

In diesem Artikel erfahren Sie:
- Was Microsoft TaskWeaver ist und was es so einzigartig macht.
- Warum Sie durch die Erweiterung von TaskWeaver mit Bright Data-Diensten die Einschränkungen von LLM überwinden können.
- Wie Sie Bright Data über ein benutzerdefiniertes Plugin in TaskWeaver integrieren können.
Lassen Sie uns eintauchen!
Was ist Microsoft TaskWeaver?
Microsoft TaskWeaver ist ein Open-Source-Agenten-Framework, das Anfragen in natürlicher Sprache in ausführbaren Python-Code umwandelt. Sein oberstes Ziel ist es, KI-Agenten zu unterstützen, die komplexe Aufgaben selbstständig planen und ausführen.
Diese Technologie funktioniert, indem sie Ihre Eingabe in umsetzbare Schritte zerlegt. Anschließend wählt sie die geeigneten Plugins aus, um das Ziel zu erreichen, generiert Python-Code zur Ausführung des Plans, führt den Code in einer sicheren Umgebung aus und gibt die Ergebnisse zurück.
TaskWeaver ist Open Source und hat auf GitHub über 6.000 Sterne erhalten. Zu den wichtigsten Funktionen, die es von anderen Produkten unterscheiden, gehören:
- Code-First-Ansatz: Wandelt Benutzeranfragen in Python-Code um und gibt Agenten die Möglichkeit, Lösungen direkt zu generieren und auszuführen.
- Plugin-Ökosystem: Unterstützt spezielle Aufgaben durch Plugins, wodurch das Framework hochgradig erweiterbar ist.
- Umfangreiche Datenverarbeitung: Arbeitet nativ mit Python-Datenstrukturen wie DataFrames und eröffnet damit Möglichkeiten für erweiterte Datenanalysen.
- Domänenanpassung: Integriert domänenspezifisches Wissen für präzisere Ergebnisse.
- Zustandsbehaftete und reflektierende Ausführung: Behält den Kontext bei und kann die eigene Codeausführung reflektieren, um sich selbst zu korrigieren.
- Sicher und offen: Führt Code in einer sicheren Umgebung aus und bietet gleichzeitig eine Open-Source-Lösung, die sofort einsatzbereit ist.
Weitere Informationen finden Sie in der offiziellen Dokumentation.
Warum TaskWeaver um Funktionen zum Abrufen von Webdaten erweitert werden sollte
LLMs sind von Natur aus durch die Daten begrenzt, mit denen sie trainiert wurden. Sie können zwar Text, Code oder Multimedia-Inhalte generieren, aber die Ausgabe basiert immer auf ihrem veralteten Wissen. Außerdem können sie nicht wie ein menschlicher Benutzer mit Live-Webseiten interagieren. Dies sind die beiden Hauptbeschränkungen aktueller KI-Modelle.
TaskWeaver überwindet diese Einschränkungen, indem es Agenten die Integration mit benutzerdefinierten Plugins ermöglicht. Plugins können als Spezialwerkzeuge betrachtet werden, mit denen das LLM Aufgaben ausführen kann, die über seine integrierten Funktionen hinausgehen, wodurch sein Anwendungsbereich und sein praktischer Nutzen effektiv erweitert werden.
Durch den Aufruf dieser Plugins kann der von einem TaskWeaver-Agenten generierte Code mit externen Umgebungen interagieren und komplexe Operationen ausführen. Bright Data bietet beispielsweise eine Reihe leistungsstarker Tools:
- Web Unlocker API: Scrapen Sie jede Website mit einer einzigen Anfrage und erhalten Sie sauberes HTML oder Markdown, mit automatisierter Handhabung von Proxys, Entsperrungen, Headern und CAPTCHAs.
- SERP-API: Sammeln Sie Suchmaschinenergebnisse von Google, Bing und anderen in großem Umfang, ohne sich um Blockierungen sorgen zu müssen.
- Web-Scraping-APIs: Rufen Sie strukturierte, geparste Daten von bekannten Websites wie Amazon, Instagram, LinkedIn, Yahoo Finance und anderen ab.
- Und andere Bright Data-Lösungen…
Mit Zugriff auf Plugins, die eine Verbindung zu solchen Diensten herstellen, kann ein TaskWeaver-Agent das Web durchsuchen, Inhalte extrahieren und strukturierte Daten in Echtzeit von beliebten Domains abrufen. Dadurch kann die KI komplexe, unternehmensgerechte Workflows verarbeiten, die weit über das hinausgehen, was ein Standard-LLM allein leisten könnte.
So integrieren Sie Bright Data über ein benutzerdefiniertes Plugin in TaskWeaver
In diesem Tutorial-Abschnitt erfahren Sie, wie Sie einen TaskWeaver-Agenten mit Bright Data für die Abfrage von Webdaten integrieren können.
Insbesondere erfahren Sie, wie Sie eine TaskWeaver-Anwendung mit einem benutzerdefinierten Tool erweitern können, das eine Verbindung zur Bright Data Web Unlocker API herstellt. Auf diese Weise kann Ihr Code-First-Agent Daten von jeder Webseite im Internet abrufen und entsprechend Ihren Anforderungen verarbeiten.
Hinweis: Eine ähnliche Vorgehensweise finden Sie in unserem Integrationsleitfaden für smoleagents, einen weiteren Code-First-Agenten mit KI-Technologie.
Befolgen Sie die nachstehenden Anweisungen sorgfältig!
Voraussetzungen
Um dieses Tutorial durchzuführen, benötigen Sie:
- Python 3.10 oder höher lokal installiert: Erforderlich, um TaskWeaver und seine Plugins auszuführen.
- Git lokal installiert: Notwendig, um das TaskWeaver-Repository von GitHub zu klonen.
- Der Docker-Daemon muss ausgeführt werden: Muss ausgeführt werden, um Fehler bei der Codeüberprüfungsfunktion (die optional ist) zu vermeiden.
- Einen OpenAI-API-Schlüssel (oder den API-Schlüssel eines anderen unterstützten LLMs).
Um mit Bright Data arbeiten zu können, benötigen Sie außerdem:
- Ein Bright Data-Konto mit einem API-Schlüssel.
- Eine in Ihrem Konto konfigurierte Web Unlocker-Zone.
Machen Sie sich noch keine Gedanken über die Konfiguration von Bright Data, da dies in einem eigenen Schritt behandelt wird.
