
Wenn Sie eine RAG-Anwendung ( Retrieval-Augmented Generation ) entwickeln, benötigen Sie aktuelle Daten zu Ihrem Thema – keine statische PDF-Datei aus einem Tutorial. Das Scrapen echter Artikel ist jedoch mit Anti-Bot-Barrieren und blockierten Anfragen verbunden. Selbst wenn Sie über Daten verfügen, müssen Sie diese noch in Blöcke aufteilen, einbetten, indexieren und die Abfragefunktion einrichten.
Dieses Tutorial erledigt all das. Bright Data findet und scrapt Artikel zu jedem Thema, Weaviate speichert und durchsucht sie, und Sie erhalten Antworten mit Quellenangaben in einem einzigen Python-Skript.
TL;DR
Verwandeln Sie jedes Thema in eine durchsuchbare Wissensdatenbank mit Frage-Antwort-Funktion – angetrieben von Live-Webdaten statt veralteten Trainingsdaten.
- Die Bright Data SERP-API findet echte Artikel-URLs zu deinem Thema; Web Unlocker scrapt sie (sogar von Anti-Bot-geschützten Seiten).
- Weaviate vektorisiert Textabschnitte automatisch über Cohere, indiziert sie mit einer hybriden Suche und generiert zitierte Antworten in einem einzigen API-Aufruf
- Führen Sie
python3 pipeline.pyaus, geben Sie ein Thema ein und erhalten Sie innerhalb von Minuten zitierte RAG-Antworten. - Vollständiger Quellcode auf GitHub – klonen und ausführen
Holen Sie sich Ihre API-Schlüssel und probieren Sie es mit Ihrem eigenen Thema aus.
So sieht die endgültige Ausgabe aus:

Führen Sie die Pipeline in 3–5 Minuten aus
Wenn Sie bereits über API-Schlüssel verfügen, führen Sie die Pipeline jetzt aus:
# 1. Klone das Repo (erfordert Python 3.10+)
git clone https://github.com/triposat/weaviate-bright-data-rag.git
cd weaviate-bright-data-rag
# 2. Installiere die Abhängigkeiten
pip3 install -r requirements.txt
# 3. Erstellen Sie Ihre .env-Datei
cp .env.example .env
# Bearbeiten Sie .env und geben Sie Ihre API-Schlüssel ein (siehe „API-Schlüssel abrufen“ weiter unten)
# 4. Führen Sie die Pipeline aus
python3 pipeline.pyDie Pipeline fragt nach einem Thema und erkennt automatisch Ihre Bright Data-Zonen. Sie findet und scrapt echte Artikel. Sie zerlegt diese in Chunks und speichert sie in Weaviate (automatisch vektorisierte Daten über Cohere), führt Demo-Abfragen durch und wechselt in den interaktiven Modus, damit Sie eigene Fragen stellen können.
Beziehen Sie Ihre API-Schlüssel (kostenloser Einstieg)
Sie benötigen 3 API-Schlüssel – einen von jedem Dienst. Für Cohere und Weaviate ist keine Kreditkarte erforderlich; Bright Data gewährt Ihnen bei der Anmeldung ein kostenloses Testguthaben.
1. Bright Data API-Schlüssel
Erstellen Sie einen API-Schlüssel und 2 Zonen:
- Registrieren Sie sich auf brightdata.com
- Gehen Sie zu „Account Settings“ → „Users and API keys“
- Erstellen Sie einen neuen API-Schlüssel → kopieren Sie ihn → fügen Sie ihn als Wert für
BRIGHT_DATA_API_TOKENin Ihre.env-Datei ein
Die Pipeline benötigt außerdem 2 Zonen: SERP-API und Web Unlocker. Überprüfen Sie unter „Proxies & Scraping“ → „Meine Zonen“, ob Sie diese bereits haben. Wenn Sie sie nicht sehen, erstellen Sie sie:
- Gehen Sie zu Proxies & Scraping → wählen Sie Meine Zonen
- Wähle „Hinzufügen“ → wähle den Zonentyp „SERP-API“ → gib einen beliebigen Namen ein (z. B.
„serp“) → speichere - Wählen Sie erneut „Hinzufügen“ → wählen Sie den Zonentyp „Unlocker API“ → geben Sie einen beliebigen Namen ein (z. B.
unlocker) → speichern
Sie müssen keine Zonennamen oder Passwörter kopieren. Die Pipeline erkennt diese automatisch anhand Ihres API-Schlüssels.
2. Cohere-API-Schlüssel (kostenlos)
Cohere übernimmt in dieser Pipeline sowohl die Einbettung als auch die Generierung:
- Gehen Sie zu dashboard.cohere.com
- Registrieren Sie sich mit Google, GitHub oder per E-Mail – keine Kreditkarte erforderlich
- Dein Test-API-Schlüssel wird im Dashboard angezeigt – kopiere ihn
- Der Testplan ist rate-begrenzt, aber großzügig (der automatisierte Lauf verbraucht weniger als 20 Aufrufe; jede interaktive Frage fügt 2 weitere hinzu)
3. Weaviate Cloud-Anmeldedaten (kostenlos)
Erstellen Sie einen kostenlosen Sandbox-Cluster, um Ihre Vektoren zu speichern und abzufragen:
- Gehen Sie zu console.weaviate.cloud
- Melden Sie sich mit Google oder GitHub an
- Wählen Sie „Cluster erstellen“ → wählen Sie „Sandbox (kostenlos)“ → wählen Sie eine Region → erstellen
- Warten Sie ca. 30 Sekunden, wählen Sie dann Ihren Cluster aus → Registerkarte „Details“
- Kopieren Sie den REST-Endpunkt (Ihre Cluster-URL) und den API-Schlüssel
Hinweis: Sandbox-Cluster laufen nach 14 Tagen ab. Wenn Ihr Cluster abläuft, erstellen Sie einen neuen und aktualisieren Sie die URL und den Schlüssel in Ihrer .env-Datei. Führen Sie pipeline.py erneut aus, um Ihre Daten erneut zu importieren.
Sobald Sie alle 3 Schlüssel haben, kehren Sie zum Abschnitt „Pipeline in 3–5 Minuten ausführen“ zurück und befolgen Sie die Schritte zum Klonen/Installieren.
