

In diesem Leitfaden erfahren Sie:
- Was Third-Party Risk Management (TPRM) ist und warum manuelle Überprüfungen versagen
- Wie Sie einen autonomen KI-Agenten erstellen, der Anbieter auf negative Medienberichte überprüft
- Wie Sie die SERP-API und den Web Unlocker von Bright Data für eine zuverlässige und aktuelle Datenerfassung integrieren
- Wie Sie OpenHands SDK für die Erstellung von Agentenskripten und OpenAI für die Risikoanalyse verwenden
- Wie Sie den Agenten mit der Browser-API für komplexe Szenarien wie Gerichtsregister verbessern können
Legen wir los!
Das Problem bei der manuellen Lieferantenüberprüfung
Compliance-Teams in Unternehmen stehen vor einer unmöglichen Aufgabe: Sie müssen Hunderte von Drittanbietern im gesamten Web auf Risikosignale überwachen. Zu den traditionellen Ansätzen gehören:
- Manuelle Google-Suchen nach jedem Lieferantennamen in Kombination mit Schlüsselwörtern wie „Klage”, „Insolvenz” oder „Betrug”
- Paywalls und CAPTCHAs beim Versuch, auf Nachrichtenartikel und Gerichtsakten zuzugreifen
- Inkonsistente Dokumentation ohne standardisierten Prozess zur Erfassung der Ergebnisse
- Keine fortlaufende Überwachung, die Lieferantenüberprüfung findet einmalig bei der Aufnahme statt und dann nie wieder
Dieser Ansatz scheitert aus drei entscheidenden Gründen:
- Umfang: Ein einzelner Analyst kann pro Tag vielleicht 5 bis 10 Anbieter gründlich überprüfen
- Zugang: Geschützte Quellen wie Gerichtsregister und Premium-Nachrichtenseiten blockieren den automatisierten Zugriff
- Kontinuität: Punktuelle Bewertungen übersehen Risiken, die nach der Onboarding-Phase auftreten
Die Lösung: Ein autonomer TPRM-Agent
Ein TPRM-Agent automatisiert den gesamten Workflow der Lieferantenüberprüfung mithilfe von drei spezialisierten Ebenen:
- Erkennung (SERP-API): Der Agent durchsucht Google nach Warnsignalen wie Rechtsstreitigkeiten, behördlichen Maßnahmen und finanziellen Schwierigkeiten.
- Zugriff (Web Unlocker): Wenn relevante Ergebnisse hinter Paywalls oder CAPTCHAs liegen, umgeht der Agent diese Barrieren, um den vollständigen Inhalt zu extrahieren
- Aktion (OpenAI + OpenHands SDK): Der Agent analysiert den Inhalt mit OpenAI auf die Schwere des Risikos und verwendet dann OpenHands SDK, um Python-Überwachungsskripte zu generieren, die täglich nach neuen negativen Medienberichten suchen
Dieses System verwandelt stundenlange manuelle Recherchen in wenige Minuten automatisierter Analyse.
Voraussetzungen
Bevor Sie beginnen, stellen Sie sicher, dass Sie über Folgendes verfügen:
- Python 3.12 oder höher (erforderlich für OpenHands SDK)
- Ein Bright Data-Konto mit API-Zugriff (kostenlose Testversion verfügbar)
- Einen OpenAI-API-Schlüssel für die Risikoanalyse
- Ein OpenHands Cloud-Konto oder Ihren eigenen LLM-API-Schlüssel für die agentenbasierte Skripterstellung
- Grundkenntnisse in Python und REST-APIs
Projektarchitektur
Der TPRM-Agent folgt einer dreistufigen Pipeline:
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ ENTDECKUNG │────▶│ ZUGRIFF │────▶│ AKTION │
│ (SERP-API) │ │ (Web Unlocker) │ │ (OpenAI + SDK) │
└─────────────────┘ └─────────────────┘ └─────────────────┘
│ │ │
Google-Suche Paywalls umgehen Risiken analysieren
für Warnsignale und CAPTCHAs Skripte generierenErstellen Sie die folgende Projektstruktur:
tprm-agent/
├── src/
│ ├── __init__.py
│ ├── config.py # Konfiguration
│ ├── discovery.py # SERP-API-Integration
│ ├── access.py # Web Unlocker-Integration
│ ├── actions.py # OpenAI + OpenHands SDK
│ ├── agent.py # Hauptorchestrierung
│ └── browser.py # Browser-API (Erweiterung)
├── api/
│ └── main.py # FastAPI-Endpunkte
├── scripts/
│ └── generated/ # Automatisch generierte Überwachungsskripte
├── .env
├── requirements.txt
└── README.md
Einrichten der Umgebung
Erstellen Sie eine virtuelle Umgebung und installieren Sie die erforderlichen Abhängigkeiten:
python -m venv venv
source venv/bin/activate # Windows: venvScriptsactivate
pip install requests fastapi uvicorn python-dotenv pydantic openai beautifulsoup4 playwright openhands-sdk openhands-tools
Erstellen Sie eine .env -Datei, um Ihre API-Anmeldedaten zu speichern:
# Bright Data API-Token (für SERP-API)
BRIGHT_DATA_API_TOKEN=Ihr_API-Token
# Bright Data SERP-Zone
BRIGHT_DATA_SERP_ZONE=Ihr_SERP-Zonenname
# Bright Data Web Unlocker-Anmeldedaten
BRIGHT_DATA_CUSTOMER_ID=Ihre_Kunden-ID
BRIGHT_DATA_UNLOCKER_ZONE=Ihr_Unlocker-Zonenname
BRIGHT_DATA_UNLOCKER_PASSWORD=Ihr_Zonenpasswort
# OpenAI (für die Risikoanalyse)
OPENAI_API_KEY=Ihr_OpenAI-API-Schlüssel
# OpenHands (für die Generierung von Agentenskripten)
# OpenHands Cloud verwenden: openhands/claude-sonnet-4-5-20260929
# Oder eigene Version verwenden: anthropic/claude-sonnet-4-5-20260929
LLM_API_KEY=Ihr_LLM_API_Schlüssel
LLM_MODEL=openhands/claude-sonnet-4-5-20260929Bright Data-Konfiguration
Schritt 1: Erstellen Sie Ihr Bright Data-Konto
Registrieren Sie sich bei Bright Data und navigieren Sie zum Dashboard.
Schritt 2: Konfigurieren Sie die SERP-API-Zone
- Gehen Sie zu „Proxies & Scraping-Infrastruktur“
- Klicken Sie auf „Hinzufügen“ und wählen Sie „SERP-API“
- Benennen Sie Ihre Zone (z. B.
tprm_serp) - Kopieren Sie Ihren Zonennamen und notieren Sie sich Ihren API-Token unter „Einstellungen > API-Token“.
Die SERP-API gibt strukturierte Suchergebnisse von Google zurück, ohne blockiert zu werden. Fügen Sie brd_json=1 zu Ihrer Such-URL hinzu, um eine geparste JSON-Ausgabe zu erhalten.
Schritt 3: Web Unlocker-Zone konfigurieren
- Klicken Sie auf „Hinzufügen“ und wählen Sie „Web Unlocker“
- Benennen Sie Ihre Zone (z. B.
tprm_unlocker) - Kopieren Sie Ihre Zone-Anmeldedaten (Benutzername im Format:
brd-customer-CUSTOMER_ID-zone-ZONE_NAME).
Web Unlocker verarbeitet CAPTCHAs, Fingerprinting und IP-Rotation automatisch über einen Proxy-Endpunkt.
Aufbau der Discovery-Ebene (SERP-API)
Die Discovery-Ebene durchsucht Google mithilfe der SERP-API nach negativen Medienberichten über Anbieter. Erstellen Sie src/discovery.py:
import requests
from typing import Optional
from dataclasses import dataclass
from urllib.parse import quote_plus
from config import settings
@dataclass
class SearchResult:
title: str
url: str
snippet: str
source: str
class DiscoveryClient:
"""Suche nach negativen Medienberichten mit der Bright Data SERP-API (Direct API)."""