Schritt 1: Erstellen Sie ein Microsoft TaskWeaver-Projekt
Erstellen Sie zunächst einen Projektordner für Ihr TaskWeaver-Projekt und navigieren Sie im Terminal dorthin:
mkdir taskweaver-bright-data-example
cd taskweaver-bright-data-exampleErstellen Sie innerhalb des Projektordners eine virtuelle Umgebung:
python -m venv .venvAktivieren Sie diese anschließend. Führen Sie unter Linux/macOS folgenden Befehl aus:
source .venv/bin/activateAlternativ können Sie unter Windows folgenden Befehl ausführen:
.venvScriptsactivateInstallieren Sie nun TaskWeaver mit den folgenden Befehlen:
git clone https://github.com/microsoft/TaskWeaver.git
cd TaskWeaver
pip install -r requirements.txtDadurch wird TaskWeaver/ in Ihren Projektordner geklont und alle Abhängigkeiten werden in der virtuellen Umgebung installiert, die Sie gerade mit pip erstellt haben.
TaskWeaver läuft als Prozess und benötigt ein Projektverzeichnis zum Speichern von Plugins, Konfigurationsdateien und Sitzungsdaten. Das soeben geklonte Repository enthält ein Beispielprojekt im Verzeichnis TaskWeaver/project/: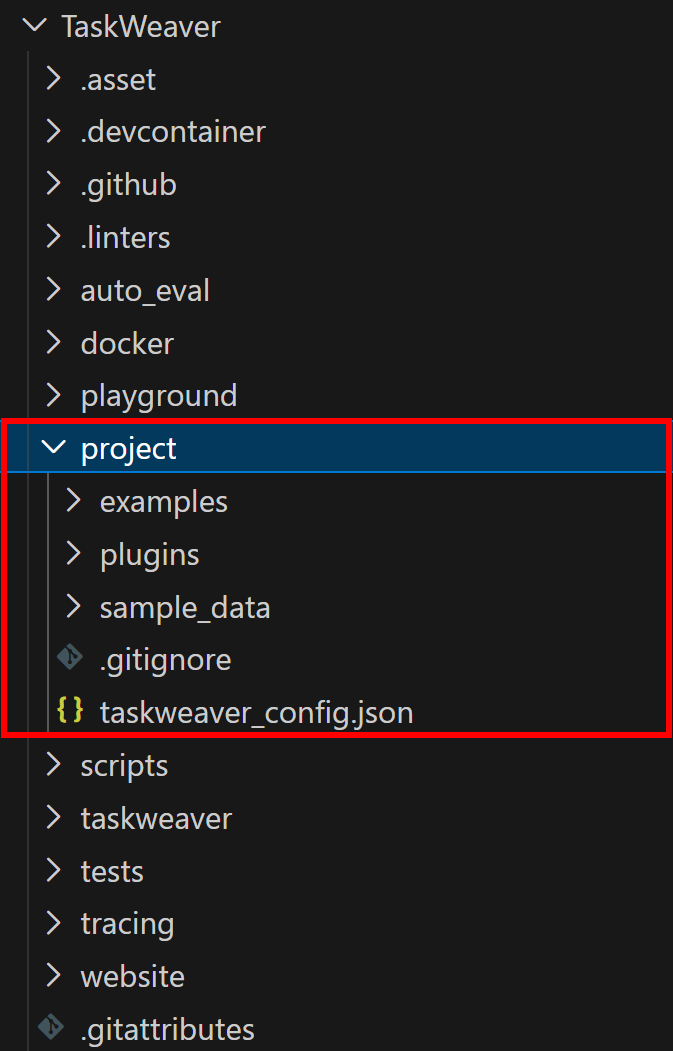
Kopieren Sie den Inhalt des Projektordners in Ihren Arbeitsbereich. Danach sollte Ihr Ordner taskweaver-bright-data-example/ wie folgt aussehen:
taskweaver-bright-data-example/
├─ .venv/
├─ TaskWeaver/
├─ plugins/ # Ordner zum Speichern Ihrer Plugins
├─ examples/
│ ├─ planner_examples/ # Beispiel-Planerskripte
│ └─ code_generator_examples/ # Beispiel-Codegeneratorskripte
├─ sample_data/ # Optionale Beispieldatensätze
├─ .gitignore
└─ taskweaver_config.json # ProjektkonfigurationsdateiInsbesondere enthält ein typisches Microsoft TaskWeaver-Projektverzeichnis bestimmte Ordner und Dateien, wie in der offiziellen Dokumentation beschrieben.
Laden Sie taskweaver-bright-data-example/ in Ihre bevorzugte Python-IDE, z. B. Visual Studio Code oder PyCharm.
Starten Sie die Anwendung bei aktiver virtueller Umgebung, während Sie sich noch im Ordner /TaskWeaver befinden, mit:
python -m taskweaverDadurch wird der TaskWeaver-Prozess aus dem Ordner /TaskWeaver gestartet, der die Projektdateien und das Verzeichnis aus dem Ordner taskweaver-bright-data-example/ lädt.
Wenn alles funktioniert, sollte Folgendes in Ihrem Terminal angezeigt werden:
Erfolgreich! Microsoft TaskWeaver funktioniert. Nach dem ersten Ausführen der Anwendung werden die folgenden Ordner erstellt:
workspace/: Speichert Sitzungsdaten für Ihr Projekt.logs/: Speichert vom Programm generierte Protokolldateien.
Hinweis: Wenn Sie jetzt versuchen, eine Eingabeaufforderung einzugeben, schlägt dies fehl, da Sie noch eine Verbindung zu einem LLM konfigurieren müssen. Dies wird im nächsten Schritt behandelt.
Schritt 2: Konfigurieren Sie das LLM in TaskWeaver
TaskWeaver unterstützt eine Vielzahl von LLMs. In diesem Tutorial integrieren wir ein OpenAI-Modell, aber Sie können die Anweisungen leicht an jeden anderen unterstützten LLM-Anbieter anpassen.
Um das GPT-4.1-Mini-Modell in TaskWeaver zu konfigurieren, stellen Sie sicher, dass Ihre Datei taskweaver_config.json in taskweaver-bright-data-example/ Folgendes enthält:
{
"llm.api_key": "<YOUR_OPENAI_API_KEY>",
"llm.model": "gpt-4.1-mini"
}Ersetzen Sie <IHR_OPENAI_API_SCHLÜSSEL> durch Ihren tatsächlichen OpenAI-API-Schlüssel.