So funktioniert die RAG-Pipeline von Anfang bis Ende
Die Pipeline umfasst 4 Schritte – Datenerfassung, Verarbeitung, Vektorspeicherung und Generierung:
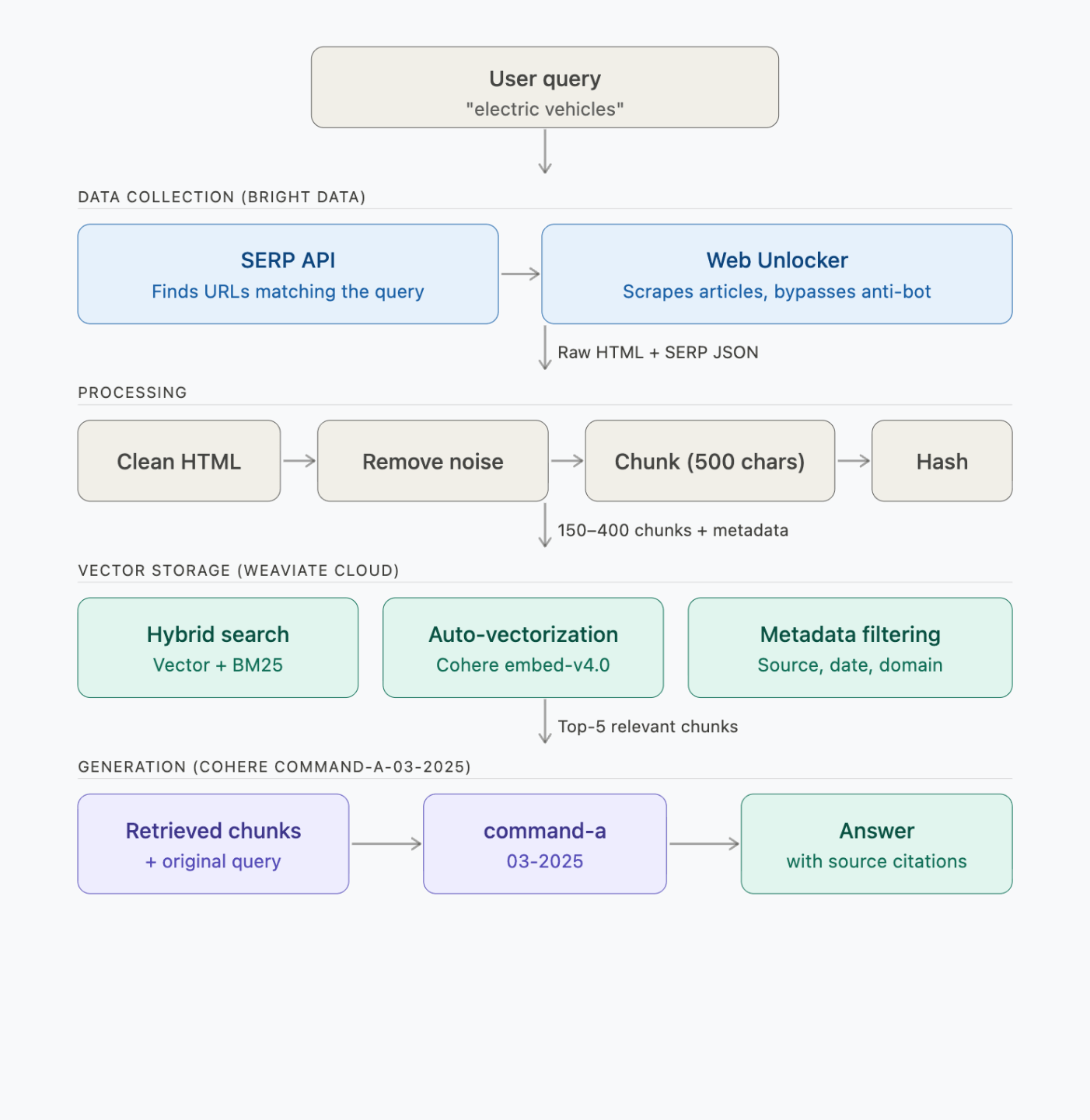
Jeder Schritt führt folgende API-Aufrufe durch:
| Schritt | Was wird ausgeführt | Zeit | API-Aufrufe |
|---|---|---|---|
| 1. Suchen + Scrapen | Bright Data SERP + Web Unlocker | ~2–3 Min. | 2 SERP- + 6 Scrape-Anfragen |
| 2. Verarbeiten + Chunk | Lokal (BeautifulSoup + Chunker) | <1 Sek. | 0 |
| 3. Einbetten + Speichern | Weaviate → Cohere embed-v4.0 | ~30–60 Sek. | ~150–400 Einbettungen (im Stapel) |
| 4. Abfrage (3 Demos) | Weaviate → Cohere command-a-03-2025 | ~5 Sek./Abfrage | 1 Suche + 1 Generierung pro Abfrage |
Was Bright Data in der Pipeline leistet
Bright Data ist eine Webdatenplattform. In dieser Pipeline übernimmt sie zwei Rollen:
| Produkt | Was es in dieser Pipeline tut |
|---|---|
| SERP-API | Sie geben ein Thema ein, die SERP-API durchsucht Google und gibt echte Artikel-URLs zurück – es sind keine fest codierten URLs erforderlich |
| Web Unlocker | Scrapt 6 Artikel pro Thema, einschließlich Websites mit Anti-Bot-Schutz – jeweils 200.000 bis 1,8 Millionen Zeichen |
Diese Pipeline nutzt die SERP-API und den Web Unlocker. Weitere Ansätze zur Datenerfassung finden Sie in der vollständigen Produktliste von Bright Data.
Warum Bright Data für RAG nutzen
Hier sind einige Punkte, die beim Scraping für RAG wichtig sind:
- Zuverlässiges Web-Scraping. Web Unlocker übernimmt automatisch Wiederholungsversuche, IP-Rotation und Browser-Fingerprinting, sodass die Pipeline nicht mitten im Lauf auf Anti-Bot-Seiten ins Stocken gerät.
- LLM-fähige Ausgabe. Die Crawl-API gibt sauberes Markdown anstelle von rohem HTML zurück, wodurch die Vorverarbeitung für Einbettungspipelines entfällt (dieses Tutorial verwendet Web Unlocker + BeautifulSoup, aber die Crawl-API ist der schnellere Weg, wenn Sie kein rohes HTML benötigen).
- Skalierbarkeit. In diesem Tutorial werden 6 Artikel gescrapt. In der Produktion benötigen Sie möglicherweise 6.000. Die KI-Infrastruktur von Bright Data unterstützt das gleichzeitige Scraping in dieser Größenordnung, ohne dass Sie Änderungen am Code vornehmen müssen.
- Compliance. Bright Data hat GDPR-Konformität und CCPA-Konformität und verlangt eine Identitätsprüfung, bevor vollständiger Netzwerkzugriff gewährt wird.
Was Weaviate in der Pipeline leistet
Weaviate ist eine Open-Source-Vektordatenbank. Sie führt Abruf und Generierung in einem einzigen API-Aufruf durch, sodass Sie das LLM nicht separat aufrufen müssen.
Hier speichert Weaviate die gescrapten Chunks und vektorisiert sie über Cohere. Bei einer Abfrage führt es eine hybride Suche durch und generiert eine Antwort über seine generative Such-API.
| Funktion | So funktioniert es in dieser Pipeline |
|---|---|
| Hybride Suche | Kombiniert semantische Vektoren (70 %) mit BM25-Keyword-Matching (30 %) über einen einstellbaren Alpha -Parameter |
| Integrierte generative Suche | Ruft die Top-5-Chunks ab und generiert zitierte Antworten in einem einzigen Aufruf von generate.hybrid() |
| Automatische Vektorisierung | Weaviate ruft die Cohere-Embedding-API beim Import automatisch auf – Sie müssen keinen Embedding-Code schreiben |
| Metadaten-Filterung | Speichert Quell-URL, Domain, Zeitstempel des Scrapes und Inhaltstyp zusammen mit jedem Chunk |
Weaviate im großen Maßstab
Weaviate verfügt außerdem über Funktionen, die diese Pipeline nicht nutzt, die aber bei Skalierung wichtig sind:
- Unter der BSD-3-Klausel-Lizenz – Sie können bei Bedarf selbst hosten oder forken
- Mehrere Bereitstellungsoptionen – Weaviate Cloud (kostenlose Sandbox), Dedicated Cloud, selbst gehostetes Kubernetes
- Mandantenfähigkeit – über 50.000 Mandanten pro Knoten für SaaS-Anwendungen
- Rotationsquantisierung – 4-fache Vektorkomprimierung bei 98–99 % Recall
Erstellen Sie die RAG-Pipeline Schritt für Schritt
Jeder der folgenden Schritte zeigt die Kernlogik aus pipeline.py. Der vollständige Quellcode ist auf GitHub verfügbar.
