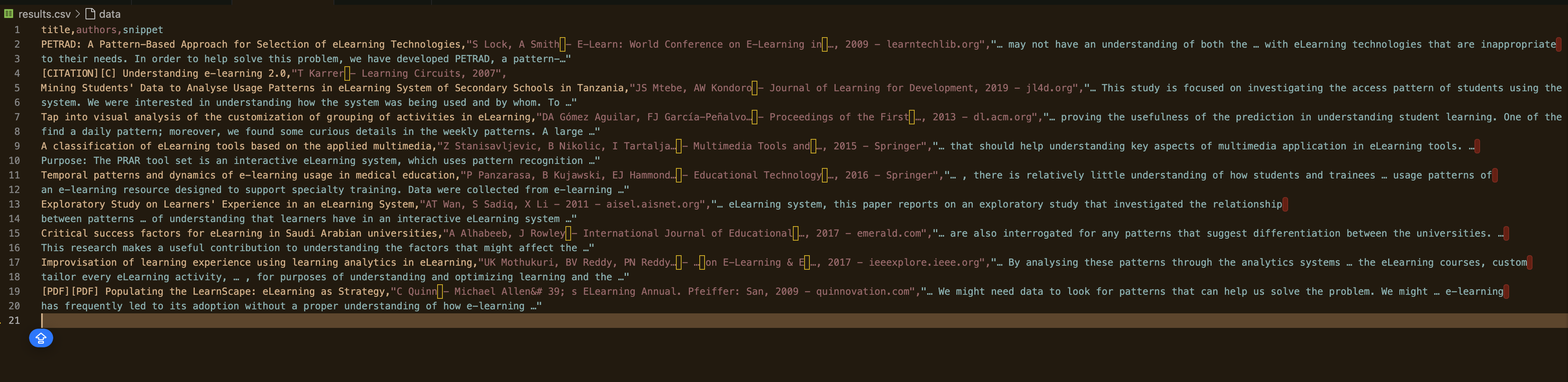
Führen Sie nun das Skript aus und geben Sie die Anzahl der zu scrapend Seiten an:
python gscholar_scraper.py "understanding elearning patterns" 2
Ihre Ausgabe sollte wie folgt aussehen:
So vermeiden Sie IP-Sperren
Die meisten Websites verfügen über Anti-Bot-Maßnahmen, die Muster automatisierter Anfragen erkennen, um das Scraping zu verhindern. Wenn eine Website ungewöhnliche Aktivitäten feststellt, kann Ihre IP-Adresse gesperrt werden.
Beim Erstellen dieses Skripts gab es beispielsweise einen Punkt, an dem die zurückgegebene Antwort nur leere Daten enthielt:
Leerer Datenrahmen
Spalten: []
Index: []
In diesem Fall wurde Ihre IP-Adresse möglicherweise bereits gesperrt. In diesem Szenario müssen Sie eine Lösung finden, um zu verhindern, dass Ihre IP-Adresse markiert wird. Im Folgenden finden Sie einige Techniken, mit denen Sie IP-Sperren vermeiden können.
Verwenden Sie Proxy
Proxy-Dienste helfen Ihnen, Anfragen auf mehrere IP-Adressen zu verteilen, sodass die Wahrscheinlichkeit einer Sperrung geringer ist. Wenn Sie beispielsweise eine Anfrage über einen Proxy weiterleiten, leitet der Proxy-Server die Anfragen direkt an die Website weiter. Auf diese Weise sieht die Website Ihre Anfrage nur von der IP-Adresse des Proxys und nicht von Ihrer eigenen. Wenn Sie erfahren möchten, wie Sie einen Proxy in Ihrem Projekt implementieren können, lesen Sie diesen Artikel.
IPs rotieren
Eine weitere Technik zur Vermeidung von IP-Sperren besteht darin, Ihr Skript so einzurichten, dass die IP-Adressen nach einer bestimmten Anzahl von Anfragen rotiert werden. Sie können dies manuell tun odereinen Proxy-Dienst verwenden, der die IPs automatisch für Sie rotiert. Dadurch wird es für die Website schwieriger, Ihre IP zu erkennen und zu sperren, da die Anfragen so aussehen, als kämen sie von verschiedenen Benutzern.
Virtuelle private Netzwerke einbinden
Ein virtuelles privates Netzwerk (VPN) maskiert Ihre IP-Adresse, indem es Ihren Internetverkehr über einen Server an einem anderen Standort leitet. Sie können ein VPN mit Servern in verschiedenen Ländern einrichten, um Datenverkehr aus verschiedenen Regionen zu simulieren. Außerdem wird Ihre echte IP-Adresse verborgen, sodass es für Websites schwieriger wird, Ihre Aktivitäten anhand der IP-Adresse zu verfolgen und zu blockieren.
Fazit
In diesem Artikel haben wir untersucht, wie man mit Python Daten aus Google Scholar scrapen kann. Wir haben eine virtuelle Umgebung eingerichtet, wichtige Pakete wie Beautiful Soup, Pandas und Selenium installiert und Skripte geschrieben, um Suchergebnisse abzurufen und zu analysieren. Wir haben auch eine Paginierung implementiert, um mehrere Seiten zu scrapen, und Techniken zur Vermeidung von IP-Blockierungen diskutiert, wie z. B. die Verwendung von Proxy, rotierenden IPs und VPNs.
Manuelles Scraping kann zwar erfolgreich sein, bringt jedoch oft Herausforderungen wie IP-Sperren und die Notwendigkeit einer kontinuierlichen Skriptwartung mit sich. Um Ihre Datenerfassung zu vereinfachen und zu verbessern, sollten Sie die Lösungen von Bright Data in Betracht ziehen. Unser Residential-Proxy-Netzwerk bietet ein hohes Maß an Anonymität und Zuverlässigkeit und sorgt dafür, dass Ihre Scraping-Aufgaben reibungslos und ohne Unterbrechungen ausgeführt werden. Darüber hinaus übernehmen unsere Web-Scraper-APIs automatisch die IP-Rotation und die CAPTCHA-Lösung, wodurch Sie Zeit und Aufwand sparen. Entdecken Sie unsere umfangreiche Auswahl an Datensätzen, die auf verschiedene Anforderungen zugeschnitten sind und sofort einsatzbereit sind.
Bringen Sie Ihre Datenerfassung auf die nächste Stufe –melden Sie sich noch heutefür eine kostenlose Testversion bei Bright Data an und erleben Sie effiziente, zuverlässige Scraping-Lösungen für Ihre Projekte.





