

In diesem Artikel erfahren Sie:
- Was Langfuse ist und was es bietet.
- Warum Unternehmen und Nutzer es für die Überwachung und Verfolgung von KI-Agenten benötigen.
- Wie Sie es in einen komplexen, realen KI-Agenten integrieren können, der mit LangChain erstellt wurde und mit Bright Data für Websuche und Web-Scraping-Funktionen verbunden ist.
Lassen Sie uns eintauchen!
Was ist Langfuse?
Langfuse ist eine Open-Source- und Cloud-basierte LLM-Engineering-Plattform, die Ihnen beim Debuggen, Überwachen und Verbessern von Anwendungen mit großen Sprachmodellen hilft. Sie bietet Observability-, Tracing-, Prompt-Management- und Evaluierungstools, die den gesamten KI-Entwicklungsworkflow unterstützen.
Zu den wichtigsten Funktionen gehören:
- Beobachtbarkeit und Tracing: Verschaffen Sie sich einen umfassenden Einblick in Ihre LLM-Anwendungen mit Traces, Sitzungsübersichten und Metriken wie Kosten, Latenz und Fehlerraten. Dies ist entscheidend für das Verständnis der Leistung und die Diagnose von Problemen.
- Prompt-Management: Ein versionskontrolliertes System zum gemeinsamen Erstellen, Verwalten und Iterieren von Prompts, ohne die Codebasis zu verändern.
- Auswertung: Tools zur Auswertung des Anwendungsverhaltens, einschließlich der Erfassung von menschlichem Feedback, modellbasierter Bewertung und automatisierter Tests anhand von Datensätzen.
- Zusammenarbeit: Unterstützt Team-Workflows mit Anmerkungen, Kommentaren und gemeinsamen Erkenntnissen.
- Erweiterbarkeit: Vollständig Open Source, mit flexiblen Integrationsoptionen für verschiedene Tech-Stacks.
- Bereitstellungsoptionen: Verfügbar als gehosteter Cloud-Dienst (mit einer kostenlosen Stufe) oder als selbst gehostete Installation für Teams, die die vollständige Kontrolle über Daten und Infrastruktur benötigen.
Warum Sie Langfuse in Ihren KI-Agenten integrieren sollten
Die Überwachung von KI-Agenten mit Langfuse ist insbesondere für Unternehmen von grundlegender Bedeutung. Nur so können Sie das Maß an Beobachtbarkeit, Kontrolle und Zuverlässigkeit erreichen, das Produktionsumgebungen erfordern.
Schließlich interagieren KI-Agenten in realen Szenarien mit sensiblen Daten, komplexer Geschäftslogik und externen APIs. Daher benötigen Sie eine Möglichkeit, genau zu verfolgen und zu verstehen, wie sich der Agent verhält, was er kostet und wie zuverlässig er arbeitet.
Langfuse bietet End-to-End-Tracing, detaillierte Metriken und Debugging-Tools, mit denen (auch nicht-technische) Teams jeden Schritt eines KI-Workflows überwachen können, von der Eingabe von Eingabeaufforderungen bis hin zu Modellentscheidungen und Tool-Aufrufen.
Für Unternehmen bedeutet dies weniger blinde Flecken, eine schnellere Lösung von Vorfällen und eine stärkere Einhaltung interner Governance- und externer Vorschriften. Darüber hinaus unterstützt Langfuse auch das Prompt-Management und die Prompt-Bewertung, sodass Teams Prompts in großem Umfang versionieren, testen und optimieren können.
So verwenden Sie Langfuse zur Verfolgung eines mit LangChain und Bright Data erstellten KI-Agenten zur Compliance-Überwachung
Um die Verfolgungs- und Überwachungsfunktionen von Langfuse zu demonstrieren, benötigen Sie zunächst einen KI-Agenten, den Sie instrumentieren können. Aus diesem Grund erstellen wir einen realistischen KI-Agenten mit LangChain, der auf Bright Data-Lösungen für die Websuche und das Web-Scraping basiert.
Hinweis: Langfuse und Bright Data unterstützen eine Vielzahl von KI-Agenten-Frameworks. LangChain wurde hier nur aus Gründen der Einfachheit und zu Demonstrationszwecken ausgewählt.
Dieser unternehmensgerechte KI-Agent übernimmt Compliance-bezogene Aufgaben, indem er
- ein internes PDF-Dokument lädt, das einen Unternehmensprozess beschreibt (z. B. Datenverarbeitungs-Workflows)
- Analyse des Dokuments mit einem LLM, um wichtige Aspekte des Datenschutzes und der Regulierung zu identifizieren.
- Websuchen zu verwandten Themen mithilfe der Bright Data SERP-API durchführt.
- Zugriff auf die Top-Seiten (mit Priorität für Regierungswebsites) im Markdown-Format über die Bright Data Web Unlocker API.
- die gesammelten Informationen verarbeitet und aktualisierte Erkenntnisse liefert, um regulatorische Probleme zu vermeiden.
Als Nächstes wird dieser Agent mit Langfuse verbunden, um Laufzeitinformationen, Metriken und andere relevante Daten zu verfolgen.
Eine allgemeine Übersicht über die Architektur dieses Projekts finden Sie in der folgenden schematischen Darstellung: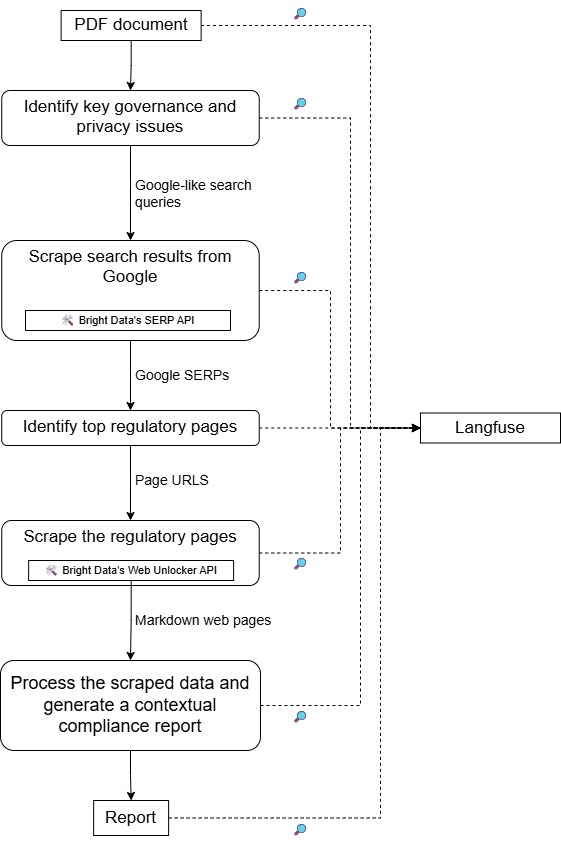
Befolgen Sie die nachstehenden Anweisungen!
Voraussetzungen
Bevor Sie beginnen, stellen Sie sicher, dass Sie über Folgendes verfügen:
- Python 3.10 oder höher auf Ihrem Rechner installiert ist.
- Einen OpenAI-API-Schlüssel.
- Ein Bright Data-Konto mit eingerichteten SERP-API- und Web Unlocker-API-Zonen sowie einem API-Schlüssel.
- Ein Langfuse-Konto mit konfigurierten öffentlichen und geheimen API-Schlüsseln.
Machen Sie sich keine Gedanken über die Einrichtung der Bright Data- und Langfuse-Konten, da Sie in den folgenden Schritten durch diesen Vorgang geführt werden. Es ist auch hilfreich, über grundlegende Kenntnisse der KI-Agenten-Instrumentierung zu verfügen, um zu verstehen, wie Langfuse Laufzeitdaten verfolgt und verwaltet.
Schritt 1: Richten Sie Ihr LangChain-KI-Agent-Projekt ein
Führen Sie den folgenden Befehl in Ihrem Terminal aus, um einen neuen Ordner für Ihr LangChain-KI-Agentenprojekt zu erstellen:
mkdir compliance-tracking-KI-agentDieses Verzeichnis compliance-tracking-ai-agent/ stellt den Projektordner für Ihren KI-Agenten dar, den Sie später über Langfuse instrumentieren werden.
Navigieren Sie in den Ordner und erstellen Sie darin eine virtuelle Python-Umgebung:
cd compliance-tracking-KI-agent
python -m venv .venvÖffnen Sie den Projektordner in Ihrer bevorzugten Python-IDE. Sowohl Visual Studio Code mit der Python-Erweiterung als auch PyCharm sind geeignete Optionen.
Erstellen Sie im Projektordner ein Python-Skript mit dem Namen agent.py:
compliance-tracking-KI-agent/
├─── .venv/
└─── agent.py # <------------Derzeit ist agent.py leer. Hier werden Sie später Ihren KI-Agenten über LangChain definieren.
Aktivieren Sie als Nächstes die virtuelle Umgebung. Führen Sie unter Linux oder macOS in Ihrem Terminal folgenden Befehl aus:
source venv/bin/activateUnter Windows führen Sie stattdessen Folgendes aus:
venv/Scripts/activateNach der Aktivierung installieren Sie die Projektabhängigkeiten mit diesem Befehl:
pip install langchain langchain-openai langgraph langchain-brightdata langchain-community pypdf python-dotenv langfuseDiese Bibliotheken decken folgenden Bereich ab:
langchain,langchain-openaiundlanggraph: Zum Erstellen und Verwalten eines KI-Agenten, der auf einem OpenAI-Modell basiert.langchain-brightdata: Zur Integration von LangChain mit Bright Data-Diensten unter Verwendung offizieller Tools.langchain-communityundpypdf: Bereitstellung von APIs zum Lesen und Verarbeiten von PDF-Dateien über die zugrunde liegendepypdf-Bibliothek.python-dotenv: Zum Laden von Anwendungsgeheimnissen, wie API-Schlüsseln für Drittanbieter, aus einer.env-Datei.langfuse: Zur Instrumentierung Ihres KI-Agenten, um nützliche Traces und Telemetriedaten entweder in der Cloud oder lokal zu sammeln.
Fertig! Sie verfügen nun über eine vollständig eingerichtete Python-Entwicklungsumgebung zum Erstellen Ihres KI-Agenten.
Schritt 2: Konfigurieren des Lesens von Umgebungsvariablen
Ihr KI-Agent wird sich mit Drittanbieterdiensten wie OpenAI, Bright Data und Langfuse verbinden. Um zu vermeiden, dass Anmeldedaten in Ihrem Skript fest codiert werden, und um es für den Einsatz in Unternehmen produktionsreif zu machen, konfigurieren Sie das Skript so, dass es diese aus einer .env-Datei liest. Genau aus diesem Grund haben wir python-dotenv installiert!
Fügen Sie in agent.py zunächst den folgenden Import hinzu:
from dotenv import load_dotenvErstellen Sie als Nächstes eine .env -Datei in Ihrem Projektordner:
compliance-tracking-KI-agent/
├─── .venv/
├─── agent.py
└─── .env # <------------In dieser Datei werden alle Ihre Anmeldedaten, API-Schlüssel und Geheimnisse gespeichert.
