

TL;DR: In dieser Anleitung erfahren Sie, wie Sie in Ruby Daten von einer Website extrahieren können und warum Ruby eine der effektivsten Sprachen für das Web Scraping ist.
Diese Anleitung behandelt Folgendes:
- Eignet sich Ruby für das Web Scraping?
- Ruby´s beste Edelsteine für das Web Scraping
- Erstellen eines Web Scrapers in Ruby
Eignet sich Ruby für das Web Scraping?
Ruby ist eine interpretierte, quelloffene, dynamisch geschriebene Programmiersprache, die die funktionale, objektorientierte und prozedurale Entwicklung unterstützt. Sie ist einfach gestaltet, mit einer eleganten Syntax, die leicht zu schreiben und natürlich zu lesen ist. Da sie den Fokus auf die Produktivität legt, ist sie zu einer beliebten Wahl für verschiedene Anwendungen geworden, auch für das Web Scraping.
Da eine Vielzahl von Bibliotheken von Drittanbietern verfügbar ist, eignet sich Ruby hervorragend für das Web Scraping. Die Bibliotheken werden „Edelsteine“ genannt und für fast jede Aufgabe gibt es einen. Wenn es darum geht, programmatisch Informationen aus dem Internet abzurufen, gibt es Edelsteine zum Herunterladen von Websites, zum Analysieren ihres HTML-Inhalts und zum Extrahieren von Daten aus diesen Seiten.
Zusammenfassend lässt sich sagen, dass Web Scraping in Ruby nicht nur möglich, sondern dank der vielen verfügbaren Bibliotheken auch einfach ist. Finden wir heraus, welche am beliebtesten sind!
Ruby´s beste Edelsteine für das Web Scraping
Im Folgenden finden Sie die drei besten Web-Scraping-Bibliotheken für Ruby:
- Nokogiri(鋸): Eine robuste und flexible HTML- und XML-Parser-Bibliothek mit einer vollständigen API zum Durchlaufen und Manipulieren von HTML/XML-Dokumenten, die es einfach macht, relevante Daten daraus zu extrahieren.
- Mechanize: Eine Bibliothek mit Headless-Browser-Funktionalität, die eine High-Level-API für die Automatisierung der Interaktion mit Websites bietet. Sie kann Cookies speichern und senden, Weiterleitungen verarbeiten, Links verfolgen und Formulare übermitteln. Außerdem bietet sie einen Verlauf, mit dem die besuchten Websites zurückverfolgt werden können.
- Selenium: Eine Ruby-Anbindung des beliebtesten Frameworks für das automatisierte Testen von Websites. Sie kann einen Browser anweisen, mit einer Website so zu interagieren, wie es ein menschlicher Benutzer tun würde. Diese Technologie spielt eine Schlüsselrolle bei der Umgehung von Anti-Bot-Lösungen und beim Scraping von Websites, die für die Darstellung oder den Abruf von Daten auf JavaScript angewiesen sind.
Voraussetzungen
Bevor Sie einen Code schreiben, müssen Sie Ruby auf Ihrem Computer installieren. Folgen Sie der nachstehenden Anleitung für das jeweilige Betriebssystem.
Ruby unter macOS installieren
Ruby ist seit der 2015 veröffentlichten Version 10.11 (El Capitan) standardmäßig in macOS enthalten. Angesichts der Tatsache, dass macOS nativ auf Ruby angewiesen ist, um einige Funktionen bereitzustellen, sollten Sie es nicht manipulieren. Es wird nicht empfohlen, die native Ruby-Version mit „brew install ruby“ oder „update ruby mac“ zu aktualisieren, da so einige integrierte Funktionen zerstört werden könnten.
Ruby unter Windows installieren
Laden Sie das Paket RubyInstaller herunter, starten Sie es und folgen Sie dem Installationsassistenten, um Ruby einzurichten. Ein Neustart des Systems kann erforderlich sein. Ab Windows 10 können Sie auch das Windows-Subsystem für Linux verwenden, um Ruby nach der folgenden Anleitung zu installieren.
Ruby unter Linux installieren
Der beste Weg, eine Ruby-Umgebung unter Linux einzurichten, ist die Installation über einen Paketmanager.
Unter Debian und Ubuntu führen Sie Folgendes aus:
sudo apt-get install ruby-fullBei anderen Distributionen ist der auf dem Terminal auszuführende Befehl ein anderer. Konsultieren Sie die Anleitung auf der offiziellen Website um zu sehen, welche Paketmanagementsysteme unterstützt werden.
Unabhängig von Ihrem Betriebssystem sollten Sie nun überprüfen, ob Ruby funktioniert:
ruby -vDas Ergebnis sollte in etwa wie folgt aussehen:
ruby 3.2.2 (2023-03-30 revision e51014f9c0)Klasse! Sie sind nun bereit, mit dem Web Scraping in Ruby zu beginnen!
