

In diesem Tutorial erfahren Sie:
- Was Haystack ist und warum die Integration von Bright Data seine KI-Pipelines und -Agenten auf die nächste Stufe hebt.
- Wie Sie loslegen können.
- Wie Sie Haystack mit Bright Data mithilfe benutzerdefinierter Tools integrieren.
- Wie Sie Haystack mit über 60 Tools verbinden, die über Web MCP verfügbar sind.
Lassen Sie uns loslegen!
Haystack: Was es ist und warum Tools zum Abrufen von Webdaten benötigt werden
Haystack ist ein Open-Source-KI-Framework für die Erstellung produktionsreifer Anwendungen mit LLMs. Es ermöglicht Ihnen die Erstellung von RAG-Systemen, KI-Agenten und fortschrittlichen Datenpipelines, indem es Komponenten wie Modelle, Vektordatenbanken und Tools zu modularen Workflows verbindet.
Haystack bietet die Flexibilität, Anpassungsmöglichkeiten und Skalierbarkeit, die erforderlich sind, um KI-Projekte vom Konzept bis zur Bereitstellung zu begleiten. All das in einer Open-Source-Bibliothek mit über 23.000 GitHub-Stars.
Doch egal, wie ausgefeilt Ihre Haystack-Anwendung auch sein mag, sie unterliegt dennoch den grundlegenden Einschränkungen von LLMs: veraltetes Wissen aus statischen Trainingsdaten und fehlender Live-Webzugriff!
Die Lösung ist die Integration mit einem Webdatenanbieter für KI wie Bright Data, der Tools für Web-Scraping, Suche, Browser-Automatisierung und vieles mehr bietet – und so das volle Potenzial Ihres KI-Systems ausschöpft!
Voraussetzungen
Um diesem Tutorial folgen zu können, benötigen Sie:
- Python 3.9+ lokal installiert.
- Ein Bright Data-Konto mit einem konfigurierten API-Schlüssel.
- Einen OpenAI-API-Schlüssel (oder einen API-Schlüssel von einem anderen von Haystack unterstützten LLM).
Wenn Sie dies noch nicht getan haben, folgen Sie der offiziellen Anleitung, um Ihr Konto einzurichten und einen Bright Data API-Schlüssel zu generieren. Bewahren Sie ihn an einem sicheren Ort auf, da Sie ihn in Kürze benötigen werden.
Einige Kenntnisse über die Produkte und Dienstleistungen von Bright Data sind ebenfalls hilfreich, ebenso wie ein grundlegendes Verständnis der Funktionsweise von Tools und der MCP-Integration in Haystack.
Der Einfachheit halber gehen wir davon aus, dass Sie bereits über ein Python-Projekt mit einer virtuellen Umgebung verfügen. Installieren Sie Haystack mit dem folgenden Befehl:
pip install haystack-KISie haben nun alles, was Sie benötigen, um mit der Bright Data-Integration in Haystack zu beginnen. Hier werden wir zwei Ansätze untersuchen:
- Definieren Sie benutzerdefinierte Tools mit der Anmerkung
@tool. - Laden Sie ein
MCPToolvom Bright Data Web MCP-Server.
Definieren benutzerdefinierter Bright Data-basierter Tools in Haystack
Eine Möglichkeit, auf die Funktionen von Bright Data in Haystack zuzugreifen, ist die Definition benutzerdefinierter Tools. Diese Tools werden über eine API in benutzerdefinierten Funktionen in Bright Data-Produkte integriert.
Um diesen Prozess zu vereinfachen, verwenden wir das Bright Data Python SDK, das eine Python-API bereitstellt, die sich leicht aufrufen lässt:
- Web Unlocker API: Scrapen Sie jede Website mit einer einzigen Anfrage und erhalten Sie sauberes HTML oder JSON, während die gesamte Proxy-, Entsperrungs-, Header- und CAPTCHA-Verarbeitung automatisiert ist.
- SERP-API: Sammeln Sie Suchmaschinenergebnisse von Google, Bing und vielen anderen in großem Umfang, ohne sich um Blockierungen sorgen zu müssen.
- Web-Scraping-APIs: Rufen Sie strukturierte, geparste Daten von beliebten Websites wie Amazon, Instagram, LinkedIn, Yahoo Finance und anderen ab.
- Und andere Bright Data-Lösungen…
Wir werden die wichtigsten SDK-Methoden in Haystack-fähige Tools umwandeln, sodass jeder KI-Agent oder jede Pipeline von der Bright Data-gestützten Webdatenabfrage profitieren kann!
Schritt 1: Installieren und Einrichten des Bright Data Python SDK
Beginnen Sie mit der Installation des Bright Data Python SDK über das brightdata-sdk PyPI-Paket:
pip install brightdata-sdkImportieren Sie die Bibliothek und initialisieren Sie eine BrightDataClient -Instanz:
import os
from brightdata import BrightDataClient
os.environ["BRIGHTDATA_API_TOKEN"] = "<YOUR_BRIGHT_DATA_API_KEY>" # Ersetzen Sie diesen Platzhalter durch Ihren Bright Data API-Schlüssel.
# Initialisieren Sie den Bright Data Python SDK-Client.
client = BrightDataClient(
token=BRIGHT_DATA_API_KEY,
)Ersetzen Sie den Platzhalter <YOUR_BRIGHT_DATA_API_KEY> durch den API-Schlüssel, den Sie im Abschnitt „Voraussetzungen“ generiert haben.
Vermeiden Sie bei produktionsreifem Code die feste Codierung Ihres API-Schlüssels im Skript. Das Bright Data Python SDK erwartet ihn aus der Umgebungsvariablen BRIGHTDATA_API_TOKEN. Setzen Sie daher Ihre Umgebungsvariable global auf Ihren Bright Data API-Schlüssel oder laden Sie ihn mit dem Python-Dotenv-Paket aus einer .env-Datei.
