

In diesem Tutorial lernen Sie, wie Sie ein Kotlin-Web-Scraping- Skript erstellen. Im Einzelnen lernen Sie:
- Warum Kotlin eine großartige Sprache für das Scraping einer Website ist
- Welche die besten Kotlin-Scraping-Bibliotheken sind.
- Wie Sie einen Kotlin-Scraper von Grund auf erstellen.
Lassen Sie uns loslegen!
Ist Kotlin eine brauchbare Option für das Web-Scraping?
TL;DR: Ja, das ist es! Und es ist vielleicht sogar besser als Java!
Kotlin ist eine statisch typisierte, plattformübergreifende Allzweck-Programmiersprache, deren Standardbibliothek auf der Java-Klassenbibliothek basiert. Das Besondere an Kotlin ist sein prägnanter und unterhaltsamer Ansatz beim Programmieren. Es wird von Google unterstützt, das es als bevorzugte Sprache für die Android-Entwicklung ausgewählt hat.
Dank seiner Interoperabilität mit der JVM unterstützt es alle Java-Scraping-Bibliotheken. So können Sie das umfangreiche Ökosystem der Java-Bibliotheken nutzen, jedoch mit einer prägnanteren und intuitiveren Syntax. Das ist eine Win-Win-Situation!
Darüber hinaus verfügt Kotlin über einige native Bibliotheken, darunter HTML-Parser und Bibliotheken zur Browserautomatisierung, die die Datenextraktion vereinfachen. Entdecken Sie einige der beliebtesten!
Die besten Kotlin-Web-Scraping-Bibliotheken
Hier ist eine Liste einiger der besten Web-Scraping-Bibliotheken für Kotlin:
- skrape{it}: Eine Kotlin-basierte HTML/XML-Test- und Web-Scraping-Bibliothek zum Parsing und Interpretieren von HTML. Sie enthält mehrere Daten-Fetcher, mit denen skrape{it} sowohl als traditioneller HTML-Parser als auch als Headless-Browser für das clientseitige DOM-Rendering fungieren kann.
- chrome-reactive-kotlin: Ein in Kotlin geschriebener Low-Level-DevTools-Protokoll-Client zur programmgesteuerten Steuerung von Chromium-basierten Browsern.
- ksoup: Eine leichtgewichtige Kotlin-Bibliothek, die von Jsoup inspiriert ist. Ksoup bietet Methoden zum Parsing von HTML, zum Extrahieren von HTML-Tags, Attributen und Text sowie zum Kodieren und Dekodieren von HTML-Entitäten.
Vergessen Sie nicht, dass Kotlin mit Java kompatibel ist. Das bedeutet, dass Sie jede andere Web-Scraping-Bibliothek in Java verwenden können. Eine davon ist Jsoup, einer der beliebtesten HTML-Parser auf dem Markt. Weitere Informationen finden Sie in unserem Leitfaden zum Web-Scraping mit Jsoup.
Voraussetzungen
Befolgen Sie die nachstehenden Anweisungen, um Ihre Kotlin-Umgebung für das Web-Scraping einzurichten.
Einrichten der Umgebung
Um eine Kotlin-Anwendung auf Ihrem Rechner zu schreiben und auszuführen, benötigen Sie ein lokal installiertes JDK (Java Development Kit). Laden Sie die neueste LTS-Version des JDK von der Oracle-Website herunter, führen Sie das Installationsprogramm aus und folgen Sie den Anweisungen des Installationsassistenten. Zum Zeitpunkt der Erstellung dieses Artikels ist dies Java 21.
Anschließend benötigen Sie ein Tool, um Abhängigkeiten zu verwalten und Ihre Kotlin-Anwendung zu erstellen. Sowohl Gradle als auch Maven sind hervorragende Optionen, sodass Sie Ihr bevorzugtes Java-Build-Tool frei wählen können. Da Gradle Kotlin als DSL-Sprache (Domain-Specific Language) unterstützt, entscheiden wir uns für Gradle. Beachten Sie, dass Sie das Tutorial auch als Maven-Benutzer problemlos befolgen können.
Laden Sie Maven oder Gradle herunter und installieren Sie es. Gradle ist besonders empfindlich gegenüber der Java-Version, laden Sie also unbedingt das richtige Paket herunter. Die funktionierende Gradle-Version für Java 21 ist größer oder gleich Version 8.5.
Zuletzt benötigen Sie eine Kotlin-IDE. Visual Studio Code mit der Kotlin Language Extension und IntelliJ IDEA Community Edition sind zwei hervorragende kostenlose Optionen.
Fertig! Sie haben nun eine Kotlin-fähige Umgebung eingerichtet!
Erstellen Sie ein Kotlin-Projekt
Erstellen Sie einen Projektordner für Ihr Kotlin-Web-Scraping-Projekt und geben Sie ihn im Terminal ein:
mkdir KotlinWebScraper
cd KotlinWebScraperWir haben das Verzeichnis „KotlinWebScraper” genannt, aber Sie können ihm einen beliebigen Namen geben.
Starten Sie als Nächstes den folgenden Befehl im Projektordner, um eine Gradle-Anwendung zu erstellen:
gradle init --type kotlin-applicationWährend des Vorgangs werden Ihnen einige Fragen gestellt. Sie sollten „Kotlin” als Build-Skript-DSL auswählen und Ihrer Anwendung einen geeigneten Paketnamen wie com.kotlin.scraper geben. Bei den anderen Fragen sollten die Standardantworten ausreichend sein.
Am Ende des Initialisierungsvorgangs wird Folgendes angezeigt:
Wählen Sie das Build-Skript-DSL aus:
1: Kotlin
2: Groovy
Geben Sie Ihre Auswahl ein (Standard: Kotlin) [1..2] 1
Projektname (Standard: KotlinWebScraper):
Quellpaket (Standard: kotlinwebscraper): com.kotlin.scraper
Geben Sie die Zielversion von Java ein (min. 8) (Standard: 21):
Build mit neuen APIs und Funktionen generieren (einige Funktionen können sich in der nächsten Minor-Version ändern)? (Standard: nein) [ja, nein]
> Aufgabe: init
Weitere Informationen zu Gradle finden Sie in unseren Beispielen unter https://docs.gradle.org/8.5/samples/sample_building_kotlin_applications.html
BUILD SUCCESSFUL in 2m 10s
2 ausführbare Aufgaben: 2 ausgeführtFantastisch! Der Ordner „KotlinWebScraper” enthält nun ein Gradle-Projekt.
Öffnen Sie den Ordner in Ihrer Kotlin-IDE, warten Sie, bis die erforderlichen Hintergrundaufgaben abgeschlossen sind, und sehen Sie sich die Hauptdatei „App.kt” im Paket „com.kotlin.scraper” an. Diese sollte folgenden Inhalt haben:
/*
* Diese Kotlin-Quelldatei wurde durch die Gradle-Aufgabe „init” generiert.
*/
package com.kotlin.scraping.demo
class App {
val greeting: String
get() {
return "Hello World!"
}
}
fun main() {
println(App().greeting)
}Dies ist ein einfaches Kotlin-Skript, das „Hello World!” im Terminal ausgibt.
