

In diesem Leitfaden erfahren Sie:
- Die Definition eines Datensatzes
- Die besten Methoden zum Erstellen von Datensätzen
- Wie man einen Datensatz in Python erstellt
- Wie man einen Datensatz in R erstellt
Lassen Sie uns loslegen!
Was ist ein Datensatz?
Ein Datensatz ist eine Sammlung von Daten, die sich auf ein bestimmtes Thema, einen bestimmten Bereich oder eine bestimmte Branche beziehen. Datensätze können verschiedene Arten von Informationen umfassen – darunter Zahlen, Texte, Bilder, Videos und Audiodateien – und in Formaten wie CSV, JSON, XLS, XLSX oder SQL gespeichert werden.
Im Wesentlichen besteht ein Datensatz aus strukturierten Daten, die auf einen bestimmten Zweck ausgerichtet sind.
Die 5 besten Strategien zum Erstellen eines Datensatzes
Entdecken Sie die 5 besten Strategien zum Erstellen von Datensätzen und analysieren Sie deren Funktionsweise sowie ihre Vor- und Nachteile.
Strategie Nr. 1: Auslagerung der Aufgabe
Die Einrichtung und Verwaltung einer Geschäftseinheit für die Erstellung von Datensätzen ist möglicherweise nicht machbar oder praktikabel. Dies gilt insbesondere, wenn Ihnen die internen Ressourcen oder die Zeit dafür fehlen. In einem solchen Szenario ist eine effektive Strategie für die Erstellung von Datensätzen die Auslagerung der Aufgabe.
Outsourcing bedeutet, den Prozess der Erstellung von Datensätzen an externe Experten oder spezialisierte Agenturen zu delegieren, anstatt ihn intern zu bearbeiten. Dieser Ansatz ermöglicht es Ihnen, die Fähigkeiten von Fachleuten oder Organisationen zu nutzen, die Erfahrung in der Datenerfassung, -bereinigung und -formatierung haben.
An wen sollten Sie die Erstellung von Datensätzen auslagern? Nun, viele Unternehmen bieten gebrauchsfertige Datensätze oder maßgeschneiderte Datenerfassungsdienste an. Weitere Informationen finden Sie in unserem Leitfaden zu den besten Websites für Datensätze.
Diese Anbieter verwenden fortschrittliche Techniken, um sicherzustellen, dass die abgerufenen Daten korrekt sind und gemäß Ihren Spezifikationen formatiert werden. Durch die Auslagerung können Sie sich auf andere wichtige Aspekte Ihres Unternehmens konzentrieren. Es ist jedoch wichtig, einen zuverlässigen Partner auszuwählen, der Ihren Qualitätsansprüchen gerecht wird.
Vorteile:
- Sie müssen sich um nichts kümmern
- Datensätze von jeder Website in jedem Format
- Historische oder aktuelle Daten
Nachteile
- Sie haben keine vollständige Kontrolle über den Datenabrufprozess
- Mögliche Probleme hinsichtlich der Einhaltung der DSGVO und des CCPA
- Möglicherweise nicht die kostengünstigste Lösung
Strategie Nr. 2: Daten aus öffentlichen APIs abrufen
Viele Plattformen, von sozialen Netzwerken bis hin zu E-Commerce-Websites, bieten öffentliche APIs, die eine Fülle von Daten offenlegen. Die API von X ermöglicht beispielsweise den Zugriff auf Informationen über öffentliche Konten, Beiträge und Antworten.
Das Abrufen von Daten aus öffentlichen APIs ist eine effektive Methode zum Erstellen von Datensätzen. Der Grund dafür ist, dass diese Endpunkte Daten in einem strukturierten Format zurückgeben, wodurch es einfacher ist, aus ihren Antworten einen Datensatz zu generieren. Es überrascht nicht, dass APIs eine der besten Strategien für die Datenbeschaffung sind.
Durch die Nutzung dieser APIs können Sie schnell große Mengen an glaubwürdigen Daten direkt von etablierten Plattformen sammeln. Der größte Nachteil besteht darin, dass Sie die Nutzungsbeschränkungen und Nutzungsbedingungen der API einhalten müssen.
