

In diesem Artikel erfahren Sie:
- Was ein Web-Scraping-Dienst ist und was er bietet.
- Nach welchen Kriterien Sie die besten Web-Scraping-Dienste vergleichen sollten.
- Die besten Web-Scraping-Dienste, bewertet und verglichen nach diesen Kriterien.
- Eine Übersichtstabelle für einen schnellen Überblick über die führenden Dienste für Web-Scraping.
Lassen Sie uns loslegen!
Was ist ein Web-Scraping-Dienst?
Ein Web-Scraping-Dienst sammelt, verarbeitet und liefert strukturierte Daten von öffentlichen Websites in Ihrem Auftrag. Anstatt intern Scraper zu erstellen und zu warten, legen Sie Ihre Datenanforderungen fest, und der Anbieter kümmert sich um die Extraktion, Skalierung, Datenbereinigung, Qualitätssicherung und Lieferung.
Diese Dienste umfassen in der Regel Compliance-Unterstützung, Überwachung und flexible Lieferformate, wodurch sie sich ideal für Unternehmen eignen, die zuverlässige Webdaten ohne operativen Aufwand benötigen.
Extra: Web-Scraping-Dienst vs. Web-Scraping-Tool
Web-Scraping-Dienste sollten nicht mit Web-Scraping-Tools verwechselt werden. Der Hauptunterschied liegt im Umfang:
- Web-Scraping-Dienste bieten in der Regel eine vollständig verwaltete Lösung, bei der der Anbieter den gesamten Scraping-Prozess auf der Grundlage Ihrer Anforderungen übernimmt. Sie liefern also ein „Scraping as a Service“-Erlebnis.
- Web-Scraping-Tools bieten ein Self-Service-Erlebnis und geben Ihnen Zugriff auf Lösungen wie Web-Unblocker, Cloud-Browser oder Open-Source-Bibliotheken, mit denen Sie Ihre eigenen Scraper erstellen und ausführen können.
Wenn Sie stattdessen nach Tools suchen, lesen Sie unseren Artikel über die besten Tools für Web-Scraping.
Nun sind wir bereit, die besten Web-Scraping-Dienste vorzustellen!
Aspekte, die bei der Auswahl der besten Web-Scraping-Dienste zu berücksichtigen sind
Es gibt viele Scraping-Dienste auf dem Markt, und es ist schwierig, den richtigen zu finden. Um sie effektiv zu vergleichen, müssen Sie jeden Anbieter anhand klar definierter Kriterien bewerten.
Im Einzelnen sind die wichtigsten Aspekte, die bei der Auswahl der besten Web-Scraping-Dienste zu berücksichtigen sind, folgende
- Workflow: Wie der Anbieter den Prozess vom ersten Kontakt bis zur endgültigen Datenlieferung abwickelt.
- Datenlieferung: Unterstützte Datenformate, Liefermethoden, Häufigkeiten usw.
- Unterstützte Branchen: Die Arten von Szenarien, die der Dienst abdeckt, wie E-Commerce, Immobilien, Marktforschung und mehr.
- Infrastruktur: Die Grundlage, auf der der Scraping-Dienst aufgebaut ist, einschließlich der Fachkompetenz des Teams, der Skalierbarkeit, der Zuverlässigkeit und der Eigenschaften der zugrunde liegenden Proxy- und Datenerfassungssysteme.
- Reputation: Die Anzahl der Unternehmen, die den Dienst nutzen, namhafte Kunden oder Partner und die allgemeine Glaubwürdigkeit auf dem Markt.
- Support: Wie der Web-Scraping-Dienst den Kundensupport und die Kommunikation während des gesamten Prozesses gewährleistet.
- Compliance: Ob und wie die gesammelten Daten den Datenschutz- und Privatsphärenbestimmungen entsprechen.
- Preise: Das Preismodell, die Flexibilität bei der Abrechnung und die Skalierung der Kosten je nach Nutzung oder Datenvolumen.
Die 9 besten Web-Scraping-Dienste
Entdecken Sie die besten Web-Scraping-Dienste, die sorgfältig ausgewählt, verglichen und nach den zuvor genannten Kriterien bewertet wurden.