Hinweis: Zum Zeitpunkt der Erstellung dieses Artikels unterstützt TaskWeaver keine GPT-5-Modelle. Wenn Sie versuchen, ein GPT-5-Modell zu konfigurieren, wird die folgende Fehlermeldung angezeigt:
{'error': {'message': "Nicht unterstützter Parameter: 'max_tokens' wird von diesem Modell nicht unterstützt. Verwenden Sie stattdessen 'max_completion_tokens'.", 'type': 'invalid_request_error', 'param': 'max_tokens', 'code': 'unsupported_parameter'}}Fantastisch! Ihr TaskWeaver-Projekt wird nun vom OpenAI GPT-4.1-Mini-Modell unterstützt und ist bereit, Eingaben zu verarbeiten.
Schritt 3: Richten Sie eine Bright Data Web Unlocker API-Zone ein
Um Ihren TaskWeaver-Agenten mit Bright Data für Web-Scraping-Funktionen zu verbinden, müssen Sie zunächst einige vorbereitende Schritte durchführen. Im Einzelnen müssen Sie Ihr Bright Data-Konto vorbereiten, indem Sie eine Web Unlocker-Zone konfigurieren.
Wenn Sie noch kein Konto haben, erstellen Sie ein Bright Data-Konto. Andernfalls melden Sie sich einfach an. Sobald Sie in Ihrem Konto sind, navigieren Sie zur Seite „Proxies & Scraping”. Suchen Sie im Abschnitt „My Zones” in der Tabelle nach einer Zeile mit der Bezeichnung „Web Unlocker API”: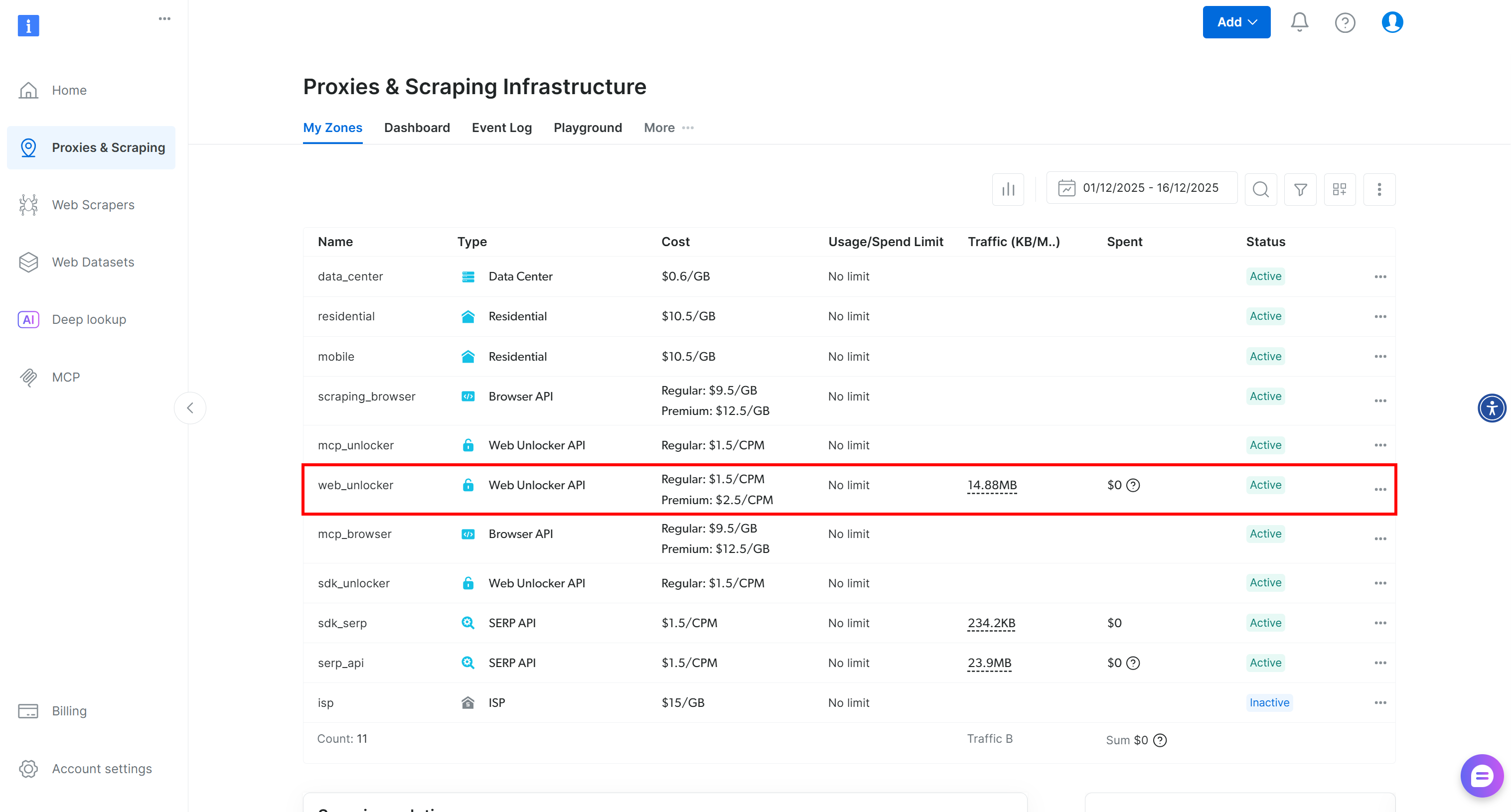