Vorteile:
- Zugriff auf offizielle Daten
- Einfache Integration in jede Programmiersprache
- Erhalt strukturierter Daten direkt von der Quelle
Nachteile
- Nicht alle Plattformen verfügen über öffentliche APIs
- Sie müssen die vom API-Anbieter auferlegten Einschränkungen einhalten
- Die von diesen APIs zurückgegebenen Daten können sich im Laufe der Zeit ändern
Strategie Nr. 3: Suchen Sie nach offenen Daten
Offene Daten sind Datensätze, die der Öffentlichkeit kostenlos zur Verfügung gestellt werden. Diese Daten werden hauptsächlich in Forschungsarbeiten und wissenschaftlichen Publikationen verwendet, können aber auch für geschäftliche Zwecke wie Marktanalysen genutzt werden.
Offene Daten sind vertrauenswürdig, da sie von seriösen Quellen wie Regierungen, gemeinnützigen Organisationen und akademischen Einrichtungen bereitgestellt werden. Diese Organisationen bieten offene Datenrepositorien zu einer Vielzahl von Themen an, darunter soziale Trends, Gesundheitsstatistiken, Wirtschaftsindikatoren, Umweltdaten und vieles mehr.
Beliebte Websites, auf denen Sie offene Daten abrufen können, sind unter anderem:
- Data.gov: Ein umfassendes Repository mit Daten der US-Bundesregierung.
- Open Data Portal der Europäischen Union: Bietet Datensätze aus ganz Europa.
- World Bank Open Data: Bietet globale Wirtschafts- und Entwicklungsdaten.
- UN Data: Bietet eine Vielzahl von Datensätzen zu globalen sozialen und wirtschaftlichen Indikatoren.
- Registry of Open Data on AWS: Eine Plattform zum Auffinden und Teilen von Datensätzen, die über AWS-Ressourcen verfügbar sind.
Offene Daten sind eine beliebte Methode zur Erstellung von Datensätzen, da sie die Notwendigkeit der Datenerfassung überflüssig machen, indem sie frei verfügbare Daten bereitstellen. Dennoch müssen Sie die Qualität, Vollständigkeit und Lizenzbedingungen der Daten überprüfen, um sicherzustellen, dass sie den Anforderungen Ihres Projekts entsprechen.
Vorteile:
- Kostenlose Daten
- Gebrauchsfertige, große, vollständige Datensätze
- Datensätze, die von vertrauenswürdigen Quellen wie Regierungsbehörden unterstützt werden
Nachteile
- Bietet in der Regel nur Zugriff auf historische Daten
- Erfordert einigen Aufwand, um nützliche Erkenntnisse für Ihr Unternehmen zu gewinnen
- Möglicherweise finden Sie nicht die Daten, die Sie interessieren
Strategie Nr. 4: Datensätze von GitHub herunterladen
GitHub hostet zahlreiche Repositorys mit Datensätzen für verschiedene Zwecke, von maschinellem Lernen und Datenwissenschaft bis hin zu Softwareentwicklung und Forschung. Diese Datensätze werden von Einzelpersonen und Organisationen geteilt, um Feedback zu erhalten und einen Beitrag zur Community zu leisten.
In einigen Fällen enthalten diese GitHub-Repositorys auch Code zur Verarbeitung, Analyse und Untersuchung der Daten.
Zu den bemerkenswerten Repositorys, aus denen Sie Repositorys beziehen können, gehören:
- Awesome Public Datasets: Eine kuratierte Sammlung hochwertiger Datensätze aus verschiedenen Bereichen, darunter Finanzen, Klima und Sport. Sie dient als Drehscheibe für die Suche nach Datensätzen zu bestimmten Themen oder Branchen.
- Kaggle-Datensätze: Kaggle, eine bekannte Plattform für Data-Science-Wettbewerbe, hostet einige seiner Datensätze auf GitHub. Benutzer können mit nur wenigen Klicks Kaggle-Datensätze erstellen, indem sie von GitHub-Repositorys ausgehen.
- Andere offene Daten-Repositorys: Mehrere Organisationen und Forschungsgruppen nutzen GitHub, um offene Datensätze zu hosten.
Diese Repositorys bieten bereits vorhandene Datensätze, die sofort verwendet oder an Ihre Bedürfnisse angepasst werden können. Der Zugriff darauf erfordert einen einzigen Git-Clone-Befehl oder einen Klick auf die Schaltfläche „Herunterladen“.
Vorteile:
- Sofort einsatzbereite Datensätze
- Code zur Analyse und Interaktion mit den Daten
- Viele verschiedene Datenkategorien zur Auswahl
Nachteile
- Mögliche Lizenzprobleme
- Die meisten dieser Repositorien sind nicht auf dem neuesten Stand
- Generische Daten, nicht auf Ihre Bedürfnisse zugeschnitten
Strategie Nr. 5: Erstellen Sie Ihren eigenen Datensatz mit Web-Scraping
Web-Scraping ist der Prozess der Extraktion von Daten aus Webseiten und deren Umwandlung in ein nutzbares Format.
