

In diesem Artikel werden wir Folgendes behandeln:
- Was der Playwright MCP-Server ist und wie er für Web Scraping verwendet werden kann
- Die verschiedenen im Playwright MCP-Server verfügbaren Tools
- Wie der Bright Data Web MCP-Server eine einfachere Alternative für Web Scraping bieten kann.
Tauchen wir ein!
Der Playwright MCP-Server
Playwright ist weithin als Browser-Automatisierungstool bekannt und wird häufig zum Testen und Automatisieren von Browseraufgaben verwendet. Der Playwright MCP Server baut auf dieser Funktionalität auf, nur dass er dieses Mal nicht für die direkte menschliche Nutzung, sondern für KI-Agenten konzipiert ist.
Wenn Sie den Server ausführen, können Sie einen beliebigen MCP-Host anschließen und KI-Agenten Zugriff auf das vollständige Automatisierungstoolkit von Playwright gewähren.
Das bedeutet, dass Ihr KI-Agent wie ein Mensch mit einem Webbrowser interagieren und Aktionen wie Online-Einkäufe, Abrufen der neuesten Nachrichten, Beantworten von E-Mails und vieles mehr ausführen kann.
In diesem Artikel liegt der Schwerpunkt auf Web Scraping. Mit Playwright MCP Server erhalten Sie die Low-Level-Tools, die nicht nur für die Browser-Automatisierung, sondern auch für das Scrapen und Extrahieren von Daten direkt aus dem Web durch einen LLM erforderlich sind.
Der Playwright MCP-Server
Wie jeder MCP-Server verfügt auch der Playwright MCP-Server über eine Reihe von Tools, die einem KI-Agenten zur Verfügung gestellt werden können. Diese Tools entsprechen direkt den Playwright-APIs, die Entwickler bereits kennen und verwenden. Sehen wir uns einige der wichtigsten davon an:
- Browser_Klick: Ermöglicht es dem KI-Agenten, auf Elemente zu klicken, genau wie ein Mensch mit einer Maus.
- Browser_drag: Ermöglicht Drag-and-Drop-Interaktionen.
- Browser_Schließen: Schließt die Browser-Instanz.
- Browser_evaluate: Ermöglicht dem KI-Agenten die Ausführung von JavaScript-Code direkt auf der Seite.
- Browser_datei-upload: Verarbeitet Datei-Uploads über den Browser.
- Browser_fill_form: Füllt Formulare auf einer Webseite aus.
- Browser_Hover: Bewegt den Mauszeiger über Elemente.
- Browser_navigieren: Navigiert zu einer beliebigen URL.
- Browser_taste_drücken: Simuliert das Drücken von Tasten, so dass der Agent vollen Zugriff auf die Tastatureingabe hat.
Mit all diesen Werkzeugen, die dem KI-Agenten zur Verfügung stehen, kann er sich leicht durch das Web bewegen und Daten auslesen. Sehen wir uns an, wie wir das machen können.
Web-Scraping mit dem Playwright MCP-Server
In diesem Abschnitt führen wir eine Web-Scraping-Aufgabe mit dem Playwright MCP-Server durch. Unser KI-Agent wird die neuesten Preisinformationen für die iPhone 16-Modelle sammeln. Der Einfachheit halber beschränken wir die Aufgabe auf eine einzige Quelle: Best Buy.
Konfigurieren des Servers
Um den Playwright-MCP-Server auszuführen, benötigen wir einen MCP-Host. Sie können einen beliebigen Host Ihrer Wahl verwenden, z. B. Claude Desktop, Cursor oder Gemini CLI. Für diesen Artikel verwenden wir VS Code.
Der Playwright-MCP-Server ist ein lokaler MCP-Server, der in Node.js implementiert ist. Bevor Sie fortfahren, sollten Sie also sicherstellen, dass Sie Node installiert haben.
Um den Server einzurichten, müssen wir die folgende Konfiguration zu unserem MCP-Host hinzufügen:
{
"Server": {
"playwright": {
"Befehl": "npx",
"args": [
"@playwright/mcp@latest"
]
}
}
}Diese Konfiguration gilt für die Einrichtung von MCP-Servern in VS Code, obwohl sie bei anderen MCP-Hosts leicht abweichen kann. Sobald die Einrichtung abgeschlossen ist, hat unser KI-Agent Zugriff auf die vom Server bereitgestellten Tools. Damit können wir mit dem Scraping beginnen.
