

In diesem Artikel geht es um Folgendes:
- Web Scraping mit Frontend-JavaScript
- Voraussetzungen
- Web-Scraping-Bibliotheken für Node.js
- Fazit
Web Scraping mit Frontend-JavaScript
Frontend-JavaScript ist zum Web Scraping nur bedingt geeignet: Zum einen müssten Sie Ihr JavaScript-Web-Scraping-Skript direkt in der Browserkonsole ausführen. Dies ist kein Vorgang, der programmgesteuert durchgeführt werden kann.
Insbesondere können Sie Daten auf einer Seite von der Konsole aus wie folgt scrapen:

Zweitens müssten Sie, um Daten von anderen Webseiten abrufen zu können, diese über AJAX herunterladen. Beachten Sie allerdings, dass Webbrowser eine Same-Origin Policy auf AJAX anwenden. Mit Frontend-JavaScript können Sie somit nur auf Webseiten innerhalb desselben Ursprungs zugreifen.
Ein einfaches Beispiel soll verdeutlichen, was dies bedeutet. Nehmen wir an, Sie besuchen eine Seite von brightdata.com. In diesem Fall könnte Ihr JavaScript-Frontend-Skript zum Web Scraping nur Webseiten unter der Domain brightdata.com herunterladen.
Das heißt aber keineswegs, dass JavaScript keine gute Technologie für das Web Crawling ist. Mit Node.js können Sie JavaScript auf Servern ausführen und so die oben genannten Einschränkungen umgehen.
Nun soll erläutert werden, wie Sie mit Node.js einen JavaScript Web Scraper erstellen können.
Voraussetzungen
Bevor Sie mit der Erstellung der Node.js-Web-Scraping-Anwendung beginnen können, müssen folgende Voraussetzungen erfüllt sein:
- Node.js 18+ mit npm 8+: Geeignet ist jede LTS-Version (Long Term Support) von Node.js 18+ einschließlich npm. Dieses Tutorial basiert auf Node.js 18.12 mit npm 8.19 (der zum Zeitpunkt der Fertigstellung neuesten LTS-Version von Node.js).
- Eine IDE, die JavaScript unterstützt: Für dieses Tutorial wurde die Community Edition von IntelliJ IDEA ausgewählt, doch es kann auch jede beliebige andere IDE mit JavaScript- und Node.js-Unterstützung verwendet werden.
Klicken Sie auf die oben angeführten Links und führen Sie die Installationsassistenten aus, um die notwendigen Einstellungen vorzunehmen. Durch Starten des unten stehenden Befehls in Ihrem Endgerät können Sie überprüfen, ob Node.js korrekt installiert wurde:
node -vDas Ergebnis sollte in etwa wie folgt aussehen:
v18.12.1Prüfen Sie ebenso, ob npm korrekt installiert wurde:
npm -v Daraufhin sollte eine Zeichenkette wie die folgende ausgegeben werden:
8.19.2Die beiden zuvor genannten Befehle geben die Version von Node.js bzw. npm an, die auf Ihrem Rechner allgemein verfügbar ist.
Großartig! Nun können Sie lernen, wie das JavaScript Web Scraping in Node.js funktioniert!
Die besten JavaScript Web-Scraping-Bibliotheken für Node.js
Sehen wir uns jetzt die besten JavaScript-Bibliotheken für Web Scraping in Node.js an:
- Axios: Eine einfach zu verwendende Bibliothek, die Sie bei der Erstellung von HTTP-Anfragen in JavaScript unterstützt. Sie können Axios – einen der beliebtesten JavaScript-HTTP-Clients auf dem Markt – sowohl im Browser als auch in Node.js verwenden.
- Cheerio: Eine kompakte Bibliothek, die eine jQuery-ähnliche API zur Untersuchung von HTML- und XML-Dokumenten bietet. Mit Cheerio kann man ein HTML-Dokument parsen, HTML-Elemente auswählen und Daten daraus extrahieren. Mit anderen Worten: Cheerio stellt eine fortschrittliche Web-Scraping-API bereit.
- Selenium: Eine Bibliothek, die mehrere Programmiersprachen unterstützt und mit der Sie automatisierte Tests für Webanwendungen erstellen können. Außerdem eignet sie sich aufgrund ihrer Funktionen als Headless Browser zum Web Scraping.