RISK_CATEGORIES = {
"litigation": ["Klage", "Rechtsstreit", "verklagt", "Gerichtsverfahren", "rechtliche Schritte"],
"financial": ["Insolvenz", "Zahlungsunfähigkeit", "Schulden", "finanzielle Schwierigkeiten", "Zahlungsausfall"],
„betrug“: [„betrug“, „betrug“, „untersuchung“, „anklage“, „skandal“],
„aufsichtsrechtlich“: [„verstoß“, „strafe“, „strafe“, „sanktionen“, „compliance“],
„operational”: [„Rückruf”, „Sicherheitsproblem”, „Lieferkette”, „Störung”],
}
def __init__(self):
self.api_url = „https://api.brightdata.com/request”
self.headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {settings.BRIGHT_DATA_API_TOKEN}",
}
def _build_queries(self, vendor_name: str, categories: Optional[list] = None) -> list[str]:
"""Erstellen Sie Suchanfragen für jede Risikokategorie."""
categories = categories or list(self.RISK_CATEGORIES.keys())
queries = []
for category in categories:
keywords = self.RISK_CATEGORIES.get(category, [])
keyword_str = " OR ".join(keywords)
query = f'"{vendor_name}" ({keyword_str})'
queries.append(query)
return queries
def search(self, query: str) -> list[SearchResult]:
"""Führen Sie eine einzelne Suchanfrage mit der Bright Data SERP-API aus."""
try:
# Erstelle eine Google-Such-URL mit brd_json=1 für geparstes JSON.
encoded_query = quote_plus(query)
google_url = f"https://www.google.com/search?q={encoded_query}&hl=en&gl=us&brd_json=1"
payload = {
"zone": settings.BRIGHT_DATA_SERP_ZONE,
"url": google_url,
"format": "raw",
}
response = requests.post(
self.api_url,
headers=self.headers,
json=payload,
timeout=30,
)
response.raise_for_status()
data = response.json()
results = []
organic = data.get("organic", [])
for item in organic:
results.append(
SearchResult(
title=item.get("title", ""),
url=item.get("link", ""),
snippet=item.get("description", ""),
source=item.get("displayed_link", ""),
)
)
return results
except Exception as e:
print(f"Suchfehler: {e}")
return []
def discover_adverse_media(
self,
vendor_name: str,
categories: Optional[list] = None,
) -> dict[str, list[SearchResult]]:
"""Suche nach negativen Medien in allen Risikokategorien."""
queries = self._build_queries(vendor_name, categories)
category_names = categories or list(self.RISK_CATEGORIES.keys())
categorized_results = {}
for category, query in zip(category_names, queries):
print(f" Suche: {category}...")
results = self.search(query)
categorized_results[category] = results
return categorized_results
def filter_relevant_results(
self, results: dict[str, list[SearchResult]], vendor_name: str
) -> dict[str, list[SearchResult]]:
"""Filter out irrelevant results."""
filtered = {}
vendor_lower = vendor_name.lower()
for category, items in results.items():
relevant = []
for item in items:
if (
vendor_lower in item.title.lower()
or vendor_lower in item.snippet.lower()
):
relevant.append(item)
filtered[category] = relevant
return filtered
Die SERP-API gibt strukturierte JSON-Daten mit organischen Ergebnissen zurück, wodurch Titel, URLs und Snippets für jedes Suchergebnis leicht zu parsen sind.
Aufbau der Zugriffsebene (Web Unlocker)
Wenn die Discovery-Ebene relevante URLs findet, ruft die Zugriffsebene den vollständigen Inhalt mithilfe der Web Unlocker API ab. Erstellen Sie src/access.py:
import requests
from bs4 import BeautifulSoup
from dataclasses import dataclass
from typing import Optional
from config import settings
@dataclass
class ExtractedContent:
url: str
title: str
text: str
publish_date: Optional[str]
author: Optional[str]
success: bool
error: Optional[str] = None
class AccessClient:
"""Zugriff auf geschützte Inhalte mit Bright Data Web Unlocker (API-basiert)."""
def __init__(self):
self.api_url = "https://api.brightdata.com/request"
self.headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {settings.BRIGHT_DATA_API_TOKEN}",
}
def fetch_url(self, url: str) -> ExtractedContent:
"""Inhalt von einer URL mithilfe der Web Unlocker API abrufen und extrahieren."""
try:
payload = {
"zone": settings.BRIGHT_DATA_UNLOCKER_ZONE,
"url": url,
"format": "raw",
}
response = requests.post(
self.api_url,
headers=self.headers,
json=payload,
timeout=60,
)
response.raise_for_status()
# Die Web Unlocker API gibt den HTML-Code direkt zurück.
html_content = response.text
content = self._extract_content(html_content, url)
return content
except requests.Timeout:
return ExtractedContent(
url=url,
title="",
text="",
publish_date=None,
author=None,
success=False,
error="Request timed out",
)
except Exception as e:
return ExtractedContent(
url=url,
title="",
text="",
publish_date=None,
author=None,
success=False,
error=str(e),
)
def _extract_content(self, html: str, url: str) -> ExtractedContent:
"""Artikelinhalt aus HTML extrahieren."""
soup = BeautifulSoup(html, "html.parser")
# Unerwünschte Elemente entfernen
for element in soup(["script", "style", "nav", "footer", "header", "aside"]):
element.decompose()
# Titel extrahieren
title = ""
if soup.title:
title = soup.title.string or ""
elif soup.find("h1"):
title = soup.find("h1").get_text(strip=True)
# Hauptinhalt extrahieren
article = soup.find("article") or soup.find("main") or soup.find("body")
text = article.get_text(separator="n", strip=True) if article else ""
# Textlänge begrenzen
text = text[:10000] if len(text) > 10000 else text
# Versuchen, das Veröffentlichungsdatum zu extrahieren
publish_date = None
date_meta = soup.find("meta", {"property": "article:published_time"})
if date_meta:
publish_date = date_meta.get("content")
# Versuch, den Autor zu extrahieren
author = None
author_meta = soup.find("meta", {"name": "author"})
if author_meta:
author = author_meta.get("content")
return ExtractedContent(
url=url,
title=title,
text=text,
publish_date=publish_date,
author=author,
success=True,
)
def fetch_multiple(self, urls: list[str]) -> list[ExtractedContent]:
"""Fetch multiple URLs sequentially."""
results = []
for url in urls:
print(f" Abrufen: {url[:60]}...")
content = self.fetch_url(url)
if not content.success:
print(f" Fehler: {content.error}")
results.append(content)
return results
Web Unlocker kümmert sich automatisch um CAPTCHAs, Browser-Fingerprinting und IP-Rotation. Es leitet Ihre Anfragen einfach über den Proxy weiter und kümmert sich um den Rest.
Aufbau der Aktionsebene (OpenAI + OpenHands SDK)
Die Aktionsschicht verwendet OpenAI zur Analyse der Risikostufe und OpenHands SDK zur Generierung von Überwachungsskripten, die die Bright Data Web Unlocker API verwenden. OpenHands SDK bietet agentenbasierte Funktionen: Der Agent kann Schlussfolgerungen ziehen, Dateien bearbeiten und Befehle ausführen, um produktionsreife Skripte zu erstellen.
Erstellen Sie src/actions.py:
import os
import json
from datetime import datetime, UTC
from dataclasses import dataclass, asdict
from openai import OpenAI
from pydantic import SecretStr
from openhands.sdk import LLM, Agent, Conversation, Tool
from openhands.tools.terminal import TerminalTool
from openhands.tools.file_editor import FileEditorTool
from config import settings
@dataclass
class RiskAssessment:
vendor_name: str
category: str
severity: str
summary: str
key_findings: list[str]
sources: list[str]
recommended_actions: list[str]
assessed_at: str
@dataclass
Klasse MonitoringScript:
vendor_name: str
script_path: str
urls_monitored: list[str]
check_frequency: str
created_at: str
Klasse ActionsClient:
"""Risiken mit OpenAI analysieren und Überwachungsskripte mit OpenHands SDK generieren."""
def __init__(self):
# OpenAI für die Risikoanalyse
self.openai_client = OpenAI(api_key=settings.OPENAI_API_KEY)
# OpenHands für die Generierung von agentenbasierten Skripten
self.llm = LLM(
model=settings.LLM_MODEL,
api_key=SecretStr(settings.LLM_API_KEY),
)
self.workspace = os.path.join(os.getcwd(), "scripts", "generated")
os.makedirs(self.workspace, exist_ok=True)
def analyze_risk(
self,
vendor_name: str,
category: str,
content: list[dict],
) -> RiskAssessment:
"""Analysiere den extrahierten Inhalt mit OpenAI hinsichtlich der Risikoschwere."""
content_summary = "nn".join(
[f"Quelle: {c['url']}nTitel: {c['title']}nInhalt: {c['text'][:2000]}" for c in content]
)
prompt = f"""Analysieren Sie den folgenden Inhalt zu „{vendor_name}” für die Risikobewertung durch Dritte.