Das Erstellen von Datensätzen durch Web-Scraping ist aus mehreren Gründen ein beliebter Ansatz:
- Zugriff auf riesige Datenmengen: Das Internet ist die größte Datenquelle der Welt. Mit Web-Scraping können Sie diese umfangreiche Ressource nutzen und Informationen sammeln, die mit anderen Mitteln möglicherweise nicht verfügbar sind.
- Flexibilität: Sie können auswählen, welche Daten abgerufen werden sollen, in welchem Format die Datensätze erstellt werden sollen und wie oft die Daten aktualisiert werden sollen.
- Anpassung: Passen Sie Ihre Datenextraktion an spezifische Anforderungen an, z. B. die Extraktion von Daten aus Nischenmärkten oder zu speziellen Themen, die nicht in öffentlichen Datensätzen enthalten sind.
So funktioniert Web-Scraping in der Regel:
- Identifizieren Sie die Zielwebsite
- Untersuchen Sie die Webseiten, um eine Strategie für die Datenextraktion zu entwickeln
- Erstellen Sie ein Skript, um eine Verbindung zu den Zielseiten herzustellen.
- Parsing des HTML-Inhalts der Seiten
- Wählen Sie die DOM-Elemente aus, die die gewünschten Daten enthalten
- Extrahieren Sie Daten aus diesen Elementen
- Exportieren Sie die gesammelten Daten in das gewünschte Format, z. B. JSON, CSV oder XLSX.
Beachten Sie, dass das Skript für das Web-Scraping in praktisch jeder Programmiersprache geschrieben werden kann, z. B. Python, JavaScript oder Ruby. Weitere Informationen finden Sie in unserem Artikel über die besten Sprachen für das Web-Scraping. Werfen Sie auch einen Blick auf die besten Tools für das Web-Scraping.
Da die meisten Unternehmen wissen, wie wertvoll ihre Daten sind, schützen sie diese mit Anti-Bot-Technologien, selbst wenn sie auf ihrer Website öffentlich zugänglich sind. Diese Lösungen können die automatisierten Anfragen Ihrer Skripte blockieren. In unserem Tutorial zum Thema „Web-Scraping ohne Blockierung” erfahren Sie, wie Sie diese Maßnahmen umgehen können.
Wenn Sie außerdem wissen möchten, wie sich Web-Scraping vom Abrufen von Daten aus öffentlichen APIs unterscheidet, lesen Sie unseren Artikel über Web-Scraping vs. API.
Vorteile:
- Öffentliche Daten von jeder Website
- Sie haben die Kontrolle über den Datenextraktionsprozess
- Kostengünstige Lösung, die mit den meisten Programmiersprachen funktioniert
Nachteile
- Anti-Bot- und Anti-Scraping-Lösungen könnten Sie daran hindern
- Erfordert etwas Wartungsaufwand
- Erfordert möglicherweise eine benutzerdefinierte Datenaggregationslogik
So erstellen Sie Datensätze in Python
Python ist eine führende Sprache für Data Science und daher eine beliebte Wahl für die Erstellung von Datensätzen. Wie Sie gleich sehen werden, sind für die Erstellung eines Datensatzes in Python nur wenige Zeilen Code erforderlich.
Hier konzentrieren wir uns auf das Scraping von Informationen zu allen Datensätzen, die im Bright Data Dataset Marketplace verfügbar sind:
Folgen Sie der Anleitung, um das Ziel zu erreichen!
Eine ausführlichere Anleitung finden Sie in unserem Python-Web-Scraping-Leitfaden.
Schritt 1: Installation und Einrichtung
Wir gehen davon aus, dass Sie Python 3+ auf Ihrem Rechner installiert und ein Python-Projekt eingerichtet haben.
Zunächst müssen Sie die für dieses Projekt erforderlichen Bibliotheken installieren:
- requests: Zum Senden von HTTP-Anfragen und Abrufen der mit Webseiten verbundenen HTML-Dokumente.
- Beautiful Soup: Zum Parsing von HTML- und XML-Dokumenten und zum Extrahieren von Daten aus Webseiten.
- pandas: Zum Bearbeiten von Daten und zum Exportieren in CSV-Datensätze.