Wenn Sie keine Zeile mit der Bezeichnung „Web Unlocker API“ sehen, bedeutet dies, dass eine solche Zone in Ihrem Bright Data-Konto noch nicht eingerichtet wurde. Um eine solche Zone zu erstellen, scrollen Sie nach unten zum Abschnitt „Unlocker API“ und klicken Sie auf „Zone erstellen“, um eine hinzuzufügen: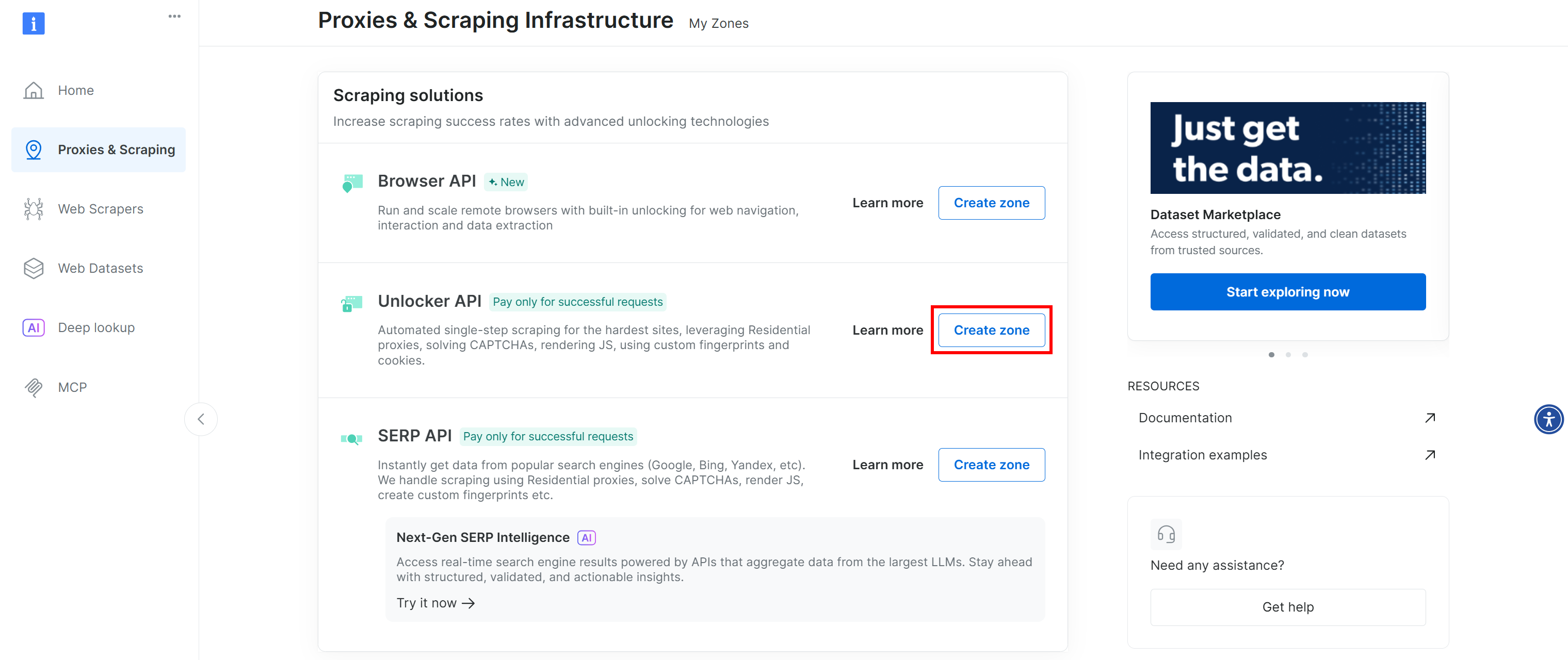
Erstellen Sie eine Web Unlocker API-Zone und geben Sie ihr einen Namen, z. B. web_unlocker (oder einen beliebigen anderen Namen). Merken Sie sich den Namen der Zone, da Sie ihn benötigen, um über die API in einem benutzerdefinierten Plugin auf den Dienst zuzugreifen.
Stellen Sie auf der Seite der Web Unlocker-Zone sicher, dass der Schalter auf „Active“ (Aktiv) steht, um zu bestätigen, dass die Zone aktiviert ist.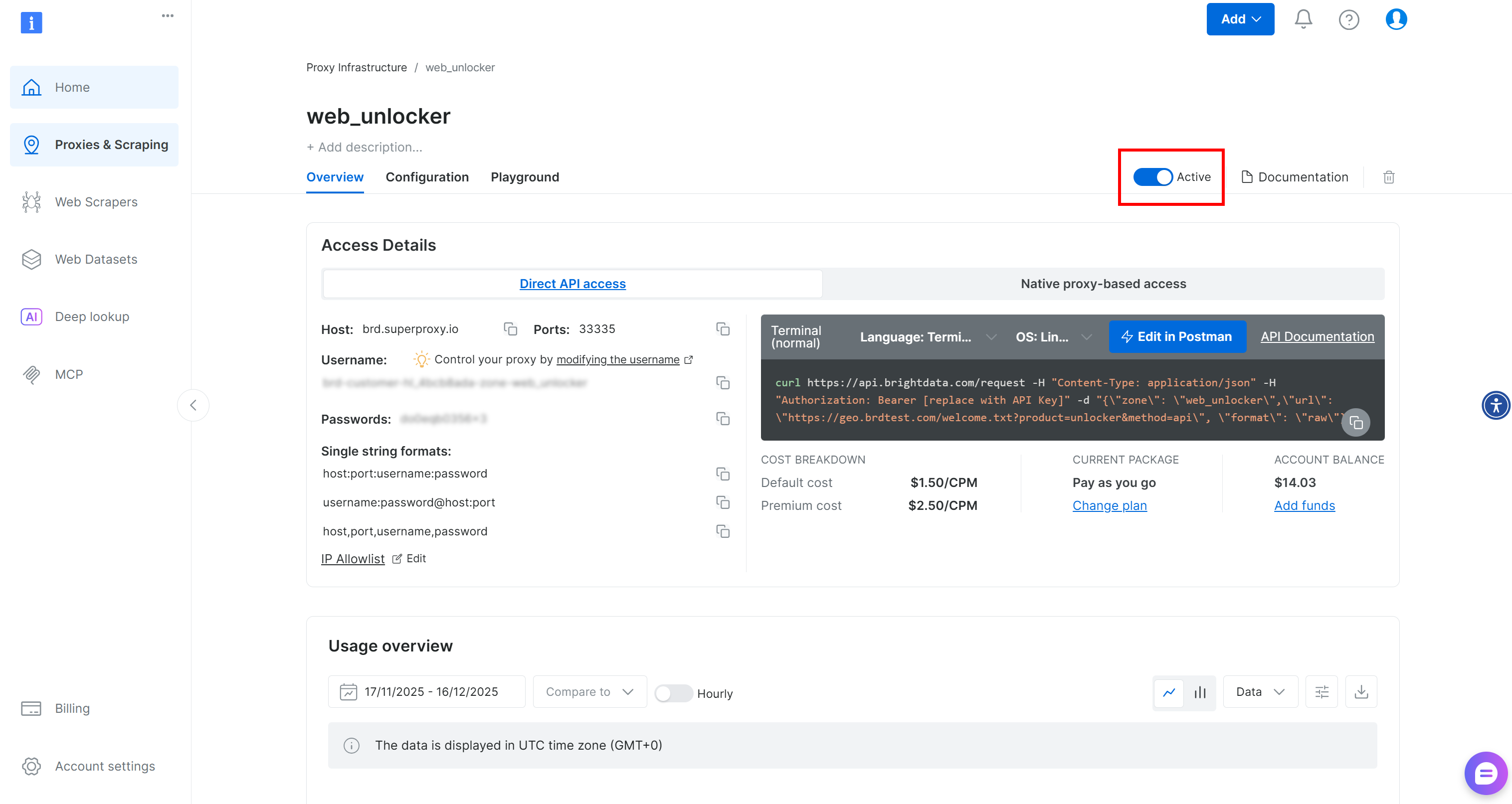
Befolgen Sie abschließend die offizielle Anleitung, um Ihren Bright Data API-Schlüssel zu generieren. Bewahren Sie ihn sicher auf, da Sie ihn in Kürze benötigen werden.