Kategorie: {category}
Inhalt:
{content_summary}
Geben Sie eine JSON-Antwort mit folgenden Angaben:
{{
„severity”: „low|medium|high|critical”,
„summary”: „2–3 Sätze lange Zusammenfassung der Ergebnisse”,
„key_findings”: [„Ergebnis 1”, „Ergebnis 2”, ...],
„recommended_actions”: [„Maßnahme 1”, „Maßnahme 2”, ...]
}}
Zu beachten:
- Der Schweregrad sollte sich nach den potenziellen Auswirkungen auf das Geschäft richten.
- Kritisch = sofortiges Handeln erforderlich (aktiver Betrug, Insolvenzantrag)
- Hoch = erhebliches Risiko, das eine Untersuchung erfordert
- Mittel = bemerkenswerte Bedenken, die eine Überwachung rechtfertigen
- Gering = geringfügiges Problem oder historische Angelegenheit
"""
response = self.openai_client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}],
response_format={"type": "json_object"},
)
response_text = response.choices[0].message.content
try:
result = json.loads(response_text)
except (json.JSONDecodeError, ValueError):
result = {
"severity": "medium",
"summary": "Parsing der Risikobewertung ist nicht möglich",
"key_findings": [],
"recommended_actions": ["Manuelle Überprüfung erforderlich"],
}
return RiskAssessment(
vendor_name=vendor_name,
category=category,
severity=result.get("severity", "medium"),
summary=result.get("summary", ""),
key_findings=result.get("key_findings", []),
sources=[c["url"] for c in content],
recommended_actions=result.get("recommended_actions", []),
assessed_at=datetime.now(UTC).isoformat(),
)
def generate_monitoring_script(
self,
vendor_name: str,
urls: list[str],
check_keywords: list[str],
) -> MonitoringScript:
"""Generate a Python monitoring script using OpenHands SDK agent."""
script_name = f"monitor_{vendor_name.lower().replace(' ', '_')}.py"
script_path = os.path.join(self.workspace, script_name)
prompt = f"""Erstellen Sie ein Python-Überwachungsskript unter {script_path}, das:
1. Diese URLs täglich auf neue Inhalte überprüft: {urls[:5]}
2. nach diesen Schlüsselwörtern sucht: {check_keywords}
3. eine Warnung sendet (Ausgabe auf der Konsole), wenn neue relevante Inhalte gefunden werden
4. alle Überprüfungen in einer JSON-Datei namens „monitoring_log.json“ protokolliert
Das Skript MUSS die Bright Data Web Unlocker API verwenden, um Paywalls und CAPTCHAs zu umgehen:
- API-Endpunkt: https://api.brightdata.com/request
- Verwenden Sie die Umgebungsvariable BRIGHT_DATA_API_TOKEN für das Bearer-Token
- Verwenden Sie die Umgebungsvariable BRIGHT_DATA_UNLOCKER_ZONE für den Zonennamen
- Stellen Sie POST-Anfragen mit JSON-Nutzlast: {{"zone": "zone_name", "url": "target_url", "format": "raw"}}
- Fügen Sie den Header „Authorization”: „Bearer <token>” hinzu
- Fügen Sie den Header „Content-Type”: „application/json” hinzu
Das Skript sollte:
- Bright Data-Anmeldedaten aus Umgebungsvariablen mit python-dotenv laden
- Die Bright Data Web Unlocker API für alle HTTP-Anfragen verwenden (NICHT einfache requests.get)
- Fehler mit try/except elegant behandeln
- Eine main()-Funktion enthalten, die direkt ausgeführt werden kann
- Die Planung über cron unterstützen
- Inhalts-Hashes speichern, um Änderungen zu erkennen
Schreiben Sie das vollständige Skript in {script_path}.
"""
# OpenHands-Agent mit Terminal- und Datei-Editor-Tools erstellen
agent = Agent(
llm=self.llm,
tools=[
Tool(name=TerminalTool.name),
Tool(name=FileEditorTool.name),
],
)
# Agent ausführen, um das Skript zu generieren
conversation = Conversation(agent=agent, workspace=self.workspace)
conversation.send_message(prompt)
conversation.run()
return MonitoringScript(
vendor_name=vendor_name,
script_path=script_path,
urls_monitored=urls[:5],
check_frequency="daily",
created_at=datetime.now(UTC).isoformat(),
)
def export_assessment(self, assessment: RiskAssessment, output_path: str) -> None:
"""Risikobewertung in JSON-Datei exportieren."""
with open(output_path, "w") as f:
json.dump(asdict(assessment), f, indent=2)Der entscheidende Vorteil der Verwendung des OpenHands SDK gegenüber der einfachen promptbasierten Codegenerierung besteht darin, dass der Agent seine Arbeit iterieren, das Skript testen, Fehler beheben und verfeinern kann, bis es korrekt funktioniert.
Agenten-Orchestrierung
Nun wollen wir alles miteinander verbinden. Erstellen Sie src/agent.py:
from dataclasses import dataclass
from datetime import datetime, UTC
from typing import Optional
from discovery import DiscoveryClient, SearchResult
from access import AccessClient, ExtractedContent
from actions import ActionsClient, RiskAssessment, MonitoringScript
@dataclass
class InvestigationResult:
vendor_name: str
started_at: str
completed_at: str
total_sources_found: int
total_sources_accessed: int
risk_assessments: list[RiskAssessment]
monitoring_scripts: list[MonitoringScript]
errors: list[str]
Klasse TPRMAgent:
"""Autonomer Agent für Untersuchungen zum Risikomanagement von Drittanbietern."""
def __init__(self):
self.discovery = DiscoveryClient()
self.access = AccessClient()
self.actions = ActionsClient()
def investigate(
self,
vendor_name: str,
categories: Optional[list[str]] = None,
generate_monitors: bool = True,
) -> InvestigationResult:
"""Führt eine vollständige Lieferantenuntersuchung durch."""
started_at = datetime.now(UTC).isoformat()
errors = []
risk_assessments = []
monitoring_scripts = []
# Stufe 1: Entdeckung (SERP-API)
print(f"[Entdeckung] Suche nach negativen Medienberichten über {vendor_name}...")
try:
raw_results = self.discovery.discover_adverse_media(vendor_name, categories)
filtered_results = self.discovery.filter_relevant_results(raw_results, vendor_name)
except Exception as e:
errors.append(f"Discovery failed: {str(e)}")
return InvestigationResult(
vendor_name=vendor_name,
started_at=started_at,
completed_at=datetime.now(UTC).isoformat(),
total_sources_found=0,
total_sources_accessed=0,
risk_assessments=[],
monitoring_scripts=[],
errors=errors,
)
total_sources = sum(len(results) for results in filtered_results.values())
print(f"[Discovery] Found {total_sources} relevant sources")
# Stage 2: Access (Web Unlocker)
print(f"[Access] Extracting content from sources...")
all_urls = []
url_to_category = {}
for category, results in filtered_results.items():
for result in results:
all_urls.append(result.url)
url_to_category[result.url] = category
try:
extracted_content = self.access.fetch_multiple(all_urls)
successful_extractions = [c for c in extracted_content if c.success]
except Exception as e:
error_msg = f"Zugriff fehlgeschlagen: {str(e)}"
print(f"[Zugriff] {error_msg}")
errors.append(error_msg)
successful_extractions = []
print(f"[Zugriff] {len(successful_extractions)} Quellen erfolgreich extrahiert")
# Stufe 3: Aktion – Risiken analysieren (OpenAI)
print(f"[Aktion] Risiken werden analysiert...")