Scraping mit dem MCP-Server
Der erste Schritt besteht darin, zur BestBuy-Website zu navigieren. Dazu weisen wir den KI-Agenten einfach an, die Website zu öffnen, und er wird das Tool Browser_navigate verwenden, um dorthin zu gelangen.
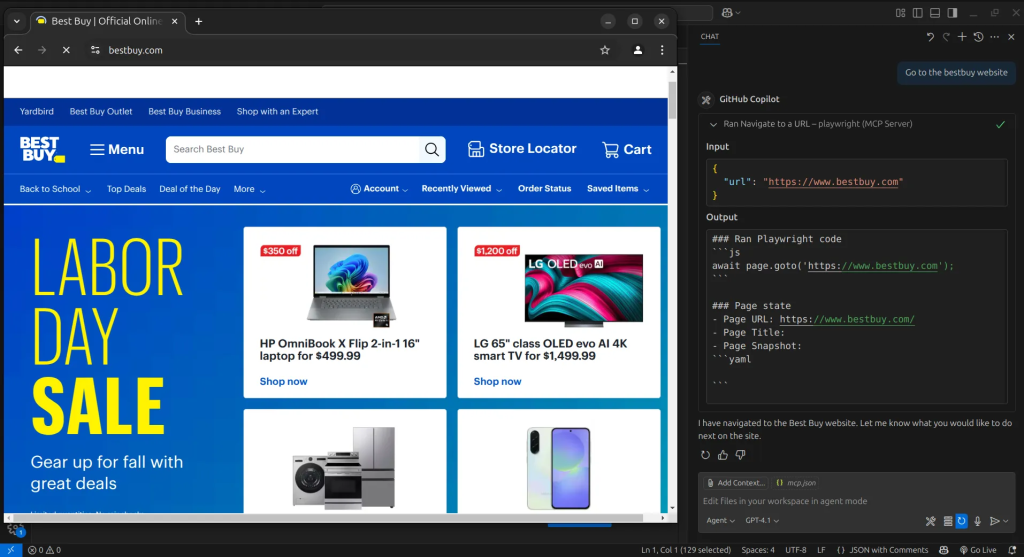
Als nächstes weisen wir den KI-Agenten an, nach dem iPhone 16 zu suchen. Dazu verwendet er das Tool Browser_press_key, um die Suchanfrage einzugeben.

Dann klickt der KI-Agent mit dem Werkzeug Browser_click auf die Suchschaltfläche.
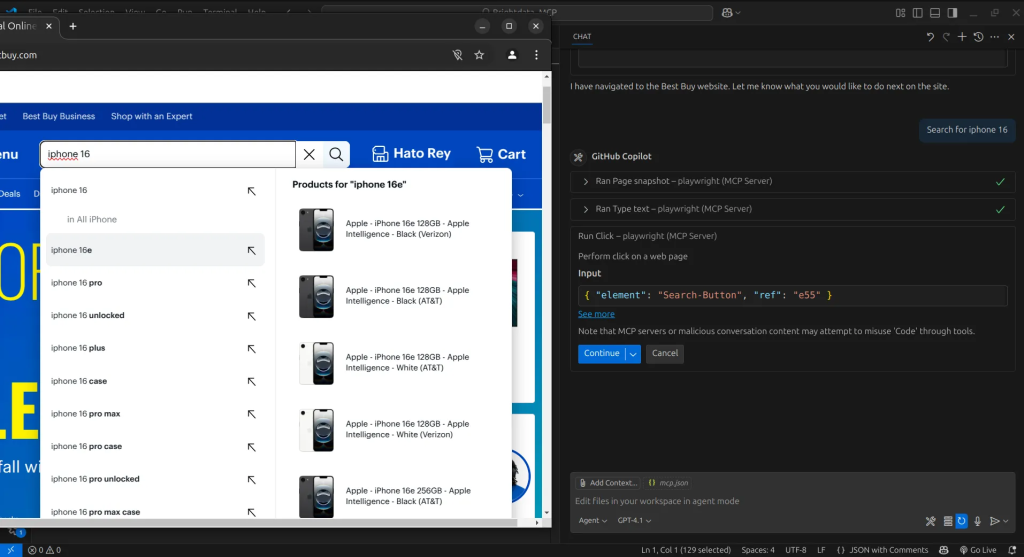
Auf diese Weise erhalten wir unsere Ergebnisse. Bei jedem Schritt, den der Agent beim Navigieren auf der Seite macht, wird ein Schnappschuss des aktuellen Zustands erstellt. Anhand dieser Momentaufnahmen können wir den Agenten anweisen, die von uns benötigten Informationen zu extrahieren und in ein strukturiertes Format zu bringen.