BrightDataClient richtet automatisch die Standardzonen „Web Unlocker“ und „SERP-API“ in Ihrem Bright Data-Konto ein: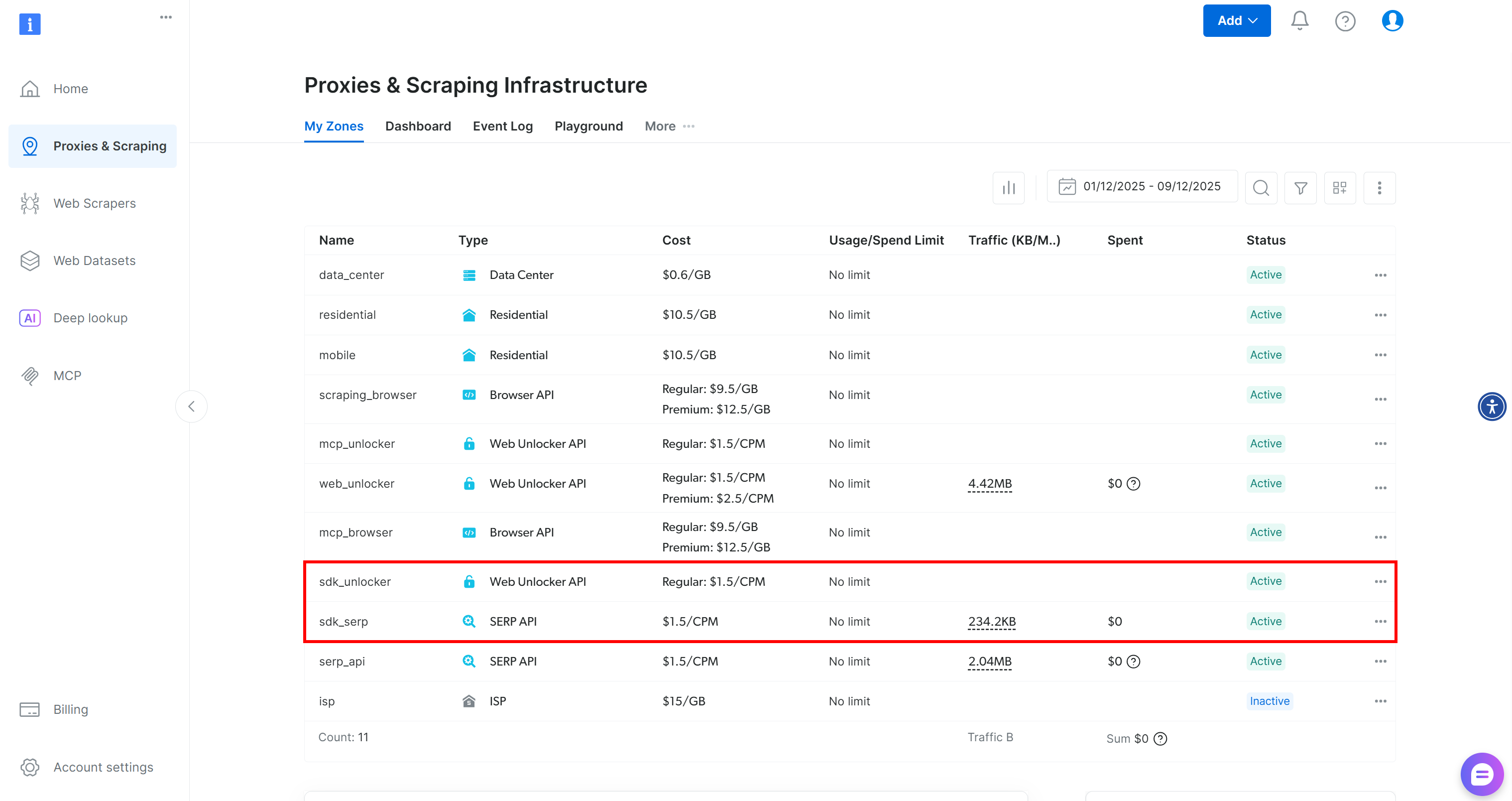
Diese beiden Zonen werden vom SDK benötigt, um seine über 60 Tools verfügbar zu machen.
Wenn Sie bereits benutzerdefinierte Zonen eingerichtet haben, geben Sie diese wie in der Dokumentation beschrieben an:
client = BrightDataClient(
serp_zone="serp_api", # Ersetzen Sie dies durch den Namen Ihrer SERP-API-Zone.
web_unlocker_zone="web_unlocker", # Ersetzen Sie dies durch den Namen Ihrer Web Unlocker-API-Zone.
)Fantastisch! Sie sind nun bereit, die Bright Data Python SDK-Methoden in Haystack-Tools umzuwandeln.
Schritt 2: Wandeln Sie die SDK-Funktionen in Tools um
In diesem Abschnitt erfahren Sie, wie Sie die SERP-API- und Web Unlocker-Methoden aus dem Bright Data Python SDK in Haystack-Tools umwandeln können. Nachdem Sie dies gelernt haben, können Sie jede andere SDK-Methode oder jeden direkten API-Aufruf ganz einfach in ein Haystack-Tool umwandeln.
Beginnen Sie damit, die SERP-API-Methode so umzuwandeln, dass sie als KI-fähiges Tool ausgeführt werden kann:
from brightdata import SearchResult
from typing import Union, List
import json
from haystack.tools import Tool
parameters = {
"type": "object",
"properties": {
"query": {
"type": ["string", "array"],
"items": {"type": "string"},
"description": "Die Suchanfrage oder eine Liste von Suchanfragen, die bei Google ausgeführt werden sollen."
},
"kwargs": {
"type": "object",
"description": "Zusätzliche optionale Parameter für die Suche (z. B. Standort, Sprache, Gerät, Anzahl der Ergebnisse)."
}
},
"required": ["query"]
}
def serp_api_output_handler(results: Union[SearchResult, List[SearchResult]]) -> str:
if isinstance(results, list):
# Verarbeitet eine Liste von SearchResult-Instanzen.
output = [result.data for result in results]
else:
# Verarbeitet ein einzelnes SearchResult.
output = results.data
return json.dumps(output)
serp_api_tool = Tool(
name="serp_api_tool",
description="Ruft die Bright Data SERP-API auf, um Websuchen durchzuführen und SERP-Daten von Google abzurufen.",
parameters=parameters,
function=client.search.google,
outputs_to_string={ "handler": serp_api_output_handler },
outputs_to_state= {
"documents": {"handler": serp_api_output_handler }
}
)Der obige Ausschnitt definiert ein Haystack-Tool für die Bright Data SERP-API. Zum Erstellen des Tools sind ein Name, eine Beschreibung, ein JSON-Schema, das den Eingabeparametern entspricht, und die Funktion erforderlich, die in ein Tool konvertiert werden soll.
Nun gibt client.search.google() ein spezielles Objekt zurück. Daher benötigen Sie einen benutzerdefinierten Ausgabe-Handler, um die Ausgabe der Funktion in eine Zeichenfolge umzuwandeln. Dieser Handler konvertiert die Ergebnisse in JSON und ordnet sie sowohl einer Zeichenfolgenausgabe als auch dem Agentenstatus zu.
Das soeben definierte Tool kann nun von KI-Agenten oder Pipelines verwendet werden, um Google-Suchen durchzuführen und strukturierte SERP-Daten abzurufen.
Erstellen Sie auf ähnliche Weise ein Tool zum Aufrufen der Web Unlocker-Methode:
parameters = {
"type": "object",
"properties": {
"url": {
"type": ["string", "array"],
"items": {"type": "string"},
"description": "Die URL oder Liste von URLs, die gescrapt werden sollen."
},
"country": {
"type": "string",
"description": "Optionaler Ländercode zur Lokalisierung des Scrapings."
},
},
"required": ["url"]
}
def web_unlocker_output_handler(results: Union[ScrapeResult, List[ScrapeResult]]) -> str:
if isinstance(results, list):
# Eine Liste von ScrapeResult-Instanzen verarbeiten
output = [result.data for result in results]
else:
# Ein einzelnes ScrapeResult verarbeiten
output = results.data
return json.dumps(output)
web_unlocker_tool = Tool(
name="web_unlocker_tool",
description="Ruft die Bright Data Web Unlocker API auf, um Webseiten zu scrapen und deren Inhalt abzurufen.",
parameters=parameters,
function=client.scrape.generic.url,
outputs_to_string={"handler": web_unlocker_output_handler},
outputs_to_state={"scraped_data": {"handler": web_unlocker_output_handler}}
)Mit diesem neuen Tool können KI-Agenten Webseiten scrapen und auf deren Inhalte zugreifen, selbst wenn diese durch Anti-Scraping- oder Anti-Bot-Lösungen geschützt sind.
Großartig! Sie haben nun zwei Bright Data Haystack-Tools zur Verfügung.
Schritt 3: Übergeben Sie die Tools an einen Haystack-KI-Agenten
Die oben genannten Tools können direkt aufgerufen, an Chat-Generatoren weitergeleitet, in Haystack-Pipelines verwendet oder in KI-Agenten integriert werden. Wir zeigen Ihnen den KI-Agenten-Ansatz, aber Sie können die anderen drei Methoden ganz einfach testen, indem Sie der Dokumentation folgen.