Erstellen eines Web Scrapers in Ruby
In diesem Abschnitt erfahren Sie, wie Sie in Ruby einen Web Scraper erstellen können. Dieses automatisierte Skript ruft Daten von der Homepage von Bright Dataab. Im Einzelnen geschieht Folgendes:
- Verbinden mit der Zielwebsite
- Auswahl der gewünschten HTML-Elemente aus dem DOM
- Extrahieren von Daten aus diesen Elementen
- Umwandlung der gescrapten Daten in einfach zu analysierende Formate wie CSV und JSON
Zum Zeitpunkt des Schreibens sieht der Nutzer beim Besuch der Ziel-Website Folgendes:
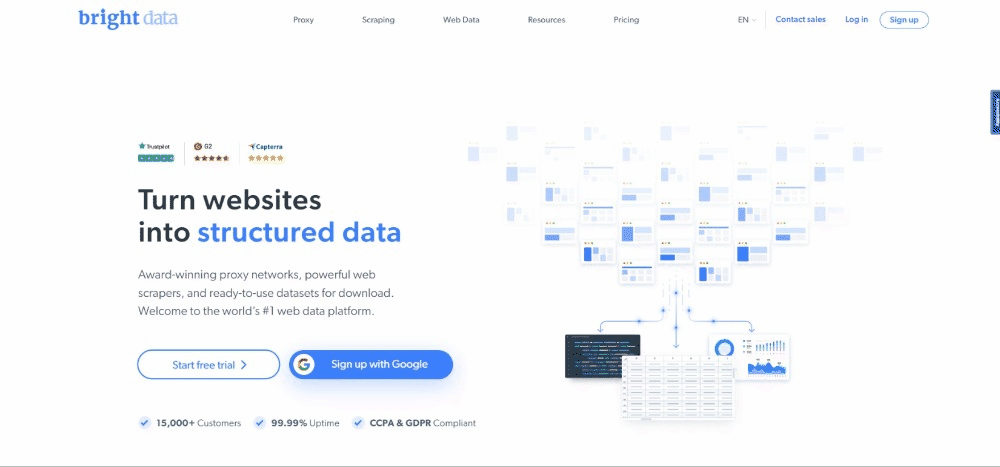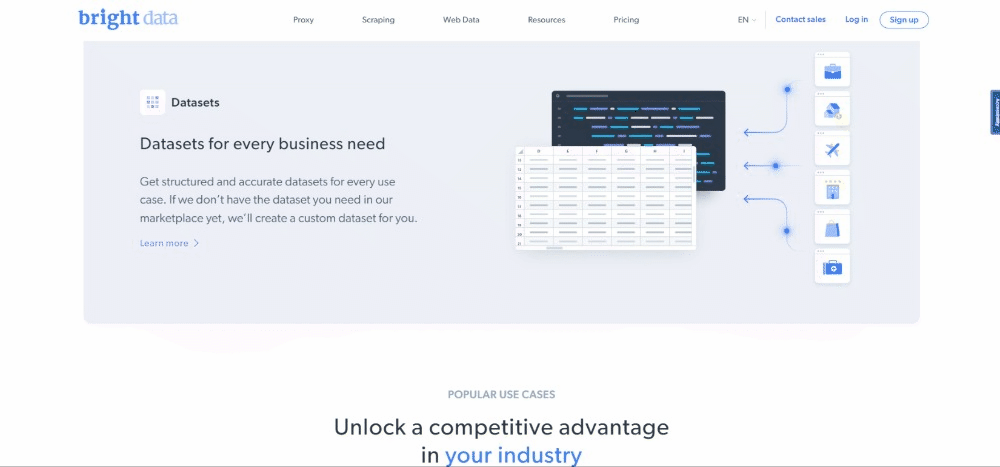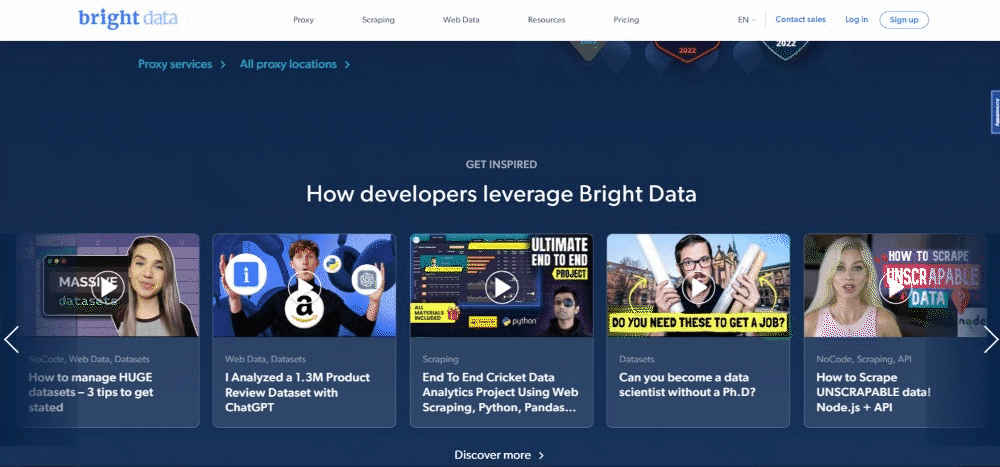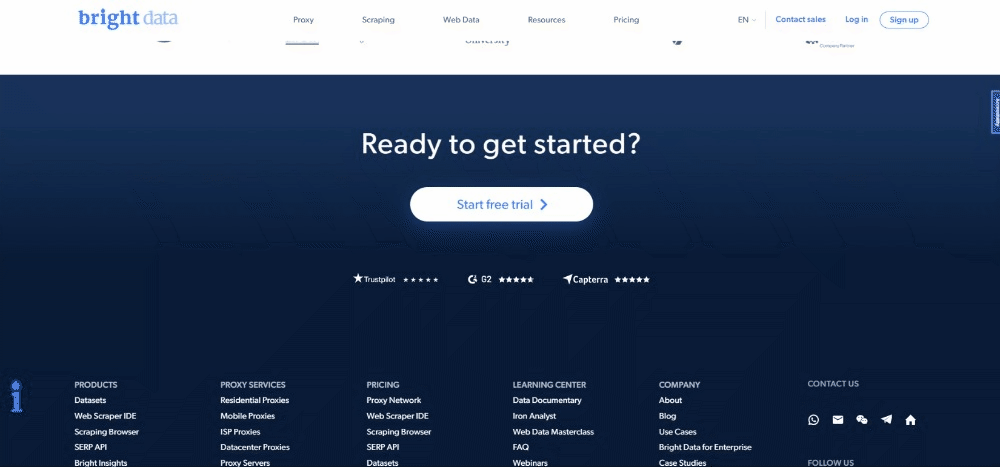
Denken Sie daran, dass die Homepage von Bright Data häufig geändert wird und wenn Sie diesen Artikel lesen möglicherweise nicht mehr gleich aussieht.