Laden Sie in agent.py die Umgebungsvariablen aus .env mit dieser Codezeile:
load_dotenv()Cool! Ihr Skript kann nun sicher Werte aus der .env-Datei lesen.
Schritt 3: Bereiten Sie Ihr Bright Data-Konto vor
Die LangChain Bright Data-Tools funktionieren, indem sie eine Verbindung zu den in Ihrem Konto konfigurierten Bright Data-Diensten herstellen. Für dieses Projekt werden insbesondere die folgenden beiden Tools benötigt:
BrightDataSERP: Ruft Suchmaschinenergebnisse ab, um relevante regulatorische Webseiten zu finden. Es stellt eine Verbindung zur SERP-API von Bright Data her.BrightDataUnblocker: Greift auf alle öffentlichen Websites zu, auch wenn diese geografisch beschränkt oder durch Bots geschützt sind. Dadurch kann der Agent Inhalte von einzelnen Webseiten scrapen und daraus lernen. Es stellt eine Verbindung zur Web Unblocker API von Bright Data her.
Mit anderen Worten: Um diese beiden Tools nutzen zu können, benötigen Sie ein Bright Data-Konto, in dem sowohl eine SERP-API-Zone als auch eine Web Unblocker API-Zone eingerichtet sind. Konfigurieren wir sie!
Wenn Sie noch kein Bright Data-Konto haben, erstellen Sie zunächst eines. Andernfalls melden Sie sich an. Gehen Sie zu Ihrem Dashboard und navigieren Sie dann zur Seite „Proxies & Scraping”. Überprüfen Sie dort die Tabelle „My Zones”: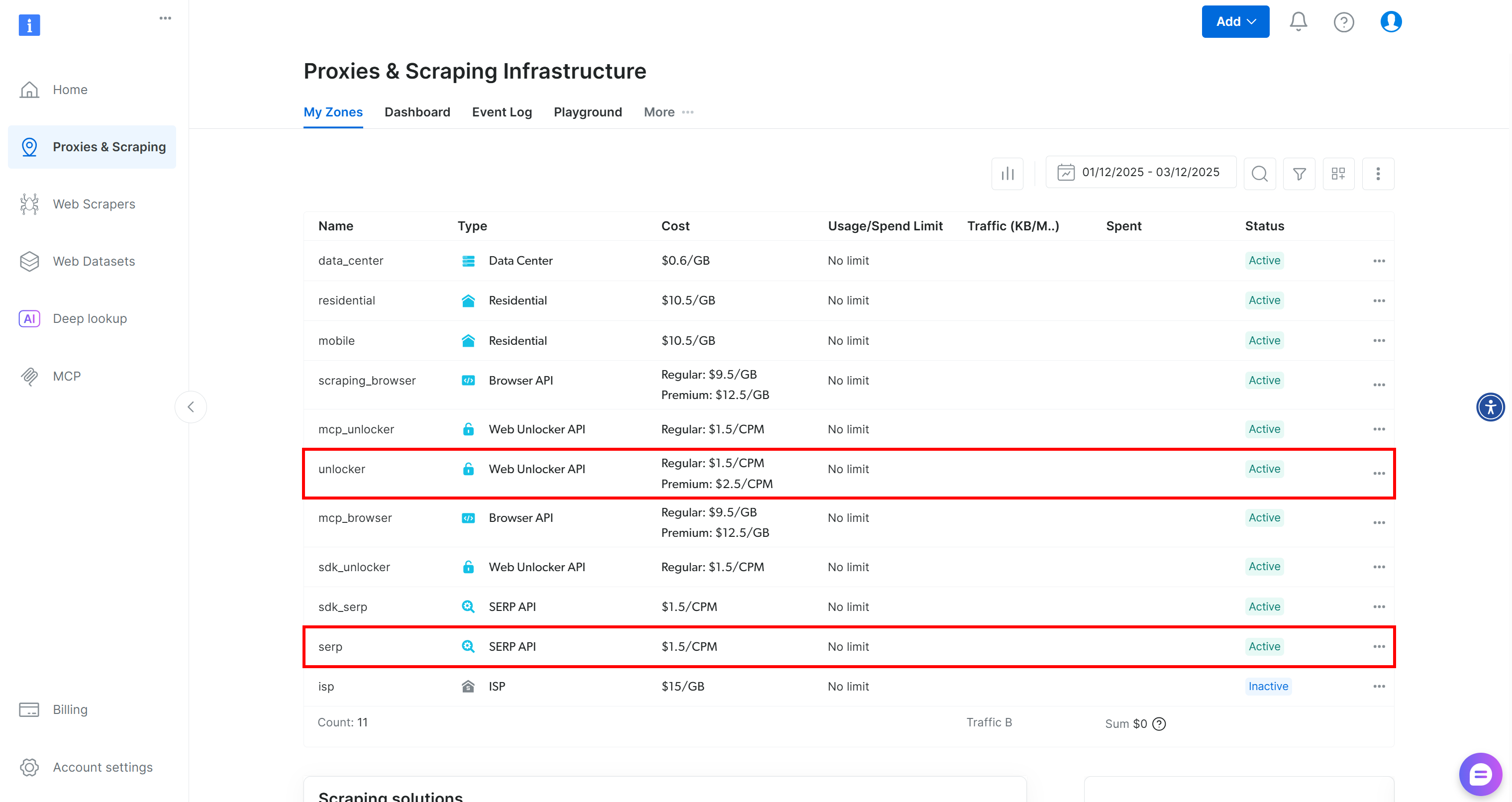
Wenn die Tabelle bereits eine Web Unlocker API-Zone namens „unlocker” und eine SERP-API-Zone namens „serp” enthält, können Sie loslegen. Der Grund dafür ist:
- Das
BrightDataSERPLangChain-Tool verbindet sich automatisch mit einer SERP-API-Zone namens„serp”. - Das
BrightDataUnblockerLangChain-Tool verbindet sich automatisch mit einer Web Unblocker API-Zone namens„web_unlocker”.
Weitere Informationen finden Sie in der Dokumentation zu Bright Data x LangChain.
Wenn Sie diese beiden erforderlichen Zonen nicht eingerichtet haben, können Sie sie ganz einfach erstellen. Scrollen Sie auf den Karten „Unblocker API“ und „SERP-API“ nach unten, klicken Sie auf die Schaltfläche „Zone erstellen“ und folgen Sie den Anweisungen des Assistenten, um die beiden Zonen mit den erforderlichen Namen hinzuzufügen: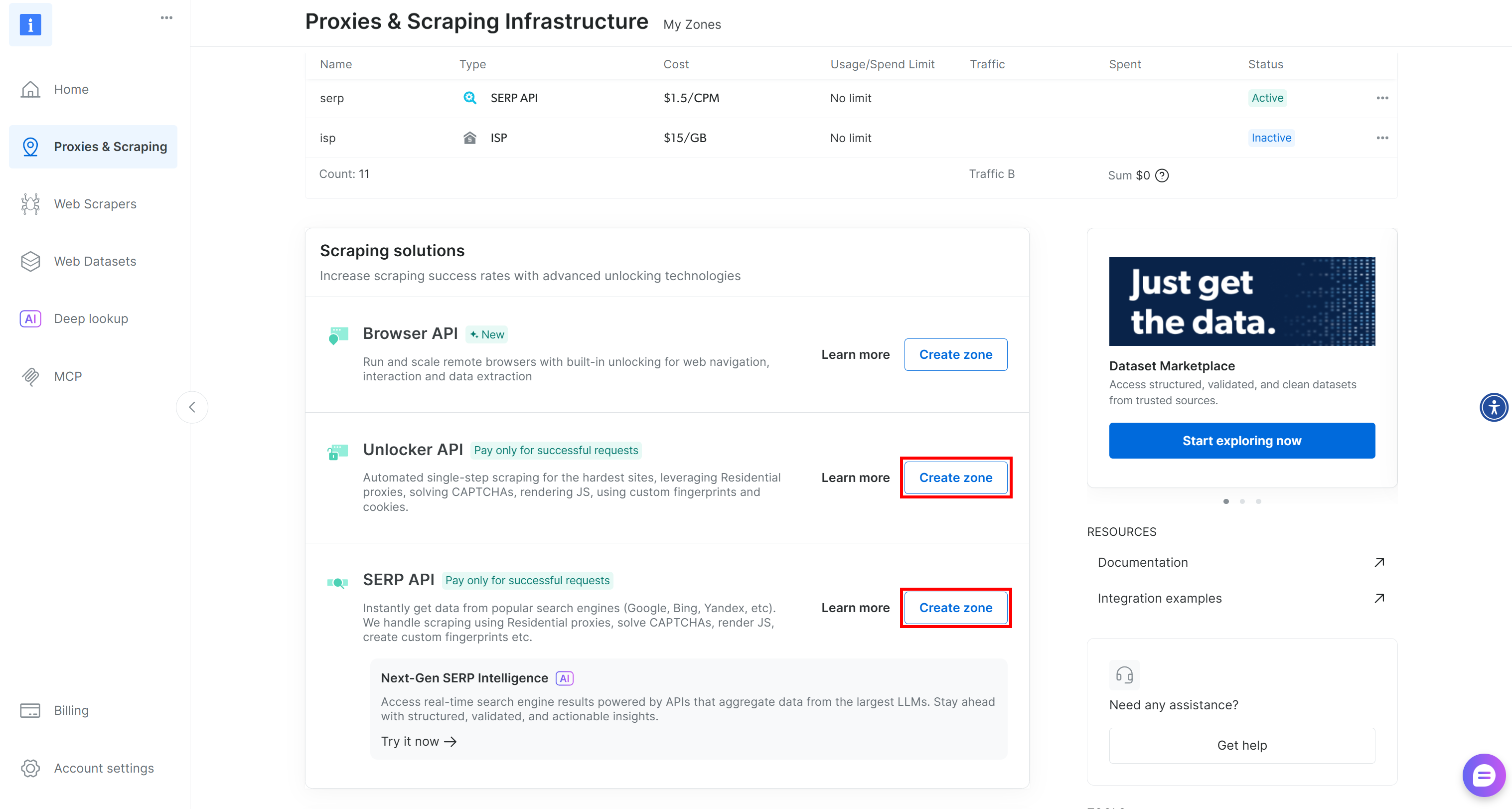
Eine Schritt-für-Schritt-Anleitung finden Sie auf diesen beiden Dokumentationsseiten:
Zuletzt müssen Sie den LangChain Bright Data-Tools mitteilen, wie sie sich mit Ihrem Konto verbinden sollen. Dazu verwenden Sie Ihren Bright Data API-Schlüssel, der für die Authentifizierung verwendet wird.
Generieren Sie Ihren Bright Data API-Schlüssel und speichern Sie ihn wie folgt in Ihrer .env -Datei:
BRIGHT_DATA_API_KEY="<IHR_BRIGHT_DATA_API_SCHLÜSSEL>"Das war’s schon! Sie haben nun alle Voraussetzungen erfüllt, um Ihr LangChain-Skript über die offiziellen Tools mit den Bright Data-Lösungen zu verbinden.