Zunächst benötigt ein Haystack-KI-Agent eine LLM-Engine. In diesem Beispiel verwenden wir ein OpenAI-Modell, aber jedes andere unterstützte LLM ist ebenfalls geeignet:
from haystack.components.generators.chat import OpenAIChatGenerator
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_API_KEY>" # Ersetzen Sie dies durch Ihren OpenAI-API-Schlüssel
# Initialisieren Sie die LLM-Engine
chat_generator = OpenAIChatGenerator(
model="gpt-5-mini"
)Wie bereits betont, laden Sie den OpenAI-API-Schlüssel aus der Umgebung in ein Produktionsskript. Hier haben wir das Modell gpt-5-mini konfiguriert, aber jedes OpenAI-Modell, das Tool-Aufrufe unterstützt, funktioniert. Andere unterstützte Generatoren sind ebenfalls kompatibel.
Verwenden Sie als Nächstes die LLM-Engine zusammen mit den Tools, um einen Haystack-KI-Agenten zu erstellen:
from haystack.components.agents import Agent
agent = Agent(
chat_generator=chat_generator,
tools=[serp_api_tool, web_unlocker_tool], # Die Bright Data-Tools
)Beachten Sie, wie die beiden Bright Data-Tools an die Tools-Eingabe des Agenten übergeben werden. Dadurch kann der KI-Agent, der von OpenAI GPT-5 Mini angetrieben wird, die benutzerdefinierten Bright Data-Tools aufrufen. Mission erfüllt!
Schritt 4: KI-Agent ausführen
Um die Integration von Haystack und Bright Data zu testen, betrachten Sie eine Aufgabe, die eine Websuche und das Web-Scraping umfasst. Verwenden Sie beispielsweise diese Eingabeaufforderung:
Identifizieren Sie die drei wichtigsten aktuellen Börsennachrichten über das Unternehmen Google zu verschiedenen Themen, rufen Sie die Artikel auf und erstellen Sie eine kurze Zusammenfassung für jeden Artikel. Dies gibt allen, die an einer Investition in Google interessiert sind, einen schnellen Überblick.
Verwenden Sie den folgenden Ausschnitt, um diese Eingabeaufforderung in Ihrem Bright Data-basierten Haystack-Agenten auszuführen:
from haystack.dataclasses import ChatMessage
agent.warm_up()
prompt = """
Identifizieren Sie die drei wichtigsten aktuellen Börsennachrichten über das Unternehmen Google zu verschiedenen Themen, rufen Sie die Artikel auf und geben Sie eine kurze Zusammenfassung für jeden Artikel.
"""
chat_message = ChatMessage.from_user(prompt)
response = agent.run(messages=[chat_message])Drucken Sie anschließend die vom KI-Agenten erzeugte Antwort zusammen mit Details zur Tool-Nutzung aus:
for msg in response["messages"]:
role = msg._role.value
if role == "tool":
# Tool-Ausgaben protokollieren
for content in msg._content:
print("=== Tool-Ausgabe ===")
print(json.dumps(content.result, indent=2))
elif role == "assistant":
# Log assistant final messages
for content in msg._content:
if hasattr(content, "text"):
print("=== Assistant Response ===")
print(content.text)Perfekt! Jetzt müssen wir nur noch den vollständigen Code ansehen und ausführen, um zu überprüfen, ob er funktioniert.
Schritt 5: Vollständiger Code
Der endgültige Code für Ihren Haystack-KI-Agenten, der mit den Bright Data-Tools verbunden ist, lautet:
# pip install haystack-ai brightdata-sdk
import os
from brightdata import BrightDataClient, SearchResult, ScrapeResult
from typing import Union, List
import json
from haystack.tools import Tool
from haystack.components.generators.chat import OpenAIChatGenerator
from haystack.components.agents import Agent
from haystack.dataclasses import ChatMessage
# Setzen Sie die erforderlichen Umgebungsvariablen.
os.environ["BRIGHTDATA_API_TOKEN"] = "<YOUR_BRIGHT_DATA_API_KEY>" # Ersetzen Sie dies durch Ihren Bright Data API-Schlüssel.
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_API_KEY>" # Ersetzen Sie dies durch Ihren OpenAI API-Schlüssel.
# Initialisieren Sie den Bright Data Python SDK-Client
client = BrightDataClient(
serp_zone="serp_api", # Ersetzen Sie dies durch den Namen Ihrer SERP-API-Zone
web_unlocker_zone="web_unlocker", # Ersetzen Sie dies durch den Namen Ihrer Web Unlocker-API-Zone
)
# Verwandeln Sie client.search.google() aus dem Bright Data Python SDK in ein Haystack-Tool
parameters = {
"type": "object",
"properties": {
"query": {
"type": ["string", "array"],
"items": {"type": "string"},
"description": "Die Suchanfrage oder eine Liste von Suchanfragen, die bei Google ausgeführt werden sollen."
},
"kwargs": {
"type": "object",
"description": "Zusätzliche optionale Parameter für die Suche (z. B. Standort, Sprache, Gerät, Anzahl der Ergebnisse)."
}
},
"required": ["query"]
}
def serp_api_output_handler(results: Union[SearchResult, List[SearchResult]]) -> str:
if isinstance(results, list):
# Verarbeitet eine Liste von SearchResult-Instanzen.
output = [result.data for result in results]
else:
# Verarbeitet ein einzelnes SearchResult.
output = results.data
return json.dumps(output)
serp_api_tool = Tool(
name="serp_api_tool",
description="Ruft die Bright Data SERP-API auf, um Websuchen durchzuführen und SERP-Daten von Google abzurufen.",
parameters=parameters,
function=client.search.google,
outputs_to_string={ "handler": serp_api_output_handler },
outputs_to_state= {
"documents": {"handler": serp_api_output_handler }
})
# client.scrape.generic.url() aus dem Bright Data Python SDK in ein Haystack-Tool umwandeln
parameters = {
"type": "object",
"properties": {
"url": {
"type": ["string", "array"],
"items": {"type": "string"},
"description": "Die URL oder Liste von URLs, die gescrapt werden sollen."
},
"country": {
"type": "string",
"description": "Optionaler Ländercode zur Lokalisierung des Scrapings."
},
},
"required": ["url"]
}
def web_unlocker_output_handler(results: Union[ScrapeResult, List[ScrapeResult]]) -> str:
if isinstance(results, list):
# Behandeln Sie eine Liste von ScrapeResult-Instanzen.
output = [result.data for result in results]
else:
# Behandeln Sie ein einzelnes ScrapeResult.
output = results.data
return json.dumps(output)
web_unlocker_tool = Tool(
name="web_unlocker_tool",
description="Ruft die Bright Data Web Unlocker API auf, um Webseiten zu scrapen und deren Inhalt abzurufen.",
parameters=parameters,
function=client.scrape.generic.url,
outputs_to_string={"handler": web_unlocker_output_handler},
outputs_to_state={"scraped_data": {"handler": web_unlocker_output_handler}}
)
# Initialisieren Sie die LLM-Engine.
chat_generator = OpenAIChatGenerator(
model="gpt-5-mini")
# Initialisieren Sie einen Haystack-KI-Agenten.
agent = Agent(
chat_generator=chat_generator,
tools=[serp_api_tool, web_unlocker_tool], # Die Bright Data-Tools
)
## Den Agenten ausführen
agent.warm_up()
prompt = """
Identifizieren Sie die drei wichtigsten aktuellen Börsennachrichten über das Unternehmen Google zu verschiedenen Themen, greifen Sie auf die Artikel zu und geben Sie eine kurze Zusammenfassung für jeden Artikel.