Um zu überprüfen, ob es funktioniert, starten Sie das Skript mit dem folgenden Gradle-Befehl:
./gradlew runWarten Sie, bis das Projekt erstellt und ausgeführt wurde, und Sie sehen Folgendes:
> Task :app:run
Hello World!
BUILD SUCCESSFUL in 3s
3 actionable tasks: 2 executed, 1 up-to-dateSie können die Gradle-Protokollmeldungen ignorieren. Konzentrieren Sie sich stattdessen auf die Meldung „Hello World!”, die genau der erwarteten Ausgabe des Skripts entspricht. Mit anderen Worten: Ihre Kotlin-Einrichtung funktioniert wie vorgesehen.
Es ist Zeit, Web-Scraping mit Kotlin durchzuführen!
Erstellen eines Web-Scraping-Kotlin-Skripts
In diesem Schritt-für-Schritt-Abschnitt erfahren Sie, wie Sie einen Web-Scraper in Kotlin erstellen. Insbesondere lernen Sie, wie Sie ein automatisiertes Skript definieren, das Daten aus der Quotes-Scraping-Sandbox-Website extrahiert.
Auf hoher Ebene wird das Kotlin-Web-Scraping-Skript, das Sie gleich programmieren werden, Folgendes tun:
- Verbindung zur Zielseite herstellen.
- Die HTML-Elemente mit den Zitaten auf der Seite auswählen.
- Extrahiert die gewünschten Daten aus diesen Elementen.
- diesen Vorgang für alle Zitate auf den Websites wiederholt und dabei jede Paginierungsseite besucht
- Exportiert die gesammelten Daten im CSV-Format.
So sieht die Zielseite aus:
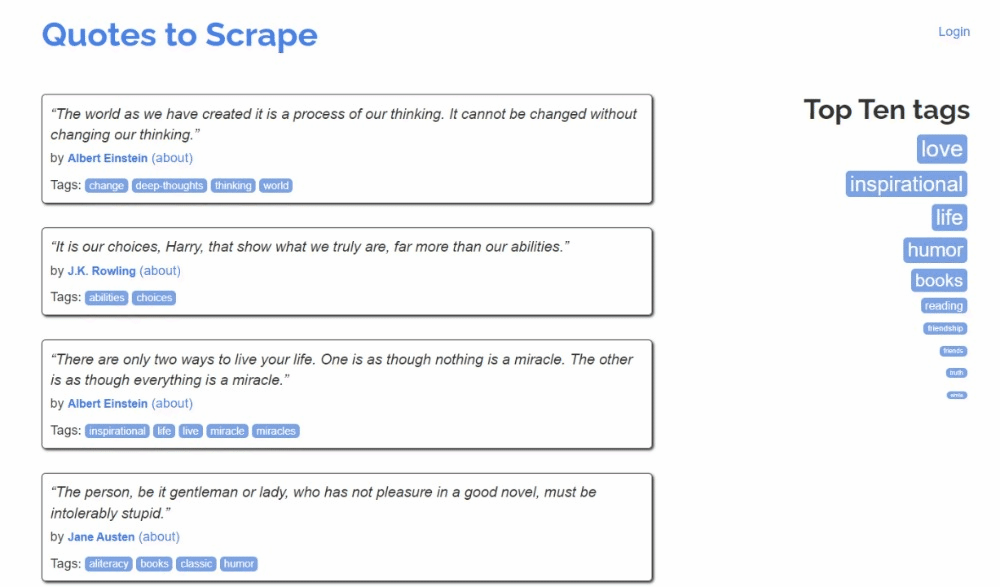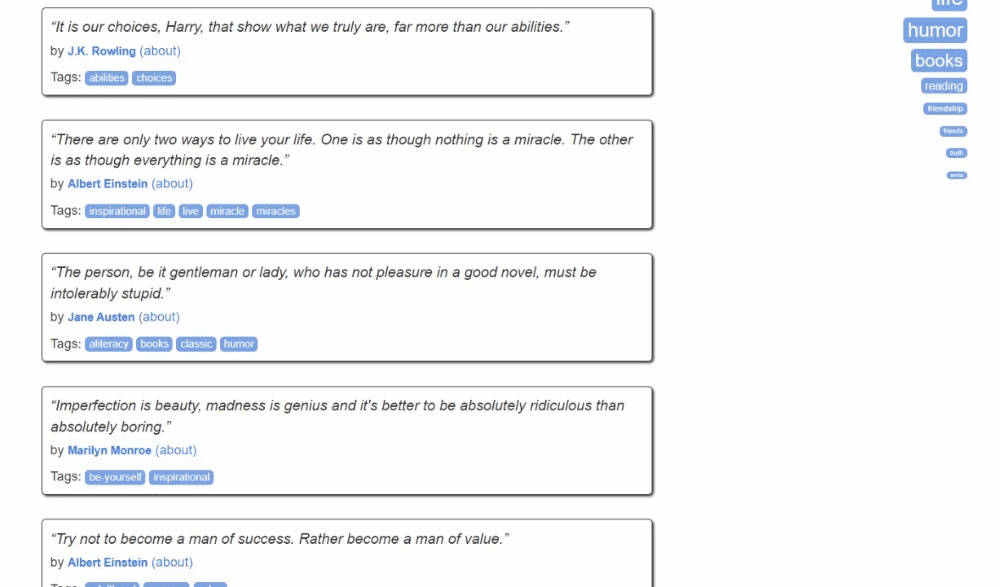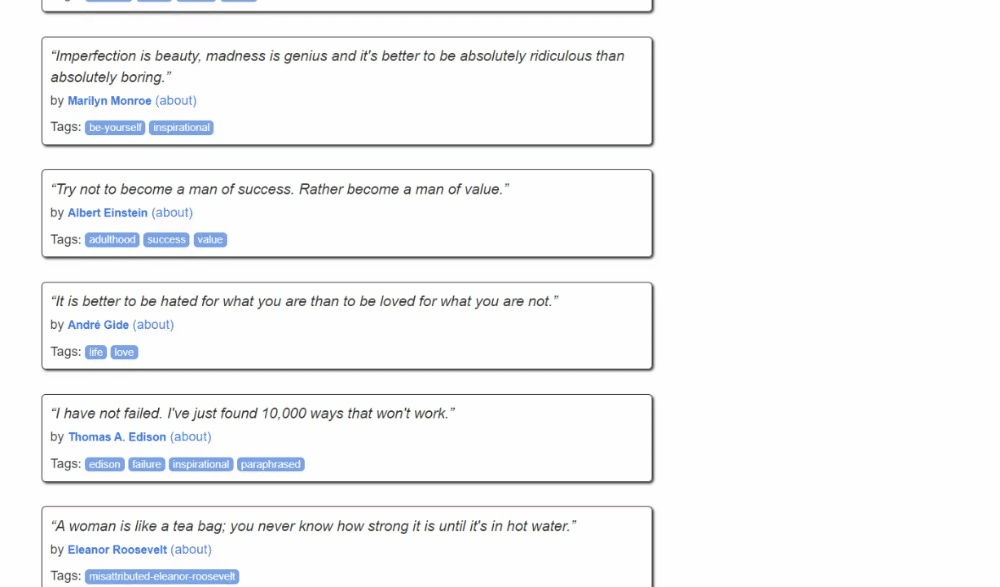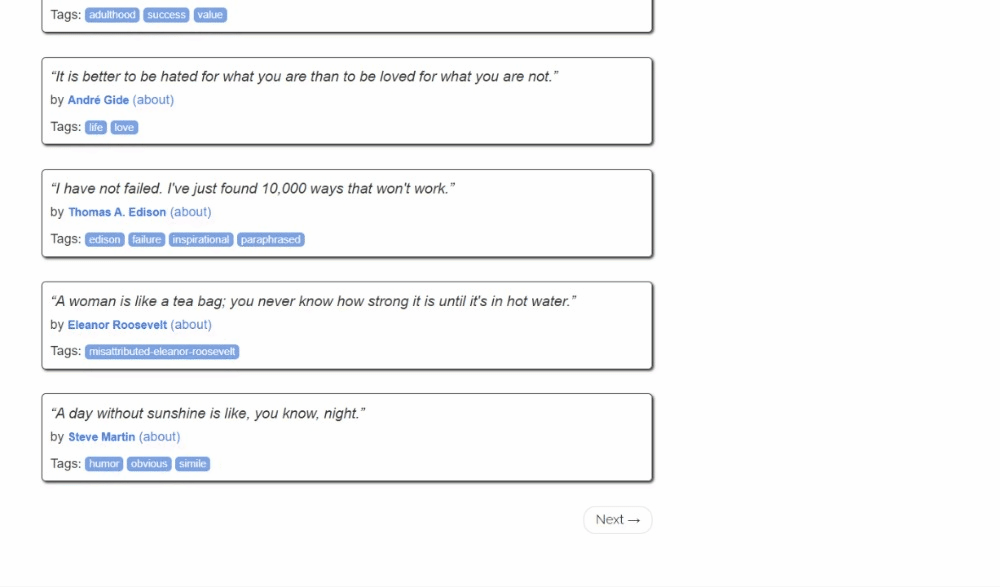
Befolgen Sie die folgenden Schritte und erfahren Sie, wie Sie Web-Scraping in Kotlin durchführen können!
Schritt 1: Installieren Sie die Scraping-Bibliothek
Als Erstes müssen Sie herausfinden, welche Kotlin-Web-Scraping-Bibliotheken für Ihre Ziele am besten geeignet sind. Dazu müssen Sie die Zielwebsite untersuchen.
Rufen Sie also die Sandbox-Website „Quotes To Scrape“ in Ihrem Browser auf. Klicken Sie mit der rechten Maustaste auf einen leeren Bereich und wählen Sie die Option „Untersuchen“, um die DevTools zu öffnen. Gehen Sie zur Registerkarte „Netzwerk“, laden Sie die Seite neu und sehen Sie sich den Abschnitt „Fetch/XHR“ an.
