
In diesem Artikel erfahren Sie:
- Wie Sie einen produktionsreifen KI-Agenten erstellen, der Konversationen in Datenbanken speichert
- Wie Sie intelligente Datenextraktion und Entitätsverfolgung implementieren
- Wie Sie eine robuste Fehlerbehandlung mit automatischer Wiederherstellung erstellen
- Wie Sie Ihren Agenten mit Echtzeit-Webdaten von Bright Data verbessern
Los geht’s!
Die Herausforderung staatenloser KI-Gespräche
Aktuelle KI-Agenten arbeiten in der Regel als zustandslose Systeme. Sie behandeln jede Konversation als separates Ereignis. Dieser Mangel an historischem Kontext führt dazu, dass Benutzer Informationen wiederholen müssen. Dies führt zu betrieblichen Ineffizienzen und Frustration bei den Benutzern. Darüber hinaus verpassen Unternehmen die Möglichkeit, Langzeitdaten für die Personalisierung oder Verbesserung ihrer Dienstleistungen zu nutzen.
Datenpersistente KI löst dieses Problem, indem sie alle Interaktionen in einer strukturierten Datenbank aufzeichnet. Durch die kontinuierliche Aufzeichnung können diese Systeme den historischen Kontext speichern, bestimmte Entitäten über einen längeren Zeitraum verfolgen und vergangene Interaktionsmuster nutzen, um eine konsistente und personalisierte Benutzererfahrung zu bieten.
Was wir entwickeln: Datenbank-vernetztes KI-Agentensystem
Wir werden einen produktionsreifen KI-Agenten entwickeln, der Nachrichten mit LangChain und GPT-4 verarbeitet. Er speichert jede Konversation in PostgreSQL. Er extrahiert Entitäten und Erkenntnisse in Echtzeit. Er speichert den vollständigen Konversationsverlauf über mehrere Sitzungen hinweg. Er verwaltet Fehler mit automatischen Wiederholungssystemen. Er bietet Überwachung mit Protokollierung.
Das System wird Folgendes verarbeiten:
- Datenbankschema mit korrekten Beziehungen und Indizes
- LangChain-Agent mit benutzerdefinierten Datenbanktools
- Automatische Konversationspersistenz und Entitätsextraktion
- Hintergrundverarbeitungs-Pipeline für die Datenerfassung
- Fehlerbehandlung mit Transaktionsmanagement
- Abfrage-Schnittstelle zum Abrufen historischer Daten
- RAG-Integration mit Bright Data für Web Intelligence
Voraussetzungen
Richten Sie Ihre Entwicklungsumgebung mit folgenden Komponenten ein:
- Python 3.10 oder höher. Erforderlich für moderne asynchrone Funktionen und Typ-Hinweise
- PostgreSQL 14+ oder SQLite 3.35+. Datenbank für Datenpersistenz
- OpenAI-API-Schlüssel. Für den Zugriff auf GPT-4. Erhalten Sie ihn von der OpenAI-Plattform
- LangChain. Framework zum Erstellen von KI-Agenten. Siehe Dokumentation
- Virtuelle Python-Umgebung. Hält Abhängigkeiten isoliert. Siehe
venv-Dokumentation
Einrichtung der Umgebung
Erstellen Sie Ihr Projektverzeichnis und installieren Sie Abhängigkeiten:
mkdir database-agent
cd database-agent
python -m venv venv
# macOS/Linux: source venv/bin/activate
# Windows: venv\Scripts\activate
pip install langchain langchain-openai sqlalchemy psycopg2-binary python-dotenv pydanticErstellen Sie eine neue Datei namens agent.py und fügen Sie die folgenden Importe hinzu:
import os
import json
import logging
import time
from datetime import datetime, timedelta
from typing import List, Dict, Any, Optional
from queue import Queue
from threading import Thread
# SQLAlchemy-Importe
from sqlalchemy import create_engine, Column, Integer, String, Text, DateTime, Float, JSON, ForeignKey, text
from sqlalchemy.orm import sessionmaker, relationship, Session, declarative_base
from sqlalchemy.pool import QueuePool
from sqlalchemy.exc import SQLAlchemyError
# LangChain-Importe
from langchain.agents import AgentExecutor, create_openai_functions_agent
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain.tools import Tool
from langchain_openai import ChatOpenAI
from langchain.memory import ConversationBufferMemory
from langchain.schema import HumanMessage, AIMessage, SystemMessage
# RAG-Importe
from langchain_community.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
import requests
# Einrichtung der Umgebung
from dotenv import load_dotenv
load_dotenv()
# Protokollierung konfigurieren
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)Erstellen Sie eine .env -Datei mit Ihren Anmeldedaten:
# Datenbankkonfiguration
DATABASE_URL="postgresql://username:password@localhost:5432/agent_db"
# Oder für SQLite: DATABASE_URL="sqlite:///./agent_data.db"
# API-Schlüssel
OPENAI_API_KEY="your-openai-api-key"
# Optional: Bright Data (für Schritt 7)
BRIGHT_DATA_API_KEY="Ihr-Bright-Data-API-Schlüssel"
# Anwendungseinstellungen
AGENT_MODEL="gpt-4-turbo-preview"
CONNECTION_POOL_SIZE=5
MAX_RETRIES=3Sie benötigen:
- Datenbank-URL: Verbindungszeichenfolge für PostgreSQL oder SQLite
- OpenAI-API-Schlüssel: Für die Agentenintelligenz über GPT-4
- Bright Data API-Schlüssel: Optional, für Echtzeit-Webdaten in Schritt 7
Erstellen Ihres mit der Datenbank verbundenen KI-Agenten
Schritt 1: Entwerfen des Datenbankschemas
Entwerfen Sie Tabellen für Benutzer, Konversationen, Nachrichten und extrahierte Entitäten. Das Schema verwendet Fremdschlüssel und Beziehungen, um die Datenintegrität zu gewährleisten.
Base = declarative_base()
class User(Base):
"""Benutzerprofil-Tabelle – speichert Benutzerinformationen und Präferenzen."""
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
user_id = Column(String(255), unique=True, nullable=False, index=True)
name = Column(String(255))
email = Column(String(255))
preferences = Column(JSON, default={})
created_at = Column(DateTime, default=datetime.utcnow)
last_active = Column(DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)
# Beziehungen
conversations = relationship("Conversation", back_populates="user", cascade="all, delete-orphan")
def __repr__(self):
return f"<User(user_id='{self.user_id}', name='{self.name}')>"
class Conversation(Base):
"""Conversation session table - tracks individual conversation sessions."""
__tablename__ = 'conversations'
id = Column(Integer, primary_key=True)
conversation_id = Column(String(255), unique=True, nullable=False, index=True)
user_id = Column(Integer, ForeignKey('users.id'), nullable=False)
title = Column(String(500))
summary = Column(Text)
status = Column(String(50), default='active') # aktiv, archiviert, gelöscht
meta_data = Column(JSON, default={})
created_at = Column(DateTime, default=datetime.utcnow)
updated_at = Column(DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)
# Beziehungen
user = relationship("User", back_populates="conversations")
messages = relationship("Message", back_populates="conversation", cascade="all, delete-orphan")
entities = relationship("Entity", back_populates="conversation", cascade="all, delete-orphan")
def __repr__(self):
return f"<Conversation(id='{self.conversation_id}', user='{self.user_id}')>"
class Message(Base):
"""Individuelle Nachrichtentabelle – speichert jede Nachricht in einer Konversation."""
__tablename__ = 'messages'
id = Column(Integer, primary_key=True)
conversation_id = Column(Integer, ForeignKey('conversations.id'), nullable=False, index=True)
role = Column(String(50), nullable=False) # user, assistant, system
content = Column(Text, nullable=False)
tokens = Column(Integer)
model = Column(String(100))
meta_data = Column(JSON, default={})
created_at = Column(DateTime, default=datetime.utcnow)
# Beziehungen
conversation = relationship("Conversation", back_populates="messages")
def __repr__(self):
return f"<Message(role='{self.role}', conversation='{self.conversation_id}')>"
class Entity(Base):
"""Extrahierte Entitätentabelle – speichert benannte Entitäten, die aus Konversationen extrahiert wurden."""