Projekteinrichtung und Importe
Beginnen Sie mit dem Importieren der Abhängigkeiten und dem Laden der Anmeldedaten aus Ihrer .env -Datei:
import os
import sys
import time
import hashlib
import requests
import urllib3
from urllib.parse import quote
from datetime import datetime, timezone
from dotenv import load_dotenv
from bs4 import BeautifulSoup
import weaviate
from weaviate.classes.init import Auth
from weaviate.classes.config import Configure, Property, DataType
urllib3.disable_warnings()
load_dotenv()
# Anmeldedaten aus .env laden
COHERE_API_KEY = os.getenv("COHERE_API_KEY")
WEAVIATE_URL = os.getenv("WEAVIATE_URL")
WEAVIATE_API_KEY = os.getenv("WEAVIATE_API_KEY")
BD_API_TOKEN = os.getenv("BRIGHT_DATA_API_TOKEN")
COLLECTION_NAME = "WebResearch"
def clean_url(url):
"""Behebt nbsp-Artefakte in URLs (aufgrund von -Kodierungsproblemen auf einigen Websites)."""
cleaned = url.replace("nbsp", "-")
while "--" in cleaned:
cleaned = cleaned.replace("--", "-")
return cleaned
def clean_generated_text(text):
"""Bereinigt LLM-generierten Text für die Anzeige im Terminal."""
text = text.replace("**", "")
text = text.replace("nbsp", "-")
while "--" in text:
text = text.replace("--", "-")
return textBevor irgendetwas unternommen wird, überprüft die Pipeline, ob alle erforderlichen Anmeldedaten in Ihrer .env-Datei festgelegt sind:
def validate_env():
"""Prüft, ob alle erforderlichen Umgebungsvariablen gesetzt sind."""
missing = []
if not BD_API_TOKEN:
missing.append("BRIGHT_DATA_API_TOKEN")
if not COHERE_API_KEY:
missing.append("COHERE_API_KEY")
if not WEAVIATE_URL:
missing.append("WEAVIATE_URL")
if not WEAVIATE_API_KEY:
missing.append("WEAVIATE_API_KEY")
if missing:
print("FEHLER: Fehlende Umgebungsvariablen in der .env-Datei:")
for var in missing:
print(f" - {var}")
# ... gibt Beispielformat für .env aus ...
print("nIm Blogbeitrag erfährst du, wie du die einzelnen Schlüssel erhältst (alles kostenlos für den Start).")
sys.exit(1)Sie müssen keine Zonennamen oder Passwörter konfigurieren – die Pipeline ermittelt diese automatisch anhand Ihres API-Schlüssels:
def discover_bright_data_credentials():
"""
Ermittelt automatisch die Bright Data-Proxy-Anmeldedaten aus dem API-Schlüssel.
Funktioniert für jedes Bright Data-Konto. Es sind keine fest codierten Werte erforderlich.
"""
headers = {"Authorization": f"Bearer {BD_API_TOKEN}"}
# 1. Aktive Zonen abrufen
zones = requests.get(
"https://api.brightdata.com/zone/get_active_zones", headers=headers
).json()
# Die erste Zone jedes Typs auswählen (falls mehrere vorhanden sind, den Namen explizit festlegen)
zone_names = {}
for z in zones:
if z["type"] not in zone_names:
zone_names[z["type"]] = z["name"]
# „unblocker“ ist der API-Name für das Produkt „Web Unlocker“
unlocker_zone = zone_names.get("unblocker")
serp_zone = zone_names.get("serp")
# 2. Zonenpasswörter abrufen
unlocker_pwd = requests.get(
f"https://api.brightdata.com/zone/passwords?zone={unlocker_zone}",
headers=headers,
).json()["passwords"][0]
serp_pwd = requests.get(
f"https://api.brightdata.com/zone/passwords?zone={serp_zone}",
headers=headers,
).json()["passwords"][0]
# 3. Kunden-ID abrufen (der Kosten-Endpunkt gibt {customer_id: cost_data} zurück)
cost = requests.get(
f"https://api.brightdata.com/Zone/cost?zone={unlocker_zone}",
headers=headers,
).json()
customer_id = list(cost.keys())[0]
return customer_id, unlocker_zone, unlocker_pwd, serp_zone, serp_pwdKlonen Sie das Repo, fügen Sie Ihren API-Schlüssel hinzu, und die Pipeline erledigt den Rest.
Schritt 1: Artikel mit Bright Data finden und scrapen
Die Pipeline nutzt die SERP-API, um Artikel-URLs zu Ihrem Thema zu finden, und scrapt diese dann einzeln über Web Unlocker:
def get_bd_proxy(customer_id, zone, password):
"""Erstelle die Bright Data-Proxy-URL."""
proxy = f"http://brd-customer-{customer_id}-zone-{zone}:{password}@brd.superproxy.io:33335"
return {"http": Proxy, "https": Proxy}
def search_serp(query, customer_id, zone, password, num=10):
"""Google über die Bright Data SERP-API durchsuchen und organische Ergebnisse zurückgeben."""
proxies = get_bd_proxy(customer_id, zone, password)
# brd_json=1 weist Bright Data an, strukturiertes JSON anstelle von rohem HTML zurückzugeben
search_url = f"https://www.google.com/search?q={quote(query)}&brd_json=1&num={num}"
try:
# verify=False umgeht die SSL-Überprüfung für den BD-Proxy.
# Für die Produktion installieren Sie stattdessen das Bright Data CA-Zertifikat:
# https://docs.brightdata.com/general/account/ssl-certificate
response = requests.get(search_url, proxies=proxies, timeout=30, verify=False)
if response.status_code == 200:
data = response.json()
return [
{
"title": item.get("title", ""),
"url": item.get("link", ""),
"description": item.get("description", ""),
}
for item in data.get("organic", [])
]
except Exception as e:
print(f"SERP-Fehler: {str(e)[:60]}", end=" ", flush=True)
return []search_serp() sendet die Anfrage über den Bright Data SERP-Proxy und gibt strukturiertes JSON (Titel, URLs, Beschreibungen) zurück. Der Parameter brd_json=1 weist Bright Data an, das Google-HTML für Sie in sauberes JSON zu parsen.
Als Nächstes führt find_articles_for_topic() zwei SERP-Abfragen pro Thema durch und filtert die Ergebnisse, während scrape_url() jeden Artikel über Web Unlocker abruft:
def find_articles_for_topic(topic, customer_id, serp_zone, serp_pwd):
"""Verwende die Bright Data SERP-API, um echte Artikel-URLs zu einem Thema zu finden."""
search_queries = [
f"{topic} Aktuelle Nachrichten und Trends",
f"{topic} Leitfaden zur eingehenden Analyse",
]
# Domains überspringen, die keine Artikelinhalte liefern (Videos, Feeds, soziale Medien)
skip_domains = {
"youtube.com", "twitter.com", "x.com", "facebook.com", "instagram.com",
"reddit.com", "linkedin.com", "wikipedia.org", "amazon.com", "tiktok.com",
}
skip_extensions = (".pdf", ".doc", ".ppt", ".xls", ".zip", ".mp4", ".mp3")
all_urls = []
seen_domains = set()
serp_docs = []
for query in search_queries:
results = search_serp(query, customer_id, serp_zone, serp_pwd, num=10)
if results:
# SERP-Titel und -Beschreibungen als Dokument speichern, damit das LLM
# auf Artikelzusammenfassungen zurückgreifen kann, selbst wenn das vollständige Scraping fehlschlägt
serp_text = f"Google-Suchergebnisse für: {query}nn"
for r in results:
serp_text += f"Titel: {r['title']}nURL: {r['url']}n"
serp_text += f"Zusammenfassung: {r['description']}nn"
serp_docs.append({
"url": f"https://google.com/search?q={quote(query)}",
"html": serp_text,
"scraped_at": datetime.now(timezone.utc).isoformat(),
"is_serp": True,
})
# Artikel-URLs extrahieren (1 pro Domain für Vielfalt)
for r in results:
url = r.get("url", "")
if not url:
continue
domain = url.split("/")[2] if "://" in url else ""
base_domain = ".".join(domain.split(".")[-2:])
if base_domain in skip_domains:
continue
if any(url.lower().endswith(ext) for ext in skip_extensions):
continue
if base_domain in seen_domains:
continue # Ein Artikel pro Domain für mehr Vielfalt
seen_domains.add(base_domain)
all_urls.append(url)
return all_urls[:6], serp_docs # Top 6 URLs
def scrape_url(url, customer_id, zone, password, retries=2):
"""Eine URL mit Bright Data Web Unlocker und automatischem Wiederholungsversuch scrapen."""