- Playwright: Ein von Microsoft entwickeltes Tool für die Erstellung automatisierter Testskripte für Webanwendungen. Damit können Sie den Browser anweisen, bestimmte Aktionen durchzuführen. Auf diese Weise kann Playwright als Lösung mit Headless Browser zum Web Scraping verwendet werden.
- Puppeteer: Ein von Google entwickeltes Tool für die Automatisierung des Testens von Webanwendungen. Puppeteer baut auf dem DevTools-Protokoll von Chrome auf. Ebenso wie Selenium und Playwright ermöglicht es die programmatische Interaktion mit dem Browser wie bei einem menschlichen Benutzer. Erfahren Sie mehr über die Unterschiede zwischen Selenium und Puppeteer.
Erstellen eines JavaScript Web Scrapers in Node.js
In diesem Abschnitt erfahren Sie, wie man einen JavaScript Web Scraper in Node.js erstellt, der in der Lage ist, automatisch Daten aus einer Website zu extrahieren. Die Zielwebseite ist die Homepage von Bright Data. Das Ziel des Web-Scraping-Prozesses mit Node.js ist es, die relevanten HTML-Elemente der Seite auszuwählen, Daten daraus abzurufen und die gescrapten Daten in ein nützlicheres Format zu konvertieren.
Zum Zeitpunkt der Erstellung dieses Tutorials sieht das Layout der Homepage von Bright Data folgendermaßen aus:

Wie Sie sehen können, enthält die Homepage von Bright Data eine Fülle von Daten und Informationen in unterschiedlichen Formaten, von Textbeschreibungen bis hin zu Abbildungen. Darüber hinaus beinhaltet sie eine Menge nützlicher Links. Hier erfahren Sie, wie Sie all diese Daten abrufen können.
Sehen wir uns nun in einer Schritt-für-Schritt-Anleitung an, wie das Scrapen von Daten mit Node.js funktioniert!
Schritt 1: Erstellen eines Node.js-Projekts
Legen Sie zunächst den Ordner an, der Ihr Node.js-Projekt zum Web Scraping enthalten soll:
mkdir web-scraper-nodejsNun sollte ein leeres Verzeichnis web-scraper-nodejs vorhanden sein. Sie können dem Projektordner einen beliebigen Namen geben. Öffnen Sie den Ordner mit:
cd web-scraper-nodejsInitialisieren Sie anschließend ein npm-Projekt mit:
npm init -yMit diesem Befehl wird ein neues npm-Projekt für Sie eingerichtet. Bitte beachten Sie, dass das Flag -y erforderlich ist, um mit npm ein Standardprojekt zu initialisieren, ohne dass ein interaktiver Prozess durchlaufen wird. Wird das Flag -y weggelassen, werden Ihnen im Endgerät einige Fragen gestellt.
web-scraper-nodejs sollte nun ein package.json mit folgendem Aufbau enthalten:
{
"name": "web-scraper-nodejs",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo "Error: no test specified" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC"
}Erstellen Sie anschließend eine index.js-Datei im Stammverzeichnis Ihres Projekts und initialisieren Sie diese wie nachfolgend beschrieben:
// index.js
console.log("Hello, World!")In dieser JavaScript-Datei wird die Node.js-Logik für das Web Scraping hinterlegt.
Öffnen Sie Ihre package.json-Datei und fügen Sie das folgende Skript in den Abschnitt scripts ein:
"start": "node index.js"Führen Sie nun den folgenden Befehl in Ihrem Endgerät aus, um das Node.js-Skript zu starten:
npm run startDas Ergebnis sollte wie folgt aussehen:
Hello, World!Dies bedeutet, dass Ihre Node.js-App ordnungsgemäß funktioniert. Öffnen Sie jetzt das Projekt in Ihrer IDE und beginnen Sie mit dem Schreiben einer Scraping-Logik in Node.js!
Benutzer von IntelliJ IDEA sollten Folgendes angezeigt bekommen:

Schritt 2: Installation von Axios und Cheerio
Nun ist es an der Zeit, die für die Implementierung des Web Scrapers in Node.js erforderlichen Abhängigkeiten zu installieren. Um herauszufinden, welche JavaScript-Web-Scraping-Bibliotheken Sie übernehmen sollten, besuchen Sie die Zielwebseite, klicken Sie mit der rechten Maustaste auf einen leeren Bereich und wählen Sie die Option „Untersuchen“. Daraufhin sollte sich das DevTools-Fenster Ihres Browsers öffnen. Sehen Sie sich auf der Registerkarte „Netzwerk“ den Abschnitt „Fetch/XHR“ an.