1. Bright Data
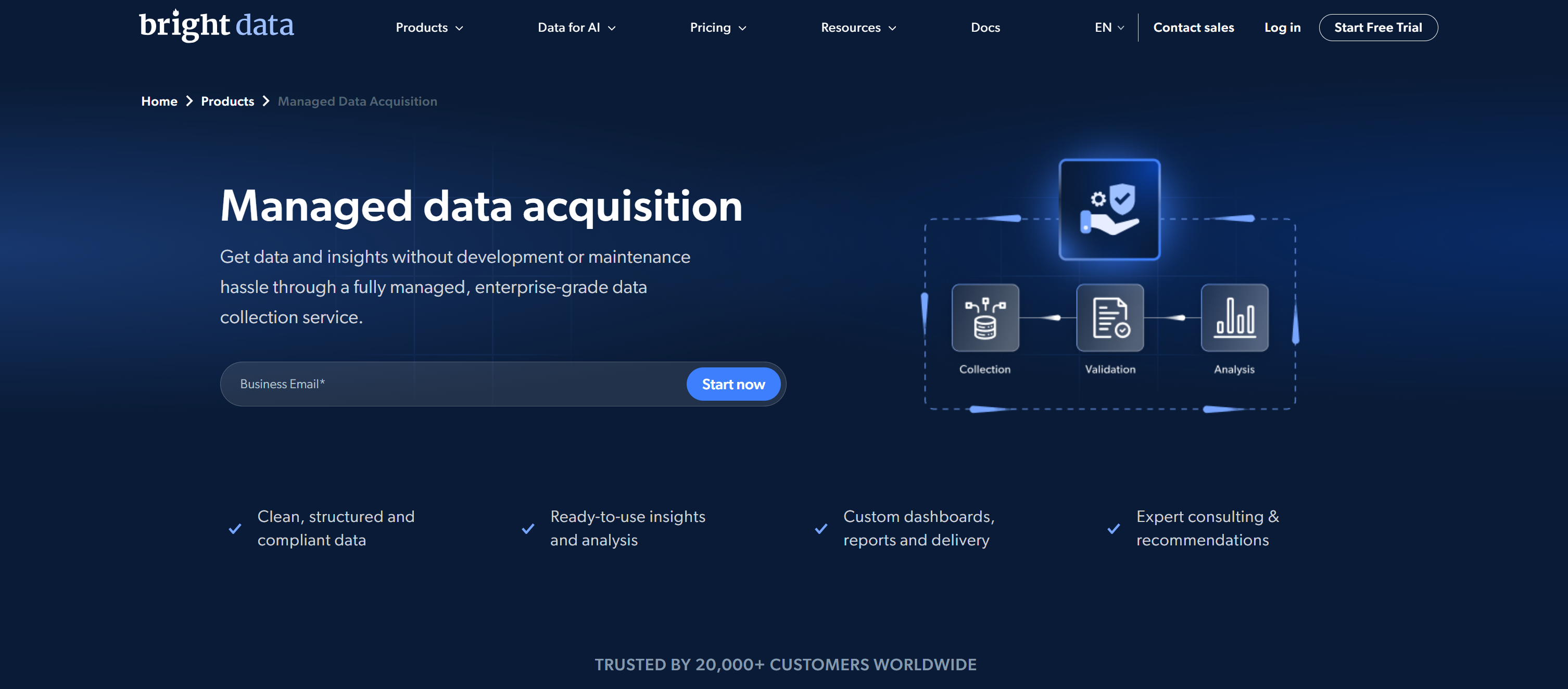
Bright Data ist eine führende All-in-One-Webdatenplattform für Proxys und Web-Scraping. Dank seiner breiten Produktpalette hilft es Ihnen, öffentliche Webdaten in großem Umfang über eine Infrastruktur der Enterprise-Klasse, leistungsstarke APIs und eines der größten Proxy-Netzwerke der Branche zu sammeln.
Insbesondere seine Web-Scraping-Dienste zeichnen sich durch einen vollständig verwalteten End-to-End-Ansatz namens „Managed Data Acquisition” aus.
Bright Data stellt nicht nur Tools zur Verfügung, sondern fungiert auch als Daten-Concierge. Sie geben Ihre Geschäftsziele an, und Bright Data entwirft, sammelt, validiert, bereichert und liefert strukturierte Daten über Dashboards, Berichte und Einblicke. Dieser Ansatz macht das Unternehmen zu einem der besten Managed-Data-Collection-Anbieter weltweit.
Mit mehr als 150 Millionen IPs, fortschrittlicher Anti-Bot-Technologie, KI-gestützter Datenermittlung und strikter GDPR-Konformität/CCPA erreicht Bright Data mit Managed Data Acquisition eine außergewöhnliche Zuverlässigkeit, Skalierbarkeit und Datenqualität.
Diese Fähigkeiten, zusammen mit engagierten Experten, SLA-gestützter Verfügbarkeit und flexiblen Lieferoptionen, machen Bright Data zum wohl besten Web-Scraping-Dienst für Unternehmen jeder Größe.
Workflow:
- Projektstart: Arbeiten Sie mit den Experten von Bright Data zusammen, um Datenquellen, KPIs und die Erkenntnisse zu definieren, die Sie zur Erreichung Ihrer Geschäftsziele benötigen.
- Datenerfassung: Bright Data verwaltet und skaliert den gesamten Datenextraktionsprozess, wobei ein dedizierter Projektmanager die Ausführung und den Fortschritt überwacht.
- Datenvalidierung und -anreicherung: Die gesammelten Daten werden bereinigt, dedupliziert, abgeglichen und kontinuierlich überwacht, um Genauigkeit, Konsistenz und Zuverlässigkeit zu gewährleisten.
- Bereitstellung von Berichten und Erkenntnissen: Daten und Erkenntnisse werden über benutzerdefinierte Dashboards und umsetzbare Empfehlungen von Bright Data-Experten bereitgestellt.
Datenlieferung:
- Tägliche, wöchentliche oder monatliche Lieferung mit benutzerdefinierten Lieferformaten und -methoden, die auf die Kundenanforderungen zugeschnitten sind.
- Saubere, strukturierte und vollständig validierte Datensätze.
- Unterstützung für Echtzeit-, geplante und historische Daten mit Optionen für KI-gesteuerte Datenermittlung, -extraktion und -anreicherung.