proxies = get_bd_proxy(customer_id, Zone, password)
# Keine benutzerdefinierten Header erforderlich: Web Unlocker verwaltet User-Agent,
# Cookies und Fingerabdrücke automatisch.
for attempt in range(retries + 1):
try:
# verify=False umgeht die SSL-Überprüfung für den BD-Proxy.
# Für die Produktion installieren Sie stattdessen das Bright Data CA-Zertifikat:
# https://docs.brightdata.com/general/account/ssl-certificate
response = requests.get(
url, proxies=proxies, timeout=60, verify=False
)
if response.status_code == 200:
return {
"url": url,
"html": response.text,
"scraped_at": datetime.now(timezone.utc).isoformat(),
}
else:
print(f"HTTP {response.status_code}", end=" → ", flush=True)
except Exception as e:
print(f"Fehler: {str(e)[:60]}", end=" → ", flush=True)
if attempt < retries:
time.sleep(2)
return Nonecollect_data() kombiniert beide Schritte – SERP findet die URLs, Web Unlocker scrapt sie:
def collect_data(topic, customer_id, unlocker_zone, unlocker_pwd, serp_zone, serp_pwd):
"""Finde Artikel zum Thema über SERP und scrape sie anschließend mit Web Unlocker."""
documents = []
# 1. Artikel-URLs über die SERP-API finden
urls_to_scrape, serp_docs = find_articles_for_topic(
topic, customer_id, serp_zone, serp_pwd
)
if not urls_to_scrape:
return []
# 2. Die gefundenen Artikel mit Web Unlocker scrapen
for i, url in enumerate(urls_to_scrape):
domain = url.split("/")[2] if "://" in url else url
print(f" ({i+1}/{len(urls_to_scrape)}) {domain}... ", end="", flush=True)
result = scrape_url(url, customer_id, unlocker_zone, unlocker_pwd)
if result:
documents.append(result)
print(f"OK ({len(result['html']):,} Zeichen)")
else:
print("FEHLER (Überspringen)")
# 3. SERP-Ergebnisse als zusätzliche Dokumente hinzufügen
documents.extend(serp_docs)
return documentsDie Ausführung mit „OpenAI vs Google vs Anthropic KI-Race“ liefert folgende Ausgabe:
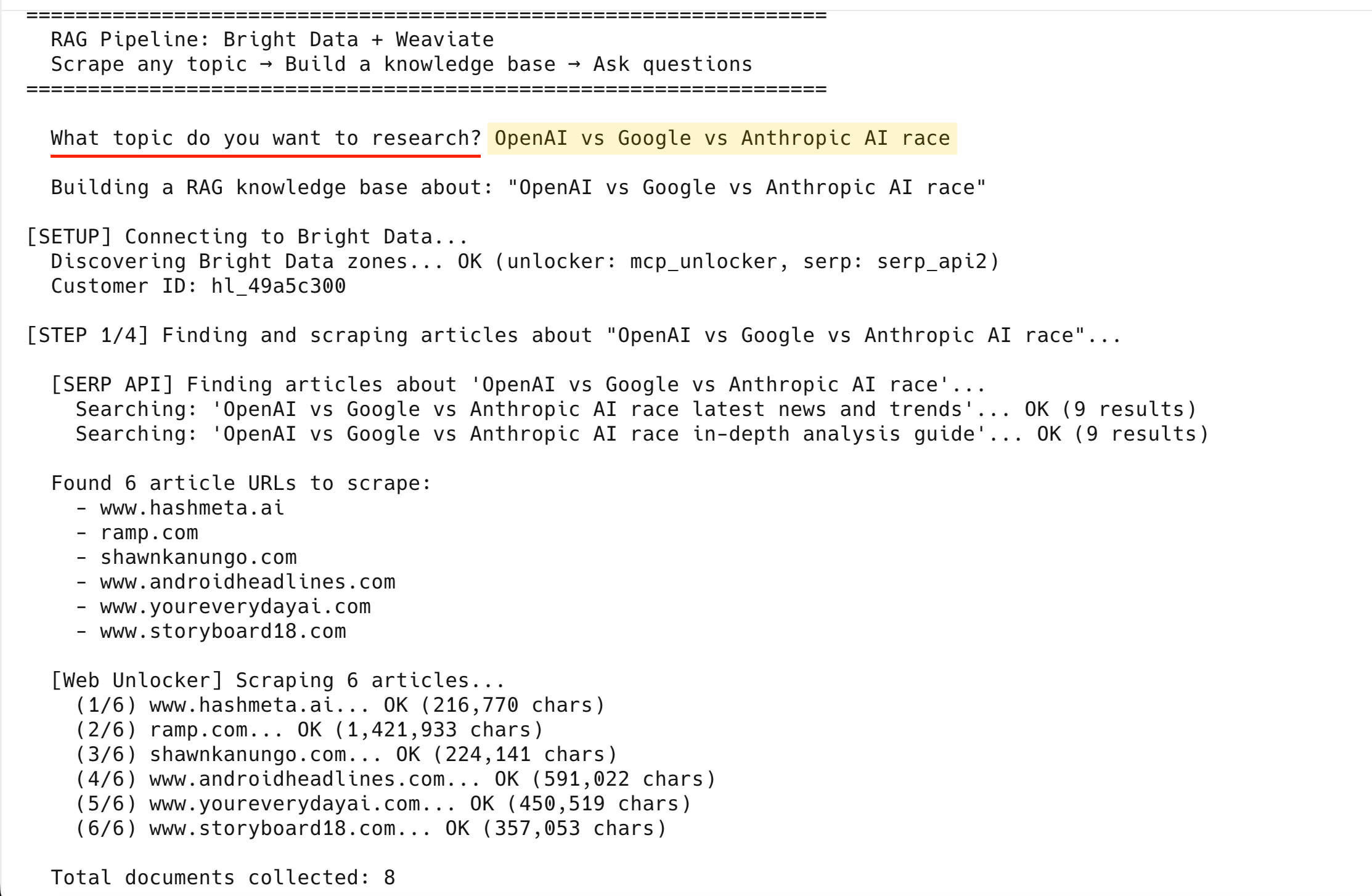
[SERP-API] Suche nach Artikeln zu 'OpenAI vs Google vs Anthropic KI-Race'...
Suche: 'OpenAI vs Google vs Anthropic KI-Race latest news and trends'... OK (9 Ergebnisse)
Suche: 'OpenAI vs Google vs Anthropic KI-Race in-depth analysis guide'... OK (9 Ergebnisse)
6 Artikel-URLs zum Scrapen gefunden:
- www.hashmeta.ai
- ramp.com
- shawnkanungo.com
- www.androidheadlines.com
- www.youreverydayai.com
- www.storyboard18.com
[Web Unlocker] 6 Artikel werden gescrapt...
(1/6) www.hashmeta.ai... OK (216.770 Zeichen)
(2/6) ramp.com... OK (1.421.933 Zeichen)
(3/6) shawnkanungo.com... OK (224.141 Zeichen)
(4/6) www.androidheadlines.com... OK (591.022 Zeichen)
(5/6) www.youreverydayai.com... OK (450.519 Zeichen)
(6/6) www.storyboard18.com... OK (357.053 Zeichen)
Insgesamt gesammelte Dokumente: 8Alle 6 wurden erfolgreich gescrapt – die 2 SERP-Ergebnisseiten ergeben insgesamt 8 Dokumente.