Oben sehen Sie die von Ihrer Zielwebseite ausgeführten AJAX-Anfragen. Beim Öffnen der drei von der Website ausgeführten XHR-Anfragen werden Sie feststellen, dass diese keine relevanten Daten liefern. Dies bedeutet, dass die gewünschten Daten direkt in den Quellcode der Webseite eingebettet sind. Genau das geschieht in der Regel bei serverseitig gerenderten Websites.
Die Zielwebseite ist für den Abruf von Daten oder das Rendering nicht auf JavaScript angewiesen. Daher benötigen Sie kein Tool, das JavaScript im Browser ausführen kann. Mit anderen Worten: Es muss keine Headless-Browser-Bibliothek verwendet werden, um Daten aus der Zielwebseite zu extrahieren. Sie können eine solche Bibliothek durchaus verwenden, aber dies ist nicht zwingend erforderlich.
Da Bibliotheken mit Headless-Browser-Funktionen Webseiten in einem Browser öffnen, führt dies zu einem Overhead. Das liegt daran, dass Browser schwerfällige Anwendungen sind. Der genannte Overhead kann durch die Verwendung von Cheerio in Kombination mit Axios leicht vermieden werden.
Installieren Sie daher code>cheerio und axios mit:
npm install cheerio axiosImportieren Sie anschließend code>cheerio und axios, indem Sie die folgenden zwei Codezeilen in index.js einfügen:
// index.js
const cheerio = require("cheerio")
const axios = require("axios")Wir werden nun ein Node.js-Web-Scraping-Skript programmieren, das das Web Scraping mit Cheerio und Axios durchführt!
Schritt 3: Download Ihrer Zielwebsite
Verwenden Sie Axios, um mit folgenden Codezeilen eine Verbindung zu Ihrer Zielwebsite herzustellen:
// downloading the target web page
// by performing an HTTP GET request in Axios
const axiosResponse = await axios.request({
method: "GET",
url: "https://brightdata.com",
})Dank der Methode request() von Axios können Sie jede beliebige HTTP-Anfrage ausführen. Um den Quellcode einer Webseite herunterzuladen, müssen Sie eine HTTP-GET-Anfrage an die URL der Seite stellen. Im Normalfall würde Axios sofort ein Promise zurückgeben. Mit dem Schlüsselwort await können Sie auf ein Promise warten und synchron dessen Wert abrufen.
Bitte beachten Sie, dass eine Fehlermeldung ausgegeben wird, falls request() fehlschlägt. Dies kann mehrere Gründe haben, angefangen von einer ungültigen URL bis hin zu einem vorübergehend nicht verfügbaren Server. Bedenken Sie auch, dass einige Systeme Anti-Scraping-Maßnahmen einsetzen. Eine der beliebtesten Maßnahmen ist dabei das Blockieren von Anfragen ohne einen gültigen User-Agent HTTP-Header. Erfahren Sie mehr über User-Agents für Web Scraping.
Axios verwendet standardmäßig den folgenden User-Agent:
axios <axios_version>So sieht der von einem Browser verwendete User-Agent nicht aus. Daher können Anti-Scraping-Technologien Node.js Web Scraper erkennen und blockieren.
Legen Sie einen gültigen User-Agent-Header in Axios fest, indem Sie das folgende Attribut zu dem an request() übergebenen Objekt hinzufügen:
headers: {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36"
}Das Attribut headers ermöglicht es Ihnen, jeden HTTP-Header in Axios festzulegen.
Ihre index.js-Datei sollte nun wie folgt aussehen:
// index.js
const cheerio = require("cheerio")
const axios = require("axios")
async function performScraping() {
// downloading the target web page
// by performing an HTTP GET request in Axios
const axiosResponse = await axios.request({
method: "GET",
url: "https://brightdata.com",
headers: {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36"
}
})
}
performScraping()Bitte beachten Sie, dass Sie await nur in Funktionen verwenden können, die mit async gekennzeichnet sind. Daher müssen Sie Ihre JavaScript-Web-Scraping-Logik in die async-Funktion performScraping() einbetten.