- Individuelle Berichte, Dashboards und Analysen, einschließlich websiteübergreifender und historischer Crawls.
Unterstützte Branchen:
- E-Commerce, Immobilien, Social Media und Content-Plattformen, Stellenanzeigen und Rekrutierungsdaten, Marktforschung und Wettbewerbsanalyse, KI, maschinelles Lernen, Einzelhandelsanalysen und branchenübergreifende Einblicke sowie viele andere branchenspezifische Anwendungsfälle.
Infrastruktur:
- 99,99 % Plattform-Verfügbarkeit mit unbegrenzter Skalierbarkeit.
- Über 150 Millionen Residential-Proxys für Privathaushalte, Mobile-Proxys, ISP-Proxys und Datacenter-Proxys in 195 Ländern.
- Proprietäre Technologien für CAPTCHA-Lösung, Anti-Bot-Umgehung und strukturierte Datenextraktion über Hunderte von beliebten Domains hinweg.
Reputation:
- Vertrauen von über 20.000 Kunden weltweit.
- Zu den namhaften Kunden zählen Deloitte, Pfizer, McDonald’s, Moody’s, Nokia, eToro, die Vereinten Nationen und viele andere.
- G2: 4,6/5 (283 Bewertungen)
- Capterra: 4,7/5 (67 Bewertungen)
- Truspilot: 4,3/5 (906 Bewertungen)
Support:
- Spezieller Daten-Concierge rund um die Uhr verfügbar.
- Optionen für benutzerdefinierte SLAs.
Compliance:
- Vollständig konform mit DSGVO, CCPA und anderen globalen Datenschutzbestimmungen.
- Die Datenerfassung erfolgt in Übereinstimmung mit den Richtlinien der Website und ethischen Beschaffungsstandards.
Preise
- Beginnt bei 2.500 $ pro Monat für Jahresprojekte.
- Die Preise variieren je nach Umfang, Datenvolumen, Häufigkeit und Komplexität des Projekts.
- ROI-Rechner auf der offiziellen Webseite verfügbar.
2. Zyte
Zyte ist ein Datenauszugsunternehmen, das KI-gesteuerte Tools und Dienste zum Scraping von Daten aus Websites anbietet. Das Unternehmen ist vor allem für die Entwicklung des Open-Source-Frameworks Scrapy bekannt, bietet aber auch verwaltete Web-Scraping-Dienste an. In diesem Fall erstellt das Team maßgeschneiderte Scraping-Pipelines für Sie. Die Daten werden in Ihrem bevorzugten Format und an Ihrem bevorzugten Zielort geliefert, wobei die DSGVO und andere Datenschutzbestimmungen eingehalten werden.
Workflow:
- Entwicklung: Zyte erstellt, betreibt und wartet die gesamte Datenpipeline. Es sind keine internen technischen Maßnahmen erforderlich.
- Lieferung: Die Daten werden Ihnen gemäß dem vereinbarten Schema und Format zugesandt.
Datenlieferung:
- Flexible Crawling-Häufigkeiten basierend auf den Projektanforderungen.
- Saubere, strukturierte Datensätze, die in Formaten wie JSON, CSV und anderen geliefert werden, mit Lieferoptionen wie Amazon S3-Buckets.
- Unterstützung für vollständig benutzerdefinierte Schemata, je nach Plan und Anwendungsfall.
- 99,99 % Qualitätssicherung.
Unterstützte Branchen:
- E-Commerce, KI und maschinelles Lernen, Stellenanzeigen und Personalbeschaffung, Nachrichten und Medien, Immobilien und Branchenverzeichnisse.
Infrastruktur:
- Vollständig verwaltete, cloudbasierte Datenauszugsinfrastruktur, die auf Skalierbarkeit und Zuverlässigkeit ausgelegt ist.
Reputation:
- G2: 4,3/5 (93 Bewertungen)
- Capterra: 4,4/5 (43 Bewertungen)
- Trustpilot: 3,7/5 (15 Bewertungen)
Support:
- 24/7-Support für Unternehmen verfügbar.
Compliance:
- Ausdrückliche Übereinstimmung mit der DSGVO und globalen Datenschutzbestimmungen.
- Interne Rechtsexperten, die sich auf die Einhaltung der Vorschriften zur Extraktion von Webdaten spezialisiert haben.
Preise:
- Individuelle Tarife ab 1.000 US-Dollar pro Monat.
- Die Preise variieren je nach Datentyp, Schema, Crawling-Häufigkeit, Liefermethode und Grad der Anpassung.
3. Apify

Apify ist eine Full-Stack-Cloud-Plattform für Web-Scraping und Datenextraktion, mit der Sie automatisierte Web-Aufgaben in großem Umfang erstellen, ausführen und verwalten können. Darüber hinaus nutzt das Apify-Team diese Infrastruktur, um Ihnen über seine verwalteten Web-Scraping-Dienste maßgeschneiderte Scraper zu erstellen. In diesem Szenario werden die Preise und Datenoptionen auf die spezifischen Anforderungen Ihres Projekts zugeschnitten.
Denken Sie daran: Apify lässt sich mit Bright Data integrieren, wie in unseren Dokumenten und in einem speziellen Tutorial-Blogbeitrag erläutert.