Öffnen Sie das Terminal in der aktivierten virtuellen Umgebung im Ordner Ihres Projekts und führen Sie Folgendes aus:
pip install requests beautifulsoup4 pandasNach der Installation können Sie diese Bibliotheken in Ihr Python-Skript importieren:
import requests
from bs4 import BeautifulSoup
import pandas as pdSchritt 2: Verbindung zur Zielwebsite herstellen
Rufen Sie den HTML-Code der Seite ab, aus der Sie Daten extrahieren möchten. Verwenden Sie die Bibliothek „requests“, um eine HTTP-Anfrage an die Zielwebsite zu senden und deren HTML-Inhalt abzurufen:
url = 'https://brightdata.com/products/Datensätze'
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36' }
response = requests.get(url=url, headers=headers)Weitere Informationen finden Sie in unserer Anleitung zum Festlegen eines User-Agents in Python-Anfragen.
Schritt 3: Implementieren Sie die Scraping-Logik
Nachdem Sie den HTML-Inhalt erhalten haben, führen Sie das Parsing mit BeautifulSoup aus und extrahieren Sie die benötigten Daten daraus. Wählen Sie die HTML-Elemente aus, die die gewünschten Daten enthalten, und rufen Sie die Daten daraus ab:
# den abgerufenen HTML-Code analysieren
soup = BeautifulSoup(response.text, 'html.parser')
# wo die gescrapten Daten gespeichert werden sollen
data = []
# Scraping-Logik
dataset_elements = soup.select('.datasets__loop .datasets__item--wrapper')
for dataset_element in dataset_elements:
dataset_item = dataset_element.select_one('.datasets__item')
title = dataset_item.select_one('.datasets__item--title').text.strip()
url_item = dataset_item.select_one('.datasets__item--title a')
if (url_item is not None):
url = url_item['href']
else:
url = None
type = dataset_item.get('aria-label', 'regular').lower()
data.append({
'title': title,
'url': url,
'type': type
})Schritt 4: In CSV exportieren
Verwenden Sie pandas, um die gescrapten Daten in ein DataFrame- -Objekt zu konvertieren und in eine CSV-Datei zu exportieren.
df = pd.DataFrame(data, columns=data[0].keys())
df.to_csv('dataset.csv', index=False)Schritt 5: Skript ausführen
Ihr endgültiges Python-Skript enthält die folgenden Codezeilen:
import requests
from bs4 import BeautifulSoup
import pandas as pd
# Senden Sie eine GET-Anfrage an die Zielwebsite mit einem benutzerdefinierten User-Agent
url = 'https://brightdata.com/products/Datensätze'
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36' }
response = requests.get(url=url, headers=headers)
# den abgerufenen HTML-Code analysieren
soup = BeautifulSoup(response.text, 'html.parser')
# wo die gescrapten Daten gespeichert werden sollen
data = []
# Scraping-Logik
dataset_elements = soup.select('.datasets__loop .datasets__item--wrapper')
for dataset_element in dataset_elements:
dataset_item = dataset_element.select_one('.datasets__item')
title = dataset_item.select_one('.datasets__item--title').text.strip()
url_item = dataset_item.select_one('.datasets__item--title a')
if (url_item is not None):
url = url_item['href']
else:
url = None
type = dataset_item.get('aria-label', 'regular').lower()
data.append({
'title': title,
'url': url,
'type': type
})
# Exportieren als CSV
df = pd.DataFrame(data, columns=data[0].keys())
df.to_csv('dataset.csv', index=False)Starten Sie es, und die folgende Datei „dataset.csv” erscheint im Ordner Ihres Projekts:
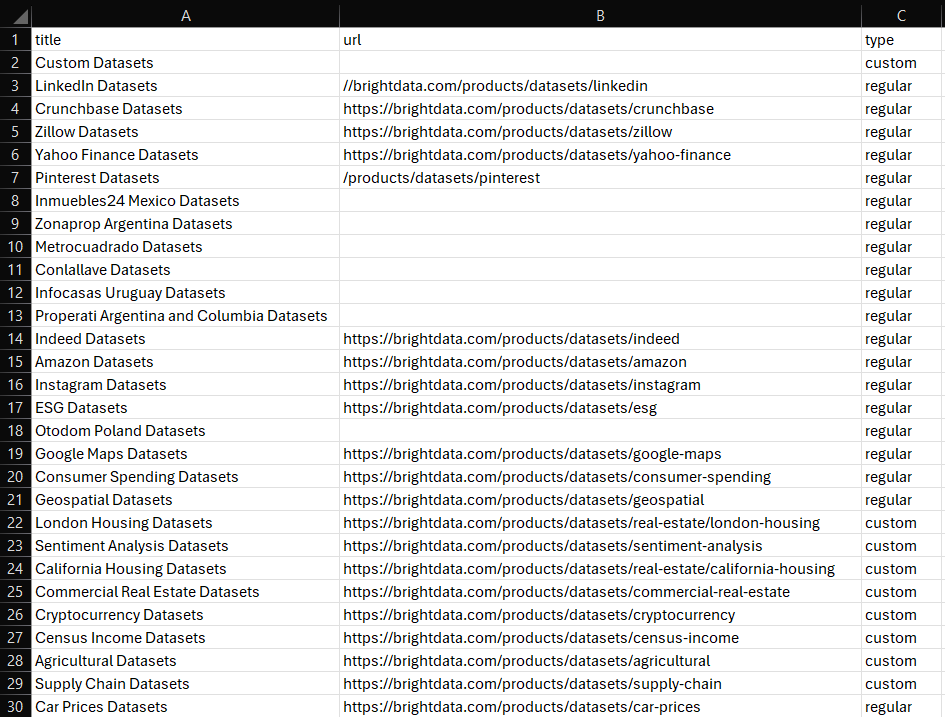
Et voilà! Jetzt wissen Sie, wie man Datensätze in Python erstellt.