Folgendes sollte angezeigt werden:
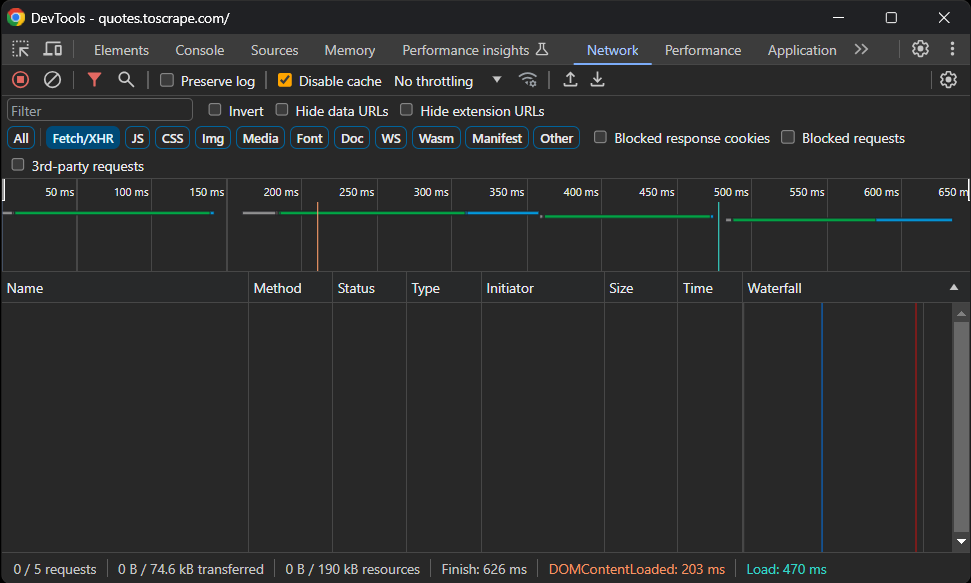
Keine AJAX-Anfragen! Mit anderen Worten: Die Zielseite ruft keine Daten dynamisch über JavaScript ab. Das bedeutet, dass der Server Seiten mit allen relevanten Daten, die im HTML-Code eingebettet sind, an die Clients zurückgibt.
Daher reicht eine HTML-Parsing-Bibliothek völlig aus. Sie können weiterhin ein Browser-Automatisierungstool verwenden, aber das Laden und Rendern der Seite in einem Browser würde nur einen Leistungsaufwand bedeuten und keinen wirklichen Vorteil bringen.
Daher ist skrape{it} eine gute Wahl, um das Ziel des Web-Scrapings zu erreichen. Fügen Sie es zu den Abhängigkeiten Ihres Projekts hinzu, indem Sie diese Zeile in das Abhängigkeitsobjekt Ihrer Datei build.gradle.kts einfügen:
implementation("it.skrape:skrapeit:1.2.2")Wenn Sie Maven verwenden, fügen Sie diese Zeilen zum Tag <dependencies> in Ihrer pom.xml hinzu:
<dependency>
<groupId>it.skrape</groupId>
<artifactId>skrapeit</artifactId>
<version>1.2.2</version>
</dependency>Wenn Sie IntelliJ IDEA verwenden, zeigt die IDE eine Schaltfläche zum Neuladen der Projektabhängigkeiten und zur Installation der neuen Bibliothek an. Klicken Sie darauf, um skrape{it} zu installieren.
Alternativ können Sie die neue Abhängigkeit auch manuell mit diesem Gradle-Befehl installieren:
./gradlew build --refresh-dependenciesDer Installationsvorgang kann eine Weile dauern, haben Sie also bitte etwas Geduld.
Als Nächstes können Sie skrape{it} in Ihrem App.kt-Skript verwenden, indem Sie die folgenden Importe hinzufügen:
import it.skrape.core.*
import it.skrape.fetcher.*Vergessen Sie nicht, dass kkrape{it} mit vielen Daten-Fetchern ausgestattet ist. Der Einfachheit halber haben wir hier alle importiert. Gleichzeitig benötigen Sie jedoch nur HttpFetcher, einen klassischen HTTP-Client, der eine HTTP-Anfrage an die angegebene URL sendet und eine geparste Antwort zurückgibt.
Großartig! Sie haben nun alles, was Sie für das Web-Scraping mit Kotlin benötigen!