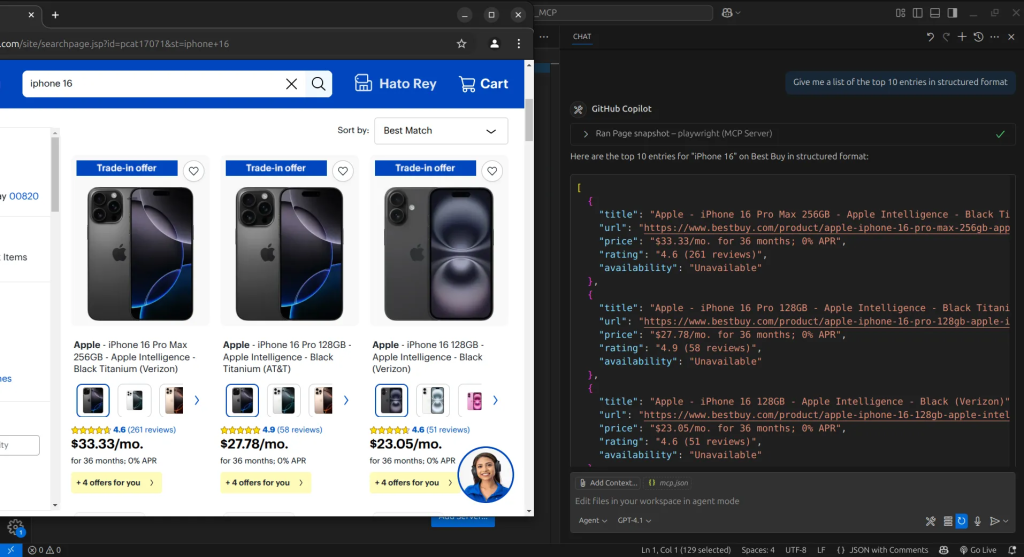
Mit diesem Ansatz haben wir die Website erfolgreich gescannt. Obwohl wir damit die volle Kontrolle haben und fast alles tun können, was wir wollen, ist es immer noch recht niedrigschwellig. Das kann sich als übertrieben anfühlen, wenn unser einziges Ziel das Scrapen von Daten ist, da wir die umfassenderen Web-Automatisierungsfunktionen vielleicht nicht benötigen.
Als Nächstes wollen wir uns ansehen, wie der Bright Data Web MCP-Server dieselbe Aufgabe aus einer viel höher angesiedelten Perspektive erfüllen kann.
Bright Data Web MCP-Server: Ein anspruchsvoller Web Scraping MCP-Server
Der Bright Web Data MCP-Server verfügt über eine Reihe von High-Level-Tools, die speziell für Web Scraping entwickelt wurden. Dazu gehören Tools zum Extrahieren von Daten aus Plattformen wie Amazon, zum Abrufen von Personen- und Unternehmensprofilen und sogar zum Sammeln von Instagram-Profilen, Posts und Reels.
Im Gegensatz zu Playwright MCP, das auf einer niedrigeren Ebene arbeitet, vereinfacht der Bright Data Web MCP-Server den Scraping-Prozess für Ihren KI-Agenten. Er verarbeitet sogar Webseiten, die durch Bot-Erkennung oder CAPTCHA geschützt sind, und ermöglicht Ihrem Agenten einen zuverlässigen Zugriff, wo herkömmliche Methoden versagen könnten.
In diesem Exkurs verwenden wir den Bright Data Web MCP-Server, um dieselbe Aufgabe auszuführen, die wir zuvor mit Playwright MCP in Angriff genommen haben. Der Server bietet von Haus aus zwei Kerntools:
- Suchmaschinentool
- Scrapen von Daten als Markdown-Tool
Weitere Tools können durch die Aktivierung des Pro-Modus freigeschaltet werden, aber für den Moment bleiben wir bei diesen beiden. Weitere Details finden Sie in diesem Artikel.
Konfigurieren des Servers
Im Gegensatz zum Playwright-MCP-Server, der lokal ausgeführt wird, handelt es sich beim Bright Data Web MCP-Server um einen Remote-MCP-Server. Das bedeutet, dass der Konfigurationsprozess etwas anders ist. Im Folgenden wird beschrieben, wie Sie ihn in VS Code einrichten können:
"BrightData": {
"url": "https://mcp.brightdata.com/mcp?token=YOUR_API_KEY",
}Für die Verbindung benötigen Sie Ihren Bright Data-API-Schlüssel. Nach der Konfiguration ist Ihr Agent bereit, mit dem Scraping zu beginnen.