Wenn Web Unlocker nach 3 Versuchen bei einer URL fehlschlägt, überspringt die Pipeline diese und fährt mit den verbleibenden Artikeln fort.
Zu diesem Zeitpunkt hast du 8 Rohdokumente (6 Artikel + 2 SERP-Ergebnisseiten). Bereinige und zerlege sie nun für die Einbettung.
Schritt 2: Bereinigen und Aufteilen der Daten
Roh-HTML besteht zu ~90 % aus Rauschen. Der Verarbeitungsschritt filtert dies heraus, um sauberen Text zu erhalten, und teilt ihn in 500-Zeichen-Chunks (~125 Token) auf, die nach Möglichkeit an Satzgrenzen unterteilt werden.
Die Blockgröße steuert einen zentralen RAG-Kompromiss: Kleinere Blöcke (200–500 Zeichen) ermöglichen eine präzise Faktenabrufung, während größere Blöcke (1000–2000 Zeichen) dem LLM mehr Kontext liefern, allerdings auf Kosten von ungenaueren Suchergebnissen. Die Standardgröße von 500 Zeichen eignet sich gut für faktenbasierte Fragen („Wie hoch ist die Erfolgsquote von Anthropic gegenüber OpenAI im Unternehmensbereich?“). Erhöhen Sie die chunk_size auf 1500–2000 für Abfragen, die einen breiteren Kontext benötigen, wie Zusammenfassungen oder Vergleiche.
Die Überlappung von 50 Zeichen verhindert Informationsverlust an den Grenzen – ohne sie wird ein Satz, der sich über zwei Blöcke erstreckt, aufgeteilt, und keiner der Blöcke enthält den vollständigen Gedanken.
def clean_html(html, is_serp=False):
"""HTML zu sauberem Text bereinigen, dabei Navigation, Anzeigen und Standardtext entfernen."""
if is_serp:
return html # SERP-Ergebnisse sind bereits sauberer Text
soup = BeautifulSoup(html, "html.parser")
# Störende Elemente entfernen
for tag in soup(["nav", "footer", "header", "script", "style",
"aside", "iframe", "noscript", "svg", "form", "button"]):
tag.decompose()
# Gängige Anzeigen-/Cookie-/Popup-Container entfernen
for selector in [".ad", ".ads", ".cookie", ".popup", ".modal", ".sidebar",
"#cookie-banner", "#ad-container", "[role='banner']",
"[role='navigation']", "[role='complementary']"]:
for el in soup.select(selector):
el.decompose()
text = soup.get_text(separator="n", strip=True)
lines = [line.strip() for line in text.splitlines() if line.strip()]
return "n".join(lines)
def chunk_text(text, chunk_size=500, chunk_overlap=50):
"""Teilt den Text in überlappende Blöcke auf, wobei an Satzgrenzen getrennt wird.
Die Überlappung stellt sicher, dass Sätze an Blockgrenzen nicht zwischen den Blöcken verloren gehen."""
if len(text) <= chunk_size:
return [text]
chunks = []
start = 0
while start < len(text):
end = start + chunk_size
# Versuche, an einer Satzgrenze zu trennen
if end < len(text):
for sep in [". ", ".n", "nn", "n", " "]:
last_sep = text[max(start, end - 100):end].rfind(sep)
if last_sep != -1:
end = max(start, end - 100) + last_sep + len(sep)
break
chunk = text[start:end].strip()
if chunk and len(chunk) > 50:
chunks.append(chunk)
start = end - chunk_overlap
return chunks
def process_documents(documents):
"""Alle Dokumente bereinigen, in Blöcke zerlegen und Metadaten hinzufügen."""
all_chunks = []
for doc in documents:
is_serp = doc.get("is_serp", False)
clean_text = clean_html(doc["html"], is_serp=is_serp)
if len(clean_text) < 100:
continue
chunks = chunk_text(clean_text)
domain = doc["url"].split("/")[2] if "://" in doc["url"] else "unknown"
for i, chunk in enumerate(chunks):
all_chunks.append({
"text": chunk,
"source_url": doc["url"],
"source_domain": domain,
"scraped_at": doc["scraped_at"],
"chunk_index": i,
"total_chunks": len(chunks),
"content_hash": hashlib.md5(chunk.encode()).hexdigest(),
"content_type": "serp_result", wenn is_serp, sonst "article",
})
return all_chunksNach der Verarbeitung werden aus 8 Dokumenten ~150–400 bereinigte Textblöcke (abhängig von der Artikel-Länge), jeweils mit Metadaten (Quell-URL, Domain, Zeitstempel, Inhalts-Hash).
Schritt 3: Einbetten und Speichern in Weaviate
Stellen Sie eine Verbindung zur Weaviate Cloud her, erstellen Sie eine Sammlung mit Cohere-Vektorisierung und importieren Sie alle Chunks im Batch.
def connect_weaviate():
"""Verbinde dich mit der Weaviate Cloud mit verlängerten Timeouts."""
client = weaviate.connect_to_weaviate_cloud(
cluster_url=WEAVIATE_URL,
auth_credentials=Auth.api_key(WEAVIATE_API_KEY),
headers={"X-Cohere-Api-Key": COHERE_API_KEY},
additional_config=weaviate.classes.init.AdditionalConfig(
timeout=weaviate.classes.init.Timeout(init=30, query=60, insert=120),
),
skip_init_checks=True, # Verhindert gRPC-Timeout bei inaktiven Sandboxes
)
if not client.is_ready():
print(" FEHLER: Weaviate-Cluster ist nicht bereit.")
print(" Überprüfen Sie Ihre WEAVIATE_URL und WEAVIATE_API_KEY in .env")
print(" Stellen Sie sicher, dass Ihr Sandbox-Cluster unter console.weaviate.cloud läuft")
sys.exit(1)
return client
def setup_collection(client):
"""Erstelle die Sammlung mit hybrider Suche + generativer Konfiguration."""
# Löscht alle vorhandenen Sammlungen mit diesem Namen – eine erneute Ausführung mit einem
# neuen Thema ersetzt die bisherige Wissensdatenbank und erweitert sie nicht.
if client.collections.exists(COLLECTION_NAME):
client.collections.delete(COLLECTION_NAME)
print(f" Vorhandene Sammlung '{COLLECTION_NAME}' gelöscht")
client.collections.create(
name=COLLECTION_NAME,
description="Über Bright Data für RAG gescrapte Webartikel",
# Cohere embed-v4.0: Vektorisiert Text automatisch beim Import
vector_config=Configure.Vectors.text2vec_cohere(
model="embed-v4.0",
),
# Cohere command-a-03-2025: generiert RAG-Antworten zum Zeitpunkt der Abfrage
generative_config=Configure.Generative.cohere(
model="command-a-03-2025",
),
properties=[
Property(name="text", data_type=DataType.TEXT,
description="Der Textinhalt des Chunks"),
Property(name="source_url", data_type=DataType.TEXT,
skip_vectorization=True),
Property(name="source_domain", data_type=DataType.TEXT,
skip_vectorization=True),
Property(name="scraped_at", data_type=DataType.TEXT,
skip_vectorization=True),
Property(name="chunk_index", data_type=DataType.INT,
skip_vectorization=True),
Property(name="total_chunks", data_type=DataType.INT,
skip_vectorization=True),
Property(name="content_hash", data_type=DataType.TEXT,
skip_vectorization=True),
Property(name="content_type", data_type=DataType.TEXT,
skip_vectorization=True),
],
)
print(f" Sammlung '{COLLECTION_NAME}' erstellt")Ein paar Dinge, die es zu beachten gilt:
skip_vectorization=Truefür Metadatenfelder – nur dasTextfeld wird eingebettet, was API-Aufrufe spart und sauberere Vektoren erzeugtcontent_hashwird pro Chunk gespeichert – nutze dies, um das erneute Einbetten unveränderter Inhalte zu überspringen, wenn du eine Logik für inkrementelles erneutes Scraping hinzufügst (die aktuelle Pipeline importiert bei jedem Lauf die Daten neu)
Verhalten bei erneuter Ausführung: Die Pipeline löscht die Sammlung bei jedem Durchlauf und erstellt sie neu. Die Ausführung mit „KI race“ und anschließend „quantum computing“ ersetzt die KI-Race-Daten. Um mehrere Themen beizubehalten, ändern Sie
COLLECTION_NAMEin einen eindeutigen Namen pro Thema (z. B.WebResearch_ai_race,WebResearch_quantum).