Schritt 2: Laden Sie die Zielseite herunter und führen Sie ein Parsing des HTML-Codes durch
Entfernen Sie in App.kt die App-Klasse und fügen Sie die folgenden Zeilen in die main()-Funktion ein, um mit skrape{it} eine Verbindung zur Zielseite herzustellen:
skrape(HttpFetcher) {
// eine HTTP-GET-Anfrage an die angegebene URL senden
request {
url = "https://quotes.toscrape.com/"
}
}Im Hintergrund verwendet skrape{it} die zuvor erwähnte HttpFetcher-Klasse, um eine synchrone HTTP-GET-Anfrage an die angegebene URL zu senden.
Wenn Sie sicherstellen möchten, dass das Skript wie gewünscht funktioniert, fügen Sie den folgenden Abschnitt in die Definition skrape(HttpFetcher) ein:
response {
// den HTML-Quellcode abrufen und ausgeben
htmlDocument {
print(html)
}
}Dadurch wird skrape{it} mitgeteilt, was mit der Serverantwort geschehen soll. Konkret greift es auf die geparste Antwort zu und gibt dann den HTML-Code der Seite aus.
Ihr App.kt Kotlin-Scraping-Skript sollte nun Folgendes enthalten:
package com.kotlin.scraper
import it.skrape.core.*
import it.skrape.fetcher.*
fun main() {
skrape(HttpFetcher) {
// eine HTTP-GET-Anfrage an die angegebene URL senden
request {
url = "https://quotes.toscrape.com/"
}
response {
// den HTML-Quellcode abrufen und ausgeben
htmlDocument {
print(html)
}
}
}
}Führen Sie das Skript aus, und es wird Folgendes ausgegeben:
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Quotes to Scrape</title>
<link rel="stylesheet" href="/static/bootstrap.min.css">
<link rel="stylesheet" href="/static/main.css">
</head>
<body>
<!-- der Kürze halber ausgelassen... -->Das ist genau der HTML-Code der Zielseite. Gut gemacht!
Schritt 3: Überprüfen Sie den Seiteninhalt
Der nächste Schritt wäre, die Scraping-Logik zu definieren. Aber wie können Sie das tun, ohne zu wissen, wie Sie die Elemente auf der Seite auswählen können? Deshalb ist es wichtig, einen zusätzlichen Schritt zu machen und die Struktur der Zielseite zu überprüfen.
Öffnen Sie Quotes To Scrape erneut in Ihrem Browser. Klicken Sie mit der rechten Maustaste auf ein Zitat-Element und wählen Sie „Untersuchen”, um die DevTools wie unten gezeigt zu öffnen:
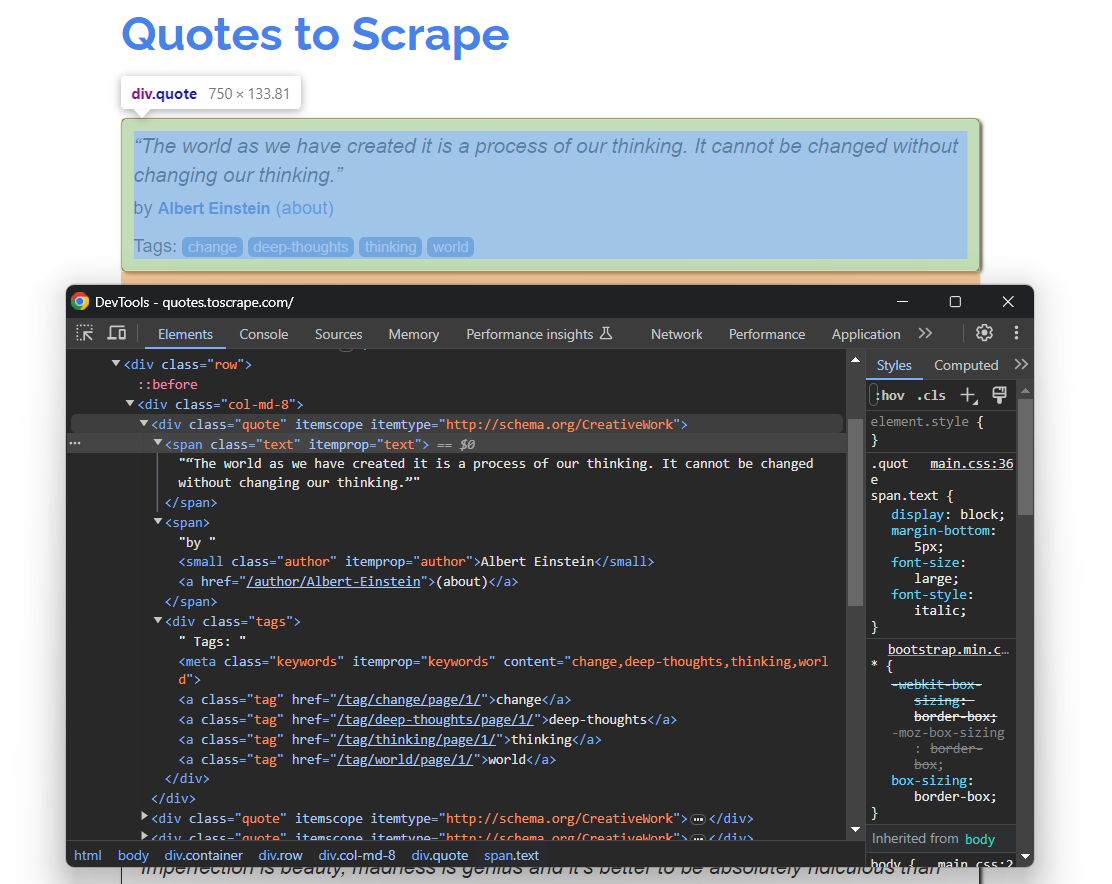
Hier können Sie sehen, dass jede Zitatkarte ein .quote-HTML-Element ist, das Folgendes umschließt:
- Ein .text-Element mit dem Zitattext.
- Ein .author-Element mit dem Namen des Autors.
- Mehrere .tag-Elemente, die jeweils ein einzelnes Tag anzeigen.
Beachten Sie, dass nicht alle Zitate den Tag-Abschnitt haben:

Die oben genannten CSS-Selektoren helfen Ihnen dabei, die gewünschten DOM-Elemente auf der Seite auszuwählen, um Daten daraus zu extrahieren. Sie benötigen außerdem eine Klasse, in der diese Daten gespeichert werden können. Fügen Sie daher die folgende Quote-Klassendefinition oben in Ihrem Web-Scraping-Kotlin-Skript hinzu:
class Quote(var text: String, var author: String, tags: List<String>?) {
var tags: MutableList<String> = ArrayList()
init {
if (tags != null) {
this.tags.addAll(tags)
}
}
}Da die Seite mehrere Zitate enthält, instanziieren Sie eine Liste von Quote-Objekten in main():
val quotes: MutableList<Quote> = ArrayList()Am Ende des Skripts enthält quotes alle Zitate, die von der Website gesammelt wurden.
Verwenden Sie das, was Sie hier verstanden und definiert haben, um im nächsten Schritt die Scraping-Logik zu implementieren!