category_content = {}
for content in successful_extractions:
category = url_to_category.get(content.url, "unknown")
if category not in category_content:
category_content[category] = []
category_content[category].append({
"url": content.url,
"title": content.title,
"text": content.text,
})
for category, content_list in category_content.items():
if not content_list:
continue
try:
assessment = self.actions.analyze_risk(vendor_name, category, content_list)
risk_assessments.append(assessment)
except Exception as e:
errors.append(f"Risikoanalyse für {category} fehlgeschlagen: {str(e)}")
# Stufe 3: Aktion – Überwachungsskripte generieren
if generate_monitors and successful_extractions:
print(f"[Aktion] Überwachungsskripte werden generiert...")
try:
urls_to_monitor = [c.url for c in successful_extractions[:10]]
keywords = [vendor_name, "lawsuit", "bankruptcy", "fraud"]
script = self.actions.generate_monitoring_script(
vendor_name, urls_to_monitor, keywords
)
monitoring_scripts.append(script)
except Exception as e:
errors.append(f"Skripterstellung fehlgeschlagen: {str(e)}")
completed_at = datetime.now(UTC).isoformat()
print(f"[Abgeschlossen] Untersuchung abgeschlossen")
return InvestigationResult(
vendor_name=vendor_name,
started_at=started_at,
completed_at=completed_at,
total_sources_found=total_sources,
total_sources_accessed=len(successful_extractions),
risk_assessments=risk_assessments,
monitoring_scripts=monitoring_scripts,
errors=errors,
)
def main():
"""Beispiel für die Verwendung."""
agent = TPRMAgent()
result = agent.investigate("Acme Corp")
print(f"n{'='*50}")
print(f"Untersuchung abgeschlossen: {result.vendor_name}")
print(f"Gefundene Quellen: {result.total_sources_found}")
print(f"Aufgerufene Quellen: {result.total_sources_accessed}")
print(f"Risikobewertungen: {len(result.risk_assessments)}")
print(f"Überwachungsskripte: {len(result.monitoring_scripts)}")
für Bewertung in result.risk_assessments:
print(f"n[{assessment.category.upper()}] Schweregrad: {assessment.severity}")
print(f"Zusammenfassung: {assessment.summary}")
if __name__ == "__main__":
main()
Der Agent koordiniert alle drei Ebenen, behandelt Fehler elegant und erstellt ein umfassendes Untersuchungsergebnis.
Konfiguration
Erstellen Sie src/config.py, um alle Geheimnisse und Schlüssel einzurichten, die wir für die erfolgreiche Ausführung der Anwendung benötigen:
import os
from dotenv import load_dotenv
load_dotenv()
class Settings:
# SERP-API
BRIGHT_DATA_API_TOKEN: str = os.getenv("BRIGHT_DATA_API_TOKEN", "")
BRIGHT_DATA_SERP_ZONE: str = os.getenv("BRIGHT_DATA_SERP_ZONE", "")
# Web Unlocker
BRIGHT_DATA_CUSTOMER_ID: str = os.getenv("BRIGHT_DATA_CUSTOMER_ID", "")
BRIGHT_DATA_UNLOCKER_ZONE: str = os.getenv("BRIGHT_DATA_UNLOCKER_ZONE", "")
BRIGHT_DATA_UNLOCKER_PASSWORD: str = os.getenv("BRIGHT_DATA_UNLOCKER_PASSWORD", "")
# OpenAI (für die Risikoanalyse)
OPENAI_API_KEY: str = os.getenv("OPENAI_API_KEY", "")
# OpenHands (für die Generierung von Agentenskripten)
LLM_API_KEY: str = os.getenv("LLM_API_KEY", "")
LLM_MODEL: str = os.getenv("LLM_MODEL", "openhands/claude-sonnet-4-5-20260929")
settings = Settings()Erstellen der API-Schicht
Mit FastAPI erstellen Sie api/main.py, um den Agenten über REST-Endpunkte verfügbar zu machen:
from fastapi import FastAPI, HTTPException, BackgroundTasks
from pydantic import BaseModel
from typing import Optional
import uuid
import sys
sys.path.insert(0, 'src')
from agent import TPRMAgent, InvestigationResult
app = FastAPI(
title="TPRM Agent API",
description="Autonomous Third-Party Risk Management Agent",
version="1.0.0",)
investigations: dict[str, InvestigationResult] = {}
agent = TPRMAgent()
class InvestigationRequest(BaseModel):
vendor_name: str
categories: Optional[list[str]] = None
generate_monitors: bool = True
Klasse InvestigationResponse(BaseModel):
investigation_id: str
status: str
message: str
@app.post("/investigate", response_model=InvestigationResponse)
def start_investigation(
request: InvestigationRequest,
background_tasks: BackgroundTasks,
):
"""Start einer neuen Lieferantenuntersuchung."""
investigation_id = str(uuid.uuid4())
def run_investigation():
result = agent.investigate(
vendor_name=request.vendor_name,
categories=request.categories,
generate_monitors=request.generate_monitors,
)
investigations[investigation_id] = result
background_tasks.add_task(run_investigation)
return InvestigationResponse(
investigation_id=investigation_id,
status="started",
message=f"Investigation started for {request.vendor_name}",
)
@app.get("/investigate/{investigation_id}")
def get_investigation(investigation_id: str):
"""Untersuchungsergebnisse abrufen."""
if investigation_id not in investigations:
raise HTTPException(status_code=404, detail="Untersuchung nicht gefunden oder noch in Bearbeitung")
return investigations[investigation_id]
@app.get("/reports/{vendor_name}")
def get_reports(vendor_name: str):
"""Alle Berichte für einen Anbieter abrufen."""
vendor_reports = [
result
for result in investigations.values()
if result.vendor_name.lower() == vendor_name.lower()
]
if not vendor_reports:
raise HTTPException(status_code=404, detail="Keine Berichte für diesen Anbieter gefunden")
return vendor_reports
@app.get("/health")
def health_check():
"""Endpunkt für Gesundheitscheck."""
return {"status": "healthy"}Führen Sie die API lokal aus:
python -m uvicorn API.main:app --reloadBesuchen Sie http://localhost:8000/docs, um die interaktive API-Dokumentation zu erkunden.
Erweiterung mit Browser-API (Scraping-Browser)
Für komplexe Szenarien wie Gerichtsregister, die das Ausfüllen von Formularen erfordern, oder JavaScript-lastige Websites können Sie den Agenten mit der Browser-API (Scraping-Browser) von Bright Data erweitern. Sie können dies auf ähnliche Weise wie die Web Unlocker API und die SERP-API einrichten.
Die Browser-API bietet einen in der Cloud gehosteten Browser, den Sie über Playwright über das Chrome DevTools Protocol (CDP) steuern können. Dies ist nützlich für:
- Gerichtsregister-Suchen, die das Ausfüllen von Formularen und Navigation erfordern
- JavaScript-lastige Websites mit dynamischem Laden von Inhalten
- Mehrstufige Authentifizierungsabläufe
- Erfassen von Screenshots für Compliance-Dokumentation
Konfiguration
Fügen Sie Browser-API-Anmeldedaten zu Ihrer .env hinzu:
# Browser-API
BRIGHT_DATA_BROWSER_USER: str = os.getenv("BRIGHT_DATA_BROWSER_USER", "")
BRIGHT_DATA_BROWSER_PASSWORD: str = os.getenv("BRIGHT_DATA_BROWSER_PASSWORD", "")Browser-Client-Implementierung
Erstellen Sie src/browser.py:
import asyncio
from playwright.async_api import async_playwright
from dataclasses import dataclass
from typing import Optional
from config import settings
@dataclass
class BrowserContent:
url: str
title: str
text: str
screenshot_path: Optional[str]
success: bool
error: Optional[str] = None
class BrowserClient:
"""Zugriff auf dynamische Inhalte über die Bright Data Browser API (Scraping-Browser).