Workflow:
- Ihnen werden ein dedizierter technischer Projektmanager, ein leitender Ingenieur und ein Account Manager zugewiesen, die an Ihrem Projekt arbeiten.
Datenlieferung:
- Die Lieferformate und -methoden werden an die Anforderungen Ihres Projekts angepasst.
- Integrierte Überwachungssysteme überprüfen die Datenqualität, verfolgen den Fertigstellungsgrad und bestätigen die Lieferung.
Unterstützte Branchen:
- Hängt vom jeweiligen Projekt ab.
Infrastruktur:
- Skalierbare Infrastruktur, die bis zu 500.000 API-Anfragen pro Minute unterstützt und monatlich 1 PB an Daten verarbeitet.
- Team von mehr als 150 Ingenieuren.
Reputation:
- Vertrauen von über 10.000 Kunden weltweit.
- Zu den bekannten Kunden zählen Accenture, Siemens, T-Mobile, Roche, Intercom, Microsoft, Samsung, Decathlon, die Princeton University, Amgen, die Europäische Kommission und OpenTable.
- G2: 4,7/5 (324 Bewertungen)
- Capterra: 4,8/5 (373 Bewertungen)
- Trustpilot: 4,8/5 (329 Bewertungen)
Support:
- SLA auf Unternehmensebene mit dedizierten Projektteams.
- Support während der Zeitzonen der Kunden für Kunden in der EU und den USA verfügbar.
Compliance:
- Fokus auf ethisches Web-Scraping und GDPR-Konformität.
- NDA und maximale Privatsphäre für Projekte und Datensätze garantiert.
- Sie behalten das vollständige geistige Eigentum an den gelieferten Lösungen.
Preise:
- Ab 2.000 $ pro Monat.
- Die Preise hängen von der Komplexität des Projekts, den Zielwebsites, Blockierungen, Datenmengen und SLA-Parametern ab.
4. BrowseAI
Browse AI ist eine no-code, KI-gestützte Lösung, mit der Sie Daten aus Websites ohne Programmierkenntnisse extrahieren und überwachen können. Darüber hinaus bietet es verwaltete Web-Scraping-Dienste und unterstützt Branchen wie E-Commerce, Immobilien, Recht und Finanzen. Sie erhalten dedizierte Account Manager, flexible Lieferungen und Preise, die sich nach der Komplexität des Projekts richten.
Workflow:
- Erfassung und Planung der Anforderungen: Das Team von Browse KI ermittelt Ihre genauen Anforderungen hinsichtlich Datenextraktion, Zielwebsites und Integration.
- Maßgeschneiderte Entwicklung und Qualitätsprüfung: Erfahrene Web-Scraping-Ingenieure erstellen, testen und transformieren Ihre maßgeschneiderte Lösung und gewährleisten so die Genauigkeit und Qualität der Daten.
- Start, Implementierung und Lieferung: Der erste vollständige Datensatz wird mit vollständiger Dokumentation und optionaler Schulung geliefert.
- Laufende Datenlieferung und -verwaltung: Ihr Account Manager überwacht die Leistung, kümmert sich um die gesamte Wartung und Skalierung und sorgt für eine kontinuierliche Optimierung.
Datenlieferung:
- Geplante Lieferung gemäß Ihren Anforderungen (E-Mail, AWS S3 oder andere Methoden).
- Mehrstufige Qualitätssicherung durch automatisierte Validierung, Anomalieerkennung und manuelle Stichproben.
- Funktionen zur Nachbearbeitung und Transformation von Daten, um saubere, einheitliche Datensätze zu erstellen.
Unterstützte Branchen:
- E-Commerce, Immobilien, Stellenanzeigen, Rechtsdaten, Lead-Generierung, Finanzforschung, Marktforschung und Medienbeobachtung.
Infrastruktur:
- KI-gestützte Infrastruktur auf Unternehmensniveau, die Milliarden von Datensätzen verarbeiten kann.
Reputation:
- G2: 4,8/5 (54 Bewertungen)
- Capterra: 4,5/5 (60 Bewertungen)
- Trustpilot: 3,1/5 (12 Bewertungen)
Support:
- Engagierter Account Manager und technisches Team.
- Individuelle Einarbeitung, Schulung und Unterstützung bei der Migration verfügbar.
Compliance:
- DSGVO-konform.
- Anwendung ethischer und rechtmäßiger Verfahren zur Datenextraktion.
Preise:
- Ab 500 $ pro Monat.
- Einrichtungsdienste (für Onboarding oder Migration) beginnen bei 250 $ zusätzlich zu den Plattformgebühren.
- Die Preise richten sich nach Datenvolumen, Komplexität und individuellen Anforderungen.
5. Grepsr

Grepsr ist ein vollständig verwalteter Datenextraktions- und Web-Scraping-Dienst für Unternehmen jeder Größe. Er bietet benutzerdefinierte Workflows und Multi-Channel-Lieferung mit einer 99-prozentigen Datenzuverlässigkeitsgarantie. Beachten Sie, dass die Preisgestaltung und Compliance-Praktiken nicht öffentlich bekannt gegeben werden.