Weitere Informationen zur Vorbereitung von KI-fähigen Vektordatensätzen finden Sie im Bright Data-Leitfaden.
Die Funktion store_chunks() fügt alle Chunks im Batch in die Sammlung ein:
def store_chunks(client, chunks):
"""Chunks stapelweise in Weaviate importieren (automatisch vektorisiert über Cohere)."""
collection = client.collections.use(COLLECTION_NAME)
with collection.batch.fixed_size(batch_size=50) as batch:
for chunk in chunks:
batch.add_object(properties=chunk)
failed = len(collection.batch.failed_objects) if collection.batch.failed_objects else 0
if failed > 0:
print(f" Erster Fehler: {collection.batch.failed_objects[0].message[:120]}")
return failedbatch.fixed_size(50) importiert mehrere Batches gleichzeitig, um den Durchsatz zu erhöhen, anstatt die Einfügungen einzeln durchzuführen. Im Testlauf wurden alle Chunks ohne Fehler importiert. Weaviate ruft Cohere auf, um jeden Chunk beim Import einzubetten.
Schritt 4: Abfrage mit hybrider Suche und Generierung
Nachdem alle Chunks eingebettet und indiziert sind, fragen Sie sie mit der Funktion rag_query() ab. Diese ruft generate.hybrid() auf, um Abruf und Generierung in einer einzigen Anfrage durchzuführen:
def rag_query(client, question, alpha=0.7, limit=5):
"""Führe eine RAG-Abfrage mit der hybriden Suche von Weaviate + generativer KI aus."""
collection = client.collections.use(COLLECTION_NAME)
response = collection.generate.hybrid(
query=question,
alpha=alpha, # 0.7 = 70 % semantisch, 30 % Schlüsselwort
limit=limit,
grouped_task=f"""Beantworten Sie diese Frage auf der Grundlage der unten aufgeführten abgerufenen Dokumente:
"{question}"
Anweisungen:
- Gib eine klare, umfassende Antwort
- Gib für jede wichtige Aussage die Quell-URL an
- Wenn Informationen veraltet oder widersprüchlich erscheinen, weise darauf hin
- Halte die Antwort prägnant, aber informativ (2–4 Absätze)""",
)
print(f"n F: {question}")
print(f" {'─' * 60}")
if response.generated:
print(f" A: {clean_generated_text(response.generated)}")
else:
print(" A: (Keine Antwort generiert – überprüfe deinen Cohere-API-Schlüssel)")
# Trenne Artikelquellen von SERP-Zusammenfassungsabschnitten
article_sources = []
serp_sources = []
gesehene_URLs = set()
for obj in response.objects:
url = obj.properties.get("source_url", "unknown")
if url in gesehene_URLs:
continue
gesehene_URLs.add(url)
content_type = obj.properties.get("content_type", "")
domain = obj.properties.get("source_domain", "")
if content_type == "serp_result":
serp_sources.append((domain, url))
else:
article_sources.append((domain, clean_url(url)))
print(f"n Quellen ({len(response.objects)} Chunks abgerufen):")
for domain, url in article_sources:
print(f" - [{domain}] {url}")
if not article_sources and serp_sources:
print(" (Basierend auf SERP-Zusammenfassungen – keine Artikel-Chunks gefunden)")
return responseBei einer reinen Vektorsuche könnten exakte Begriffe wie „GPT-5“ oder „Claude Code“ übersehen werden. Bei einer reinen Stichwortsuche werden semantisch verwandte Inhalte übersehen. Die Mischung mit alpha=0,7 bietet Ihnen beides. Der BlockMax-WAND-Algorithmus von Weaviate sorgt dafür, dass die BM25-Stichwortkomponente auch bei großem Umfang schnell bleibt.
Mit limit=5 ruft die Abfrage die fünf besten Chunks ab – genug Kontext für eine detaillierte Antwort, ohne das LLM mit Rauschen zu überlasten. Erhöhen Sie den Wert auf 10 für allgemeine Fragen, die mehrere Unterthemen umfassen; verringern Sie ihn auf 3 für präzise Faktenabfragen. Der Parameter grouped_task sendet alle abgerufenen Chunks in einer einzigen Eingabeaufforderung an Cohere, sodass dieses eine einzige Antwort verfassen kann. Die Alternative single_prompt generiert eine Antwort pro Chunk – nützlich für Zusammenfassungen einzelner Dokumente, jedoch nicht für quellenübergreifende Antworten.
Weitere Optionen finden Sie in der Bright Data-Übersicht zu semantischen Such-APIs.
Führen Sie alle 4 Schritte zusammen
Die Funktion `main()` führt die gesamte Pipeline aus. Sie wählen ein Thema aus und sie erledigt den Rest:
def main():
print("=" * 65)
print(" RAG-Pipeline: Bright Data + Weaviate")
print(" Beliebiges Thema scrapen → Wissensdatenbank aufbauen → Fragen stellen")
print("=" * 65)
# ── Umgebung validieren ──
validate_env()
# ── Benutzer nach einem Thema fragen ──
print()
try:
topic = input(" Welches Thema möchten Sie recherchieren? ").strip()
except (EOFError, KeyboardInterrupt):
print("n Auf Wiedersehen!")
return
if not topic:
print(" Kein Thema eingegeben. Beende das Programm.")
return
print(f'n Erstelle eine RAG-Wissensdatenbank zu: "{topic}"')
# ── Bright Data-Anmeldedaten automatisch ermitteln ──
print("n[SETUP] Verbindung zu Bright Data wird hergestellt...")
cust_id, unlocker_zone, unlocker_pwd, serp_zone, serp_pwd = (
discover_bright_data_credentials()
)
# ── Schritt 1: Artikel zum Thema finden und scrapen ──
print(f'n[SCHRITT 1/4] Artikel zu „{topic}“ finden und scrapen...')
documents = collect_data(
topic, cust_id, unlocker_zone, unlocker_pwd, serp_zone, serp_pwd
)
print(f"n Insgesamt gesammelte Dokumente: {len(documents)}")
if not documents:
print(" FEHLER: Keine Dokumente gesammelt. Versuchen Sie es mit einem anderen Thema.")
return
# ── Schritt 2: Verarbeiten und in Blöcke aufteilen ──
print("n[SCHRITT 2/4] Dokumente werden verarbeitet und in Blöcke aufgeteilt...")
chunks = process_documents(documents)
print(f" {len(chunks)} Chunks aus {len(documents)} Dokumenten erstellt")
if not chunks:
print(" FEHLER: Es wurden keine Chunks erstellt. Die Dokumente sind möglicherweise zu kurz.")
return
# ── Schritt 3: In Weaviate speichern ──
print("n[SCHRITT 3/4] Speichern in Weaviate (Einbettung + Indizierung)...")
print(" Verbindung zu Weaviate Cloud herstellen...", end=" ", flush=True)
client = connect_weaviate()
print("OK")
print(" Sammlung einrichten...")
setup_collection(client)
print(f" Importieren von {len(chunks)} Chunks (automatische Vektorisierung über Cohere)...")