__tablename__ = 'entities'
id = Column(Integer, primary_key=True)
conversation_id = Column(Integer, ForeignKey('conversations.id'), nullable=False, index=True)
entity_type = Column(String(100), nullable=False, index=True) # Person, Organisation, Ort usw.
entity_value = Column(String(500), nullable=False)
context = Column(Text)
confidence = Column(Float, default=0.0)
meta_data = Column(JSON, default={})
extracted_at = Column(DateTime, default=datetime.utcnow)
# Beziehungen
conversation = relationship("Conversation", back_populates="entities")
def __repr__(self):
return f"<Entity(type='{self.entity_type}', value='{self.entity_value}')>"
class AgentLog(Base):
"""Agent-Betriebsprotokolltabelle – speichert Betriebsprotokolle zur Überwachung."""
__tablename__ = 'agent_logs'
id = Column(Integer, primary_key=True)
conversation_id = Column(String(255), index=True)
level = Column(String(50), nullable=False) # INFO, WARNING, ERROR
operation = Column(String(255), nullable=False)
message = Column(Text, nullable=False)
error_details = Column(JSON)
execution_time = Column(Float) # in Sekunden
created_at = Column(DateTime, default=datetime.utcnow)
def __repr__(self):
return f"<AgentLog(level='{self.level}', operation='{self.operation}')>"Das Schema definiert fünf Kerntabellen. User speichert Profile mit JSON-Einstellungen für flexible Daten. Conversation verfolgt Sitzungen mit Statusverfolgung. Message enthält einzelne Nachrichten mit Rollenindikatoren für Nachrichten von Benutzern und Assistenten. Entity erfasst extrahierte Informationen mit Konfidenzwerten. AgentLog bietet eine Operationsverfolgung für die Überwachung. Fremdschlüssel gewährleisten die referenzielle Integrität. Indizes für häufig abgefragte Felder optimieren die Leistung. Die Einstellung cascade="all, delete-orphan" bereinigt zugehörige Datensätze, wenn übergeordnete Datensätze gelöscht werden.
Schritt 2: Einrichten der Datenbankverbindungsschicht
Konfigurieren Sie den Datenbankverbindungsmanager mit SQLAlchemy. Der Manager übernimmt das Connection Pooling, die Zustandsprüfungen und die automatische Wiederholungslogik für die Zuverlässigkeit.
class DatabaseManager:
"""
Verwaltet Datenbankverbindungen und -operationen.
Funktionen:
- Verbindungspooling für eine effiziente Ressourcennutzung
- Integritätsprüfungen zur Überprüfung der Datenbankverbindung
- Automatische Tabellenerstellung
"""
def __init__(self, database_url: str, pool_size: int = 5, max_retries: int = 3):
"""
Initialisiert den Datenbankmanager.
Argumente:
database_url: Datenbankverbindungszeichenfolge (z. B. „sqlite:///./agent_data.db”)
pool_size: Anzahl der im Pool zu verwaltenden Verbindungen
max_retries: Maximale Anzahl von Wiederholungsversuchen für fehlgeschlagene Vorgänge
"""
self.database_url = database_url
self.max_retries = max_retries
# Engine mit Verbindungspooling erstellen
self.engine = create_engine(
database_url,
poolclass=QueuePool,
pool_size=pool_size,
max_overflow=10,
pool_pre_ping=True, # Verbindungen vor der Verwendung überprüfen
echo=False # Für SQL-Debugging auf True setzen
)
# Session Factory erstellen
self.SessionLocal = sessionmaker(
bind=self.engine,
autocommit=False,
autoflush=False
)
logger.info(f"✓ Datenbank-Engine mit {pool_size} Verbindungspool erstellt")
def initialize_database(self):
"""Erstellen Sie alle Tabellen in der Datenbank."""
try:
Base.metadata.create_all(bind=self.engine)
logger.info("✓ Datenbanktabellen erfolgreich erstellt")
except Exception as e:
logger.error(f"❌ Fehler beim Erstellen der Datenbanktabellen: {e}")
raise
def get_session(self) -> Session:
"""Neue Datenbanksitzung zum Ausführen von Vorgängen abrufen."""
return self.SessionLocal()
def health_check(self) -> bool:
"""
Datenbankverbindung überprüfen.
Rückgabewerte:
bool: True, wenn die Datenbank fehlerfrei ist, andernfalls False.
"""
try:
with self.engine.connect() as conn:
conn.execute(text("SELECT 1"))
logger.info("✓ Datenbank-Funktionsprüfung bestanden")
return True
except Exception as e:
logger.error(f"❌ Datenbank-Funktionsprüfung fehlgeschlagen: {e}")
return FalseDer DatabaseManager stellt Verbindungen mithilfe des Connection Pooling von SQLAlchemy her. Die Einstellung pool_size=5 sorgt für fünf persistente Verbindungen und damit für Effizienz. Die Option pool_pre_ping überprüft die Verbindungen vor der Verwendung. Dadurch werden Fehler aufgrund veralteter Verbindungen verhindert. Der Wiederholungsmechanismus versucht fehlgeschlagene Vorgänge bis zu dreimal mit exponentiellem Backoff. Er behandelt vorübergehende Netzwerkprobleme.
Schritt 3: Aufbau des LangChain-Agentenkerns
Erstellen Sie den KI-Agenten mit LangChain und benutzerdefinierten Tools, die mit der Datenbank interagieren. Der Agent verwendet Funktionsaufrufe, um Informationen zu speichern und den Konversationsverlauf abzurufen.
class DataPersistentAgent:
"""
KI-Agent mit Datenbank-Persistenzfunktionen.
Dieser Agent:
- Speichert Konversationen über mehrere Sitzungen hinweg.
- Speichert und ruft Benutzerinformationen ab.
- Extrahiert und speichert wichtige Entitäten.
- Liefert personalisierte Antworten auf Grundlage des Verlaufs.
"""
def __init__(
self,
db_manager: DatabaseManager,
model_name: str = "gpt-4-turbo-preview",
temperature: float = 0.7
):
"""
Initialisieren Sie den datenpersistenten Agenten.
Args:
db_manager: Datenbankmanager-Instanz
model_name: Zu verwendendes LLM-Modell (Standard: gpt-4-turbo-preview)
temperature: Modelltemperatur für die Generierung von Antworten
"""
self.db_manager = db_manager
self.model_name = model_name
# LLM initialisieren
self.llm = ChatOpenAI(
model=model_name,
temperature=temperature,
openai_api_key=os.getenv("OPENAI_API_KEY")
)
# Tools für Agenten erstellen
self.tools = self._create_agent_tools()
# Agentenaufforderung erstellen
self.prompt = self._create_agent_prompt()
# Speicher initialisieren
self.memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True
)
# Agenten erstellen
self.agent = create_openai_functions_agent(
llm=self.llm,
tools=self.tools,
prompt=self.prompt
)
# Agent-Executor erstellen
self.agent_executor = AgentExecutor(
agent=self.agent,
tools=self.tools,
memory=self.memory,
verbose=True,
handle_parsing_errors=True,
max_iterations=5
)
logger.info(f"✓ Datenpersistenter Agent mit {model_name} initialisiert")
def _create_agent_tools(self) -> List[Tool]:
"""Benutzerdefinierte Tools für Datenbankoperationen erstellen."""
def save_user_info(user_data: str) -> str:
"""Benutzerinformationen in der Datenbank speichern."""
try:
data = json.loads(user_data)
session = self.db_manager.get_session()
user = session.query(User).filter_by(user_id=data['user_id']).first()
if not user:
user = User(**data)
session.add(user)
else:
for key, value in data.items():
setattr(user, key, value)
session.commit()
session.close()
return f"✓ Benutzerinformationen erfolgreich gespeichert"
except Exception as e:
logger.error(f"Speichern der Benutzerinformationen fehlgeschlagen: {e}")
return f"❌ Fehler beim Speichern der Benutzerinformationen: {str(e)}"
def retrieve_user_history(user_id: str) -> str:
"""Konversationsverlauf des Benutzers abrufen."""
try:
session = self.db_manager.get_session()
user = session.query(User).filter_by(user_id=user_id).first()
if not user:
return "Kein Benutzer gefunden"
conversations = session.query(Conversation).filter_by(user_id=user.id).order_by(Conversation.created_at.desc()).limit(5).all()
history = []
for conv in conversations:
messages = session.query(Message).filter_by(conversation_id=conv.id).all()
history.append({
'conversation_id': conv.conversation_id,
'created_at': conv.created_at.isoformat(),
'message_count': len(messages),
'summary': conv.summary
})
session.close()
return json.dumps(history, indent=2)
except Exception as e:
logger.error(f"Failed to retrieve history: {e}")
return f"❌ Error retrieving history: {str(e)}"
def extract_entities(text: str) -> str:
"""Entitäten aus Text extrahieren und in Datenbank speichern."""
try:
entities = []
# Einfache Schlüsselwort-Extraktion (durch geeignetes NER ersetzen)
keywords = ['important', 'key', 'critical']
for keyword in keywords:
if keyword in text.lower():
entities.append({
'entity_type': 'keyword',
'entity_value': keyword,
'confidence': 0.8
})
return json.dumps(entities, indent=2)
except Exception as e:
logger.error(f"Failed to extract entities: {e}")
return f"❌ Error extracting entities: {str(e)}"
tools = [
Tool(
name="SaveUserInfo",
func=save_user_info,
description="Save user information to the database. Input should be a JSON string with user details."