Großartig! Sie haben nun alles eingerichtet, um das Web Unlocker API-Plugin von Bright Data in Ihrer TaskWeaver-Anwendung zu verwenden.
Schritt 4: Definieren Sie das TaskWeaver Web Unlocker-Plugin für die Bright Data-Integration
Plugins sind Einheiten, die vom Code-Interpreter von TaskWeaver orchestriert werden können. Genauer gesagt ist jedes Plugin eine Python-Funktion, die innerhalb des generierten Codes aufgerufen werden kann.
In TaskWeaver umfasst ein Plugin zwei Dateien:
- Plugin-Implementierung: Eine Python-Datei, die das Plugin definiert.
- Plugin-Schema: Eine YAML-Datei, die die Eingaben, Ausgaben und Metadaten des Plugins definiert.
Beide Dateien sollten im Unterordner „plugins/“ Ihres Projekts abgelegt werden.
In diesem Fall müssen Sie ein Plugin hinzufügen, das die Bright Data Web Unlocker API aufruft. Weitere Informationen zum Aufrufen dieses API-Endpunkts finden Sie in der offiziellen Dokumentation.
Installieren Sie in Ihrer aktiven virtuellen Umgebung zunächst einen Python-HTTP-Client wie Requests:
pip install requestsFügen Sie dann eine Plugin-Datei namens web_unlocker.py in den Ordner plugins/ ein. Definieren Sie sie wie folgt:
# taskweaver-bright-data-example/plugins/web_unlocker.py
import requests
from taskweaver.plugin import Plugin, register_plugin
@register_plugin
class WebUnlockerPlugin(Plugin):
def __call__(
self,
url: str,
data_format: str = None
):
# Konfigurationswerte für API-Aufruf lesen
bright_data_api_key = self.config.get("api_key")
zone = self.config.get("zone", "web_unlocker")
default_format = self.config.get("data_format", "markdown")
# Von der Bright Data API für die Authentifizierung erforderliche HTTP-Header
headers = {
"Authorization": f"Bearer {bright_data_api_key}",
"Content-Type": "application/json"
}
# An Bright Data Web Unlocker gesendete Anfrage-Nutzlast
payload = {
"zone": zone,
"url": url,
"format": "raw", # Um die Antwort direkt im Hauptteil zu erhalten
"data_format": data_format oder default_format
}
# Anfrage an Bright Data Web Unlocker API senden
response = requests.post(
"https://api.brightdata.com/request",
json=payload,
headers=headers,
)
# Ausnahme für HTTP-Antworten, die nicht 2xx sind, auslösen
response.raise_for_status()
# Antwortinhalt und HTTP-Statuscode extrahieren
content = response.text
status = response.status_code
# Zusammenfassung in natürlicher Sprache an das LLM zurückgeben
description = (
f"Seite erfolgreich mit Bright Data Web Unlocker abgerufen "
f"(HTTP {status}, {len(content)} Zeichen)."
)
# Die abgerufene Seite als Artefakt im Sitzungsarbeitsbereich speichern
self.ctx.add_artifact(
name="web_unlocker_page",
file_name="page_content.md",
type="txt",
val=content
)
# Sowohl den Rohinhalt als auch eine für Menschen lesbare Beschreibung zurückgeben
return content, descriptionDieses Plugin ruft eine Webseite über die Bright Data Web Unlocker API ab. Zunächst liest es die Konfigurationswerte aus dem YAML-Konfigurationsabschnitt des Plugins (wird in Kürze definiert) mit self.config.get().
Anschließend sendet es eine HTTP-Anfrage, überprüft sie auf Fehler und speichert die abgerufene Seite über self.ctx.add_artifact() als Artefakt im Arbeitsbereich, sodass Sie das Ergebnis während und nach der Ausführung überprüfen können. Schließlich gibt es sowohl den Rohinhalt der Seite als auch eine für Menschen lesbare Zusammenfassung zur Verwendung durch das LLM zurück.
Hinweis: Standardmäßig ist der Aufruf der Bright Data Web Unlocker API so konfiguriert, dass er Webseiteninhalte im Markdown-Format zurückgibt, was ideal für die LLM-Erfassung ist. Dies ist eine nützliche Funktion der Web Unlocker API, die KI-Integrationen unterstützt und die Inhaltsverarbeitung vereinfacht.
Großartig! Bevor der TaskWeaver-Agent dieses Plugin verwenden kann, müssen Sie auch die YAML-Schema-Datei des Plugins angeben.
Schritt 5: Fahren Sie mit der Definition des Plugin-Schemas fort
Das Plugin-Schema legt fest, wie das LLM in TaskWeaver das Plugin versteht und aufruft. Dies muss im YAML-Format geschrieben werden. Erstellen Sie daher eine Datei mit dem Namen web_unlocker.yaml im Ordner plugins/ wie folgt:
# taskweaver-bright-data-example/plugins/web_unlocker.yaml
name: web_unlocker
enabled: true
plugin_only: true
description: >-
Ruft Webseiten mithilfe der Bright Data Web Unlocker API ab und entsperrt sie,
umgeht Anti-Bot-Schutzmaßnahmen und gibt saubere Seiteninhalte zurück.
parameters:
- name: url
type: str
required: true
description: Die vollständige URL der abzurufenden Webseite.
- name: data_format
type: str
required: false
description: Ausgabeformat des Seiteninhalts („markdown” oder roher HTML-Code, wenn nicht angegeben).
returns:
- name: content
type: str
description: Der entsperrte Seiteninhalt.