Schritt 4: Konfigurieren Sie die LangChain Bright Data Tools
Bereiten Sie in Ihrer Datei agent.py die LangChain Bright Data-Tools wie folgt vor:
from langchain_brightdata import BrightDataUnlocker, BrightDataSERP
bright_data_serp_api_tool = BrightDataSERP()
bright_data_web_unlocker_api_tool = BrightDataUnlocker() Hinweis: Sie müssen Ihren Bright Data API-Schlüssel nicht manuell angeben. Beide Tools versuchen automatisch, ihn aus der Umgebungsvariablen BRIGHT_DATA_API_KEY zu lesen, die Sie zuvor in Ihrer .env-Datei festgelegt haben.
Schritt 5: Integrieren Sie das LLM
Ihr KI-Agent für die Compliance-Verfolgung benötigt ein Gehirn, das durch ein LLM-Modell dargestellt wird. In diesem Beispiel ist OpenAI der ausgewählte LLM-Anbieter. Fügen Sie also zunächst Ihren OpenAI-API-Schlüssel zur .env-Datei hinzu:
OPENAI_API_KEY="<IHR_OPENAI_API-SCHLÜSSEL>"Initialisieren Sie anschließend in der Datei agent.py die LLM-Integration wie folgt:
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
model="gpt-5-mini",
) Hinweis: Das hier konfigurierte Modell ist GPT-5 Mini, aber Sie können jedes andere OpenAI-Modell verwenden.
Wenn Sie OpenAI nicht verwenden möchten, befolgen Sie die offiziellen LangChain-Anleitungen, um eine Verbindung zu einem anderen LLM-Anbieter herzustellen.
Großartig! Sie haben nun alles, was Sie benötigen, um einen LangChain-KI-Agenten zu definieren.
Schritt 6: Definieren Sie den KI-Agenten
Ein LangChain-Agent benötigt ein LLM, einige optionale Tools und eine Systemaufforderung, um das Verhalten des Agenten zu definieren.
Kombinieren Sie alle diese Komponenten zu einem LangChain-Agenten wie folgt:
from langchain.agents import create_agent
# Definieren Sie eine Systemaufforderung, die den Agenten über seine Compliance- und Datenschutzaufgaben informiert
system_prompt = """
Sie sind Experte für Compliance-Tracking. Ihre Aufgabe ist es, Dokumente auf potenzielle regulatorische und datenschutzrechtliche Probleme zu analysieren.
Ihre Analyse wird durch die Recherche nach aktualisierten Regeln und maßgeblichen Quellen im Internet mithilfe der Tools von Bright Data unterstützt, darunter die SERP-API und der Web Unlocker.
Liefern Sie genaue, unternehmensgerechte Erkenntnisse und stellen Sie sicher, dass alle Ergebnisse durch Zitate aus dem Originaldokument und maßgeblichen externen Quellen untermauert sind.
"""
# Liste der für den Agenten verfügbaren Tools
tools=[bright_data_serp_api_tool, bright_data_web_unlocker_api_tool]
# Definieren Sie den KI-Agenten
agent = create_agent(
llm=llm,
tools=tools,
system_prompt=system_prompt,
)Die Funktion create_agent() erstellt eine graphbasierte Agent-Laufzeitumgebung mit LangGraph. Ein Graph besteht aus Knoten (Schritten) und Kanten (Verbindungen), die definieren, wie Ihr Agent Informationen verarbeitet. Der Agent bewegt sich durch diesen Graphen und führt verschiedene Arten von Knoten aus. Weitere Details finden Sie in der offiziellen Dokumentation.
Im Grunde genommen repräsentiert die Variable „agent” nun Ihren KI-Agenten mit Bright Data-Integration für die Nachverfolgung und Analyse der Compliance. Fantastisch!
Schritt 7: Starten Sie den Agenten
Bevor Sie den Agenten starten, benötigen Sie eine Eingabeaufforderung, die die Compliance-Verfolgungsaufgabe und das zu analysierende Dokument beschreibt.
Beginnen Sie mit dem Lesen des eingegebenen PDF-Dokuments:
from langchain_community.document_loaders import PyPDFDirectoryLoader
# Alle PDF-Dokumente aus dem Eingabeordner laden
input_folder = "./input"
loader = PyPDFDirectoryLoader(input_folder)
# Alle Seiten aus allen PDF-Dateien im Eingabeordner laden
docs = loader.load()
# Alle Seiten aus den PDF-Dateien zu einer einzigen Zeichenfolge für die Analyse kombinieren
internal_document_to_analyze = "nn".join([doc.page_content for doc in docs])Hierbei wird der pypdf -Community-Dokumentlader von LangChain verwendet, um alle Seiten aus den PDF-Dateien in Ihrem Ordner „input/“ zu lesen und deren Text in einer einzigen Zeichenfolgenvariablen zusammenzufassen.
Fügen Sie einen Ordner „input/“ in Ihrem Projektverzeichnis hinzu:
compliance-tracking-KI-agent/
├─── .venv/
├─── input/ # <------------
├─── agent.py
└─── .envDieser Ordner enthält die PDF-Dateien, die der Agent auf Datenschutz-, Regulierungs- oder Compliance-bezogene Probleme hin analysiert.
Angenommen, Ihr Ordner „input/“ enthält ein einziges Dokument, dann enthält die Variable „internal_document_to_analyze“ dessen vollständigen Text. Dieser kann nun in eine Eingabeaufforderung eingebettet werden, die den Agenten eindeutig anweist, die Analyseaufgabe auszuführen:
from langchain_core.prompts import PromptTemplate
# Definieren Sie eine Eingabeaufforderungsvorlage, um den Agenten durch den Arbeitsablauf zu führen.
prompt_template = PromptTemplate.from_template("""
Angesichts des folgenden PDF-Inhalts:
1. Lassen Sie das LLM diesen analysieren, um die wichtigsten Aspekte zu identifizieren, die im Hinblick auf den Datenschutz untersucht werden sollten.
2. Übersetzen Sie diese Aspekte in bis zu 3 sehr kurze (nicht mehr als 5 Wörter), prägnante und spezifische Suchanfragen, die für Google geeignet sind.
3. Führen Sie Websuchen für diese Anfragen mit dem SERP-API-Tool von Bright Data durch (Suche nach Seiten in englischer Sprache, beschränkt auf die Vereinigten Staaten).
4. Greifen Sie mit dem Web Unlocker-Tool von Bright Data auf die bis zu 5 besten Webseiten (ohne PDF-Seiten) im Markdown-Datenformat zu (mit Vorrang für Regierungswebsites).
5. Verarbeiten Sie die gesammelten Informationen und erstellen Sie einen abschließenden, prägnanten Bericht, der Zitate aus dem Originaldokument und Erkenntnisse aus den gescrapten Seiten enthält, um regulatorische Probleme zu vermeiden.
PDF-INHALT:
{pdf}
""")
# Füllen Sie die Vorlage mit dem Inhalt der PDF-Dateien
prompt = prompt_template.format(pdf=internal_document_to_analyze)Übergeben Sie schließlich die Eingabeaufforderung an den Agenten und führen Sie sie aus:
# Streamen Sie die Antwort des Agenten, während Sie jeden Schritt mit Langfuse verfolgen.
for step in agent.stream(
{"messages": [{"role": "user", "content": prompt}]},
stream_mode="values",
):
step["messages"][-1].pretty_print()Mission abgeschlossen! Ihr Bright Data-gestützter LangChain-KI-Agent ist nun bereit für die Bearbeitung von Dokumentenanalysen und regulatorischen Rechercheaufgaben auf Unternehmensebene.
Schritt 8: Erste Schritte mit Langfuse
Sie haben nun einen Punkt erreicht, an dem Ihr KI-Agent implementiert ist. In der Regel möchten Sie nun Langfuse für die Produktionsverfolgung und -überwachung hinzufügen. Schließlich instrumentieren Sie in der Regel bereits vorhandene Agenten.
Erstellen Sie zunächst ein Langfuse-Konto. Sie werden zur Seite „Organisationen” weitergeleitet, wo Sie eine neue Organisation erstellen müssen. Klicken Sie dazu auf die Schaltfläche „Neue Organisation”: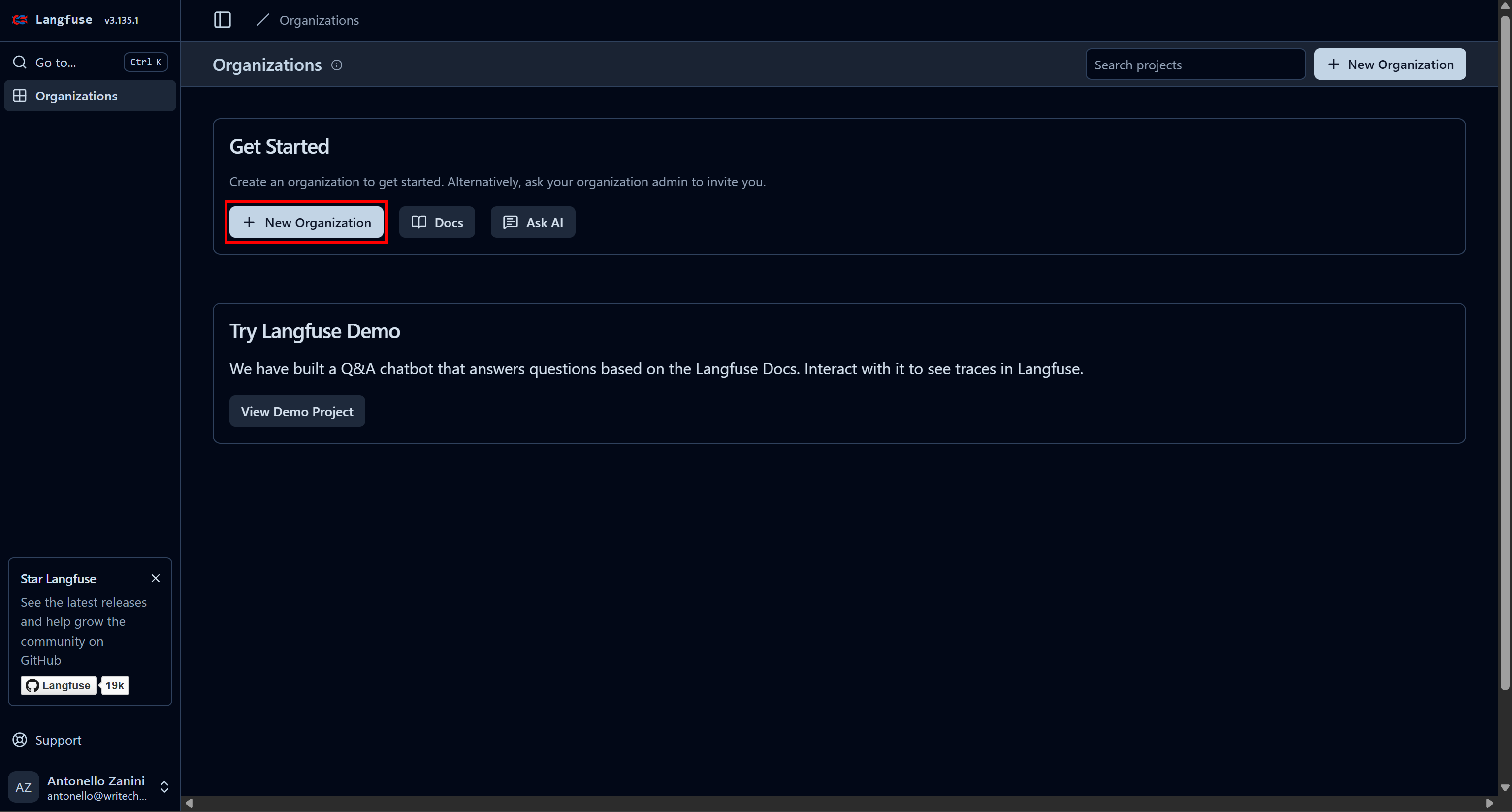
Geben Sie Ihrer Organisation einen Namen und fahren Sie mit dem Assistenten fort, bis Sie zum letzten Schritt „Projekt erstellen“ gelangen: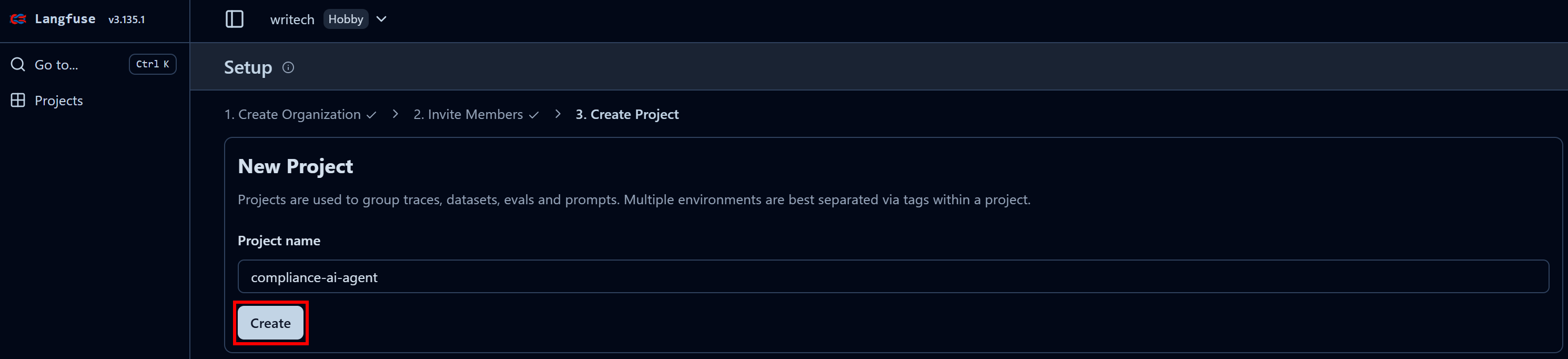
Benennen Sie Ihr Projekt im letzten Schritt beispielsweise „compliance-tracking-KI-agent“ und klicken Sie auf die Schaltfläche „Erstellen“. Sie werden dann zur Ansicht „Projekteinstellungen“ weitergeleitet. Navigieren Sie von dort zur Seite „API-Schlüssel“: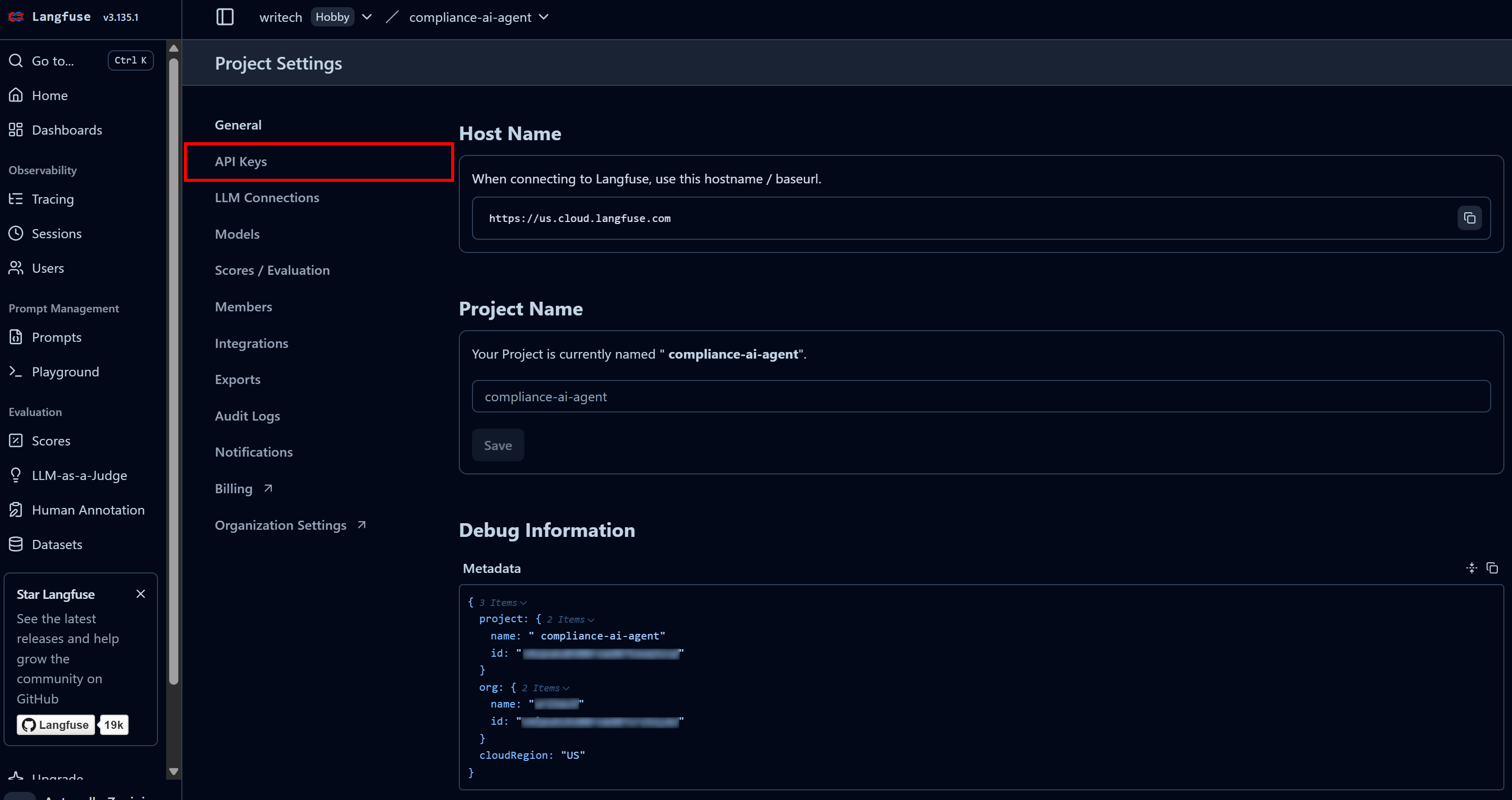
Klicken Sie im Abschnitt „Projekt-API-Schlüssel“ auf „Neue API-Schlüssel erstellen“: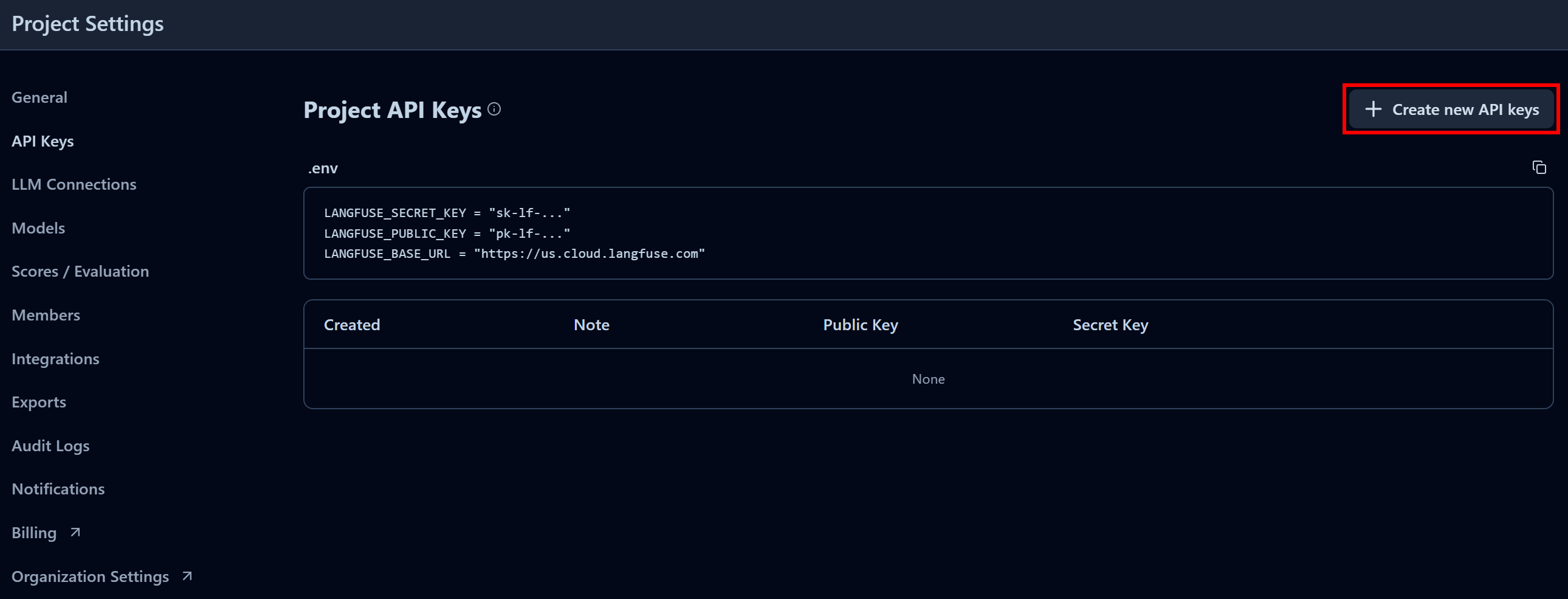
Geben Sie im angezeigten Modalfenster einen Namen für Ihren API-Schlüssel ein und klicken Sie auf „API-Schlüssel erstellen“: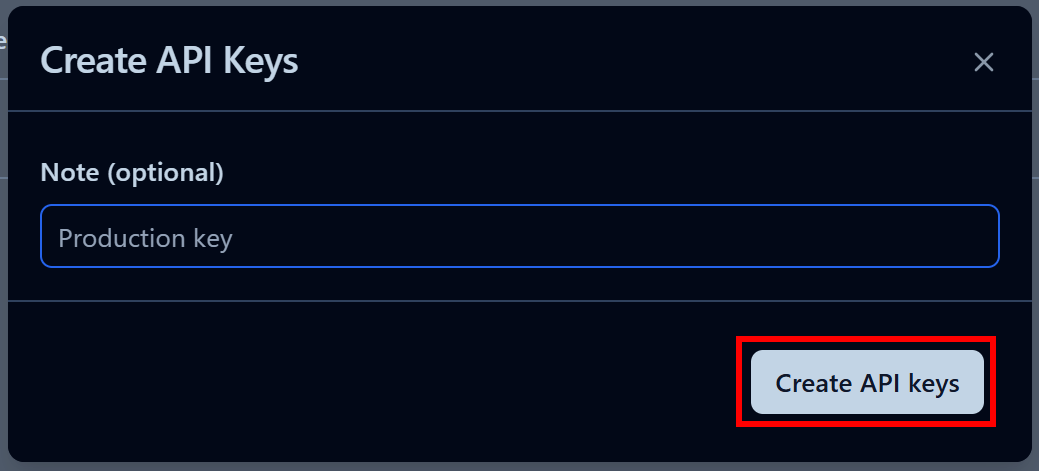
Sie erhalten einen öffentlichen und einen geheimen API-Schlüssel. Für eine schnelle Integration klicken Sie im Abschnitt „.env“ auf die Schaltfläche „In Zwischenablage kopieren“: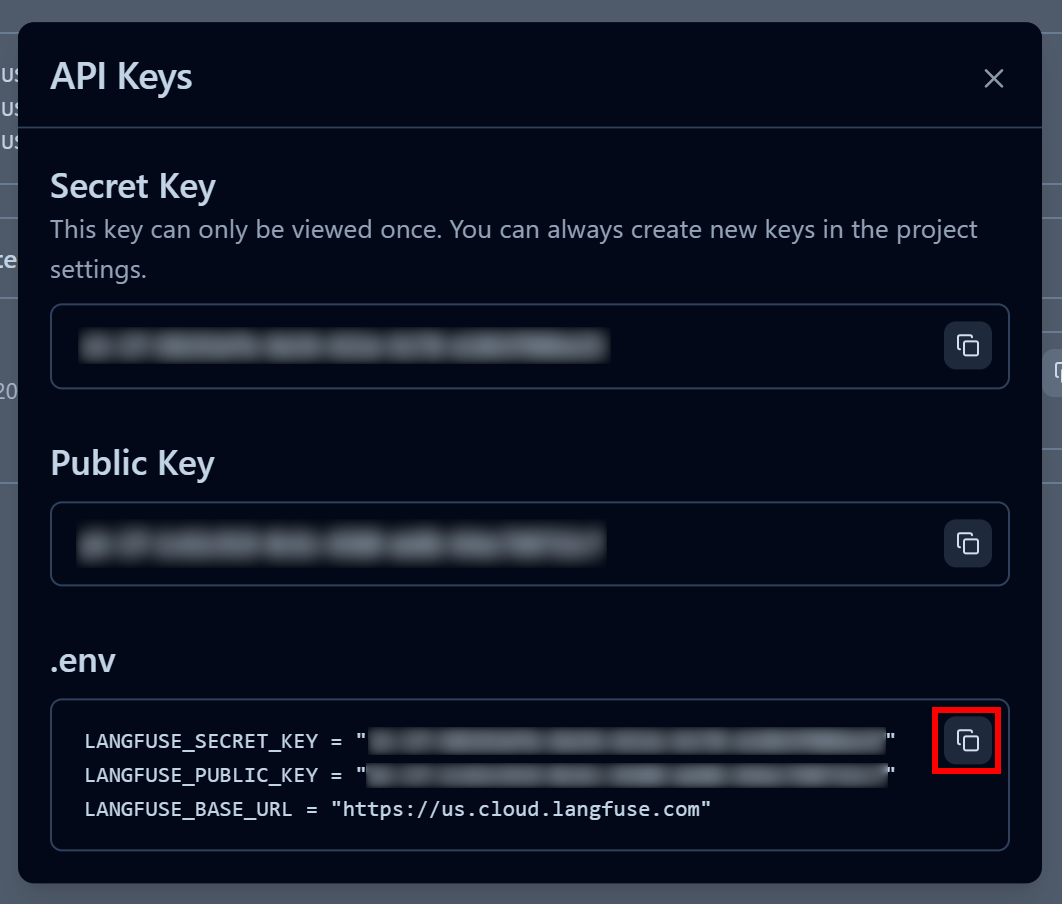
Fügen Sie anschließend die kopierten Umgebungsvariablen in die .env -Datei Ihres Projekts ein:
LANGFUSE_SECRET_KEY = "<YOUR_LANGFUSE_SECRET_KEY>"
LANGFUSE_PUBLIC_KEY = "<YOUR_LANGFUSE_PUBLIC_KEY>"
LANGFUSE_BASE_URL = "<YOUR_LANGFUSE_BASE_URL>"Großartig! Ihr Skript kann sich nun mit Ihrem Langfuse Cloud-Konto verbinden und nützliche Trace-Informationen für die Überwachung und Beobachtbarkeit senden.
Schritt 9: Langfuse-Tracking integrieren
Langfuse bietet vollständige Unterstützung für LangChain (sowie viele andere Frameworks zum Erstellen von KI-Agenten), sodass kein benutzerdefinierter Code erforderlich ist.
Um Ihren LangChain-KI-Agenten mit Langfuse zu verbinden, müssen Sie lediglich den Langfuse-Client initialisieren und einen Callback-Handler erstellen:
from langfuse import get_client
from langfuse.langchain import CallbackHandler
# Laden Sie Umgebungsvariablen aus der .env-Datei.
load_dotenv()
# Langfuse-Client für Tracking und Beobachtbarkeit initialisieren
langfuse = get_client()
# Langfuse-Callback-Handler erstellen, um Langchain-Agent-Interaktionen zu erfassen
langfuse_handler = CallbackHandler()
Übergeben Sie dann den Langfuse-Callback-Handler beim Aufruf des Agenten:
for step in agent.stream(
{"messages": [{"role": "user", "content": prompt}]},
stream_mode="values",