),
Tool(
name="RetrieveUserHistory",
func=retrieve_user_history,
description="Konversationsverlauf eines Benutzers aus der Datenbank abrufen. Die Eingabe sollte die user_id sein."
),
Tool(
name="ExtractEntities",
func=extract_entities,
description="Extrahiert wichtige Entitäten aus Text und speichert sie in der Datenbank. Die Eingabe sollte der zu analysierende Text sein."
)
]
return tools
def _create_agent_prompt(self) -> ChatPromptTemplate:
"""Agent-Prompt-Vorlage erstellen."""
system_message = """Sie sind ein hilfreicher KI-Assistent, der sich Gespräche merken und daraus lernen kann.
Sie haben Zugriff auf die folgenden Tools:
- SaveUserInfo: Speichern Sie Benutzerinformationen, um sich für zukünftige Gespräche daran zu erinnern.
- RetrieveUserHistory: Suchen Sie nach früheren Gesprächen mit einem Benutzer.
- ExtractEntities: Extrahieren und speichern Sie wichtige Informationen aus Gesprächen.
Verwenden Sie diese Tools, um personalisierte, kontextbezogene Antworten zu geben. Überprüfen Sie vor Ihrer Antwort immer, ob Sie bereits frühere Gespräche mit einem Benutzer geführt haben.
Speichern Sie wichtige Informationen proaktiv für zukünftige Gespräche.“““
prompt = ChatPromptTemplate.from_messages([
("system", system_message),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad")
])
return prompt
def chat(self, user_id: str, message: str, conversation_id: Optional[str] = None) -> Dict[str, Any]:
"""
Verarbeitet eine Chat-Nachricht und speichert sie in der Datenbank.
Diese Methode umfasst:
1. Erstellen oder Abrufen von Unterhaltungen
2. Speichern von Benutzernachrichten in der Datenbank
3. Generieren von Agent-Antworten
4. Speichern von Agent-Antworten in der Datenbank
5. Protokollieren von Vorgängen zur Überwachung
Argumente:
user_id: Eindeutige Kennung für den Benutzer
message: Text der Benutzernachricht
conversation_id: Optionale Unterhaltungs-ID, um eine bestehende Unterhaltung fortzusetzen
Rückgabewerte:
dict: Enthält conversation_id, response und execution_time
"""
start_time = datetime.utcnow()
try:
# Konversation abrufen oder erstellen
session = self.db_manager.get_session()
if conversation_id:
conversation = session.query(Conversation).filter_by(conversation_id=conversation_id).first()
else:
# Neue Konversation erstellen
user = session.query(User).filter_by(user_id=user_id).first()
if not user:
user = User(user_id=user_id, name=user_id)
session.add(user)
session.commit()
conversation = Conversation(
conversation_id=f"conv_{user_id}_{datetime.utcnow().timestamp()}",
user_id=user.id,
title=message[:100]
)
session.add(conversation)
session.commit()
# Benutzernachricht speichern
user_message = Message(
conversation_id=conversation.id,
role="user",
content=message,
model=self.model_name
)
session.add(user_message)
session.commit()
# Antwort des Agenten abrufen
response = self.agent_executor.invoke({
"input": f"[Benutzer-ID: {user_id}] {message}"
})
# Assistenz-Nachricht speichern
assistant_message = Message(
conversation_id=conversation.id,
role="assistant",
content=response['output'],
model=self.model_name
)
session.add(assistant_message)
session.commit()
# Vorgang protokollieren
execution_time = (datetime.utcnow() - start_time).total_seconds()
log_entry = AgentLog(
conversation_id=conversation.conversation_id,
level="INFO",
operation="chat",
message="Chat erfolgreich verarbeitet",
execution_time=execution_time
)
session.add(log_entry)
session.commit()
# conversation_id vor dem Schließen der Sitzung extrahieren
conversation_id_result = conversation.conversation_id
session.close()
logger.info(f"✓ Chat für Benutzer {user_id} in {execution_time:.2f}s verarbeitet")
return {
'conversation_id': conversation_id_result,
'response': response['output'],
'execution_time': execution_time
}
except Exception as e:
logger.error(f"❌ Fehler bei der Verarbeitung des Chats: {e}")
# Fehler protokollieren
session = self.db_manager.get_session()
error_log = AgentLog(
conversation_id=conversation_id or "unknown",
level="ERROR",
operation="chat",
message=str(e),
error_details={'exception_type': type(e).__name__}
)
session.add(error_log)
session.commit()
session.close()
raiseDer DataPersistentAgent umschließt den Funktionsaufruf-Agenten von LangChain mit Datenbank-Tools. Das Tool „SaveUserInfo” speichert Benutzerdaten, indem es Benutzerdatensätze erstellt oder aktualisiert. Das Tool „RetrieveHistory” fragt vergangene Konversationen ab, um Kontextinformationen bereitzustellen. Die Systemaufforderung weist den Agenten an, Informationen proaktiv zu speichern und den Verlauf zu überprüfen. Der „ConversationBufferMemory” verwaltet den kurzfristigen Kontext innerhalb von Sitzungen. Der Datenbankspeicher sorgt für langfristige Persistenz über Sitzungen hinweg.
Schritt 3.5: Erstellen des Datenerfassungsmoduls
Entwickeln Sie Tools zum Extrahieren und Strukturieren von Daten aus Konversationen. Der Collector generiert Zusammenfassungen, extrahiert Präferenzen und identifiziert Entitäten mithilfe des LLM.
Klasse DataCollector:
"""
Sammelt und strukturiert Daten aus Agentengesprächen.
Dieses Modul:
- Erstellt Gesprächszusammenfassungen
- Extrahiert Benutzereinstellungen aus dem Gesprächsverlauf
- Identifiziert und speichert benannte Entitäten
"""
def __init__(self, db_manager: DatabaseManager, llm: ChatOpenAI):
"""
Initialisiert den Datensammler.
Argumente:
db_manager: Datenbankmanager-Instanz
llm: Sprachmodell für die Textanalyse
"""
self.db_manager = db_manager
self.llm = llm
logger.info("✓ Datensammler initialisiert")
def extract_conversation_summary(self, conversation_id: str) -> str:
"""
Generieren und Speichern einer Gesprächszusammenfassung mit LLM.
Argumente:
conversation_id: ID des zusammenzufassenden Gesprächs
Rückgabewerte:
str: Generierter Zusammenfassungstext
"""
try:
session = self.db_manager.get_session()
conversation = session.query(Conversation).filter_by(conversation_id=conversation_id).first()
if not conversation:
return "Conversation not found"
messages = session.query(Message).filter_by(conversation_id=conversation.id).all()
# Konversationstext erstellen
conv_text = "n".join([
f"{msg.role}: {msg.content}" for msg in messages
])
# Zusammenfassung mit LLM erstellen
summary_prompt = f"""Fassen Sie die folgende Konversation in 2–3 Sätzen zusammen und erfassen Sie dabei die wichtigsten Themen und Ergebnisse:
{conv_text}
Zusammenfassung:"""
summary_response = self.llm.invoke([HumanMessage(content=summary_prompt)])
summary = summary_response.content
# Konversation mit Zusammenfassung aktualisieren
conversation.summary = summary
session.commit()
session.close()
logger.info(f"✓ Zusammenfassung für Gespräch {conversation_id} generiert")
return summary
except Exception as e:
logger.error(f"Zusammenfassung konnte nicht generiert werden: {e}")
return ""
def extract_user_preferences(self, user_id: str) -> Dict[str, Any]:
"""
Extrahiert und speichert Benutzereinstellungen aus dem Konversationsverlauf.