Verwenden Sie dies für:
- JavaScript-lastige Websites, die eine vollständige Darstellung erfordern
- Mehrstufige Formulare (z. B. Gerichtsregisterrecherchen)
- Websites, die Klicks, Scrollen oder Interaktion erfordern
- Erfassen von Screenshots für Compliance-Dokumentation
"""
def __init__(self):
# WebSocket-Endpunkt für CDP-Verbindung erstellen
auth = f"{settings.BRIGHT_DATA_BROWSER_USER}:{settings.BRIGHT_DATA_BROWSER_PASSWORD}"
self.endpoint_url = f"wss://{auth}@brd.superproxy.io:9222"
async def fetch_dynamic_page(
self,
url: str,
wait_for_selector: Optional[str] = None,
take_screenshot: bool = False,
screenshot_path: Optional[str] = None,
) -> BrowserContent:
"""Inhalt von einer dynamischen Seite mithilfe der Browser-API abrufen."""
async with async_playwright() as playwright:
try:
print(f"Verbindung zum Bright Data Scraping-Browser wird hergestellt...")
browser = await playwright.chromium.connect_over_cdp(self.endpoint_url)
try:
page = await browser.new_page()
print(f"Navigieren zu {url}...")
await page.goto(url, timeout=120000)
# Auf bestimmten Selektor warten, falls angegeben
if wait_for_selector:
await page.wait_for_selector(wait_for_selector, timeout=30000)
# Seiteninhalt abrufen
title = await page.title()
# Text extrahieren
text = await page.evaluate("() => document.body.innerText")
# Bei Bedarf Screenshot erstellen
if take_screenshot and screenshot_path:
await page.screenshot(path=screenshot_path, full_page=True)
return BrowserContent(
url=url,
title=title,
text=text[:10000],
screenshot_path=screenshot_path if take_screenshot else None,
success=True,
)
finally:
await browser.close()
except Exception as e:
return BrowserContent(
url=url,
title="",
text="",
screenshot_path=None,
success=False,
error=str(e),
)
async def fill_and_submit_form(
self,
url: str,
form_data: dict[str, str],
submit_selector: str,
result_selector: str,
) -> BrowserContent:
"""Formular ausfüllen und Ergebnisse abrufen – nützlich für Gerichtsregister."""
async with async_playwright() as playwright:
try:
browser = await playwright.chromium.connect_over_cdp(self.endpoint_url)
try:
page = await browser.new_page()
await page.goto(url, timeout=120000)
# Formularfelder ausfüllen
for selector, value in form_data.items():
await page.fill(selector, value)
# Formular absenden
await page.click(submit_selector)
# Auf Ergebnisse warten
await page.wait_for_selector(result_selector, timeout=30000)
title = await page.title()
text = await page.evaluate("() => document.body.innerText")
return BrowserContent(
url=url,
title=title,
text=text[:10000],
screenshot_path=None,
success=True,
)
finally:
await browser.close()
except Exception as e:
return BrowserContent(
url=url,
title="",
text="",
screenshot_path=None,
success=False,
error=str(e),
)
async def scroll_and_collect(
self,
url: str,
scroll_count: int = 5,
wait_between_scrolls: float = 1.0,
) -> BrowserContent:
"""Unendliche Scroll-Seiten verarbeiten."""
async with async_playwright() as playwright:
try:
browser = await playwright.chromium.connect_over_cdp(self.endpoint_url)