Mit diesem Web Scraping wird beabsichtigt, die Informationen über den Anwendungsfall, die in den folgenden Karten enthalten sind, zu erhalten:
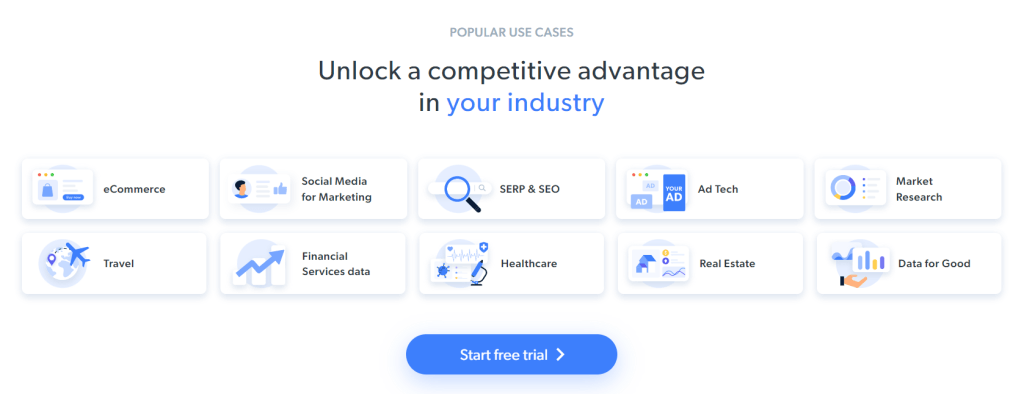
Folgen Sie der nachstehenden Schritt-für-Schritt Anleitung und lernen Sie, wie man Web Scraping in Ruby durchführt!
Schritt 1: Initialisieren Sie ein Ruby-Projekt
Bevor Sie beginnen, müssen Sie Ihr Ruby-Projekt einrichten. Starten Sie das Terminal, erstellen Sie den Projektordner, und geben Sie ihn ein mit:
mkdir ruby-web-scraper
cd ruby-web-scraperDas Verzeichnis ruby-web-scraper wird Ihren Scraper enthalten.
Als nächstes initialisieren Sie die Datei scraper.rb im Projektordner mit folgendem Inhalt:
puts "Hello, World!"Der obige Schnipsel ist das einfachste aller Ruby-Skripte.