- name: description
type: str
description: Eine Zusammenfassung der Abrufoperation in natürlicher Sprache.
configurations:
api_key: <YOUR_BRIGHT_DATA_API_KEY> # Ersetzen Sie dies durch Ihren Bright Data API-Schlüssel.
zone: web_unlocker # Ersetzen Sie dies durch den Namen Ihrer Web Unlocker-Zone.
data_format: markdownDie obige YAML-Datei beschreibt die Ein- und Ausgänge der Funktion __call__() in der zuvor definierten Klasse WebUnlockerPlugin. Dank dieses Schemas versteht das LLM von TaskWeaver, wie das Plugin web_unlocker.py funktioniert und wie es im generierten Python-Code aufgerufen wird.
Geben Sie im Abschnitt „Konfigurationen” Ihren Bright Data API-Schlüssel, den Namen Ihrer Web Unlocker-Zone und das gewünschte Ausgabeformat an. Ersetzen Sie die Felder „api_key” und „zone” durch die Werte, die Sie in Schritt 3 eingerichtet haben.
Das war’s schon! Die Integration von TaskWeaver und Bright Data ist abgeschlossen.
Hinweis: Sie können denselben Ansatz verwenden, um andere Bright Data-Dienste über die API zu integrieren, z. B. die SERP-API oder Web-Scraping-APIs.
Schritt 6: Testen Sie den TaskWeaver-Agenten
Nun ist es an der Zeit zu überprüfen, ob der Code-First-Agent in TaskWeaver nun das von Bright Data bereitgestellte Plugin aufrufen kann. Die Idee ist, dass der generierte Code die Plugin-Funktion aufruft und auf die Web-Unlocking-Funktionen der Web Unlocker API zugreift.
Um dies zu testen, versuchen Sie es mit einer Eingabeaufforderung wie dieser:
Rufen Sie das neueste MCP-Änderungsprotokoll von „https://modelcontextprotocol.io/specification/2025-11-25/changelog“ ab und listen Sie die Änderungen auf.Diese Aufgabe wäre für ein Standard-LLM normalerweise unmöglich, da sie ein benutzerdefiniertes Tool erfordert, um zu einer URL zu navigieren und Informationen daraus zu extrahieren. Mit TaskWeaver + Bright Data kann der Agent dies jedoch bewältigen!
Starten Sie die TaskWeaver-Anwendung mit:
python -m taskweaverFügen Sie die Eingabeaufforderung ein und drücken Sie die Eingabetaste. Sie sollten nun etwa Folgendes sehen: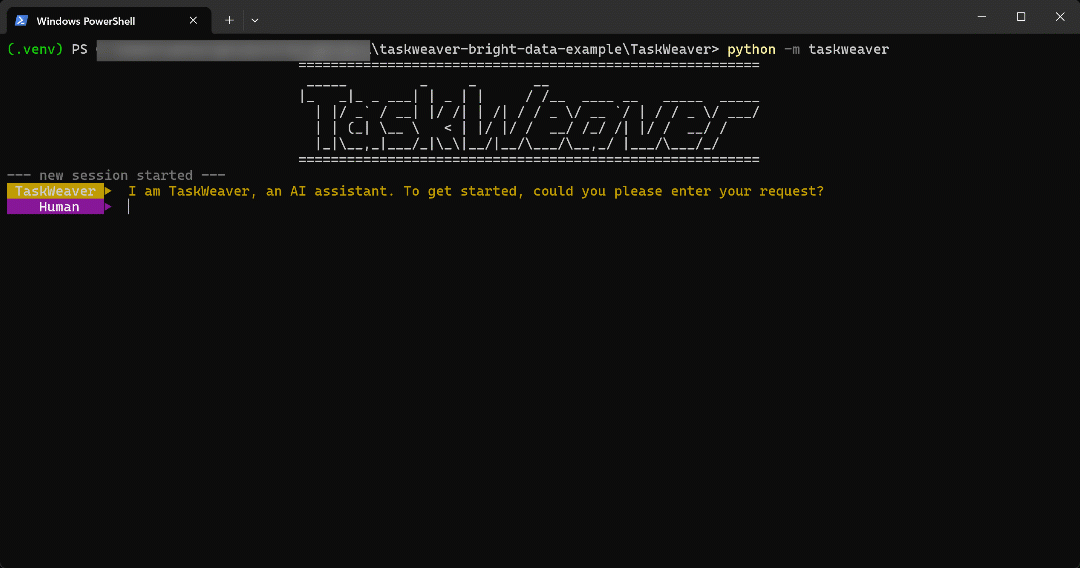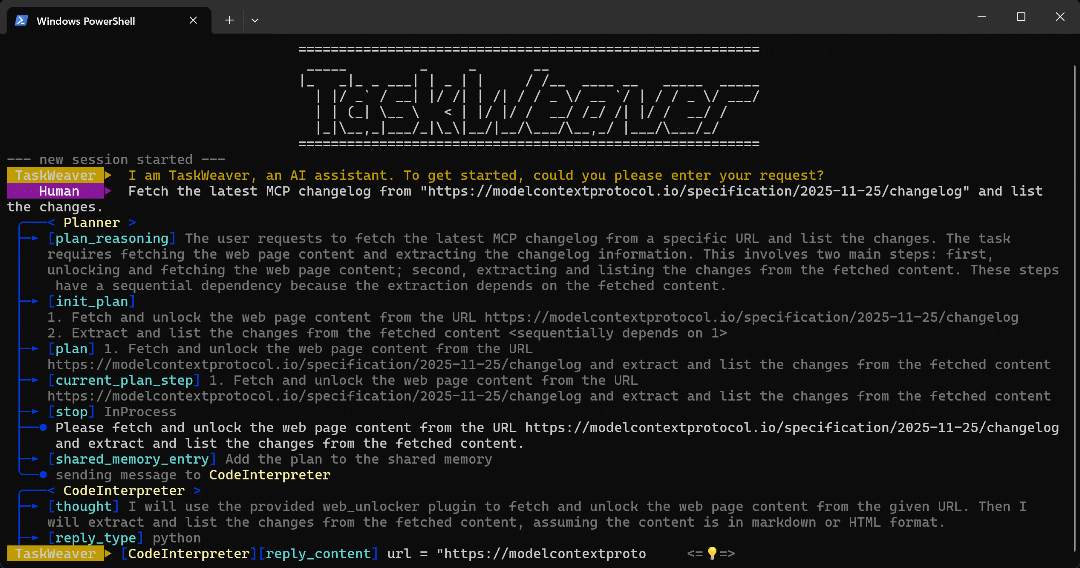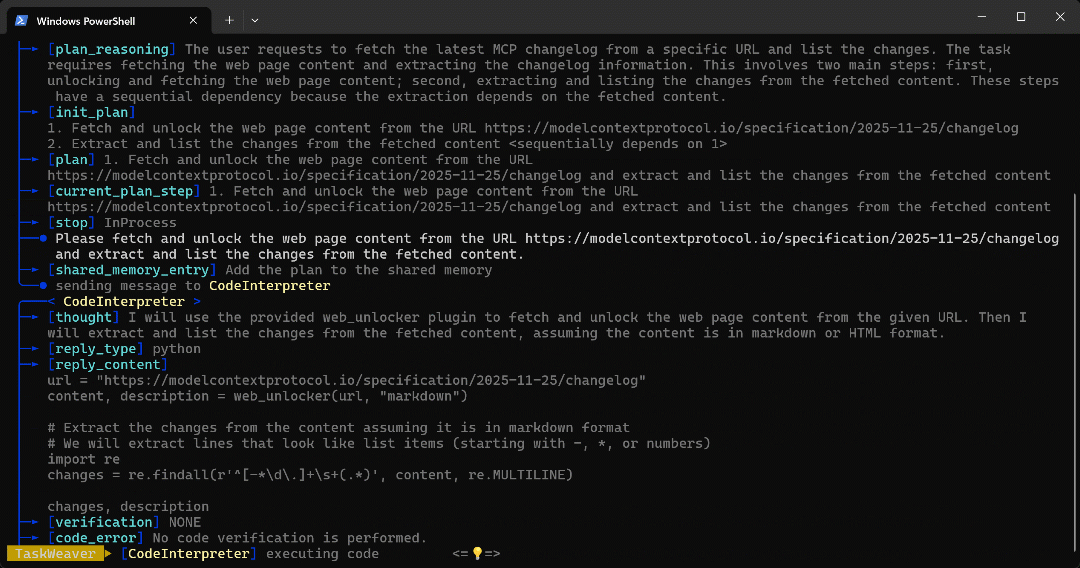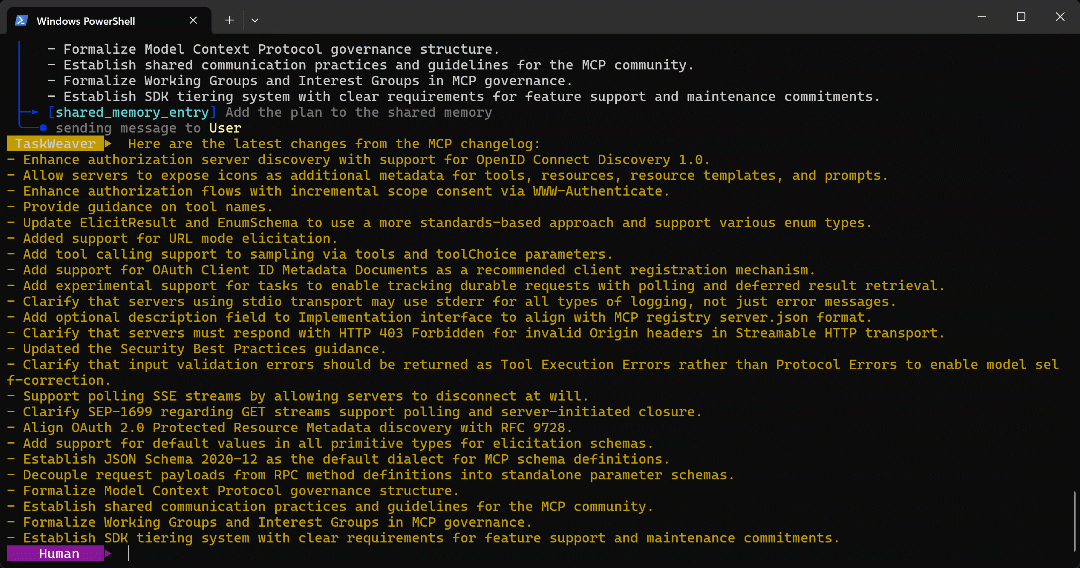
