

In diesem Leitfaden erfahren Sie Folgendes:
- Was Cloudflare ist
- Warum seine WAF-Lösung für Ihre Scraping-Skripte eine Herausforderung darstellt
- Wie man Cloudflare WAF mithilfe von All-in-One-Lösungen umgeht
- Wie man jede der wichtigsten Anti-Bot-Maßnahmen in Angriff nimmt, auf die sie sich stützt
Legen wir also gleich los!
Was ist Cloudflare?
Als Webinfrastruktur- und Sicherheitsunternehmen betreibtCloudflare eines der größten Netzwerke des Internets. Das Unternehmen bietet ein umfassendes Serviceangebot, das Websites schneller und sicherer machen soll.
Cloudflare fungiert vorrangig als CDN (Content Delivery Network), das Website-Inhalte in einem globalen Netzwerk zwischenspeichert, um die Ladezeiten zu verbessern und die Latenz zu reduzieren. Darüber hinaus bietet es Funktionen wie DDoS-Schutz (Distributed-Denial-of-Service), eine WAF (Web Application Firewall), Bot-Management, DNS-Dienste und vieles mehr.
Mit der Integration in das Cloudflare-Netzwerk können Websites innerhalb kürzester Zeit mehr Sicherheit gewinnen und von einer optimierten Leistung profitieren. Aus diesem Grund ist Cloudflare für Millionen von Websites weltweit die Lösung der Wahl.
Ein kurzer Überblick zu Cloudflare WAF
Bei einer WAF, kurz für „Web Application Firewall“, handelt es sich um ein Sicherheitssystem, das den HTTP-Verkehr zwischen einer Webanwendung und dem Internet filtert und überwacht. Sie trägt dazu bei, Websites vor Angriffen wie DDoS, Cross-Site-Scripting (XSS), SQL-Injection und anderen bösartigen Aktivitäten zu schützen.
Insbesondere die Cloudflare WAF ist eine der weltweit meistgenutzten WAF-Lösungen. Diese Beliebtheit beruht auf der weit verbreiteten Nutzung von Cloudflare als CDN. Für Websites, die bereits auf Cloudflare gehostet werden, ist die Aktivierung der WAF mit Standardkonfigurationen bereits durch wenige Klicks möglich.
Folgende wichtige Anti-Bot-Technologien und -Verfahren werden von Cloudflare WAF eingesetzt:
- Ratenbegrenzung: Begrenzung der Anzahl von Anfragen, die eine einzelne IP-Adresse innerhalb eines bestimmten Zeitraums stellen kann, um DDoS-Angriffe zu stoppen und Brute-Force-Angriffe zu verhindern.
- JavaScript-Herausforderungen: Überprüfung, ob ein Besucher JavaScript ausführen kann, da dies ein typisches Verhalten echter Benutzer ist.
- Turnstile-CAPTCHA: CAPTCHA-Tests für verdächtige Bots.
- IP-Reputation: Pflege einer Reputationsdatenbank, um verdächtige IP-Adressen unverzüglich abzublocken.
- Verhaltensanalyse: Beobachtung des Besucherverhaltens, um automatisierte Muster oder ungewöhnliche Aktivitäten zu erkennen.
Wenn eine Website durch Cloudflare WAF gesichert ist, werden in der Regel eine bzw. mehrere Anti-Bot-Lösungen zum Blockieren automatisierter Anfragen eingesetzt. Gerade die Kombination dieser Abwehrmaßnahmen stellt eine besondere Herausforderung beim Scraping einer durch Cloudflare gesicherten Website dar.
Erste Lösungsansätze zur Vermeidung von Cloudflare-Blockaden beim Scraping einer Website
Entdecken Sie die besten Lösungen und Ideen für einen ersten Ansatz zum Web-Scraping auf durch Cloudflare gesicherten Websites.
Vollständige Umgehung von Cloudflare
Denken Sie daran, dass Cloudflare als CDN fungiert, d. h. es speichert und verbreitet Website-Inhalte auf mehreren geografisch verteilten Servern. Über Cloudflare verteilte Websites sind daher typischerweise nur über Server im CDN-Netzwerk zugänglich.
Nehmen wir nun an, Sie könnten die IP-Adresse des Website-Servers, der sich hinter dem CDN befindet, ermitteln. Dies hätte zur Folge, dass Sie mit der Website interagieren und dabei Cloudflare vollständig umgehen können. Schließlich kann Cloudflare ausschließlich Anfragen auswerten, die durch dessen Netzwerk geleitet werden.