"""
chat_message = ChatMessage.from_user(prompt)
response = agent.run(messages=[chat_message])
## Ausgabe in strukturiertem Format mit Informationen zur Tool-Verwendung drucken
for msg in response["messages"]:
role = msg._role.value
if role == "tool":
# Tool-Ausgaben protokollieren
for content in msg._content:
print("=== Tool-Ausgabe ===")
print(json.dumps(content.result, indent=2))
elif role == "assistant":
# Log assistant final messages
for content in msg._content:
if hasattr(content, "text"):
print("=== Assistant Response ===")
print(content.text)Et voilà! Mit nur etwa 130 Zeilen Code haben Sie gerade einen KI-Agenten erstellt, der das Internet durchsuchen und scrapen kann, eine Vielzahl von Aufgaben erfüllt und mehrere Anwendungsfälle abdeckt.
Schritt 6: Testen Sie die Integration
Starten Sie Ihr Skript, und Sie sollten ein Ergebnis wie dieses sehen: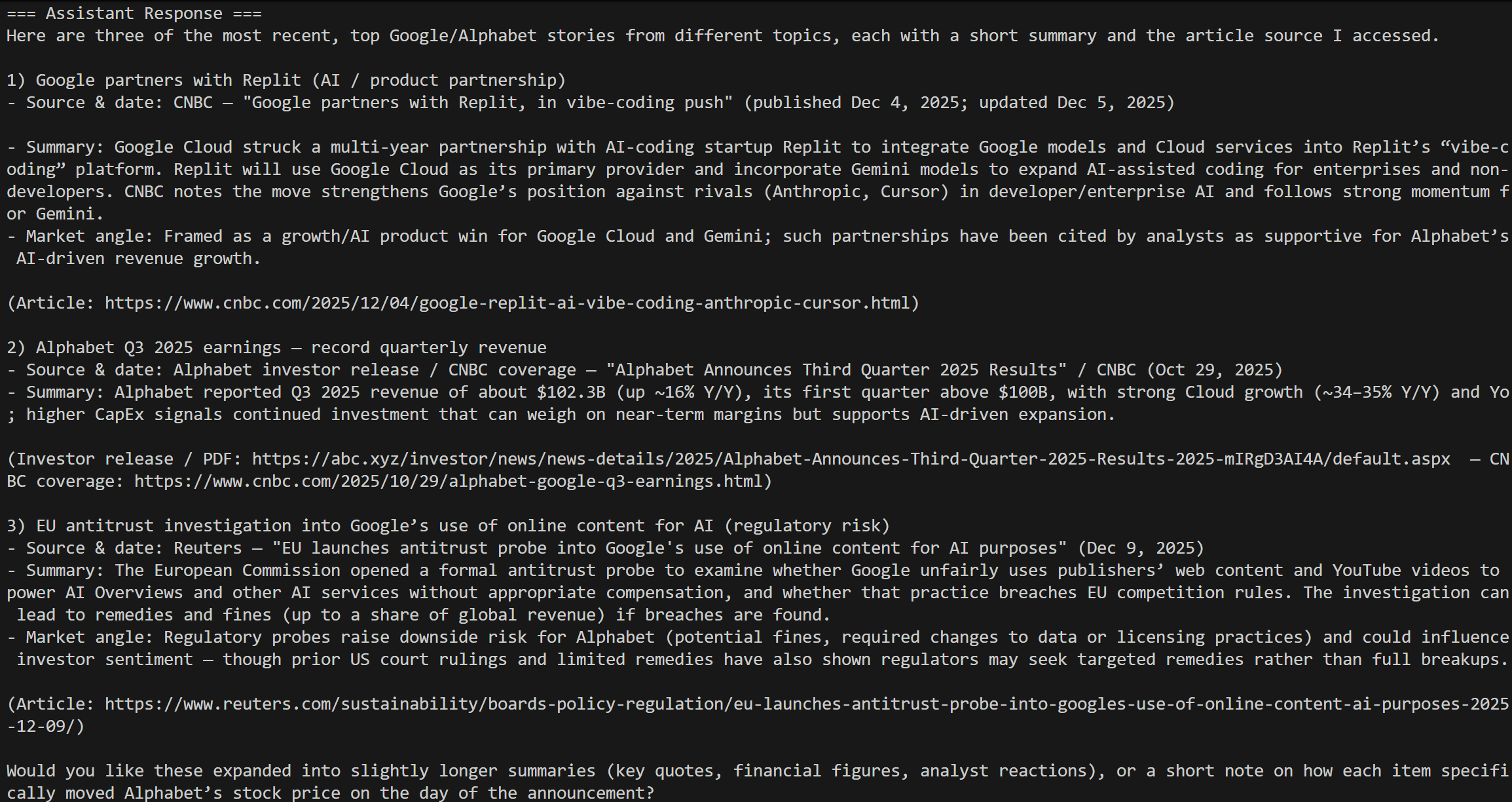
Das entspricht genau den Ergebnissen für die heutige Suchanfrage „Google-Börsennachrichten“, genau wie erwartet!
Beachten Sie, dass ein Standard-KI-Agent dies nicht alleine leisten kann. Vanilla-LLMs haben ohne externe Tools keinen direkten Zugriff auf das Live-Web und Suchmaschinen. Selbst integrierte Grounding-Tools sind in der Regel eingeschränkt, langsam und können nicht so skaliert werden, dass sie auf jede Website zugreifen können, wie es Bright Data kann.