config={"callbacks": [langfuse_handler]} # <--- Langfuse-Integration
):
step["messages"][-1].pretty_print()Das war’s schon! Ihr LangChain-KI-Agent ist nun vollständig instrumentiert. Alle Laufzeitinformationen werden an Langfuse gesendet und können in der Web-App angezeigt werden.
Schritt 10: Endgültiger Code
Ihre Datei „agent.py“ sollte nun Folgendes enthalten:
from dotenv import load_dotenv
from langchain_brightdata import BrightDataUnlocker, BrightDataSERP
from langchain_openai import ChatOpenAI
from langchain.agents import create_agent
from langchain_community.document_loaders import PyPDFDirectoryLoader
from langchain_core.prompts import PromptTemplate
from langfuse import get_client
from langfuse.langchain import CallbackHandler
# Laden Sie Umgebungsvariablen aus der .env-Datei.
load_dotenv()
# Langfuse-Client für Tracking und Beobachtbarkeit initialisieren
langfuse = get_client()
# Langfuse-Callback-Handler erstellen, um Langchain-Agent-Interaktionen zu erfassen
langfuse_handler = CallbackHandler()
# Bright Data-Tools initialisieren
bright_data_serp_api_tool = BrightDataSERP()
bright_data_web_unlocker_api_tool = BrightDataUnlocker()
# Initialisieren Sie das große Sprachmodell.
llm = ChatOpenAI(
model="gpt-5-mini",)
# Definieren Sie eine Systemaufforderung, die den Agenten über seine Compliance- und Datenschutzaufgaben informiert.
system_prompt = """
Sie sind Experte für Compliance-Tracking. Ihre Aufgabe ist es, Dokumente auf potenzielle regulatorische und datenschutzrechtliche Probleme zu analysieren.
Ihre Analyse wird durch die Recherche nach aktualisierten Regeln und maßgeblichen Quellen im Internet mithilfe der Tools von Bright Data, einschließlich der SERP-API und des Web Unlocker, unterstützt.
Liefern Sie genaue, unternehmensgerechte Erkenntnisse und stellen Sie sicher, dass alle Ergebnisse durch Zitate aus dem Originaldokument und maßgeblichen externen Quellen untermauert sind.
"""
# Liste der für den Agenten verfügbaren Tools
tools=[bright_data_serp_api_tool, bright_data_web_unlocker_api_tool]
# Definieren Sie den KI-Agenten
agent = create_agent(
llm=llm,
tools=tools,
system_prompt=system_prompt,
)
# Alle PDF-Dokumente aus dem Eingabeordner laden
input_folder = "./input"
loader = PyPDFDirectoryLoader(input_folder)
# Alle Seiten aus allen PDF-Dateien im Eingabeordner laden
docs = loader.load()
# Alle Seiten aus den PDFs zu einer einzigen Zeichenfolge für die Analyse kombinieren
internal_document_to_analyze = "nn".join([doc.page_content for doc in docs])
# Eine Prompt-Vorlage definieren, um den Agenten durch den Workflow zu führen
prompt_template = PromptTemplate.from_template("""
Angesichts des folgenden PDF-Inhalts:
1. Lassen Sie das LLM diesen analysieren, um die wichtigsten Aspekte zu identifizieren, die im Hinblick auf den Datenschutz untersucht werden sollten.
2. Übersetzen Sie diese Aspekte in bis zu 3 sehr kurze (nicht mehr als 5 Wörter), prägnante und spezifische Suchanfragen, die für Google geeignet sind.
3. Führen Sie Websuchen für diese Suchanfragen mit dem SERP-API-Tool von Bright Data durch (Suche nach Seiten in englischer Sprache, beschränkt auf die Vereinigten Staaten).
4. Greifen Sie mit dem Web Unlocker-Tool von Bright Data auf die bis zu 5 besten Webseiten (ohne PDF-Seiten) im Markdown-Datenformat zu (mit Vorrang für Regierungswebsites).
5. Verarbeiten Sie die gesammelten Informationen und erstellen Sie einen abschließenden, prägnanten Bericht, der Zitate aus dem Originaldokument und Erkenntnisse aus den gescrapten Seiten enthält, um regulatorische Probleme zu vermeiden.
PDF-INHALT:
{pdf}
""")
# Füllen Sie die Vorlage mit dem Inhalt der PDF-Dateien.
prompt = prompt_template.format(pdf=internal_document_to_analyze)
# Streamen Sie die Antwort des Agenten, während Sie jeden Schritt mit Langfuse verfolgen.
for step in agent.stream(
{"messages": [{"role": "user", "content": prompt}]},
stream_mode="values",
config={"callbacks": [langfuse_handler]} # <--- Langfuse-Integration
):
step["messages"][-1].pretty_print()Wow! Mit nur etwa 75 Zeilen Python-Code haben Sie dank LangChain, Bright Data und Langfuse einen unternehmensfähigen KI-Agenten für die Analyse von Vorschriften und Compliance erstellt.
Schritt 11: Ausführen des Agenten
Denken Sie daran, dass Ihr KI-Agent eine PDF-Datei benötigt, um zu funktionieren. Nehmen wir für dieses Beispiel an, Sie möchten die regulatorische Analyse für das folgende Dokument durchführen:
Dies ist ein Beispiel für ein Dokument im Unternehmensstil, das auf hoher Ebene die von einem Unternehmen angewandten Verfahren zur Verarbeitung von Benutzerdaten beschreibt.