Workflow:
- Teilen Sie Ihre Datenanforderungen mit: Sie werden gebeten, Details zu Zielwebsites, Datenfeldern und Anwendungsfällen anzugeben. Grepsr prüft die Machbarkeit und richtet den Projekt-Workflow ein.
- Zahlung und erster Durchlauf: Sie erhalten ein transparentes Angebot. Nach der Zahlung wird in einem ersten Extraktionsdurchlauf die Datenqualität und die Durchführbarkeit des Projekts überprüft.
- Zuweisung eines Account Managers: Ein dedizierter Manager überwacht das Projekt.
- Musterprüfung und Datenlieferung: Sie prüfen und genehmigen die Musterdaten und erhalten dann die vollständige Extraktion mit automatisierter und manueller Qualitätssicherung, die über den von Ihnen bevorzugten Kanal geliefert wird.
Datenlieferung:
- Strukturierte Webdaten werden per E-Mail, Dropbox, FTP, Webhooks, Slack und mehr geliefert.
- Vollständig validierte, bereinigte und verwertbare Datensätze.
- 99 % Datenzuverlässigkeit.
Unterstützte Branchen:
- E-Commerce, KI/ML, Wohnungs- und Immobilienwesen, Unternehmensberatung, Stellenangebote und Humankapital, Gesundheitswesen und andere Anwendungsfälle in Unternehmen.
Infrastruktur:
- KI-gestützte Plattform, die täglich mehr als 600 Millionen Datensätze verarbeiten und mehr als 10.000 Webquellen durch Parsing analysieren kann.
- Erfahrenes Team mit über 10 Jahren Erfahrung im Bereich Web-Scraping.
Reputation:
- Vertrauen von globalen Unternehmen, darunter BlackSwan, Pearson, Kearney, Rightmove, BCG und Roku.
- G2: 4,5/5 (23 Bewertungen)
- Capterra: 4,7/5 (83 Bewertungen)
- Trustpilot: — (0 Bewertungen)
Support:
- Engagierte Account Manager für jedes Projekt
- Kollaborative Plattform für Echtzeitkommunikation und Projektverfolgung.
Compliance:
- Nicht bekannt gegeben.
Preise:
- Nicht öffentlich bekannt gegeben.
6. ScrapeHero
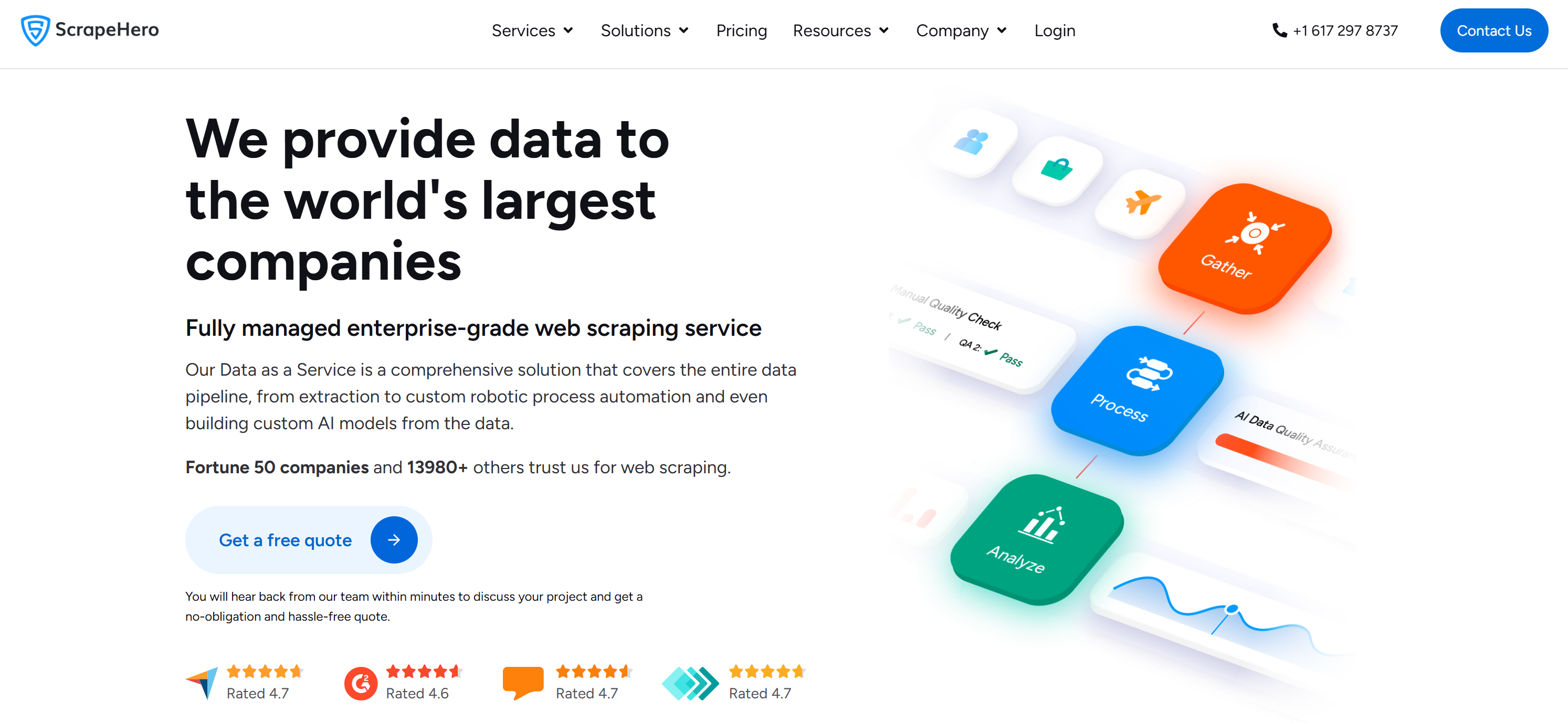
ScrapeHero ist ein vollständig verwalteter Web-Scraping-Dienstleister, der große Mengen öffentlicher Webdaten extrahiert, strukturiert und bereitstellt. Das Unternehmen übernimmt die Entwicklung und Wartung kundenspezifischer Scraper, die Datenbereinigung, Qualitätsprüfungen und die Integration über APIs oder geplante Importe. Es unterstützt mehrere Branchen und Datenformate.