Schritt 4: Implementieren Sie die Scraping-Logik
skrape{it} hat eine besondere Art, HTML-Knoten auf einer Seite auszuwählen. Um einen CSS-Selektor auf die Seite anzuwenden, müssen Sie einen Abschnitt innerhalb von htmlDocument mit dem gleichen Namen wie der CSS-Selektor definieren:
skrape(HttpFetcher) {
// request section...
response {
htmlDocument {
// select all ".quote" HTML elements on the page
".quote" {
// scraping logic...
}
}
}
}Innerhalb des Abschnitts „.quote“ können Sie dann einen Abschnitt findAll definieren. Dieser enthält die Logik, die auf jeden HTML-Knoten „quote“ angewendet wird, der mit dem angegebenen CSS-Selektor ausgewählt wurde. Mit findFirst erhalten Sie hingegen nur das erste ausgewählte Element.
Hinter den Kulissen sind all diese Abschnitte nichts anderes als Kotlin-Lambda-Funktionen. Aus diesem Grund können Sie mit ihnen in einem forEach-Abschnitt innerhalb von findAll auf das einzelne DOM-Element zugreifen. Falls Sie damit nicht vertraut sind: Es handelt sich um den impliziten Namen eines einzelnen Parameters in einem Lambda.
Es folgt einer ähnlichen Logik, basiert jedoch auf Methoden und Attributen. Anschließend können Sie eine Scraping-Logik implementieren, um die gewünschten Daten aus jedem Zitat zu extrahieren, ein Quote-Objekt zu instanziieren und es wie folgt zur Zitatsliste hinzuzufügen:
".quote" {
findAll {
forEach {
// Scraping-Logik für ein einzelnes Zitat-Element
val text = it.findFirst(".text").text
val author = it.findFirst(".author").text
val tags = try {
it.findAll(".tag").map { tag -> tag.text }
} catch(e: ElementNotFoundException) {
null
}
// Erstellen Sie ein Quote-Objekt und fügen Sie es zur Liste hinzu.
val quote = Quote(
text = text,
author = author,
tags = tags
)
quotes.add(quote)
}
}
}Dank des Textattributs können Sie den inneren Text eines HTML-Elements abrufen. Da nicht alle Quote-HTML-Elemente Tags enthalten, müssen Sie die ElementNotFoundException behandeln. Diese wird von findAll ausgelöst, wenn der angegebene CSS-Selektor mit keinem Knoten auf der Seite übereinstimmt.
Importieren Sie ElementNotFoundException mit:
import it.skrape.selects.ElementNotFoundException
Fügen Sie alle Snippets zusammen und protokollieren Sie die im Array „quotes” enthaltenen Daten:
package com.kotlin.scraper
import it.skrape.core.*
import it.skrape.fetcher.*
import it.skrape.selects.ElementNotFoundException
// Definieren Sie eine Klasse, um die gescrapten Daten in Kotlin darzustellen.
class Quote(var text: String, var author: String, tags: List<String>?) {
var tags: MutableList<String> = ArrayList()
init {
if (tags != null) {
this.tags.addAll(tags)
}
}
}
fun main() {
// wo die gescrapten Daten gespeichert werden sollen
val quotes: MutableList<Quote> = ArrayList()
skrape(HttpFetcher) {
// eine HTTP-GET-Anfrage an die angegebene URL senden
request {
url = "https://quotes.toscrape.com/"
}
response {
htmlDocument {
// alle ".quote"-HTML-Elemente auf der Seite auswählen
".quote" {
findAll {
forEach {
// Scraping-Logik für ein einzelnes Zitat-Element
val text = it.findFirst(".text").text
val author = it.findFirst(".author").text
val tags = try {
it.findAll(".tag").map { tag -> tag.text }
} catch(e: ElementNotFoundException) {
null
}
// Quote-Objekt erstellen und zur Liste hinzufügen
val quote = Quote(
text = text,
author = author,
tags = tags
)
quotes.add(quote)
}
}
}
}
}
}
// Protokollieren Sie die gescrapten Daten.
for (quote in quotes) {
println("Text: ${quote.text}")
println("Autor: ${quote.author}")
println("Tags: ${quote.tags.joinToString("; ")}")
println()
}
}Beachten Sie die Verwendung von joingToString(), um die Tags-Liste zu einer durch Kommas getrennten Zeichenfolge zusammenzufügen.
Wenn Sie das Skript ausführen, erhalten Sie nun:
Text: „Die Welt, wie wir sie geschaffen haben, ist ein Produkt unseres Denkens. Sie kann nicht verändert werden, ohne unser Denken zu verändern.“