Die Protokolle enthalten alle Details der SERP-API-Aufrufe: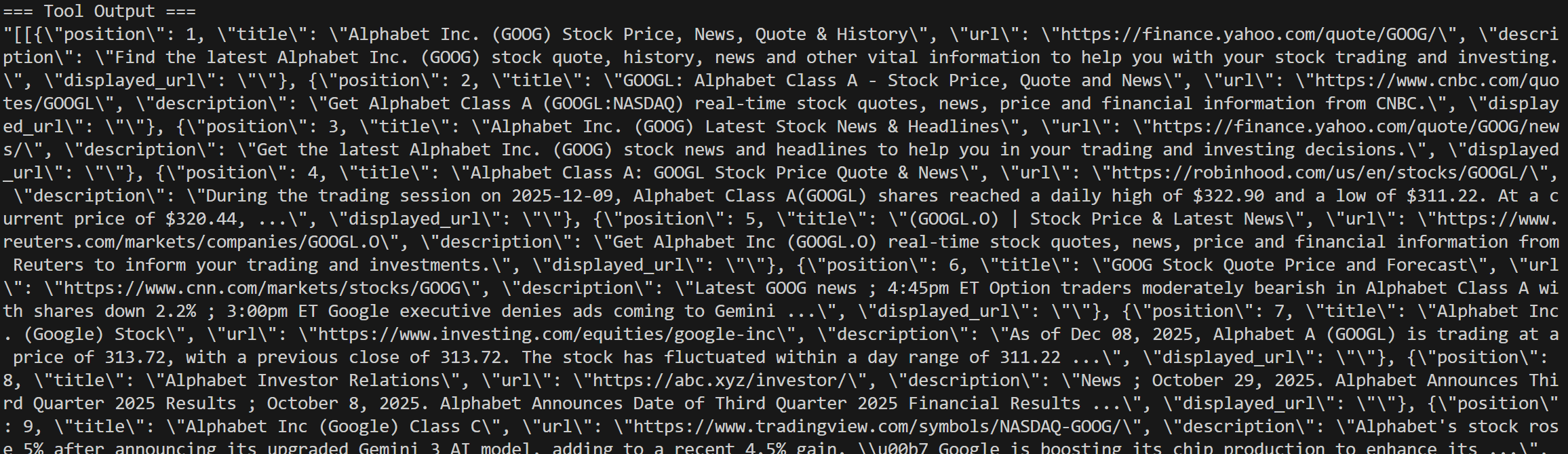
Sie sehen auch die Web Unlocker-Aufrufe für die ausgewählten Nachrichtenartikel aus den Google-Suchergebnissen: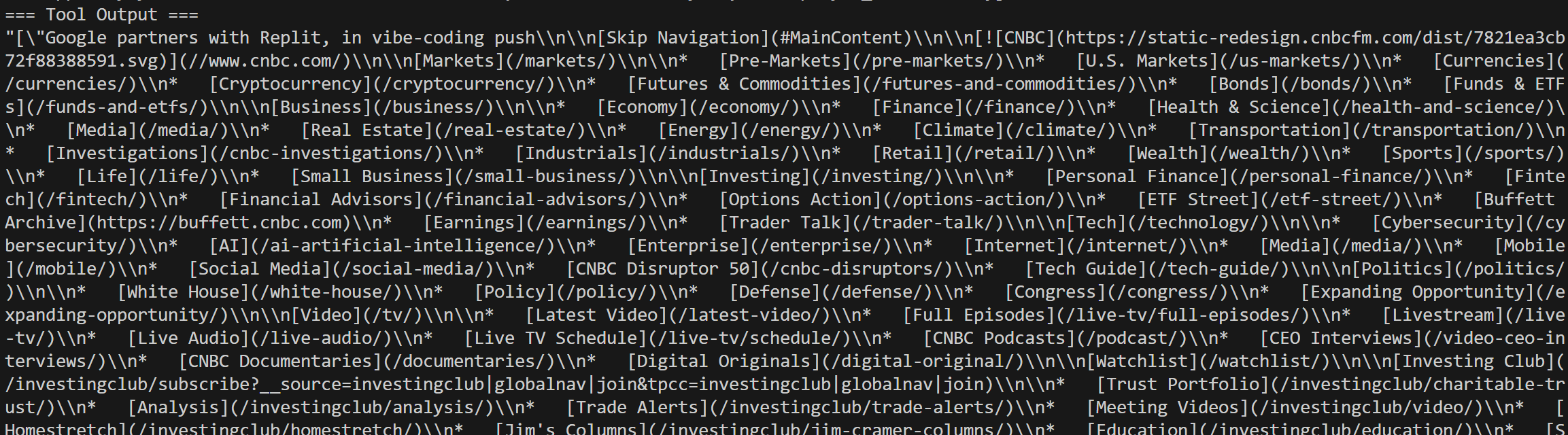
Et voilà! Sie haben nun einen Haystack-KI-Agenten, der vollständig in die Bright Data-Tools integriert ist.
Bright Data Web MCP-Integration in Haystack
Eine weitere Möglichkeit, Haystack mit Bright Data zu verbinden, ist über Web MCP. Dieser MCP-Server stellt viele der leistungsstärksten Funktionen von Bright Data als große Sammlung von KI-fähigen Tools zur Verfügung.
Web MCP umfasst mehr als 60 Tools, die auf der Web-Automatisierungs- und Datenerfassungsinfrastruktur von Bright Data aufbauen. Selbst in der kostenlosen Version erhalten Sie Zugriff auf zwei äußerst nützliche Tools:
| Tool | Beschreibung |
|---|---|
search_engine |
Ruft Ergebnisse von Google, Bing oder Yandex im JSON- oder Markdown-Format ab. |
scrape_as_markdown |
Kratzen Sie jede Webseite in sauberes Markdown, während Sie Anti-Bot-Maßnahmen umgehen. |
Wenn Sie dann die Premium-Stufe (Pro-Modus) aktivieren, ermöglicht Web MCP die Extraktion strukturierter Daten für große Plattformen wie Amazon, Zillow, LinkedIn, YouTube, TikTok, Google Maps und viele andere. Außerdem enthält es Tools für automatisierte Browser-Aktionen.
Sehen wir uns an, wie Sie Bright Datas Web MCP in Haystack nutzen können!
Voraussetzungen
Das Open-Source-Paket Web MCP basiert auf Node.js. Das bedeutet, dass Sie Node.js auf Ihrem Rechner installiert haben müssen, wenn Sie Web MCP lokal ausführen und Ihren Haystack-KI-Agenten damit verbinden möchten.
Alternativ können Sie eine Verbindung zur Remote-Instanz von Web MCP herstellen, was keinerlei lokale Einrichtung erfordert.
Schritt 1: Installieren Sie die MCP-Haystack-Integration
Führen Sie in Ihrem Python-Projekt den folgenden Befehl aus, um die MCP-Haystack-Integration zu installieren:
pip install mcp-haystackDieses Paket ist erforderlich, um auf die Klassen zuzugreifen, mit denen Sie eine Verbindung zu einem lokalen oder Remote-MCP-Server herstellen können.
Schritt 2: Web-MCP lokal testen
Bevor Sie Haystack mit dem Web-MCP von Bright Data verbinden, stellen Sie sicher, dass Ihr lokaler Rechner den MCP-Server lokal ausführen kann.
Hinweis: Web MCP ist auch als Remote-Server (über SSE und Streamable HTTP) verfügbar. Diese Option eignet sich besser für Szenarien auf Unternehmensebene.
Erstellen Sie zunächst ein Bright Data-Konto. Wenn Sie bereits ein Konto haben, melden Sie sich einfach an. Für eine schnelle Einrichtung folgen Sie den Anweisungen im Abschnitt„MCP“Ihres Dashboards: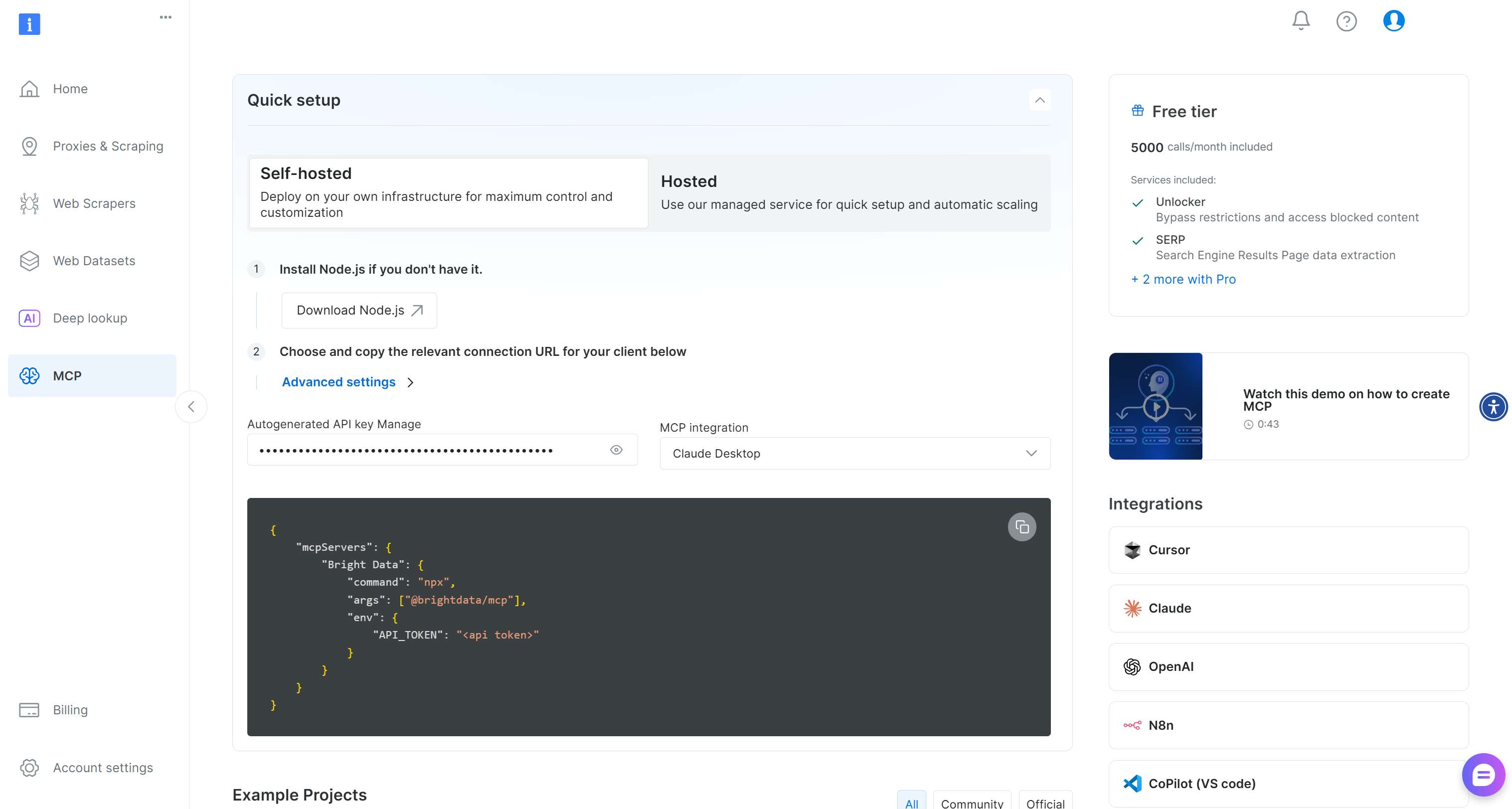
Andernfalls finden Sie weitere Anleitungen in den folgenden Anweisungen.