So erstellen Sie einen Datensatz in R
R ist eine weitere Sprache, die von Forschern und Datenwissenschaftlern häufig verwendet wird. Nachfolgend finden Sie das entsprechende Skript – entsprechend dem zuvor in Python gezeigten – zum Erstellen eines Datensatzes in R:
library(httr)
library(rvest)
library(dplyr)
library(readr)
# Senden Sie eine GET-Anfrage an die Zielseite mit einem benutzerdefinierten User-Agent.
url <- "https://brightdata.com/products/Datensätze"
headers <- add_headers(`User-Agent` = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36")
response <- GET(url, headers)
# Parse the retrieved HTML
page <- read_html(response)
# Where to store the scraped data
data <- tibble()
# Scraping logic
dataset_elements <- page %>%
html_nodes(".datasets__loop .datasets__item--wrapper")
for (dataset_element in dataset_elements) {
title <- dataset_element %>%
html_node(".datasets__item .datasets__item--title") %>%
html_text(trim = TRUE)
url_item <- dataset_element %>%
html_node(".datasets__item .datasets__item--title a")
url <- if (!is.null(url_item)) {
html_attr(url_item, "href")
} else {
""
}
type <- dataset_element %>%
html_attr("aria-label", "regular") %>%
tolower()
data <- bind_rows(data, tibble(
title = title,
url = url,
type = type
))
}
# Exportieren in CSV
write_csv(data, "dataset.csv")Weitere Anleitungen finden Sie in unserem Tutorial zum Web-Scraping mit R.
Fazit
In diesem Blogbeitrag haben Sie gelernt, wie Sie Datensätze erstellen. Sie haben verstanden, was ein Datensatz ist, und verschiedene Strategien zu seiner Erstellung kennengelernt. Außerdem haben Sie gesehen, wie Sie die Web-Scraping-Strategie in Python und R anwenden können.
Bright Data betreibt ein großes, schnelles und zuverlässiges Proxy-Netzwerk, das von vielen Fortune-500-Unternehmen und über 20.000 Kunden genutzt wird. Dieses wird verwendet, um Daten auf ethische Weise aus dem Internet abzurufen und sie auf einem riesigen Marktplatz für Datensätze anzubieten, der Folgendes umfasst:
- Geschäftsdatensätze: Daten aus wichtigen Quellen wie LinkedIn, CrunchBase, Owler und Indeed.
- E-Commerce-Datensätze: Daten von Amazon, Walmart, Target, Zara, Zalando, Asos und vielen anderen.
- Immobiliendatensätze: Daten von Websites wie Zillow, MLS und anderen.
- Social-Media-Datensätze: Daten von Facebook, Instagram, YouTube und Reddit.
- Finanzdatensätze: Daten von Yahoo Finance, Market Watch, Investopedia und anderen.
Wenn diese vorgefertigten Optionen Ihren Anforderungen nicht entsprechen, sollten Sie unsere maßgeschneiderten Datenerfassungsdienste in Betracht ziehen.
Darüber hinaus bietet Bright Data eine breite Palette leistungsstarker Scraping-Tools, darunter Web Scraper APIs und Scraping-Browser.
Melden Sie sich jetzt an und finden Sie heraus, welche Produkte und Dienstleistungen von Bright Data Ihren Anforderungen am besten entsprechen.