Arbeitsablauf:
- Beratung: ScrapeHero bewertet Ihre spezifischen Anforderungen und schlägt einen maßgeschneiderten Plan vor.
- Entwicklung: Das Team erstellt maßgeschneiderte Scraping-Lösungen und integriert diese in Ihre Systeme.
- Nutzung: Die Lösung läuft kontinuierlich und wird ständig gewartet und optimiert.
Datenlieferung:
- Unterstützt mehrere Formate wie JSON, CSV und andere strukturierte Ausgaben, mit Lieferung über APIs oder cloudbasierte S3-Pipelines.
- Beinhaltet Nachbearbeitung wie Datensatzabgleich, Deduplizierung und Formatierung, um verwertbare Daten bereitzustellen.
Unterstützte Branchen:
- E-Commerce, Gesundheitswesen, Finanzwesen, Reise- und Gastgewerbe, Fertigung und Logistik.
Infrastruktur:
- Skalierbare Plattform, die in der Lage ist, große Datenmengen zu verarbeiten, darunter Tausende von Seiten pro Sekunde und Millionen von Webseiten pro Tag.
- Kann komplexe Websites mit JavaScript/AJAX, CAPTCHAs und IP-Blacklisting scrapen.
Reputation:
- G2: 4,7/5 (60 Bewertungen)
- Capterra: 4,7/5 (26 Bewertungen)
- Trustpilot: 3,2/5 (2 Bewertungen)
Support:
- Serviceoptionen auf Unternehmensebene verfügbar.
- Support durch über 100 Entwickler mit Fachkenntnissen in den Bereichen Web-Scraping, KI und maßgeschneiderte Automatisierungslösungen.
Compliance:
- Gesammelte Daten werden nicht gespeichert oder weiterverkauft, sodass Sie die volle Kontrolle behalten.
Preise:
- Werden nicht öffentlich bekannt gegeben.
7. PromptCloud
PromptCloud ist ein DaaS-Anbieter (Data-as-a-Service), der sich auf die groß angelegte, benutzerdefinierte Extraktion von Webdaten mithilfe von Cloud-Technologie, Automatisierung und KI spezialisiert hat. Das Unternehmen liefert saubere, strukturierte Daten in verschiedenen Formaten für verschiedene Branchen und bietet dedizierten technischen Support. Beachten Sie, dass die Preise nicht veröffentlicht werden und das Unternehmen nicht auf Trustpilot gelistet ist.
Arbeitsablauf:
- Definition und Strategieentwicklung: PromptCloud beginnt mit einem Gespräch, um Ihre Geschäftsziele zu verstehen und gemeinsam die optimale Datenstruktur und den optimalen Lieferplan zu entwerfen.
- Entwicklung maßgeschneiderter Crawler: Ingenieure erstellen maßgeschneiderte, adaptive Crawler, die Websites jeder Komplexität verarbeiten können.
- Datenvalidierung und -verfeinerung: Sie erhalten eine kostenlose Datenprobe zur Überprüfung und Freigabe, um vor der Live-Schaltung Vertrauen in die Datenqualität zu gewinnen.
- Automatisierte Lieferung und Überwachung: Live-Datenpipelines werden rund um die Uhr überwacht, wobei saubere, validierte Daten über die ausgewählten Kanäle geliefert werden.
Datenlieferung:
- Unterstützte Datenformate: JSON, CSV und XML, mit Liefermethoden wie API, S3, FTP und anderen.
- 99,9 % Datenqualitätsgarantie.
Unterstützte Branchen:
- Automobilindustrie, E-Commerce und Einzelhandel, Finanzen und Fintech, Gesundheitswesen, Personalwesen und Personalbeschaffung, Recht und Compliance, Logistik und Lieferkette, Immobilien, Reise und Gastgewerbe und mehr.
Infrastruktur:
- Proprietäre KI-gestützte Plattform mit adaptiven Crawlern, die sich automatisch an Änderungen auf Websites anpassen, unterstützt durch eine Premium-Proxy-Infrastruktur.
Reputation:
- Vertrauen von namhaften Kunden wie Apple, Uber, McKinsey, Flipkart, Bosch, Unilever, Samsung, HP, IBM, Boston Consulting Group und vielen mehr.