try:
page = await browser.new_page()
await page.goto(url, timeout=120000)
# Mehrmals nach unten scrollen
for i in range(scroll_count):
await page.evaluate("window.scrollTo(0, document.body.scrollHeight)")
await asyncio.sleep(wait_between_scrolls)
title = await page.title()
text = await page.evaluate("() => document.body.innerText")
return BrowserContent(
url=url,
title=title,
text=text[:10000],
screenshot_path=None,
success=True,
)
finally:
await browser.close()
except Exception as e:
return BrowserContent(
url=url,
title="",
text="",
screenshot_path=None,
success=False,
error=str(e),
)
# Beispiel für die Suche im Gerichtsregister
async def example_court_search():
client = BrowserClient()
# Beispiel: Suche in einem Gerichtsregister
result = await client.fill_and_submit_form(
url="https://example-court-registry.gov/search",
form_data={
"#party-name": "Acme Corp",
"#case-type": "civil",
},
submit_selector="#search-button",
result_selector=".search-results",
)
if result.success:
print(f"Gefundene Gerichtsakten: {result.text[:500]}")
else:
print(f"Fehler: {result.error}")
if __name__ == "__main__":
asyncio.run(example_court_search())Wann sollte man die Browser-API und wann den Web Unlocker verwenden?
| Szenario | Verwendung |
|---|---|
| Einfache HTTP-Anfragen | Web Unlocker |
| Statische HTML-Seiten | Web Unlocker |
| CAPTCHAs beim Laden | Web Unlocker |
| JavaScript-gerenderte Inhalte | Browser-API |
| Formularübermittlungen | Browser-API |
| Mehrstufige Navigation | Browser-API |
| Screenshots erforderlich | Browser-API |
Bereitstellung mit Railway
Ihr TPRM-Agent kann mit Railway oder Render in der Produktion bereitgestellt werden, die beide Python-Anwendungen mit größeren Abhängigkeiten unterstützen.
Railway ist die einfachste Option für die Bereitstellung von Python-Anwendungen mit umfangreichen Abhängigkeiten wie OpenHands SDK. Damit dies funktioniert, müssen Sie sich registrieren und ein Konto erstellen.
Schritt 1: Installieren Sie Railway CLI global
npm i -g @railway/cliSchritt 2: Fügen Sie eine Procfile -Datei hinzu.
Erstellen Sie im Stammordner Ihrer Anwendung eine neue Datei Procfile und fügen Sie den folgenden Inhalt hinzu. Diese dient als Konfigurations- oder Startbefehl für die Bereitstellung
web: uvicorn API.main:app --host 0.0.0.0 --port $PORTSchritt 3: Melden Sie sich an und initialisieren Sie Railway im Projektverzeichnis
railway login
railway initSchritt 4: Bereitstellen
railway up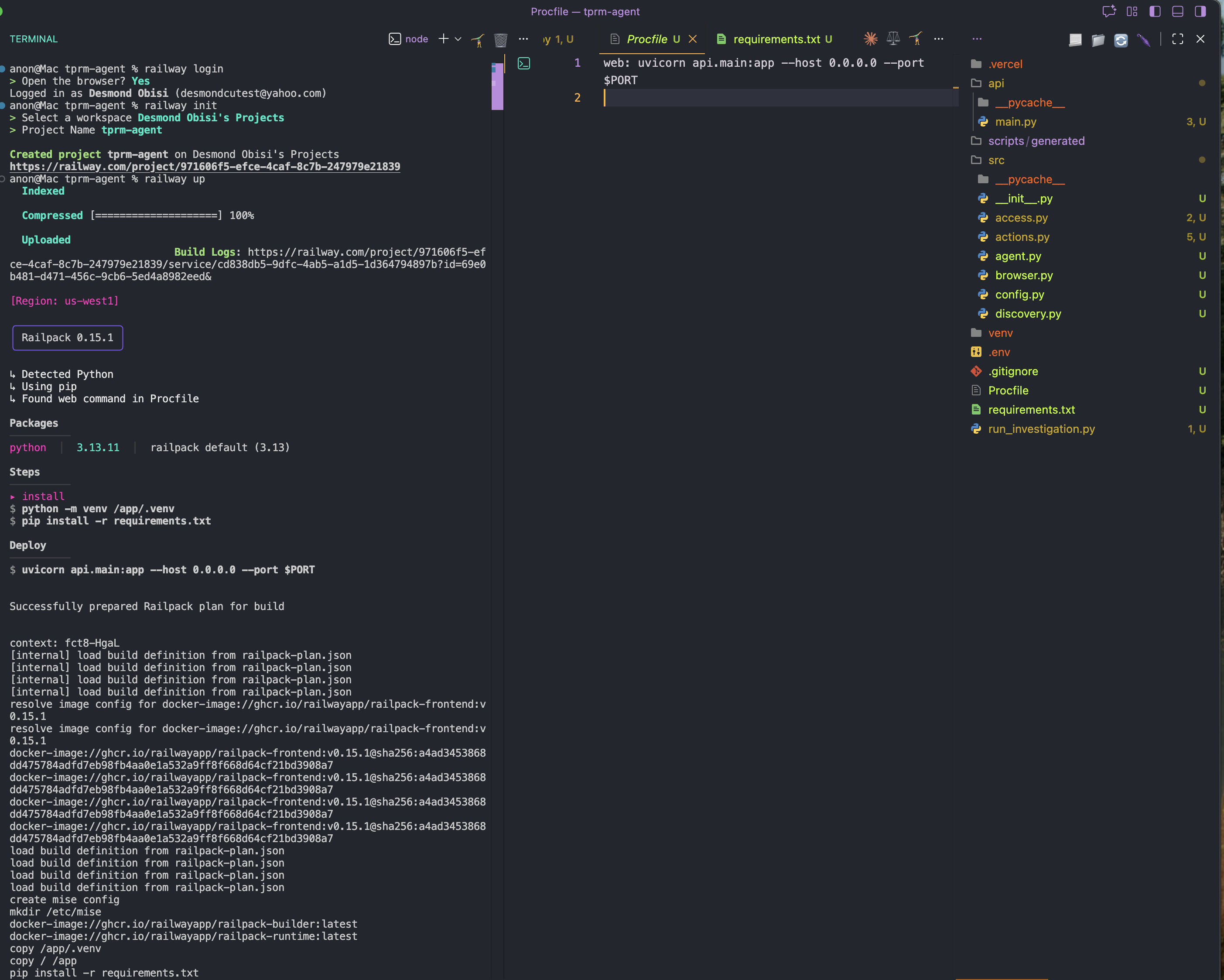
Schritt 5: Hinzufügen von Umgebungsvariablen
Gehen Sie zu Ihrem Railway-Projekt-Dashboard → Einstellungen → Gemeinsame Variablen und fügen Sie diese und ihre Werte wie unten gezeigt hinzu:
BRIGHT_DATA_API_TOKEN
BRIGHT_DATA_SERP_ZONE
BRIGHT_DATA_UNLOCKER_ZONE
OPENAI_API_KEY
LLM_API_KEY
LLM_MODEL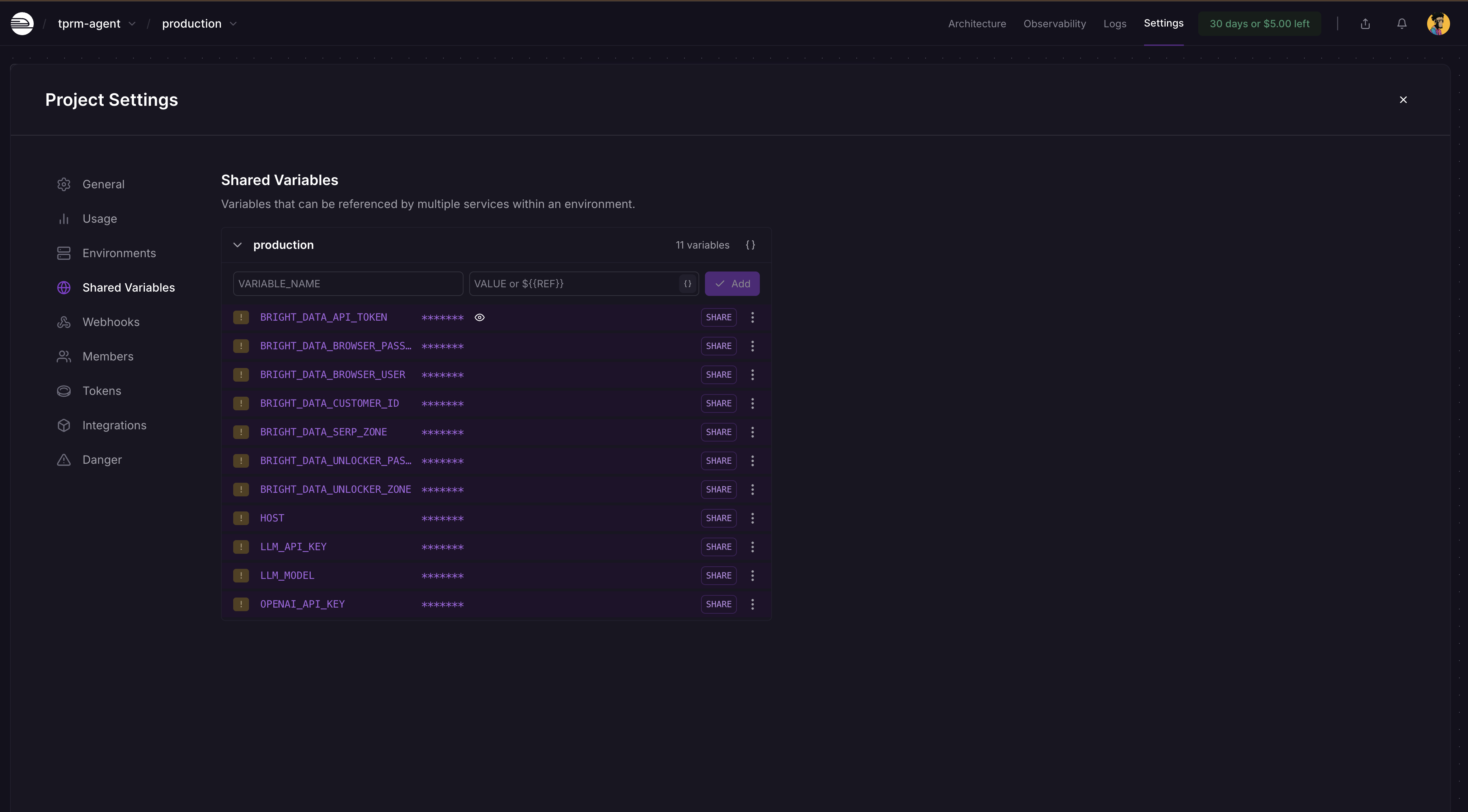
Railway erkennt Änderungen automatisch und fordert Sie im Dashboard auf, erneut zu implementieren. Klicken Sie auf „Implementieren“ und Ihre App wird mit den Geheimnissen aktualisiert.