Als nächstes werden wir die Zielwebseite analysieren, um eine Strategie für das Web Scraping zu definieren.
Schritt 4: Untersuchen der HTML-Seite
Auf der Homepage von Bright Data finden Sie eine Liste von Branchen, in denen Bright Data eingesetzt werden kann. Diese Daten sind für das Scrapen interessant.
Klicken Sie mit der rechten Maustaste auf eines dieser HTML-Elemente und wählen Sie „Untersuchen“:
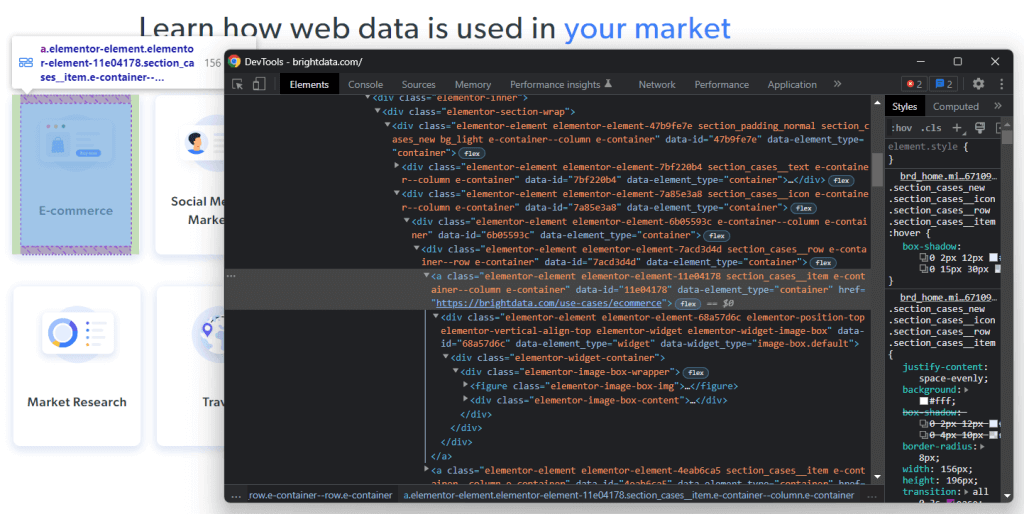
Bei der Analyse des HTML-Codes des ausgewählten Knotens werden Sie feststellen, dass es sich bei der Karte um ein <a>-HTML-Element handelt. Dieses -Element beinhaltet Folgendes:
- Ein
<figure>-HTML-Element mit dem Bild, das dem Branchenfeld zugeordnet ist - Ein
<div>-HTML-Element mit dem Namen des Branchenfelds
Sehen Sie sich nun die CSS-Klassen an, welche diese HTML-Elemente kennzeichnen. Anhand dieser Klassen können Sie CSS-Selektoren definieren, die für die Auswahl der betreffenden HTML-Elemente aus dem DOM erforderlich sind. Beachten Sie dabei, dass die.elementor-element-7a85e3a8
<div> enthalten sind. Mit den folgenden CSS-Selektoren können Sie dann aus einer Karte alle relevanten Daten extrahieren:
.elementor-image-box-img img.elementor-image-box-content .elementor-image-box-title
Die gleiche Logik können Sie auch anwenden, um die CSS-Selektoren zu definieren, die erforderlich sind, um:
- Die Gründe zu extrahieren, warum Bright Data Branchenführer ist.
- Die Gründe auszuwählen, die das Kundenerlebnis bei Bright Data zum besten auf dem Markt machen.
Die Zielwebseite enthält somit drei Scraping-Ziele:
- Daten zu den Branchen, in denen Sie die Vorteile von Bright Data nutzen können.
- Daten zu den Gründen, warum Bright Data Branchenführer ist.
- Daten darüber, warum Bright Data das beste Kundenerlebnis in der Branche bietet.