Argumente:
user_id: ID des zu analysierenden Benutzers
Rückgabewerte:
dict: Extrahierte Einstellungen
"""
try:
session = self.db_manager.get_session()
user = session.query(User).filter_by(user_id=user_id).first()
if not user:
return {}
# Aktuelle Konversationen abrufen
conversations = session.query(Conversation).filter_by(user_id=user.id).order_by(Conversation.created_at.desc()).limit(10).all()
all_messages = []
for conv in conversations:
messages = session.query(Message).filter_by(conversation_id=conv.id).all()
all_messages.extend([msg.content for msg in messages if msg.role == "user"])
if not all_messages:
return {}
# Präferenzen mit LLM analysieren
analysis_prompt = f"""Analysiere die folgenden Nachrichten eines Benutzers und extrahiere dessen Präferenzen, Interessen und Kommunikationsstil.
Nachrichten:
{chr(10).join(all_messages[:20])}
Gib ein JSON-Objekt mit der folgenden Struktur zurück:
{{
"interests": ["interest1", "interest2"],
„communication_style”: „description”,
„preferred_topics”: [„topic1”, „topic2”],
„language_preference”: „language”
}}"""
response = self.llm.invoke([HumanMessage(content=analysis_prompt)])
try:
# JSON aus Antwort extrahieren
content = response.content
if '```json' in content:
content = content.split('```json')[1].split('```')[0].strip()
elif '```' in content:
content = content.split('```')[1].split('```')[0].strip()
preferences = json.loads(content)
# Benutzereinstellungen aktualisieren
user.preferences = preferences
session.commit()
logger.info(f"✓ Einstellungen für Benutzer {user_id} extrahiert")
return preferences
except json.JSONDecodeError:
logger.warning("Fehler beim Parsing der JSON-Einstellungen")
return {}
finally:
session.close()
except Exception as e:
logger.error(f"Extrahieren der Einstellungen fehlgeschlagen: {e}")
return {}
def extract_entities_with_llm(self, conversation_id: str) -> List[Dict[str, Any]]:
"""
Extrahieren benannter Entitäten mit LLM.
Argumente:
conversation_id: ID der zu analysierenden Konversation
Rückgabewerte:
list: Liste der extrahierten Entitäten
"""
try:
session = self.db_manager.get_session()
conversation = session.query(Conversation).filter_by(conversation_id=conversation_id).first()
if not conversation:
return []
messages = session.query(Message).filter_by(conversation_id=conversation.id).all()
conv_text = "n".join([msg.content for msg in messages])
# Entitäten mit LLM extrahieren
entity_prompt = f"""Extrahieren Sie benannte Entitäten aus der folgenden Konversation. Identifizieren Sie:
- Personen (PERSON)
- Organisationen (ORG)
- Orte (LOC)
- Daten (DATE)
- Produkte (PRODUCT)
- Technologien (TECH)
Konversation:
{conv_text}
Geben Sie ein JSON-Array von Entitäten mit folgendem Format zurück:
[
{{"type": "PERSON", "value": "John Doe", "context": "erwähnt als Teamleiter"}},
{{"type": "ORG", "value": "Acme Corp", "context": "Kundenunternehmen"}}
]"""
response = self.llm.invoke([HumanMessage(content=entity_prompt)])
try:
content = response.content
if '```json' in content:
content = content.split('```json')[1].split('```')[0].strip()
elif '```' in content:
content = content.split('```')[1].split('```')[0].strip()
entities_data = json.loads(content)
# Entitäten in Datenbank speichern
saved_entities = []
for entity_data in entities_data:
entity = Entity(
conversation_id=conversation.id,
entity_type=entity_data['type'],
entity_value=entity_data['value'],
context=entity_data.get('context', ''),
confidence=0.9 # LLM-Extraktion hat hohe Zuverlässigkeit
)
session.add(entity)
saved_entities.append(entity_data)
session.commit()
session.close()
logger.info(f"✓ {len(saved_entities)} Entitäten aus der Konversation {conversation_id} extrahiert")
return saved_entities
except json.JSONDecodeError:
logger.warning("Failed to parse entities JSON")
return []
except Exception as e:
logger.error(f"Failed to extract entities: {e}")
return []Der DataCollector verwendet das LLM zur Analyse von Konversationen. Die Methode extract_conversation_summary erstellt prägnante Zusammenfassungen von Konversationen. Die Methode extract_user_preferences analysiert Nachrichtenmuster, um die Interessen und Kommunikationsstile der Benutzer zu identifizieren. Die Methode extract_entities_with_llm verwendet strukturierte Eingabeaufforderungen, um benannte Entitäten wie Personen, Organisationen und Technologien zu extrahieren. Alle extrahierten Daten werden zur späteren Verwendung in der Datenbank gespeichert.
Schritt 4: Aufbau der intelligenten Datenverarbeitungs-Pipeline
Implementieren Sie eine Hintergrundverarbeitung, um die Datenerfassung zu verarbeiten, ohne den Agenten zu blockieren. Die Pipeline verwendet Worker-Threads und Warteschlangen, um Zusammenfassungen und Entitäten zu verarbeiten.
Klasse DataProcessingPipeline:
"""
Asynchrone Datenverarbeitungs-Pipeline.
Diese Pipeline:
- Verarbeitet Konversationen im Hintergrund.
- Erstellt Zusammenfassungen.
- Extrahiert Entitäten, ohne den Hauptablauf zu blockieren.
- Aktualisiert regelmäßig die Benutzereinstellungen.
"""
def __init__(self, db_manager: DatabaseManager, collector: DataCollector, batch_size: int = 10):
"""
Initialisieren Sie die Verarbeitungspipeline.
Argumente:
db_manager: Datenbankmanager-Instanz
collector: Datensammler für Verarbeitungsvorgänge
batch_size: Anzahl der in jedem Stapel zu verarbeitenden Elemente
"""
self.db_manager = db_manager
self.collector = collector
self.batch_size = batch_size
# Verarbeitungswarteschlangen
self.summary_queue = Queue()
self.entity_queue = Queue()
self.preference_queue = Queue()
# Worker-Threads
self.workers = []
self.running = False
logger.info("✓ Datenverarbeitungs-Pipeline initialisiert")
def start(self):
"""Hintergrundverarbeitungs-Worker starten."""
self.running = True
# Worker-Threads erstellen
summary_worker = Thread(target=self._process_summaries, daemon=True)
entity_worker = Thread(target=self._process_entities, daemon=True)
preference_worker = Thread(target=self._process_preferences, daemon=True)
summary_worker.start()
entity_worker.start()
preference_worker.start()
self.workers = [summary_worker, entity_worker, preference_worker]
logger.info("✓ 3 Hintergrundverarbeitungs-Worker gestartet")
def stop(self):
"""Hintergrundverarbeitungs-Worker stoppen."""
self.running = False
for worker in self.workers:
worker.join(timeout=5)
logger.info("✓ Hintergrundverarbeitungs-Worker gestoppt")
def queue_conversation_for_processing(self, conversation_id: str, user_id: str):
"""
Konversation zu Verarbeitungswarteschlangen hinzufügen.