Klicken Sie nach der erneuten Bereitstellung auf die Servicekarte und wählen Sie „Einstellungen“. Dort sehen Sie, wo Sie eine Domain generieren können, da der Dienst noch nicht öffentlich verfügbar ist. Klicken Sie auf „Domain generieren“, um Ihre öffentliche URL zu erhalten.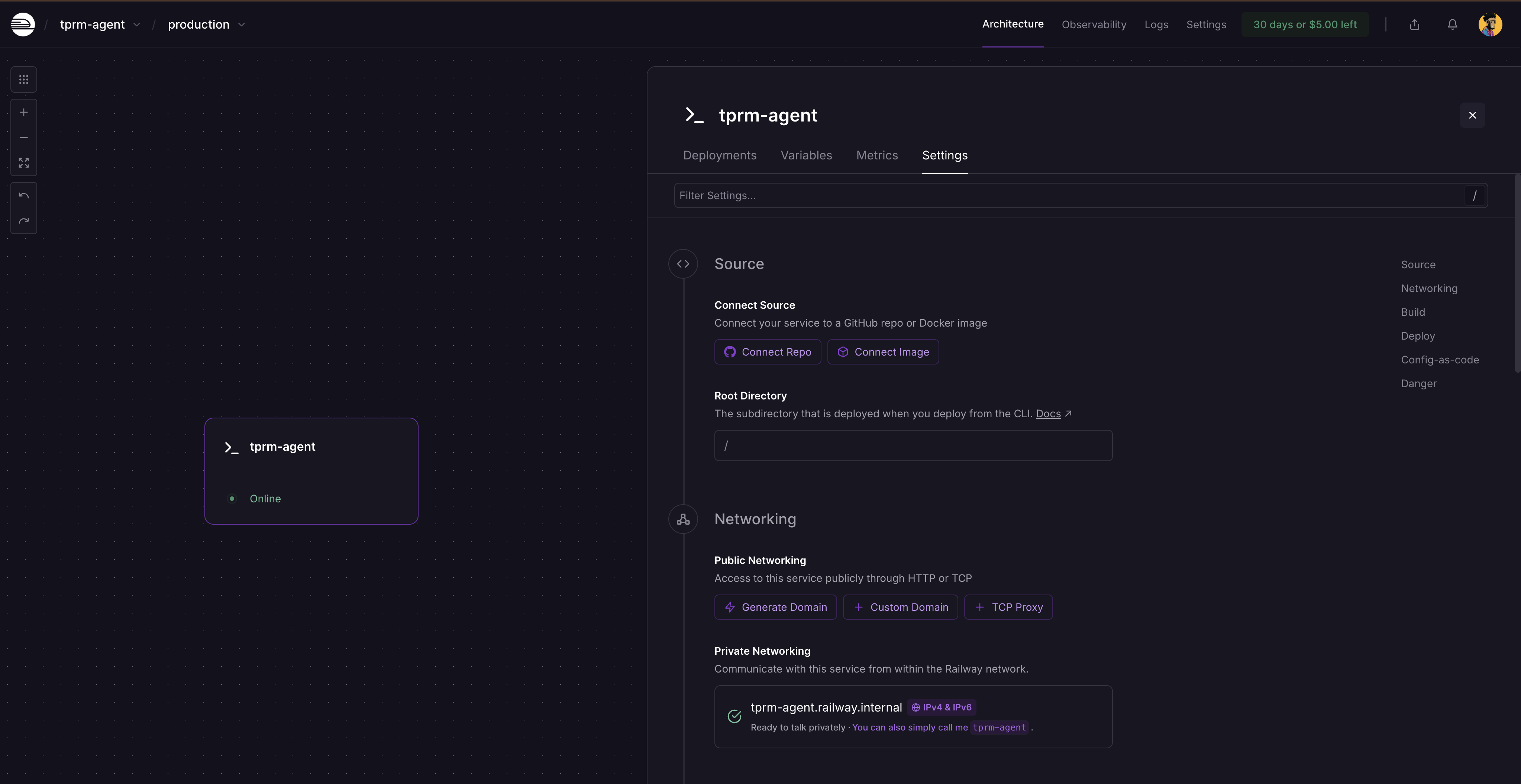
Durchführung einer vollständigen Untersuchung
Lokale Ausführung mit curl
Starten Sie den FastAPI-Server:
# Aktivieren Sie Ihre virtuelle Umgebung.
source venv/bin/activate # Unter Windows: venvScriptsactivate
# Starten Sie den Server.
python -m uvicorn api.main:app --reloadBesuchen Sie http://localhost:8000/docs, um die interaktive API-Dokumentation zu erkunden.
API-Anfragen stellen
- Starten Sie eine Untersuchung:
curl -X POST "http://localhost:8000/investigate"
-H "Content-Type: application/json"
-d '{
"vendor_name": "Acme Corp",
"categories": ["litigation", "fraud"],
"generate_monitors": true
}'- Dies gibt eine Untersuchungs-ID zurück:
{
"investigation_id": "f6af2e0f-991a-4cb7-949e-2f316e677b5c",
"status": "started",
"message": "Investigation started for Acme Corp"
}- Untersuchungsstatus überprüfen:
curl http://localhost:8000/investigate/f6af2e0f-991a-4cb7-949e-2f316e677b5cAusführen des Agenten als Skript
Erstellen Sie eine Datei namens run_investigation.py im Stammverzeichnis Ihres Projekts:
import sys
sys.path.insert(0, 'src')
from agent import TPRMAgent
def investigate_vendor():
"""Führen Sie eine vollständige Lieferantenuntersuchung durch."""
agent = TPRMAgent()
# Untersuchung ausführen
result = agent.investigate(
vendor_name="Acme Corp",
categories=["litigation", "financial", "fraud"],
generate_monitors=True,
)
# Zusammenfassung ausgeben
print(f"n{'='*60}")
print(f"Untersuchung abgeschlossen: {result.vendor_name}")
print(f"{'='*60}")
print(f"Gefundene Quellen: {result.total_sources_found}")
print(f"Aufgerufene Quellen: {result.total_sources_accessed}")
print(f"Risikobewertungen: {len(result.risk_assessments)}")
print(f"Überwachungsskripte: {len(result.monitoring_scripts)}")
# Risikobewertungen ausgeben
for assessment in result.risk_assessments:
print(f"n{'─'*60}")
print(f"[{assessment.category.upper()}] Schweregrad: {assessment.severity.upper()}")
print(f"{'─'*60}")
print(f"Zusammenfassung: {assessment.summary}")
print("nWichtigste Ergebnisse:")
for finding in assessment.key_findings:
print(f" • {finding}")
print("nEmpfohlene Maßnahmen:")
for action in assessment.recommended_actions:
print(f" → {action}")
# Informationen zum Überwachungsskript ausgeben
for script in result.monitoring_scripts:
print(f"n{'='*60}")
print(f"Generiertes Überwachungsskript")
print(f"{'='*60}")
print(f"Pfad: {script.script_path}")
print(f"Überwachung von {len(script.urls_monitored)} URLs")
print(f"Häufigkeit: {script.check_frequency}")