Hierzu kann man sich DNS-Verlaufs-Suchtools wie SecurityTrails zunutze machen, um alle historischen DNS-Datensätze zu ermitteln, aus denen die IP-Adresse des ursprünglichen Servers hervorgeht. Sobald Sie die IP-Adresse in Erfahrung gebracht haben, können Sie versuchen, Anfragen direkt an den Server zu senden und Cloudflare zu umgehen.
Problematisch ist, dass der Server möglicherweise über zusätzliche Konfigurationen verfügt, um nur Anfragen aus dem IP-Bereich von Cloudflare zu akzeptieren. Dadurch wäre eine direkte Verbindung zur Website nahezu unmöglich, ohne gleich blockiert zu werden. Hinzu kommt, dass es ziemlich schwierig und unwahrscheinlich ist, die ursprüngliche Server-IP überhaupt zu finden.
Kostenlose Cloudflare-Solver
Im Internet gibt es mehrere kostenlose und Open-Source-Bibliotheken, die Cloudflare umgehen können. Einige der beliebtesten sind:
- Cloudscraper: Ein Python-Modul, das die Anti-Bot-Herausforderungen von Cloudflare bewältigt.
- Cfscrape: Ein schlankes PHP-Modul zur Umgehung der Anti-Bot-Seiten von Cloudflare.
- Humanoid: Ein Node.js-Paket zur Umgehung der Anti-Bot-JavaScript-Herausforderungen von Cloudflare.
Obwohl diese Lösungen vorübergehend funktionieren können, sollte man bedenken, dass Anti-Scraping ein Katz-und-Maus-Spiel ist. Das, was heute funktioniert, kann morgen schon nicht mehr funktionieren, da Cloudflare seine Schutzmechanismen ständig aktualisiert.
Wenig überraschend ist, dass die meisten dieser Projekte seit Jahren keine Aktualisierungen mehr erhalten haben. Das liegt vor allem daran, dass die Entwickler aufgrund ihrer ständigen Bemühungen, mit den Aktualisierungen von Cloudflare Schritt zu halten, schließlich aufgegeben haben.
Hochwertige Cloudflare-Solvers
Im Allgemeinen ist die beste Lösung für das Scraping einer Cloudflare-geschützten Website die Verwendung eines Premium-Produkts. Die Kosten gewährleisten regelmäßige Aktualisierungen durch Experten im Bereich Scraping, was die hohe Zuverlässigkeit gegenüber den Abwehrmechanismen von Cloudflare aufrechterhält.
Zusätzlich stellen erstklassige Anbieter wie Bright Data rund um die Uhr technischen Support bereit, um bei der Behebung von Problemen zu helfen. Sollten Sie auf der Suche nach einer professionellen Cloudflare-Scraping-Lösung sein, testen Sie unseren Scraping-Browser.
Als cloudbasierter, skalierbarer GUI-Browser lässt er sich in Playwright, Puppeteer, Selenium sowie alle anderen Headless-Browser-Bibliotheken integrieren. Zur Gewährleistung einer hohen Effektivität gegenüber Cloudflare umfasst er Funktionen wie IP-Rotation, CAPTCHA-Lösungsfähigkeiten, User-Agent-Rotation und vieles mehr.
Scraping einer Cloudflare-geschützten Website: DIY-Ansatz zur Umgehung von Anti-Bots
Cloudflare zu knacken ist kompliziert, insbesondere wenn Sie keine hochwertige All-in-One-Lösung verwenden möchten. Wenn Sie diesen Weg einschlagen möchten, sollten Sie alle Schutzmaßnahmen gegen Bots von Cloudflare berücksichtigen und Möglichkeiten finden, diese zu umgehen.
In diesem Abschnitt finden Sie einige der nützlichsten High-Level-Techniken, um Cloudflare zu umgehen und Websites zu scrapen, deren Inhalte durch die WAF geschützt sind. Ausführliche Anweisungen finden Sie in unserem Leitfaden zur Umgehung von Cloudflare.
Also, fangen wir an!
JavaScript-Rendering
Zu den gängigsten Techniken, die Cloudflare zur Erkennung von Bots einsetzt, zählen JavaScript-Herausforderungen. Diese JavaScript-Skripte sind in Webseiten eingebettet und werden während des Renderns vom Browser ausgeführt. Dabei werden bestimmte Prüfungen durchgeführt, um festzustellen, mit welcher Wahrscheinlichkeit es sich bei dem Besucher um einen Bot handelt:

Ergibt sich aus diesen Abfragen der Verdacht, dass es sich bei Ihnen um einen Bot handelt, wird ein CAPTCHA angezeigt. Andernfalls wird Ihnen der Zugriff auf den Seiteninhalt gewährt.