Führen Sie ihn in Ihrem Terminal aus, um zu überprüfen, ob er funktioniert:
ruby scraper.rbFolgende Meldung sollte ausgeben werden:
Hello, World!Nun ist es an der Zeit, Ihr Projekt in Ihre integrierte Entwicklungsumgebung (Integrated Development Environment, IDE) zu importieren und mit der Definition einer fortgeschrittenen Scraping-Logik in Ruby zu beginnen! In dieser Anleitung erfahren Sie, wie Sie Visual Studio Code (VS Code) für die Entwicklung mit Ruby einrichten. Aber auch jede andere Ruby-IDE ist geeignet.
Da VS Code Ruby nicht nativ unterstützt, müssen Sie zunächst die Ruby-Erweiterung hinzufügen. Starten Sie Visual Studio Code, klicken Sie an der linken Leiste auf das Symbol „Extensions“ und geben Sie oben in die Sucheingabe „Ruby“ ein.
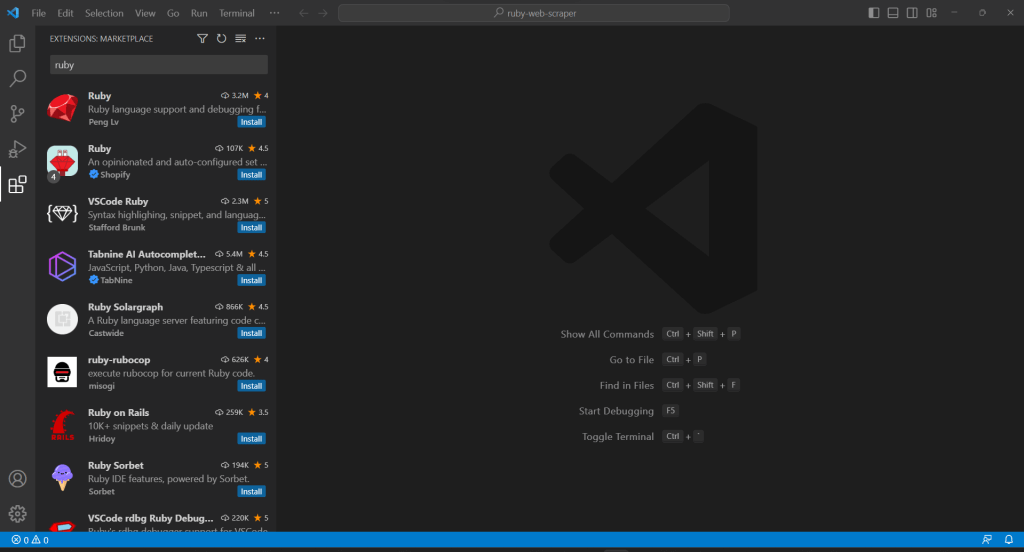
Klicken Sie auf dem ersten Element auf die Schaltfläche „Install“, um die Ruby-Hervorhebungsfunktionen zu VS Code hinzuzufügen. Warten Sie, bis das Plugin zur IDE hinzugefügt wird. Öffnen Sie dann das Verzeichnis ruby-web-scraper mit „File“, „Open Folder…“
Um mit der Bearbeitung der Datei zu beginnen, klicken Sie auf die Datei scraper.rb unter der Leiste „EXPLORER“:
Schritt 2: Wählen Sie die Scraping-Bibliothek
Das Erstellen eines Web Scrapers in Ruby ist mit der richtigen Bibliothek sehr viel einfacher. Aus diesem Grund sollten Sie einen der oben vorgestellten Edelsteine verwenden. Um herauszufinden, welche Ruby-Bibliothek für das Web-Scraping sich am besten für Ihr Vorhaben eignet, müssen Sie zunächst Ihre Ziel-Website analysieren.
Besuchen Sie deshalb die Ziel-Website in Ihrem Browser, klicken Sie mit der rechten Maustaste auf eine leere Stelle im Hintergrund und wählen Sie die Option „Inspect“. Dadurch werden die Entwicklertools Ihres Browsers gestartet. Gehen Sie in Chrome auf die Registerkarte „Network“ und erkunden Sie den Abschnitt „Fetch/XHR“.