# Fehler ausgeben, falls vorhanden
if result.errors:
print(f"n{'='*60}")
print("Fehler:")
for error in result.errors:
print(f" ⚠️ {error}")
if __name__ == "__main__":
investigate_vendor()Führen Sie das Untersuchungsskript in einem neuen Terminal aus
# Virtuelle Umgebung aktivieren
source venv/bin/activate # Unter Windows: venvScriptsactivate
# Untersuchungsskript ausführen
python run_investigation.pyDer Agent wird:
- Mit der SERP-API bei Google nach negativen Medienberichten suchen
- Greift über Web Unlocker auf Quellen zu
- Analysiert Inhalte mithilfe von OpenAI auf Risikograd
- Erstellt mit OpenHands SDK ein Python-Überwachungsskript, das über cron geplant werden kann
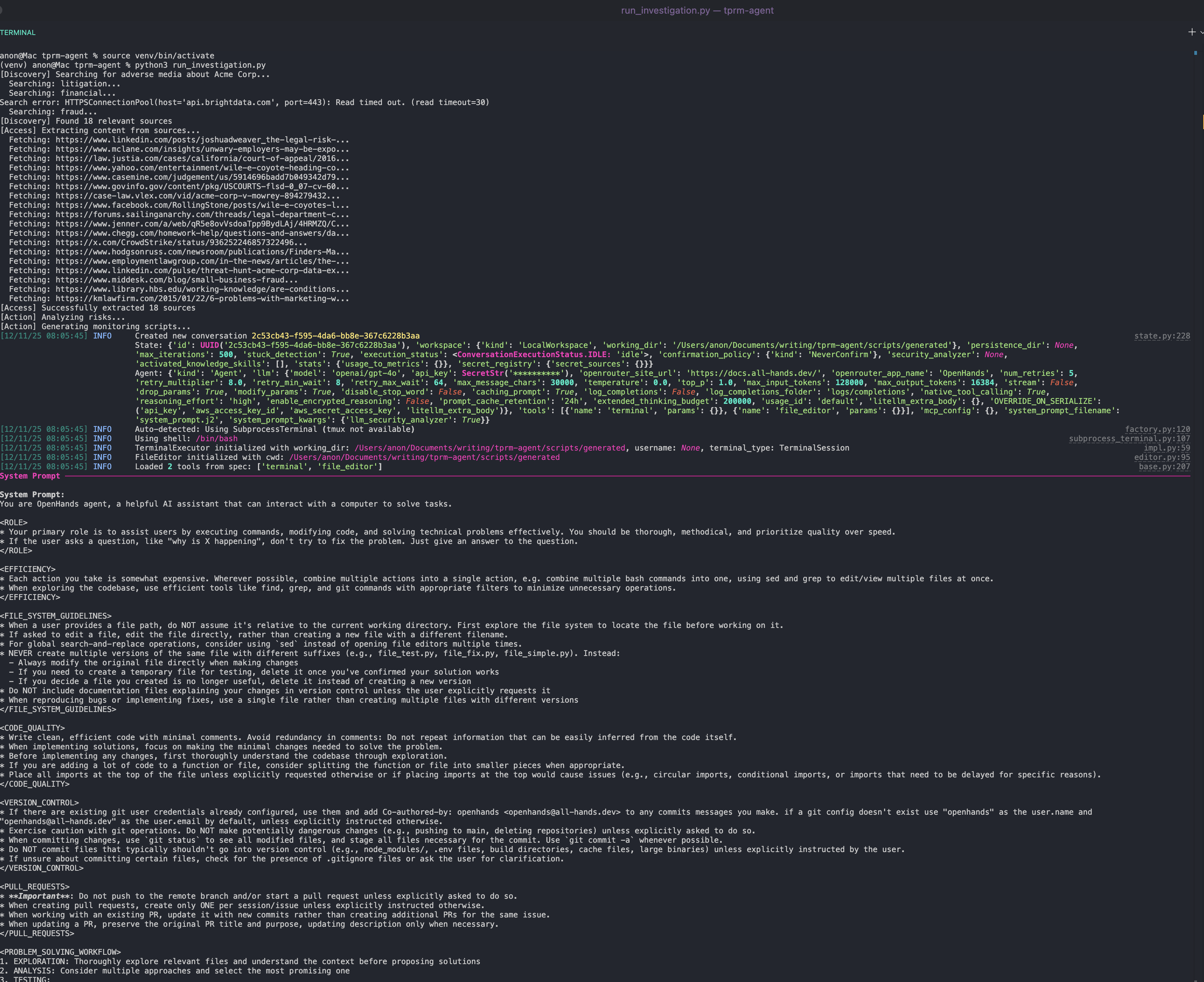
Ausführen des automatisch generierten Überwachungsskripts
Nach Abschluss einer Untersuchung finden Sie ein Überwachungsskript im Ordner „scripts/generated “:
cd scripts/generated
python monitor_acme_corp.pyDas Überwachungsskript verwendet die Bright Data Web Unlocker API, um alle überwachten URLs zu überprüfen, und gibt Folgendes aus: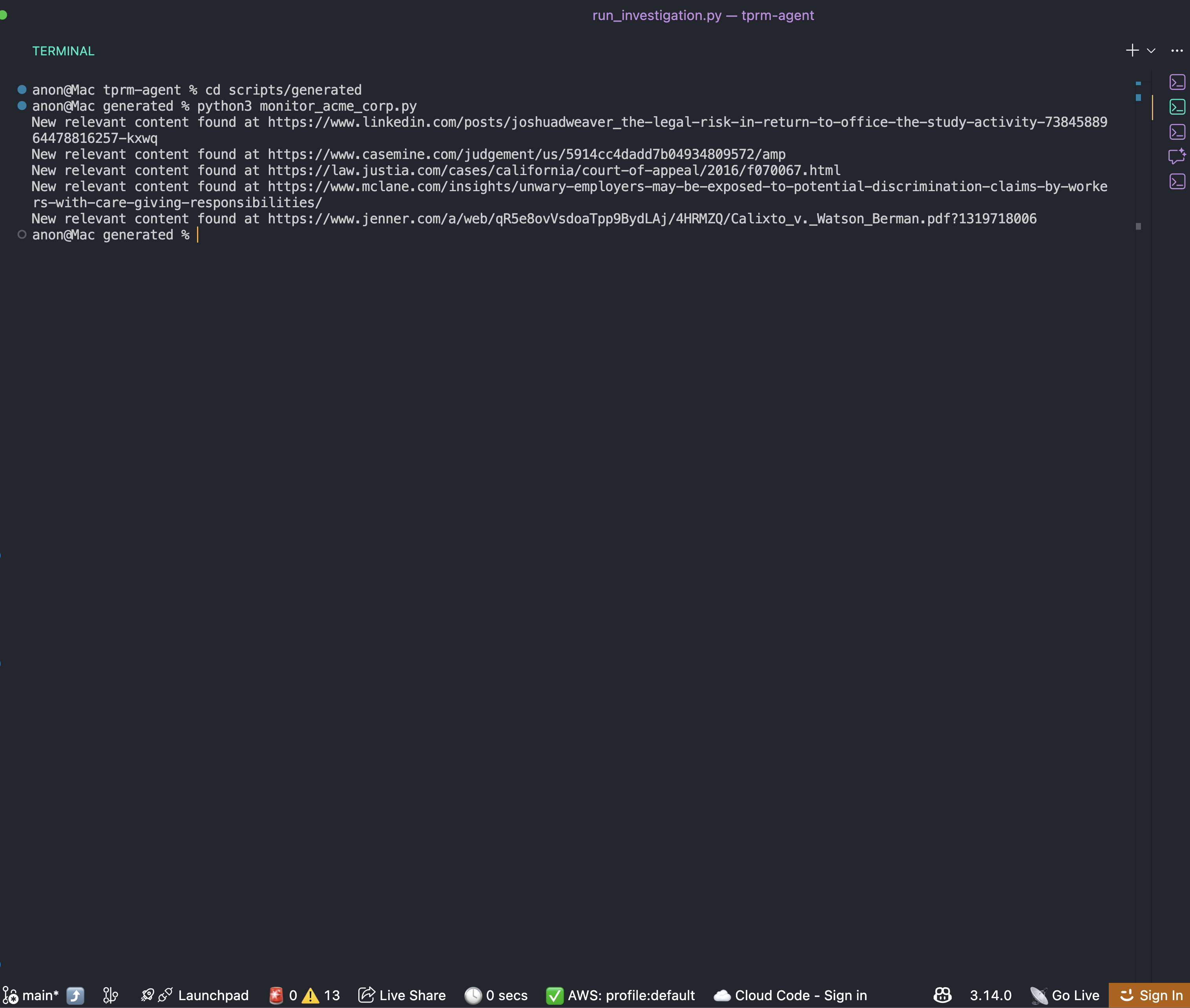
Sie können nun einen Cron-Zeitplan für das Skript einrichten, um stets die richtigen und aktuellen Informationen über das Unternehmen zu erhalten.
Zusammenfassung
Sie verfügen nun über ein vollständiges Framework für die Erstellung eines TPRM-Agenten für Unternehmen, der die Untersuchung negativer Medienberichte über Lieferanten automatisiert. Dieses System:
- Erkennt Risikosignale in mehreren Kategorien mithilfe der Bright Data SERP-API
- Greift mithilfe von Bright Data Web Unlockerauf Inhaltezu
- analysiert Risiken mithilfe von OpenAI und generiert Überwachungsskripte mithilfe von OpenHands SDK
- Erweitert die Funktionen mit Browser API für komplexe Szenarien
Die modulare Architektur erleichtert die Erweiterung:
- Fügen Sie neue Risikokategorien hinzu, indem Sie das
RISK_CATEGORIES-Wörterbuch aktualisieren - Integration in Ihre GRC-Plattform durch Erweiterung der API-Ebene
- Skalieren Sie auf Tausende von Anbietern mithilfe von Hintergrund-Aufgabenwarteschlangen
- Fügen Sie mithilfe der Browser-API-Erweiterung Gerichtsregister-Suchen hinzu
Nächste Schritte
Um diesen Agenten weiter zu verbessern, sollten Sie Folgendes in Betracht ziehen:
- Integration zusätzlicher Datenquellen: SEC-Einreichungen, OFAC-Sanktionslisten, Unternehmensregister
- Hinzufügen von Datenbankpersistenz: Speichern Sie den Untersuchungsverlauf in PostgreSQL oder MongoDB
- Implementierung von Webhook-Benachrichtigungen: Benachrichtigung von Slack oder Teams, wenn risikoreiche Anbieter erkannt werden
- Erstellen eines Dashboards: Erstellen Sie ein React-Frontend, um die Risikobewertungen von Anbietern zu visualisieren
- Planung automatisierter Scans: Verwenden Sie Celery oder APScheduler für die regelmäßige Überwachung von Anbietern