Wie Sie sehen können, macht der Agent Folgendes:
- Der TaskWeaver
Plannererstellt zunächst einen Plan zur Ausführung der Aufgabe. - Der Plan wird dann an den internen
CodeInterpreter-Agenten gesendet, der Python-Code generiert, um das Ziel zu erreichen. - Der Python-Code ruft das Web Unlocker API-Plugin auf und extrahiert dann alle Aufzählungspunkte im Artikel mithilfe eines regulären Ausdrucks.
- Der Code wird ausgeführt, und die gewünschten Daten werden über die Web Unlocker API abgerufen und im Arbeitsbereichsordner gespeichert, wie mit
self.ctx.add_artifact()konfiguriert. - Die zurückgegebenen Markdown-Daten, die den Inhalt der durch die URL angegebenen Seite enthalten, werden an den
Plannerzurückgesendet, der mit dem nächsten Schritt fortfährt. - Die Liste der aus der Zielseite extrahierten Aufzählungspunkte wird wie vorgesehen an den Benutzer zurückgegeben.
Großartig! Der TaskWeaver-Agent funktioniert einwandfrei. Nehmen wir uns etwas Zeit, um die erzeugte Ausgabe zu überprüfen.
Schritt 7: Erkunden Sie die Ausgabe
Die endgültige Ausgabe des Agent-Laufs lautet:
Wie Sie auf der Zielseite überprüfen können, entspricht diese Liste genau den Informationen, die im MCP-Änderungsprotokoll zu finden sind:
Insbesondere hat der Agent die Ausgabe durch den folgenden Python-Code erzeugt:
url = "https://modelcontextprotocol.io/specification/2025-11-25/changelog"
content, description = web_unlocker(url, "markdown")
# Extrahieren Sie die Änderungen aus dem Inhalt, vorausgesetzt, er ist im Markdown-Format.
# Wir extrahieren Zeilen, die wie Listenelemente aussehen (beginnend mit -, * oder Zahlen).
import re
changes = re.findall(r'^[-*d.]+s+(.*)', content, re.MULTILINE)
changes, descriptionBeachten Sie, wie das generierte Snippet die Funktion web_unlocker() aufruft, um die Eingabeseite im Markdown-Format abzurufen. Anschließend wird sie mit einer einfachen regulären Ausdrucksfolge verarbeitet, um die relevanten Informationen zu extrahieren.