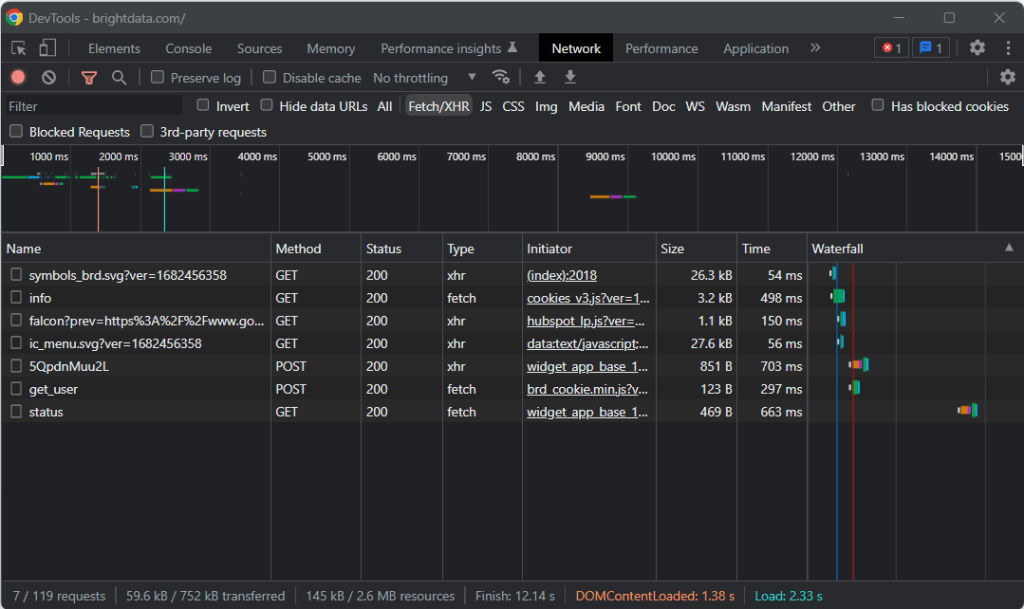
Wie Sie im Screenshot oben sehen können, gibt es nur sieben AJAX-Anfragen. Wenn Sie die einzelnen XHR-Aufrufe genauer betrachten, stellen Sie fest, dass sie keine aussagekräftigen Daten enthalten. Das bedeutet, dass die Ziel-Website den Inhalt während des Renderns nicht abruft. Das vom Server zurückgegebene HTML-Dokument enthält also bereits alle Daten, die dem Benutzer angezeigt werden sollen.
Das ist ein Beweis dafür, dass die Ziel-Website kein JavaScript für den Datenabruf oder das Rendering verwendet. Mit anderen Worten: Für das Web Scraping benötigen Sie keinen Edelstein mit Headless-Browser-Funktionen. Sie können immer noch Mechanize oder Selenium verwenden, aber sie würden gewisse Leistungseinbußen verursachen. Schließlich läuft im Hintergrund eine Browser-Instanz, die Ressourcen benötigt.
Deshalb sollten Sie sich für einen einfachen HTML/XML-Parser wie Nokogiri entscheiden. Installieren Sie diesen über den Edelstein Nokogiri mit:
gem install nokogiriDann können Sie die Bibliothek importieren, indem Sie die folgende Zeile am Anfang Ihrer scraper.rb-Datei einfügen:
require "nokogiri"Vergewissern Sie sich, dass Ihre Ruby-IDE keine Fehler meldet. Schon können Sie Daten in Ruby scrapen!
Schritt 3: Verwenden Sie HTTParty, um die Ziel-Website zu erhalten
Um das HTML-Dokument der Ziel-Website zu analysieren, müssen Sie es zunächst mit einer HTTP GET-Anfrage herunterladen. Ruby verfügt über einen integrierten HTTP-Client namens Net::HTTP, aber seine Syntax ist etwas umständlich und nicht besonders intuitiv. Anstelle dessen sollten Sie HTTParty verwenden, die beliebteste Ruby-Bibliothek zur Durchführung von HTTP-Anfragen.
Installieren Sie sie über den Edelstein httparty mit:
gem install httparty
Then, import it in the scraper.rb file:
require "httparty"
Use HTTParty to connect to the target page with:
response = HTTParty.get("https://brightdata.com/")Die get()-Methode ermöglicht es Ihnen, eine GET-Anfrage an die als Parameter übergebene URL zu stellen. Das Feld response.body enthält das vom Server zurückgegebene HTML-Dokument.
Beachten Sie, dass die über get() gestellte HTTP-Anfrage fehlschlagen kann. Wenn das geschieht, löst HTTParty eine Ausnahme aus und bricht die Ausführung Ihres Skripts mit einer Fehlermeldung ab. Es kann zahlreiche Gründe für einen solchen Fehlschlag geben, aber in der Regel liegt es daran, dass eine von der Ziel-Website eingesetzte Anti-Bot-Technologie Ihre automatisierten Anfragen abgefangen und blockiert hat. Die einfachsten Anti-Scraping-Systeme filtern normalerweise Anfragen, die keinen gültigen User-Agent HTTP-Header haben. Werfen Sie einen Blick auf unseren Artikel zum Einstieg in User-Agents für Web Scraping.
Wie jeder andere HTTP-Client verwendet auch HTTParty einen Platzhalter-User-Agent. Dieser unterscheidet sich im Allgemeinen stark von den Agenten, die von gängigen Browsern verwendet werden, sodass die Anfragen von Anti-Bot-Lösungen leicht entdeckt werden können. Um zu vermeiden, dass Sie deswegen blockiert werden, können Sie in HTTParty einen gültigen User-Agent angeben. Tun Sie das folgendermaßen:
response = HTTParty.get("https://brightdata.com/", {
headers: { "User-Agent" => "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36"},
})Die mit dieser get()-Funktion durchgeführte Anfrage wird dem Server nun als von Google Chrome 112 kommend angezeigt.