failed = store_chunks(client, chunks)
print(f" Importiert: {len(chunks) - failed} erfolgreich, {failed} fehlgeschlagen")
# Anzahl überprüfen
collection = client.collections.use(COLLECTION_NAME)
count = collection.aggregate.over_all(total_count=True).total_count
print(f" Gesamtzahl der Objekte in Weaviate: {count}")
# ── Schritt 4: Demo-Abfragen + Interaktiver Modus ──
print(f'n[SCHRITT 4/4] RAG-Abfragen zu „{topic}“...')
print("=" * 65)
demo_queries = [
f"Was sind die neuesten Entwicklungen und Trends bei {topic}?",
f"Was sind die größten Herausforderungen und Risiken bei {topic}?",
f"Wie sehen die Zukunftsaussichten für {topic} aus?",
]
for question in demo_queries:
rag_query(client, question)
print()
# ── Zusammenfassung ──
print("=" * 65)
print(" Pipeline abgeschlossen!")
print(f' Thema: "{topic}"')
print(f" - {len(documents)} Quellen über Bright Data gescrapt")
print(f" - {count} Chunks in Weaviate gespeichert")
print(f" - {len(demo_queries)} Demo-RAG-Abfragen ausgeführt")
print("=" * 65)
# ── Interaktiver Modus ──
print(f'n Ihre Wissensdatenbank zu "{topic}" ist bereit!')
print(" Fragen Sie alles. Geben Sie 'quit' ein, um das Programm zu beenden.n")
while True:
try:
user_question = input(" Ihre Frage: ").strip()
except (EOFError, KeyboardInterrupt):
print("n Auf Wiedersehen!")
break
if not user_question:
continue
if user_question.lower() in ("quit", "exit", "q"):
print(" Auf Wiedersehen!")
break
rag_query(client, user_question)
print()
client.close()
if __name__ == "__main__":
main()Ausführen:
python3 pipeline.pyRAG-Antworten aus dem Testlauf zum KI-Wettlauf
Die Pipeline wurde mit dem Thema „OpenAI vs. Google vs. Anthropic KI-Wettlauf“ ausgeführt. Dies sind Beispiel-RAG-Antworten aus einem Testlauf – Ihre Ergebnisse spiegeln die Artikel wider, die zum Zeitpunkt der Ausführung verfügbar sind.
Abfrage 1: „Was sind die neuesten Entwicklungen und Trends im KI-Wettlauf zwischen OpenAI, Google und Anthropic?“
Der KI-Wettlauf zwischen OpenAI, Google und Anthropic entwickelt sich weiterhin rasant, wobei jedes Unternehmen seine einzigartigen Stärken ausspielt. OpenAI behält seinen Vorsprung bei Umsatz und Verbraucherakzeptanz und profitiert dabei von seinem First-Mover-Vorteil. Anthropic holt bei der Akzeptanz in Unternehmen auf, dank spezialisierter Tools wie Claude Code und einer Erfolgsquote von 70 % bei direkten Vergleichen unter Unternehmen, die KI-Dienste erwerben. Google bringt unübertroffene Rechenressourcen und eine nahtlose Integration innerhalb seines Ökosystems mit.
Quellen: shawnkanungo[.]com, hashmeta[.]ki, ramp[.]com
Frage 2: „Was sind die größten Herausforderungen und Risiken im Wettlauf zwischen OpenAI, Google und Anthropic KI?“
OpenAI steht vor der Herausforderung, sein Innovationstempo aufrechtzuerhalten und gleichzeitig seine Unabhängigkeit zu bewahren, insbesondere da es bei Rechenressourcen auf Partnerschaften angewiesen ist. Google kämpft mit bürokratischer Trägheit und läuft Gefahr, sein Kerngeschäft mit Suchmaschinenwerbung zu kannibalisieren, da dialogorientierte KI die Anzahl der Anzeigenklicks verringert. Anthropic, das sich als „Safety-First“-Unternehmen positioniert, muss seinen Fokus auf Interpretierbarkeit in einem leistungsorientierten Markt in Marktanteile umsetzen.
Quellen: hashmeta[.]ki, shawnkanungo[.]com
Frage 3: „Wie sehen die Zukunftsaussichten im Wettlauf zwischen OpenAI, Google und Anthropic KI aus?“
OpenAI ist führend bei Umsatz und Verbraucherakzeptanz, wobei seine Roadmap GPT-5 und Investitionen zur Senkung der Inferenzkosten umfasst. Der zukünftige Erfolg von Anthropic hängt davon ab, ob regulatorische Anforderungen an die Erklärbarkeit entstehen – seine frühen Investitionen in Sicherheit und Interpretierbarkeit könnten einen erheblichen Vorteil bieten. Google bleibt ein starker Konkurrent, insbesondere bei der Anpassung von Tools wie Gemini an spezifische Anwendungsfälle und der Integration von KI in alltägliche Arbeitsabläufe.
Quellen: hashmeta[.]ki, shawnkanungo[.]com
Jede Antwort basiert auf Artikeln, die während desselben Pipeline-Laufs gesammelt wurden. Jede Quellenangabe verweist auf eine in Schritt 1 gesammelte Quelle – Sie können jede Behauptung überprüfen, indem Sie die URL öffnen. Wenn Sie nach etwas fragen, das in den gesammelten Artikeln nicht behandelt wird, gibt das Modell dies an oder liefert eine weniger detaillierte Antwort.
Nach den Demo-Abfragen wechselt die Pipeline in den interaktiven Modus, in dem Sie Ihre eigenen Fragen stellen können:

In die Produktion gehen
Wenn Sie dies in der Produktion benötigen, benötigen Sie Mandantenfähigkeit, Compliance und Kostenkontrolle. (Für einen Überblick sehen Sie sich an, wie RAG in einen Tech-Stack für Produktions-KI-Agenten passt.)
Mandantenfähigkeit für Datenisolierung
Wenn Sie RAG für mehrere Kunden aufbauen, bietet die Multi-Tenancy von Weaviate jedem Mandanten einen dedizierten Shard mit isolierten Vektorindizes:
from weaviate.classes.config import Configure
from weaviate.classes.tenants import Tenant
# Multi-Tenancy für die Sammlung aktivieren
collection = client.collections.create(
name="WebContent",
multi_tenancy_config=Configure.multi_tenancy(enabled=True),
# ... Vektorisierung + generative Konfiguration
)
# Jeder Kunde erhält einen eigenen isolierten Mandanten
collection.tenants.create([
Tenant(name="customer_a"),
Tenant(name="customer_b"),
Tenant(name="customer_c"),
])
# Daten pro Mandant scrapen und speichern
tenant_collection = collection.with_tenant("customer_a")
with tenant_collection.batch.dynamic() as batch:
for chunk in customer_a_chunks:
batch.add_object(properties=chunk)Ein einzelner Knoten unterstützt mehr als 50.000 aktive Mandanten – ein Cluster mit 20 Knoten bewältigt eine Million.
Kostenoptimierung
4 Techniken senken die Kosten, wenn Ihre Datenmengen wachsen:
- Weaviate-Rotationsquantisierung – 4-fache Vektorkomprimierung bei 98–99 % Recall.
- Inhalts-Hashing – das Feld
`content_hash`ermöglicht inkrementelle Aktualisierungen, bei denen unveränderte Chunks nicht erneut eingebettet werden (siehe Schritt 3 oben) skip_vectorization=Truefür Metadatenfelder – nur das Einbetten, was wichtig ist.- Bright Data Dataset Marketplace – nutze vorab gesammelte Datensätze, anstatt für gängige Domains zu scrapen.
Diese Punkte sind wichtig, sobald Sie über einen Einzelbenutzer-Prototyp hinausgehen.