Autor: Albert Einstein
Tags: Veränderung; tiefgründige Gedanken; Denken; Welt
# der Kürze halber ausgelassen...
Text: „Ein Tag ohne Sonnenschein ist wie, na ja, die Nacht.“
Autor: Steve Martin
Tags: Humor; offensichtlich; GleichnisWow! Sie haben gerade gelernt, wie man mit Kotlin Web-Scraping durchführt!
Schritt 5: Fügen Sie die Crawling-Logik hinzu
Sie haben gerade Daten von einer einzelnen Seite gescrapt, aber die Liste der Zitate erstreckt sich über mehrere Seiten. Wenn Sie bis zum Ende der Seite scrollen, sehen Sie eine Schaltfläche „Weiter →“ mit einem Link zur folgenden Seite:
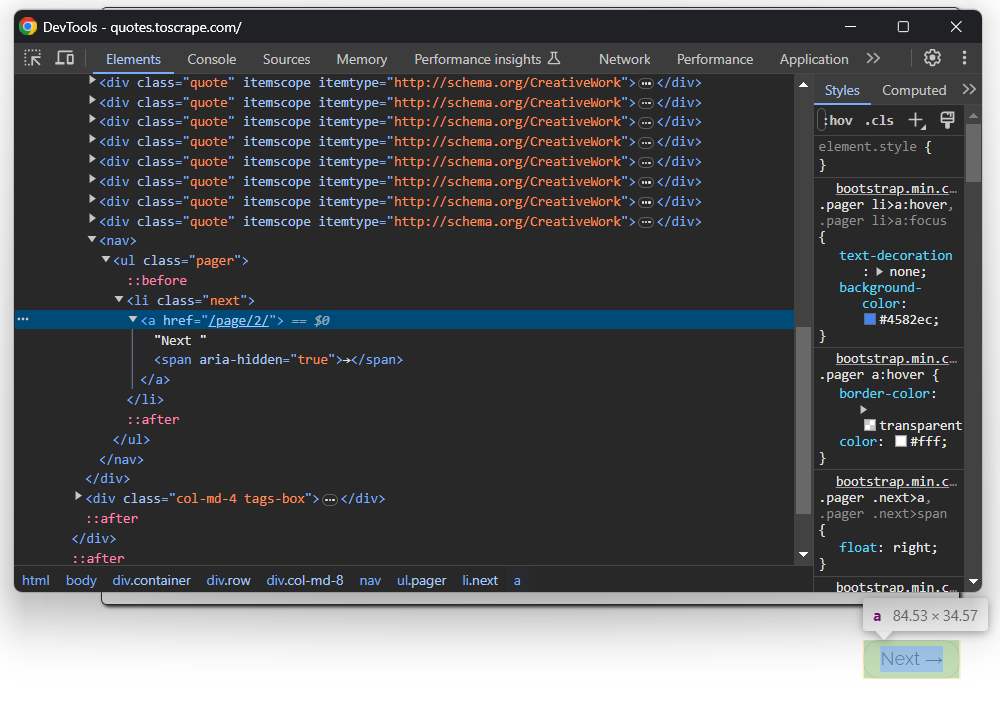
Dies gilt für alle Seiten außer der letzten:
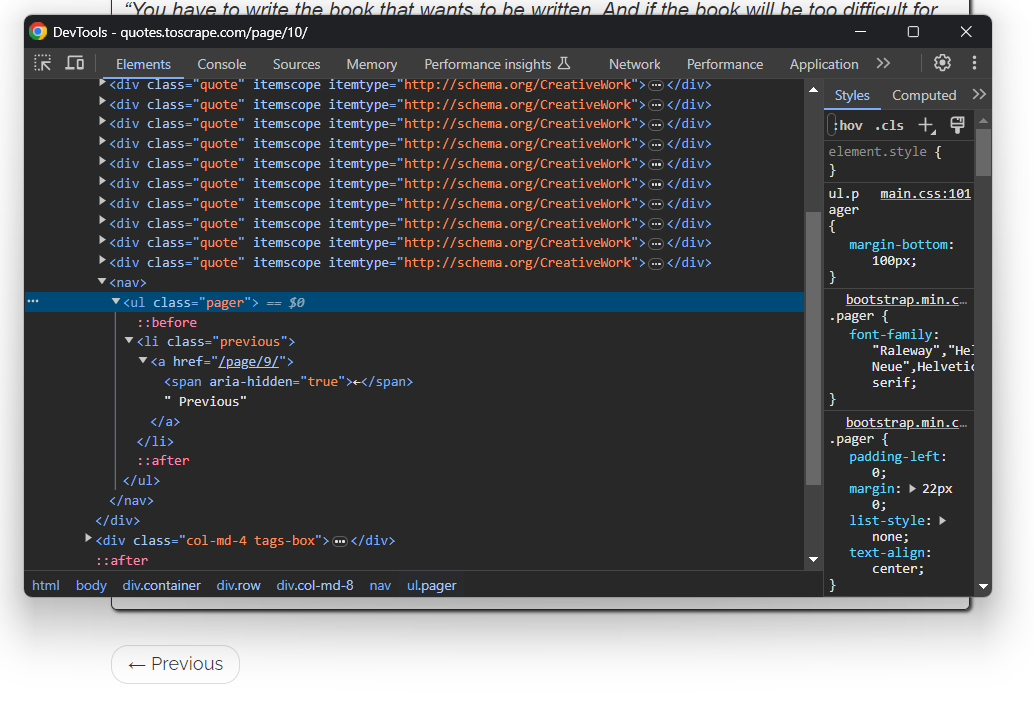
Um Web-Crawling in Kotlin durchzuführen und jedes Zitat auf der Website zu scrapen, müssen Sie Folgendes tun:
- Scrapen Sie alle Zitate von der aktuellen Seite.
- Wählen Sie das Element „Weiter →“ aus, falls vorhanden, und extrahieren Sie daraus die URL der nächsten Seite.
- Wiederholen Sie den ersten Schritt auf der neuen Seite.
Implementieren Sie den oben genannten Algorithmus wie folgt:
Anstatt eine einzelne Seite zu scrapen und dann anzuhalten, basiert das Skript nun auf einer while-Schleife. Diese wird so lange wiederholt, bis keine Seiten mehr zu scrapen sind. Dies geschieht, wenn der CSS-Selektor .next eine ElementNotFoundException-Ausnahme auslöst, was bedeutet, dass die Schaltfläche „Weiter →” nicht auf der Seite vorhanden ist und Sie sich somit auf der letzten Paginierungsseite der Website befinden.
Beachten Sie, dass der Abschnitt „htmlDocument“ mehrere CSS-Selektor-Abschnitte enthalten kann. Jeder wird in der angegebenen Reihenfolge ausgeführt. Wenn Sie das Kotlin-Skript zum Web-Scraping erneut starten, werden nun alle 100 Zitate auf der Website gespeichert.
Großartig! Die Kotlin-Web-Scraping- und Crawling-Logik ist fertig. Jetzt muss nur noch der Logging-Code mit der Datenexportlogik entfernt werden.
Schritt 7: Exportieren Sie die gescrapten Daten in CSV
Die gesammelten Daten werden derzeit in einer Liste von Quote-Objekten gespeichert. Das Drucken auf dem Terminal ist nützlich, aber der Export in CSV ist der beste Weg, um das Beste aus den Daten herauszuholen. So können andere Mitglieder Ihres Teams diese Daten filtern, lesen und analysieren.
Kotlin bietet Ihnen alles, was Sie zum Erstellen und Befüllen einer CSV-Datei benötigen, aber die Verwendung einer Bibliothek macht alles einfacher. Eine beliebte Kotlin-native Bibliothek zum Lesen und Schreiben von CSV-Dateien ist kotlin-csv.
Fügen Sie sie in build.gradle.kts zu den Abhängigkeiten Ihres Projekts hinzu:
implementation("com.github.doyaaaaaken:kotlin-csv-jvm:1.9.3")Oder wenn Sie Maven verwenden:
<dependency>
<groupId>com.github.doyaaaaaken</groupId>
<artifactId>kotlin-csv-jvm</artifactId>
<version>1.9.3</version>
</dependency>Installieren Sie die Bibliothek und importieren Sie sie in Ihre App.kt-Datei:
import com.github.doyaaaaaken.kotlincsv.dsl.*Jetzt kannst du Zitate mit nur wenigen Zeilen Code in eine CSV-Datei exportieren:
val header = listOf("quote", "author", "tags")
val csvContent: List<List<String>> = quotes.map { quote ->
listOf(
quote.text,
quote.author,
quote.tags.joinToString("; ")
)
}
csvWriter().open("quotes.csv") {
writeRow(header)
writeRows(csvContent)
}Beachten Sie, dass List<String> die Darstellung eines CSV-Datensatzes in kotlin-csv ist. Definieren Sie zunächst einen Datensatz für die Kopfzeile. Konvertieren Sie dann die Zitate in die gewünschten Daten. Initialisieren Sie als Nächstes einen CSV-Writer, erstellen Sie eine Datei quotes.csv und füllen Sie diese mit writeRow() und writeRows().
Das war’s schon! Jetzt müssen Sie sich nur noch den endgültigen Code Ihres Kotlin-Web-Scraping-Skripts ansehen.