Um also eine von Cloudflare geschützte Seite anzugreifen, ist ein Browser-Automatisierungstool wie Playwright, Selenium oder Puppeteer erforderlich. Mit diesen Tools können Browser so eingestellt werden, dass sie wie normale Benutzer mit Websites interagieren. Erfahren Sie mehr in unserem Leitfaden zum Web-Scraping mit Playwright.
Bei Headless-Browsern besteht das Problem, dass sie aufgrund ihrer Standardkonfigurationen von Anti-Bot-Erkennungssystemen entdeckt werden können. Um dem vorzubeugen, sollten Sie Bibliotheken wie Playwright Stealth oder Puppeteer Stealth über Puppeteer Extra verwenden, mit denen sich die Aktivitäten von Headless-Browsern verschleiern lassen.
CAPTCHA-Auflösung
Wenn Cloudflare vermutet, dass Sie ein Bot sein könnten, wird es versuchen, Sie mit einem Turnstile-CAPTCHA zu stoppen:

Je nach Konfiguration kann das CAPTCHA ein einfacher Klick-basierter Test wie das obige oder ein komplexeres Puzzle wie das folgende sein:

Die Automatisierung der CAPTCHA-Auflösung ist komplex gestaltet, da CAPTCHAs Tests darstellen, die eigens darauf ausgelegt sind, Bots von Menschen zu unterscheiden. Sollte Ihr Headless-Browser auf eine solche Herausforderung stoßen, können Sie die in unserem Leitfaden zur Umgehung von CAPTCHAs mit Python beschriebenen Techniken ausprobieren.
Als zuverlässigere Lösung, deren Funktion unabhängig von der in Ihrem Scraping-Skript verwendeten Technologie ist, sollten Sie den Cloudflare-Turnstile-Solver von Bright Data in die engere Wahl einbeziehen. Dieser löst Cloudflare-Turnstile-CAPTCHAs zügig und vollautomatisch für Sie.
Umgehung von Durchsatzratenbegrenzungen
Werden von derselben IP-Adresse innerhalb eines kurzen Zeitraums zu viele Anfragen gestellt, wird Cloudflare Ihre IP-Adresse wahrscheinlich vorübergehend oder sogar dauerhaft sperren. Dies stellt insofern ein Problem dar, als dass dadurch Ihr Scraping-Vorgang unterbrochen wird und der Ruf Ihrer IP-Adresse Schaden nimmt.
Bei der oben beschriebenen Technik, die zur Abwehr von DDoS-Angriffen und unerwünschten automatisierten Anfragen eingesetzt wird, spricht man von Ratenbegrenzung. Ihre IP-Adresse kann nur schwer geändert werden, da sie an das mit Ihnen verbundene Netzwerk gekoppelt ist. Die einzige effektive Möglichkeit, eine IP-Rotation zu implementieren und Sperrungen zu vermeiden, ist die Nutzung eines Proxy-Dienstes.
Durch Lösungen wie Residential-Proxys lassen sich die Anfragen Ihres Skripts so darstellen, als kämen sie von realen Geräten, die sich an einem bestimmten Standort befinden. Erfahren Sie mehr über unsere Angebote zu Residential-Proxys.
Browser-Spoofing
Browser verbrauchen selbst im Headless-Modus viele Ressourcen. Die Erstellung eines Scraping-Vorgangs um eine Cloudflare-geschützte Website herum unter Verwendung eines Browser-Automatisierungstools kann daher zu einem ressourcenintensiven Prozess führen. Eventuell sind dafür mehrere Server und eine komplexe Architektur erforderlich.
Zur Vermeidung des damit verbundenen Aufwands – und in Fällen, in denen die WAF von Cloudflare nicht zu aggressiv konfiguriert wurde – bietet sich ein anderer Ansatz an. Das Konzept sieht vor, automatisierte Anfragen von HTTP-Clients zu senden, die echte Browser imitieren, was als Browser-Spoofing bezeichnet wird.
Sinn des Ganzen ist es, Ihre HTTP-Anfragen so aussehen zu lassen, als stammten sie von einem normalen Browser. Dieses Ergebnis lässt sich durch das Setzen bestimmter HTTP-Header wie User-Agent erzielen. Weitere Informationen finden Sie in unserem Leitfaden zum besten User-Agent für Web-Scraping.