Argumente:
conversation_id: ID der zu verarbeitenden Konversation
user_id: ID des Benutzers für die Präferenzerfassung
"""
self.summary_queue.put(conversation_id)
self.entity_queue.put(conversation_id)
self.preference_queue.put(user_id)
logger.info(f"✓ Konversation {conversation_id} zur Verarbeitung in die Warteschlange gestellt")
def _process_summaries(self):
"""Worker zur Verarbeitung von Konversationszusammenfassungen."""
while self.running:
try:
if not self.summary_queue.empty():
conversation_id = self.summary_queue.get()
self.collector.extract_conversation_summary(conversation_id)
self.summary_queue.task_done()
else:
time.sleep(1)
except Exception as e:
logger.error(f"Fehler im Zusammenfassungs-Worker: {e}")
def _process_entities(self):
"""Worker für die Verarbeitung der Entitätsextraktion."""
while self.running:
try:
if not self.entity_queue.empty():
conversation_id = self.entity_queue.get()
self.collector.extract_entities_with_llm(conversation_id)
self.entity_queue.task_done()
else:
time.sleep(1)
except Exception as e:
logger.error(f"Fehler im Entitäts-Worker: {e}")
def _process_preferences(self):
"""Worker zur Verarbeitung von Benutzereinstellungen."""
while self.running:
try:
if not self.preference_queue.empty():
user_id = self.preference_queue.get()
self.collector.extract_user_preferences(user_id)
self.preference_queue.task_done()
else:
time.sleep(1)
except Exception as e:
logger.error(f"Fehler im Präferenz-Worker: {e}")
def get_queue_status(self) -> Dict[str, int]:
"""
Aktuelle Warteschlangengrößen abrufen.
Gibt zurück:
dict: Warteschlangengrößen für jeden Verarbeitungstyp
"""
return {
'summary_queue': self.summary_queue.qsize(),
'entity_queue': self.entity_queue.qsize(),
'preference_queue': self.preference_queue.qsize()
}Die ProcessingPipeline trennt die Datenerfassung von der Nachrichtenverarbeitung. Wenn eine Konversation abgeschlossen ist, wird sie zu den Warteschlangen hinzugefügt, anstatt sofort verarbeitet zu werden. Separate Worker-Threads ziehen Elemente aus diesen Warteschlangen und verarbeiten sie im Hintergrund. Dadurch wird verhindert, dass die Datenerfassung die Antworten der Agenten blockiert. Die Einstellung daemon=True stellt sicher, dass die Worker beendet werden, wenn das Hauptprogramm beendet wird. Die Überwachung des Warteschlangenstatus hilft dabei, Verarbeitungsrückstände zu verfolgen.
Schritt 5: Hinzufügen von Echtzeitüberwachung und Protokollierung
Erstellen Sie ein Überwachungssystem, um die Leistung der Agenten zu verfolgen, Fehler zu erkennen und Berichte zu erstellen. Der Monitor analysiert Protokolle, um Einblicke in den Betrieb zu gewinnen.
Klasse AgentMonitor:
"""
Echtzeitüberwachung und Erfassung von Metriken.
Dieses Modul:
- Verfolgt Leistungsmetriken
- Überwacht den Systemzustand
- Erstellt Analyseberichte
"""
def __init__(self, db_manager: DatabaseManager):
"""
Agent-Monitor initialisieren.
Args:
db_manager: Datenbankmanager-Instanz
"""
self.db_manager = db_manager
logger.info("✓ Agent-Monitor initialisiert")
def get_performance_metrics(self, hours: int = 24) -> Dict[str, Any]:
"""
Leistungsmetriken für den angegebenen Zeitraum abrufen.
Argumente:
hours: Anzahl der Stunden, die zurückverfolgt werden sollen
Rückgabewerte:
dict: Leistungsmetriken einschließlich Anzahl der Vorgänge und Fehlerraten
"""
try:
session = self.db_manager.get_session()
cutoff_time = datetime.utcnow() - timedelta(hours=hours)
# Protokolle abfragen
logs = session.query(AgentLog).filter(
AgentLog.created_at >= cutoff_time
).all()
# Metriken berechnen
total_operations = len(logs)
error_count = len([log for log in logs if log.level == "ERROR"])
avg_execution_time = sum([log.execution_time or 0 for log in logs]) / max(total_operations, 1)
# Anzahl der Konversationen abrufen
conversations = session.query(Conversation).filter(
Conversation.created_at >= cutoff_time
).count()
messages = session.query(Message).join(Conversation).filter(
Message.created_at >= cutoff_time
).count()
session.close()
metrics = {
'time_period_hours': hours,
'total_operations': total_operations,
'error_count': error_count,
'error_rate': error_count / max(total_operations, 1),
'avg_execution_time': avg_execution_time,
'conversations_created': conversations,
'messages_processed': messages
}
logger.info(f"✓ Generierte Leistungsmetriken für die letzten {hours} Stunden")
return metrics
except Exception as e:
logger.error(f"Fehler beim Abrufen der Leistungsmetriken: {e}")
return {}
def health_check(self) -> Dict[str, Any]:
"""
Gesundheitscheck durchführen.
Rückgabewerte:
dict: Gesundheitsstatus einschließlich Datenbankkonnektivität und Fehlerraten
"""
try:
# Datenbankkonnektivität überprüfen
db_healthy = self.db_manager.health_check()
# Aktuelle Fehlerrate überprüfen
metrics = self.get_performance_metrics(hours=1)
recent_errors = metrics.get('error_count', 0)
# Gesamtzustand bestimmen
is_healthy = db_healthy and recent_errors < 10
health_status = {
'status': 'healthy' if is_healthy else 'degraded',
'database_connected': db_healthy,
'recent_errors': recent_errors,
'timestamp': datetime.utcnow().isoformat()
}
logger.info(f"✓ Zustandsprüfung: {health_status['status']}")
return health_status
except Exception as e:
logger.error(f"Gesundheitscheck fehlgeschlagen: {e}")
return {
'status': 'unhealthy',
'error': str(e),
'timestamp': datetime.utcnow().isoformat()
}Der AgentMonitor bietet Einblick in den Systembetrieb. Er verfolgt Metriken wie Gesamtoperationen, Fehlerraten und durchschnittliche Ausführungszeiten, indem er die AgentLog-Tabelle abfragt. Die Methode get_metrics berechnet Statistiken über konfigurierbare Zeitfenster. Die Methode get_error_report ruft detaillierte Fehlerinformationen für die Fehlerbehebung ab. Diese Überwachung ermöglicht eine proaktive Erkennung von Problemen. Hohe Fehlerraten lösen eine Untersuchung aus, bevor Benutzer davon betroffen sind.
Schritt 6: Erstellen der Abfrage-Schnittstelle
Erstellen Sie Abfragefunktionen zum Abrufen und Analysieren gespeicherter Daten. Die Schnittstelle bietet Methoden zum Suchen von Konversationen, Verfolgen von Entitäten und Generieren von Analysen.
Klasse DataQueryInterface:
"""
Schnittstelle zum Abfragen gespeicherter Agentendaten.
Dieses Modul bietet Methoden zum:
- Abfragen von Benutzeranalysen
- Abrufen des Konversationsverlaufs
- Suchen nach bestimmten Informationen
"""
def __init__(self, db_manager: DatabaseManager):
"""
Initialisieren der Abfrage-Schnittstelle.
Argumente:
db_manager: Datenbankmanager-Instanz
"""
self.db_manager = db_manager
logger.info("✓ Abfrage-Schnittstelle initialisiert")
def get_user_analytics(self, user_id: str) -> Dict[str, Any]:
"""
Analysen für einen bestimmten Benutzer abrufen.
Argumente:
user_id: ID des zu analysierenden Benutzers
Rückgabewerte:
dict: Benutzeranalysen einschließlich Konversationsanzahl und Präferenzen
"""
try:
session = self.db_manager.get_session()
user = session.query(User).filter_by(user_id=user_id).first()
if not user:
return {}
# Anzahl der Konversationen abrufen
conversation_count = session.query(Conversation).filter_by(user_id=user.id).count()
# Anzahl der Nachrichten abrufen
message_count = session.query(Message).join(Conversation).filter(
Conversation.user_id == user.id
).count()
# Anzahl der Entitäten abrufen
entity_count = session.query(Entity).join(Conversation).filter(
Conversation.user_id == user.id
).count()
# Zeitbereich abrufen
first_conversation = session.query(Conversation).filter_by(
user_id=user.id
).order_by(Conversation.created_at).first()
last_conversation = session.query(Conversation).filter_by(
user_id=user.id
).order_by(Conversation.created_at.desc()).first()
session.close()
analytics = {
'user_id': user_id,
'name': user.name,
'conversation_count': conversation_count,
'message_count': message_count,
'entity_count': entity_count,
'preferences': user.preferences,
'first_interaction': first_conversation.created_at.isoformat() if first_conversation else None,
'last_interaction': last_conversation.created_at.isoformat() if last_conversation else None,
'avg_messages_per_conversation': message_count / max(conversation_count, 1)
}
logger.info(f"✓ Generierte Analysen für Benutzer {user_id}")
return analytics
except Exception as e:
logger.error(f"Fehler beim Abrufen der Benutzeranalysen: {e}")
return {}Die QueryInterface bietet Methoden für den Zugriff auf gespeicherte Daten. Die Methode get_user_conversations ruft den vollständigen Konversationsverlauf mit optionaler Einbeziehung von Nachrichten ab. Die Methode „search_conversations“ führt eine Volltextsuche über den Nachrichteninhalt mithilfe des ILIKE-Operators von SQL durch. Die Methode „get_entity_mentions“ findet alle Konversationen, in denen bestimmte Entitäten erwähnt wurden. Die Methode „get_user_analytics“ generiert Statistiken über die Benutzeraktivität. Diese Abfragen ermöglichen die Erstellung von Dashboards, die Generierung von Berichten und die Schaffung personalisierter Erlebnisse.