Der derzeitige Inhalt von scraper.rb sieht so aus:
require "nokogiri"
require "httparty"
# get the target page
response = HTTParty.get("https://brightdata.com/", {
headers: {
"User-Agent" => "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36",
},
})
# scraping logic...
Schritt 4: Parsen Sie das HTML-Dokument mit Nokogiri
Um das mit der Ziel-Website verbundene HTML-Dokument zu parsen, übergeben Sie dessen Inhalt an die Nokogiri-Funktion HTML():
doc = Nokogiri::HTML(response.body)Sie können nun die DOM Manipulation und das Explorations-API verwenden, die über die doc-Variable angeboten werden. Die beiden wichtigsten Methoden zur Auswahl von HTML-Elementen sind:
- xpath(): Die Liste der HTML-Knoten, die der XPath-Abfrage entspricht, wird zurückgegeben.
- css(): Die Liste der HTML-Knoten, die dem CSS-Selektor entsprechen, und die als Parameter übergeben wurde, wird zurückgegeben.
Beide Ansätze funktionieren, aber CSS-Abfragen sind in der Regel der einfachste Weg, um auszudrücken, wonach Sie suchen.
Schritt 5: Definieren Sie die CSS-Selektoren für die gewünschten HTML-Elemente
Um zu verstehen, wie man die gewünschten HTML-Elemente auf der Ziel-Website auswählt, müssen Sie das DOM analysieren. Besuchen Sie die Homepage von Bright Data in Ihrem Browser, klicken Sie mit der rechten Maustaste auf eine der Karten, die Sie interessieren, und wählen Sie „Inspect“:
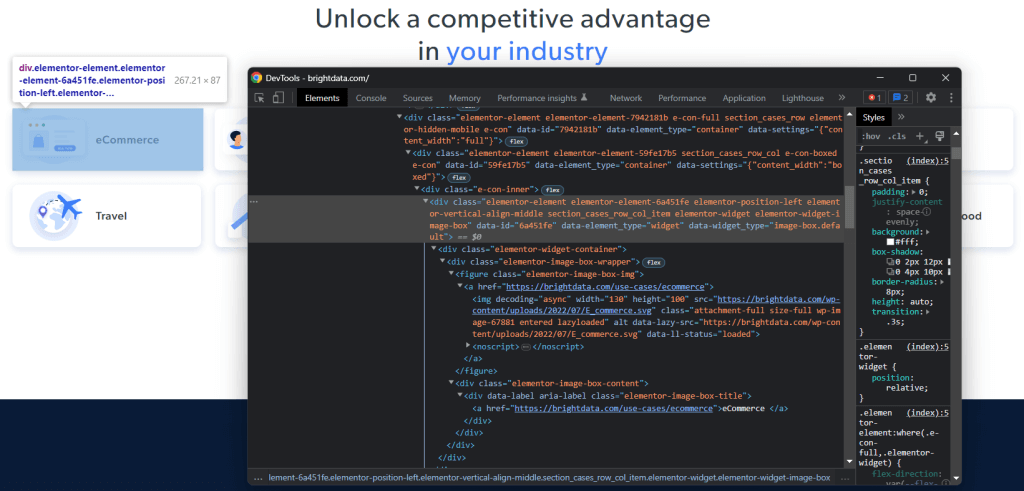
Nehmen Sie sich etwas Zeit, um den HTML-Code im Abschnitt DevTools zu erkunden. Alle Anwendungsfallkarten sind
- <figure>mit einem<img>-HTML-Element, das das mit der Branche verbundene Bild zeigt, und ein<a>-Element, das die URL zur Branchenseite enthält.
- Ein<div>HTML-Element, das den Branchennamen in einem Tag namens <a>speichert.
Ziel der Datenextraktion mit dem Ruby Scraper ist, die URL des Bildes, die URL der Website und den Branchennamen von den einzelnen Karten zu erhalten.
Um gute CSS-Selektoren zu definieren, sollten Sie Ihre Aufmerksamkeit auf die CSS-Klassen richten, die den betreffenden DOM-Knoten zugeordnet sind. Sie werden feststellen, dass Sie mit dem folgenden CSS-Selektor alle Anwendungsfallkarten erhalten können:
.section_cases_row_col_itemVon jeder Karte können Sie dann die Knoten, auf denen die relevanten Daten gespeichert sind, aus den untergeordneten Elementen<figure>-und<div>auswählen:
- figure img
- figure a
- .elementor-image-box-content a
Schritt 6: Scrapen Sie die Daten einer Website mit Nokogiri
Verwenden Sie nun Nokogiri, um die gewünschten Daten von der Ziel-HTML-Webseite abzurufen.