Schritt 5: Auswahl von HTML-Elementen mit Cheerio
Cheerio bietet verschiedene Optionen zur Auswahl von HTML-Elementen aus einer Webseite. Zunächst jedoch muss Cheerio initialisiert werden mit:
// parsing the HTML source of the target web page with Cheerio
const $ = cheerio.load(axiosResponse.data)Die load() akzeptiert HTML-Inhalte in String-Form. Beachten Sie, dass das Axios-Antwortobjekt die von der HTTP-Anfrage gelieferten Daten im Attribut data enthält. In diesem Fall wird data den vom Server gelieferten HTML-Quellcode der Webseite speichern. Sie übergeben also axiosResponse.data an load(), um Cheerio zu initialisieren.
Sie sollten die Cheerio-Variable $ aufrufen, da Cheerio im Wesentlichen die gleiche Syntax wie jQuery verwendet. Dadurch sind Sie in der Lage, jQuery-Schnipsel aus dem Internet zu kopieren.
Um ein HTML-Element mit Cheerio auszuwählen, verwenden Sie seine Klasse mit:
const htmlElement = $(".elementClass")Der Abruf eines HTML-Elements by ID ist ebenfalls möglich: mit:
const htmlElement = $("#elementId")Im Einzelnen können Sie HTML-Elemente auswählen, indem Sie einen beliebigen gültigen CSS-Selektor an $ übergeben, so wie Sie es in jQuery tun würden. Außerdem können Sie die Auswahllogik mit der find()-Methode verketten:
// retrieving the list of industry cards
const industryCards = $(".elementor-element-7a85e3a8").find(".e-container")find() verschafft Ihnen Zugriff auf die Nachkommen des aktuellen HTML-Elements, gefiltert über einen CSS-Selektor. Anschließend können Sie mithilfe der Methode each() eine Liste von Cheerio-Knoten wie folgt durchlaufen:
// iterating over the list of industry cards
$(".elementor-element-7a85e3a8")
.find(".e-container")
.each((index, element) => {
// scraping logic...
})Sehen wir uns nun an, wie man mit Cheerio Daten aus den relevanten HTML-Elementen extrahieren kann.
Schritt 6: Scrapen von Daten einer Zielwebseite mit Cheerio
Sie können die oben dargestellte Logik erweitern, um die gewünschten Daten aus den ausgewählten HTML-Elementen wie folgt zu extrahieren:
// initializing the data structure
// that will contain the scraped data
const industries = []
// scraping the "Learn how web data is used in your market" section
$(".elementor-element-7a85e3a8")
.find(".e-container")
.each((index, element) => {
// extracting the data of interest
const pageUrl = $(element).attr("href")
const image = $(element).find(".elementor-image-box-img img").attr("data-lazy-src")
const name = $(element).find(".elementor-image-box-content .elementor-image-box-title").text()
// filtering out not interesting data
if (name && pageUrl) {
// converting the data extracted into a more
// readable object
const industry = {
url: pageUrl,
image: image,
name: name
}
// adding the object containing the scraped data
// to the industries array
industries.push(industry)
}
})Dieses Node.js-Schnipsel zum Web Scraping wählt alle Branchenkarten auf der Homepage von Bright Data aus. Dann werden alle Elemente der HTML-Karte durchlaufen. Für jede Karte werden die URL der mit der Karte verknüpften Webseite, das Bild und die Bezeichnung der Branche ausgelesen. Mithilfe der Cheerio-Methoden attr() und text() können Sie den Wert des HTML-Attributs bzw. den Text abrufen. Schließlich werden die gescrapten Daten in einem Objekt gespeichert und zum Array industries hinzugefügt.
Am Ende der each()-Schleife enthält industries alle Daten, die im Zusammenhang mit dem ersten Scraping-Ziel relevant sind. Als nächstes gehen wir darauf ein, wie auch die beiden anderen Ziele erreicht werden können.
Gleichermaßen können Sie die Daten, die begründen, weshalb Bright Data Branchenführer ist, wie folgt abrufen:
const marketLeaderReasons = []
// scraping the "What makes Bright Data
// the undisputed industry leader" section
$(".elementor-element-ef3e47e")
.find(".elementor-widget")
.each((index, element) => {
const image = $(element).find(".elementor-image-box-img img").attr("data-lazy-src")
const title = $(element).find(".elementor-image-box-title").text()
const description = $(element).find(".elementor-image-box-description").text()
const marketLeaderReason = {
title: title,
image: image,
description: description,
}
marketLeaderReasons.push(marketLeaderReason)
})Zu guter Letzt können Sie Daten zu den Gründen, warum Bright Data ein großartiges Kundenerlebnis bietet, folgendermaßen auslesen:
const customerExperienceReasons = []
// scraping the "The best customer experience in the industry" section
$(".elementor-element-288b23cd .elementor-text-editor")
.find("li")
.each((index, element) => {
const title = $(element).find("strong").text()
// since the title is part of the text, you have
// to remove it to get only the description
const description = $(element).text().replace(title, "").trim()
const customerExperienceReason = {
title: title,
description: description,
}
customerExperienceReasons.push(customerExperienceReason)
})Herzlichen Glückwunsch! Sie wissen jetzt, wie Sie alle drei Scraping-Ziele mithilfe von Node.js umsetzen können!