Scraping mit dem MCP-Server
Zunächst weisen wir den Agenten an, eine Websuche nach dem Preis des iPhone 16 durchzuführen.

Der Agent verwendet dann das Suchmaschinentool des Servers, um die Anfrage auszuführen.

Nachdem er die Ergebnisse erhalten hat, weisen wir den Agenten an, Informationen von einer Website unserer Wahl zu extrahieren, in diesem Fall dem Apple Store. Der Agent verwendet dann das Scrape Data as Markdown-Tool, um den Inhalt zu extrahieren, und gibt ihn im Markdown-Format zurück, das der Agent leicht verarbeiten und verstehen kann.
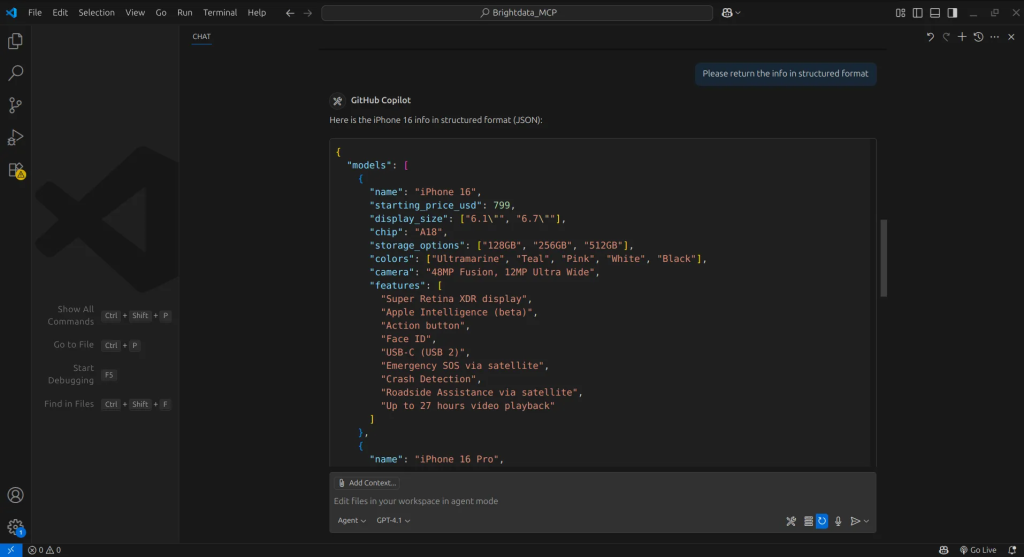
Mit den extrahierten Informationen können wir den Agenten anweisen, sie in ein strukturiertes Format zu bringen, und schon haben wir unsere Daten.
In diesem Beispiel haben wir nur zwei Tools verwendet, um die Scraping-Aufgabe zu erledigen. Der Bright Data Web MCP-Server bietet jedoch auch zusätzliche Tools im Pro-Modus, die Sie für fortgeschrittenere Anwendungsfälle nutzen können. Weitere Beispiele finden Sie in diesem ausführlichen Artikel.
Fazit
In diesem Artikel haben wir untersucht, wie MCP-Server zum Scrapen des Webs mit Hilfe von KI-Agenten verwendet werden können. Zunächst haben wir uns den Playwright MCP-Server angesehen, der einen Low-Level-Zugriff auf die Browser-Automatisierung bietet und Ihrem Agenten die volle Kontrolle über jede Interaktion gibt. Anschließend haben wir uns den Web MCP-Server von Bright Data angesehen, der auf einer höheren Ebene arbeitet und Ihren Agenten mit speziellen Tools ausstattet, die speziell für das Web-Scraping entwickelt wurden, sogar auf Websites, die durch Bot-Erkennung geschützt sind.
Beide Ansätze haben ihre Stärken. Playwright ist ideal, wenn Sie eine fein abgestufte Browserkontrolle benötigen, während Bright Data den Prozess vereinfacht, so dass Sie sich ausschließlich auf die Extraktion der benötigten Informationen konzentrieren können.
Jetzt sind Sie an der Reihe, mit beiden MCP-Servern zu experimentieren und zu entscheiden, welcher für Ihr nächstes Projekt am besten geeignet ist.