Häufige Fehler und wie man sie behebt
Wenn Sie auf ein Problem stoßen, überprüfen Sie zunächst diese Tabelle:
| Problem | Ursache | Behebung |
|---|---|---|
Weaviate gRPC DEADLINE_EXCEEDED |
Der Sandbox-Cluster war während des Scrapings inaktiv | Führen Sie pipeline.py erneut aus – das Skript stellt die Verbindung automatisch wieder her. Sollte das Problem weiterhin bestehen, überprüfen Sie Ihren Cluster in der Weaviate-Konsole |
Cohere-API-Ratenbegrenzung (429) |
Der Testzugang unterliegt einer Ratenbegrenzung | Warten Sie eine Minute und versuchen Sie es erneut oder überprüfen Sie die Nutzung im Cohere-Dashboard. Der automatisierte Lauf verwendet weniger als 20 Aufrufe; jede interaktive Abfrage fügt 2 weitere hinzu |
Keine Web Unlocker-Zone gefunden |
Ihr Bright Data-Konto verfügt über keine Web Unlocker-Zone | Gehen Sie zu Bright Data → Proxies & Scraping → Meine Zonen → Erstellen Sie eine Web Unlocker-Zone |
Keine SERP-API-Zone gefunden |
Ihr Bright Data-Konto verfügt über keine SERP-Zone | Gehen Sie zu Bright Data → Proxies & Scraping → Meine Zonen → Erstellen Sie eine SERP-API-Zone |
HTTP 403 bei allen URLs |
Web Unlocker-Wiederholungsversuche erschöpft | Versuchen Sie es mit einem anderen Thema – einige Nischen-Websites verwenden strenge Anti-Bot-Sperren. Erfahren Sie, wie Sie CAPTCHAs umgehen können, um erweiterte Optionen zu nutzen |
Weaviate-Cluster nicht bereit |
Sandbox abgelaufen (14-Tage-Limit) | Erstellen Sie eine neue Sandbox in der Weaviate-Konsole und aktualisieren Sie die .env-Datei |
| Cohere-Modell nicht verfügbar | command-a-03-2025 oder embed-v4.0 wurde eingestellt |
Überprüfen Sie die verfügbaren Modelle unter docs.cohere.com/docs/models und aktualisieren Sie den Parameter model= in setup_collection() |
ModuleNotFoundError: Kein Modul namens „weaviate“ |
Abhängigkeiten nicht installiert | Führen Sie pip3 install -r requirements.txt aus dem Projektverzeichnis aus |
Wenn Ihr Fehler nicht aufgeführt ist, überprüfen Sie die vollständige Ausgabe – die Pipeline protokolliert jeden Schritt mit Details.
Anwendungsfälle
Die gleiche Architektur funktioniert für jedes Thema. Einige Ideen:
- Wettbewerbsanalyse – Thema: „Preisstrategie von Wettbewerber X“. Die Pipeline durchsucht die Websites von Wettbewerbern, Preisseiten und Analystenberichte. Fragen Sie dann: „Wie schneidet die Unternehmenspreisgestaltung von Wettbewerber X im Vergleich zu unserer ab?“
- Marktforschung – Thema: „Fintech-Trends Südostasien“. Durchforstet regionale Nachrichten und Branchenpublikationen und ermöglicht Fragen wie : „Was sind die wichtigsten aufkommenden Fintech-Trends in Südostasien?“
- E-Commerce – Thema: „Markt für nachhaltige Mode“. Durchforstet Marktberichte und Marktforschung. „Welche nachhaltigen Modemarken gewinnen Marktanteile?“
- Technische Recherche – Thema: „Best Practices für Kubernetes-Sicherheit“. Durchforstet technische Blogs und Sicherheitshinweise, sodass Sie nach bestimmten CVEs oder Fehlkonfigurationen fragen können.
Was als Nächstes entwickelt werden soll
Dies ist ein funktionierender Prototyp mit bekannten Einschränkungen:
- Ersetzt bei jedem Lauf die gesamte Sammlung (keine inkrementellen Updates) – verwenden Sie
content_hash, um Unterschiede hinzuzufügen - Verarbeitet nur Text; Tabellen, Bilder und PDFs in den gescrapten Seiten werden verworfen
- Findet Inhalte über die Google-Suche – für bestimmte URLs übergebe diese direkt an `
scrape_url()` - Läuft als CLI für einen einzelnen Benutzer
Von hier aus haben Sie folgende Möglichkeiten:
- Planung – führen Sie die Pipeline als Cron-Job aus, um Ihre Wissensdatenbank auf dem neuesten Stand zu halten
- Mandantenfähigkeit – Weisen Sie jedem Kunden einen eigenen isolierten Shard zu (siehe Abschnitt „In die Produktion gehen“ oben)
- Verschiedene Datenquellen – nutzen Sie die Bright Data Web Scraper API für strukturierte Amazon- oder LinkedIn-Daten oder die Crawl API für Markdown-Daten der gesamten Website
- Frontend –
rag_query()in einen Flask- oder FastAPI-Endpunkt einbinden und eine Chat-Benutzeroberfläche anschließen - Agentisches RAG – ein agentisches RAG-System erstellen, das selbstständig entscheidet, wann und was gescrapt werden soll
- LangChain – Portieren Sie die Pipeline auf LangChain mit Bright Data für integrierte Kettenorchestrierung und Speicher
Häufig gestellte Fragen
Welche Themen eignen sich für diese Pipeline?
Jedes Thema, zu dem es Artikel im offenen Web gibt. Die Pipeline nutzt die Bright Data SERP-API, um Google nach Ihrem Thema zu durchsuchen, und scrapt dann die obersten Ergebnisse. Nischenthemen mit weniger indizierten Seiten liefern weniger Artikel, aber die Pipeline funktioniert trotzdem – sie nutzt einfach alles, was sie findet.
Wie viel kostet die Nutzung?
Alle drei Dienste bieten kostenlose Einstiegsmöglichkeiten. Der Testzugang von Cohere ist kostenlos und erfordert keine Kreditkarte. Weaviate Cloud bietet einen kostenlosen Sandbox-Cluster an, und Bright Data bietet eine kostenlose Testversion für die SERP-API und den Web Unlocker an.
Kann ich ein anderes Einbettungsmodell oder LLM verwenden?
Ja. Ändern Sie den Modellparameter in setup_collection() sowohl für die Einbettung als auch für die Generierung. Weaviate unterstützt standardmäßig die Vektorisierer von Cohere, OpenAI, Google und Hugging Face. Um zu wechseln, tauschen Sie text2vec_cohere gegen text2vec_openai aus, aktualisieren Sie den API-Schlüssel-Header in connect_weaviate() und führen Sie die Pipeline erneut aus.
Wie halte ich die Wissensdatenbank auf dem neuesten Stand?
Führen Sie pipeline.py erneut mit demselben Thema aus. Die Pipeline löscht die alte Sammlung und erstellt eine neue mit den neu gescrapten Daten. Für den produktiven Einsatz fügen Sie eine content_hash-Prüfung hinzu, um die erneute Einbettung von unveränderten Datenblöcken zu überspringen. Planen Sie die Pipeline als Cron-Job ein, um die Daten in beliebigen Intervallen automatisch zu aktualisieren.
Was ist, wenn ich bereits URLs zum Scrapen habe?
Überspringen Sie den SERP-Erkennungsschritt. Ersetzen Sie in collect_data() den Aufruf von find_articles_for_topic() durch Ihre eigene URL-Liste und übergeben Sie jede URL an scrape_url(). Der Rest der Pipeline (Chunking, Einbettung, Abfrage) funktioniert auf die gleiche Weise.
Wie kann ich mehr als 6 Artikel scrapen?
Ändere den [:6] -Ausschnitt am Ende von find_articles_for_topic() in eine höhere Zahl (z. B. [:12]). Du kannst auch weitere Suchanfragen zur search_queries-Liste hinzufügen, um ein breiteres Spektrum an Ergebnissen zu erhalten. Mehr Artikel bedeuten eine längere Scraping-Zeit und mehr Chunks, aber der Rest der Pipeline erledigt das automatisch.