Speichern Sie es als user-data-processing-workflow.pdf und legen Sie es im Ordner input/ in Ihrem Projektverzeichnis ab: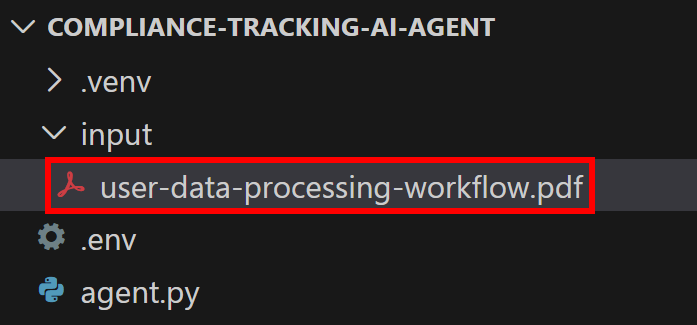
Auf diese Weise kann das Skript darauf zugreifen und es in die Eingabeaufforderung des Agenten einbetten.
Führen Sie den LagnChain-KI-Agenten mit folgendem Befehl aus:
python agent.py Im Terminal werden Sie Spuren der Aufrufe der Bright Data-Tools sehen, wie zum Beispiel diese: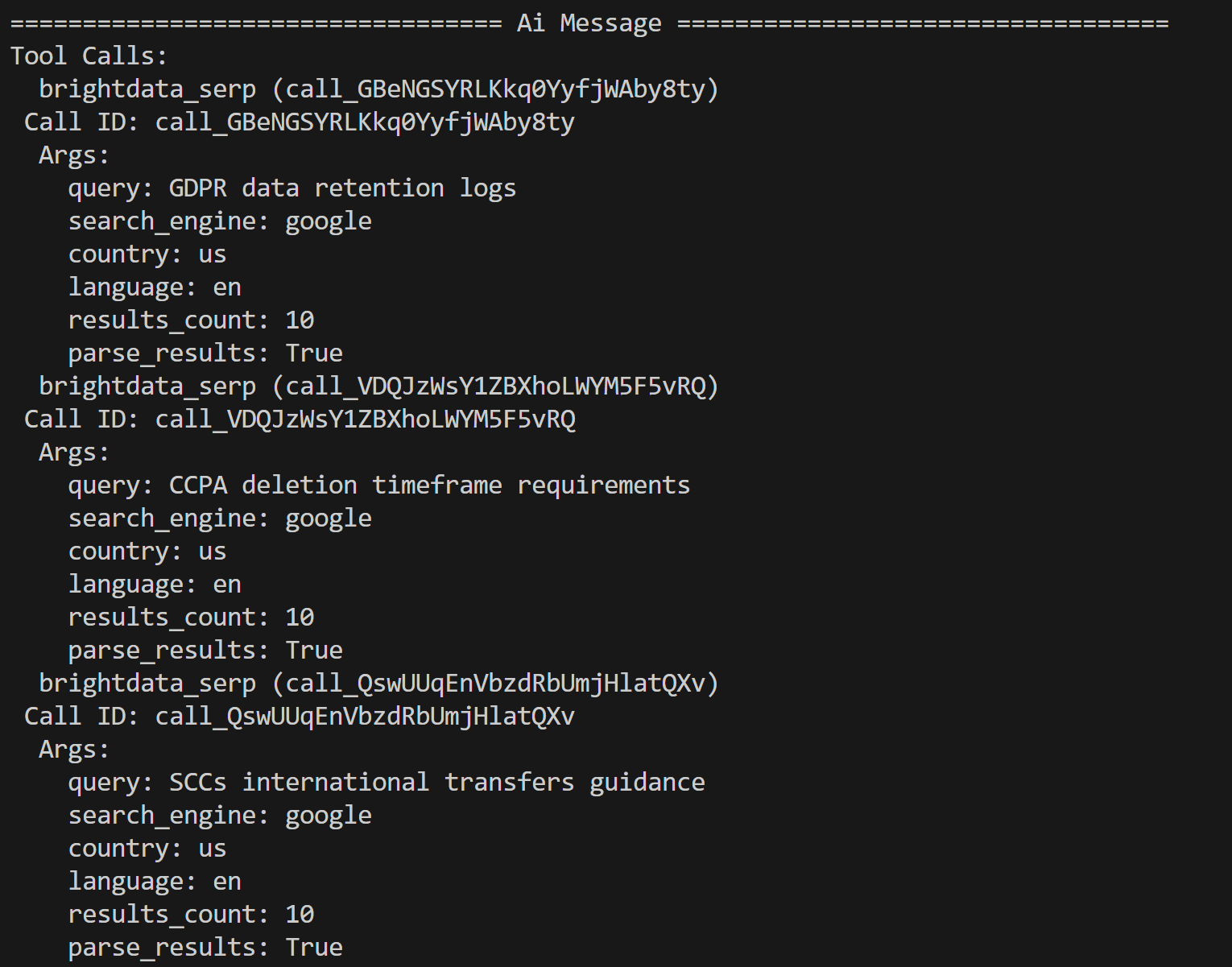
Der KI-Agent hat anhand des PDF-Inhalts die folgenden drei Suchanfragen für weitere Recherchen identifiziert:
- „GDPR-Datenaufbewahrungsprotokolle”
- „CCPA-Löschfristanforderungen”
- „SCCs international transfers guidance”
Diese Abfragen stehen im Zusammenhang mit potenziellen regulatorischen und datenschutzrechtlichen Problemen, die vom LLM im Eingabedokument hervorgehoben wurden.
Aus den Ergebnissen der Bright Data SERP-API, die Google-Suchergebnisse für diese Abfragen enthält, wählt der Agent die wichtigsten Seiten aus und scrapt sie über das Web Unblocker API-Tool: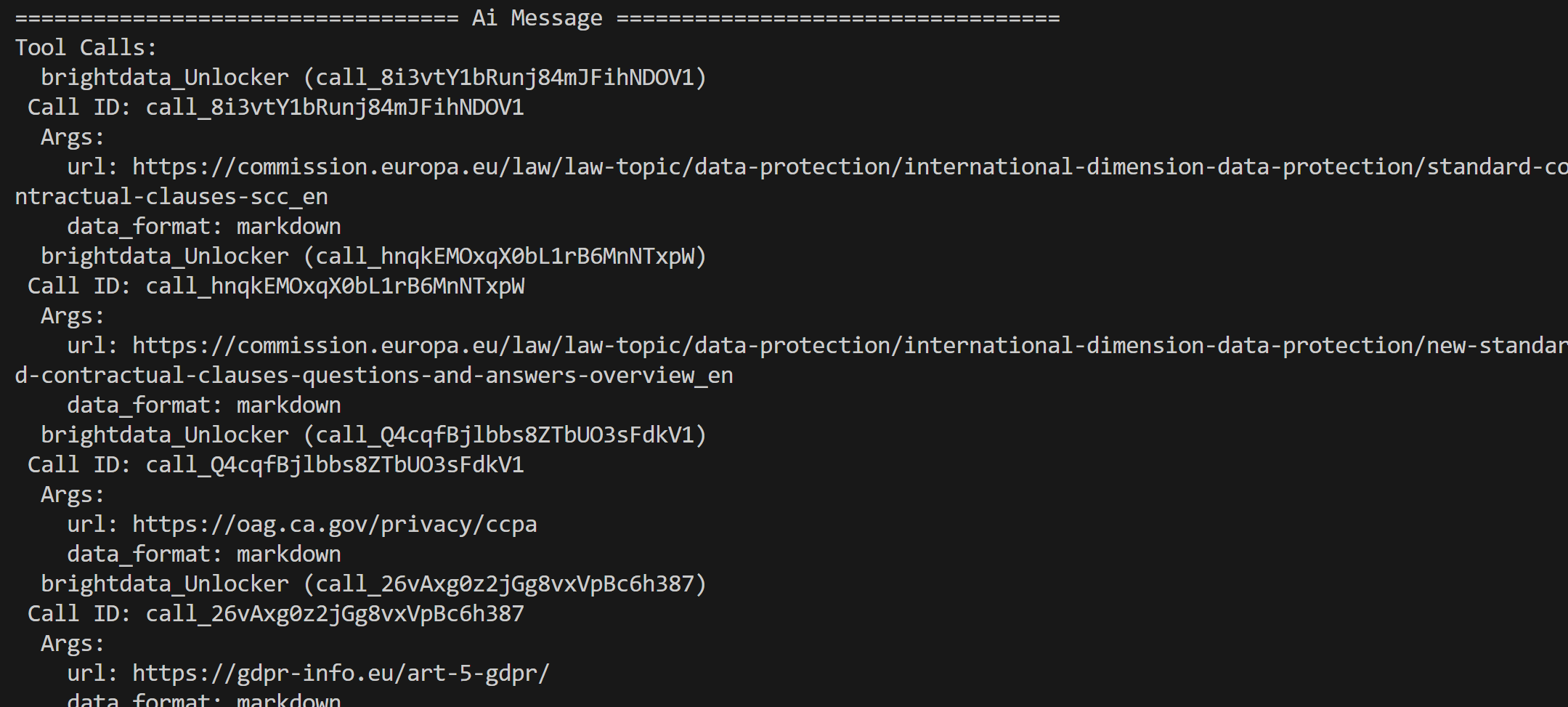
Der Inhalt dieser Seiten wird dann verarbeitet und in einem abschließenden Bericht zur regulatorischen Analyse zusammengefasst.
Et voilà! Ihr KI-Agent funktioniert wie am Schnürchen. Jetzt ist es an der Zeit, die Auswirkungen der Langfuse-Integration auf die Beobachtbarkeit und Nachverfolgung zu überprüfen.