Schritt 7: Aufbau eines RAG mit Echtzeit-Webdaten von Bright Data
Erweitern Sie Ihren datenbankgebundenen Agenten mit RAG-Funktionen aus der Echtzeit-Web-Intelligence von Bright Data. Diese Integration kombiniert Ihren Konversationsverlauf mit aktuellen Webdaten für bessere Antworten.
Klasse BrightDataRAGEnhancer:
"""
Erweitern Sie Ihren datenpersistenten Agenten mit der Web-Intelligence von Bright Data.
Dieses Modul:
- Ruft Echtzeit-Webdaten von Bright Data ab.
- Speichert Webdaten in einem Vektorspeicher für RAG.
- Erweitert den Agenten mit webgestütztem Wissen.
"""
def __init__(self, api_key: str, db_manager: DatabaseManager):
"""
Initialisieren Sie den RAG-Enhancer mit Bright Data.
Argumente:
api_key: Bright Data API-Schlüssel
db_manager: Datenbankmanager-Instanz
"""
self.api_key = api_key
self.db_manager = db_manager
self.base_url = "https://api.brightdata.com"
# Initialisiere Vektorspeicher für RAG
self.embeddings = OpenAIEmbeddings()
self.vector_store = Chroma(
embedding_function=self.embeddings,
persist_directory="./chroma_db"
)
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200
)
logger.info("✓ Bright Data RAG Enhancer initialisiert")
def fetch_dataset_data(
self,
dataset_id: str,
filters: Optional[Dict[str, Any]] = None,
limit: int = 1000
) -> List[Dict[str, Any]]:
"""
Daten aus dem Bright Data Dataset Marketplace abrufen.
Argumente:
dataset_id: ID des abzurufenden Datensatzes
filters: Optionale Filter für Daten
limit: Maximale Anzahl der abzurufenden Datensätze
Rückgabewerte:
list: Abgerufene Datensatzdatensätze
"""
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
endpoint = f"{self.base_url}/Datensätze/v3/snapshot/{dataset_id}"
params = {
"format": "json",
"limit": limit
}
if filters:
params["filter"] = json.dumps(filters)
try:
response = requests.get(endpoint, headers=headers, params=params)
response.raise_for_status()
data = response.json()
logger.info(f"✓ Retrieved {len(data)} records from Bright Data dataset {dataset_id}")
return data
except Exception as e:
logger.error(f"Fehler beim Abrufen des Bright Data-Datensatzes: {e}")
return []
def ingest_web_data_to_rag(
self,
dataset_records: List[Dict[str, Any]],
text_fields: List[str],
metadata_fields: Optional[List[str]] = None
) -> int:
"""
Webdaten in den RAG-Vektorspeicher einlesen.
Argumente:
dataset_records: Datensätze aus Bright Data
text_fields: Als Textinhalt zu verwendende Felder
metadata_fields: In die Metadaten aufzunehmende Felder
Rückgabewerte:
int: Anzahl der importierten Dokumentteile
"""
try:
documents = []
for record in dataset_records:
# Textfelder kombinieren
text_content = " ".join([
str(record.get(field, ""))
for field in text_fields
if record.get(field)
])
if not text_content.strip():
continue
# Metadaten erstellen
metadata = {
"source": "bright_data",
"record_id": record.get("id", "unknown"),
"timestamp": datetime.utcnow().isoformat()
}
if metadata_fields:
for field in metadata_fields:
if field in record:
metadata[field] = record[field]
# Text in Teile aufteilen
chunks = self.text_splitter.split_text(text_content)
for chunk in chunks:
documents.append({
"content": chunk,
"metadata": metadata
})
# Zum Vektorspeicher hinzufügen
if documents:
texts = [doc["content"] for doc in documents]
metadatas = [doc["metadata"] for doc in documents]
self.vector_store.add_texts(
texts=texts,
metadatas=metadatas
)
logger.info(f"✓ {len(documents)} Dokumentenstücke in RAG aufgenommen")
return len(documents)
except Exception as e:
logger.error(f"Failed to ingest web data to RAG: {e}")
return 0
def create_rag_enhanced_agent(
self,
base_agent: DataPersistentAgent
) -> DataPersistentAgent:
"""
Enhance existing agent with RAG capabilities.
Argumente:
base_agent: Zu erweiternder Basisagent
Rückgabewerte:
DataPersistentAgent: Mit RAG-Tool erweiterter Agent
"""
def rag_search(query: str) -> str:
"""Sucht sowohl im Konversationsverlauf als auch in Webdaten."""
try:
# Aus dem Konversationsverlauf abrufen
session = self.db_manager.get_session()
messages = session.query(Message).filter(
Message.content.ilike(f'%{query}%')
).order_by(Message.created_at.desc()).limit(5).all()
results = []
for msg in messages:
results.append({
'content': msg.content,
'source': 'conversation_history',
'relevance': 0.8
})
session.close()
# Aus dem Vektorspeicher (Webdaten) abrufen
try:
vector_results = self.vector_store.similarity_search_with_score(query, k=5)
for doc, score in vector_results:
results.append({
'content': doc.page_content,
'source': 'web_data',
'relevance': 1 - score
})
except Exception as e:
logger.error(f"Abruf aus Vektorspeicher fehlgeschlagen: {e}")
if not results:
return "Keine relevanten Informationen gefunden."
# Kontext formatieren
context_text = "nn".join([
f"[{item['source']}] {item['content'][:200]}..."
for item in results[:5]
])
return f"Abgerufener Kontext:n{context_text}"
except Exception as e:
logger.error(f"RAG-Suche fehlgeschlagen: {e}")
return f"Fehler bei der Suche: {str(e)}"
# RAG-Tool zum Agenten hinzufügen
rag_tool = Tool(
name="SearchKnowledgeBase",
func=rag_search,
description="Sucht sowohl im Gesprächsverlauf als auch in Echtzeit-Webdaten nach relevanten Informationen. Die Eingabe sollte eine Suchanfrage sein."
)
base_agent.tools.append(rag_tool)
# Agenten mit neuen Tools neu erstellen
base_agent.agent = create_openai_functions_agent(
llm=base_agent.llm,
tools=base_agent.tools,
prompt=base_agent.prompt
)
base_agent.agent_executor = AgentExecutor(
agent=base_agent.agent,
tools=base_agent.tools,
memory=base_agent.memory,
verbose=True,
handle_parsing_errors=True,
max_iterations=5
)
logger.info("✓ Verbesserter Agent mit RAG-Funktionen")
return base_agentDer BrightDataEnhancer integriert Echtzeit-Webdaten in Ihren Agenten. Die Methode fetch_dataset ruft strukturierte Daten aus dem Marktplatz von Bright Data ab. Die Methode ingest_to_rag verarbeitet diese Daten und zerlegt sie in Blöcke. Sie speichert sie in einer Chroma-Vektordatenbank für die semantische Suche. Die Methode retrieve_context führt eine hybride Suche durch. Sie kombiniert den Datenbankverlauf mit einer Vektorähnlichkeitssuche. Die Methode „create_rag_tool” verpackt diese Funktionalität als LangChain-Tool, das der Agent verwendet. Die Methode „enhance_agent” fügt diese RAG-Fähigkeit zu Ihrem bestehenden Agenten hinzu. Sie ermöglicht es dem Agenten, Fragen sowohl anhand des internen Konversationsverlaufs als auch anhand aktueller externer Daten zu beantworten.