- Über 14 Jahre Erfahrung in der Scraping-Branche.
- G2: 4,6/5 (17 Bewertungen)
- Capterra: 4,2/5 (14 Bewertungen)
- Trustpilot: — (0 Bewertungen)
Support:
- Team von über 100 Dateningenieuren und Analysten, die operativen Support leisten.
Konformität:
- DSGVO- und CCPA-konform.
- Prozesse respektieren
robots.txtfür Web-Scraping und Datenschutzrichtlinien von Websites.
Preise:
- Nicht öffentlich bekannt gegeben.
8. ProWebScraper
ProWebScraper ist eine cloudbasierte Plattform, die groß angelegte, no-code Web-Scraping-Prozesse mit Managed Services unterstützt. Sie bietet außerdem Managed Scraping Services, die Verarbeitung dynamischer Inhalte, automatisierte Qualitätssicherung und Projekte mit bis zu 500.000 Seiten pro Tag, mit dediziertem Support und benutzerdefinierter Skripteinrichtung. Die Preise sind jedoch nicht öffentlich bekannt gegeben und es fehlt eine Trustpilot-Präsenz, trotz positiver Bewertungen auf G2 und Capterra.
Arbeitsablauf:
- Anforderungsanalyse: ProWebScraper arbeitet mit Ihnen zusammen, um Ihre spezifischen Datenanforderungen und Geschäftsziele zu verstehen.
- Individuelle Scraping-Einrichtung: Experten konfigurieren Scraper und schreiben benutzerdefinierte Skripte oder verwenden vorgefertigte Scraper, um die erforderlichen Daten zu extrahieren.
- Datenbereinigung und -verarbeitung: Rohdaten werden zu genauen, strukturierten und verwertbaren Erkenntnissen verarbeitet.
- Geplante Datenlieferung: Die Daten werden nach dem vom Kunden gewünschten Zeitplan geliefert und in seine Systeme integriert.
- Kontinuierliche Überwachung und Optimierung: Die Scraper werden proaktiv überwacht und angepasst, um einen unterbrechungsfreien Datenfluss und eine optimale Leistung zu gewährleisten.
Datenlieferung:
- Unterstützt mehrere Formate (z. B. CSV, JSON, Excel und XML) und liefert Daten an bestehende Systeme oder Cloud-Plattformen wie AWS, Dropbox und Azure.
- Unterstützt geplante, fortlaufende und groß angelegte Datenextraktionsprojekte.
- Beinhaltet automatisierte Validierung und manuelle Qualitätssicherung, um Genauigkeit und Zuverlässigkeit zu gewährleisten.
Unterstützte Branchen:
- Hängt vom jeweiligen Scraping-Projekt ab.
Infrastruktur:
- Unterstützt die gleichzeitige Extraktion von Hunderten von Websites mit bis zu 500.000 gescrapten Seiten pro Tag.
- Fortschrittliche Technologie für den Umgang mit dynamischen Inhalten, AJAX, unendlichem Scrollen und Anti-Scraping-Maßnahmen.
Reputation:
- Über 21 Jahre Branchenerfahrung.
- Vertrauen von Unternehmen und Start-ups gleichermaßen, darunter Kunden wie Samsung, Red Bull, Walmart, Zoominfo, Bayer, Hasbro, L’Oréal und die Asiatische Entwicklungsbank.
- G2: 4,6/5 (25 Bewertungen)
- Capterra: 5,0/5 (1 Bewertung)
- Trustpilot: — (0 Bewertungen)
Support
- Engagierter Account Manager, Scraping-Ingenieur und QA-Spezialist für jedes Projekt.
Compliance:
- Einhaltung gesetzlicher und ethischer Web-Scraping-Praktiken zur Risikominimierung.
Preise:
- Werden nicht öffentlich bekannt gegeben.
9. WebScrapingAPI

WebScrapingAPI bietet eine verwaltete, skalierbare Infrastruktur, die täglich über eine Milliarde Seiten aus verschiedenen Branchen verarbeiten kann. Es liefert strukturierte Daten in flexiblen Formaten über benutzerdefinierte Workflows und entwicklerorientierten Support. Obwohl es branchenübergreifend vielseitig einsetzbar ist, hat es nur begrenzte Reputationswerte, unklare Compliance-Details und nicht veröffentlichte Preise, was für einige Benutzer Nachteile sein können.
Workflow:
- Das Team von WebScrapingAPI nimmt sich Zeit, um Ihre Bedürfnisse zu verstehen, stellt die richtigen Fragen und liefert eine auf Ihre Bedürfnisse zugeschnittene Lösung.
Datenlieferung:
- Unterstützt JSON, CSV und andere Formate mit flexiblen Cloud-Lieferoptionen.
- Bietet standardisierte und maßgeschneiderte Datenschemata.
- Vordefinierte Crawling-Frequenzen, um aktuelle Informationen zu erhalten.
Unterstützte Branchen:
- E-Commerce, soziale Medien, Stellenanzeigen, Immobilien, Marktforschung, Preisüberwachung, Markenüberwachung, Finanzdaten, SEO/SEM, Reise und Gastgewerbe, Cybersicherheit, Gesundheitswesen und andere.