Bevor Sie sich in die Logik des Data Scraping vertiefen, denken Sie daran, dass Sie einige Datenstrukturen benötigen, in denen Sie die erfassten Daten speichern können. Zu diesem Zweck können Sie mit Struct eine Anwendungsfall-Klasse in einer einzigen Zeile definieren. Das tun Sie mit:
UseCase = Struct.new(:image, :url, :name)In Ruby können Sie mit Struct ein oder mehrere Attribute in derselben Datenklasse bündeln. Das obige Struct enthält die drei Attribute, die den Informationen entsprechen, die von jeder Anwendungsfallkarte abgerufen werden sollen.
Initialisieren Sie ein leeres Anwendungsfall-Array und implementieren Sie die Scraping-Logik, um es aufzufüllen:
# initialize the list of objects
# that will store all retrieved data
use_cases = []
# select all use case HTML elements
use_case_cards = doc.css(".section_cases_row_col_item")
# iterate over the HTML cards
use_case_cards.each do |use_case_card|
# extract the data of interest
image = use_case_card.at_css("figure img").attribute("data-lazy-src").value
url = use_case_card.at_css("figure a").attribute("href").value
name = use_case_card.at_css(".elementor-image-box-content a").text
# instantiate an UseCase object with the
# collected data
use_case = UseCase.new(url, image, name)
# add the UseCase instance to the array
# of scraped objects
use_cases.push(use_case)
endDer obige Schnipsel wählt alle Anwendungsfallkarten aus und durchläuft sie. Dann werden mit at_css() von jeder Karte die URL des Bildes, die URL der Branchenseite und der Name gescrapt. Dies ist eine Nokogiri-Funktion, die das erste Element zurückgibt, das die CSS-Abfrage erfüllt, und einen Tastenkürzel darstellt für:
image = use_case_card.css("figure img").first.attribute("data-lazy-src").valueSchließlich werden die abgerufenen Daten verwendet, um ein neues Anwendungsfall-Objekt zu instanziieren und der Liste hinzuzufügen.
Web Scraping in Ruby mit Nokogiri ist ganz einfach. Mit attribut() können Sie ein Attribut aus dem aktuellen HTML-Element auswählen. Über das Feld „Value“ können Sie dann den Wert abrufen. Auf ähnliche Weise gibt das Textfeld direkt den gesamten, im aktuellen HTML-Knoten enthaltenen Text als einfache Zeichenkette zurück.
Sie könnten jetzt noch weiter gehen und auch die Seiten des Anwendungsfalls Branche scrapen. Sie haben die Möglichkeit den hier angezeigten Links zu folgen und eine neue, darauf zugeschnittene Scaping-Logik zu implementieren. Willkommen in der Welt des Web Crawling und Web Scraping!
Großartig! Sie haben soeben gelernt, wie Sie Ihre Scraping-Ziele mit Ruby erreichen können. Es stehen jedoch noch einige Lektionen aus.
Schritt 7: Exportieren Sie die gescrapten Daten
Nach der Ausführung von each() loop wird use_cases die gescrapten Daten in Ruby-Objekten enthalten. Dies ist allerdings nicht das beste Format zur Weitergabe der Daten an andere Teams. Glücklicherweise verfügt Ruby über integrierte CSV- und JSON-Umwandlungsfunktionen. Erfahren Sie, wie Sie die abgerufenen Daten nach CSV und JSON exportieren können.
Für den CSV-Export importieren Sie den folgenden Edelstein:
import "csv"Er ist Teil der Standard API von Ruby und bietet eine vollständige Schnittstelle für den Umgang mit CSV-Dateien und -Daten.
Nutzen Sie ihn, um das Array use_cases in eine output.csv-Datei zu exportieren (siehe unten):
# populate the CSV output file
CSV.open("output.csv", "wb") do |csv|
# write the CSV header
csv << ["url", "image", "name"]
# transfrom each use case scraped info to a
# CSV record
use_cases.each do |use_case|
csv << use_case
end
endDer obige Schnipsel erstellt die Datei output.csv. Dann öffnet er sie und initialisiert sie mit dem Kopfsatz. Anschließend durchläuft er das use_cases-Array und fügt es in die CSV-Datei ein. Wenn Sie den <<-Operator verwenden, konvertiert Ruby automatisch jede use_case-Instanz in ein String-Array, das von der integrierten CSV-Klasse benötigt wird.