Ausführen Ihres vollständigen datenpersistenten Agentensystems
Führen Sie alle Komponenten zusammen, um ein funktionsfähiges System zu erstellen.
def main():
"""Haupt-Ausführungsablauf, der die Zusammenarbeit aller Komponenten demonstriert."""
print("=" * 60)
print("Datenpersistentes KI-Agentensystem – Initialisierung")
print("=" * 60)
# Schritt 1: Datenbank initialisieren
print("n[Schritt 1] Datenbankverbindung einrichten...")
db_manager = DatabaseManager(
database_url=os.getenv("DATABASE_URL"),
pool_size=5,
max_retries=3
)
db_manager.initialize_database()
# Schritt 2: Kernagenten initialisieren
print("n[Schritt 2] KI-Agentenkern erstellen...")
agent = DataPersistentAgent(
db_manager=db_manager,
model_name=os.getenv("AGENT_MODEL", "gpt-4-turbo-preview")
)
# Schritt 3: Initialisieren des Datensammlers
print("n[Schritt 3] Erstellen des Datenerfassungsmoduls...")
collector = DataCollector(db_manager, agent.llm)
# Schritt 4: Verarbeitungs-Pipeline initialisieren
print("n[Schritt 4] Datenverarbeitungs-Pipeline implementieren...")
pipeline = DataProcessingPipeline(db_manager, collector)
pipeline.start()
# Schritt 5: Überwachung initialisieren
print("n[Schritt 5] Überwachung und Protokollierung hinzufügen...")
monitor = AgentMonitor(db_manager)
# Schritt 6: Abfrage-Schnittstelle initialisieren
print("n[Schritt 6] Abfrage-Schnittstelle erstellen...")
query_interface = DataQueryInterface(db_manager)
# Schritt 7: Optionale Bright Data RAG-Erweiterung
print("n[Schritt 7] RAG-Erweiterung (optional)...")
bright_data_key = os.getenv("BRIGHT_DATA_API_KEY")
if bright_data_key and bright_data_key != "your-bright-data-api-key":
print("Abrufen von Echtzeit-Webdaten aus Bright Data...")
enhancer = BrightDataRAGEnhancer(bright_data_key, db_manager)
# Beispiel: Abrufen und Einlesen von Webdaten
web_data = enhancer.fetch_dataset_data(
dataset_id="example_dataset_id",
limit=100
)
if web_data:
enhancer.ingest_web_data_to_rag(
dataset_records=web_data,
text_fields=["title", "content", "description"],
metadata_fields=["url", "published_date"]
)
# Agenten mit RAG verbessern
agent = enhancer.create_rag_enhanced_agent(agent)
print("✓ Agent mit Bright Data RAG-Funktionen verbessert")
else:
print("⚠️ Bright Data API-Schlüssel nicht gefunden – Integration von Webdaten wird übersprungen")
print("n" + "=" * 60)
print("Demo-Konversationen")
print("=" * 60)
# Demo-Benutzerinteraktionen
test_user = "demo_user_001"
# Erste Konversation
print("n📝 Konversation 1:")
response1 = agent.chat(
user_id=test_user,
message="Hallo! Ich interessiere mich für maschinelles Lernen."
)
print(f"Agent: {response1['response']}n")
# Warteschlange zur Verarbeitung
pipeline.queue_conversation_for_processing(
response1['conversation_id'],
test_user
)
# Zweite Konversation
print("📝 Konversation 2:")
response2 = agent.chat(
user_id=test_user,
message="Helfen Sie mir, neuronale Netze zu verstehen?",
conversation_id=response1['conversation_id']
)
print(f"Agent: {response2['response']}n")
# Auf Hintergrundverarbeitung warten
print("⏳ Daten werden im Hintergrund verarbeitet...")
time.sleep(5)
print("n" + "=" * 60)
print("Analytik & Überwachung")
print("=" * 60)
# Leistungskennzahlen abrufen
metrics = monitor.get_performance_metrics(hours=1)
print(f"n📊 Leistungskennzahlen:")
print(f" - Gesamtzahl der Vorgänge: {metrics.get('total_operations', 0)}")
print(f" - Fehlerquote: {metrics.get('error_rate', 0):.2%}")
print(f" - Durchschnittliche Ausführungszeit: {metrics.get('avg_execution_time', 0):.2f}s")
print(f" - Erstellte Konversationen: {metrics.get('conversations_created', 0)}")
print(f" - Verarbeitete Nachrichten: {metrics.get('messages_processed', 0)}")
# Benutzeranalysen abrufen
analytics = query_interface.get_user_analytics(test_user)
print(f"n👤 Benutzeranalysen:")
print(f" - Anzahl der Konversationen: {analytics.get('conversation_count', 0)}")
print(f" - Anzahl der Nachrichten: {analytics.get('message_count', 0)}")
print(f" - Anzahl der Entitäten: {analytics.get('entity_count', 0)}")
print(f" - Durchschnittliche Nachrichten pro Konversation: {analytics.get('avg_messages_per_conversation', 0):.1f}")
# Zustandsprüfung
health = monitor.health_check()
print(f"n🏥 Systemzustand: {health['status']}")
# Warteschlangenstatus
queue_status = pipeline.get_queue_status()
print(f"n📋 Verarbeitungswarteschlangen:")
print(f" - Zusammenfassungswarteschlange: {queue_status['summary_queue']}")
print(f" - Entitätswarteschlange: {queue_status['entity_queue']}")
print(f" - Präferenzwarteschlange: {queue_status['preference_queue']}")
# Pipeline stoppen
pipeline.stop()
print("n" + "=" * 60)
print("Datenpersistentes Agentensystem – abgeschlossen")
print("=" * 60)
print("n✓ Alle Daten in Datenbank gespeichert")
print("✓ Hintergrundverarbeitung abgeschlossen")
print("✓ System bereit für den Produktionsbetrieb")
if __name__ == "__main__":
try:
main()
except KeyboardInterrupt:
print("nn⚠️ Ordnungsgemäßes Herunterfahren...")