Schritt 12: Überprüfen Sie die Agent-Traces in Langfuse
Sobald Ihr KI-Agent mit der Ausführung seiner Aufgabe beginnt, werden die Daten in Ihrem Langfuse-Dashboard angezeigt. Beachten Sie insbesondere, wie die Anzahl der „Traces” von 0 auf 1 steigt und wie die Modellkosten steigen: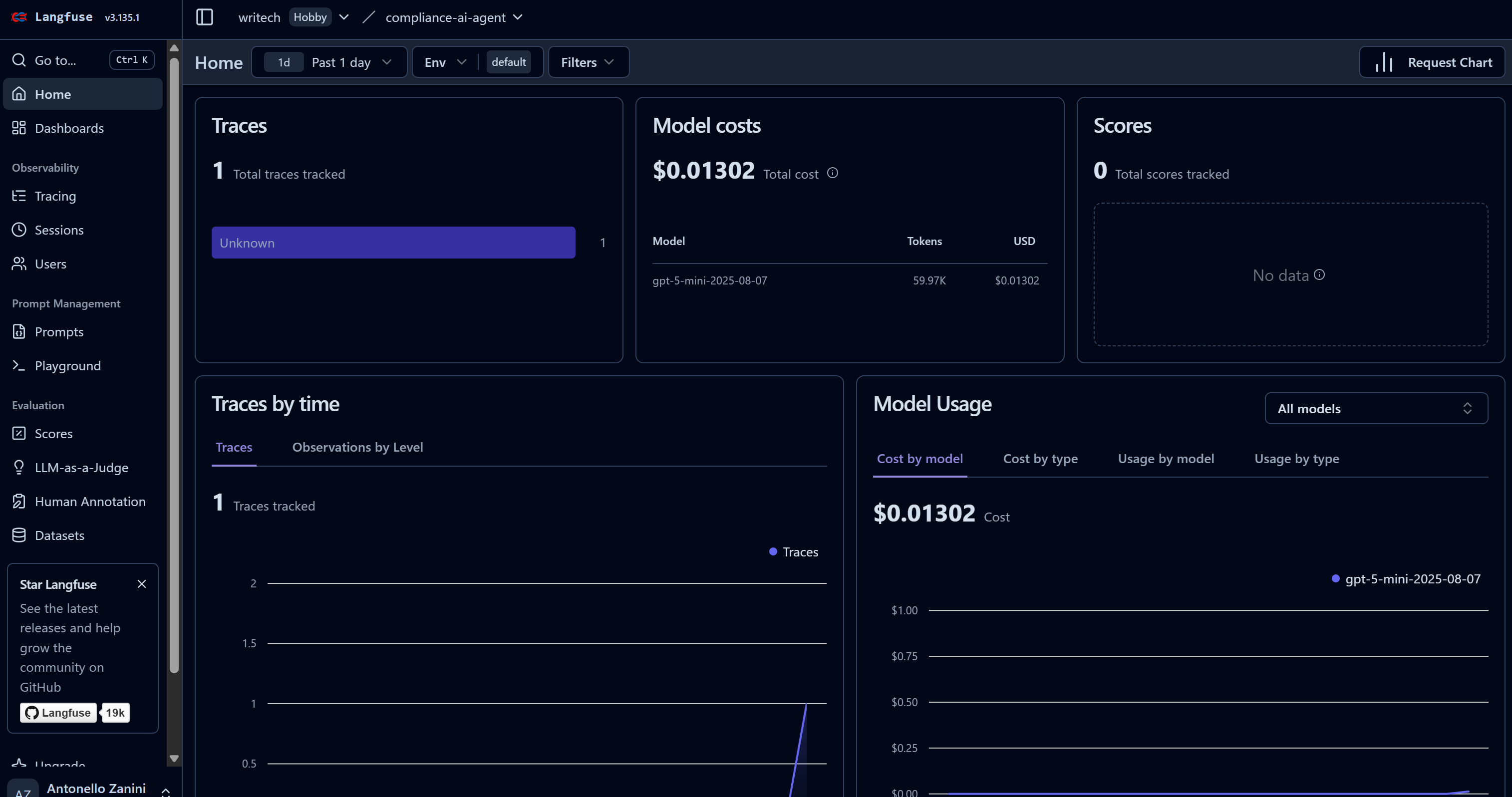
Dieses Dashboard hilft Ihnen, die Kosten sowie viele andere nützliche Kennzahlen zu überwachen.
Um alle Informationen zu einem bestimmten Agentenlauf anzuzeigen, gehen Sie zur Seite „Tracing” und klicken Sie auf die entsprechende Trace-Zeile für Ihren Agenten: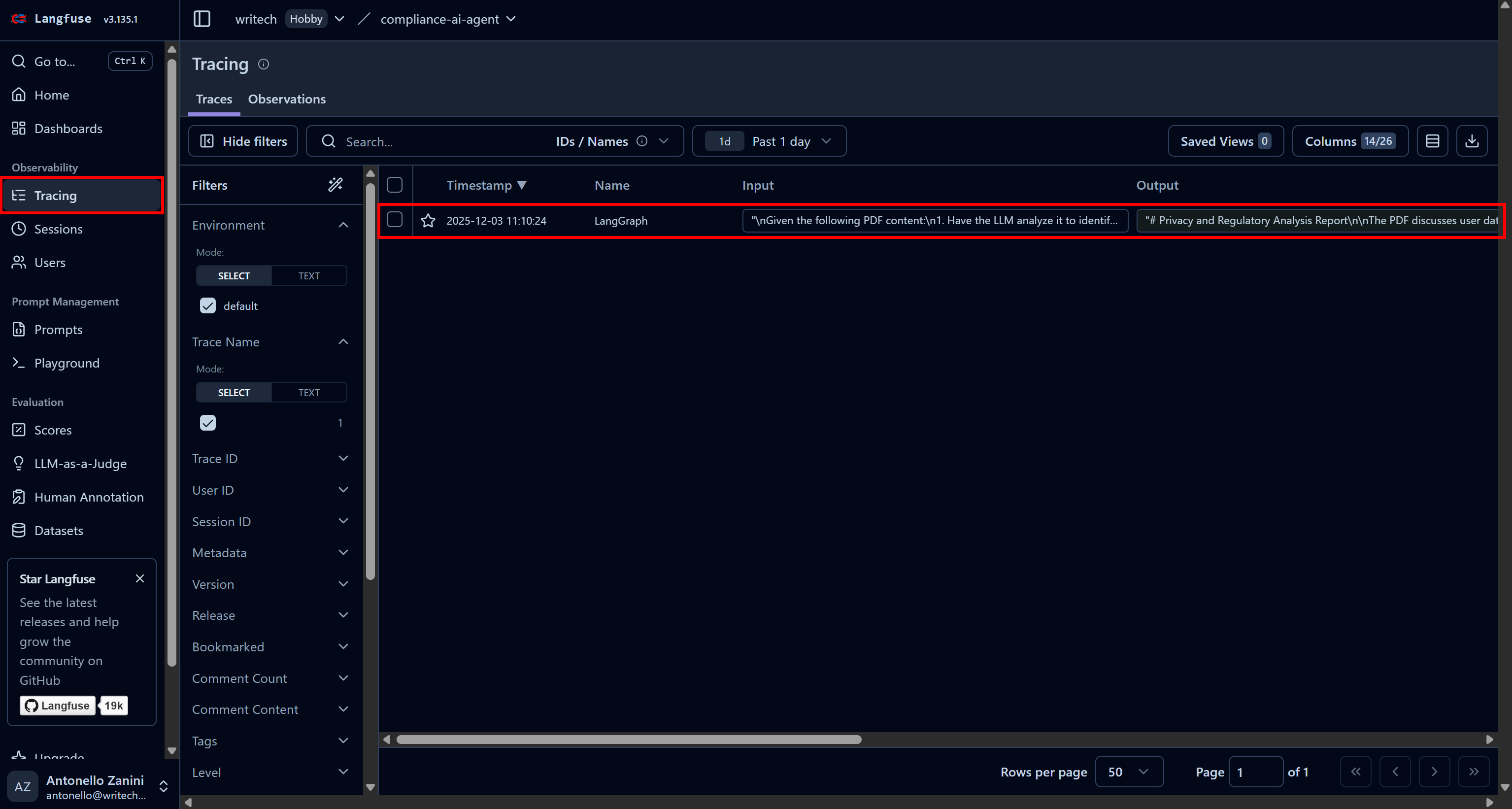
Auf der linken Seite der Webseite öffnet sich ein Fenster mit detaillierten Informationen zu jedem Schritt, den Ihr Agent ausgeführt hat.
Konzentrieren Sie sich auf den ersten Knoten „ChatOpenAI”. Dieser zeigt an, dass der Agent die Bright Data SERP-API bereits dreimal aufgerufen hat, während die Web Unlocker-API noch nicht aufgerufen wurde: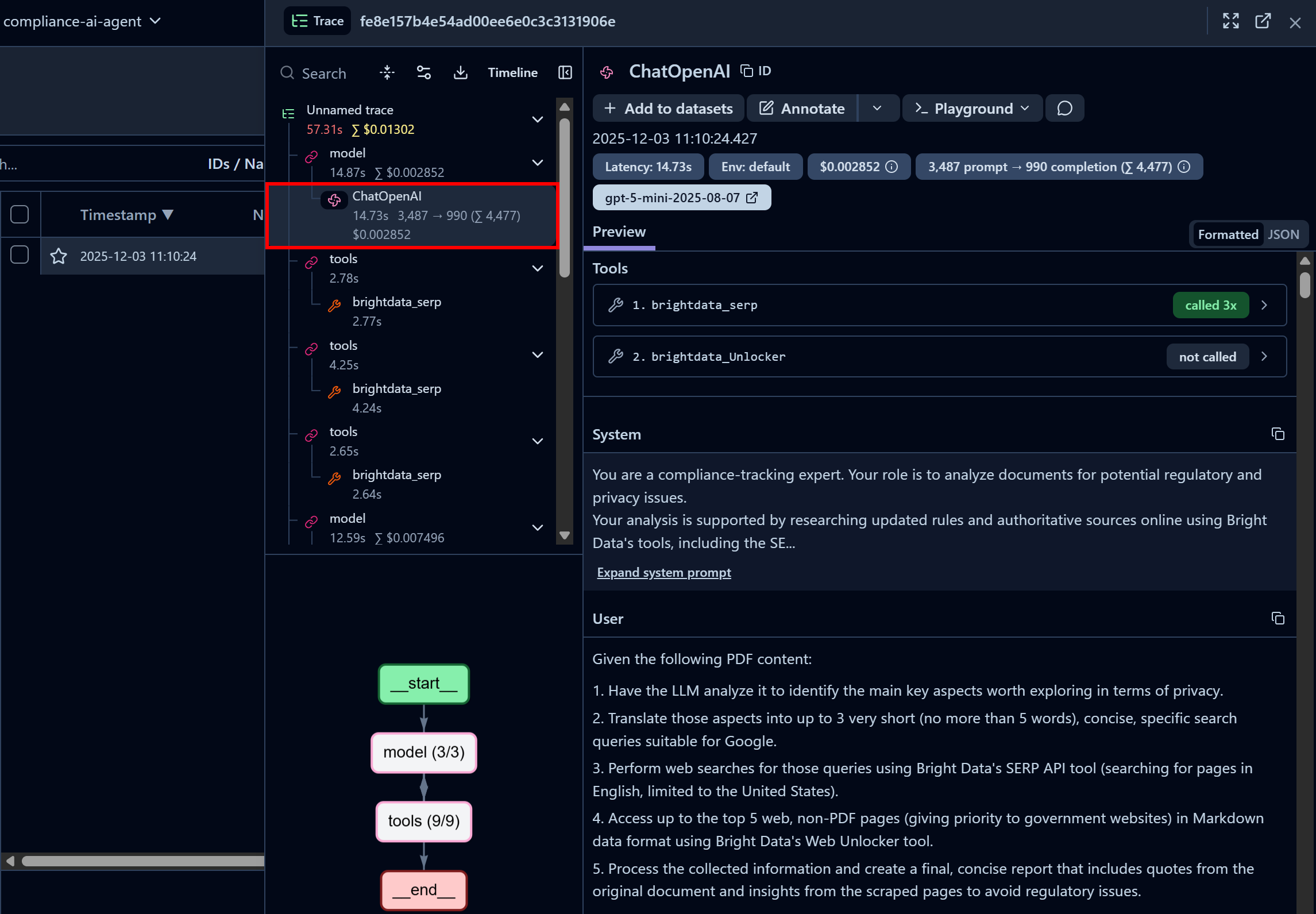
Hier können Sie auch die in Ihrem Code konfigurierte Systemaufforderung und die an den Agenten übergebenen Benutzeraufforderungen überprüfen. Darüber hinaus können Sie auf Informationen wie Latenz, Kosten, Zeitstempel und mehr zugreifen. Außerdem hilft ein interaktives Flussdiagramm in der unteren linken Ecke dabei, den Ablauf des Agenten Schritt für Schritt zu visualisieren und zu untersuchen.