Generieren Sie zunächst Ihren Bright Data API-Schlüssel. Bewahren Sie ihn an einem sicheren Ort auf, da Sie ihn in Kürze zur Authentifizierung Ihrer lokalen Web MCP-Instanz benötigen.
Installieren Sie dann das Web-MCP global auf Ihrem Rechner über das @brightdata/mcp -Paket:
npm install -g @brightdata/mcpÜberprüfen Sie, ob der MCP-Server funktioniert, indem Sie Folgendes ausführen:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcpOder, gleichwertig, in PowerShell:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; npx -y @brightdata/mcpErsetzen Sie den Platzhalter <YOUR_BRIGHT_DATA_API> durch Ihren Bright Data API-Schlüssel. Die beiden (gleichwertigen) Befehle legen die erforderliche API_TOKEN- Umgebungsvariable fest und starten den Web-MCP-Server.
Wenn dies erfolgreich ist, sollten Sie ähnliche Protokolle wie die folgenden sehen:
Beim ersten Start erstellt Web MCP zwei Zonen in Ihrem Bright Data-Konto:
mcp_unlocker: Eine Zone für Web Unlocker.mcp_browser: Eine Zone für die Browser-API.
Diese beiden Dienste werden vom Web-MCP benötigt, um seine über 60 Tools zu betreiben.
Um zu überprüfen, ob die Zonen erstellt wurden, rufen Sie die Seite„Proxies & Scraping-Infrastruktur“in Ihrem Dashboard auf. Sie sollten beide Zonen in der Tabelle aufgeführt sehen:
Beachten Sie, dass Sie mit der kostenlosen Version von Web MCP nur Zugriff auf die Tools „search_engine” und „scrape_as_markdown” haben.
Um alle Tools freizuschalten, aktivieren Sie den Pro-Modus, indem Sie die Umgebungsvariable PRO_MODE="true" setzen:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcpOder unter Windows:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; $Env:PRO_MODE="true"; npx -y @brightdata/mcpDer Pro-Modus schaltet alle über 60 Tools frei, ist jedoch nicht in der kostenlosen Version enthalten und kann zusätzliche Kosten verursachen.
Gut gemacht! Sie haben nun bestätigt, dass der Web-MCP-Server auf Ihrem Rechner korrekt läuft. Beenden Sie den Prozess, da Sie Haystack so konfigurieren werden, dass es den Server lokal startet und sich mit ihm verbindet.
Schritt 3: Verbindung zu Web MCP in Haystack herstellen
Verwenden Sie die folgenden Codezeilen, um eine Verbindung zu Web MCP herzustellen:
from haystack_integrations.tools.mcp import StdioServerInfo, MCPToolset
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>" # Ersetzen Sie dies durch Ihren Bright Data API-Schlüssel.
# Konfiguration für die Verbindung mit dem Web-MCP-Server über STDIO
web_mcp_server_info = StdioServerInfo(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": BRIGHT_DATA_API_KEY,
"PRO_MODE": "true" # Pro-Tools aktivieren (optional)
}
)Das oben genannte StdioServerInfo-Objekt spiegelt den zuvor getesteten npx -Befehl wider, verpackt ihn jedoch in eine Form, die Haystack verwenden kann. Es enthält auch die Umgebungsvariablen, die zur Konfiguration des Web-MCP-Servers erforderlich sind:
API_TOKEN: Erforderlich. Setzen Sie diesen Wert auf den zuvor generierten Bright Data API-Schlüssel.PRO_MODE: Optional. Entfernen Sie diese Einstellung, wenn Sie die kostenlose Stufe beibehalten und nur auf die Tools„search_engine”und„scrape_as_markdown”zugreifen möchten.