except Exception as e:
logger.error(f"Systemfehler: {e}")
import traceback
traceback.print_exc()Führen Sie Ihr mit der Datenbank verbundenes Agentensystem aus:
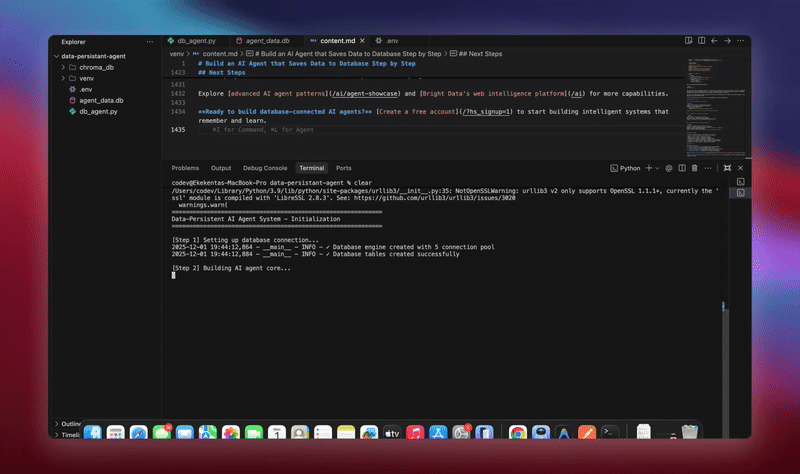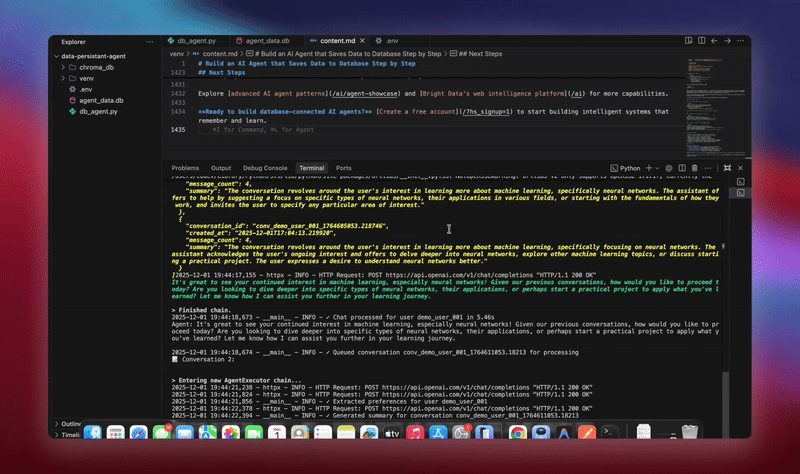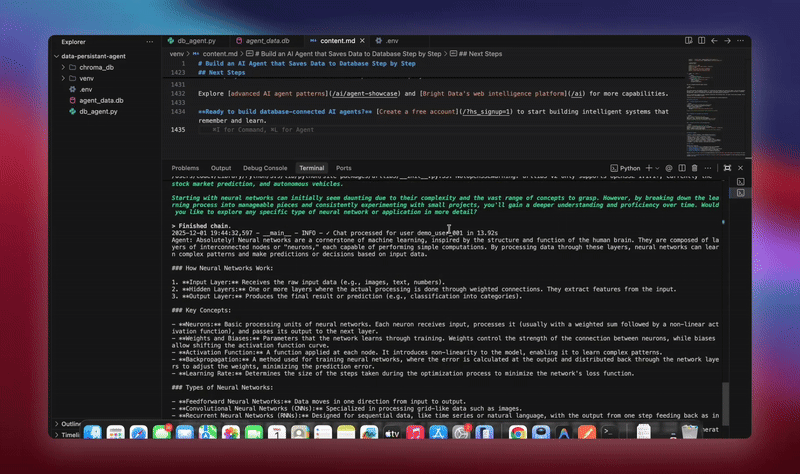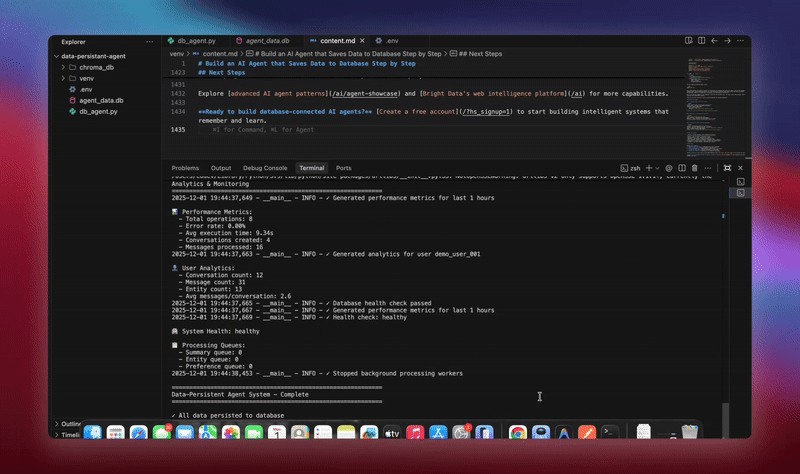
python agent.pyDas System führt den gesamten Workflow aus. Es initialisiert die Datenbank und erstellt alle Tabellen. Es richtet den LangChain-Agenten mit Datenbank-Tools ein. Es startet Hintergrundprozesse für die Verarbeitung. Es verarbeitet Demo-Konversationen und speichert sie in der Datenbank. Es extrahiert Entitäten und generiert Zusammenfassungen im Hintergrund. Es zeigt Echtzeit-Analysen und -Metriken an.
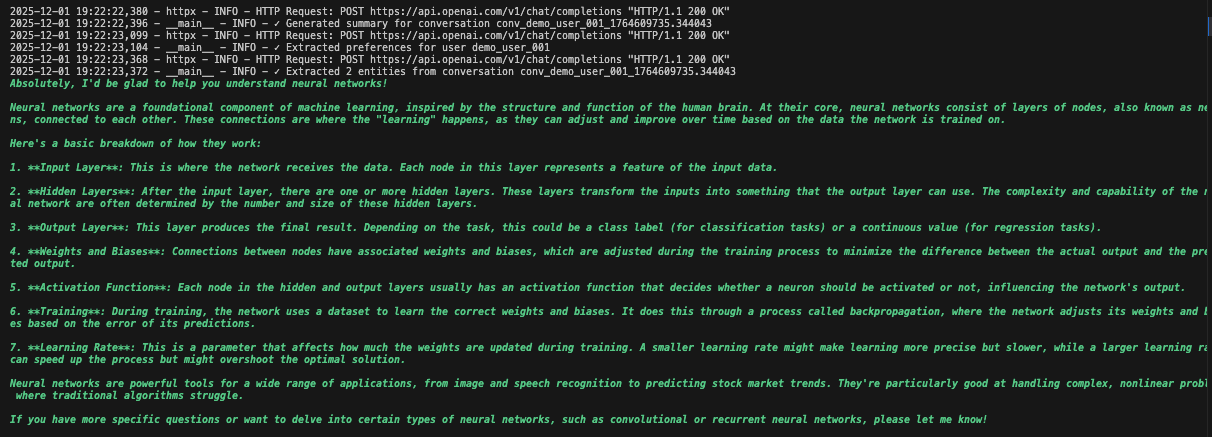
Sie sehen detaillierte Protokolle, während jede Komponente Daten initialisiert und verarbeitet. Der Agent speichert jede Nachricht. Er extrahiert Erkenntnisse. Er behält den vollständigen Konversationskontext bei.
Praktische Anwendungsfälle
1. Kundensupport mit vollständiger Historie
# Agent ruft vergangene Interaktionen ab
support_agent = DataPersistentAgent(db_manager)
response = support_agent.chat(
user_id="customer_123",
message="Ich habe immer noch dieses Verbindungsproblem")
# Agent sieht frühere Konversationen über Verbindungsprobleme2. Persönlicher KI-Assistent mit Lernfunktion
# Agent lernt im Laufe der Zeit Präferenzen
query_interface = QueryInterface(db_manager)
analytics = query_interface.get_user_analytics("user_456")
# Zeigt Interaktionsmuster, Präferenzen und häufige Themen3. Forschungsassistent mit Wissensdatenbank
# Kombiniert den Gesprächsverlauf mit Webdaten
enhancer = BrightDataEnhancer(api_key, db_manager)
enhancer.ingest_to_rag(research_data, ["title", "abstract", "content"])
agent = enhancer.enhance_agent(agent)
# Der Agent bezieht sich sowohl auf frühere Diskussionen als auch auf die neuesten ForschungsergebnisseZusammenfassung der Vorteile
| Funktion | Ohne Datenbank | Mit Datenbank Persistenz |
|---|---|---|
| Speicher | Geht beim Neustart verloren | Permanenter Speicher |
| Personalisierung | Keine | Basierend auf vollständiger Historie |
| Analytik | Nicht möglich | Vollständige Interaktionsdaten |
| Fehlerbehebung | Manueller Eingriff | Automatischer Wiederholungsversuch und Protokollierung |
| Skalierbarkeit | Einzelinstanz | Mehrere Instanzen mit gemeinsamem Status |
| Einblicke | Verloren nach Sitzung | Extrahiert und nachverfolgt |
Zusammenfassung
Sie verfügen nun über ein produktionsreifes KI-Agentensystem, das Konversationen in Datenbanken speichert. Das System speichert jede Interaktion, extrahiert Entitäten und Erkenntnisse, verwaltet den vollständigen Konversationsverlauf und bietet Überwachung mit automatischer Fehlerbehebung.
Verbessern Sie es, indem Sie eine Benutzerauthentifizierung für sicheren Zugriff hinzufügen, Dashboards zur Visualisierung von Analysen erstellen, Einbettungen für die semantische Suche implementieren, API-Endpunkte für die Integration erstellen oder es mit Docker für Skalierbarkeit bereitstellen. Das modulare Design ermöglicht eine einfache Anpassung an Ihre spezifischen Anforderungen.
Entdecken Sie erweiterte KI-Agentenmuster und die Web-Intelligence-Plattform von Bright Data für weitere Funktionen.
Erstellen Sie ein kostenloses Konto, um mit dem Aufbau intelligenter Systeme zu beginnen, die sich merken und lernen.