Denken Sie daran, dass Sie Daten von anderen Webseiten sammeln können, indem Sie den Links folgen, die Sie auf der aktuellen Seite ausfindig gemacht haben. Genau darum geht es beim Web Crawling. Sie können also eine Web-Scraping-Logik definieren, um auch aus diesen Seiten Daten zu extrahieren.
industries, marketLeaderReasons und customerExperienceReasons speichern alle gescrapten Daten in JavaScript-Objekten. Im nächsten Schritt erfahren Sie, wie Sie sie die Daten in ein nützlicheres Format umwandeln können.
Schritt 7: Konvertieren der extrahierten Daten in JSON
JSON gehört, wenn es um JavaScript geht, zu den besten Datenformaten. Dies liegt daran, dass JSON von JavaScript abgeleitet ist und im Allgemeinen von API als Format für die Datenannahme oder -rückgabe verwendet wird. Es ist also wahrscheinlich, dass Sie Ihre JavaScript-Scraping-Daten in JSON konvertieren müssen. Dies lässt sich mit der folgenden Logik leicht realisieren:
// trasforming the scraped data into a general object
const scrapedData = {
industries: industries,
marketLeader: marketLeaderReasons,
customerExperience: customerExperienceReasons,
}
// converting the scraped data object to JSON
const scrapedDataJSON = JSON.stringify(scrapedData)Zuerst müssen Sie ein JavaScript-Objekt erstellen, das sämtliche gescrapten Daten enthält. Anschließend können Sie dieses JavaScript-Objekt mithilfe von JSON.stringify() in JSON umwandeln.
scrapedDataJSON enthält dann folgende JSON-Daten:
{
"industries": [
{
"url": "https://brightdata.com/use-cases/ecommerce",
"image": "https://brightdata.com/wp-content/uploads/2022/07/E_commerce.svg",
"name": "E-commerce"
},
// ...
{
"url": "https://brightdata.com/use-cases/data-for-good",
"image": "https://brightdata.com/wp-content/uploads/2022/07/Data_for_Good_N.svg",
"name": "Data for Good"
}
],
"marketLeader": [
{
"title": "Most reliable",
"image": "https://brightdata.com/wp-content/uploads/2022/01/reliable.svg",
"description": "Highest quality data, best network uptime, fastest output "
},
// ...
{
"title": "Most efficient",
"image": "https://brightdata.com/wp-content/uploads/2022/01/efficient.svg",
"description": "Minimum in-house resources needed"
}
],
"customerExperience": [
{
"title": "You ask, we develop",
"description": "New feature releases every day"
},
// ...
{
"title": "Tailored solutions",
"description": "To meet your data collection goals"
}
]
}Herzlichen Glückwunsch! Sie haben damit begonnen, eine Verbindung zu einer Website herzustellen, und sind nun in der Lage, deren Daten zu scrapen und in JSON zu konvertieren. Jetzt können Sie sich das komplette Node.js-Skript zum Web Scraping ansehen.