Sehen Sie sich nun einen Bright Data SERP-API-Toolaufrufknoten an: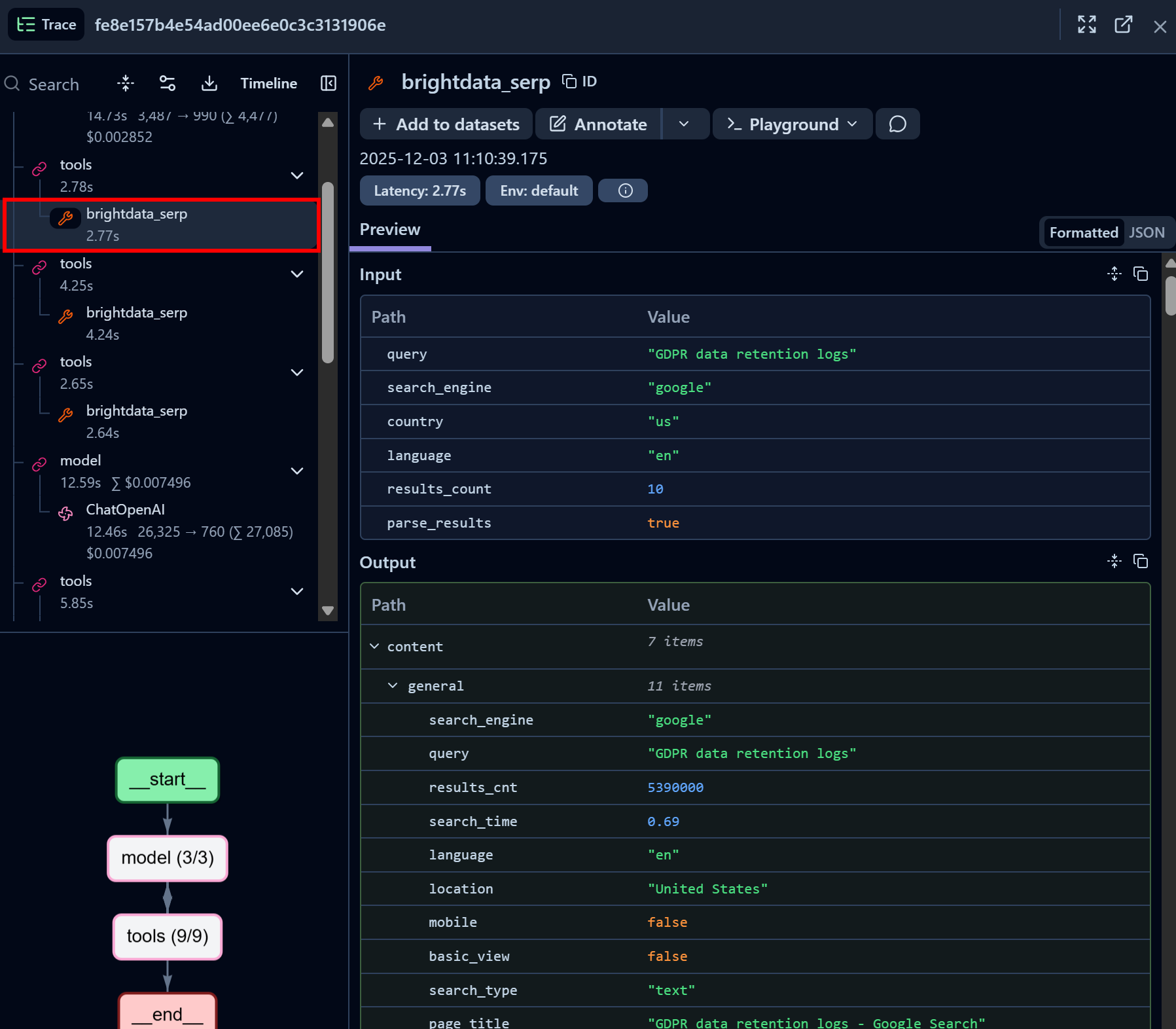
Beachten Sie, wie das Bright Data SERP-API-LangChain-Tool erfolgreich SERP-Daten für die angegebene Suchanfrage im JSON-Format zurückgegeben hat (was sich hervorragend für die LLM-Erfassung in KI-Agenten eignet). Dies zeigt, dass die Integration mit der Bright Data SERP-API einwandfrei funktioniert.
Wenn Sie jemals versucht haben, Google-Suchergebnisse in Python zu scrapen, wissen Sie, wie schwierig das sein kann. Dank der SERP-API von Bright Data ist dieser Prozess sofort, schnell und vollständig KI-fähig.
Konzentrieren Sie sich ebenfalls auf einen Aufrufknoten des Bright Data Web Unlocker-API-Tools: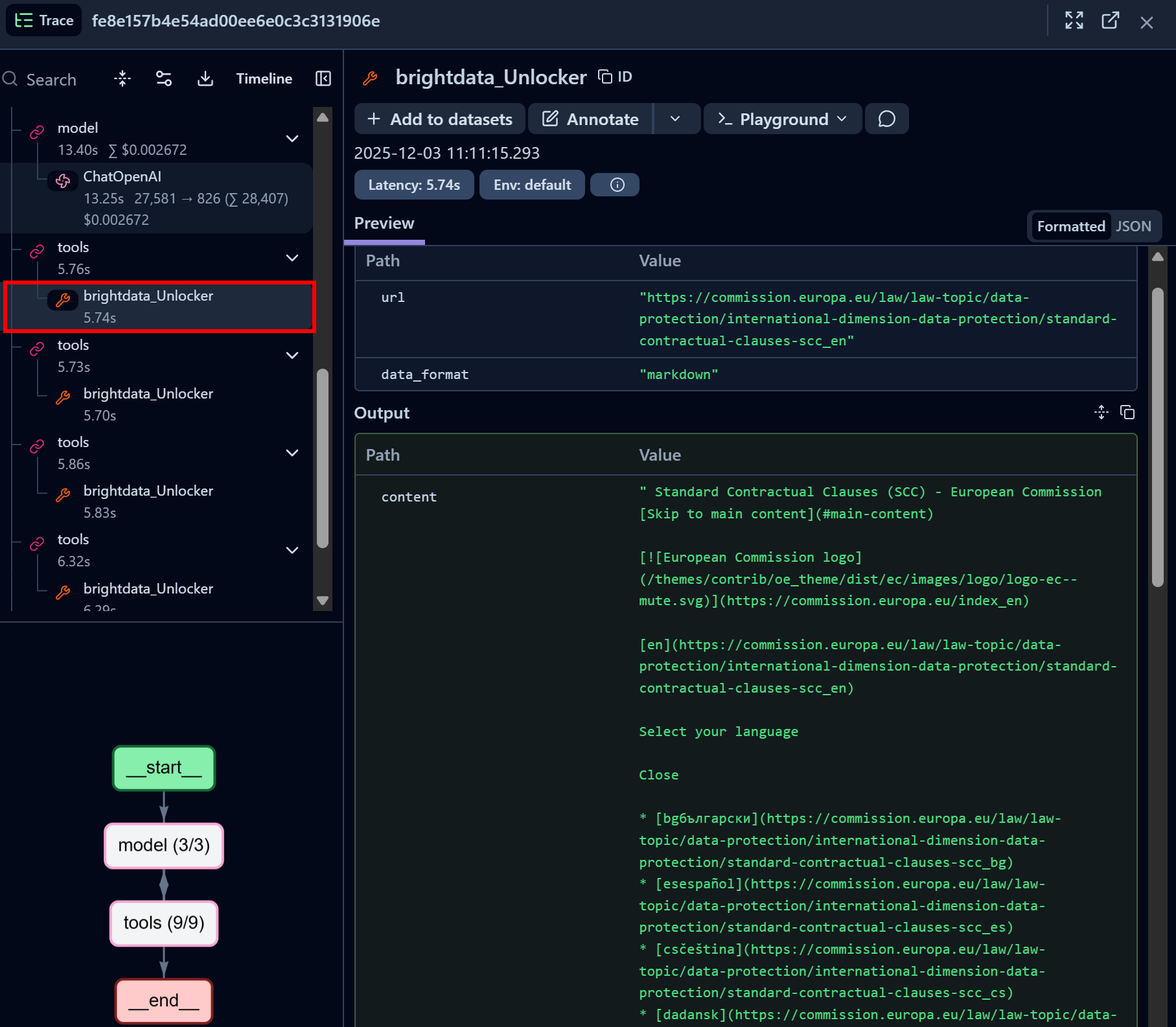
Das Bright Data Web Unlocker LangChain-Tool hat erfolgreich auf die identifizierte Seite zugegriffen und sie im Markdown-Format zurückgegeben.
Die Web Unlocker API gibt Ihrem KI-Agenten die Möglichkeit, programmgesteuert auf jede Governance-Website (oder andere Webseiten) zuzugreifen, ohne sich um Blockierungen sorgen zu müssen, und erhält als Ergebnis eine KI-optimierte Version der Seite, die für die LLM-Erfassung geeignet ist.
Großartig! Die Integration von Langfuse + LangChain + Bright Data ist nun abgeschlossen. Langfuse kann mit vielen anderen Lösungen zur Erstellung von KI-Agenten integriert werden, die alle ebenfalls von Bright Data unterstützt werden.
Nächste Schritte
Um diesen KI-Agenten mit Langfuse-Integration noch unternehmensgerechter zu machen, sollten Sie die folgenden Erkenntnisse berücksichtigen:
- Fügen Sie eine Prompt-Verwaltung hinzu: Verwenden Sie die Prompt-Verwaltungsfunktionen von Langfuse, um Prompts für Ihre LLM-Anwendungen zu speichern, zu versionieren und abzurufen.
- Berichte exportieren: Erstellen Sie einen Abschlussbericht und speichern Sie ihn entweder auf der Festplatte, in einem freigegebenen Ordner oder senden Sie ihn per E-Mail an die relevanten Stakeholder.
- Definieren Sie ein benutzerdefiniertes Dashboard: Passen Sie das Langfuse-Dashboard so an, dass nur die für Ihr Team oder Ihre Stakeholder relevanten Kennzahlen angezeigt werden.
Fazit
In diesem Tutorial haben Sie gelernt, wie Sie Ihren KI-Agenten mit Langfuse überwachen und verfolgen können. Im Detail haben Sie gesehen, wie Sie einen LangChain-KI-Agenten instrumentieren, der auf den KI-fähigen Webzugriffslösungen von Bright Data basiert.
Wie bereits erwähnt, lässt sich Bright Data genau wie Langfuse in eine Vielzahl von KI-Lösungen integrieren, von Open-Source-Tools bis hin zu unternehmensgerechten Plattformen. Auf diese Weise können Sie Ihren Agenten mit leistungsstarken Funktionen zum Abrufen und Durchsuchen von Webdaten verbessern und gleichzeitig seine Leistung und sein Verhalten über Langfuse überwachen.
Melden Sie sich kostenlos bei Bright Data an und probieren Sie noch heute unsere KI-fähigen Webdatenlösungen aus!