Schritt 8: Alles zusammenfügen
Hier ist der endgültige Code Ihres Kotlin-Scrapers:
package com.kotlin.scraper
import it.skrape.core.*
import it.skrape.fetcher.*
import it.skrape.selects.ElementNotFoundException
import com.github.doyaaaaaken.kotlincsv.dsl.*
// Definieren Sie eine Klasse, um die gescrapten Daten in Kotlin darzustellen.
class Quote(var text: String, var author: String, tags: List<String>?) {
var tags: MutableList<String> = ArrayList()
init {
if (tags != null) {
this.tags.addAll(tags)
}
}
}
fun main() {
// wo die gescrapten Daten gespeichert werden sollen
val quotes: MutableList<Quote> = ArrayList()
// die URL der nächsten Seite, die besucht werden soll
var nextUrl: String? = "https://quotes.toscrape.com/"
// bis keine Seite mehr zu besuchen ist
while (nextUrl != null) {
skrape(HttpFetcher) {
// HTTP-GET-Anfrage an die angegebene URL senden
request {
url = nextUrl!!
}
response {
htmlDocument {
// alle ".quote"-HTML-Elemente auf der Seite auswählen
".quote" {
findAll {
forEach {
// Scraping-Logik für ein einzelnes Zitat-Element
val text = it.findFirst(".text").text
val author = it.findFirst(".author").text
val tags = try {
it.findAll(".tag").map { tag -> tag.text }
} catch (e: ElementNotFoundException) {
null
}
// Quote-Objekt erstellen und zur Liste hinzufügen
val quote = Quote(
text = text,
author = author,
tags = tags
)
quotes.add(quote)
}
}
}
// Crawling-Logik
try {
".next a" {
findFirst {
nextUrl = "https://quotes.toscrape.com" + attribute("href")
}
}
} catch (e: ElementNotFoundException) {
nextUrl = null
}
}
}
}
}
// Erstellen einer Datei „quotes.csv” und Befüllen dieser
// mit den gescrapten Daten
val header = listOf("quote", "author", "tags")
val csvContent: List<List<String>> = quotes.map { quote ->
listOf(
quote.text,
quote.author,
quote.tags.joinToString("; ")
)
}
csvWriter().open("quotes.csv") {
writeRow(header)
writeRows(csvContent)
}
}Können Sie das glauben? Dank skrape{it} können Sie Daten von einer ganzen Website mit weniger als 100 Zeilen Code abrufen!
Führen Sie Ihr Kotlin-Skript für das Web-Scraping mit folgendem Befehl aus:
./gradlew runHaben Sie etwas Geduld, während der Scraper jede Seite der Zielwebsite durchläuft. Wenn er fertig ist, erscheint eine Datei namens quotes.csv im Stammverzeichnis Ihres Projekts. Öffnen Sie sie, und Sie sollten die folgenden Daten sehen:
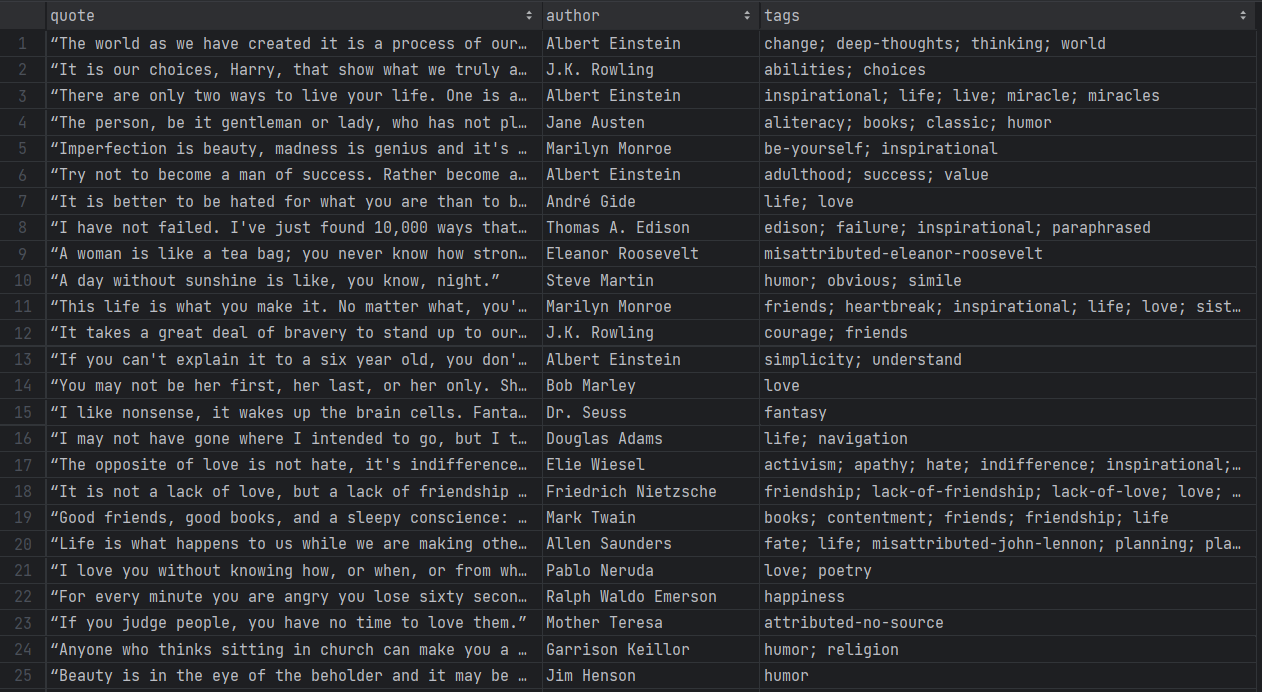
Et voilà! Sie haben mit unstrukturierten Daten auf Online-Seiten begonnen und haben diese nun in einer leicht zu durchsuchenden CSV-Datei!
Vermeiden Sie IP-Sperren in Kotlin mit einem Proxy
Eine der größten Herausforderungen beim Web-Scraping mit Kotlin ist es, nicht von Anti-Bot-Technologien blockiert zu werden. Diese Systeme können die automatisierte Natur Ihres Skripts erkennen und Ihre IP sperren. Auf diese Weise stoppen sie Ihren Scraping-Vorgang.
Wie kann man das vermeiden? Mit einem Proxy!
Befolgen Sie die folgenden Schritte und erfahren Sie, wie Sie einen Bright Data-Proxy in Kotlin integrieren können.
Einrichten eines Proxys in Bright Data
Bright Data ist der beste Proxy-Server auf dem Markt und überwacht Tausende von Proxy-Servern auf der ganzen Welt. Wenn es um IP-Rotation geht, ist ein Residential-Proxy der beste Proxy-Typ.
Wenn Sie bereits ein Konto haben, melden Sie sich zunächst bei Bright Data an. Andernfalls erstellen Sie ein kostenloses Konto. Sie erhalten Zugriff auf das folgende Benutzer-Dashboard:
Klicken Sie wie unten gezeigt auf die Schaltfläche „Proxy-Produkte anzeigen“:
Sie werden zur folgenden Seite „Proxies & Scraping-Infrastruktur“ weitergeleitet:
Scrollen Sie nach unten, suchen Sie die Karte „Residential-Proxys“ und klicken Sie auf die Schaltfläche „Get started“:
Sie gelangen zum Konfigurations-Dashboard für Residential-Proxys. Folgen Sie den Anweisungen des Assistenten und richten Sie den Proxy-Dienst entsprechend Ihren Anforderungen ein. Wenn Sie Fragen zur Konfiguration des Proxys haben, wenden Sie sich bitte an den 24/7-Support.