Greifen Sie anschließend mit folgendem Befehl auf alle von Web MCP bereitgestellten Tools zu:
web_mcp_toolset = MCPToolset(
server_info=web_mcp_server_info,
invocation_timeout=180 # 3 Minuten
)Überprüfen Sie, ob die Integration funktioniert, indem Sie alle Tools laden und deren Informationen ausgeben:
web_mcp_toolset.warm_up()
for tool in web_mcp_toolset.tools:
print(f"Name: {tool.name}")
print(f"Description: {tool.name}n")Wenn Sie den Pro-Modus verwenden, sollten Sie alle über 60 verfügbaren Tools sehen: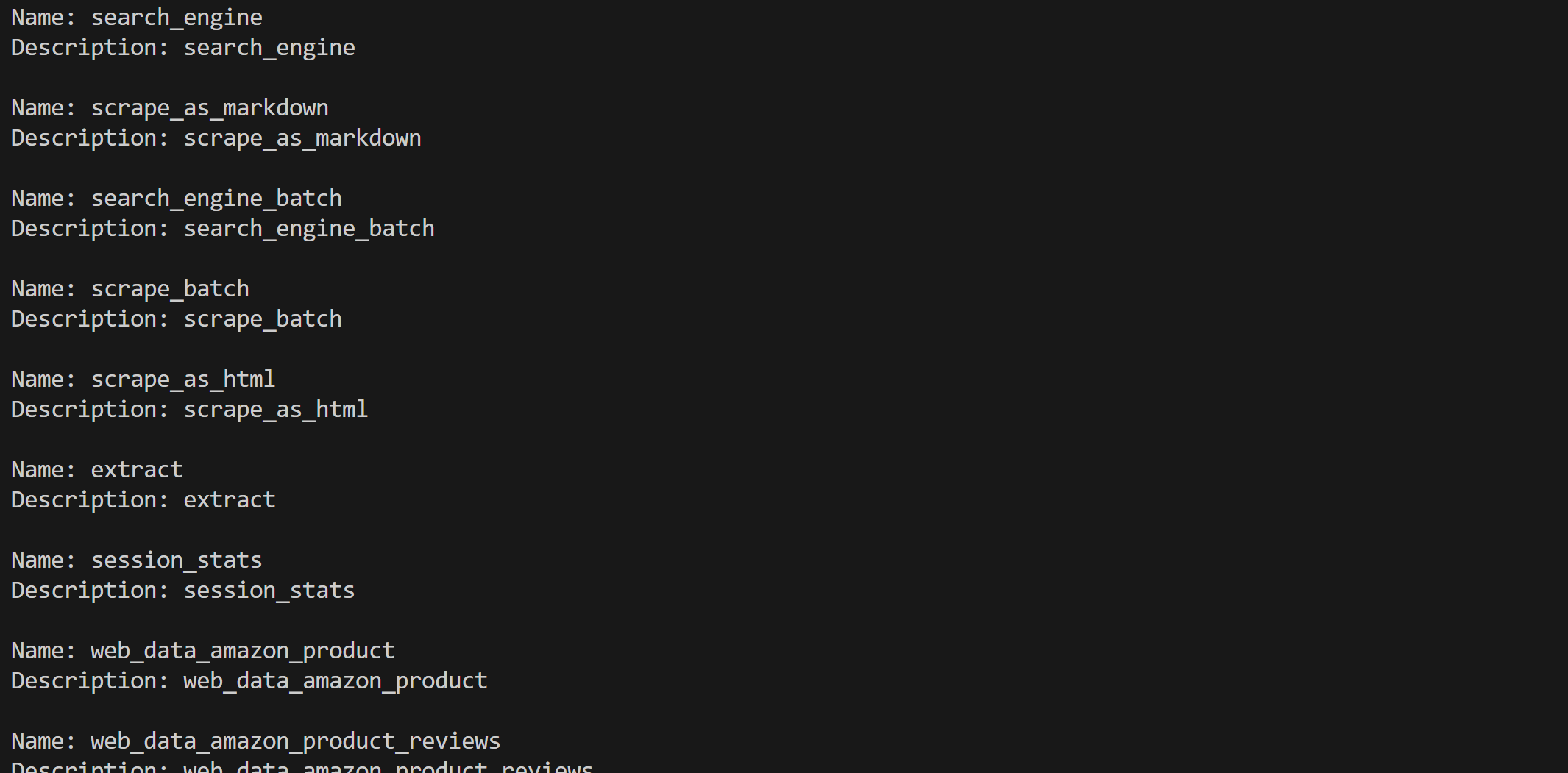
Das war’s schon! Die Bright Data Web MCP-Integration in Haystack funktioniert einwandfrei.
Schritt 4: Testen Sie die Integration
Nachdem alle Tools eingerichtet sind, verwenden Sie sie in einem KI-Agenten (wie zuvor gezeigt) oder einer Haystack-Pipeline. Angenommen, Sie möchten, dass ein KI-Agent diese Eingabe verarbeitet:
Geben Sie einen Markdown-Bericht mit nützlichen Erkenntnissen aus der folgenden Crunchbase-Unternehmens-URL zurück:
„https://www.crunchbase.com/organization/apple“Dies ist ein Beispiel für eine Aufgabe, die Web-MCP-Tools erfordert.
Führen Sie sie in einem Agenten mit folgendem Befehl aus:
agent = Agent(
chat_generator=chat_generator,
tools=web_mcp_toolset, # Die Bright Data Web MCP-Tools
)
## Führen Sie den Agenten aus
agent.warm_up()
prompt = """
Geben Sie einen Markdown-Bericht mit nützlichen Erkenntnissen aus der folgenden Crunchbase-Unternehmens-URL zurück:
„https://www.crunchbase.com/organization/apple“
"""
chat_message = ChatMessage.from_user(prompt)
response = agent.run(messages=[chat_message])Das Ergebnis wäre: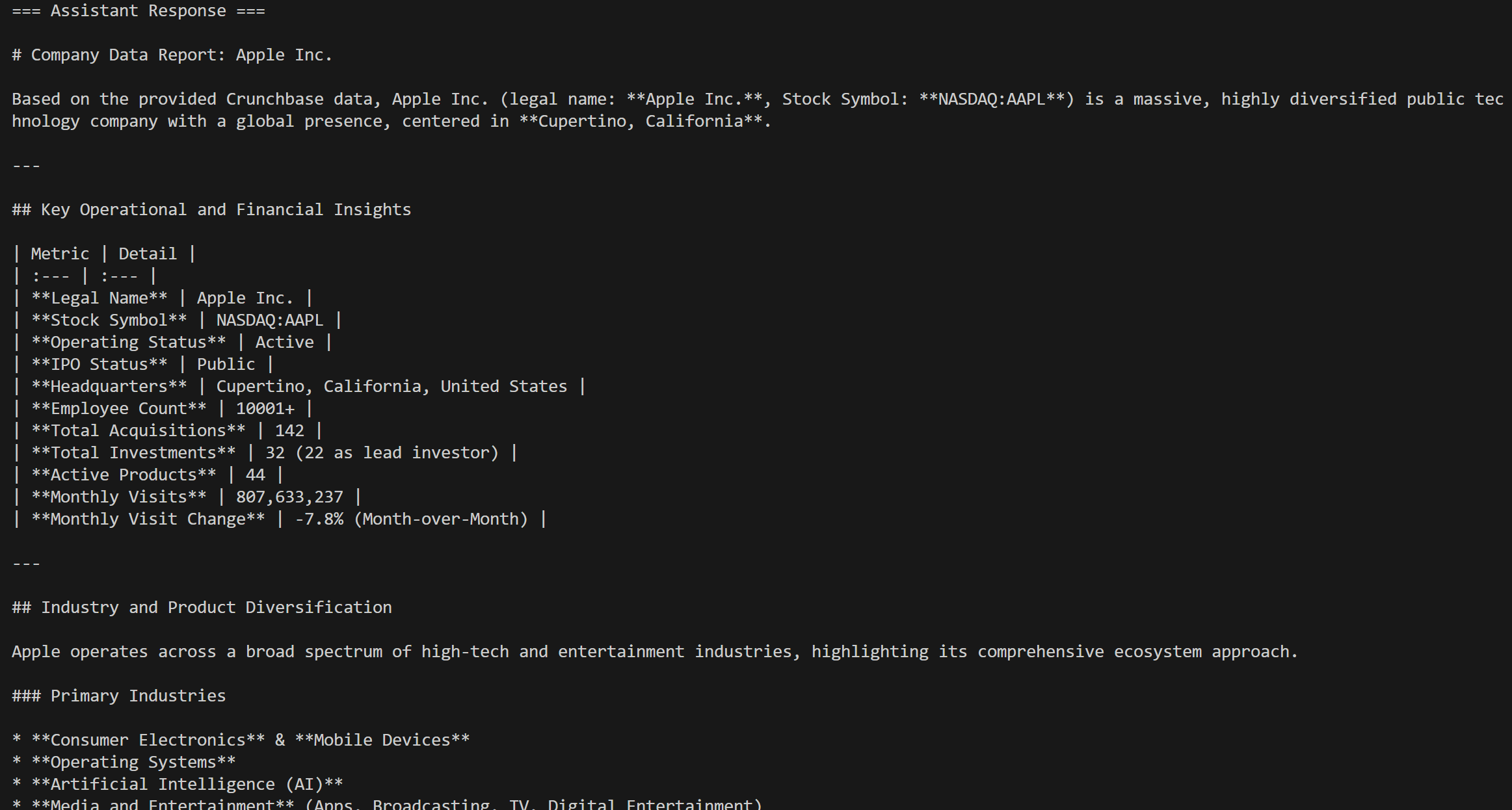
Das aufgerufene Tool ist das Pro-Tool web_data_crunchbase_company: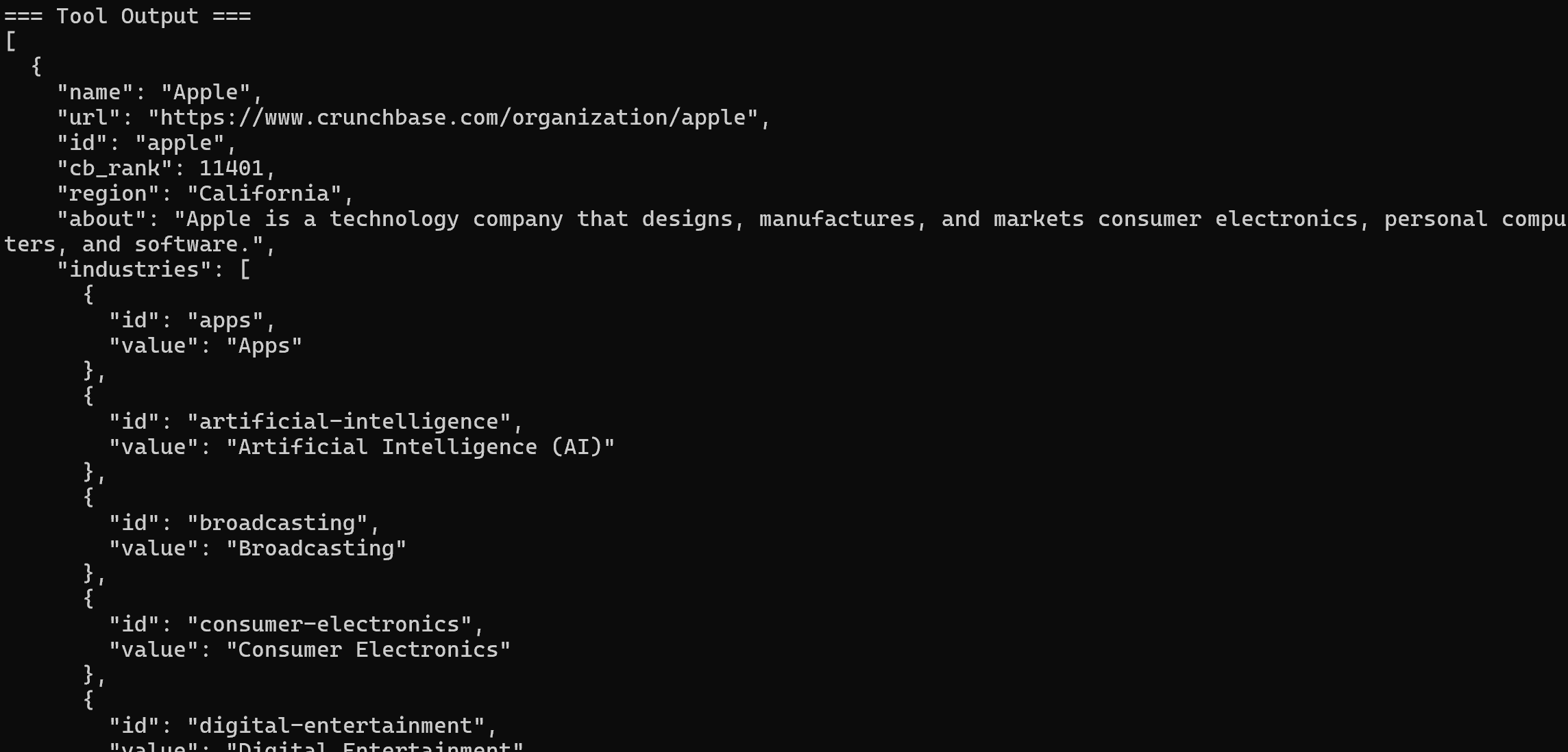
Im Hintergrund nutzt dieses Tool den Bright Data Crunchbase Scraper, um strukturierte Informationen aus der angegebenen Crunchbase-Seite zu extrahieren.
Crunchbase-Scraping ist definitiv etwas, das ein normales LLM nicht alleine bewältigen kann! Dies beweist die Leistungsfähigkeit der Web-MCP-Integration in Haystack, die eine lange Liste von Anwendungsfällen unterstützt.
Schritt 5: Vollständiger Code
Der vollständige Code für die Verbindung von Bright Data Web MCP in Haystack lautet:
# pip install haystack-ai mcp-haystack
from haystack_integrations.tools.mcp import StdioServerInfo, MCPToolset
import os
from haystack.components.generators.chat import OpenAIChatGenerator