Unter komplexeren Bedingungen reicht dieser Trick allein möglicherweise nicht aus. Dennoch kann Cloudflare Ihre Anfragen aufgrund des TLS-Fingerabdrucks als von einem HTTP-Client und nicht von einem Browser ausgehend erkennen:
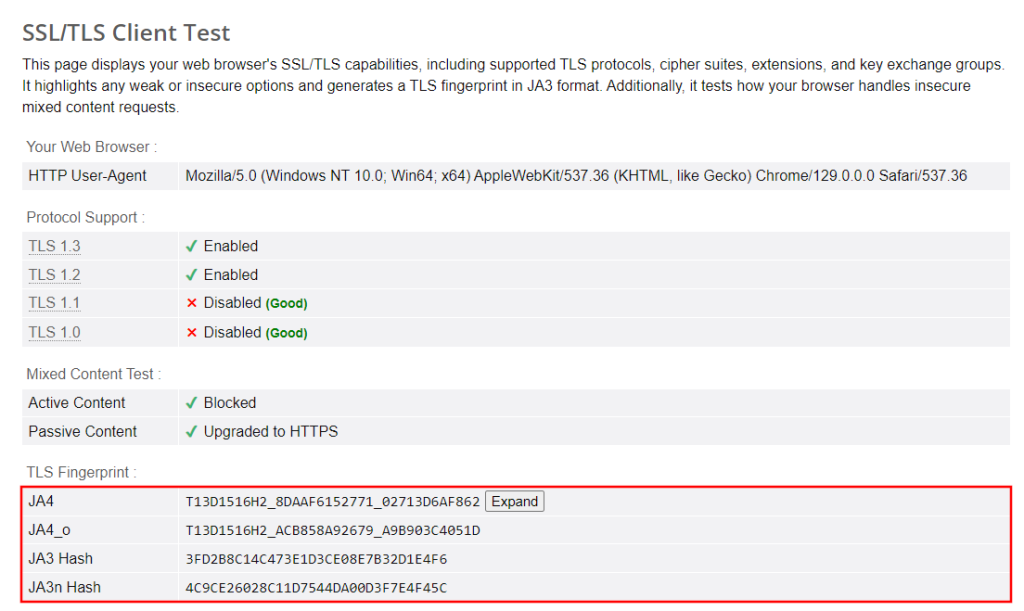
Für diejenigen, die mit diesem Konzept nicht vertraut sind: Beim TLS-Fingerprinting wird ein Client anhand der Methode identifiziert, mit der er sichere Verbindungen über TLS herstellt. Um den TLS-Fingerabdruck eines Browsers nachzubilden, können Sie, wie in unserem dedizierten Tutorial erläutert, einen HTTP-Client wie curl-impersonate einsetzen.
Fazit
In diesem Artikel wurden Ihnen mehrere Tipps und Tricks zum Scrapen von Cloudflare-geschützten Websites vorgestellt. Cloudflare ist der beliebteste CDN-Dienst am Markt und bietet zudem fortschrittliche Anti-Bot-Lösungen. Die Umgehung der Anti-Scraping-Maßnahmen von Cloudflare stellt, wie Sie hier gelernt haben, zwar eine Herausforderung, aber nichts Unmögliches dar.
Ganz gleich, für welchen Ansatz Sie sich entscheiden, denken Sie daran, dass alles mit professionellen, schnellen und zuverlässigen Scraping-Lösungen einfacher wird, wie z. B.:
- Web-Unlocker: Umgeht selbstständig Ratenbegrenzungen, Fingerprinting und andere Anti-Bot-Einschränkungen, sodass eine nahtlose öffentliche Webdatenerfassung gewährleistet ist.
- CAPTCHA-Solver: Automatisches Lösen verschiedener Arten von CAPTCHAs, wodurch der Zugriff auf Inhalte jeder beliebigen Webseite oder die Durchführung von Interaktionen ganz ohne manuelle Eingriffe ermöglicht wird.
- Scraping-Browser: Vollständig gehosteter Browser, der das Scraping dynamischer Webdaten bei gleichzeitiger Automatisierung des Prozesses zur Aufhebung der Sperrung von Websites ermöglicht.
Dank der umfangreichen Palette an Scraping-Tools von Bright Data war es noch nie so einfach, Daten aus Cloudflare-geschützten Websites zu extrahieren!
Melden Sie sich jetzt an, um herauszufinden, welche der von Bright Data angebotenen Lösungen Ihren Anforderungen am besten entspricht. Starten Sie noch heute eine kostenlose Testversion!