Gehen Sie zur Registerkarte „Zugriffsparameter“ und rufen Sie den Host, den Port, den Benutzernamen und das Passwort Ihres Proxys wie folgt ab:
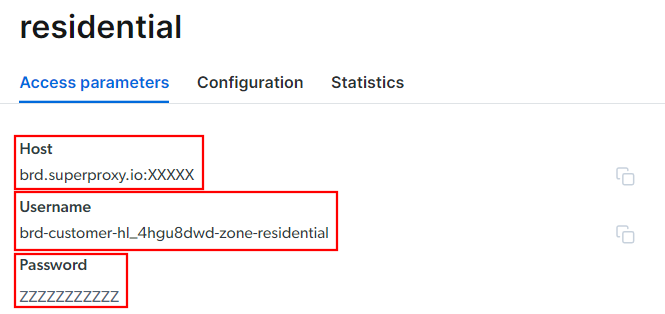
Beachten Sie, dass das Feld „Host“ bereits den Port enthält.
Das ist alles, was Sie benötigen, um die Proxy-URL zu erstellen und in skrape{it} zu verwenden. Fügen Sie alle Informationen zusammen und erstellen Sie eine URL mit der folgenden Syntax:
<Benutzername>:<Passwort>@<Host>In diesem Fall wäre das beispielsweise:
brd-customer-hl_4hgu8dwd-Zone-residential:[email protected]:XXXXXAktivieren Sie „Aktiver Proxy”, befolgen Sie die letzten Anweisungen, und schon können Sie loslegen!

Integrieren Sie den Proxy in Kotlin
Der Ausschnitt für die Bright Data-Integration in skrape{it} sieht wie folgt aus:
skrape(HttpFetcher) {
request {
url = "https://quotes.toscrape.com/"
proxy = proxyBuilder {
type = Proxy.Type.HTTP
host = "brd.superproxy.io"
port = XXXXX
}
authentication = basic {
username = "brd-customer-hl_4hgu8dwd-Zone-residential"
password = "ZZZZZZZZZZ"
}
}
// ...
}Wie Sie sehen, läuft alles auf die Verwendung der Proxy- und Authentifizierungsoptionen hinaus. Von nun an wird skrape{it} die Anfrage an die angegebene URL über den Bright Data-Proxy stellen. Auf Wiedersehen, IP-Sperren!
Halten Sie Ihre Kotlin-Web-Scraping-Aktivitäten ethisch und respektvoll
Das Web-Scraping ist eine effektive Methode, um nützliche Daten für verschiedene Anwendungsfälle zu sammeln. Denken Sie daran, dass das Endziel darin besteht, diese Daten abzurufen, und nicht, die Zielwebsite zu beschädigen. Daher müssen Sie diese Aufgabe mit den richtigen Vorsichtsmaßnahmen angehen.
Befolgen Sie die folgenden Tipps, um verantwortungsbewusstes Kotlin-Web-Scraping durchzuführen:
- Zielen Sie nur auf öffentlich zugängliche Informationen ab: Konzentrieren Sie sich auf das Abrufen von Daten, die auf der Website öffentlich zugänglich sind. Vermeiden Sie stattdessen Seiten, die durch Anmeldedaten oder andere Formen der Autorisierung geschützt sind. Das Scraping privater oder sensibler Daten ohne entsprechende Berechtigung ist unethisch und kann rechtliche Konsequenzen nach sich ziehen.
- Beachten Sie die robots.txt-Datei: Jede Website verfügt über eine robots.txt-Datei, in der die Regeln für den Zugriff automatisierter Crawler auf ihre Seiten festgelegt sind. Um ethische Scraping-Praktiken zu wahren, müssen Sie diese Richtlinien einhalten. Weitere Informationen finden Sie in unserem Leitfaden zu robots.txt für Web-Scraping.
- Begrenzen Sie die Häufigkeit Ihrer Anfragen: Zu viele Anfragen in kurzer Zeitführen zu einer Überlastung des Servers und beeinträchtigen die Leistung der Website für alle Benutzer. Dies kann auch zu Maßnahmen zur Begrenzung der Anfragefrequenz führen und dazu, dass Sie gesperrt werden. Vermeiden Sie aus diesem Grund eine Überlastung des Zielservers, indem Sie Ihren Anfragen zufällige Verzögerungen hinzufügen.
- Überprüfen und befolgen Sie die Nutzungsbedingungen der Website: Bevor Sie eine Website scrapen, lesen Sie deren Nutzungsbedingungen. Diese können Informationen zu Urheberrechten, geistigen Eigentumsrechten und Richtlinien zur Verwendung der Daten enthalten.
- Verlassen Sie sich auf vertrauenswürdige und aktuelle Scraping-Tools: Wählen Sie seriöse Anbieter und entscheiden Sie sich für Tools und Bibliotheken, die gut gepflegt und regelmäßig aktualisiert werden. Nur so können Sie sicherstellen, dass sie den neuesten ethischen Kotlin-Scraping-Grundsätzen entsprechen. Wenn Sie Zweifel haben, lesen Sie unseren Artikel darüber, wie Sie den besten Web-Scraping-Dienst auswählen.
Fazit
In diesem Leitfaden haben Sie gesehen, warum Kotlin eine großartige Sprache für das Web-Scraping ist, insbesondere im Vergleich zu Java. Sie haben auch eine Liste der besten Kotlin-Scraping-Bibliotheken gesehen. Anschließend haben Sie gelernt, wie Sie mit skrape{it} einen Scraper erstellen, der Daten aus mehreren Seiten einer realen Website extrahiert. Wie Sie hier erfahren haben, ist das Web-Scraping mit Kotlin einfach und erfordert nur wenige Zeilen Code.
Die größte Herausforderung für Ihren Scraping-Vorgang sind Anti-Bot-Lösungen. Websites setzen diese Systeme ein, um ihre Daten vor automatisierten Skripten zu schützen, indem sie diese blockieren, bevor sie auf ihre Seiten zugreifen können. Es ist nicht einfach, diese zu umgehen, und es erfordert fortschrittliche Tools. Glücklicherweise hat Bright Data die Lösung für Sie!
Hier sind einige der Scraping-Produkte, die Bright Data anbietet:
- Web Scraper API: Einfach zu verwendende APIs für den programmatischen Zugriff auf strukturierte Webdaten aus Dutzenden beliebter Domains.
- Scraping-Browser: Ein cloudbasierter, steuerbarer Browser, der JavaScript-Rendering-Funktionen bietet und gleichzeitig Browser-Fingerprinting, CAPTCHAs, automatische Wiederholungsversuche und vieles mehr für Sie übernimmt. Er lässt sich in die gängigsten Automatisierungs-Browser-Bibliotheken wie Playwright und Puppeteer integrieren.
- Web Unlocker: Eine Unlocking-API, die nahtlos den rohen HTML-Code jeder Seite zurückgeben kann und dabei alle Anti-Scraping-Maßnahmen umgeht.
Sie möchten sich überhaupt nicht mit Web-Scraping beschäftigen, sind aber dennoch an Online-Daten interessiert? Entdecken Sie die gebrauchsfertigen Datensätze von Bright Data!