Versuchen Sie, das Skript auszuführen, und zwar mit:
ruby scraper.rbDie Datei output.csv mit den unten aufgeführten Daten wird im Stammverzeichnis Ihres Projekts erstellt:
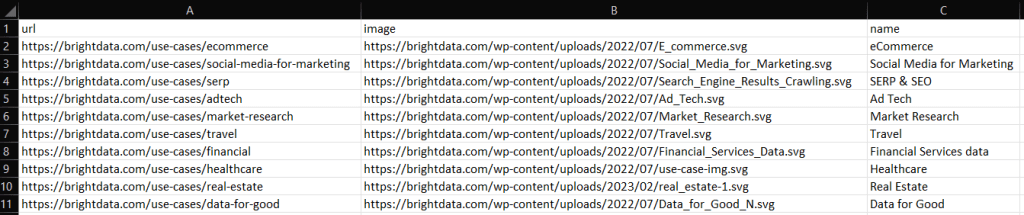
Auf ähnliche Weise können Sie use_cases nach output.json exportieren:
# propulate the JSON output file
File.open("output.json", "wb") do |json|
json << JSON.pretty_generate(use_cases.map { |u| Hash[u.each_pair.to_a] })
endDadurch wird die folgende JSON-Datei erzeugt:
[
{
"image": "https://brightdata.com/use-cases/ecommerce",
"url": "https://brightdata.com/wp-content/uploads/2022/07/E_commerce.svg",
"name": "eCommerce "
},
// ...
{
"image": "https://brightdata.com/use-cases/data-for-good",
"url": "https://brightdata.com/wp-content/uploads/2022/07/Data_for_Good_N.svg",
"name": "Data for Good"
}
]Et voilà! Jetzt wissen Sie, wie Sie in Ruby ein Structs-Array in CSV und JSON umwandeln können!
Schritt 8: Fügen Sie alles zusammen
Hier finden Sie den vollständigen Code des Ruby Scrapers:
# scraper.rb
require "nokogiri"
require "httparty"
require "csv"
# get the target page
response = HTTParty.get("https://brightdata.com/", {
headers: {
"User-Agent" => "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36",
},
})
# parse the HTML document retrieved with the GET request
doc = Nokogiri::HTML(response.body)
# define a class where to keep the scraped data
UseCase = Struct.new(:image, :url, :name)
# initialize the list of objects
# that will store all retrieved data
use_cases = []
# select all use case HTML elements
use_case_cards = doc.css(".section_cases_row_col_item")
# iterate over the HTML cards
use_case_cards.each do |use_case_card|
# extract the data of interest
image = use_case_card.at_css("figure img").attribute("data-lazy-src").value
url = use_case_card.at_css("figure a").attribute("href").value
name = use_case_card.at_css(".elementor-image-box-content a").text
# instantiate an UseCase object with the
# collected data
use_case = UseCase.new(url, image, name)
# add the UseCase instance to the array
# of scraped objects
use_cases.push(use_case)
end
# populate the CSV output file
CSV.open("output.csv", "wb") do |csv|
# write the CSV header
csv << ["url", "image", "name"]
# transfrom each use case scraped info to a
# CSV record
use_cases.each do |use_case|
csv << use_case
end
end
# propulate the JSON output file
File.open("output.json", "wb") do |json|
json << JSON.pretty_generate(use_cases.map { |u| Hash[u.each_pair.to_a] })
endIn etwa 50 Zeilen Code können Sie in Ruby ein Skript zum Data Scraping erstellen!
Fazit
In dieser Anleitung haben Sie erfahren, warum Ruby eine großartige Sprache für das Scrapen im Internet ist. Sie hatten auch die Gelegenheit, die besten Ruby-Edelsteine (Bibliotheken) für das Web Scraping kennenzulernen und zu erfahren, warum sie so gut sind und welche Funktionen sie bieten. Dann haben Sie sich damit beschäftigt, wie man Nokogiri und die Standard-API von Ruby verwendet, um einen Ruby-Scraper zu erstellen, mit dem Sie eine tatsächlich vorhandene Website scrapen können. Wie Sie gesehen haben, sind für das Data Scraping mit Ruby nur wenige Zeilen Code erforderlich.
Unterschätzen Sie jedoch nicht die Hürden, die Sie bei der Extraktion von Daten aus Webseiten zu überwinden haben. Auf immer mehr Websites wurden Anti-Bot- und Anti-Scraping-Systeme zum Schutz der Daten implementiert. Diese Technologien sind in der Lage, die von Ihrem Ruby Scraping-Skript durchgeführten Anfragen zu erkennen und den Zugriff auf die Website zu verhindern. Glücklicherweise können Sie mit Bright Data`s Web Scraper-IDE der nächsten Generation einen Web Scraper erstellen, der diese Blockaden umgeht.
Sie wollen sich zwar nicht mit Web Scraping beschäftigen, sind aber an Daten aus dem Internet interessiert? Sehen Sie sich unsere gebrauchsfertigen Datensätze an.