Infrastruktur:
- Verwaltete, skalierbare Scraping-Infrastruktur, die täglich über 1 Milliarde Webseiten verarbeiten kann.
- Proprietäre Technologien für die strukturierte Datenextraktion und automatisierte Nachbearbeitung.
Reputation:
- G2: — (0 Bewertungen)
- Capterra: — (0 Bewertungen)
- Trustpilot: 3,1/5 (7 Bewertungen)
Support:
- Über 100 Entwickler sorgen für Qualitätssicherung und operativen Support.
- Optionen für Standard-, Premium- und Enterprise-Level-SLAs.
Compliance:
- Nicht bekannt gegeben.
Preise:
- Nicht öffentlich bekannt gegeben.
Die besten Web-Scraping-Dienste: Übersichtstabelle
Vergleichen Sie die oben genannten besten Web-Scraping-Dienste auf einen Blick in dieser Übersichtstabelle:
| Web-Scraping-Dienst | Arbeitsablauf | Branchen | Infrastruktur | Kunden | GDPR-Konformität | CCPA-Konformität | Öffentlicher ROI-Rechner |
|---|---|---|---|---|---|---|---|
| Bright Data | Strukturiert, mehrstufig | E-Commerce, Immobilien, soziale Medien, Stellenangebote, KI, Einzelhandel und mehr als 10 weitere Bereiche | 99,99 % Verfügbarkeit, über 150 Millionen Proxys, CAPTCHA- und Anti-Bot-Technologie | Über 20.000, darunter Deloitte, Pfizer, McDonald’s, Nokia | ✅ | ✅ | ✅ |
| Zyte | Strukturiert, mehrstufig | E-Commerce, KI, Jobs, Nachrichten, Immobilien und andere | Cloudbasiert, skalierbar, zuverlässig | — (Unbekannt) | ✅ | — (Unbekannt) | ❌ |
| Apify | Unstrukturiert (projektabhängig) | Projektspezifisch | 500.000 API-Anfragen/Minute, 1 PB/Monat, über 150 Ingenieure | Über 10.000, darunter Accenture, Siemens, Microsoft | ✅ | — (Unbekannt) | ❌ |
| BrowseAI | Strukturiert, mehrstufig | E-Commerce, Immobilien, Stellenangebote, Recht, Finanzen | KI-gestützt, für Unternehmen geeignet | — (Unbekannt) | ✅ | — (Unbekannt) | ❌ |
| Grepsr | Strukturiert, mehrstufig | E-Commerce, KI/ML, Immobilien, Gesundheitswesen, Beratung | Über 600 Millionen Datensätze pro Tag, über 10.000 Quellen, KI-gestützt | Umfasst BlackSwan, Pearson, BCG, Roku | — (Unbekannt) | — (Unbekannt) | ❌ |
| ScrapeHero | Strukturiert, mehrstufig | E-Commerce, Gesundheitswesen, Finanzen, Reisen, Logistik | Tausende Seiten/Sekunde, AJAX- und CAPTCHA-Unterstützung | — (Unbekannt) | — (Unbekannt) | — (Unbekannt) | ❌ |
| PromptCloud | Strukturiert, mehrstufig | Automobilindustrie, E-Commerce, Finanzwesen, Gesundheitswesen, Logistik | KI-gestützte Premium-Proxys | Umfasst Apple, Uber, McKinsey, Flipkart | ✅ | ✅ | ❌ |
| ProWebScraper | Strukturiert, mehrstufig | Projektspezifisch | 500.000 Seiten/Tag, dynamische/AJAX-Unterstützung | Umfasst Samsung, Red Bull, Walmart | — (Unbekannt) | — (Unbekannt) | ❌ |
| WebScrapingAPI | Unstrukturiert (projektabhängig) | E-Commerce, soziale Medien, Immobilien, Finanzen, Gesundheitswesen | 1 Milliarde+ Seiten/Tag, skalierbar, verwaltet | — (Unbekannt) | — (Unbekannt) | — (Unbekannt) | ❌ |
Fazit
In diesem Artikel haben Sie einige der besten Web-Scraping-Dienste kennengelernt, mit denen Sie Online-Daten entsprechend Ihren individuellen Anforderungen abrufen können. Sie haben erfahren, was diese Dienste bieten und wie Sie sie effektiv vergleichen können.
Der führende Web-Scraping-Dienstleister ist Bright Data, dank seiner vollständig verwalteten Datenerfassungsdienste auf Unternehmensniveau. Diese ermöglichen es Ihnen, die benötigten Daten und Erkenntnisse ohne Entwicklungs- oder Wartungsaufwand zu erhalten.
Bright Data zeichnet sich dadurch aus, dass es über ein Proxy-Netzwerk mit 150 Millionen IPs verfügt, eine Verfügbarkeit von 99,99 % erreicht und eine Erfolgsquote von 99,99 % aufweist. In Kombination mit einem 24/7-Prioritäts-Support, Optionen für benutzerdefinierte SLAs und flexiblen Datenlieferformaten und -zeitplänen war das Sammeln von Webdaten noch nie so einfach.
Erstellen Sie noch heute ein Bright Data-Konto und sprechen Sie mit einem unserer Datenexperten darüber, wie unsere Scraping-Dienste Ihrem Unternehmen helfen können!