Um zu überprüfen, ob die Web Unlocker API den Seiteninhalt in Markdown zurückgegeben hat, überprüfen Sie die Dateien im Ordner workspace/. Jeder Agent-Lauf erzeugt einen Sitzungsunterordner unter workspace/sessions/, der einen Unterordner für diesen bestimmten Lauf enthält.
Im Ordner cwd/ finden Sie die .md-Datei, die über den Aufruf self.ctx.add_artifact() erstellt wurde. Öffnen Sie sie, um den von der Web Unlocker-API zurückgegebenen Inhalt anzuzeigen: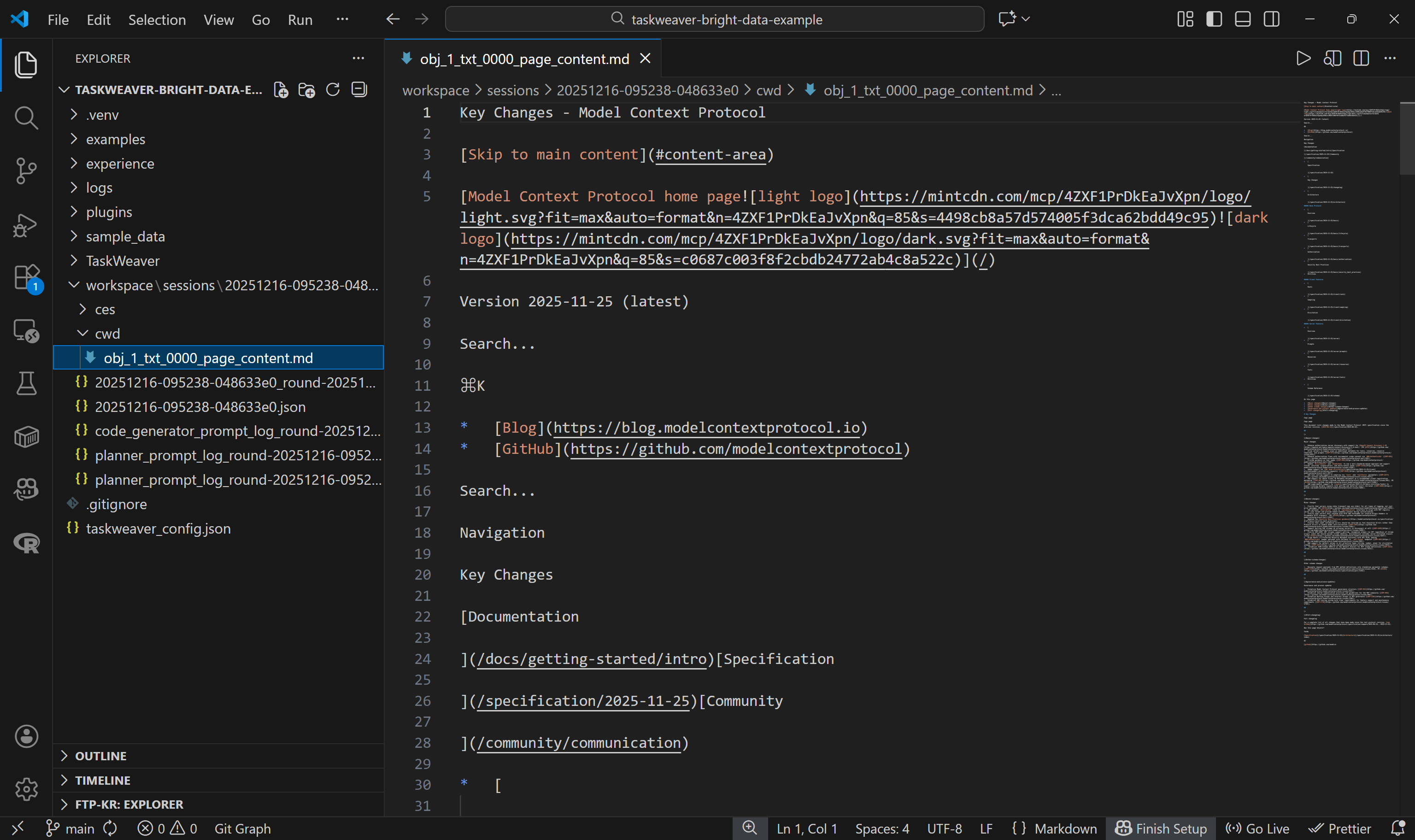
Dieser entspricht genau der Markdown-Version der Zielseite, was bedeutet, dass die Web Unlocker-API-Funktion im generierten Python-Code einwandfrei funktioniert hat. Wow!
Bringen Sie Ihren Agenten nun weiter voran. Experimentieren Sie mit verschiedenen Eingabeaufforderungen, um realistischere, unternehmensgerechte Szenarien zu bewältigen.
Et voilà! Sie haben erfolgreich einen Code-First-KI-Agenten erstellt, der mit Bright Data über TaskWeaver integriert ist. Dieser Agent kann zuverlässig KI-fähige Daten von jeder Webseite abrufen.
Nächste Schritte
Die hier gezeigte Integration ist ein grundlegendes Beispiel. Um Ihren TaskWeaver-Agenten auf die nächste Stufe zu heben und produktionsreif zu machen, sollten Sie die folgenden Verbesserungen in Betracht ziehen:
- Integrieren Sie zusätzliche Bright Data-Lösungen wie die SERP-API, um dem Agenten die Möglichkeit zu geben, das Web zu durchsuchen und Live-Daten zu sammeln.
- Konfigurieren Sie die Web-Benutzeroberfläche als Spielwiese für die vereinfachte Entwicklung, das Testen und die Überwachung Ihres Agenten.
- Aktivieren Sie erweiterte Funktionen wie Prompt-Komprimierung, automatische Plugin-Auswahl undTelemetrie/Beobachtbarkeit, um die Leistung, Skalierbarkeit und Wartbarkeit zu verbessern.
Fazit
In diesem Tutorial haben Sie gesehen, wie Sie Bright Data über benutzerdefinierte Plugins, die eine Verbindung zu externen APIs herstellen, in TaskWeaver integrieren können.
Diese Konfiguration ermöglicht Websuchen in Echtzeit, strukturierte Datenextraktion, Zugriff auf Live-Web-Feeds und automatisierte Web-Interaktionen. Durch die Nutzung der gesamten Palette der Bright Data-Dienste für KI erschließen Sie das volle Potenzial Ihrer Code-First-KI-Agenten!
Erstellen Sie noch heute ein kostenloses Bright Data-Konto und sichern Sie sich unsere KI-fähigen Webdatenlösungen.