from haystack.components.agents import Agent
from haystack.dataclasses import ChatMessage
import json
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_API_KEY>" # Ersetzen Sie ihn durch Ihren Bright Data API-Schlüssel.
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>" # Ersetzen Sie ihn durch Ihren Bright Data API-Schlüssel.
# Konfiguration für die Verbindung zum Web MCP-Server über STDIO
web_mcp_server_info = StdioServerInfo(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": BRIGHT_DATA_API_KEY,
"PRO_MODE": "true" # Pro-Tools aktivieren (optional)
})
# Laden der verfügbaren MCP-Tools, die vom Web-MCP-Server bereitgestellt werden
web_mcp_toolset = MCPToolset(
server_info=web_mcp_server_info,
invocation_timeout=180, # 3 Minuten
tool_names=["web_data_crunchbase_company"]
)
# Initialisieren Sie die LLM-Engine
chat_generator = OpenAIChatGenerator(
model="gpt-5-mini")
# Initialisieren Sie einen Haystack-KI-Agenten
agent = Agent(
chat_generator=chat_generator,
tools=web_mcp_toolset, # Die Bright Data Web-MCP-Tools
)
## Den Agenten ausführen
agent.warm_up()
prompt = """
Geben Sie einen Markdown-Bericht mit nützlichen Erkenntnissen aus der folgenden Crunchbase-Unternehmens-URL zurück:
"https://www.crunchbase.com/organization/apple"
"""
chat_message = ChatMessage.from_user(prompt)
response = agent.run(messages=[chat_message])
## Ausgabe in strukturiertem Format mit Informationen zur Tool-Verwendung drucken
for msg in response["messages"]:
role = msg._role.value
if role == "tool":
# Tool-Ausgaben protokollieren
for content in msg._content:
print("=== Tool-Ausgabe ===")
print(json.dumps(content.result, indent=2))
elif role == "assistant":
# Log assistant final messages
for content in msg._content:
if hasattr(content, "text"):
print("=== Assistant Response ===")
print(content.text)Fazit
In diesem Leitfaden haben Sie gelernt, wie Sie die Bright Data-Integration in Haystack nutzen können, sei es durch benutzerdefinierte Tools oder über MCP.
Diese Konfiguration ermöglicht es KI-Modellen in Haystack-Agenten und -Pipelines, Websuchen durchzuführen, strukturierte Daten zu extrahieren, auf Live-Webdaten-Feeds zuzugreifen und Webinteraktionen zu automatisieren. All dies wird durch die vollständige Palette von Diensten im Ökosystem von Bright Data für KI ermöglicht.
Erstellen Sie kostenlos ein Bright Data-Konto und entdecken Sie unsere leistungsstarken KI-fähigen Webdaten-Tools!