Alles zusammenfügen
So sieht der Web Scraper in Node.js aus:
// index.js
const cheerio = require("cheerio")
const axios = require("axios")
async function performScraping() {
// downloading the target web page
// by performing an HTTP GET request in Axios
const axiosResponse = await axios.request({
method: "GET",
url: "https://brightdata.com/",
headers: {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36"
}
})
// parsing the HTML source of the target web page with Cheerio
const $ = cheerio.load(axiosResponse.data)
// initializing the data structures
// that will contain the scraped data
const industries = []
const marketLeaderReasons = []
const customerExperienceReasons = []
// scraping the "Learn how web data is used in your market" section
$(".elementor-element-7a85e3a8")
.find(".e-container")
.each((index, element) => {
// extracting the data of interest
const pageUrl = $(element).attr("href")
const image = $(element).find(".elementor-image-box-img img").attr("data-lazy-src")
const name = $(element).find(".elementor-image-box-content .elementor-image-box-title").text()
// filtering out not interesting data
if (name && pageUrl) {
// converting the data extracted into a more
// readable object
const industry = {
url: pageUrl,
image: image,
name: name
}
// adding the object containing the scraped data
// to the industries array
industries.push(industry)
}
})
// scraping the "What makes Bright Data
// the undisputed industry leader" section
$(".elementor-element-ef3e47e")
.find(".elementor-widget")
.each((index, element) => {
// extracting the data of interest
const image = $(element).find(".elementor-image-box-img img").attr("data-lazy-src")
const title = $(element).find(".elementor-image-box-title").text()
const description = $(element).find(".elementor-image-box-description").text()
// converting the data extracted into a more
// readable object
const marketLeaderReason = {
title: title,
image: image,
description: description,
}
// adding the object containing the scraped data
// to the marketLeaderReasons array
marketLeaderReasons.push(marketLeaderReason)
})
// scraping the "The best customer experience in the industry" section
$(".elementor-element-288b23cd .elementor-text-editor")
.find("li")
.each((index, element) => {
// extracting the data of interest
const title = $(element).find("strong").text()
// since the title is part of the text, you have
// to remove it to get only the description
const description = $(element).text().replace(title, "").trim()
// converting the data extracted into a more
// readable object
const customerExperienceReason = {
title: title,
description: description,
}
// adding the object containing the scraped data
// to the customerExperienceReasons array
customerExperienceReasons.push(customerExperienceReason)
})
// trasforming the scraped data into a general object
const scrapedData = {
industries: industries,
marketLeader: marketLeaderReasons,
customerExperience: customerExperienceReasons,
}
// converting the scraped data object to JSON
const scrapedDataJSON = JSON.stringify(scrapedData)
// storing scrapedDataJSON in a database via an API call...
}
performScraping()Wie hier zu sehen ist, können Sie mit weniger als 100 Zeilen Code einen Web Scraper in Node.js erstellen. Mithilfe von Cheerio und Axios können Sie eine HTML-Webseite herunterladen, parsen und automatisch alle darin enthaltenen Daten abrufen. Danach können Sie die gescrapten Daten ganz einfach in JSON umwandeln. Genau darum geht es beim Web Scraping mit Node.js.
Starten Sie Ihren Web Scraper in Node.js mit:
npm run startEt voilà! Sie haben soeben gelernt, wie das JavaScript Web Scraping in Node.js funktioniert!
Fazit
In diesem Tutorial haben Sie erfahren, warum Web Scraping im Frontend mit JavaScript nur bedingt tauglich ist und warum Node.js eine bessere Lösung dafür darstellt. Darüber hinaus haben Sie einen Blick darauf geworfen, was für die Erstellung eines Web-Scraping-Skripts in Node.js benötigt wird und wie das Web Scraping in JavaScript funktioniert. Insbesondere haben Sie anhand eines realen Anwendungsbeispiels gelernt, wie man mithilfe von Cheerio und Axios eine JavaScript-Web-Scraping-Anwendung in Node.js erstellt. Wie Sie wissen, sind für Web Scraping mit Node.js nur ein paar Zeilen Code erforderlich.
Bedenken Sie jedoch, dass Web Scraping nicht unbedingt ein Kinderspiel ist. Dies liegt daran, dass es viele Herausforderungen zu meistern gilt. Immer häufiger werden Anti-Scraping- und Anti-Bot-Lösungen eingesetzt. Vermeiden lässt sich all dies glücklicherweise mit einem Web-Scraping-Tool der nächsten Generation, das Ihnen Bright Data zur Verfügung stellt. Sie möchten sich nicht mit Web Scraping auseinandersetzen? Sehen Sie sich unsere Datensätze an.
Wenn Sie mehr darüber erfahren möchten, wie Sie Blockaden vermeiden können, entscheiden Sie sich für einen Web-Proxy der verschiedenen bei Bright Data verfügbaren Proxy-Dienste oder verwenden Sie den erweiterten Web Unlocker.




